1.本发明涉及一种基于dna自裂酶的selex用于筛选适配体的方法。
背景技术:
2.selex技术实际上是一个筛选过程,起始于庞大的随机核酸序列库。从理论上讲,该文库包含两个固定端,可以进行pcr扩增,中间有一个随机区域,通常为40个核苷酸,这就产生了440个不同序列的理论文库,然后将这种含有大约1015个不同的分子的随机文库与靶物质一起孵育,然后分离与靶物质结合的核酸分子,再经过pcr扩增与靶物质结合的dna。重复此过程,直到分离出对靶物质具有高亲和力的dna池为止。然后对该池进行测序和表征,以鉴定具有最高亲和力的适体。selex策略已被用于鉴定从小分子到多肽等各种靶标的适配体。尽管通用的selex方法已被广泛使用,但仍然有许多高级的selex方法被开发出来,改善和加快了筛选过程。例如,传统的selex使用纯蛋白作为体外选择的靶标,但是纯蛋白的三维结构可能与细胞表面的三维结构不同,所以开发了基于细胞的selex来解决该问题。同时cell-selex也扩大了适配体在疾病诊断和预后中的应用。传统的selex过程繁琐,昂贵且耗时,因此提出了新的selex技术来简化程序和提高选择效率。
技术实现要素:
3.本发明的主要目的,在于提供一种筛选适配体的方法。
4.本发明解决其技术问题的所采用的技术方案是:
5.一种筛选适配体的方法,包括如下步骤:
6.1)将随机序列插入到自裂酶中,使自裂酶失去自我剪切功能;
7.2)随机序列与靶标分子结合,自裂酶自我剪切功能恢复,发生自我剪切;
8.3)通过对发生剪切的序列重复分离与筛选富集到能感应靶标分子的适配体。
9.本发明技术方案与背景技术相比,具有如下优点:
10.利用酶自我剪切的特性可以达到精准分离与小分子结合并发生剪切的序列,简化了复杂的实验设计。
附图说明
11.下面结合附图和实施例对本发明作进一步说明。
12.图1为自建库序列信息。
13.图2为空切。marker为公司订购的113nt和86nt的ssdna,template为l-别异亮氨酸与zn2 共同孵育后发生剪切后的剪切片段,片段长度为86nt。比对86ntmarker把空胶切下,进行逐步的富集.。
14.图3为i-r3-random文库ri扩增。纯化后的剪切产物经过第一对引物扩增30个循环的pcr产物,产物长度为98bp。
15.图4为i-r3-random文库ri扩增。纯化后98bp的产物经过第二对引物扩增得到全长
113bp的双链dna。
16.图5为不对称pcr方法拆分双链dna。产物1-6是相同条件下拆分单链的结果,是为了制备丰富的下一轮单链dna文库。
17.图6为i-r3-random筛选结果。第五轮筛选后在第86nt处出现了一个明显的条带。marker为在公司订购的113nt与86nt的ssdna。
18.图7为空切。marker为公司订购的95nt的ssdna,clv product为l-别异亮氨酸与zn2 共同孵育后发生剪切后的剪切片段,片段长度为95nt。比对95nt marker把空胶切下,进行逐步的富集。
19.图8为用5’生物素化的上游引物扩增出全长108bp
20.图9为适配体富集的dna条带。a.第7轮dna条带;b.第9轮dna条带;c.第12轮dna条带。
21.图10为ir3-i-dna适配体与l-别异构亮氨酸结合特异性结果。(a)ir3-i-dna的序列和二级结构。(b)通过聚丙烯酰胺凝胶电泳(page)凝胶分离裂解产物。dna切割的比例是5'和3'切割产物的条带强度除以总dna的条带强度。前体(pre)、5'切割产物(5'clv)、3'切割产物(3'clv)。(c)配体l-异亮氨酸、异亮氨酸和亮氨酸的结构。allo-iso-leu、iso-leu和leu代表配体l-allo-isoleucine、isoleucine和leucine。
22.以上所述,仅为本发明较佳实施例而已,故不能依此限定本发明实施的范围,即依本发明专利范围及说明书内容所作的等效变化与修饰,皆应仍属本发明涵盖的范围内。
具体实施方式
23.在本发明中,能使用的自裂酶种类包括dna断裂型脱氧核酶或rna断裂型脱氧核酶。其中,dna断裂型脱氧核酶包括类手枪脱氧核酶(pist0l-like dnazyme,pldz),9nl27,i-r3,等。
24.rna断裂型脱氧核酶的种类包括ag10x,pscu10,8n-cd16,gr5,pbe22,lu12,c313d以及tm7等。
25.优选地,随机序列的长度为10-100个碱基。进一步优选,随机序列的长度为40-70个碱基。
26.优选地,随机文库单链dna分子数目达到1
×
10
15
以上,保证随机文库的丰富度。优选地,随机文库单链dna分子数目1
×
10
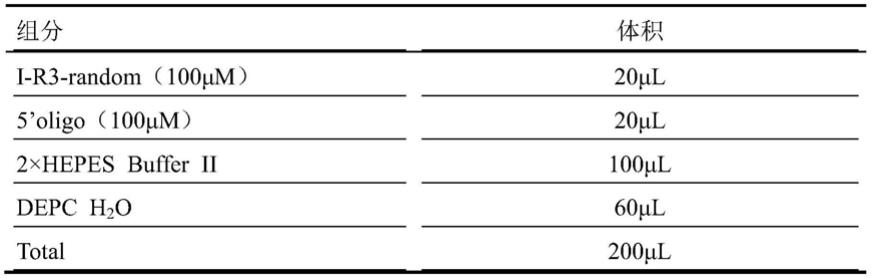
15-1
×
10
18
。
27.优选地,步骤2)中,是在含有金属离子的缓冲溶液中发生自我剪切。
28.优选地,在步骤2)之前,先用含金属离子的缓冲液的孵育筛选去除随机文库中已经形成剪切结构的序列。
29.优选地,步骤3)中,通过不对称pcr和链霉素磁珠法将双链dna拆分成单链的dna文库,再用含生物素的寡核苷酸序列将其固定进入下一轮筛选,通过多次循环筛选和扩增达到富集的目的。
30.实施例1
31.将随机序列插入具有自我剪切功能的dna自裂酶的非剪切功能部分,破坏其原有的剪切二级结构,在靶分子的作用下使随机序列形成特定二级结构,使dna自裂酶恢复剪切结构后发生剪切。所述的随机文库为:
32.i-r3-random:5
’‑
gtaacgtagttgagctg-n60-tgacgttgaagcgttacgcagctgtgggttgattcc-3’33.ii-r1-ramdom:5’biotin-catgaccactaggagcatctttggcg-n47-taggggaataaatctttgggcacctagtggtcatg-3’34.其中,n60和n47分别代表60个或47个随机碱基。
35.具体步骤包括如下:
36.一、r1-random随机文库的筛选
37.1.i-r3 dna随机文库的制备。将订购的随机文库按比例稀释到100μm然后与5’端生物素修饰的寡核苷酸序(5’oligo)列结合。使文库正确折叠。
38.表1 template oligo ssdna折叠
[0039][0040]
按上述体系将样品混合均匀放入pcr仪中,将pcr反应程序设置如下:
[0041][0042]
2.将文库和含生物素寡核苷酸序列固定于链霉素亲和磁珠。
[0043]
a.链霉素亲和磁珠在使用前,先将磁珠涡旋振荡仪振荡20s。充分混匀。
[0044]
b.将所需体积的purimag beads移入无核酸酶的微量离心管中。用磁力架分离磁性颗粒。注意:50μl 10mg/ml(500μg)足以结合125pmol生物素化寡核苷酸或生物素化pcr产物
[0045]
c.除去上清液,用100ul结合缓冲液(binding buffer:20mm tris
·
cl,1.0m nacl,1mm edta,0.02%x-100;ph 7.8)洗涤3次。
[0046]
d.去除上清液。在100ul结合缓冲液中重悬磁珠。
[0047]
e.在室温下,将结合上生物素寡核苷酸序列的单链dna文库与重新悬浮的磁珠孵育1h。,轻柔混合。
[0048]
f.用磁力架分离珠子,并用1
×
hepes buffer1洗涤磁珠3次。
[0049]
g.将珠粒重悬在50μl 2
×
hepes buffer1中。现在,寡核苷酸包被的颗粒适用于下游应用。
[0050]
3.zn
2
孵育除去dna文库中已经形成剪切结构的序列。向上述混合物中加入50μl的2
×
hepes buffer 2;37℃孵育4h。除去上清,并用1
×
hepes buffer 2洗涤第三次。
[0051]
4.制胶,向40ml的10%page中加入320μl 10%的过硫酸铵(aps)溶液混合均匀倒入铺好的制胶板插上梳子,等待胶体凝固。
[0052]
5.l-别异亮氨酸的结合。加入100μm的l-别异亮氨酸(靶标分子),再加入2
×
hepes buffer2。37℃孵育20min。保留上清液。
[0053]
6.浓缩上清液。用乙醇沉淀法将上清液中的序列沉淀出来,洗去多余的盐离子。具体操作如下:
[0054]
a.加入3倍体积的无水乙醇,1/10倍体积的醋酸钠溶液,20mg/ml糖原(1μl/ml)。
[0055]
b.将上述步骤的溶液混匀放入-20℃,2h。
[0056]
c.离心机提前预冷至4℃。
[0057]
d.将混合溶液从-20℃取出,14,000rpm离心20min,弃去上清。
[0058]
e.用70%的乙醇漂洗。14,000rpm离心20min,弃去上清。
[0059]
f.重复步骤e。
[0060]
g.室温晾干,加入10μldepc水,充分溶解。
[0061]
7.向浓缩过的样品中加入10μl 2
×
loading buffer,总体系共20μl。
[0062]
8.上样,marker为公司订购的113nt和86nt的ssdna。600v,2h。
[0063]
9.染色。50μl的1
×
tbe缓冲溶液中加入5μl的sybr gold核酸染料,电泳完毕后将胶块侵泡15min。
[0064]
10.照胶。
[0065]
11.切胶纯化,对照marker的长度切下发生剪切的条带。没有富集到足够的量之前,都比着marker的大小进行空切(图2)。
[0066]
12.对纯化出来的序列进行pcr扩增,用第一对引物primer-for-ir3(序列:5'-gtaacgtagttgagctg,seq id no:1)与primer-rev i-ir3(序列:5'-ctgcgtaacgcttcaacgtca,seq id no:1)进行扩增,条带长度为98bp。
[0067]
表2 i-r3-random文库ri扩增
[0068][0069]
按上述体系将样品混合均匀放入pcr仪中,将pcr反应程序设置如下:
[0070][0071]
13.将pcr产物进行1%琼脂糖凝胶电泳。将pcr产物的98bp条带(图3)切胶纯化出来进行下一步pcr程序。通常每一轮纯化产物一般50~80ng/μl,共30μl。为了确保dna库的丰富度。将得到的纯化产物的2/3用于下一轮扩增。
[0072]
14.第二次pcr扩增。用第二对引物primer-for-ir3(序列:5'-gtaacgtagttgagctg,seq id no:3)和primer-rev ii-ir3(序列:5'-ggaatcaacccacagctgcgtaacgcttcaacgtca,seq id no:4)扩增出113bp全长。
[0073]
表3 i-r3-random文库rii扩增
[0074][0075]
按上述体系将样品混合均匀放入pcr仪中,反应程序设置如下:15.将上述pcr产物进行琼脂糖凝胶电泳。将113bp的产物(图4)切胶纯化出来进行后
[0076]
[0077]
续实验。通常每一轮第二次扩增的pcr纯化产物一般50~80ng/μl,共30μl。为了确保dna库的丰富度。将得到的纯化产物的2/3用于下一步dna单链的拆分。
[0078]
16.不对称pcr法拆分单链。拆分单链时选用的上下游引物比为60:1,循环数为30cycles,退火温度为50℃。
[0079]
表4不对称pcr反应
[0080][0081][0082]
按上述体系将样品混合均匀放入pcr仪中,反应程序设置如下:
[0083][0084]
17.将上一步的不对称pcr产物进行琼脂糖凝胶电泳将113nt的产物(图5)切胶纯化出来进行后续实验。
[0085]
当i-r3dna随机文库筛选到第五轮时出现了明显条带(图6),将其切下,进行自建库高通量测序。
[0086]
本实施例文库的测序数据量1gb,因此在测序时需要将多个文库样品混在同1条lane中,为了能够把测序数据按样本分离,在构建文库的时候,需要用不同index对文库进行标记。自建库的序列信息见图1。
[0087]
本实施例使用的接头为p5和p7,它们是flow cell上的共价连接的接头,可以分别于片段的两条单链结合,使得片段被固定lane中。具体实验步骤如下:
[0088]
①
将i-r3-random第四轮产物纯化出来备用。ii-r1-random的第九轮、第17轮产物纯化备用
[0089]
表5 i-r3-random文库第5轮产物自建库
[0090][0091]
表6 ii-r1-random文库第7轮产物自建库
[0092][0093]
表7 ii-r1-random文库第9轮产物自建库
[0094][0095][0096]
表8 ii-r1-random文库第12轮产物自建库按上述体系将样品混合均匀放入pcr仪
中,将pcr反应程序设置如下:
[0097][0098]
①
计算产物长度,在1.0%的琼脂糖凝胶找到对应长度的条带进行切胶纯化。采用sanp rep柱式dna胶回收试剂盒(上海生工)进琼脂糖凝胶的切胶纯化。具体步骤如下:
[0099]
a.准备工作。
[0100]
i.检查wash solution中是否已经加入乙醇。
[0101]
ii.检查buffer b2是否出现沉淀。
[0102]
iii.将水浴锅调至55℃。
[0103]
b.从琼脂糖凝胶中割下含目标片段的胶块,称重。
[0104]
c.加入胶块重量3-6倍的buffer b2,50℃水浴5-10分钟溶胶。
[0105]
d.(选做)对于《500bp的片段,加入1/3buffer b2体积的异丙醇。
[0106]
e.将溶胶液移入吸附柱中,8,000
×
g离心30秒。倒掉收集管中液体。
[0107]
f.加入500μl wash solution,9,000
×
g离心30秒,倒掉收集管中液体。
[0108]
g.重复步骤6一次。
[0109]
h.空吸附柱于9,000
×
g离心1分钟。
[0110]
i.将吸附柱放入一个干净的1.5ml离心管中,在吸附膜中央加入15-40μl elution buffer,室温静置1分钟后,离心1分钟。保存管中dna溶液。
[0111]
②
测序;等待数据释放
[0112]
③
测序数据分析
[0113]
根据统计结果进行二级结构预测.最终获得一条能与别构异亮氨酸结合的核酸适配体(ir3-i-dna),序列是:5'-gtaacgtagttgagctgtcacgctcaaggaagatctaaacggtccgcgcaatcacgtaactggaagatccttgagcgtgacgttgaagcgttacgcagctgtgggttgattcc(seq id no:5)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
