用于治疗aml的多肽
1.本发明涉及一种多肽,其包含(i)与急性骨髓性白血病(aml)细胞的至少一个表面标志物结合的结合肽,和(ii)包含至少一个t细胞表位的免疫原性肽;以及涉及与之相关的手段和方法。
2.急性骨髓性白血病(aml)是一组异质性癌症,其中血细胞的髓系细胞增殖并在血液和/或骨髓中积聚。aml的症状是本领域已知的并特别包括典型的白血病症状。对aml的分类方案是本领域已知的,例如,who 2008年aml分类和法国-美国-英国(fab)分类。
3.通过免疫,对象的免疫系统针对抗原变得更强。尤其是适应性免疫系统,即赋予个体的免疫系统识别、记忆和应对潜在病原体的能力的免疫系统部分,已经引起了强烈的医学兴趣(kaech et al.(2002),nature reviews immunology 2(4):251-62;pulendran and ahmed(2006),cell 124(4):849-63)。一方面,它已被广泛用在疫苗接种中以赋予对原本可能致命的疾病的免疫力。它还被用于通过识别肿瘤抗原来消除癌细胞,取得了不同程度的成功。另一方面,在强免疫反应不适宜的疾病中适应性免疫系统的衰减引起关注,例如在过敏、哮喘或自身免疫性疾病中。
4.b细胞在免疫系统中的主要作用是在其激活后产生抗原特异性抗体。激活需要b细胞表面上的b细胞受体(bcr)与其同源抗原结合。bcr的这种激活导致b细胞的激活,b细胞经历成熟和克隆扩增,其后以这种方式产生的部分细胞变成产生对所述抗原具有特异性的抗体的浆细胞。
5.适应性免疫系统的另一个重要分支是表位特异性t细胞。在人类中,这些细胞在其表面上具有t细胞受体,其识别结构域对抗原性肽(t细胞表位)和主要组织相容性复合体(mhc)蛋白之间的确定的复合体是特异性的。如果t细胞受体参与同源相互作用,则t细胞被激活、增殖并在免疫反应中执行其激活或抑制任务。
6.mhc分子有两种形式:mhc i类在每个人类细胞的表面上表达并基本上随机地呈递源自细胞的胞质溶胶中存在的蛋白质的肽;因此,它们给出细胞的蛋白质组库的连续概貌并允许识别例如在细胞的病毒感染过程中或癌病变中的非正常蛋白质表达。为了识别mhc i类分子-肽复合体,t细胞受体需要cd8表面蛋白作为辅助受体。因此存在表达cd8辅助受体的t细胞的亚类,称为cd8 -t细胞;它们的主要但非排他性功能是消除呈递肽的体细胞,其指示所述细胞中的潜在致病过程,例如病毒感染,这是为什么它们也被称为细胞毒性t细胞的原因。
7.mhc ii类基本上在专职抗原呈递细胞(apc)上表达。在这些细胞上,呈递的肽源自apc主要通过内吞作用摄入的蛋白质。mhc ii类的识别需要辅助受体cd4,其仅在cd4 t细胞的表面上表达。这些t细胞(也称为辅助性t细胞)的主要作用是激活cd8 -t细胞、巨噬细胞和b细胞。合适的表位向apc的递送因此导致这些表位经由mhc ii类呈递到辅助性t细胞,其继而激活这些t细胞并导致免疫系统的其他分支的激活。然而,细胞毒性cd4 t细胞已被确定为重要的免疫介质,例如,对病毒。
8.因此,本领域需要提供用于aml的免疫治疗的可靠手段。特别地,需要提供将至少部分避免上述现有技术缺点的手段和方法。
9.该问题通过具有独立权利要求的特征的多肽、多核苷酸、载体、宿主细胞和方法来解决。在从属权利要求中列出了可以单独的方式或以任何任意组合实现的优选实施方案。
10.因此,本发明涉及一种多肽,其包含
11.(i)与急性骨髓性白血病(aml)细胞的至少一个表面标志物结合的结合肽,和
12.(ii)包含至少一个t细胞表位的免疫原性肽。
13.如在下文中使用的,术语“具有”、“包含”或“包括”或其任何任意语法变型以非排他方式使用。因此,这些术语既可指除了由这些术语引入的特征之外在上下文中描述的实体中不存在更多的特征的情况,也可指还存在一个或多于一个更多的特征的情况。作为一个实例,表达“a具有b”、“a包含b”和“a包括b”都可指其中除b外在a中不存在其他要素的情况(即,其中a仅且排他地由b组成的情况)并可指其中除b外在实体a中还存在一个或多于一个更多的要素如要素c、要素c和d或甚至更多的要素的情况。
14.此外,如在下文中使用的,术语“优选地”、“更优选地”、“最优选地”、“特别地”、“更特别地”、“具体地”、“更具体地”或类似的术语与任选的特征结合使用而不限制更多的可能性。因此,由这些术语引入的特征是任选的特征而不旨在以任何方式限制权利要求的范围。本领域技术人员将认识到,本发明可通过使用替代的特征来执行。类似地,由“在一个实施方案中”或类似的表达引入的特征旨在是任选的特征,而对本发明的更多实施方案没有任何限制,对本发明的范围没有任何限制,且对组合以这样的方式引入的特征与本发明的其他任选或非任选特征的可能性没有任何限制。
15.如本文所用,术语“标准条件”,如果没有另外说明,则指iupac标准环境温度和压力(satp)条件,即优选地,25℃的温度和100kpa的绝对压力;还优选地,标准条件包括为7的ph。而且,如果没有另外指示,则术语“约”指指示值加上相关领域中普遍接受的技术精度,优选地指指示值
±
20%,更优选
±
10%,最优选
±
5%。此外,术语“基本上”表示不存在会对指示的结果或用途有影响的偏差,即潜在的偏差不会导致指示的结果偏离超过
±
20%,更优选
±
10%,最优选
±
5%。因此,“基本上由
……
组成”指包括所指定的组分但不包括除以杂质存在的材料、因用来提供组分的过程而存在的不可避免的材料和出于实现本发明的技术效果之外的目的而添加的组分外的其他组分。例如,使用表述“基本上由
……
组成”定义的组合物涵盖任何已知的可接受的添加剂、赋形剂、稀释剂、载体等。优选地,基本上由一组组分组成的组合物将包含小于5重量%,更优选小于3重量%,甚至更优选小于1重量%,最优选小于0.1重量%的一种或多于一种未指定组分。在核酸序列的上下文中,术语“基本上相同”表示至少80%,优选至少90%,更优选至少98%,最优选至少99%的%同一性值。如将理解的,术语基本上相同包括100%同一性。上述内容比照地适用于术语“基本上互补”。
16.如本文所用,术语“多肽”涉及包含至少结合肽和至少一个免疫原性肽的任何化学分子,如下文所指定。应理解,结合肽与免疫原性肽之间的化学连接不一定是肽键。本发明还设想结合肽与免疫原性肽之间的化学键为酯键、二硫键或本领域技术人员已知的任何其他合适的共价化学键。还设想了其解离常数低到使得免疫原性肽将仅在可忽略的程度上从结合肽解离的非共价键。优选地,所述非共价键的解离常数小于10-5
mol/l(如在strep-tag:strep-tactin结合时是这种情况)、小于10-6
mol/l(如在strep-tagii:strep-tactin结合时是这种情况)、小于10-8
mol/l、小于10-10
mol/l、或小于10-12
mol/l(如对链霉亲和素:生物素结合而言是这种情况)。确定解离常数的方法是本领域技术人员公知的并包括例如光谱滴
id no:32的氨基酸序列的hc缔合。因此,在一个优选的实施方案中,前述多肽具有cll1结合活性,优选人cll1结合活性。
20.在一个优选的实施方案中,多肽包含包含seq id no:36的氨基酸序列的抗体重链的可变结构域(vh)和/或包含seq id no:37的氨基酸序列的抗体轻链的可变结构域(vl)。在一个进一步优选的实施方案中,多肽包含包含seq id no:38的氨基酸序列的抗fr-β抗体的重链(hc)的序列,优选由包含seq id no:39的核酸序列的多核苷酸编码。在一个进一步优选的实施方案中,多肽包含包含seq id no:40的氨基酸序列的抗fr-β抗体的轻链(lc)的序列,优选由包含seq id no:41的核酸序列的多核苷酸编码。如本领域技术人员所理解的,在一个优选的实施方案中,前述包含前述hc的多肽优选与抗fr-β抗体的lc,特别是与前述包含seq id no:40的氨基酸序列的lc缔合;如本领域技术人员所理解的,在一个优选的实施方案中,前述包含前述lc的多肽优选与抗fr-β抗体的hc,特别是与前述包含seq id no:38的氨基酸序列的hc缔合。因此,在一个优选的实施方案中,前述多肽具有fr-β结合活性,优选人fr-β结合活性。
21.在一个优选的实施方案中,融合多肽包含seq id no:48的氨基酸序列,优选基本上由seq id no:48的氨基酸序列组成,更优选由seq id no:48的氨基酸序列组成,优选由包含seq id no:49的核酸序列的多核苷酸编码;或者包含seq id no:50的氨基酸序列,优选基本上由seq id no:50的氨基酸序列组成,更优选由seq id no:50的氨基酸序列组成,优选由包含seq id no:51的核酸序列的多核苷酸编码;或者包含seq id no:52的氨基酸序列,优选基本上由seq id no:52的氨基酸序列组成,更优选由seq id no:52的氨基酸序列组成,优选由包含seq id no:53的核酸序列的多核苷酸编码;如本领域技术人员所理解,前述融合多肽优选与抗cll1抗体的轻链(lc)缔合,优选与包含seq id no:28的氨基酸序列的抗cll1抗体的轻链(lc)缔合。
22.在一个优选的实施方案中,融合多肽包含seq id no:54的氨基酸序列,优选基本上由seq id no:54的氨基酸序列组成,更优选由seq id no:54的氨基酸序列组成,优选由包含seq id no:55的核酸序列的多核苷酸编码;或者包含seq id no:56的氨基酸序列,优选基本上由seq id no:56的氨基酸序列组成,更优选由seq id no:56的氨基酸序列组成,优选由包含seq id no:57的核酸序列的多核苷酸编码;或者包含seq id no:58的氨基酸序列,优选基本上由seq id no:58的氨基酸序列组成,更优选由seq id no:58的氨基酸序列组成,优选由包含seq id no:59的核酸序列的多核苷酸编码;如本领域技术人员所理解,前述融合多肽优选与抗cll1抗体的轻链(lc)缔合,优选与包含seq id no:34的氨基酸序列的抗cll1抗体的轻链(lc)缔合。
23.在一个优选的实施方案中,融合多肽包含seq id no:60的氨基酸序列,优选基本上由seq id no:60的氨基酸序列组成,更优选由seq id no:60的氨基酸序列组成,优选由包含seq id no:61的核酸序列的多核苷酸编码;或者包含seq id no:62的氨基酸序列,优选基本上由seq id no:62的氨基酸序列组成,更优选由seq id no:62的氨基酸序列组成,优选由包含seq id no:63的核酸序列的多核苷酸编码;或者包含seq id no:64的氨基酸序列,优选基本上由seq id no:64的氨基酸序列组成,更优选由seq id no:64的氨基酸序列组成,优选由包含seq id no:65的核酸序列的多核苷酸编码;如本领域技术人员所理解,前述融合多肽优选与抗cll1抗体的轻链(lc)缔合,优选与包含seq id no:40的氨基酸序列的
抗cll1抗体的轻链(lc)缔合。
24.优选地,多肽具有以下活性中的至少一种,优选至少两种,更优选所有活性:(i)与aml细胞的表面标志物结合,(ii)引起mhc-ii分子环境中免疫原性多肽在aml细胞表面上的呈递,和(iii)诱导识别所述免疫原性肽的同源t细胞的激活。优选地,所述t细胞为细胞毒性t细胞,更优选为cd4 细胞毒性t细胞。优选地,术语多肽包括多肽变体,条件是它们具有一种或多于一种如上文所指定的活性。
25.如本文所用,术语“多肽变体”指包含至少一种如本文别处指定的多肽或融合多肽的任何化学分子,其具有所指示的活性,但与指示的所述多肽或融合多肽的一级结构不同。因此,多肽变体优选为具有所指示的活性的突变蛋白。优选地,多肽变体包含具有对应于如上指定的多肽中包含的100至2000个,更优选200至1800个,甚至更优选300至1600个,最优选500至1500个连续氨基酸的氨基酸序列的氨基酸序列的肽。此外,还涵盖前述多肽的其他多肽变体。这样的多肽变体具有与特定多肽至少基本上相同的生物活性。此外,应理解,如根据本发明提及的多肽变体应具有由于至少一个氨基酸置换、缺失和/或添加而不同的氨基酸序列,其中所述变体的氨基酸序列仍在如所指定的程度上与特定多肽的氨基酸序列相同。两个氨基酸序列之间的同一性程度可通过本领域公知的算法来确定。优选地,通过在比较窗口上比较两个最佳比对的序列来确定同一性程度,其中比较窗口中的氨基酸序列片段与和其最佳比对所比较的序列相比可能包含添加或缺失(例如,空位或突出)。计算百分数的做法是,优选在多肽的全长上确定两个序列中出现相同氨基酸残基的位置数以产生匹配位置数,然后将匹配位置数除以比较窗口中的总位置数并将结果乘以100而产生序列同一性的百分数。用于比较的序列的最佳比对可通过下述方法进行:smith和waterman(1981)的局部同源性算法,needleman和wunsch(1970)的同源性比对算法,pearson和lipman(1988)的搜索相似性方法,这些算法的计算机化实现(威斯康星遗传学软件包中的gap、bestfit、blast、pasta和tfasta,genetics computer group(gcg),575 science dr.,madison,wi),或目视检查。鉴于已识别出用于比较的两个序列,故优选采用gap和bestfit来确定它们的最佳比对和因此同一性程度。优选地,对于空位权重使用5.00的默认值,而对于空位权重长度(gap weight length)使用0.30的默认值。本文提及的多肽变体可以是等位基因变体或任何其他物种特异性同源物、旁系同源物或直系同源物。此外,本文提及的多肽变体包括特定多肽的片段或前述类型的多肽变体,只要这些片段和/或变体具有一种或多于一种如本文所提及的生物学活性即可。这样的片段可以是或可源自例如多肽的降解产物或剪接变体。还包括由于翻译后修饰如磷酸化、糖基化、泛素化、sumo化或十四烷基化、因引入非天然氨基酸和/或因成为肽模拟物而不同的变体。
26.优选地,多肽或融合多肽还包含可检测的标签。术语“可检测的标签”是指添加或引入到本发明的多肽中的一段氨基酸。优选地,标签应加到本发明的多肽的c-或n-末端。该段氨基酸应允许通过特异性识别所述标签的抗体检测融合多肽,或其应允许形成功能性构象,如螯合剂,或其应允许通过荧光可视化。优选的标签为myc-标签、flag-标签、6-his-标签、ha-标签、gst-标签或gfp-标签。这些标签是本领域公知的。优选地,如上文所指定的标签,更优选myc-标签、flag-标签、6-his-标签、ha-标签、gst-标签或gfp-标签,不是如本文所提及的免疫原性肽。
27.技术人员应理解,术语“急性骨髓性白血病”和“aml”在更广泛的意义上指血细胞
的髓系细胞的不适当增殖。aml的症状是本领域已知的并特别包括典型的白血病症状。优选地,aml是一种白血病,其中如下文所指定的aml细胞在对象中快速生长并在血液和/或骨髓中积聚。对aml的分类方案是本领域已知的,例如,who 2008年aml分类和法国-美国-英国(fab)分类。优选地,包括在这些分类之一中的任何aml类型为如本文所提及的aml。更优选地,aml为急性成髓细胞白血病、急性早幼粒细胞白血病、急性粒单核细胞白血病或急性单核细胞白血病,更优选aml为急性成髓细胞白血病、急性早幼粒细胞白血病或急性粒单核细胞白血病。
28.如本文所用,术语“aml细胞”在更广泛的意义上指在患有aml的对象中不适当地增殖的血细胞的髓系细胞或指源自其的细胞系;因此,优选地,aml细胞为癌细胞。优选地,aml细胞为骨髓谱系的白血病细胞,优选成髓细胞、单核细胞、巨核细胞或红细胞谱系,优选成髓细胞谱系。更优选地,aml细胞为(i)成髓细胞,(ii)早幼粒细胞,(iii)髓细胞,或(iv)(i)至(iii)中任一项的祖细胞。优选地,aml细胞表达主要组织相容性复合体ii(mhc-ii)或可诱导表达mhc-ii;因此,aml细胞优选在其自然状态下和/或在用诱导mhc-ii表达的试剂,特别是ifnγ处理后在其表面上具有可检测的量的mhc-ii。
29.如本文所用,术语“表面标志物”指至少部分地存在于aml细胞的表面上即在其细胞膜的外侧上的任何分子。表面标志物为大分子,优选具有至少1kda,更优选至少10kda的分子量,优选为多肽,包括经修饰的多肽如糖蛋白、多糖、或本领域技术人员认为适宜的任何其他大分子。优选地,表面标志物包含至少一个可被结合多肽识别,即优选地暴露于aml细胞的外部的表位。优选地,表面标志物被细胞内化;优选地,所述内化由周转内化(turnover internalization)介导,优选表面标志物在aml细胞的表面上的半衰期为至多2天,更优选至多1天,甚至更优选至多12小时,还更优选至多6小时。还优选地,表面标志物的内化是可诱导的,优选通过结合肽与所述表面标志物的结合。优选地,表面标志物基本上是特异性的,更优选是对骨髓谱系的细胞特异性的;更优选地,表面标志物对aml细胞是特异性的;因此,优选地,表面标志物在非aml细胞的表面上表达的量比在所述aml细胞的表面上表达的量低至少2倍,优选低至少5倍,更优选低至少10倍,最优选低至少25倍。优选地,aml细胞的表面标志物为多肽,优选选自cd371(例如,同种型x6,genbank acc.no.xp_006719099.1)、prame(genbank acc.no.cag30435.1)、cd123(例如,同种型1,genbank acc.no.np_002174.1)、cd138(genbank acc.no.np_002988.4)、tim-3(genbank acc.no.afo66593.1)、cd34、cd38、cd25、cd32和cd96;优选选自cd371、prame和cd123,更优选选自cd371和prame。在一个优选的实施方案中,aml细胞的表面标志物选自cd371、cd123和fr-β(folr2,例如genbank acc no.np_001107006.1)。如本领域技术人员将理解的,表面标志物可以各种同种型存在,例如,剪接变体、糖基化变体等。因此,指示的上述genbank acc.no.是示例性的而不排除其他同种型。
30.如本文所用,术语“结合肽”指以允许所述结合肽被aml细胞内化的亲和力与如本文别处指定的aml细胞的至少一种表面标志物结合的任何肽。优选地,所述结合肽与所述表面标志物的结合的解离常数小于10-5
mol/l、小于10-6
mol/l、小于10-7
mol/l、小于10-8
mol/l、或小于10-9
mol/l。优选地,结合肽为抗体。
31.如本文所用,术语“抗体”指来自iga、igd、ige、igg或igm的任何类别的可溶性免疫球蛋白。针对表面标志物的抗体可通过公知的方法制备,例如使用纯化蛋白或源自其的合
适片段作为抗原。优选地,本发明的抗体为单克隆抗体、多克隆抗体。抗体可以是人或人源化抗体、灵长类化或嵌合抗体或其片段。更优选地,抗体为单链抗体或纳米抗体,更优选为单链抗体。作为本发明的抗体,还包括双特异性抗体、合成抗体、抗体片段(如fab、fv或scfv片段等)或任何这些的化学修饰衍生物。优选地,本发明的抗体应与如本文指定的表面标志物特异性结合(即不与其他多肽或肽交叉反应)。可通过各种公知的技术测试特异性结合。抗体或其片段可通过使用例如harlow and lane
″
antibodies,a laboratory manual
″
,csh press,cold spring harbor,1988中描述的方法获得。单克隆抗体可通过最初见述于and milstein(1975),nature 256,495和galfr
é
(1981),meth.enzymol.73,3中的技术制备,其包括小鼠骨髓瘤细胞与源自免疫哺乳动物的脾细胞的融合。
32.优选地,结合肽在氨基酸序列上与免疫原性肽连续,即结合肽和免疫原性肽形成融合多肽。还优选地,结合肽为包含重链(hc)和轻链(lc)的抗体。优选地,结合肽包含抗cd123抗体的重链的序列,优选包含seq id no:10的氨基酸序列;以及抗cd123抗体的轻链(lc)的序列,优选包含seq id no:8的氨基酸序列。还优选地,结合肽包含抗cll1抗体的重链的序列,优选包含seq id no:18的氨基酸序列;以及抗cll1抗体的轻链(lc)的序列,优选包含seq id no:16的氨基酸序列。
33.如本文所用,术语“免疫原性肽”指包含至少一个t细胞表位的肽。如本领域技术人员所知,t细胞表位为包含在多肽中的连续氨基酸序列,其可与将在任何有核细胞(mhc-i)或基本上专职抗原呈递细胞(mhc-ii)的表面上呈递的主要组织相容性复合体(mhc)i类或ii类分子结合。本领域技术人员知道如何预测在mhc-i或mhc-ii上呈递的免疫原性肽(nielsen et al.,(2004),bioinformatics,20(9),1388-1397),bordner(2010),plos one 5(12):e14383)以及如何评价特定肽的结合(例如,bernardeau et al.,(2011),j immunol methods,371(1-2):97-105)。另外,t细胞表位可在公共数据库中获得,例如来自www.iedb.org的免疫表位数据库。优选地,t细胞表位为mhc-ii表位。优选地,t细胞表位为包含在通常感染对象或所述对象已针对其接种了疫苗的传染原,优选病毒的蛋白质中的表位;或为包含在肿瘤抗原的蛋白质中的表位。优选地,t细胞表位为包含在至少针对所述传染原的疫苗中的表位。优选地,t细胞表位为包含在传染原的蛋白质中的表位,所述传染原选自疱疹病毒,特别是爱泼斯坦-巴尔病毒(ebv)和巨细胞病毒、麻疹病毒、风疹病毒、腮腺炎病毒、水痘病毒、流感病毒、脊髓灰质炎病毒、甲型肝炎病毒、乙型肝炎病毒、轮状病毒、乳头状瘤病毒、白喉棒状杆菌、破伤风梭菌、百日咳博德特氏菌、流感嗜血杆菌、肺炎球菌属、脑膜炎球菌属,更优选为包含在ebv的蛋白质中的表位。优选地,传染原为建立潜伏感染的传染原,优选为ebv或乳头状瘤病毒,并且t细胞表位为其潜伏基因产物的表位。优选地,免疫原性肽包含mhc-ii肽,优选基本上由mhc-ii肽组成,更优选由mhc-ii肽组成,和任选地n-末端和/或c-末端接头肽,其中所述一种或两种接头肽优选具有至多20个,更优选至多10个,还更优选至多5个氨基酸的独立选择长度。优选地,免疫原性肽包含来自爱泼斯坦-巴尔病毒(ebv)的潜伏基因的至少一个t细胞表位,优选至少一个mhc-ii表位。还优选地,免疫原性肽包含至少一个来自ebna-1、ebna-lp、ebna-2、ebna-3a、ebna-3b、ebna-3c、lmp-1、lmp-2a或bzlf1的t细胞表位。优选地,aml细胞的表面上至少一种类型的mhc-ii为hla-drb1*1301(genbank acc no.lc257799.1)并且所述免疫原性肽为ebna1-1c3(seq id no:7)、ebna3b-b9(seq id no:2)或bzlf1-3h11(seq id no:1);或者aml细胞的表面上的mhc-ii为
hla-drb1*1101(genbank ac.no.ab829528.1)并且所述免疫原性肽为ebna1-3g2(seq id no:3)、ebna3b-3f7(seq id no:4)、ebna3c-1b2/3h10(seq id no:5);或者aml细胞的表面上的mhc-ii为hla-drb1*11(genbank ac.no.ay375861.1)并且所述免疫原性肽为ebna1-3e10(seq id no:6)。在一个优选的实施方案中,免疫原性肽选自seq id no:1至7和42至47。在一个优选的实施方案中,aml细胞的表面上至少一种类型的mhc-ii为hla-drb1*1301并且免疫原性肽为gp3501d6.(seq id no:42)。在一个进一步优选的实施方案中,免疫原性肽为ebna2pep(seq id no:43),或为来自ebv毒株b95.8的ebna1(seq id no:44),或为来自ebv毒株b95.8的ebna3c的片段,例如,如seq id no:45、46或47中所示。
34.有利地,在本发明的基础工作中发现,本文描述的构建体适合于诱导细胞毒性t细胞反应,特别是针对对象中的aml细胞的cd4 细胞毒性t细胞反应,从而有助于aml治疗。
35.上述定义比照地适用于以下内容。下面进一步作出的附加定义和解释也比照地适用于本说明书中描述的所有实施方案。
36.本发明还涉及编码本发明的多肽的多核苷酸。
37.如本文所用,术语“多核苷酸”指包含编码多肽的核酸序列的多核苷酸,其中所述多肽具有如本文别处指定的多肽的活性。用于测量前面提到的活性的合适测定法在所附的实施例中描述。根据本说明书已获得编码具有前述生物学活性的多肽的多核苷酸;因此,所述多核苷酸优选包含seq id no:13、15、21或23中所示的核酸序列,其分别编码具有如seq id no:12、14、20或22中所示的氨基酸序列的多肽。
38.如本文所用,术语多核苷酸优选包括具体指示的多核苷酸的变体。更优选地,术语多核苷酸指所指示的特定多核苷酸。然而,应理解,由于遗传密码的简并,具有特定氨基酸序列的多肽也可由多种多核苷酸编码。技术人员知道如何选择编码具有特定氨基酸序列的多肽的多核苷酸,也知道如何根据用于表达所述多核苷酸的生物体的密码子使用来优化多核苷酸中使用的密码子。因此,如本文所用,术语“多核苷酸变体”指与本文相关的多核苷酸的变体,其包含特征在于序列可通过至少一个核苷酸置换、添加和/或缺失而从前述特定的核酸序列衍生得到的核酸序列,其中所述多核苷酸变体应具有针对特定的多核苷酸指定的活性,即,应编码根据本发明的多肽。此外,应理解,如根据本发明提及的多核苷酸变体应具有由于至少一个核苷酸置换、缺失和/或添加而不同的核酸序列。优选地,所述多核苷酸变体为特定多核苷酸的直系同源物、旁系同源物或另一同源物。还优选地,所述多核苷酸变体为特定多核苷酸的天然存在的等位基因。多核苷酸变体还涵盖包含能够与前述特定的多核苷酸杂交的核酸序列的多核苷酸,优选地,在严格杂交条件下。这些严格条件是技术人员已知的并可见于current protocols in molecular biology,john wiley&sons,n.y.(1989),6.3.1-6.3.6中。严格杂交条件的一个优选实例为在大约45℃下在6x氯化钠/柠檬酸钠(=ssc)中,然后于50至65℃下在0.2x ssc、0.1%sds中进行一个或多于一个洗涤步骤的杂交条件。技术人员知道,这些杂交条件随核酸的类型而异,并在例如存在有机溶剂时在温度和缓冲液的浓度方面也不同。例如,在“标准杂交条件”下,温度随核酸的类型而异,在42℃至58℃之间,水性缓冲液浓度为0.1x至5x ssc(ph 7.2)。如果前述缓冲液中存在有机溶剂,例如50%的甲酰胺,则标准条件下的温度为大约42℃。dna:dna杂交体的杂交条件优选为例如0.1x ssc和20℃至45℃,优选30℃至45℃。dna:rna杂交体的杂交条件优选为例如0.1x ssc和30℃至55℃,优选45℃至55℃。前述杂交温度为例如针对长度为大约100bp(=
碱基对)且g c含量为50%的核酸在不存在甲酰胺的情况下所确定。通过参考教科书如上面提到的教科书或以下教科书,本领域技术人员知道如何确定所需的杂交条件:sambrook et al.,
″
molecular cloning”,cold spring harbor laboratory,1989;hames and higgins(ed.)1985,”nucleic acids hybridization:a practical approach”,irl press at oxford university press,oxford;brown(ed.)1991,
″
essential molecular biology:a practical approach”,irl press at oxford university press,oxford。或者,多核苷酸变体可通过基于pcr的技术获得,如基于混合寡核苷酸引物的dna扩增,即使用针对本发明的多肽的保守结构域的简并引物。多肽的保守结构域可通过本发明的多核苷酸的核酸序列或多肽的氨基酸序列与其他生物体的序列的序列比较来识别。作为模板,可使用来自细菌、真菌、植物或优选来自动物的dna或cdna。此外,变体包括包含与特定指示的核酸序列至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少98%或至少99%相同的核酸序列的多核苷酸。而且,还涵盖包含编码与特定指示的氨基酸序列至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少98%或至少99%相同的氨基酸序列的核酸序列的多核苷酸。优选地,在整个氨基酸或核酸序列区域上计算同一性百分数值。技术人员可使用基于各种算法的一系列程序来比较不同的序列。在此背景下,needleman和wunsch或smith和waterman的算法给出特别可靠的结果。为了进行序列比对,使用程序pileup(j.mol.evolution.,25,351-360,1987,higgins et al.,cabios,51989:151-153)或程序gap and bestfit needleman and wunsch(j.mol.biol.48;443453(1970))和smith and waterman(adv.appl.math.2;482-489(1981))],其是gcg软件包(genetics computer group,575 science drive,madison,wisconsin,usa 53711(1991))的一部分。上面以百分数(%)记载的序列同一性值优选在整个序列区域上使用程序gap用以下设置确定:空位权重:50,长度权重:3,平均匹配:10.000,平均错配:0.000,除非另有说明,否则应始终使用这些设置作为序列比对的标准设置。
39.包含任何具体指定的核酸序列的片段的多核苷酸也作为本发明的一种变体多核苷酸而涵盖,条件是所编码的多肽具有一种或多于一种如所指定的活性。因此,该片段仍应编码仍具有如所指定的活性的多肽。相应地,所编码的多肽可包含赋予所述生物学活性的本发明多肽的结构域或由赋予所述生物学活性的本发明多肽的结构域组成。如本文所指的片段优选包含任何一个特定核酸序列的至少150个、至少200个、至少500个或至少1000个连续核苷酸或者编码包含任何一个特定氨基酸序列的至少200个、至少300个、至少500个、至少800个、至少1000个或至少1500个连续氨基酸的氨基酸序列。
40.本发明的多核苷酸由前述核酸序列组成、基本上由前述核酸序列组成或包含前述核酸序列。因此,它们也可含有更多的核酸序列。具体而言,本发明的多核苷酸可编码融合蛋白,其中所述融合蛋白的一个配偶体为由上面记载的核酸序列编码的多肽。这样的融合蛋白可作为另外的部分包含用于监测表达的多肽,即可充当可检测标志物或充当用作纯化目的的辅助措施的所谓“标签”。用于不同目的的标签是本领域公知的并在本文别处描述。
41.本发明的多核苷酸应优选作为分离的多核苷酸(即从其天然环境中分离)或以遗传修饰形式提供。优选地,多核苷酸为dna(包括cdna),或为rna。该术语涵盖单链以及双链的多核苷酸。此外,优选地,还包括经化学修饰的多核苷酸,包括天然存在的经修饰的多核苷酸如糖基化或甲基化的多核苷酸或经人工修饰的那些如生物素化的多核苷酸。
42.本发明还涉及包含本发明的多核苷酸的载体。
43.术语“载体”优选地涵盖技术人员认为适宜的任何类型的载体,包括噬菌体、质粒、病毒或逆转录病毒载体以及人工染色体,如细菌或酵母人工染色体。此外,该术语还涉及允许靶向构建体随机或定点整合到基因组dna中的靶向构建体。优选地,这样的靶标构建体包含足够长度的dna用于同源或异源重组,如下文详细描述的。优选地,包含本发明的多核苷酸的载体还包含用于在宿主中繁殖和/或选择的可选择标志物。可通过本领域公知的各种技术将载体并入到宿主细胞中。例如,质粒载体可在沉淀物如磷酸钙沉淀物或氯化铷沉淀物中或者在与带电荷的脂质的复合物中或在基于碳的团簇如富勒烯中引入。或者,可通过热休克或电穿孔技术引入质粒载体。在一个优选的实施方案中,载体为细菌载体。还优选地,载体为真核载体。
44.更优选地,在本发明的载体中,多核苷酸与表达控制序列可操作地连接,从而允许在原核或真核细胞或其分离的级分中表达。所述多核苷酸的表达包括多核苷酸的转录,优选转录为可翻译的mrna。确保在真核细胞、优选哺乳动物细胞中表达的调控元件是本领域公知的。它们优选地包含确保转录的起始的调控序列和任选地确保转录的终止和转录本的稳定的poly-a信号。另外的调控元件可包括转录增强子以及翻译增强子。允许在原核宿主细胞中表达的可能的调控元件包括例如大肠杆菌中的lac、trp或tac启动子,而允许在真核宿主细胞中表达的调控元件的实例有酵母中的aox1或gal1启动子或cmv-、sv40-、rsv-启动子(劳斯肉瘤病毒)、cmv-增强子、sv40-增强子或哺乳动物和其他动物细胞中的球蛋白内含子。此外,可诱导表达控制序列可用于本发明所涵盖的表达载体中。这样的可诱导载体可包含tet或lac操纵子序列或可由热休克或其他环境因素诱导的序列。合适的表达控制序列是本领域公知的。除了负责转录的起始的元件外,这样的调控元件还可包含转录终止信号,如多核苷酸下游的sv40-poly-a位点或tk-poly-a位点。在此上下文中,合适的表达载体是本领域已知的,如okayama-berg cdna表达载体pcdv1(pharmacia)、pbluescript(stratagene)、pcdm8、prc/cmv、pcdna1、pcdna3(invitrogen)或psport1(gibco brl)。可使用本领域技术人员公知的方法来构建重组病毒载体;参见例如sambrook,molecular cloning:a laboratory manual,cold spring harbor laboratory(1989)n.y.和ausubel,current protocols in molecular biology,green publishing associates and wiley interscience,n.y.(1994)中描述的技术。
45.本发明还涉及包含根据本发明的多肽、根据本发明的多核苷酸和/或根据本发明的载体的宿主细胞。
46.如本文所用,术语“宿主细胞”指能够接收并优选维持本发明的多核苷酸和/或载体的任何细胞。更优选地,宿主细胞能够表达在所述多核苷酸和/或载体上编码的本发明的多肽。优选地,所述细胞为细菌细胞,更优选本领域已知的普通实验室细菌菌株的细胞,最优选埃希氏菌属菌株,特别是大肠杆菌菌株。还优选地,宿主细胞为真核细胞,优选酵母细胞,例如,面包酵母菌株的细胞,或者为动物细胞。更优选地,宿主细胞为昆虫细胞或哺乳动物细胞,特别是人、小鼠或大鼠细胞。还更优选地,宿主细胞为人细胞。优选地,宿主细胞为如上文所指定的aml细胞。
47.本发明还涉及根据本发明的多肽、根据本发明的多核苷酸和/或根据本发明的载体,其用于药物中。本发明还涉及根据本发明的多肽、根据本发明的多核苷酸和/或根据本
发明的载体,其用于aml的治疗中。
48.本发明还涉及一种刺激aml特异性t细胞的方法,其包括
49.(a)使aml细胞与本发明的多肽、本发明的多核苷酸和/或本发明的载体接触,
50.(b)使(a)的aml细胞与t细胞接触,和
51.(c)从而刺激aml特异性t细胞。
52.优选地,刺激aml特异性t细胞的方法为体外方法。然而,其也可在体内进行,例如如下文所指定作为治疗aml的方法的一部分。此外,所述方法可包括除了上面明确提到的那些外的步骤。例如,更多的步骤可涉及例如为步骤a)提供aml细胞的样本,例如在来自对象的样本中,或在步骤b)之后孵育和扩增t细胞。此外,所述步骤中的一个或多于一个可由自动化设备执行。另外,可重复单个步骤或整个方法。
53.如本发明的方法的上下文中所用,术语“接触”是本领域技术人员理解的。优选地,该术语涉及使本发明的多肽、多核苷酸、载体或宿主细胞与对象或优选地细胞(例如,aml细胞)物理接触,即允许前述组分相互作用。
54.如本领域技术人员将理解的,在刺激aml特异性t细胞的方法的上下文中,结合肽优选对如上文所指定的aml细胞具有特异性。另外,技术人员将理解,优选地,生成的aml特异性t细胞为细胞毒性t细胞,优选为cd4 细胞毒性t细胞。优选地,所述aml特异性t细胞对与本发明的多肽、本发明的多核苷酸和/或本发明的载体接触的aml细胞是特异性的。
55.本发明还涉及一种识别用于治疗急性骨髓性白血病(aml)的多肽的方法,其包括
56.(a)提供与所述aml的细胞(aml细胞)的表面标志物结合的结合肽,
57.(b)确定由所述aml细胞表达的至少一种hla-ii亚型;和
58.(c)基于(a)和(b)的结果,识别用于治疗aml的多肽。
59.优选地,识别多肽的方法为体外方法。此外,其可包括除了上面明确提到的那些外的步骤,并且所述步骤中的一个或多于一个可由自动化设备执行。
60.术语“提供针对表面标志物的抗体”在本文中在广义上使用,指提供及于合适的抗体的任何模式。因此,在上述上下文中,提供可以是抗体的物理产生,可以是提供编码抗体的多核苷酸,或者甚至可以是在数据库中计算机识别合适的抗体,任选地包括其氨基酸序列或编码其氨基酸序列的核酸序列。
61.如本文所用,术语“确定由所述aml细胞表达的至少一种hla-ii亚型”指识别存在于至少一种aml细胞的表面上的至少一种hla-ii亚型。优选地,hla-ii亚型从样本中包含的至少一种类型的aml细胞识别出来。因此,在样品包含多于一种类型的aml细胞的情况下,如果在一种类型的aml细胞上识别出一种hla-ii亚型,那么该方法就足够了。识别hla-ii亚型的方法是本领域已知的并包括免疫学方法,即使用亚型特异性抗体来确定。更优选地,hla-ii亚型通过对编码基因或更优选地编码rna测序来识别,例如,通过cdna测序。
62.如本文所用,术语“样本”是指来自体液的样本,优选血液、血浆、血清、唾液或尿液,或源自例如活检、细胞、组织或器官的样本,特别是来自心脏。更优选地,样本为血液样本、骨髓样本或者血液或骨髓来源的样本。优选地,样本包含或怀疑包含aml细胞。用于获得前述不同类型的生物学样本的技术是本领域公知的。例如,可通过采血获得血液样本。优选地,样本可在用于本发明的方法之前经预处理。如下文更详细地描述的,所述预处理可包括从其他样本成分释放或分离aml细胞、从包含在样本中的细胞释放多核苷酸所需的处理,或
技术人员认为适宜的其他预处理。如前所述经预处理的样本也由如根据本发明所用的术语“样本”所涵盖。
63.用于治疗aml的多肽基于前面的步骤(a)和(b)的结果来识别。因此,优选地,如果(i)多肽与目标aml细胞结合并优选地如上文所指定被内化;和(ii)如果多肽包含被目标aml细胞的hla-ii亚型呈递、优选高效地呈递的免疫原性肽,则该多肽被识别为是合适的。本领域技术人员可获得用于预测特定hla-ii亚型的肽呈递的合适工具;此外,适合于被给定的hla-ii亚型呈递的肽可在通常可访问的数据库例如www.iedb.org中找到。
64.识别用于治疗的多肽的方法可包括进一步的步骤。例如,其可包括在步骤(b)之前和优选地在步骤(a)之前提供aml细胞的样本,优选地对象的aml细胞的样本的步骤。另外,识别步骤之后可跟着物理产生步骤(c)中识别出的多肽的步骤。此外,可配制多肽,例如,作为药物组合物。
65.术语“对象”指具有对生物体外来分子产生免疫反应的能力的后生动物生物体。优选地,对象为动物,更优选哺乳动物,最优选人类。优选地,对象已知或怀疑患有aml。
66.根据上文,本发明还涉及一种产生用于治疗急性骨髓性白血病(aml)的多肽的方法,其包括
67.(a)根据本发明的方法识别用于治疗aml的多肽,和
68.(b)产生用于治疗aml的多肽。
69.本发明还涉及一种在已知或怀疑患有aml的对象中治疗急性骨髓性白血病(aml)的方法,其包括
70.使所述对象与用于治疗aml的多肽,优选根据本发明的多肽接触,和从而治疗aml。
71.术语“治疗(treating/treatment)”是指在显著程度上改善本文提及的疾病或病症或伴随其的症状。如本文所用的所述治疗还包括在本文提及的疾病或病症方面完全恢复健康。应理解,如本文所用的术语治疗可能不对所有待治疗的对象都有效。然而,该术语应要求,优选地,统计学显著部分的患有本文提及的疾病或病症的对象可被成功治疗。本领域技术人员可使用各种公知的统计评估工具例如置信区间的确定、p-值确定、学生t-检验、mann-whitney检验等毫不费力地确定一个部分是否是统计学显著的。优选的置信区间为至少90%、至少95%、至少97%、至少98%或至少99%。p-值优选为0.1、0.05、0.01、0.005或0.0001。优选地,治疗应对给定队列或群体中至少10%、至少20%、至少50%、至少60%、至少70%、至少80%或至少90%的对象有效。治疗方法可包括更多的治疗步骤,这些步骤可在如所指定的步骤之前或之后或者可同时施用。合适的另外的治疗可以是例如化学疗法、放射疗法、手术或另外的免疫疗法。
72.本发明还涉及患有急性骨髓性白血病(aml)的对象的样本用于识别用于治疗aml的多肽的用途,优选地根据识别用于治疗aml的多肽的方法。
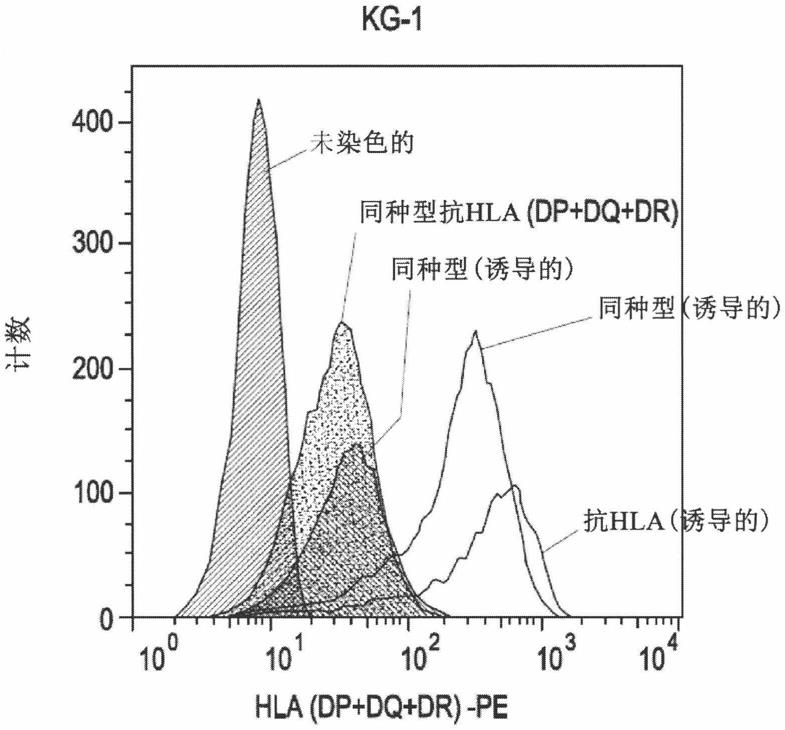
73.鉴于上述内容,特别地设想以下实施方案:
74.1.一种多肽,其包含
75.(i)与急性骨髓性白血病(aml)细胞的至少一个表面标志物结合的结合肽,和
76.(ii)包含至少一个t细胞表位的免疫原性肽。
77.2.实施方案1的多肽,其中所述aml细胞为骨髓谱系的白血病细胞,优选成髓细胞、单核细胞、巨核细胞或红细胞谱系,优选成髓细胞谱系。
78.3.实施方案1或2的多肽,其中所述aml细胞为(i)成髓细胞,(ii)早幼粒细胞,(iii)髓细胞,或(iv)(i)至(iii)中任一项的祖细胞。
79.4.实施方案1至3中任一项的多肽,其中所述aml细胞表达主要组织相容性复合体ii(mhc-ii)或可诱导表达mhc-ii。
80.5.实施方案1至4中任一项的多肽,其中aml细胞的所述表面标志物为多肽,优选选自cd371、prame、cd123、cd138和tim-3,优选选自cd371、prame和cd123,更优选选自cd371和prame,还优选选自cd371、cd123和fr-β。
81.6.实施方案1至5中任一项的多肽,其中所述结合肽为抗体。
82.7.实施方案1至6中任一项的多肽,其中所述结合肽为单链抗体。
83.8.实施方案1至7中任一项的多肽,其中所述免疫原性肽包含至少一个包含在通常感染所述对象或所述对象已针对其接种了疫苗的传染原,优选病毒的蛋白质中的t细胞表位;或包含在肿瘤抗原的蛋白质中的t细胞表位。
84.9.实施方案8的多肽,其中所述t细胞表位为包含在至少针对所述传染原的疫苗中的表位。
85.10.实施方案8或9的多肽,其中所述传染原选自爱泼斯坦-巴尔病毒(ebv)、麻疹病毒、风疹病毒、腮腺炎病毒、水痘病毒、流感病毒、脊髓灰质炎病毒、甲型肝炎病毒、乙型肝炎病毒、轮状病毒、乳头状瘤病毒、白喉棒状杆菌、破伤风梭菌、百日咳博德特氏菌、流感嗜血杆菌、肺炎球菌属、脑膜炎球菌属,优选为ebv。
86.11.实施方案1至10中任一项的多肽,其中所述传染原为建立潜伏感染的传染原,优选为ebv或乳头状瘤病毒,并且其中所述t细胞表位为其潜伏基因产物的表位。
87.12.实施方案1至11中任一项的多肽,其中所述免疫原性肽包含mhc-ii肽,优选基本上由mhc-ii肽组成。
88.13.实施方案1至12中任一项的多肽,其中所述免疫原性肽包含至少一个来自爱泼斯坦-巴尔病毒(ebv)的潜伏基因的t细胞表位。
89.14.实施方案1至13中任一项的多肽,其中所述免疫原性肽包含至少一个来自ebna-1、ebna-lp、ebna-2、ebna-3a、ebna-3b、ebna-3c、lmp-1、lmp-2a或bzlf1的t细胞表位。
90.15.实施方案1至14中任一项的多肽,其中所述mhc-ii为hla-drb1*1301并且所述免疫原性肽为ebna1-1c3、ebna3b-b9或bzlf1-3h11;或者其中所述mhc-ii为hla-drb1*1101并且所述免疫原性肽为ebna1-3g2、ebna3b-3f7、ebna3c-1b2或ebna3c-3h10;或者其中所述mhc-ii为hla-drb1*11并且所述免疫原性肽为ebna1-3e10。
91.16.实施方案1至15中任一项的多肽,其中所述多肽包含seq id no:12的氨基酸序列,优选基本上由seq id no:12的氨基酸序列组成,更优选由seq id no:12的氨基酸序列组成,优选由包含seq id no:13的核酸序列的多核苷酸编码;或者包含seq id no:14的氨基酸序列,优选基本上由seq id no:14的氨基酸序列组成,更优选由seq id no:14的氨基酸序列组成,优选由包含seq id no:15的核酸序列的多核苷酸编码;或者包含seq id no:20的氨基酸序列,优选基本上由seq id no:20的氨基酸序列组成,更优选由seq id no:20的氨基酸序列组成,优选由包含seq id no:21的核酸序列的多核苷酸编码;或者包含seq id no:22的氨基酸序列,优选基本上由seq id no:22的氨基酸序列组成,更优选由seq id no:22的氨基酸序列组成,优选由包含seq id no:23的核酸序列的多核苷酸编码。
92.17.一种多核苷酸,其编码根据实施方案1至16中任一项的多肽。
93.18.一种载体,其包含根据实施方案17的多核苷酸。
94.19.一种宿主细胞,其包含根据实施方案1至16中任一项的多肽、根据实施方案17的多核苷酸和/或根据实施方案18的载体。
95.20.根据实施方案1至16中任一项的多肽、根据实施方案17的多核苷酸、根据实施方案18的载体和/或根据实施方案19的宿主细胞,其用于药物。
96.21.根据实施方案1至16中任一项的多肽、根据实施方案17的多核苷酸、根据实施方案18的载体和/或根据实施方案19的宿主细胞,其用于aml的治疗。
97.22.一种刺激aml特异性t细胞的方法,其包括
98.(a)使aml细胞与根据实施方案1至16中任一项的多肽、根据实施方案17的多核苷酸、根据实施方案18的载体和/或根据实施方案19的宿主细胞接触,
99.(b)使(a)的aml细胞与t细胞接触,和
100.(c)从而刺激aml特异性t细胞。
101.23.实施方案22的方法,其中所述aml特异性t细胞为细胞毒性t细胞,优选为cd4 细胞毒性t细胞。
102.24.一种识别用于治疗急性骨髓性白血病(aml)的多肽的方法,其包括
103.(a)提供与所述aml的细胞(aml细胞)的表面标志物结合的结合肽,
104.(b)确定由所述aml细胞表达的至少一种hla-ii亚型;和
105.(c)基于(a)和(b)的结果,识别用于治疗aml的多肽。
106.25.一种产生用于治疗急性骨髓性白血病(aml)的多肽的方法,其包括
107.(a)根据根据实施方案24的方法识别用于治疗aml的多肽,和
108.(b)产生用于治疗aml的多肽。
109.26.一种在已知或怀疑患有aml的对象中治疗急性骨髓性白血病(aml)的方法,其包括
110.使所述对象与用于治疗aml的多肽,优选根据实施方案1至16中任一项的多肽接触;和从而治疗aml。
111.27.患有急性骨髓性白血病(aml)的对象的样本用于识别用于治疗aml的多肽的用途,优选地根据实施方案24的方法。
112.本说明书中引用的所有参考文献就其整个公开内容和本说明书中具体提及的公开内容通过引用并入本文。
附图说明
113.图1:(a)实验工作流程;(b)至(d)示出了用多个aml细胞系在暴露于ebv表位bzlf1-3h11(b)、ebna1-3g2(c)或ebna3c-3h10(d)后进行的干扰素γ释放测定的结果。如说明文字中所指示,在t细胞测定之前,一些细胞系还用干扰素γ进行了处理。lcl为用作阳性对照的ebv阳性细胞,单独的t细胞和未暴露于肽的细胞用作阴性对照。条形图中给出了暴露于各种ebv肽的aml细胞系与对该抗原具有特异性的t细胞共培养后的干扰素分泌。
114.图2:aml细胞系kg-1的表面处hla ii类的表达。示出了各种对照抗体。
115.图3:通过facs确定各种aml细胞系的表面处cll-1的表达。
116.图4:针对cll-1(左)和cd123(右)的不同agab也能够与未修饰的抗体一样与其靶标结合。用于测试结合的aml细胞系为kg-1(a)、monomac-6(b)和nomo-1(c);未染色:未染色的对照;同种型:同种型对照,wt:野生型抗体(即无免疫原性肽),3g2:ebna1-3g2,3h10:ebna3c-3h10,3h11:bzlf1-3h11。
117.图5:图表示出了用kg-1 aml细胞系在暴露于各种量的对cll-1或cd123具有特异性的agab并携带所指示的ebv表位(bzlf13h10、ebna13g2)后进行的干扰素γ释放测定的结果(上方小图)。不含抗原部分的天然抗体用作阴性对照(wt)。下方小图示出了对仅暴露于肽3g2或3h10的aml kg-1细胞进行的t细胞测定的结果。
118.图6:图表示出了用monomac 6 aml细胞系在暴露于各种量的对cll-1或cd123具有特异性且携带所指示的ebv表位(bzlf1-3h10、ebna1-3g2)的agab后进行的干扰素γ释放测定的结果(上方小图)。不含抗原部分的天然抗体用作阴性对照(wt)。下方小图示出了对仅暴露于肽3g2或3h10的aml monomac 6细胞进行的t细胞测定的结果。
119.图7:a)图表示出了用mv4-11 aml细胞系在暴露于各种量(100ng-0,1ng每5.104个靶细胞)的对cll-1、cd123或fr-β具有特异性且携带所指示的ebv表位(gp350 1d6)的igg2a agab后进行的干扰素γ释放测定的结果。不含抗原部分的天然抗体用作阴性对照(天然-仅100ng)。还使用各种量的表位来证实agab刺激的优越性。每5.104个靶细胞使用105个效应cd4
t细胞(e∶t比率=2∶1);b)图表示出了用mv4-11 aml细胞系在暴露于各种量(100ng-0,1ng每5.104个靶细胞)的对cll-1、cd123或fr-β具有特异性且携带所指示的ebv表位(gp350 1d6)的igg2a agab后进行的颗粒酶b释放测定的结果。不含抗原部分的天然抗体用作阴性对照(天然-仅100ng)。还使用各种量的表位来证实agab刺激的优越性。每5.104个靶细胞使用105个效应cd4
t细胞(e∶t比率=2∶1)。
120.图8:a)图表示出了用mutz-3 aml细胞系在暴露于10ng每5.104个靶细胞的对cll-1、cd123或fr-β具有特异性且携带所指示的ebv表位(ebna3c 3h10)的igg2a agab后进行的干扰素γ释放测定的结果。不含抗原部分的天然抗体用作阴性对照(天然)。每5.104个靶细胞使用105个效应cd4
t细胞(e∶t比率=2∶1);b)图表示出了用mutz-3 aml细胞系在暴露于10ng每5.104个靶细胞的对cll-1、cd123或fr-β具有特异性且携带所指示的ebv表位(ebna3c 3h10)的igg2a agab后进行的颗粒酶b释放测定的结果。不含抗原部分的天然抗体用作阴性对照(天然)。每5.104个靶细胞使用105个效应cd4
t细胞(e∶t比率=2∶1)。
121.以下实施例将仅示意本发明。无论如何,它们不应解释为限制本发明的范围。
122.实施例1:aml细胞系上表面标志物的表达
123.使用对hla-dr、cd123、cd138、cd371、tim-3、prame具有特异性的抗体对如所指示的aml细胞系染色并通过facs分析。一些细胞系在用hla-dr特异性抗体染色之前用干扰素γ刺激。使用同种型对照作为阴性对照以排除非特异性染色(表1)。
124.此外,使用对hla-dr具有特异性的抗体对aml细胞系染色并通过facs分析;图2中示出了一个实例。一些细胞系在用hla-dr特异性抗体染色之前用干扰素γ刺激。使用同种型对照和未染色的样本作为阴性对照以排除非特异性染色。
125.此外(图3),使用对cll-1具有特异性的抗体对aml细胞系染色并通过facs分析。使用同种型对照和未染色的样本作为阴性对照以排除非特异性染色。
126.表1示出了在从急性骨髓性白血病患者确立的6个细胞系的表面处hla ii类分子
hla-dr和多种细胞标志物(cd123、cd138、cd371、tim-3、prame)的表达。
127.表1:aml细胞系的表面标志物; 指示表达,neg指示无法检测到表达,可诱导表示可通过用干扰素γ处理细胞来诱导hla ii类表达。
[0128][0129]
表2:aml细胞系的hla drb1单倍型;数据来自tron细胞系门户网站(德国美因茨);n.a.:无可用数据
[0130]
细胞系hla drb1hl-6011:30
′
/13:01
′
kg-111:01/03:17
′
molm-14n.a.monomac-601:01/11:01nomo-104:05
′
/14:103oci-aml201:03/04:01
′
mutz-310:01/11:01mv4-1101:01/13:02
[0131]
实施例2:与aml细胞系的hla单倍型匹配的表位的确定
[0132]
与hla亚型结合的ebv肽取自文献(参见yu et al.(2015),blood 125(10):1601;adhikary et al(2006),jem 203(4):995;mautner et al.(2004),j.immunol.34:2500)。由aml细胞系表达的hla亚型由文献或测序确定。该信息允许将aml细胞系与它们预期能够呈递的ebv肽相匹配。
[0133]
表3:与aml细胞系的hla单倍型匹配的表位;(?):表达不清楚。
[0134][0135]
实施例3:aml细胞的肽呈递
[0136]
用这些肽与白细胞介素2一起刺激对先前从感染病毒的人分离的ebv肽特异性的人t细胞数周。将aml细胞系暴露于增加的浓度的肽(实施例2)一天,然后充分洗涤并与对它们所暴露于的肽特异性的预活化t细胞混合。一天后,使用特异性抗体通过elisa对这些培养物的上清液中的干扰素γ释放进行定量(图1)。
[0137]
实施例4:抗体-免疫原性肽融合多肽(agab)的结合
[0138]
使用对cll-1或cd123具有特异性的agab通过facs对aml细胞系染色。使用同种型对照作为阴性对照以排除非特异性染色。使用用于生成agab的抗体作为对照(图4)。
[0139]
实施例5:t细胞的激活
[0140]
用这些肽与白细胞介素2一起刺激对先前从感染病毒的人分离的ebv肽特异性的人t细胞数周。将aml细胞系暴露于增加的浓度的肽或含相同的肽的agab一天,然后充分洗涤并与对agab中所含的肽或对它们所暴露于的单独的肽具有特异性的预活化t细胞混合。一天后,使用特异性抗体通过elisa对这些培养物的上清液中的干扰素γ释放进行定量。不含抗原部分的天然抗体用作阴性对照(wt)(图5)。
[0141]
此外(图6),用这些肽与白细胞介素2一起刺激对先前从感染病毒的人分离的ebv肽特异性的人t细胞数周。将aml细胞系暴露于增加的浓度的肽或含相同的肽的agab一天,然后充分洗涤并与对agab中所含的肽或对它们所暴露于的单独的肽具有特异性的预活化t细胞混合。一天后,使用特异性抗体通过elisa对这些培养物的上清液中的干扰素γ释放进行定量。不含抗原部分的天然抗体用作阴性对照。
[0142]
虽然实施例3至5使用igg1亚型构建体进行,但以下实施例6和7使用igg2a亚型进行:
[0143]
实施例6:通过aml细胞系mv4-11激活
[0144]
类似于实施例5的过程,在t细胞活化测定(tca)中使用mv4-11 aml细胞,该测定使用如所指示的构建体并测定干扰素-γ分泌(图7a)或颗粒酶b产生(图7b)作为t细胞活化的参数。
[0145]
实施例7:
[0146]
类似于实施例5的过程,在t细胞活化测定(tca)中使用mutz-3 aml细胞,该测定使用如所指示的构建体并测定干扰素-γ分泌(图8a)或颗粒酶b产生(图8b)作为t细胞活化的参数。
[0147]
文献:
[0148]
adhikary et al(2006),jem 203(4):995
[0149]
bernardeau et al.,(2011),j immunol methods,371(1-2):97-105
[0150]
bordner(2010),plos one 5(12):e14383
[0151]
galfr
é
(1981),meth.enzymol.73,3,
[0152]
kaech et al.(2002),nature reviews immunology 2(4):251-62
[0153]
and milstein(1975),nature 256,495
[0154]
mautner et al.(2004),j.immunol.34:2500
[0155]
nielsen et al.,(2004),bioinformatics,20(9),1388-1397
[0156]
pulendran and ahmed(2006),cell 124(4):849-63
[0157]
yu et al.(2015),blood 125(10):1601
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。