1.本发明属于人类语言处理技术领域,尤其涉及一种基于双向上下文的非自回归语音识别网络、方法、设备及存储介质。
背景技术:
2.语音识别在车载应用、语音唤醒、人机交流和智能家居等场景中有着广泛的应用。语音识别模型的输入为语音,而输出为该语音内容中的文字。传统的语音识别技术一般为自回归的解码方式,即文字的输出是串行的,该方法精度较高,但速度远远达不到实时性的要求。相对的,非自回归方法的字符预测是并行的,可以满足实时性的要求,但是非自回归方法不能较好地对语言信息进行建模,且解码前一般需要提前确定输出序列长度,相比于自回归方法,长度预测困难,识别精度较低。在过去的很长时间里,学术界与产业界涌现出大量提升非自回归语音识别能力的方法。目前工业界普遍应用的方法基于ctc(connectionist temporal classification)(alex graves, santiago fernandez, et al. connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks[c]. international conference on machine learning, 2006: 369
–
376.),但ctc方法只对输入的语音特征进行建模,导致输出文字间有很强的条件独立假设,输出的文字之间无法利用相互之间的语言信息,且ctc方法的计算复杂度为输入语音帧长度的平方,计算复杂度高。近年来,随着各领域方法的相互融合借鉴,首先在机器翻译领域被提出的transformer(ashish vaswani, noam shazeer, niki parmar, jakob uszkoreit, llion jones, et al. attention is all you need[c]. conference and workshop on neural information processing systems, 2017: 5998
–
6008.)也被广泛应用于语音识别任务中,由于transformer方法可以同时对语音和语言信息进行建模,所以众多基于transformer结构的非自回归方法被提出来用于解决语音识别的问题。
[0003]
本发明聚焦于非自回归语音识别问题。在语音识别问题中,能否充分利用语音信息和语言信息决定了识别结果的好坏,但非自回归方法对语言信息的利用率普遍较低,识别结果较差。为了提高非自回归方法的性能,yosuke 等人(yosuke higuchi, shinji watanabe, nanxin chen, tetsuji ogawa, and tetsunori kobayashi. mask ctc: nonautoregressive end
‑
to
‑
end asr with ctc and mask predict[c].conference of the international speech communication association, 2020: 3655
–
3659.)提出将编码器输出的部分文字作为解码器的输入,通过将低置信度的文字打掩码,并利用未打掩码的文字提供的语言信息对打掩码的文字进行重新预测。tian等人(zhengkun tian, jiangyan yi, jianhua tao, ye bai, shuai zhang, et al. spike
‑
triggered non
‑
autoregressive transformer for end
‑
to
‑
end speech recognition[c]. conference of the international speech communication association, 2020: 5026
–
5030.)为了加快识别速度,直接将编码器输出的部分语音编码特征作为解码器的输入,极大地加快了
识别的速度。为了减小长度预测错误,yosuke等人(yosuke higuchi, hirofumi inaguma, shinji watanabe, tetsuji ogawa, and tetsunori kobayashi. improved mask
‑
ctc for non
‑
autoregressive end
‑
to
‑
end asr[c]. international conference on acoustics, speech and signal processing,2021: 8363
–
8367.)设计了长度预测解码器,该解码器可在解码过程中动态调整输出序列的长度,从而减小长度预测错误。此外,为了进一步减小解码器建模的难度,增加解码器可利用的文字信息,song等人(xingchen song, zhiyong wu, yiheng huang, chao weng, dan su, helen meng.non
‑
autoregressive transformer asr with ctc
‑
enhanced decoder input[c]. international conference on acoustics, speech and signal processing,2021: 5894
–
5898.)提出直接将编码器输出的全部文字作为解码器的输入,并利用单向的上下文对输出进行预测。但是上述方法或者需要根据概率掩盖掉部分语言信息,或者直接只使用单向的语言信息,限制了解码器可以利用的语言信息,造成了语言信息的浪费。
[0004]
在自回归和流式语音识别中,存在关于双向语言信息的研究,如dong等人(dong m, he d, luo c, et al. transformer with bidirectional decoder for speech recognition[c]. conference of the international speech communication association,2020: 1773
–
1777.)提出使用两个解码器分别利用从左到右和从右到左的单向信息,但该方法的每个解码器仍是单向的,仍然会造成语言信息的浪费。其他方法也均使用两个完全分离的解码器分别对单向的语言信息进行建模,但其结构复杂且同样会造成反向语言信息的损失。
技术实现要素:
[0005]
本发明的目的在于提供一种基于双向上下文的非自回归语音识别网络、方法、设备及存储介质,旨在解决非自回归语音识别方法中使用单向上下文进行预测导致的语言信息无法被充分利用的问题。
[0006]
一方面,本发明提供一种基于双向上下文的非自回归语音识别网络,其特征在于,所述语音识别网络采用transformer的编码器
‑
解码器结构,其中,所述语音识别网络的编码器用于对输入的语音特征进行初步识别,得到初步识别结果;所述语音识别网络的解码器用于利用由所述初步识别结果提供的双向语言信息对所述初步识别结果进行调整,并输出最终的语音识别结果,其中,所述解码器通过预设的、应用于所述解码器的每个多头自注意力层的注意力掩码利用所述双向语言信息。
[0007]
优选地,所述注意力掩码为一个二维矩阵,所述二维矩阵的主对角线元素均为0,所述主对角线以外的元素均为1。
[0008]
优选地,所述解码器将位置编码作为所述解码器第一个多头自注意力层的q,并将相同的k和v输入到所述解码器的每一个多头自注意力层中。
[0009]
另一方面,本发明还提供了一种基于双向上下文的非自回归语音识别网络的语音识别方法,所述方法包括:通过训练好的语音识别网络的编码器对输入的语音特征进行初步识别,得到初步
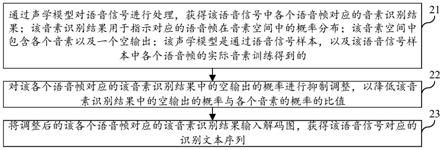
识别结果;通过训练好的语音识别网络的解码器对所述初步识别结果进行调整,输出最终的语音识别结果,其中,所述解码器利用由所述初步识别结果提供的双向语言信息对所述初步识别结果进行调整。
[0010]
优选地,通过训练好的语音识别网络的编码器对输入语音进行初步识别之前,还包括:使用训练集对所述语音识别网络的解码器和编码器进行联合训练,直至所述语音识别网络的损失值最小,得到所述训练好的语音识别网络。
[0011]
优选地,所述编码器和所述解码器联合损失函数如下:其中,为所述联合损失函数,为所述编码器的连接时序分类损失,为所述解码器的交叉熵损失,为超参数。
[0012]
优选地,所述解码器采用自适应停止迭代机制对所述初步识别结果进行调整。
[0013]
优选地,所述初步识别结果包括文字序列长度,所述解码器基于所述文字序列长度并行输出所述语音识别结果。
[0014]
另一方面,本发明还提供了一种语音识别设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述方法的步骤。
[0015]
另一方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上所述方法的步骤。
[0016]
在本发明实施例中,语音识别网络采用transformer的编码器
‑
解码器结构,语音识别网络的编码器用于对输入的语音特征进行初步识别,得到初步识别结果,语音识别网络的解码器用于利用由初步识别结果提供的双向语言信息对初步识别结果进行调整,并输出最终的语音识别结果,其中,解码器通过预设的、应用于解码器的第一个多头自注意力层的注意力掩码利用双向语言信息,从而充分了利用了语言信息,提高了语音识别效果,且相较于使用两个单向解码器分别利用单向语言信息的方法,结构更加高效统一。
附图说明
[0017]
图1a是本发明实施例一提供的基于双向上下文的非自回归语音识别网络的结构示意图;图1b是本发明实施例一提供的使用解码器学习双向上下文及其他方法的实现流程图;图1c是本发明实施例一提供的基于transformer解码器改进后解码器的结构示例图;图1d是本发明实施例一提供的注意力掩码的结构示例图;图2是本发明实施例二提供的基于双向上下文的非自回归语音识别方法的实现流程图;以及图3是本发明实施例五提供的语音识别设备的结构示意图。
具体实施方式
[0018]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0019]
以下结合具体实施例对本发明的具体实现进行详细描述:实施例一:图1a示出了本发明实施例一提供的基于双向上下文的非自回归语音识别网络的结构,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:在语音识别问题中,transformer结构中的解码器可以利用输入文字序列中的语言信息对输出进行预测。自回归语音识别的做法是利用当前位置之前输出的文字提供的语言信息进行预测,由于自回归方法是串行解码的,所以只能利用之前时间输出的文字信息。许多非自回归方法使用单向语言信息进行预测,然而,非自回归是并行输出文字序列的,使用单向的语言信息会造成反向语言信息的浪费。因此,本实施例提供的基于双向上下文的非自回归语音识别网络采用transformer的编码器
‑
解码器结构,以使用双向的语言信息进行语音识别,整个语音识别网络可以端到端地进行训练和测试。本实施例中提出的双向上下文即双向的语言信息,包括从左到右和从右到左两个方向。
[0020]
如图1a所示,本实施例提供的语音识别网络主要包括依次连接的编码器11和解码器12,编码器11用于对输入语音进行初步识别,得到初步识别结果,解码器12用于利用由初步识别结果提供的双向语言信息对初步识别结果进行调整,并输出最终的语音识别结果。其中,解码器通过预设的、应用于解码器的每个多头自注意力层的注意力掩码利用双向语言信息。图1b为本实施例提供的使用解码器学习双向上下文及其他方法的示例图,附图1b中,y1、y2和y3为字符,eos(end of sentence)为结束标志符,sos(start of sentence)为开始标志符,图1b的(a)为使用单向解码器学习从左到右的上下文,图1b的(b)为使用单向解码器学习从右向左的上下文,图1b的(c)为本实施例提供的使用解码器学习双向上下文。
[0021]
具体实现中,该语音识别网络的编码器11可采用speech transformer(linhao dong, shuang xu, and bo xu. speech
‑
transformer: a no
‑
recurrence sequence
‑
to
‑
sequence model for speech recognition[c]. international conference on acoustics, speech and signal processing, 2018: 5884
–
5888.)中的编码器结构,该结构中编码器主要由自注意力层和全连接层构成,编码器通过提取输入语音特征的全局特征,输出编码的语音特征和文字序列;解码器将编码器编码的语音特征和文字序列作为输入,通过进一步地提取语音信息和语言信息,对识别结果进行预测。在通过进一步提取的语音信息和语言信息对识别结果进行预测时,每一个位置都可以利用双向的语言信息对自身进行更新,即使原始的输入序列中有错误的识别结果,解码器也可以根据输入序列中的其他文字对自身识别结果做出调整。进一步地,解码器的输出序列可以重新输入到解码器中,通过迭代的方式进行识别,以略微牺牲解码速度的代价进一步的降低字符错误率。因为编码器并没有对语言信息进行建模,即输出的文字彼此之间有着比较强的条件独立假设,而解码器可以利用输入的文字序列提供的语言信息,消除条件独立假设,输出更加精确的识别结果。
[0022]
上述的迭代次数可以预先设定,优选地,解码器采用自适应停止迭代机制对初步
识别结果进行调整,以提高解码速度。具体地,自适应停止迭代机制可以理解为,当本次迭代解码器的输出和输入完全相同时,迭代自动停止,因为下一次迭代时,每一个位置可以利用的语言信息与本次迭代的相同,所以迭代结果不会改变。自适应停止迭代机制有效地提高了解码速度。
[0023]
优选地,该语音识别网络还包括卷积下采样层,该卷积下采样层用于对输入的语音信号进行下采样,并将下采样后得到的语音特征输入到编码器中,从而通过下采样,消除语音信号中的冗余帧,并降低整个网络的计算复杂度。具体实现中,语音信号可首先经过卷积下采样层进行n倍下采样,例如,4倍下采样,下采样后得到的语音特征即作为编码器的输入。
[0024]
在本发明实施例中,语音识别需要解决两个问题,分别是长度的预测问题和输出文字的识别问题。对于非自回归语音识别,所有的文字都是并行输出的,解码器在解码之前,需要提前确定整个输出序列的长度。优选地,初步识别结果包括文字序列长度,解码器基于文字序列长度并行输出语音识别结果,从而实现了实时运算。其中,编码器可采用ctc(连接时序分类, connectionist temporal classification)损失,以使编码器在测试时可以对序列的长度进行预测,解码器可采用ce(cross entropy,交叉熵)损失,以使解码器可以利用编码器输出的序列提供的双向语言信息进行重新预测。由于解码器采用编码器输出的语音特征作为输入的一部分,所以编码器和解码器可以进行联合训练,从而优选地,编码器和解码器联合损失函数如下:其中,为联合损失函数,为编码器的连接时序分类损失,为解码器的交叉熵损失,为超参数。即,使用ctc损失和ce损失联合训练。
[0025]
在本发明实施例中,解码器中的每个位置都可以利用双向的上下文进行预测,但是双向的上下文带来了信息泄露的问题。简单地说,信息泄露问题指在训练时,解码器的输出可以看到输入的相关信息,而信息泄露会造成在测试时解码器无法对输入进行重新预测,从而丧失利用语言信息对结果进行调整的能力。
[0026]
为防止信息泄露,优选地,解码器将位置编码作为解码器第一个多头自注意力层的q,并将相同的k和v输入到解码器的每一个多头自注意力层中。具体实现中,如附图1c所示,可在原始transformer解码器的基础上,对解码器输入的queries(查询,q)、keys(键,k)和values(值,v)进行改进,附图1c中包括字符编码、位置编码、多头源注意力层和多头自注意力层,由于解码器中存在残差连接,所以获取位置编码的映射,并可将作为解码器第一个多头自注意力层的q。
[0027]
其中,为位置编码的线性映射,为线性映射,p为位置编码(positional encoding)。
[0028]
然后,将相同的k和v输入到解码器的每一个多头自注意力层:,1 ≤i ≤ i其中,i为解码器的多头自注意力层的总层数,i为当前的多头自注意力层的层数,
c为字符嵌入(character embedding)。解码器的多头源注意力层的k和v可基于编码状态确定。
[0029]
另外,为防止信息泄露,上述的注意力掩码还用于使每个位置无法看到与自身位置相关的语言信息。如附图1d所示,优选地,注意力掩码是一个二维的矩阵,该矩阵的主对角线元素均为0,其余元素都为1,即该注意力掩码使每一个位置对自身的注意力权重均为0,以防止信息泄露。
[0030]
在本发明实施例中,语音识别网络采用transformer的编码器
‑
解码器结构,语音识别网络的编码器用于对输入的语音特征进行初步识别,得到初步识别结果,语音识别网络的解码器用于利用由初步识别结果提供的双向语言信息对初步识别结果进行调整,并输出最终的语音识别结果,其中,解码器通过预设的、应用于解码器的每个多头自注意力层的注意力掩码利用双向语言信息,从而充分了利用了语言信息,提高了语音识别效果,且相较于使用两个单向解码器分别利用单向语言信息的方法,结构更加高效统一。
[0031]
实施例二:图2示出了本发明实施例二提供的基于双向上下文的非自回归语音识别方法的实现流程,本发明实施例二基于实施例一实现,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:在步骤s201中,通过训练好的语音识别网络的编码器对输入的语音特征进行初步识别,得到初步识别结果。
[0032]
本发明实施例适用于语音识别设备,该语音识别设备可以为手机、平板电脑、可穿戴设备、智能音箱、车载设备、笔记本电脑、超级移动个人计算机(ultra
‑
mobile personal computer,umpc)、上网本、个人数字助理(personal digital assistant,pda)等设备,本技术实施例对语音识别设备的具体类型不作任何限制。
[0033]
在本发明实施例中,在通过训练好的语音识别网络的编码器对输入的语音特征进行初步识别之前,需要对语音识别网络进行训练,在对语音识别网络进行训练时,优选地,使用训练集对语音识别网络的解码器和编码器进行联合训练,直至语音识别网络的损失值最小,得到训练好的语音识别网络,从而实现了端到端地进行训练,降低了训练复杂度和运行时间。其中,联合训练即同时训练编码器和解码器。
[0034]
在对该语音识别网络进行训练时,语音识别网络的损失值可使用编码器与解码器各自的损失值进行加权求和计算,不同的权重代表不同的参数更新程度,通过调整该权重,获得最好的模型。优选地,编码器和解码器联合损失函数如下:其中,为联合损失函数,为编码器的连接时序分类损失,为解码器的交叉熵损失,为超参数。即,使用ctc损失和ce损失联合训练。
[0035]
在对语音识别网络进行训练时,优选地,使用频谱增强和速度扰动两种数据增广策略对训练集中的数据进行数据增广,以增强语音识别网络的鲁棒性。
[0036]
在步骤s202中,通过训练好的语音识别网络的解码器对初步识别结果进行调整,输出最终的语音识别结果,其中,解码器利用由初步识别结果提供的双向语言信息对初步识别结果进行调整。
[0037]
在本发明实施例中,在通过训练好的语音识别网络的解码器对初步识别结果进行
调整时,每一个位置都可以利用到双向的语言信息对自身进行更新,即使原始的输入序列中有错误的识别结果,解码器也可以根据输入序列中的其他文字对自身识别结果做出调整。进一步地,解码器的输出序列可以重新输入到解码器中,通过迭代的方式进行识别,以略微牺牲解码速度的代价进一步的降低字符错误率。优选地,解码器采用自适应停止迭代机制对初步识别结果进行调整,以提高解码速度。具体地,自适应停止迭代机制可以理解为,当本次迭代解码器的输出和输入完全相同时,迭代自动停止。
[0038]
优选地,初步识别结果包括文字序列长度,解码器基于文字序列长度并行输出语音识别结果,从而实现了实时运算。
[0039]
在本发明实施例中,通过训练好的语音识别网络的编码器对输入的语音特征进行初步识别,得到初步识别结果,通过训练好的语音识别网络的解码器对初步识别结果进行调整,输出最终的语音识别结果,其中,解码器利用由初步识别结果提供的双向语言信息对初步识别结果进行调整,从而充分了利用了语言信息,提高了识别效果,且相较于使用两个单向解码器分别利用单向语言信息的方法,结构更加高效统一。
[0040]
下面结合一个实验例来对本实施例提供的车牌定位方法进行进一步地验证说明:(1)本实验例使用的语料库:aishell1语料库,该语料库为希尔贝壳中文普通话开源语音语料库,是希尔贝壳中文普通话语音数据库aishell
‑
asr0009的一部分。该语料库录制过程在安静室内环境中,400名来自中国不同口音区域的发言人参与录制,使用音频降采样为16khz的高保真麦克风(44.1khz,16
‑
bit)制作,录音时长178小时。经过专业语音校对人员转写标注,并通过严格质量检验。此语料库文本正确率在95%以上,分为训练集、开发集和测试集。
[0041]
magicdata语料库,该语料库由magic data科技公司发布,为中文普通话语音语料库。该语料库录制过程在安静室内环境中,1000名中国大陆普通话母语人士参与录制,使用手机进行录音,录音时长755小时。此语料库文本正确率在98%以上,同样分为训练集、开发集、测试集。
[0042]
(2)实验描述:模型训练时,本实验例使用频谱增强和速度扰动两种数据增广策略,增强模型的鲁棒性。本实验例采用pytorch1.7.0深度学习框架,利用adam优化策略和梯度累加策略训练,其中的动量参数设置为β_1=0.9和β_2=0.999。初始学习率设置为0.0001,训练批量为32。所有的实验都是在一台含有4块nvidia titan xp gpu的机器上进行。
[0043]
本实验例使用的语料库为两个开源的普通话中文语料库,两语料库的语音均为干净的语音。在训练时,使用ctc和ce损失联合训练,其中ctc损失权重设置为0.3,ce损失权重设置为0.7。网络中存在多个dropout层,drop概率均设置为0.1。
[0044]
(3)实验结果:为了评估本实验例的有效性,本实验例在上述提到的语料库中进行了语音识别测试。将本实施例提供的方法与目前主流的自回归及非自回归语音识别方法进行了对比实验,包括kermit、laso、st
‑
nar、masked
‑
nat、cass
‑
nat、ctc
‑
enhanced transformer、ts
‑
nat和ar transformer。
[0045]
实验结果见表1和表2,表1和表2分别为aishell1语料库和magicdata语料库的实验结果,其中nat
‑
bc(non
‑
autoregressive transformer with bidirectional contexts)
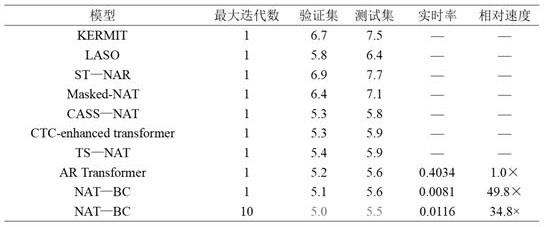
代表本实施例描述的方法。结果表明本实施例描述的方法在不同语料库下的字符错误率比其他所有非自回归方法都要低,且在保持与自回归方法相近字符错误率的情况下,识别速度要显著快于自回归方法,可以达到实时性的要求。其中,字符错误率包括插入、替换和删除三种错误,实时率在数值上等于计算机处理单位时间的语音信号需要花费的时间,相对速度为模型相对于自回归transformer模型的速度。
[0046]
表1表2为了进一步验证本实施例描述的方法中使用双向上下文的优势,将解码器中的双向上下文替换成单向上下文,在magicdata语料库上进行了对比实验。性能见表3。由表3可见,在不同的迭代次数下,双向上下文都取得了更低的字符错误率,迭代多次的字符错误率要比迭代一次的字符错误率更低。值得注意的是,通过迭代多次的方式,双向上下文的字符错误率比单向上下文下降的更多,这更凸显了双向上下文的优越性。
[0047]
表3实施例三:图3示出了本发明实施例三提供的语音识别设备的结构,为了便于说明,仅示出了与本发明实施例相关的部分。
[0048]
本发明实施例的语音识别设备3包括处理器30、存储器31以及存储在存储器31中并可在处理器30上运行的计算机程序32。该处理器30执行计算机程序32时实现上述各方法实施例中的步骤,例如图2所示的步骤s201至s202。
[0049]
在本发明实施例中,语音识别网络采用transformer的编码器
‑
解码器结构,语音识别网络的编码器用于对输入的语音特征进行初步识别,得到初步识别结果,语音识别网络的解码器用于利用由初步识别结果提供的双向语言信息对初步识别结果进行调整,并输出最终的语音识别结果,其中,解码器通过预设的、应用于解码器的每个多头自注意力层的注意力掩码利用双向语言信息,从而充分了利用了语言信息,提高了语音识别效果,且相较于使用两个单向解码器分别利用单向语言信息的方法,结构更加高效统一。
[0050]
实施例四:在本发明实施例中,提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现上述方法实施例中的步骤,例如,图2所示的步骤s201至s202。
[0051]
在本发明实施例中,语音识别网络采用transformer的编码器
‑
解码器结构,语音识别网络的编码器用于对输入的语音特征进行初步识别,得到初步识别结果,语音识别网络的解码器用于利用由初步识别结果提供的双向语言信息对初步识别结果进行调整,并输出最终的语音识别结果,其中,解码器通过预设的、应用于解码器的每个多头自注意力层的注意力掩码利用双向语言信息,从而充分了利用了语言信息,提高了语音识别效果,且相较于使用两个单向解码器分别利用单向语言信息的方法,结构更加高效统一。
[0052]
本发明实施例的计算机可读存储介质可以包括能够携带计算机程序代码的任何实体或装置、记录介质,例如,rom/ram、磁盘、光盘、闪存等存储器。
[0053]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。