1.本发明属于语音识别领域,特别涉及一种基于回译的无声语音识别方法和系统。
背景技术:
2.语言是人类最直接最简单的交流方式,目前语音识别发展非常迅速,已经有了非常多落地场景并被投入使用,随着深度学习及相关计算资源的迅猛发展,语音识别领域也焕发出蓬勃生机。
3.但是由于在实际生活场景中存在着广泛而普遍的噪声,使得语音识别效果大打折扣。而且公众场景下信息传递的保密性也是语音识别存在的问题。在实际场景中,某些不能发出声音的特殊场合,还有做过喉部切除手术的患者,无声语音有非常重要的实用价值。
4.唇语识别和表面肌电信号的语音识别都为无声语音识别做出了贡献。人类的发音是依靠唇部和喉部肌肉运动结合发音器官产生的,通过肌电采集装置可以记录说话时肌肉收缩的生物电信号,这为基于表面肌电信号的无声语音识别提供了可能。目前的无声语音识别技术一般通过对固定指令集建立分类模型实现。但在广泛的真实场景中,将无声语音转换为有声语音更符合习惯。而对音频恢复而言,当前的工作多侧重于从有声语音期间记录的肌电信号恢复音频,而非从无声语音生成音频。实验表明,这种直接将在有声语音上训练得到的肌电信号转音频信号模型,迁移到无声语音肌电信号的方法效果不佳。这种直接迁移的方法忽略了两种说话模式之间的差异,无声肌电信号中有些肌肉受到限制,产生的动作电位较小。同时,语言是富于变化且多种多样的,单纯依赖于分类的方法不能有效解决问题。
5.现有肌电数据集大都采集的是被试发声状态下的面部喉部肌电信号,较为缺乏无声情况下的肌电数据。在采集时,由于无声表面肌电信号无法根据采集人员到的发声判断是否存在漏词或说错的情况,无声表面肌电信号的采集质量无法有效保证,数据采集成本高。
技术实现要素:
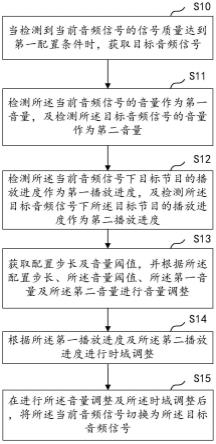
6.本发明提出了一种基于回译的无声语音识别方法,包括:
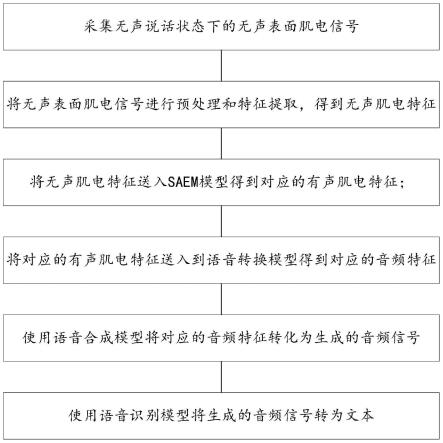
7.采集无声说话状态下的无声表面肌电信号;
8.将无声表面肌电信号进行预处理和特征提取,得到无声肌电特征;
9.将无声肌电特征送入saem模型得到对应的有声肌电特征;
10.将对应的有声肌电特征送入到语音转换模型得到对应的音频特征;
11.使用语音合成模型将对应的音频特征转化为生成的音频信号,使用语音识别模型将生成的音频信号转为文本。
12.进一步地,所述saem模型,通过如下方式训练获得:
13.采集无声说话状态下的无声表面肌电信号及对应的信息,采集有声说话状态下的有声表面肌电信号和对应的音频信号;
14.对采集的无声表面肌电信号、有声表面肌电信号进行预处理和特征提取,得到无声肌电特征、有声肌电特征;
15.将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练saem模型和asem模型;
16.使用回译的方法优化saem模型。
17.进一步地,所述编码器-解码器网络为一个seq2seq网络,网络以conformer为编码器、自回归循环网络为解码器;
18.编码器由多个conformer模块组成,conformer模块由前馈神经网络子模块、多头注意力子模块,卷积子模块三个子模块组成,每个子模块之间使用残差连接;
19.所述前馈神经网络子模块,包括一个layernorm层,一个线性层,一个swish激活函数和dropout,计算方式如式(9)所示:
[0020][0021][0022]
其中,xi表示第i个维度输入;
[0023]
所述多头注意力子模块,包括一个layernorm,一个相对位置编码,一个dropout和一个自注意力机制,计算方式如式(10)所示:
[0024][0025]
其中,xi表示第i个维度输入;
[0026]
所述卷积子模块,包括一个layernorm,两个point-wise卷积,一个线性门单元,一个depth-wise卷积、一个batchnorm和一个dropout,计算方式如式(11)所示:
[0027]
[0028]
其中,xi表示第i个维度输入;
[0029]
整个conformer块的计算方式如式(12)所示:
[0030][0031]
其中,x是解码器的输入序列,x={x1,x2,
…
,xi,
…
xn},xi表示第i维信号特征输入,ffn()表示前馈神经网络子模块,mhsa()表示多头自注意力子模块,conv()表示卷积子模块,yi表示第i维conformer块的计算结果,;
[0032]
解码器是一个自回归循环神经网络,由一层pre-net网络、两层lstm、attention层、线性层和sigmoid组成,其计算方式如式(13)所示:
[0033][0034]
其中,x是解码器的输入序列,x={x1,x2,
…
,xi,
…
xn},x'都是中间变量,context是上下文向量,初始时被初始化为0;h是循环神经网络的隐藏向量;c是循环神经网络的记忆单元向量;s是编码器的输出,s={s1,s2,
…
,si,
…
sm},frame是解码器预测的信号特征,stop_token是解码的终止条件,在进行预测时,当stop_token大于某一阈值时,就终止预测;
[0035]
pre-net是双层全连接网络,每层由256个隐藏relu单元组成,表示为式(14)所示:
[0036]
prenet(x)=relu(relu(xwa ba)wb bb)
ꢀꢀ
(14)
[0037]
其中,wa是x的权重系数,ba是xwa的偏移量,wb是reluxwa ba)的权重系数,bb是relu(relu(xwa ba)wb的偏移量,relu(
·
)是激活函数,x是输入序列。
[0038]
进一步地,所述将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练生成saem模型和asem模型,包括:
[0039]
输入进入编码器网络和输入进入解码器网络;
[0040]
所述输入进入编码器网络包括:
[0041]
输入进入confromer模块;
[0042]
在conformer模块中,输入通过前馈神经网络子模块并乘以0.5进行缩放,加上原始输入,作为多头注意力子模块的输入;
[0043]
然后经过多头注意力子模块后,与输入相加,作为卷积子模块输入;
[0044]
再通过卷积子模块提取特征信息,与卷积子模块的输入相加,作为另一个前馈神经网络子模块的输入;
[0045]
最后输入经过前馈神经网络子模块,与输入相加,对结果进行归一化后,获得编码器网络的输出;
[0046]
输入进入解码器网络包括:
[0047]
解码器网络的输入和编码器网络的输出一起进入解码器网络进行解码;
[0048]
首先解码器网络的输入进入pre-net网络;
[0049]
pre-net的输出和注意力上下文向量拼接在一起,送入第一层lstm网络;第一层lstm的隐藏层结果和编码器网络的输出一起送入attention层得到注意力上下文向量,将第一层lstm的隐藏层结果和注意力上下文向量再次拼接在一起,送入第二次lstm网络,得到第二层lstm网络的隐藏层向量,将隐藏层向量与注意力上下文向量拼接,通过线性层得到输出,每一帧输出通过sigmoid层得到终止值;
[0050]
当输入为无声肌电特征,输出为有声肌电特征时,编码器-解码器网络用于训练无声肌电到有声肌电转换的saem模型;
[0051]
当输入为有声肌电特征,输出为无声肌电特征时,编码器-解码器网络用于训练有声肌电到无声肌电转换的asem模型。
[0052]
进一步地,所述使用回译的方法优化saem模型包括:
[0053]
将有声肌电特征aemg输入asem模型中生成无声肌电特征semg',将伪无声肌电特征semg'——aemg作为伪平行语料,和原来的平行语料semg——aemg一起作为训练数据,训练saem;使用mseloss作为损失优化函数;
[0054]
mseloss如下式(15)所示:
[0055][0056]
其中,yi是真实结果,是模型预测结果,n是样本数目。
[0057]
进一步地,所述语音转换模型,通过如下方式训练获得:
[0058]
建立转换网络,将提取的有声肌电特征及音频特征送入转换网络训练得到语音转换模型;
[0059]
所述转换网络由transformer编码器后接一个linear层组成;
[0060]
其中,编码器由多个编码块组成,每个编码块由多头注意力和前向神经网络两个子模块构成,对每个子模块的输出结果进行dropout并与输入一起进行标准化,并作为下一子模块的输入;每个子模块之间使用残差连接,子模块输入设置为相同维度;
[0061]
前向神经网络为全连接前馈网络,使用两个线性变换,激活函数为relu;
[0062]
多头注意力层使用点积注意力,输入为query、key、value向量,维度分别为dk、dk、dv,query、key、value是输入经过不同线性变换的结果;在计算时,分别计算query和不同key的点积,将点积结果除以并使用softmax函数计算key对应权重;使用矩阵进行并
行计算,编码块的计算如式(16)所示:
[0063][0064]
其中,q、k、v为query、key、value向量组成的矩阵,dk是k的维度,concat是拼接操作,headi是多头注意力中不同的头,attention_output是多头注意力模块残差连接后的输出,为中间计算结果,output是最终输出。wo是多头注意力线性变换的权重;
[0065]
转换网络使用transformer编码器对输入进行特征提取,后接一个linear层对提取的高维特征降维至mfcc特征维度,完成转换;
[0066]
所述有声肌电特征和音频特征,使用如下方式获得:
[0067]
采集有声说话状态下的有声表面肌电信号和对应的音频信号;
[0068]
对采集的有声表面肌电信号和音频信号进行预处理和特征提取,得到有声肌电特征和音频特征。
[0069]
进一步地,所述进行预处理和特征提取,包括:
[0070]
对采集的表面肌电信号进行滤波和工频噪声降噪;
[0071]
采用移动平均法对滤波降噪后的面部肌电信号进行活动段检测,分割出有效面部肌电信号段;
[0072]
提取出有效面部肌电信号段的时域特征;
[0073]
提取音频信号梅尔频率倒谱系数特征;
[0074]
所述提取音频信号梅尔频率倒谱系数特征包括:
[0075]
对采集的音频信号进行预加重、分帧、加窗;
[0076]
对每一个短时分析窗,通过快速傅里叶变换得到对应的变换后频谱;
[0077]
将变换后频谱通过mel滤波器组得到mel频谱;
[0078]
对mel频谱进行离散余弦变换得到mfcc系数;
[0079]
使用mfcc系数计算mfcc动态特征。
[0080]
本发明还提出一种基于回译的无声语音识别系统,所述系统包括:
[0081]
采集模块,用于采集无声说话状态下的无声表面肌电信号;
[0082]
处理模块,用于将无声表面肌电信号进行预处理和特征提取,得到无声肌电特征;
[0083]
无声转有声模块,用于将无声肌电特征送入saem模型得到对应的有声肌电特征;
[0084]
有声转音频模块,用于将对应的有声肌电特征送入到语音转换模型得到对应的音频特征;
[0085]
音特转音号模块,用于使用语音识别模型将对应的音频特征转化为生成的音频信号,
[0086]
音频转文本模块,用于使用语音识别模型将生成的音频信号转为文本。
[0087]
进一步地,所述saem模型,通过如下方式训练获得:
[0088]
采集无声说话状态下的无声表面肌电信号及对应的信息,采集有声说话状态下的有声表面肌电信号和对应的音频信号;
[0089]
对采集的无声表面肌电信号、有声表面肌电信号进行预处理和特征提取,得到无声肌电特征、有声肌电特征;
[0090]
将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练saem模型和asem模型;
[0091]
使用回译的方法优化saem模型。
[0092]
进一步地,所述使用回译的方法优化saem模型包括:
[0093]
将有声肌电特征aemg输入asem模型中生成无声肌电特征semg',将伪无声肌电特征semg'——aemg作为伪平行语料,和原来的平行语料semg——aemg一起作为训练数据,训练saem;使用mseloss作为损失优化函数;
[0094]
mseloss如下式(15)所示:
[0095][0096]
其中,yi是真实结果,是模型预测结果,n是样本数目。
[0097]
本发明所设计的一种基于回译的无声语音识别方法和系统,在模型训练方面做了改进,提出了一种利用编码器-解码器网络进行无声肌电信号和有声肌电信号间的转换,并且有创新性地将机器翻译中回译的方法迁移到肌电信号上,从而利用非平行数据提升无声语音识别效果,最终提升无声语音识别效果。
附图说明
[0098]
图1示出了本发明实施例中一种基于回译的无声语音识别方法的流程示意图;
[0099]
图2示出了本发明实施例中一种基于回译的无声语音识别系统的结构示意图;
[0100]
图3示出了本发明实施例中一种基于回译的无声语音识别方法中平行语料回译方法的示意图;
[0101]
图4示出了本发明实施例中一种基于回译的无声语音识别方法中非平行语料回译方法的示意图;
[0102]
图5示出了本发明实施例中一种基于回译的无声语音识别方法中编码器-解码器网络结构示意图;
[0103]
图6示出了本发明实施例中一种基于回译的无声语音识别方法中编码器-解码器网络中conformer模块网络结构示意图;
[0104]
图7示出了本发明实施例中一种基于回译的无声语音识别方法中转换模型的示意图;
[0105]
图8示出了本发明实施例中一种基于回译的无声语音识别方法中转换模型的示意图。
具体实施方式
[0106]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
[0107]
本发明设计一种基于回译的无声语音识别方法,如图1所示,包括:
[0108]
s1:采集无声说话状态下的无声表面肌电信号及对应的信息,采集有声说话状态下的有声表面肌电信号和对应的音频信号。
[0109]
表面肌电信号作为生物电信号,记录了肌肉运动信息,是肌肉中各个运动单元动作电位在时间和空间上的叠加。当人无声说话状态或有声说话状态时,脸部肌肉均会产生相应的表面肌电信号:无声表面肌电信号或有声表面肌电信号。
[0110]
采集无声表面肌电信号时,同时采集相同文本对应的有声表面肌电信号,用做平行语料。
[0111]
可以使用semg(表面肌电信号)采集装置采集相应的表面肌电信号。在采集有声表面肌电信号时,同时进行采集对应的音频信号。
[0112]
可以使用但不限于以下方式采集无声说话状态下的无声表面肌电信号及对应的信息:给出具体文字内容,其内容与有声说话时内容相同,当被采集人无声说话时,采集其无声表面肌电信号。
[0113]
在模型建立时,需要同时采集无声说话状态下的无声表面肌电信号及对应的信息,采集有声说话状态下的有声表面肌电信号和对应的音频信号。在进行无声语音识别时,仅需要采集无声说话状态下的无声表面肌电信号。
[0114]
s2:对采集的表面肌电信号和音频信号进行预处理和特征提取。
[0115]
采集的面部肌电信号包括无声表面肌电信号及有声表面肌电信号。采集的面部肌电信号和音频信号进行预处理和特征提取后,分别获得无声肌电特征、有声肌电特征和音频特征。
[0116]
s21:对采集的表面肌电信号进行滤波和工频噪声降噪。
[0117]
面部肌电信号采集过程中电极和皮肤表面形成偏移,采集过程中电极线移动、皮肤表面形变等产生移动伪迹噪声,主要分布在低频段,会对无声语音识别造成影响。面部肌电信号的有效信息范围在30~500hz,本发明采用高通滤波进行滤波,包括对无声表面肌电信号及有声表面肌电信号进行滤波。
[0118]
工频噪声是由交流电的工频干扰引起的,工频噪声的去除使用50hz的无限冲激响应陷波器,同时使用100hz,150hz,200hz,250hz和350hz的凹陷滤波器进行相应倍频的滤波。
[0119]
滤波和降噪后,获得滤波降噪后的面部肌电信号。无声肌电特征和有声肌电特征对应生成滤波降噪后的无声肌电信号和滤波降噪后的有声肌电信号。滤波降噪后的面部肌电信号包括滤波降噪后的无声肌电信号和滤波降噪后的有声肌电信号。
[0120]
s22:采用移动平均法对滤波降噪后的面部肌电信号进行活动段检测,分割出有效面部肌电信号段。
[0121]
目前活动段检测的方法主要有三种,分别是移动平均法、短时傅里叶变换法、基于
熵的理论方法。本发明使用移动平均法对滤波降噪后的面部肌电信号进行活动段检测。
[0122]
对所有通道的面部肌电信号绝对值求和再求其平均值,利用移动窗口,取一些连续时间段内面部肌电信号,求其局部绝对平均值,若其后点的均值都超过一定阈值,那么这就是动作开始点,反之,若其后若干点均值都小于阈值,则被认为是动作终止。通过这种方式,分割出有效面部肌电信号段,从而排除无效段的噪声干扰。
[0123]
滤波降噪后的无声肌电信号和滤波降噪后的有声肌电信号分割出有效无声肌电信号段和有效有声肌电信号段,有效面部肌电信号段包括有效无声肌电信号段和有效有声肌电信号段。
[0124]
s23:提取出有效面部肌电信号段的时域特征。
[0125]
时域特征包括高频成分、低频成分的平均值和均方值,信号的过零率。过零率(zero-crossingrate,zcr)是指在每帧中信号过零点的次数,即信号从负数变成正数,或信号从正转负。
[0126]
可以使用但是不限于三角滤波器将每个通道的信号分成高频和低频成分,再分别求高频成分、低频成分的平均值、均方及信号的过零率。
[0127]
有效面部肌电信号段提取出时域特征后,得到有效面部肌电信号段时域特征。有效面部肌电信号段时域特征包括有效无声肌电信号段时域特征和有效有声肌电信号段时域特征。
[0128]
s24:提取音频信号梅尔频率倒谱系数动态特征。
[0129]
梅尔频率倒谱系数(mfcc)是一种在语音识别和语音生成领域被广泛使用的特征。
[0130]
提取音频信号梅尔频率倒谱系数动态特征包括:
[0131]
s241:对采集的音频信号进行预加重、分帧、加窗。
[0132]
预加重是为了降低口唇辐射的影响,提高音频信号信噪比,使用差分方程实现预加重,如式(1)所示:
[0133]
y(n)=x(n)-α*x(n-1)
ꢀꢀ
(1)
[0134]
其中,n为音频信号的采样点,x(n)为采样点n所对应的音频信号,α为滤波器系数,y(n)为预加重后的音频信号。
[0135]
由于在信号处理中只能处理平稳,而音频信号在非常短的时间范围内可以认为是平稳信号,因此需要将语音分成小段,即使用分帧处理加重后的音频信号。以200个采样点为一帧长度,以50采样点为相邻帧移动的距离,不足一帧时补零。
[0136]
加窗是为了解决信号非周期截断造成的频谱拖尾现象泄露问题,使得信号更为连续。本发明可以使用多种加窗方式进行加窗,对已经分帧的音频信号进行加窗,如汉明窗、汉宁窗、矩形窗等。加窗后生成若干短时分析窗。
[0137]
s242:对每一个短时分析窗,通过快速傅里叶变换得到对应的变换后频谱。
[0138]
使用快速傅里叶变换(fft,fastfouriertransform)对每一个短时分析窗进行变换,得到对应的频谱。为满足fft“分治”策略,需要对帧长进行补零,使补零后长度为2的幂次方。
[0139]
使用式(2)得到对应的变换后频谱:
[0140]
[0141]
其中,y(k)为语音信号经fft变换后频谱,y(n)为输入的语音信号,n为傅里叶变换的点数,j表示复数。
[0142]
s243:将变换后频谱通过mel滤波器组得到mel频谱。
[0143]
人耳所听到的频率与声音频率并不成线性正比关系,使用mel频率更符合人耳听觉特性。因此需将实际频率尺度转换为mel频率尺度,如式(3)所示:
[0144][0145]
其中,f为原频谱,mel(f)为转换后的mel频谱。
[0146]
在mel频率域上确定最低频率mel_low、最高频率mel_high和mel滤波器个数l。
[0147]
将每一个三角滤波器中心频率c(l)在mel频率上等间隔分配。设o(l)、c(l)、h(l)分别为第l个三角形滤波器的最低频率(即mel_low)、中心频率、最高频率(即mel_high),则:
[0148]
c(l)=h(l-1)=o(l 1)
ꢀꢀ
(4)
[0149]
每个三角形滤波器w
l
(k)如式(5)所示:
[0150][0151]
其中,w
l
(k)为三角滤波器的频率响应,k为频率。
[0152]
使用三角滤波器对变换后频谱进行滤波,每一个三角滤波器输出的对数能量为对应的mel频谱,如式(6)所示:
[0153][0154]
其中,l为mel滤波器个数。
[0155]
s244:对mel频谱进行离散余弦变换得到mfcc系数。
[0156]
对mel频谱进行离散余弦变换(dct)得到mfcc系数,如式(7)所示:
[0157][0158]
l是三角滤波器个数,q是mfcc系数阶数,通常取12-16。
[0159]
s245:使用mfcc系数计算mfcc动态特征。
[0160]
mfcc系数仅体现了当前帧的语音特性,是mfcc的静态特征,为了使特征体现时序连续性,可对静态特征进行差分,得到静态特征的一阶差分,如式(8)所示:
[0161][0162]
d(t)是第t个一阶差分值,c(t)是第t个倒谱系数值,q是倒谱系数的最大阶数,k是一阶差分的时间差,一般可取1或取2。
[0163]
静态特征的二阶差分则将上式结果再次代入进行计算即可。
[0164]
最后,再将静态特征和一阶差分、二阶差分值合并起来得到mfcc动态特征。
[0165]
mfcc动态特征即提取音频信号梅尔频率倒谱系数特征后得到音频特征。
[0166]
s23与s24不分先后顺序,可以同时进行,也可以任意顺序进行。
[0167]
s3:将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练生成saem模型和asem模型。
[0168]
本发明的编码器-解码器网络为一个seq2seq网络,网络以conformer为编码器、自回归循环网络为解码器,如图5所示。
[0169]
编码器由多个conformer模块组成,如图6所示,conformer模块由前馈神经网络子模块(feed forward module)、多头注意力子模块(multi-head self-attention module)、卷积子模块(convolution module)三个子模块组成,每个子模块之间使用残差连接。
[0170]
所述前馈神经网络子模块,包括一个layernorm层,一个线性层,一个swish激活函数和dropout,前馈神经网络子模块计算方式记为y1=ffn(x),如式(9)所示:
[0171][0172][0173]
其中,xi表示第i个维度输入,x'i、x
″i、x
″′i都是中间变量;其中swish()激活函数如下所示:
[0174]
f(x)=x
·
sigmoid(x)
[0175]
x是变量,sigmoid函数为
[0176]
所述多头注意力子模块,包括一个layernorm,一个相对位置编码,一个dropout和一个自注意力机制,多头注意力子模块计算方式记为y2=mhsa(x),如式(10)所示:
[0177][0178]
其中,xi表示第i个维度输入,x'i、x
″i都是中间变量。
[0179]
所述卷积子模块,包括一个layernorm,两个point-wise卷积,一个线性门单元(gatedlinearunit),一个depth-wise卷积,一个batchnorm和一个dropout,卷积子模块计算方式记为y3=conv(x),如式(11)所示:
[0180][0181]
其中,xi表示第i个维度输入,x'i、x
″i、x
″′i都是中间变量。
[0182]
整个conformer块的计算方式如式(12)所示:
[0183][0184]
其中,x是解码器的输入序列,x={x1,x2,
…
,xi,
…
xn},xi表示第i维信号特征输入,ffn()表示前馈神经网络子模块,mhsa()表示多头自注意力子模块,conv()表示卷积子模块,yi表示第i维conformer块的计算结果,x'
i1
、x
″
i1
都是中间变量。
[0185]
解码器是一个自回归循环神经网络,根据编码器的输出序列和解码器的输入序列预测输出,每次预测一帧。解码器由一层pre-net网络、两层lstm、attention层、线性层和sigmoid组成,其计算方式如式(13)所示:
[0186][0187]
其中,x是解码器的输入序列,x={x1,x2,
…
,xi,
…
xn},x'都是中间变量,context是上下文向量,初始时被初始化为0;h是循环神经网络的隐藏向量;c是循环神经网络的记忆单元向量;s是编码器的输出,s={s1,s2,
…
,si,
…
sm},frame是解码器预测的信号特征,stop_token是解码的终止条件,在进行预测时,当stop_token大于某一阈值时,就终
止预测。
[0188]
其中,pre-net是双层全连接网络,每层由256个隐藏relu单元组成,可以表示为式(14)所示:
[0189]
prenet(x)=relu(relu(xwa ba)wb bb)
ꢀꢀ
(14)
[0190]
其中,wa是x的权重系数,bx是xwa的偏移量,wb是relu(xwa ba)的权重系数,bb是relu(relu(xwa ba)wb的偏移量,relu(
·
)是激活函数,x是输入序列。pre-net对于模型学习注意力是非常有用的。
[0191]
在编码器-解码器网络,输入进入编码器网络:输入进入confromer模块,在conformer模块中输入通过前馈神经网络子模块并乘以0.5进行缩放,加上原始输入,作为多头注意力子模块的输入;然后经过多头注意力子模块后与输入相加作为卷积子模块输入;再通过卷积子模块提取特征信息,与卷积模块的输入相加,作为另一个前馈神经网络子模块的输入;最后输入经过前馈神经网络子模块与输入相加,对结果进行归一化为编码器网络的输出;解码器网络的输入和编码器网络的输出一起进入解码器网络进行解码,首先解码器的输入经过双层全连接网络(pre-net),pre-net的输出和注意力上下文向量拼接在一起(注意力上下文向量被初始化为零,经过一步计算后被更新),送入第一层lstm网络,第一层lstm的隐藏层结果和编码器网络的输出一起送入attention层,得到注意力上下文向量,将第一层lstm的隐藏层结果和注意力上下文向量再次拼接在一起,送入第二次lstm网络,得到第二层lstm网络的隐藏层向量,将隐藏层与注意力上下文向量拼接,通过线性层得到输出,每一帧输出通过sigmoid层得到终止值。
[0192]
当输入为无声肌电特征,输出为有声肌电特征时,这个seq2seq网络用于训练无声肌电到有声肌电转换的saem模型。当输入为有声肌电特征,输出为无声肌电特征时,这个seq2seq网络用于训练有声肌电到无声肌电转换的asem模型。
[0193]
s4:使用回译的方法优化saem模型。
[0194]
本发明使用回译(back translation)的方法,提高无声肌电转有声肌电效果,用于优化saem模型,如图3、图4所示。
[0195]
语料,即语言材料。语料是语言学研究的内容。语料是构成语料库的基本单元。平行语料,指收录了具有同一含义的不同表示的语料,以机器翻译为例,即两种语言文本的语料,两种语言的文本互为译文。由于无声肌电——有声肌电的平行语料数据集较少,采集无声肌电信号难度较高,本发明采用回译的方法充分利用非平行语料——有声肌电,提升识别效果。
[0196]
回译是机器翻译中常见的数据增强方法,用于解决训练时“源语言——目标语言”样本对数据不足的问题。在机器翻译领域中的具体做法是将目标语言y翻译为源语言x',该翻译通过模型推理实现,将翻译得到的“伪源语言x'——y”作为平行语料和原来的平行语料一起,训练源语言到目标语言的机器翻译模型。一般是通过将数翻译为另一种语言再译回源语言。
[0197]
本发明使用这种数据增强的方法,将该方法用于优化saem模型。
[0198]
在s3中,已经分别得到了无声肌电转有声肌电模型saem和有声肌电转无声肌电模型asem。对于较为丰富的非平行有声肌电语料,使用回译的方法,将有声肌电特征aemg输入asem模型中生成无声肌电特征semg',将伪无声肌电特征semg'——aemg作为伪平行语料,
和原来的平行语料semg——aemg一起作为训练数据,训练saem,理想情况下,生成的新有声肌电特征aemg'应该与原肌电特征aemg有相同的分布,可以用mse loss作为损失优化函数,亦或其他衡量数据分布的损失函数。
[0199]
mse loss如下式(15)所示:
[0200][0201]
其中,yi是真实结果,是模型预测结果,n是样本数目。
[0202]
本发明在模型训练时只优化saem模型。
[0203]
当saem模型训练好后,将无声肌电特征送入saem模型,得到对应的有声肌电特征。
[0204]
s5:建立一个有声肌电特征到音频特征的语音转换模型,并使用语音转换模型对对应的有声肌电特征进行转换。
[0205]
本发明还通过训练,得到语音转换模型,用于将有声肌电特征转为音频特征。
[0206]
本发明先建立转化网络,在建立网络时,可选择双向lstm网络、双向gru网络、transformer encoder(transformer的编码器)等。以下以transformer的编码器作为转换网络结构为例进行说明。
[0207]
转换网络由transformer编码器后接一个linear层组成,如图7所示,其中,编码器由多个编码块组成,每个编码块由多头注意力(multi-head self-attention mechanism)和前向神经网络(fully connected feed-forward network)两个子模块构成,对每个子模块的输出结果进行dropout并与输入残差连接后进行标准化,并作为下一子模块的输入。子模块输入设置为相同维度。通过子模块之间使用残差连接和标准化,提升模型准确性,加速模型收敛。前向神经网络为全连接前馈网络,使用两个线性变换,激活函数为relu。其中多头注意力使用点积注意力,输入为query、key、value向量,维度分别为dk、dk、dv,query、key、value是输入经过不同线性变换的结果。在计算时,分别计算query和不同key的点积,将点积结果除以并使用softmax函数计算key对应权重。将q、k、v分为h个部分,每个部分关注不同的内容,qi,ki,vi就是q、k、v的第i部分。每个qi,ki,vi计算的注意力结果headi称为一个头。编码块如图8所示,其计算如式(16)所示:
[0208][0209]
其中,q、k、v为query、key、value向量组成的矩阵,dk是k的维度,concat是拼接操作,headi是多头注意力中不同的头,attention_output是多头注意力模块残差连接后的输出,为中间计算结果,output是最终输出。wo是多头注意力线性变换的权重。
[0210]
转换网络首先使用transformer编码器对输入进行特征提取,后接一个linear层对提取的高维特征降维至mfcc特征维度,完成转换。将提取的有声肌电特征及音频特征送入转换网络中,其中,有声肌电特征为输入,音频特征为输出,辅助使用音频的对应文本对齐信息对预测结果进行限制,损失函数使用mse loss或其他损失函数,如dtw对齐距离等。通过训练,得到语音转换模型。
[0211]
生成语音转换模型后,将对应的有声肌电特征转为对应的音频特征。
[0212]
s6:建立一个音频特征到语音信号的语音合成模型,使用语音合成模型将对应的音频特征转换为生成的音频信号,使用现有语音识别模型将生成的音频信号转为文本。
[0213]
本发明采用常用的声码器模型wavenet建立语音合成模型。将音频特征及对应的音频信号,送入wavenet模型中进行训练,生成语音合成模型。
[0214]
使用语音合成模型将对应的音频特征转换为生成的音频信号,再使用现有语音识别模型将生成的音频信号转为文本。语音识别模型可以有多种选择,如科大讯飞、云知声、腾讯等语音识别系统等。
[0215]
本发明实施例提供了一种基于回译的无声语音识别的系统,如图2所示,
[0216]
所述系统包括:
[0217]
采集模块,用于采集无声说话状态下的无声表面肌电信号;
[0218]
处理模块,用于将无声表面肌电信号进行预处理和特征提取,得到无声肌电特征;
[0219]
无声转有声模块,用于将无声肌电特征送入saem模型得到对应的有声肌电特征;
[0220]
有声转音频模块,用于将对应的有声肌电特征送入到语音转换模型得到对应的音频特征;
[0221]
音特转音号模块,用于使用语音合成模型将对应的音频特征转化为生成的音频信号,
[0222]
音频转文本模块,用于使用语音识别模型将生成的音频信号转为文本。
[0223]
所述saem模型,通过如下方式训练获得:
[0224]
采集无声说话状态下的无声表面肌电信号及对应的信息,采集有声说话状态下的有声表面肌电信号和对应的音频信号;
[0225]
对采集的无声表面肌电信号、有声表面肌电信号进行预处理和特征提取,得到无声肌电特征、有声肌电特征;
[0226]
将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练saem模型和asem模型;
[0227]
使用回译的方法优化saem模型。
[0228]
所述使用回译的方法优化saem模型包括:
[0229]
将有声肌电特征aemg输入asem模型中生成无声肌电特征semg',将伪无声肌电特征semg'——aemg作为伪平行语料,和原来的平行语料semg——aemg一起作为训练数据,训练saem;使用mse loss作为损失优化函数;
[0230]
mse loss如下式(15)所示:
[0231][0232]
其中,yi是真实结果,是模型预测结果,n是样本数目。
[0233]
本发明所设计的一种基于回译的无声语音识别方法和系统,在模型训练方面做了改进,提出了一种利用编码器-解码器网络进行无声肌电信号和有声肌电信号间的转换,并且有创新性地将机器翻译中回译的方法迁移到肌电信号上,从而利用非平行数据提升无声语音识别效果,最终提升无声语音识别效果。
[0234]
以上仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。