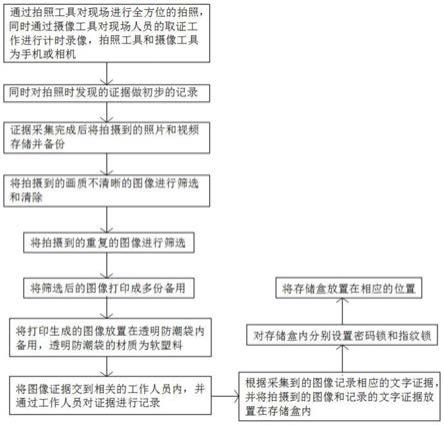
1.本发明涉及一种图像识别与语言输入技术,属于语言信息技术领域,具体为一种通过眼动追踪来协助瘫痪失语者语言输出的系统。
背景技术:
2.现实中存在病人出现丧失语言输出的情形。例如:嘴部无法说话且手脚瘫痪的病人、发声器官插管且手脚不方便活动的病人。这些病人既不能说话,也不能写字,只能通过他人询问,自身眨眼等原始方法进行低效的沟通。
3.中国讯飞和美国微软的眼动追踪键盘输入法,其大致原理是:通过让用户佩戴眼镜式屏幕,在屏幕上显示虚拟键盘,然后通过眼动仪追踪用户视线,获取用户视线注视的键盘上的按键来实现虚拟键盘打字功能。
4.存在的问题:
5.(1)存在不会使用键盘输入、或使用键盘输入效率低下的用户,例如:不会拼音等键盘输入法的人、视力不佳不易区分紧密排列字母按键的人等等。所以,此类用户,不适合上述虚拟键盘。
6.(2)上述现有虚拟键盘输入,未能考虑用户与周围环境的交互。例如:身边对话者说出的语言内容、周围环境中可以看到的物品或文字、周围可以听到的非语言类声响等等。
7.(3)上述现有虚拟键盘输入,未能直接提供用户的个性化交互信息。例如:病人的最紧急的疼痛、呼吸困难、如厕、进食进水等信息;病人身边亲人姓名、常用物品、常去地点等信息;病人的喜怒哀乐等情感信息。
技术实现要素:
8.本发明要解决部分用户不会键盘输入法、或因视力等原因导致键盘输入法效率低下,从而无法使用眼镜式屏幕和眼动仪追踪来进行语言输入的问题。
9.本发明要解决使用眼镜式屏幕和眼动仪追踪的虚拟键盘输入法中,无法为用户提供与周围交互环境和用户个性化需求相关的快速语言输入的问题。
10.一种通过眼动追踪来协助瘫痪失语者语言输出的系统,包括硬件部分、软件部分;
11.硬件部分包括:外部识别摄像头:用于拍摄外部环境;
12.头戴式透镜眼镜显示器:半透明设计,用户透过显示器看到周围环境;
13.视频输出接口:将头戴式透镜眼镜显示器中显示的内容,实时输出到外部视频播放设备;
14.眼动仪:追踪用户眼镜焦点,完成互动操作;
15.以及麦克风、扬声器;
16.软件部分包括:词典联想组句模块:显示备选的词语或语句;
17.声音文本互转模块:将语言类和非语言类声音转换为文本;
18.图像识别模块:将图像识别为文本;
19.词典存储模块:存储用户按时间顺序注视过的和输出的“物品组 文本组”记录;
20.眼动词语编辑模块:对用户注视的词语显示编辑功能菜单。
21.进一步地,所述系统包含前台学习模式:用于用户主动的向系统进行外部环境相关语言的输入;
22.后台学习模式:用于系统在后台识别与学习用户的语音和注视过的物品,用户无需确认操作;
23.词典训练分析模式:用于系统对词典存储模块中的图像和文本进行模型训练,最终获得的模型为:当向模型输入某图像或词语时,模型输出所对应的最相关的文本;
24.正常使用模式:系统通过用户视线停留的物品,自动生成可选的文本,用户选择确认后,文本通过声音文本互转模块生成语音,并通过扬声器播放;
25.紧急使用模式:系统中设有特殊预置文本词典,供用户在紧急情况下使用。
26.进一步地,所述前台学习模式的具体流程如下:
27.(1)外部识别摄像头开启,将视频信号传递给图像识别模块,图像识别模块识别视场中的物品;
28.(2)眼动仪跟踪用户视线,确定用户视线停留过的物品;
29.(3)用户说话,进行语音输出;
30.(4)系统开始计时;
31.(5)麦克风收集用户上述语音,并将语音数据传递给声音文本互转模块;
32.(6)声音文本互转模块将上述语音转换成备选文本选项;
33.(7)头戴式透镜眼镜显示器高亮显示用户视线停留的物品,图像识别模块将此物品转换为备选文本选项并显示在物品旁边;
34.(8)眼动仪记录用户眼动切换注视物品的时刻;
35.(9)用户语音输出结束;
36.(10)系统停止计时;
37.(11)头戴式透镜眼镜显示器显示上述备选文本选项、和眼动仪确定的用户视线停留过的物品截图,文本选项按眼动时刻进行文本分隔,并按用户语音输出和视线停留的时刻顺序进行排列;在计时时间段内,第n时刻的文本和第n时刻眼动仪确定的用户视线停留的物品一同高亮显示,文本分割为词语,并标注词性;
38.(12)用户通过眼动词语编辑模块编辑上述分隔显示的词语;
39.(13)头戴式透镜眼镜显示器提示用户进行确认;
40.(14)用户通过眼动仪注视提示来进行确认;
41.(15)用户确认后,上述文本选项和一组物品截图,按照上述时刻顺序,作为一条“物品组 文本组”记录,存储到词典存储模块;
42.(16)回到并重复步骤(2)
‑
(15),继续向系统的词典存储模块输入更多的“物品组 文本组”记录;
43.(17)结束前台学习模式。
44.进一步地,所述后台学习模式的具体流程如下:
45.(1)外部识别摄像头开启,将视频信号传递给图像识别模块,图像识别模块识别视场中的物品;
46.(2)眼动仪跟踪用户视线,确定用户视线停留过的物品;
47.(3)用户说话,进行语音输出;
48.(4)系统开始计时;
49.(5)麦克风收集用户时长为t的语音片段,并将语音数据传递给声音文本互转模块;
50.(6)声音文本互转模块将上述语音片段转换成文本;
51.(7)图像识别模块将此物品转换为文本;
52.(7)眼动仪记录用户眼动切换注视物品的时刻;
53.(8)用户语音输出结束;
54.(9)系统停止计时;
55.(10)系统后台调取计时时间段内的文本和眼动仪确定的用户视线停留过的物品截图,文本选项按眼动时刻进行文本分割,并按用户语音输出和视线停留的时刻顺序进行排列;在计时时间段内,第n时刻的文本和第n时刻眼动仪确定的用户视线停留的物品进行对齐;文本分割为词语,并标注词性;
56.(11)上述文本选项和一组物品截图,按照上述时刻顺序,作为一条“物品组 文本组”记录,存储到词典存储模块;
57.(12)回到并重复步骤(3)
‑
(11),继续向词典存储模块输入更多的“物品组 文本组”记录;
58.(13)结束后台学习模式。
59.进一步地,所述词典训练分析模式的具体流程如下:
60.(1)提取词典存储模块中按眼动时刻拆分存储的“物品组 文本组”;
61.(2)提取每个文本片段里的词语,并标注每个词语的词性;
62.(3)将词典存储的“物品组 文本组”输入到训练系统进行学习训练;
63.(4)词典模型训练:物品图像作为输入参数,带有词性的词语作为输出参数;
64.(5)参数权重设置:前台学习模式中物品图像对应的词语的权重,大于后台学习模式中物品图像对应的词语的权重;
65.(6)词典模型训练完毕;
66.(7)当向模型输入一个或多个物品图像或词语时,输出为一个文本列表,文本列表包含词语,词语按词性进行分类,每个词性分类中的各个词语按相关度从高到低进行排序。
67.进一步地,所述正常使用模式的具体流程如下:
68.(1)外部识别摄像头开启,将视频信号传递给图像识别模块,图像识别模块识别视场中的物品;
69.(2)眼动仪跟踪用户视线,确定用户视线停留过的物品;
70.(3)头戴式透镜眼镜显示器,高亮显示用户视线停留的物品;
71.(4)物品图像输入到词典模型,头戴式透镜眼镜显示器显示词典模型输出的文本列表,文本列表中包含按词性分类和相关度高低排序的候选文本;
72.(5)用户通过眼动仪来选择词语;
73.(6)系统将用户已选择的词语按照用户选择的顺序,组成原始句子;
74.(7)词典联想组句模块,调取用户的词典模型,将候选词语,按照词典模型中的规
则,进行重新排序,生成多个联想句子;
75.(8)系统通过麦克风收集周围环境中的语言类声响;
76.(9)系统通过声音文本互转模块,将上述语言类声响,转换为文本,并分割成词语,显示在头戴式透镜眼镜显示器中,作为步骤(4)中的候选词语,供用户选择;
77.(10)系统监测上述周围环境中语言类声响转换成的文本是否为问句;
78.(11)若系统监测到上述问句,头戴式透镜眼镜显示器中显示快速应答选项,用语通过眼动仪来选择进行回答;
79.(12)系统通过麦克风收集周围环境中的非语言类声响;
80.(13)系统通过声音文本互转模块,将上述非语言类声响,转换为文本,并分割成词语,显示在头戴式透镜眼镜显示器中,作为步骤(4)中的候选词语,供用户选择;
81.(14)重复(4)
‑
(13)的步骤;
82.(15)原始句子和联想句子,组成候选句子列表,用户通过眼动仪来选择候选句子;
83.(16)确定选择后的句子,在头戴式透镜眼镜显示器中,显示于待发声区域;
84.(17)系统在头戴式透镜眼镜显示器中,存在一个或多个待发声区域;
85.(18)待发声区域的句子中的词语分隔显示;
86.(19)用户通过眼动词语编辑模块来编辑上述分隔显示的词语;
87.(20)待发声区域句子旁,设置快捷编辑按钮,用户通过眼动仪选择快捷编辑按钮后,系统弹出句子编辑选项;
88.(21)头戴式透镜眼镜显示器中,在待发声区域旁,设置发声按钮;
89.(22)用户通过眼动仪来选择发声;
90.(23)通过声音文本互转模块将上述待发声区域的句子转化成语音,语音通过扬声器播放出来;
91.(24)所有在正常模式中,经用户确定发声的句子,也作为一条“物品组 文本组”记录,存储到词典存储模块。
92.进一步地,所述紧急使用模式的具体流程如下:
93.(1)头戴式透镜眼镜显示器中,在明显位置设置紧急模式激活区;
94.(2)用户通过眼动仪来激活紧急使用模式;
95.(3)系统在头戴式透镜眼镜显示器中显示预置的紧急文本词语;
96.(4)用户通过眼动仪选择词语;
97.(5)特殊预置文本词典根据用户已选择的词语,生成联想词语列表;
98.(6)用户通过眼动仪在上述联想词语列表中选择词语,系统通过特殊预置文本词典,将已选择的所有词语,按词典中句子生成规则生成联想句子;
99.(7)回到步骤(5),直到用户生成最终的句子,并显示于头戴式透镜眼镜显示器中的待发声区域;
100.(8)通过声音文本互转模块将上述待发声区域的句子转化成语音,语音通过扬声器播放出来;
101.(9)用户一旦激活紧急使用模式,系统扬声器发出警报声,吸引其他人员前来协助;
102.(10)视频输出接口会自动输出头戴式透镜眼镜显示器中显示的视频,以使其他人
员实时指导用户的想法,并快速了解用户意图。
103.有益效果:本发明通过学习用户本身周围的环境物品和环境声音输入,和用户个体本身的语言历史习惯,使用户可以更有效率的将周围环境转换为更贴近自己习惯的语言输出,可以为瘫痪失语者等用户得以和外部进行基本且重要的语言交流。
附图说明
104.图1是本发明中的前台学习模式中的物体识别;
105.图2是本发明中的前台学习模式中的用户输出的语音转换成文本;
106.图3是本发明中的后台学习模式中用户先后注视过的两个物体;
107.图4是本发明系统后台对用户注视过的物体和用户输出语言的后台分析;
108.图5是本发明正常使用模式中系统对物品的识别文本和用户按顺序注视选择文本;
109.图6是本发明正常使用模式中生成的原始句子和联想句子以及用户对句子进行编辑;
110.图7是本发明正常使用模式中系统将外部语言问句的声音转换为文本并提供快速应答选项;
111.图8是本发明正常使用模式中用户对外部语言转换的文本进行选择造句;
112.图9是本发明正常使用模式中系统将外部非语言声音转化为文本并提供候选句子;
113.图10是本发明紧急使用模式中用户激活紧急候选词;
114.图11是本发明紧急使用模式中用户选择候选词后系统提供联想候选句子。
具体实施方式
115.本发明公开了一种通过眼动追踪来协助瘫痪失语者语言输出的系统,包括硬件部分、软件部分;
116.硬件部分包括:外部识别摄像头:用于拍摄外部环境;
117.头戴式透镜眼镜显示器:半透明设计,用户透过显示器看到周围环境;
118.视频输出接口:将头戴式透镜眼镜显示器中显示的内容,实时输出到外部视频播放设备;
119.眼动仪:追踪用户眼镜焦点,完成互动操作;
120.以及麦克风、扬声器;
121.软件部分包括:词典联想组句模块,用于显示备选的词语或语句;
122.声音文本互转模块,用于将语言类和非语言类声音转换为文本;
123.图像识别模块,用于将图像识别为文本;
124.词典存储模块,用于存储用户按时间顺序注视过的和输出的“物品组 文本组”记录;
125.眼动词语编辑模块,用于对用户注视的词语显示编辑功能菜单。
126.系统包含五种模式,分别为:
127.前台学习模式,用于用户主动的向系统进行外部环境相关语言的输入;
128.后台学习模式,用于系统在后台识别与学习用户的语音和注视过的物品,用户无需确认操作;
129.词典训练分析模式,用于系统对词典存储模块中的图像和文本进行模型训练,最终获得的模型为:当向模型输入某图像或词语时,模型输出所对应的最相关的文本;
130.正常使用模式,系统通过用户视线停留的物品,自动生成可选的文本,用户选择确认后,文本通过声音文本互转模块生成语音,并通过扬声器播放;
131.紧急使用模式,系统中设有特殊预置文本词典,供用户在生命健康等重要的紧急特殊情况下使用。
132.实施例1:
133.前台学习模式举例:
134.(1)如图1所示,用户视线先后注视物品:杯子和茶叶盒。眼动仪记录,第1秒注视杯子,第2秒注视茶叶盒。
135.(2)物品旁显示图像识别模块识别出来的备选文本,如图,杯子识别为“杯子、缸子、水杯”,茶叶盒识别为“茶、茶叶、盒子、罐子”。
136.(3)如图2所示,用户语音输出“拿杯子泡杯茶喝”,按眼动时刻分隔,第1秒说出“拿杯子”,第2秒说出“泡杯茶喝”。
137.(4)系统将用户语音转化成文本,分割成词语,并标注词性。
138.(5)头戴式透镜眼镜显示器,将用户注视过的物品,按眼动时间顺序排列显示:用户语音转化的文本,也按眼动时间顺序分隔进行排列。
139.(6)用户注视分隔词语“杯子”,激活词语编辑模块,“杯子”下方显示出图像识别模块识别出来的、或“杯子”的同义词等:“缸子、水杯”等。
140.(7)用户可以注视相应的词语,替换到句子中的“杯子”。
141.(8)用户注视“确认”按钮,将这组“物品组 文本组”记录,即{第一秒:[水杯图像],[拿](动词),[杯子](名词),[缸子](名词),[水杯](名词);第2秒:[茶叶盒图像],[泡](动词),[杯](量词),[茶](名词),[茶叶](名词),[盒子](名词),[罐子](名词)},存储到词典存储模块。
[0142]
实施例2:
[0143]
后台学习模式举例:
[0144]
(1)如图3所示,用户视线先后注视物品:杯子和咖啡盒。眼动仪记录,第1秒注视杯子,第2秒注视咖啡盒。
[0145]
(2)如图4所示,系统后台图像识别模块识别出图像对应的备选文本,如图,杯子识别为“杯子、缸子、水杯”,咖啡盒识别为“咖啡、盒子、罐子”。
[0146]
(3)用户语音输出“拿杯子冲杯咖啡喝吧”,按眼动时刻分隔,第1秒说出“拿杯子”,第2秒说出“冲杯咖啡喝吧”。
[0147]
(4)系统后台将用户语音转化成文本,分割成词语,并标注词性。
[0148]
(5)系统后台将这组“物品组 文本组”记录,即{第一秒:[水杯图像],[拿](动词),[杯子](名词),[缸子](名词),[水杯](名词);第2秒:[咖啡盒图像],[冲](动词),[杯](量词),[咖啡](名词),[盒子](名词),[罐子](名词),[喝](动词),[吧](助词)},存储到词典存储模块。
[0149]
实施例3:
[0150]
正常使用模式举例:
[0151]
(1)如图5所示,图像识别模块识别出视场中的人脸和咖啡盒子。人脸识别出两个选项“小王”和“小张”。咖啡盒子分别被识别出动词“冲”和“喝”、名词“咖啡”和“罐子”。
[0152]
(2)用户按顺序分别注视了“小王”、“冲”、“咖啡”、“喝”。如图6所示,系统按此顺序,组成的原始句子为“小王冲咖啡喝”。
[0153]
(3)词典联想组句模块,调取用户的词典模型,将上述用户注视过的词语,在词典模型中搜索并分析。此例中,如图6所示,用户词典模型中搜索到包含候选词语“小王”、“喝”和“咖啡”的历时句子:“小王请喝咖啡”。
[0154]
(4)如图6所示,用户注视联想句子“小王请喝咖啡”中的名词“咖啡”,激活眼动词语编辑模块,系统弹出词语菜单,此例中“咖啡”下方弹出了可替换的同类词“茶”。
[0155]
(5)用户最终用“茶”替换“咖啡”,则最终确认后的句子为“小王请喝茶”,显示于待发声区域。
[0156]
(6)用户通过选择“发声”,系统通过声音文本互转模块将上述待发声区域的句子转化成语音,语音通过扬声器播放出来。
[0157]
(7)系统通过麦克风收集周围环境中的语言类声响。如图7所示,此例中,小王回话“谢谢,我给你也冲杯茶吗?”[0158]
(8)如图7所示,系统通过声音文本互转模块,将小王的回话,转换为文本,并分割成词语,显示在头戴式透镜眼镜显示器中。
[0159]
(9)如图7所示,系统监测到小王的回话为问句,头戴式透镜眼镜显示器中显示快速应答选项,“好的谢谢”和“不用谢谢”。用户可通过眼动仪来选择进行回答。
[0160]
(10)如图8所示,此处用户选择通过注视小王回话中的分割词语来组成新的原始句子。
[0161]
(11)用户按顺序选择了“我”、“冲”、注视“茶”激活菜单,并在同类语中注视选择了“咖啡”。
[0162]
(12)如图8所示,则最终句子为“我冲咖啡”,显示于待发声区域。
[0163]
(13)用户通过选择“发声”,系统通过声音文本互转模块将上述待发声区域的句子转化成语音,语音通过扬声器播放出来。
[0164]
(14)如图9所示,系统通过麦克风收集周围环境中的非语言类声响。此例中,系统收集到环境音中的敲门声。
[0165]
(15)系统通过声音文本互转模块,将此敲门声,转换为文本“敲门声”,并分割成词语。
[0166]
(16)如图9所示,用户词典模型进行联想和历史句子搜索,提供了三个候选句子“有人敲门”、“去开门”和“你爸回来了”。
[0167]
(17)用户可选择相应句子进行发声。
[0168]
实施例4:
[0169]
紧急使用模式举例:
[0170]
(1)如图10所示,头戴式透镜眼镜显示器中,在右上角明显位置,设置紧急模式激活区。
[0171]
(2)用户通过眼动仪来激活紧急使用模式。
[0172]
(3)如图10所示,系统在头戴式透镜眼镜显示器中显示预置的紧急文本词语:“疼、厕所、呼吸”。
[0173]
(4)如图11所示,用户通过眼动仪来选择了词语“疼”。
[0174]
(5)特殊预置文本词典根据用户已选择的词语,生成联想文本列表。如图11所示,“心脏疼”、“头疼”、“胃疼”。
[0175]
(6)用户通过选择“发声”,声音文本互转模块将上述待发声区域的句子转化成语音,语音通过扬声器播放出来。
[0176]
(7)用户一旦激活紧急使用模式,系统扬声器发出警报声,吸引其他人员前来协助。
[0177]
(8)用户一旦激活紧急使用模式,视频输出接口会自动输出头戴式透镜眼镜显示器中显示的视频,以使其他人员可以实时指导用户的想法,并快速了解用户意图。
[0178]
实施例5:
[0179]
词典训练分析模式举例:
[0180]
(1)提取词典存储模块中按眼动时刻顺序拆分存储的“物品组 文本组”;
[0181]
(2)将所有文本拆分为词语,并标注每个词语的词性,包括:人名、名词、动词、量词、介词、语气助词、形容词、否定词等。
[0182]
(3)给定一个物品图像,按以下顺序搜索词典存储模块中的文本:
①
此物品被图像识别模块识别出的文本、
②
此物体在此眼动时刻对应的文本组中出现频率最多的名词、
③
动词、
④
形容词、
⑤
量词等等。
[0183]
(4)给定一个文本词语,搜索此词语在所有文本组中前后n个词语内,出现频率最多的
①
名词、
②
动词、
③
形容词、
④
量词,等等。n可以取1,2,3等整数。
[0184]
(5)参数权重设置:前台学习模式中物品图像或词语对应的文本的频率权重,大于后台学习模式中物品图像或词语对应的文本的频率权重;
[0185]
(6)当向模型输入一个或多个物品图像或文本词语时,输出为一个文本列表,文本列表包含词语,词语按词性进行分类,每个词性分类中的各个词语按上述频率从高到低进行排序。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。