重组肽-mhc复合物结合蛋白及其生成和用途
1.相关专利申请的交叉引用
2.本技术要求以下申请的优先权的权益:2019年12月11日提交的ep19215433.4;2019年12月11日提交的ep19215434.2;2019年12月11日提交的ep19215435.9;2019年12月11日提交的ep19215436.7;2020年3月4日提交的ep20161059.9;以及2020年6月19日提交的ep20181234.4。这六个专利申请的公开内容以引用方式整体并入本文用于所有目的。
技术领域
3.本发明涉及一种产生对肽-mhc(pmhc)复合物具有结合特异性的重组结合蛋白的方法。本发明还涉及包含一个、两个或更多个对pmhc复合物具有结合特异性的经设计的重复结构域(优选经设计的锚蛋白重复结构域)的重组结合蛋白,并且还涉及这样的结合蛋白:其还包含对在免疫细胞(优选t细胞)的表面上表达的蛋白具有结合特异性的结合因子。此外,本发明涉及编码此类结合蛋白或重复结构域的核酸、包含此类结合蛋白或核酸的药物组合物,以及此类结合蛋白、核酸或药物组合物在用于治疗或诊断疾病(包括癌症、感染性疾病和自体免疫疾病)的方法中的用途。
背景技术:
4.主要组织相容性复合物(mhc)i类分子在细胞内的异常或外来蛋白质的监视中起关键作用。来源于内源性蛋白的肽被装载到mhc i类分子的肽结合槽上,然后显示在细胞表面上。此类mhc i类复合物在所有有核细胞(包括恶性细胞)中表达。肽-mhc(pmhc)复合物被cd8 细胞毒性t淋巴细胞(ctl)上的t细胞受体(tcr)识别。肽-mhc复合物的呈递提供了细胞内环境对循环ctl的快照(reeves和james,immunology 150:16-24(2016))。ctl响应于检测到异常或外来抗原(例如癌蛋白,或者细菌蛋白或病毒蛋白)而被激活,导致对呈递细胞的破坏。ctl在某些自体免疫疾病中,在误识别“自身”抗原时也被激活(bodis等人,rheumatol.ther.5:5-20(2018))。
5.呈递肿瘤特异性或感染因子特异性肽的mhc i类复合物代表了一类独特且有前景的用于癌症和感染性疾病的免疫疗法的细胞表面靶标。已经开发了不同的方法来尝试利用这类靶标,包括疫苗、过继性细胞疗法和tcr样抗体。在肿瘤相关抗原中,癌症睾丸抗原(cta)被认为是免疫疗法的良好候选靶标,因为它们的特征在于在正常的体细胞组织中的受限表达和在肿瘤组织中的再表达。各种癌症类型中最常报道的cta之一是黑素瘤相关抗原a3(mage-a3)(j exp clin cancer res.2019年7月8日;38(1):294.doi:10.1186/s13046-019-1272-2)。而且,已经发现几种cta会诱导自发免疫应答,ny-eso-1是最具免疫原性中的一种(thomas等人,front immunol.2018;9:947)。在感染因子特异性肽中,ebv核抗原1(ebna-1)是在所有ebv相关恶性肿瘤中发现的唯一病毒蛋白(j gen virol.2009年9月;90(pt 9):2251-2259)。而且,乙型肝炎病毒(hbv)核衣壳抗原的序列18-27被具有急性自限性hbv感染的hla-a2阳性患者的ctl广泛识别,并且代表基于肽的治疗性疫苗的主要成分,该疫苗旨在刺激慢性乙型肝炎患者的抗病毒ctl应答(hepatology.1997年10月;26(4):
1027-34.c)。
6.一直以来,治疗性开发病毒或肿瘤特异性肽-mhc复合物的一个障碍是胸腺选择后tcr对肽-mhc复合物的亲和力天生就低。这种低亲和力造成了限制,尤其是考虑到病毒或肿瘤特异性肽-mhc复合物通常以低密度存在于病毒感染细胞或肿瘤细胞的表面上。为了克服该障碍,已开发了亲和力增强的tcr,并且在临床研究中测试了表达此类亲和力增强的tcr的工程化t细胞。据报道,亲和力增强的tcr可能缺乏特异性,并且在一些情况下,表达亲和力增强的tcr的工程化t细胞已经引起严重的、有时甚至致命的医疗并发症,这是由于tcr对来源于无关蛋白质的表位的意外识别(参见例如linette等人,blood 122(6):863-871(2013))。亲和力增强的tcr也正被开发为可溶性tcr,但可溶性tcr的表达具有挑战性。
7.已经报道了许多对呈递病毒或肿瘤特异性肽的mhc i类复合物具有结合特异性的tcr样抗体。其中一些用杂交瘤技术分离。然而,通过杂交瘤技术分离pmhc特异性tcr样抗体一直以来受到许多因素的阻碍,包括需要筛选数百个或甚至数千个克隆、低免疫原性、由于免疫优势造成独特克隆很少,以及对精细特异性的控制很差(参见例如,porgador等人,immunity 6:715-726(1997);bernardeau等人,eur.j.immunol.,35(10):2864-2875(2005);skora等人,proc.natl.acad.sci.usa 112(32):9967-9972(2015))。更多的tcr样抗体已使用噬菌体展示技术分离。然而,从噬菌体展示文库分离的tcr样抗体的亲和力通常相对低,并且通常不足以用于治疗目的(参见例如chames等人,proc.natl.acad.sci.usa 97:7969-7974(2000))。为了生成具有足够高亲和力的tcr样抗体,已经开发了用于亲和力成熟的系统。例如,一种这样的用于tcr样抗体亲和力成熟的系统将诱变、文库和酵母展示、结构测定和分子建模结合起来(zhao等人,leukemia 29(11):2238-2247(2015))。zhao等人只有采用这种复杂且劳动密集型的亲和力成熟方法,才能够将tcr样抗体的结合亲和力提高到约100倍,以获得具有足够大亲和力的pmhc特异性结合蛋白。综上所述,开发以足够大亲和力特异性地结合疾病相关肽-mhc复合物的分子迄今为止一直具有挑战性,并且目前的方法通常涉及难以获得的表达系统和/或耗时费力的过程,诸如筛选大量杂交瘤克隆或亲和力成熟。
8.因此,仍然需要生产pmhc特异性结合蛋白的新方法、需要新的pmhc特异性结合蛋白,并且需要用于治疗和表征受益于pmhc特异性结合的疾病(包括癌症、自体免疫疾病和感染性疾病)的治疗和诊断方法。
技术实现要素:
9.本发明提供一种生产对肽-mhc(pmhc)复合物具有结合特异性的重组结合蛋白的方法。本发明还提供包含一个、两个或更多个对pmhc复合物具有结合特异性的经设计的重复结构域(优选经设计的锚蛋白重复结构域)的重组结合蛋白,并且还提供这样的结合蛋白:其还包含对在免疫细胞(优选t细胞)的表面上表达的蛋白具有结合特异性的结合因子。此外,本发明提供编码此类结合蛋白或重复结构域的核酸、包含此类结合蛋白或核酸的药物组合物,以及此类结合蛋白、核酸或药物组合物在用于治疗或诊断哺乳动物(包括人)的疾病(诸如癌症、自体免疫疾病和感染性疾病)的方法中的用途。
10.本发明的产生对pmhc复合物具有结合特异性的重组结合蛋白的方法在生成以高亲和力和/或特异性结合到所选择的靶标pmhc复合物的结合蛋白方面令人惊奇地有效果且
有效率。开发以足够大亲和力特异性地结合疾病相关pmhc复合物的分子迄今为止一直具有挑战性,并且目前的方法通常涉及难以获得的表达系统和/或耗时费力的过程,诸如筛选大量杂交瘤克隆或亲和力成熟。本文所公开的本发明方法既不涉及难以获得的表达系统,也不需要耗时费力的过程,诸如上文提到的那些。此外,本发明的结合蛋白与靶标肽-mhc复合物之间的结合相互作用出乎意料地涉及靶标肽中相对大量的氨基酸残基。据信,靶标肽中的大量相互作用残基反映了在不同pmhc复合物的大范围内与靶标肽-mhc复合物的高选择性或特异性结合相互作用。似乎本发明的结合蛋白的pmhc特异性重复结构域可以提供在空间上与复合肽-mhc表面以特异性结合相互作用很好地匹配的结合表面。此外,本发明的结合蛋白的pmhc特异性重复结构域可以在n-末端封端模块和/或c-末端封端模块中包含特定氨基酸序列基序,从而导致经设计的重复结构域和包含经设计的重复结构域的蛋白的药代动力学特性改善。本发明的方法和结合蛋白还提供了这样的优点:即两个或更多个相同和/或不同的pmhc特异性重复结构域可以容易地组合在一个结合蛋白中(生成例如二价结合蛋白、双互补位结合蛋白或双特异性结合蛋白),从而允许适应和优化结合蛋白的结合亲合力、结合亲和力、结合特异性和/或效力。而且,本发明的结合蛋白甚至可以还包含对在免疫细胞的表面上表达的蛋白(诸如,作为在细胞毒性t细胞中表达的t细胞受体复合物的一部分或在天然杀伤(nk)细胞中表达的激活受体的蛋白)具有结合特异性的结合因子。这种免疫细胞接合剂形式(例如,t细胞接合剂形式或nk细胞接合剂形式)的本发明的结合蛋白可以有利地用于激活免疫细胞(例如t细胞或nk细胞)的方法和/或以定位和靶向方式接合免疫系统的方法中。此外,将一个或多个pmhc特异性重复结构域连接到结合因子的接头的长度出乎意料地影响本发明的结合蛋白以免疫细胞接合剂形式,诸如t细胞接合剂形式使用的效力。此外,本发明的方法和结合蛋白允许特异性地靶向细胞内蛋白及其他对象,从而促进许多新的诊断和治疗机会,例如针对癌症、感染性疾病和自体免疫疾病。
11.在一个方面,本发明提供了一种产生肽-mhc(pmhc)特异性结合蛋白的方法,其中所述结合蛋白包含对靶标肽-mhc复合物具有结合特异性的经设计的重复结构域,该方法包括以下步骤:
12.(a)提供经设计的重复结构域的集合;
13.(b)提供重组的靶标肽-mhc复合物;以及
14.(c)筛选所述经设计的重复结构域的集合的对所述靶标肽-mhc复合物的特异性结合,以获得至少一个对所述靶标肽-mhc复合物具有结合特异性的经设计的重复结构域。在一个优选的实施方案中,所述经设计的重复结构域是经设计的锚蛋白重复结构域。
15.在另一方面,本发明提供了一种重组结合蛋白,其包含可通过上述方法获得的经设计的重复结构域。
16.在另一方面,本发明提供了一种重组结合蛋白,其包含第一经设计的重复结构域,其中所述第一重复结构域对第一靶标肽-mhc复合物具有结合特异性。在一个优选的实施方案中,所述第一靶标肽来源于与疾病或疾患相关联的蛋白质。作为示例,在一个特定的优选实施方案中,所述第一靶标肽选自由以下项组成的组:(i)来源于在肿瘤细胞中表达的蛋白的肽;(ii)来源于感染因子(优选病毒感染因子)的蛋白的肽;以及(iii)来源于与自体免疫疾患相关联的蛋白的肽。
17.在一个特定方面,所述第一靶标肽来源于细胞内蛋白,优选地在肿瘤细胞中表达
的细胞内蛋白,诸如ny-eso-1或mage-a3。在一个优选方面,来源于ny-eso-1的靶标肽包含seq id no:19或seq id no:34的氨基酸序列或由所述氨基酸序列组成,并且来源于mage-a3的靶标肽包含seq id no:155的氨基酸序列或由所述氨基酸序列组成。在另一个方面,所述第一靶标肽来源于病毒感染因子的蛋白,优选病毒特异性蛋白,诸如ebna-1或hbv核心抗原(hbcag)。在一个优选方面,来源于ebna-1的靶标肽包含seq id no:92的氨基酸序列或由所述氨基酸序列组成,并且来源于hbcag的靶标肽包含seq id no:255的氨基酸序列或由所述氨基酸序列组成。
18.在一个优选方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一经设计的重复结构域,其中所述第一重复结构域是经设计的锚蛋白重复结构域。
19.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于ny-eso-1,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于ny-eso-1,并且其中所述第一锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。
20.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于mage-a3,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:175至217,以及(2)其中seq id no:175至217中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于mage-a3,并且其中所述第一锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:156至173的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:156至173的倒数第二个位置处的a任选地被l取代并且/或者seq id no:156至173的最后一个位置处的a任选地被n取代。
21.在另一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于ebna-1,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:111至154,以及(2)其中seq id no:111至154中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于ebna-1,并且其中所述第一锚蛋白重复结构域
包含与seq id no:93至110中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:93至110的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:93至110的倒数第二个位置处的a任选地被l取代并且/或者seq id no:93至110的最后一个位置处的a任选地被n取代。
22.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于hbcag,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:231至254,以及(2)其中seq id no:231至254中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一靶标肽来源于hbcag,并且其中所述第一锚蛋白重复结构域包含与seq id no:220至230中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:220至230的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:220至230的倒数第二个位置处的a任选地被l取代并且/或者seq id no:220至230的最后一个位置处的a任选地被n取代。
23.在另一个优选方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一经设计的重复结构域,其中所述第一重复结构域包含n-末端和/或c-末端封端模块。
24.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有其中位置8处的氨基酸是q和/或位置15处的氨基酸是l的氨基酸序列,其中该n-末端封端模块的位置的所述位置编号使用seq id no:276的位置编号通过与seq id no:276比对来确定。seq id no:276是与seq id no:5相同的n-末端封端模块,除了seq id no:5的位置1处的g和位置2处的s缺失以外。因此,seq id no:276中的位置8对应于seq id no:5中的位置10,并且seq id no:276中的位置15对应于seq id no:5中的位置17。换句话说,所述第一锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有其中位置10处的氨基酸是q和/或位置17处的氨基酸是l的氨基酸序列,其中该n-末端封端模块的位置的所述位置编号使用seq id no:5的位置编号通过与seq id no:5比对来确定。优选地,所述比对不包括氨基酸空位。序列比对生成是本领域众所周知的程序。
25.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域包含c-末端封端模块,该c-末端封端模块具有其中位置14处的氨基酸是r和/或位置18处的氨基酸是q的氨基酸序列,其中该c-末端封端模块的位置的位置编号使用seq id no:13的位置编号通过与seq id no:13比对来确定。优选地,所述比对不包括氨基酸空位。
26.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域包含(i)具有其中位置8处的氨基酸是q且位置15处的氨基酸是l的氨基酸序列的n-末端封端模块,和/或(ii)具有其中位置14处的氨基酸是r且位置18处的氨基酸是q的氨基酸序列的c-末端封端模块。优选地,该n-末端封端模块的位置的所述位置编号使用seq id no:276的位置编
号通过与seq id no:276比对来确定,并且该c-末端封端模块的位置的所述位置编号使用seq id no:13的位置编号通过与seq id no:13比对来确定。优选地,所述比对不包括氨基酸空位。
27.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna(seq id no:276),其中在除位置8和位置15之外的位置中至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
28.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域包含c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa(seq id no:13),其中在除位置14和位置18之外的位置中seq id no:13的至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
29.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第一靶标肽-mhc复合物具有结合特异性的第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna(seq id no:276),其中在除位置8和位置15之外的位置中至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa(seq id no:13),其中在除位置14和位置18之外的位置中seq id no:13的至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
30.在一个特定方面,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二经设计的重复结构域。在一个优选的实施方案中,所述第二靶标肽来源于与疾病或疾患相关联的蛋白质。作为示例,在一个特定的优选实施方案中,所述第二靶标肽选自由以下项组成的组:(i)来源于在肿瘤细胞中表达的蛋白的肽;(ii)来源于感染因子(优选病毒感染因子)的蛋白的肽;以及(iii)来源于与自体免疫疾患相关联的蛋白的肽。
31.在一个特定方面,所述第二靶标肽来源于与所述第一靶标肽相同的蛋白。在一个实施方案中,所述第二靶标肽具有与所述第一靶标肽相同的氨基酸序列。在一个实施方案中,所述第二重复结构域具有与所述第一重复结构域相同的氨基酸序列。在一个实施方案中,所述第二重复结构域与所述第一重复结构域相比具有不同的氨基酸序列。在一个实施方案中,与所述第一靶标肽相比,所述第二靶标肽具有不同的氨基酸序列。
32.在一个特定方面,所述第二靶标肽来源于与所述第一靶标肽所来源的蛋白不同的蛋白。
33.在一个优选方面,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc
复合物具有结合特异性的第二经设计的重复结构域,其中所述第二重复结构域是经设计的锚蛋白重复结构域。在一个特定方面,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于ny-eso-1,并且其中所述第二锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于ny-eso-1,并且其中所述第二锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。
34.在另一个特定方面,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于mage-a3,并且其中所述第二锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:175至217,以及(2)其中seq id no:175至217中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于mage-a3,并且其中所述第二锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:156至173的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:156至173的倒数第二个位置处的a任选地被l取代并且/或者seq id no:156至173的最后一个位置处的a任选地被n取代。
35.在另一个特定方面,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于ebna-1,并且其中所述第二锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:111至154,以及(2)其中seq id no:111至154中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于ebna-1,并且其中所述第二锚蛋白重复结构域包含与seq id no:93至110中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:93至110的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:93至110的倒数第二个位置处的a任选地被l取代并且/或者seq id no:93至110的最后一个位置处的a任选地被n取代。
36.在另一个特定方面,本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于hbcag,并且其中所述第二锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:231至254,以及(2)其中seq id no:231至254中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。在一个特定的实施方案中,
本发明提供这样的重组结合蛋白:其还包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二靶标肽来源于hbcag,并且其中所述第二锚蛋白重复结构域包含与seq id no:220至230中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:220至230的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:220至230的倒数第二个位置处的a任选地被l取代并且/或者seq id no:220至230的最后一个位置处的a任选地被n取代。
37.在另一个优选方面,本发明提供这样的重组结合蛋白:其包含对第二靶标肽-mhc复合物具有结合特异性的第二经设计的重复结构域,其中所述第二重复结构域包含n-末端和/或c-末端封端模块。
38.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有其中位置8处的氨基酸是q和/或位置15处的氨基酸是l的氨基酸序列,其中该n-末端封端模块的位置的所述位置编号使用seq id no:276的位置编号通过与seq id no:276比对来确定。换句话说,所述第二锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有其中位置10处的氨基酸是q和/或位置17处的氨基酸是l的氨基酸序列,其中该n-末端封端模块的位置的所述位置编号使用seq id no:5的位置编号通过与seq id no:5比对来确定。优选地,所述比对不包括氨基酸空位。序列比对生成是本领域众所周知的程序。
39.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域包含c-末端封端模块,该c-末端封端模块具有其中位置14处的氨基酸是r和/或位置18处的氨基酸是q的氨基酸序列,其中该c-末端封端模块的位置的位置编号使用seq id no:13的位置编号通过与seq id no:13比对来确定。优选地,所述比对不包括氨基酸空位。
40.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域包含(i)具有其中位置8处的氨基酸是q且位置15处的氨基酸是l的氨基酸序列的n-末端封端模块,和/或(ii)具有其中位置14处的氨基酸是r且位置18处的氨基酸是q的氨基酸序列的c-末端封端模块。优选地,该n-末端封端模块的位置的所述位置编号使用seq id no:276的位置编号通过与seq id no:276比对来确定,并且该c-末端封端模块的位置的所述位置编号使用seq id no:13的位置编号通过与seq id no:13比对来确定。优选地,所述比对不包括氨基酸空位。
41.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna(seq id no:276),其中在除位置8和位置15之外的位置中至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
42.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域包含c-末
端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa(seq id no:13),其中在除位置14和位置18之外的位置中seq id no:13的至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
43.在一个特定方面,本发明提供这样的重组结合蛋白:其包含对第二靶标肽-mhc复合物具有结合特异性的第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna(seq id no:276),其中在除位置8和位置15之外的位置中至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa(seq id no:13),其中在除位置14和位置18之外的位置中seq id no:13的至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
44.在一个特定方面,本发明提供这样的重组结合蛋白,其中所述结合蛋白包含多肽,所述多肽包含与seq id no:16至18中的任一者具有至少80%氨基酸序列同一性的氨基酸序列。
45.在一个优选方面,重复结构域与其靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少一个、至少两个、至少三个、至少四个、至少五个、至少六个或至少七个氨基酸残基的相互作用。在一个实施方案中,重复结构域与其靶标肽-mhc复合物的结合替代性地包括或还包括所述重复结构域与所述mhc的至少一个氨基酸残基的相互作用。
46.在一个特定方面,本发明提供此类pmhc特异性重组结合蛋白,其中所述结合蛋白还包含对在免疫细胞(优选t细胞或nk细胞,更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的结合因子。在一个实施方案中,在t细胞表面上表达的所述蛋白是作为t细胞受体复合物的一部分的蛋白。作为一个示例,在一个特定的实施方案中,本发明提供此类pmhc特异性重组结合蛋白,其中所述结合蛋白还包含对cd3具有结合特异性的结合因子。在另一个实施方案中,在nk细胞的表面上表达的所述蛋白是nk细胞的激活受体。nk细胞的此类激活受体的示例包括:cd16(也称为fcγriia)、nkg2d、slam家族成员和天然细胞毒性受体nkp30、nkp44和nkp46。
47.在一个优选方面,本发明提供这样的重组结合蛋白:其还包含对免疫细胞的表面上表达的蛋白具有结合特异性的结合因子,其中所述结合因子是经设计的重复结构域,优选经设计的锚蛋白重复结构域。
48.在另一方面,本发明提供编码本发明的经设计的重复结构域或编码本发明的pmhc特异性重组结合蛋白的核酸,以及包含本发明的pmhc特异性重组结合蛋白或核酸和药学上可接受的载剂和/或稀释剂的药物组合物。
49.在另一方面,本发明提供了一种在哺乳动物(优选人)中肿瘤定位激活免疫细胞(诸如t细胞或nk细胞)的方法,该方法包括向所述哺乳动物施用本发明的pmhc特异性重组结合蛋白或核酸的步骤,其中所述结合蛋白还包含对免疫细胞的表面上表达的蛋白具有结合特异性的结合因子,并且其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重
复结构域)所述第二靶标肽来源于在肿瘤细胞中表达的蛋白。
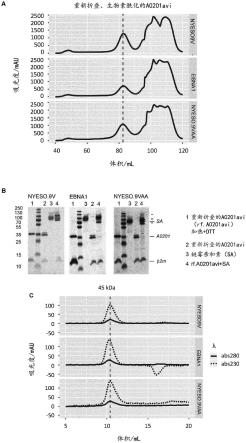
50.在另一方面,本发明提供了根据本发明的pmhc特异性重组结合蛋白或核酸,其用于在哺乳动物(优选人)中肿瘤定位激活免疫细胞(诸如t细胞或nk细胞)的方法中,其中所述结合蛋白还包含对在免疫细胞的表面上表达的蛋白具有结合特异性的结合因子,并且其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在肿瘤细胞中表达的蛋白。
51.在另一方面,本发明提供了一种在哺乳动物(优选人)中感染定位激活免疫细胞(诸如t细胞或nk细胞)的方法,该方法包括向所述哺乳动物施用本发明的pmhc特异性重组结合蛋白或核酸的步骤,其中所述结合蛋白还包含对免疫细胞的表面上表达的蛋白具有结合特异性的结合因子,并且其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于感染因子的蛋白。
52.在另一方面,本发明提供了一种用于治疗医学病症的方法,该方法包括向对该治疗有需要的患者施用治疗有效量的本发明的pmhc特异性重组结合蛋白、核酸或药物组合物的步骤。
53.在另一方面,本发明提供了本发明的pmhc特异性重组结合蛋白、核酸或药物组合物,其用于治疗医学病症的方法中。
54.在另一方面,本发明提供了一种诊断哺乳动物(优选人)的医学病症的方法,该方法包括以下步骤:
55.(i)使从所述哺乳动物获得的细胞或组织样品与本发明的pmhc特异性重组结合蛋白接触;以及
56.(ii)检测所述结合蛋白与所述细胞或组织样品的特异性结合。
57.在一个特定方面,所述医学病症是癌症、感染性疾病(优选病毒感染性疾病)或自体免疫疾病。在一个实施方案中,所述医学病症是癌症。在一个实施方案中,所述医学病症是感染性疾病,优选病毒感染性疾病。在一个实施方案中,所述医学病症是自体免疫疾病。
58.在另一方面,本发明提供了一种靶向患有肿瘤的患者中的肿瘤细胞以破坏肿瘤细胞的方法,该方法包括向该患者施用治疗有效量的本发明的pmhc特异性重组结合蛋白、核酸或药物组合物的步骤,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在肿瘤细胞中表达的蛋白,优选在肿瘤细胞中表达的胞内蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死肿瘤细胞的毒性因子。
59.在另一方面,本发明提供了本发明的pmhc特异性重组结合蛋白、核酸或药物组合物,其用于靶向患有肿瘤的患者中的肿瘤细胞以破坏肿瘤细胞的方法中,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在肿瘤细胞中表达的蛋白,优选在肿瘤细胞中表达的胞内蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死肿瘤细胞的毒性因子。
60.在另一方面,本发明提供了一种靶向患有病毒感染性疾病的患者中的受感染细胞以破坏所述受感染细胞的方法,该方法包括向该患者施用治疗有效量的本发明的pmhc特异性重组结合蛋白、核酸或药物组合物的步骤,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在所述受感染细胞中表达的蛋白,优选病毒特异性蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死受感染细胞的毒性
因子。
61.在另一方面,本发明提供了本发明的pmhc特异性重组结合蛋白、核酸或药物组合物,其用于靶向患有病毒感染性疾病的患者中的受感染细胞以破坏所述受感染细胞的方法中,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在所述受感染细胞中表达的蛋白,优选病毒特异性蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死受感染细胞的毒性因子。
附图说明
62.图1a至图1c:对生物素酰化pmhc复合物(生物素-pmhc)的质量控制测试。(a)用于分离生物素酰化nyesopmhc、nyesoaapmhc和ebnapmhc复合物的制备型尺寸排阻色谱法(sec)。在洗脱液中测量在280nm处的紫外(uv)吸光度。(b)在不存在或存在链霉亲和素的情况下对浓缩和重新折叠的复合物的sds-page分析。(c)三联体pmhc复合物的分析尺寸排阻色谱法。在洗脱液中测量在280nm和230nm处的uv吸光度。
63.图2:包含对靶标肽-mhc复合物具有结合特异性的重复结构域的结合蛋白的高效表达和纯化。从大肠杆菌(e.coli)培养物中以高纯度纯化对nyesopmhc具有结合特异性的高度可溶性结合蛋白。示出了nyesopmhc特异性蛋白#21在sec运行后(在imac之后)获得的具有洗脱级分的代表性sds-page凝胶。该凝胶用考马斯蓝(coomassie blue)染色。
64.图3a至图3c:本发明的结合蛋白与靶标肽-mhc复合物的特异性高亲和力结合。示出了蛋白#21与nyesopmhc(a)、nyesoaapmhc(b)和ebnapmhc(c)结合的代表性spr迹线。蛋白#21以高亲和力与nyesopmhc结合,而未检测到与其它两种pmhc复合物的结合。结合迹线中的常规峰值是机器伪影并且可以忽略。
65.图4a和图4b:本发明的结合蛋白的有利生物物理特性和与靶标肽-mhc复合物的特异性结合。(a)蛋白#21的代表性均相时间分辨荧光(htrf)测定结果显示与nyesopmhc的高度特异性靶标结合。未检测到蛋白#21与nyesoaapmhc或ebnapmhc的结合。(b)蛋白#21的尺寸排阻色谱法(sec)显示单一单分散峰,其在对应于单个蛋白#21分子的预期质量的位置处洗脱。未检测到聚集体或多聚体的迹线。
66.图5a至图5f:代表性结合蛋白与细胞的结合。将t2细胞用ny-eso-1-9v(157
–
165)肽(ny-eso脉冲处理细胞)或ebna-1(562-570)肽(ebna脉冲处理细胞)进行脉冲处理,或用不含任何肽的缓冲液处理(未经脉冲处理的细胞)。示出了所标明的结合蛋白与(a)ny-eso脉冲细胞、(b)未经脉冲处理的细胞、(c)ny-eso脉冲细胞、(d)ny-eso脉冲细胞和(e)未经脉冲处理的细胞的滴定结合曲线。还示出了tce蛋白#21与ebna脉冲处理细胞的滴定结合曲线(f)。
67.图6a至图6c:使用t2细胞作为靶标细胞的t细胞激活测定。(a)用ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞(黑色条形)和未经脉冲处理的t2细胞(灰色条形)在不同tce蛋白(1pm)的存在下与效应cd8
t细胞(bk112)一起温育:(1)tce
蛋白#23,(2)tce蛋白#24,(3)tce蛋白#25,(4)tce蛋白#26,(5)tce蛋白#27,(6)tce蛋白#28,(7)tce蛋白#29,(8)tce蛋白#30,(9)tce蛋白#31,(10)tce蛋白#32,(11)tce蛋白#33,(12)tce蛋白#21,(13)tce蛋白#20,(14)tce蛋白#22,和(15)无tce蛋白。通过facs检测这些t细胞中的细胞内干扰素-γ(ifn-γ)。(b)-(c)在类似的t细胞激活测定中,tce蛋白#21(b)和tce蛋白#32(c)在较宽的浓度范围内(从0.01pm到1nm)滴定,如所标明的那样。
68.图7:使用肿瘤细胞作为靶标细胞的t细胞激活测定。将im9肿瘤细胞(圆形符号)或mcf-7肿瘤细胞(三角形符号)在不同浓度的tce蛋白#21的存在下与效应cd8
t细胞(bk112)一起温育。作为对照,将效应cd8
t细胞(bk112)在不同浓度的tce蛋白#21的存在下但在不存在肿瘤细胞的情况下(正方形符号)温育。通过facs检测这些t细胞中的细胞内ifn-γ。ag:抗原(在这里是ny-eso-1-9v(157-165)肽)。两种肿瘤细胞系都是hla-a2
。
69.图8a至图8e:使用肿瘤细胞作为靶标细胞的t细胞激活测定。将im9肿瘤细胞(圆形符号)或mcf-7肿瘤细胞(三角形符号)在不同浓度的所标明的结合蛋白的存在下与作为效应细胞的供体的外周血单核细胞(pbmc)一起温育。作为对照,将pbmc在不同浓度的所标明的结合蛋白的存在下但在不存在肿瘤细胞的情况下(正方形符号)温育。通过facs检测cd8
t细胞中的cd25表达。
70.图9a至图9e:使用肿瘤细胞作为靶细胞的t细胞活化测定。将im9肿瘤细胞或mcf-7肿瘤细胞在不同浓度的所标明的结合蛋白的存在下与作为效应细胞的供体的pbmc一起温育,如图8那样。定量细胞上清液中干扰素-γ(ifn-γ)的水平作为t细胞激活的额外量度。
71.图10a至图10e:使用肿瘤细胞作为靶标细胞的t细胞激活测定。将im9肿瘤细胞或mcf-7肿瘤细胞在不同浓度的所标明的结合蛋白的存在下与作为效应细胞的供体的pbmc一起温育,如图8那样。定量细胞上清液中肿瘤坏死因子-α(tnf-α)的水平作为t细胞激活的额外量度。
72.图11a至图11e:通过丙氨酸扫描诱变分析靶标肽结合。在t细胞激活测定中,使用经脉冲处理的t2细胞作为靶标细胞并且使用bk112 t细胞作为效应细胞,测试所标明的结合蛋白与ny-eso-1-9v(157-165)肽及其一系列丙氨酸突变变体的功能性结合。标明了ny-eso-1-9v(157-165)肽中被丙氨酸替代的氨基酸残基和位置。使用未经脉冲处理的t2细胞作为对照。检测细胞内ifn-γ作为t细胞激活的量度。
73.图12:示出通过本发明的代表性结合蛋白介导的效应细胞的靶标pmhc依赖性靶标细胞杀伤的细胞毒性测定。将效应细胞(外周血单核细胞(pbmc))和靶标细胞(经脉冲处理的t2细胞(pt2)或未经脉冲处理的t2细胞(npt2))在不同浓度(0.01nm、0.1nm、1nm)的tce形式的nyesopmhc特异性结合蛋白(tce蛋白#21(d))的存在下温育。示出了在不同温育时间处的凋亡水平(总绿色目标面积)。
74.图13:使用t2细胞作为靶标细胞的t细胞激活测定。用ny-eso-1-9v(157-165)肽进
行脉冲处理的t2细胞(黑色条形)和未经脉冲处理的t2细胞(灰色条形)在tce形式的不同二价或双互补位结合蛋白(0.1pm)或对照的存在下与效应cd8
t细胞(bk112)一起温育:(1)tce bp蛋白#20/#21,(2)tce bp蛋白#21/#22,(3)tce bv蛋白#21/#21,(4)包含对人血清白蛋白具有结合特异性的锚蛋白重复结构域,而不是对nyesopmhc具有结合特异性的锚蛋白重复结构域的tce蛋白,以及(5)未添加tce蛋白。通过facs检测这些t细胞中的细胞内干扰素-γ(ifn-γ)。
75.图14a和图14b:包含对靶标pmhc复合物具有结合特异性的两个重复结构域的代表性结合蛋白与细胞的结合。将t2细胞用ny-eso-1-9v(157
–
165)肽进行脉冲处理(经脉冲处理的细胞)或用不含任何肽的缓冲液处理(未经脉冲处理的细胞)。示出了所标明的结合蛋白与经脉冲处理的细胞(a)和未经脉冲处理的细胞(b)的滴定结合曲线。
76.图15a和图15b:使用肿瘤细胞作为靶标细胞的t细胞激活测定。将im9肿瘤细胞(圆形符号)或mcf-7肿瘤细胞(三角形符号)在不同浓度的所标明的结合蛋白的存在下与作为效应细胞的供体的外周血单核细胞(pbmc)一起温育,所述所标明的结合蛋白包含对靶标pmhc复合物具有结合特异性的两个重复结构域。作为对照,将pbmc在不同浓度的所标明的结合蛋白的存在下但在不存在肿瘤细胞的情况下(正方形符号)温育。通过facs检测cd8
t细胞中的cd25表达。
77.图16a和图16b:使用肿瘤细胞作为靶标细胞的t细胞激活测定。将im9肿瘤细胞或mcf-7肿瘤细胞在不同浓度的所标明的结合蛋白的存在下与作为效应细胞的供体的pbmc一起温育,所述所标明的结合蛋白包含对靶标pmhc复合物具有结合特异性的两个重复结构域,如图15那样。定量细胞上清液中ifn-γ(a)和tnf-α(b)的水平作为t细胞激活的额外量度。
78.图17:通过丙氨酸扫描诱变分析靶标肽结合。在t细胞激活测定中,使用经脉冲处理的t2细胞作为靶标细胞并且使用bk112 t细胞作为效应细胞,测试包含对靶标pmhc复合物具有结合特异性的两个重复结构域的所标明的结合蛋白与ny-eso-1-9v(157-165)肽及其一系列丙氨酸突变变体的功能性结合。标明了ny-eso-1-9v(157-165)肽中被丙氨酸替代的氨基酸残基和位置。使用未经脉冲处理的t2细胞作为对照。检测细胞内ifn-γ作为依赖于结合蛋白与靶标细胞的结合的t细胞激活的量度。
79.图18a至图18f:使用肿瘤细胞作为靶标细胞的t细胞激活测定。将u266b1肿瘤细胞(圆形符号)或colo205肿瘤细胞(正方形符号)((a)和(b))、经转染以表达ny-eso-1的mcf-7肿瘤细胞(圆形符号)或未转染的mcf-7肿瘤细胞(正方形符号)((c)和(d))以及im9肿瘤细胞(圆形符号)和mcf-7肿瘤细胞(正方形符号)((e)和(f))在不同浓度的所标明的本发明代表性结合蛋白(呈tce形式)的存在下与作为效应细胞的供体的外周血单核细胞(pbmc)一起温育。在(a)、(c)和(e)中使用tce蛋白#21,且在(b)、(d)和(f)中使用tce 蛋白#32。通过facs检测cd8
t细胞中的cd69表达。ag:nyesopmhc。
80.图19a和图19b:示出通过本发明的代表性结合蛋白介导的效应细胞的靶标pmhc依赖性靶标细胞杀伤的细胞毒性测定。经脉冲处理的(pt2)或未经脉冲处理的(np t2)t2细胞(a)和hla-a2
/ny-eso-1
肿瘤细胞(im9,u266b1)或hla-a2
/ny-eso-1-肿瘤细胞(mcf-7)(b)作为靶标细胞与效应cd8
t细胞一起在存在或不存在tce形式的nyesopmhc特异性结合
蛋白(tce 蛋白#21)(1nm)的情况下温育。如所标明的那样,使用不同比率(30:1、10:1、5:1和1:1)的效应细胞与靶标细胞(e:t)。将通过铬释放测定获得的t2细胞(a)或肿瘤细胞(b)的特异性裂解百分比针对不同的效应:靶标比率进行绘图。ag:nyesopmhc。
81.图20a和图20b:示出通过本发明的代表性结合蛋白介导的效应细胞的靶标pmhc依赖性靶标细胞杀伤的细胞毒性测定。这些图示出了如图19a和图19b中所述,但是使用tce形式的不同nyesopmhc特异性结合蛋白(tce蛋白#32)的实验。
82.图21a和图21b:通过x扫描诱变分析靶标肽结合。tce形式的nyesopmhc特异性结合蛋白((a)中的tce蛋白#21;(b)中的tce蛋白#32)与ny-eso-1-9v(157
–
165)肽及其一系列单突变变体的功能性结合在t细胞激活测定中,使用经脉冲处理的t2细胞作为靶标细胞并且使用bk112 t细胞作为效应细胞进行测试。靶标肽序列的每个氨基酸被其它19个标准氨基酸中的每一个替代。在表的左侧标明了ny-eso-1-9v(157-165)肽中被另一氨基酸替代的氨基酸残基和位置,并且在表的顶部标明了替代氨基酸。检测细胞内ifn-γ作为依赖于结合蛋白与靶标细胞的结合的t细胞激活的量度。每个实验均以两个独立的重复进行。值平均并且针对每个位置中的相应野生型残基(黑色阴影字段)归一化为100%。所有高于30%的值,标明没有丧失或不完全丧失t细胞激活,以粗体和浅色阴影标记。
83.图22和图23:tce形式的pmhc特异性结合蛋白引起的t细胞激活取决于将pmhc特异性结合结构域与cd3特异性结合因子连接的接头的长度。将hla-a2
/ny-eso-1
肿瘤细胞(im9)(实线)或hla-a2
/ny-eso-1-肿瘤细胞(mcf-7)(虚线)在存在或不存在具有不同接头长度的tce蛋白#21(图22)或具有不同接头长度的tce蛋白#32(图23)的情况下与pbmc一起温育48小时。48小时后,测量cd8
t细胞的cd25表达。示出了在存在tce蛋白的情况下获得的结果。在不存在tce蛋白的情况下没有观察到t细胞激活。ag:抗原/ny-eso-1。接头长度:标准、xxs、xs、s和l(参见实施例11)。
84.图24和图25:tce形式的pmhc特异性结合蛋白引起的t细胞激活取决于将pmhc特异性结合结构域与cd3特异性结合因子连接的接头的长度。将hla-a2
/ny-eso-1
肿瘤细胞(u266b1)(实线)或hla-a2
/ny-eso-1-肿瘤细胞(colo205)(虚线)在存在或不存在具有不同接头长度的tce蛋白#21(图24)或具有不同接头长度的tce蛋白#32(图25)的情况下与pbmc一起温育48小时。48小时后,测量cd8
t细胞的cd25表达。示出了在存在tce蛋白的情况下获得的结果。在不存在tce蛋白的情况下没有观察到t细胞激活。ag:抗原/ny-eso-1。接头长度:标准、xxs、xs、s和l(参见实施例11)。
85.图26。经设计的锚蛋白重复结构域的变体(各自经由相同的多肽接头遗传连接到对血清白蛋白具有结合特异性的相同的经设计的锚蛋白重复结构域)在小鼠中的药代动力学特征。(a)蛋白#281及变体蛋白#282和#283在小鼠中的药代动力学特征。(b)蛋白#284及变体蛋白#285、#286和#287在小鼠中的药代动力学特征。(c)蛋白#288及变体蛋白#289、#290和#291在小鼠中的药代动力学特征。(d)蛋白#292及变体蛋白#293、#294和#295在小鼠中的药代动力学特征。如实施例17中所述,使用balb/c小鼠和1mg/kg静脉给药进行实验。蛋白#281至#295(分别包含seq id no:281至295,各自在n-末端具有his标签(seq id no:326);图中标明符号)如实施例17中所述产生和纯化。c:浓度,以[nm]为单位;t:时间,以[小
时]为单位。
具体实施方式
[0086]
如本文所公开和举例说明的,本公开提供了特异性靶向肽-mhc复合物的经设计的重复蛋白,优选经设计的锚蛋白重复蛋白。经设计的重复蛋白文库(包括经设计的锚蛋白重复蛋白文库)(wo2002/020565;binz等人,nat.biotechnol.22,575-582,2004;stumpp等人,drug discov.today13,695-701,2008)可以用于选择以高亲和力结合到其靶标的靶标特异性的经设计的重复结构域。此类靶标特异性的经设计的重复结构域进而可以用作用于治疗疾病的重组结合蛋白的有价值的组分。尚未显示经设计的重复蛋白文库是否可以用于鉴定以高亲和力特异性地结合到复合表位的蛋白,诸如肽-mhc复合物所呈递的蛋白。一直以来众所周知的是,很难生成以足够大亲和力特异性地结合疾病相关肽-mhc复合物的分子。
[0087]
经设计的锚蛋白重复蛋白是一类结合分子,其具有克服单克隆抗体限制的潜力,从而允许新型治疗方法。此类锚蛋白重复蛋白可以包含单个经设计的锚蛋白重复结构域,或者可以包含两个、三个、四个、五个或更多个具有相同或不同靶标特异性的经设计的锚蛋白重复结构域的组合(stumpp等人,drug discov.today 13,695-701,2008;美国专利9,458,211)。仅包含单个经设计的锚蛋白重复结构域的锚蛋白重复蛋白为小蛋白质(14kda),其可被选择为以高亲和力和特异性结合给定靶蛋白。这些特征以及在一种蛋白中组合两个、三个、四个、五个或更多个经设计的锚蛋白重复结构域的可能性使得经设计的锚蛋白重复蛋白成为理想的激动性、拮抗性和/或抑制性药物候选物。此外,此类锚蛋白重复蛋白可被工程化以携带各种效应子功能,例如细胞毒性剂或半衰期延长剂,从而实现全新的药物形式。总之,经设计的锚蛋白重复蛋白为具有超过现有抗体药物的潜力的下一代蛋白质治疗剂的示例。
[0088]
是molecular partners ag(switzerland)拥有的商标。
[0089]
在一个方面,本发明提供了一种产生肽-mhc(pmhc)特异性结合蛋白的方法,其中所述结合蛋白包含对靶标肽-mhc复合物具有结合特异性的经设计的重复结构域,该方法包括以下步骤:
[0090]
(a)提供经设计的重复结构域的集合;
[0091]
(b)提供重组的靶标肽-mhc复合物;以及
[0092]
(c)筛选所述经设计的重复结构域的集合的对所述靶标肽-mhc复合物的特异性结合,以获得至少一个对所述靶标肽-mhc复合物具有结合特异性的经设计的重复结构域。
[0093]
在一个实施方案中,所述经设计的重复结构域是经设计的锚蛋白重复结构域,并且所述经设计的重复结构域的集合是经设计的锚蛋白重复结构域的集合。
[0094]
在一个实施方案中,所述集合包括含有固定位置和随机化位置的经设计的重复结构域,并且其中所述集合的经设计的重复结构域在至少一个随机化位置上彼此不同。
[0095]
在一个实施方案中,所述经设计的重复蛋白的集合由核糖体展示技术提供。
[0096]
在一个实施方案中,该方法还包括以下步骤:(i)提供第二重组肽-mhc复合物,其中所述第二肽-mhc复合物的所述肽包含与所述靶标肽有至少一个氨基酸残基差异的氨基酸序列;以及(ii)通过负选择从所述集合中去除对所述第二重组肽-mhc复合物具有结合特异性的经设计的重复结构域。
[0097]
在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m、或低于3
×
10-10
m、或低于2
×
10-10
m、或低于10-10
m的解离常数(kd)结合到所述靶标肽-mhc复合物。在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域在pbs中以低于10-7
m的解离常数(kd)结合到所述靶标肽-mhc复合物。
[0098]
在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少一个、至少两个、至少三个、至少四个、至少五个、至少六个或至少七个氨基酸残基的相互作用。因此,在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少一个氨基酸残基的相互作用。在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少两个氨基酸残基的相互作用。在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少三个氨基酸残基的相互作用。在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少四个氨基酸残基的相互作用。在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少五个氨基酸残基的相互作用。在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少六个氨基酸残基的相互作用。在一个实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少七个氨基酸残基的相互作用。在一个另外的或替代性的实施方案中,对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述mhc的至少一个氨基酸残基的相互作用。
[0099]
用于确定参与蛋白之间或蛋白与肽之间的结合相互作用的氨基酸残基的方法(诸如丙氨酸扫描诱变)是本领域技术人员熟知的。
[0100]
在本发明的上下文中,参与对靶标肽-mhc复合物具有结合特异性的结合蛋白或经设计的重复结构域与该靶标肽-mhc复合物之间的结合相互作用的靶标肽的氨基酸残基的典型和优选的确定如实施例7所述通过丙氨酸扫描诱变来进行。因此,在一个实施方案中,参与对靶标肽-mhc复合物具有结合特异性的本发明的结合蛋白或经设计的重复结构域与该靶标肽-mhc复合物之间的结合相互作用的靶标肽的所述氨基酸残基通过丙氨酸扫描诱变来确定。在一个实施方案中,参与对靶标肽-mhc复合物具有结合特异性的本发明的结合蛋白或经设计的重复结构域与该靶标肽-mhc复合物之间的结合相互作用的靶标肽的所述氨基酸残基如实施例7所述通过丙氨酸扫描诱变来确定。
[0101]
在本发明的上下文中,用语“对靶标肽-mhc复合物具有结合特异性的所述重复结构域与所述靶标肽-mhc复合物的结合包括所述重复结构域与所述靶标肽的至少一个、至少两个、至少三个、至少四个、至少五个、至少六个或至少七个氨基酸残基的相互作用”或类似
的用语,是指靶标肽的下述任何氨基酸残基:其突变为丙氨酸导致在如实施例7所述的测定(或类似测定)中t细胞激活与野生型肽相比降低至少50%。
[0102]
本发明的发明人已经发现,要获得本发明的包含对靶标肽-mhc复合物具有结合特异性的锚蛋白重复结构域的结合蛋白与该靶标肽之间的特异性相互作用,重要的是存在数量大得惊人的肽残基。例如,在所附的实施例中,已经鉴定了对于获得本发明的包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白与该ny-eso-1靶标肽之间的特异性相互作用很重要的几个肽残基(参见图11)。发明人推论出,该发现可以反映由本发明的经设计的锚蛋白重复结构域形成的结合表面与由其他结合蛋白(诸如抗体和t细胞受体(tcr))形成的结合表面之间的结构差异。不受任何理论的束缚,据信参与重复结构域与其靶标肽的结合的氨基酸残基的数量越多,结合特异性就越高。在一个实施方案中,所述靶标肽选自由以下项组成的组:(i)来源于在肿瘤细胞中表达的蛋白的肽;(ii)来源于感染因子(诸如细菌感染因子或病毒感染因子,优选病毒感染因子)的蛋白的肽;以及(iii)来源于与自体免疫疾患相关联的蛋白的肽。在一个实施方案中,所述靶标肽来源于细胞内蛋白,优选地在肿瘤细胞中表达的细胞内蛋白。在一个实施方案中,所述靶标肽来源于ny-eso-1。在一个实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。在一个实施方案中,所述靶标肽来源于mage-a3。在一个实施方案中,所述靶标肽具有seq id no:155的氨基酸序列。在一个实施方案中,所述靶标肽来源于感染因子的蛋白,诸如病毒感染因子的蛋白,优选病毒特异性蛋白。在一个实施方案中,所述靶标肽来源于ebna-1。在一个实施方案中,所述靶标肽具有seq id no:92的氨基酸序列。在一个实施方案中,所述靶标肽来源于hbcag。在一个实施方案中,所述靶标肽具有seq id no:255的氨基酸序列。
[0103]
在一个实施方案中,所述mhc是mhc i类。在一个实施方案中,所述mhc i类是hla-a*02。在一个实施方案中,所述hla-a*02是hla-a*0201。在一个实施方案中,所述hla-a*0201具有seq id no:73的氨基酸序列。替代性地,在另一个实施方案中,所述mhc不是hla-a*02。在一个实施方案中,所述mhc i类是hla-a*01。在一个实施方案中,所述hla-a*01是hla-a*0101。在一个实施方案中,所述hla-a*0101具有seq id no:218的氨基酸序列。替代性地,在另一个实施方案中,所述mhc不是hla-a*01。
[0104]
在另一方面,本发明涉及一种重组结合蛋白,其包含可通过如本文所述的本发明方法之一获得的经设计的重复结构域。
[0105]
在另一方面,本发明涉及一种重组结合蛋白,其包含第一经设计的重复结构域,其中所述第一重复结构域对第一靶标肽-mhc复合物具有结合特异性。
[0106]
在一个优选的实施方案中,本发明的结合蛋白包含对第一靶标肽-mhc复合物具有结合特异性的第一经设计的重复结构域,其中所述第一靶标肽选自由以下项组成的组:(i)来源于在肿瘤细胞中表达的蛋白的肽;(ii)来源于感染因子(诸如细菌感染因子或病毒感染因子,优选病毒感染因子)的蛋白的肽;以及(iii)来源于与自体免疫疾患相关联的蛋白的肽。
[0107]
在一个实施方案中,所述第一靶标肽来源于细胞内蛋白,优选地在肿瘤细胞中表达的细胞内蛋白。在一个实施方案中,所述第一靶标肽来源于肿瘤特异性细胞内蛋白。在一个实施方案中,所述第一靶标肽来源于ny-eso-1。在一个实施方案中,所述第一靶标肽具有seq id no:19或seq id no:34的氨基酸序列。在一个实施方案中,所述第一靶标肽来源于
mage-a3。在一个实施方案中,所述第一靶标肽具有seq id no:155的氨基酸序列。在一个实施方案中,所述靶标肽来源于感染因子的蛋白,诸如病毒感染因子的蛋白,优选病毒特异性蛋白。在一个实施方案中,所述靶标肽来源于ebna-1。在一个实施方案中,所述靶标肽具有seq id no:92的氨基酸序列。在一个实施方案中,所述靶标肽来源于hbcag。在一个实施方案中,所述靶标肽具有seq id no:255的氨基酸序列。在一个优选的实施方案中,所述第一mhc是mhc i类。在一个实施方案中,所述第一mhc i类是hla-a*02。在一个实施方案中,所述hla-a*02是hla-a*0201。在一个实施方案中,所述hla-a*0201具有seq id no:73的氨基酸序列。替代性地,在另一个实施方案中,所述第一mhc不是hla-a*02。在一个实施方案中,所述第一mhc i类是hla-a*01。在一个实施方案中,所述hla-a*01是hla-a*0101。在一个实施方案中,所述hla-a*0101具有seq id no:218的氨基酸序列。替代性地,在另一个实施方案中,所述第一mhc不是hla-a*01。
[0108]
在一个实施方案中,所述第一重复结构域在pbs中以低于10-7
m的解离常数(kd)结合到所述第一靶标肽-mhc复合物。
[0109]
在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的所述结合包括所述第一重复结构域与所述第一靶标肽的至少一个、至少两个、至少三个、至少四个、至少五个、至少六个或至少七个氨基酸残基的相互作用。因此,在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一靶标肽的至少一个氨基酸残基的相互作用。在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一靶标肽的至少两个氨基酸残基的相互作用。在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一靶标肽的至少三个氨基酸残基的相互作用。在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一靶标肽的至少四个氨基酸残基的相互作用。在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一靶标肽的至少五个氨基酸残基的相互作用。在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一靶标肽的至少六个氨基酸残基的相互作用。在一个实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一靶标肽的至少七个氨基酸残基的相互作用。在一个另外的或替代性的实施方案中,所述第一重复结构域与所述第一靶标肽-mhc复合物的结合包括所述第一重复结构域与所述第一mhc的至少一个氨基酸残基的相互作用。
[0110]
在一个优选的实施方案中,所述第一经设计的重复结构域是经设计的锚蛋白重复结构域。在一个特别优选的实施方案中,所述第一经设计的锚蛋白重复结构域是如本文的任何方面或任何实施方案中更具体地描述的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域。
[0111]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含锚蛋白重复模块。
[0112]
在一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成
的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。因此,在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。因此,在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由seq id no:37至72组成的组的氨基酸序列。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0113]
在一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42、54、55和67至72,以及(2)其中seq id no:37至42、54、55和67至72中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。因此,在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42、54、55和67至72,以及(2)其中seq id no:37至42、54、55和67至72中的任一者中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42、54、55和67至72,以及(2)其中seq id no:37至42、54、55和67至72中的任一者中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42、54、55和67至72,以及(2)其中seq id no:37至42、54、55和67至72中的任一者中的至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由seq id no:37至42、54、55和67至72组成的组的氨基酸序列。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0114]
在一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42和67至69,以及(2)其中seq id no:37至42和67至69中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。因此,在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42和67至69,以及(2)其中seq id no:37至42和67至69中的任一者中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42和67至69,以及(2)其中seq id no:37至42和67至69中的任一者中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白
重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42和67至69,以及(2)其中seq id no:37至42和67至69中的任一者中的至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述锚蛋白重复模块包含选自由seq id no:37至42和67至69组成的组的氨基酸序列。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0115]
在另一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:111至154,以及(2)其中seq id no:111至154中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个优选的实施方案中,所述靶标肽具有seq id no:92的氨基酸序列。
[0116]
在再一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:175至217,以及(2)其中seq id no:175至217中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个优选的实施方案中,所述靶标肽具有seq id no:155的氨基酸序列。
[0117]
在再一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:231至254,以及(2)其中seq id no:231至254中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个优选的实施方案中,所述靶标肽具有seq id no:255的氨基酸序列。
[0118]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块和第二锚蛋白重复模块。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端。
[0119]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和第三锚蛋白重复模块。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。
[0120]
在一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和任选地第三锚蛋白重复模块,其中所述第一锚蛋白重复模块、所述第二锚蛋白重复模块和(如果存在)所述第三锚蛋白重复模块中的每一者独立地包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至72,以及(2)其中seq id no:37至72中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述第一锚蛋白重复模块、所述第二锚蛋白重
复模块和(如果存在)所述第三锚蛋白重复模块中的每一者独立地包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42、54、55和67至72,以及(2)其中seq id no:37至42、54、55和67至72中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述第一锚蛋白重复模块、所述第二锚蛋白重复模块和(如果存在)所述第三锚蛋白重复模块中的每一者独立地包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37至42和67至69,以及(2)其中seq id no:37至42和67至69中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0121]
在一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块和第二锚蛋白重复模块,其中所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:54,以及(2)其中seq id no:54中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:55,以及(2)其中seq id no:55中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0122]
在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:54,以及(2)其中seq id no:54中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:55,以及(2)其中seq id no:55中的至多6个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:54,以及(2)其中seq id no:54中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:55,以及(2)其中seq id no:55中的至多5个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:54,以及(2)其中seq id no:54中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:55,以及(2)其中seq id no:55中的至多4个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:54,以及(2)其中seq id no:54中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:55,以及(2)其中seq id no:55中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:54,以及(2)其中seq id no:54中的
至多2个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:55,以及(2)其中seq id no:55中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:54,以及(2)其中seq id no:54中的1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:55,以及(2)其中seq id no:55中的1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含seq id no:54的氨基酸序列,并且所述第二锚蛋白重复模块包含seq id no:55的氨基酸序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0123]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和第三锚蛋白重复模块,其中所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37,以及(2)其中seq id no:37中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:38,以及(2)其中seq id no:38中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:39,以及(2)其中seq id no:39中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0124]
在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37,以及(2)其中seq id no:37中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:38,以及(2)其中seq id no:38中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:39,以及(2)其中seq id no:39中的至多6个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37,以及(2)其中seq id no:37中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:38,以及(2)其中seq id no:38中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:39,以及(2)其中seq id no:39中的至多5个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚
蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37,以及(2)其中seq id no:37中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:38,以及(2)其中seq id no:38中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:39,以及(2)其中seq id no:39中的至多4个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37,以及(2)其中seq id no:37中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:38,以及(2)其中seq id no:38中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:39,以及(2)其中seq id no:39中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37,以及(2)其中seq id no:37中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:38,以及(2)其中seq id no:38中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:39,以及(2)其中seq id no:39中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:37,以及(2)其中seq id no:37中的1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:38,以及(2)其中seq id no:38中的1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:39,以及(2)其中seq id no:39中的1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含seq id no:37的氨基酸序列,并且所述第二锚蛋白重复模块包含seq id no:38的氨基酸序列,并且所述第三锚蛋白重复模块包含seq id no:39的氨基酸序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0125]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和第三锚蛋白重复模块,其中所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:40,以及(2)其中seq id no:40中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:41,以及(2)其中seq id no:41中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:42,以
及(2)其中seq id no:42中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0126]
在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:40,以及(2)其中seq id no:40中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:41,以及(2)其中seq id no:41中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:42,以及(2)其中seq id no:42中的至多6个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:40,以及(2)其中seq id no:40中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:41,以及(2)其中seq id no:41中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:42,以及(2)其中seq id no:42中的至多5个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:40,以及(2)其中seq id no:40中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:41,以及(2)其中seq id no:41中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:42,以及(2)其中seq id no:42中的至多4个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:40,以及(2)其中seq id no:40中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:41,以及(2)其中seq id no:41中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:42,以及(2)其中seq id no:42中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:40,以及(2)其中seq id no:40中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:41,以及(2)其中seq id no:41中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:42,以及(2)其中seq id no:42中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:40,以及(2)其中seq id no:40中的1个氨基酸被另一氨基酸取代的序列,并且
所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:41,以及(2)其中seq id no:41中的1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:42,以及(2)其中seq id no:42中的1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含seq id no:40的氨基酸序列,并且所述第二锚蛋白重复模块包含seq id no:41的氨基酸序列,并且所述第三锚蛋白重复模块包含seq id no:42的氨基酸序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0127]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和第三锚蛋白重复模块,其中所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:67,以及(2)其中seq id no:67中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:68,以及(2)其中seq id no:68中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:69,以及(2)其中seq id no:69中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0128]
在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:67,以及(2)其中seq id no:67中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:68,以及(2)其中seq id no:68中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:69,以及(2)其中seq id no:69中的至多6个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:67,以及(2)其中seq id no:67中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:68,以及(2)其中seq id no:68中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:69,以及(2)其中seq id no:69中的至多5个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:67,以及(2)其中
seq id no:67中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:68,以及(2)其中seq id no:68中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:69,以及(2)其中seq id no:69中的至多4个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:67,以及(2)其中seq id no:67中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:68,以及(2)其中seq id no:68中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:69,以及(2)其中seq id no:69中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:67,以及(2)其中seq id no:67中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:68,以及(2)其中seq id no:68中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:69,以及(2)其中seq id no:69中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:67,以及(2)其中seq id no:67中的1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:68,以及(2)其中seq id no:68中的1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:69,以及(2)其中seq id no:69中的1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含seq id no:67的氨基酸序列,并且所述第二锚蛋白重复模块包含seq id no:68的氨基酸序列,并且所述第三锚蛋白重复模块包含seq id no:69的氨基酸序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0129]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和第三锚蛋白重复模块,其中所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:70,以及(2)其中seq id no:70中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:71,以及(2)其中seq id no:71中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:72,以及(2)其中seq id no:72中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至
多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0130]
在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:70,以及(2)其中seq id no:70中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:71,以及(2)其中seq id no:71中的至多6个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:72,以及(2)其中seq id no:72中的至多6个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:70,以及(2)其中seq id no:70中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:71,以及(2)其中seq id no:71中的至多5个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:72,以及(2)其中seq id no:72中的至多5个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:70,以及(2)其中seq id no:70中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:71,以及(2)其中seq id no:71中的至多4个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:72,以及(2)其中seq id no:72中的至多4个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:70,以及(2)其中seq id no:70中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:71,以及(2)其中seq id no:71中的至多3个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:72,以及(2)其中seq id no:72中的至多3个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:70,以及(2)其中seq id no:70中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:71,以及(2)其中seq id no:71中的至多2个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:72,以及(2)其中seq id no:72中的至多2个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:70,以及(2)其中seq id no:70中的1个氨基酸被另一氨基酸取代的序列,并且所述第二锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:71,以
及(2)其中seq id no:71中的1个氨基酸被另一氨基酸取代的序列,并且所述第三锚蛋白重复模块包含选自由以下项组成的组的氨基酸序列:(1)seq id no:72,以及(2)其中seq id no:72中的1个氨基酸被另一氨基酸取代的序列。在一个实施方案中,在这样的锚蛋白重复结构域中,所述第一锚蛋白重复模块包含seq id no:70的氨基酸序列,并且所述第二锚蛋白重复模块包含seq id no:71的氨基酸序列,并且所述第三锚蛋白重复模块包含seq id no:72的氨基酸序列。在一个实施方案中,所述第一锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第二锚蛋白重复模块的n-末端,并且所述第二锚蛋白重复模块位于所述锚蛋白重复结构域内的所述第三锚蛋白重复模块的n-末端。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0131]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和任选地第三锚蛋白重复模块,其中所述第一锚蛋白重复模块、所述第二锚蛋白重复模块和(如果存在)所述第三锚蛋白重复模块中的每一者独立地包含选自由以下项组成的组的氨基酸序列:(1)seq id no:111至154,以及(2)其中seq id no:111至154中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个优选的实施方案中,所述靶标肽具有seq id no:92的氨基酸序列。
[0132]
在再一个特定实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含第一锚蛋白重复模块、第二锚蛋白重复模块和任选地第三锚蛋白重复模块,其中所述第一锚蛋白重复模块、所述第二锚蛋白重复模块和(如果存在)所述第三锚蛋白重复模块中的每一者独立地包含选自由以下项组成的组的氨基酸序列:(1)seq id no:175至217,以及(2)其中seq id no:175至217中的任一者中的至多9个、或至多8个、或至多7个、或至多6个、或至多5个、或至多4个、或至多3个、或至多2个、或至多1个氨基酸被另一氨基酸取代的序列。在一个优选的实施方案中,所述靶标肽具有seq id no:155的氨基酸序列。
[0133]
在一个优选的实施方案中,如本文所述和所提及的所述锚蛋白重复模块的所有所述氨基酸取代发生在所述锚蛋白重复模块的框架位置中,其中通常所述模块的总体结构不受这些取代的影响。
[0134]
在一个优选的实施方案中,如本文所述和提及的所述锚蛋白重复模块的所有所述氨基酸取代发生在除seq id no:37至60、62至66和68至72的所述锚蛋白重复模块的随机化位置3、4、6、14和15或seq id no:61和67的所述锚蛋白重复模块的随机化位置3、4、6、13和14之外的位置中。在另一个优选的实施方案中,如本文所述和提及的所述锚蛋白重复模块的所有所述氨基酸取代发生在除seq id no:111至122和124至154的所述锚蛋白重复模块的随机化位置3、4、6、14和15或seq id no:123的所述锚蛋白重复模块的随机化位置3、4、6、15和16之外的位置中。在另一个优选的实施方案中,如本文所述和所提及的所述锚蛋白重复模块的所有所述氨基酸取代发生在所述锚蛋白重复模块的除seq id no:175至217的随机化位置3、4、6、14和15之外的位置中。在另一个优选的实施方案中,如本文所述和所提及的所述锚蛋白重复模块的所有所述氨基酸取代发生在所述锚蛋白重复模块的除seq id no:231至254的随机化位置3、4、6、14和15之外的位置中。
[0135]
在再一个优选的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域还包含n-末端和/或c-末端封端模块。
[0136]
根据本发明,对靶标肽-mhc复合物具有结合特异性的本发明的锚蛋白重复结构域的n-末端封端模块具有可以包含或可以不包含位置1处的氨基酸g和/或位置2处的氨基酸s的氨基酸序列。在seq id no:5中提供了这样的n-末端封端模块的示例,该模块具有包含位置1处的氨基酸g和/或位置2处的氨基酸s的氨基酸序列。在seq id no:276中提供了这样的n-末端封端模块的示例,该模块具有不包含位置1处的氨基酸g和/或位置2处的氨基酸s的氨基酸序列。因此,seq id no:5和seq id no:276是相同的,除了seq id no:5的位置1处的g和位置2处的s在seq id no:276中缺失以外。因此技术人员容易理解,上文关于包含本发明的表面设计的n-末端封端模块所提供的位置编号可以根据这些氨基酸残基是否存在而变化。因此,具有其中位置8处的氨基酸是q和/或位置15处的氨基酸是l,其中所述位置编号通过参考seq id no:276来定义的氨基酸序列的n-末端封端模块,对应于具有其中位置10处的氨基酸是q和/或位置17处的氨基酸是l,其中所述位置编号通过参考seq id no:5来定义的氨基酸序列的n-末端封端模块,在其n-末端包含“gs”序列。在以下,seq id no:276通常将用作参考序列。
[0137]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有其中位置8处的氨基酸是q和/或位置15处的氨基酸是l的氨基酸序列,其中该n-末端封端模块的位置的所述位置编号使用seq id no:276的位置编号通过与seq id no:276比对来确定。优选地,所述比对不包括氨基酸空位。序列比对生成是本领域众所周知的程序。
[0138]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含c-末端封端模块,该c-末端封端模块具有其中位置14处的氨基酸是r和/或位置18处的氨基酸是q的氨基酸序列,其中该c-末端封端模块的位置的位置编号使用seq id no:13的位置编号通过与seq id no:13比对来确定。优选地,所述比对不包括氨基酸空位。
[0139]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含(i)n-末端封端模块,该n-末端封端模块具有其中位置8处的氨基酸是q和/或位置15处的氨基酸是l的氨基酸序列,和/或(ii)c-末端封端模块,该c-末端封端模块具有其中位置14处的氨基酸是r和/或位置18处的氨基酸是q的氨基酸序列。在一个实施方案中,本发明的经设计的锚蛋白重复结构域包含(i)n-末端封端模块,该n-末端封端模块具有其中位置8处的氨基酸是q和/或位置15处的氨基酸是l的氨基酸序列,和/或(ii)c-末端封端模块,该c-末端封端模块具有其中位置14处的氨基酸是r和/或位置18处的氨基酸是q的氨基酸序列。在一个实施方案中,本发明的经设计的锚蛋白重复结构域包含(i)n-末端封端模块,该n-末端封端模块具有其中位置8处的氨基酸是q且位置15处的氨基酸是l的氨基酸序列,和(ii)c-末端封端模块,该c-末端封端模块具有其中位置14处的氨基酸是r且位置18处的氨基酸是q的氨基酸序列。优选地,该n-末端封端模块的位置的所述位置编号使用seq id no:276的位置编号通过与seq id no:276比对来确定,并且该c-末端封端模块的位置的所述位置编号使用seq id no:13的位置编号通过与seq id no:13比对来确定。优选地,所述比对不包括氨基酸空位。
[0140]
在再一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna(seq id no:276),其中在除位置8和位置15之外的位置中至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
[0141]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa(seq id no:13),其中在除位置14和位置18之外的位置中seq id no:13的至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
[0142]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna(seq id no:276),其中在除位置8和位置15之外的位置中至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa(seq id no:13),其中在除位置14和位置18之外的位置中seq id no:13的至多10个氨基酸、至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
[0143]
在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多9个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多8个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多7个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、
至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多6个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多5个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多4个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多3个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多2个氨基酸任选地被其它氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。在一个实施方案中,所述经设计的锚蛋白重复结构域包含:(i)n-末端封端模块,该n-末端封端模块具有氨基酸序列dlgkkllqaaragqldevrellkagadvna,其中在除位置8和位置15之外的位置中至多一个氨基酸任选地被另一氨基酸交换,和(ii)c-末端封端模块,该c-末端封端模块具有氨基酸序列qdksgktpadlaaraghqdiaevlqkaa,其中在除位置14和位置18之外的位置中至多9个氨基酸、至多8个氨基酸、至多7个氨基酸、至多6个氨基酸、至多5个氨基酸、至多4个氨基酸、至多3个氨基酸、至多2个氨基酸或至多一个氨基酸任选地被其它氨基酸交换。
[0144]
申请人惊奇地发现,在经设计的锚蛋白重复结构域的n-末端封端模块的上述位置
(即位置8和位置15)和/或c-末端封端模块的上述位置(即位置14和位置18)包含上述氨基酸中的一者或多者的锚蛋白结合结构域引起经设计的锚蛋白重复结构域和包含经设计的锚蛋白重复结构域的蛋白的药代动力学特性改善(包括终末半衰期延长)(实施例17和图26)。
[0145]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:20至33中的任一者的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含选自seq id no:20至33的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0146]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含与seq id no:20、21、27、32和33中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:20、21、27、32和33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20、21、27、32和33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20、21、27、32和33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21、27、32和33中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:20、21、27、32和33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20、21、27、32和33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20、21、27、32和33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21、27、32和33中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:
20、21、27、32和33中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21、27、32和33中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21、27、32和33中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:20、21、27、32和33中的任一者的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含选自seq id no:20、21、27、32和33的氨基酸序列,其中seq id no:20、21、27、32和33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20、21、27、32和33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20、21、27、32和33的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0147]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含与seq id no:20、21和32中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:20、21和32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20、21和32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20、21和32的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21和32中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:20、21和32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20、21和32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20、21和32的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21和32中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21和32中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21和32中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20、21和32中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:20、21和32中的任一者的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含选自seq id no:20、21和32的氨基酸序列,其中seq id no:20、21和32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20、21和32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20、21和32的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0148]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含与seq id no:20具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:20的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复
id no:27的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:27的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:27的倒数第二个位置处的a任选地被l取代并且/或者seq id no:27的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:27的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含seq id no:27的氨基酸序列,其中seq id no:27的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:27的倒数第二个位置处的a任选地被l取代并且/或者seq id no:27的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0151]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含与seq id no:32具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:32的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:32的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:32的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含seq id no:32的氨基酸序列,其中seq id no:32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:32的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0152]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含与seq id no:33具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:33的位置1处的g和/或位置2处的s
任选地缺失,并且其中seq id no:33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:33的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含seq id no:33的氨基酸序列,其中seq id no:33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:33的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0153]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域包含与seq id no:93至110中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:93至110的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:93至110的倒数第二个位置处的a任选地被l取代并且/或者seq id no:93至110的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:93至110中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:93至110的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:93至110的倒数第二个位置处的a任选地被l取代并且/或者seq id no:93至110的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:93至110中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:93至110中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:93至110中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:93至110中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:93至110中的任一者的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含选自seq id no:93至110的氨基酸序列,其中seq id no:93至110的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:93至110的倒数第二个位置处的a任选地被l取代并且/或者seq id no:93至110的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:92的氨基酸序列。
[0154]
在一个特定的实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的
经设计的锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:156至173的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:156至173的倒数第二个位置处的a任选地被l取代并且/或者seq id no:156至173的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少80%氨基酸序列同一性的氨基酸序列,其中seq id no:156至173的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:156至173的倒数第二个位置处的a任选地被l取代并且/或者seq id no:156至173的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:156至173中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:156至173中的任一者的氨基酸序列。因此,在一个实施方案中,所述锚蛋白重复结构域包含选自seq id no:156至173的氨基酸序列,其中seq id no:156至173的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:156至173的倒数第二个位置处的a任选地被l取代并且/或者seq id no:156至173的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:155的氨基酸序列。
[0155]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m、或低于3
×
10-10
m、或低于2
×
10-10
m、或低于10-10
m的解离常数(kd)结合所述靶标肽-mhc复合物。因此,在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于10-7
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于5
×
10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于3
×
10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于2
×
10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于5
×
10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于3
×
10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于2
×
10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于5
×
10-10
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于3
×
10-10
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个
实施方案中,所述锚蛋白重复结构域在pbs中以低于2
×
10-10
m的解离常数(kd)结合所述靶标肽-mhc复合物。在一个实施方案中,所述锚蛋白重复结构域在pbs中以低于10-10
m的解离常数(kd)结合所述靶标肽-mhc复合物。
[0156]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:20至33中的任一者的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含氨基酸序列seq id no:20至33中的任一者,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0157]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于5
×
10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、100%氨基酸序列同一性的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:20至33中的任一者的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计
的锚蛋白重复结构域在pbs中以低于5
×
10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含seq id no:20至33中的任一者的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0158]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于2
×
10-8
m的解离常数(kd)结合所述第一靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、100%氨基酸序列同一性的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20至33中的任一者具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:20至33中的任一者的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于2
×
10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含seq id no:20至33中的任一者的氨基酸序列,其中seq id no:20至33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20至33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20至33的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0159]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含与seq id no:20具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:20的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:20具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:
20具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:20的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含氨基酸序列seq id no:20,其中seq id no:20的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:20的倒数第二个位置处的a任选地被l取代并且/或者seq id no:20的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0160]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含与seq id no:21具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:21的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:21的倒数第二个位置处的a任选地被l取代并且/或者seq id no:21的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:21具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:21具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:21具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:21具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:21的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含氨基酸序列seq id no:21,其中seq id no:21的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:21的倒数第二个位置处的a任选地被l取代并且/或者seq id no:21的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0161]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m的解离常数(kd)结合所述第一靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含与seq id no:27具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:27的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:27的倒数第二个位置处的a任选地被l取代并且/或者seq id no:27的最后一个
位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:27具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:27的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含氨基酸序列seq id no:27,其中seq id no:27的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:27的倒数第二个位置处的a任选地被l取代并且/或者seq id no:27的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0162]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含与seq id no:32具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:32的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:32具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:32的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m的解离常数(kd)结合所述靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含氨基酸序列seq id no:32,其中seq id no:32的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:32的倒数第二个位置处的a任选地被l取代并且/或者seq id no:32的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0163]
在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m、或低于3
×
10-10
m、或低于2
×
10-10
m的解离常数(kd)结合所述靶标肽-mhc复合物,并
且所述经设计的锚蛋白重复结构域包含与seq id no:33具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列,其中seq id no:33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:33的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少90%氨基酸序列同一性的氨基酸序列。在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少93%氨基酸序列同一性的氨基酸序列;并且在另一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述锚蛋白重复结构域包含与seq id no:33具有至少98%氨基酸序列同一性的氨基酸序列;并且在一个实施方案中,所述锚蛋白重复结构域包含seq id no:33的氨基酸序列。因此,在一个实施方案中,根据本发明的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m、或低于3
×
10-10
m、或低于2
×
10-10
m的解离常数(kd)结合所述第一靶标肽-mhc复合物,并且所述经设计的锚蛋白重复结构域包含氨基酸序列seq id no:33,其中seq id no:33的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:33的倒数第二个位置处的a任选地被l取代并且/或者seq id no:33的最后一个位置处的a任选地被n取代。在一个优选的实施方案中,所述靶标肽具有seq id no:19或seq id no:34的氨基酸序列。
[0164]
在本发明的上下文中,在实施例2中描述了通过表面等离子体共振(spr)分析进行的对靶标肽-mhc复合物具有结合特异性的本发明的重组结合蛋白或经设计的重复结构域的解离常数(kd)的典型和优选的确定。因此,在一个实施方案中,本发明的重组结合蛋白或经设计的重复结构域的靶标肽-mhc复合物的所述结合特异性在pbs中通过表面等离子体共振(spr)测定。在一个实施方案中,本发明的重组结合蛋白或经设计的重复结构域的靶标肽-mhc复合物的所述结合特异性如实施例2中所述在pbs中通过表面等离子体共振(spr)测定。
[0165]
在本发明的一个方面,本发明的重组结合蛋白还包含对第二靶标肽-mhc复合物具有结合特异性的第二经设计的重复结构域。
[0166]
在一个优选的实施方案中,所述第二靶标肽选自由以下项组成的组:(i)来源于在肿瘤细胞中表达的蛋白的肽;(ii)来源于感染因子(诸如细菌感染因子或病毒感染因子,优选病毒感染因子)的蛋白的肽;以及(iii)来源于与自体免疫疾患相关联的蛋白的肽。
[0167]
在一个实施方案中,所述第二靶标肽来源于细胞内蛋白,优选地在肿瘤细胞中表达的细胞内蛋白。在一个实施方案中,所述第二靶标肽来源于在肿瘤细胞中表达的细胞内蛋白。
[0168]
在一个实施方案中,所述第二靶标肽来源于感染因子(优选病毒感染因子)的蛋白。在一个实施方案中,所述第二靶标肽来源于病毒特异性蛋白。
[0169]
在一个实施方案中,对第二靶标肽-mhc复合物具有结合特异性的所述第二重复结构域在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m、或低于3
×
10-10
m、或低于2
×
10-10
m、或低于10-10
m的解离常数(kd)结合到所述第二靶标肽-mhc复合物。在一个实施方案中,对第二靶标肽-mhc复合物具有结合特异性的所述第二重复结构域在pbs中以低于10-7
m的解离常数(kd)结合到所述第二靶标肽-mhc复合物。
[0170]
在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少一个、至少两个、至少三个、至少四个、至少五个、至少六个或至少七个氨基酸残基的相互作用。因此,在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少一个氨基酸残基的相互作用。在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少两个氨基酸残基的相互作用。在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少三个氨基酸残基的相互作用。在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少四个氨基酸残基的相互作用。在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少五个氨基酸残基的相互作用。在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少六个氨基酸残基的相互作用。在一个实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二靶标肽的至少七个氨基酸残基的相互作用。在一个另外的或替代性的实施方案中,所述第二重复结构域与所述第二靶标肽-mhc复合物的所述结合包括所述第二重复结构域与所述第二mhc的至少一个氨基酸残基的相互作用。
[0171]
在一个实施方案中,所述第二mhc是mhc i类。在一个实施方案中,所述第二mhc是hla-a*02。在一个实施方案中,所述hla-a*02是hla-a*0201。在一个实施方案中,所述hla-a*0201具有seq id no:73的氨基酸序列。替代性地,在另一个实施方案中,所述第二mhc不是hla-a*02。
[0172]
在一个实施方案中,所述第二mhc是mhc i类。在一个实施方案中,所述第二mhc是hla-a*01。在一个实施方案中,所述hla-a*01是hla-a*0101。在一个实施方案中,所述hla-a*0101具有seq id no:218的氨基酸序列。替代性地,在另一个实施方案中,所述第二mhc不是hla-a*01。
[0173]
在一个实施方案中,所述第二靶标肽来源于与所述第一靶标肽相同的蛋白。在一个实施方案中,所述第二靶标肽具有与所述第一靶标肽相同的氨基酸序列。在另一个实施方案中,所述第二重复结构域具有与所述第一重复结构域相同的氨基酸序列。替代性地,在另一个实施方案中,与所述第一重复结构域相比,所述第二重复结构域具有不同的氨基酸序列。在一个实施方案中,与所述第一靶标肽相比,所述第二靶标肽具有不同的氨基酸序列。
[0174]
在另一个实施方案中,所述第二靶标肽来源于与所述第一靶标肽所来源的蛋白不同的蛋白。
[0175]
在一个优选的实施方案中,所述第二经设计的重复结构域是经设计的锚蛋白重复结构域。在一个特别优选的实施方案中,所述第二经设计的锚蛋白重复结构域是如本文的
任何方面和任何实施方案中更具体地描述的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域。
[0176]
在本发明的一个方面,本发明的重组结合蛋白还包含对第三靶标肽-mhc复合物具有结合特异性的第三经设计的重复结构域。在一个优选的实施方案中,所述第三经设计的重复结构域是经设计的锚蛋白重复结构域。在一个特别优选的实施方案中,所述第三经设计的锚蛋白重复结构域是如本文的任何方面和任何实施方案中更具体地描述的对靶标肽-mhc复合物具有结合特异性的经设计的锚蛋白重复结构域。
[0177]
在本发明的上下文中,当本发明的重组结合蛋白包含第一经设计的重复结构域和第二经设计的重复结构域时,并且当所述第一重复结构域和所述第二重复结构域对相同的靶标肽-mhc复合物具有结合特异性时,即第二靶标肽具有与第一靶标肽相同的氨基酸序列时,并且当所述第一重复结构域和所述第二重复结构域在序列上相同时,所述重组结合蛋白是二价的。在本发明的上下文中,当本发明的重组结合蛋白包含第一经设计的重复结构域和第二经设计的重复结构域时,并且当所述第一重复结构域和所述第二重复结构域对相同的靶标肽-mhc复合物具有结合特异性时,即第二靶标肽具有与第一靶标肽相同的氨基酸序列时,并且当所述第一重复结构域和所述第二重复结构域在序列上不同时,所述重组结合蛋白是双互补位的。在本发明的上下文中,当本发明的重组结合蛋白包含第一经设计的重复结构域和第二经设计的重复结构域时,并且当所述第一重复结构域和所述第二重复结构域对不同的靶标肽-mhc复合物具有结合特异性时,即第二靶标肽与第一靶标肽相比具有不同的氨基酸序列时,所述重组结合蛋白是双特异性的。不同的靶标肽可以来源于相同的蛋白或不同的蛋白。在本发明的上下文中,相同的定义类似地适用于本发明的包含第一经设计的重复结构域、第二经设计的重复结构域和第三经设计的重复结构域的重组结合蛋白,其中第一经设计的重复结构域、第二经设计的重复结构域和第三经设计的重复结构域中的每一者对靶标肽-mhc复合物具有结合特异性。
[0178]
在一个实施方案中,本发明的重组结合蛋白是单价、二价、三价、多价、单互补位、双互补位、三互补位、多互补位、单特异性、双特异性、三特异性或多特异性的。在一个特定的实施方案中,本发明的重组结合蛋白是单价的。在一个特定的实施方案中,本发明的重组结合蛋白是二价的。在一个特定的实施方案中,本发明的重组结合蛋白是三价的。在一个特定的实施方案中,本发明的重组结合蛋白是多价的。在一个特定的实施方案中,本发明的重组结合蛋白是单互补位的。在一个特定的实施方案中,本发明的重组结合蛋白是双互补位的,在一个特定的实施方案中,本发明的重组结合蛋白是三互补位的,在一个特定的实施方案中,本发明的重组结合蛋白是多互补位的。在一个特定的实施方案中,本发明的重组结合蛋白是单特异性的。在一个特定的实施方案中,本发明的重组结合蛋白是双特异性的。在一个特定的实施方案中,本发明的重组结合蛋白是三特异性的。在一个特定的实施方案中,本发明的重组结合蛋白是多特异性的。应当理解,上述实施方案能够彼此组合。作为一个示例,本发明的包含对第一种pmhc复合物具有特异性的两个相同重复结构域并且还包含对第二种不同的pmhc复合物具有特异性的第三重复结构域的重组结合蛋白将同时是二价和双特异性的。因此,在一个特定的实施方案中,本发明的重组结合蛋白是单价、二价、三价或多价和单互补位、双互补位、三互补位或多互补位和/或单特异性、双特异性、三特异性或多特异性的任何组合。
[0179]
作为非限制性示例,根据本发明的二价结合蛋白可以包含至少出现两次的具有seq id no:21的氨基酸序列的重复结构域。此类二价蛋白的示例由seq id no:16提供。作为另一非限制性示例,根据本发明的双互补位结合蛋白可以包含至少一个具有seq id no:20的氨基酸序列的重复结构域和至少一个具有seq id no:21的氨基酸序列的重复结构域,或者它可以包含至少一个具有seq id no:21的氨基酸序列的重复结构域和至少一个具有seq id no:22的氨基酸序列的重复结构域。此类双互补位蛋白的示例分别由seq id no:17和seq id no:18提供。
[0180]
在一个实施方案中,当本发明的重组结合蛋白包含两个或更多个锚蛋白重复结构域时,例如当本发明的重组结合蛋白包含两个或三个锚蛋白重复结构域时,所述两个或更多个锚蛋白重复结构域(例如所述两个或三个锚蛋白重复结构域)可以用肽接头连接。在一个实施方案中,所述肽接头是富含脯氨酸-苏氨酸的肽接头。在一个实施方案中,所述肽接头是富含脯氨酸-苏氨酸的肽接头seq id no:1或2。在一个实施方案中,所述两个或更多个锚蛋白重复结构域(例如所述两个或三个锚蛋白重复结构域)用富含脯氨酸-苏氨酸的肽接头seq id no:1或2连接。在另一个实施方案中,所述肽接头是富含甘氨酸-丝氨酸的肽接头。在一个实施方案中,所述肽接头是富含甘氨酸-丝氨酸的肽接头seq id no:3。在一个实施方案中,所述两个或更多个锚蛋白重复结构域(例如所述两个或三个锚蛋白重复结构域)用富含甘氨酸-丝氨酸的肽接头seq id no:3连接。在一个实施方案中,当本发明的重组结合蛋白包含三个或更多个锚蛋白重复结构域时,所述三个或更多个锚蛋白重复结构域可以用不同的肽接头(例如富含脯氨酸-苏氨酸的肽接头和富含丝氨酸-甘氨酸的肽接头,诸如肽接头seq id no:1至3)连接。
[0181]
在一个实施方案中,本发明的重组结合蛋白包含两个或三个锚蛋白重复结构域,其中所述两个或三个锚蛋白重复结构域中的每一个独立地包含如本文的任何方面和任何实施方案中更具体地描述的锚蛋白重复模块。
[0182]
在一个实施方案中,该重组结合蛋白包含对靶标肽-mhc复合物具有结合特异性的两个锚蛋白重复结构域,其中所述两个锚蛋白重复结构域中的每一个独立地包含如本文的任何方面和任何实施方案中更具体地描述的锚蛋白重复模块。
[0183]
在一个实施方案中,本发明的重组结合蛋白包含对靶标肽-mhc复合物具有结合特异性的两个锚蛋白重复结构域,其中所述两个锚蛋白重复结构域中的每一个均包含如本文的任何方面和任何实施方案中更具体地描述的第一锚蛋白重复模块和第二锚蛋白重复模块。
[0184]
在一个实施方案中,本发明的重组结合蛋白包含对靶标肽-mhc复合物具有结合特异性的两个锚蛋白重复结构域,其中所述两个锚蛋白重复结构域中的每一个均包含如本文的任何方面和任何实施方案中更具体地描述的第一锚蛋白重复模块、第二锚蛋白重复模块和第三锚蛋白重复模块。
[0185]
在一个实施方案中,本发明的重组结合蛋白包含对靶标肽-mhc复合物具有结合特异性的两个或三个锚蛋白重复结构域,其中所述两个或三个锚蛋白重复结构域中的每一个独立地包含如本文的任何方面和任何实施方案中更具体地描述的氨基酸序列。
[0186]
在一个实施方案中,本发明的重组结合蛋白包含对靶标肽-mhc复合物具有结合特异性的恰好两个锚蛋白重复结构域,其中所述两个锚蛋白重复结构域中的每一个独立地包
含如本文的任何方面和任何实施方案中更具体地描述的氨基酸序列。
[0187]
在一个实施方案中,本发明的重组结合蛋白包含对靶标肽-mhc复合物具有结合特异性的三个锚蛋白重复结构域,其中所述三个锚蛋白重复结构域中的每一个独立地包含如本文的任何方面和任何实施方案中更具体地描述的氨基酸序列。
[0188]
在一个实施方案中,本发明的重组结合蛋白包含对靶标肽-mhc复合物具有结合特异性的恰好三个锚蛋白重复结构域,其中所述三个锚蛋白重复结构域中的每一个独立地包含如本文的任何方面和任何实施方案中更具体地描述的氨基酸序列。
[0189]
在一个实施方案中,本发明的重组结合蛋白包含由分别对第一和第二靶标肽-mhc复合物具有结合特异性的用肽接头连接的第一和第二锚蛋白重复结构域组成的多肽,其中所述多肽包含与seq id no:16至18中的任一者具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%氨基酸序列同一性的氨基酸序列或由所述氨基酸序列组成,其中seq id no:16至18的位置1处的g和/或位置2处的s任选地缺失,并且其中seq id no:16至18的所述锚蛋白重复结构域中的每个锚蛋白重复结构域的倒数第二个位置处的a任选地被l取代和/或seq id no:16至18的所述锚蛋白重复结构域中的每个锚蛋白重复结构域的最后一个位置处的a任选地被n取代。因此,在一个实施方案中,所述多肽包含与seq id no:16至18中的任一者具有至少80%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述多肽包含与seq id no:16至18中的任一者具有至少90%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述多肽包含与seq id no:16至18中的任一者具有至少93%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述多肽包含与seq id no:16至18中的任一者具有至少95%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述多肽包含与seq id no:16至18中的任一者具有至少98%氨基酸序列同一性的氨基酸序列。在一个实施方案中,所述多肽包含seq id no:16至18中的任一者的氨基酸序列。在一个实施方案中,所述多肽由seq id no:16至18中的任一者的氨基酸序列组成。在一个实施方案中,包含由两个pmhc特异性锚蛋白重复结构域组成的多肽的所述重组结合蛋白在pbs中以低于10-7
m、或低于5
×
10-8
m、或低于3
×
10-8
m、或低于2
×
10-8
m、或低于10-8
m、或低于5
×
10-9
m、或低于3
×
10-9
m、或低于2
×
10-9
m、或低于10-9
m、或低于5
×
10-10
m、或低于3
×
10-10
m、或低于2
×
10-10
m、或低于10-10
m的解离常数(kd)结合靶标肽-mhc复合物。在一个优选的实施方案中,所述第一靶标肽和所述第二靶标肽独立地具有seq id no:19或seq id no:34的氨基酸序列。
[0190]
在一个实施方案中,本发明的重组结合蛋白包含如本文的任何方面和任何实施方案中更具体地描述的对靶标肽-mhc复合物具有结合特异性的单个经设计的锚蛋白重复结构域,或者包含如本文的任何方面和任何实施方案中更具体地描述的对靶标肽-mhc复合物具有结合特异性的两个、三个、四个、五个或更多个经设计的锚蛋白重复结构域的组合。
[0191]
在本发明的一个方面,本发明的重组结合蛋白还包含结合因子。
[0192]
在一个特定的实施方案中,所述结合因子对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性。在另一个实施方案中,在t细胞表面上表达的所述蛋白是作为t细胞受体复合物的一部分的蛋白。作为一个示例,在一个特定的实施方案中,本发明的重组结合蛋白还包含对分化簇3(cd3)具有结合特异性的结合因子。
[0193]
在本发明的上下文中,结合因子可以是抗体、抗体模拟物(包括支架蛋白或重复蛋白)、经设计的重复结构域(优选经设计的锚蛋白重复结构域),或者本领域已知的任何其他合适的结合分子。在一个实施方案中,所述结合因子是抗体。在另一个实施方案中,所述结合因子是经设计的重复结构域,优选经设计的锚蛋白重复结构域。
[0194]
在一个特定的实施方案中,所述结合因子包含对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的抗体,或者由该抗体组成。在另一个实施方案中,在t细胞表面上表达的所述蛋白是作为t细胞受体复合物的一部分的蛋白。作为一个示例,在一个特定的实施方案中,本发明的重组结合蛋白还包含对cd3具有结合特异性的抗体。
[0195]
在一个特定的实施方案中,所述结合因子包含对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的经设计的重复结构域(优选经设计的锚蛋白重复结构域),或者由该经设计的重复结构域(优选经设计的锚蛋白重复结构域)组成。在另一个实施方案中,在t细胞表面上表达的所述蛋白是作为t细胞受体复合物的一部分的蛋白。作为一个示例,在一个特定的实施方案中,本发明的重组结合蛋白还包含对cd3具有结合特异性的经设计的锚蛋白重复结构域。
[0196]
在一个实施方案中,所述结合因子连接、缀合、融合或以其他方式物理附接到所述pmhc特异性锚蛋白重复结构域或者所述两个、三个或更多个pmhc特异性锚蛋白重复结构域。在一个实施方案中,所述结合因子共价连接到所述pmhc特异性锚蛋白重复结构域或者所述两个、三个或更多个pmhc特异性锚蛋白重复结构域。在一个实施方案中,所述结合因子用肽接头共价连接到所述pmhc特异性锚蛋白重复结构域或者所述两个、三个或更多个pmhc特异性锚蛋白重复结构域。在一个实施方案中,所述肽接头是富含脯氨酸-苏氨酸的肽接头。在一个实施方案中,所述肽接头是富含脯氨酸-苏氨酸的肽接头seq id no:1或2。在一个实施方案中,所述结合因子用富含脯氨酸-苏氨酸的肽接头seq id no:1或2共价连接到所述pmhc特异性锚蛋白重复结构域或者所述两个、三个或更多个pmhc特异性锚蛋白重复结构域。在另一个实施方案中,所述肽接头是富含甘氨酸-丝氨酸的肽接头。在一个实施方案中,所述肽接头是富含甘氨酸-丝氨酸的肽接头seq id no:3。在一个实施方案中,所述结合因子用富含甘氨酸-丝氨酸的肽接头seq id no:3共价连接到所述pmhc特异性锚蛋白重复结构域或者所述两个、三个或更多个pmhc特异性锚蛋白重复结构域。
[0197]
本发明的发明人惊奇且意外地发现,所述结合因子与所述pmhc特异性锚蛋白重复结构域(或者所述两个、三个或更多个pmhc特异性锚蛋白重复结构域)之间的接头越短,t细胞接合剂形式的构建体的效力越高(参见实施例11)。因此,在另一个优选的实施方案中,本文所述的肽接头的氨基酸序列的长度小于38个氨基酸,优选至多37个、更优选至多24个、甚至更优选至多18个、甚至更优选至多11个、最优选至多6个氨基酸。在另一个优选的实施方案中,所述肽接头的氨基酸序列的长度为1个至37个、1个至24个、1个至23个、1个至18个、1个至17个、1个至11个、1个至10个、1个至6个、6个至37个、6个至24个、6个至23个、6个至18个、6个至17个或6个至11个氨基酸残基。优选地,所述肽接头是富含脯氨酸-苏氨酸的肽接头。在另一个优选的实施方案中,所述肽接头的氨基酸序列的长度少于18个氨基酸并且为至少1个氨基酸,即,所述肽接头的长度为1个至17个氨基酸。在一个实施方案中,所述接头具有如以seq id no:1和277至280中的任一者提供的氨基酸序列。在一个优选的实施方案
中,所述肽接头具有如以seq id no:278提供的氨基酸序列。在一个更优选的实施方案中,所述肽接头具有如以seq id no:279提供的氨基酸序列。在一个最优选的实施方案中,所述肽接头具有如以seq id no:280提供的氨基酸序列。
[0198]
在本发明的一个方面,本发明的重组结合蛋白包含一个、两个、三个或更多个如本文方面和实施方案中的任一者更具体地描述的pmhc特异性锚蛋白重复结构域,并且进一步包含cd3特异性结合因子,其中所述结合因子与所述pmhc特异性锚蛋白重复结构域(或所述两个、三个或更多个pmhc特异性锚蛋白重复结构域)之间的接头是如以上实施方案中任一者所描述的肽接头。优选地,所述肽接头是长度为1个至17个氨基酸的富含脯氨酸-苏氨酸的肽接头(诸如,具有如seq id no:279或seq id no:280中提供的氨基酸序列的肽接头)。
[0199]
在本发明的一个方面,本发明的重组结合蛋白(其中所述结合蛋白包含如本文的任何方面和任何实施方案中更具体地描述的一个、两个、三个或更多个pmhc特异性锚蛋白重复结构域,并且其中所述结合蛋白还包含cd3特异性结合因子)能够促进t细胞的感染定位激活或肿瘤定位激活。在此类情况下,本发明的重组结合蛋白能够以t细胞接合剂形式用于针对呈递靶标肽-mhc复合物的肿瘤细胞和/或呈递靶标肽-mhc复合物的感染性细胞局部激活t细胞。
[0200]
在本发明的一个方面,本发明的重组结合蛋白能够抑制所述第一靶标肽-mhc复合物和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽-mhc复合物被t细胞受体识别。换句话讲,本发明的重组结合蛋白能够抑制免疫系统识别靶标肽-mhc复合物的能力。在此类情况下,本发明的重组结合蛋白可以用于治疗自体免疫疾病。可以通过本领域技术人员已知的任何合适的方法或通过合适的t细胞激活测定,诸如本技术的实施例中描述的测定或其变型来测量t细胞受体对靶标肽-mhc复合物的识别。
[0201]
在一个实施方案中,本发明的重组结合蛋白还包含多肽标签。在本发明的上下文中,多肽标签为附接到多肽/蛋白的氨基酸序列,其中所述氨基酸序列可用于纯化、检测或靶向所述多肽/蛋白,或者其中所述氨基酸序列改善所述多肽/蛋白的物理化学行为,或者其中所述氨基酸序列具有效应子功能。结合蛋白的单个多肽标签可直接或经由肽接头连接到结合蛋白的其他部分。多肽标签在本领域中是众所周知的,并且是本领域技术人员完全可用的。多肽标签的示例为小的多肽序列,例如his、ha、myc、flag或strep标签;或多肽,诸如允许检测所述多肽/蛋白质的酶(例如,碱性磷酸酶)或可用于靶向的多肽(诸如,免疫球蛋白或其片段)和/或可用作效应分子的多肽。
[0202]
在一个实施方案中,本发明的重组结合蛋白还包含肽接头。在本发明的上下文中,肽接头为能够连接例如两个蛋白结构域、多肽标签和蛋白结构域、蛋白结构域和非蛋白质化合物或聚合物(诸如聚乙二醇)、蛋白结构域和生物活性分子、蛋白结构域和t细胞特异性锚蛋白重复结构域、或者两个序列标签的氨基酸序列。肽接头是本领域技术人员已知的。示例的列表在专利申请wo2002/020565的说明书中提供。此类接头的具体示例为可变长度的甘氨酸-丝氨酸接头和脯氨酸-苏氨酸接头。甘氨酸-丝氨酸接头的示例为氨基酸序列gs和seq id no:3的氨基酸序列,并且脯氨酸-苏氨酸接头的示例为seq id no:1、seq id no:2和seq id nos:277至280的氨基酸序列。
[0203]
在另一方面,本发明涉及编码本发明的经设计的重复结构域或本发明的pmhc特异性重组结合蛋白的氨基酸序列的核酸。在一个实施方案中,本发明涉及编码本发明的pmhc
特异性重组结合蛋白的氨基酸序列的核酸。在一个实施方案中,本发明涉及编码本发明的经设计的重复结构域的氨基酸序列的核酸。在一个实施方案中,本发明涉及编码选自由seq id no:20至33组成的组的氨基酸序列的核酸。在一个实施方案中,本发明涉及编码选自由seq id no:20、21、25、32和33组成的组的氨基酸序列的核酸。在一个实施方案中,本发明涉及编码选自由seq id no:20、21和33组成的组的氨基酸序列的核酸。在一个实施方案中,本发明涉及编码氨基酸序列seq id no:20的核酸。在一个实施方案中,本发明涉及编码氨基酸序列seq id no:21的核酸。在一个实施方案中,本发明涉及编码氨基酸序列seq id no:27的核酸。在一个实施方案中,本发明涉及编码氨基酸序列seq id no:32的核酸。在一个实施方案中,本发明涉及编码氨基酸序列seq id no:33的核酸。在一个实施方案中,本发明涉及seq id no:78的核酸序列,该核酸序列编码seq id no:20的氨基酸序列。在一个实施方案中,本发明涉及seq id no:79的核酸序列,该核酸序列编码seq id no:21的氨基酸序列。在一个实施方案中,本发明涉及seq id no:80的核酸序列,该核酸序列编码seq id no:32的氨基酸序列。此外,本发明涉及包含本发明的任何核酸的载体。核酸是本领域技术人员熟知的。在实施例中,使用核酸在大肠杆菌中产生本发明的经设计的锚蛋白重复结构域或重组结合蛋白。
[0204]
在另一个方面,本发明涉及一种包含本发明的pmhc特异性重组结合蛋白和/或本发明的核酸以及任选地药学上可接受的载剂和/或稀释剂的药物组合物。
[0205]
药学上可接受的载体和/或稀释剂是本领域技术人员已知的,并且将在下文更详细地说明。更进一步,提供了一种诊断组合物,其包含上文提到的重组结合蛋白和/或核酸(特别是本发明的重组结合蛋白)中的一者或多者。
[0206]
药物组合物包含重组结合蛋白和/或核酸,优选如本文的任何方面或任何实施方案中更具体地描述的重组结合蛋白和/或核酸,以及药学上可接受的载剂、赋形剂或稳定剂,例如,如remington's pharmaceutical sciences第16版,osol,a.编辑,1980中所述。
[0207]
本领域技术人员已知的合适载体、赋形剂或稳定剂包括例如盐水、林格氏溶液、右旋糖溶液、汉克氏溶液、固定油,油酸乙酯、5%右旋糖盐水、增强等渗性和化学稳定性的物质、缓冲液和防腐剂。其它合适载体包括本身不诱导产生对接受组合物的个体有害的抗体的任何载体,诸如蛋白质、多糖、聚乳酸、聚乙醇酸、聚合氨基酸和氨基酸共聚物。药物组合物还可以是组合制剂,其包含另外的活性剂,诸如抗癌剂或抗血管生成剂,或另外的生物活性化合物。
[0208]
待用于体内给药的制剂必须是无菌的或经过消毒的。这很容易通过无菌过滤膜过滤实现。
[0209]
在一个实施方案中,药物组合物包含至少一种如本文所述的重组结合蛋白和洗涤剂(诸如非离子洗涤剂)、缓冲剂(诸如磷酸盐缓冲剂),以及糖(诸如蔗糖)。在一个实施方案中,此类组合物包含如上所述的重组结合蛋白和pbs。
[0210]
在另一方面,本发明提供了一种在哺乳动物(优选人)中肿瘤定位激活免疫细胞(优选t细胞)的方法,该方法包括以下步骤:向所述哺乳动物施用本发明的pmhc特异性重组结合蛋白,该pmhc特异性重组结合蛋白包含对第一靶标肽-mhc复合物具有结合特异性的第一重复结构域并且任选地包含对第二靶标肽-mhc复合物具有结合特异性的第二重复结构域,并且还包含对在免疫细胞(优选t细胞)的表面上表达的蛋白具有结合特异性的结合因
子,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在肿瘤细胞中表达的蛋白。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于在肿瘤细胞中表达的细胞内蛋白。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于肿瘤特异性蛋白。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于细胞内肿瘤特异性蛋白。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于ny-eso-1。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽具有seq id no:19或seq id no:34的氨基酸序列。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于mage-a3。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽具有seq id no:155的氨基酸序列。在一个实施方案中,所述结合因子对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性。在一个实施方案中,所述结合因子是对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的抗体。在一个实施方案中,所述结合因子是对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的经设计的重复结构域。在一个实施方案中,所述结合因子是对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的经设计的锚蛋白重复结构域。在一个优选的实施方案中,在免疫细胞的表面上表达的所述蛋白是作为t细胞受体复合物的一部分的蛋白,诸如cd3。在一个实施方案中,所述第一锚蛋白重复结构域和/或(如果存在)所述第二锚蛋白重复结构域是如本文的任何方面和任何实施方案中更具体地描述的经独立设计的对靶标肽-mhc复合物具有结合特异性的锚蛋白重复结构域。
[0211]
还提供了本发明的pmhc特异性重组结合蛋白、本发明的核酸或本发明的药物组合物,其用于如本文所述的肿瘤定位激活免疫细胞的方法中。
[0212]
在另一方面,本发明提供了一种在哺乳动物(优选人)中感染定位激活免疫细胞(优选t细胞)的方法,该方法包括以下步骤:向所述哺乳动物施用本发明的pmhc特异性重组结合蛋白,该pmhc特异性重组结合蛋白包含对第一靶标肽-mhc复合物具有结合特异性的第一重复结构域并且任选地包含对第二靶标肽-mhc复合物具有结合特异性的第二重复结构域,并且还包含对在免疫细胞(优选t细胞)的表面上表达的蛋白具有结合特异性的结合因子,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于感染因子的蛋白。在一个实施方案中,所述感染是病毒感染。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于病毒感染因子的蛋白。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于病毒特异性蛋白。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于ebna-1。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽具有seq id no:92的氨基酸序列。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽来源于hbcag。在一个实施方案中,所述第一靶标肽和/或(如果存在)所述第二靶标肽具有seq id no:255的氨基酸序列。在一个实施方案中,所述结合因子对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性。在一个实施方案中,所述结合因子是对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的抗体。在一个实施方案中,所述结合因子是对在免疫细胞(优选t细胞,
甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的经设计的重复结构域。在一个实施方案中,所述结合因子是对在免疫细胞(优选t细胞,甚至更优选cd8 细胞毒性t细胞)的表面上表达的蛋白具有结合特异性的经设计的锚蛋白重复结构域。在一个优选的实施方案中,在免疫细胞的表面上表达的所述蛋白是作为t细胞受体复合物的一部分的蛋白,诸如cd3。在一个实施方案中,所述第一锚蛋白重复结构域和/或(如果存在)所述第二锚蛋白重复结构域是如本文的任何方面和任何实施方案中更具体地描述的经独立设计的对靶标肽-mhc复合物具有结合特异性的锚蛋白重复结构域。
[0213]
还提供了本发明的pmhc特异性重组结合蛋白、本发明的核酸或本发明的药物组合物,其用于如本文所述的感染定位激活免疫细胞的方法中。
[0214]
在另一方面,本发明提供了一种用于治疗医学病症的方法,该方法包括向对该治疗有需要的患者施用治疗有效量的本发明的pmhc特异性重组结合蛋白、本发明的核酸或者本发明的药物组合物的步骤。
[0215]
还提供了本发明的pmhc特异性重组结合蛋白、核酸或药物组合物,其用于如本文所述的治疗医学病症的方法中。
[0216]
在另一方面,本发明提供了一种诊断哺乳动物(优选人)的医学病症的方法,该方法包括以下步骤:
[0217]
(i)使从所述哺乳动物获得的细胞或组织样品与本发明的重组结合蛋白接触;以及
[0218]
(ii)检测所述结合蛋白与所述细胞或组织样品的特异性结合。在一个实施方案中,所述组织是肿瘤组织。
[0219]
在本发明的上下文中,术语“医学病症”、“疾病”和“疾患”可互换使用,包括但不限于癌症、感染性疾病和自体免疫疾病。在一个优选的实施方案中,所述医学病症是癌症、感染性疾病(优选病毒感染性疾病)或自体免疫疾病。在一个优选的实施方案中,所述医学病症是癌症。在一个实施方案中,这种癌症选自由以下项组成的组:上皮恶性肿瘤(原发性和转移性),包括但不限于肺癌、结直肠癌、胃癌、膀胱癌、卵巢癌和乳腺癌;血细胞恶性肿瘤,包括但不限于白血病、淋巴瘤和骨髓瘤;肉瘤,包括但不限于骨和软组织肉瘤;以及黑素瘤。在一个优选的实施方案中,这种癌症选自由以下项组成的组:脂肪肉瘤、成神经细胞瘤、滑膜肉瘤、黑素瘤和卵巢癌。在另一个优选的实施方案中,这种癌症选自由以下项组成的组:黑素瘤、肺癌、肝癌、胃癌、皮肤癌、成神经细胞瘤、软组织肉瘤、膀胱癌、睾丸癌和卵巢癌。在一个优选的实施方案中,所述医学病症是感染性疾病,优选病毒感染性疾病。在一个实施方案中,这种感染性疾病是由乙型肝炎病毒(hbv)引起的病毒感染。在另一个实施方案中,这种感染性疾病是由eb病毒(ebv)引起的病毒感染。在一个优选的实施方案中,所述医学病症是自体免疫疾病。在一个实施方案中,这种自体免疫疾病选自由以下项组成的组:系统性红斑狼疮、类风湿性关节炎和i型糖尿病。
[0220]
在一个实施方案中,本发明涉及根据本发明的药物组合物、核酸或重组结合蛋白用于治疗疾病的用途。为此目的,将根据本发明的药物组合物、核酸或重组结合蛋白以治疗有效量施用给对其有需要的患者。给药可包括局部给药、口服给药和肠胃外给药。典型的给药途径是肠胃外给药。在肠胃外给药中,本发明的药物组合物将与上述药学上可接受的赋形剂联合被配制成单位剂量可注射形式,诸如溶液、混悬液或乳液。给药的剂量和模式将取
决于待治疗的个体和具体疾病。
[0221]
另外,考虑将上文提到的药物组合物或重组结合蛋白中的任一种用于治疗疾患。
[0222]
在一个实施方案中,静脉内应用如本文所述的本发明的所述重组结合蛋白或药物组合物。对于肠胃外应用,所述重组结合蛋白或药物组合物能够以治疗有效量快速浓注或缓慢输注。
[0223]
在一个实施方案中,本发明涉及一种治疗医学病症的方法,该方法包括向需要这种治疗的患者施用治疗有效量的本发明的重组结合蛋白、核酸或药物组合物的步骤。在一个实施方案中,本发明涉及本发明的重组结合蛋白、核酸或药物组合物用于治疗医学病症的用途。在一个实施方案中,本发明涉及本发明的重组结合蛋白、核酸或药物组合物,其用于治疗医学病症。在一个实施方案中,本发明涉及本发明的药物组合物、重组结合蛋白或核酸作为用于治疗医学病症的药物的用途。在一个实施方案中,本发明涉及本发明的药物组合物、重组结合蛋白或核酸用于制造药物的用途。在一个实施方案中,本发明涉及本发明的药物组合物、重组结合蛋白或核酸用于制造用于治疗医学病症的药物的用途。在一个实施方案中,本发明涉及一种用于制造用于治疗医学病症的药物的方法,其中本发明的药物组合物、重组结合蛋白或核酸是该药物的活性成分。在一个实施方案中,本发明涉及一种使用本发明的药物组合物、重组结合蛋白或核酸来治疗医学病症的方法。
[0224]
在另一个实施方案中,本发明涉及本发明的重组结合蛋白、核酸或药物组合物用于制造用于治疗医学病症(优选瘤性疾病,更优选癌症)的药物的用途。
[0225]
在一个实施方案中,本发明涉及一种用于治疗目的的包含上文提到的经设计的锚蛋白重复结构域中的任一者的重组结合蛋白。
[0226]
在一个方面,本发明涉及一种包括本发明的重组结合蛋白的试剂盒。在一个实施方案中,本发明涉及一种包括编码本发明的重组结合蛋白的核酸的试剂盒。在一个实施方案中,本发明涉及一种包括本发明的药物组合物的试剂盒。在一个实施方案中,本发明涉及一种包括本发明的重组结合蛋白、和/或编码本发明的重组结合蛋白的核酸、和/或本发明的药物组合物的试剂盒。在一个实施方案中,本发明涉及一种试剂盒,其包括:重组结合蛋白,所述重组结合蛋白包含一个或多个本发明的肽-mhc特异性锚蛋白重复结构域,例如一个或多个独立地具有seq id no:20、seq id no:21、seq id no:27、seq id no:32或seq id no:33的氨基酸序列的肽-mhc特异性锚蛋白重复结构域;和/或编码重组结合蛋白的核酸,所述重组结合蛋白包含一个或多个本发明的肽-mhc特异性锚蛋白重复结构域,例如一个或多个独立地具有seq id no:20、seq id no:21、seq id no:27、seq id no:32或seq id no:33的氨基酸序列的肽-mhc特异性锚蛋白重复结构域;和/或药物组合物,所述药物组合物包含重组结合蛋白,所述重组结合蛋白包含一个或多个本发明的肽-mhc特异性锚蛋白重复结构域,例如一个或多个独立地具有seq id no:20、seq id no:21、seq id no:27、seq id no:32或seq id no:33的氨基酸序列的肽-mhc特异性锚蛋白重复结构域。
[0227]
在另一方面,本发明提供了一种靶向患有肿瘤的患者中的肿瘤细胞以破坏肿瘤细胞的方法,该方法包括向该患者施用治疗有效量的本发明的结合蛋白、核酸或药物组合物的步骤,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在肿瘤细胞中表达的蛋白,优选在肿瘤细胞中表达的细胞内蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死肿瘤细胞的毒性因子。
[0228]
还提供了本发明的重组结合蛋白、核酸或药物组合物,其用于靶向患有肿瘤的患者中的肿瘤细胞以破坏肿瘤细胞的方法中,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在肿瘤细胞中表达的蛋白,优选在肿瘤细胞中表达的细胞内蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死肿瘤细胞的毒性因子。
[0229]
在另一方面,本发明提供了一种靶向患有病毒感染性疾病的患者中的受感染细胞以破坏所述受感染细胞的方法,该方法包括向该患者施用治疗有效量的本发明的结合蛋白、核酸或药物组合物的步骤,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在所述受感染细胞中表达的蛋白,优选病毒特异性蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死受感染细胞的毒性因子。
[0230]
还提供了本发明的重组结合蛋白、核酸或药物组合物,其用于靶向患有病毒感染性疾病的患者中的受感染细胞以破坏所述受感染细胞的方法中,其中所述第一靶标肽和/或(如果所述结合蛋白包含所述第二重复结构域)所述第二靶标肽来源于在所述受感染细胞中表达的蛋白,优选病毒特异性蛋白。在一个实施方案中,所述结合蛋白还包含能够杀死受感染细胞的毒性因子。
[0231]
在一个优选的实施方案中,待通过本发明的治疗方法或通过本发明的结合蛋白、核酸或药物组合物治疗的医学病症是选自由以下项组成的组的癌症或肿瘤:脂肪肉瘤、成神经细胞瘤、滑膜肉瘤、黑素瘤和卵巢癌。在另一个优选的实施方案中,本发明的重组结合蛋白对肽-mhc(pmhc)复合物具有结合特异性,其中肽来源于ny-eso-1。
[0232]
本发明不限于实施例中描述的具体实施方案。
[0233]
本说明书涉及在所附序列表中公开的许多氨基酸序列、核酸序列和seq id no,该序列表全文以引用方式并入本文。
[0234]
定义
[0235]
除非本文另有定义,否则本文所用的所有技术和科学术语应具有本发明所属领域的普通技术人员通常理解的含义。
[0236]
在本发明的上下文中,术语“集合”是指包含至少两个不同的实体或成员的群体。优选地,这样的集合包括至少105个、更优选地超过107个并且最优选地超过109个不同的成员。“集合”也可以称为“文库”或“多个”。
[0237]
术语“核酸分子”是指多核苷酸分子,其可以是单链或双链的核糖核酸(rna)分子或脱氧核糖核酸(dna)分子,包括dna或rna的经修饰形式和人造形式。核酸分子可以以分离的形式存在,或者被包含在重组核酸分子或载体中。
[0238]
在本发明的上下文中,术语“蛋白质”是指包含多肽的分子,其中多肽的至少一部分通过在单个多肽链内和/或多个多肽链之间形成二级、三级和/或四级结构而具有或能够获得限定的三维排列。如果蛋白质包含两个或更多个多肽链,则各个多肽链可非共价连接或共价连接,例如通过两个多肽之间的二硫键连接。通过形成二级和/或三级结构而单独具有或能够获得限定的三维排列的蛋白质部分被称为“蛋白质结构域”。这种蛋白质结构域是本领域技术人员熟知的。
[0239]
在重组蛋白、重组多肽等中使用的术语“重组”是指所述蛋白质或多肽是通过使用本领域技术人员熟知的重组dna技术产生的。例如,可将编码多肽的重组dna分子(例如,通
过基因合成产生)克隆到细菌表达质粒(例如,pqe30,qiagen公司)、酵母表达质粒、哺乳动物表达质粒或植物表达质粒,或者能够体外表达的dna中。如果例如将此类重组细菌表达质粒插入适当的细菌(例如,大肠杆菌(escherichia coli))中,则这些细菌可产生由该重组dna编码的多肽。对应产生的多肽或蛋白质被称为重组多肽或重组蛋白。
[0240]
在本发明的上下文中,术语“结合蛋白”是指包含结合结构域的蛋白质。结合蛋白还可包含两个、三个、四个、五个或更多个结合结构域。优选地,所述结合蛋白是重组结合蛋白。更优选地,本发明的结合蛋白包含对pmhc复合物具有结合特异性的锚蛋白重复结构域。
[0241]
此外,任何此类结合蛋白均可以包含附加多肽(诸如多肽标签、肽接头、与其他具有结合特异性的蛋白质结构域的融合、细胞因子、激素或拮抗剂),或者本领域技术人员熟知的化学修饰(诸如偶联到聚乙二醇、毒素、小分子、抗生素等)。在一些实施方案中,该结合蛋白还包含对免疫细胞表面上表达的蛋白具有结合特异性的结合因子。在一些实施方案中,该结合蛋白还包含能够杀死肿瘤细胞和/或受感染细胞的毒性因子。毒性因子的示例包括但不限于长春碱、多柔比星、拓扑异构酶i抑制剂、卡奇霉素、倍癌霉素-羟基苯甲酰胺-氮杂吲哚(duba)、吡咯并苯并二氮杂二聚体(pbd)和微管抑制剂家族的衍生物,诸如耳他汀和美登素,例如单甲基耳他汀e(mmae)、单甲基耳他汀f(mmaf)、药物美登木素生物碱1(dm1)和药物美登木素生物碱4(dm4)。
[0242]
术语“结合结构域”意指对靶标表现出结合特异性的蛋白质结构域。优选地,所述结合结构域是重组结合结构域。
[0243]
术语“靶标”是指单独的分子,诸如核酸分子、肽、多肽或蛋白、碳水化合物或任何其他天然存在的分子,包括此类单独的分子的任何部分;或者两种或更多种此类分子的复合物;或者整个细胞或组织样品;或者任何非天然化合物。优选地,靶标是天然存在的或非天然的多肽或蛋白质,或含有化学修饰(例如天然或非天然的磷酸化、乙酰化或甲基化)的多肽或蛋白质。在本发明的上下文中,肽-mhc复合物以及肽-mhc呈递细胞和组织是pmhc特异性结合蛋白的靶标。此外,cd3细胞和表达cd3的细胞(诸如t细胞)是本发明的还包含对免疫细胞的表面上表达的蛋白(诸如cd3)具有结合特异性的结合因子的pmhc特异性结合蛋白的靶标。
[0244]
在本发明的上下文中,术语“多肽”涉及由多个(即两个或更多个)经由肽键连接的氨基酸的链组成的分子。优选地,多肽由八个以上经由肽键连接的氨基酸组成。术语“多肽”还包括通过半胱氨酸的s-s桥连接在一起的氨基酸的多个链。多肽是本领域技术人员熟知的。
[0245]
专利申请wo2002/020565和forrer等人,2003(forrer,p.,stumpp,m.t.,binz,h.k.,pl
ü
ckthun,a.,2003.febs letters 539,2-6)包含重复蛋白特征和重复结构域特征、技术和应用的一般描述。术语“重复蛋白”是指包含一个或多个重复结构域的蛋白质。优选地,重复蛋白包含一个、两个、三个、四个、五个或六个重复结构域。此外,所述重复蛋白可包含附加的非重复蛋白质结构域、多肽标签和/或肽接头。重复结构域可以是结合结构域。
[0246]
术语“重复结构域”是指包含两个或更多个连续重复模块作为结构单元的蛋白质结构域,其中所述重复模块具有结构和序列同源性。优选地,重复结构域还包含n-末端和/或c-末端的封端模块。为了清楚起见,封端模块可以是重复模块。本领域从业人员根据以下各项的示例熟知此类重复结构域、重复模块和封端模块、序列基序以及结构同源性和序列
同源性:锚蛋白重复结构域(binz等人,j.mol.biol.332,489
–
503,2003;binz等人,2004年,同前;wo2002/020565;wo2012/069655)、富含亮氨酸的重复结构域(wo2002/020565)、三角形四肽重复结构域(main,e.r.,xiong,y.,cocco,m.j.,d'andrea,l.,regan,l.,structure 11(5),497-508,2003)和犰狳重复结构域(wo2009/040338)。本领域技术人员还熟知,此类重复结构域不同于包含重复氨基酸序列的蛋白质,其中每个重复氨基酸序列能够形成单个结构域(例如纤连蛋白的fn3结构域)。
[0247]
术语“锚蛋白重复结构域”是指包含两个或更多个连续锚蛋白重复模块作为结构单元的重复结构域,其中所述锚蛋白重复模块具有结构同源性和序列同源性。
[0248]
如在经设计的重复蛋白、经设计的重复结构域等中所用,术语“经设计的”是指此类重复蛋白和重复结构域分别是人造的并且在自然界中不存在的性质。本发明的结合蛋白是经设计的重复蛋白,并且它们包含至少一个经设计的重复结构域。优选地,所述经设计的重复结构域是经设计的锚蛋白重复结构域。
[0249]
术语“靶标相互作用残基”是指有助于与靶标直接相互作用的重复模块的氨基酸残基。
[0250]
术语“框架残基”或“框架位置”是指重复模块的以下氨基酸残基:其有助于折叠拓扑结构,即有助于所述重复模块的折叠或有助于与相邻模块的相互作用。此类贡献可为与重复模块中其他残基的相互作用,或是对如α-螺旋或β-片层中存在的多肽主链构象的影响,或是参与形成直链多肽或环的氨基酸延伸。
[0251]
此类框架和靶标相互作用残基可通过分析由物理化学方法(诸如x射线晶体学、nmr和/或cd光谱)获得的结构数据,或通过与结构生物学和/或生物信息学领域从业者熟知的已知和相关结构信息进行比较来鉴定。
[0252]
术语“重复模块”是指经设计的重复结构域的重复氨基酸序列和结构单元,其最初来源于天然存在的重复蛋白的重复单元。包含在重复结构域中的每个重复模块来源于天然存在的重复蛋白家族或亚家族(优选锚蛋白重复蛋白家族)的一个或多个重复单元。此外,重复结构域中包含的每个重复模块可包含从同源重复模块导出的“重复序列基序”,该同源重复模块从靶标上选择的重复结构域获得,例如如实施例1中所述,并且具有相同的靶标特异性。
[0253]
因此,术语“锚蛋白重复模块”是指最初来源于天然存在的锚蛋白重复蛋白的重复单元的重复模块。锚蛋白重复蛋白是本领域技术人员熟知的。
[0254]
重复模块可以包含具有为了选择靶标特异性重复结构域而在文库中未被随机化的氨基酸残基的位置(“非随机化位置”或“固定位置”在本文中可互换使用)和具有为了选择靶标特异性重复结构域而在文库中已被随机化的氨基酸残基的位置(“随机化位置”)。非随机化位置包含框架残基。随机化位置包含靶标相互作用残基。“已被随机化”意指在重复模块的氨基酸位置处允许两个或更多个氨基酸,例如,其中允许通常二十种天然存在的氨基酸中的任一种,或者其中允许二十种天然存在的氨基酸中的大多数,诸如除半胱氨酸之外的氨基酸,或除甘氨酸、半胱氨酸和脯氨酸之外的氨基酸。出于本专利申请的目的,seq id no:37至60、62至66、68至72、111至122、124至154、175至217和231至254的氨基酸残基3、4、6、14和15,seq id no:61和67的氨基酸残基3、4、6、13和14以及seq id no:123的氨基酸残基3、4、6、15和16为本发明的锚蛋白重复模块的随机位置。
[0255]
术语“重复序列基序”是指从一个或多个重复模块导出的氨基酸序列。优选地,所述重复模块来自对相同靶标具有结合特异性的重复结构域。此类重复序列基序包含框架残基位置和靶标相互作用残基位置。所述框架残基位置对应于重复模块的框架残基位置。同样,所述靶标相互作用残基位置对应于重复模块的靶标相互作用残基的位置。重复序列基序包含非随机化位置和随机化位置。
[0256]
术语“重复单元”是指包含一种或多种天然存在的蛋白质的序列基序的氨基酸序列,其中所述“重复单元”存在于多个拷贝中,并且表现出确定蛋白质折叠的所有所述基序共有的限定的折叠拓扑结构。此类重复单元的示例包括富含亮氨酸的重复单元、锚蛋白重复单元、犰狳重复单元、三十四肽重复单元、heat重复单元和富含亮氨酸的变体重复单元。
[0257]
术语“结合特异性”、“对靶标具有结合特异性”、“特异性地结合到靶标”、“以高特异性结合到靶标”、“特异于靶标”或“靶标特异性”等意指,结合蛋白或结合结构域在pbs中以比其结合到不相关蛋白(诸如大肠杆菌麦芽糖结合蛋白(mbp))更低的解离常数结合(即,其以更高的亲和力结合)到靶标。优选地,在pbs中对靶标的解离常数(“k
d”)为至少102;更优选地,至少103;更优选地,至少104;或更优选地,比对mbp的对应解离常数低至少105倍。确定蛋白质-蛋白质相互作用的解离常数的方法,诸如基于表面等离子共振(spr)的技术(例如,spr均衡分析)或等温滴定量热法(itc)是本领域技术人员熟知的。如果在不同条件(例如,盐浓度、ph)下进行测量,则具体蛋白质-蛋白质相互作用的测量kd值可以是变化的。因此,优选地利用标准化蛋白质溶液和标准化缓冲液(诸如,pbs)来进行kd值的测量。通过表面等离子体共振(spr)分析进行的对pmhc具有结合特异性的本发明重组结合蛋白的解离常数(kd)的典型和优选的确定描述于实施例2中。
[0258]
术语“约”意指所提及的值 /-20%;例如,“约50”应意指40至60。
[0259]
术语“pbs”意指含有137mm nacl、10mm磷酸盐和2.7mm kcl并且ph为7.4的磷酸盐缓冲水溶液。
[0260]
主要组织相容性复合物(mhc)是一组基因,其编码在细胞表面上发现的帮助免疫系统识别外来物质的蛋白。由主要组织相容性复合物编码的蛋白或此类蛋白的复合物被称为“mhc蛋白”或“mhc分子”。mhc蛋白存在于所有高等脊椎动物中。最值得注意的是将肽呈递给免疫细胞受体(诸如t细胞受体)的mhc i类和ii类糖蛋白。在人类中,主要组织相容性复合物也被称为人白细胞抗原(hla)系统。
[0261]
如本文所用,术语“mhc”是指主要组织相容性复合物,优选哺乳动物的主要组织相容性复合物,甚至更优选人的主要组织相容性复合物。如本文所用,术语“hla”是指人白细胞抗原系统。mhc分子展示肽并将其呈递给脊椎动物的免疫系统。术语“肽抗原”和“mhc肽抗原”在本文中可互换使用,并且是指可以结合在mhc分子的肽结合槽中的mhc配体。肽抗原通常具有经由肽键连接的介于8个至25个之间的氨基酸。mhc肽抗原可以是自身肽或非自身肽。该肽抗原通常可以通过mhc分子呈递给免疫系统。mhc i类分子通常将该肽抗原呈递给cd8阳性t细胞,而mhc ii类分子通常将该肽抗原呈递给cd4阳性t细胞。在本发明的上下文中,被本发明的结合蛋白特异性结合的肽抗原(当该肽抗原结合到mhc分子时)也被称为“靶标肽”。因此,术语“肽-mhc复合物”、“pmhc复合物”、“肽-mhc”和“pmhc”在本技术中可互换使用,并且是指通过肽抗原与mhc分子结合而形成的复合物。优选地,mhc分子是mhc i类分子。还优选地,肽是来源于在肿瘤细胞中表达的蛋白的肽、来源于感染因子(例如病毒感染因
子)的蛋白的肽,或者来源于与自体免疫疾患相关联的蛋白的肽。在一个优选的实施方案中,在肿瘤细胞中表达的所述蛋白是肿瘤特异性蛋白。
[0262]
术语“肿瘤特异性蛋白”意指在肿瘤细胞中表达并且在许多或所有非肿瘤发生组织中不表达或仅以较低水平表达、或者除在肿瘤组织中表达之外仅还在有限数量的非肿瘤发生组织中表达的蛋白。优选地,肿瘤特异性蛋白具有引发癌症特异性免疫应答的能力。肿瘤特异性蛋白的示例是本领域技术人员已知的,包括但不限于mage-a1、mage-a3、mage-a4、ny-eso-1、prame、ct83、ssx2等。
[0263]
术语“病毒特异性蛋白”意指在病毒感染的细胞中从病毒基因组表达而在未感染的宿主细胞中不表达的蛋白。病毒特异性蛋白的示例是本领域技术人员已知的,包括但不限于ebna-1、ebna-2、ebna-3、lmp-1、lmp-2、nsp1、nsp2、nsp4、nsp5、nsp6、e1、e2、hbx、hbsag、hbcag等。
[0264]
与自体免疫疾患相关联的蛋白的示例是本领域技术人员已知的,包括但不限于羧肽酶h、嗜铬粒蛋白a、胰岛素、β-抑制蛋白、水通道蛋白-4、瓜氨酸化蛋白等。
[0265]“靶标肽-mhc复合物”是指肽-mhc复合物,其中肽抗原是靶标肽。
[0266]
更优选地,肽抗原来源于细胞内蛋白,甚至更优选地在肿瘤细胞中表达的细胞内蛋白或肿瘤特异性蛋白。
[0267]
最优选地,肽抗原来源于ny-eso-1。ny-eso-1或纽约食管鳞状细胞癌1是众所周知的睾丸癌抗原(cta),在许多癌症类型中再表达(wo98/14464;chen y t等人,proc natl acad sci usa 1997,94:1914-18;scanlan等人,2004,cancer immunity,4,1)。其引发自发体液免疫应答和细胞免疫应答的能力与其限制性表达模式一起使其成为癌症免疫疗法的良好候选靶标(thomas r等人,front immunol.2018;9:947)。具体而言,ny-eso-1例如在脂肪肉瘤、成神经细胞瘤、滑膜肉瘤、黑素瘤和卵巢癌中以非常高的频率表达。ny-eso-1的蛋白和多核苷酸序列在genbank登录号u87459版本u87459.1中提供。优选地,来源于ny-eso-1的肽抗原具有氨基酸序列sllmwitqv(seq id no:19)或sllmwitqc(seq id no:34)。
[0268]
替代性地,肽抗原可以来源于mage-a3。mage-a3或黑素瘤相关抗原3是人类中由magea3基因编码的蛋白。癌症/睾丸抗原mage-a3是黑素瘤抗原基因(mage)家族的成员,其具有限于睾丸的表达并且在癌细胞中异常表达。已经发现mage-a3在各种恶性肿瘤中广泛表达,包括黑素瘤、乳腺癌、头颈癌、肺癌、胃癌、皮肤鳞状细胞癌、结直肠癌等。mage-a3相对受限的表达及其免疫原性已使其成为免疫疗法的理想靶标(int j med sci.2018;15(14):1702
–
1712)。mage-a3的蛋白和多核苷酸序列在genpept登录号np_005353版本np_005353.1中提供。优选地,来源于mage-a3的肽抗原具有氨基酸序列evdpighly(seq id no:155)。
[0269]
肽抗原还可以来源于感染因子的蛋白,例如病毒感染因子的蛋白,优选病毒特异性蛋白。病毒感染因子可以是爱泼斯坦-巴尔病毒(ebv),其中所述ebv的蛋白优选为病毒特异性蛋白。病毒感染因子可以是乙型肝炎病毒(hbv),其中所述hbv的蛋白优选为病毒特异性蛋白。
[0270]
肽抗原可以来源于ebna-1。ebna-1或爱泼斯坦-巴尔核抗原1是检测到的首个爱泼斯坦-巴尔病毒(ebv)蛋白并且是最广泛研究的。ebna1在ebv感染的潜伏和裂解模式两者中表达,但是主要在潜伏期中进行研究,在潜伏期中它发挥多种重要作用。ebv潜伏期中ebna1的重要性反映下述事实中:在ebna1是在增殖细胞中和在所有ebv相关肿瘤中以所有潜伏期
形式表达的唯一病毒蛋白(scientifica(cairo).2012;2012:438204)。优选地,来源于ebna-1的肽抗原具有氨基酸序列fmvflqthi(seq id no:92)。
[0271]
替代性地,肽抗原可以来源于乙型肝炎病毒核心抗原(hbcag)。优选地,来源于hbcag的肽抗原是hbv核心抗原的序列18-27,在本文中缩写为“hbvc18”或“c18肽”,并且具有氨基酸序列flpsdffpsv(seq id no:255)。
[0272]
如在“来源于肿瘤特异性蛋白的肽”、“来源于细胞内蛋白的肽”、“来源于感染因子的蛋白的肽”、“来源于与自体免疫疾患相关联的蛋白的肽”等中所使用的术语“来源于
…
的肽”是指相应蛋白的分子部分或肽片段。这种肽片段可以由正常蛋白或致病蛋白的降解产生,以便与细胞表面上的mhc分子缔合而被呈递(即展示),以便被某些淋巴细胞(诸如t细胞)识别。所呈递的肽可以是自身肽或非自身肽,并且生物体的免疫系统通常可以区分自身肽与非自身肽,从而阻止生物体的免疫系统靶向其自身的细胞。替代性地,这种肽片段可以通过本领域已知的方法产生。优选地,肽来源于细胞内蛋白。
[0273]
术语“结合因子”是指能够特异性地结合靶标分子的任何分子,包括例如抗体、抗体片段、适体、肽(例如,williams等人,j biol chem266:5182-5190(1991))、抗体模拟物、重复蛋白(例如,经设计的锚蛋白重复蛋白)、受体蛋白和靶标分子的任何其他天然存在的相互作用配偶体,并且可以包括天然蛋白和经修饰或经遗传工程化(例如以包括非天然残基和/或以缺少天然残基)的蛋白。
[0274]
结合结构域的术语“负选择”或“反选择”意指从结合结构域的集合中选择性去除不适合或较不适合本发明目的的结合结构域。在本发明的上下文中,负选择或反选择优选地意指从经设计的重复结构域的集合中选择性去除对肽-mhc复合物而非靶标肽-mhc复合物具有结合特异性或者对不同pmhc复合物的共同hla-a支架具有结合特异性的不需要的经设计的重复结构域。用于负选择或反选择集合中不需要的成员(诸如结合结构域集合中不需要的结合结构域)的方法是本领域技术人员已知的,诸如本技术中实施例1中使用的方法。
[0275]
如本文所用,术语“肽-mhc呈递细胞”是指能够在细胞表面上表达或展示肽-mhc的任何细胞。这包括但不限于肿瘤细胞、受感染细胞、与自体免疫疾患相关联的细胞、经典的抗原呈递细胞(诸如树突状细胞、巨噬细胞和b细胞),以及已被制备用于展示结合到外源施用肽的mhc分子的细胞(诸如经肽脉冲处理的t2细胞)。
[0276]
如本文所用,术语“表达cd3的细胞”是指在细胞表面上表达cd3(分化簇3)的任何细胞,包括但不限于t细胞诸如细胞毒性t细胞(cd8 t细胞)和t辅助细胞(cd4 t细胞)。
[0277]
术语“t细胞的肿瘤定位激活”意指与非肿瘤组织相比,t细胞优先在肿瘤组织中被激活。
[0278]
术语“t细胞的感染定位激活”意指与未感染组织相比,t细胞优先在受感染组织中被激活。
[0279]
术语“医学病症”(或“疾患”或“疾病”)包括但不限于自体免疫疾患、炎性疾患、视网膜病变(特别是增殖性视网膜病变)、神经退行性疾患、感染性疾病、代谢疾病和肿瘤性疾病。本文所述的重组结合蛋白中的任一种可以用于制备用于治疗这种疾患,特别是选自由以下项组成的组的疾患的药物:自体免疫疾患、炎性疾患、免疫疾患、感染性疾病(例如病毒性或细菌性感染性疾病)和肿瘤性疾病。“医学病症”可能是以不适当的细胞增殖为特征的
病症。医学病症可能是过度增生病症。本发明具体涉及一种治疗医学病症的方法,该方法包括向需要这种治疗的患者施用治疗有效量的本发明的重组结合蛋白或药物组合物的步骤。在一个优选的实施方案中,所述医学病症是肿瘤性疾病。如本文所用,术语“肿瘤性疾病”是指以细胞生长或肿瘤快速增殖为特征的细胞或组织的异常状态或病症。在一个实施方案中,所述医学病症是恶性肿瘤性疾病。在一个实施方案中,所述医学病症是癌症。在另一个优选的实施方案中,所述医学病症是感染性疾病。在另一个优选的实施方案中,所述医学病症是自体免疫疾病。术语“治疗有效量”是指足以对患者产生期望效应的量。
[0280]
术语“抗体”不仅意指完整的抗体分子,而且意指保留免疫原结合能力的抗体分子的任何片段和变体。此类片段和变体也是本领域熟知的,并且经常在体外和体内使用。因此,术语“抗体”涵盖完整免疫球蛋白分子、抗体片段(诸如fab、fab’、f(ab')2和单链v区片段(scfv))、双特异性抗体、嵌合抗体、人源化抗体、抗体融合多肽和非常规抗体。
[0281]
术语“癌症”和“癌性”在本文中用来指或描述哺乳动物中通常以未受调控的细胞生长为特征的生理状况。癌症涵盖实体瘤和液体瘤,以及原发性肿瘤和转移。“肿瘤”包含一个或多个癌细胞。实体瘤通常还包含肿瘤基质。癌症的示例包括但不限于原发性和转移性癌、淋巴瘤、胚细胞瘤、肉瘤、骨髓瘤、黑素瘤和白血病,以及任何其他上皮和血细胞恶性肿瘤。此类癌症的更具体的示例包括脑癌、膀胱癌、乳腺癌,卵巢癌、肾癌、结直肠癌、胃癌、头颈癌、肺癌、胰腺癌、前列腺癌、恶性黑素瘤、骨肉瘤、软组织肉瘤、上皮癌、鳞状细胞癌、透明细胞肾癌、头/颈鳞状细胞癌、肺腺癌、肺鳞状细胞癌、非小细胞肺癌(nsclc)、肾细胞癌、小细胞肺癌(sclc)、三阴性乳腺癌、急性成淋巴细胞性白血病(all)、急性髓性白血病(aml)、慢性淋巴细胞性白血病(cll)、慢性髓性白血病(cml)、弥漫性大b细胞淋巴瘤(dlbcl)、滤泡性淋巴瘤、霍奇金氏淋巴瘤(hl)、套细胞淋巴瘤(mcl)、多发性骨髓瘤(mm)、骨髓增生异常综合征(mds)、非霍奇金氏淋巴瘤(nhl)、头颈部鳞状细胞癌(scchn)、慢性髓细胞性白血病(cml)、小淋巴细胞性淋巴瘤(sll)、恶性间皮瘤、脂肪肉瘤、成神经细胞瘤或滑膜肉瘤。
[0282]
术语“治疗有效量”是指足以在受试者中诱导期望的生物学结果、药理学结果或治疗结果的量。在本发明的上下文中,治疗有效量意指以适用于任何医学治疗的合理的效/险比治疗或预防疾病或疾患的结合蛋白的足够的量。
[0283]
术语“治疗”是指治疗性治疗和预防性或防止性措施。需要治疗的那些患者包括已经患有疾患的那些患者,以及要预防疾患的那些患者。
[0284]
用于治疗目的的术语“哺乳动物”是指被分类为哺乳动物的任何动物,包括人、家养动物和农场动物、非人灵长类动物,以及动物园动物、运动型动物或宠物动物,诸如狗、马、猫、牛等。术语“自体免疫疾病”和“自体免疫疾患”在本文中用于指代或描述以下疾患:其中哺乳动物的免疫系统针对哺乳动物的自身组织或者本质上对哺乳动物无害的抗原产生体液或细胞免疫应答,从而在这种哺乳动物中产生组织损伤。自体免疫疾患的示例有许多,包括但不限于系统性红斑狼疮、类风湿性关节炎和i型糖尿病。自体免疫疾病还包括急性肾小球肾炎、阿狄森氏病、成年发作型特发性甲状旁腺功能减退症(aoih)、全秃、肌萎缩性脊髓侧索硬化症、强直性脊柱炎、自体免疫再生障碍性贫血、自体免疫溶血性贫血、白塞氏病、乳糜泻、慢性活动性肝炎、crest综合征、克隆氏病、皮肌炎、扩张性心肌病、嗜酸性粒细胞增多-肌痛综合征、获得性大疱性表皮松解症(eba)、巨细胞动脉炎、古德帕斯丘综合征、格雷夫斯氏病、吉兰-巴雷综合征、血色素沉着病、亨-舍二氏紫癜、特发性iga肾病、胰岛
素依赖型糖尿病(iddm)、幼年型类风湿性关节炎、兰伯特-伊顿综合征、线性iga皮肤病、红斑狼疮、多发性硬化症、重症肌无力、心肌炎、发作性嗜睡症、坏死性血管炎、新生儿狼疮综合征(nle)、肾病综合征、类天疱疮、天疱疮、多肌炎、原发性硬化性胆管炎、银屑病、急进性肾小球肾炎(rpgn)、瑞特综合征、类风湿性关节炎、硬皮病、干燥综合征、僵人综合征、甲状腺炎和溃疡性结肠炎。
[0285]
术语“感染性疾病”和“感染”在本文中用于指代或描述微生物在身体组织中的侵入和增殖,尤其是引起病理症状。感染性疾病的示例包括但不限于病毒性疾病和细菌性疾病,诸如hiv感染、西尼罗河病毒感染,甲型肝炎、乙型肝炎和丙型肝炎,天花、结核病、水疱性口炎病毒(vsv)感染、呼吸道合胞病毒(rsv)感染、人乳头状瘤病毒(hpv)感染、sars、流感、埃博拉病毒、病毒性脑膜炎、疱疹、炭疽、莱姆病和大肠杆菌感染,等等。
[0286]
实施例
[0287]
下文公开的起始材料和试剂是本领域技术人员已知的,是可商购获得的和/或可使用熟知的技术制备。
[0288]
材料
[0289]
化学品购自sigma-aldrich(usa)。寡核苷酸得自microsynth(switzerland)。除非另有说明,否则dna聚合酶、限制酶和缓冲液得自new england biolabs(usa)或fermentas/thermo fisher scientific(usa)。诱导型大肠杆菌表达菌株用于克隆和蛋白质生产,例如大肠杆菌xl1-blue(stratagene,usa)或bl21(novagen,usa)。
[0290]
分子生物学
[0291]
除非另有说明,否则根据已知方案执行方法(参见例如sambrook j.、fritsch e.f.和maniatis t.,molecular cloning:a laboratory manual,cold spring harbor laboratory 1989,new york)。
[0292]
经设计的锚蛋白重复蛋白文库
[0293]
用于生成经设计的锚蛋白重复蛋白文库的方法已经描述于下列文献中:例如,美国专利号7,417,130;binz等人,2003年,同前;binz等人,2004年,同前。通过此类方法,可构建具有随机化锚蛋白重复模块和/或随机化封端模块的经设计的锚蛋白重复蛋白文库。例如,此类文库可以因此基于固定的n-末端封端模块(例如n-末端封端模块seq id no:5、6或7)或根据seq id no:8的随机化n-末端封端模块、根据序列基序seq id no:9、10或11的一个或多个随机化重复模块以及固定的c-末端封端模块(例如c-末端封端模块seq id no:12、13或14)或根据seq id no:15的随机化c-末端封端模块进行组装。优选地,此类文库被组装成在重复或封端模块的随机化位置处不具有氨基酸c、g、m、n(在g残基前面)和p中的任一者。此外,根据序列基序seq id no:9、10或11的随机化重复模块可以在位置10和/或位置17处进一步随机化;根据序列基序seq id no:8的随机化n-末端封端模块可以在位置7和/或位置9处进一步随机化;并且根据序列基序seq id no:15的随机化c-末端封端模块可以在位置10、11和/或17处进一步随机化。
[0294]
此外,此类文库中的此类随机化模块可包含具有随机化氨基酸位置的附加的多肽环插入。此类多肽环插入的示例是抗体的互补决定区(cdr)环文库或从头生成的肽文库。例如,可使用人核糖核酸酶l的n-末端锚蛋白重复结构域的结构(anaka,n.,nakanishi,m,kusakabe,y,goto,y.,kitade,y,nakamura,k.t.,embo j.23(30),3929-3938,2004)作为指
no:76;fairhead和howarth,2015)的密码子优化的hla-a*0201(hla-a*0201avi;seq id no:77)和野生型人β2-微球蛋白(hβ2m)在大肠杆菌bl21(de3)中在37℃处以包含体(ib)的形式表达,并且将其在ib纯化后溶解在50mm mes、5mm edta、5mm dtt、8m尿素(ph 6.5)中。hla-a*0201avi和hβ2m分子在相应肽的存在下,分别在25mg、30mg和15mg的最终浓度下,按照500ml体积在50mm tris ph 8.3、230mm l-精氨酸、3mm edta、255μm gssg;2.5mm gsh;250μm pmsf中重新折叠。所得三种pmhc复合物是(1)包含ny-eso-1-9v(157-165)肽的nyesopmhc,(2)包含ny-eso-1-9vaa(157-165)肽的nyesoaapmhc,和(3)包含ebna-1(562-570)肽的ebnapmhc(参见表1)。
[0305]
为了生物素酰化,将样品浓缩至7.5ml的体积,并且使用pd10柱将缓冲液交换到为100mm tris(ph 7.5)、150mm nacl、5mm mgcl2(ph 7.5)。通过添加5mm atp、400μm生物素、200μm pmsf和20μg bira酶使hla-a*0201avi生物素酰化。bira是按照shen等人,2009描述的程序内部生产的。使用尺寸排阻色谱法(superdex 200hiload 16/600)在补充有150mm nacl、1mm edta、10%甘油的pbs中分离重新折叠的三联体生物素酰化复合物。将样品浓缩至约1mg/ml并且以25μl和50μl等分试样的形式用液氮快速冷冻。
[0306]
表1:用于选择和筛选经设计的锚蛋白重复蛋白的pmhc复合物
[0307][0308][0309]
为了质量控制目的,将25μg生物素酰化pmhc复合物(生物素-pmhc)与50μg链霉亲和素(iba lifesciences)一起在添加或不添加100mm dtt的情况下温育,并在95℃处温育5分钟。将50μg样品运行分析尺寸排阻色谱法(ge superdex 200 10/300gl)。生物素酰化nyesopmhc、nyesoaapmhc和ebnapmhc复合物全部以约82ml的最大峰值从superdex 200hiload 16/600柱洗脱(图1a)。尺寸排阻后获得的nyesopmhc、nyesoaapmhc和ebnapmhc复合物的最终量分别为约3.5mg、3.5mg和5mg。浓缩和解冻的快速冷冻的重新折叠复合物的sds-page分析标明生物素酰化有效,因为hla-a*0201avi几乎完全结合到链霉亲和素(图1b)。分析尺寸排阻色谱法揭示保留体积的单峰对应于45kda的表观分子量,接近三联体pmhc复合物约48kda的理论分子量(mw)(图1c)。
[0310]
通过核糖体展示技术选择nyesopmhc特异性锚蛋白重复蛋白
[0311]
pmhc特异性锚蛋白重复蛋白的选择使用nyesopmhc复合物(作为靶标)、如上所述的锚蛋白重复蛋白文库和已确立的方案(参见例如zahnd,c.、amstutz,p.和pl
ü
ckthun,a.,nat.methods 4,69-79,2007)通过核糖体展示技术(hanes和pl
ü
ckthun,同前)进行。每轮选择后,逆转录(rt)-pcr循环数不断减少,从而由于结合物的富集而调整收率。前四轮选择采用标准核糖体展示选择,使用降低靶标浓度和增加洗涤严格性来增加从第1轮到第4轮的选择压力(binz等人,2004,同前),但并入了不常见的反选择步骤。
[0312]
在多轮核糖体展示期间,结合了反选择(或负选择)步骤,其中将三元复合物与含有另一种肽的相应同种型hla分子一起预温育,然后仅转移到靶标nyesopmhc复合物中,以便将锚蛋白重复蛋白的结合导向嵌入肽表位并远离共同的hla-a支架。换句话讲,进行反选择(或负选择)是为了反选择主要结合到pmhc复合物的共同hla-a支架而不是结合到由嵌入肽提供的特定表位的锚蛋白重复蛋白。此外,还对与由用于反选择的嵌入肽提供的表位交叉反应的锚蛋白重复蛋白进行反选择。这里,使用包含ebna-1(562-570)肽的ebnapmhc复合物进行反选择。
[0313]
详细地讲,对于反选择步骤,用100μl 66nm中性亲和素的pbs溶液包被nunc maxisorp板,并且在4℃处温育过夜。第二天,在反选择步骤之前,用每孔300μl pbst将maxisorp 96孔微板洗涤三次,然后用300μlpbst-bsa在4℃处以700rpm旋转阻断1小时。在将孔排空后,将100μl的50nm生物素酰化pmhc反选择靶标的pbst-bsa溶液添加到每个孔中,在4℃处以700rpm旋转1小时。在该温育步骤期间,单独进行根据核糖体展示方案的mrna体外翻译。在体外翻译和生成三元复合物(即mrna、核糖体和翻译的锚蛋白重复蛋白)之后不久,弃去pmhc-pbst-bsa溶液并用300μl pbst将nunc maxisorp微板孔洗涤三次,最后与含有bsa的tris洗涤缓冲液(wbt-bsa)一起温育。就在实际反选择步骤之前,弃去wbt-bsa溶液,然后将体外翻译三元复合物的150μl(对于第一轮选择)或100μl(对于第2轮至第4轮选择)等分试样连续分三次转移到容纳固定的反选择pmhc靶标的nunc maxisorp孔,并且在这三个孔中的制备nunc maxisorp孔中并且在三个孔的每个孔中在4℃处温育20分钟。在反选择过程结束时,将每个选择池的100μl三元复合物等分试样全部组合,并且将相应体积带入如上所述对实际靶标pmhc复合物的选择中。
[0314]
如粗提取物htrf所示所选择的克隆特异性结合nyesopmhc复合物
[0315]
使用标准方案,使用表达锚蛋白重复蛋白的大肠杆菌细胞的粗提取物,通过均相时间分辨荧光(htrf)测定来鉴定溶液中特异性结合nyesopmhc的单独选择的锚蛋白重复蛋白。将通过核糖体展示选择的锚蛋白重复蛋白克隆到pqe30(qiagen)表达载体中,将其转化到大肠杆菌xl1-blue(stratagene)中,将其铺板在lb-琼脂(含有1%葡萄糖和50μg/ml氨苄青霉素)上,然后在37℃处温育过夜。将单个菌落挑取到含有165μl生长培养基(含有1%葡萄糖和50μg/ml氨苄青霉素的lb)的96孔板中(每个克隆在单个孔中),并以800rpm振荡在37℃处温育过夜。将含50μg/ml氨苄青霉素的150μl新鲜lb培养基与8.5μl过夜培养物一起接种于新鲜的96深孔板中。在37℃和850rpm处温育120分钟后,用iptg(0.5mm最终浓度)诱导表达并持续6小时。通过将板离心来收获细胞,弃去上清液并将沉淀物在-20℃处冷冻过夜,然后重悬于8.5μl b-perii(thermo scientific)中,并在室温处振荡(600rpm)温育一小时。然后,添加160μl pbs,并通过离心(3220g持续15min)去除细胞碎片。
[0316]
将每个裂解克隆的提取物作为pbstb(补充有0.1%tween 和0.2%(w/v)bsa
的pbs,ph7.4)中的1:200稀释液(最终浓度)与20nm(最终浓度)生物素酰化pmhc复合物、1:400(最终浓度)的抗6his-d2htrf抗体-fret受体缀合物(cisbio)和1:400(最终浓度)的抗strep-tb抗体fret供体缀合物(cisbio,france)一起施加到384孔板的孔中,并在4℃处温育120分钟。使用340nm激发波长及用于背景荧光检测的620
±
10nm发射滤光片和用于检测特异性结合的荧光信号的665
±
10nm发射滤光片,在tecan m1000上读出htrf。
[0317]
测试每种裂解克隆的提取物与三种生物素酰化pmhc复合物即nyesopmhc、nyesoaapmhc和ebnapmhc中的每一种的结合,以便评估对靶标nyesopmhc复合物的结合和特异性。nyesoaapmhc和ebnapmhc充当不同于nyesopmhc的pmhc复合物,以允许选择对nyesopmhc具有高结合特异性的锚蛋白重复蛋白。
[0318]
为了计算每种锚蛋白重复蛋白对nyesopmhc的特异性,确定靶标nyesopmhc的htrf信号与不同nyesoaapmhc的htrf信号的比率。与在nyesoaapmhc上相比,在靶标nyesopmhc上生成至少25倍的htrf信号的所有结合物被认为是特异性命中并且继续进行测序。令人惊讶地,通过此类粗细胞提取物htrf分析筛选数百个克隆,揭示了对nyesopmhc有特异性的许多不同锚蛋白重复结构域。锚蛋白重复蛋白与包含hla支架和短肽的复合表位(其中仅肽与未特异性结合的其它复合表位不同)的特异性结合之前尚未得以证实并且使用抗体或tcr技术开发此类复合表位的特异性结合物一直具有挑战性。
[0319]
将总共95个命中使用测序服务在microsynth(balgach;switzerland)进行测序。特异性结合nyesopmhc的所选择的锚蛋白重复结构域的氨基酸序列的示例在seq id no:20至33中提供。
[0320]
如下所述,将这些对nyesopmhc具有结合特异性的锚蛋白重复结构域克隆到基于pqe(qiagen,germany)的表达载体中,从而提供n-末端his标签(seq id no:4)以有利于简单蛋白纯化。例如,构建编码以下锚蛋白重复蛋白的表达载体:
[0321]
蛋白#20(seq id no:20,其具有融合到其n末端的his标签(seq id no:4));
[0322]
蛋白#21(seq id no:21,其具有融合到其n末端的his标签(seq id no:4));
[0323]
蛋白#22(seq id no:22,其具有融合到其n末端的his标签(seq id no:4));
[0324]
蛋白#23(seq id no:23,其具有融合到其n末端的his标签(seq id no:4));
[0325]
蛋白#24(seq id no:24,其具有融合到其n末端的his标签(seq id no:4));
[0326]
蛋白#25(seq id no:25,其具有融合到其n末端的his标签(seq id no:4));
[0327]
蛋白#26(seq id no:26,其具有融合到其n末端的his标签(seq id no:4));
[0328]
蛋白#27(seq id no:27,其具有融合到其n末端的his标签(seq id no:4));
[0329]
蛋白#28(seq id no:28,其具有融合到其n末端的his标签(seq id no:4));
[0330]
蛋白#29(seq id no:29,其具有融合到其n末端的his标签(seq id no:4));
[0331]
蛋白#30(seq id no:30,其具有融合到其n末端的his标签(seq id no:4));
[0332]
蛋白#31(seq id no:31,其具有融合到其n末端的his标签(seq id no:4));
[0333]
蛋白#32(seq id no:32,其具有融合到其n末端的his标签(seq id no:4));以及
[0334]
蛋白#33(seq id no:33,其具有融合到其n末端的his标签(seq id no:4))。
[0335]
nyesopmhc特异性锚蛋白重复蛋白的高水平和可溶性表达
[0336]
为了进一步分析,在大肠杆菌细胞中表达如上所述的在粗细胞提取物htrf中显示特异性nyesopmhc结合的所选择的克隆,并根据标准方案使用其his标签进行纯化。使用25ml固定过夜培养物(tb,1%葡萄糖、50mg/l的氨苄青霉素;37℃)接种500ml培养物(tb,50mg/l氨苄青霉素,37℃)。在600nm处1.0至1.5的吸光度下,用0.5mm iptg诱导培养物并在37℃处温育4-5小时,同时振荡。将培养物离心,并将所得沉淀重悬于25ml tbs
500
(50mm tris
–
hcl,500mm nacl,ph8)中并裂解(超声处理或弗氏压碎器)。裂解后,将样品与50ku dnase/ml混合,温育15分钟,然后在62.5℃处热处理30分钟,离心并收集上清液并过滤。向匀浆中添加triton x100(1%(v/v)最终浓度)和咪唑(20mm最终浓度)。根据本领域技术人员已知的标准方案和树脂,将蛋白在镍-次氮基三乙酸(ni-nta)柱上进行纯化,随后在系统上进行尺寸排阻色谱法。另选地,所选择的不含his标签的锚蛋白重复结构域通过在大肠杆菌中高细胞密度发酵产生并根据本领域技术人员已知的标准树脂和方案通过一系列色谱法和超滤/渗滤步骤纯化。从大肠杆菌培养物(每升培养物至多200mg锚蛋白重复蛋白)中纯化对nyesopmhc具有结合特异性的高度可溶性锚蛋白重复蛋白,如从4%-12%sds-page估计的纯度》95%。对于蛋白#21而言,此类sds-page分析的代表性示例示于图2中。
[0337]
实施例2:通过表面等离子体共振(spr)分析确定对nyesopmhc具有结合特异性的锚蛋白重复蛋白的解离常数(kd)
[0338]
使用proteon表面等离子体共振(spr)仪器(biorad)分析经纯化的锚蛋白重复蛋白对nyesopmhc靶标的结合亲和力,并且根据本领域技术人员已知的标准程序进行测量。类似地,还分析了纯化的锚蛋白重复蛋白对nyesoaapmhc和ebnapmhc复合物的结合亲和力,以比较锚蛋白重复蛋白对nyesopmhc靶标的结合并且确认结合特异性。
[0339]
简而言之,将生物素酰化的nyesopmhc、nyesoaapmhc和ebnapmhc稀释于pbst(pbs,ph7.4,含有0.005%tween)中,并在nlc芯片(biorad)上包被至约500个共振单位(ru)的水平(对于多迹线spr测量,分别为1000ru)。然后通过注射含有锚蛋白重复蛋白的单浓度
或连续稀释液的150μl运行缓冲液(pbs,ph7.4,含0.005%),该连续稀释液覆盖3.7nm至300nm之间的浓度范围用于多迹线spr测量或为250nm用于单迹线测量(结合率测量),随后以100μl/min的恒定流速注射运行缓冲液流至少60分钟(解离率测量),来测量锚蛋白重复蛋白和pmhc复合物的相互作用。未进行靶标再生。从注射锚蛋白重复蛋白后获得的共振单位(ru)迹线中减去点间的信号(即ru值)。基于从结合率测量和解离率测量获得的spr迹线,测定相应锚蛋白重复蛋白相对于pmhc复合物的结合率和解离率。
[0340]
作为代表性示例,图3a-图3c示出了对于蛋白#21与nyesopmhc(图3a)、nyesoaapmhc(图3b)和ebnapmhc(图3c)结合所获得的spr迹线。使用本领域技术人员已知的标准程序,由估计的结合率和解离率计算解离常数(kd)。选择的锚蛋白重复蛋白与nyesopmhc的结合相互作用的kd值被确定为在低纳摩尔范围内或为更低的值。这些选择的锚蛋白重复蛋白中没有一个显示出可测量的与nyesoaapmhc或ebnapmhc的结合相互作用。表2提供了作为示例的一些选择的锚蛋白重复蛋白的kd值。
[0341]
表2.锚蛋白重复蛋白-nyesopmhc相互作用的kd值
[0342][0343]
图4a和图4b示出了蛋白#21的进一步表征,作为本发明的nyesopmhc特异性锚蛋白重复结构域的代表性示例。使用htrf测定研究蛋白#21与nyesopmhc、nyesoaapmhc和ebnapmhc的结合,证明了与nyesopmhc的高度特异性靶标结合(图4a)。未观察到蛋白#21与nyesoaapmhc或ebnapmhc的结合。
[0344]
还使用superdex 200柱通过尺寸排阻色谱法(sec)研究蛋白#21的生物物理特性。将蛋白#21以50μm浓度注射。sec洗脱曲线显示单一单分散峰,其在对应于单个蛋白#21分子的预期质量的位置处洗脱(图4b)。未检测到聚集体或多聚体的迹线。
[0345]
这些实验数据和kd值证明,可以使用例如如实施例1中所述的筛选和选择程序生成对特异性pmhc复合物(例如nyesopmhc复合物)具有高结合亲和力和特异性以及具有有益的生物物理特性的经设计的锚蛋白重复蛋白。
[0346]
实施例3:对nyesopmhc具有结合特异性的锚蛋白重复蛋白与细胞的结合
[0347]
在对nyesopmhc具有结合特异性的锚蛋白重复结构域的生物物理表征之后,还测试了它们的细胞结合。为此目的,使用t2细胞(crl-1992
tm
),这些细胞是缺乏抗原加工相关转运(tap)蛋白复合物的t-淋巴细胞和b-淋巴细胞的杂化物,并且因此是用于研究抗原加工和t细胞识别的模型系统。t2细胞为hla-a2阳性和ny-eso-1阴性。这些细胞可以负载有与hla-a2结合的肽,诸如ny-eso-1-9v(157-165)肽,从而在其表面上生成相应的pmhc复合物。
[0348]
肽的滴定显示,向t2细胞中添加μm范围的肽会生成足够的pmhc复合物以允许研究锚蛋白重复结构域与在hla-a2与所添加的肽之间形成的pmhc复合物的结合(数据未示出)。在37℃处用20μm的ny-eso-1-9v(157-165)肽或ebna-1(562-570)肽对t2细胞进行脉冲处理过夜。并行地,用不含任何肽的缓冲液处理t2细胞(未经脉冲处理的细胞)。以不同浓度向细胞中添加对nyesopmhc具有结合特异性的锚蛋白重复蛋白,并且在4℃处温育30分钟后,使用抗his标签抗体(penta
·
his alexa fluor 488conjugate,qiagen)通过流式细胞术确定锚蛋白重复蛋白与细胞的结合。
[0349]
作为代表性示例,图5a和图5b示出了对于蛋白#20、蛋白#21和蛋白#22,使用经ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞(图5a)和未经脉冲处理的t2细胞(图5b)获得的结合曲线。使用本领域技术人员已知的标准程序确定与用ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞的结合的ec50值。确定选择的锚蛋白重复蛋白的ec50值处于低纳摩尔范围内,证明与细胞有效结合。表3提供了作为示例的所选择的锚蛋白重复蛋白的ec50值。
[0350]
表3.与用ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞的结合的ec
50
值
[0351][0352]
为了测试对nyesopmhc具有结合特异性的锚蛋白重复结构域以免疫细胞接合剂形式起作用的能力,使用常规克隆方法将选择的锚蛋白重复结构域遗传连接到对免疫细胞表面上表达的蛋白具有结合特异性的结合因子。通过该程序,生成了包含对nyesopmhc具有结合特异性的锚蛋白重复结构域并且还包含对cd3具有结合特异性的结合因子的结合蛋白。
[0353]
如上所述测试此类结合蛋白以t细胞接合剂(tce)形式结合到经过脉冲处理的t2细胞的能力。如图5c和图5d所示,蛋白#20、蛋白#21和蛋白#22与用ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞的特异性结合在t细胞接合剂形式(tce蛋白#20、tce蛋白#21和tce蛋白#22)中是保守的。tce蛋白#20、tce蛋白#21和tce蛋白#22并未与未经脉冲处理的t2细胞(图5e),或与用ebna-1(562-570)肽进行脉冲处理的t2细胞结合(除了在高浓度下有较少结合外),如针对tce蛋白#21示例性所示(图5f)。在包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白与tce形式的相同结合蛋白之间未观察到显著的结合差异(图5d)。确定t细胞接合剂形式的锚蛋白重复蛋白的ec50值处
于低纳摩尔范围内,证明与细胞有效结合。表4提供了作为示例的所选择的t细胞接合剂形式的锚蛋白重复蛋白的ec50值。
[0354]
表4.与用ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞的结合的ec
50
值
[0355][0356]
总之,包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白能够特异性结合到细胞表面上的nyesopmhc,其ec50在低纳摩尔范围内。与细胞表面上的nyesopmhc的结合是特异性的,因为未观察到与未经脉冲处理的t2细胞或与用不相关肽进行脉冲处理的t2细胞的结合。当nyesopmhc特异性锚蛋白重复结构域连接到对免疫细胞表面上表达的蛋白,诸如t细胞表面上表达的cd3(t细胞接合剂(tce)形式)具有结合特异性的结合因子时,特异性结合特性是保守的。
[0357]
实施例4:使用经脉冲处理的t2细胞,通过包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白实现t细胞激活
[0358]
在t细胞激活测定中分析tce形式的nyesopmhc特异性锚蛋白重复结构域在结合到nyesopmhc展示靶标细胞时激活t细胞的能力。
[0359]
将用ny-eso-1-9v(157
–
165)肽脉冲处理的t2细胞用作nyesopmhc展示靶标细胞。效应细胞是bk112 t细胞,其为从健康供体扩增的单克隆cd8
t细胞(levitsky等人,j.immunol.161:594-601(1998))。对于t细胞激活测定,将t2细胞在37℃下用10μm肽脉冲处理过夜。在不同浓度(例如1pm)的tce蛋白的存在下,以1:5的效应细胞与靶标细胞比率添加效应bk112 t细胞,并且在37℃下温育4小时至5小时。然后通过荧光激活细胞分选(facs)测定cd8 t细胞中的细胞内ifn-γ,作为t细胞激活的量度。用于facs的试剂包括apc小鼠抗人ifn-γ和来自bd biosciences的pacific blue
tm
小鼠抗人cd8。
[0360]
图6示出了在该t细胞激活测定中测试一组tce形式的不同nyesopmhc特异性锚蛋白重复结构域(1pm))的结果。tce形式的nyesopmhc特异性锚蛋白重复结构域为(对应于图6中x轴处的编号):(1)tce蛋白#23、(2)tce蛋白#24、(3)tce蛋白#25、(4)tce蛋白#26、(5)tce蛋白#27、(6)tce蛋白#28、(7)tce蛋白#29、(8)tce蛋白#30、(9)tce蛋白#31、(10)tce蛋白#32、(11)tce蛋白#33、(12)tce蛋白#21、(13)tce蛋白#20和(14)tce蛋白#22。作为对照,还在未添加tce蛋白的情况下进行实验(15)。温育4小时之后,通过facs确定t细胞中的细胞内ifn-γ。
[0361]
所有14种tce蛋白在经脉冲处理的t2细胞中存在靶标肽-mhc复合物的情况下均特异性地介导t细胞激活,但在未经脉冲处理的t2细胞中不存在靶标肽-mhc复合物的情况下没有(或以低得多的水平)特异性地介导t细胞激活。对于那些tce蛋白,用未经脉冲处理的t2细胞在1pm的tce蛋白下也检测到信号,在较低浓度的
tce蛋白下获得经脉冲处理和未经脉冲处理的t2细胞之间的较大窗口(数据未示出)。因此,所有这些tce形式的nyesopmhc特异性锚蛋白重复结构域均能够特异性地激活效应t细胞,这取决于nyesopmhc展示靶标细胞的存在。
[0362]
在相似的t细胞激活测定中进一步示出了效应t细胞的特异性激活对nyesopmhc显示靶标细胞的存在的依赖性,其中在更宽的浓度范围内滴定tce蛋白。图6b和图6c示出了tce蛋白#21(b)和tce蛋白#32(c)的此类实验的结果。在存在经脉冲处理的t2细胞的情况下,通过两种tce蛋白以非常低的浓度(亚皮摩尔)开始并且在测试的整个浓度范围内(高达纳摩尔)实现效应t细胞的特异性激活。相反,在存在未经脉冲处理的t2细胞的情况下,在整个浓度范围内未观察到t细胞激活。这确认了tce形式的nyesopmhc特异性锚蛋白重复结构域特异性地激活效应t细胞的能力,这取决于nyesopmhc展示靶标细胞的存在。
[0363]
实施例5:使用肿瘤细胞,通过包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白实现t细胞激活
[0364]
在t细胞激活测定中还使用肿瘤细胞系作为靶标细胞分析tce形式的nyesopmhc特异性锚蛋白重复结构域在结合到nyesopmhc展示靶标细胞时介导t细胞激活的能力。使用内源性地表达hla-a2和ny-eso-1(因此是hla-a2
ny-eso-1
细胞)并且在其表面上展示nyesopmhc的肿瘤细胞系(im9;ccl-159
tm
))和表达hla-a2但不表达ny-eso-1(因此是hla-a2
ny-eso-1-细胞)并且在其表面上不展示nyesopmhc的肿瘤细胞系(mcf-7;htb-22
tm
)比较t细胞激活。将bk112 t细胞用作效应细胞,并且基本上如实施例4中所述,但用不同的靶标细胞进行实验。作为对照,对效应bk112 t细胞进行相同的处理,不同的是不添加靶标细胞。
[0365]
如针对tce蛋白#21示例性所示,tce形式的nyesopmhc特异性锚蛋白重复结构域可以在表达nyesopmhc的肿瘤细胞(im9)的存在下有效地激活t细胞(图7,圆形符号)。使用本领域技术人员已知的标准程序确定tce蛋白#21对im9肿瘤细胞激活的ec50值为18.7nm,证明了tce蛋白的有效活性。相比之下,在存在不在其细胞表面上表达nyesopmhc的肿瘤细胞(mcf-7)的情况下(图7,三角形符号)或者如果没有向t细胞中添加肿瘤细胞(即仅有bk112 t细胞)(图7,正方形符号),未观察到t细胞的激活。
[0366]
这些数据标明,tce形式的pmhc特异性锚蛋白重复结构域可以在与肿瘤细胞表面上的靶标肽-mhc复合物结合时有效地激活t细胞。
[0367]
实施例6:使用肿瘤细胞,通过包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白实现免疫细胞激活
[0368]
在t细胞激活测定中还使用肿瘤细胞系作为靶标细胞并且使用从供体分离的外周血单核细胞(pbmc)作为效应细胞分析tce形式的nyesopmhc特异性锚蛋白重复结构域在结合到nyesopmhc展示靶标细胞时介导t细胞激活的能力。使用内源性地表达hla-a2和ny-eso-1并且在其表面上展示nyesopmhc的肿瘤细胞系(im9)以及表达hla-a2但不表达ny-eso-1并且在其表面上不展示nyesopmhc的肿瘤细胞系(mcf-7)来比较免疫细胞激活(还参见实施例5)。将从供体分离的pbmc用作效应细胞。
[0369]
对于t细胞激活测定,将靶标肿瘤细胞与效应pbmc以5:1的效应细胞与靶标细胞比率组合,以不同浓度添加tce形式的nyesopmhc特异性锚蛋白重复结构域,并且将混合物在37℃处温育48小时。然后将上清液储存在-80℃处用于进一步分析(例如ifn-γ和tnf-α定量),并且通过facs测定cd8
t细胞上激活标记物(cd25和cd69)的水平(使用cd25单克隆抗体(bc96)、percp-cyanine5.5,ebioscience
tm
;和来自bd biosciences的alexa488小鼠抗人cd8和pe-cy
tm
7小鼠抗人cd69)。作为对照,对效应pbmc进行相同的处理,不同的是不添加靶标细胞。如所标明的那样,在图8a至图8e中示出了在与tce蛋白#20、tce蛋白#21、tce蛋白#27、tce蛋白#32和tce蛋白#33一起温育后获得的cd25水平。针对cd69获得类似的结果(数据未示出)。
[0370]
数据证明,在存在表达nyesopmhc的肿瘤细胞(im9)的情况下,tce形式的nyesopmhc特异性锚蛋白重复结构域可以有效地激活来源于供体的天然cd8
t细胞(图8a至图8e,圆形符号)。使用本领域技术人员已知的标准程序确定在im9肿瘤细胞的存在下tce蛋白对t细胞激活的ec50值。ec50值处于低nm范围内或为更低的值(表5),证明tce蛋白的有效活性。
[0371]
表5.在im9肿瘤细胞的存在下激活t细胞的ec
50
值
[0372][0373]
与im9细胞对比,在存在不在其细胞表面上表达nyesopmhc的肿瘤细胞(mcf-7)的情况下(图8a至图8e,三角形符号)或者如果没有向t细胞中添加肿瘤细胞(即仅有pbmc)(图8a至图8e,正方形符号),未观察到t细胞的激活(或仅在高得多的tce 蛋白浓度下有少量激活)。
[0374]
作为免疫细胞激活的额外量度,在温育后定量细胞上清液中干扰素-γ(ifn-γ)和肿瘤坏死因子-α(tnf-α)的水平(参见上文)。遵循制造商提供的方案(procartalplextm多重免疫测定epx01a-10228-901和-10223-90,thermo fischer scientific)。简而言之,将上清液添加到预包被有细胞因子特异性捕获抗体的颜色编码珠粒的混合物中。添加对感兴趣的细胞因子具有特异性的二次生物素酰化检测抗体并形成抗体-细胞因子夹心。然后添加pe缀合的链霉亲和素并使其与生物素酰化的检测抗体结合,并且添加读数缓冲液允许用mag/pix luminex仪器获取数据。可以使用所提供的标准来计算细胞因子水平。
[0375]
在im9肿瘤细胞的存在下上清液中的ifn-γ水平(图9a至图9e)和tnf-α水平(图10a至图10e)以tce蛋白浓度依赖性方式强烈增加。这些结果确认tce形式的nyesopmhc特异性锚蛋白重复结构域可以在表达nyesopmhc的肿瘤细胞(im9)的存在下有效地介导t细胞激活。此外,在存在不在其细胞表面上表达nyesopmhc的肿瘤细胞(mcf-7)的情况下,未观察到ifn-γ(图9a至图9e)和tnf-α(图10a至图10e)的增加(或仅在高得多的tce蛋白浓度下有较小增加)。在该实施例中描述的所有测定中,tce蛋
白#33已经在比其它测试的tce蛋白更低的浓度下有效,但在较高浓度下具有较低特异性。
[0376]
还使用内源性地表达hla-a2和ny-eso-1并且在其表面上展示nyesopmhc的另一种肿瘤细胞系(u266b1)以及表达hla-a2但不表达ny-eso-1并且在其表面上不展示nyesopmhc的另一种肿瘤细胞系(colo205)进行了如以上在该实施例中描述的类似t细胞激活测定。此外,还进行了类似的测定,比较mcf-7肿瘤细胞(在其细胞表面上不表达nyesopmhc)和经过转染以表达ny-eso-1并且因此在其细胞表面上表达nyesopmhc的mcf-7肿瘤细胞。与tce蛋白#21或tce蛋白#32一起温育后获得的cd69水平在图18a至图18f中示出,如所标明的那样,作为t细胞激活的量度。对于本发明测试的结合蛋白中的每种结合蛋白,仅在其细胞表面上表达nyesopmhc的肿瘤细胞(u266b1、经过转染的mcf-7、im9)的存在下观察到显著的t细胞激活,但在其细胞表面上不表达nyesopmhc的肿瘤细胞(colo205、mcf-7)的存在下未观察到显著的t细胞激活。
[0377]
总之,这些数据显示,包含对靶标肽-mhc复合物具有结合特异性的锚蛋白重复结构域和对t细胞表面上表达的蛋白具有结合特异性的结合因子两者的重组结合蛋白可以在与肿瘤细胞表面上的靶标肽-mhc复合物结合后有效地激活t细胞。
[0378]
实施例7:通过丙氨酸扫描诱变分析包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白对靶标肽的结合特异性
[0379]
为了分析对nyesopmhc具有结合特异性的锚蛋白重复结构域与nyesopmhc靶标之间的特异性相互作用,进行丙氨酸扫描诱变。为此目的,在t细胞激活测定中测试了ny-eso-1-9v(157
–
165)肽及其一系列变体,在这些变体的每一者中,ny-eso-1-9v(157
–
165)肽的一个氨基酸被丙氨酸替代。该测定使用经脉冲处理的t2细胞作为靶标细胞,并且使用bk112 t细胞作为效应细胞,基本上如实施例4中所述。如果ny-eso-1-9v(157
–
165)肽中的氨基酸残基对于对nyesopmhc具有结合特异性的锚蛋白重复结构域与nyesopmhc靶标之间的结合相互作用很重要,则如果该氨基酸残基被丙氨酸替代,则将观察到t细胞激活减少或观察不到t细胞激活。
[0380]
从genscript获得丙氨酸突变肽,它们具有以下序列:allmwitqv(seq id no:81;位置1处的s变为a)、slamwitqv(seq id no:82;位置3处的l变为a)、sllawitqv(seq id no:83;位置4处的m变为a)、sllmaitqv(seq id no:84;位置5处的w变为a)、sllmwatqv(seq id no:85;位置6处的i变为a)、sllmwiaqv(seq id no:86;位置7处的t变为a)、sllmwitav(seq id no:87;位置8处的q变为a)和salmwitqa(seq id no:88;位置2处的l变为a且位置9处的v变为a)。在具有seq id no:88的肽中,锚定位置2和9均被丙氨酸取代。位置2和位置9处的锚定残基对于肽与hla分子的结合至关重要。用ny-eso-1-9v(157
–
165)肽和每种突变肽(10μm)对t2细胞进行脉冲处理。在tce蛋白存在下,将经脉冲处理的t2细胞与效应bk112 t细胞以1:5的效应细胞与靶标细胞比率一起温育。
[0381]
丙氨酸扫描诱变分析显示哪些肽残基对于tce蛋白与nyesopmhc靶标之间的结合相互作用很重要(图11a至图11e)。这些数据证明,在每种情况下,至少3个肽残基对于该结合相互作用很重要,从而当突变为丙氨酸时,与ny-eso-1-9v(157
–
165)肽相比导致t细胞激活降低至少50%。令人惊讶的是,在一些情况下,与定位跨越几乎整个肽段序
列的至少5个肽残基的相互作用对于锚蛋白重复结构域与靶标肽-mhc复合物的结合很重要。作为一个示例,对于蛋白#20,ny-eso-1-9v(157
–
165)靶标肽的至少位置3、4、5、6和7对于导致t细胞激活的功能性结合相互作用很重要(图/11g)。作为另一个示例,对于蛋白#21,ny-eso-1-9v(157
–
165)靶标肽的至少位置4、5、6、7和8对于导致t细胞激活的功能性结合相互作用很重要(图11b)。作为另一个示例,对于蛋白#32,ny-eso-1-9v(157
–
165)靶标肽的至少位置1、3、4、5、6和7对于导致t细胞激活的功能性结合相互作用很重要(图11d)。如所预期的,当位置2和位置9处的两个锚定残基突变时或当使用未经脉冲处理的t2细胞时,未观察到导致t细胞激活的功能性结合相互作用。
[0382]
总之,这些数据显示,要获得包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白与ny-eso-1-9v(157
–
165)靶标肽之间的特异性相互作用,重要的是存在数量大得惊人的肽残基。该发现可以反映由经设计的锚蛋白重复结构域形成的结合表面与由其他结合蛋白(诸如抗体和t细胞受体(tcr))形成的结合表面之间的结构差异。
[0383]
实施例8:通过包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白介导的效应细胞对靶标细胞的pmhc依赖性杀伤
[0384]
在测定(essen biosciences)中按照制造商提供的方案测试包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的tce形式的结合蛋白介导效应细胞对靶标细胞的pmhc依赖性杀伤的能力。
[0385]
简而言之,将效应细胞(外周血单核细胞(pbmc))和靶标细胞(经脉冲处理的t2细胞(pt2)或未经脉冲处理的t2细胞(npt2))在不同浓度(0.01nm、0.1nm、1nm)的tce形式的nyesopmhc特异性锚蛋白重复蛋白(tce蛋白#21(d))的存在下温育。效应细胞与靶标细胞的比率为20:1。添加半胱天冬酶3/7试剂,一种在细胞凋亡期间裂解以释放绿色荧光dna染料并因此将核dna染色的底物。每两小时对细胞进行扫描,并且可以随着时间跟踪肿瘤细胞死亡的水平。
[0386]
结果表示在图12中,该图示出了细胞凋亡水平(总绿色目标面积)。包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的tce形式的结合蛋白能够以浓度依赖性方式有效地介导对在其表面上展示nyesopmhc的靶标细胞(pt2细胞)的杀伤。相比之下,在其表面上不展示nyesopmhc的靶标细胞(npt2细胞)上未观察到显著影响。
[0387]
还在不同类型的测定中测试包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的tce形式的结合蛋白介导效应细胞对靶标细胞的pmhc依赖性杀伤的能力。这里,不仅使用经脉冲处理或未经脉冲处理的t2细胞作为靶标细胞,而且还使用在其细胞表面上表达(im9;u266b1)或不表达(mcf-7)nyesopmhc的肿瘤细胞。
[0388]
简而言之,将放射性标记的(cr51)t2细胞(用ny-eso-1-9v(157-165)肽进行脉冲处理的或未经脉冲处理的)或放射性标记的(cr51)hla-a2
/ny-eso-1
肿瘤细胞系(im9,u266b1)或hla-a2
/ny-eso-1-肿瘤细胞系(mcf-7)作为靶标细胞与预先激活的效应cd8
t细胞一起在存在或不存在1nm的tce蛋白#21或tce蛋白#32的情况下温育4小时。温育后,用umaplate topcount nxt微板闪烁计数器测定上清液中来自裂解的靶标细胞的放射性释放的量。将通过铬释放测定获得的t2细胞或肿瘤细胞的特异性裂解百分
165)肽进行脉冲处理的t2细胞用作展示nyesopmhc的靶标细胞,并且将bk112 t细胞用作效应细胞。基本上如实施例4中所述进行t细胞激活测定。
[0397]
图13示出了在该t细胞激活测定中测试tce形式的不同二价和双互补位nyesopmhc特异性锚蛋白重复结构域(0.1pm))的结果。tce形式的nyesopmhc特异性锚蛋白重复蛋白是(对应于图13中x轴处的编号)(1)tce bp蛋白#20/#21、(2)tce bp蛋白#21/#22和(3)tce bv蛋白#21/#21。作为对照,还用包含对人血清白蛋白具有结合特异性的锚蛋白重复结构域,而不是对nyesopmhc具有结合特异性的锚蛋白重复结构域进行实验(4)或在不添加tce蛋白的情况下进行实验(5)。
[0398]
所有三种二价或双互补位tce蛋白在经脉冲处理的t2细胞的存在下均特异性地介导t细胞激活,但在未经脉冲处理的t2细胞的存在下没有(或以低得多的水平)特异性地介导t细胞激活。因此,tce形式的二价和双互补位nyesopmhc特异性锚蛋白重复蛋白均能够特异性地激活效应t细胞,这取决于nyesopmhc展示靶标细胞的存在。
[0399]
与nyesopmhc展示细胞的特异性结合
[0400]
使用实施例3中描述的t2细胞结合测定研究二价或双互补位pmhc特异性结合蛋白与靶标肽-mhc复合物展示细胞特异性结合的能力。还测试tce形式的结合蛋白。实验基本上如实施例3中所述进行。
[0401]
作为示例,图14a和图14b示出了对于bp蛋白#21/#22和tce bp蛋白#21/#22,使用经ny-eso-1-9v(157
–
165)肽进行脉冲处理的t2细胞(图14a)和未经脉冲处理的t2细胞(图14b)获得的结合曲线。使用本领域技术人员已知的标准程序确定与用ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞的结合的ec50值。确定这些双互补位nyesopmhc特异性锚蛋白重复蛋白的ec50值处于低纳摩尔范围内(表6),证明与细胞有效结合。在双互补位结合蛋白(bp蛋白#21/#22)与tce形式的相同双互补位结合蛋白(tce bp 蛋白#21/#22)之间,与经脉冲处理或未经脉冲处理的t2细胞的结合没有显著差异。
[0402]
表6.与用ny-eso-1-9v(157-165)肽进行脉冲处理的t2细胞的结合的ec
50
值
[0403][0404]
总之,包含两个对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白能够特异性且有效地结合到细胞表面上的nyesopmhc,其ec50在低纳摩尔范围内。与细胞表面上的nyesopmhc的结合是特异性的,因为未观察到与未经脉冲处理的t2细胞的结合。当nyesopmhc特异性锚蛋白重复结构域连接到对免疫细胞表面上表达的蛋白,诸如t细胞表面上表达的cd3(t细胞接合剂(tce)形式)具有结合特异性的结合因子时,特异性且有效的结合特性是保守的。
[0405]
在表达nyesopmhc的肿瘤细胞的存在下的免疫细胞激活
[0406]
在t细胞激活测定中还使用肿瘤细胞系作为靶标细胞并且使用从供体分离的外周血单核细胞(pbmc)作为效应细胞,在基本上如实施例6所述进行的测定中,分析tce形式的二价和双互补位nyesopmhc特异性锚蛋白重复蛋白在结合到nyesopmhc展示靶标细胞时激活t细胞的能力。
[0407]
如所标明的那样,图15a和图15b中示出了在与二价结合蛋白tce bv蛋白#21/#21或双互补位结合蛋白tce bp蛋白#20/#21温育后获得的t细胞激活标记物cd25的水平。数据证明,在存在表达nyesopmhc的肿瘤细胞(im9)的情况下,tce形式的二价或双互补位nyesopmhc特异性锚蛋白重复蛋白可以有效地介导来源于供体的天然cd8
t细胞的激活(图15a和图15b,圆形符号)。使用本领域技术人员已知的标准程序确定在im9肿瘤细胞的存在下二价或双互补位tce蛋白对t细胞激活的ec50值。ec50值处于低nm范围内或为更低的值(表7),证明二价和双互补位tce蛋白的有效活性。
[0408]
表7.在im9肿瘤细胞的存在下激活t细胞的ec
50
值
[0409][0410]
与im9细胞对比,在存在不在其细胞表面上表达nyesopmhc的肿瘤细胞(mcf-7)的情况下(图15a和图15b,三角形符号)或者如果没有向t细胞中添加肿瘤细胞(即仅有pbmc)(图15a和图15b,正方形符号),未观察到t细胞的激活(或仅在高得多的tce蛋白浓度下有少量激活)。
[0411]
作为免疫细胞激活的额外量度,在与双互补位结合蛋白(tce bp蛋白#20/#21)温育后定量细胞上清液中干扰素-γ(ifn-γ)和肿瘤坏死因子-α(tnf-α)的水平,基本上如实施例6中所述。在im9肿瘤细胞的存在下上清液中的ifn-γ水平(图16a)和tnf-α水平(图16b)以tce蛋白浓度依赖性方式强烈增加。这些结果确认tce形式的双互补位nyesopmhc特异性锚蛋白重复蛋白可以在表达nyesopmhc的肿瘤细胞(im9)的存在下有效地介导t细胞的激活。在存在不在其细胞表面上表达nyesopmhc的肿瘤细胞(mcf-7)的情况下,未观察到ifn-γ(图16a)和tnf-α(图16b)的显著增加。
[0412]
总之,这些数据显示,包含两个对靶标肽-mhc复合物具有结合特异性的锚蛋白重复结构域和对t细胞表面上表达的蛋白具有结合特异性的结合因子的重组结合蛋白可以在与肿瘤细胞表面上的靶标肽-mhc复合物结合后有效地激活t细胞。
[0413]
通过丙氨酸扫描诱变分析靶标肽结合的特异性。
[0414]
为了分析包含两个对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白与nyesopmhc靶标之间的特异性相互作用,基本上如实施例7中所述进行丙氨酸扫描诱变。
[0415]
图17中示出了对于双互补位结合蛋白tce bp 蛋白#20/#21(1pm)的丙氨酸扫描诱变分析。这些数据证明,至少3个肽残基,即位置4、5和6处的残基对于这种双互补位结合蛋白与靶标细胞表面上的靶标肽-mhc复合物之间的结合相互作用很重要。如所预
期的,当位置2和位置9处的两个锚定残基突变时或当使用未经脉冲处理的t2细胞时,未观察到结合。
[0416]
实施例10:通过x扫描诱变分析包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白对靶标肽的结合特异性
[0417]
为了进一步分析对nyesopmhc具有结合特异性的锚蛋白重复结构域与nyesopmhc靶标之间的特异性相互作用,进行x扫描诱变。为此目的,在t细胞激活测定中测试ny-eso-1-9v(157-165)肽及其一系列单突变变体。对于变体肽,ny-eso-1-9v(157-165)肽的每个氨基酸被蛋白中发现的其它19种标准氨基酸中的每一种替代。这些突变肽获自genscript。该测定使用经脉冲处理的t2细胞作为靶标细胞,并且使用bk112 t细胞作为效应细胞,基本上如实施例4中所述。简而言之,将t2细胞用突变肽(10μm)中的每一种进行脉冲处理,并且与效应cd8
t细胞(bk112 t细胞)一起在存在允许野生型肽的ec90水平的tce蛋白浓度(tce蛋白#21:1pm;tce蛋白#32:10pm)的情况下温育4小时。温育后,通过facs检测细胞内ifn-γ。每个实验均以两个独立的重复进行。
[0418]
x扫描诱变分析在实施例7中描述的丙氨酸扫描诱变上扩展。测试ny-eso-1-9v(157-165)肽的每个位置处的其它19种氨基酸中的每一种允许表征包含对nyesopmhc具有结合特异性的锚蛋白重复蛋白的本发明结合蛋白与细胞表面上展示的nyesopmhc复合物之间的结合相互作用的特异性。此类分析显示,肽的给定位置处的氨基酸残基允许还是不允许有效的结合相互作用。此外,此类分析允许识别潜在交叉反应性肽。
[0419]
为了进一步分析,对在t细胞激活测定的独立重复中获得的细胞内ifn-γ值进行平均,并且针对每个位置的相应野生型残基(黑色阴影字段)归一化为100%。平均和归一化的分析结果对于tce蛋白#21示于图21a中且对于tce蛋白#32示于图21b中。所有高于30%的值,标明没有丧失或不完全丧失t细胞激活,以粗体和浅色阴影标记。
[0420]
x扫描分析确认,包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的本发明的结合蛋白与mhc i类分子的肽结合沟槽中呈递的ny-eso-1-9v(157-165)肽的多个残基相互作用。对于测试的tce蛋白,即tce蛋白#21和tce蛋白#32,与至少5个肽残基的相互作用对于锚蛋白重复结构域与靶标肽-mhc复合物的结合很重要。对于蛋白#21,ny-eso-1-9v(157
–
165)靶标肽的至少位置4、5、6、7和8对于导致t细胞激活的功能性结合相互作用很重要(图21a)。对于蛋白#32,ny-eso-1-9v(157
–
165)靶标肽的至少位置3、4、5、6和7对于导致t细胞激活的功能性结合相互作用很重要(图21b)。在这些结论中未考虑位置2和位置9,因为这些位置的残基是锚定残基,其对于肽与hla分子的结合至关重要。
[0421]
使用expasy prosite数据库(https://prosite.expasy.org/scanprosite/)搜索潜在交叉反应性肽鉴定出tce蛋白#21的43个独特人肽序列和tce蛋白#32的68个独特人肽序列。这些数字与先前针对天然t细胞受体报道的值相当。
[0422]
总之,这些数据再次显示,要获得包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白与ny-eso-1-9v(157
–
165)靶标肽之间的特异性相互作用,重要的是存在数量大得惊人的肽残基。该发现可以反映由经设计的锚蛋白重复结构域形成的结合表面与
由其他结合蛋白(诸如抗体和t细胞受体(tcr))形成的结合表面之间的结构差异。
[0423]
此外,结果证明产生本文所述的肽-mhc(pmhc)特异性结合蛋白的方法允许对靶向pmhc复合物(诸如,肿瘤特异性或肿瘤相关pmhc复合物)并且具有有利特性的结合蛋白进行有效的鉴定和表征。该方法允许有效地产生对靶标pmhc复合物具有高亲和力并且具有与天然或亲和力成熟的t细胞受体相当的特异性水平的pmhc特异性结合蛋白,如通过经x扫描和体外细胞测定所鉴定的少量潜在交叉反应性肽所评估的那样。
[0424]
实施例11:接头长度对通过包含对nyesopmhc具有结合特异性的锚蛋白重复结构域的结合蛋白实现的免疫细胞激活的影响
[0425]
为了测试t细胞接合剂(tce)形式的本发明结合蛋白中的pmhc特异性结合结构域与cd3特异性结合因子之间的接头的长度对tce形式的此类结合蛋白的效力的影响,在t细胞激活测定中使用不同的肿瘤细胞系测试了包含用不同长度的接头连接到cd3结合结构域的nyesopmhc结合结构域的不同构建体。
[0426]
接头长度设计与缩写
[0427]
生成了tce形式的以下结合蛋白,其包含蛋白#21或蛋白#32作为nyesopmhc特异性结合结构域:
[0428]
表8:tce结合蛋白和使用的接头
[0429][0430]
表9:在表8的结合蛋白中测试的接头的概述
[0431][0432]
t细胞激活测定中tce形式的结合蛋白的效力和特异性
[0433]
在t细胞激活测定中使用不同的肿瘤细胞系测试了用不同接头生成的tce形式的结合蛋白的效力和特异性。一些肿瘤细胞系(im9和u266b1)内源性地表达ny-eso-1并且在它们的细胞表面上以pmhc复合物的形式呈递ny-eso-1靶标肽。其他肿瘤细胞系(mcf7和colo205)不表达ny-eso-1,因此不在其细胞表面上以pmhc复合物的形式呈递ny-eso-1靶标
肽。
[0434]
基本上如以上实施例6中所述进行t细胞激活测定。相应地,将靶标肿瘤细胞与效应pbmc以5:1的效应细胞与靶标细胞比率组合,以不同浓度添加tce形式的nyesopmhc特异性锚蛋白重复结构域(参见表8中的构建体),并且将混合物在37℃处温育48小时。通过facs(使用cd25单克隆抗体(bc96),percp-cyanine5.5,ebioscience
tm
;和来自bd biosciences的alexa488小鼠抗人cd8)确定cd8 t细胞上的激活标记物cd25的水平。作为对照,对效应pbmc进行相同的处理,不同的是不添加靶标细胞。如实施例6中一样使用相同组的肿瘤细胞。
[0435]
在结合蛋白的存在下获得的t细胞激活水平示于图22至图25中。随着接头长度缩短,观察到增强的效力。对于用最短接头(xxs)设计的构建体观察到最高的效力,用第二最短接头(xs)设计的构建体的效力与用较长接头设计的构建体相比也显著增强。对于所测试的任何细胞系,均未观察到非特异性激活水平的增加。
[0436]
从图22所示数据获得的ec50值列于下表10中。
[0437]
表10:从图22所示数据获得的ec50值
[0438][0439]
从图23所示数据获得的ec50值列于下表11中。
[0440]
表11:从图23所示数据获得的ec50值
[0441][0442]
从图24所示数据获得的ec50值列于下表12中。
[0443]
表12:从图24所示数据获得的ec50值
[0444][0445]
从图25所示数据获得的ec50值列于下表13中。
[0446]
表13:从图25所示数据获得的ec50值
[0447][0448]
从数据可以得出结论,对于tce形式的pmhc特异性结合结构域,优选使用至少与l接头一样短、更优选至少与标准接头一样短、更优选至少与s接头一样短、更优选至少与xs接头一样短、更优选至少与xxs接头一样短并且最优选与xxs接头一样短或大约一样短的接头。在该实施例中提供的特定接头是具有优选长度的此类接头的示例。
[0449]
实施例12:选择包含对ebna-1肽-mhc复合物(ebna1pmhc)具有结合特异性的锚蛋白重复结构域的结合蛋白
[0450]
概述
[0451]
使用核糖体展示技术(hanes,j.和pl
ü
ckthun,a.,pnas 94,4937-42,1997),以类似于binz等人,2004(同前)描述的方式从文库中选择对ebna-1肽-mhc复合物(ebna1pmhc)具有结合特异性的多个锚蛋白重复结构域,具体条件和附加的反选择步骤如下所述。通过大肠杆菌粗提物均相时间分辨荧光(htrf)评估所选择的克隆对重组ebna1pmhc和其他pmhc复合物的结合和特异性,表明成功选择了多种ebna1pmhc特异性结合蛋白。例如,seq id no:93至110的锚蛋白重复结构域构成所选择的结合蛋白的氨基酸序列,所述结合蛋白包含对ebna1pmhc具有结合特异性的锚蛋白重复结构域。来自此类对ebna1pmhc具有结合特异性的锚蛋白重复结构域的单独锚蛋白重复模块在例如seq id no:111至154中提供。
[0452]
生产生物素酰化pmhc复合物作为靶标和选择材料
[0453]
hla-a*0201(seq id no:73)、人β2-微球蛋白(hβ2m;seq id no:
‑‑
74)和ebna-1肽
之一(fmvflqthi;seq id no:92)或者seq id no:19或seq id no:35的ny-eso-1相关肽的三联体复合物根据已确立的方案(garboczi等人,1992;celie等人,2009)产生。包含接头(gsggsggsagg;seq id no:75和用于生物素酰化的avi标签(glndifeaqkiewhe;seq id no:76;fairhead和howarth,2015)的密码子优化的hla-a*0201(hla-a*0201avi;seq id no:77)和野生型人β2-微球蛋白(hβ2m)在大肠杆菌bl21(de3)中在37℃处以包含体(ib)的形式表达,并且将其在ib纯化后溶解在50mm mes、5mm edta、5mm dtt、8m尿素(ph 6.5)中。hla-a*0201avi和hβ2m分子在相应肽的存在下,分别在25mg、30mg和15mg的最终浓度下,按照500ml体积在50mm tris ph 8.3、230mm l-精氨酸、3mm edta、255μmgssg;2.5mm gsh;250μm pmsf中重新折叠。所得pmhc复合物是(1)包含seq id no:92的ebna-1肽的ebna1pmhc,(2)包含seq id no:19的肽的nyesopmhc,和(3)包含seq id no:35的肽的nyesoaapmhc。
[0454]
为了生物素酰化,将样品浓缩至7.5ml的体积,并且使用pd10柱将缓冲液交换到为100mm tris(ph 7.5)、150mm nacl、5mm mgcl2(ph 7.5)。通过添加5mm atp、400μm生物素、200μm pmsf和20μg bira酶使hla-a*0201avi生物素酰化。bira是按照shen等人,2009描述的程序内部生产的。使用尺寸排阻色谱法(superdex 200hiload 16/600)在补充有150mm nacl、1mm edta、10%甘油的pbs中分离重新折叠的三联体生物素酰化复合物。将样品浓缩至约1mg/ml并且以25μl和50μl等分试样的形式用液氮快速冷冻。
[0455]
为了质量控制目的,将25μg生物素酰化pmhc复合物(生物素-pmhc)与50μg链霉亲和素(iba lifesciences)一起在添加或不添加100mm dtt的情况下温育,并在95℃处温育5分钟。将50μg样品运行分析尺寸排阻色谱法(ge superdex 200 10/300gl)。生物素酰化ebna1pmhc、nyesopmhc和nyesoaapmhc复合物全部以约82ml的最大峰值从superdex 200hiload 16/600柱洗脱。浓缩和解冻的快速冷冻的重新折叠复合物的sds-page分析标明生物素酰化有效,因为hla-a*0201avi几乎完全结合到链霉亲和素。分析尺寸排阻色谱法揭示保留体积的单峰对应于接近三联体pmhc复合物的理论分子量(mw)的表观分子量(45kda)。
[0456]
通过核糖体展示技术选择ebna1pmhc特异性锚蛋白重复蛋白
[0457]
pmhc特异性锚蛋白重复蛋白的选择使用ebna1pmhc复合物(作为靶标)、如上所述的锚蛋白重复蛋白文库和已建立的方案(参见例如zahnd,c.、amstutz,p.和pl
ü
ckthun,a.,nat.methods 4,69-79,2007)通过核糖体展示技术(hanes和pl
ü
ckthun,同前)进行。每轮选择后,逆转录(rt)-pcr循环数不断减少,从而由于结合物的富集而调整收率。前四轮选择采用标准核糖体展示选择,使用降低靶标浓度和增加洗涤严格性来增加从第1轮到第4轮的选择压力(binz等人,2004,同前),但并入了不常见的反选择步骤。
[0458]
在多轮核糖体展示期间,结合了反选择(或负选择)步骤,其中将三元复合物与含有另一种肽的相应同种型hla分子一起预温育,然后仅转移到靶标ebna1pmhc复合物中,以便将锚蛋白重复蛋白的结合导向嵌入肽表位并远离共同的hla-a支架。换句话讲,进行反选择(或负选择)是为了反选择主要结合到pmhc复合物的共同hla-a支架而不是结合到由嵌入肽提供的特定表位的锚蛋白重复蛋白。此外,还对与由用于反选择的嵌入肽提供的表位交叉反应的锚蛋白重复蛋白进行反选择。这里,将nyesopmhc复合物用于反选择。
[0459]
详细地讲,对于反选择步骤,用100μl 66nm中性亲和素的pbs溶液包被nunc maxisorp板,并且在4℃处温育过夜。第二天,在反选择步骤之前,用每孔300μl pbst将
maxisorp 96孔微板洗涤三次,然后用300μlpbst-bsa在4℃处以700rpm旋转阻断1小时。在将孔排空后,将100μl的50nm生物素酰化pmhc反选择靶标的pbst-bsa溶液添加到每个孔中,在4℃处以700rpm旋转1小时。在该温育步骤期间,单独进行根据核糖体展示方案的mrna体外翻译。在体外翻译和生成三元复合物(即mrna、核糖体和翻译的锚蛋白重复蛋白)之后不久,弃去pmhc-pbst-bsa溶液并用300μl pbst将nunc maxisorp微板孔洗涤三次,最后与含有bsa的tris洗涤缓冲液(wbt-bsa)一起温育。就在实际反选择步骤之前,弃去wbt-bsa溶液,然后将体外翻译三元复合物的150μl(对于第一轮选择)或100μl(对于第2轮至第4轮选择)等分试样连续分三次转移到容纳固定的反选择pmhc靶标的nunc maxisorp孔,并且在这三个孔中的制备nunc maxisorp孔中并且在三个孔的每个孔中在4℃处温育20分钟。在反选择过程结束时,将每个选择池的100μl三元复合物等分试样全部组合,并且将相应体积带入如上所述对实际靶标pmhc复合物的选择中。
[0460]
如粗提取物htrf所示所选择的克隆特异性结合ebna1pmhc复合物
[0461]
使用标准方案,使用表达锚蛋白重复蛋白的大肠杆菌细胞的粗提取物,通过均相时间分辨荧光(htrf)测定来鉴定溶液中特异性结合ebna1pmhc的单独选择的锚蛋白重复蛋白。将通过核糖体展示选择的锚蛋白重复蛋白克隆到pqe30(qiagen)表达载体中,将其转化到大肠杆菌xl1-blue(stratagene)中,将其铺板在lb-琼脂(含有1%葡萄糖和50μg/ml氨苄青霉素)上,然后在37℃处温育过夜。将单个菌落挑取到含有165μl生长培养基(含有1%葡萄糖和50μg/ml氨苄青霉素的lb)的96孔板中(每个克隆在单个孔中),并以800rpm振荡在37℃处温育过夜。将含50μg/ml氨苄青霉素的150μl新鲜lb培养基与8.5μl过夜培养物一起接种于新鲜的96深孔板中。在37℃和850rpm处温育120分钟后,用iptg(0.5mm最终浓度)诱导表达并持续6小时。通过将板离心来收获细胞,弃去上清液并将沉淀物在-20℃处冷冻过夜,然后重悬于8.5μl b-perii(thermo scientific)中,并在室温处振荡(600rpm)温育一小时。然后,添加160μl pbs,并通过离心(3220g持续15min)去除细胞碎片。
[0462]
将每个裂解克隆的提取物作为pbstb(补充有0.1%tween 和0.2%(w/v)bsa的pbs,ph7.4)中的1:200稀释液(最终浓度)与20nm(最终浓度)生物素酰化pmhc复合物、1:400(最终浓度)的抗6his-d2htrf抗体-fret受体缀合物(cisbio)和1:400(最终浓度)的抗strep-tb抗体fret供体缀合物(cisbio,france)一起施加到384孔板的孔中,并在4℃处温育120分钟。使用340nm激发波长及用于背景荧光检测的620
±
10nm发射滤光片和用于检测特异性结合的荧光信号的665
±
10nm发射滤光片,在tecan m1000上读出htrf。
[0463]
测试每种裂解克隆的提取物与两种生物素酰化pmhc复合物即ebna1pmhc和nyesopmhc中的每一种的结合,以便评估对靶标ebna1pmhc复合物的结合和特异性。nyesopmhc充当不同于ebna1pmhc的pmhc复合物,以允许选择对ebna1pmhc具有高结合特异性的锚蛋白重复蛋白。
[0464]
为了计算每种锚蛋白重复蛋白对ebna1pmhc的特异性,确定靶标ebna1pmhc的htrf信号与不同nyesopmhc的htrf信号的比率。与在nyesopmhc上相比,在靶标ebna1pmhc上生成至少25倍的htrf信号的所有结合物被认为是特异性命中并且继续进行测序。令人惊讶地,通过此类粗细胞提取物htrf分析筛选数百个克隆,揭示了对ebna1pmhc有特异性的许多不同锚蛋白重复结构域。锚蛋白重复蛋白与包含hla支架和短肽的复合表位(其中仅肽与未特异性结合的其它复合表位不同)的特异性结合之前尚未得以证实并且使用抗体或tcr技术
开发此类复合表位的特异性结合物一直具有挑战性。
[0465]
实施例13:选择包含对mage-a3肽-mhc复合物(magea3pmhc)具有结合特异性的锚蛋白重复结构域的结合蛋白
[0466]
概述
[0467]
使用核糖体展示技术(hanes,j.和pl
ü
ckthun,a.,pnas 94,4937-42,1997),以类似于binz等人,2004(同前)描述的方式从文库中选择对mage-a3肽-mhc复合物(magea3pmhc)具有结合特异性的多个锚蛋白重复结构域,具体条件和附加的反选择步骤如下所述。通过大肠杆菌粗提物均相时间分辨荧光(htrf)评估所选择的克隆对重组magea3pmhc和其他pmhc复合物的结合和特异性,表明成功选择了多种magea3pmhc特异性结合蛋白。例如,seq id no:156至173的锚蛋白重复结构域构成所选择的结合蛋白的氨基酸序列,所述结合蛋白包含对magea3pmhc具有结合特异性的锚蛋白重复结构域。来自此类对magea3pmhc具有结合特异性的锚蛋白重复结构域的单独锚蛋白重复模块在例如seq id no:175至217中提供。
[0468]
生产生物素酰化pmhc复合物作为靶标和选择材料
[0469]
hla-a*0101(seq id no:218)、人β2-微球蛋白(hβ2m;seq id no:
‑‑
74)和mage-a3肽之一(evdpighly;seq id no:155)或titin(esdpivaqy,seq id no:174)根据已确立的方案(garboczi等人,1992;celie等人,2009)产生。包含接头(gsggsggsagg;seq id no:75和用于生物素酰化的avi标签(glndifeaqkiewhe;seq id no:76;fairhead和howarth,2015)的密码子优化的hla-a*0101(hla-a*0101avi;seq id no:219)和野生型人β2-微球蛋白(hβ2m)在大肠杆菌bl21(de3)中在37℃处以包含体(ib)的形式表达,并且将其在ib纯化后溶解在50mm mes、5mm edta、5mm dtt、8m尿素(ph 6.5)中。hla-a*0101avi和hβ2m分子在相应肽的存在下,分别在25mg、30mg和15mg的最终浓度下,按照500ml体积在50mm tris ph 8.3、230mm l-精氨酸、3mm edta、255μm gssg;2.5mm gsh;250μm pmsf中重新折叠。所得pmhc复合物是(1)包含seq id no:155的mage-a3肽的magea3pmhc,和(2)包含seq id no:174的titin肽的titinpmhc。
[0470]
为了生物素酰化,将样品浓缩至7.5ml的体积,并且使用pd10柱将缓冲液交换到为100mm tris(ph 7.5)、150mm nacl、5mm mgcl2(ph7.5)。通过添加5mm atp、400μm生物素、200μm pmsf和20μg bira酶使hla-a*0101avi生物素酰化。bira是按照shen等人,2009描述的程序内部生产的。使用尺寸排阻色谱法(superdex 200hiload 16/600)在补充有150mm nacl、1mm edta、10%甘油的pbs中分离重新折叠的三联体生物素酰化复合物。将样品浓缩至约1mg/ml并且以25μl和50μl等分试样的形式用液氮快速冷冻。
[0471]
为了质量控制目的,将25μg生物素酰化pmhc复合物(生物素-pmhc)与50μg链霉亲和素(iba lifesciences)一起在添加或不添加100mm dtt的情况下温育,并在95℃处温育5分钟。将50μg样品运行分析尺寸排阻色谱法(ge superdex 200 10/300gl)。生物素酰化magea3pmhc和titinpmhc复合物均以约82ml的最大峰值从superdex 200hiload 16/600柱洗脱。浓缩和解冻的快速冷冻的重新折叠复合物的sds-page分析标明生物素酰化有效,因为hla-a*0101avi几乎完全结合到链霉亲和素。分析尺寸排阻色谱法揭示保留体积的单峰对应于接近三联体pmhc复合物的理论分子量(mw)的表观分子量。
[0472]
通过核糖体展示技术选择magea3pmhc特异性锚蛋白重复蛋白
[0473]
pmhc特异性锚蛋白重复蛋白的选择使用magea3pmhc复合物(作为靶标)、如上所述的锚蛋白重复蛋白文库和已建立的方案(参见例如zahnd,c.、amstutz,p.和pl
ü
ckthun,a.,nat.methods 4,69-79,2007)通过核糖体展示技术(hanes和pl
ü
ckthun,同前)进行。每轮选择后,逆转录(rt)-pcr循环数不断减少,从而由于结合物的富集而调整收率。前四轮选择采用标准核糖体展示选择,使用降低靶标浓度和增加洗涤严格性来增加从第1轮到第4轮的选择压力(binz等人,2004,同前),但并入了不常见的反选择步骤。
[0474]
在多轮核糖体展示期间,结合了反选择(或负选择)步骤,其中将三元复合物与含有另一种肽的相应同种型hla分子一起预温育,然后仅转移到靶标magea3pmhc复合物中,以便将锚蛋白重复蛋白的结合导向嵌入肽表位并远离共同的hla-a支架。换句话讲,进行反选择(或负选择)是为了反选择主要结合到pmhc复合物的共同hla-a支架而不是结合到由嵌入肽提供的特定表位的锚蛋白重复蛋白。此外,还对与由用于反选择的嵌入肽提供的表位交叉反应的锚蛋白重复蛋白进行反选择。这里,将titinpmhc复合物用于反选择。
[0475]
详细地讲,对于反选择步骤,用100μl 66nm中性亲和素的pbs溶液包被nunc maxisorp板,并且在4℃处温育过夜。第二天,在反选择步骤之前,用每孔300μl pbst将maxisorp 96孔微板洗涤三次,然后用300μl pbst-bsa在4℃处以700rpm旋转阻断1小时。在将孔排空后,将100μl的50nm生物素酰化pmhc反选择靶标的pbst-bsa溶液添加到每个孔中,在4℃处以700rpm旋转1小时。在该温育步骤期间,单独进行根据核糖体展示方案的mrna体外翻译。在体外翻译和生成三元复合物(即mrna、核糖体和翻译的锚蛋白重复蛋白)之后不久,弃去pmhc-pbst-bsa溶液并用300μl pbst将nunc maxisorp微板孔洗涤三次,最后与含有bsa的tris洗涤缓冲液(wbt-bsa)一起温育。就在实际反选择步骤之前,弃去wbt-bsa溶液,然后将体外翻译三元复合物的150μl(对于第一轮选择)或100μl(对于第2轮至第4轮选择)等分试样连续分三次转移到容纳固定的反选择pmhc靶标的nunc maxisorp孔,并且在这三个孔中的制备nunc maxisorp孔中并且在三个孔的每个孔中在4℃处温育20分钟。在反选择过程结束时,将每个选择池的100μl三元复合物等分试样全部组合,并且将相应体积带入如上所述对实际靶标pmhc复合物的选择中。
[0476]
如粗提取物htrf所示所选择的克隆特异性结合magea3pmhc复合物
[0477]
使用标准方案,使用表达锚蛋白重复蛋白的大肠杆菌细胞的粗提取物,通过均相时间分辨荧光(htrf)测定来鉴定溶液中特异性结合magea3pmhc的单独选择的锚蛋白重复蛋白。将通过核糖体展示选择的锚蛋白重复蛋白克隆到pqe30(qiagen)表达载体中,将其转化到大肠杆菌xl1-blue(stratagene)中,将其铺板在lb-琼脂(含有1%葡萄糖和50μg/ml氨苄青霉素)上,然后在37℃处温育过夜。将单个菌落挑取到含有165μl生长培养基(含有1%葡萄糖和50μg/ml氨苄青霉素的lb)的96孔板中(每个克隆在单个孔中),并以800rpm振荡在37℃处温育过夜。将含50μg/ml氨苄青霉素的150μl新鲜lb培养基与8.5μl过夜培养物一起接种于新鲜的96深孔板中。在37℃和850rpm处温育120分钟后,用iptg(0.5mm最终浓度)诱导表达并持续6小时。通过将板离心来收获细胞,弃去上清液并将沉淀物在-20℃处冷冻过夜,然后重悬于8.5μl b-perii(thermo scientific)中,并在室温处振荡(600rpm)温育一小时。然后,添加160μl pbs,并通过离心(3220g持续15min)去除细胞碎片。
[0478]
将每个裂解克隆的提取物作为pbstb(补充有0.1%tween和0.2%(w/v)bsa的pbs,ph7.4)中的1:200稀释液(最终浓度)与20nm(最终浓度)生物素酰化pmhc复合物、1:400
(最终浓度)的抗6his-d2htrf抗体-fret受体缀合物(cisbio)和1:400(最终浓度)的抗strep-tb抗体fret供体缀合物(cisbio,france)一起施加到384孔板的孔中,并在4℃处温育120分钟。使用340nm激发波长及用于背景荧光检测的620
±
10nm发射滤光片和用于检测特异性结合的荧光信号的665
±
10nm发射滤光片,在tecan m1000上读出htrf。
[0479]
测试每种裂解克隆的提取物与两种生物素酰化pmhc复合物即magea3pmhc和titinpmhc中的每一种的结合,以便评估对靶标magea3pmhc复合物的结合和特异性。titinpmhc充当不同于magea3pmhc的pmhc复合物,以允许选择对magea3pmhc具有高结合特异性的锚蛋白重复蛋白。
[0480]
为了计算每种锚蛋白重复蛋白对magea3pmhc的特异性,确定靶标magea3pmhc的htrf信号与不同titinpmhc的htrf信号的比率。与在titinpmhc上相比,在靶标magea3pmhc上生成至少25倍的htrf信号的所有结合物被认为是特异性命中并且继续进行测序。令人惊讶地,通过此类粗细胞提取物htrf分析筛选数百个克隆,揭示了对magea3pmhc有特异性的许多不同锚蛋白重复结构域。锚蛋白重复蛋白与包含hla支架和短肽的复合表位(其中仅肽与未特异性结合的其它复合表位不同)的特异性结合之前尚未得以证实并且使用抗体或tcr技术开发此类复合表位的特异性结合物一直具有挑战性。
[0481]
实施例14:通过表面等离子体共振(spr)分析确定对magea3pmhc具有结合特异性的锚蛋白重复蛋白的解离常数(kd)
[0482]
为了测试对magea3pmhc具有结合特异性的锚蛋白重复结构域以免疫细胞接合剂形式起作用并且以该形式结合到magea3pmhc的能力,使用常规克隆方法将选择的锚蛋白重复结构域遗传连接到对免疫细胞表面上表达的蛋白具有结合特异性的结合因子。通过该过程,生成了包含对magea3pmhc具有结合特异性的锚蛋白重复结构域并且还包含对cd3具有结合特异性的结合因子的结合蛋白。用常规层析方法将这些蛋白纯化。
[0483]
使用proteon表面等离子体共振(spr)仪器(biorad)分析经纯化的锚蛋白重复蛋白对magea3pmhc靶标的结合亲和力,并且根据本领域技术人员已知的标准程序进行测量。
[0484]
使用本领域技术人员已知的标准程序,由估计的结合率和解离率计算解离常数(kd)。选择的锚蛋白重复蛋白与magea3pmhc的结合相互作用的kd值被确定为大部分在低纳摩尔范围内或为更低的值。这些选择的锚蛋白重复蛋白中没有一个显示出可测量的与对照肽的结合相互作用。作为对照,并行测试与titin肽-mhc的结合。未检测到与titin肽-mhc的显著结合,证明了结合的特异性。表14提供了作为示例的一些选择的锚蛋白重复蛋白的kd值。
[0485]
表14.锚蛋白重复蛋白-magea3pmhc相互作用的kd值
[0486][0487]
实施例15:选择包含对hbvc18肽-mhc复合物(hbvc18pmhc)具有结合特异性的锚蛋白重复结构域的结合蛋白
[0488]
概述
[0489]
使用核糖体展示技术(hanes,j.和pl
ü
ckthun,a.,pnas 94,4937-42,1997),以类似于binz等人,2004(同前)描述的方式从文库中选择对hbvc18肽-mhc复合物(hbvc18pmhc)具有结合特异性的多个锚蛋白重复结构域,具体条件和附加的反选择步骤如下所述。通过大肠杆菌粗提物均相时间分辨荧光(htrf)评估所选择的克隆对重组hbvc18pmhc和其他pmhc复合物的结合和特异性,表明成功选择了多种hbvc18pmhc特异性结合蛋白。例如,seq id no:220至230的锚蛋白重复结构域构成所选择的结合蛋白的氨基酸序列,所述结合蛋白包含对hbvc18pmhc具有结合特异性的锚蛋白重复结构域。来自此类对hbvc18pmhc具有结合特异性的锚蛋白重复结构域的单独锚蛋白重复模块在例如seq id no:231至254中提供。
[0490]
生产生物素酰化pmhc复合物作为靶标和选择材料
[0491]
hla-a*0201(seq id no:73)、人β2-微球蛋白(hβ2m;seq id no:74)和表15中列出的肽之一的生物素酰化三联体复合物根据已确立的方案(garboczi等人,1992;celie等人,2009)产生。
[0492]
表15:用于生成pmhc复合物以选择和筛选经设计的锚蛋白重复蛋白的肽
[0493][0494]
与hbvc18肽同源的氨基酸用下划线标出。
[0495]
实验中使用的所有pmhc复合物均进行先前的质量控制测试。
[0496]
通过核糖体展示技术选择hbvc18pmhc特异性锚蛋白重复蛋白
[0497]
pmhc特异性锚蛋白重复蛋白的选择使用hbvc18pmhc复合物(作为靶标)、如上所述的锚蛋白重复蛋白文库和已建立的方案(参见例如zahnd,c.、amstutz,p.和pl
ü
ckthun,a.,nat.methods 4,69-79,2007)通过核糖体展示技术(hanes和pl
ü
ckthun,同前)进行。每轮选择后,逆转录(rt)-pcr循环数不断减少,从而由于结合物的富集而调整收率。前四轮或前五轮选择采用标准核糖体展示选择,使用降低靶标浓度和增加洗涤严格性来增加从第1轮到第4轮的选择压力(binz等人,2004年,同前)。如下所述,将不寻常的反选择步骤结合到该选择策略中。
[0498]
在多轮核糖体展示期间,结合了反选择(或负选择)步骤,其中将三元复合物与含有另一种肽的相应同种型hla分子一起预温育,然后仅转移到靶标hbvc18pmhc复合物中,以便将锚蛋白重复蛋白的结合导向嵌入肽表位并远离共同的hla-a支架。换句话讲,进行反选择(或负选择)是为了反选择主要结合到pmhc复合物的共同hla-a支架而不是结合到由嵌入肽提供的特定表位的锚蛋白重复蛋白。此外,还对与由用于反选择的嵌入肽提供的表位交叉反应的锚蛋白重复蛋白进行反选择。此处,将肽hbe183(flltrilti)、hbe183mut(fllrilti)、ebna-1(fmvflqthi)和ny-eso-1(sllmwitqv)用于反选择。
[0499]
详细地讲,用100μl 66nm中性亲和素的pbs溶液包被nunc maxisorp板,并且在4℃下温育过夜。第二天,在反选择步骤之前,用每孔300μlpbst将maxisorp 96孔微板洗涤三次,然后用300μl pbst-bsa在4℃下以700rpm旋转阻断1小时。在将孔排空后,将100μl的50nm生物素酰化pmhc反选择靶标的pbst-bsa溶液添加到每个孔中,在4℃下以700rpm旋转1小时。在该温育步骤期间,进行mrna体外翻译。在翻译和生成三元复合物混合物之后不久,
弃去pmhc-pbst-bsa溶液,用300μl pbst将nunc maxisorp微板孔洗涤三次,最后与wbt-bsa一起温育。对于实际的反选择步骤,弃去wbt-bsa溶液,随后将翻译的三元复合物的100μl(对于第2至第5轮选择分别为该体积,对于第一轮选择为150μl)等分试样分三次转移,以制备容纳固定的反选择pmhc靶标的nunc maxisorp孔,并且在这三个孔中的每个孔中在4℃下温育20分钟。在反选择过程结束时,将每个选择池的100μl三元复合物等分试样再次合并,并且将相应体积带入实际靶标的选择中。
[0500]
在第4轮和第5轮核糖体展示选择之后,将所述池与bamhi和psti一起克隆到细菌表达载体中,然后转化到大肠杆菌xl-1blue中,并铺板在lb/glu/amp琼脂平板上。
[0501]
如通过粗提物htrf所确定的(数据未显示),选择的克隆特异性地结合到hbvc18pmhc复合物。
[0502]
此外,用常规层析方法将蛋白纯化。
[0503]
实施例16:通过表面等离子体共振(spr)分析确定对hbvc18pmhc具有结合特异性的锚蛋白重复蛋白的解离常数(kd)
[0504]
为了测试对hbvc18pmhc具有结合特异性的锚蛋白重复结构域以免疫细胞接合剂形式起作用并且以该形式结合到hbvc18pmhc的能力,使用常规克隆方法将选择的锚蛋白重复结构域遗传连接到对免疫细胞表面上表达的蛋白具有结合特异性的结合因子。通过该过程,生成了包含对hbvc18pmhc具有结合特异性的锚蛋白重复结构域并且还包含对cd3具有结合特异性的结合因子的结合蛋白。用常规层析方法将这些蛋白纯化。
[0505]
使用proteon表面等离子体共振(spr)仪器(biorad)分析经纯化的锚蛋白重复蛋白对hbvc18pmhc靶标的结合亲和力,并且根据本领域技术人员已知的标准程序进行测量。
[0506]
使用本领域技术人员已知的标准程序,由估计的结合率和解离率计算解离常数(kd)。选择的锚蛋白重复蛋白与hbvc18pmhc的结合相互作用的kd值被确定为在低纳摩尔范围内或为更低的值。这些选择的锚蛋白重复蛋白中没有一个显示出可测量的与对照肽的结合相互作用。表16提供了作为示例的一些选择的锚蛋白重复蛋白的kd值。
[0507]
表16.锚蛋白重复蛋白-hbvc18pmhc相互作用的kd值
[0508][0509][0510]
实施例17:蛋白变体的小鼠药代动力学特征
[0511]
本实施例提供了产生改善的药代动力学特征的经设计的锚蛋白重复结构域的氨
基酸序列。令人惊讶地发现,可以通过在设计的锚蛋白重复结构域中施加某些氨基酸突变来调节药代动力学特性。
[0512]
蛋白的表达和纯化
[0513]
将编码由seq id no:281至325组成的经设计的锚蛋白重复结构域中每一者的dna克隆到基于pqe(qiagen,germany)的表达载体中,从而提供n末端his标签以有利于简单的蛋白纯化,如下所述。在大肠杆菌中产生由seq id no:281至325组成的蛋白(另外具有融合到其n末端的his标签(seq id no:326)),将其纯化至均质,并储存在pbs缓冲液中。用于产生和纯化蛋白的方法是本领域的从业者众所周知的。蛋白#281至#325由两个经设计的锚蛋白重复结构域组成,其中一个经设计的锚蛋白重复结构域是对血清白蛋白具有结合特异性的经设计的锚蛋白重复结构域。
[0514]
另选地,在大肠杆菌中产生由seq id no:281至325组成的蛋白(在n末端处另外具有氨基酸gs),将其纯化至均质,并储存在pbs缓冲液中。在氨基酸gs位于n末端的情况下,因为起始met之后是小gly残基,因此由表达载体另外编码的met残基在大肠杆菌细胞质中被有效地从所表达的多肽上切除。在下述药代动力学分析实验中,由seq id no:281至325组成的另外在n末端处具有氨基酸gs的蛋白表现出与由seq id no:281至325组成的另外具有融合至其n末端的his标签(seq id no:326)的蛋白等效的结果。
[0515]
小鼠药代动力学特征测量
[0516]
使用如上所述产生的蛋白#281至#295在雌性balb/c小鼠中进行药代动力学分析。通过静脉内注射将蛋白质以1mg/kg施用到尾静脉中。将分成两组(每组3只小鼠)的六只小鼠用于每种蛋白质。对于每种蛋白,在注射后5分钟、24小时、72小时和168小时从一组的小鼠,以及在注射后6小时、48小时、96小时和168小时从另一组的小鼠收集血液。使血样在室温下静置,并使用本领域技术人员熟知的程序离心以产生血清,然后储存在-80℃下待分析。使用兔单克隆抗-darpin抗体作为捕获试剂以及抗-rgs-his抗体-hrp缀合物作为检测试剂,并使用标准曲线,通过夹心elisa测定蛋白#281至#295的血清浓度。使用本领域技术人员众所周知的常规兔免疫和杂交瘤生成技术生成单克隆抗-darpin抗体,并且在浓度测定实验之前验证单克隆抗体与蛋白#281至#295的结合。简而言之,将每孔100μl山羊抗兔抗体(10nm)(thermo scientific)的pbs溶液在4℃处固定在maxisorp板(nunc,denmark)中过夜。用300μl pbst(补充有0.1%tween 20的pbs)洗涤5次后,在室温下将孔用300μl pbst-c(补充有0.25%酪蛋白的pbst)封闭1小时,同时在titramax 1000摇床(heidolph,germany)上以450rpm振荡。如上所述洗涤5次后,在室温下添加100μl/孔兔抗darpin抗体(5nm)的pbst-c溶液持续1小时并伴以450rpm振荡。如上所述洗涤5次后,在室温下添加稀释于pbst-c中的血清样品或标准参照物的不同稀释液持续2小时并伴以450rpm振荡。在如上所述洗涤5次后,在室温下添加50μl小鼠抗-rgs-his抗体-hrp缀合物(qiagen)(100ng/ml)的pbst-c溶液持续30分钟并伴以450rpm振荡。在如上所述洗涤5次后,使用50μl tmb底物使elisa显影。5分钟后,使用100μl 1m h2so4停止反应。然后记录od(od 450nm-od 620nm)。使用标准软件诸如phoenix winnonlin(certara,princeton,usa)或graphpadprism(graphpad software,la jolla,usa)和标准分析诸如非隔室分析来测定药代动力学参数,全部都是本领域技术人员所熟知的。所得药代动力学特征在图26中示出。来源于测量的药代动力学参数即曲线下面积、清除率、分布体积和半衰期分别列于表177、表188、表1919和表2020中。
[0517]
表17.蛋白#281至#283的小鼠药代动力学参数
[0518][0519]
*该表中的蛋白#281至#283表示由seq id no:281至283的相应氨基酸序列组成的且另外包含n末端his标签(seq id no:326)的蛋白。
[0520]
表18.蛋白#284至#287的小鼠药代动力学参数
[0521][0522]
*该表中的蛋白#284至#287表示由seq id no:284至287的相应氨基酸序列组成的且另外包含n末端his标签(seq id no:326)的蛋白。
[0523]
表19.蛋白#288至#291的小鼠药代动力学参数
[0524][0525]
*该表中的蛋白#288至#291表示由seq id no:288至291的相应氨基酸序列组成的且另外包含n末端his标签(seq id no:326)的蛋白。
[0526]
表20.蛋白#292至#295的小鼠药代动力学参数
[0527][0528]
*该表中的蛋白#292至#295表示由seq id no:292至295的相应氨基酸序列组成的且另外包含n末端his标签(seq id no:326)的蛋白。
[0529]
这些发现标明,这里描述的序列修饰产生改善的药代动力学特性。具体而言,蛋白#282和#283表现出比蛋白#281更慢的清除率、更大的曲线下面积和更长的终末半衰期。
同样,蛋白#285、#286和#287表现出比蛋白#284更慢的清除率、更大的曲线下面积和更长的终末半衰期。类似地,蛋白#289、#290和#291表现出比蛋白#288更慢的清除率、更大的曲线下面积和更长的终末半衰期。并且蛋白#293、#294和#295表现出比蛋白#292更慢的清除率、更大的曲线下面积和更长的终末半衰期。
[0530]
当比较蛋白#296至#310的小鼠药代动力学参数时,获得类似的结果。具体而言,蛋白#297和#298表现出比蛋白#296更慢的清除率、更大的曲线下面积和更长的终末半衰期。同样,蛋白#300、#301和#302表现出比蛋白#299更慢的清除率、更大的曲线下面积和更长的终末半衰期。类似地,蛋白#304、#305和#306表现出比蛋白#303更慢的清除率、更大的曲线下面积和更长的终末半衰期。并且蛋白#308、#309和#310表现出比蛋白#307更慢的清除率、更大的曲线下面积和更长的终末半衰期。同样,当比较蛋白#311至#325的小鼠药代动力学参数时,获得类似的结果。具体而言,蛋白#312和#313表现出比蛋白#311更慢的清除率、更大的曲线下面积和更长的终末半衰期。同样,蛋白#315、#316和#317表现出比蛋白#314更慢的清除率、更大的曲线下面积和更长的终末半衰期。类似地,蛋白#319、#320和#321表现出比蛋白#318更慢的清除率、更大的曲线下面积和更长的终末半衰期。并且蛋白#323、#324和#325表现出比蛋白#322更慢的清除率、更大的曲线下面积和更长的终末半衰期。因此,当使用对血清白蛋白具有结合特异性的不同的经设计的锚蛋白重复结构域作为半衰期延长的手段时,观察到序列修饰对蛋白在小鼠中的药代动力学特性的影响。因此,当使用不同的接头序列(例如,富含pro-thr的接头而不是富含gly-ser的接头)时,也观察到序列修饰对蛋白在小鼠中的药代动力学特性的影响。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。