1.本技术涉及声学测量领域,尤其涉及室内声学参数测定方法、模型构建方法、装置及电子设备。
背景技术:
2.室内的声学参数,如混响时间等,对于建筑声学设计、实施和改造具有关键的意义,同时也是评估该房间是否满足声学设计和声学功能的核心指标。
3.传统的测量方法分为直接法和间接法,参见gb/t36075-2018“声学室内声学参量测量”和gb/t 4959-2011“厅堂扩声特性测量方法”。直接法如声源中断法,即在房间内播放宽频噪声信号,然后突然中断,通过声级计、数字采集设备等记录下该信号衰减的过程并分析得到室内的混响时间;间接法通过在室内产生一个脉冲信号,如发令枪、扎气球、点燃鞭炮等,或者用人工声源播放mls序列、扫频信号等形式,记录并得到该房间内的脉冲响应,利用脉冲响应对时间方向积分的方法得到混响时间、语音传输指数、早期反射声、清晰度和明晰度等室内声学指标。
4.上述的两种方法,对硬件、软件和测量人员,都有较高的要求:硬件上需要用功率放大器、无指向多面体声源、信号发生器、连接的线缆等,软件上需要相关的专用声学分析、计算软件,这些软硬件都价格昂贵,且体积较大,携带不方便;人员方面需要熟悉测量的标准,具有一定的测量经验,经过专业的培训方可执行测量任务,同时根据待测房间的大小不同,至少需要配备2人以上方可完成。这些特性都大大限制了室内声学参数测量的效率、测量成本居高不下、甚至在广大二三线城市都无法找到专业设备和合格人员进行测量,造成了大量功能房间(如办公室、教室、培训室、会议室等)声学性能无法获知,更谈不上针对性的声学改造和提升。
5.近些年来随着机器学习的技术不断发展,利用在室内录取一段清晰的语音信号,获取目标语谱图,再利用机器学习的各种模型和算法,加入事先用传统方法测量得到的声学参数进行训练,可以实现在新的房间测量室内声学参数的目的,如专利cn111785292a。但是该方法对于背景噪声的要求较高,也需要录取较长时间的语音,并且在此期间需要保持较安静的状态,不利于短时间大规模的测量,测量结果也被房间内的信噪比所影响。
6.因此,需要寻找一种测定方法简单便捷且测定结果准确的室内声学参数测定方法。
7.申请内容
8.本技术的目的在于提供一种室内声学参数测定方法、模型构建方法、装置及电子设备,其能简便快捷地测定待测房间的室内声学参数。
9.为实现上述申请目的,本技术提出了如下技术方案:
10.第一方面,提供室内声学参数测定方法,所述测定方法包括:
11.获取与当前所在的待测房间中的目标声信号对应的待处理音频数据;
12.基于所述待处理音频数据生成相应的目标语谱图;
13.基于所述目标语谱图,通过预先构建的室内声学参数测定模型进行预测获得所述待测房间的目标室内声学参数;
14.所述目标声信号为猝发声或脉冲信号中的一种。
15.在一种较佳的实施方式中,所述获取与当前所在的待测房间中的目标声信号对应的待处理音频数据,包括:
16.获取当前所在待测房间中预设时长的初始音频数据;
17.对所述初始音频数据进行预处理获得待处理音频数据;
18.判断所述待处理音频数据是否为猝发声或脉冲信号。
19.在一种较佳的实施方式中,所述判断所述待处理音频数据是否为猝发声或脉冲信号,包括:
20.对所述待处理音频数据进行端点检测;
21.将所述待处理音频数据进行分帧并计算每一音频帧的平均幅度,并确定平均幅度最大的音频帧max;
22.确定有效脉冲前边界帧及有效脉冲后边界帧以确定有效脉冲宽度;
23.分别所述计算待处理音频数据的上升比及下降比;
24.根据所述有效脉冲宽度、所述上升比及所述下降比判断所述待处理音频是否为猝发声或脉冲信号。
25.在一种较佳的实施方式中,所述基于所述待处理音频数据生成相应的目标语谱图,包括:
26.将所述待处理音频数据按照预设时长划分为至少一个单位音频数据;
27.对每一所述单位音频数据进行端点检测以获得至少一段有效声音片段;
28.基于所述至少一段有效声音片段生成至少一个目标语谱图。
29.在一种较佳的实施方式中,所述对每一所述单位音频数据进行端点检测以获得至少一段有效声音片段,包括:
30.对所述单位音频数据进行分帧处理获得至少一个音频帧;
31.对所述至少一个音频帧进行特征提取,获得至少一个与任一所述音频帧对应的特征参数;
32.根据所述至少一个所述特征参数对所述至少一个音频帧进行分类,确定所述至少一个音频帧中的至少一个有效音频帧;
33.将所述至少一个有效音频帧合并获得所述至少一段有效声音片段。
34.在一种较佳的实施方式中,所述根据所述至少一个所述特征参数对所述至少一个音频帧进行分类,确定所述至少一个音频帧中的至少一个有效音频帧,包括:
35.基于所述至少一个音频帧的音频率计算相应的能量;
36.判断任一所述音频帧的能量是否属于预设阈值;
37.若是,则任一所述音频帧为有效音频帧。
38.在一种较佳的实施方式中,所述基于所述至少一段有效声音片段生成至少一个目标语谱图,包括:
39.将所述至少一段有效声音片段进行滤波处理获得至少一端滤波后有效声音片段;
40.将所述至少一端滤波后有效声音片段进行傅里叶变换获得至少一个目标语谱图,
所述至少一个目标语谱图包括至少一个频带的声信号能量随时间的分布。
41.在一种较佳的实施方式中,所述测定方法还包括:预先构建室内声学参数测定模型,包括:
42.获取至少一个房间的至少一个音频数据样本及相应测得的至少一个室内声学参数样本;
43.基于所述至少一个音频数据样本生成相应的至少一个语谱图样本;
44.基于所述至少一个语谱图样本及所述至少一个室内声学参数样本构建所述室内声学参数测定模型。
45.在一种较佳的实施方式中,所述基于所述至少一个语谱图样本及所述至少一个室内声学参数样本构建所述室内声学参数测定模型,包括:
46.对所述至少一个语谱图样本进行特征提取获得至少一个语谱图特征;
47.基于所述至少一个语谱图特征及所述至少一个室内声学参数样本,在预设损失函数的监督下进行预设神经网络的参数更新,获得所述室内声学参数测定模型。
48.在一种较佳的实施方式中,所述待处理音频数据及至少一个音频数据样本的信噪比大于25db。
49.第二方面,提供一种室内声学参数测定模型构建方法,所述测定模型构建方法包括:
50.获取至少一个房间的至少一个音频数据样本及相应测得的至少一个室内声学参数样本;
51.基于所述至少一个音频数据样本生成相应的至少一个语谱图样本;
52.基于所述至少一个语谱图样本及所述至少一个室内声学参数样本构建所述室内声学参数测定模型;
53.所述音频数据样本为猝发声或脉冲信号中的一种。
54.第三方面,提供一种室内声学参数测定装置,所述测定装置包括:
55.获取模块,用于获取与目标声信号对应的待处理音频数据;所述目标声信号为猝发声或脉冲信号中的一种;
56.生成模块,用于基于所述待处理音频数据生成相应的目标语谱图;
57.测定模块,用于基于所述目标语谱图,通过预先构建的室内声学参数测定模型进行预测获得相应的目标室内声学参数。
58.第四方面,提供一种电子设备,包括:
59.一个或多个处理器;以及
60.与所述一个或多个处理器关联的存储器,所述存储器用于存储程序指令,所述程序指令在被所述一个或多个处理器读取执行时,执行如第一方面中任意一项所述的操作。
61.第五方面,提供一种计算机可读存储介质,其上存储有计算机程序,
62.其中,该程序被处理器执行时实现如第一方面中任一项所述的方法。
63.与现有技术相比,本技术具有如下有益效果:
64.本技术提供了一种室内声学参数测定方法、模型构建方法、装置及电子设备,其中的室内声学参数测定方法包括获取与当前所在的待测房间中的目标声信号对应的待处理音频数据;基于待处理音频数据生成相应的目标语谱图;基于目标语谱图,通过预先构建的
室内声学参数测定模型进行预测获得所述待测房间的目标室内声学参数;音频数据样本为猝发声或脉冲信号中的一种;该室内声学参数测定方法的操作时间极短,通过简单的录音设备获得音频数据并结合预设模型即可测定待测房间的室内声学参数,故对人员、设备的要求较低,极大地提高了室内声学参数测定的便捷性并有效降低测定成本;进一步,该测定方法基于机器学习方法预先构建的室内声学参数测定模型实现,以待处理音频数据相应的目标语谱图为输入,以目标室内声学参数为输出,从而实现室内声学参数的准确测定。
附图说明
65.图1是本实施例中室内声学参数测定方法的流程图;
66.图2是本实施例中判断待处理音频数据是否为猝发声或脉冲信号的流程图;
67.图3是本实施例中室内声学参数测定模型构建方法的流程图;
68.图4是本实施例中室内声学参数测定装置的结构图。
具体实施方式
69.为使本技术的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
70.在本技术的描述中,需要理解的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本技术的描述中,除非另有说明,“多个”的含义是两个或两个以上。
71.针对目前室内声学参数测定方法对于测定人员、设备要求较高的现状,本实施例体提供一种简单快捷的室内声学参数测定方法,其对于测定人员及设备要求较低,且测定精度较高。
72.下面将结合具体的实施例对室内声学测定方法、模型构建方法、装置及电子设备做进一步具体的描述。
73.实施例
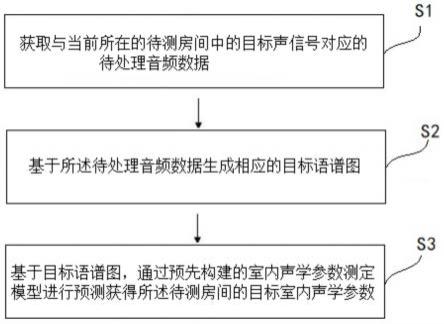
74.如图1所示,本实施例提供一种室内声学参数测定方法,包括如下步骤:
75.s1、获取与当前所在的待测房间中的目标声信号对应的待处理音频数据。
76.通常的,本实施例中的待处理音频数据的信噪比大于25db,以能清楚地与环境音做区分。
77.示例性的,目标声信号为在当前所在的待测房间内发出猝发声或脉冲信号中的一种,包括但不限于单次的发令枪声、扎破大气球的声音、鞭炮声、电火花声、鼓掌声等。此类声信号的脉冲声压级较高,较易与环境音区分以进行目标声信号提取,故可以在很多背景噪声影响大的场所进行测量,测量的有效频段也向低频延伸,对环境的要求大大降低。
78.具体地,步骤s1包括:
79.s11、获取当前所在待测房间中预设时长的初始音频数据;
80.具体的,本实施例可采用普通的/便携式的录音设备,如手机、录音笔等设备录制
该初始音频数据。针对前述涉及的目标声信号类型,录制时间可以为1~10分钟等较短的时长。因此,该室内声学参数测定方法对设备要求不高,录制时间短,快捷方便。
81.s12、对初始音频数据进行预处理获得待处理音频数据。
82.在一种优选的实施方式中,对初始音频数据进行预处理通常包括但不限于预加重、分帧、加窗等,目的是消除发声设备本身和由于初始音频信号的设备所带来的混叠、高次谐波失真、高频等等因素,对初始音频信号质量的影响,尽可能保证后续音频处理得到的信号更均匀、平滑,为信号参数提取提供优质的参数,提高音频处理质量。
83.s13、判断待处理音频数据是否为猝发声或脉冲信号。
84.具体的,如图2所示,步骤s13包括:
85.s131、对待处理音频数据进行端点检测,找到声音的开始点和结束点。
86.s132、将待处理音频数据进行分帧并计算每一音频帧的平均幅度,并确定平均幅度最大的音频帧max,其平均幅度为m(max)。
87.具体的,采用如下公式(1)计算任一音频帧的平均幅值m(i):
[0088][0089]
其中,p表示第i个音频帧中任一采样位点序数;l表示每一音频帧的采样位点数,示例性的,当采样率为16000hz时,l取160。将待处理音频数据所有的音频帧按序排列并将平均幅度最大的音频帧记为max。
[0090]
s133、确定有效脉冲前边界帧及有效脉冲后边界帧以确定有效脉冲宽度。
[0091]
具体的,在步骤s132确定平均幅度最大的音频帧max之后,向前n帧找到有效脉冲前边界帧,记为max-n。该有效脉冲前边界帧的平均幅度为m(max)*tv1,tv1取值优选0.2。以及,在音频帧max向后m帧找到有效脉冲后边界帧,记为max m,该有效脉冲后边界帧的平均幅度为m(max)*tv2,tv2取值优选0.3。因此,该有效脉冲声的宽度为m n帧。其中,m、n分别为音频帧间隔数量,且m>1,n>1。
[0092]
s134、分别计算上升比r1及下降比r2。
[0093]
上升比r1是有效脉冲声宽度m n帧的平均幅度与有效脉冲声开始前的前v帧平均幅度的平均值之比,以如下公式(2)所示计算获得:
[0094][0095]
其中,j、h均为整数,且k≥1。
[0096]
下降比r2是脉冲声m n帧平均幅度与有效脉冲声结束后的后m帧平均幅度的平均值之比,以如下公式(3)所示计算获得:
[0097][0098]
其中,j、h均为整数,且h≥1。
[0099]
s135、根据有效脉冲宽度、上升比及下降比判断待处理音频是否为猝发声或脉冲信号。
[0100]
判断待处理音频数据的脉冲宽度(m n)是否小于预先设置的音频数据的脉冲宽度
阈值tw,以及判断上升比r1是否大于预设上升比阈值tr1,以及判断下降比r2是否大于下降比阈值tr2。若判断结果均为是,则判断待处理音频数据为猝发声或脉冲信号,执行下述步骤s2,若其中任一项判断结果为否,则判断不是猝发声或脉冲信号,结束。
[0101]
示例性的,tw为10,tr1为40,tr2为30。
[0102]
s2、基于待处理音频数据生成相应的目标语谱图。
[0103]
步骤s2具体包括:
[0104]
s21、将待处理音频数据按照预设时长划分为至少一个单位音频数据。
[0105]
s22、对每一单位音频数据进行端点检测以获得至少一段有效声音片段。
[0106]
进一步,步骤s22具体包括:
[0107]
s221、对任一单位音频数据进行分帧处理获得至少一个音频帧;
[0108]
s222、对至少一个音频帧进行特征提取,获得至少一个与任一音频帧对应的特征参数;
[0109]
s223、根据至少一个特征参数对至少一个音频帧进行分类,确定至少一个音频帧中的至少一个有效音频帧。
[0110]
更进一步的,步骤s223包括:
[0111]
基于至少一个音频帧的音频率计算相应的能量;
[0112]
判断任一音频帧的能量是否属于预设阈值;
[0113]
若是,则该任一音频帧为有效音频帧用于下一步骤s224;若否,则该任一音频帧为无效音频帧,舍弃。
[0114]
示例性的,在对音频帧进行能量计算时,第i帧语音信号yi(n)的短时能量公式为采用如下式(4)计算获得:
[0115][0116]
式中,yi(n)是分帧处理后第i帧的语音信号数值,n=1,2,
…
,l,i=1,2,
…
,fn,l表示每一音频帧的采样位点数,e(i)为第i帧的短时能量。
[0117]
yi(n)满足如下式(5):
[0118]
yi(n)=w(n)*x((i-1)*inc n)
ꢀꢀꢀꢀ
(5)
[0119]
式中,x(n)为语音波形时域信号,w(n)为加窗函数,inc为帧移长度;n为分帧后的总帧数。1≤n≤l,1≤i≤f。
[0120]
s224、将至少一个有效音频帧合并获得至少一段有效声音片段。
[0121]
当然,在步骤s214后,还需对获得的至少一段有效声音片段作平滑处理,以便后续处理。
[0122]
s23、基于至少一段有效声音片段生成至少一个目标语谱图。
[0123]
进一步,步骤s23包括:
[0124]
s231、将至少一段有效声音片段进行滤波处理获得至少一段滤波后有效声音片段;
[0125]
s232、将至少一端滤波后有效声音片段进行傅里叶变换获得至少一个目标语谱图,所述至少一个目标语谱图包括至少一个频带的声信号能量随时间的分布。
[0126]
当然,上述至少一个频带,也可以是倍频程或三分之一倍频程等预设值,此处不作
限制。
[0127]
需要说明的是,当划分后的一个单位音频时长t(t》0),则任一目标语谱图包括至少一个频带的声信号能量在t时长内随时间的分布。
[0128]
s3、基于目标语谱图,通过预先构建的室内声学参数测定模型进行预测获得该待测房间的目标室内声学参数。
[0129]
室内声学参数,指房间的混响时间、语音传输指数、早期反射声、清晰度和明晰度等,与房间本身的结构及所采用的建筑材料相关。
[0130]
进一步的,当获得目标语谱图后,通过室内声学参数测定模型对目标语谱图进行特征提取获得至少一个目标语谱图特征;基于至少一个目标语谱图特征,通过室内声学参数测定模型获得该待测房间目标室内声学参数,包括但不限于各频带的混响时间、语音传输指数、早期反射声、清晰度和明晰度。
[0131]
当然,在进行测定之前,如图3所示,该测定方法还包括s0、预先构建室内声学参数测定模型,故本实施例进一步提供一种室内声学参数测定模型构建方法,该测定模型构建方法包括:
[0132]
s01、获取至少一个房间的至少一个音频数据样本及相应测得的至少一个室内声学参数样本。其中,音频数据样本为猝发声或脉冲信号中的一种。
[0133]
同样的,本实施例中的至少一个室内声学参数样本的信噪比均大于25db,以能清楚地与环境音做区分。
[0134]
s02、基于至少一个音频数据样本生成相应的至少一个语谱图样本;该步骤s02的操作与上述步骤s2相似,此处不再赘述。
[0135]
s03、基于至少一个语谱图样本及至少一个室内声学参数样本构建室内声学参数测定模型。
[0136]
其中,步骤s03具体包括:
[0137]
s03a、对至少一个语谱图样本进行特征提取获得至少一个语谱图特征;
[0138]
s03b、基于至少一个语谱图特征及至少一个室内声学参数样本,在预设损失函数监督下进行预设神经网络的参数更新,获得室内声学参数测定模型。
[0139]
在一种较佳的实施方式中,预设神经网络包括但不限于卷积神经网络cnn、循环神经网络rnn、卷积循环神经网络crnn等。当采用cnn/crnn进行训练时,网络结构包括p个block,每个block包含但不限于卷积层、归一化层、激活层、lstm层等。
[0140]
以及,预设损失函数采用回归损失函数,包括安不限于l1 loss、l2 loss及smooth l1 loss。
[0141]
综上,本实施例提供的室内声学参数测定方法的操作时间极短,通过简单的录音设备获得音频数据即可,故对人员、设备的要求较低,极大地提高了室内声学参数测定的便捷性并有效降低测定成本;进一步,该测定方法基于机器学习方法预先构建的室内声学参数测定模型,以待处理音频数据相应的目标语谱图为输入,以目标室内声学参数为输出,从而实现室内声学参数的准确测定。
[0142]
本实施例还提供一种室内声学参数测定装置,如图4所示,该测定装置包括:
[0143]
获取模块,用于获取与当前所在的待测房间中的目标声信号对应的待处理音频数据;其中,目标声信号为猝发声或脉冲信号中的一种。
[0144]
生成模块,用于基于所述待处理音频数据生成相应的目标语谱图。
[0145]
进一步,生成模块包括:
[0146]
划分子模块,用于将所述待处理音频数据按照预设时长划分为至少一个单位音频数据;
[0147]
第一生成子模块,用于对每一所述单位音频数据进行端点检测以获得至少一段有效声音片段。
[0148]
更进一步,第一生成子模块包括:
[0149]
第一处理单元,包括对任一所述单位音频数据进行分帧处理获得至少一个音频帧。
[0150]
第一提取单元,用于对所述至少一个音频帧进行特征提取,获得至少一个与任一所述音频帧对应的特征参数。
[0151]
分类单元,用于根据所述至少一个所述特征参数对所述至少一个音频帧进行分类,确定所述至少一个音频帧中的至少一个有效音频帧。
[0152]
具体地,分类单元具体用于:
[0153]
基于所述至少一个音频帧的音频率计算相应的能量;
[0154]
判断任一所述音频帧的能量是否属于预设阈值;
[0155]
若是,则任一所述音频帧为有效音频帧。
[0156]
合并单元,用于将所述至少一个有效音频帧合并获得所述至少一段有效声音片段。
[0157]
第二生成子模块,用于基于所述至少一段有效声音片段生成至少一个目标语谱图。
[0158]
具体地,第二生成子模块包括:
[0159]
滤波单元,用于将所述至少一段有效声音片段进行滤波处理获得至少一段滤波后有效声音片段;
[0160]
第二处理单元,用于将至少一段滤波后有效声音片段进行傅里叶变换获得至少一个目标语谱图,所述至少一个目标语谱图包括至少一个频带的声信号能量随时间的分布。
[0161]
测定模块,用于基于所述目标语谱图,通过预先构建的室内声学参数测定模型进行预测获得所述待测房间的目标室内声学参数。
[0162]
该室内声学参数测定装置还包括模型构建模块,用于预先构建室内声学参数测定模型,模型构建模块包括:
[0163]
获取子模块,用于获取至少一个房间的至少一个音频数据样本及相应测得的至少一个室内声学参数样本;所述音频数据样本为猝发声或脉冲信号中的一种。
[0164]
第三生成子模块,用于基于所述至少一个音频数据样本生成相应的至少一个语谱图样本;
[0165]
模型构建子模块,用于基于所述至少一个语谱图样本及所述至少一个室内声学参数样本构建所述室内声学参数测定模型。
[0166]
其中,模型构建子模块包括:
[0167]
第二提取单元,用于对所述至少一个语谱图样本进行特征提取获得至少一个语谱图特征;
[0168]
模型构建单元,用于基于所述至少一个语谱图特征及所述至少一个室内声学参数样本,在预设损失函数的监督下进行预设神经网络的参数更新,获得所述室内声学参数测定模型。
[0169]
需要说明的是:上述实施例提供的室内声学参数测定装置在进行室内声学参数测定业务时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将系统的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的室内声学参数测定装置与室内声学参数测定方法的实施例属于同一构思,即该装置是基于该方法的,其具体实现过程详见方法实施例,这里不再赘述。
[0170]
以及,本实施例还提供一种电子设备,包括:
[0171]
一个或多个处理器;以及
[0172]
与所述一个或多个处理器关联的存储器,所述存储器用于存储程序指令,所述程序指令在被所述一个或多个处理器读取执行时,执行如室内声学参数测定方法任意一项所述的操作。
[0173]
关于执行程序指令所执行的室内声学参数测定方法,具体执行细节及相应的有益效果与前述方法中的描述内容是一致的,此处将不再赘述。
[0174]
以及,本实施例还提供一种计算机可读存储介质,其上存储有计算机程序,其中,该程序被处理器执行时实现如室内声学参数测定方法中任一项所述的方法。
[0175]
上述所有可选技术方案,可以采用任意结合形成本技术的可选实施例,即可将任意多个实施例进行组合,从而获得应对不同应用场景的需求,均在本技术的保护范围内,在此不再一一赘述。
[0176]
需要说明的是,以上所述仅为本技术的较佳实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。