1.本发明涉及计算机视觉领域中的视觉关系检测技术,具体涉及一种基于上下文图注意力机制的场景图生成方法。
背景技术:
2.场景图是图像内容的结构化表示,它是一种以图像目标为顶点、物体间关系为连接边的图形结构。场景图不仅编码场景中的各个目标的语义和空间信息,还表示每对目标之间的关系,作为目标及其成对关系的抽象表示,包含更高级别的场景理解知识。尽管目前使用深度学习技术在目标检测等方面取得了一定成就,但是从可视化数据推断出图像的结构化表示仍然是一个具有挑战性的任务,因此场景图生成相关技术的研究有着较大的价值,从而支撑更多下游的视觉理解应用。
3.现有的场景图生成方法主要分为目标与视觉关系联合推理的单阶段生成方法以及目标与关系分别检测的两阶段方法。imp(iterative message passing,迭代信息传递)算法是被广泛采用的单阶段场景图算法。其通过卷积神经网络提取图像中的目标特征与目标关系特征,再将这些特征分别输入至代表目标和关系的gru(gated recurrent unit,门控循环单元)中,分别代表场景图中的结点和边的表示,然后根据场景图的拓扑结构,利用相邻结点或者边的隐藏状态生成消息,在结点和边的gru中进行消息的迭代传播,最后通过gru的特征表示进行关系预测,从而生成场景图。
4.imp通过信息的迭代传递来捕捉目标之间的视觉关系,但是它仅仅通过图像中的视觉信息完成关系的检测,而没有利用外部知识来辅助场景图的推理,并且imp仅使用局部的特征(目标特征、目标关系特征)进行信息传递,没有充分利用图像的全局上下文信息,造成场景图生成的准确率不高。
5.kern(knowledge
‑
embedded routing networks,知识嵌入的路由网络)是具有代表性的目标和关系分别检测的两阶段场景图生成方法。其通过目标对之间的统计相关性的先验知识获得一个图形结构,在使用目标检测算法生成一系列目标候选区域后,使用图神经网络来传播图形结构上结点的信息,以捕捉更多的上下文特征,从而预测这些目标的类别。然后再使用另一个图形结构将识别出来的目标对与可能存在的关系进行关联,并且使用图神经网络来推断这些目标之间的关系以生成场景图。
6.kern通过结合目标之间的统计信息对关系检测进行建模,但是模型仅仅通过统计信息中的概率信息来初始化图结构,而没有充分挖掘这些统计信息中的语义信息,从而没有能够较好的缓解数据集中样本分布不平衡的问题。
技术实现要素:
7.本发明所要解决的技术问题是:提出一种基于上下文图注意力机制的场景图生成方法,通过充分挖掘外部知识以及目标的上下文信息,从而提高场景图生成的准确率。
8.本发明解决上述技术问题采用的技术方案是:
9.一种基于上下文图注意力机制的场景图生成方法,包括以下步骤:
10.a、训练视觉关系检测模型:
11.a1、对样本数据集中的样本图像进行目标检测,获取图像中目标的类别分布信息、空间特征以及视觉特征;
12.a2、通过目标的类别分布信息从词向量工具中获取对应目标的外部知识向量;
13.a3、对所述目标的外部知识向量、空间特征以及视觉特征进行上下文融合,获得融合后的特征向量;
14.a4、根据目标的类别分布信息生成图像中目标的邻接矩阵,并结合步骤a3中融合后的特征向量进行图注意力网络的初始化;
15.a5、利用样本数据集中的统计信息计算目标关系的频率系数,并利用目标上下文特征计算图注意力系数;
16.a6、通过图注意力网络的信息迭代获得目标的最终向量表示并计算目标之间的关系;
17.a7、通过计算出来的目标之间的关系以及目标的损失函数进行梯度下降更新,从而生成视觉关系检测模型;
18.b、针对待检测图像,根据视觉关系检测模型生成场景图:
19.通过视觉关系检测模型预测图像中目标的关系,将图像中的目标形式化为图形结构的结点,将目标之间的关系形式化为图形结构的边,最后生成图像的场景图表示。
20.作为进一步优化,步骤a1中,采用faster r
‑
cnn模型对样本图像进行目标检测。
21.作为进一步优化,步骤a2中,所述词向量工具采用glove词向量模型;
22.所述获取对应目标的外部知识向量的方法为:向glove词向量模型输入目标类别分布信息,所述目标类别分布信息为目标分类概率向量,并从目标分类概率向量中获取最大值概率的类别,然后根据目标分类概率向量的维度以及最大值概率的类别将其转换成one
‑
hot编码,通过one
‑
hot编码与glove词向量做向量乘法得到相应目标类别的词向量。
23.作为进一步优化,步骤a3中,所述对所述目标的外部知识向量、目标空间特征以及目标的视觉特征进行上下文融合,获得融合后的特征向量,具体包括:
24.分别对目标空间特征和目标的视觉特征进行编码;
25.将目标的外部知识向量、编码后的目标空间特征和编码后的目标视觉特征输入双向gru网络中进行视觉语义信息融合,输出上下文特征向量。
26.作为进一步优化,步骤a4中,所述根据目标的类别分布信息生成图像中目标的邻接矩阵,并结合步骤a3中融合后的特征向量进行图注意力网络的初始化,具体包括:
27.根据目标的类别分布信息,生成目标结点之间的全连接图,获得目标结点之间的邻接矩阵;然后根据邻接矩阵信息,采用各目标的上下文特征向量对相应的目标结点进行初始化,获得特征初始化的图形网络结构。
28.作为进一步优化,步骤a5中,所述利用样本数据集中的统计信息计算目标关系的频率系数,并利用目标上下文特征计算图注意力系数,具体包括:
29.计算目标关系的频率系数:
30.根据样本数据集中的标签信息,统计出当样本数据集中目标i出现时,与目标j之间存在关系的概率p
ij
,并输出f
ij
=1
‑
p
ij
作为目标i与目标j之间的频率系数;
31.计算图注意力系数:
32.首先,对各目标的上下文特征h
i
进行线性化:
33.z
i
=w1h
i
,其中,w1为非线性变换的权重,z
i
为线性化之后的目标上下文特征;
34.然后,通过leakyrelu函数对目标i和目标j进行非线性变换:
35.e
ij
=leakyrelu(w2[z
i
,z
j
]),其中e
ij
为目标i和目标j的非线性变换特征,w2为非线性变换的权重;
[0036]
接着,通过softmax函数求出目标i与其相邻结点之间的图注意力系数:
[0037]
其中n(i)表示目标结点i的邻接目标结点,k为n(i)的子节点,e
ik
为目标i和目标k的非线性变换特征。
[0038]
作为进一步优化,步骤a6中,所述通过图注意力网络的信息迭代获得目标的最终向量表示并计算目标之间的关系,具体包括:
[0039]
基于各目标线性化后的上下文特征z
i
、频率系数f
ij
和图注意力系数α
ij
,通过聚合邻接目标结点的信息更新上下文特征的特征表示:
[0040][0041]
其中,l表示第l次迭代;
[0042]
从而获得经过信息迭代后的各目标的最终特征向量;
[0043]
然后,将每两个目标的最终特征向量输入至全连接层,通过softmax函数得到每两个目标的关系分类,将获得的所述关系分类中最高的关系类别作为此两个目标之间的关系。
[0044]
作为进一步优化,步骤a7中,所述通过计算出来的目标之间的关系以及目标的损失函数进行梯度下降更新,从而生成视觉关系检测模型,具体包括:
[0045]
以图像中目标之间的关系预测结果、目标的分类结果以及样本数据集中目标的标签和目标间的关系标签作为输入,通过目标和目标间关系的交叉熵计算损失,进行梯度更新,从而进行模型的迭代训练,最后输出视觉关系检测模型。
[0046]
本发明的有益效果是:
[0047]
(1)本发明通过图注意力机制来计算目标特征之间的注意力系数,并且将统计信息融合到信息传递过程中,通过注意力系数和统计信息的频率系数进行上下文信息的迭代传递,从而使模型更加关注少数类别以缓解数据集中的样本分布不平衡的问题。
[0048]
(2)本发明使用目标检测的结果来初始化图神经网络的图形结构,保留了所有目标潜在的连接边,以充分挖掘图像中目标之间的关系,使得目标之间关系识别的准确率也得到了提高,进而提高场景图生成的准确率。
[0049]
(3)本发明结合外部知识,通过多特征融合来充分挖掘视觉特征、空间特征、外部知识中的上下文信息,以捕捉上下文特征中的语义信息来辅助场景图生成的关系推理,,从而提高场景图生成的准确率。
附图说明
[0050]
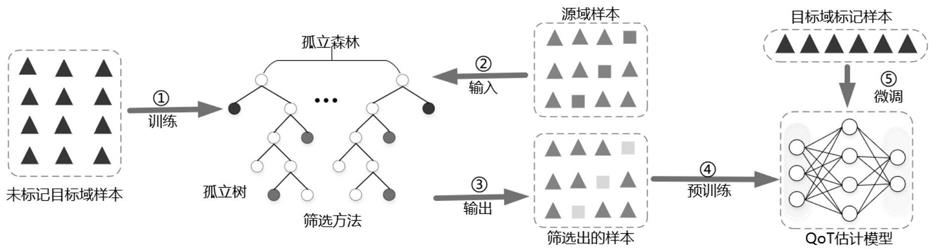
图1为本发明实施例中的视觉关系检测模型训练流程图。
具体实施方式
[0051]
本发明旨在提出一种基于上下文图注意力机制的场景图生成方法。该方法首先训练视觉关系检测模型,具体为首先对样本数据集中的样本图像进行目标检测,获取图像中目标视觉特征、目标空间特征以及目标的分类信息;其次,通过目标分类信息从词向量工具中获取相应目标的外部知识向量,并对目标视觉特征、目标空间特征进行编码,使用双向的gru网络融合外部知识、视觉特征以及空间特征。然后,通过目标分类信息生成图像中目标的邻接矩阵,再结合目标的上下文特征进行图神经网络的初始化,接着利用样本数据集中的统计信息计算目标关系的频率系数以及基于目标上下文特征计算图注意力系数,通过图神经网络的信息迭代获得目标的最终向量表示用于计算目标之间的关系。最后通过关系和目标损失进行梯度下降,生成视觉关系检测模型。对于待检测图像,通过视觉关系检测模型获取图像中目标之间的关系。将图像中的目标形式化为图形结构的结点,目标之间的关系形式化为图形结构的边,最后生成图像的场景图表示。
[0052]
实施例:
[0053]
本实施例中的基于上下文图注意力机制的场景图生成方法包括训练视觉关系检测模型以及针对待检测图像,根据视觉关系检测模型生成场景图两个部分。
[0054]
视觉关系检测模型的训练流程如图1所示,其包括以下步骤:
[0055]
s1、输入样本图像进行目标检测:
[0056]
本步骤中,对样本数据集中的样本图像进行目标检测,获取图像中目标的类别分布信息、空间特征以及视觉特征;具体实现包括以下子步骤:
[0057]
s11、特征图提取:
[0058]
输入长为n宽为m的样本图像至faster r
‑
cnn模型中;
[0059]
faster r
‑
cnn模型的目标检测网络的主干网络由vgg
‑
16组成,其包括5个卷积池化层:
[0060]
前两个卷积池化层的结构均为采用依次连接的:conv_layer(卷积层)、relu(激活函数)、conv_layer(卷积层)、relu(激活函数)、pooling_layer(池化层);
[0061]
第三、第四个卷积池化层的结构均为采用依次连接的:conv_layer(卷积层)、relu(激活函数)、conv_layer(卷积层)、relu(激活函数)、conv_layer(卷积层)、relu(激活函数)、pooling_layer(池化层)。
[0062]
第五个卷积池化层的结构为采用依次连接的:conv_layer(卷积层)、relu(激活函数)、conv_layer(卷积层)、relu(激活函数)、conv_layer(卷积层)、relu(激活函数)。
[0063]
其中,所有的卷积操作使用3*3的滑动窗口,步长为1,padding(填充)为1;
[0064]
所有的池化操作使用2*2的滑动窗口,步长为2,padding(填充)为0;
[0065]
对于n*m*1大小的图像,因为卷积操作的padding为1,所以卷积层不改变特征图的长度和宽度,而池化操作会使特征图的长宽减少为原来的一半。所以样本图像经过vgg
‑
16主干网络处理后,输出大小为(n/16)*(m/16)*512的特征图。
[0066]
s12、候选区域提取:
[0067]
本部分以维度是(n/16)*(m/16)*512的特征图作为输入,首先通过一个3*3的卷积层,再分别通过两个1*1的卷积层分别得到18维和36维的向量。18维的向量代表9个anchor(边框)是否为背景的概率,36维的向量表示为9个anchor的四个坐标值信息。这两个向量再加上之前提取的特征图通过roi pooling(感兴趣区域)层,输出每个候选区域的7*7*512维的目标视觉特征。
[0068]
s13、目标分类与边界框回归:
[0069]
本部分以各候选区域7*7*512维的目标特征作为输入,首先输入至两个包含4096个单元的全连接层中,再分别输入包含c个单元的全连接层和包含c*4个单元的全连接层,从而分别输出c维的目标分类概率向量和c*4维的坐标回归值(空间特征)。其中c是目标的类别个数,采用的数据集为视觉基因组(visual genome,vg)其包含150类目标,所以c=151(包含一个背景类)。
[0070]
s2、获取对应目标的外部知识向量:
[0071]
本步骤中,通过目标的类别分布信息从词向量工具glove中获取对应目标的外部知识向量,具体为:
[0072]
输入c维的目标分类概率向量,并从目标分类概率向量中获取最大值概率的类别,然后根据目标分类概率向量的维度以及最大值概率的类别将其转换成one
‑
hot编码,通过one
‑
hot编码与glove词向量做向量乘法得到相应目标类别的词向量,词向量维度为300维,故可以总共输出151*300维的词向量。
[0073]
s3、进行上下文融合,获得融合后的特征向量:
[0074]
本步骤中,对所述目标的外部知识向量、空间特征以及视觉特征进行上下文融合,获得融合后的特征向量,具体为:
[0075]
s31、视觉特征编码:
[0076]
输入每个候选区域7*7*512维的目标特征,取7*7维度上的均值,输出每个候选区域512维的目标特征;
[0077]
s32、空间信息编码:
[0078]
输入4维的坐标信息,依次通过包含32个单元的全连接层和包含128个单元的全连接层编码,输出128维的空间特征;
[0079]
s33、多特征融合:
[0080]
输入512维的视觉特征、300维的知识向量以及128维的空间特征的连接向量,输入至两个双向的gru中以融合视觉语义信息,输出2048维的上下文特征向量h
i
。
[0081]
s4、图注意力传播:
[0082]
本步骤中,首先根据目标的类别分布信息生成图像中目标的邻接矩阵,并结合融合后的特征向量进行图注意力网络的初始化;再利用样本数据集中的统计信息计算目标关系的频率系数,并利用目标上下文特征计算图注意力系数;最后进行图注意力网络的信息迭代传递。
[0083]
具体为:
[0084]
s41、生成邻接矩阵:
[0085]
本部分输入c维的目标分类概率向量,根据目标的分类结果,生成目标结点之间的全连接图,输出目标结点之间的邻接矩阵。
[0086]
s42、特征初始化:
[0087]
本部分输入目标结点之间的邻接矩阵与每个目标的2048维上下文特征向量,根据邻接矩阵的信息,使用相应目标的上下文特征对相应的目标结点进行初始化,输出特征初始化的图形网络结构。
[0088]
s43、频率系数计算:
[0089]
本部分输入样本数据集vg中的标签信息,统计当数据集中目标i出现时,与j之间存在关系的概率p
ij
,为了使数据集中的少数样本获得更多的注意力,输出f
ij
=1
‑
p
ij
作为目标i与目标j之间的频率系数。
[0090]
s44、图注意力系数计算:
[0091]
本部分输入目标结点之间的邻接矩阵与每个目标的2048维上下文特征向量h
i
,首先通过包含128个单元的全连接层对每个目标上下文特征进行线性化z
i
=w1h
i
,其中w1为非线性变换的权重,z
i
为线性化之后的目标上下文特征。其次通过leakyrelu函数对目标结点i和目标结点j进行非线性变换e
ij
=leakyrelu(w2[z
i
,z
j
]),其中e
ij
为目标结点i和目标结点j的非线性变换特征,w2为非线性变换的权重。再通过softmax函数求出目标i与其相邻结点之间的图注意力系数其中n(i)表示目标结点的邻接目标结点,最后输出图注意力系数α
ij
。
[0092]
s45、信息迭代传递:
[0093]
本部分输入每个目标上下文特征的线性化表示z
i
、频率系数f
ij
、图注意力系数α
ij
。通过聚合邻接结点的信息更新上下文特征的特征表示其中上标l表示第l次迭代过程。最后输出信息迭代后每个目标的2048维特征向量h
i~
。
[0094]
s5、关系分类:
[0095]
本步骤中,是通过图注意力网络的信息迭代所获得的目标的最终向量表示计算目标之间的关系,具体为:
[0096]
输入每个目标的2048维特征向量h
i~
,将每两个目标的特征向量依次输入至包含512个单元和51个单元的全连接层,最后通过softmax函数得到每两个目标在51类关系中的分类,并取关系分类最高的关系类别作为该目标对之间的关系。最后输出图像中目标之间的关系。
[0097]
s6、梯度更新:
[0098]
本步骤中,是通过计算出来的目标之间的关系以及目标的损失函数进行梯度下降更新,从而生成视觉关系检测模型;具体为:
[0099]
输入图像中目标之间的关系预测结果、目标的分类结果以及数据集中目标的标签与关系标签。通过目标和关系的交叉熵计算损失,进行梯度更新,从而进行模型的迭代训练。最后输出视觉关系检测模型。
[0100]
在获得训练完成的视觉关系检测模型后,就可以利用该模型进行图像目标和目标关系检测生成场景图,具体为:输入待检测图像到视觉关系检测模型,输出目标之间的关系分布;将目标形式化为图形结构的结点,目标之间的关系形式化为图形结构的边,通过将图像中所有的目标和关系形式化为节点和边,最后输出图像的场景图表示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。