1.本发明涉及结核分枝杆菌检测技术领域,尤其涉及一种结核分枝杆菌多线耐药基因鉴定的方法和装置。
背景技术:
2.目前市面上针对结核分枝杆菌药敏检测的方法,主要分为基于菌株培养的药敏检测和基于分子生物学的荧光定量pcr方法。
3.基于菌株培养的药敏检测,将结核分枝杆菌涂在培养板上,待结核分枝杆菌铺满整个平板后,在菌板上放置不同剂量的药物。继续培养一段时间后观察药物周围出现菌斑的大小,从而判断细菌的耐受程度。该技术需要在较严格的生物安全实验室进行,同时需要2-3个月的时间才能出结果。
4.基于分子生物学的荧光定量pcr方法,将结核分枝杆菌进行核酸提取后,通过特异引物进行扩增,荧光检测核酸序列突变的信息,提示细菌的药物耐受性。该方法耗时只需要半天至一天的时间,但目前市面上只有针对一线的药物常见突变位点的检测试剂盒,另外该方法无法检测移码突变或者无突变热点的突变。
5.目前市面上还没有基于全基因组测序的结核分枝杆菌耐药位点检测产品,也没有基于二代测序的结核分枝杆菌突变检测分析软件。因此,市面急需一款快速且全面的检测方式,对结核分枝杆菌多种药物的耐药基因进行全面且快速检测。
技术实现要素:
6.本发明的目的在于提供一种结核分枝杆菌多线耐药基因鉴定的方法和装置,能够高效分析高通量下机数据,在一次检测中覆盖多种药物及其对应的耐药位点,检测精度高。
7.根据本发明的第一方面,本发明提供一种结核分枝杆菌多线耐药基因鉴定的方法,包括:
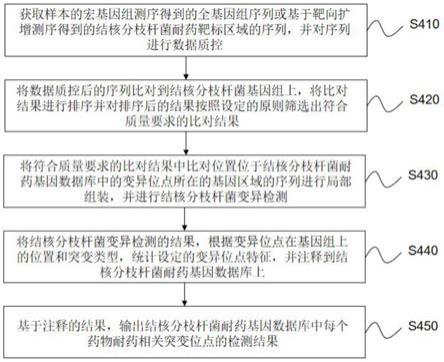
8.获取样本的宏基因组测序得到的全基因组序列或基于靶向扩增测序得到的结核分枝杆菌耐药靶标区域的序列,并对上述序列进行数据质控;
9.将上述数据质控后的序列比对到结核分枝杆菌基因组上,将比对结果进行排序并对排序后的结果按照设定的原则筛选出符合质量要求的比对结果;
10.将符合质量要求的比对结果中比对位置位于结核分枝杆菌耐药基因数据库中的变异位点所在的基因区域的序列进行局部组装,并进行结核分枝杆菌变异检测;
11.将上述结核分枝杆菌变异检测的结果,根据变异位点在基因组上的位置和突变类型,统计设定的变异位点特征,并注释到结核分枝杆菌耐药基因数据库上;
12.基于上述注释的结果,输出结核分枝杆菌耐药基因数据库中每个药物耐药相关突变位点的检测结果。
13.在优选实施例中,上述结核分枝杆菌耐药基因数据库包括表1所示的药物及对应的药敏基因和突变位点:
14.表1
15.[0016][0017]
在优选实施例中,上述结核分枝杆菌耐药靶标区域的序列,通过能够覆盖上述结核分枝杆菌耐药基因数据库中的变异位点的引物扩增得到,其中上述引物包括seq id no:1-12所示的序列。
[0018]
在优选实施例中,上述设定的原则包括:保留比对长度不小于90%的序列;保留比对错误率不大于5%的序列;保留比对上的序列中比对质量不小于30的序列。
[0019]
在优选实施例中,上述局部组装并进行结核分枝杆菌变异检测的步骤包括:
[0020]
对比对位置位于结核分枝杆菌耐药基因数据库中变异位点所在的基因区域的序列进行局部组装,并保留所有可能的突变情况;
[0021]
识别有突变的位点,并对不同类型的突变进行识别和区分;
[0022]
对同时有多种突变的情况进行识别,以实现是否存在突变或存在几种突变单体型识别的目的;
[0023]
对同一区域同时存在多个保守snp的情况,对这些位点的深度、突变率、原始比对序列进行溯源统计,以区分多核苷酸多态性或多个snp;
[0024]
对比对结果中存在的插入或缺失进行偏移识别,以对突变进行正确的位点注释。
[0025]
在优选实施例中,上述设定的变异位点特征包括变异位点情况、变异率、位点深度和深度比值。
[0026]
在优选实施例中,上述注释步骤还包括假阳性注释,其包括:
[0027]
过滤掉未达到阳性阈值的位点;
[0028]
过滤掉突变位点的深度比不符合要求的位点;
[0029]
过滤掉同批次交叉污染造成的假阳性。
[0030]
在优选实施例中,上述方法还包括:
[0031]
从上述数据质控后的序列中随机抽取部分序列,比对到分枝杆菌序列数据库,计算最优比对上每个分枝杆菌序列的占比,并根据比对情况进行物种鉴定,给出样本中所含的分枝杆菌。
[0032]
根据本发明的第二方面,本发明提供一种结核分枝杆菌多线耐药基因鉴定的装置,包括:
[0033]
数据获取和质控单元,用于获取样本的宏基因组测序得到的全基因组序列或基于靶向扩增测序得到的结核分枝杆菌耐药靶标区域的序列,并对上述序列进行数据质控;
[0034]
结核分枝杆菌基因组比对单元,用于将上述数据质控后的序列比对到结核分枝杆菌基因组上,将比对结果进行排序并对排序后的结果按照设定的原则筛选出符合质量要求的比对结果;
[0035]
变异检测单元,用于将符合质量要求的比对结果中比对位置位于结核分枝杆菌耐药基因数据库中的变异位点所在的基因区域的序列进行局部组装,并进行结核分枝杆菌变异检测;
[0036]
变异位点注释单元,用于将上述结核分枝杆菌变异检测的结果,根据变异位点在基因组上的位置和突变类型,统计设定的变异位点特征,并注释到结核分枝杆菌耐药基因数据库上;
[0037]
检测结果输出单元,用于基于上述注释的结果,输出结核分枝杆菌耐药基因数据库中每个药物耐药相关突变位点的检测结果。
[0038]
根据本发明的第三方面,本发明提供一种计算机可读存储介质,其包括程序,上述程序能够被处理器执行以实现如第一方面的方法。
[0039]
本发明通过对宏基因组测序得到的全基因组序列,或基于靶向扩增测序得到的耐
药靶标区域的序列,与结核分枝杆菌的序列进行对比分析,得到在结核分枝杆菌全基因组上的全部突变信息,并根据药敏的实际位点筛选存在的相应耐药基因突变。本发明基于结核分枝杆菌和其他可能造成感染的分枝杆菌构建全面且高质量的参考序列库,有效提高检测准确度,辅助报告解读,有助于基于二代测序的结核分枝杆菌的鉴定与多线耐药基因检测试剂盒的推广应用。
[0040]
具体而言,本发明的有益效果体现在:
[0041]
本发明针对基于结核分枝杆菌全基因组核酸测序和基于耐药基因核酸靶向扩增测序的结果变异位点检测的需求,构建药物与对应耐药位点的数据库,能够高效分析高通量的下机数据,在一次检测中覆盖多种药物及其对应的耐药位点,检测精度高。
[0042]
此外,本发明设计的多重靶向pcr扩增引物,具有特异性高,扩增效率高的优势,可满足耐药基因靶向富集的功能,达成对靶标耐药突变精准检出的目的。
附图说明
[0043]
图1为本发明实施例中针对覆盖检测位点的基因设计特异引物的流程图;
[0044]
图2为本发明实施例中测序数据的信息分析流程的基本步骤;
[0045]
图3为本发明实施例中根据实际位点的检测需求有针对性设计的变异位点检测流程图;
[0046]
图4为本发明实施例中结核分枝杆菌多线耐药基因鉴定的方法流程图;
[0047]
图5为本发明实施例中结核分枝杆菌多线耐药基因鉴定的装置结构框图。
具体实施方式
[0048]
下面通过具体实施方式结合附图对本发明作进一步详细说明。在以下的实施方式中,很多细节描述是为了使得本发明能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他材料、方法所替代。
[0049]
另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。
[0050]
本发明针对结核分枝杆菌全基因组核酸测序和靶向核酸测序的结果变异位点检测的需求,开发了一种同时兼容全基因组测序和基于靶向扩增两种测序数据的自动化信息分析的方法和装置。本发明的自动化程度高,降低了计算机技术的条件要求。针对高通量的下机数据能高效地完成分析,提高了药物种类范围和检测精度。
[0051]
本发明通过对已有文献的调研和国内流行耐药突变株,构建了针对目前使用的一二三线药物的耐药位点的数据库,实现一次检测覆盖结核分枝杆菌全基因组上所有药物耐药突变的目的。并针对耐药数据库中所有位点,设计了一系列相对其他物种特异的引物,达成对靶标耐药突变精准检出的目的。
[0052]
本发明的技术方案包括以下内容,需要说明的是,为使本发明被充分理解,以下内容中包括很多技术细节,这些技术细节并非本发明必需的,不能理解为对本发明保护范围的限制。
[0053]
(1)耐药基因数据库构建
[0054]
本发明根据现有的文献报道、国内流行耐药突变的调研及合作医院提供的耐药信息,构建了包括多线的结核分枝杆菌治疗的药物(包括异烟肼、利福平、链霉素和乙胺丁醇)、多种基因突变的数据库,如表1所示:
[0055]
表1耐药基因数据库信息表
[0056]
[0057][0058]
(2)引物设计和特异性评估
[0059]
如图1所示,按照以下步骤对结核分枝杆菌基因组包含(1)中耐药突变位点的基因进行引物设计:
[0060]
1.将参考的结核分枝杆菌基因组切割为长度为50bp,滑动窗口为10bp的短序列。
[0061]
2.将切割后的序列比对到nt库,挑选出比对不上除结核分枝杆菌复合群的所有区域,并按序列位置拼接。
[0062]
3.挑选能覆盖数据库中耐药突变位点的序列并设计引物。
[0063]
引物特异性评估方法如下:
[0064]
1.物种特异性:将每对引物blast比对到nt库,获得物种信息。如果成对引物有比对到非结核物种,且比对结果满足条件:错配数(mismatch)<=2bp,未比对上的碱基数(unmap)<=3bp(包含gap数),且扩增区域(不包括引物)<3kb,则不是物种特异,否则才是物种特异。
[0065]
2.基因特异性:下载结核复合群基因组序列(基因组序列 gff文件)。将每对引物blast比对到结核复合群基因组序列,获得比对位置信息,要求比对结果满足条件:mismatch<=2bp,unmap<=3bp(包含gap数),且扩增区域(不包括引物)<3kb,并提取扩增区域序列。扩增区域序列与基因模板序列比对,如果全部扩增区域序列与靶标基因模板序列匹配,且比对一致率(identity)>=97%,比对率(maprate)>=90%,则为基因特异性。
[0066]
3.非特异扩增:根据第2步结果,如果成对引物中某一条引物与另一条引物都比对不到靶标基因区域,或比对到不同基因区域,或比对到不同染色体,则为非特异性扩增。
[0067]
4.非成对引物两两组合可能性:由于第一对引物r的对比位点在相邻的第二对引物的f后面则具有组合可能,这种情况下排除其中一对引物。
[0068]
实际通过上述步骤设计了能覆盖耐药基因数据库所有位点以及结核分枝杆菌基因组上的特异片段的引物,共计6对,覆盖6个基因区域。具体引物如表2所示:
[0069]
表2引物列表
[0070]
[0071][0072]
将上述设计的所有引物按10p、5p和2.5p共3个梯度的投入量等比进行混合,每个梯度3个重复进行扩增实验,证明引物的可行性。具体每个区域扩增的深度情况如表3所示:
[0073]
表3引物可行性测序结果
[0074]
[0075][0076]
从结果可得出,相同样本中添加不同用量的引物,每个靶标区域均能检出,且深度具有统计意义。
[0077]
(3)数据质控
[0078]
如图2所示,从以下三个方面对原始测序数据(宏基因组测序得到的全基因组序列或基于靶向扩增测序得到的结核分枝杆菌耐药靶标区域的序列)进行过滤:
[0079]
方面一:将与接头序列有50%一致性的序列认定为接头序列并过滤。
[0080]
方面二:将测序质量值低于10的碱基认定为低质量碱基,如一条序列中有10%的碱基为低质量碱基,则过滤掉该序列。
[0081]
方面三:过滤包含3个及以上n碱基的序列。
[0082]
(4)分枝杆菌序列数据库比对及物种鉴定
[0083]
如图2所示,将(3)中过滤后的序列随机抽取1%,比对到分枝杆菌序列数据库。统计比对结果中比对长度不小于80%,且比对错误率不大于10%的序列,计算最优比对上每个分枝杆菌序列的占比。根据比对情况进行物种鉴定并给出样本中所含的分枝杆菌。鉴定算法如下:计算最优比对每个分枝杆菌序列条数,并且根据已经统计好的数据库中分枝杆菌间序列相似性图谱(profile)及分枝杆菌自身序列特异性图谱(profile),对分枝杆菌在样本中的检出条数进行校正,最终给出样本中检出所含分枝杆菌及其序列条数。
[0084]
(5)结核分枝杆菌基因组比对及质控
[0085]
如图2所示,将(3)中过滤后的序列比对到结核分枝杆菌基因组上。比对结果使用samtools软件进行排序,排序后的结果按照以下原则筛选高质量序列,并对筛选后的比对结果建立索引:
[0086]
原则一:保留比对长度不小于90%的序列,即单条序列比对上参考序列对长度不小于90%的全长。
[0087]
原则二:保留比对错误率不大于5%的序列,即比对上的部分中,与参考基因序列不一致的碱基数小于5%。
[0088]
原则三:比对上的序列,比对质量不能小于30。
[0089]
(6)变异检测
[0090]
如图2所示,针对(1)中的变异位点列表以及(5)中的比对结果,通过一套变异检测方法,对变异热点区域进行局部组装以及变异位点的检测。如图3所示,该方法实现了以下
功能:
[0091]
a.变异热点区域的局部组装:对比对位置在(1)中变异位点所在的基因区域的序列进行局部组装,并保留所有可能的突变情况。
[0092]
b.不同突变类型的识别与区分:识别有突变的位点,排除错配碱基的错误率高、在序列末端等因素,对不同类型的突变进行识别及区分。
[0093]
c.局部区域变异热点的单体型识别:对与变异热点位点同时有多种碱基突变的情况,通过概率型校正算法对样本中同时存在单个位点多种突变的概率进行识别,排除掉测序错误、pcr引入的扩增错误、序列可信度等造成的影响。从而达到突变位点是否存在突变或存在几种突变单体型识别的目的。
[0094]
d.多核苷酸多态性(mnp)识别:在一个突变热点区域同时存在多个保守snp的情况下,是否为同时突变会导致不同蛋白质突变时,对这些位点的深度、突变率、原始比对序列进行溯源统计,区分mnp或多个snp的情况。
[0095]
e.插入或缺失(indel)偏移识别:当比对结果中存在indel时,将能覆盖到该区域的序列重新比对到参考基因组,通过与c中相同的概率校正算法判断indel的真实性。并在indel相邻区域中存在的其它突变,根据序列比对的方向、indel大小等信息,对突变进行正确的位点注释。
[0096]
(7)变异位点注释分析
[0097]
如图2所示,将(6)中的结核分枝杆菌变异检测结果,根据变异位点在基因组上的位置、突变类型,结合该结核分枝杆菌上的基因分布情况,统计以下指标,并注释到(1)中的耐药基因数据库上:
[0098]
a.变异位点情况(mutation):指定基因位点的碱基及氨基酸突变内容。
[0099]
b.变异率(mutationrate):对应位点变异的碱基个数占检测到该位点总个数的百分比。
[0100]
c.位点深度(depth):检测到对应位点的总个数。
[0101]
d.深度比值(depth_ratio):位点深度与结核分枝杆菌上平均深度的比值。
[0102]
为了保证突变位点的准确性,在位点注释模块中加入了假阳性质控算法。对检出的位点按以下几个方面进行假阳性注释:
[0103]
a.是否达到检出阈值:前期通过对一系列已知突变位点的临床样本检出情况进行以roc的阳性阈值训练。在这个模块中,过滤掉未达到阳性阈值的位点。
[0104]
b.深度比:计算突变位点的深度与其基因上平均深度的比值,如果突变位点的深度显著高于或低于该基因的平均深度,则认为该位点的检出不可信,过滤掉对应位点。
[0105]
c.同批次交叉干扰:当同批次样本中存在高深度高频突变时,由于条形码序列(barcode)合成纯度的问题,可能会造成同批次的交叉污染。因而,对(1)中所有对保证位点,统计原始测序突变位点条数的总和,当非高频高深度样本的突变序列条数达到总批次突变条数的比值小于千分之一时,认为该样本检出的对应位点为假阳性,进行过滤。
[0106]
(8)报告生成
[0107]
如图2所示,基于python语言自动生成检测样本的word文档格式的检测分析报告,报告展示内容包括以下几个方面:
[0108]
a.受检样本的基本信息:包括菌株编号、样本编号、样本类型、培养方法、培养时长
和核酸浓度。
[0109]
b.受检者的基本信息:包括受检者姓名和药物使用情况。
[0110]
c.送检单位信息:包括送检医生和送检医院。
[0111]
d.检测结果:包括与每个药物耐药相关的突变检出情况。
[0112]
e.检出位点备注:包括d中检出突变位点造成耐药的原因及文献出处。
[0113]
本发明的一个实施例提供一种结核分枝杆菌多线耐药基因鉴定的方法,如图4所示,包括如下步骤:
[0114]
s410:获取样本的宏基因组测序得到的全基因组序列或基于靶向扩增测序得到的结核分枝杆菌耐药靶标区域的序列,并对上述序列进行数据质控。
[0115]
在本发明的一个优选实施例中,上述结核分枝杆菌耐药靶标区域的序列,通过能够覆盖结核分枝杆菌耐药基因数据库中的变异位点的引物扩增得到,其中引物包括表2中seq id no:1-12所示的序列。
[0116]
s420:将上述数据质控后的序列比对到结核分枝杆菌基因组上,将比对结果进行排序并对排序后的结果按照设定的原则筛选出符合质量要求的比对结果。
[0117]
在本发明的一个优选实施例中,设定的原则包括:保留比对长度不小于90%的序列;保留比对错误率不大于5%的序列;保留比对上的序列中比对质量不小于30的序列。
[0118]
s430:将符合质量要求的比对结果中比对位置位于结核分枝杆菌耐药基因数据库中的变异位点所在的基因区域的序列进行局部组装,并进行结核分枝杆菌变异检测。
[0119]
在本发明的一个优选实施例中,上述结核分枝杆菌耐药基因数据库包括表1所示的药物及对应的药敏基因和突变位点。
[0120]
在本发明的一个优选实施例中,该步骤包括:
[0121]
对比对位置位于结核分枝杆菌耐药基因数据库中变异位点所在的基因区域的序列进行局部组装,并保留所有可能的突变情况;
[0122]
识别有突变的位点,并对不同类型的突变进行识别和区分;
[0123]
对同时有多种突变的情况进行识别,以实现是否存在突变或存在几种突变单体型识别的目的;
[0124]
对同一区域同时存在多个保守snp的情况,对这些位点的深度、突变率、原始比对序列进行溯源统计,以区分多核苷酸多态性或多个snp;
[0125]
对比对结果中存在的插入或缺失进行偏移识别,以对突变进行正确的位点注释。
[0126]
s440:将上述结核分枝杆菌变异检测的结果,根据变异位点在基因组上的位置和突变类型,统计设定的变异位点特征,并注释到结核分枝杆菌耐药基因数据库上。
[0127]
在本发明的一个优选实施例中,上述设定的变异位点特征包括变异位点情况、变异率、位点深度和深度比值。
[0128]
在本发明的一个优选实施例中,上述注释步骤还包括假阳性注释,其包括:
[0129]
过滤掉未达到阳性阈值的位点;
[0130]
过滤掉突变位点的深度比不符合要求的位点;
[0131]
过滤掉同批次交叉污染造成的假阳性。
[0132]
s450:基于上述注释的结果,输出结核分枝杆菌耐药基因数据库中每个药物耐药相关突变位点的检测结果。
[0133]
在本发明的一个优选实施例中,上述方法还包括:
[0134]
从上述数据质控后的序列中随机抽取部分序列,比对到分枝杆菌序列数据库,计算最优比对上每个分枝杆菌序列的占比,并根据比对情况进行物种鉴定,给出样本中所含的分枝杆菌。
[0135]
对应于本发明的结核分枝杆菌多线耐药基因鉴定的方法,本发明的实施例还提供一种结核分枝杆菌多线耐药基因鉴定的装置,如图5所示,包括:数据获取和质控单元510,用于获取样本的宏基因组测序得到的全基因组序列或基于靶向扩增测序得到的结核分枝杆菌耐药靶标区域的序列,并对上述序列进行数据质控;结核分枝杆菌基因组比对单元520,用于将上述数据质控后的序列比对到结核分枝杆菌基因组上,将比对结果进行排序并对排序后的结果按照设定的原则筛选出符合质量要求的比对结果;变异检测单元530,用于将符合质量要求的比对结果中比对位置位于结核分枝杆菌耐药基因数据库中的变异位点所在的基因区域的序列进行局部组装,并进行结核分枝杆菌变异检测;变异位点注释单元540,用于将上述结核分枝杆菌变异检测的结果,根据变异位点在基因组上的位置和突变类型,统计设定的变异位点特征,并注释到结核分枝杆菌耐药基因数据库上;检测结果输出单元550,用于基于上述注释的结果,输出结核分枝杆菌耐药基因数据库中每个药物耐药相关突变位点的检测结果。
[0136]
本领域技术人员可以理解,上述实施方式中各种方法的全部或部分功能可以通过硬件的方式实现,也可以通过计算机程序的方式实现。当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器、随机存储器、磁盘、光盘、硬盘等,通过计算机执行该程序以实现上述功能。例如,将程序存储在设备的存储器中,当通过处理器执行存储器中程序,即可实现上述全部或部分功能。另外,当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序也可以存储在服务器、另一计算机、磁盘、光盘、闪存盘或移动硬盘等存储介质中,通过下载或复制保存到本地设备的存储器中,或对本地设备的系统进行版本更新,当通过处理器执行存储器中的程序时,即可实现上述实施方式中全部或部分功能。
[0137]
因此,本发明的一种实施例中提供一种计算机可读存储介质,其包括程序,该程序能够被处理器执行以实现如本发明的结核分枝杆菌多线耐药基因鉴定的方法。
[0138]
以下通过实施例详细说明本发明的技术方案和效果,应当理解,实施例仅是示例性的,不能理解为对本发明的限制。
[0139]
实施例1
[0140]
从医院获得结核分枝杆菌样本共48例。该批样本一同使用mgiseq-2000平台进行测序,产生的数据先做预先处理,然后将处理后的数据直接比对到结核分枝杆菌基因组和内标序列库,并将处理后的数据随机抽取一定比例的序列,比对到分枝杆菌序列库。比对到分枝杆菌序列库的结果,统计样本中各分枝杆菌的比例,比对到内标序列库的结果,统计样本中内标序列的条数。比对结核分枝杆菌基因组的结果过滤掉低质量的比对序列后,进行变异检测。最后通过变异检测的结果,统计对应样本中各药物敏感位点的突变情况,计算其变异率、深度等指标,最终生成检测报告。
[0141]
分析结果:
[0142]
表4中示出了48例样本中24例样本质控的结果,主要包括下机数据量、过滤后的数
据量、结核分枝杆菌序列数和比例、非结核分枝杆菌的占比、内标序列数、质控结果等。
[0143]
表4样本质控结果
[0144][0145]
[0146]
[0147]
[0148]
[0149]
[0150][0151]
表5中示出了编号为up543tbtest0150-db11的样本耐药基因的检测结果,展示了样本所有数据库中耐药位点的检测结果,包括密码子突变情况、深度、变异率等。
[0152]
表5样本检测结果
[0153]
[0154]
[0155][0156]
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。