结合新型冠状病毒(sars-cov-2)s蛋白多肽的核酸适配体及其用途
技术领域
1.本发明涉及生物检测领域。
背景技术:
2.新型冠状病毒致病性强、传染快,现有的检测手段包括核酸检测、抗体检测和抗原检测。
3.新冠病毒有四种主要的结构蛋白:刺突蛋白(spikeprotein,s蛋白),核衣壳蛋白(nucleocapsid,n蛋白),膜蛋白(membraneprotein,m蛋白)和包膜蛋白(envelopeprotein,e蛋白)。人体一旦感染病毒,这些结构蛋白可作为免疫原刺激浆细胞产生特异性抗体。已经批准的抗原检测产品,多是以新冠病毒n蛋白作为抗原检测的靶标。抗原检测的样本来源通常是鼻腔、咽喉或唾液等,其一大特点是可快速出结果,可实现对疑似人群的早期分流,操作相对简便,价格也是三种检测方式中较为便宜的一种,但现有的抗原检测的灵敏度较低。
4.现有的研究表明,新型冠状病毒致病性强、传染快,主要通过其外膜s蛋白与人类宿主细胞ace受体相互作用,进而与宿主细胞融合、病毒大量复制、宿主致病等系列反应。与此同时,冠状病毒的s蛋白也是不同毒株之间的重要标识区、可具有毒株识别的特异性。
技术实现要素:
5.本发明的目的是提供一种来自于新型冠状病毒(sars-cov-2)s蛋白的靶标多肽,其特征在于:所述靶标多肽的氨基酸序列为seqidno.1;
6.所述seqidno.1的氨基酸序列如下:
7.dkntvavkyktkdggnsdskskrsdnkvtadagkygdcg。
8.基于上述的靶标多肽的应用,所述靶标多肽seqidno.1应用于识别新型冠状病毒(sars-cov-2)。
9.本发明要求保护一种基于上述的靶标多肽的应用,所述靶标多肽seqidno.1作为特异性识别新型冠状病毒(sars-cov-2)的靶点。
10.本发明要求保护一种基于上述的靶标多肽的应用,基于所述靶标多肽seqidno.1获取适配体。
11.本发明要求保护一组适配体,所述适配体的核酸序列为seqidno.2、seqidno.3、seqidno.4、seqidno.5、seqidno.6、seqidno.7或seqidno.8;
12.seqidno.2:ggtgactgctactgtgttggccctaccgggggttttttattatgtgtcgtatgtcagttgatcgccacacatccaagcagaacc
13.seqidno.3:ggtgactgctactgtgttggccctccgggggaaaatagctccaatacatatggagttacggtcgccacacatccaagcagaacc
14.seqidno.4:ggtgactgctactgtgttggccctacggggtcatattagtgtcttccattctgtg
tcagttggcccacacatcca agcagaacc
15.seq id no.5:ggtgactgctactgtgttgggcccagaagct caaaaagattacacctaaccttccccggaggggccacacatcc aagcagaacc
16.seq id no.6:ggtgactgctactgtgttggccctacggggt tgaacgttcgatattcgtggtacaacatgagcgccacacatcc aagcagaacc
17.seq id no.7:ggtgactgctactgtgttggccctacggggt ttacaatgataaatcttcatccgatgcgcctgc ccacacatcc aagcagaacc
18.seq id no.8:ggtgactgctactgtgttgggcctccggggg gtacgtgaattttcgctacaattccactgcgtaccacacatcca agcagaacc。
19.进一步,上述的适配体,是基于所述的靶标多肽(靶标物质)s eq id no.1获得。
20.本发明要求保护基于上述的适配体的应用,其特征在于:所述适配体应用于结合新型冠状病毒(sars-cov-2)s蛋白多肽。
21.本发明要求保护基于上述的适配体的应用,其特征在于:所述适配体应用于制备识别如权利要求1所述的靶标多肽的药物。
22.本发明要求保护基于上述的适配体的应用,其特征在于:所述适配体应用于制备识别新型冠状病毒(sars-cov-2)s蛋白的药物。
23.本发明要求保护基于上述的适配体的应用,其特征在于:所述适配体应用于制备识别新型冠状病毒(sars-cov-2)的药物。
24.本发明的技术效果是毋庸置疑的,该氨基酸序列为s蛋白关键致病区域和特异性区域。该适配体的高特异性及高亲和力达到精确识别新型冠状病毒(sars-cov-2)的目的。其应用于检测药物中,可以实现高通量、快速精准检测、精度高、稳定性好等优点,更好适应新型冠状病毒的快速检测问题。
附图说明
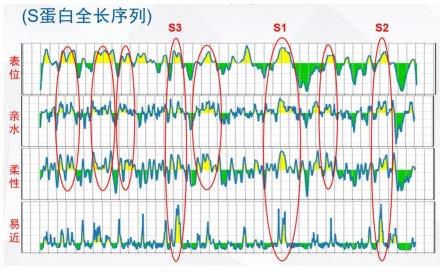
25.图1.s蛋白全长序列的生物信息分析
26.图2.源自s蛋白的三个多肽的生物信息分析;
27.图3.模板多肽人工合成后的hplc纯化
28.图4.模板多肽人工合成后的hplc纯化
29.图5.原始dna文库的建立
30.图6.1-10轮selex筛选适配体的pcr退火温度
31.图7.1-10轮selex筛选适配体的电泳图
32.图8.1-10轮selex筛选适配体的亲和力
33.图9.针对48个适配体序列实验的荧光强度。
具体实施方式
34.下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。
35.实施例1:
36.本实施例公开一种来自于新型冠状病毒(sars-cov-2)s蛋白的靶标多肽,其特征在于:所述靶标多肽的氨基酸序列为seqidno.1;
37.所述seqidno.1的氨基酸序列如下:
38.dkntvavkyktkdggnsdskskrsdnkvtadagkygdcg。
39.参见图1,图1为新型冠状病毒(sars-cov-2)s蛋白全长序列的生物信息分析本技术通过研究分析(参见图2,对多段多肽的研究分析结果),确定图中s1为最佳多肽,即上述seqidno.1。
40.实施例2:
41.本实施例基于实施例1的seqidno.1氨基酸序列进行合成。如图3和图4所示,本实施例针对合成序列ms鉴定和hplc纯化。
42.实施例3:
43.本实施例针对合成的氨基酸序列,如图5所示,进行dna文库序列及合成、hplc纯化、原始库建立电泳:
44.其中:
45.ssdna库5
′‑
ggtgactgctactgtgttgg-n44-ccacacatccaagcagaacc-3
′
46.上游引物5
′‑
ggtgactgctactgtgttgg-3
′
47.下游引物5
′‑
ggttctgcttggatgtgtgg-3
′
48.本实施例进行selex筛选,1-10轮selex筛选过程的退火温度图如图6。每轮筛选过程中,pcr的退火温度不全相同,需要通过t度实验探索确定,1-10轮selex筛选的退火温度见图6。从图中所见,随着筛选的进行,pcr反应的退火温度呈现逐渐升高趋势。
49.1-10轮selex筛选适配体的电泳图如图7。每一轮筛选均获得较清晰的适配体条带。
50.1-10轮selex筛选适配体的亲和力(荧光强度)如图8,随着筛选的进行,适配体的亲和力逐渐升高。
51.测序与序列分析,获得一组适配体,所述适配体的核酸序列为seqidno.2、seqidno.3、seqidno.4、seqidno.5、seqidno.6、seqidno.7或seqidno.8;
52.seqidno.2:ggtgactgctactgtgttggccctaccgggggttttttattatgtgtcgtatgtcagttgatcgccacacatccaagcagaacc
53.seqidno.3:ggtgactgctactgtgttggccctccgggggaaaatagctccaatacatatggagttacggtcgccacacatccaagcagaacc
54.seqidno.4:ggtgactgctactgtgttggccctacggggtcatattagtgtcttccattctgtgtcagttggcccacacatccaagcagaacc
55.seqidno.5:ggtgactgctactgtgttgggcccagaagctcaaaaagattacacctaaccttccccggaggggccacacatccaagcagaacc
56.seqidno.6:ggtgactgctactgtgttggccctacggggttgaacgttcgatattcgtggtacaacatgagcgccacacatccaagcagaacc
57.seqidno.7:ggtgactgctactgtgttggccctacggggtttacaatgataaatcttcatccgatgcgcctgcccacacatccaagcagaacc
58.seqidno.8:ggtgactgctactgtgttgggcctccggggggtacgtgaattttcgctacaattc
cactgcgtaccacacatcca agcagaacc。
59.进一步,本实施例采用了包括上述序列的48个适配体序列进行实验,源自新冠肺炎病毒s蛋白的多肽包被荧光酶标板(不透光),以荧光标记的48个适配体序列分别与之结合,测定荧光强度。其中,编号为fam-3、fam-19、fam-22、fam-23、fam-45、fam-68、 fam-94的实验组荧光强度》10000(见表1),上述实验组的序列分别对应seq id no.2~8。
60.表1:
[0061][0062][0063]
进一步,本实施例中,、选取荧光值》13000的四个适配体,通过两两组合的夹心elisa法,检测哪些组合的荧光值最高。结果如表2所示,提示19-19,19-68,19-03,19-22组合的检测效率较高,其中19-19最高。
[0064]
适配体编号及标记方法03-fam19-fam22-fam68-fam03-biotin2084245567330673931219-biotin6032478556***574493681522-biotin4040450369349335414768-biotin53736676293897036572
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
