本说明书涉及预测蛋白质结构。
蛋白质是通过氨基酸的序列指定(具体说明)的。氨基酸是包括氨基官能团和羧基官能团以及对氨基酸特异的侧链(即原子团)的有机化合物。蛋白质折叠是指氨基酸的序列折叠成三维构型的物理过程。蛋白质的结构定义在蛋白质进行蛋白质折叠后,蛋白质的氨基酸序列中原子的三维构型。当在由肽键连接的序列中时,氨基酸可称为氨基酸残基。
可使用机器学习模型进行预测。机器学习模型接收输入,并基于接收的输入生成输出(例如,预测的输出)。一些机器学习模型是参数模型,并基于接收的输入和模型的参数的值生成输出。蛋白质的结构可基于指定蛋白质的氨基酸序列来预测。
一些机器学习模型是采用多层模型来对于接收的输入生成输出的深度模型。例如,深度神经网络是深度机器学习模型,其包括输出层和一个或多个隐藏层,所述隐藏层各自将非线性变换应用到接收的输入以生成输出。
技术实现要素:
本说明书描述在一个或多个位置的一台或多台计算机上作为计算机程序实施的系统,其执行蛋白质结构预测。
根据第一方面,提供由一个或多个数据处理装置进行的用于确定由氨基酸序列指定的蛋白质的预测的结构的方法。该方法包括获得对于蛋白质的多序列比对(MSA)。该方法可进一步包括从多序列比对且对于蛋白质的氨基酸序列中的各氨基酸对来确定氨基酸对的相应的初始嵌入。该方法可进一步包括使用包括多个自注意力神经网络层的成对嵌入(对嵌入,pair embedding)神经网络来处理氨基酸对的初始嵌入,以生成各氨基酸对的最终嵌入。然后,该方法可包括基于各氨基酸对的最终嵌入来确定蛋白质的预测的结构。
该方法的一些优点在后面描述。例如,该方法的实施生成“成对”嵌入,其将在蛋白质中氨基酸对之间的关系编码。(例如,对于蛋白质中氨基酸对的成对嵌入可将在该氨基酸对中相应的指定的原子(例如碳α原子)之间的关系编码)然后,这些可由随后的神经网络层处理以确定额外信息,特别地蛋白质的预测的结构。在实施中,折叠神经网络处理成对嵌入以确定预测的结构,例如,在结构参数诸如对于蛋白质的碳原子的原子坐标或骨架扭转角度。稍后描述这样的折叠神经网络的实例实施,但是也可使用其他。在一些实施中,使用最终成对嵌入以确定氨基酸序列中各(单个)氨基酸的初始嵌入,并且该单个嵌入可单独使用或者与成对嵌入联合使用来确定预测的结构。
在实施中,各自注意力神经网络层接收各氨基酸对的当前嵌入,并在氨基酸对的当前嵌入上或在这些嵌入的真子集(合适的子集)上使用注意力来更新当前嵌入。例如,自注意力神经网络层可确定应用于当前嵌入(或子集)的注意力权重集以更新当前嵌入,例如基于当前嵌入的注意力加权求和。
在一些实施中,氨基酸对的当前嵌入排列(布置)成二维阵列(数组)。然后,自注意力神经网络层可包括行式和/或列式自注意力神经网络层,例如,交替序列。行(或列)式自注意力神经网络层可仅在位于与氨基酸对的当前嵌入相同的行(或列)中的氨基酸对的当前嵌入上使用注意力来更新氨基酸对的当前嵌入。
已经发现,使用自注意力显著地改善预测的结构的准确性,例如,通过生成更容易处理的嵌入来确定预测的结构参数。行和列式处理有助于以减少的计算资源实现这点。
各氨基酸对的初始嵌入可通过将MSA分成聚类(簇,cluster)氨基酸序列的集和(较大的)额外氨基酸序列的集来确定。然后可生成各集的嵌入,并且可使用额外氨基酸序列的嵌入来更新聚类氨基酸序列的嵌入。然后,更新的聚类氨基酸序列的嵌入可用于确定氨基酸对的初始嵌入。以这种方式,为了计算效率,可使用大的额外氨基酸序列的集来丰富较小的氨基酸序列(聚类氨基酸序列)的集的嵌入的信息。所述处理可通过交叉注意力神经网络进行。交叉注意力神经网络可包括如下神经网络:其在额外氨基酸序列的嵌入上使用注意力(即,应用到额外氨基酸序列的嵌入的注意力权重)来更新聚类氨基酸序列的嵌入。任选地,该方法可进一步涉及在聚类氨基酸序列的嵌入上使用注意力来更新额外氨基酸序列的嵌入。可重复地进行聚类氨基酸序列以及任选地额外氨基酸序列的嵌入的更新,例如在时间上顺序地或使用顺序的神经网络层。
在第二方面,提供系统,其包括:一台或多台计算机;以及通信地连接(耦合)到一台或多台计算机的一个或多个储存设备,其中一个或多个储存设备存储指令,所述指令当由一台或多台计算机执行时使得一台或多台计算机进行包括第一方面的方法的操作(运行)的操作。
在第三方面,提供存储指令的一个或多个非暂时性计算机储存介质,所述指令当由一台或多台计算机执行时使得一台或多台计算机进行包括第一方面的方法的操作的操作。
本文中描述的方法和系统可用于获得配体诸如药物或工业酶的配体。例如,获得配体的方法可包括获得靶(目标)氨基酸序列,特别地靶蛋白质的氨基酸序列,并使用靶氨基酸序列作为氨基酸序列来进行如以上或本文中所述的计算机实施的方法,以确定靶蛋白质的(三级)结构,即预测的蛋白质结构。然后,该方法可包括评估一种或多种候选配体与靶蛋白质的结构的相互作用。该方法可进一步包括取决于相互作用的评估的结果选择所述候选配体的一种或多种作为配体。
在一些实施中,评估相互作用可包括评估候选配体与靶蛋白质的结构的结合。例如,评估相互作用可包括鉴别对于生物效应以足够亲和力结合的配体。在一些其他实施中,评估相互作用可包括评估候选配体与对靶蛋白质例如酶的功能有影响的靶蛋白质的结构的关联。评估可包括评估候选配体和靶蛋白质的结构之间的亲和力或者评估相互作用的选择性。
(多个)候选配体可得自候选配体的数据库,和/或可通过对候选配体的数据库中的配体进行改变(改性)(例如通过对候选配体的结构或氨基酸序列进行改变)而得到,和/或可通过候选配体的逐步或迭代组装/优化而得到。
可使用其中对用户操作显示候选配体和靶蛋白质的结构的图形模型的计算机辅助的途径进行候选配体与靶蛋白质的结构的相互作用的评估,和/或可部分或完全地自动进行评估,例如使用标准分子(蛋白质-配体)对接软件。在一些实施中,评估可包括确定对于候选配体的相互作用分数,其中相互作用分数包括候选配体和靶蛋白质之间的相互作用的度量。相互作用分数可取决于相互作用的强度和/或特异性,例如,分数取决于结合自由能。候选配体可取决于其分数进行选择。
在一些实施中,靶蛋白质包括受体或酶,并且配体是受体或酶的激动剂或拮抗剂。在一些实施中,该方法可用于鉴别细胞表面标记物的结构。这然后可用于鉴别结合至细胞表面标记物的配体,例如抗体或标记诸如荧光标记。这可用于鉴别和/或处理(治疗)癌细胞。
在一些实施中,(多个)候选配体可包括小分子配体,例如分子质量<900道尔顿的有机化合物。在一些其他实施中,(多个)候选配体可包括多肽配体,即由氨基酸序列定义的。
该方法的一些实施可用于确定候选多肽配体、例如药物或工业酶的配体的结构。然后可评估其与靶蛋白质结构的相互作用;可使用如本文中所述的计算机实施的方法或使用常规的物理研究技术诸如x射线晶体学和/或磁共振技术来确定靶蛋白质结构。
因此,在另一方面,提供获得多肽配体(例如,分子或其序列)的方法。该方法可包括获得一种或多种候选多肽配体的氨基酸序列。该方法可进一步包括进行如以上或本文中所述的计算机实施的方法,使用候选多肽配体的氨基酸序列作为氨基酸序列,以确定候选多肽配体的(三级)结构。该方法可进一步包括经由电脑模拟(in silico)和/或通过物理研究获得靶蛋白质的靶蛋白质结构,并评估一种或多种候选多肽配体各自的结构与靶蛋白质结构之间的相互作用。该方法可进一步包括取决于评估的结果选择候选多肽配体的一种或多种作为多肽配体。
如前所述,评估相互作用可包括评估候选多肽配体与靶蛋白质的结构的结合,例如,鉴别对于生物效应以足够亲和力结合的配体,和/或评估候选多肽配体与对靶蛋白质例如酶的功能有影响的靶蛋白质的结构的关联,和/或评估候选多肽配体与靶蛋白质的结构之间的亲和力,或评估相互作用的选择性。在一些实施中,多肽配体可为适体。
该方法的实施可进一步包括合成,即制造,小分子或多肽配体。配体可通过任何常规的化学技术合成和/或可为已经可得的,例如,可来自化合物库或可使用组合化学合成。
该方法可进一步包括在体外和/或体内测试配体的生物活性。例如,可测试配体的ADME(吸收、分布、代谢、排泄)和/或毒理学性质,以筛选出不合适的配体。测试可包括,例如,使候选小分子或多肽配体与靶蛋白质接触,并测量蛋白质的表达或活性的变化。
在一些实施中,候选(多肽)配体可包括:分离的抗体、分离的抗体的片段、单可变域抗体、双或多特异性抗体、多价抗体、双可变域抗体、免疫缀合物(免疫偶联物)、纤连蛋白分子、adnectin、DARPin、avimer、affibody、抗运载蛋白(anticalin)、affilin、蛋白质表位模拟物(mimetic)或其组合。候选(多肽)配体可包括具有突变或化学改性的氨基酸Fc区的抗体,例如,其当与野生型Fc区相比时防止或降低ADCC(抗体依赖性细胞毒性)活性和/或增加半衰期。
错误折叠的蛋白质与许多疾病有关。因此,在另一方面,提供鉴别蛋白质错误折叠疾病存在的方法。该方法可包括:获得蛋白质的氨基酸序列,并使用蛋白质的氨基酸序列进行如以上或本文中所述的计算机实施的方法以确定蛋白质的结构。该方法可进一步包括获得从人体或动物体获得的蛋白质的版本的结构,例如通过常规的(物理)方法。然后,该方法可进一步包括:将所述蛋白质的结构与从所述体获得的版本的结构进行比较,并取决于比较的结果鉴别蛋白质错误折叠疾病的存在。即,通过与经由电脑模拟确定的结构的比较,可确定来自所述体的蛋白质的版本的错误折叠。
在一些其他方面,如以上或本文中所述的计算机实施的方法可用于从其氨基酸序列鉴别靶蛋白质上的活性/结合/封闭位点。
可实施本说明书中描述的主题的具体实施方式以实现以下优点的一个或多个。
本说明书中描述的蛋白质结构预测系统可通过如下预测蛋白质的结构:通过共同训练的神经网络的集合的单次前向传播,其可花费不到一秒钟。相反,一些常规的系统通过如下预测蛋白质的结构:在可能的蛋白质结构的空间中的扩展搜索过程以优化标量分数函数,例如,使用模拟退火或梯度下降技术。这样的搜索过程可需要数百万次搜索迭代,并消耗数百个中央处理单元(CPU)小时。与通过迭代搜索过程预测蛋白质结构的系统相比,通过神经网络的集合的单次前向传播预测蛋白质结构可使本说明书中描述的结构预测系统能够消耗更少的计算资源(例如,存储和计算能力)。此外,本说明书中描述的结构预测系统可(在一些情况中)以与计算更密集的结构预测系统相当或更高的准确性来预测蛋白质结构。
为了生成预测的蛋白质结构,本说明书中描述的结构预测系统通过使用由神经网络层实施的学习操作来处理对应于蛋白质的多序列比对(MSA)而生成表示蛋白质的嵌入的集合。相反,一些常规的系统依赖于通过人工特征工程技术来生成MSA特征。使用学习的神经网络操作而不是人工特征工程技术来处理MSA可使本说明书中描述的结构预测系统能够比一些常规的系统更准确地预测蛋白质结构。
本说明书中描述的结构预测系统处理MSA以生成“成对”嵌入的集合,其中各成对嵌入对应于蛋白质中相应的氨基酸对。然后,该系统通过一系列自注意力神经网络层处理成对嵌入来丰富成对嵌入,并使用丰富的成对嵌入来预测蛋白质结构。生成和丰富成对嵌入使结构预测系统能够开发在蛋白质中氨基酸对之间关系的有效表示,从而有助于准确的蛋白质结构预测。相反,一些常规的系统依赖于“单个”嵌入(即,其各自对应于相应的氨基酸,而不是氨基酸对),这对于开发用于蛋白质结构预测的有效表示可为不太有效的。使用成对嵌入可使本说明书中描述的结构预测系统能够比其他方法更准确地预测蛋白质结构。
蛋白质的结构决定蛋白质的生物功能。因此,确定蛋白质结构可有助于理解生命过程(例如,包括许多疾病的机理)和设计蛋白质(例如,作为药物,或作为用于工业过程的酶)。例如,哪些分子(例如药物)将与蛋白质结合(以及结合将发生在哪里)取决于蛋白质的结构。由于药物的有效性可受到它们结合到蛋白质(例如,在血液中)的程度的影响,因此确定不同蛋白质的结构可为药物开发的一个重要方面。然而,使用物理实验(例如,通过x射线晶体学)来确定蛋白质结构可为耗时且非常昂贵的。因此,本说明书中描述的蛋白质预测系统可有助于涉及蛋白质的生物化学研究和工程(例如,药物开发)的领域。
本说明书主题的一种或多种实施方式的细节在附图和以下描述中阐述。由说明书、附图和权利要求,所述主题的其他特征、方面和优点将变得明晰。
附图说明
图1显示实例蛋白质结构预测系统。
图2说明“网格转换器(transformer)”神经网络架构的实例。
图3显示实例多序列比对(MSA)嵌入系统。
图4是未折叠的蛋白质和折叠的蛋白质的图示。
图5是用于确定预测的蛋白质结构的实例过程的流程图。
各附图中相同的附图标记和名称表示相同的元件。
具体实施方式
本说明书描述了用于预测蛋白质的结构,即,用于预测在蛋白质进行蛋白质折叠后的蛋白质中氨基酸序列的三维构型的结构预测系统。
为了预测蛋白质的结构,结构预测系统处理对应于蛋白质的多序列比对(MSA)以生成作为“成对”嵌入的集合的蛋白质的表示。各成对嵌入对应于蛋白质中的氨基酸对,并且结构预测系统通过使用在成对嵌入之间共享信息的一系列自注意力神经网络层重复地更新成对嵌入来丰富成对嵌入。
结构预测系统处理成对嵌入以生成蛋白质中各氨基酸的相应的“单个”嵌入,并使用折叠神经网络处理单个嵌入以生成蛋白质的预测的结构。蛋白质的预测的结构可由定义蛋白质中各氨基酸的空间位置以及任选地旋转的结构参数的集来定义。
在下面更详细地描述这些特征和其他特征。
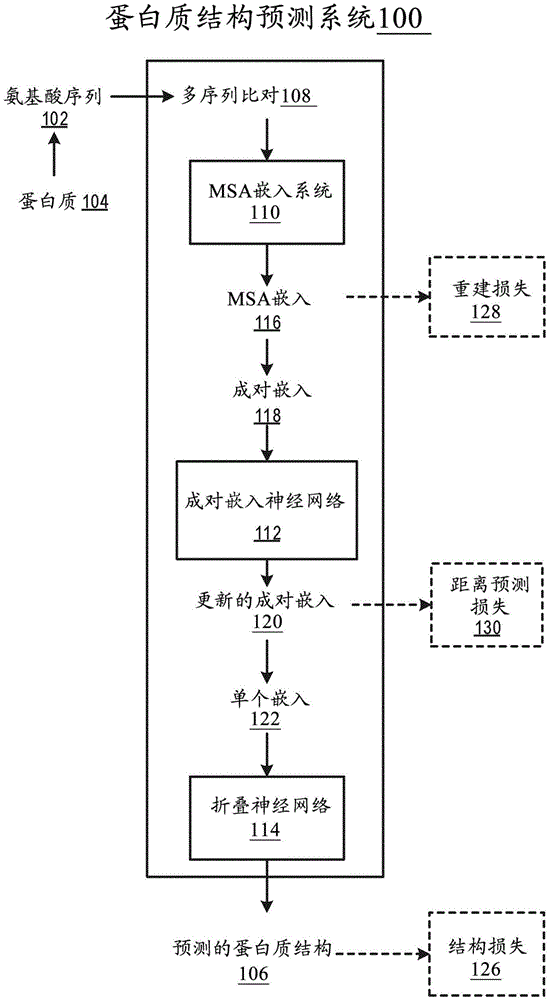
图1显示实例蛋白质结构预测系统100。蛋白质结构预测系统100是在一个或多个位置的一台或多台计算机上作为计算机程序实施的系统的实例,其中实施下述的系统、组件和技术。
结构预测系统100配置为处理定义蛋白质104的氨基酸序列102的数据,以生成蛋白质104的预测的结构106。氨基酸序列102中的各氨基酸是包括氨基官能团和羧基官能团以及对所述氨基酸特异的侧链(即原子团)的有机化合物。预测的结构106定义在蛋白质104进行蛋白质折叠后的蛋白质104的氨基酸序列102中的原子的三维(3-D)构型的估计。
如在整个本说明书中使用的术语“蛋白质”可理解为指由一个或多个氨基酸序列指定的任何生物分子。例如,术语蛋白质可以理解为指蛋白质域(即,氨基酸序列的一部分,其可几乎独立于氨基酸序列的其余部分进行蛋白质折叠)或蛋白质复合体(即,其由多个相关的氨基酸序列指定)。
氨基酸序列102可以任何合适的数字格式表示。例如,氨基酸序列102可表示为一系列独热向量(one-hot vector)。在该实例中,各独热向量表示氨基酸序列102中的相应氨基酸。对于各不同的氨基酸(例如,预定数量的氨基酸,例如21个),独热向量具有不同的分量。表示具体氨基酸的独热向量在对应于该具体氨基酸的分量中具有值1(或一些其他预定值)且在其他分量中具有值0(或一些其他预定值)。
蛋白质104的预测的结构106由结构参数的集的值定义。对于蛋白质104中的各氨基酸,结构参数的集可包括:(i)位置参数,和(ii)旋转参数。
对于氨基酸的位置参数可指定氨基酸中的指定原子在蛋白质结构中的预测的3-D空间位置。指定原子可为氨基酸中的α碳原子,即氨基酸中氨基官能团、羧基官能团和侧链键合的碳原子。对于氨基酸的位置参数可在任何合适的坐标系、例如三维[x,y,z]笛卡尔坐标系中表示。
对于氨基酸的旋转参数可指定在蛋白质结构中氨基酸的预测的“取向”。更具体地,旋转参数可指定3-D空间旋转操作,其如果应用于位置参数的坐标系则使氨基酸中的三个“主链”原子相对于旋转的坐标系呈现固定位置。氨基酸中的三个主链原子是指氨基酸中氮、α碳和羰基碳原子(或者,例如,氨基酸中的α碳、氮和氧原子)的连接系列。对于氨基酸的旋转参数可表示为例如行列式(决定子)等于1的标准正交3×3矩阵。
通常,对于氨基酸的位置和旋转参数定义对于该氨基酸的自我中心参照系。在该参照系中,对于各氨基酸的侧链可从原点开始,并且沿着侧链的第一键(即α碳-β碳键)可沿着定义的方向。
为了生成预测的结构106,结构预测系统100获得对应于蛋白质104的氨基酸序列102的多序列比对(MSA)108。MSA 108指定氨基酸序列102与多个额外氨基酸序列(例如,来自其他例如同源蛋白质)的序列比对。MSA 108可例如通过使用任何合适的计算序列比对技术(例如渐进比对构建)处理氨基酸序列的数据库来生成。MSA 108中的氨基酸序列可被理解为具有进化关系,例如,其中MSA 108中的各氨基酸序列可共享共同的祖先。MSA108中的氨基酸序列之间的相关性可将与预测蛋白质104的结构相关的信息编码。MSA108可使用为与氨基酸序列相同的独热编码,具有用于氨基酸残基的插入(或缺失)的额外类别。
结构预测系统100从氨基酸序列102和MSA 108生成预测的结构106,其使用:(1)多序列比对嵌入系统110(即“MSA嵌入系统”),(2)成对嵌入神经网络112,和(3)折叠神经网络114,其各自接下来被更详细地描述。如本文中所使用的,“嵌入”可为数值的有序集合,例如数值的向量或矩阵。
MSA嵌入系统110配置成处理MSA 108以生成MSA嵌入116。MSA嵌入116是MSA 108的替代表示,其包括对应于MSA 108的各氨基酸序列中的各氨基酸的相应嵌入。MSA嵌入可表示为具有维度M×N×E的矩阵,其中M是MSA 108中序列的数量,N是MSA 108中各氨基酸序列中氨基酸的数量(其可与氨基酸序列的长度相同),且E是对应于MSA 108的各氨基酸的嵌入的维度。
在一个实例中,MSA嵌入系统110可如下生成MSA嵌入M:
其中是作为独热氨基酸嵌入向量的1-D阵列的氨基酸序列102的表示,hθ(·)是应用于1-D阵列的各嵌入的学习线性投影运算,是作为独热氨基酸嵌入向量的2-D阵列的MSA 108的表示(其中2-D阵列的各行对应于MSA的相应氨基酸序列),hφ(·)是应用于2-D阵列的各嵌入的学习线性投影运算,并且运算表示将加到的各行。
参考图3更详细地描述MSA嵌入系统110的另一实例。参考图3描述的MSA嵌入系统110可生成仅对应于MSA 108中的序列的真子集的嵌入,例如,以减少计算资源消耗。此外,参考图3描述的MSA嵌入系统110可使用自注意力神经网络层在MSA 108中的氨基酸序列内和氨基酸序列之间“共享”信息,从而生成可有助于蛋白质结构106的更有效预测的更多信息的MSA嵌入116。
在生成MSA嵌入116之后,结构预测系统100将MSA嵌入116转换成作为成对嵌入118的集合的替代表示。各成对嵌入118对应于蛋白质的氨基酸序列102中的氨基酸对。氨基酸序列102中的氨基酸对是指氨基酸序列102中的第一氨基酸和第二氨基酸,并且可能的氨基酸对的集由以下给出:
{(Ai,Aj):1≤i,j≤N} (2)
其中N是氨基酸序列102中的氨基酸的数量,即氨基酸序列102的长度,Ai是氨基酸序列102中位置i处的氨基酸,Aj是序列中位置j处的氨基酸,并且N是氨基酸序列102中的氨基酸的数量(即,氨基酸序列102的长度)。成对嵌入118的集合可表示为具有维度N×N×F的矩阵,其中N是氨基酸序列102中氨基酸的数量,并且F是各成对嵌入118的维度。
结构预测系统100可从MSA嵌入116生成成对嵌入118,例如,通过计算MSA嵌入116与其自身的外积,边缘化(marginalizing)(例如,平均)出外积的MSA维度,以及组合外积的嵌入维度。例如,成对嵌入118可生成为:
其中M表示MSA嵌入116(例如,具有索引MSA中的序列的第一维度,索引MSA中各序列中的氨基酸的第二维度,以及索引各氨基酸的嵌入的通道的第三维度),表示乘M以生成“左”编码嵌入L的权重矩阵,表示乘M以生成“右”编码嵌入R的权重矩阵,表示组合左编码和右编码嵌入以生成成对嵌入P的权重矩阵。等式(3)至(5)使用爱因斯坦求和符号,其中仅出现在等式的右侧的重复指数被隐式求和(implicitly summed over)。
换句话说,结构预测系统100可通过计算MSA嵌入116的“外积均值”从MSA嵌入116生成成对嵌入118,其中MSA嵌入被视为嵌入的M×N阵列(即,其中阵列的各嵌入具有维度E)。外积均值定义如下的一系列运算:其当应用于MSA嵌入116时生成定义成对嵌入118的嵌入的N×N阵列(即,其中N是蛋白质中氨基酸的数量)。
为了计算MSA嵌入116的外积均值,系统100可对MSA嵌入116应用外积均值运算,并且作为外积均值运算的结果鉴别(确认)成对嵌入118。为了计算外积均值,系统生成张量A(·),例如,由以下给出:
其中res1,res2∈{1,...,N},其中N是蛋白质中氨基酸的数量,ch1ch2∈{1,...,E},其中E是表示MSA嵌入的嵌入的M×N阵列的各嵌入中的通道的数量,M是表示MSA嵌入的嵌入的M×N阵列中的行数,LeftAct(m,res1,ch1)是应用于位于表示MSA嵌入的嵌入的M×N阵列中由“m”索引的行和由“res1”索引的列处的嵌入的通道ch1的线性运算(例如,由矩阵乘法定义),并且RightAct(m,res2,ch2)是应用于位于表示MSA嵌入的嵌入的M×N阵列中由“m”索引的行和由“res2”索引的列处的嵌入的通道ch2的线性运算(例如,由矩阵乘法定义)。外积均值的结果是通过将张量A的(ch1,ch2)维度展平(flattening)和线性投影而生成的。任选地,系统可进行作为计算外积均值的一部分的一个或多个层归一化运算(例如,如参考Jimmy Lei Ba等的“Layer Normalizaiton”,arXiv:1607.06450所描述的)。
通常,MSA嵌入116可明确参照MSA 108的多个氨基酸序列来表达,例如,作为嵌入的2-D阵列,其中2-D阵列的各行对应于MSA 108的相应氨基酸序列。因此,MSA嵌入116的格式可不适合于预测蛋白质104的结构106,其不具有明确的对MSA 108的单独氨基酸序列的依赖性。相反,成对嵌入118表征蛋白质104中相应氨基酸对之间的关系并在没有明确参考来自MSA 108的多个氨基酸序列的情况下表达,且因此是用于预测蛋白质结构106的更方便的数据表示。
成对嵌入神经网络112配置为处理成对嵌入的集合,以更新成对嵌入的值,即,以生成更新的成对嵌入120。成对嵌入神经网络112通过使用一个或多个“自注意力”神经网络层处理成对嵌入来更新它们。如在整个本文件中所使用的,自注意力层通常指如下的神经网络层:其更新嵌入的集合,即,接收嵌入的集合并输出更新的嵌入。为了更新给定嵌入,自注意力层确定在给定嵌入和一个或多个所选嵌入的每一个之间的相应“注意力权重”,然后使用(i)注意力权重和(ii)所选嵌入来更新给定嵌入。为了方便,自注意力层可以说是使用“在”所选嵌入“上”的注意力来更新给定嵌入。
在一个实例中,自注意力层可接收输入嵌入的集合并且为了更新嵌入xi,自注意力层可确定注意力权重其中和aj表示xi和xj之间的注意力权重,如下:
其中Wq和Wk是学习参数矩阵,softmax(·)表示soft-max归一化运算,并且c是常数。使用注意力权重,自注意力层可如下更新嵌入xi:
其中Wv是学习参数矩阵。
除了自注意力神经网络层之外,成对嵌入神经网络可包括可与自注意力层交织的其他神经网络层,例如线性神经网络层。在一个实例中,成对嵌入神经网络112具有在本文中被称为“网格转换器神经网络架构”的神经网络架构,其将参考图2更详细地描述。
结构预测系统100使用成对嵌入118来生成对应于蛋白质104中各氨基酸的相应“单个”嵌入122。在一个实例中,结构预测系统可生成对应于氨基酸i的单个嵌入Si,如下:
其中Pi,j是对应于氨基酸对(Ai,Aj)的成对嵌入,Ai是氨基酸序列102中位置i处的氨基酸,并且Aj是氨基酸序列102中位置j处的氨基酸。在另一实例中,结构预测系统可进一步将等式(9)的右手侧乘以因子1/N,即,实施均值池化(mean pooling)而不是总和池化。在另一实例中,结构预测系统可将单个嵌入作为成对嵌入矩阵的对角线鉴别(确认),即,使得对应于氨基酸i的单个嵌入Si由Pi,i(即,对应于氨基酸对(Ai,Aj)的成对嵌入)给出。在另一实例中,在使用成对嵌入神经网络112处理成对嵌入118之前,结构预测系统可将额外行的嵌入增补(append)到成对嵌入(其中额外行的嵌入可用随机值或默认值初始化)。在该实例中,成对嵌入的集合可表示为具有维度(N 1)×N×F的矩阵,其中N是氨基酸序列中氨基酸的数量且F是各成对嵌入的维度。在该实例中,在使用成对嵌入神经网络112处理成对嵌入之后,结构预测系统可从更新的成对嵌入120中提取增补行的嵌入,并且将提取的嵌入作为单个嵌入122鉴别(确认)。
折叠神经网络114配置成通过处理包括单个嵌入122、成对嵌入120或两者的输入来生成指定结构参数的值的输出,所述结构参数的值定义蛋白质的预测的结构106。在一个实例中,折叠神经网络114可使用一个或多个神经网络层(例如,卷积或全连接神经网络层)来处理单个嵌入122、成对嵌入120或两者,以生成指定蛋白质104的结构参数的值的输出。
训练引擎可从端到端训练结构预测系统100以优化结构损失126、以及任选地一个或多个辅助损失例如重建损失128、距离预测损失130或两者,其各自接下来将更详细地描述。训练引擎可在包括多个训练实例的训练数据的集上训练结构预测系统100。各训练实例可指定:(i)包括氨基酸序列和对应MSA的训练输入,以及(ii)应该由结构预测系统100通过处理训练输入而生成的靶蛋白质结构。用于训练结构预测系统100的靶蛋白质结构可使用实验技术(例如x射线晶体学)来确定。
结构损失126可表征以下之间的相似性:(i)由结构预测系统100生成的预测的蛋白质结构,和(ii)应该已经由结构预测系统生成的靶蛋白质结构。例如,结构损失可由以下给出:
其中N是蛋白质中氨基酸的数量,ti表示对于氨基酸f的预测的位置参数,Ri表示由对于氨基酸i的预测的旋转参数指定的3×3旋转矩阵,是对于氨基酸i的靶位置参数,表示由对于氨基酸i的靶旋转参数指定的3×3旋转矩阵,A是常数,是指由预测的旋转参数Ri指定的3×3旋转矩阵的逆(倒数),是指由靶旋转参数指定的3×3旋转矩阵的逆,并且(·) 表示校正线性单元(ReLU)运算。
参照等式(10)-(12)定义的结构损失可理解为对蛋白质中各氨基酸对的损失求平均。项tij定义氨基酸j在氨基酸i的预测参照系中的预测空间位置,并且定义氨基酸j在氨基酸i的实际参照系中的实际空间位置。这些项对氨基酸i和j的预测和实际旋转是敏感的,并且因此比仅对预测和实际的在氨基酸之间的距离敏感的损失项携带更丰富的信息。优化结构损失促使结构预测系统100生成准确地模拟(接近)真实蛋白质结构的预测的蛋白质结构。
(无监督的)重建损失128在预测来自在MSA嵌入116的生成之前被“破坏(corrupt)”的MSA 108的氨基酸的身份中度量结构预测系统100的准确性。更具体地,结构预测系统100可在MSA嵌入116的生成之前通过如下破坏MSA 108:随机选择表示MSA 108中特定位置处的氨基酸身份的形符(token)以进行修改或掩蔽。结构预测系统100可通过如下修改表示MSA 108中位置处的氨基酸身份的形符:将其用标识不同氨基酸的随机选择的形符代替。结构预测系统100可考虑不同氨基酸在MSA 108中出现的频率,作为修改标识MSA 108中氨基酸的形符的一部分。例如,结构预测系统100可在可能的氨基酸的集上生成概率分布,其中与氨基酸相关联的概率基于氨基酸在MSA108中出现的频率。结构预测系统100可通过如下在修改MSA 108中使用氨基酸概率分布:根据所述概率分布对破坏的氨基酸身份随机采样。结构预测系统100可通过如下来掩蔽表示MSA中位置处的氨基酸身份的形符:将所述形符用特别指定的空形符替换。
为了评估重建损失128,结构预测系统100处理MSA嵌入116(例如使用线性神经网络层)以预测MSA 108中各被破坏的位置处的氨基酸的真实身份。重建损失128可为例如MSA 108中被破坏的位置处的氨基酸的预测和真实身份之间的交叉熵损失。在重建损失128的计算期间,可忽视MSA 108的未被破坏的位置处的氨基酸的身份。
距离预测损失130在预测蛋白质结构中氨基酸对之间的物理距离中度量结构预测系统100的准确性。为了评估距离预测损失130,结构预测系统100(例如,使用线性神经网络层)处理由成对嵌入神经网络112生成的成对嵌入118,以生成距离预测输出。距离预测输出表征蛋白质结构106中各氨基酸对之间的预测距离。在一个实例中,距离预测输出可对于蛋白质中的各氨基酸对指定在氨基酸对之间的可能距离范围的集上的概率分布。可能距离范围的集可由例如{(0,5],(5,10],(10,20],(20,∞)}给出,其中距离可以埃(或任何其他合适的测量单位)度量。距离预测损失130可为例如蛋白质中氨基酸对之间的预测和实际距离(范围)之间的交叉熵损失,例如1-热范围箱(1-hot range bin)和基础真实(ground truth)结构之间的交叉熵损失。(第一氨基酸和第二氨基酸之间的距离可指第一氨基酸中的指定原子和第二氨基酸中对应的指定原子之间的距离。指定原子可为例如碳α原子)。在一些实施中,距离预测输出可理解为定义结构参数或为结构参数的一部分,所述结构参数定义预测的蛋白质结构108。
通常,训练结构预测系统100以优化辅助损失可导致结构预测系统生成中间表示(例如,MSA嵌入和成对嵌入),其对与蛋白质结构预测的最终目标相关的信息编码。因此,优化辅助损失可使结构预测系统100能够更准确地预测蛋白质结构。
训练引擎可在多次训练迭代的训练数据上训练结构预测系统100,例如使用随机梯度下降训练技术。
图2说明“网格转换器”神经网络架构200的实例。网格转换器神经网络配置成接收具有初始值的嵌入的集合,通过一个或多个残差块202处理嵌入的集合,和输出嵌入的集合的更新值。为了方便,下面的描述将涉及被逻辑地组织成嵌入的二维阵列的嵌入的集合。例如,各嵌入可为对应于蛋白质中氨基酸对的成对嵌入,如参考图1所述的。在该实例中,成对嵌入可理解为以二维阵列逻辑地排列的,其中阵列中位置(i,j)处的嵌入是对应于蛋白质的氨基酸序列中位置i和j处的氨基酸对的成对嵌入。在另一实例中,各嵌入可为来自MSA嵌入的氨基酸的嵌入。在该实例中,嵌入可理解为逻辑地排列成二维阵列的,其中阵列中位置(i,j)处的嵌入是对应于MSA中第i个氨基酸序列中第j个氨基酸的嵌入。
网格转换器架构的各残差块202包括实施“行式自注意力”的自注意力层204、实施“列式自注意力”的自注意力层206、以及过渡块(transition block)208。为了减少计算资源消耗,行式和列式自注意力层仅在输入嵌入的真子集上使用注意力来更新各输入嵌入,如将在下面更详细地描述的。
行式自注意力层204仅在与嵌入的二维阵列中的嵌入的相同行中的那些嵌入上使用注意力来更新各嵌入。例如,行式自注意力层在相同行(即,由阴影线区域212指示的)中的嵌入上使用注意力来更新嵌入210(即,由变黑的方形指示的)。残差块202还可将对于行式自注意力层204的输入增添到行式自注意力层204的输出。
列式自注意力层206仅在与嵌入的二维阵列中的嵌入的相同列中的那些嵌入上使用注意力来更新各嵌入。例如,列式自注意力层在相同列(即,由阴影线区域216指示的)中的嵌入上使用自注意力来更新嵌入214(即,由变黑的方形指示的)。残差块202还可将对于列式自注意力层的输入增添到列式自注意力层的输出。
过渡块208可通过使用一个或多个线性神经网络层处理嵌入来更新所述嵌入。残差块202还可将对于过渡块的输入增添到过渡块的输出。
网格转换器架构200可包括多个残差块。例如,在不同的实施中,网格转换器架构200可包括5个残差块、15个残差块或45个残差块。
图3显示实例多序列比对(MSA)嵌入系统110。MSA嵌入系统110是在在一个或多个位置的一台或多台计算机上作为计算机程序实施的系统的实例,其中实施下述的系统、组件和技术。
MSA嵌入系统110配置为处理多序列比对(MSA)108以生成MSA嵌入116。生成包括MSA108中各氨基酸序列的各氨基酸的相应嵌入的MSA嵌入116可为计算密集型的,例如,在其中MSA包括大量的长的氨基酸序列的情况下。因此,为了减少计算资源消耗,MSA嵌入系统110可对于整个MSA中的氨基酸序列的仅一部分(称为“聚类序列”302)生成MSA嵌入116。
MSA嵌入系统110可从MSA108选择聚类序列302,例如通过从MSA108随机选择预定数量的氨基酸序列,例如128或256个氨基酸序列。MSA 108中未被选为聚类序列302的剩余氨基酸序列在本文中将被称为“额外序列”304。通常,聚类序列302的数量被选择为显著小于额外序列304的数量,例如,聚类序列302的数量可比额外序列304的数量小数量级(一个数量级)。
MSA嵌入系统110可生成聚类序列302的聚类嵌入306和额外序列304的额外嵌入308,例如,使用上面参考等式(1)描述的技术。
然后,MSA嵌入系统110可使用交叉注意力神经网络310来处理聚类嵌入306和额外嵌入308,以生成更新的聚类嵌入312。交叉注意力神经网络310包括一个或多个交叉注意力神经网络层。交叉注意力神经网络层接收两个独立的嵌入的集合,其中一个可被指定为“可变的”且另一个可被指定为“静态的”,并且在另一个(静态的)嵌入的集合上使用注意力来更新一个(可变的)嵌入的集合。即,交叉注意力层可理解为用从静态的嵌入的集合中提取的信息来更新可变的嵌入的集合。
在一个实例中,交叉注意力神经网络310可包括一系列残差块,其中各残差块包括两个交叉注意力层和(一个)过渡块。第一交叉注意力层可接收聚类嵌入306作为可变的嵌入的集合和额外嵌入308作为静态的嵌入的集合,并且之后用来自额外嵌入308的信息更新聚类嵌入306。第二交叉注意力层可接收额外嵌入308作为可变的嵌入的集合和聚类嵌入306作为静态的嵌入的集合,并且之后用来自聚类嵌入306的信息更新额外嵌入308。各残差块可进一步包括在第二交叉注意力层之后的过渡块,该过渡块使用一个或多个线性神经网络层来更新聚类嵌入。对于交叉注意力层和过渡块二者,残差块可将对于所述层/块的输入增添到所述层/块的输出。
在一些情况下,为了改善计算效率,交叉注意层可通过如下实施“全局”交叉注意力的形式:为各氨基酸序列(例如,在聚类或额外序列中)确定相应的注意力权重,即,而不是为每一个氨基酸确定相应的注意力权重。在这些情况下,氨基酸序列中的各氨基酸共享与所述氨基酸序列相同的注意力权重。
交叉注意力神经网络310可理解为用来自额外嵌入308的信息来丰富聚类嵌入306(且反之亦然)。在由交叉注意力神经网络310进行的操作完成之后,额外嵌入308被丢弃,并且仅聚类嵌入312用于生成MSA嵌入116。
MSA嵌入系统110通过使用自注意力神经网络314(例如,具有参考图2描述的网格转换器架构)处理聚类嵌入312来生成MSA嵌入116。使用自注意力神经网络314处理聚类嵌入312可通过在聚类序列内和聚类序列之间的嵌入中“共享”信息来增强聚类嵌入。
MSA嵌入系统110可提供自注意力神经网络314的输出(即,对应于更新的聚类嵌入306)作为MSA嵌入116。
图4是未折叠的蛋白质和折叠的蛋白质的图示。未折叠的蛋白质是氨基酸的无规卷曲。未折叠的蛋白质经历蛋白质折叠并折叠成3D构型。蛋白质结构经常包括稳定的局部折叠模式,诸如α螺旋(例如,如402所示的)和β片层。
图5是用于确定预测的蛋白质结构的实例过程500的流程图。为了方便,过程500将被描述为由位于一个或多个位置的一台或多台计算机的系统进行。例如,根据本说明书适当编程的蛋白质结构预测系统(例如,图1的蛋白质结构预测系统100)可进行过程500。
所述系统获得对于指定蛋白质的氨基酸序列的多序列比对(502)。
所述系统处理多序列比对以确定对于蛋白质氨基酸序列中各氨基酸对的相应的初始嵌入(504)。
所述系统使用包括多个自注意力神经网络层的成对嵌入神经网络来处理氨基酸对的初始嵌入,以生成各氨基酸对的最终嵌入(506)。成对嵌入神经网络的各自注意力层可配置成:(i)接收各氨基酸对的当前嵌入,以及(ii)在氨基酸对的当前嵌入上使用注意力来更新各氨基酸对的当前嵌入。在一些情况下,成对嵌入神经网络的自注意力层可在行式自注意力层和列式自注意力层之间交替。
所述系统基于各氨基酸对的最终嵌入来确定蛋白质的预测的结构(508)。例如,所述系统可处理氨基酸对的最终嵌入以生成对于蛋白质中各氨基酸的相应的“单一”嵌入,且使用折叠神经网络处理单一嵌入以确定蛋白质的预测的结构。
本说明书关于系统和计算机程序组件使用术语“配置”。一台或多台计算机的系统配置成进行特定操作或动作意味着,系统已经在其上安装在操作中使系统进行这些操作或动作的软件、固件、硬件或它们的组合。一个或多个计算机程序配置成进行特定操作或动作意味着,一个或多个程序包括当由数据处理装置执行时使装置进行所述操作或动作的指令。
本说明书中描述的主题和功能操作的实施方式可在数字电子电路、有形体现的计算机软件或固件、计算机硬件中实施,包括本说明书中公开的结构及其结构等同物、或者它们的一个或多个的组合。本说明书中描述的主题的实施方式可作为如下实施:一个或多个计算机程序,即编码在有形非易失性储存介质上的计算机程序指令的一个或多个模块,用于由数据处理装置执行或用于控制数据处理装置的操作。计算机储存介质可为机器可读储存设备、机器可读储存基底、随机或串行存取存储设备,或者它们的一个或多个的组合。替代地或附加地,程序指令可编码在人工生成的传播信号上,例如,机器生成的电、光或电磁信号,其被生成以编码信息用于传输到合适的接收器装置以由数据处理装置执行。
术语“数据处理装置”是指数据处理硬件,并且包含用于处理数据的所有种类的装置、设备和机器,例如包括可编程处理器、计算机或多处理器或计算机。装置还可为或进一步包括专用逻辑电路,例如FPGA(现场可编程门阵列)或ASIC(专用集成电路)。除了硬件之外,装置可任选地包括为计算机程序创建执行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统、或它们的一个或多个的组合的代码。
计算机程序(其也可称为或描述为程序、软件、软件应用、app、模块、软件模块、脚本或代码)可以任何形式的编程语言编写,包括编译或解释语言,或者声明性或过程性语言;和它可以任何形式部署,包括作为独立程序或作为模块、组件、子例程或在计算环境中适于使用的其他单元。程序可对应于文件系统中的文件,但不需要对应于文件系统中的文件。程序可存储在保存其他程序或数据的文件的一部分中,例如,存储在标记语言文档中的一个或多个脚本中、在专用于所讨论的程序的单个文件中、或者在多个协作文件中,例如,存储一个或多个模块、子程序、或代码的部分的文件。计算机程序可部署为在一台计算机或位于一个地点或分布在多个地点并通过数据通信网络互连的多计算机上执行。
在本说明书中,术语“引擎”广义地用于指被编程来进行一个或多个特定功能的基于软件的系统、子系统或过程。通常,引擎将作为安装在一个或多个位置的一台或多台计算机上的一个或多个软件模块或组件实施。在一些情况下,一台或多台计算机将专用于特定的引擎;在其他情况下,可在相同的一台或多台计算机上安装和运行多引擎。
本说明书中描述的过程和逻辑流程可通过执行一个或多个计算机程序以通过对输入数据操作并生成输出来执行功能的一个或多个可编程计算机来进行。所述过程和逻辑流程也可通过专用逻辑电路(例如FPGA或ASIC)、或者通过专用逻辑电路和一个或多个编程的计算机的组合来进行。
适于执行计算机程序的计算机可基于通用或专用微处理器或两者,或者任何其他种类的中央处理单元。通常,中央处理单元将从只读存储器或随机存取存储器或两者接收指令和数据。计算机的基本元件是用于进行或执行指令的中央处理单元以及用于存储指令和数据的一个或多个存储设备。中央处理单元和存储器可由专用逻辑电路来补充或并入其中。通常,计算机还将包括或可操作地连接到一个或多个用于存储数据的大容量储存设备(例如,磁盘、磁光盘或光盘)以从其接收数据或向其传送数据或两者。然而,计算机不需要具有这样的设备。此外,计算机可嵌入在另外的设备中,举几个例来说,例如,移动电话、个人数字助理(PDA)、移动音频或视频播放器、游戏控制台、全球定位系统(GPS)接收器、或便携式储存设备(例如通用串行总线(USB)闪存驱动器)。
适于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储设备,包括例如半导体存储设备,例如EPROM、EEPROM和闪存设备;磁盘,例如内部硬盘或可移动盘;磁光盘;以及CDROM和DVD-ROM盘。
为了提供与用户的交互,本说明书中描述的主题的实施方式可在计算机上实施,该计算机具有用于向用户显示信息的显示设备(例如CRT(阴极射线管)或LCD(液晶显示器)监视器),以及用户可通过其向计算机提供输入的键盘和定点设备(例如鼠标或轨迹球)。也可使用其他类型的设备来提供与用户的交互;例如,提供给用户的反馈可为任何形式的传感反馈,例如视觉反馈、听觉反馈或触觉反馈;并且可以任何形式接收来自用户的输入,包括声音、语音或触觉输入。此外,计算机可通过向用户使用的设备发送文档和从其接收文档来与用户交互,例如,通过响应于从用户设备上的网络浏览器接收的请求,向网络浏览器发送网页。此外,计算机可通过如下与用户交互:向个人设备(例如,运行消息应用的智能手机)发送文本消息或其他形式的消息,并作为反馈接收来自用户的响应消息。
用于实施机器学习模型的数据处理装置还可包括例如专用硬件加速器单元用于处理机器学习训练或生产(即推理、工作负载)的公共和计算密集型部分。
机器学习模型可使用机器学习框架来实施和部署,例如TensorFlow框架、微软认知工具包(Microsoft Cognitive Toolkit)框架、Apache Singa框架、或Apache MXNet框架。
本说明书中描述的主题的实施方式可在计算系统中实施,该计算系统包括后端组件(例如作为数据服务器),或者包括中间件组件(例如应用服务器),或者包括前端组件(例如具有图形用户界面的客户端计算机、网页浏览器、或用户可通过其与本说明书中描述的主题的实施交互的app),或者一个或多个这样的后端、中间件或前端组件的任何组合。系统的组件可通过数字数据通信的任何形式或介质、例如通信网络来互连。通信网络的实例包括局域网(LAN)和广域网(WAN),例如因特网。
计算系统可包括客户端和服务器。客户端和服务器通常彼此远离,并且典型地通过通信网络进行交互。客户端和服务器的关系由于在相应的计算机上运行且彼此具有客户端-服务器关系的计算机程序而产生。在一些实施方式中,服务器向用户设备发送数据(例如HTML页面),例如为了向与充当客户端的设备交互的用户显示数据并从该用户接收用户输入。在用户设备处生成的数据(例如用户交互的结果)可从所述设备在服务器处被接收。
虽然本说明书包含许多具体的实施细节,但是这些不应该被解释为对任何发明的范围或可要求保护的范围的限制,而是对具体发明的具体实施方式可为特有的特征的描述。本说明书中在单独的实施方式的上下文中描述的某些特征也可在单个实施方式中组合实施。相反,在单个实施方式的上下文中描述的多种特征也可在多个实施方式中单独地或以任何合适的子组合实施。此外,尽管特征可在上面被描述为以某些组合起作用,并且甚至最初被如此要求保护,但是来自所要求保护的组合的一个或多个特征在一些情况下可从该组合中删除,并且所要求保护的组合可涉及子组合或子组合的变体。
类似地,尽管操作以具体的次序在权利要求中叙述和在附图中描绘,但是这不应理解为要求这样的操作以所述具体的次序或以顺序的次序进行,或者要求所有操作被进行,以实现期望的结果。在一些情况下,多任务和并行处理可为有利的。此外,上述实施方式中的多种系统模块和组件的分离不应理解为在所有实施方式中要求这样的分离,并且应理解,所描述的程序组件和系统通常可一起集成在单个软件产品中或者打包到多个软件产品中。
已经描述了主题的具体实施方式。其他实施方式在以下权利要求的范围内。例如,权利要求中所叙述的动作可以不同的次序进行,且仍然实现期望的结果。作为一个实例,附图中描绘的过程不一定要求所示的具体次序或顺序的次序以实现期望的结果。在一些情况下,多任务和并行处理可为有利的。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。