1.本发明属于通讯技术领域,特别涉及一种消除不同说话特性的缄默通讯方法和系统。
背景技术:
2.自动语音识别(automatic speech recognition,asr)技术已经十分普及,大大推动了人工智能领域的发展,然而它的识别率也会受到一些因素的限制,比如在吵闹的工厂中,周围环境会产生干扰使语音识别的准确率受到影响;日常生活中人们在很多场合需要保护自己的隐私,语音识别就会出现一些弊端,因此不依靠声学信号的通讯方法显得尤为可贵。
3.随着缄默通讯技术的发展,使用的方法主要可以分为以下几类:通过采集唇部光学图像数据实现图像到语音信号的转换;使用表面肌电信号传感器采集无声说话时面部及喉部肌肉的电信号,从脑电图解析语言中枢的语言信号,通过记录说话者脑电图情况,模拟语音产生的过程。
4.虽然说扩大数据集可以提高缄默语音识别的准确率,但是采集一个很大的数据库费时费力,对每一名被试者也有不同程度的说话要求,语速过快会造成信号的粘连,增大了错误识别的可能性,说话幅度过小,也会增加模型训练的难度。因此本发明提出了一个语速和幅值的自适应调节方法,通过监测信号的时间范围和幅值状态,解决现有的基于面部肌电信号的缄默通讯系统中信号多样化和训练难度大的问题,从而提高肌电信号的鲁棒性和泛化能力,实现了不同的人对缄默通讯系统的适应性,提高了缄默通讯系统的识别准确率。
技术实现要素:
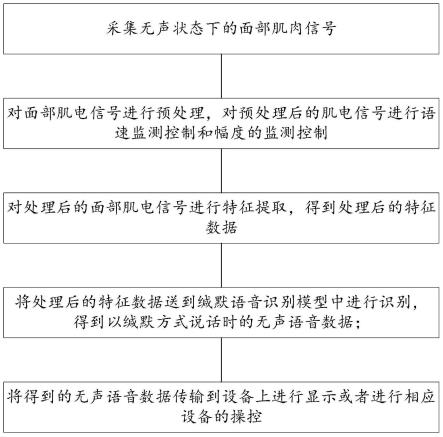
5.本发明提出了一种消除不同说话特性的缄默通讯方法,包括:
6.采集无声状态下的面部肌电信号;
7.对面部肌电信号进行预处理,对预处理后的面部肌电信号进行语速监测控制和幅度的监测控制;
8.对处理后的面部肌电信号进行特征提取,得到处理后的特征数据;
9.将处理后的特征数据送到缄默语音识别模型中进行识别,得到以缄默方式说话时的无声语音数据;将得到的无声语音数据传输到设备上进行显示或者进行相应设备的操控。
10.进一步地,所述对预处理后的肌电信号进行语速监测控制包括:
11.监测预处理后的肌电信号的时间范围;当预处理后的肌电信号的序列长度小于时间阈值,使用插帧技术将预处理后的肌电信号铺展至固定长度。
12.进一步地,所述使用插帧技术将监测预处理后的肌电信号铺展至固定长度包括:
13.采用super-slomo神经网络的插帧技术将预处理后的肌电信号铺展至固定长度;
14.所述super-slomo神经网络包括两个u-net网络,用一个u-net网络计算帧与帧之
间的双向信号流,在每个时间步长上对这些信号流进行线性拟合,以近似中间帧的信号,使用另一个u-net网络来对近似的信号进行改善,并且预测柔性可见性映射关系,最后,将前后两帧信号进行扭曲和线性融合,从而形成中间帧;
15.所述中间帧的预测计算如式(4)所示:
16.i
t
=(1-t)*g(i0,s
t
→0) t*g(i1,s
t
→1)
ꢀꢀ
(4)
17.其中,t是中间帧的位置信息,g(i0,s
t
→0)是初始帧到中间帧的信号流的转换,g(i1,s
t
→1)是结束帧到中间帧的信号流转换;
18.i
t
和i0之间的信号流如式(5)所示:
19.s
t
→0=-(1-t)ts0→1 t2s1→0ꢀꢀ
(5)
20.其中,s
t
→0是初始帧到中间帧的预测信号流,即正向信号流信息,t是中间帧的位置信息,s0→1是初始帧到结束帧的信号流信息,s1→0是结束帧到初始帧的信号流信息;
21.i
t
和i1之间的信号流如式(6)所示:
22.s
t
→1=(1-t)2s0→
1-t(1-t)s1→0ꢀꢀ
(6)
23.其中,s
t
→1是结束帧到中间帧的预测信号流,即反向信号流信息,t是中间帧的位置信息,s0→1是初始帧到结束帧的信号流信息,s1→0是结束帧到初始帧的信号流信息;
24.将中间帧插入到原信号流中,重新生成新的中间帧。
25.进一步地,所述u-net网络左侧是由卷积和max pooling构成,为压缩路径;压缩路径由5block组成,每个block使用了2有效卷积和1个max pooling降采样,每个block的卷积核数目为:32,64,128,256,512;采样之后input个数乘2;
26.所述u-net网络右侧部分由卷积和bilinear upsampling构成,为扩展路径;扩展路径由5block组成,每个block的卷积核数目为512,256,128,64,32;前四个block开始之前通过反卷积将input的尺寸乘2,同时将其个数减半;之后和左侧对称的压缩路径的input合并。
27.进一步地,所述幅度的监测控制包括:
28.监测语速调节后的肌电信号的绝对平均值;若语速调节后的肌电信号的绝对平均值小于所设定的信号阈值,便对整个语速调节后的肌电信号进行等比例调节处理。
29.进一步地,所述将整个语速处理后的肌电信号进行等比例调节包括:训练时调节和识别时调节;
30.所述训练时调节包括:检索一名用户的所有指令,将该用户所有信号中的绝对平均值的最大值标记为该用户的信号界值;检索其他用户的信号界值,对比不同用户之间的信号界值,将其中的最大值设置为信号阈值;
31.幅值调节使用如式(8)所示,
[0032][0033]
其中,x是欠调制状态的信号,xi是原始的欠调制状态信号的绝对平均值,x
p
是当前指令信号阈值,xo是幅值调节后信号的数据值;
[0034]
所述识别时调节包括:
[0035]
以模型生成时得到的信号阈值为标准进行调节;
[0036]
幅值调节使用如式(8)所示,
[0037][0038]
其中,x是欠调制状态的信号,xi是原始的欠调制状态信号的绝对平均值,x
p
是当前指令信号阈值,xo是幅值调节后信号的数据值。
[0039]
进一步地,所述对面部肌电信号进行预处理,包括:对面部肌电信号进行直流偏置的去除,工频噪声的去除和有效信号段的提取。
[0040]
进一步地,所述缄默语音识别模型使用如下方式建立:
[0041]
采集无声状态下的面部肌电信号及收集对应的缄默方式说话时的无声语音数据;对面部肌电信号进行预处理,对预处理后的面部肌电信号进行语速监测控制和幅度的监测控制;对处理后的面部肌电信号进行特征提取,得到处理后的特征数据;将处理后的特征数据和对应的无声语音数据送入到卷积神经网络和门控循环单元进行特征学习。
[0042]
进一步地,所述卷积神经网络和门控循环单元包括:cnn网络和gru网络;
[0043]
其中,cnn网络作为处理后的特征数据的预训练网络,gru网络作为处理后的特征数据的解码网络;
[0044]
所述cnn网络包括两个64维的卷积,两个128维的卷积,两个256维的卷积和两个512维的卷积,不同的卷积层中间使用最大池化层连接;所述gru网络为两层gru网络,第一层包含512个隐藏层,第二层包含1024个隐藏层;所述cnn网络最后一层的池化层输出与gru网络中重置门输入连接。
[0045]
本发明还提出了一种消除不同说话特性的缄默通讯系统,所述消除不同说话特性的缄默通讯系统包括:
[0046]
采集组件,用于采集无声状态下的面部肌电信号;
[0047]
预处理组件,用于对预处理后的肌电信号进行语速监测控制和幅度的监测控制;
[0048]
特征提取组件,用于对处理后的面部肌电信号进行特征提取,得到处理后的特征数据;
[0049]
识别组件,用于将处理后的特征数据送到缄默语音识别模型中进行识别,得到以缄默方式说话时的无声语音数据;
[0050]
传送组件,用于将得到的无声语音数据传输到设备上进行显示或者进行相应设备的操控;
[0051]
模型建立组件,用于建立缄默语音识别模型,所述缄默语音识别模型使用如下方式建立:
[0052]
采集无声状态下的面部肌电信号及收集对应的缄默方式说话时的无声语音数据;对面部肌电信号进行预处理,对预处理后的肌电信号进行语速监测控制和幅度的监测控制;对处理后的面部肌电信号进行特征提取,得到处理后的特征数据;将处理后的特征数据和对应的无声语音数据送入到卷积神经网络和门控循环单元进行特征学习。
[0053]
本发明设计了一种消除不同说话特性的缄默通讯方法和系统,首先采集面部肌电信号,其次进行预处理、语速和幅度的监控处理以及特征提取,得到处理后的特征数据,最后根据处理后的特征数据训练缄默语音识别模型,进而识别以缄默方式说话时的无声语音。该方法能够获得准确率更高,识别速度更快的无声语音识别结果。
附图说明
[0054]
图1示出了本发明实施例中一种消除不同说话特性的缄默通讯方法的流程示意图;
[0055]
图2示出了本发明实施例中一种消除不同说话特性的缄默通讯系统面部肌电信号采集位置的示意图;
[0056]
图3示出了本发明实施例中u-net结构示意图;
[0057]
图4示出了本发明实施例中gru结构示意图;
[0058]
图5示出了本发明实施例中一种消除不同说话特性的缄默通讯系统结构示意图。
具体实施方式
[0059]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
[0060]
人在发声状态下说话时,声带的振动会带动口腔的振动,而在无声状态下说话时,口腔内完全没有振动,当用有声的肌电信号训练模型识别无声的语音时,准确率会受到影响,因此训练模型要采用无声状态下的面部肌电信号。嘴巴的运动对应着不同的神经电活动,将表面电极贴在运动肌肉的皮肤表面上,接着对检测到的这些表面肌电信号进行分析与解码,从而识别出说话者所说的内容。由于不同人有不同的说话特点,例如说话速度的快慢,说话幅度的大小,都会对识别结果产生很大的影响,因此通过对这两种说话特性进行处理能够一定程度上提高缄默语音的准确率。
[0061]
本发明设计一种消除不同说话特性的缄默通讯方法,如图1所示。本发明中建立模型或最终的识别,均需要通过肌电采集设备获取面部肌电数据并进行数据预处理和肌电特征提取。
[0062]
s1:采用表面贴片电极采集面部肌电信号。
[0063]
具体地,如图2所示,人在说话时面部肌肉的运动对应着不同的神经电活动,以表面贴片电极为引导电极,放置在相应肌肉的面部和喉部的皮肤上,通过测量肌肉电活动在检测电极处的电位差得到面部肌电信号。可以采用五对贴片电极采集原始一维的肌电信号,五对贴片电极分别对应上唇提肌、口轮匝肌、降下唇肌、降口角肌、肩胛舌骨肌,通过该步骤,可以采集面部肌电信号。
[0064]
建立模型时,采集无声状态下的面部肌电信号,需要同时收集对应的语言内容,即缄默方式说话时的无声语音数据。可以规定语言内容,由不同人进行无声状态下说话时,采集其对应的面部肌电信号。
[0065]
s2:对面部肌电信号进行预处理,对预处理后的肌电信号进行语速和幅度的监测控制。
[0066]
对采集到的面部肌电信号进行预处理,包括:对面部肌电信号进行直流偏置的去除,工频噪声的去除以及有效信号段的提取,得到预处理后的面部肌电信号。
[0067]
对直流偏置的去除可以直接采用10-400hz的butterworthⅰ型iir带通滤波器进行滤波。
[0068]
对工频噪声的去除可以使用50hz的iir陷波器去除工频干扰,同时还需要设置相应的倍频,去除50hz的倍频噪声。
[0069]
对有效信号段的提取,采用短时能量和短时平均过零率结合的方法:
[0070]
具体地,首先确定两个短时能量门限,一个是较高的短时能量门限,可以粗略提取有用信号段,一个是较低的平均能量门限,可以较为精确的提取有用信号段。
[0071]
设肌电波形时域信号为x(n),窗函数为w(n),一般为矩形窗或汉明窗,对肌电信号段分帧处理如式(1)所示:
[0072]
yi(n)=w(n)*x((i-1)*inc n)
ꢀꢀ
(1)
[0073]
其中,yi(n)为分帧处理后得到的第i帧肌电信号;inc为帧移长度;n的范围为1,2,
…
,l,l为帧长;i的范围为1,2,
…
,fn,fn为分帧后的总帧数。
[0074]
计算第i帧肌电信号yi(n)的短时能量如式(2)所示:
[0075][0076]
确定两个短时过零率门限,一个是较高的门限过零率,一个是较低的门限电平,短时平均过零率表示一帧信号波形穿过横轴的次数,即信号改变符号的次数,如式(3)所示:
[0077][0078]
其中,sgn为符号函数,即:
[0079][0080]
综合两个门限,低门限被超越有可能是时间很短的噪声引起的,高门限被超越基本上可以确定是由有用信号造成的,由此便可提取肌电的有效信号段。
[0081]
面部肌电信号进行预处理后,生成预处理后的面部肌电信号。
[0082]
对预处理后的肌电信号进行语速和幅度的监测控制,对于语速的监测是指监测信号的时间范围,对于幅度的监测是指监测信号的幅值状态,并通过监测结果进行相应的处理和控制。
[0083]
具体地,监测预处理后的肌电信号的时间范围是指监测信号的时间序列长度。当预处理后的肌电信号的序列长度小于时间阈值,使用插帧技术将预处理后的肌电信号铺展至固定长度。
[0084]
在一种实现方式中,采集的每一条面部肌电信号为2000ms,实际提取有效信号段后,由于不同人的说话语速不同,不同人提取到的信号时间序列也不同。因此采用super-slomo神经网络的插帧技术将预处理后提取到的有效信号,即预处理后的肌电信号铺展至固定长度,从而达到放慢语速和统一时间序列的效果。
[0085]
super-slomo神经网络是一种端到端的卷积神经网络,利用该卷积神经网络来实现补帧的操作。super-slomo神经网络包括两个u-net网络,先用一个u-net网络计算帧与帧之间的双向信号流,在每个时间步长上对这些信号流进行线性拟合,以近似中间帧的信号,使用另一个u-net来对近似的信号进行改善,并且预测柔性可见性映射关系,最后,将前后两帧信号进行扭曲和线性融合,从而形成中间帧。如图3所示是u-net架构示意图。
[0086]
网络的左侧是由卷积和max pooling构成的一系列降采样操作,为压缩路径。压缩路径由5block组成,每个block使用了2有效卷积和1个max pooling降采样,每个block的卷积核数目为:32,64,128,256,512;采样之后input个数乘2。
[0087]
网络的右侧部分为扩展路径,是由卷积和bilinearupsampling构成的一系列上采样操作。同样由5block组成,每个block具体为512,256,128,64,32,每个block开始之前通过反卷积将input的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的input合并,由于左侧压缩路径和右侧扩展路径的input的尺寸不一样,u-net是通过将压缩路径的input裁剪到和扩展路径相同尺寸的input进行归一化的input。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的输出结果。
[0088]
中间帧i
t
可以通过初始帧i0结合信号流的转换g()而形成,也可以通过结束帧i1结合信号流转换而形成,本发明使用两者的线性组合。信号流是两帧之间的关系拟合函数,使用非线性函数拟合,中间帧的预测计算公式如式(4)所示:
[0089]it
=(1-t)*g(i0,s
t
→0) t*g(i1,s
t
→1)
ꢀꢀ
(4)
[0090]
其中,t是中间帧的位置信息,g(i0,s
t
→0)是初始帧到中间帧的信号流的转换,g(i1,s
t
→1)是结束帧到中间帧的信号流转换。
[0091]
由于中间帧本身是需要预测的,不是预先存在的,因此需要用i0和i1之间的信号流对i
t
和i0、i1之间的信号流进行近似,如式(5)(6)所示:
[0092]st
→0=-(1-t)ts0→1 t2s1→0ꢀꢀ
(5)
[0093]
其中,s
t
→0是初始帧到中间帧的预测信号流,即正向信号流信息,t是中间帧的位置信息,s0→1是初始帧到结束帧的信号流信息,s1→0是结束帧到初始帧的信号流信息。
[0094]st
→1=(1-t)2s0→
1-t(1-t)s1→0ꢀꢀ
(6)
[0095]
其中,s
t
→1结束帧到中间帧的预测信号流,即反向信号流信息,t是中间帧的位置信息,s0→1是初始帧到结束帧的信号流信息,s1→0是结束帧到初始帧的信号流信息。
[0096]
最终的架构设计分为两个阶段,第一阶段将i0和i1输入到信号流计算中,得到两者之间正向和反向的信号流;第二阶段再以i0和i1到i
t
之间的近似信号流为输入,得到近似信号流的增量,结合这些量,即将中间帧插入到原信号流中,循环生成新的中间帧,并重新插入,最终得到增加帧后的信号,即语速调节后的肌电信号。
[0097]
以下以通过第一帧信号(i1)和第五帧信号(i5)预测中间的第三帧信号(i3)为例,本领域技术人员能够得出从第1帧与第2n-1帧预测第n帧的方式。第三帧信号的预测结果为(i3),具体操作为:
[0098]
首先,将i1和i5输入到信号流的计算中,计算出第一帧和第五帧之间的信号流,即非线性关系,得到s1→5和s5→1,再以s1→5和s5→1作为输入,送入中间帧信号流的预测算法中,得到i5和i1到i3之间的近似信号流,即s3→1和s3→5。
[0099]
其次,将i1、i5、s3→1和s3→5作为输入送入中间帧的预测公式中,得到中间帧信息,最后将中间帧信息插入到原始信号中,得到增加帧后的信号。以此类推,使用i1、i3能够得到i2,使用i3、i5能够得到i4。实际操作中,通过i1与i
2n-1
得到in,将in插入到原始信号中后继续生成新的中间帧,最终使预处理后的肌电信号铺展至固定长度,得到语速调节后的肌电信号。
[0100]
具体地,监测滤波后信号的幅值状态是指监测信号的一段时间内幅度绝对平均值
大小。绝对平均值如式(7)所示。
[0101][0102]
其中,xj为信号第j时刻幅度值。
[0103]
由于不同人的说话幅度大小不同,具体采集到的信号幅值差别很大。先对语速调节后的肌电信号进行绝对平均值的提取,若语速调节后的肌电信号的绝对平均值在对应时间段内小于所设定的信号阈值,则认为该肌电信号幅度处于欠调制状态。通过设定的信号阈值计算出欠调制的比例值,并将整个语速调节后的肌电信号送入幅值调节算法中进行等比例调节,若幅度不小于所设定的信号阈值,则直接进行下一步特征提取。
[0104]
面部肌电信号的数据集包含多名用户的数据,每名用户的数据包含多条不同的指令,每条指令重复多次。在训练时,首先检索一名用户的所有指令,将该用户所有指令中的绝对平均值的最大值标记为该用户的信号界值。如a用户数据包含a1、a2、a3、a4、a5共5条指令,对于a1、a2、a3、a4、a5分别求得其幅度对应的绝对平均值a1’、a2’、a3’、a4’、a5’。取a1’、a2’、a3’、a4’、a5’中最大值为a用户信号界值。
[0105]
其次检索其他用户的信号界值,对比不同用户之间的信号界值,将其中的最大值设置为信号阈值。如a、b、c三名用户的个人数据集中分别包含n条指令。先检索用户a中所有指令中的绝对平均值的最大值,并将该最大值设为用户a的界值,假设a用户的信号界值为a。同理检索用户b、c所有指令的绝对平均值的最大值,并将其设为其对应的信号界值,假设b用户的信号界值为b,c用户的信号界值为c。对比a、b、c三个值的大小,由于个体的说话差异,b用户的界值b最大,将b标记为信号阈值,用来对a用户和c用户滤波后信号进行幅值的调节,消除幅值差异对指令识别的影响,减少分类误差。在识别一条新的信号时,首先需要将已经训练好的模型中信号的阈值,作为本次识别的信号阈值,对新信号的幅值范围进行调节,其次将调节后的信号送入分类模型中进行相应指令的识别,最后输出识别结果。
[0106]
模型训练好后进行识别时,以该模型生成时得到信号阈值为标准进行调节,即模型中所有存在信号界值最大值设置为信号阈值。这个值也等于在模型训练前最后一刻生成的信号阈值值。当模型训练好后,信号阈值已经被固定。训练过程中,数据集属于一直增长状态,其信号阈值随数据集变化而变化。
[0107]
识别时,根据已经得到的数据阈值,提前设定幅值的信号阈值范围,对新采集的信号进行幅值的调节。
[0108]
幅值调节均使用如式(8)所示,幅值调节算法的具体原理是等比例放大。
[0109][0110]
其中,x是欠调制状态的信号,xi是原始的欠调制状态信号的绝对平均值,x
p
是当前指令阈值大小,xo是幅值调节后信号的数据值。
[0111]
需要注意的是,幅值调节的目的是消除不同人的说话特异性,增大指令间的差异性,因此需要遍历当前所有的数据。
[0112]
预处理后并经过的语速和幅度的监测控制后,生成处理后的面部肌电信号。
[0113]
s3:对处理后的面部肌电信号进行特征提取,得到处理后的特征数据。
[0114]
虽然mfsc特征提取最初是用于音频信号上的,但是相关研究表明也能用于作为基
于表面肌电信号的无声语音识别的特征。
[0115]
对处理后的面部肌电信号提取梅尔频率谱系数特征,及其包含了动态特征信息的一阶差分和二阶差分系数,得到面部肌肉运动的动态特征数据。该动态特征数据可以直接进行神经网络训练和识别,通过该步骤,可以得到面部肌电信号的特征数据。
[0116]
对处理后的面部肌电信号进行特征提取后,得到处理后的特征数据。
[0117]
s4:根据处理后的特征数据,采用深度学习的方法训练缄默语音识别模型。
[0118]
本发明采用深度学习中的卷积神经网络(cnn)和门控循环单元(gru)相结合的方式训练缄默语音识别模型,其输入为处理后的特征数据,输出为其对应的语言内容,即缄默方式说话时的无声语音数据。模型训练好后,将处理后的特征数据输入到训练好的缄默语音识别模型,可以得到以缄默方式说话时对应的无声语言内容。cnn用于训练空间特征,gru用于训练时序特征;卷积神经网络和门控循环单元的融合的训练效果比较好。
[0119]
本发明中,卷积神经网络包括卷积层、激活函数层、池化层。卷积层是通过特定数目的卷积核(滤波器),对输入的多通道特征图进行扫描和运算,从而得到多个拥有更高层语义信息的输出特征图。卷积核不断地扫描整个输入特征图,最终得到输出特征图。
[0120]
激活函数是在深度神经网络中后一层节点的输入和前一层节点的输出之间的一种自定义的映射关系,通常使用非线性函数作为激活函数,加入非线性激活函数后,神经网络能够更好的拟合目标函数。理论上通过多层神经网络和非线性激活函数的组合可以任意逼近训练样本中数据输入和标签之间的关系。本发明,可以使用的激活函数包括sigmoid函数、tanh函数、relu函数和leakyrelu函数等。
[0121]
池化层的池化操作主要针对特征图中的非重叠区域,主要包括均值池化、最大池化和全局平局池化。池化操作的本质是降采样,不仅能显著降低参数量,也能在一定程度上防止模型出现过拟合,还能够保持对输入图像的旋转、伸缩、平移操作的不变性。
[0122]
经过卷积层、池化层和激活函数层后,得到样本属于各个类别的概率分布情况,全连接层通过概率识别出属于哪一个类别。在多分类问题中,cnn中最后全连接层的输出使用softmax函数,softmax的计算公式如式(9)所示,softmax函数的输入,输出为预测对象分类结果的概率:
[0123][0124]
其中,xm为最后一层的神经元节点的输出,n表示分类结果的总数。
[0125]
gru神经网络是循环神经网络的一个分支,如图4所示,是lstm网络的一种效果等价的变体,为了解决rnn网络中长期依赖的问题而提出,它比lstm的结构更加简单,更易于计算和进行训练,在gru神经网络包括两个门控单元:更新门和重置门。gru神经网络具体的训练过程如下:
[0126]
首先,先通过上一个传输下来的状态h
t-1
和当前节点的输入x
t
来获取两个门控状态。其中r为控制重置的门控,z为控制更新的门控。
[0127]
(1)重置门:重置门控制前一状态有多少信息被写入到当前的候选集上,重置门越小,前一状态的信息被写入的越少。在该门控单元中,先将上一层的输出h
t-1
和本层要输入的序列数据x
t
进行拼接,通过一个sigmoid激活函数,得到输出为r
t
;r
t
的输出取值在[0,1]区间,表示前一状态信息被写入的数据量,1是“完全保留”,0是“完全舍弃”,如式(10)所示。
[0128]rt
=sigmoid(wr*[h
t-1
,x
t
] br)
ꢀꢀ
(10)
[0129]
其中,x
t
是当前的输入数据;h
t-1
是上一个节点传递下来的隐状态,包含了之前节点的相关信息;wr为gru网络模型重置门控单元中拼接后输入的权重参数,wr的初始值是通过一组输入信号与对应的输出之间的关系计算出来的,随着数据的不断增加和神经网络的迭代更新,训练出最终的权重值;br为gru网络模型重置门的偏置参数,初始值设为1,作为偏置项的基底,然后让网络去训练偏置项,使得偏置项在训练的过程中不断调整以得到最终值。
[0130]
(2)更新门:用于控制前一时刻的状态信息,被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。在该门控单元中,将上一层的输出h
t-1
和本层要输入的序列数据x
t
进行拼接,通过一个sigmoid激活函数,得到输出为z
t
,如式(11)所示。
[0131]zt
=sigmoid(w
t
*[h
t-1
,x
t
] bz)
ꢀꢀ
(11)
[0132]
其中,x
t
是当前的输入数据;h
t-1
是上一个节点传递下来的隐状态;w
t
为gru网络模型更新门控单元中拼接后输入的权重参数,w
t
的初始值是通过一组输入信号与对应的输出之间的关系计算出来的,随着数据的不断增加和神经网络的迭代更新,训练出最终的权重值;bz为gru网络模型更新门的偏置参数,初始值设为1,作为偏置项的基底,然后让网络去训练偏置项,使得偏置项在训练的过程中不断调整以得到最终值。
[0133]
在gru网络的记忆阶段,将r
t
·ht-1
与x
t
作为输入进行拼接,并通过一个tanh激活函数来将数据放缩到-1~1的范围内,得到输出如式(12)所示。
[0134][0135]
其中,x
t
是当前的输入数据;h
t-1
是上一个节点传递下来的隐状态;r
t
是重置门控单元得到的输出值;为更新门控单元中拼接后输入的权重参数,的初始值是通过一组输入信号与对应的输出之间的关系计算出来的,随着数据的不断增加和神经网络的迭代更新,训练出最终的权重值;为gru网络模型更新门的偏置参数。
[0136]
在更新记忆阶段,同时进行了遗忘和记忆两个步骤。如式(13)所示,最终得到更新记忆阶段的输出h
t
。
[0137][0138]
其中,z
t
、h
t-1
与作为输入;z
t
是更新门控得到的输出数据;h
t-1
是上一个节点传递下来的隐状态;是记忆阶段得到的输出;(1-z
t
)
·ht-1
表示对原本隐藏状态的选择性“遗忘”;表示对包含当前节点信息的进行选择性“记忆”。
[0139]
输出使用sigmoid激活函数得到一个[0,1]区间取值的y
t
,如式(14)所示。
[0140]yt
=sigmoid(wo*h
t
by)
ꢀꢀ
(14)
[0141]
其中,更新记忆阶段的输出h
t
作为输入;wo为更新记忆阶段的输出h
t
的对应的权重参数;by为该输出公式的偏置参数;wo的初始值是通过一组输入信号与其对应的输出之间的关系计算出来的,随着数据的不断增加和神经网络的迭代更新,训练出最终的权重值;对于偏置参数首先将by的初始值设为1,作为偏置项的基底,然后让网络去训练偏置项,使得偏置项在训练的过程中不断调整以得到最终值。
[0142]
在本发明中,cnn网络作为肌电特征的预训练网络,gru作为肌电特征的解码网络。cnn网络包括两个64维的卷积,两个128维的卷积,两个256维的卷积和两个512维的卷积,不同的卷积层中间使用最大池化层连接;解码网络使用了两层gru网络,第一层包含512个隐藏层,第二层包含1024个隐藏层。将cnn网络最后一层的池化层输出与gru网络中重置门输入连接,实现两个网络的融合,形成一个完整的缄默语音识别模型。
[0143]
s5:将处理后的特征数据输入到训练好的缄默语音识别模型中,得到以缄默方式说话时的无声语音数据,将得到的无声语音数据传输到设备上进行显示或者进行相应设备的操控。
[0144]
具体地,采集另一组无声状态下的面部肌电信号,分别经过数据预处理,对语速和幅度的监测处理;特征提取后送入训练好的缄默语音识别模型中进行识别,得到缄默状态下的无声语音数据。
[0145]
具体地,识别出缄默状态下的无声语音数据后,可以通过无线通信装置将其发送到语音接收设备,实现缄默通讯。在一种可能的实现方式中,通过wifi将识别出的无声语音发送到语音接收设备,可选地,还可以进行有线连接和蓝牙连接。
[0146]
本发明实施例提供了一种消除不同说话特性的缄默通讯的系统,如图5所示,包括:
[0147]
采集组件,用于采集无声状态下的面部肌电信号;
[0148]
预处理组件,用于对预处理后的肌电信号进行语速监测控制和幅度的监测控制;接收采集组件传来的面部肌电信号,生成处理后的面部肌电信号;
[0149]
特征提取组件,用于对处理后的面部肌电信号进行特征提取,得到处理后的特征数据;接收预处理组件传来的处理后的面部肌电信号,生成处理后的特征数据;
[0150]
识别组件,用于将处理后的特征数据送到缄默语音识别模型中进行识别,得到以缄默方式说话时的无声语音数据;接收特征提取组件传来的处理后的特征数据;
[0151]
传送组件,用于将得到的无声语音数据传输到设备上进行显示或者进行相应设备的操控;接收识别组件传来的无声语音数据;
[0152]
模型建立组件,用于建立缄默语音识别模型,所述缄默语音识别模型使用如下方式建立:
[0153]
采集无声状态下的面部肌电信号及收集对应的缄默方式说话时的无声语音数据;对面部肌电信号进行预处理,对预处理后的肌电信号进行语速监测控制和幅度的监测控制;对处理后的面部肌电信号进行特征提取,得到处理后的特征数据;将处理后的特征数据和对应的无声语音数据送入到卷积神经网络和门控循环单元进行特征学习。
[0154]
其中,所述使用插帧技术将监测预处理后的肌电信号铺展至固定长度包括:采用super-slomo神经网络的插帧技术将预处理后提取到的有效信号铺展至固定长度;所述super-slomo神经网络包括两个u-net网络,用一个u-net网络计算帧与帧之间的双向信号流,在每个时间步长上对这些信号流进行线性拟合,以近似中间帧的信号,使用另一个u-net网络来对近似的信号进行改善,并且预测柔性可见性映射关系,最后,将前后两帧信号进行扭曲和线性融合,从而形成中间帧;
[0155]
所述中间帧的预测计算如式(4)所示:
[0156]it
=(1-t)*g(i0,s
t
→0) t*g(i1,s
t
→1)
ꢀꢀ
(4)
[0157]
其中,t是中间帧的位置信息,g(i0,s
t
→0)是初始帧到中间帧的信号流的转换,g(i1,s
t
→1)是结束帧到中间帧的信号流转换;
[0158]it
和i0之间的信号流如式(5)所示:
[0159]st
→0=-(1-t)ts0→1 t2s1→0ꢀꢀ
(5)
[0160]
其中,s
t
→0是初始帧到中间帧的预测信号流,即正向信号流信息,t是中间帧的位置信息,s0→1是初始帧到结束帧的信号流信息,s1→0是结束帧到初始帧的信号流信息;
[0161]it
和i1之间的信号流如式(6)所示:
[0162]st
→1=(1-t)2s0→
1-t(1-t)s1→0ꢀꢀ
(6)
[0163]
其中,s
t
→1是结束帧到中间帧的预测信号流,即反向信号流信息,t是中间帧的位置信息,s0→1是初始帧到结束帧的信号流信息,s1→0是结束帧到初始帧的信号流信息。
[0164]
所述u-net网络左侧是由卷积和max pooling构成,为压缩路径;压缩路径由5block组成,每个block使用了2有效卷积和1个max pooling降采样,每个block的卷积核数目为:32,64,128,256,512;采样之后input个数乘2;
[0165]
所述u-net网络右侧部分由卷积和bilinear upsampling构成,为扩展路径;扩展路径由5block组成,每个block的卷积核数目为512,256,128,64,32;前四个block开始之前通过反卷积将input的尺寸乘2,同时将其个数减半;之后和左侧对称的压缩路径的input合并。
[0166]
所述幅度的监测控制包括:监测语速调节后的肌电信号的绝对平均值的大小;若需要检测的信号的绝对平均值在对应时间段内小于所设定的阈值,便对整个语速处理后的肌电信号进行等比例调节处理。
[0167]
所述将整个语速处理后的肌电信号进行等比例调节包括:
[0168]
检索每一名被试的数据,将绝对平均值最大的被试的值标记为信号的阈值;幅值调节使用如式(8)所示,
[0169][0170]
其中,x是欠调制状态的信号,xi是原始的欠调制状态信号的绝对平均值,x
p
是当前信号的阈值,xo是幅值调节后信号的数据值。
[0171]
所述卷积神经网络和门控循环单元包括:cnn网络和gru网络;
[0172]
其中,cnn网络作为处理后的特征数据的预训练网络,gru网络作为处理后的特征数据的解码网络;
[0173]
所述cnn网络包括两个64维的卷积,两个128维的卷积,两个256维的卷积和两个512维的卷积,不同的卷积层中间使用最大池化层连接;所述gru网络为两层gru网络,第一层包含512个隐藏层,第二层包含1024个隐藏层;所述cnn网络最后一层的池化层输出与gru网络中重置门输入连接。
[0174]
可以使用如下方式使用本发明的消除不同说话特性的缄默通讯:
[0175]
步骤1:用户穿戴肌电采集设备,开启设备开关。检查各个组件是否正常开启,检测通信设备是否正常,当各模块没有正常开启时,执行步骤2,提示用户开启相应组件。
[0176]
步骤2:如果设备出现问题,不能正常运作和通信时,根据提示用户检查相对应的组件;当各组件正常开启时,检测用户是否已经开始说话。当用户开始说话时,执行步骤3;
如果没有开始说话时,进入待机状态。
[0177]
步骤3:用户在静默状态下开始说话,采集组件开始采集用户无声状态下的面部肌电信号。
[0178]
步骤4:将采集得到的肌电信号送入预处理组件和特征提取组件中,进行相应的数据处理,得到处理后的特征数据。如果是训练模型,则执行步骤5,进行模型的训练;如果是识别肌电信号,则执行步骤6,默认缄默语音识别模型已经训练完毕。
[0179]
步骤5:采用机器学习或者深度学习的方法对步骤4处理后的特征数据进行模型的训练,训练一个缄默语音识别模型。
[0180]
步骤6:将经过步骤4处理后的特征数据输入预先训练好的缄默语音识别模型中,得到以缄默方式说话的无声语音数据。
[0181]
步骤7:将识别到的无声语音数据发送至通讯交互组件,完成通信交流或外部设备控制;若异常,则提示通信异常,用户重复所说内容。
[0182]
步骤8、通信完成后,检测通信环境是否关闭,若没有,则进入待机状态。
[0183]
本发明设计了一种消除不同说话特性的缄默通讯方法和系统,首先采集面部肌电信号,其次进行预处理、语速和幅度的监控处理以及特征提取,得到处理后的特征数据,最后根据处理后的特征数据训练缄默语音识别模型,进而识别以缄默方式说话时的无声语音。该方法能够获得准确率更高,识别速度更快的无声语音识别结果。
[0184]
以上仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。