1.本发明从一种用于运行机器人的方法和设备出发。
背景技术:
2.机器人在多种工业应用中被采用。通过在闭合的调节回路中的调节器,或者通过智能体(agenten),可以预先给定机器人在应用中实施的运动策略,所述智能体根据模型或者与模型无关地学会和预先给定策略。
技术实现要素:
3.通过根据独立权利要求的设备和方法,能够实现相对于传统应用被改进的应用。
4.用于运行机器人的方法,其中根据机器人和/或该机器人的环境的第一状态,并且根据第一模型的输出,确定调节量的第一部分,用于针对机器人从第一状态到第二状态的转移来操控机器人;其中根据第一状态并且与第一模型无关地,确定调节量的第二部分;其中根据第一状态并且根据第一模型的输出,利用第二模型确定质量级别;其中根据该质量级别,确定第一模型的至少一个参数;其中根据质量级别和理论值,确定第二模型的至少一个参数;其中根据奖励,确定理论值,所述奖励分配给从第一状态到第二状态的转移。经此,采用特别有效地通向目标的用于操控机器人的剩余策略,而不出现干扰学习过程的发散。
5.可以设置,确定至少一个力和至少一个力矩,所述至少一个力和所述至少一个力矩作用于机器人的末端执行器,其中根据至少一个力和至少一个力矩,确定第一状态和/或第二状态。
6.优选地,关于轴线来限定第一状态和/或第二状态,其中力引起末端执行器在轴线的方向上运动,其中力矩引起末端执行器围绕该轴线转动。所述操控对于探索和工业应用而言是特别有效的。经此,探索(也就是尤其是随机试验新动作)变得更安全。可以确保,机器人和操纵对象还有站在周围的人均不受伤。
7.可以设置,确定如下向量:所述向量限定了调节量的恒定部分,其中该向量限定第一力、第二力、第三力、第一力矩、第二力矩和第三力矩,其中针对这些力限定了不同的轴线,其中给每个力矩分配有不同的轴线中的另外的轴线。向量特别良好地适宜于描述状态,并且适宜于操控。
8.第一模型可以包括第一函数近似器、尤其是第一高斯过程或者第一人工神经网络,其中向量的第一部分限定了对此的输入,其中与向量的第二部分无关地限定输入。
9.第二模型可以包括第二函数近似器、尤其是第二高斯过程或者第二人工神经网络,其中向量限定了对此的输入。
10.可以设置:限定调节量的向量被确定;其中所述向量限定第一力、第二力、第三力、第一力矩、第二力矩和第三力矩;其中针对这些力限定不同的轴线,其中给每个力矩分配有不同的轴线中的另外的轴线;其中与第一人工神经网络的输出无关地,尤其是恒定地限定向量的第一部分,第一模型包括所述第一人工神经网络;其中根据第一人工神经网络的输
出,限定向量的第二部分。经此,以预先限定的方式和方法,利用恒定的变量可操控机器人,并且由此与任务有关地可使机器人更快速地运动到最终状态中。
11.优选地,末端执行器包括至少一个手指,所述至少一个手指具有与工件互补的部段,便于用手握地或者自定心地(selbstzentrierend)来实施所述部段的表面。经此,能够实现特别好的支撑(halt)。
12.可以根据界限来确定理论值,其中根据如下图来确定所述界限:在所述图中,节点限定机器人的状态;其中根据第一状态来确定该图的子图,所述子图包括第一节点,所述第一节点表示第一状态;其中根据分配给子图的如下节点的值来确定所述界限:从第一节点到第二节点的路径包括所述节点,所述路径表示针对机器人的最终状态。在子图中,以分析方式可确定分配给该子图的q值。所述q值可以被用作下界限。
13.优选地,根据机器人的至少一个状态来确定该图,其中针对如下节点来分配限定无结果的(folgenlose)动作的边:所述节点在图中是叶子,并且没有分配给机器人的最终状态。经此,避免针对在学习过程中的发散的原因。
14.无结果的动作可以分配给针对调节量的第一部分的尤其是恒定的值。经此,为了避免学习过程中的发散,确定特别好地适合的界限。在确定的情况下,通过嵌入无结果的动作,完全可以首先确定界限;在另外的情况下,可能可以确定比在没有无结果的动作的情况下更高的下界限。
15.优选地根据预先给定的界限,确定理论值。经此,与任务有关地,可以考虑领域知识。
16.为了训练第一人工神经网络,可以根据第二人工神经网络的输出来确定代价函数,其中在训练中学习第一人工神经网络的参数,针对所述第一人工神经网络的参数,代价函数有比针对另外的参数更小的值。
17.在针对第二人工神经网络的训练中,对于第二人工神经网络的输出,可以根据第二人工神经网络的输出和理论值来限定代价函数,其中学习第二人工神经网络的参数,针对所述第二人工神经网络的参数,代价函数有比针对另外的参数更小的值。
18.用于运行机器人的设备,其特征在于,所述设备构造来,实施根据上述权利要求中任一项所述的方法。
附图说明
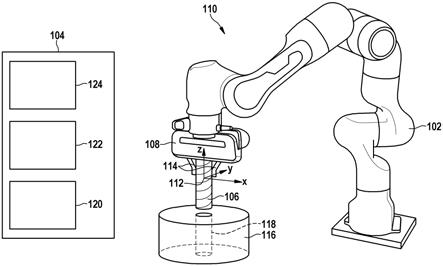
19.从下列描述和附图中得出其他有利的实施形式。在附图中:图1示出了机器人和用于运行机器人的设备的示意图,图2示出了该设备的部分的示意图,图3示出了用于运行机器人的方法中的步骤。
具体实施方式
20.图1示意性地示出了机器人102和用于运行机器人102的设备104。机器人102构造来,利用末端执行器(在该例子中为抓取装置108)抓取第一工件106。机器人102在工作空间110中可以以多种不同的姿势p运动。在该例子中,可以根据三维笛卡尔坐标系来说明姿势p。坐标系的原点112在该例子中居中地布置在抓取装置108的两个手指114之间,利用手指
114可抓取第一工件106。笛卡尔坐标系的另外的布局同样是可能的。
21.笛卡尔坐标系利用坐标x、y、z来限定针对在工作空间110中的运动的位置。
22.在图1中,在工作空间110中,示出了第二工件116。在该例子中,在第二工件116中设置有开口118,该开口118构造来,容纳第一工件106。
23.例如,第一工件106是轴、尤其是电机轴。例如,第二工件116是球轴承,所述球轴承构造来容纳轴。球轴承可以布置在电机外壳中。
24.机器人102构造来,使第一工件106在工作空间110中在根据策略的轨迹上运动,使得第一工件106在该轨迹的末端处容纳在第二工件116中。
25.设备104包括至少一个处理器120和针对指令的至少一个存储器122,在通过至少一个处理器120实施所述指令时进行在下文所描述的方法。也可以设置至少一个图形处理单元(graphical processing unit),利用所述图形处理单元可特别有效地训练函数近似器、尤其是人工神经网络。至少一个处理器120和至少一个存储器122可以实施为一个或者多个微处理器。设备104可以布置在机器人102之外,或者可以以集成到机器人102中的方式来布置设备104。可以设置有用于在处理器、存储器、操控装置和机器人102之间通信的数据线路。这些数据线路在图1中未示出。
26.设备104可以包括输出装置124,所述输出装置124构造用于操控机器人102。输出装置124可以包括输出级或者通信接口,用于操控机器人102的一个或者多个执行元件。
27.图2示意性地示出了设备104的部分。
28.设备104包括尤其是自主的智能体202,所述智能体202构造来与它的环境相互作用。
29.在每个离散的时步t,智能体202都可以观测状态,并且根据策略π实施动作,所述动作限定了接下来的状态。在每个动作之后,智能体202获得奖励。
30.该环境在该例子中通过马尔可夫决策过程来示出,所述马尔可夫决策过程具有状态、动作、转移动态和奖励函数。转移动态可以是随机的。
31.未来的奖励 的总和的期望值通过结果来限定,其中因子,当从状态出发跟踪策略π时,达到所述未来的奖励 。
32.对于在第一步骤中与策略π无关的行为,可以考虑q值。q值可以被考虑作为针对未来的奖励的总和的期望值:,当在瞬时的时步t实施动作并且从那时起遵循策略π时,达到所述未来的奖励。
33.智能体202跟踪的目标是,确定用于达到最终状态的最优策略。可以设置,确定如下指示(angabe):该指示说明,机器人102是否已完成它的任务,亦即是否已达到最终状态。通过最优策略,针对每个当前状态,选出动作,所述动作使关于所有关系到相应的状态为未来的状态的期望的奖励最大化。在该例子中,以用折扣γ来加权的方式,在未来的状态的总和中考虑对未来的状态的期望的奖励,所述总和限定了期望的奖励。
34.智能体202可以通过如下方式实现这一点:确定针对环境的q函数,并且选择动作,所述动作使该q函数在每个时步t的q值最大化。
35.q函数被用于优化函数近似器,并且例如通过根据经验和q函数的瞬时估计来估计q值,可以确定q函数:。
36.这被称为时间差学习(temporal difference learning)。可以设置,根据指示来确定,状态是否是最终状态。
37.这些函数可以通过人工神经网络来近似。例如,使用两个人工神经网络。第一人工神经网络204表示确定性策略π。第一人工神经网络204被称为演员网络(actor network)。第二人工神经网络206根据在它的输入端处的状态和动作对来确定q值。第二人工神经网络206被称为评论家网络(critic network)。该行为方式被称为深度确定性策略梯度(deep deterministic policy gradients),并且例如在t. p. lillicrap、j. j. hunt、a. pritzel、n. heess、t. erez、y. tassa、d. silver和d. wierstra的“continuous control with deep reinforcement learning”(arxiv preprint arxiv:1509.02971,2015年)中予以描述。
38.深度确定性策略梯度是针对连续的状态和动作空间的无模型的方法。为了避免在具有非线性神经网络的学习过程中的不稳定性,可以确定针对q值的界限。在该学习过程期间中采用这些界限,由此该学习过程保持稳定。
39.在学习过程中,关于智能体与环境的交互的数据被存储在重现存储器(wiedergabespeicher)中。代替将转移、奖励和关于是否已达到最终状态的指示的列表存储在重现存储器中,如下地处理这些转移、奖励和指示。也可能的是,存储该列表,并且接着不断地从所述列表中导出新的图。转移在该例子中包括状态、动作、通过在状态实施动作而达到的状态。经此达到的奖励和指示涉及该转移。代替转移的列表,设置数据图,在该数据图中,第一节点限定状态,并且第二节点限定通过在状态实施动作而达到的状态。在图中在第一节点与第二节点之间的边在该情况下限定动作。奖励和指示分配给该边。在数据图中的不同的转移可以以不同的概率而导致学习过程的发散。对于时间差学习,概率与数据图的结构有关。
40.相对于用来没有达到最终状态的另外的转移的概率,用来达到最终状态的转移产生发散的概率是最小的。相比于学习过程中的发散通过从其不可达到图中的最终状态的状态形成的概率,从其经由图中的路径可达到最终状态的状态导致学习过程的发散的概率更低。
41.可以从数据图出发来确定下界限。例如,确定数据图的如下子图:利用所述子图,在假设所述子图是完整的情况下,以分析方式可确定所有分配给该子图的q值。这些q值可以被用作针对数据图的下界限。可以先验地(也就是通过例如关于机器人102、第一工件106、第二工件116和/或要解决的任务和/或所使用的奖励函数的领域知识)限定其他的下界限和上界限。
42.采用界限的可能性在于,根据下界限lb和上界限ub来限制q函数。由此,得到q函数:。
43.在针对第二人工神经网络206的训练中,针对第二人工神经网络206的输出可以将代价函数限定为均方差(mean squared error):。
44.在该例子中,训练的目标是,学习第二人工神经网络206的参数,针对所述第二人工神经网络206的参数,代价函数有比针对另外的参数更小的值。代价函数例如以梯度下降方法被最小化。
45.可以设置的是,给数据图中的如下节点配备有无结果的工作、也就是零动作:限定动作的边都没有从所述节点出发。另外的节点也可以被配备有无结果的工作。无结果的动作在该例子中是如下动作:例如通过预先给定为零的加速度,所述动作使机器人102的状态不改变。
46.经此,避免了数据图中的如下叶子:不再有动作从所述叶子出发。下界限可以针对每次转移来确定,所述转移以无限循环结束。与没有无结果的动作的情况相比,通过无结果的动作可确定更多下界限。经此可能的是,下界限总共更窄。
47.作为针对第一人工神经网络204的输入,在该例子中使用限定状态的变量的第一部分。第一人工神经网络204的输入与限定状态的变量的第二部分无关。
48.变量可以是所估计的变量。这些变量也可以是所测量的变量,或者可以根据所测量的变量来计算或者估计这些变量。
49.在该例子中,通过在x方向上的所估计的力、在y方向上的所估计的力、在z方向上的所估计的力、围绕在x方向上延伸的轴线的转动的所估计的力矩、围绕在y方向上延伸的轴线的转动的所估计的力矩和围绕在z方向上延伸的轴线的转动的所估计的力矩,限定状态,这些力和力矩以瞬时姿势p出现在抓取装置108上。在该例子中,与所估计的力、所估计的力无关地,并且与所估计的力矩无关地,确定第一人工神经网络204的输入。变量的第二部分在该例子中没有被用作针对第一人工神经网络204的输入。这减小了维度,并且因而负责:第一人工神经网络204变得更小,而且因此可以更快速地或者更简单地训练第一人工神经网络204。在另外的应用中,可能会确定和使用对此的这些变量,其中不使用另外的变量。这对于机器人102的如下运动是特别有利的:在该运动中,第一工件106被插到开口118中,所述开口118在z方向上延伸。
50.在该例子中,通过尤其是恒定的第一部分,并且通过第二部分,限定动作。在针对抓取装置108的运动的例子中,第一部分限定了在x方向上的力、在y方向上的力、在z方向上的力和针对围绕在z方向上延伸的轴线的转动的力矩。力可以是。在该例子中,这意味着,机器人102使抓取装置108持续地沿着抓取装置108的z轴线运动。第二部分在该例子中限定了针对围绕在x方向上延伸的轴线的转动的力矩的第一理论值,和/或限定了围绕在y方向上延伸的轴线的力矩的第二理论值。在该例子中,根据第一人工神经网络204的第一输出变量,确定第一理论值。在该例子中,根据第一人工神经网络204的第二输出变量,确定第二理论值。在该例子中,这些输出变量中的每个输出变量都被缩放到为[
‑
3, 3]nm的区间上。
[0051]
总之,在该例子中,作为动作确定调节量。在该例子中,在第一部分中是,,。第一部分也可以设置另外的值。当要不同地操控机器人102时,也可以不同地构建调节量。在该例子中,向调节器208输出调节量,用于调整抓取装置108的新姿势p,所述调节器208操控所述机器人102,直至达到新姿势p。在该例子中,如果针对抓取装置108的调节器208已达到稳定状态(例如以低于预先给定的临界速度的速度已达到稳定状态),那么动作结束。可以设置,调节器208构造来,确定机器人102的状态。可以设置的是,调节器208构造来,将机器人102已达到最终状态的指示置到第一值(例如1)上。可以设置,用另外的值来初始化指示,或者要不然将指示置到另外的值(例如0)上。可以测量用于确定指示的速度,可以从所测量的变量中计算或者估计用于确定指示的速度。
[0052]
经此,机器人102将在z方向上的恒定的力施加到第一工件106上,利用该力使工件106在z方向上运动。机器人102通过在x方向和y方向上的力矩关于抓取装置108运动。
[0053]
针对另外的应用的例子是机器人102的如下运动:在该运动中,第一工件108应被旋拧到开口118中。在该情况下,围绕在z方向上延伸的轴线的连续的转动运动可能是有意义的。这可以通过如下方式予以考虑:与在x方向上的所估计的力无关地,与在y方向上的所估计的力无关地,与在z方向上的所估计的力无关地,根据所估计的力矩,根据所估计的力矩并且与所估计的力矩无关地,确定第一人工神经网络204的输入。第一人工神经网络204的第一输出在该情况下可以是针对力矩的第一理论值。第一人工神经网络204的第二输出在该情况下可以是针对力矩的第二理论值。在该情况下,与第一人工神经网络204无关地,确定用于确定调节量的另外的变量。
[0054]
奖励可以通过第一奖励函数来预先给定,所述第一奖励函数给至最终状态的转移指派了针对奖励的值,并且给每个另外的转移都指派了针对奖励的值。
[0055]
奖励可以通过第二奖励函数来预先给定,所述第二奖励函数根据抓取装置108的瞬时姿势p和该抓取装置在最终状态中的姿势p的间距给转移指派值。在该例子中,如果第二工件116将第一工件106容纳在为此设置的开口118中,则达到最终状态。
[0056]
在该例子中,为此根据位置误差,确定第一奖励。在该例子中,位置误差被确定为欧几里德差分向量的范数。例如,从来自抓取装置108的瞬时姿势p的位置和来自抓取装置108在最终状态中的姿势p的位置中,确定该差分向量。在该例子中,为此根据定向误差,确定第二奖励。在该例子中,定向误差被确定为在来自抓取装置108的瞬时姿势p的定向与来自抓取装置108在最终状态中的姿势p的定向之间的针对关于x轴线的转动的角度误差的和针对关于y轴线的转动的角度误差的范数。在该例子中,不考虑关于z轴线的转动。关于z轴线的转动可以在另外的任务(aufgabenstellungen)中被考虑。
[0057]
在该例子中,用下式:来确定第二奖励函数,该式具有可调整的第一参数=0.015和可调整的第二参数
=0.7。经此,奖励在该例子中保持在区间[
‑
1, 0]中。
[0058]
在这样的布局中,容易可能的是,在学习过程中出现发散,因为在所属的数据图中,在初始状态与最终状态之间出现大的路径长度。
[0059]
为了避免在学习过程中(也就是在训练中)的发散,设置了,在该学习过程中,采用无结果的动作,并且采用附加的上界限ub和下界限lb。在该例子中,根据最小的奖励和最大的奖励,限定上界限ub和下界限lb。在该例子中,针对q函数设置下界限和上界限0,针对所述q函数适用:。
[0060]
在该例子中,针对调节量的第二部分,限定无结果的动作。在该例子中,被限定为无结果的动作。在另外的场景中,也可以针对调节量的另外的部分限定无结果的动作。
[0061]
在该例子中,设置有学习装置210,所述学习装置210构造来,根据奖励函数中的至少一个奖励函数来确定奖励。学习装置210在该例子中构造来,确定q函数的值。可以设置的是,学习装置210构造来评估指示,并且根据指示的值,要么在利用动作到达的状态是最终状态时与q值无关地确定q函数的值,要么要不然根据q值来确定q函数的值。可以设置的是,学习装置构造来,利用下界限lb或者上界限ub来限制q函数的值。
[0062]
为了训练第一人工神经网络204,可以根据在第二人工神经网络206的输出处的q值来限定代价函数:。
[0063]
训练的目标在该例子中是,学习第一神经网络204的参数,针对所述第一神经网络204的参数,代价函数有比针对另外的参数更小的值。通过限定q值,该q值本身在该例子中是负的。代价函数因而在该例子中以梯度下降方法被最小化。
[0064]
在下文,描述了第一人工神经网络204和第二人工神经网络206的训练。为了训练,可以采用adam优化器。
[0065]
第一人工神经网络204(也就是演员网络)在该例子中包括三个完全连接的层,在该第一人工神经网络204中,两个隐藏的层分别包括100个神经元。第一人工神经网络204包括针对说明状态的力和力矩的输入层。在该例子中,使用所估计的变量的力和力矩的输入层。在该例子中,使用所估计的变量。力和力矩在该例子中可以线性地映射到状态描述的在区间[
‑
1, 1]中的值上。第一人工神经网络204包括针对限定动作的力和力矩的输出层。这些层在该例子中包括tanh激活函数。可以随机地初始化针对这些层的权重,尤其是通过glorot均匀分布初始化针对这些层的权重。输出层的输出在该例子中限定了针对动作的调节量的调节量。在该例子中,输出层是二维的。第一输出在该例子中限定了在x方向上的力矩。第二输出在该例子中限定了在y方向上的力矩。在该例子中,与第一人工神经网
funktion),所述稀疏奖励函数与第二奖励函数相比要更简单地被一般性限定。经此,应用者可以在工作中更快速地结束训练。这尤其是在如下工业环境中是有利的:在所述工业环境中,应针对任务来训练机器人102。
[0072]
通过该方法,相对于按照深度确定性策略梯度的方法,在训练中实现下列优点:相对超参数中的变化更高的稳健性(robustheit),更可靠地达到最终状态,在利用不同的随机种子(random seeds)初始化权重方面的更小的方差,相对于奖励函数的变化更高的稳健性,相对于(例如在嵌入式系统中的)有限的存储器更高的稳健性,更安全的探索。
[0073]
图3示意性地示出了用于运行机器人102的方法中的步骤。
[0074]
在步骤300中,确定至少一个力和至少一个力矩,所述至少一个力和所述至少一个力矩作用于机器人102的末端执行器108上。可以设置,确定所估计的变量,或者如所描述的那样确定相对应的变量。
[0075]
在步骤302中,根据至少一个力和至少一个力矩,确定第一状态。
[0076]
第一状态在该例子中关于轴线来限定,其中力引起末端执行器108在该轴线的方向上运动,其中力矩引起末端执行器108围绕该轴线转动。
[0077]
在该例子中,确定如下向量:所述向量限定第一状态,其中该向量限定第一力、第二力、第三力、第一力矩、第二力矩和第三力矩,其中针对这些力限定了不同的轴线,其中给每个力矩分配有不同的轴线中的另外的轴线。例如,通过所估计的变量,限定该向量。
[0078]
在步骤304中,根据机器人102和/或该机器人102的环境的第一状态,并且根据第一模型的输出,确定调节量的第一部分,用于针对机器人102从第一状态到第二状态的转移来操控机器人102。
[0079]
第一模型例如包括第一人工神经网络204。向量的第一部分在该例子中限定第一人工神经网络204的输入,用于确定调节量的第一部分。在该例子中,与向量的第二部分无关地,限定第一人工神经网络204的输入。
[0080]
在步骤306中,根据第一状态,并且与第一模型无关地,确定调节量的第二部分。
[0081]
在该例子中,限定调节量的向量被确定。该向量包括第一力、第二力、第三力、第一力矩、第二力矩和第三力矩,其中针对这些力限定不同的轴线。给每个力矩分配有不同的轴线中的另外的轴线。
[0082]
在该例子中,与第一人工神经网络204的输出无关地,尤其是恒定地限定向量的第一部分。在该例子中,根据第一人工神经网络204的输出,限定向量的第二部分。
[0083]
在该例子中,向量如针对调节量所描述的那样被确定。
[0084]
在步骤308中,根据机器人102的至少一个状态,确定数据图。在该例子中,使用最后进行的转移,以便补充数据图。限定无结果的动作的边可以被分配给如下节点:所述节点在数据图中为叶子,并且没有分配给机器人102的最终状态。可选地,无结果的动作分配给针对调节量的第一部分的尤其是恒定的值。
[0085]
在步骤310中,根据第一状态,并且根据第一模型的输出,利用第二模型确定质量级别。
[0086]
第二模型在该例子中包括第二人工神经网络206。向量在该例子中限定第二人工神经网络206的输入。第二人工神经网络206的输出在该例子中限定质量级别。
[0087]
在步骤312中,根据质量级别,确定第一模型的参数。为此,如之前针对第一人工神经网络204描述的那样,实施训练。
[0088]
在步骤314中,根据如下奖励来确定理论值:所述奖励分配给从第一状态到第二状态的转移。
[0089]
在该例子中,根据界限来确定理论值。根据数据图,确定界限。在该例子中,根据第一状态确定图的子图,并且如所描述的那样,根据q值确定界限,所述q值分配给子图的节点。
[0090]
在可选的步骤314中设置,根据预先给定的界限,确定理论值,所述预先给定的界限与任务有关地考虑领域知识。
[0091]
在步骤316中,根据质量级别和理论值,确定第二模型的至少一个参数。为此,如之前针对第二人工神经网络206所描述的那样,实施训练。
[0092]
可以按该顺序或者另外的顺序针对多个回合和/或周期(epochen)来重复该方法的步骤,以便根据最优策略来训练第一人工神经网络204,使第二人工神经网络206的q值最大化。可以设置,根据调节量ζ,操控机器人102,通过最优策略来确定所述调节量ζ。
[0093]
末端执行器108可以包括至少一个手指114,所述至少一个手指114具有与第一工件110互补的部段,并且自定心地实施所述至少一个手指114的表面。经此,在向下的恒定压力的情况下,能够实现特别好的支撑。自定心在如下高力矩的情况下也是特别重要的:所述高力矩关于工作空间110并不垂直向下作用。经此,可以避免对象的在其他情况下可能的扭转。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。