1.本发明涉及人工智能的自然语言处理领域,尤其涉及一种基于融入知识图谱子图信息及实体信息的实体链接方法。
背景技术:
2.知识库问答(knowledge base question answering,kbqa)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。分为两类方法:基于语义分析(sp)的方法和基于信息抽取(ie)的方法。其中,信息抽取方法有较为固定的模型框架、泛化性能也比较好。这类方法一般采用流水线的架构,先进行(1)实体链接,即将问题中的提及词mention链接到知识库的实体。然后进行(2)关系识别,即将问题的意图映射到知识库某个实体的某个关系上。然后通过预测得到实体和关系,在知识库中检索,得到最终问题的答案。
3.但是,实体链接任务常见的问题在于问句能提供的上下文信息量太小,同时命名实体的边界不清晰。导致问句的提及词链接到知识库实体的准确率不高。
技术实现要素:
4.基于此,为解决上小文信息量小,中文命名实体边界模糊的问题,本发明提供一种基于融入知识图谱子图信息及实体信息的实体链接方法,通过提高kbqa实体链接任务的性能,然后进一步提高整个知识库问答任务的表现,以解决上述背景中提到的问题。
5.本发明采用以下技术方案实现:
6.一种基于融入知识图谱子图信息及实体信息的实体链接方法,包括:
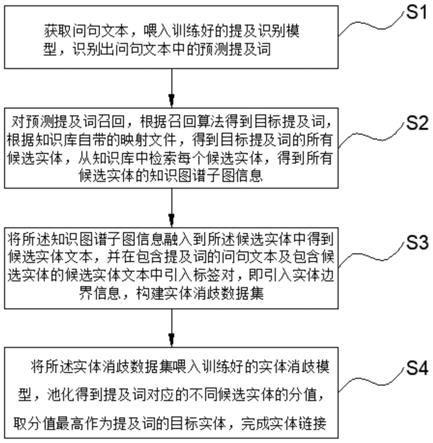
7.获取问句文本,喂入训练好的提及识别模型,识别出所述问句文本中的预测提及词(predicted meniton);
8.对预测提及词召回,根据召回算法得到目标提及词(target mention),根据知识库自带的映射文件(mention2id),得到目标提及词的所有候选实体,从知识库中检索每个候选实体,得到所有候选实体的知识图谱子图信息;
9.将所述知识图谱子图信息融入到所述候选实体中得到候选实体文本,并在包含提及词的问句文本及包含候选实体的候选实体文本中引入标签对,即引入实体边界信息,构建实体消歧数据集;
10.将所述实体消歧数据集喂入训练好的实体消歧模型,池化得到提及词对应的不同候选实体的分值,取分值最高作为提及词的目标实体,完成实体链接。
11.作为本发明进一步的方案,所述训练提及识别模型的方法包括:
12.构建提及识别预训练模型;
13.获取训练数据,对训练数据中的文本进行序列标注,标出命名实体,得到训练集;
14.将标签的训练集输入到所述提及识别预训练模型进行训练得到相应的命名实体,得到提及识别模型。
15.作为本发明进一步的方案,所述预训练模型为bert模型加入crf架构的基础模型;所述训练数据中的文本进行标签的方法为:
16.获取训练数据中的文本的句子;
17.对所述句子中的每一个中文字进行标注;
18.其中,对句子中命名实体的第一个字、命名实体中的其他字以及句子的非命名实体字标注出不同标签,命名实体为提及词。
19.作为本发明进一步的方案,所述提及词召回的方法,包括:
20.获取提及识别模型识别的预测提及词以及一个提及词跟知识库实体的映射文件;
21.从所述映射文件中得到知识图谱的全部提及词列表,遍历全部提及词列表中的项,提取所述预测提及词包含的项形成切割列表;
22.将切割列表中长度最大的项作为召回提及词,根据召回提及词与预测提及词建立召回列表;
23.遍历召回列表中的每一项,检索所述全部提及词列表中包含所述历召回列表的项,提取构建延伸列表,将延伸列表与所述立召回列表合并得到召回的实体召回列表。
24.作为本发明进一步的方案,所述候选实体文本的构建方法,包括:
25.检索知识图谱,所述知识图谱以头节点、关系、尾节点的三元组形式存储;
26.根据所述知识图谱的三元组形式,将所有与头节点相连的边和尾节点都取出作为知识图谱子图信息,得到所述候选实体的所有知识图谱子图信息;
27.将所述知识图谱子图信息拼接到所述候选实体的上下文中得到候选实体文本。
28.进一步的,所述标签对为实体消歧模型识别所述提及词和候选实体的边界信息,所述标签对分别插入所述问句文本的提及词前后和所述候选实体文本的候选实体前后。
29.作为本发明进一步的方案,所述实体消歧数据集构建为:[cls]“问句文本”[sep] “候选实体文本” [sep] 句对的正确分类。
[0030]
作为本发明进一步的方案,训练实体消歧模型的方法包括:
[0031]
基于bert模型构建bert的句子对分类任务的实体消歧预训练模型;
[0032]
将实体消歧数据集输入到所述实体消歧预训练模型进行训练得到相应的知识库实体,得到实体消歧模型。
[0033]
作为本发明进一步的方案,实体消歧模型的池化采用实体级别的最大池化策略,所述池化得到提及词对应的知识库实体为:
[0034]
根据实体级别的最大池化策略分别获取所述提及词片段的最大池化表示向量和候选实体片段的最大池化表示向量;
[0035]
将[cls]的表示向量、问句文本的提及词片段的最大池化表示向量以及候选文本的候选实体片段的最大池化表示向量进行拼接,输入前馈神经网络,通过计算得到所述问句文本中提及词所指向的知识库实体的分值;
[0036]
根据计算得到的分值对比,取最大分值的候选实体作为实体目标,得到提及词对应的知识库实体。
[0037]
进一步的,所述计算得到所述问句文本中提及词所指向的知识库实体的分值采用softmax函数。
[0038]
上述基于融入知识图谱子图信息及实体信息的实体链接方法,基于中文预训练语
言模型bert进行建模,构建bert加入crf的序列标注任务的提及词识别模型,构建bert的句子对分类任务的实体消歧模型;通过对问答文本中提及词的识别,增加召回处理过程,能有效提高提及识别的召回率,提高候选实体的排序准确率并减少错误传递;在实体消歧任务上融入知识图谱信息和实体边界信息,有效解决需要推理的情况,以及候选实体和提及词大量重叠的情况;通过特别的池化策略,一定程度上解决知识噪声的问题;整个实体链接的建模基于预训练语言模型,融入知识图谱知识有效解决推理的情况,融入语言知识一定程度上解决在训练集中的未见实体情况。
附图说明
[0039]
图1为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法的流程方框示意图。
[0040]
图2为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法中训练提及识别模型的流程方框示意图。
[0041]
图3为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法中文本进行标签的流程方框示意图。
[0042]
图4为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法中提及词召回的流程方框示意图。
[0043]
图5为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法中候选实体文本的构建的流程方框示意图。
[0044]
图6为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法中训练实体消歧模型的流程方框示意图。
[0045]
图7为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法中池化得到知识库实体的流程方框示意图。
[0046]
图8为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法中bert的句子对分类任务(a)和bert crf的序列批注任务(b)的流程图。
[0047]
图9为本发明实施例提供的基于融入知识图谱子图信息及实体信息的实体链接方法的整体框架图。
具体实施方式
[0048]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0049]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
[0050]
参阅图1和图9所示,基于融入知识图谱子图信息及实体信息的实体链接方法,包括以下步骤:
[0051]
s1、获取问句文本,喂入训练好的提及识别模型,识别出问句文本中的预测提及词。
[0052]
该步骤中,先确定训练好的提及识别模型,参见图2所示,所述提及识别模型的训练方法包括:
[0053]
s11、构建提及识别预训练模型;
[0054]
在本发明的一个实施例中,是基于中文预训练语言模型bert进行建模,在bert模型加入crf架构,形成bert crf的序列标注任务;在采用提及识别预训练模型序列标注任务的示意图如图8(b)所示;
[0055]
s12、获取训练数据,对训练数据中的文本进行序列标注,标出命名实体,得到训练集;
[0056]
在本发明的一个实施例中,所述训练数据来源于全部的原始数据,是对全部的原始数据的80%作为训练数据来训练模型,另外20%作为测试数据,以便通过测试数据直接判断模型的效果,在模型进入真实环境前改进模型。在提及识别中,对于训练数据包含书名号的位置做了特别处理,把书名号视为命名实体的一部分去进行标注,能提高包含书名号的提及词的预测准确率。
[0057]
在本发明的一个实施例中,参见图3所示,所述训练数据中的文本进行标签的方法为:
[0058]
s111、获取训练数据中的文本的句子;
[0059]
s112、对所述句子中的每一个中文字进行标注;
[0060]
其中,在本发明的一个实施例中,对句子中命名实体的第一个字、命名实体中的其他字以及句子的非命名实体字标注出不同标签,命名实体为提及词。具体的做法是将需要识别的自然语言(主要是各种语句)作为训练数据按bio的方法去标注,得到训练集。即对训练数据中的句子,每个中文字都进行标注。其中,命名实体开始的第一个字则给标签b
‑
entity,命名实体的其他字给标签i
‑
entity,表示命名实体的内部。句子的其他非命名实体的字给标签o。
[0061]
示例性地,标注方法如下表1所示:
[0062]
表1提及识别模型的数据标注案例
[0063][0064]
对句子“2013年12月永宁站的日进出人次是多少排名第几?”进行标注,标注后的句子为“2013(o)年(o)12(o)月(o)永(b)宁(i)站(i)的(o)日(o)进(o)出(o)人(o)次(o)是(o)多(o)少(o)排(o)名(o)第(o)几(o)?(o)”。其中,“永宁站”为提及词,也叫命名实体。
[0065]
又一示例性地,对句子“需提供ddo
‑
3055片临床研究方案、研究者手册等资料吗?”进行标注,标注后的句子为“需(o)提(o)供(o)d(b)d(i)o(i)
‑
(i)3(i)0(i)5(i)5(i)片(i)临(o)床(o)研(o)究(o)方(o)案(o)、(o)研(o)究(o)者(o)手(o)册(o)等(o)资(o)料(o)吗(o)?(o)”。其中,ddo
‑
3055片为提及词,也叫命名实体。
[0066]
s13、将标签的训练集输入到所述提及识别预训练模型进行训练得到相应的命名实体,得到提及识别模型。
[0067]
对于通过bio的方法去标注训练数据放入采用现成的预训练模型bert crf进行训
练,得到提及识别模型。
[0068]
训练好的模型能够对每个输入句子的每个中文字进行去三分类预测。即预测每个中文字是命名实体的开始(b
‑
entity),命名实体的内部(i
‑
entity)还是非命名实体(o)。
[0069]
s2、对预测提及词召回,根据召回算法得到目标提及词,根据知识库自带的映射文件(mention2id),得到目标提及词的所有候选实体,从知识库中检索每个候选实体,得到所有候选实体的知识图谱子图信息。
[0070]
任何一个问题输入到训练好的提及识别模型之后,会得到一个预测的提及词,将预测提及词输入提及召回模块,对预测提及词进行召回,得到更高准确率的目标提及词。
[0071]
具体地,比如问句“动物斑鸠属是属于什么目呀?”bert crf模型预测的命名实体是“动物斑鸠属”,而目标命名实体是“斑鸠属”。
[0072]
提及识别模型之后,对于错配的命名实体,其实与目标命名实体存在重叠字的情况,设计了一种召回提及词模块,其来召回更多目标命名实体,提高整个提及识别的准确率。在该步骤中,参见图4所示,所述提及词召回的方法,包括:
[0073]
s21、获取提及识别模型识别的预测提及词以及一个提及词跟知识库实体的映射文件;
[0074]
在该步骤中,具体的,输入是bert crf模型的预测实体m_p,以及一个提及词跟知识库实体的映射文件mention2id(文件的某行形如“李娜李娜(演员),李娜(篮球运动员),李娜(排球运动员)”)。其中,mention2id文件为官方数据提供。
[0075]
s22、从所述映射文件中得到知识图谱的全部提及词列表,遍历全部提及词列表中的项,提取所述预测提及词包含的项形成切割列表;
[0076]
在该步骤中,具体的,从官方数据提供的mention2id文件得到整个知识图谱所有提及词列表l_gold。遍历l_gold中的项,把预测实体m_p包含的子串(l_gold中的项)放到列表l_cut。
[0077]
s23、将切割列表中长度最大的项作为召回提及词,根据召回提及词与预测提及词建立召回列表;
[0078]
在该步骤中,具体的,找到l_cut中长度最大的作为召回的提及词。记为m_c。把m_p和m_c放入列表l_recall。
[0079]
其中,得到预测命名实体中包含的最长目标命名实体。能把“动物斑鸠属”截短为目标命名实体“斑鸠属”。
[0080]
在比如问题“你知道赵文卓甄子丹事件都有谁吗?”bert crf模型预测的命名实体是“赵文卓甄子丹”,而目标命名实体是“赵文卓甄子丹事件”。
[0081]
s24、遍历召回列表中的每一项,检索所述全部提及词列表中包含所述历召回列表的项,提取构建延伸列表,将延伸列表与所述立召回列表合并得到召回的实体召回列表。
[0082]
在该步骤中,具体的,遍历列表l_recall中的每一项,检索l_gold中哪些项包含l_recall中的项。把这些l_gold项拿出去,放到列表l_extend中。把l_extend和l_recall合并得到最终的实体召回列表l_recall。
[0083]
其中,检索l_gold的每个项(元素),得到包含预测实体“赵文卓甄子丹”的全部目标实体,能召回目标实体“赵文卓甄子丹事件”。
[0084]
本发明的提及词召回的方法,能提高提及识别的召回率,同时,有效解决流水线框
架下的错误传递问题,所谓错误传递,即对于一个问题,在第一个子任务提及识别,预测错误的话,在第二个子任务实体消歧也必定会错误下去。
[0085]
s3、将所述知识图谱子图信息融入到所述候选实体中得到候选实体文本,并在包含提及词的问句文本及包含候选实体的候选实体文本中引入标签对,即引入实体边界信息,构建实体消歧数据集。
[0086]
在该步骤中,参见图5所示,所述候选实体文本的构建方法包括:
[0087]
s31、检索知识图谱,所述知识图谱以头节点、关系、尾节点的三元组形式存储。
[0088]
在该步骤中,知识图谱(知识库)由<subject,relation,object>三元组的形式存在,分别表示为头节点,关系,尾节点。比如<永宁站(新北市),别名,永宁站>。
[0089]
s32、根据所述知识图谱的三元组形式,将所有与头节点相连的边和尾节点都取出作为知识图谱子图信息,得到所述候选实体的所有知识图谱子图信息。
[0090]
在该步骤中,具体的,将所有与头节点相连的边和尾节点都取出来,称为这个头节点的一跳子图信息,即得到所述候选实体的所有知识图谱子图信息。
[0091]
s33、将所述知识图谱子图信息拼接到所述候选实体的上下文中得到候选实体文本。
[0092]
在该步骤中,具体的,将一跳子图信息拼接到候选实体的上下文中作为句子2,即候选实体文本。
[0093]
在本发明的一个实施例中,知识库中以三元组的形式<头实体,关系,尾节点>存储所有知识,比如对于某个来自知识图谱的候选实体a,可能有多个三元组。即对应的关系1
‑
属性值1,关系2
‑
属性值2等。比如<姚明,性别,男>,<姚明,职业,篮球运动员>等。具体地,按训练格式:“候选实体 关系1 属性值1 关系2 属性值2 ....”拼接到候选实体后得到句子2。
[0094]
比如“永宁站(新北市)” “别名:永宁站,车站代码:bl37,营运系统:台北捷运,所属路线:5号线(土城线),位置:新北市土城区中央路3段105号b1,站体型式:地下车站,站台形制:岛式月台,出口数目:4,设站日期:2006年5月31日,日进出人次:29,806[1],第49名(2013年12月)”。
[0095]
在本发明中,还包括融入实体边界信息。问题文本作为句子1包含提及词。句子2包含候选实体。为了让模型学习到提及词和候选实体在上下文中的边界,分别引入了特殊的标签对插入到提及词和候选实体的前后,便签对为<e1></e1>和<e2></e2>。所述标签对为实体消歧模型识别所述提及词和候选实体的边界信息。
[0096]
所述实体消歧数据集构建为:[cls]“问句文本”[sep] “候选实体文本” [sep] 句对的正确分类。在本发明一个实施例中,基于bert的句对匹配任务,将所述数据集构建为[cls]“句子1”[sep] “句子2” [sep] 句对的正确分类,得到该数据集。
[0097]
最终输入模型的数据格式如下:
[0098]“[cls]2013年12月<e1>永宁站</e1>的日进出人次是多少排名第几?[sep]<e2>永宁站(新北市)</e2>别名:永宁站,车站代码:bl37,营运系统:台北捷运,所属路线:5号线(土城线),位置:新北市土城区中央路3段105号b1,站体型式:地下车站,站台形制:岛式月台,出口数目:4,设站日期:2006年5月31日,日进出人次:29,806[1],第49名(2013年12月),首班车:永宁站首班车时间土城线往南港展览馆:06:00,末班车:永宁站末班车时间土城线
往南港展览馆:00:00[sep]1”。
[0099]
s4、将所述实体消歧数据集喂入训练好的实体消歧模型,池化得到提及词对应的不同候选实体的分值,取分值最高作为提及词的目标实体,完成实体链接。
[0100]
在该步骤中,参见图6所示,所述训练实体消歧模型的方法包括:
[0101]
s41、基于bert模型构建bert的句子对分类任务的实体消歧预训练模型,在采用实体消歧的基础模型建模为bert的句子对分类任务的示意图如图8(a)所示;
[0102]
将实体消歧模型建模为基于bert的句子对分类模型,数据标注如下表2所示:
[0103]
表2实体消歧模型的数据标注案例
[0104][0105]
即对两个句子的关系进行预测,比如句子a(sentence a)是一个问题,句子b(sentence b)是这个问题的答案。那么句子a和句子b存在问答关系,标签为1。假如句子c不是这个问题的答案,那么句子a和句子c不存在问答关系。句子对分类任务就是预测输入的两个句子是否存在某种关系。
[0106]
s42、将实体消歧数据集输入到所述实体消歧预训练模型进行训练得到相应的知识库实体,得到实体消歧模型。
[0107]
所述实体消歧模型的池化采用实体级别的最大池化策略,参见图7所示,所述池化得到提及词对应的知识库实体为:
[0108]
s401、根据实体级别的最大池化策略分别获取所述提及词片段的最大池化表示向量和候选实体片段的最大池化表示向量;
[0109]
s402、将[cls]的表示向量、问句文本的提及词片段的最大池化表示向量以及候选文本的候选实体片段的最大池化表示向量进行拼接,输入前馈神经网络,通过计算得到所述问句文本中提及词所指向的知识库实体的分值;
[0110]
s403、根据计算得到的分值对比,取最大分值的候选实体作为实体目标,得到提及词对应的知识库实体。
[0111]
具体的,步骤s402中,计算得到所述问句文本中提及词所指向的知识库实体的分值采用softmax函数。
[0112]
在本实施例中,由于引入的子图的文本长,相较于较短的问题本身,会引入知识噪声,影响整个句子的向量表示。因此尝试了不同的池化策略来提炼上下文的表示。
[0113]
其中,两个层面5种池化策略,分别是:序列级别(即句子对的每个字)的最大池化、平均池化、注意力池化,和实体级别(即句子对中的提及词和候选实体的每个字)的最大池化、平均池化。结论是实体级别的最大池化效果最好。最终我们拼接增强的表示(实体级别的最大池化向量),和序列的表示(特殊标记[cls]的向量表示)。
[0114]
因此,在通过实体消歧模型得到关于文本的表示后,通过设计好的池化层,提出[cls]的表示向量、问句文本的提及词片段的最大池化表示向量以及候选文本的候选实体片段的最大池化表示向量进行拼接,输入全连阶层(前馈神经网络),通过一个softmax函数得到一个分值,表示这个获选实体是问题文本中提及词所指向的知识库实体的得分,即表
示作为提及词的目标实体的概率。我们取分值最高的候选实体作为目标实体。
[0115]
本发明通过提出的一个流水线的结合基于规则的召回提及词算法和基于预训练深度神经网络的实体消歧算法的实体链接解决方案,在中文数据集nlpcc2016ckbqa中,获得目前最好的表现。
[0116]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。