技术特征:
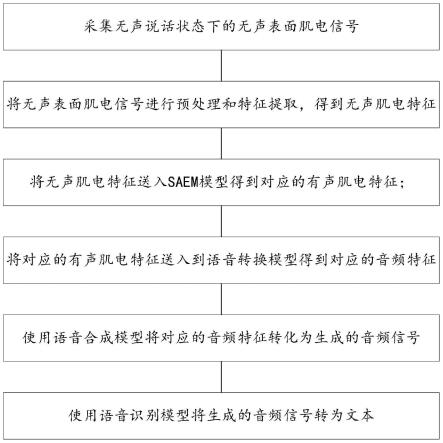
1.一种基于回译的无声语音识别方法,其特征在于,所述无声语音识别方法包括:采集无声说话状态下的无声表面肌电信号;将无声表面肌电信号进行预处理和特征提取,得到无声肌电特征;将无声肌电特征送入saem模型得到对应的有声肌电特征;将对应的有声肌电特征送入到语音转换模型得到对应的音频特征;使用语音合成模型将对应的音频特征转化为生成的音频信号,使用语音识别模型将生成的音频信号转为文本。2.根据权利要求1所述的一种基于回译的无声语音识别方法,其特征在于,所述saem模型,通过如下方式训练获得:采集无声说话状态下的无声表面肌电信号及对应的信息,采集有声说话状态下的有声表面肌电信号和对应的音频信号;对采集的无声表面肌电信号、有声表面肌电信号进行预处理和特征提取,得到无声肌电特征、有声肌电特征;将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练saem模型和asem模型;使用回译的方法优化saem模型。3.根据权利要求2所述的一种基于回译的无声语音识别方法,其特征在于,所述编码器-解码器网络为一个seq2seq网络,网络以conformer为编码器、自回归循环网络为解码器;编码器由多个conformer模块组成,conformer模块由前馈神经网络子模块、多头注意力子模块,卷积子模块三个子模块组成,每个子模块之间使用残差连接;所述前馈神经网络子模块,包括一个layernorm层,一个线性层,一个swish激活函数和dropout,计算方式如式(9)所示:其中,x
i
表示第i个维度输入;所述多头注意力子模块,包括一个layernorm,一个相对位置编码,一个dropout和一个自注意力机制,计算方式如式(10)所示:
其中,x
i
表示第i个维度输入;所述卷积子模块,包括一个layernorm,两个point-wise卷积,一个线性门单元,一个depth-wise卷积、一个batchnorm和一个dropout,计算方式如式(11)所示:其中,x
i
表示第i个维度输入;整个conformer块的计算方式如式(12)所示:整个conformer块的计算方式如式(12)所示:其中,x是解码器的输入序列,x={x1,x2,
…
,x
i
,
…
x
n
},x
i
表示第i维信号特征输入,ffn()表示前馈神经网络子模块,mhsa()表示多头自注意力子模块,conv()表示卷积子模块,y
i
表示第i维conformer块的计算结果;解码器是一个自回归循环神经网络,由一层pre-net网络、两层lstm、attention层、线性层和sigmoid组成,其计算方式如式(13)所示:
其中,x是解码器的输入序列,x={x1,x2,
…
,x
i
,
…
x
n
},x'都是中间变量,context是上下文向量,初始时被初始化为0;h是循环神经网络的隐藏向量;c是循环神经网络的记忆单元向量;s是编码器的输出,s={s1,s2,
…
,s
i
,
…
s
m
},frame是解码器预测的信号特征,stop_token是解码的终止条件,在进行预测时,当stop_token大于某一阈值时,就终止预测;pre-net是双层全连接网络,每层由256个隐藏relu单元组成,表示为式(14)所示:prenet(x)=relu(relu(xw
a
b
a
)w
b
b
b
)
ꢀꢀꢀꢀ
(14)其中,w
a
是x的权重系数,b
a
是xw
a
的偏移量,w
b
是relu(xw
a
b
a
)的权重系数,b
b
是relu(relu(xw
a
b
a
)w
b
的偏移量,relu(
·
)是激活函数,x是输入序列。4.根据权利要求3所述的一种基于回译的无声语音识别方法,其特征在于,所述将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练生成saem模型和asem模型,包括:输入进入编码器网络和输入进入解码器网络;所述输入进入编码器网络包括:输入进入confromer模块;在conformer模块中,输入通过前馈神经网络子模块并乘以0.5进行缩放,加上原始输入,作为多头注意力子模块的输入;然后经过多头注意力子模块后,与输入相加,作为卷积子模块输入;再通过卷积子模块提取特征信息,与卷积子模块的输入相加,作为另一个前馈神经网络子模块的输入;最后输入经过前馈神经网络子模块,与输入相加,对结果进行归一化后,获得编码器网络的输出;输入进入解码器网络包括:解码器网络的输入和编码器网络的输出一起进入解码器网络进行解码;首先解码器网络的输入进入pre-net网络;pre-net的输出和注意力上下文向量拼接在一起,送入第一层lstm网络;第一层lstm的隐藏层结果和编码器网络的输出一起送入attention层得到注意力上下文向量,将第一层lstm的隐藏层结果和注意力上下文向量再次拼接在一起,送入第二次lstm网络,得到第二
层lstm网络的隐藏层向量,将隐藏层向量与注意力上下文向量拼接,通过线性层得到输出,每一帧输出通过sigmoid层得到终止值;当输入为无声肌电特征,输出为有声肌电特征时,编码器-解码器网络用于训练无声肌电到有声肌电转换的saem模型;当输入为有声肌电特征,输出为无声肌电特征时,编码器-解码器网络用于训练有声肌电到无声肌电转换的asem模型。5.根据权利要求4所述的一种基于回译的无声语音识别方法,其特征在于,所述使用回译的方法优化saem模型包括:将有声肌电特征aemg输入asem模型中生成无声肌电特征semg',将伪无声肌电特征semg'——aemg作为伪平行语料,和原来的平行语料semg——aemg一起作为训练数据,训练saem;使用mse loss作为损失优化函数;mse loss如下式(15)所示:其中,y
i
是真实结果,是模型预测结果,n是样本数目。6.根据权利要求5所述的一种基于回译的无声语音识别方法,其特征在于,所述语音转换模型,通过如下方式训练获得:建立转换网络,将提取的有声肌电特征及音频特征送入转换网络训练得到语音转换模型;所述转换网络由transformer编码器后接一个linear层组成;其中,编码器由多个编码块组成,每个编码块由多头注意力和前向神经网络两个子模块构成,对每个子模块的输出结果进行dropout并与输入一起进行标准化,并作为下一子模块的输入;每个子模块之间使用残差连接,子模块输入设置为相同维度;前向神经网络为全连接前馈网络,使用两个线性变换,激活函数为relu;多头注意力层使用点积注意力,输入为query、key、value向量,维度分别为d
k
、d
k
、d
v
,query、key、value是输入经过不同线性变换的结果;在计算时,分别计算query和不同key的点积,将点积结果除以并使用softmax函数计算key对应权重;使用矩阵进行并行计算,编码块的计算如式(16)所示:其中,q、k、v为query、key、value向量组成的矩阵,d
k
是k的维度,concat是拼接操作,
head
i
是多头注意力中不同的头,attention_output是多头注意力模块残差连接后的输出,为中间计算结果,output是最终输出,w
o
是多头注意力线性变换的权重;转换网络使用transformer编码器对输入进行特征提取,后接一个linear层对提取的高维特征降维至mfcc特征维度,完成转换;所述有声肌电特征和音频特征,使用如下方式获得:采集有声说话状态下的有声表面肌电信号和对应的音频信号;对采集的有声表面肌电信号和音频信号进行预处理和特征提取,得到有声肌电特征和音频特征。7.根据权利要求6所述的一种基于回译的无声语音识别方法,其特征在于,所述进行预处理和特征提取,包括:对采集的表面肌电信号进行滤波和工频噪声降噪;采用移动平均法对滤波降噪后的面部肌电信号进行活动段检测,分割出有效面部肌电信号段;提取出有效面部肌电信号段的时域特征;提取音频信号梅尔频率倒谱系数特征;所述提取音频信号梅尔频率倒谱系数特征包括:对采集的音频信号进行预加重、分帧、加窗;对每一个短时分析窗,通过快速傅里叶变换得到对应的变换后频谱;将变换后频谱通过mel滤波器组得到mel频谱;对mel频谱进行离散余弦变换得到mfcc系数;使用mfcc系数计算mfcc动态特征。8.一种基于回译的无声语音识别系统,其特征在于,所述系统包括:采集模块,用于采集无声说话状态下的无声表面肌电信号;处理模块,用于将无声表面肌电信号进行预处理和特征提取,得到无声肌电特征;无声转有声模块,用于将无声肌电特征送入saem模型得到对应的有声肌电特征;有声转音频模块,用于将对应的有声肌电特征送入到语音转换模型得到对应的音频特征;音特转音号模块,用于使用语音识别模型将对应的音频特征转化为生成的音频信号,音频转文本模块,用于使用语音识别模型将生成的音频信号转为文本。9.根据权利要求8所述的一种基于回译的无声语音识别系统,其特征在于,所述saem模型,通过如下方式训练获得:采集无声说话状态下的无声表面肌电信号及对应的信息,采集有声说话状态下的有声表面肌电信号和对应的音频信号;对采集的无声表面肌电信号、有声表面肌电信号进行预处理和特征提取,得到无声肌电特征、有声肌电特征;将提取的无声肌电特征和有声肌电特征送入编码器-解码器网络中,训练saem模型和asem模型;使用回译的方法优化saem模型。
10.根据权利要求9所述的一种基于回译的无声语音识别系统,其特征在于,所述使用回译的方法优化saem模型包括:将有声肌电特征aemg输入asem模型中生成无声肌电特征semg',将伪无声肌电特征semg'——aemg作为伪平行语料,和原来的平行语料semg——aemg一起作为训练数据,训练saem;使用mse loss作为损失优化函数;mse loss如下式(15)所示:其中,y
i
是真实结果,是模型预测结果,n是样本数目。
技术总结
本发明公开了一种基于回译的无声语音识别方法和系统,方法包括:采集无声说话状态下的无声表面肌电信号;将无声表面肌电信号进行预处理和特征提取,得到无声肌电特征;将无声肌电特征送入SAEM模型得到对应的有声肌电特征;将对应的有声肌电特征送入到语音转换模型得到对应的音频特征;使用语音合成模型将对应的音频特征转化为生成的音频信号,使用语音识别模型将生成的音频信号转为文本。本发明所设计的一种基于回译的无声语音识别方法和系统,利用编码器-解码器网络进行无声肌电信号和有声肌电信号间的转换,并且有创新性地将机器翻译中回译的方法迁移到肌电信号上,从而利用非平行数据提升无声语音识别效果,最终提升无声语音识别效果。语音识别效果。语音识别效果。
技术研发人员:印二威 张敬 曹议丹 张亚坤 艾勇保 王凯 张皓洋 闫野
受保护的技术使用者:中国人民解放军军事科学院国防科技创新研究院
技术研发日:2022.04.25
技术公布日:2022/7/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。