硅-氧化物-氮化物-氧化物-硅多级非易失性存储器装置及其制造方法
1.相关申请的交叉引用
2.本技术是2020年3月24日提交的美国非临时申请第16/827,924号的国际申请,该美国非临时申请要求2019年11月26日提交的在先申请美国临时申请第62/940,547号的权益,所有这些申请出于所有目的通过引用整体并入本文。
技术领域
3.本公开内容总体上涉及非易失性存储器装置,更特别地涉及基于硅(半导体)-氧化物-氮化物-氧化物-硅(半导体)(sonos)的多级电荷俘获非易失性存储器(nvm)的存储器和推理装置及其制造方法。
背景技术:
4.非易失性存储器被广泛地用于将数据存储在计算机系统中,并且通常包括具有大量以行和列布置的存储器单元的存储器阵列。在一些实施方式中,存储器单元中的每一个可以至少包括诸如电荷俘获场效应晶体管(fet)、浮栅晶体管的非易失性元件,通过在控制/存储器栅极与衬底或漏极/源极区域之间施加适当极性、大小和持续时间的电压对该非易失性元件进行编程或擦除。例如,在n沟道电荷俘获fet中,正的栅极-衬底电压导致电子通过福勒-诺德海姆(fowler-nordheim)(fn)隧穿从沟道进行隧穿并被俘获在电荷俘获电介质层中,从而提高了晶体管的阈值电压(v
t
)。负的栅极-沟道电压导致空穴从沟道隧穿并被俘获在电荷俘获电介质层中,从而降低了sonos晶体管的v
t
。
5.在一些实施方式中,基于sonos的存储器阵列被用作和操作为数字数据存储装置,在该数字数据存储装置中,基于sonos单元的两个不同的v
t
或漏极电流(id)水平或值的二进制位(0和1)数据被存储。
6.存在对使用用于模拟存储器和处理的诸如sonos的nvm技术的需求,因为诸如sonos的nvm技术具有能够实现高精度的可配置的多个不同的v
t
和id(多于两个)水平。sonos存储器单元递送模拟处理所需的包括诸如人工智能(ai)应用中的神经形态计算的边缘推理计算的低延迟操作、低功率操作和低噪声操作。
7.因此,本发明的目的是将多级sonos单元制造集成到基线互补金属氧化物半导体(cmos)工艺流程中。
附图说明
8.根据以下具体实施方式并根据以下提供的附图和所附权利要求书,可以更全面地理解本发明,其中:
9.图1a是示出基于sonos的非易失性存储器晶体管或装置的截面侧视图的框图;
10.图1b示出了图1a中所描绘的基于sonos的非易失性存储器晶体管或装置的相应示意图;
11.图2是示出根据本公开内容的一个实施方式的基于sonos的非易失性存储器阵列的示意图;
12.图3a是示出根据本公开内容的擦除操作的实施方式的基于sonos的非易失性存储器阵列的段的示意图;
13.图3b是示出根据本公开内容的编程/禁止操作的实施方式的基于sonos的非易失性存储器阵列的段的示意图;
14.图4是示出根据本公开内容的实施方式的基于sonos的非易失性存储器阵列中的被完全编程的存储器晶体管的阈值电压和漏极电流(vtp或idp)的分布以及被擦除的存储器晶体管的阈值电压和漏极电流(vte或ide)的分布的代表性图;
15.图5是示出根据本公开内容的实施方式的基于多级sonos的非易失性存储器单元中的漏极电流(id)水平的分布的代表性图;
16.图6a是示出根据本公开内容的实施方式的非易失性存储器阵列中的基于sonos的存储器晶体管的不同id水平的图;
17.图6b是示出根据本公开内容的实施方式的非易失性存储器阵列中的基于sonos的存储器晶体管的电荷俘获层中的被俘获的电荷的分布的图;
18.图7是示出根据本公开内容的实施方式的示出了id西格玛和滞留退化的非易失性存储器阵列中的基于sonos的存储器晶体管的id分布的图;
19.图8是示出根据本公开内容的实施方式的将基于sonos的多级nvm晶体管集成到mos晶体管中的制造方法的实施方式的流程图;
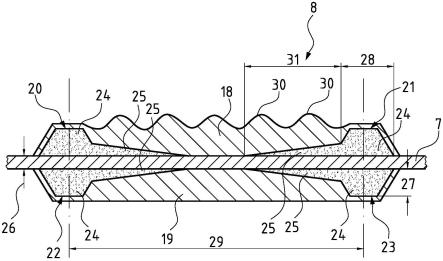
20.图9a至图9g是示出根据图8的方法的多级存储器单元的制造期间的存储器单元的一部分的截面视图的代表性图;
21.图10a是根据本公开内容的实施方式的基于sonos的多级nvm晶体管的行或列的代表性等距视图;
22.图10b、图10c和图10d是示出根据图8的方法的多级存储器单元的制造期间的存储器单元的一部分的截面视图的代表性图;
23.图11是示出结构性优化对sonos单元的id和v
t
西格玛的影响的代表性图;
24.图12a是示出根据本公开内容的选择性软擦除操作的实施方式的基于sonos的非易失性存储器阵列的段的示意图;
25.图12b是示出根据本公开内容的再填充编程/禁止操作的实施方式的基于sonos的非易失性存储器阵列的段的示意图;
26.图13是示出根据本公开内容的基于sonos的多级nvm装置的实施方式的示意性框图;
27.图14是示出常规数字乘法累加(mac)系统的实施方式的代表性框图;
28.图15是示出深度神经元网络(dnn)系统的人工神经元的实施方式的代表性图;
29.图16是示出根据本公开内容的模拟神经元网络(nn)加速器装置的实施方式的示意图;以及
30.图17是示出根据本公开内容的图16中的nn加速器装置的操作方法的实施方式的示意性流程图。
具体实施方式
31.以下描述阐述了许多具体细节,诸如具体系统、部件、方法等的示例,以便提供对主题的一些实施方式的良好理解。然而,对于本领域技术人员将明显的是,可以在没有这些具体细节的情况下实践至少一些实施方式。在其他实例中,为了避免不必要地模糊本文描述的技术,未详细描述或者以简单的框图格式呈现公知的部件或方法。因此,下文阐述的具体细节仅是示例性的。特定的实现方式可以不同于这些示例性细节,并且仍然被认为在本主题的精神和范围之内。
32.本文参照附图描述了包括基于sonos的多级nvm晶体管和金属氧化物半导体(mos)晶体管或场效应晶体管(fet)的存储器单元及制造所述存储器单元的方法的实施方式。然而,可以在没有这些具体细节中的一个或更多个的情况下或者与相关领域中的其他已知方法、材料和设备相结合来实践特定实施方式。在以下描述中,阐述了许多具体细节诸如具体材料、尺寸、浓度和工艺参数等,以提供对主题的透彻理解。在其他情况下,没有特别详细地描述公知的半导体设计和制造技术,以避免不必要地模糊本主题。说明书中对“实施方式”、“一个实施方式”、“示例实施方式”、“一些实施方式”和“各种实施方式”的引用意指结合实施方式描述的特定特征、结构或特性包括在本主题的至少一个实施方式中。此外,在说明书中各个地方出现的短语“实施方式”、“一个实施方式”、“示例实施方式”、“一些实施方式”和“各种实施方式”不一定都指的是相同的实施方式。
33.说明书包括对附图的参照,这些附图形成具体实施方式的一部分。附图示出了根据示例性实施方式的图示。以足够详细的方式对本文中也可以被称为“示例”的这些实施方式进行描述,以使得本领域技术人员能够实践本文描述的要求保护的主题的实施方式。在不脱离所要求保护的主题的范围和精神的情况下,可以对实施方式进行组合,可以利用其他实施方式,或者可以对结构、逻辑和电气作出改变。应当理解,本文描述的实施方式不旨在限制主题的范围,而是使得本领域技术人员能够实践、制造和/或使用本主题。
34.本文所使用的术语“在
……
上方”、“在
……
下方”、“之间”和“在
……
上”是指一层相对于其他层的相对位置。因此,例如,沉积或布置在另一层上方或下方的一层可以直接与另一层接触,或者可以具有一个或更多个中间层。此外,沉积或布置在层之间的一层可以直接与所述层接触或者可以具有一个或更多个中间层。相比之下,“在第二层上”的第一层与第二层接触。另外,假定在不考虑衬底的绝对取向的情况下进行相对于起始衬底沉积、修改和去除膜的操作,则提供一个层相对于其他层的相对位置。
35.除非另外明确指出,否则如根据以下讨论明显的是,应当理解,在整个说明书中,利用诸如“处理”、“计算”、“核算”、“确定”等术语的讨论指的是计算机或计算系统或类似的电子计算装置的动作和/或处理,计算系统或类似电子计算装置操纵计算系统的寄存器和/或存储器内被表示为物理(诸如,电子)量的数据并将这些数据转换成在计算系统的存储器、寄存器或其他这样的信息存储、传输或显示装置内被类似地表示为物理量的其他数据。
36.主题概述
37.根据半导体装置的一个实施方式,半导体可以包括基于sonos的nvm阵列,该基于sonos的nvm阵列包括以行和列布置的电荷俘获存储器单元。存储器单元可以被配置成存储n个模拟值(n
×
模拟值)中的一个(n是大于2的自然数)。在一个实施方式中,每个电荷俘获存储器单元可以具有存储器晶体管,该存储器晶体管包括其源极区和漏极区中的成角度的
轻掺杂漏极(ldd)注入。成角度的ldd注入至少部分地在存储器晶体管的氧化物-氮化物-氧化物(ono)层下延伸。在一个实施方式中,设置在存储器晶体管内和相邻地隔离结构上的ono层可以具有基本相同的高度。
38.在一个实施方式中,电荷俘获存储器单元中的每一个可以具有包括共享的源极区的选择晶体管,其中共享的源极区可以在基于sonos的nvm阵列的同一行的两个相邻的电荷俘获存储器单元之间共享。
39.在一个实施方式中,存储在电荷俘获存储器单元中的n
×
模拟值可以对应于存储器晶体管的n个漏极电流(id)水平(n
×
漏极电流(id)水平)和n个阈值电压(v
t
)水平(n
×
阈值电压(v
t
)水平)。在一个实施方式中,可以预先确定n
×
id水平和n
×vt
水平。
40.在一个实施方式中,n
×
id水平可以线性递增,而n
×vt
水平可以线性递减。
41.在一个实施方式中,n
×
id水平的两个相邻分布可以具有小于3%的交叠重复率。
42.在一个实施方式中,存储器晶体管的成角度的ldd注入可以具有每平方厘米1e12至1e15个原子的磷的近似范围内的掺杂剂剂量,以便使存储器晶体管的栅极诱导的漏极泄漏(gidl)电流和漏极电流(id)以及阈值电压(v
t
)分布西格玛最小化。
43.在一个实施方式中,存储器晶体管的ono层可以具有阻挡电介质层、电荷俘获层和隧道氧化物层。阻挡电介质层可以通过第一原位蒸汽生成(issg)工艺形成,使得阻挡电介质层与电荷俘获层之间的界面电荷陷阱最小化。隧道氧化物层可以通过第二issg工艺形成,使得隧道氧化物层与衬底之间以及隧道氧化物层与电荷俘获层之间的界面电荷陷阱最小化。
44.在一个实施方式中,电荷俘获层可以具有设置在下电荷俘获层上方的上电荷俘获层。上电荷俘获层可以通过第一化学气相沉积(cvd)工艺形成,该第一化学气相沉积(cvd)工艺使用包括处于第一流速的dcs/nh3混合物和n2o/nh3气体混合物的处理气体。在一个实施方式中,下电荷俘获层可以通过第二cvd工艺形成,该第二cvd工艺使用包括处于第二流速的dcs/nh3混合物和n2o/nh3气体混合物的处理气体,其中可以使第一cvd工艺下的n2o/nh3气体混合物的第一流速增加,同时使dcs/nh3的第二流速降低,以使电荷俘获层中的浅电荷陷阱的浓度最小化。
45.在一个实施方式中,相邻的隔离结构可以是使两行或两列电荷俘获存储器单元分离的浅沟槽隔离(sti)。在一个实施方式中,存储器晶体管与sti之间的界面区域中可以基本上不存在凹陷。在一个实施方式中,通过issg工艺形成的隧道氧化物可以在sti与电荷俘获存储器单元之间的sti拐角周围具有均匀的厚度。
46.在一个实施方式中,存储在电荷俘获存储器单元中的n
×
模拟值中的一个可以通过使用福勒-诺德海姆隧穿的一系列部分编程操作和部分擦除操作被写入。
47.根据半导体装置的一个实施方式,半导体装置可以具有基于sonos的nvm阵列,该基于sonos的nvm阵列被配置成用作推理装置。半导体装置可以具有多个多级存储器单元,并且每个单元可以包括存储器晶体管,该存储器晶体管包括至少部分地在存储器晶体管的氧化物-氮化物-氧化物(ono)层下延伸的成角度的轻掺杂漏极(ldd)注入。在一个实施方式中,设置在存储器晶体管内和相邻的隔离结构上的ono层可以具有基本相同的高度。该装置还可以包括数模(dac)功能,该数模(dac)功能被配置成接收和转换来自外部装置的数字信号。被转换的数字信号可以使存储在至少一列中的至少一个多级存储器单元中的模拟值被
读取。该装置还可以具有被配置成使用存储在至少一个多级存储器单元中的模拟值来执行推理操作的列多路复用器(mux)功能以及被配置成将来自列mux功能的推理操作的模拟结果转换为数字值的模数(adc)功能。
48.在一个实施方式中,同一行中的多级存储器单元可以共享sonos字线,同一列中的多级存储器单元可以共享位线,以及两个相邻列中的多级存储器单元可以被耦接至公共源极线。
49.在一个实施方式中,多级存储器单元可以被配置成存储n
×
模拟值中的一个,其中n为大于2的自然数。n
×
模拟值可以分别对应于存储器晶体管的n
×
漏极电流(id)水平和n
×
阈值电压(v
t
)水平。
50.在一个实施方式中,相邻的隔离结构可以是使两行或两列多级存储器单元分离的sti,并且存储器晶体管与sti之间的接触区域中可能不存在凹陷。
51.在一个实施方式中,存储器晶体管的成角度的ldd注入可能具有每平方厘米1e12至1e15个原子的磷的近似范围内的掺杂剂剂量。
52.根据系统的一个实施方式,该系统可以包括多个多级非易失性存储器(nvm)装置。每个多级nvm装置可以具有基于sonos的阵列,该基于sonos的阵列包括被配置成存储n
×
模拟值中的一个的存储器单元,其中,n是大于2的自然数。在一个实施方式中,存储器单元中的每一个可以具有存储器晶体管,该存储器晶体管包括至少部分地在存储器晶体管的ono层下延伸的成角度的ldd注入。ono层的阻挡氧化物层和隧道氧化物层可以通过原位蒸汽生成(issg)工艺形成为使界面电荷陷阱最小化。该系统还可以包括:数模(dac)功能,该数模(dac)功能被配置成接收和转换来自系统中的至少一个其他多级nvm装置的数字信号;列多路复用器(mux)功能,该列多路复用器功能被配置成使用存储器单元中存储的模拟值和被转换的数字信号来执行推理操作;模数(adc)功能,该模数(adc)功能被配置成将来自列mux功能的推理操作的模拟结果转换为数字值;以及总线系统,该总线系统将多个多级nvm装置彼此耦合。
53.在一个实施方式中,存储在存储器单元中的n个模拟值(n
×
模拟值)可以对应于存储器晶体管的n
×
漏极电流(id)水平和n
×
阈值电压(v
t
)水平。
54.在一个实施方式中,设置在存储器晶体管内和相邻的隔离结构上的ono层可以具有基本相同的高度。相邻的隔离结构可以是使两行或两列存储器单元分离的sti,并且存储器晶体管与sti之间的接触区域中可以不存在凹陷。
55.在一个实施方式中,多个多级nvm装置中的每一个可以被配置成作为深度神经网络(dnn)的人工神经元来执行,并且推理操作包括乘法累加(mac)操作。
56.在一个实施方式中,多个多级非易失性存储器(nvm)装置和总线系统可以设置在单个半导体管芯或封装或衬底中。在一个实施方式中,该系统还具有将多个多级nvm装置通信地耦合的总线系统。
57.实施方式的描述
58.图1a是非易失性存储器单元的截面侧视图的框图,并且在图1b中描绘了该非易失性存储器单元的对应的示意图。非易失性存储器(nvm)阵列或装置可以包括nvm单元,该nvm单元具有使用硅(半导体)-氧化物-氮化物-氧化物-硅(半导体)(sonos)或浮栅技术实现的非易失性存储器晶体管或装置以及彼此相邻或耦接设置的常规场效应晶体管(fet)。
59.在一个实施方式中,如图1a所示,非易失性存储器晶体管是sonos型电荷俘获非易失性存储器晶体管,该sonos型电荷俘获非易失性存储器晶体管可以被配置成存储二进制值(“0”或“1”)或多级模拟值(例如,0至2n)。参照图1a,nvm单元90包括形成在衬底98上的nv晶体管94的控制栅极(cg)或存储器栅极(mg)叠层。nvm单元90还包括形成在衬底98中或者可选地形成在衬底98中的浅正阱(spw)93内的在nv晶体管94的任一侧的源极97/漏极88区。spw 93可以至少部分地被封装在深负阱(dnw)99内。在一个实施方式中,源极/漏极区88和97通过nv晶体管94下面的沟道区91连接。nv晶体管94包括形成ono叠层的氧化物隧道电介质层、氮化物或氮氧化物电荷俘获层92、氧化物顶层或阻挡层。在一个实施方式中,电荷俘获层92可以是多层的,并且俘获通过fn隧穿从衬底93注入的电荷。nv晶体管94的v
t
和id值可能至少部分地由于俘获的电荷的量而改变。在一个实施方式中,高k电介质层可以形成阻挡层的至少一部分。覆盖ono层设置的多晶硅(poly)或金属栅极层可以用作控制栅极(cg)或存储器栅极(mg)。如图1a中最佳示出的,nvm单元90还包括邻近nv晶体管94设置的fet 96。在一个实施方式中,fet 96包括覆盖氧化物或高k电介质栅极电介质层设置的金属或多晶硅选择栅极(sg)。fet 96还包括形成在衬底98中或者可选地形成在衬底98中的阱93内的在fet 96的任一侧的源极/漏极区86和97。如图1a中最佳示出的,fet 96和nv晶体管94共享设置在其间的或称为内部节点97的源极/漏极区97。sg被适当地偏置v
sg
以打开或关闭fet 96下面的沟道95。如图1a所示,nvm单元90被认为具有双晶体管(2t)架构,其中,nv晶体管94和fet 96在整个本专利文献中可以分别被认为是存储器晶体管以及选择或传输晶体管。
60.在一个实施方式中,图1b描绘了具有与fet 96串联连接的非易失性(nv)晶体管94的双晶体管(2t)sonos nvm单元90。当通过v
cg
来适当地偏置cg或通过相对于衬底98或阱93在cg上施加正脉冲使得电子通过fn隧穿从反型层注入到电荷俘获层92中时,nvm单元90被编程(位值“1”)。俘获在电荷俘获层92中的电荷导致漏极88与源极97之间的电子耗尽,从而提高了使基于sonos的nv晶体管94导通所需的阈值电压(v
t
),使装置处于“编程”状态。通过在cg上施加相反偏置v
cg
或者相对于衬底98或阱93在cg上施加负脉冲,使得来自累积沟道91的空穴fn隧穿到ono叠层中来擦除nvm单元90。编程阈值电压和擦除阈值电压分别称为“vtp”和“vte”。在一个实施方式中,nv晶体管94还可以处于禁止状态(位值“0”),其中,在控制栅极(cg)相对于衬底98或阱93为脉冲正的同时(如在编程条件下),通过在nvm单元90的源极和漏极上施加正电压来禁止对先前擦除的单元(位值“0”)进行编程(位值“1”)。nv晶体管94的阈值电压(称为“vtpi”)由于干扰垂直场而变得稍微更正一些,但是该阈值电压保持被擦除(或禁止)。在一个实施方式中,vtpi也由ono叠层的电荷俘获层92将俘获的电荷(擦除状态的空穴)保持在电荷俘获层92中的能力决定。如果电荷陷阱较浅,则俘获的电荷趋于消散,并且nv晶体管94的vtpi变得更正。在一个实施方式中,nv晶体管94的vtpi倾向于随着进一步的禁止操作而衰减或上升。应当理解的是,本文中将位或二进制值“1”和“0”分配给nvm单元90的相应“编程”状态和“擦除”状态仅是为了解释的目的,而不应被解释为限制。在其他实施方式中,该分配可以颠倒或者具有其他布置。
61.在另一实施方式中,nv晶体管94可以是浮栅mos场效应晶体管(fgmos)或装置。通常,fgmos在结构上类似于上述基于sonos的nv晶体管94,主要区别在于fgmos包括电容地耦接至装置的输入的多晶硅(poly)浮栅,而不是氮化物或氮氧化物电荷俘获层92。因此,fgmos装置可以参照图1a和图1b进行描述,并且以类似的方式操作。
62.类似于基于sonos的nv晶体管94,可以通过在控制栅极与源极区和漏极区之间施加适当的偏置v
cg
以提高使fgmos装置导通所需的阈值电压v
t
来对fgmos装置进行编程。可以通过在控制栅极上施加相反的偏置v
cg
来擦除fgmos装置。
63.在一个实施方式中,源极/漏极区86可以被认为是nvm单元90的“源极”并耦接至v
sl
,而源极/漏极区88可以被认为是“漏极”并耦接至v
bl
。可选地,spw 93与v
spw
耦接,而dnw 99与v
dnw
耦接。
64.fet 96可以在编程操作或擦除操作期间防止热载流子电子注入和结击穿。fet 96还可以防止大电流在源极86与漏极88之间流动,该大电流可能导致存储器阵列中的高能耗和寄生电压降。如图1a中最佳示出的,fet 96和nv晶体管94两者都可以是n型晶体管或n沟道晶体管,其中,源极/漏极区86、88、97和dnw 99掺杂有n型材料,而spw 93和/或衬底98掺杂有p型材料。应当理解,nvm单元90还可以另外地或可替选地包括p型晶体管或p沟道晶体管,其中,源极/漏极区和阱可以根据本领域普通技术人员的实践相反地或不同地被掺杂。
65.通过制造存储器单元(诸如nvm单元90)的栅格来构造存储器阵列,存储器单元以行和列布置并且通过多个水平控制线和垂直控制线连接至外围电路系统诸如地址解码器和比较器(诸如模拟到数字(adc)功能和数字到模拟(dac)功能)。每个存储器单元包括至少一个非易失性半导体装置(诸如上文所描述的那些),并且可以具有单晶体管(1t)架构或如图1a中所描述的双晶体管(2t)架构。
66.图2是示出根据本主题的一个实施方式的nvm阵列的示意图。在一个实施方式中,如图2所示,存储器单元90具有2t架构,并且除了非易失性存储器晶体管之外,存储器单元90还包括传输或选择晶体管,例如与存储器晶体管共享公共衬底连接或内部节点的常规mosfet。在一个实施方式中,nvm阵列100包括布置成n行或n页(水平)和m列(垂直)的nvm单元90。同一行中的nvm单元90可以被认为是在同一页中。在一些实施方式中,一些行或页可以被组合在一起以形成存储器扇区。应当理解,存储器阵列的术语“行”和“列”用于说明而非限制的目的。在一个实施方式中,行是水平布置的,以及列是垂直布置的。在另一实施方式中,存储器阵列的行和列的术语可以被颠倒或以相反意义使用,或以任何取向布置。
67.在一个实施方式中,sonos字线(wls)耦接至同一行的nvm单元90的所有cg,字线(wl)耦接至同一行的nvm单元90的所有sg。在一个实施方式中,位线(bl)耦接至相同列的nvm单元90的所有漏极区域88,而公共源极线(csl)或区86耦接在阵列中的所有nvm单元之间或在阵列中的所有nvm单元之间共享。在一个替选实施方式中,csl可以在同一行的两个成对的nvm单元(诸如图3a中最佳示出的c1与c2)之间共享。csl还耦接至相同两列的所有nvm对的共享源极区。
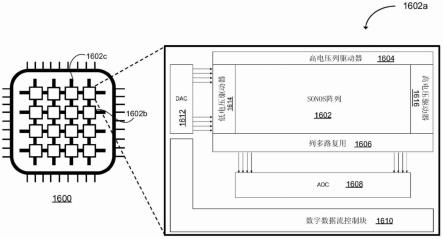
68.在闪存模式下,写操作可以包括对所选择的行(页)的批量擦除操作,随后对同一行中的单个单元进行编程操作或禁止操作。一次可以擦除的最小nvm单元块是单页(行)。一次可以被编程/禁止的最小单元块也可以是单页。
69.参照图2,nvm单元90可以成对布置,诸如nvm单元对200。在一个实施方式中,如图3a、图3b、图8a和图8b最佳所示的,nvm单元对200包括具有镜像取向的两个nvm单元90,使得每个nvm单元(例如c1和c2)的选择晶体管被设置为彼此相邻。同一nvm单元对200的nvm单元90还可以共享接收电压信号v
csl
的公共源极区。
70.图3a示出了nvm阵列100的2
×
2阵列300,以用于展示根据本公开内容的擦除操作
或硬擦除操作的实施方式。如前所述,nvm阵列100可以采用公共源极线(csl)配置。在一个实施方式中,在nvm阵列中的所有nvm单元之间或者至少在邻近列的nvm单元(例如c1与c2)之间共享一个单个csl(例如csl0)。在一个实施方式中,csl可以被设置在相邻列的nvm单元90的选择晶体管之间并在相邻列的nvm单元90的选择晶体管之间共享。在下面的描述中,为了清楚和易于解释,假设包括2
×
2阵列300的nvm阵列100中的所有晶体管都是n型晶体管。应当理解,在不失一般性的情况下,可以通过使所施加的电压的极性反转来描述p型配置,并且这样的配置在本公开内容的预期实施方式内。此外,以下描述中使用的电压和脉冲持续时间是为了便于解释而选择的,并且仅代表本主题的一个示例性实施方式。在不同的实施方式中可以采用其他电压。
71.图3a示出了nvm阵列100的段的示例性实施方式,该段可以是存储器单元的大存储器阵列的一部分。在图3a中,2
×
2存储器阵列300包括布置成两行和两列的至少四个存储器单元c1、c2、c3和c4。虽然nvm单元c1至c4可以设置在两个相邻的列中(公共源极线csl0),但是nvm单元c1至c4可以设置在两个相邻的行中或者两个不相邻的行中。nvm单元c1至c4中的每一个可以在结构上类似于如上所述的nvm单元90。
72.nvm单元c1至c4中的每一个可以包括基于sonos的存储器晶体管和选择晶体管。存储器晶体管中的每一个包括耦接至位线(例如bl0和bl1)的漏极、耦接至选择晶体管的漏极并且通过选择晶体管耦接至单个公共源极线(例如csl0)的源极。每个存储器晶体管还包括耦接至sonos字线(例如wls0)的控制栅极。选择晶体管各自包括耦接至公共源极线(例如,csl0)的源极和耦接至字线(例如,wl0)的选择栅极。
73.参照图3a,例如,页0被选择为用于擦除,而页1不(未被选择)用于擦除操作。如前所述,单页可以是在一次操作中被擦除的最小nvm单元块90。因此,通过将适当的电压施加到由所选择的行中的所有nvm单元共享的sonos字线(wls0)、衬底连接和nvm阵列100中的所有位线来一次擦除该行(页0)中的包括c1和c2的所有nvm单元。在一个实施方式中,负电压v
neg
被施加至wls0,并且正电压v
pos
经由页0中的所有nvm单元的spw和深n阱dnw、包括bl0和bl1的所有位线以及包括csl的公共源极线被施加至衬底或p阱。因此,在c1和c2的cg与存储器晶体管的衬底/p阱之间施加全擦除电压(v
neg
–vpos
)达脉冲持续时间(te至10ms),以擦除c1和c2中的任何先前俘获的电荷(如果有的话)。在一个实施方式中,包括wl0和wl1的所有字线耦接至供电电压v
pwr
。
74.仍参照图3a,当页(行)(例如页1)没有被选择为用于擦除操作时,代替地向wls1施加正电压v
pos
,使得包括c3和c4的页1中的存储器晶体管的到衬底/p阱的cg约为0v(v
pos-v
pos
)。因此,页1的nvm单元的状态保持不变(未被擦除)。
75.表i描绘了可以用于非易失性存储器的页/行0的批量擦除操作的示例性偏置电压,所述非易失性存储器与2
×
2阵列300类似具有2t架构并且包括具有n型sonos晶体管和csl的存储器单元。
[0076][0077][0078]
表i
[0079]
图3b示出了在编程操作期间nvm阵列100的段2
×
2阵列300的示例性实施方式。参照图3b,例如,nvm单元c1是要被编程为或写为逻辑“1”状态(即,被编程为截止状态)的目标单元,而已经通过如图3a所描绘的在先擦除操作被擦除为逻辑“0”状态的nvm单元c2保持在逻辑“0”或导通状态。应当理解,尽管出于说明的目的将c1和c2示出为两个相邻的单元,但是c1和c2也可以是同一行(诸如行0)上的两个分离的nvm单元。这两个目标(对c1进行编程以及禁止c2)通过以下操作完成:将第一或正高电压(v
pos
)施加至nvm阵列100的页或行0中的wls0,将第二或负高电压(v
neg
)施加至bl0以在对所选择的存储器单元进行编程时使c1的存储器晶体管偏置,同时将禁止电压(v
inhib
)施加至bl1和dnw以在禁止对未选择的存储器单元进行编程时使c2的存储器晶体管偏置,以及将公共电压施加至所有nvm单元的共享衬底或p阱spw,以及将字线(wl1和wl2)耦接至第二或负高电压(v
neg
)。在一个实施方式中,c1与c2之间或者所有nvm单元90中的公共源极线csl0可以处于第三高电压或者csl电压(v
csl
)或者允许浮动。在一个实施方式中,第三高电压v
csl
可以具有小于v
pos
或v
neg
的电压水平或绝对幅度。在一个实施方式中,可以由存储器装置中其自己的包括dac的专用电路系统(未示出)生成v
csl
。v
csl
可以具有与裕量电压v
marg
大致相同的电压水平或绝对幅度,这将在后面的部分中更详细地讨论。当v
pos
经由wls0施加至c2的存储器晶体管时,bl1上的正v
inhib
被转移至该存储器晶体管的沟道。该正v
inhib
降低了c2的存储器晶体管上的栅极-漏极/沟道电压,从而减小了编程域(programming field),使得阈值电压与vte的偏移较小。仍可能发生的电荷的隧穿被称为抑制干扰,并且被量化为(vte
–
vtpi)。在一个实施方式中,作为编程操作的结果,页0的包括c1和c2的所有nvm单元可以基于nvm单元接收的位线电压来获得二进制状态“1”(编程的
–
vtp)或“0”(禁止的
–
vtpi)。未被选择的页(诸如页1)中的nvm单元可以保持二进制状态“0”(擦除的
–
vte)。
[0080]
此外,如下文更详细描述的,具有小于v
neg
的电压水平或绝对幅度的所选择的裕量电压(v
marg
)被施加至未选择的行或页(例如,页1)中的wls1,以减少或基本消除由于对所选择的c1进行编程而导致的未选择的nvm单元c4中的编程状态位线干扰。在一个实施方式中,vmarg
的绝对电压水平或幅度可以与v
csl
相同。
[0081]
表ii描绘了可以用于对非易失性存储器进行编程的示例性偏置电压,该非易失性存储器具有2t架构并包括具有n型sonos晶体管和csl的存储器单元。
[0082]
节点电压(v)电压范围(v)wls0v
pos
例如 4.2v 3.8v至 4.6vbl0v
neg
例如-3.8v-4.0v至-3.4vwl0v
neg
例如-3.8v-4.0v至-3.4vspwv
neg
例如-3.8v-4.0v至-3.4vdnwv
inhib
例如 1.1v 1.0v至 1.2vcls0浮动/v
marg
例如-2.4v-3.0v至-2.0vwls1v
marg
例如-2.4v-3.0v至-2.0vbl1v
inhib
例如 1.1v 1.0v至 1.2vwl1v
neg
例如-3.8v-4.0v至-3.4v
[0083]
表ii
[0084]
通常,裕量电压(v
marg
)具有与第二高电压或v
neg
相同的极性,但比v
neg
高或更正,高出的电压至少等于编程状态位线干扰减少的存储器晶体管的阈值电压(v
t
)。
[0085]
图4示出了示例性的基于sonos的nvm阵列(诸如nvm阵列100)中的vtp和vte以及被编程的漏极电流(i
dp
)和被擦除的漏极电流(i
de
)分布。典型的写操作包括:如图3a所述的擦除或硬擦除操作以及之后的如图3b所述的硬编程/禁止操作。在一个实施方式中,在可靠的读取操作之后,nvm单元可以被确定为处于两种不同的二进制状态(“0”或“1”)中的一种。如图3a中描述的擦除操作也可以被认为是硬擦除,因为该擦除操作导致将被擦除的nvm单元(例如,图3a中的c1和c2)的v
t
/id移动至被擦除的v
t
/id水平(完全擦除),而不管那些单元的起始v
t
/id水平。类似地,如图3b所述的编程操作可以被认为是硬编程操作。在一个实施方式中,在硬擦除操作与硬编程/禁止操作之间不存在验证或读取操作。
[0086]
图5是示出根据本文所述的主题的一个实施方式的基于sonos的nvm模拟装置中的多级nvm存储器单元的多个漏极电流(id)水平的示意图。在一个实施方式中,多级nvm单元的id可以通过经由wls向sonos晶体管的cg施加预定电压被确定或验证,并且经由bl被读取。在其他实施方式中,可以通过本领域已知和实践的其他方法来确定id。类似于v
t
,在nvm阵列100被用作诸如nor闪存、eeprom等的数字存储器装置的实施方式中,id可以用于确定nvm单元90的二进制状态。
[0087]
在其他实施方式中,可以通过存储多个(多于两个)模拟值而在模拟装置中使用nvm阵列100。参照图4和图5,代替使用如图3a和图3b所述的硬编程操作和擦除操作将两个二进制值(“0”和“1”)中的一个写入nvm阵列100的nvm单元90,可以使用一系列部分编程操作和部分擦除操作将nvm单元90写为多个(多于两个)id或v
t
水平(对应于电荷俘获层92中的被俘获的电荷)。在实施方式中,通过对脉冲持续时间以及施加在cg和漏极或衬底上的电压差或偏置和极性进行操纵,部分编程操作和擦除操作可以使目标nvm单元的v
t
/id分别向被编程的v
t
/id水平和被擦除的v
t
/id水平移动(或靠近)。部分编程操作和擦除操作可以包括但不限于软编程操作、再填充编程操作、软擦除(行)操作、选择性软擦除(单元)操作和退火擦除(行)操作,这将在本专利文件的后面部分中进一步解释。
[0088]
在一个实施方式中,如图5中最佳所示,在模拟配置/模式下,nvm单元90可以被配置成根据其id水平表示或存储2n(4,8,16,
……
,128等)值中的一个,其中,n是大于1的自然数。在另一实施方式中,nvm单元90可以被配置成表示大于2的任意数目的值。在一个实施方式中,id1至i
d2n
分别是第一id分布至第2nid分布的平均id值。在每个id分布中,可能存在限定目标id范围的下id限制和上id限制(参见id1)。在实施方式中,可以根据系统设计和要求来预先确定平均id水平或平均v
t
水平以及它们的上限和下限。第一id分布可以近似图4中的被编程的单元分布σ3,以及第2nid分布近似图4中的被擦除的单元分布σ4。在一个实施方式中,nvm阵列100的操作性id范围可以近似为(id2n
–
id1),并且作为示例可以为(1.28μa
–
10na=1,270na)。应当理解,1,270na的操作性id范围仅是示例,并且可以是任何其他值,这取决于nvm单元、操作电压和脉冲持续时间以及系统要求/设计。在一个实施方式中,通过限定多个id水平或v
t
水平并将nvm单元90写为操作性id范围(例如1.28μa至10na)内的特定目标id水平,nvm阵列100可以用作用以存储模拟值的模拟存储器装置。在一个实施方式中,本领域普通技术人员将理解,相同的概念可以应用于将多个(多于两个)v
t
水平写入nvm单元90。
[0089]
在一个实施方式中,为了在有限的操作性id范围内实现多个不同的id水平,可以要求每个id分布具有紧密的分布(低西格玛σ),使得相邻的id分布被明显分开,以最小化错误读取,尤其是当n为大数值时。不同限定水平的id平均值也可以是线性递增的,使得δid在图5中基本上是常数,以用于准确和有效的读取/验证操作。由于基于sonos的单元(诸如nvm单元90)的固有的低id/v
t
西格玛和低功耗(v
cc
=0.81v
–
1.21v),该基于sonos的单元是多个水平的模拟存储器的良好候选。另外,由于基于sonos的单元中的编程操作和擦除操作(硬和软两者)两者都是使用fn隧穿来完成,所以可以实现具有非常低的西格玛的非常精细的id/v
t
水平的调谐。此外,基于sonos的单元可以具有高的稳健耐用性能,在-40℃至125℃的温度范围内经过100k次循环后退化极小,这可以满足大多数消费者、工业和汽车应用的需求。在一个实施方式中,在相邻的id分布之间可能存在交叠的id值502。为了可靠且准确地读取nvm单元90的id水平,id分布西格玛σ可以减小到大约低于8na,使得交叠区域502保持低于分布的1%至3%。
[0090]
图6a是示出根据本公开内容的一个实施方式的nvm单元的16(24)个id水平的图表。如图5中最佳示出的,id水平是不同的、良好分离的(低西格玛)并且线性递增的,以便保持作为模拟装置的多级nvm单元的高功能性。
[0091]
图6b是示出根据本主题的sonos晶体管的电荷俘获氮化物层中从价带到导带的陷阱密度分布的示意图。如图6b中最佳所示,浅陷阱是能级接近导带(ec)级的电荷陷阱,而深陷阱是能级在价带(ev)与ec之间的中间范围的电荷陷阱。在一个实施方式中,浅陷阱中的电荷可以导致滞留期间的电荷损失,主要是因为浅陷阱中的电荷更容易离开电荷俘获氮化物层。
[0092]
图7是示出由于id和滞留退化而导致的对多级nvm单元中的id分布的潜在影响的图表。虽然sonos晶体管94的寿命初期(bol)西格玛可能非常低,但是在滞留期间随着时间的推移可能会有严重的退化,尤其是在高温下。因此,id分布(例如,id1和id2)可以被更广泛地分布(增加的西格玛),以及相邻的id分布可以具有图7中更大的交叠部分或重复率710(例如,超过3%),这可能导致水平或值的不正确/错误的读取。在一个实施方式中,西格玛退化可能是由于氮化物层92中的“浅”陷阱中的被俘获的电荷在滞留期间丢失而“深”陷阱中的
被俘获的电荷保持被俘获。滞留期间的被俘获的电荷损失也可能导致id水平向上偏移,诸如图7中的id8和i
d8’
。
[0093]
因此,对基于sonos的nvm晶体管诸如nvm晶体管94采取结构改变或优化以改进多级nvm单元的可靠性和功能性是重要紧急的。在一个实施方式中,如图6b中最佳所示,结构性优化可以降低浅陷阱的密度和/或增加深陷阱的密度。还可以通过改变制造工艺使得电荷俘获层中的浅陷阱的密度减小并且在编程操作和擦除操作期间的fn隧穿增强来改进滞留和id/v
t
西格玛退化。在一个实施方式中,制造工艺改进可以包括sonos晶体管中的浅沟槽隔离(sti)拐角曲率的平滑、沟道中的掺杂剂分布优化、改进的氧化物层,这些将在后面的部分中示出和描述。
[0094]
图8是示出根据本公开内容的一个实施方式的将多级sonos或nvm晶体管集成到基线互补金属氧化物半导体(cmos)工艺流程中的关键制造步骤的工艺流程图。参照图8和图9a,该工艺开始于在晶片或衬底904中形成多个隔离结构或形成浅沟槽隔离(sti)902(步骤802)。隔离结构902对形成在衬底904的邻接区域、阵列行或列中的存储器单元进行隔离。例如,如图10a中最佳所示,sti 902被形成为对多级sonos晶体管的相邻行或列进行隔离。可选地和另外地,可以并入隔离结构502,以将形成在衬底904的第一区906中的多级nvm晶体管与形成在第二区908中的包括hv mos、i/o mos和lv mos的mos晶体管中的一个或更多个进行隔离。在一个实施方式中,lv mos(选择晶体管)也可以被形成在第一区906中,以对2t nvm存储器单元诸如图2中的nvm单元200进行配置。
[0095]
在一个实施方式中,隔离结构902可以包括诸如氧化物或氮化物的电介质材料,并且可以通过包括但不限于sti或硅的局部氧化(locos)的任何常规技术形成。衬底904可以是由适合于半导体装置制造的任何单晶材料构成的大块衬底(bulk substrate),或者可以包括在衬底上形成的合适材料的顶部外延层。在一个实施方式中,用于衬底904的合适的材料包括但不限于硅、锗、硅锗或iii-v族化合物半导体材料。
[0096]
如图9a中最佳所示,衬垫氧化物909可以形成在第一区906和第二区908两者中的衬底904的表面916上。在一个实施方式中,衬垫氧化物909可以是具有从大约10纳米(nm)到大约20nm的厚度的硅二氧化物(sio2),并且可以通过热氧化工艺或者原位蒸汽生成(issg)工艺或者本领域已知的其他氧化或沉积工艺来生长。应当理解,衬垫氧化物909可以不是必需的,或者可以在一些实施方式中形成。
[0097]
参照图8和图9b,然后通过衬垫氧化物909(如果存在的话)将掺杂剂注入到衬底904中,以形成其中可以形成nvm晶体管和/或mos晶体管的阱910和mos晶体管的沟道(步骤804)。根据系统设计,可以存在或不存在设置在第一区906与第二区908之间的隔离结构902。注入的掺杂剂可以是任何类型和浓度并且可以以任何能量被注入,所述任何能量包括形成用于nvm晶体管和/或mos晶体管的阱(诸如spw 93)和/或深阱(诸如dnw 99)以及形成mos晶体管的沟道所需的能量。在一个特定实施方式中,如图9b中作为示例所示,注入适当离子种类的掺杂剂以在第二区908中形成阱910,在该第二区908上或在该第二区908中可以形成输入/输出(i/o)mos晶体管915。在替选实施方式中,还可以针对nvm晶体管926和/或高电压(hv)mos晶体管914和/或低电压(lv)mos晶体管912形成阱或深阱。还应当理解,可以通过在衬底904的表面916上沉积掩模层(诸如光致抗蚀剂层)并对该掩模层进行图案化并且以适当的能量将适当的离子种类注入到适当的浓度来形成阱(诸如阱910)。
[0098]
在一个实施方式中,可以在衬底904中形成针对hv mos晶体管914、i/o mos晶体管915和lv mos晶体管912中的一个或更多个的沟道918。应当理解,hv mos晶体管914、i/o mos晶体管915和lv mos晶体管912的沟道918可以同时形成或者可以不同时形成。如同阱注入一样,可以通过在衬底904的表面916上沉积掩模层(诸如光致抗蚀剂层)并对该掩模层进行图案化并且以适当的能量将适当的离子种类注入到适当的浓度来形成沟道918。例如,在一个实施方式中,可以以从大约10千电子伏(kev)至大约100kev的能量以及从大约1e12cm-2
至大约1e14cm-2
的剂量注入bf2,以形成n型mos(nmos)晶体管。同样,可以通过以任何合适的剂量和能量注入砷(as)离子或磷(p)离子来形成p型mos(pmos)晶体管。应当理解,也可以使用注入来同时或在分开的时间使用标准光刻技术在所有三个mos晶体管914、912、915中形成沟道918,包括形成图案化光致抗蚀剂层以用于对mos晶体管914、912、915的沟道918中的一者进行掩模。
[0099]
接下来,参照图8和图9b,在衬垫氧化物909层上或覆盖衬垫氧化物909层形成图案化隧道掩模920,通过隧道掩模920中的窗口或开口注入适当类型、能量和浓度的离子(由箭头922表示)以在第一区906中形成多级nvm晶体管926的沟道924,并移除至少第二区908中的隧道掩模920和衬垫氧化物909层(步骤804)。隧道掩模920可以包括由图案化的氮化物或硅氮化物层形成的光致抗蚀剂层或硬掩模。
[0100]
在一个实施方式中,多级nvm晶体管926的沟道924可以是以从约50千电子伏(kev)至约500kev的能量和从约5e11cm-2
至约1e13cm-2
的剂量被注入铟(in)以形成n沟道多级nvm晶体管926的深铟掺杂的沟道。在一个实施方式中,注入铟以形成多级nvm晶体管926的沟道924将完成的nvm晶体管的阈值电压(v
t
)均匀性从大约150毫伏(mv)的v
t
的西格玛提高到大约100mv的v
t
的西格玛。可选地或另外地,在沟道924处以约20kev的能量和从约5e11cm-2
至约1e13cm-2
的剂量向浅掺杂沟道注入砷。可替选地,可以注入bf2以形成n沟道nvm晶体管,或者可以注入砷或磷以形成p沟道nvm晶体管。在一个替选实施方式中,多级nvm晶体管926的沟道924也可以与mos晶体管914、912、915的沟道918同时形成。在实施方式中,如图6a中最佳示出的,特定的沟道掺杂配置可以减少随机掺杂剂波动(rdf),使得v
t
和id分布的多个级的v
t
和id西格玛在完成的多级nvm晶体管926中不同且被分开。
[0101]
在一个实施方式中,如图9c所示,可以例如在使用含表面活性剂的10:1缓冲氧化物蚀刻(boe)的湿式清洗工艺中移除隧道掩模920中的窗口或开口中的衬垫氧化物909。可替选地,可以使用20:1的boe湿式蚀刻、50:1的氢氟酸(hf)湿式蚀刻、衬垫蚀刻或任何其他类似的基于氢氟酸的湿式蚀刻化学物质来执行湿式清洗工艺。在一些实施方式中,如图10a中最佳所示,sti 902上的衬垫氧化物909隔离完成的多级nvm晶体管的行(z方向)。图10a和图10b是示出沿平面a-a’的截面视图的代表性图。
[0102]
随后或同时,可以使用氧等离子体对包括光致抗蚀剂材料的隧道掩模920进行灰化或剥离。可替选地,可以使用本领域已知的湿式蚀刻工艺或干式蚀刻工艺来去除硬隧道掩模920。
[0103]
参照图8和图9d至图9e,对衬底904在第一区906中的表面916进行清洗或预清洗,多个电介质层诸如氧化物-氮化物-氧化物或ono层或氧化物-氮化物-氧化物-氮化物-氧化物或onono层被形成或被沉积(步骤806)。随后,在电介质层上或覆盖电介质层形成掩模,并且对电介质层进行蚀刻以在第一区906中形成nv栅极叠层936(步骤806)。
[0104]
预清洗可以是湿式工艺或干式工艺。在一个实施方式中,预清洗可以是使用hf随后使用标准清洗(sc1)和(sc2)的湿式工艺,并且对衬底904的材料具有高度选择性。在一个实施方式中,通常使用1:1:5的氢氧化铵(nh4oh)、过氧化氢(h2o2)和水(h2o)的溶液将sc1在30℃至80℃下执行约10分钟。在另一实施方案中,sc2是在约30℃至80℃下在1:1:10的hcl、h2o2和h2o的溶液中的短暂沉浸。
[0105]
在一个实施方式中,上述清洗工艺和预清洗工艺可以不同程度地去除衬底904的表面上的衬垫氧化物909和sti 902中的氧化物,从而导致衬底904和sti 902的顶部表面的高度不同。参照图10b,由于sti 902与多级nvm晶体管926的各自的顶部表面的高度(凹陷高度)的差异,清洗工艺可能在sti 902与多级nvm晶体管926接触的接合处创建凹陷。接触拐角中的凹陷(如图10b所示的凹陷)可能影响多级nvm晶体管926的fn隧穿,并因此不利地影响id和v
t
西格玛。在一个实施方式中,可以按照前面的描述仔细校准清洗工艺和预清洗工艺,使得sti 902和衬底904上的ono层的顶部表面基本上平整或者具有基本上相同的高度。因此,凹陷高度可以被极大地减小,并且凹陷尺寸和对fn隧穿的影响可以变得基本上不重要。
[0106]
参照图9d,电介质或nv栅极叠层936沉积开始于至少在衬底904的第一区906中的多级nvm晶体管926的沟道924上形成隧道电介质928,并且可以扩展至衬底904的形成有mos晶体管912、914、915的第二区908。隧道电介质928可以是任意材料并且具有如下任意厚度,该厚度适于允许电荷载流子在施加的栅极偏置下隧穿到上面的电荷俘获层中,同时当多级nvm晶体管926未被偏置时,保持对泄漏的适当阻挡。在某些实施方式中,隧道电介质928可以是硅二氧化物、硅氮氧化物或它们的组合,并且可以通过使用issg或自由基氧化的热氧化工艺来生长。
[0107]
在一个实施方式中,硅二氧化物隧道电介质928可以在熔炉中以热氧化工艺热生长。然而,热生长的隧道电介质928可能具有低密度,并且可能有助于在隧道电介质928与衬底904之间以及隧道电介质928与第一电荷俘获层930a之间的界面处具有界面电荷陷阱(见图9d)。在一个实施方式中,大多数界面电荷陷阱是浅陷阱(更接近导带),如图6b所示,这可能不利地影响滞留性能和id/v
t
西格玛退化。
[0108]
在另一个可以称为优选实施方式的实施方式中,可以以诸如issg工艺的自由基氧化工艺生长硅二氧化物隧道电介质928,该自由基氧化工艺涉及将氢气(h2)和氧气(o2)气体以彼此约1:1的比率流入处理室中,而没有点火事件(诸如形成等离子体),否则等离子体将通常用于使h2和o2热解以形成蒸汽。另外,允许h2和o2在近似约0.5托至约10托的范围内的压力下,在近似约900℃至约1100℃的范围内的温度下反应,以在衬底的表面处形成自由基诸如oh自由基、ho2自由基或o双自由基。执行自由基氧化工艺的持续时间近似在约1分钟至约10分钟的近似范围内,以通过衬底的被暴露的表面的氧化和消耗来影响具有从大约1.0纳米(nm)至大约4.0nm的厚度的隧道电介质928的生长。在一个实施方式中,在自由基氧化工艺下生长的隧道电介质928即使在减小的厚度的情况下也可以比通过湿式氧化技术形成的隧道电介质更密集,并且每立方厘米(cm3)由基本上更少的氢原子组成。在某些实施方式中,在能够处理多个衬底的批处理室或熔炉中执行自由基氧化工艺,以在不影响制造设备可能需要的产量(衬底/小时)要求的情况下改进高质量隧道电介质928。在一个实施方式中,与热生长的隧道电介质相比,通过issg工艺形成的隧道电介质928具有更均匀的厚度。
参照图10b和图10c,隧道电介质928尤其在sti拐角周围的均匀厚度可以减少sonos装置的sti拐角中fn注入的不均匀性。这将导致更好的id或v
t
的西格玛。
[0109]
再次参照图9d,在隧道电介质928上或覆盖隧道电介质928形成电荷俘获层。通常,如图9d中最佳所示,电荷俘获层可以是包含多个层的多层电荷俘获层930,该多层电荷俘获层930至少包括在物理上更靠近隧道电介质928的下电荷俘获层或第一电荷俘获层930a以及相对于第一电荷俘获层贫氧的上电荷俘获层或第二电荷俘获层930b,并且电荷俘获层包括分布在多层电荷俘获层930中的大部分电荷陷阱。
[0110]
多层电荷俘获层930的第一电荷俘获层930a可以包括硅氮化物(si3n4)层、富硅的硅氮化物层或硅氮氧化物(sio
x
ny(ho))层。例如,第一电荷俘获层930a可以包括厚度在约2.0nm与约6.0nm之间的硅氮氧化物层,通过cvd工艺形成该硅氮氧化物层,该cvd工艺使用比例和流速适合于提供富硅和富氧的氮氧化物层的二氯硅烷(dcs)/氨(nh3)和氮氧化物(n2o)/nh3气体混合物。
[0111]
然后,在第一电荷俘获层930a上直接或间接形成多层电荷俘获层930的第二电荷俘获层930b。在一个实施方式中,第二电荷俘获层930b可以包括硅氮化物和硅氮氧化物层,所述硅氮化物和硅氮氧化物层的氧、氮和/或硅的化学计量比不同于第一电荷俘获层930a的氧、氮和/或硅的化学计量比。第二电荷俘获层930b可以包括厚度在约2.0nm与约8.0nm之间的硅氮氧化物层,并且可以通过cvd工艺被形成或被沉积,该cvd工艺使用包括比例和流速适合于提供富硅、贫氧的顶部氮化物层的dcs/nh3和n2o/nh3气体混合物的工艺气体。在一个实施方式中,与常规操作相比,第二电荷俘获层930b的形成期间的氮氧化物(n2o)/氨(nh3)气体混合物的流速可以被增加,而第一电荷俘获层930a的形成期间的二氯硅烷(dcs)/氨(nh3)的流速可以减少。如图6b中最佳所示,流速的变化的组合可以形成具有高密度的深陷阱的电荷俘获层930。
[0112]
在另一实施方式中,可以在第一电荷俘获层930a与第二电荷俘获层930b之间形成薄电介质和/或氧化物层930c,从而使多层电荷俘获层930成为非叠层。在一些实施方式中,多层电荷俘获层930是分离的电荷俘获层,该多层电荷俘获层930还包括将第一(下)电荷俘获层930a与第二(上)电荷俘获层930b分开的薄的中间氧化物层930c。中间氧化物层930c显著地降低了电子电荷在编程期间由于隧穿进入第一电荷俘获层930a而在第二电荷俘获层930b的边界处积累的可能性,导致漏电流比常规存储器装置低。在一个实施方式中,中间氧化物层930c可以通过使用热氧化或自由基氧化来氧化到第一电荷俘获层930a的选定深度而被形成。
[0113]
如本文中所使用的,术语“富氧”和“富硅”是相对于通常在本领域中使用的具有(si3n4)的成分且折射率(ri)约为2.0的化学计量的硅氮化物或“氮化物”而言。因此,“富氧”的硅氮氧化物需要从化学计量的硅氮化物向更高重量百分比的硅和氧转变(即氮的减少)。因此,富氧的硅氮氧化物膜更像硅二氧化物,并且ri朝着纯硅二氧化物的1.45ri减小。类似地,本文中描述为“富硅”的膜需要从化学计量的硅氮化物朝向具有比“富氧”的膜少的氧的更高重量百分比的硅转变。因此,富硅的硅氮氧化物膜更像硅,并且ri朝着纯硅的3.5ri增加。
[0114]
再次参照图9d,多个电介质层还包括在电荷俘获层930或第二电荷俘获层930b上或覆盖电荷俘获层930或第二电荷俘获层930b形成的盖层932。在一些实施方式中,诸如在
示出的实施方式中,盖层932是多层盖层,该多层盖层至少包括覆盖电荷俘获层930的下盖层或第一盖层932a以及覆盖第一盖层932a的第二盖层932b。
[0115]
在一个实施方式中,第一盖层932a可以包括使用低压化学气相沉积(lpcvd)热氧化工艺沉积的厚度为2.0nm至4.0nm的高温氧化物(hto)(诸如硅二氧化物(sio2))。在一个实施方式中,第二盖层932b可以包括通过使用n2o/nh3和dcs/nh3气体混合物的cvd工艺形成的厚度在2.0nm与4.0nm之间的硅氮化物层、富硅的硅氮化物层或富硅的硅氮氧化物层。
[0116]
仍参照图8和图9d,在盖层932上或覆盖盖层932形成牺牲氧化物层934。在一个实施方式中,牺牲氧化物层934可以包括通过热氧化工艺或自由基氧化生长的高温氧化物(hto)层,并且具有2.0nm与4.0nm之间的厚度。
[0117]
接下来,仍参照图8和图9d,在牺牲氧化物层934上或覆盖牺牲氧化物层934形成图案化掩模层,并参照图9e,对牺牲氧化物层934、盖层932和电荷俘获层930以及隧道电介质层928进行蚀刻或图案化以形成nv栅极叠层936。在一个实施方式中,nv栅极叠层936可以被设置成基本上覆盖第一区906中的多级nvm晶体管926的沟道924。蚀刻工艺或图案化工艺可以进一步从衬底904的第二区908去除nv栅极叠层936的各个电介质层(步骤806)。图案化掩模层980可以包括使用标准光刻技术进行图案化的光致抗蚀剂层,并且第二区908中的nv栅极叠层936层可以使用包括一个或更多个单独步骤的干式蚀刻工艺来蚀刻或移除,所述蚀刻或移除在衬底904或未移除的衬垫氧化物909(如果存在的话)的表面上停止。在一个实施方式中,可以形成针对hv mos晶体管914的阱950。
[0118]
参照图8、图9e和图9f,在高选择性的清洗工艺中,从nv栅极叠层936中移除牺牲氧化物层934和多层盖层932中的第二盖层932b的顶部或移除基本上全部的第二盖层932b(步骤808)。该清洗工艺还去除维持在nv栅极叠层936之外的第一区906中以及第二区908中的任何氧化物(诸如隧道电介质928中的氧化物和/或衬垫氧化物909中的氧化物,以制备用于氧化物生长的衬底904。
[0119]
接下来,参照图8和图9f,在步骤808中,形成多级nvm晶体管926的阻挡氧化物层960和lv栅极氧化物层962、i/o栅极氧化物层956以及hv栅极氧化物层952。在一个实施方式中,执行氧化工艺以对第二盖层932b的剩余部分和/或多层盖层932的第一盖层932a以及可选的第二电荷俘获层930b的一部分进行氧化,以形成覆盖第二电荷俘获层930b的阻挡氧化物层960。在一个实施方式中,氧化工艺适于将第一盖层932a或第二盖层932b的剩余部分或可选的第二电荷俘获层930b的一部分进行氧化或消耗以在第一区中形成阻挡氧化层960,在此期间同时将衬底表面916的覆盖i/o mos 915或lv mos 912或hv mos 914的沟道918的至少一部分进行氧化以在第二区中形成(多个)栅极氧化层。在一个实施方式中,氧化工艺可以包括原位蒸汽生成(issg),或者氧化工艺可以包括在具有或不具有诸如等离子体的点火事件的情况下在批量或单个衬底处理室中执行的其他自由基氧化工艺。例如,在一个实施方式中,阻挡氧化物层960可以在自由基氧化工艺中生长,该自由基氧化工艺涉及将氢气(h2)和氧气(o2)以彼此大约1:1的比例流入到处理室中,而没有点火事件(诸如形成等离子体),否则等离子体将通常用于使h2和o2热解以形成蒸汽。反而,允许h2和o2在大约0.5托至5托范围内的压力下、在大约700℃至800℃范围内的温度下反应,以在剩余的第二盖层932b或第一盖层932a的表面处形成自由基,诸如oh自由基,ho2自由基或o双自由基。执行自由基氧化工艺达近似10至15分钟范围内的持续时间,以通过对多层盖层932和可选的第二电荷
俘获层930b的具有从大约3nm至大约4.5nm的厚度的部分进行氧化和消耗来实现阻挡氧化物层960的生长。在一个实施方式中,issg工艺可以产生较好质量和密度的阻挡氧化物层960,并且可以有助于在阻挡氧化物层960与第二电荷俘获层930b之间的界面处具有较低密度的界面电荷陷阱。这些界面电荷陷阱中的大多数是浅陷阱,如图6b中所示,这可能不利地影响滞留性能和id/v
t
西格玛退化。因此,通过issg工艺产生的阻挡氧化物将改进sonos装置的滞留性能。
[0120]
参照图8和图9f,可以使用rto、熔炉氧化、自由基氧化、cvd、issg或它们的组合来形成lv栅极氧化物层962、i/o栅极氧化物层956和hv栅极氧化物层952。在实施方式中,lv栅极氧化物层962、i/o栅极氧化物层956和hv栅极氧化物层952可以同时或单独形成。随后,在步骤808中,lv栅极氧化物层962、i/o栅极氧化物层956和hv栅极氧化物层952被图案化。
[0121]
参照图8和图9g,可以在第一区906中的nv栅极叠层936和第二区908中的栅极氧化物层952、956和962上形成适合于适应多级nvm晶体管926的偏置和hv mos晶体管914、i/o mos晶体管915和lv mos晶体管912的操作的任何导电或半导电材料的栅极层(步骤810)。
[0122]
在一个实施方式中,栅极层可以通过物理气相沉积形成并由包含金属的材料组成,所述包含金属的材料可以包括但不限于金属氮化物、金属碳化物、金属硅化物、铪、锆、钛、钽、铝、钌、钯、铂、钴和镍。在另一实施方式中,栅极层可以通过cvd工艺形成并且由单掺杂多晶硅层组成,然后可以对栅极层进行图案化以形成多级nvm晶体管926和mos晶体管914、915、912的控制栅极。
[0123]
再次参照图9g,随后使用掩模层(未示出)和标准光刻技术对栅极层进行图案化,以形成多级nvm晶体管926的nv栅极叠层936的栅极970、lv mos晶体管912的栅极972、i/o mos晶体管915的栅极974和hv mos晶体管914的栅极976(步骤810)。在一个实施方式中,多级nvm晶体管926的nv栅极叠层936的栅极970、hv mos晶体管914的栅极272、i/o mos晶体管915的栅极274和lv mos晶体管912的栅极276可以同时形成。在替选实施方式中,前述栅极可以被连续形成,或者成组被形成。
[0124]
参照图8和图9g,对第一间隔物层进行沉积和蚀刻以形成与mos晶体管912、915、914的栅极972、974、976和多级nvm晶体管926的栅极970相邻的第一侧壁间隔物992,以及一个或更多个轻掺杂漏极延伸部(ldd 990)可以被注入成与多级nvm晶体管926的侧壁间隔物992以及mos晶体管912、914、915中的一个或更多个相邻并在所述多级nvm晶体管926的侧壁间隔物992以及mos晶体管912、914、915中的一个或更多个下方延伸。
[0125]
图10d是示出根据本公开内容的具有ldd延伸部990的多级nvm晶体管926的实施方式的示意性框图。在一个实施方式中,第一侧壁间隔物992可以具有相对薄的长度(例如至),使得轻掺杂漏极ldd 990延伸部可以被更有效地形成。如图10d中最佳示出的,在步骤812中,轻掺杂漏极ldd 990延伸部可以至少部分地形成在nvm晶体管926的nv栅极叠层936和控制栅极970之下。在一个实施方式中,ldd990可以通过成角度地注入诸如磷的n型材料来形成,使得ldd 990可以至少部分地设置在多级nvm晶体管926的ono和cg叠层之下。在一个实施方式中,使用大约每平方厘米1e12至1e15个原子的范围内的低注入剂量、大约2kev至20kev的范围内的高能量以及大约0度至30度的范围内的倾斜角来形成成角度的ldd注入。在一个实施方式中,nvm晶体管926的内部节点和漏极处的较低剂量和较高能量的ldd 990可以有助于降低栅极诱导的漏极泄漏(gidl)电流,该栅极诱导的漏极泄漏
电流是可能的二次碰撞电离热电子(siihe)的馈送电流。gidl电流泄漏减少可以有助于改进nvm晶体管926的滞留性能和id/v
t
西格玛退化。在一个实施方式中,可以形成多级nvm晶体管926的漏极区995、内部节点区996、lv mos晶体管912的源极区997。
[0126]
参照图9g,随后,沉积并蚀刻第二间隔物层以形成多级nvm晶体管926的与nv栅极叠层936相邻的第二侧壁间隔物994。在一个实施方式中,基本上完成了多级nvm晶体管926、hv mos晶体管914、i/o mos晶体管915和lv mos晶体管912,执行源极和漏极注入以形成所有晶体管的源极区和漏极区(包括多级nvm晶体管926的漏极区995、内部节点996和lv mos晶体管的源极区997)。随后可以执行硅化物工艺。在一个或更多个替选实施方式中,如图8至图9g所示和所述的制造步骤可以被调整或修改,以制造代替或附加于集成基线cmos工艺中的基于sonos的多级nvm晶体管926的基于浮栅的nvm晶体管。应当理解,多级nvm晶体管926、lv mos晶体管912、i/o mos晶体管915和hv mos晶体管914中的多于一个可以使用如图8至图9g所述的工艺流程被同时形成。
[0127]
最后,继续标准或基线cmos工艺流程以基本完成前端装置制造(步骤816)。在一个实施方式中,完成的多级nvm晶体管926和lv mos晶体管912可以被配置成形成多级nvm单元90或1310的实施方式(诸如图2或图13中最佳示出的实施方式)。
[0128]
图11是示出结构性优化对sonos单元的id和v
t
西格玛的影响的代表性图。如前所述,制造工艺的修改包括但不限于sti拐角平滑、栅下ldd、良好质量的隧道氧化物、阻挡氧化物和多级nvm晶体管的电荷俘获层中的浅陷阱减少可以有助于改进滞留性能和id/v
t
西格玛退化。
[0129]
参照图7,通过图8至图10d中所述的结构性优化,可以提高多级nvm晶体管926的电荷俘获层中的深陷阱密度,同时降低浅陷阱密度。然而,对于诸如nor闪存或eeprom中的仅使用硬擦除和硬编程操作的常规写入算法(图3a和图3b中),电荷倾向于被俘获在浅陷阱和深陷阱两者中。在一个实施方式中,更多的电荷可以通过使用一系列部分擦除/编程操作(诸如软擦除、软编程、选择性软擦除、退火擦除和再填充编程操作)的写入算法而被俘获在深陷阱中,以将多级nvm单元的id/v
t
推移至它们各自的目标并且可以有助于将电荷从浅陷阱重新分配至深陷阱。在一个实施方式中,部分擦除和编程操作可以清空来自浅陷阱的电荷,并且反而填充深陷阱。因此,可以既改进多级nvm单元的id/v
t
西格玛退化又改进多级nvm单元的滞留。在一个实施方式中,可以在每个部分编程或擦除操作之后执行类似于通常的读取操作的验证读取操作,以确定降低的(部分编程)或升高的(部分擦除)id/v
t
水平与目标id/v
t
水平相比如何。验证读取的结果可以用于确定写入算法中部分编程/擦除操作的剩余序列。
[0130]
软擦除操作:
[0131]
在一个实施方式中,用于软擦除操作的耦接至各个节点的操作电压类似于先前图3a中所述的硬擦除操作。因此,完整的擦除电压8v(v
neg
–vpos
)仍然被施加在cg与衬底/漏极之间。相对于硬擦除操作,与硬擦除操作的te约10ms相比,软擦除脉冲的wls脉冲(例如wls0、wls1)持续时间明显较短(t软擦除约20μs)。尽管cg到漏极的电压差(例如-8v)相同,但是较短的软擦除脉冲可以仅提升而没有将所选行0中的nvm单元(例如c1、c2)的id移动到擦除的id水平。在一个实施方式中,软擦除操作可以仅在整个所选行上被执行。
[0132]
退火擦除操作:
[0133]
退火擦除操作的一般目的是解除浅陷阱中的电荷以改进后滞留性能。表iii描绘了可以用于非易失性存储器的页/行0的退火擦除操作的示例性偏置电压,该非易失性存储器与图3a中最佳示出的2
×
2阵列300类似具有2t架构并且包括具有n型sonos晶体管和csl的存储器单元。
[0134][0135][0136]
表iii
[0137]
在一个实施方式中,与擦除操作和软擦除操作不同,由于v
aepos
可以具有比v
pos
低的幅度,因此较软的擦除电压(v
neg
–vaepos
)被施加在cg与衬底/漏极之间。然而,较软或较低的擦除电压(例如6v对8v)被施加到cg达更长的脉冲持续时间(t退火擦除约50ms)。在一个实施方式中,较软的擦除脉冲可以有助于移除浅陷阱中更靠近导带的电荷。在一个实施方式中,退火擦除操作可以仅在整个所选行上执行。
[0138]
选择性软擦除:
[0139]
图12a示出了根据本公开内容的用以展示选择性软擦除操作的实施方式的nvm阵列100的2
×
2阵列800。在一个实施方式中,2
×
2阵列800可以类似于图3a和图3b中的2
×
2阵列300。在下面的描述中,为了清楚和易于解释,假设2
×
2阵列800中的所有晶体管都是n型晶体管。应当理解,不失一般性,p型配置可以通过使所施加的电压的极性反转来描述,并且这样的配置在本公开内容的预期实施方式内。另外,以下描述中使用的电压是为了便于解释而选择的,并且仅代表本主题的一个示例性实施方式。在不同的实施方式中可以采用其他电压。
[0140]
参照图12a,2
×
2存储器阵列800包括被布置成两行和两列的至少四个存储器单元c1、c2、c3和c4。虽然nvm单元c1至c4可以设置在两个相邻的列中(公共源极线csl0),但是它们可以设置在两个相邻的行中或者两个不相邻的行中。nvm单元c1至c4中的每一个可以在结构上类似于如上所述的nvm单元90。参照图3a、图3b和图5,图3a中描述的硬擦除操作可以将被擦除的nvm单元的id提高到图5中的被擦除的id水平,并且类似地,硬编程操作可以将被编程的nvm单元的id提高到图5中的被编程的id水平。在一个实施方式中,被擦除的id水平和被编程的id水平可以分布在nvm阵列100的id1至i
d2n
的操作范围之外。在另一实施方式中,
被擦除的id水平和被编程的id水平之一可以落入操作范围内。
[0141]
参照图12a,例如,页0被选择为要被擦除,而页1不(未被选择)用于选择性软擦除(sse)/禁止操作。与之前解释的硬擦除操作实施方式、软擦除操作实施方式和退火擦除操作实施方式相比,其中,单个页或行是nvm单元90的最小擦除块,同一行(例如页0)中的单个nvm单元/位或多个nvm单元/位可以被选择以用于选择性软擦除操作。未被选择的nvm单元(例如c2)反而可以被禁止。因此,通过将适当的电压施加到由行0中的所有nvm单元共享的sonos字线(wls0)、衬底连接部以及nvm阵列100中的所有位线,仅被选择的行(页0)中包括c1的被选择的nvm单元的id水平被提升(部分擦除)。在一个实施方式中,选择性软擦除(sse)负电压v
sseneg
被施加至wls0,以及sse正电压v
ssepos
被施加至页0中的所有nvm单元的bl0和dnw。在一个实施方式中,与图3a中的硬擦除操作中使用的v
neg
相比,v
sseneg
具有较小的绝对幅度,并且v
ssepos
具有比图3a中的v
pos
大的绝对幅度。v
einhib
被施加至wl0、spw、bl1和wl1,以禁止未被选择的nvm单元(诸如c2)的软擦除操作使其id升高。cls0和wls1被耦接至地或0v。在一个实施方式中,c1至c4的所有nvm单元的sg截止(wl=-1.4v),对于硬擦除操作,这些sg通常导通。
[0142]
在一个实施方式中,尽管v
sseneg
的绝对幅度较小,但仍仅在c1中的存储器晶体管的cg与bl0之间施加相对完整的擦除电压偏置(v
sseneg
–vssepos
=-7.2v)。未选择的c2中的cg与bl1之间的电压差仅为(v
sseneg
–veinhib
=-0.9v)。因此,仅被选择的c1的id可以被提升,而同一被选择的行0中的未被选择的c2的id没有被提升。在一个实施方式中,耦接至wls0的被选择的擦除操作的脉冲持续时间(tsse约20μs)比硬擦除操作中的脉冲持续时间(te约10ms)短得多。较短的sse脉冲可能不会擦除nvm单元c1中的所有先前捕获的电荷(如果存在的话)。在一个实施方式中,包括wl0和wl1的所有字线以及spw都被耦接至v
einhib
,使得未被选择的nvm单元c2、c3和c4不会像nvm单元c1中那样被部分擦除。在一个实施方式中,被选择的擦除操作的一般构思是施加相对高的擦除电压差或偏置(例如,7.2v)达短时间段(20μs),以减少仅同一行的被选择的nvm单元中的俘获电荷。在一个实施方式中,tae》te》tsse和tse。在一个实施方式中,多于一个的nvm单元可以被选择以用于sse操作,同时同一行中的多于一个的nvm单元可以被禁止使得它们的id水平保持相对不变。
[0143]
表iv描绘了可以用于非易失性存储器的页/行0和列0(仅c1)的选择性软擦除操作的示例性偏置电压,所述非易失性存储器与2
×
2阵列800类似具有2t架构并且包括具有n型sonos晶体管和csl的存储器单元。
[0144]
节点电压(v)电压范围(v)wls0v
sseneg
例如-2.3v-2.5v至-1.5vbl0v
ssepos
例如 4.9v 3.0v至 5.0vwl0v
einhib
例如-1.4v-1.6至-0.8spwv
einhib
例如-1.4v-1.6至-0.8dnwv
ssepos
例如 4.9v 3.0v至 5.0vcls0接地或0v接地或0vwls1接地或0v接地或0vbl1v
einhib
例如-1.4v-1.6至-0.8wl1v
einhib
例如-1.4v-1.6至-0.8
[0145]
表iv
[0146]
软编程操作:
[0147]
在一个实施方式中,除了耦接至被选择的wls(例如wls0)的电压之外,用于软编程(sp)/抑制操作的耦接至各个节点的操作电压类似于先前图3b中描述的硬编程/抑制操作。在一个实施方式中,v
sppos
具有比硬编程操作中的v
pos
低的幅度,使得施加在被选择的c1的cg上的编程电压可以减小。因此,在cg与bl/衬底/p阱之间施加6v的软编程电压偏置(v
neg
–vsppos
)。与硬编程操作相比,与硬编程操作的tp约5ms相比,软编程脉冲的wls脉冲(例如wls0、wls1)持续时间明显较短(tsp约10μs)。在较小的cg到漏极电压差(例如6v对8v)和较短的软编程脉冲(10μs对5ms)的情况下,软编程操作可以仅减小而不将所选择的nvm单元c1的id移动到编程的id水平。在一个实施方式中,可以禁止同一行上的未选择的nvm单元例如c2以及未选择的行上的nvm单元例如c3和c4。
[0148]
再填充编程操作:
[0149]
图12b示出了再填充编程(rp)/禁止操作期间的nvm阵列100的段2
×
2阵列800的示例性实施方式。参照图8b,例如,nvm单元c1是要被部分编程(将id水平朝向图5中的编程的id降低或移动)的目标单元,而nvm单元c2被禁止。应当理解,尽管为了说明的目的而将c1和c2示出为两个相邻的单元,但是c1和c2也可以是同一行(诸如行0)上的两个分离的nvm单元。再填充编程操作的一般目的是使用高编程电压将电荷填充在深陷阱中(见图7)以改进后滞留性能。表v描绘了可以用于非易失性存储器的页/行0的再填充编程操作的示例性偏置电压,所述非易失性存储器与图8b中最佳示出的2
×
2阵列800类似具有2t架构并且包括具有n型sonos晶体管和csl的存储器单元。
[0150]
在一个实施方式中,与软编程操作不同,由于v
rppos
可能具有与v
pos
相当但比v
pos
高的幅度以及v
rpneg
可能具有与v
neg
相当但比v
neg
高的幅度,因此在cg与衬底/漏极之间施加较硬的编程电压偏置(v
rppos
–vrpneg
)。因此,施加在被选择的c1的cg上的所得编程电压偏置与如图3b中所描述的硬编程操作中的编程电压偏置相当但略高于如图3b中所描述的硬编程操作中的编程电压偏置(例如,9v对8v)。然而,较硬的编程脉冲仅被施加至被选择的cg达非常短暂的持续时间(trp约5μs)。短的再填充编程脉冲可以减小c1的id,但不能完全对其进行编程。在一个实施方式中,tp》tsp》trp。再填充编程操作的硬编程脉冲可以有助于在深陷阱中填充电荷,所述深陷阱具有如图6b中最佳示出的价带与导带之间的能级。在一个实施方式中,类似于硬编程操作和软编程操作,未选择的nvm单元c2、c3、c4等可能被抑制。在一个实施方式中,可以在退火擦除操作之后或之前执行再填充编程操作。再填充编程操作可以通过在深陷阱中再填充电荷来恢复所选择的nvm单元的id,所述深陷阱可以在先前的退火擦除操作中从浅陷阱中清空。
[0151]
表v描绘了可以用于对具有2t架构并且包括具有n型sonos晶体管和csl的存储器单元的非易失性存储器中的nvm单元c1进行再填充编程的示例性偏置电压。
[0152][0153][0154]
表v
[0155]
图13是根据本主题的多级或模拟nvm装置1300的实施方式的示意性框图。在一个实施方式中,多级nvm阵列1302可以类似于图2中的nvm阵列100,其中,多级nvm单元1310被布置成n行和m列。可以根据图8至图9g中描述的方法来制造多级nvm单元1310,其中,结构性特征的修改(诸如平滑的sti拐角、过时的(under-date)ldd等)已经被实现。每个多级nvm单元1310可以具有2t配置(sonos晶体管和fet晶体管),并且与同一行的一个相邻单元共享csl。在一个实施方式中,诸如wls、wl、bl、spw、dnw等的其他连接也可以类似于图1a、图1b和图2中的nvm阵列100的配置。多级nvm单元1310可以被配置成具有多于两个的不同的id/v
t
水平(见图5),例如24=16或0至15个水平。在一个实施方式中,每个多级nvm单元1310可以存储模拟值0至15,所述模拟值0至15对应于每个多级nvm单元被读取时其id/v
t
水平。可以使用一系列如前所述的部分编程/禁止操作、部分擦除/禁止操作和验证步骤将模拟值写入多级nvm单元1310。例如,行a、列x位被写入值10(id/v
t
水平=10),行a、列y位被写入值5,行b、列x位被写入值8,以及行c、列z被写入值2。在实施方式中,多级nvm单元1310可以被写入与它们的在预定义的id/v
t
水平范围内的id/v
t
水平相对应的任何模拟值(例如,针对16个id/v
t
水平的0至15)。前述存储的值可以仅出于解释目的而用于本专利文件的后面部分中的操作方法的示例中,并且不应当被解释为限制。在替选实施方式中,存储的模拟值可以是与多级nvm单元1310的id/v
t
水平对应的任何预定值。
[0156]
在一个实施方式中,可以组合多个多级nvm单元1310的存储值,以存储一个模拟值。例如,两个多级nvm单元1310可以各自被配置成具有8个电平,一个单元可以存储值0至7,而另一个单元可以存储值-8至-1。当在一个操作中读取两个单元时,被组合的单元可以被认为具有代表16个模拟值而不是8个模拟值的16个水平(-8至7)。在其他实施方式中,多于两个的多级nvm单元1310可以被组合,使得可以在不需要进一步划分多级nvm单元1310的操作id/v
t
范围的情况下实现较高数量的水平。在实施方式中,可以根据一些预定算法将组合的单元设置在同一行的相邻列上或者同一列的相邻行上或者分散在多级nvm阵列1302中。在一个实施方式中,多级nvm装置1300可以用作模拟值的非易失性存储装置。在其他实
施方式中,多级nvm装置1300可以被配置成作为推理装置来执行执行算术功能。
[0157]
参照图13,多级nvm阵列1302可以经由其位线(例如bl.x、bl.y)耦接至列mux功能1304。在一个实施方式中,列mux功能1304可以具有多路复用器、电容器、晶体管和其他半导体装置。在读取操作期间,与数字nvm阵列的读取操作类似,行a、列x位的值10可以经由bl.x读出到列多路复用器(mux)功能1304。在一个实施方式中,可以在一次读取操作中选择同一列(诸如行a和行b、列x)上的多个位,使得读出的值是两个被选择的位的和(10 8=18)。在另一实施方式中,同一行(诸如行a、列x和列y)上的多个位可以被选择以用于相同的读取操作。列mux功能1304可以被配置成将两个值相加或相减(10 5=15或10
–
5=5)。在另一实施方式中,多级nvm装置1300可以被配置成执行乘法功能。例如,为了进行计算(7
×
10=70),可以读取行a列x位7次。可以通过在(耦接至sg的)wl上使用m
×
多个脉冲或者延长一个wl脉冲的脉冲持续时间(m倍)来执行乘法(m
×
存储值)。在一个实施方式中,例如,模拟值“7”可以是从可以耦接至wl的外部装置经由数模转换器(dac)1320到sg的行的输入。如图13中最佳示出的,每个dac1320至dac 1326可以耦接至一个wl或多个wl。dac 1320至dac 1326的功能之一是对选择的行进行配置以用于读取操作。应当理解,图13中所示的dac的数目、配置以及它们与nvm阵列1302的耦接仅是用于说明目的的示例之一。根据系统要求和设计,在不改变本实施方式的一般教导的情况下,其他配置也是可能的。在各种实施方式中,dac 1320至dac1326、多级nvm阵列1302和列mux功能1304可以被配置成:在具有或不具有cpu或gpu的情况下,执行简单的算术功能,诸如如在前面的示例中所示的求和、乘法等。在一个实施方式中,模拟nvm装置1300可以执行数据存储装置和推理装置两者的功能。
[0158]
然后,来自列mux功能1304的模拟结果可以输入至模数转换器(adc)或比较器1306,其中,模拟读出结果可以被转换为数字数据并被输出。在一个实施方式中,多级nvm阵列1302的全部或一部分可以被定期(诸如每24小时或48小时或其他持续时间)刷新或使其模拟值被重写。刷新操作可以使由于如图7中所述的滞留、id/v
t
降级或其他原因引起的已编程的多级nvm单元的id/v
t
水平偏移或衰减的潜在影响最小化。在另一实施方式中,模拟nvm阵列1302可以包括参考单元(图13中未示出),其中,可以从多级nvm单元1310中减去潜在的id/v
t
水平偏移的共同影响。
[0159]
图14和图15是分别示出根据本公开内容的一个实施方式的乘法累加(mac)系统和人工神经元的冯诺依曼架构的代表性框图。人工智能(ai)可以被定义为机器执行由人脑执行的认知功能(诸如推断、感知和学习)的能力。机器学习可以使用算法来寻找数据中的模式,并使用识别这些模式的模型来对任何新的数据或模式进行预测。ai应用或机器学习的核心是存在mac操作或点积操作,其中,mac操作或点积操作可能需要两个数字(输入值和权重值)、将这两个数字相乘并将结果添加到累加器中。图15中的人工神经元1504可以是深度神经网络(dnn)的以mac操作的示例为特征的部分。dnn通过实现连接低功率计算元件(神经元)和自适应存储器元件(突触)的大规模并行计算(神经形态计算)架构来模仿人脑的功能。机器学习快速增长的一个原因是图形处理单元(gpu)的可用性。在mac应用诸如系统1402中,gpu可以比通用cpu更快地执行必要的计算。使用gpu进行mac操作的缺点之一是gpu倾向于利用浮点操作,这可能远远超出了相对简单的机器学习算法(如mac操作)的需求。此外,ai应用(尤其是在边缘运行的ai应用)可能需要mac以高的功率效率运行,以减少电力需求和热量生成。现有的基于全数字冯诺依曼架构的系统(如mac系统1502)也可能由于存储
器的频繁访问而在进行计算的gpu与仅存储数据(权重值、输入值、输出值等)的存储器之间产生重大的瓶颈问题。因此,需要考虑使用低功耗存储器元件,所述低功耗存储器元件可以被配置成作为推理装置以及数据存储装置来执行。
[0160]
图16是示出根据本公开内容的一个实施方式的神经网络加速器系统的代表性框图。在一个实施方式中,基于sonos的模拟装置可以具有在本地存储模拟权重值并且并行地处理每个非易失性存储器元件的独特能力,这可以显著地消除如图14所示的大量数据移动的能量消耗。每个nvm单元可以具有多个级别(例如,4位至8位)而不是二进制级别(1位),并且每个id/v
t
级别可以表示用于进行推理的多位权重值(图15中的wi)。在一个实施方式中,级别数越高,训练准确度越高并且推理错误率越低。用于神经形态计算的典型模拟存储器的关键性能和可靠性要求是所有级别处的单元id/v
t
、滞留和噪声的西格玛。如前所述,基于sonos的nvm装置(诸如图13中的多级nvm装置1300)可以是dnn系统中用以执行人工神经元的存储功能和推理功能的良好候选。
[0161]
参照图16,神经网络加速器系统1600可以包括设置在单个衬底或封装或管芯中的多个多级nvm装置或加速器1602,所述多个多级nvm装置或加速器经由总线系统彼此耦接。每个加速器1602可以类似于图13中的多级nvm装置1300并且被类似地操作。在一个实施方式中,多级nvm装置1602可以被配置成执行mac操作。每个多级nvm装置1602可以在dnn系统中充当图15中的人工神经元1504。在一个实施方式中,sonos阵列1602可以具有布置成行和列的多个基于sonos的多级nvm单元(图16中未示出)。在其他实施方式中,sonos阵列1602可以包括多个sonos多级nvm部分或阵列。如在前面的部分中所解释的,每个多级nvm单元可以被配置成存储0至2
n-1的权重值或使用以一系列部分编程和擦除操作为特征的写算法写入的其它值。在其他实施方式中,每个多级nvm单元的模拟值可以通过其他写算法来写入。
[0162]
作为神经形态计算算法的一部分,每个多级nvm装置1602(诸如加速器1602a)可以执行以下mac功能,其中,xi是来自其他多级nvm装置1602或外部装置的输入,wi是存储的权重值,b是常数,以及f是激活函数:
[0163]
f(∑ixiwi b)
ꢀꢀꢀ
(1)
[0164]
如图16中最佳所示,xi可以是来自多级nvm装置1602b和1602c或其他多级nvm装置的数字输入。数字输入xi然后可以通过dac 1612转换成模拟信号,该模拟信号然后可以耦合至低电压驱动器1614和/或高电压驱动器1616。在一个实施方式中,低电压驱动器可以经由wl生成与来自dac 1612的接收的信号对应的用以控制多级nvm单元的sg的控制信号。高电压列驱动器1604可以生成到bl的控制信号和到wls的高电压驱动器以用于控制多级nvm单元的cg。
[0165]
可以使用图13中的示例来说明多级nvm装置1602a中的mac操作的一个实施方式,其中,i可以被设置为3。参照图13,数字输入xi可以耦合到dac 1320至dac 1326,并且x1=3,x2=5,x3=1。选定的权重值被存储在行a列x的位中(w1=10)、行b列x的位中(w2=8)以及行c列z的位中(w3=2)。权重值选择可以基于从其它多级nvm装置1602或者从诸如处理器、cpu、gpu等的外部装置接收的地址。常数b可以被选择为存储在行a列y中的模拟值(b=5)。为了计算x1
×
w1,行a和列x(存储值=10)可以被选择以用于读取。读取可以被重复x1=3次,以计算x1
×
w1。类似地,行b列x(权重值=8)可以被选择以用于x2=5次读取以计算x2
×
w2,以及行c列z(权重值=2)可以被选择以用于x3=1次读取以计算x3
×
w3。可替选地,行
a列x和行b列x两者都可以被选择以用于3次读取(以累加组合的权重值),且只有行a列x可以被选择以用于额外的2次读取。然后,行a列y处的位(b=5)可以被选择以用于读取。如前所述,列多路复用器(mux)1304或1606可以被配置成将那些结果相加在一起,以便将mac结果计算为3
×
10 5
×
8 1
×
2 2=74。应当理解,以上算法仅是使用基于sonos的多级nvm装置(诸如多级nvm装置1300和1602)来计算mac结果的一个示例,该示例用于说明的目的并且不应当被解释为限制。mac权重值(wi)可以以多种方式被存储、组织和读取,以用于根据系统设计和要求计算mac结果。在一个实施方式中,激活函数(f)可以是从整个神经网络的角度指示多级nvm装置1602的mac输出或对所述多级nvm装置1602的mac输出进行优先排序的算法。例如,先前示例的mac结果(结果=74)可能被认为不重要并被分配低优先级。在一些实施方式中,输出信号可以根据其优先级被减少或消除,并且所述执行可以在列mux功能1606或adc 1608中实施。
[0166]
随后,在一个实施方式中,模拟信号形式的mac结果(可以通过adc 1306或1608转换为数字信号。然后,数字信号可以被输出至另一或其他多级nvm装置1602,以作为用于所述多级nvm装置自己的mac操作的xi。在一个实施方式中,类似于dnn,由所有多级nvm装置1602执行的神经形态计算可以被并行执行。每个多级nvm装置1602的数字mac输出可以作为数字输入传输到其他多级nvm装置。在一些实施方式中,多个多级nvm装置1602可以被划分成多个子集。多级nvm装置1602的一个子集的数字输出可以不重复地传播到下一个子集。最后一个子集的数字输出可以作为神经形态计算或机器学习结果输出到外部装置。
[0167]
在一个实施方式中,包括数字数据流控制块1610的命令和控制电路系统(图16中未示出)是可编程的,并且被配置成引导模拟nvm装置1602内的数据流流量。命令和控制电路系统还可以提供对低电压驱动器1614和高电压驱动器1616以及高电压列驱动器1604的控制,以经由sonos字线、字线、位线、csl等向sonos阵列1602提供各种操作电压信号,所述各种操作电压信号包括但不限于至少如图3a、图3b、图12a、图12b所示的v
pos
、v
sepos
、v
rppos
、v
neg
、v
seneg
、v
csl
、v
marg
、v
inhib
等。
[0168]
本领域技术人员应当理解,图16中的神经网络加速器系统1600和模拟nvm装置1602已经出于说明的目的被简化,并且并非旨在完整地描述。特别地,多级nvm装置1602可以包括本文中没有详细示出或描述的处理功能、行解码器、列解码器、感测放大器或其他比较器以及命令和控制电路系统。
[0169]
图17是示出根据本公开内容的以基于sonos的nvm阵列/单元为特征的nn加速器系统1600的操作方法的实施方式的代表性流程图。在一个实施方式中,在步骤1702中,使用先前描述的方法将模拟权重值(wi)和其他常数值(例如b)写入nn加速器中的基于sonos的nvm阵列。在一些实施方式中,在可选步骤1712中,为了更好的滞留和窄的id/v
t
西格玛,可以定期刷新nvm阵列。随后,在步骤1704中,一个加速器的nvm阵列可以被配置成:至少基于来自其他加速器的数字输入(xi)及其存储的权重值来执行mac操作。在mac操作完成之后,在步骤1706中,一个加速器可以输出其结果,并将该结果传播到一个或更多个连接的加速器以作为所述一个或更多个连接的加速器自己的mac操作的数字输入。在一个实施方式中,步骤1704和1706可以被以并行模式重复多次。在步骤1710中,输出可以作为ai应用的机器学习中的神经形态计算的结果传输到诸如cpu、gpu的外部装置。
[0170]
因此,已经描述了基于sonos的多级非易失性存储器和将其作为诸如dnn的神经形
态计算系统中的模拟存储器装置和mac装置进行操作的方法的实施方式。尽管已经参照具体的示例性实施方式描述了本公开内容,但是明显的是,在不脱离本公开内容的更广泛的精神和范围的情况下,可以对这些实施方式进行各种修改和改变。因此,说明书和附图被认为是说明性的意义,而不是限制性的意义。
[0171]
提供本公开内容的摘要以符合要求允许读者快速确定技术公开内容的一个或更多个实施方式的性质的摘要的37c.f.r.
§
1.72(b)。提交摘要是基于这样的理解:其不会被用来解释或限制权利要求的范围或含义。另外,在前述具体实施方式中,可以看到的是,出于使本公开内容精简的目的,各种特征在单个实施方式中被组合在一起。本公开内容的方法不被解释为反映如下意图:所要求保护的实施方式需要比在每个权利要求中明确列举的特征更多的特征。而是,如所附权利要求反映的,本发明主题在于少于单个公开的实施方式中的所有特征。因此,所附权利要求由此被并入具体实施方式中,其中每个权利要求独自作为单独的实施方式。
[0172]
在描述中提及“一个实施方式”或“实施方式”意指结合该实施方式描述的特定特征、结构或特性被包括在电路或方法的至少一个实施方式中。说明书中各个地方中出现的短语“一个实施方式”不一定全部指代同一实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。