特异性结合mage-a的抗原结合蛋白
1.本发明涉及特异性结合色素瘤相关抗原a(mage-a)蛋白来源抗原的抗原结合蛋白。本发明特别提出了与mage-a抗原肽特异性结合的抗原结合蛋白,所述mage-a抗原肽包含seq id no:1或由seq id no:1组成且与主要组织相容性(mhc)蛋白形成复合体。特别地,本发明的抗原结合蛋白含有与所述mage-a肽/mhc复合体特异性结合的新型改造t细胞受体(tcr)的互补决定区(cdr)。本发明的抗原结合蛋白可用于诊断、治疗和预防表达mage-a的癌性疾病。还提出了编码本发明抗原结合蛋白的核酸、包含这些核酸的载体、表达抗原结合蛋白的重组细胞以及包含本发明抗原结合蛋白的药物组合物。
2.发明背景
3.氨基酸序列“kvlehvvrv”(seq id no:1)的mage-a肿瘤抗原(也称为mag-003肽)是mage-a4(氨基酸286-294)和mage-a8(氨基酸288-296)的一个hla-a*02:01限制性细胞毒性t淋巴细胞(ctl)表位(zheng-cai j.et al.clin dev.immunol.2010,567594)。mage-a4和mage-a8都是蛋白,并且是mage-a基因家族成员。尽管mage-a8和-a4可能在胚胎发育、肿瘤转化或肿瘤进展方面发挥作用,但它们的功能目前尚不清楚。这些蛋白已确定了多种选择性剪接变体。根据seq id no:1的mage-a抗原属于在肿瘤中表达但在睾丸和胎盘之外的正常组织中不表达的癌症/睾丸(ct)抗原。mage-a4蛋白和mrna表达等与各种癌症的发生和预后有关。主要组织相容性复合体(mhc)分子提呈的肽例如mage-a(特别是mage-a4和/或mage-a8)衍生的肽“kvlehvvrv”可能与tcr结合,因此是基于t细胞免疫疗法的靶标。因此,mage-a抗原及其表位肽已用于肿瘤免疫疗法试验。
4.虽然在开发用于癌症治疗的分子靶向药物方面取得了进展,但是,本领域仍然需要开发抗癌新药,其特异性靶向作用于对癌细胞具有高度特异性但对正常细胞不具特异性的分子。
5.因此,本发明提出了新型抗原结合蛋白,其对与mhc蛋白形成复合体的seq id no:1的肿瘤表达抗原mage-a具有特异性。
6.wo 2017/158103公开了tcr,更特别是天然tcr(例如,天然tcr r7p1d5),其与具有seq id no:1的kvlehvvrv的氨基酸序列的mage-a抗原肽和hla i类分子的复合体结合,以及这些tcr在诊断、治疗和预防癌性疾病中的用途。但是,相较于与mhc提呈病毒抗原特异性结合的tcr,与mhc提呈癌症抗原特异性结合的天然t细胞受体(tcr)亲和力通常较低(kd=1-300μm)。此现象的部分解释似乎为:胸腺中发育的t细胞在自身pep-mhc配体上被负选择(耐受诱导),从而删除了对此类pep-mhc亲和力过高的t细胞。这种低亲和力是肿瘤免疫逃逸的一种可能解释(aleksic et al.2012,eur j immunol.2012dec;42(12):3174-9)。因此,似乎需要设计与癌症抗原具有更高结合亲和力的tcr变体,用作过继细胞疗法(act)中的抗原识别构建体,或者作为可溶性方法的识别模组,即,使用双特异性分子(hickman et al.2016,j biomol screen.2016sep;21(8):769-85)。
7.但是,增加tcr的亲和力也可能增加副作用的风险。如上所述,自然中抗肿瘤相关抗原(自身蛋白)的高亲和力tcr透过胸腺选择被排除,从而避免透过交叉反应识别存在于正常组织上的自身肽。因此,简单增加tcr对靶序列的亲和力也可能增加相似非癌特异性肽
的亲和力,从而增加交叉反应的风险和对健康组织的有害细胞毒性作用。对于靶向作用于mage-a3的改造tcr,已痛苦地发现这不仅仅是理论上的风险。特别是,之前发表的结果显示:两名患者发生致命的毒性,这两名患者输注了经改造以表达靶向作用于mage-a3的tcr的t细胞,该tcr与肌肉蛋白titin中的肽发生交叉反应,但临床前研究中未预测到交叉反应性(linette gp et al.blood 2013;122:863
–
71,cameron bj,et al.sci.transl.med.2013;5:197-103)。这些患者表明,tcr改造的t细胞可能具有严重且不可预测的脱靶和器官特异性毒性。
8.因此,存在尚未满足的医疗需求,即开发并提出以更高亲和力与其靶标特异性结合的tcr或抗原结合蛋白,从而甚至可靶向作用于靶抗原肽表达较低的肿瘤细胞或细胞系降低,同时由于与脱靶肽(也称为“相似肽”)的交叉反应较低或降低而保持高安全性特征。换言之,发明人能够开发出对其靶肽表现出高结合亲和力同时又保持高肿瘤选择性的抗原结合蛋白。
9.此外,如发明人所示,mage-a特异性tcr分子tcr r7p1d5作为单链构建体或称为tcer的双特异性形式(以下称为“tcer
tm”分子或“tcer
tm”)显示了相对较低的溶解度,tcer
tm
包含与t细胞上表面分子特异性结合且与mhc-肽复合体特异性结合的部分。
10.因此,尽管tcr技术取得了进步,但是仍然需要额外的癌症疗法,特别是有效靶向作用于并杀死癌细胞的癌症疗法。特别是,需要开发新的抗原结合蛋白,其i)对于与具有所需生物学活性的mhc蛋白形成复合体的seq id no:1的肿瘤特异性mage-a肽具有选择性和特异性,ii)具有良好的代谢、药代动力学、溶解性、稳定性和/或安全性特征,和iii)可大规模生产。
11.因此,在本发明背景下,发明人改造了几种抗原结合蛋白,其包含衍生自所述亲本tcr r7p1d5的cdr变体。这些抗原结合蛋白对肽-mhc复合体的结合亲和力增加且稳定性增加和/或溶解性增加,使其更适合用于医疗用途。
12.此外,如本发明人所证明的,这些新的抗原结合蛋白有效地结合并杀死甚至低拷贝数的靶癌细胞,并有利地维持高安全性特征同时与类似肽的交叉反应性低。
13.此外,这些新的抗原结合蛋白,特别是tcer
tm
分子形式的抗原结合蛋白,对肿瘤细胞显示出高细胞毒性。例如,对于tcer
tm
分子形式的新抗原结合蛋白,对nci-h1755、hs695t细胞和u2os的半数最大有效浓度(ec50)为1至300pm、1pm至100pm的范围,尤其是对细胞为1pm至20pm之间。此外,对于健康组织的细胞系(例如:原代细胞系),与肿瘤细胞系hs695t相比,本发明抗原结合蛋白的ec50高100倍,优选为低1000倍以上,这证明了其高安全性。
14.此外,对于这些新的抗原结合蛋白,特别是tcer
tm
分子,发明人证明了在治疗性小鼠模型中即使在低剂量下也具有显著的体内肿瘤生长抑制作用。
15.因此,本发明涉及对与mhc蛋白形成复合体之mage-a衍生抗原肽具有特异性的抗原结合蛋白,其中所述抗原结合蛋白与例如天然tcr r7p1d5相比,在表达和/或纯化期间稳定性增加,例如,聚集减少。此外,所述抗原结合蛋白对例如细胞系nci-h175、hs695t细胞和u2os细胞具有高细胞毒性。
16.总之,发明人令人惊讶的发现尤其提出了相较于本领域的以下优点:(i)降低tcr或抗原结合蛋白与相似肽在健康组织上的交叉反应性并保持高肿瘤选择性;(ii)提高tcr或抗原结合蛋白的安全性特征;(iii)tcr或抗原结合蛋白发挥降低脱靶和脱肿瘤细胞毒性
作用;以及(iv)提出特异性、选择性和安全性改善的tcr或抗原结合蛋白。
17.定义
18.本文中的术语“抗原结合蛋白”系指能够与至少一种抗原,特别是本发明背景下定义的抗原结合的多肽或结合蛋白。在一优选实施方案中,所述抗原结合蛋白能够同时与两种不同抗原结合,如同例如根据双特异性抗体所已知者。本发明的抗原结合蛋白包含至少6个根据本发明背景下所定义的cdr,其最初源自tcr。在一特别实施方案中,本发明的抗原结合蛋白包含至少一个根据本发明背景下所定义的可变α结构域和至少一个可变β结构域,其最初源自tcr。
[0019]“结构域”为根据序列同源性定义的蛋白质区域,通常与特定的结构性或功能性实体有关。此类结构域的实例为:抗体轻链的可变轻链结构域、抗体重链的可变重链结构域、抗体重链的c
h1
、c
h2
和c
h3
结构域(恒定结构域)、tcrα链的可变结构域或tcrβ链的可变结构域。
[0020]
本文使用的术语“抗原”或“靶抗原”系指能够与至少一个抗原结合位点结合的分子或分子或复合体的一部分,其中,例如,所述一个抗原结合位点存在于常规抗体、常规tcr中和/或本发明的抗原结合蛋白中。
[0021]
与本发明的抗原结合蛋白特异性结合的抗原为mage-a抗原肽,其包含seq id no:1的氨基酸序列“kvlehvvrv”或由其组成,更具体地说,为与mhc蛋白形成复合体的包含seq id no:1的氨基酸序列“kvlehvvrv”或由其组成的mage-a抗原肽。
[0022]
本文所用的术语“表位”包含术语“结构性表位”和“功能性表位”。“结构性表位”为当抗原结合蛋白与抗原(例如,肽-mhc复合体)结合时,所述抗原被所述抗原结合蛋白覆盖的该些氨基酸。通常情况下,认为抗原在抗原结合蛋白氨基酸任何原子的内的所有氨基酸为被覆盖。抗原的结构性表位可透过本领域已知的方法(包括x光晶体学或nmr分析)确定。抗体的结构性表位通常包含20至30个氨基酸。tcr的结构性表位通常包含20至30个氨基酸。“功能性表位”是形成结构性表位的氨基酸的子集,包含对形成本发明抗原结合蛋白介面至关重要抗原的氨基酸(方式为:透过直接形成非共价相互作用,例如:h键、盐桥、芳族堆积或疏水相互作用;或透过间接稳定抗原的结合构象),例如透过突变扫描测定。通常情况下,与抗体结合的抗原的功能性表位包含4至6个氨基酸。通常情况下,肽-mhc复合体的功能性表位包含2至6个肽氨基酸和2至7个mhc分子的氨基酸。由于mhc i提呈肽的长度通常为8至10个氨基酸,因此,每个给定肽仅氨基酸子集为肽-mhc复合体的功能性表位的一部分。在本发明背景中,表位,特别是与本发明抗原结合蛋白结合的功能性表位包含形成结合介面所需的抗原氨基酸或由其组成,因此,功能性表位包含seq id no:1的mage-a抗原肽的至少3个氨基酸,优选为至少4个氨基酸。
[0023]“mage-a”或“黑色素瘤相关抗原a”亚家族蛋白是分子水平上确定的首批肿瘤相关抗原(van der bruggen p,et al.science.1991;254:1643
–
47)。mage-a是位于x染色体q28区域的12个基因(mage-a1至mage-a12)亚家族。mage-a亚家族蛋白成员通常仅在睾丸或胎盘中表达,其限制性表达表明它们可能在生殖细胞发育中发挥作用。在中枢神经系统以及脊髓和脑干早期发育时也检测到了mage-a蛋白,显示mage-a蛋白也可能参与神经元发育。此家族的成员编码相互具有50%至80%序列同一性的蛋白,并且所有mage蛋白质具有一个共同的mage同源结构域(mhd),该结构域是由大约170个氨基酸组成的高度保守结构域。
mage-a蛋白在癌症中表达的生物学功能和潜在调节机制目前尚不完全清楚。
[0024]“mage-a4”(即,“黑色素瘤相关抗原4”)蛋白是mage-a基因家族成员,具有seq id no:97的uniprot登录号p43358(2019年7月8日可用)。mage-a4位置被描述为在细胞质内。但是,在细胞核中也检测到了mage-a4染色,在分化良好与分化较差的癌症中细胞核和细胞质之间具有差异性分布(sarcevic b et.al.,2003,oncology 64,443-449)。mage-a4用作一种雄性生殖细胞标志物。它在生殖母细胞中不表达,但在前精原细胞和成熟生殖细胞中表达(mitchell et al.,2014,mod.pathol.27,1255-1266)。mage-a4蛋白和mrna的表达与各种癌症的发展和预后有关。
[0025]“mage-a8”或“黑色素瘤相关抗原8”蛋白是mage-a超家族成员,具有seq id no:98的uniprot登录号p43361(2019年7月8日可用)。
[0026]
根据使用blastp 2.9.0演算法透过蛋白序列比对所确定的,“mage-a4”和“mage-a8”蛋白具有72%的序列同一性(stephen f.et al.(1997)nucleic acids res.25:3389-3402)。此外,“mage-a4”和“mage-a8”均包含mag-003肽,即,kvlehvvrv(seq id no:1)。
[0027]“主要组织相容性复合体”(mhc)是一组细胞表面蛋白,对于获得性免疫系统识别脊椎动物中的外来分子至关重要,这反过来又决定了组织相容性。mhc分子的主要功能是与源自病原体的抗原结合,并将它们展示于细胞表面上,以透过适当的t细胞识别。人mhc也称为hla(人白细胞抗原)复合体(通常只称为hla)。mhc基因家族分为三个亚组:i类、ii类和iii类。肽和mhc i类的复合体由负载适当t细胞受体(tcr)的cd8阳性t细胞进行识别,而肽和mhc ii类分子的复合体由负载适当tcr的cd4阳性辅助t细胞进行识别。由于cd8依赖性和cd4依赖性这两种反应共同并协同地促进抗肿瘤作用,因此,确定和表征肿瘤相关抗原和相应t细胞受体在开发癌症免疫治疗(如:疫苗和细胞治疗)中非常重要。hla-a基因位于染色体6的短臂上并编码hla-a的较大α-链成分。hla-aα-链的变异是hla功能的关键。这种变异促进了人群中的遗传多样性。由于每种hla对某些结构的肽均具有不同的亲和力,因此,更多种类的hla意味着在细胞表面上“提呈”更多种类的抗原。每个人最多可以表达两种类型的hla-a,其中一种来自其父母。有些人将从父母双方遗传相同的hla-a,这降低了其个体hla多样性;但是,大多数人都遗传两种不同拷贝的hla-a。所有hla组都具有相同的模式。换句话说,每个人只能表达2432种已知hla-a等位基因中的一种或两种。
[0028]
在本发明的背景下,mhc i类hla蛋白可以是hla-a、hla-b或hla-c蛋白,优选为hla-a蛋白,更优选为hla-a*02。
[0029]“hla-a*02”表示特定的hla等位基因,其中字母a表示基因,而字尾“*02”表示a2血清型。
[0030]
在mhc i类依赖性免疫反应中,肽不仅能与肿瘤细胞表达的某些mhc-i类分子结合,而且它们之后还必须能被负载特异性t细胞受体(tcr)的t细胞识别。
[0031]“tcr”是免疫球蛋白超家族的异二聚体细胞表面蛋白,其与参与介导信号转导的cd3复合体的不变蛋白质相关。tcr以αβ和γδ形式存在,其结构相似,但解剖位置非常不同,也很可能功能也非常不同。天然异二聚体αβtcr和γδtcr的细胞外部分各自含有两个多肽,每个多肽都有一个膜近端恒定结构域和一个膜远端可变结构域。每个恒定和可变结构域都包括一个链内二硫键。可变结构域包含与抗体互补决定区(cdr)类似的高度多态性环。使用tcr基因疗法可克服目前的一些障碍。它通常可让受试者(患者)自己的t细胞在短时间内具
的方法中,由于在异源二聚体状态下有利的静电相互作用而能够让两个tcr链相互配对。也就是说,这两种肽主要以分离形式展开,但在混合时优先缔合以形成稳定的平行卷曲螺旋异源二聚体。这种方法可用于产生可溶性tcr,其中异源二聚体复合体透过将肽分别融合至截短的α和β链而形成。
[0038]
天然α-β异二聚体tcr具有α链和β链。每个α链都包括可变、连接和恒定区域,β链通常还包括可变区和连接区之间的短多样性区域,但是该多样性区域常被视为连接区域的一部分。tcrα和β链的恒定区或c区分别称为trac和trbc(lefranc,(2001),curr protoc immunol附录1:附录10)。每个可变区(本文称为α可变结构域和β可变结构域)都包括嵌入在框架序列中的三个互补决定区(cdr),其中一个是称为cdr3的高度可变区。α可变结构域cdr在本文中称为cdra1、cdra2、cdra3,而β可变结构域cdr在本文中称为cdrb1、cdrb2、cdrb3。存在几种类型的α链可变(vα)区和几种类型的β链可变(vβ)区,由其框架、cdr1和cdr2序列及部分定义的cdr3序列区分。vα类型透过唯一的trav号在imgt命名中提及,vβ类型透过唯一的trbv号在imgt命名中提及(folch and lefranc,(2000),exp clin immunogenet 17(1):42-54;scaviner and lefranc,(2000),exp clin immunogenet17(2):83-96;lefranc and lefranc,(2001),"t cell receptor factsbook",academic press)。关于免疫球蛋白抗体和tcr基因的更多资讯,参见lefranc mp等人(nucleic acids res.2015jan;43(database issue):d413-22;and http://www.imgt.org/)。因此,常规的tcr抗原结合位点通常包括六个cdr,包含来自α和β链可变区的cdr组,其中cdr1和cdr3序列与hla蛋白结合的肽抗原的识别和结合有关,而cdr2序列与hla蛋白的识别和结合有关。
[0039]
与抗体类似,“tcr框架区”(fr)是指插入cdr之间的氨基酸序列,即,指与单个物种中的不同tcr之间一定程度保守的tcrα和β链可变区的那些部分。每个tcr的α和β链各有四个fr,本文中分别称为fr1-a、fr2-a、fr3-a、fr4-a和fr1-b、fr2-b、fr3-b、fr4-b。因此,α链可变结构域可称为(fr1-a)-(cdra1)-(fr2-a)-(cdra2)-(fr3-a)-(cdra3)-(fr4-a),β链可变结构域可称为(fr1-b)-(cdrb1)-(fr2-b)-(cdrb2)-(fr3-b)-(cdrb3)-(fr4-b)。
[0040]
在本发明的背景下,α或β链或γ或δ链中的cdr/fr定义基于imgt定义确定(lefranc et al.dev.comp.immunol.,2003,27(1):55-77;www.imgt.org)。因此,根据所述imgt定义,提示了与tcr或tcr衍生结构域相关的cdr/fr氨基酸位置。优选情况是,第一可变结构域cdr/fr氨基酸位置的imgt位置类似于trav5的imgt编号和/或第二可变结构域cdr/fr氨基酸位置的imgt位置类似于trbv12-4的imgt编号。就γ/δtcr而言,如本文所用的术语“tcrγ可变结构域”系指无前导区(l)的tcrγv(trgv)区与tcrγj(trgj)区的串连物;术语tcrγ恒定结构域系指细胞外trgc区或c末端截短trgc序列。同样地,术语“tcrδ可变结构域”系指无前导区(l)的tcrδv(trdv)区与tcrδd/j(trdd/trdj)区的串连物,术语tcrδ恒定结构域系指细胞外trdc区域或c末端截短trdc序列。
[0041]
在“抗体”(也称为“免疫球蛋白”)中,两条重链透过二硫键相互连接,且每条重链透过一条二硫键与轻链连接。轻链有两种类型,即,λ(l)和κ(k)。重链有五个主要类型(或同种型),它们决定了抗体分子的功能活性:igm、igd、igg、iga和ige。每条链包含不同的序列结构域。轻链包括两个结构域或区,即,可变结构域(vl)和恒定结构域(cl)。重链包括四个结构域,即,一个可变结构域(vh)和三个恒定结构域(c
h1
、c
h2
和c
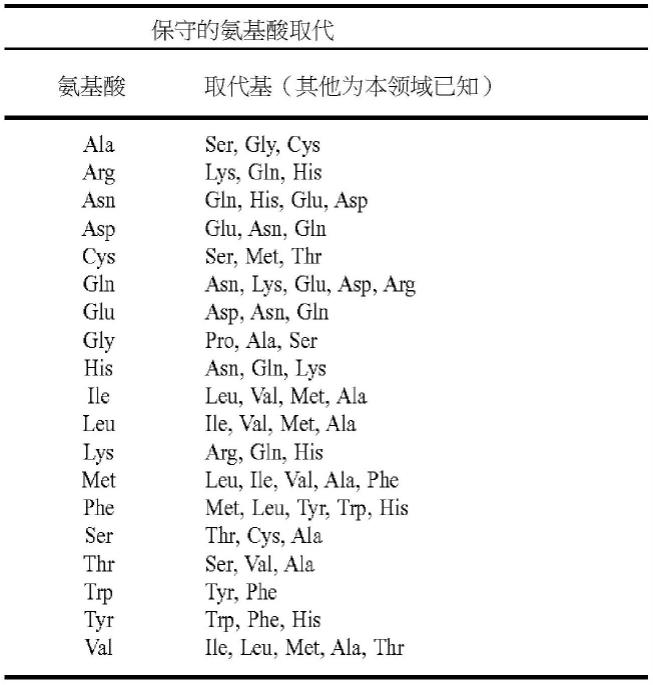
h3
,统称ch)。轻链可变区(v
l
)
和重链可变区(vh)决定了对抗原的结合识别和特异性。轻链恒定区结构域(c
l
)和重链恒定区结构域(ch)具有重要的生物学特性,例如:抗体链缔合、分泌、跨胎盘迁移、补体结合以及与fc受体(fcr)的结合。fv片段是免疫球蛋白fab片段的n-端部分,由一条轻链和一条重链的可变部分组成。抗体的特异性取决于抗体结合位点(antibody combining site,等同于antibody binding site)和抗原决定因子之间的结构互补性。抗体结合位点由主要来自高可变或互补决定区(cdr)的残基组成。有时,来自非高可变区或fr的残基会影响整体结构域结构,从而影响结合位元点。cdr是指一起确定天然免疫球蛋白结合位点天然fv区结合亲和力和特异性的氨基酸序列。免疫球蛋白轻链和重链各有三个cdr,分别称为cdr1-l、cdr2-l、cdr3-l和cdr1-h、cdr2-h、cdr3-h。因此,常规抗体抗原结合位点包括六个cdr,其包含来自各重链和轻链v区的cdr组。
[0042]
在本发明的背景下,抗体或免疫球蛋白为igm、igd、igg、iga或ige。
[0043]“抗体框架区”(fr)是指插入cdr之间的氨基酸序列,即,指与单个物种中的不同免疫球蛋白中相对保守的免疫球蛋白轻链和重链可变区的那些部分。每个免疫球蛋白的轻链和重链各有四个fr,分别称为fr1-l、fr2-l、fr3-l、fr4-l和fr1-h、fr2-h、fr3-h、fr4-h。因此,轻链可变结构域可称为(fr1-l)-(cdr1-l)-(fr2-l)-(cdr2-l)-(fr3-l)-(cdr3-l)-(fr4-l),重链可变结构域可称为(fr1-h)-(cdr1-h)-(fr2-h)-(cdr2-h)-(fr3-h)-(cdr3-h)-(fr4-h)。
[0044]
在本发明的背景下,免疫球蛋白轻链或重链(fc结构域除外)中的cdr/fr定义基于imgt定义确定(lefranc et al.dev.comp.immunol.,2003,27(1):55-77;www.imgt.org)。因此,根据所述imgt定义,提示了给定可变链的cdr1、cdr2和cdr3的氨基酸序列以及fr1、fr2、fr3、fr4和fr5的氨基酸序列。
[0045]
如本领域技术人员所了解的,抗体的结构(特别是抗体的可变重链和轻链的结构)与tcrα和β可变结构域的结构类似。因此,本发明tcr的cdr可移植至传统抗体、双特异性抗体或多特异性抗体中。
[0046]
本领域技术人员获知本发明的抗体或tcr或抗原结合蛋白的cdr的氨基酸序列后,可以较容易确定框架区,例如:tcr框架区或抗体框架区。但是,在未指出cdr的情况下,本领域技术人员可以首先基于tcr的imgt定义或抗体的imgt定义来确定cdr氨基酸序列,然后确定框架区的氨基酸序列。
[0047]
本文所使用的“人框架区”是与天然抗原结合蛋白(例如:天然人抗体或人tcr)框架区基本相同(约85%或更高,特别是90%、95%、97%、99%或100%相同)的框架区。
[0048]
术语“抗体”表示抗体及其片段,以及单结构域抗体及其片段,特别是单结构域抗体以及嵌合、人源化、双特异性或多特异性抗体的可变重链。
[0049]
本文所指的“常规抗体”是与从自然界分离的抗体具有相同结构域且包含抗体衍生cdr和框架区的抗体。同样,本文所指的“常规tcr”是包含与天然tcr具有相同结构域并包含tcr衍生cdr和框架区的tcr。
[0050]
术语“人源化抗体”系指完全或部分非人类来源的抗体,该抗体已被修饰以取代某些氨基酸,特别是重链和轻链框架区中的氨基酸,从而避免或最大程度地减少人体中的免疫反应。人源化抗体的恒定结构域主要是人ch和c
l
结构域。
[0051]
本领域中已知有很多抗体序列人源化处理方法;例如,参见综述almagro&
fransson(2008)front biosci.13:1619-1633。一种常用的方法是cdr移植或抗体重构,其涉及将供体抗体(通常为小鼠抗体)的cdr序列移植入具有不同特异性的人抗体骨架中。由于cdr移植可降低cdr移植非人抗体的结合特异性和亲和力,从而降低其生物学活性,因此,可在cdr移植抗体的选定位置引入回复突变,以保持亲本抗体的结合特异性和亲和力。使用文献和抗体数据库中的现有资讯可鉴定可能的回复突变位置。cdr移植和回复突变的另一种人源化技术是表面重塑,其中保留非人来源的非表面暴露残基,而表面残基则变为人残基。另一种替代技术称为“引导选择”(jespers et al.(1994)biotechnology 12,899),可用于从例如鼠或大鼠抗体等中衍生出保留表位和亲本抗体结合特征的完全人抗体。人源化处理的另一种方法为所谓的4d人源化。专利申请us20110027266 a1(wo2009032661a1)中描述了4d人源化方案,其在以下应用4d人源化技术进行大鼠抗体可变轻(v
l
)和重(vh)结构域人源化中举例说明。
[0052]
对于嵌合抗体,人源化通常涉及修饰可变区序列框架区。
[0053]
尽管在某些情况下可能希望改变单个cdr氨基酸残基,例如,去除糖基化位点、脱醯胺位点、异构化位点或不理想的半胱氨酸残基,但作为cdr一部分的氨基酸残基通常不会作与人源化相关的改变。n-连接糖基化透过将寡糖链连接至三肽序列asn-x-ser或asn-x-thr的天冬醯胺残基而发生,其中x可以为除pro之外的任何氨基酸。n-糖基化位点的移除可透过将asn或ser/thr残基突变为不同的残基来实现,特别是透过保守取代的方式实现。天冬醯胺和谷氨醯胺残基的脱醯胺可能取决于诸如ph和表面暴露等因素。天冬醯胺残基尤其容易发生脱醯胺(主要是存在于asn-gly序列中时),而在其他二肽序列(如asn-ala)中时则较少发生。当此类脱醯胺位点(特别是asn-gly)存在于cdr序列中时,可能希望移除该位点,通常是透过保守取代法移除其中一个涉及的残基。cdr序列中取代以移除其中一个涉及的残基也是本发明的意图。
[0054]“抗体片段”包含完整抗体的一部分,特别是完整抗体的抗原结合区或可变区。抗体片段的实例包括fv、fab、f(ab')2、fab'、dsfv、(dsfv)2、scfv、sc(fv)2、双抗体、由抗体片段形成的双特异性和多特异性抗体。抗体的片段也可以是单结构域抗体,例如:重链抗体或vhh。
[0055]
术语“fab”表示分子量约为50,000道尔顿且具有抗原结合活性的抗体片段,其中在使用蛋白酶(例如木瓜蛋白酶)处理igg而获得的片段中,h链的n端侧约一半和整个l链透过二硫键而结合在一起。
[0056]
与本发明抗原结合蛋白相关的术语“双特异性”系指对两种不同抗原具有至少两个效价和结合特异性的抗原结合蛋白,从而包括两个抗原结合位点。术语“效价”系指抗原结合蛋白结合位点的数量,例如,二价抗原结合蛋白涉及具有两个结合位点的抗原结合蛋白。应注意的是,术语效价系指结合位点的数量,其中那些结合位点可以与相同或不同的靶标结合,即,二价抗原结合蛋白可以为单特异性(即,与一个靶标结合),也可以为双特异性的(即,与两个不同的靶标结合)。靶标可以为抗原、靶肽、脱靶物(即相似肽)等。
[0057]
在本发明的背景下,优选为:至少一个抗原结合位点源自tcr,更特别地,至少一个抗原结合位点包含本发明背景下所定义的tcr衍生cdr。
[0058]
在本发明的背景下,术语“双特异性”优选为:抗原结合位点的至少一个特异性源自tcr,更特别地,至少一个抗原结合位点包含本发明背景下所定义的tcr衍生cdr。因此,本ch1-c
h2-c
h3
)和一条轻链(包含v
lb-l-v
la-c
l
)组成。因此,v
la
/v
ha
和v
la
/v
la
结构域对并行配对。
[0064]
在本发明的背景下,“双可变结构域ig形式”系指包含两条多肽链的蛋白,每条多肽链包含透过连接子(l1,l3)连接的两个可变结构域,其中两个结构域在本发明背景下定义为第一结构域和第二结构域(v1和v2),而另外两个结构域为抗体衍生重链和轻链可变结构域(v
ha
和v
hb
)。在本发明背景下的dvd-ig形式中,例如,多肽链含有组织v
1-l
1-v
ha-l
2-c
h1-c
h2-c
h3
和v
2-l
3-v
la-l
4-c
l
或v
2-l
1-v
ha-l
2-c
h1-c
h2-c
h3
和v
1-l
3-v
la-l
4-c
l
。连接连接子l1和l3的长度优选为5至20个氨基酸残基之间,例如5至15个氨基酸残基,和/或连接连接子l2和l4可能存在也可能不存在。
[0065]
抗体领域中所述的“交叉双可变结构域-ig样蛋白”代表一种形式,其中两个vh和两个vl结构域以允许可变v
h-v
l
结构域交叉配对的方式连接,所述结构域(从n-端到c-端)以vha-vhb和vlb-vla的顺序或以v
hb-v
ha
和v
la-v
lb
的顺序排列。
[0066]
在本发明的背景下,“交叉双可变结构域-ig样蛋白”系指包含两条多肽链的蛋白,每条多肽链包含透过连接子(l1、l2、l3和l4)连接的两个可变结构域,其中两个结构域在本发明背景下定义为第一结构域和第二结构域(v1和v2),而另外两个结构域为抗体衍生重链和轻链可变结构域(v
ha
、v
hb
)。在本发明背景下的cdvd-ig形式中,例如,多肽链含有组织v
1-l
1-v
ha-l
2-c
h1-c
h2-c
h3
和v
la-l
3-v
2-l
4-c
l
、v
2-l
1-v
ha-l
2-c
h1-c
h2-c
h3
和v
la-l
3-v
1-l
4-c
l
、v
ha-l
1-v
1-l
2-c
h1-c
h2-c
h3
和v
2-l
3-v
la-l
dvd3-c
l
或v
ha-l
1-v
2-l
2-c
h1-c
h2-c
h3
和v
1-l
3-v
la-l
4-c
l
。在此c
dvd
形式中,连接子(l1至l4)通常具有不同的长度,包括全甘氨酸连接子以及下文连接子部分中所述的连接子。例如,l1的长度为3至12个氨基酸残基、l2的长度为3至14个氨基酸残基、l3的长度为1至8个氨基酸残基、l4的长度为1至3个氨基酸残基,或l1的长度为5至10个氨基酸残基、l2的长度为5至8个氨基酸残基、l3的长度为1至5个氨基酸残基、l4的长度为1至2个氨基酸残基,或l1的长度为7个氨基酸残基,l2的长度为5个氨基酸残基,l3的长度为1个氨基酸残基,l4的长度为2个氨基酸残基。
[0067]
本文中“至少一个”系指一个或多个指定物件,例如1、2、3、4、5或6个或更多指定对象。例如,本文中至少一个结合位点系指1、2、3、4、5或6个或更多结合位点。
[0068]“与参考序列至少85%相同”的序列系指其全长与参考序列全长具有85%或更高序列同一性,特别是90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的序列。
[0069]
在本技术的背景下,使用整体成对比对法来计算“同一性百分比”(即,比较两个序列的全长)。比较两个或更多个序列同一性的方法是本领域所周知的。例如,可使用“针具”程序,其使用needleman-wunsch整体比对演算法(needleman and wunsch,1970j.mol.biol.48:443-453)以找到两个序列(考虑其全长)的最佳比对方法(包括间隙)。例如,针具程序可从万维网上下载,并在以下出版物中进一步描述(emboss:the european molecular biology open software suite(2000)rice,p.longden,i.and bleasby,a.trends in genetics 16,(6)pp.276—277)。根据本发明,两个多肽之间同一性百分比的计算方法为:emboss:针具(整体)程序,“gap open”参数等于10.0、“gap extend”参数等于0.5、矩阵为blosum62。
[0070]
由与参考序列“至少80%、85%、90%、95%、96%、97%、98%或99%相同”的氨基酸序列组成的蛋白可能包含相对于参考序列的氨基酸突变,例如缺失、插入和/或取代。在
发生取代时,由与参考序列至少80%、85%、90%、95%、96%、97%、98%或99%相同的氨基酸序列组成的蛋白可能对应于衍生自其他物种的同源序列(不同于参考序列)。
[0071]“氨基酸取代”可以是保守的也可以是非保守的。优选情况是,取代为保守取代,其中一个氨基酸被具有相似结构和/或化学性质的另一氨基酸所取代。
[0072]
在一实施方案中,保守取代可能包括由dayhoff在“the atlas of protein sequence and structure.vol.5”,natl.biomedical research中所述的取代,其内容透过引用整体并入本文。例如,一方面,属于以下组之一的氨基酸可彼此交换,因此构成保守交换:第1组:丙氨酸(a)、脯氨酸(p)、甘氨酸(g)、天冬醯胺(n)、丝氨酸(s)、苏氨酸(t);第2组:半胱氨酸(c)、丝氨酸(s)、酪氨酸(y)、苏氨酸(t);第3组:缬氨酸(v)、异亮氨酸(i)、亮氨酸(l)、甲硫氨酸(m)、丙氨酸(a)、苯丙氨酸(f);第4组:赖氨酸(k)、精氨酸(r)、组氨酸(h);第5组:苯丙氨酸(f)、酪氨酸(y)、色氨酸(w)、组氨酸(h);和第6组:天冬氨酸(d)、谷氨酸(e)。一方面,保守氨基酸取代可选自以下取代:t
→
a、g
→
a、a
→
i、t
→
v、a
→
m、t
→
i、a
→
v、t
→
g和/或t
→
s。
[0073]
在另一实施方案中,保守氨基酸取代可包括用相同类别的另一个氨基酸取代一种氨基酸,例如,(1)非极性:ala、val、leu、ile、pro、met、phe、trp;(2)不带电的极性:gly、ser、thr、cys、tyr、asn、gln;(3)酸性:asp、glu;和(4)碱性:lys、arg、his。其他保守氨基酸取代也可以按如下进行:(1)芳香族:phe、tyr、his;(2)质子供体:asn、gln、lys、arg、his、trp;和(3)质子受体:glu、asp、thr、ser、tyr、asn、gln(参见美国专利号10,106,805,其内容透过引用整体并入本文)。
[0074]
在另一实施方案中,保守取代可以根据表1进行。用于预测蛋白质修饰耐受性的方法可参见,例如,guo et al.,proc.natl.acad.sci.,usa,101(25):9205-9210(2004),其内容透过引用整体并入。
[0075]
表1:保守的氨基酸取代
[0076][0077]
在另一实施方案中,保守取代可能为表2中“保守取代”标题下所示的取代。如果此类取代导致生物活性改变,则可能引入表2中称为“代表性取代”的重大改变,并且在需要时筛选产品。
[0078]
表2:氨基酸取代
[0079][0080]
在一些实施方案中,抗原结合蛋白可能包括变体抗原结合蛋白,其中所述变体抗原结合蛋白包括第一多肽链(例如α链)和第二多肽链(例如β链),其与变体所衍生自的抗原结合蛋白相比,包含至多8、9、10、11、12、13、14、15个或更多氨基酸取代基,优选为在第一个可变结构域(例如vα结构域)和第二个可变结构域(例如vβ结构域)的cdr区中。就这点而言,在抗原结合蛋白的各cdr区或第一和/或第二可变结构域的所有cdr区中可能有1、2、3、4、5、6、7、8、9、10、11、12、13、14、15或更多氨基酸取代基。取代基可在第一和/或第二可变结构域的cdr中。
[0081]
在一实施方案中,变体为功能性变体。
[0082]
本文所用的术语“功能性变体”系指与亲本抗原结合蛋白具有基本或明显序列同一性或相似性的抗原结合蛋白,例如:含有保守氨基酸取代基的那些抗原结合蛋白,其中所述功能性变体保留了亲本抗原结合蛋白的生物学活性。一方面,例如,功能性变体包括本文所述抗原结合蛋白的那些变体(那么,本文所述的抗原结合蛋白本身称为亲本抗原结合蛋白),其保留与亲本抗原结合蛋白相似、相同或更高程度的靶细胞识别能力。相较于亲本抗原结合蛋白,例如,功能性变体可以含有一种氨基酸序列,该序列与亲本抗原结合蛋白的氨
基酸序列至少80%、85%、90%、95%、96%、97%、98%或99%相同。
[0083]
例如,功能性变体可以包含具有至少一个保守氨基酸取代基的亲本抗原结合蛋白的氨基酸序列。可选或另外的情况是,功能性变体可以包含具有至少一个非保守氨基酸取代基的亲本抗原结合蛋白的氨基酸序列。在这种情况下,非保守氨基酸取代优选为不干扰或不抑制功能性变体的生物学活性。优选情况是,非保守氨基酸取代可增强功能性变体的生物学活性,从而增加相对于亲本抗原结合蛋白的功能性变体生物学活性。
[0084]
本公开内容的修饰tcr、多肽和抗原结合蛋白(包括功能性部分和功能性变体)可能具有任何长度,即,可以包含任何数目的氨基酸,但前提是修饰tcr、多肽或蛋白(或其功能性部分或功能性变体)保留其生物学活性,例如:与抗原特异性结合、检测宿主中患病细胞或治疗或预防宿主中疾病的能力等。
[0085]
本发明的抗原结合蛋白(包括功能性部分和功能性变体)可以包含替代一种或多种天然氨基酸的合成氨基酸。此类合成氨基酸为本领域所已知的,例如,可以包括氨基环己烷羧酸、正亮氨酸、α-氨基正癸酸、高丝氨酸、s-乙醯氨基甲基-半胱氨酸、反式3-和反式4-羟脯氨酸、4-氨基苯基丙氨酸、4-硝基苯基丙氨酸、4-氯苯基丙氨酸、4-羧基苯基丙氨酸、β-苯基丝氨酸、β-羟基苯丙氨酸、苯甘氨酸、α-萘丙氨酸、环己基丙氨酸、环己基甘氨酸、吲哚啉-2-羧酸、1,2,3,4-四氢异喹啉-3-羧酸、氨基丙二酸、氨基丙二酸单醯胺、n'-苄基-n'-甲基赖氨酸、n
′
,n'-二苄基赖氨酸、6-羟基赖氨酸、鸟氨酸、α-氨基环戊烷羧酸、α-氨基环己烷羧酸、α-氨基环庚烷羧酸、α-(2-氨基-2-降冰片烷)-羧酸、α,γ-二氨基丁酸、α,β-二氨基丙酸、高苯丙氨酸和α-叔丁基甘氨酸。
[0086]
在一实施方案中,本发明的抗原结合蛋白(包括功能性部分和功能性变体)可以被糖基化、醯胺化、羧基化、磷酸化、酯化、n-醯化、环化(例如,透过二硫键)或转化成酸加成盐和/或任选地被二聚化或多聚化或共轭。
[0087]
本公开的抗原结合蛋白可以为合成的、重组的、分离的和/或纯化的。
[0088]
本文的“共价键”系指,例如:二硫键或透过多肽连接子等连接子或连接子序列连接的肽键或共价键。
[0089]
本文所用的术语“连接子”系指一个或多个氨基酸残基,其插入两个结构域之间从而为例如单链构建体中、本发明抗原结合蛋白的第一可变结构域和第二可变结构域之间和任选地轻链和重链可变结构域的可变结构域之间的结构域提供充分迁移性,从而正确折叠以形成抗原结合位点,或者在双特异性抗原结合蛋白的情况下以本发明抗原结合蛋白的交叉配对(以codv形式或某些双抗体形式)或平行配对形式(例如:以dvd形式)形成抗原结合位点和至少一个其他抗原结合位点。
[0090]
在一些实施方案中,连接子由0个氨基酸组成,这表示该连接子不存在。在氨基酸序列水平上,在可变结构域之间或可变结构域与恒定结构域之间的转换处分别插入连接子。由于已熟知免疫球蛋白结构域以及tcr结构域的大致尺寸,因此,可确定结构域之间的转换。本领域技术人员已知,结构域转换的精确位置可透过定位不会形成二级结构元件(例如β-折叠或α-螺旋)的肽延伸段来确定(如透过实验资料证明),或者可使用建模或二级结构预测技术鉴定或假设。在本发明背景下使用的连接子术语系指但不限于称为l1,、l2、l3、l4、l5和l6的连接子。
[0091]
只要不在各自背景下另行指定,连接子(例如l1,、l2、l3、l4、l5和l6)的长度可以为
至少1至30个氨基酸。在一些实施方案中,连接子(例如l1,、l2、l3、l4、l5和l6)的长度可以为2-25、2-20或3-18个氨基酸。在一些实施方案中,连接子(例如l1,、l2、l3、l4、l5和l6)的长度为不超过14、13、12、11、10、9、8、7、6或5个氨基酸的肽。在其他实施方案中,连接子(例如l1,、l2、l3、l4、l5和l6)的长度可以为5-25、5-15、4-11、10-20或20-30个氨基酸。在其他实施方案中,连接子(例如l1,、l2、l3、l4、l5和l6)的长度可以约为2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个氨基酸。在特定实施方案中,连接子(例如l1、l2、l3、l4、l5和l6)长度可能为小于24、小于20、小于16、小于12、小于10(例如5至24、10至24或5-10)个氨基酸残基。在一些实施方案中,所述连接子的长度等于1个或多个氨基酸残基,例如:大于1、大于2、大于5、大于10、大于20个氨基酸残基、大于22个氨基酸残基。
[0092]
示例性连接子(例如l1、l2、l3、l4、l5和l6)包含选自氨基酸组的氨基酸序列或由其组成,所述氨基酸组由tvaap(seq id no:99)、gggs(seq id no:100)、ggggs(seq id no:101)、ggsgg(seq id no:140)、tvlrt(seq id no:102)、tvssas(seq id no:103)、gggsgggg(seq id no:96)、ggggsgt(seq id no:148)、ggsggggsgg(seq id no:141)、ggggsggggs(seq id no:104)、ggsggggsggggsgg(seq id no:143)、ggggsaaa(seq id no:105)、ggggsggggsgt(seq id no:155)ggggsggggsggggs(seq id no:106)、ggggsggggsggggsgt(seq id no:161)、ggggsggggsggggsggggsgt(seq id no:163)、ggsggggsggggsggggsgg(seq id no:144)、ggggsggggsggggsggggsggggsgt(seq id no:165)、ggggsggggsggggsggggsggggsgs(seq id no:107)、ggsggggsggggsggggsggggsgg(seq id no:145)、ggggsggggsggggsggggsggggs(seq id no:108)、gsaddakkdaakkdgks(seq id no:146)、ggqgsggtgsggqgsggtgsggqgs(seq id no:147)、tvlssas(seq id no:109)和ggggsggggsggggsggggs(seq id no:110),特別是gggsgggg(seq id no:96)、ggggsggggsggggsggggs(seq id no:110)和ggggsggggsggggsggggsggggs(seq id no:108)组成。
[0093]
在本发明背景下使用的术语“fc结构域”包含下文进一步定义的天然fc结构域以及fc结构域变体和序列。与fc变体和天然fc分子一样,术语“fc结构域”包括单体或多聚体形式的分子,无论其是从完整抗体中酶切还是透过其他方式产生。
[0094]
本文所用的术语“天然fc”是指包含由抗体酶切或透过其他方式产生的非抗体结合片段的序列的分子,不论其为单体形式还是多聚体形式,并且可能包含铰链区。天然fc的原始免疫球蛋白来源特别是来源于人,可以为任何免疫球蛋白,优选为igg1或igg2,最优选为igg1。天然fc分子由单体多肽组成,而所述单体多肽可透过共价键(即,二硫键)和非共价键缔合为二聚体或多聚体形式。天然fc分子的单体亚基之间的分子间二硫键数量为1-4个,具体取决于类别(例如:igg、iga和ige)或亚类别(例如:igg1、igg2、igg3、iga1和igga2)。天然fc的一个实例为由木瓜蛋白酶酶切igg产生的二硫键结合二聚体。本文所用的术语“天然fc”是单体、二聚体和多聚体形式的通称。天然fc氨基酸序列的一个实例为seq id no:111的氨基酸序列,其是ighg1*01的天然fc氨基酸序列。
[0095]“铰链”或“铰链区”或“铰链结构域”通常是指位于c
h1
结构域和c
h2
结构域之间重链的柔性部分。它长约25个氨基酸,分为“上铰链”、“中间铰链”或“核心铰链”和“下铰链”。“铰链子结构域”是指上铰链、中(或核心)铰链或下铰链。本文中igg1、igg2、igg3和igg4分子铰
id no:112氨基酸序列或由其组成的fc结构域中,“臼”突变与半胱氨酸氨基酸取代基y349c1存在于包含seq id no:113氨基酸序列或由其组成的fc结构域中。
[0110]
在一些实施方案中,其中一个多肽的fc结构域(例如f
c1
)在其c
h3
结构域中包含氨基酸取代基t366w(杵),而另一个多肽的fc结构域(例如f
c2
)在其c
h3
结构域中包含氨基酸取代基t366s、l368a和y407v(臼),反之亦然。
[0111]
在一些实施方案中,其中一个多肽的fc结构域(例如f
c1
)在其c
h3
结构域中包含或进一步包含氨基酸取代基s354c,而另一个多肽的fc结构域(例如f
c2
)在其c
h3
结构域中包含或进一步包含氨基酸取代基y349c,反之亦然。
[0112]
因此,在一些实施方案中,其中一个多肽的fc结构域(例如f
c1
)在其c
h3
结构域中包含氨基酸取代基s354c和t366w(杵),而另一个多肽的fc结构域(例如f
c2
)在其c
h3
结构域中包含氨基酸取代基y349c、t366s、l368a和y407v(臼),反之亦然。
[0113]
如wei等人所述,透过纳入一个多肽上的氨基酸取代基k409a和另一多肽上的f405k可以进一步扩展该组氨基酸取代基(structural basis of a novel heterodimeric fc for bispecific antibody production,oncotarget.2017)。因此,在一些实施方案中,其中一个多肽的fc结构域(例如f
c1
)在其c
h3
结构域中包含或进一步包含氨基酸取代基k409a,而另一个多肽的fc结构域(例如f
c2
)在其c
h3
结构域中包含或进一步包含氨基酸取代基f405k,反之亦然。
[0114]
在某些情况下,人工引入的半胱氨酸桥可改善抗原结合蛋白的稳定性,最理想状况是不干扰抗原结合蛋白的结合特性。此类半胱氨酸桥可进一步改善异二聚化。
[0115]
在本领域中,例如在ep 2 970 484中已描述了进一步的氨基酸取代(例如:带电对取代),从而改善所得蛋白的异二聚化。
[0116]
因此,在一些实施方案中,其中一个多肽的fc结构域(例如f
c1
)包含或进一步包含带电对取代基e356k、e356r、d356r或d356k和d399k或d399r,而另一个多肽的fc结构域(例如f
c2
)包含或进一步包含带电对取代基r409d、r409e、k409e或k409d和n392d、n392e、k392e或k392d,反之亦然。
[0117]
在另一实施方案中,一条或两条(优选为两条多肽链)上的fc结构域可包含一个或多个抑制fcγ受体(fcγr)结合的改变。此类改变可以包括l234a、l235a。
[0118]
透过将由铰链、c
h2
和c
h3
结构域或其部分组成的fc部分纳入抗原结合蛋白中,更具体地纳入双特异性抗原结合蛋白中,出现了由fc:fc-γ受体(fcgr)相互作用诱导的这些分子的非特异性固定的问题。fcgr由不同的细胞表面分子(fcgri、fcgriia、fcgriib、fcgriii)组成,其与igg分子的fc部分显示的表位元元具有不同的亲和力。由于i)对分子的药代动力学的影响和ii)对免疫效应细胞的脱靶激活,这种非特异性(即,不是由双特异性分子的两个结合结构域中的任一个诱导)固定是不利的,因此,已确定消融fcgr结合性的各种fc变体和突变。在此背景下,morgan et al.1995,immunology(the n-terminal end of the ch2 domain of chimeric human igg1 anti-hla-dr is necessary for c1q,fcyri and fcyriii binding)公开了人igg1的残基233-236与来自人igg2的相应序列交换(即,残基233p、234v和235a,其中在第236位置不存在氨基酸),导致消除fcgri结合、消除c1q结合并减少fcgriii结合。ep1075496公开了具有fc区变异的抗体和其他含fc的分子(例如,233p、234v、235a中的一个或多个,且在第236位置无残基或g以及327g、330s和331s),其中
重组抗体能够与靶分子结合而不引发显著的补体依赖性裂解或细胞介导的靶标破坏。
[0119]
因此,在一些实施方案中,fc区包含或进一步包含一种或多种选自233p、234v、235a、236(无残基)或g、327g、330s、331s组成组中的氨基酸或缺失,优选为fc区包含或进一步包含氨基酸233p、234v、235a、236(无残基)或g以及选自327g、330s、331s组成组中的一个或多个氨基酸,最优选为fc区包含或进一步包含氨基酸233p、234v、235a、236(无残基)和331s。
[0120]
在另一实施方案中,fc结构域包含或进一步包含氨基酸取代基n297q、n297g或n297a,优选为n297q。
[0121]
氨基酸取代基“n297q”、“n297g”或“n297a”是指消除fc结构域内天然n-糖基化位点的第297位置的氨基酸取代基。此氨基酸取代基可进一步阻止fc-γ-受体相互作用,并可降低终蛋白产物(即本发明的抗原结合蛋白)的变异性,这是由糖残基所致,描述参见,例如,tao,mh and morrison,sl(j immunol.1989oct 15;143(8):2595-601.)一文。
[0122]
在一进一步实施方案中,特别是无轻链时,fc结构域包含或进一步包含氨基酸取代基s220c。氨基酸取代“s220c”可删除形成ch1-cl二硫键的半胱氨酸。
[0123]
在一些实施方案中,fc结构域包含或进一步包含至少两个额外的半胱氨酸残基,例如:s354c和y349c或l242c和k334c,其中s354c位于一个多肽的fc结构域中(例如:f
c1
),而y349c位于另一个多肽的fc结构域(例如:f
c2
),以形成异二聚体和/或其中l242c和k334c位于一个或两个多肽的f
c1
或f
c2
的同一fc结构域中,以形成结构域内c-c桥。
[0124]
当提及多肽(即,本发明的抗原结合蛋白)或核苷酸序列时,“纯化的”和“分离的”系指所示的分子在基本上不存在同类型其他生物大分子的情况下存在。本文所用的术语“纯化的”特别是指存在至少75%、85%、95%或98%重量的相同类型生物大分子。
[0125]
编码特定多肽的“分离的”核酸分子系指一种核酸分子,其基本上没有不编码目标多肽的其他核酸分子;但是,所述分子可能包括一些额外的碱基或部分,其不会对组合物的基本特性产生有害影响。
[0126]“结构域”可以是任何蛋白质区域,其通常根据序列同源性定义并通常与特定的结构性或功能性实体有关。
[0127]“重组”分子是透过重组手段制备、表达、产生或分离的分子。
[0128]
术语“基因”是指编码或对应于特定氨基酸序列的dna序列,所述特定氨基酸序列包含一种或多种蛋白质或酶的全部或部分,可能包括也可能不包括调节性dna序列,例如:启动子序列,其确定例如基因表达的条件。某些不是结构性基因的基因可能由dna转录为rna,但不会转译为氨基酸序列。其他基因可充当结构性基因的调节因子或dna转录的调节因子。特别地,术语基因可用于编码蛋白质的基因组序列,即,包含调节因子、启动子、内含子和外显子序列的序列。
[0129]“亲和力”理论上定义为抗原结合蛋白与抗原之间的平衡结合,在本发明背景下,定义为抗原结合蛋白与其抗原,即,包含seq id no:1的氨基酸序列或由其组成且与mhc蛋白形成复合体的mage-a抗原肽之间的平衡结合。例如,亲和力可以一半最大有效浓度(ec
50
)或平衡解离常数(kd)表示。
[0130]“k
d”是抗原结合蛋白与其抗原之间的平衡解离常数,即koff/kon之比。kd和亲和力成反比。kd值与抗原结合蛋白浓度有关,kd值越低,抗原结合蛋白的亲和力越高。亲和力(即,
kd值)可透过多种已知方法进行实验评估,例如:使用表面等离子共振(spr)或生物膜层干涉(bli)技术测量缔合和解离速率,下文“抗原结合蛋白”章节做更详细的描述。
[0131]“一半最大有效浓度”,也称为“ec
50”,通常是指在指定的暴露时间之后诱导介于基线和最大值中间的反应的分子浓度。ec
50
和亲和力成反比,ec
50
值越低,分子的亲和力越高。在一实施例中,“ec
50”是指本发明的抗原结合蛋白浓度,其在指定的暴露时间之后诱导介于基线和最大值中间的反应,更具体地,是指在指定的暴露时间之后诱导介于基线和最大值中间的反应的本发明的抗原结合蛋白浓度。ec50值可透过多种已知方法进行实验评估,例如:使用ifn-γ释放测定法或ldh释放测定法,如下文“抗原结合蛋白”章节做更详细的描述。
[0132]“cd3”是一种蛋白质复合体,由四条不同的链组成。在哺乳动物中,复合体包含一条cd3γ链、一条cd3δ链和两条cd3ε链。这些链与称为t细胞受体(tcr)的分子和ζ链缔合,以在t淋巴细胞中产生激活信号。
[0133]“cd28”也在t细胞上表达,可提供t细胞激活所需的共刺激信号。cd28在t细胞增生和存活、细胞因子产生以及2型t辅助细胞发育中发挥重要作用。
[0134]“cd134”也称为ox40。cd134/ox40在激活后24至72小时后表达,可用于定义次级共刺激分子。
[0135]“4-1bb”能够与抗原提呈细胞(apc)上的4-1bb-配体结合,从而产生t细胞的共刺激信号。
[0136]“cd5”是主要在t细胞上发现的受体的另一实例,在b细胞上也发现低水平cd5。
[0137]“cd95”是修饰t细胞功能的受体的另一实例,也称为fas受体,其透过在其他细胞表面上表达的fas-配体介导凋亡信号传导。据报告,cd95可调节静息t淋巴细胞中tcr/cd3驱动信号传导通路。
[0138]“nk细胞特异性受体分子”为,例如,cd16(一种低亲和力fc受体)和nkg2d。
[0139]
存在于t细胞和自然杀伤(nk)细胞表面上的受体分子的一个实例为cd2和cd2超家族的其他成员。cd2能够充当t细胞和nk细胞上的共刺激分子。
[0140]
本发明背景下上文(ii)中提及的“跨膜区”可以为,例如,tcrα或β跨膜结构域。
[0141]“胞质信号传导区”可以为,例如,tcrα或β细胞内结构域。
[0142]
本文中的“诊断剂”系指可检测的分子或物质,例如:萤光分子、放射性分子或本领域已知的(直接或间接)提供信号的任何其他标记物。
[0143]
本领域已知的“萤光分子”包括异硫氰酸萤光素(fitc),藻红蛋白(pe),用于蓝色镭射的萤光团(例如,percp、pe-cy7、pe-cy5、fl3和apc或cy5、fl4),用于红色、紫色或紫外镭射的萤光团(例如,太平洋蓝、太平洋橙)。
[0144]“放射性分子”包括但不限于用于闪烁显像检查的放射性原子,例如:i
123
、i
124
、in
111
、re
186
、re
188
、tc
99
。本发明的抗原结合蛋白可能还包含用于核磁共振(nmr)成像(也称为磁共振成像,mri)的自旋标记物,例如:碘-123、铟-111、氟-19、碳-13、氮-15、氧-17、釓、锰或铁。
[0145]
此类诊断剂可能与抗原结合蛋白直接偶联(即,物理连接),也可间接连接。
[0146]
本文中的“治疗剂”系指具有治疗作用的药物。在一实施方案中,此类治疗剂可为生长抑制剂,例如:细胞毒性剂或放射性同位素。
[0147]
可无差别使用的“生长抑制剂”或“抗增生剂”系指在体外或体内抑制细胞(特别是肿瘤细胞)生长的化合物或组合物。
[0148]
本文所用的术语“细胞毒性剂”系指抑制或妨碍细胞功能和/或导致细胞破坏的物质。术语“细胞毒性剂”意图包括化学治疗剂、酶、抗生素和毒素(例如:细菌、真菌、植物或动物来源的小分子毒素或酶活性毒素,包括其片段和/或变体)以及下文公开的各种抗肿瘤剂或抗癌药。在一些实施方案中,细胞毒性剂为紫杉醇、长春蔓、紫杉烷、美登木素或美登木素类似物(例如,dm1或dm4)、小分子药物、妥美霉素或吡咯苯二氮卓衍生物、隐藻素衍生物、瘦霉素衍生物、奥瑞他汀或海兔毒素类似物、前药、拓扑异构酶ii抑制剂、dna烷基化剂、抗微管蛋白剂、cc-1065或cc-1065类似物。
[0149]
术语“放射性同位素”意图包括适合于治疗癌症的放射性同位素,例如:at
211
、bi
212
、er
169
、i
131
、i
125
、y
90
、in
111
、p
32
、re
186
、re
188
、sm
153
、sr
89
以及lu的放射性同位素。此类放射性同位素通常主要发射β射线。在一实施方案中,放射性同位素为α发射体同位素,更确切地说为发射α辐射线的钍227。
[0150]
本文的“pk修饰部分”系指修饰本发明抗原结合蛋白药代动力学(pk)的部分。因此,所述部分特别修饰本发明抗原结合蛋白的体内半衰期和分布。在一优选实施方案中,pk修饰部分增加抗原结合蛋白的半衰期。pk修饰部分的实例包括但不限于peg(dozier et al.,(2015)int j mol sci.oct 28;16(10):25831-64and jevsevar et al.,(2010)biotechnol j.jan;5(1):113-28)、pas化(schlapschy et al.,(2013)protein eng des sel.aug;26(8):489-501)、白蛋白(dennis et al.,(2002)j biol chem.sep 20;277(38):35035-43)、抗体和/或非结构化多肽的fc部分(schellenberger et al.,(2009)nat biotechnol.dec;27(12):1186-90)。
[0151]“半衰期(t
1/2
)”通常系指积贮在活生物体中的半数药物或其他物质透过正常生物过程被代谢或排除所需的时间。因此,在本发明背景中,半衰期系指在例如小鼠中排除半数本发明抗原结合蛋白所需的时间。半衰期可以透过本领域熟知的方法测定。在一实施例中,半衰期如实施例10中所详细描述的测定。因此,在一实施例中,透过以下方法来测定半衰期:给予(例如,透过静脉内给予)例如小鼠(例如,超免疫缺陷nog小鼠)本发明的抗原结合蛋白,然后在不同时间点(例如,0h、0.1h、2h、8h、24h、48h、120h、240h和360h的时间点)从例如眼球后丛中收集血浆样本。然后透过本领域已知的技术(例如elisa)、使用不同的设置(例如fc
–vl
测定法和cd3
–
pmhc测定法)来测定抗原结合蛋白的血浆水平。通常透过从相应的标准曲线插补来获得样本的血浆浓度,然后通常透过不同时间点所获得的血浆水平的线性回归来确定半衰期。
[0152]
抗原结合蛋白
[0153]
使用wo 2017/158103所公开的tcr r7p1d5作为起点,本发明人设计、生产和检测了tcr可变α(vα)和可选的可变β(vβ)结构域变体,其为使用酵母筛选测定法的单链(sctcr)形式(如本文实施例1和2中所述)或为进一步优化可溶性双特异性sctcr构建体的结合亲和力以及产率和稳定性的单链双特异性tcr构建体(如本文实施例4中所述)。用这种方法,发明人鉴定出可变α结构域以及任选的β结构域的不同变体,更特别地,可变α结构域的cdra3(含5个变体)的不同变体,其可有利地与亲本tcr的cdra1、cdra2、cdrb1、cdrb2和/或cdrb3组合,或与针对cdra1(1个变体)、cdra2(3个变体)、cdrb1(1个变体)、cdrb2(5个变体)和/或
cdrb3(1个变体)发现的任何cdr变体组合,这些变体具有的优势是让本发明的抗原结合蛋白以高亲和力且亦以高特异性与靶标(即mage-a抗原肽,其包含seq id no:1的氨基酸序列且与mhc蛋白形成复合体,优选为与hla-a*02形成复合体)结合。
[0154]
发明人在各实施例中证明:cdr可用于act的tcr、单链tcr构建体以及其他双特异性形式,因而在原理上证明了所鉴定的cdr变体可用于产生不同抗原结合蛋白,这些蛋白对mage-a抗原肽(其包含seq id no:1的氨基酸序列且与mhc蛋白形成复合体,优选为与hla-a*02形成复合体)具有高亲和力且亦具有高特异性。
[0155]
此外,发明人发现:使tcr可变α(vα)和可变β(vβ)结构域的框架发生突变可改善可溶性双特异性sctcr构建体的结合特异性以及产率和稳定性,如本文实施例4中所述。
[0156]
在实施例5-8中,发明人设计、表达并成功检测了例如,tcer
tm
形式的抗原结合蛋白抗肿瘤细胞系的体外和体内疗效,所述抗原结合蛋白与人tcr-cd3复合体特异性结合以及与包含结合于mhc i类分子(例如hla-a*02:01)的seq id no:1的mage-a肽的肽:mhc复合体特异性结合。为了靶向作用于tcr-cd3复合体,修饰了衍生自cd3特异性人源化抗体hucht1的vh和v
l
结构域,如zhu et al.(j immunol,1995,155,1903
–
1910)所述,或衍生自α/βtcr特异性抗体bma031的vh和v
l
结构域,如shearman et al.(j immunol,1991,147,4366-73)所述,并用于那些实施例中。为了靶向作用于mage-a:mhc复合体,可利用包含本文所公开cdr的vα和vβ结构域,从而形成稳定性和亲和力成熟的抗原结合蛋白。相同的v
l
和vh、vα和vβ结构域进一步用于人单链t细胞受体形式,其进一步包含fab结构域(包含c
h1-铰链和c
l
),如实施例4中所述。
[0157]
因此,本发明涉及与mage-a抗原肽特异性结合的抗原结合蛋白,所述mage-a抗原肽包含seq id no:1的氨基酸序列“kvlehvvrv”或由其组成,其中所述抗原肽与mhc蛋白形成复合体,所述抗原结合蛋白包含:
[0158]
(a)包含第一可变结构域的第一条多肽链,所述第一可变结构域包含三个互补决定区(cdr)cdra1、cdra2和cdra3,其中:
[0159]-cdra1包含氨基酸序列“x1sssty”seq id no:72或由其组成,其中x1为任何氨基酸,优选为d或e,更优选为e,或与seq id no:72不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),
[0160]-cdra2包含氨基酸序列“ix1sx2x3dx
4”seq id no:73或由其组成,其中x1至x4为任何氨基酸,并且其中优选为x1为f或y,更优选为y,x2为n或s,优选为s,x3为q或m,优选为q,x4为m、v、s或q,优选为s或q,更优选为q。
[0161]-cdra3包含氨基酸序列“caex1x2sx3skiif”seq id no:77或由其组成,其中x1至x3为任何氨基酸,并且其中优选为x1为a、f或m,更优选为m,优选为x2为s、t或n,更优选为t,优选为x3为e或a,优选为e,前提是:如果cdra1包含氨基酸序列seq id no:5或由其组成并且cdra2包含氨基酸序列seq id no:6或由其组成,则cdra3不包含“caeyssaskiif”(seq id no:7)也不是由其组成,优选前提是:cdra3不包含“caeyssaskiif”(seq id no:7)也不是由其组成,或
[0162]-cdra3包含氨基酸序列“caex1x2sx3skiif”seq id no:77或由其组成,其中x1至x3为任何氨基酸,优选为x1为f、m或a,优选为m,优选为x2为s、t或n,更优选为t,优选为x3为e或
a,优选为e,以及
[0163]
(b)包含第二可变结构域的第二条多肽链,所述第二可变结构域包含三个互补决定区(cdr)cdrb1、cdrb2和cdrb3,其中:
[0164]-cdrb1包含氨基酸序列“x1ghdy”seq id no:78或由其组成,其中x1为任何氨基酸,优选为s或p,更优选为p,或与seq id no:78不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),
[0165]-cdrb2包含氨基酸序列“fx1x2x3x4p”seq id no:79或由其组成,其中x1至x4为任何氨基酸,优选为x1为c或n,更优选为c,优选为x2为y或n,更优选为y,优选为x3为g或n,更优选为g,优选为x4为h、v、t、a或m,优选为h或t,最优选为t,其中当优选为x1为c时,fr3-b氨基酸序列在氨基酸第66位置处包含氨基酸66c,和
[0166]-cdrb3包含氨基酸序列“casrax1tgelff”seq id no:82或由其组成,其中x1为任何氨基酸,优选为d或n,更优选为d,或与seq id no:82不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),
[0167]
在一特别的优选方案中,本发明涉及与mage-a抗原肽特异性结合的抗原结合蛋白,所述mage-a抗原肽包含seq id no:1的氨基酸序列“kvlehvvrv”或由其组成,其中所述抗原肽与mhc蛋白形成复合体,所述抗原结合蛋白包含:
[0168]
(a)包含第一可变结构域的第一条多肽链,所述第一可变结构域包含三个互补决定区(cdr)cdra1、cdra2和cdra3,其中:
[0169]-cdra1包含氨基酸序列seq id no:5或由其组成,或与seq id no:5不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),
[0170]-cdra2包含氨基酸序列seq id no:6或由其组成,或与seq id no:6不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),和
[0171]-cdra3包含氨基酸序列“caex1x2sx3skiif”seq id no:77或由其组成,其中x1至x3为任何氨基酸,并且其中优选为x1为a、f或m,更优选为m,优选为x2为s、t或n,更优选为t,优选为x3为e或a,优选为e,前提是:如果cdra1包含氨基酸序列seq id no:5或由其组成并且cdra2包含氨基酸序列seq id no:6或由其组成,则cdra3不包含“caeyssaskiif”(seq id no:7)也不是由其组成,优选前提是:cdra3不包含“caeyssaskiif”(seq id no:7)也不是由其组成,或cdra3包含氨基酸序列“caex1x2sx3skiif”seq id no:77或由其组成,其中x1至x3为任何氨基酸,优选为x1为f、m或a,优选为m,优选为x2为s、t或n,更优选为t,优选为x3为e或a,优选为e,以及其中:
[0172]
(b)包含第二可变结构域的第二条多肽链,所述第二可变结构域包含三个互补决定区(cdr)cdrb1、cdrb2和cdrb3,其中:
[0173]-cdrb1包含氨基酸序列seq id no:12或由其组成,或与seq id no:12不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),
[0174]-cdrb2包含氨基酸序列seq id no:13或由其组成,或与seq id no:13不同的氨基
酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),和
[0175]-cdrb3包含氨基酸序列seq id no:14或由其组成,或与seq id no:14不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个、三或四个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基)。
[0176]
在一特别的优选方案中,本发明涉及与mage-a抗原肽特异性结合的抗原结合蛋白(例如,可溶性抗原结合蛋白),所述mage-a抗原肽包含seq id no:1的氨基酸序列“kvlehvvrv”或由其组成,其中所述抗原肽与mhc蛋白形成复合体,所述抗原结合蛋白包含:
[0177]
a)包含第一可变结构域的第一条多肽链,所述第一可变结构域包含三个互补决定区(cdr)cdra1、cdra2和cdra3,其中:
[0178]-cdra1包含氨基酸序列“x1sssty”seq id no:72或由其组成,其中x1为任何氨基酸,优选为d或e,更优选为e,或与seq id no:72不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),
[0179]-cdra2包含氨基酸序列“iyssqdx
1”seq id no:74或由其组成,其中x1为任何氨基酸,优选为q、v或s,优选q,
[0180]-cdra3包含氨基酸序列“caemtseskiif”seq id no:35或由其组成,或与seq id no:35不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个、三或四个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),以及
[0181]
(b)包含第二可变结构域的第二条多肽链,所述第二可变结构域包含三个互补决定区(cdr)cdrb1、cdrb2和cdrb3,其中:
[0182]-cdrb1包含氨基酸序列“x1ghdy”seq id no:78或由其组成,其中x1为任何氨基酸,优选为s或p,更优选为p,或与seq id no:78不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),
[0183]-cdrb2包含氨基酸序列“fcygx1p”seq id no:81或由其组成,其中x1为任何氨基酸,优选为h、v、a或t,优选t,或与seq id no:81不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个或两个氨基酸取代基,更优选为一个氨基酸取代基,并且其中当优选为cdrb2包含氨基酸序列“fcygx1p”seq id no:81或由其组成时,fr3-b氨基酸序列在氨基酸第66位置处包含氨基酸66c,
[0184]-cdrb3包含氨基酸序列“casrax1tgelff”seq id no:82或由其组成,其中x1为任何氨基酸,优选为d或n,更优选为d,或与seq id no:82不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,优选为一个、两个、三个或四个氨基酸取代基,优选为一个或两个氨基酸取代基(例如一个氨基酸取代基)。
[0185]
如上所述,在一些实施方案中,cdrb2氨基酸序列在第57位置处包含氨基酸57c,此氨基酸优选与优选在fr3b氨基酸序列第66位置处存在的半胱氨酸一起形成二硫键。因此,在优选实施方案中,当cdrb2氨基酸序列在第57位置处包含氨基酸57c时,则fr3-b氨基酸序列优选为在氨基酸第66位置处包含氨基酸66c,反之亦然。因此,在一些实施方案中,fr3b氨基酸序列优选为在此第66位置处包含氨基酸取代基,因此,在一些相关实施方案中,fr3b氨
基酸序列包含氨基酸取代基i66c。
[0186]
在一些实施方案中,本发明背景下的cdra1包含seq id no:5或seq id no:55的氨基酸序列或由其组成。
[0187]
在一实施方案中,本发明背景下的cdra2包含以下氨基酸序列或由其组成:
[0188]“iyssqdx
1”seq id no:74,其中,x1为任何氨基酸,优选为q、v或s,更优选为q,或seq id no:6,或与seq id no:74或seq id no:6不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,例如,一个、两个或三个氨基酸取代基,更优选为一个氨基酸取代基,优选cdra2包含氨基酸序列“iyssqdx
1”seq id no:74或由其组成,其中,x1为任何氨基酸,优选为q、v或s,更优选为q,或与seq id no:74不同的氨基酸序列,不同点为:至少有一个氨基酸取代基,例如,一个、两个或三个氨基酸取代基,更优选为一个氨基酸取代基。
[0189]
在一些实施方案中,本发明背景下的cdra2包含氨基酸序列或由其组成,所述氨基酸序列选自由氨基酸序列seq id no:6和seq id no:56、57和59,优选为seq id no:6和seq id no:56组成的组。
[0190]
在一些实施方案中,cdra3包含氨基酸序列或由其组成,所述氨基酸序列选自由氨基酸序列seq id no:35、36、37、38、39优选为seq id no:35组成的组。
[0191]
在一些实施方案中,cdrb1包含seq id no:12或seq id no:62的氨基酸序列或由其组成。
[0192]
在一些实施方案中,cdrb2包含以下氨基酸序列或由其组成:
[0193]
‑“
fnnnvp”seq id no:13或
[0194]
‑“
fcygx1p”seq id no:81,其中,x1为任何氨基酸,优选为h、v、a或t,更优选为t,并且其中优选情况为:当cdrb2包含氨基酸序列“fcygx1p”seq id no:81或由其组成时,fr3-b氨基酸序列在氨基酸第66位置处包含氨基酸66c,或
[0195]
与seq id no:13或81不同的氨基酸序列,不同点为:有至少一个氨基酸取代基,
[0196]
例如:一个、两个或三个氨基酸取代基,更优选为一个氨基酸取代基。
[0197]
在一些实施方案中,本发明背景下的cdrb2包含氨基酸序列或由其组成,所述氨基酸序列选自由氨基酸序列seq id no:13和seq id no:63、64、65、66和70,优选为seq id no:13和seq id no:65组成的组,并且其中优选情况是:当cdrb2包含氨基酸序列seq id no:63、64、65、66或70或由其组成时,fr3-b氨基酸序列优选为在氨基酸第66位置处包含氨基酸66c。
[0198]
在一实施方案中,本发明背景下的cdrb3包含seq id no:14或seq id no:71的氨基酸序列或由其组成。
[0199]
在一特定实施方案中,本发明的抗原结合蛋白包含
[0200]
a)包含第一可变结构域的第一条多肽链,所述第一可变结构域包含三个互补决定区(cdr)cdra1、cdra2和cdra3,其中:
[0201]-cdra1包含氨基酸序列seq id no:5或由其组成,
[0202]-cdra2包含氨基酸序列seq id no:6或由其组成,和
[0203]-cdra3包含氨基酸序列或由其组成,所述氨基酸序列选自由氨基酸序列seq id no:35、36、37、38、39,优选为seq id no:35、36、37、38,更优选为seq id no:35和38(例如seq id no:35)组成的组,并且其中(b)包含第二可变结构域的第二条多肽链,所述第二可
变结构域包含三个互补决定区(cdr)cdrb1、cdrb2和cdrb3,其中:
[0204]-cdrb1包含氨基酸序列seq id no:12或由其组成,
[0205]-cdrb2包含氨基酸序列seq id no:13或由其组成,和
[0206]-cdrb3包含氨基酸序列seq id no:14或由其组成。
[0207]
在一特定实施方案中,抗原结合蛋白包含
[0208]
a)包含第一可变结构域的第一条多肽链,所述第一可变结构域包含三个互补决定区(cdr)cdra1、cdra2和cdra3,其中:
[0209]-cdra1包含seq id no:5或seq id no:55,优选为seq id no:55的氨基酸序列或由其组成,
[0210]-cdra2包含氨基酸序列或由其组成,所述氨基酸序列选自由氨基酸序列seq idno:56、57和59,优选为seq id no:56和59,更优选为seq id no:56组成的组,
[0211]-cdra3包含氨基酸序列seq id no:35或由其组成,
[0212]
(b)包含第二可变结构域的第二条多肽链,所述第二可变结构域包含三个互补决定区(cdr)cdrb1、cdrb2和cdrb3,其中:
[0213]-cdrb1包含氨基酸序列seq id no:62或由其组成,
[0214]-cdrb2包含氨基酸序列或由其组成,所述氨基酸序列选自由氨基酸序列seq id no:63、64、65、66和70,优选为seq id no:65组成的组,并且其中优选情况是:当cdrb2包含氨基酸序列seq id no:63、64、65、66或70或由其组成时,fr3-b氨基酸序列优选为在氨基酸第66位置处包含氨基酸66c,和
[0215]-cdrb3包含seq id no:14或seq id no:71,优选为seq id no:71的氨基酸序列或由其组成。
[0216]
本发明进一步涉及抗原结合蛋白,其包含本发明背景下公开所公开cdr氨基酸序列的变体,通常为cdra1、cdra2、cdra3、cdrb1、cdrb2和/或cdrb3的变体,此类变体可能至少包含一个,例如四个、三个、两个或一个,优选为一个、两个或三个氨基酸取代基,其中优选的氨基酸取代基数量优选的取决于各cdr的长度。
[0217]
因此,在一些实施方案中,cdra1包含与本文所公开cdra1氨基酸序列不同的氨基酸序列或由其组成,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基或仅一个氨基酸取代基,其中所述氨基酸取代基优选为在氨基酸第28、29、36、37和38位置中的任何一处,更优选为第28位置处。
[0218]
在一些实施方案中,cdra2包含与本文所公开cdra2氨基酸序列不同的氨基酸序列或由其组成,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基或仅一个氨基酸取代基,其中所述氨基酸取代基优选为在氨基酸第56或65位置处,更优选为第65位置处。
[0219]
在一些实施方案中,cdra3包含与本文所公开cdra3氨基酸序列不同的氨基酸序列或由其组成,不同点为:至少有一个氨基酸取代基,优选为一个、两个、三个或四个氨基酸取代基,优选为一个或两个氨基酸取代基或仅一个氨基酸取代基,其中所述氨基酸取代基优选为在氨基酸第105、106、107、108、109、113、114、115、116和117位置中的任何一处。
[0220]
在一些实施方案中,cdrb1包含与本文所公开cdrb1氨基酸序列不同的氨基酸序列或由其组成,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,
优选为一个或两个氨基酸取代基(例如一个氨基酸取代基),其中所述氨基酸取代基优选为在氨基酸第27、28、29、37和38位置中的任何一处,更优选为第27和38位置处。
[0221]
在一些实施方案中,cdrb2包含与本文所公开cdrb2氨基酸序列不同的氨基酸序列或由其组成,不同点为:至少有一个氨基酸取代基,优选为一个、两个或三个氨基酸取代基,优选为一个或两个氨基酸取代基或仅一个氨基酸取代基,其中所述氨基酸取代基优选为在氨基酸第56位置处。
[0222]
在一些实施方案中,cdrb3包含与本文所公开cdrb3氨基酸序列不同的氨基酸序列或由其组成,不同点为:至少有一个氨基酸取代基,优选为一个、两个、三个或四个氨基酸取代基,优选为一个或两个氨基酸取代基或仅一个氨基酸取代基,其中所述氨基酸取代基优选为在氨基酸第105、106、107、108、109、113、114、115、116、117位置中的任何一处。
[0223]
上文所指的氨基酸取代基的定义见上文“定义”章节,优选为氨基酸取代基为保守氨基酸取代基。如本领域技术人员所了解的一样,包含本文定义cdr氨基酸序列的第一可变结构域和包含本文定义cdr氨基酸序列的第二可变结构域一起形成抗原结合位点,其中所述抗原结合位点与mage-a抗原肽结合,所述抗原肽包含seq id no:1氨基酸序列“kvlehvvrv”或由其组成且与mhc蛋白形成复合体。
[0224]
三个互补决定区(cdr)cdra1、cdra2和cdra3衍生自tcr的可变α结构域,因此,如本领域技术人员所了解的一样,在一些实施方案中,第一可变结构域也可指可变α结构域。类似地,三个互补决定区(cdr)cdrb1、cdrb2和cdrb3衍生自所述tcr的可变β结构域。因此,如本领域技术人员进一步了解的一样,第二可变结构域也可指可变β结构域。更特别地,包含本发明背景下定义的α可变框架氨基酸序列和α可变cdr(例如序列(fr1-a)-(cdra1)-(fr2-a)-(cdra2)-(fr3-a)-(cdra3)-(fr4-a))的第一可变结构域可称为可变α结构域和/或包含本发明背景下定义的β可变框架氨基酸序列和β可变cdr(例如序列(fr1-b)-(cdrb1)-(fr2-b)-(cdrb2)-(fr3-b)-(cdrb3)-(fr4-b))的第二可变结构域可称为可变β结构域。
[0225]
在一些实施方案中,cdr可在抗体框架序列中进行移植。因此,在一实施例中,在第一可变结构域背景下定义的cdr可在轻链可变结构域中进行移植,所述第一可变结构域因此包含序列(fr1-l)-(cdra1)-(fr2-l)-(cdra2)-(fr3-l)-(cdra3)-(fr4-l)或由其组成,并可称为轻链可变结构域。在同一实施例中,在第二可变结构域背景下定义的cdr可在重链可变结构域中进行移植,所述第二可变结构域因此包含序列(fr1-h)-(cdrb1)-(fr2-h)
–
(cdrb2)-(fr3-h)
–
(cdrb3)-(fr4-h)或由其组成,并可称为重链可变结构域。但是,本领域技术人员也会了解,在第一可变结构域背景下定义的cdr也可在重链可变结构域中移植,并且在第二可变结构域背景下定义的cdr也可在轻链可变结构域中移植,以上考虑经适当修改后适用。
[0226]
在本发明的背景下,本发明抗原结合蛋白的cdr与天然和亲本tcr r7p1d5的cdr不同,如wo 2017/158103中公开内容所述,至少在所述亲本tcr r7p1d5的cdra3的氨基酸序列中不同。如本领域技术人员所了解的,上文所定义的cdra3不包含氨基酸序列“caeyssaskiif”(seq id no:7)也不由其组成,其是亲本tcr r7p1d5的cdra3。
[0227]
在一实施方案中,本文在本发明抗原结合蛋白背景下所定义的第一可变结构域和第二可变结构域根据imgt编号在第44位置处可能包含氨基酸取代基。在一优选实施方案中,第44位置处的所述氨基酸被另一种合适氨基酸取代,以改善配对。在特定的实施方案
中,优选为其中所述抗原结合蛋白为tcr的实施方案中,所述氨基酸取代改善例如链的配对(即α和β链的配对或γ和δ的配对),在一优选实施方案中,第一可变结构域第44位置处(v144)以及第二可变结构域第44位置处(v244)存在的一个或两个氨基酸被取代为选自由v144d/v244r、
v1
44r/v244d、
v1
44e/v244k、v144k/v244e、v144d/v244k、v144k/v244d、v144r/v244e;v144e/v244r、v144l/v244w、v144w/v244l、v144v/v244w、v144w/v244v组成的氨基酸对组的氨基酸对v144/v244。
[0228]
因此,在另一实施方案中,抗原结合蛋白可进一步包括选自由以下组成组的优选取代对之一(v144/v244):v1q44d/v2q44r;v1q44r/v2q44d;v1q44e/v2q44k;v1q44k/v2q44e;v1q44d/v2q44k;v1q44k/v2q44d;v1q44e/v2q44r;v1q44r/v2q44e;v1q44l/v2q44w;v1q44w/v2q44l;v1q44v/v2q44w;和v1q44w/v2q44v;v1w44d/v2q44r;v1w44r/v2q44d;v1w44e/v2q44k;v1w44k/v2q44e;v1w44d/v2q44k;v1w44k/v2q44d;v1w44e/v2q44r;v1w44r/v2q44e;v1w44l/v2q44w;v1w44/v2q44l;v1w44v/v2q44w;和v1w44/v2q44v;v1h44d/v2q44r;v1h44r/v2q44d;v1h44e/v2q44k;v1h44k/v2q44e;v1h44d/v2q44k;v1h44k/v2q44d;v1h44e/v2q44r;v1h44r/v2q44e;v1h44l/v2q44w;v1h44w/v2q44l;v1h44v/v2q44w;和v1h44w/v2q44v;v1k44d/v2q44r;v1k44r/v2q44d;v1k44e/v2q44k;v1k44/v2q44e;v1k44d/v2q44k;v1k44/v2q44d;v1k44e/v2q44r;v1k44r/v2q44e;v1k44l/v2q44w;v1k44w/v2q44l;v1k44v/v2q44w;和v1k44w/v2q44v;v1e44d/v2q44r;v1e44r/v2q44d;v1e44/v2q44k;v1e44k/v2q44e;v1e44d/v2q44k;v1e44k/v2q44d;v1e44/v2q44r;v1e44r/v2q44e;v1e44l/v2q44w;v1e44w/v2q44l;v1e44v/v2q44w;和v1e44w/v2q44v;v1q44d/v2r44;v1q44r/v2r44d;v1q44e/v2r44k;v1q44k/v2r44e;v1q44d/v2r44k;v1q44k/v2r44d;v1q44e/v2r44;v1q44r/v2r44e;v1q44l/v2r44w;v1q44w/v2r44l;v1q44v/v2r44w;和v1q44w/v2r44v;v1w44d/v2r44;v1w44r/v2r44d;v1w44e/v2r44k;v1w44k/v2r44e;v1w44d/v2r44k;v1w44k/v2r44d;v1w44e/v2r44;v1w44r/v2r44e;v1w44l/v2r44w;v1w44/v2r44l;v1w44v/v2r44w;和v1w44/v2r44v;v1h44d/v2r44;v1h44r/v2r44d;v1h44e/v2r44k;v1h44k/v2r44e;v1h44d/v2r44k;v1h44k/v2r44d;v1h44e/v2r44;v1h44r/v2r44e;v1h44l/v2r44w;v1h44w/v2r44l;v1h44v/v2r44w;和v1h44w/v2r44v;v1k44d/v2r44;v1k44r/v2r44d;v1k44e/v2r44k;v1k44/v2r44e;v1k44d/v2r44k;v1k44/v2r44d;v1k44e/v2r44;v1k44r/v2r44e;v1k44l/v2r44w;v1k44w/v2r44l;v1k44v/v2r44w;和v1k44w/v2r44v;v1e44d/v2r44;v1e44r/v2r44d;v1e44/v2r44k;v1e44k/v2r44e;v1e44d/v2r44k;v1e44k/v2r44d;v1e44r/v2r44e;v1e44l/v2r44w;v1e44w/v2r44l;v1e44v/v2r44w;和v1e44w/v2r44v;v1q44d/v2k44r;v1q44r/v2k44d;v1q44e/v244k;v1q44k/v2k44e;v1q44d/v244k;v1q44k/v2k44d;v1q44e/v2k44r;v1q44r/v2k44e;v1q44l/v2k44w;v1q44w/v2k44l;v1q44v/v2k44w;和v1q44w/v2k44v;v1w44d/v2k44r;v1w44r/v2k44d;v1w44e/v244k;v1w44k/v2k44e;v1w44d/v244k;v1w44k/v2k44d;v1w44e/v2k44r;v1w44r/v2k44e;v1w44l/v2k44w;v1w44/v2k44l;v1w44v/v2k44w;和v1w44/v2k44v;v1h44d/v2k44r;v1h44r/v2k44d;v1h44e/v244k;v1h44k/v2k44e;v1h44d/v244k;v1h44k/v2k44d;v1h44e/v2k44r;v1h44r/v2k44e;v1h44l/v2k44w;v1h44w/v2k44l;v1h44v/v2k44w;和v1h44w/v2k44v;v1k44d/v2k44r;v1k44r/v2k44d;v1k44e/v244k;v1k44/v2k44e;v1k44d/v244k;v1k44/v2k44d;v1k44e/v2k44r;v1k44r/v2k44e;v1k44l/v2k44w;v1k44w/v2k44l;v1k44v/v2k44w;和v1k44w/v2k44v;v1e44d/v2k44r;v1e44r/v2k44d;v1e44/v244k;v1e44k/v2k44e;v1e44d/v244k;v1e44k/v2k44d;v1e44/v2k44r;v1e44r/v2k44e;v1e44l/
id no:87具有至少85%同一性的氨基酸序列或由其组成,
[0243]-fr2-b包含“lfwyrqtmmrglelliy”seq id no:88氨基酸序列或与seq id no:88具有至少85%同一性的氨基酸序列或由其组成,
[0244]-fr3-b包含“iddsgmpedrfsakmpnasfstlkiqpseprdsavyf”seq id no:89氨基酸序列或与seq id no:89具有至少85%同一性的氨基酸序列或由其组成,或
[0245]-fr4-b包含“gegsrltvl”seq id no:90氨基酸序列或与seq id no:90具有至少85%同一性的氨基酸序列或由其组成。
[0246]
在一实施方案中,所述第一可变结构域还包含一个或多个选自由fr1-a、fr2-a、fr3-a和fr4-a组成组的框架区,优选为fr1-a、fr2-a、fr3-a和fr4-a,其中
[0247]-fr1-a包含“edveqslflsvregdssvinctyt”seq id no:83氨基酸序列或与seq id no:83具有至少90%同一性的氨基酸序列或由其组成;
[0248]-fr2-a包含“lywykqepgaglqllty”seq id no:84氨基酸序列或与seq id no:84具有至少90%同一性的氨基酸序列或由其组成,
[0249]-fr3-a包含“kqdqrltvllnkkdkhlslriadtqtgdsaiyf”seq id no:85氨基酸序列或与seq id no:85具有至少90%同一性的氨基酸序列或由其组成;
[0250]-fr4-a包含“gsgtrlsirp”seq id no:86氨基酸序列或与seq id no:86具有至少90%同一性的氨基酸序列或由其组成;和
[0251]
所述第二可变结构域还包含一个或多个选自由fr1-b、fr2-b、fr3-b和fr4-b组成组的框架区,优选为fr1-b、fr2-b、fr3-b和fr4-b,其中
[0252]-fr1-b包含“dagviqsprhevtemgqevtlrckpi”seq id no:87氨基酸序列或与seq id no:87具有至少90%同一性的氨基酸序列或由其组成;
[0253]-fr2-b包含“lfwyrqtmmrglelliy”seq id no:88氨基酸序列或与seq id no:88具有至少90%同一性的氨基酸序列或由其组成;
[0254]-fr3-b包含“iddsgmpedrfsakmpnasfstlkiqpseprdsavyf”seq id no:89氨基酸序列或与seq id no:89具有至少90%同一性的氨基酸序列或由其组成;或
[0255]-fr4-b包含“gegsrltvl”seq id no:90氨基酸序列或与seq id no:90具有至少90%同一性的氨基酸序列或由其组成。
[0256]
在一实施方案中,所述第一可变结构域还包含一个或多个选自由fr1-a、fr2-a、fr3-a和fr4-a组成组的框架区,优选为fr1-a、fr2-a、fr3-a和fr4-a,其中
[0257]-fr1-a包含“edveqslflsvregdssvinctyt”seq id no:83氨基酸序列或与seq id no:83具有至少95%同一性的氨基酸序列或由其组成;
[0258]-fr2-a包含“lywykqepgaglqllty”seq id no:84氨基酸序列或与seq id no:84具有至少95%同一性的氨基酸序列或由其组成,
[0259]-fr3-a包含“kqdqrltvllnkkdkhlslriadtqtgdsaiyf”seq id no:85氨基酸序列或与seq id no:85具有至少95%同一性的氨基酸序列或由其组成;
[0260]-fr4-a包含“gsgtrlsirp”seq id no:86氨基酸序列或与seq id no:86具有至少95%同一性的氨基酸序列或由其组成;
[0261]
和
[0262]-所述第二可变结构域还包含一个或多个选自由fr1-b、fr2-b、fr3-b和fr4-b组成
组的框架区,优选为fr1-b、fr2-b、fr3-b和fr4-b,其中
[0263]-fr1-b包含“dagviqsprhevtemgqevtlrckpi”seq id no:87氨基酸序列或与seq id no:87具有至少95%同一性的氨基酸序列或由其组成;
[0264]-fr2-b包含“lfwyrqtmmrglelliy”seq id no:88氨基酸序列或与seq id no:88具有至少95%同一性的氨基酸序列或由其组成;
[0265]-fr3-b包含“iddsgmpedrfsakmpnasfstlkiqpseprdsavyf”seq id no:89氨基酸序列或与seq id no:89具有至少95%同一性的氨基酸序列或由其组成;或
[0266]-fr4-b包含“gegsrltvl”seq id no:90氨基酸序列或与seq id no:90具有至少95%同一性的氨基酸序列或由其组成。
[0267]
因此,本发明的抗原结合蛋白优选为进一步包含恒定结构域,例如,如上所述的α恒定结构和/或β恒定结构域,或γ和/或δ恒定结构域。优选情况为,α和β恒定结构域和/或γ和δ恒定结构域包含不存在于天然tcr中的其他突变,以加强两条转基因链(即α和β链)的配对。例如,trac的第48位置以及trbc1或trbc2的第57位置可以被半胱氨酸残基取代。此类修饰的进一步实施例如上所述。本发明抗原结合蛋白中包含的α恒定结构域和β恒定结构域的实例为seq id no:8(tcr r7p1d5的α恒定结构域)和seq id no:15(tcr r7p1d5的β恒定结构域)。
[0268]
在一实施方案中,本发明抗原结合分子包含上文所定义的tcr分子,例如,包含至少一个α可变结构域和一个β可变结构域(α/βtcr)的分子或包含至少一个γ可变结构域或δ可变结构域的分子。换言之,此类tcr为异二聚体分子,即α/β和γ/δ异二聚体。
[0269]
为了用于过继细胞治疗(act),α/β或γ/δ异二聚体tcr可能被转染至患者的t细胞中为具有细胞质结构域和跨膜结构域的全长链。恒定结构域可包含合适的突变,即,二硫键,以改善所需转基因α/β或γ/δ链的配对,并减少内源性α/β或γ/δ与各别转基因链的配对。因此,本发明的抗原结合蛋白优选为进一步包含恒定结构域,例如,如上文所述的α恒定结构域和/或β恒定结构域。优选情况为,α和β恒定结构域包含不存在于天然tcr中的其他突变,以分别加强两条链(即α和β链或γ和δ链)的配对。例如,trac的第48位置以及trbc1或trbc2的第57位置被半胱氨酸残基取代。本发明抗原结合蛋白中包含的α恒定结构域和β恒定结构域的实例为seq id no:8(tcr r7p1d5的α恒定结构域)和seq id no:15(tcr r7p1d5的β恒定结构域)。
[0270]
在一优选实施方案中,tcr包含α链和β链,该α链包含α可变结构域并进一步包含α恒定结构域,该α可变结构域包含cdr1α、cdr2α和cdr3α;该β链包含β可变结构域并且进一步包含β恒定结构域,该β可变结构域包含cdr1β、cdr2β和cdr3β。在一个进一步优选的实施方案中,α可变结构域包含三个互补决定区(cdr)cdra1、cdra2和cdra3,其中cdra1包含氨基酸序列seq id no:5或由其组成,cdra2包含氨基酸序列seq id no:6或由其组成,cdra3包含选自由氨基酸序列seq id no:35、36、37、38、39(优选为氨基酸序列seq id no:35、36、37、38,更优选为氨基酸序列seq id no:35和38,例如seq id no:35)组成组中的氨基酸序列或由其组成;β可变结构域包含三个互补决定区(cdr)cdrb1、cdrb2和cdrb3,其中cdrb1包含氨基酸序列seq id no:12或由其组成,cdrb2包含氨基酸序列seq id no:13或由其组成,cdrb3包含氨基酸序列seq id no:14或由其组成。
[0271]
在一优选实施方案中,tcr包含α链和β链,该α链包含α可变结构域并进一步包含α
b、fr3-b和fr4-b可与参考序列seq id no:83、seq id no:84、seq id no:85、seq id no:86、seq id no:87、seq id no:88、seq id no:89和seq id no:90不同,不同点仅为保守氨基酸取代基。
[0278]
可对本发明抗原结合蛋白的氨基酸序列和相应的dna序列分别进行修饰和改变,并且仍可产生具有所需特性的功能性抗原结合蛋白或多肽。可在第一或第二可变结构域中,特别是在第一和/或第二可变结构域中包含的框架区中或每个cdr中或所有cdr中进行修饰。
[0279]
本发明的发明人还发现,透过使用亲本tcr r7p1d5的框架区,抗原结合蛋白框架区中特定的氨基酸取代基具有有利作用。特别是,氨基酸取代基s19a或s19v,优选为s19v,对于表达可溶性单链tcr构建体至关重要,特别是除了在其第二个氨基酸位置包含y的cdra2氨基酸序列(即,cdra2中,根据imgt氨基酸57为y(57y))之外。此外,发明人发现,单独或组合使用fr2-a中的氨基酸取代基a48k和l50p、fr2-b中的m46p和m47g可增加本发明可溶性抗原结合蛋白的表达产量。发明人还证明,fr2-b中的i54f可增加可溶性抗原结合蛋白的表达产量,特别是根据imgt在第109位置包含d的cdrb3氨基酸序列之外,可增加可溶性抗原结合蛋白的稳定性。另外,发明人发现fr2-b中的i54f取代显著提高了可溶性抗原结合蛋白的特异性。
[0280]
因此,在一实施方案中,本发明抗原结合蛋白的框架区包含至少一个氨基酸取代基,优选为1、2、3、4、5、6、7、8、9或10个,更优选为1至5个、2至5个(例如:3或4个)选自包含以下的氨基酸取代基组中的氨基酸取代基:
[0281]-fr1-a中第19位置处的氨基酸取代基,其中所述氨基酸取代基优选为s19a、s19v,更优选为s19v
[0282]-fr2-a中第48和/或第50位置处的氨基酸取代基,其中所述第48位置处的氨基酸取代基优选为a48k,所述第50位置处的氨基酸取代基优选为l50p,
[0283]-fr2-b中第46、47和/或54位置处的氨基酸取代基,其中所述第46、47和54位置处的氨基酸取代基分别优选为m46p、m47g和i54f,其中,当上面定义的cdrb3氨基酸序列在第109位置处包含氨基酸109d时,优选第54位置处的所述氨基酸为i54f,
[0284]-fr3-b中第66位置处的氨基酸取代基,其中所述第66位置处的氨基酸取代基分别优选为i66c,其中,当上面定义的cdrb2氨基酸序列在第57位置处包含氨基酸57c时,优选第66位置处的所述氨基酸为66c,
[0285]
并且其中取代基的位置根据imgt命名法给出,其中所述氨基酸取代基与亲本tcr r7p1d5的相应框架氨基酸序列的氨基酸序列相比任选地给出。
[0286]
在一优选实施方案中,本发明抗原结合蛋白的框架区包含氨基酸取代基s19v、a48k和i54f或s19v、a48k,优选为s19v、a48k和i54f,其中取代基的位置根据imgt命名法给出。在一实施方案中,所述氨基酸取代的组合有利于进一步与包含氨基酸序列“casrax1tgelff”seq id no:82或由其组成的cdrb3组合,其中,x1为d,或根据imgt编号,其中cdrb3氨基酸在第109位置处包含氨基酸109d。在另一个优选实施方案中,当上文定义的cdrb2氨基酸序列第57位置包含57c时,本发明抗原结合蛋白的框架区还包含氨基酸取代基i66c,其中优选为fr3-b包含氨基酸取代基i66c。
[0287]
因此,在一实施方案中,所述第一可变结构域还包含一个或多个选自由fr1-a、
fr2-a、fr3-a和fr4-a组成组的框架区,优选为所有框架区,其中
[0288]-fr1-a包含“edveqslflsvregdsvvinctyt”seq id no:91氨基酸序列或与seq id no:91具有至少85%同一性的氨基酸序列或由其组成,其中优选为与seq id no:91具有至少85%同一性的所述氨基酸序列包含氨基酸19v(seq id no:91加下划线),
[0289]-fr2-a包含“lywykqepgkglqllty”seq id no:92氨基酸序列或与seq id no:92具有至少85%同一性的氨基酸序列或由其组成,其中优选为与seq id no:92具有至少85%同一性的所述氨基酸序列包含氨基酸48k(seq id no:91加下划线)和任选为第50位置处的氨基酸取代基,优选为l50p,
[0290]-fr3-a包含“kqdqrltvllnkkdkhlslriadtqtgdsaiyf”seq id no:85氨基酸序列或与seq id no:85具有至少85%同一性的氨基酸序列或由其组成,
[0291]-fr4-a包含“gsgtrlsirp”seq id no:86氨基酸序列或与seq id no:86具有至少85%同一性的氨基酸序列或由其组成,和
[0292]
所述第二可变结构域还包含一个或多个框架区,优选为选自由fr1-b、fr2-b、fr3-b和fr4-b组成组的框架区,其中
[0293]-fr1-b包含“dagviqsprhevtemgqevtlrckpi”seq id no:87氨基酸序列或与seq id no:87具有至少85%同一性的氨基酸序列或由其组成,
[0294]-fr2-b包含“lfwyrqtmmrglellfy”seq id no:93氨基酸序列或与seq id no:93具有至少85%同一性的氨基酸序列或由其组成,其中优选为与seq id no:93具有至少85%同一性的所述氨基酸序列包含氨基酸54f和任选为第46和/或47位置处的氨基酸取代基,其中第46和/或47位置处的所述氨基酸取代基分别优选为m46p和/或m47g,
[0295]-fr3-b包含“iddsgmpedrfsakmpnasfstlkiqpseprdsavyf”seq id no:89氨基酸序列或与seq id no:89具有至少85%同一性的氨基酸序列或由其组成,或包含“cddsgmpedrfsakmpnasfstlkiqpseprdsavyf”seq id no:94氨基酸序列或与seq id no:94具有至少85%同一性的氨基酸序列或由其组成,其中优选为与seq id no:94具有至少85%同一性的所述氨基酸序列包含氨基酸66c,并且其中,当上面定义的cdrb2氨基酸序列在第57位置处包含氨基酸57c时,fr3-b优选包含与包含氨基酸66c的seq id no:94具有至少85%同一性的氨基酸序列或由其组成,
[0296]-fr4-b包含“gegsrltvl”seq id no:90氨基酸序列或与seq id no:90具有至少85%同一性的氨基酸序列或由其组成。
[0297]
本文所述抗原结合蛋白的变体考虑并明确指使用“与参考序列至少85%相同”的措辞,如上文“定义”章节所定义。例如,序列fr1-a、fr2-a、fr3-a和fr4-a以及fr1-b、fr2-b、fr3-b和fr4-b可适当地与参考序列seq id no:91、seq id no:92、seq id no:85、seq id no:86、seq id no:87、seq id no:93和seq id no:89或seq id no:94、seq id no:90不同,不同点在于:至少有一个氨基酸取代基,特别是至少有一个保守氨基酸取代基和/或规范残基取代基。特别是,第一可变结构域和第二可变结构域的序列fr1-a、fr2-a、fr3-a和fr4-a以及fr1-b、fr2-b、fr3-b和fr4-b可与参考序列seq id no:91、seq id no:92、seq id no:85、seq id no:86、seq id no:87、seq id no:93和seq id no:89或seq id no:94、seq id no:90不同,不同点仅为保守氨基酸取代基。
[0298]
可对本发明抗原结合蛋白的氨基酸序列和编码它们的相应dna序列进行修饰和改
变,并且仍可产生具有所需特性的功能性抗原结合蛋白或多肽。
[0299]
因此,在一实施方案中,本发明涉及一种抗原结合蛋白,其包含
[0300]
(i)包含第一可变结构域的第一多肽链,所述第一可变结构域包含选自由以下组成组的氨基酸序列:
[0301]“edveqslflsvregdssvinctytdssstylywykqepgaglqlltyifsnmdmkqdqrltvllnkkdkhlslriadtqtgdsaiyfcaemtseskiifgsgtrlsirp”seq id no:118、
[0302]“edveqslflsvregdssvinctytdssstylywykqepgaglqlltyifsnmdmkqdqrltvllnkkdkhlslriadtqtgdsaiyfcaeftseskiifgsgtrlsirp”seq id no:119、
[0303]“edveqslflsvregdssvinctytdssstylywykqepgaglqlltyifsnmdmkqdqrltvllnkkdkhlslriadtqtgdsaiyfcaefnseskiifgsgtrlsirp”seq id no:120、
[0304]“edveqslflsvregdssvinctytdssstylywykqepgaglqlltyifsnmdmkqdqrltvllnkkdkhlslriadtqtgdsaiyfcaefssaskiifgsgtrlsirp”seq id no:121、
[0305]“edveqslflsvregdssvinctytdssstylywykqepgaglqlltyifsnmdmkqdqrltvllnkkdkhlslriadtqtgdsaiyfcaeatseskiifgsgtrlsirp”seq id no:122,优选为seq id no:118和seq id no:121,更优选为seq id no:118,或者与选自由seq id no 118至122组成组的氨基酸序列至少具有85%同一性的氨基酸序列,并且其中,在seq id no 118至122的情况下,与选自由seq id no:118至122组成组的氨基酸序列具有至少85%同一性的氨基酸序列优选分别包含seq id no:5的cdra1、seq id no:6的cdra2和seq id no:35、36、37、38、39的cdra3的氨基酸序列,和
[0306]
ii)包含第二可变结构域的第二多肽链,所述第二可变结构域包含seq id no:11的氨基酸序列或与seq id no:11具有至少85%同一性的氨基酸序列,其中与seq id no:11的氨基酸序列具有至少85%同一性的氨基酸序列优选为分别包含seq id no:12、13和14的cdrb1、cdrb2和cdrb3的氨基酸序列,或
[0307]
iii)包含第一可变结构域的第一多肽链,所述第一可变结构域包含以下氨基酸序列:
[0308]“edveqslflsvregdsvvinctytdssstylywykqepgkglqlltyiyssqdqkqdqrltvllnkkdkhlslriadtqtgdsaiyfcaemtseskiifgsgtrlsirp”seq id no:151或
[0309]“edveqslflsvregdsvvinctytessstylywykqepgkglqlltyiyssqdqkqdqrltvllnkkdkhlslriadtqtgdsaiyfcaemtseskiifgsgtrlsirp”seq id no:152,优选为与seq id no:151或152氨基酸序列具有至少85%同一性的氨基酸序列,并且其中优选与seq id no:151的氨基酸序列具有少85%同一性的氨基酸序列优选包含seq id no:5的cdra1、seq id no:56的cdra2和seq id no:35的cdra3的氨基酸序列,其中优选与seq id no:152的氨基酸序列具有少85%同一性的氨基酸序列优选包含seq id no:55的cdra1、seq id no:56的cdra2和seq id no:35的cdra3的氨基酸序列,并且优选还包含氨基酸19v和/或48k,和
[0310]
iv)包含第二可變結構域的第二多肽鏈,所述第二可變結構域包含以下氨基酸序列:
[0311]“dagviqsprhevtemgqevtlrckpipghdylfwyrqtmmrglellfyfcygtpcddsgmpedrfsakmpnasfstlkiqpseprdsavyfcasrantgelffgegsrltvl”seq id no:149或
[0312]“dagviqsprhevtemgqevtlrckpipghdylfwyrqtmmrglellfyfcygtpcddsgmpedrfsa
kmpnasfstlkiqpseprdsavyfcasradtgelffgegsrltvl”seq id no:150,并且其中优选为与seq id no:149氨基酸序列具有至少85%同一性的氨基酸序列优选包含seq id no:62的cdrb1、seq id no:65的cdrb2和seq id no:14的cdrb3的氨基酸序列,并且其中优选与seq id no:150的氨基酸序列具有少85%同一性的氨基酸序列包含seq id no:62的cdrb1、seq id no:65的cdrb2和seq id no:71的cdrb3的氨基酸序列,并且优选还包含氨基酸54f和/或66c。
[0313]
在一实施方案中,抗原结合蛋白为抗体或其片段,或双特异性抗体或其片段,或t细胞受体(tcr)或其片段,或双特异性t细胞受体(tcr)或其片段。抗体和tcr及各自的片段的定义见上文“定义”章节。
[0314]
在一实施方案中,抗原结合蛋白来源于人,其被理解为由人抗原基因座产生,因此包含人序列,特别是人tcr或抗体序列。
[0315]
在一实施方案中,第一多肽和第二多肽特别透过共价键连接在一起。
[0316]
在一实施方案中,抗原结合蛋白为一种可溶性蛋白。
[0317]“定义”章节中定义的“共价连接”、“连接子序列”或“多肽连接子”(见“连接子”)。
[0318]
在一实施方案中,本发明抗原结合蛋白还包含以下一种或多种:
[0319]
(i)一个或多个其他抗原结合位点;
[0320]
(ii)跨膜区,任选为包括胞质信号传导区;
[0321]
(iii)诊断剂;
[0322]
(iv)治疗剂;或
[0323]
(v)pk修饰部分。
[0324]
如本领域技术人员熟悉的,例如在抗体背景下,抗原结合位点通常由6个与抗原结合的cdr形成。
[0325]
在本发明的背景下,上文(i)中提及的一个或多个其他抗原结合位点优选为选自与抗原结合的结合位点,其中所述抗原选自由抗原cd3(例如:cd3γ、cd3δ和cd3ε链)、cd4、cd7、cd8、cd10、cd11b、cd11c、cd14、cd16、cd18、cd22、cd25、cd28、cd32a、cd32b、cd33、cd41、cd41b、cd42a、cd42b、cd44、cd45ra、cd49、cd55、cd56、cd61、cd64、cd68、cd94、cd90、cd117、cd123、cd125、cd134、cd137、cd152、cd163、cd193、cd203c、cd235a、cd278、cd279、cd287、nkp46、nkg2d、gitr、fcεri、tcrα/β、tcrγ/δ、hla-dr或效应细胞的抗原组成的组,优选为cd3、tcrα/β或cd28,更优选为cd3和tcrα/β。
[0326]“cd3”和“cd28”的定义见上文定义章节。
[0327]
在一些实施方案中,(i)中提及的一个或多个其他抗原结合位点中的一个能够与t细胞特异性受体分子和/或天然杀伤细胞(nk细胞)特异性受体分子结合。在一特定实施方案中,抗原结合蛋白与cd3 t细胞共受体形成复合体。
[0328]
在一优选实施方案中,(i)中提及的一个或多个其他抗原结合位点之一能够与tcrα/β结合。
[0329]
在一些实施方案中,t细胞特异性受体为cd3 t细胞共受体。
[0330]
在一些实施方案中,t细胞特异性受体为cd28、cd134、4-1bb、cd5或cd95。
[0331]“cd134”、“4-1bb”、“cd5”、“cd95”和“nk细胞特异性受体分子”的定义见上文定义章节。“跨膜区”、“胞质信号传导区”、“诊断剂”、“治疗剂”和“pk修饰部分”的定义见上文定
义章节。
[0332]
在一些实施方案中,本发明的抗原结合蛋白直接或经由可裂解或不可裂解连接子共价附着于至少一种生长抑制剂。附着于此类至少一种生长抑制剂的抗原结合蛋白也可称为缀合物。
[0333]
制备此类缀合物(例如:免疫缀合物)的描述参见申请wo2004/091668或hudecz,f.,methods mol.biol.298:209-223(2005)和kirin et al.,inorg chem.44(15):5405-5415(2005),并且可能被本领域技术人员转移至制备本发明的抗原结合蛋白,所述抗原结合蛋白附着有此类至少一种生长抑制剂。
[0334]
在至少一种生长抑制剂附着背景下的“连接子”系指包含共价键或原子链的化学部分,其将多肽共价附着于药物部分。
[0335]
缀合物可透过体外方法制备。为了使药物或前药与抗体连接,使用连接基团。合适的连接基团为本领域所熟知的,包括二硫键、硫醚基团、酸不稳定基团、光不稳定基团、肽酶不稳定基团和酯酶不稳定基团。本发明的抗原结合蛋白与细胞毒性剂或生长抑制剂的缀合可使用多种双功能蛋白偶联剂进行,包括但不限于n-琥珀醯亚胺基吡啶二硫代丁酸盐(spdb)、丁酸4-[(5-硝基-2-吡啶基)二硫]-2,5-二氧-1-吡咯烷基酯(硝基spdb)、4-(吡啶-2-基二硫烷基)-2-磺基丁酸(磺基-spdb)、n-琥珀醯亚胺基(2-吡啶二硫基)丙酸酯(spdp)、琥珀醯亚胺基(n-马来醯亚胺甲基)环己烷-1-羧酸盐(smcc)、亚氨基噻烷(it)、亚氨基酯的双功能衍生物(如:己二亚氨二甲酯hcl)、活性酯(如:辛二酸二琥珀醯亚胺酯)、醛(如:戊二醛)、双叠氮化合物(如:双-(对叠氮苯甲醯基)-己二胺)、双重氮衍生物(如:双-(对重氮苯甲醯基)-乙二胺)、二异氰酸酯(如:甲苯2,6-二异氰酸酯)和双活性氟化合物(如:1,5-二氟-2,4-二硝基苯)。例如,可按vitetta et al(1987)一文所述制备蓖麻毒蛋白免疫毒素。碳标记1-异硫氰酸根合苄基甲基二亚乙基三胺五乙酸(mx-dtpa)是用于放射性核苷酸与抗体缀合的一种示例性螯合剂(wo 94/11026)。
[0336]
连接子可以为“可裂解连接子”,其促进细胞毒性剂或生长抑制剂在细胞中释放。例如,可使用酸不稳定连接子、肽酶敏感连接子、酯酶不稳定连接子、光不稳定连接子或含二硫键连接子(参见,例如美国专利号5,208,020)。连接子也可能为“不可裂解连接子”(例如smcc连接子),在某些情况下可能使耐受性更好。
[0337]
或者,包含本发明抗体以及细胞毒性或生长抑制性多肽的融合蛋白可透过重组技术或肽合成制备。dna的长度可能包含编码缀合物的两个部分的相应区域,所述两个部分彼此相邻或由编码连接子肽的区域隔开,所述连接子肽不破坏缀合物所需性质。
[0338]
本发明的抗原结合蛋白还可用于依赖性酶介导前药疗法中,方法为:透过使多肽与前药活化酶缀合,所述前药活化酶将前药(例如:肽基化学治疗剂,参见wo 81/01145)转化为活性抗癌药物(参见,例如,wo 88/07378和美国专利号4,975,278)。
[0339]
在一实施方案中,本发明抗原结合蛋白还包含以下一种或多种:酶、细胞因子(例如:人il-2、il-7或il-15)、纳米载体或核酸。
[0340]
在一优选实施方案中,抗原结合蛋白呈双特异性。该双特异性抗原结合蛋白在本文中也称为“双特异性分子”。
[0341]
在本领域中描述了许多不同的双特异性形式,并在上文“定义”章节中的“形式”下进行了描述。制备不同形式蛋白质的技术在本领域中也进行了公开(在相应章节中引用),
因此本领域技术人员可以用本文公开的形式较容易地使用本发明背景下定义的cdr或可变结构域。在本文实施例章节中也公开了抗原结合蛋白(例如:sctcr)或可溶性双特异性结合蛋白(例如:tcer
tm
)的制备。本领域技术人员会了解,轻链和重链可变结构域可以为平行方向,且α和β可变结构域可以为平行方向,如以dvd形式一样,或者轻链和重链可变结构域可以为交叉方向,且α和β可变结构域可以为交叉方向,如以codv形式一样。
[0342]
因此,本发明进一步涉及包含两条形成两个抗原结合位点(a和b)的多肽链的抗原结合蛋白,其中第一条多肽链具有下式表示的结构:
[0343]v3
–
l
1-v
4-l2–cl
ꢀꢀ
[i]
[0344]
其中,v3为第三可变结构域;v4为第四可变结构域;l1和l2为连接子;l2可能存在也可能不存在;cl为轻链恒定结构域或其一部分且可能存在也可能不存在;
[0345]
其中第二条多肽链具有下式表示的结构:
[0346]v5-l
3-v
6-l4–ch1
ꢀꢀ
[ii]
[0347]
其中,v5为第五可变结构域;v6为第六可变结构域;l3和l4为连接子;l4可能存在也可能不存在;c
h1
为重链恒定结构域1或其一部分且存在或不存在;其中
[0348]v3
或v4为上文定义的第一可变结构域,而v5或v6为上文定义的第二可变结构域,或
[0349]v5
或v6在本发明背景下定义为第一可变结构域,而v3或v4在本发明背景下定义为第二可变结构域,其中
[0350]v3
为上文所定义的第一可变结构域而v5为第二可变结构域,并且v4为轻链可变结构域而v6为重链可变结构域,或者v4为重链可变结构域而v6为轻链可变结构域,或,
[0351]v3
为上文所定义的第二可变结构域而v5为第一可变结构域,并且v4为轻链可变结构域而v6为重链可变结构域,或者v4为重链可变结构域而v6为轻链可变结构域,或,
[0352]v3
为上文所定义的第一可变结构域而v6为第二可变结构域,并且v4为轻链可变结构域而v5为重链可变结构域,或者v4为重链可变结构域而v5为轻链可变结构域,或
[0353]v3
为上文所定义的第二可变结构域而v6为第一可变结构域,并且v4为轻链可变结构域而v5为重链可变结构域,或者v4为重链可变结构域而v5为轻链可变结构域,
[0354]v4
为上文所定义的第一可变结构域而v5为第二可变结构域,并且v3为轻链可变结构域而v6为重链可变结构域,或者v3为重链可变结构域而v6为轻链可变结构域,或
[0355]v4
为上文所定义的第二可变结构域而v5为第一可变结构域,并且v3为轻链可变结构域而v6为重链可变结构域,或者v3为重链可变结构域而v6为轻链可变结构域,
[0356]
其中,轻链可变结构域和重链可变结构域一起形成一个抗原结合位点b,并且其中上文定义的第一和第二可变结构域形成一个抗原结合位点a。连接子l1、l2、l3、l4的定义见上文“定义”章节。但是,在一些实施方案中,有些连接子长度对于特定形式可能为优选。但是,关于连接子长度及其氨基酸序列的知识属于本领域的常识,而连接子以及用于不同形式的连接子和氨基酸序列属于现有技术的一部分,并在上文引用的公开中披露。
[0357]
本领域技术人员会了解,在上文所定义的第一可变结构域和第二可变结构域中形成的抗原结合位点a与本发明背景下所述的mage-a肽/mhc复合体特异性结合。
[0358]
在一优选实施方案中,v3为本发明背景下所定义的第一可变结构域而v6为第二可变结构域,并且v4为轻链可变结构域而v5为重链可变结构域,或
[0359]v3
为本发明背景下所定义的第一可变结构域而v6为第二可变结构域,并且v4为重
链可变结构域而v5为轻链可变结构域。
[0360]
在一实施方案中,式[i]的多肽在式[i]多肽的c-端还包含连接子(l5)和fc结构域或其部分,和/或其中,式[ii]的多肽在式[ii]多肽的c-端还包括连接子(l6)和fc结构域或其部分。
[0361]
fc结构域的定义见上文“定义”章节。
[0362]
在一实施方案中,抗原结合蛋白包含两条形成两个抗原结合位点(a和b)的多肽链,其中一条多肽链具有式[iii]表示的结构:
[0363]v3-l
1-v
4-l
2-c
l-l
5-f
c1
ꢀꢀ
[iii]
[0364]
以及一条多肽链具有式[iv]表示的结构:
[0365]v5-l
3-v
6-l
4-c
h1-l
6-f
c2
ꢀꢀ
[iv]
[0366]
其中v3、l1、v4、l2、c
l
、v5、l3、v6、l4、c
h1
的定义见上文,并且其中l5和l6为存在或不存在的连接子,且其中fc1和fc2为fc结构域,且其中fc1和fc2相同或不同,优选为不同。fc结构域的定义见上文“定义”章节。
[0367]
在一实施方案中,fc1包含氨基酸序列seq id no:113(臼)或由其组成,fc2包含氨基酸序列seq id no:112(杵)或由其组成,反之亦然,
[0368]
更优选地,当v4或v3为重链可变结构域时,fc1包含氨基酸序列seq id no:113或由其组成,因此,当v5或v6为轻链可变结构域时,fc2包含氨基酸序列seq id no:112或由其组成,或
[0369]
当v4或v3为轻链可变结构域时,fc1包含氨基酸序列seq id no:112或由其组成,因此,当v5或v6为重链可变结构域时,fc2包含氨基酸序列seq id no:113或由其组成。
[0370]
在一实施方案中,重链可变结构域(vh)和轻链可变结构域(vl)一起形成一个结合位点b,其与选自由cd3(例如:cd3γ、cd3δ和cd3ε链)cd4、cd7、cd8、cd10、cd11b、cd11c、cd14、cd16、cd18、cd22、cd25、cd28、cd32a、cd32b、cd33、cd41、cd41b、cd42a、cd42b、cd44、cd45ra、cd49、cd55、cd56、cd61、cd64、cd68、cd94、cd90、cd117、cd123、cd125、cd134、cd137、cd152、cd163、cd193、cd203c、cd235a、cd278、cd279、cd287、nkp46、nkg2d、gitr、fcεri、tcrα/β、tcrγ/δ、hla-dr所组成组中的抗原结合和/或与效应细胞结合。
[0371]
在另一实施方案中,重链可变结构域(vh)和轻链可变结构域(v
l
)一起形成一个结合位点,所述结合位点与t细胞特异性受体分子和/或天然杀伤细胞(nk细胞)特异性受体分子结合,其中t细胞特异性受体分子和天然杀伤细胞(nk细胞)特异性受体分子的定义见上文“定义”章节。
[0372]
在一实施方案中,轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:154或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:156或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:157或由其组成而重链可变结构域包含氨基酸序列seq id no:158或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:159或由其组成而重链可变结构域包含氨基酸序列seq id no:160或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:162或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:164或由其组成。
[0373]
优选为,轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:154或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:156或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:159或由其组成而重链可变结构域包含氨基酸序列seq id no:160或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:162或由其组成,或者轻链可变结构域包含氨基酸序列seq id no:153或由其组成而重链可变结构域包含氨基酸序列seq id no:164或由其组成,更优选为,轻链可变结构域包含氨基酸序列seq id no:159或由其组成而重链可变结构域包含氨基酸序列seq id no:160或由其组成。
[0374]
从实施例中可以看出,本发明的发明人在原理上证明了本发明背景下定义的cdr的使用,更具体地如上文定义的tcer
tm
形式的可变结构域(实施例)。
[0375]
因此,在一优选实施方案中,抗原结合蛋白包含形成两个抗原结合位点的两条多肽链,其中一条多肽链具有由式[iii]表示的结构:
[0376]v3-l
1-v
4-l
2-c
l-l
5-f
c1
ꢀꢀ
[iii]
[0377]
以及一条多肽链具有式[iv]表示的结构:
[0378]v5-l
3-v
6-l
4-c
h1-l
6-f
c2
ꢀꢀ
[iv]
[0379]
其中l2、c
l
、l5和l4、c
h1
、l6不存在,并且
[0380]
其中v3、l1、v4、v5、l3、v6如上文所定义,
[0381]
优选为,v3为本发明背景下所定义的第一可变结构域而v6为第二可变结构域,并且v4为轻链可变结构域而v5为重链可变结构域,或者优选为v3为本发明背景下所定义的第一可变结构域而v6为第二可变结构域,并且v4为重链可变结构域而v5为轻链可变结构域,和
[0382]
优选为,l1和l3包含(seq id no:96)的氨基酸序列“gggsgggg”或由其组成,和
[0383]
优选为,fc1包含氨基酸序列seq id no:113或由其组成,fc2包含氨基酸序列seq id no:112或由其组成,反之亦然,
[0384]
更优选为,当v4为重链可变结构域时,fc1包含氨基酸序列seq id no:113或由其组成,因此,当v5为轻链可变结构域时,fc2包含氨基酸序列seq id no:112或由其组成,或
[0385]
更优选为,当v4为轻链可变结构域时,fc1包含氨基酸序列seq id no:112或由其组成,因此,当v5为重链可变结构域时,fc2包含氨基酸序列seq id no:113或由其组成,和
[0386]
轻链可变结构域和重链可变结构域一起形成一个抗原结合位点,其优选与如上文所定义的抗原(优选为cd3、tcrα/β或cd28,更优选为cd3或tcrα/β)结合,
[0387]
并且其中第一和第二可变结构域形成一个抗原结合位点,其与本发明背景下定义的mage-a抗原肽特异性结合。
[0388]
本实施方案的抗原结合蛋白可称为双特异性tcr或称为含fc的双特异性tcr/mab双抗体。本实施方案的抗原结合蛋白也可称为tcer
tm
。
[0389]“tcer
tm”为双特异性t细胞受体(tcr),是可溶性抗原结合蛋白,其包含两个抗原结合结构域——如本发明背景下定义的第一和第二可变结构域以及由抗体的重链和轻链可变结构域形成的另外一种抗原结合结构域,也称为募集子,例如:针对cd3或针对tcrα/β的可变轻链和重链可变结构域。
[0390]
在一优选实施方案中,抗原结合蛋白(例如tcer
tm
)包含
[0391]-氨基酸序列(seq id no:135)的式v
3-l
1-v
4-l
2-c
l-l
5-f
c1
[iii]的一个第一多肽:
[0392][0393][0394]
其中,l2、c
l
、l5不存在,并且包含序列seq id no:138(seq id no:5、seq id no:59和seq id no:35的cdra1、cdra2、cdra3以粗体表示)的v3(成熟的tcr衍生α可变结构域)、序列seq id no:96的l1(下划线)、序列seq id no:160的v4(抗tcrαβvh)和序列seq id no:113的fc1(以斜体和下划线表示);和
[0395]-氨基酸序列(seq id no:136)的式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的一个第二多肽:
[0396][0397]
其中,l4、c
h1
、l6不存在,并且包含序列seq id no:159的v5(抗tcrαβv
l
)、seq id no:96的序列l3(下划线)、序列seq id no:150(seq id no:62、seq id no:65、seq id no:71的cdra1、cdra2、cdra3以粗体表示)的v6(tcr衍生β可变结构域)和序列seq id no:112的fc2(以斜体和下划线表示),其中,fc1和fc2序列包含半胱氨酸至丝氨酸的氨基酸取代基(以粗体字表示的s)因为无需透过所述半胱氨酸连接轻链、igg1铰链区的氨基酸取代基类似igg2铰链可消除fc-γ受体的相互作用(在第233至235和331s位置以粗体字表示的pva)、n297q氨基酸取代基(以粗体字表示的q)可消除fc部分内的n-糖基化位点从而消除fc-γ受体的相互作用,和另外如果是fc1中的臼突变(y349c、t366s、l368a和y407v)和如果是fc2中的杵突变(s354c和t366w)。因此,在一优选实施方案中,fc1具有序列seq id no:113而fc2具有序列seq id no:112。
[0398]
在另一优选实施方案中,抗原结合蛋白(例如tcer
tm
)包含一个具有氨基酸序列(seq id no:136)的式v
3-l
1-v
4-l
2-c
l-l
5-f
c1
[iii]的第一多肽:
[0399]
[0400][0401]
其中,l2、c
l
、l5不存在,并且包含序列seq id no:159的v3(抗tcrαβv
l
)、序列seq id no:96的l1(下划线部分)、序列seq id no:150(具有seq id no:62、seq id no:65、seq id no:71序列的cdra1、cdra2、cdra3以粗体表示)的v4(tcr衍生β可变结构域)和序列seq id no:112的fc1(斜体和下划线部分);和
[0402]
一个具有氨基酸序列(seq id no:137)的式v
5-l
3-v
6-l
4-ch
1-l
6-f
c2
[iv]的第二多肽:
[0403][0404]
其中,l4、c
h1
、l6不存在,并且包含序列seq id no:151(具有seq id no:5、seq id no:56和seq id no:35的cdra1、cdra2、cdra3以粗体表示)的v5(成熟的tcr衍生α可变结构域)、序列seq id no:96的l3(下划线部分)、序列seq id no:160的v6(抗tcrαβvh)和序列seq id no:113的fc2(斜体和下划线部分),
[0405]
其中,fc1和fc2序列包含:半胱氨酸至丝氨酸的氨基酸取代(s以粗体字表示),因为没有轻链需要透过igg1铰链区的所述半胱氨酸氨基酸取代连接以类似igg2铰链从而消除fc-γ受体的相互作用(在第233至235位置以粗体字表示的pva和331s);n297q氨基酸取代(q以粗体字表示)以移除fc部分内的n-糖基化位点,从而消除fc-γ受体的相互作用;以及如果是fc2中的臼突变(y349c、t366s、l368a和y407v)和如果是fc1中的杵突变(s354c和t366w)。因此,在一优选实施方案中,fc1具有序列seq id no:112而fc2具有序列seq id no:113。
[0406]
在另一优选实施方案中,抗原结合蛋白(例如tcer
tm
)包含一个具有氨基酸序列(seq id no:131)的式v
3-l
1-v
4-l
2-c
l-l
5-f
c1
[iii]的第一多肽:
[0407][0408][0409]
其中,l2、c
l
、l5不存在,并且包含序列seq id no:151(具有seq id no:5、seq id no:56和seq id no:35的cdra1、cdra2、cdra3以粗体表示)的v3(成熟的tcr衍生α可变结构
域)、序列seq id no:96的l1(下划线部分)、序列seq id no:153的v4(抗tcrαβv
l
)和序列seq id no:112的fc1(斜体和下划线部分);和
[0410]
一个具有氨基酸序列(seq id no:130)的式v
5-l
3-v
6-l
4-c
h1-l
6-f
c2
[iv]的第二多肽:
[0411][0412]
其中,l4、c
h1
、l6不存在,并且包含序列seq id no:154的v5(抗tcrαβv
l
)、序列seq id no:96的l3(下划线部分)、序列seq id no:151(具有seq id no:62、seq id no:65、seq id no:71序列的cdra1、cdra2、cdra3以粗体表示)的v6(tcr衍生β可变结构域)和序列seq id no:113的fc2(斜体和下划线部分),
[0413]
其中,fc1和fc2序列包含:半胱氨酸至丝氨酸的氨基酸取代(s以粗体字表示),因为没有轻链需要透过igg1铰链区的所述半胱氨酸氨基酸取代连接以类似igg2铰链从而消除fc-γ受体的相互作用(在第233至235位置以粗体字表示的pva和331s);n297q氨基酸取代(q以粗体字表示)以移除fc部分内的n-糖基化位点,从而消除fc-γ受体的相互作用;以及如果是fc2中的臼突变(y349c、t366s、l368a和y407v)和如果是fc1中的杵突变(s354c和t366w)。因此,在一优选实施方案中,fc1具有序列seq id no:112而fc2具有序列seq id no:113。
[0414]
在另一优选实施方案中,抗原结合蛋白(例如tcer
tm
)包含一个具有氨基酸序列(seq id no:133)的式v
3-l
1-v
4-l
2-c
l-l
5-f
c1
[iii]的第一多肽:
[0415][0416][0417]
其中,l2、c
l
、l5不存在,并且包含序列seq id no:152(具有seq id no:55、seq id no:56和seq id no:35的cdra1、cdra2、cdra3以粗体表示)的v3(成熟的tcr衍生α可变结构域)、序列seq id no:96的l1(下划线部分)、序列seq id no:154的v4(抗tcrαβv
l
)和序列seq id no:112的fc1(斜体和下划线部分);和
[0418]
一个具有氨基酸序列(seq id no:130)的式v
5-l
3-v
6-l
4-c
h1-l
6-f
c2
[iv]的第二多肽:
[0419][0420]
其中,l4、c
h1
、l6不存在,并且包含序列seq id no:154的v5(抗tcrαβvl)、序列seq id no:96的l3(下划线部分)、序列seq id no:151(具有seq id no:62、seq id no:65、seq id no:71序列的cdrb1、cdrb2、cdrb3以粗体表示)的v6(tcr衍生β可变结构域)和序列seq id no:113的fc2(斜体和下划线部分),
[0421]
其中,fc1和fc2序列包含:半胱氨酸至丝氨酸的氨基酸取代(s以粗体字表示),因为没有轻链需要透过igg1铰链区的所述半胱氨酸氨基酸取代连接以类似igg2铰链从而消除fc-γ受体的相互作用(在第233至235位置以粗体字表示的pva和331s);n297q氨基酸取代(q以粗体字表示)以移除fc部分内的n-糖基化位点,从而消除fc-γ受体的相互作用;以及如果是fc2中的臼突变(y349c、t366s、l368a和y407v)和如果是fc1中的杵突变(s354c和t366w)。因此,在一优选实施方案中,fc1具有序列seq id no:112而fc2具有序列seq id no:113。
[0422]
在一实施方案中,本发明涉及一种抗原结合蛋白,其包含
[0423]
i)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:127的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:128的氨基酸序列或由组成,
[0424]
ii)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:127的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:130的氨基酸序列或由组成,
[0425]
iii)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:131的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:130的氨基酸序列或由组成,
[0426]
iv)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:133的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:130的氨基酸序列或由组成,
[0427]
v)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:135的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:136的氨基酸序列或由组成,
[0428]
vi)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:137的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:136的氨
基酸序列或由组成,
[0429]
vii)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:139的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:136的氨基酸序列或由组成,
[0430]
viii)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:131的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:142的氨基酸序列或由组成,
[0431]
ix)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:133的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:142的氨基酸序列或由组成,
[0432]
x)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:131的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:136的氨基酸序列或由组成,
[0433]
xi)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:133的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:136的氨基酸序列或由组成,
[0434]
xii)式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽,其包含seq id no:133的氨基酸序列或由其组成,以及式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽,其包含seq id no:166的氨基酸序列或由组成,
[0435]
优选为iii)至xi),更优选为iii)和iv)。
[0436]
在一更优选实施方案中,本发明涉及一种抗原结合蛋白,其包含由氨基酸序列seq id no:131组成的式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽以及由氨基酸序列seq id no:130组成的式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽;或本发明涉及一种抗原结合蛋白,其包含由氨基酸序列seq id no:133组成的式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽以及由氨基酸序列seq id no:130组成的式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽;或本发明涉及一种抗原结合蛋白,其包含由氨基酸序列seq id no:135组成的式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽以及由氨基酸序列seq id no:136组成的式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽;或本发明涉及一种抗原结合蛋白,其包含由氨基酸序列seq id no:137组成的式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽以及由氨基酸序列seq id no:136组成的式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽;或本发明涉及一种抗原结合蛋白,其包含由氨基酸序列seq id no:139组成的式v
3-l
1-v
4-l
2-c
l-l
5-fc1[iii]的第一多肽以及由氨基酸序列seq id no:136组成的式v
5-l
3-v
6-l
4-c
h1-l
6-fc2[iv]的第二多肽。
[0437]
针对效应子功能,还可能需要对本发明的抗原结合蛋白进行修饰,从而增强或降低抗原结合蛋白的抗原依赖性细胞介导细胞毒性(adcc)和/或补体依赖性细胞毒性(cdc)。这可透过在抗原结合蛋白的fc区中引入一个或多个氨基酸取代基来实现,本文中在本发明抗原结合蛋白的背景下也称为fc-变体。替代地或另外地,可在fc区中引入半胱氨酸残基,从而在该区形成链间二硫键。由此产生的异二聚体抗原结合蛋白可改善或降低内在化能力和/或增加补体介导细胞杀伤力和/或抗体依赖性细胞的细胞毒性(adcc)(caron pc.et al.1992;and shopes b.1992)。
[0438]
本发明抗原结合蛋白的另一类型氨基酸修饰可用于改变抗原结合蛋白的原始糖基化模式,即,透过删除抗原结合蛋白中存在的一个或多个碳水化合物部分,和/或添加抗原结合蛋白中不存在的一个或多个糖基化位点。三肽序列天冬醯胺-x-丝氨酸和天冬醯胺-x-苏氨酸中出现任何一个(其中x为脯氨酸以外的任何氨基酸)都会产生潜在的糖基化位点。添加或删除抗原结合蛋白的糖基化位点可透过改变氨基酸序列以使其包含一个或多个上述三肽序列(用于n-连接的糖基化位点)而方便地实现。
[0439]
另一类型的修饰涉及移除透过电脑或实验方法鉴定的序列,这可能导致抗原结合蛋白制备产生降解产物或异质性。例如,天冬醯胺和谷氨醯胺残基的脱醯胺可能取决于诸如ph和表面暴露等因素。天冬醯胺残基尤其容易发生脱醯胺(主要是存在于asn-gly序列中时),而在其他二肽序列(如asn-ala)中时则较少发生。当此类脱醯胺位点(特别是asn-gly)存在于本发明的抗原结合蛋白中时,可能希望移除该位点,通常是透过保守取代法移除其中一个涉及的残基。序列中此类取代以移除其中一个或多个涉及的残基也是本发明的意图。
[0440]
另一种类型的共价修饰涉及将糖苷在化学或酶学上偶联至抗原结合蛋白。这些程序的优点在于:它们无需在对n-或o-连接糖基化具有糖基化能力的宿主细胞中产生抗原结合蛋白。根据所使用的偶联方式,糖可附着至(a)精氨酸和组氨酸,(b)游离羧基,(c)游离巯基团,例如:半胱氨酸基团,(d)游离羟基团,例如:丝氨酸、苏氨酸或羟脯氨酸基团,(e)芳香残基,例如:苯丙氨酸、酪氨酸或色氨酸残基,或(f)谷氨醯胺的醯胺基团。例如,wo87/05330中描述了此类方法。
[0441]
移除抗原结合蛋白上存在的任何碳水化合物部分可在化学上或酶学上实现。化学去糖基化需要将抗原结合蛋白暴露于化合物三氟甲磺酸或等效化合物。此处理可导致连接糖(n-乙醯氨基葡糖或n-乙醯半乳糖胺)之外的大多数或所有糖裂解,同时让抗原结合蛋白保持完整。化学脱糖基化的描述见sojahr h.et al.(1987)和edge,as.et al.(1981)。抗体上碳水化合物部分的酶切可透过使用多种内切和外切糖苷酶来实现,参见thotakura,nr.et al.(1987)。
[0442]
抗原结合蛋白的另一种类型共价修饰包含将抗原结合蛋白与多种非蛋白质聚合物(例如:聚乙二醇、聚丙二醇或聚氧化烯)之一连接,方法为美国专利号4,640,835;4,496,689;4,301,144;4,670,417;4,791,192或4,179,337规定的方法。
[0443]
在一特别实施方案中,抗原结合蛋白为tcr。
[0444]
在一特别实施方案中,tcr为人tcr。因此,在一实施方案中,所述第一可变结构域包含于tcrα或γ链;和/或其中所述第二可变结构域包含于tcrβ或δ链。在一实施方案中,所述tcr为α-β异二聚体,并且包含α链trac恒定结构域序列和β链trbc1或trbc2恒定结构域序列。
[0445]
α链trac恒定结构域序列和β链trbc1或trbc2恒定结构域如下,也称为tcr恒定结构域序列。在一实施方案中,tcr恒定结构域序列可源自任何合适的物种,如任何哺乳动物,例如:人、大鼠、猴、兔、驴或小鼠,优选为人。在一些优选实施方案中,tcr恒定结构域序列可例如透过引入异源序列、优选为小鼠序列来稍加修饰,这可能增加tcr的表达和稳定性。此外,可以引入现有技术中已知的进一步稳定化突变(例如wo 2018/104407、pct/ep2018/069151、wo 2011/044186,、wo 2014/018863),例如,替换可变区中的不利氨基酸和/或在
tcr c结构域之间引入二硫键以及去除不配对的半胱氨酸。
[0446]
特别地,tcr恒定结构域序列可透过截短或取代修饰,以删除trac外显子2的cys4与trbc1或trbc2外显子2的cys2之间的天然二硫键。α和/或β链恒定结构域序列也可透过用半胱氨酸残基代替trac的thr 48和trbc1或trbc2的ser 57来修饰,所述半胱氨酸在tcr的α和β恒定结构域之间形成二硫键。trbc1或trbc2还可在恒定结构域的第75位置包含半胱氨酸至丙氨酸的突变,在恒定结构域的第89位置包含天冬醯胺至天冬氨酸的突变。相对于天然trac和/或trbc1/2序列,恒定结构域可另外或替代地包含其他突变、替代或删除。术语trac和trbc1/2包含天然多态变体,例如:trac第4位置的n至k(bragado et al in!immunol.1994feb;6(2):223-30)。
[0447]
在一实施方案中,tcr呈嵌合性。
[0448]
本文的“嵌合tcr”系指tcr,其中tcr链包含来自多个物种的序列。优选情况为,本发明背景下的tcr可包含α链,其包含α链的人可变区和例如鼠tcrα链的鼠恒定区。
[0449]
在一实施方案中,本发明的抗原结合蛋白为单链tcr(sctcr)或单链双特异性抗体。在本实施方案中,第一多肽和第二多肽共价连接在一起,其中共价连接的定义见上文“定义”章节。
[0450]
sctcr可包含第一tcr链(例如,α链)的可变区的多肽和整个(全长)第二tcr链(例如,β链)的多肽,反之亦然。此外,sctcr可以任选地包含一个或多个将两个或多个多肽连接在一起的连接子。例如,连接子可以是肽,其将两个单链连接在一起,如本文所述。还提供了本发明的sctcr,其与人细胞因子如il-2、il-7或il-15融合。
[0451]
在一实施方案中,所述单链tcr为选自由vα-lt-vβ、vβ-lt-vα、vα-ca-lt-vβ、vα-cb-lt-vβ、vα-lt-vβ-cb、vα-lt-vβ-ca、vα-ca-lt-vβ-cb、vα-cb-lt-vβ-ca、优选为vα-lt-vβ、vβ-lt-vα组成组的一种单链形式,其中vα为上文所定义的第一可变结构域,其中vβ为上文所定义的第二可变结构域,ca和cb分别为存在或不存在的tcrα和β恒定区,lt为存在或不存在且如上文“定义”章节中定义的连接子。
[0452]
在一实施方案中,此类单链tcr可进一步包含至少一个另外的可变结构域,优选为一个或两个另外的可变结构域(不论透过c还是n-端连接)。
[0453]
在一实施方案中,此类另外的可变结构域可透过另一连接子lk连接。在一优选实施方案中,连接子lk为上文所定义的连接子或氨基酸序列seq id no:114的c
h1-铰链序列。
[0454]
本发明还包括展示本发明抗原结合蛋白的颗粒,特别是tcr,以及包含于颗粒文库的所述颗粒。此类颗粒包括但不限于噬菌体、酵母、核糖体或哺乳动物细胞。产生此类颗粒和文库的方法为本领域已知的(例如,参见wo2004/044004;wo01/48145,chervin et al.(2008)j.immuno.methods 339.2:175-184)。
[0455]
此外,本发明的发明人在实施例(特别是实施例3)中证明:本发明的抗原结合蛋白与靶抗原(即,与mhc蛋白复合,优选与hla-a*02复合的mage-a抗原肽)高特异性结合,即,抗原结合蛋白与鉴定的表位特异性结合。
[0456]
因此,本发明的抗原结合蛋白与mage-a抗原肽特异性结合,所述mage-a抗原肽包含seq id no:1的氨基酸序列“kvlehvvrv”或由其组成,其中所述抗原肽优选与mhc蛋白复合,优选与hla-a*02复合。更特别地,在一实施方案中,抗原结合蛋白与表位特异性结合,所述表位包含seq id no:1的mage-a抗原肽的至少三个或至少四个氨基酸位置或由其组成,
优选为至少3个、至少4个氨基酸位置,优选为选自由seq id no:1的氨基酸序列的氨基酸第1、5、7和8位置或1、3、5、7和8位置、尤其是第1、5和7位置组成的组的至少3个(例如,3或4个)、优选为3个氨基酸。根据所使用的方法和所选的临界值,确切表位的确定方法可能会略有不同。本发明的抗原结合蛋白具有主要与氨基酸第1、5和7位置结合这一性质,因此,不显著与相似肽nomap-1-0320、nomap-1-1223和odc-001结合。
[0457]
在一实施方案中,本发明的抗原结合蛋白不会显著地与mage-a抗原肽变体结合,所述mage-a抗原肽变体包含seq id no:1的氨基酸序列或由其组成,其中第1、5和7位置中的至少一个、第1、5、7和8位置中的至少一个或第1、3、5、7和8位置中的至少一个被取代,优选被取代为丙氨酸。
[0458]
在本发明的抗原肽变体和抗原结合蛋白背景下(特别是tcr或其片段或双特异性tcr及其片段,例如t细胞表达的抗原结合蛋白),“不显著与......结合”通常表示在功能性分析(例如,在tcr激活分析中,诸如上述ifn-γ释放)中,优选在相同实验条件下,反应(例如,针对上文所述抗原肽变体检测到的信号)为反应(即,针对由seq id no:1的氨基酸序列“kvlehvvrv”组成的mage-a肽获得的信号)的30%以下、25%以下、20%以下、15%以下,优选为30%以下。在本发明的抗原肽变体和抗原结合蛋白背景下,特别是本发明的可溶性抗原结合蛋白背景下,“不显著与......结合”通常表示,优选在相同实验条件下,结合测定法(例如生物膜层干涉术)中针对抗原肽变体测定的kd与针对由seq id no:1的氨基酸序列“kvlehvvrv”组成的mage-a肽测定的kd相比,可增加3倍以上、3.5倍以上、4倍以上、4.5倍以上、5倍以上,优选为3倍以上,例如3至10倍,其中针对抗原肽变体获得的信号优选为背景信号,其中抗原肽变体或mage-a肽与mhc分子复合。
[0459]
根据上述内容,在一实施方案中,本发明的抗原结合蛋白(特别是可溶性抗原结合蛋白)与上文所述以mhc蛋白复合体的形式(优选为hla-a*02复合体的形式)的mage-a抗原肽变体结合的亲和力比对特定抗原(即,本发明背景下所述的mage-a抗原肽,其与mhc蛋白复合,优选为与hla-a*02复合)的亲和力降低,并且其中对mage-a抗原肽变体复合体的相应kd增加3倍以上、3.5倍以上、4倍以上、4.5倍以上、5倍以上,优选为3倍以上,例如3至10倍。术语“亲和力”和“k
d”的定义见上文“定义”章节。
[0460]
mhc蛋白(特别是mhc i类和hla-a*02蛋白)的定义见上文“定义”章节。
[0461]
在一实施方案中,本发明抗原结合蛋白的特征在于具有亲和力成熟的抗原结合蛋白,其能够特异性地和任意选择性地与mage-a抗原肽/mhc复合体结合。
[0462]
本发明的抗原结合蛋白与上文指定的mage-a抗原肽复合体特异性结合,更特别地与上文定义的seq id no:1表位结合,并且可区分其各自的靶标即mage-抗原肽以及其不与之显著结合的其他类似肽。
[0463]
术语“特异性”或“特异性结合”表示抗原结合蛋白将其与之结合的靶标肽序列(“表位”)和相似表位、肽或蛋白区分开来的能力,即,抗原结合蛋白与第一抗原“特异性结合”时,其对第二抗原就不发生显著的交叉反应。
[0464]
在本发明背景下的“类似肽”也可以称为“脱靶物”,涉及长度通常包含8至16个氨基酸的肽。本发明背景下的类似肽通常由mhc提呈。此外,本发明背景下的类似肽包含与mage-a抗原肽的氨基酸序列相似的氨基酸序列或由其组成,更特别地,与mage-a抗原肽表位相比,这些肽包含表位,其中与构成相应mage-a肽表位的氨基酸相比,一些或所有氨基酸
的氨基酸的生化/生物物理特性相同和/或相似。由于这种序列相似性,类似肽可能会被抗原结合蛋白结合,在这种情况下,例如,如果类似肽由mhc蛋白提呈并因此被抗原结合蛋白(如tcr)结合,则给定的抗原结合蛋白(例如tcr)与类似肽结合的能力不会导致所需的t细胞反应,但可能导致不良反应。此类不良反应可能为“肿瘤外”副作用,例如在lowdell等人2018年12月4日发表的《细胞疗法》(cytotherapy)第7页报告的与健康组织肽交叉反应的特定tcr的交叉反应。本发明背景下的类似肽选自例如正常组织提呈的hla-a*02结合肽的数据库(xpresident数据库),依据是,基于例如对mag-003的高度序列相似性(相似性blast搜索)。由于这些不良反应,本发明的抗原结合蛋白因此被改造以避免与类似肽(特别是下面列出的类似肽)结合。
[0465]
因此,本发明背景下的相似肽选自由以下肽组成的列表:由seq id no:23的氨基酸序列组成的肽rabgap1l-001、由seq id no:24的氨基酸序列组成axin1-001、由seq id no:25的氨基酸序列组成的ano5-001、由seq id no:26的氨基酸序列组成的tpx2-001、由seq id no:27的氨基酸序列组成的syne3-001、由seq id no:28的氨基酸序列组成的mia3-001、由seq id no:29的氨基酸序列组成的herc4-001、由seq id no:30的氨基酸序列组成的psme2-001、由seq id no:31的氨基酸序列组成的heatr5a-001、由seq id no:32的氨基酸序列组成的cnot1-003、由seq id no:33的氨基酸序列组成的tep1-003、由seq id no:34的氨基酸序列组成的pitpnm3-001、由seq id no:129的氨基酸序列组成的zfc-001、由seq id no:171的氨基酸序列组成的ints4-002、由seq id no:172的氨基酸序列组成的samh-001、由seq id no:173的氨基酸序列组成的ppp1ca-006、由seq id no:174的氨基酸序列组成的rpl-007、由seq id no:175的氨基酸序列组成的setd1a-001、由seq id no:176的氨基酸序列组成的nomap-1-0320、由seq id no:177的氨基酸序列组成的nomap-1-1223、由seq id no:178的氨基酸序列组成的odc-001、由seq id no:179的氨基酸序列组成的col6a3-010、由seq id no:180的氨基酸序列组成的fam115a-001、由seq id no:181的氨基酸序列组成的phtf2-001、以及由seq id no:181的氨基酸序列组成的rpp1-001。
[0466]
在一实施方案中,本发明的抗原结合蛋白,特别是tcr或其片段或双特异性tcr及其片段,例如t细胞表达的抗原结合蛋白,不结合或不显著结合于至少1个,例如至少2个、至少3个、至少4个、至少5个,例如1、2、3、4、5个,优选为至少3个,或3个或所有选自由rabgap1l-001、axin1-001、ano5-001、tpx2-001、syne3-001、mia3-001、herc4-001、psme2-001、heatr5a-001、cnot1-003、tep1-003、pitpnm3-001,优选为heatr5a-001、herc4-001和cnot1-003组成的列表中的类似肽,条件是:当所述类似肽与mhc蛋白形成复合体,优选与hla-a*02复合时。这在本发明背景下是重要的优点,因为与类似肽(即,脱靶)结合可能会增加副作用的风险,因此,本发明的抗原结合蛋白不与本文所列类似肽发生交叉反应这一事实使其成为一种有前景的抗癌治疗药物。
[0467]
在类似肽的背景下和本发明抗原结合蛋白(特别是tcr或其片段或双特异性tcr及其片段,例如,t细胞表达的抗原结合蛋白)的背景下,“不显著与......结合”也可称为“不交叉反应”,在本文中系指例如在功能测定中,与mage-a相比,抗原结合蛋白对类似肽/mhc测得的功能反应,其中,抗原结合蛋白对类似肽/mhc的反应是相同抗原结合蛋白在相同实验环境下对mage-a抗原肽/mhc复合体的反应的30%以下、20%以下、10%以下、5%以下,例如:8%、6%、5%,优选为5%。在一实施例中,所述反应为表达所述抗原结合蛋白的t细胞的
功能性反应,且在类似肽背景下使用上文以及实施例3和图5所述的ifn-γ释放测定法测定。
[0468]
此外,在一实施方案中,本发明的抗原结合蛋白,特别是本发明的可溶性抗原结合蛋白不结合或不显著结合于至少1个类似肽,例如至少2个、至少3个、至少4个、至少5个,例如1、2、3、4、5个,优选为至少3个,或3个或所有选自由rabgap1l-001、axin1-001、ano5-001、tpx2-001、syne3-001、mia3-001、herc4-001、psme2-001、heatr5a-001、cnot1-003、tep1-003、pitpnm3-001、ints4-002、samh-001、ppp1ca-006、rpl-007、setd1a-001、nomap-1-0320、nomap-1-1223、odc-001、col6a3-010、fam115a-001、phtf2-001和rpp1-001,优选为cnot1-003、syne3-001、tpx2-001、psme2-001,更优选为syne3-001、tpx2-001、psme2-001组成的肽组中的类似肽,条件是:当所述类似肽与mhc蛋白形成复合体,优选与hla-a*02复合时。
[0469]
在一实施例中,当ints4-002、samh-001、ppp1ca-006、rpl-007、setd1a-001、nomap-1-0320、nomap-1-1223和odc-001(例如ints4-002、samh-001、ppp1ca-006、rpl-007、setd1a-001或nomap-1-0320、nomap-1-1223、odc-001)、col6a3-010、fam115a-001、phtf2-001和rpp1-001(例如ppp1ca-006、rpl-007和setd1a-001)与mhc蛋白形成复合体时(优选为与hla-a*02复合时),本发明的抗原结合蛋白(特别是本发明的可溶性抗原结合蛋白)不与所述相似肽结合或不显著结合。
[0470]
在类似肽的背景下以及在抗原结合蛋白(例如,本发明的可溶性抗原结合蛋白)的背景下,本文中“不显著与......结合”的特征在于亲和力降低、解离速率较快和/或结合信号较低,特别是解离速率较快和/或结合信号较低。例如,在本发明的背景下,抗原结合蛋白对至少一个类似肽/mhc复合体的结合反应小于50%、小于45%、小于40%、小于30%、小于20%、小于10%、小于5%、小于4%或小于3%相同抗原结合蛋白对mage-a抗原肽/mhc复合体的结合反应,条件为:实验环境相同、抗原结合蛋白浓度相同,和/或,例如,在本发明的背景下,抗原结合蛋白与至少一种类似肽/mhc复合体结合,其亲和力与其对特定抗原(即,本文所述的mage-a抗原肽/mhc复合体)的亲和力相比下降,其中,对各类似肽的相应kd增加5、7、10、15、20、30、40、50、100、200、300、400、500、600、700、800、900、1000倍,优选为5、7、10、15、20、30、40、50、100倍,优选为20至100倍,更优选为30至100倍,例如40至100倍,通常为40到50倍。例如,当抗原结合蛋白以1nm的kd与mag-003/mhc复合体结合,而抗原结合蛋白以100nm的kd与例如rabgap1l-001/mhc复合体结合时,则抗原结合蛋白与rabgap1l-001/mhc结合的kd增加100倍,因而亲和力降低100倍。在这些实施例中,结合反应、解离常数和结合亲和力优选使用例如实施例4和5中所述的生物膜层干涉技术来测量。在一些进一步的实施例中,抗原结合蛋白以与对特定抗原(即本文所述的mage-a抗原肽/mhc复合体)亲和力相比较低的亲和力与至少一种相似肽/mhc复合体结合,其中,与特定抗原(即mage-a抗原肽/mhc复合体)的亲和力相比,对cnot1-003、ints4-002和samh-001的各自kd增加了1000倍以上,对col6a3-010、phtf2-001、rpp1-001和fam115a-001的kd增加了500倍以上,此时,kd值通常例如采用生物层干涉法测量,如实施例5中所述。
[0471]
在另一实施例中,抗原结合蛋白,例如14-iso1-bma(36)或114-iso2-ucht1(17),对mhc复合体中的odc-001、nomap-1-0320和nomap-1-1223有结合反应,透过实施例5中所述的生物层干涉法测量时,反应小于5%、小于4%、小于3%、小于2%(例如小于1.5%)。
[0472]
在一实施方案中,本发明的抗原结合蛋白(特别是本发明的可溶性抗原结合蛋白)与包含seq id no:1的氨基酸序列或由其组成的mage-a抗原肽和hla分子(优选为hla-a*02)特异性结合,其kd≤100μm、≤50μm、≤30μm、≤25μm、≤1μm、≤500nm、≤100nm、≤50nm、≤10nm,优选为50pm至100μm、50pm至10μm、50pm至1μm,更优选为50pm至500nm、50pm至100nm、50pm至50nm和50pm至10nm。因此,本发明的抗原结合蛋白(例如本发明的可溶性抗原结合蛋白)对包含氨基酸序列seq id no:1或由其组成且与hla分子(优选为hla-a*02)复合的mage-a抗原肽的亲和力(kd)为≤200nm、≤150nm、≤120nm、110nm,优选为≤100nm,特别是50pm至100nm、100pm至100nm、1nm至10nm。“k
d”和“亲和力”的定义见上文“定义”章节。
[0473]
测量亲和力(如kd)的方法为本领域技术人员已知的,包括:例如表面等离子体共振和生物膜层干涉法。如本领域技术人员所知,用于那些实验的实验条件(例如,所使用的缓冲液、蛋白质浓度)可能对结果产生影响。
[0474]
在一相关实施方案中,本发明的抗原结合蛋白(特别是tcr或其片段或双特异性tcr或其片段,例如:t细胞表达的抗原结合蛋白)对包含氨基酸序列seq id no:1或由其组成的mage-a抗原肽与hla分子的复合体的亲和力(kd)为≤100μm、≤50μm、≤30μm、≤25μm、≤1μm,优选为≤25μm,例如,500nm至100μm、500nm至50μm、500nm至25μm。
[0475]
在一特定实施方案中,本发明的抗原结合蛋白是可溶的。可溶性抗原结合蛋白可包括但不限于,例如,抗体或其片段,或双特异性抗体或其片段,tcr片段或双特异性tcr或sctcr。在一相关实施方案中,抗原结合蛋白(优选为可溶性)与包含氨基酸序列seq id no:1或由其组成的mage-a抗原肽与hla分子(优选为hla-a*02)的复合体结合,kd为≤100nm、≤50nm、≤10nm、≤1nm,例如,10pm至100nm、10pm至50nm、10pm至10nm,特别是50pm至100nm、100pm至50nm、100pm至10nm。
[0476]
因此,在一实施例中,本发明的抗原结合蛋白表达为例如上文所述的可溶性tcer
tm
,并分析其对hla-a*02/mag-003单体的结合亲和力。通常,例如使用制造商推荐的设置在octet red384系统上进行测量。简言之,通常在30℃和例如1000rpm转速下以例如pbs、0.05%吐温-20、0.1%bsa用作缓冲液来测量结合动力学。抗原结合蛋白被载入至生物感测器(例如fab2g或ahc)上或在溶液中分析。
[0477]
在一实施方案中,任选地与参考蛋白相比,本发明抗原结合蛋白的亲和力增加。
[0478]
本文的“参考蛋白”系指与本发明抗原结合蛋白进行比较的蛋白。在一实施方案中,参考蛋白直接作用于与本发明蛋白相同的靶标,即与mhc蛋白复合的mage-a抗原肽,更优选地,所述参考蛋白与对其进行比较的抗原结合蛋白具有相同的形式。在一特定实施方案中,参考蛋白与对其比较的抗原结合蛋白具有相同的形式,并且参考蛋白包含亲本tcr r7p1d5的cdr或α和β可变结构域。
[0479]
如本文所公开的,本发明的抗原结合蛋白识别和/或结合于包含seq id no:1的氨基酸序列“kvlehvvrv”或由其组成的mage-a抗原肽与hla分子(优选为hla-a*02)的复合体。因此,mag-003和hla分子存在于i类主要组织相容性复合体(mhc)中,并且抗原结合蛋白与所述复合体的结合可在结合后引发免疫反应。在一些实施方案中,与参考蛋白诱导的免疫反应相比,本发明抗原结合蛋白诱导的免疫反应增加。
[0480]
因此,在一实施方案中,本发明的抗原结合蛋白诱导免疫反应,优选为其中免疫反应的特征在于干扰素(ifn)γ水平增加。因此,在一实施例中,免疫反应的特征可透过优选
使用ifn-γ释放测定法测定的ec
50
值来描述。
[0481]
在一实施方案中,抗原结合蛋白的ec
50
[nm]值(优选由ifn-γ释放法测定)低于参考蛋白的ec
50
,优选为抗原结合蛋白的ec
50
[nm]值比参考蛋白的ec
50
[nm]值低2倍,优选为低2、3、4、5、6、7、8倍(例如,低2至9倍),并且其中ec
50
值为mhc(优选为hla-a*02)表达细胞上测定的最大ifn-γ释放量一半的浓度[nm],所述mhc表达细胞优选为载有seq id no:1的抗原肽。在一实施例中,所指的ec
50
通常透过elisa法测定,例如,在电穿孔的cd8 t细胞与载有连续稀释的mage-a抗原肽(优选为seq id no:1的mage-a抗原肽)的t2细胞共培养后测定。优选为参考蛋白和与之比较的抗原结合蛋白具有相同的形式,且参考蛋白包含亲本tcr r7p1d5的cdr或α和β可变结构域,其中ec50优选在相同的实验环境中测定。
[0482]
在一实施方案中,抗原结合蛋白对mage-a/mhc复合体提呈细胞具有反应性,且对mage-a/mhc复合体提呈细胞的ec
50
值(优选透过ifn-γ释放测定法或ldh释放测定法测定)小于100nm、小于50nm、小于10nm、小于900pm、小于500pm、小于300pm、小于200pm、小于150pm、小于100pm、小于50pm、小于20pm、小于10pm,例如0.1nm至20nm,例如0.5nm至15nm、0.8nm至12nm、0.8nm至10nm、0.8nm至10nm、0.8nm至10nm或例如1pm至150pm、1至100pm、1至50pm、1至20pm、1至20pm。
[0483]
在一实施方案中,抗原结合蛋白为tcr并且对mage-a/mhc复合体提呈细胞的ec
50
值(优选透过ifn-γ释放测定法测定)小于1 2nm、小于10nm、小于9nm、小于8nm、小于6nm、小于4nm,例如0.1nm至20nm,例如0.5nm至15nm、0.8nm至12nm、0.8nm至10nm、0.8nm至10nm、0.8nm至10nm。
[0484]
在此实施方案中,ec
50
使用表达本发明不同抗原结合蛋白的cd8 t细胞(20,000个细胞/孔)测定,并透过t2细胞(20,000个细胞/孔)共同培养后释放的ifn-γ水平进行测定,所述t2细胞载入有稀释系列的mag-003(seq id no:1)。
[0485]
在一实施方案中,抗原结合蛋白为一种可溶性分子,例如,tcer
tm
,并对mage-a/mhc复合体提呈细胞的ec
50
值小于200pm、小于150pm、小于100pm、小于50pm、小于20pm、小于10pm、1pm至150pm、1pm至100pm、1pm至50pm、1pm至20pm。在此实施方案中,ec
50
使用表达本发明不同抗原结合蛋白的cd8 t细胞(100,000个细胞/孔)并用在内源性水平下提呈mag-003的肿瘤细胞系共培养后确定释放ldh水平来测定,优选为细胞系为在表面上提呈约1071个与mhc蛋白复合的mag-003肽的hs695t,优选为细胞系为在表面上提呈约3918个与mhc蛋白复合的mag-003肽的nci-h1755,或优选为细胞系为在表面上提呈约125个与mhc蛋白复合的mag-003肽的u2os。
[0486]
本发明的抗原结合蛋白具有高安全性特征。
[0487]
本文中“安全性特征”系指区分肿瘤细胞与健康组织细胞的能力,这通常透过测定安全窗来确定。
[0488]
本文中的“安全窗”或“治疗窗”系指诱导肿瘤细胞系中100%细胞毒性所需化合物的一半最大浓度与诱导健康组织细胞中100%细胞毒性所需化合物的一半最大浓度相比的倍数。如果对于相关抗原结合蛋白,针对肿瘤细胞系测定的ec
50
为1pm而针对例如原代细胞测定的ec
50
值为1000pm,则安全窗为1000,这是因为针对肿瘤细胞系的ec
50
比针对原代细胞的ec
50
小1000倍。
[0489]
在一实施方案中,本发明的抗原结合蛋白对mage-a/mhc复合体提呈细胞的ec
50
比
针对健康组织细胞的ec
50
高≥100、≥500、≥1000、≥2000、≥3000、≥4000、≥5000、≥6000、≥8000、≥10000倍,例如,针对mage-a/mhc复合体提呈细胞的ec
50
比针对健康组织细胞的ec
50
值高500至12000倍,优选为高1000至10000倍。
[0490]
本文中的“mage-a/mhc复合体提呈细胞”系指在其表面提呈mage-a肽/mhc复合体的细胞,其中所述mage-a/mhc复合体的拷贝数通常可透过本领域技术人员熟知的方法测定。在一实施方案中,mage-a/mhc复合体为靶细胞,例如:癌细胞,其中所述癌症的定义见下文“治疗方法和用途”章节。在本发明的背景下,与正常(健康)组织细胞表面上的所述复合体水平相比,mage-a肽/mhc复合体在mage-a/mhc复合体提呈细胞(特别是癌细胞)的细胞表面上过度提呈。“过度提呈”意指mage-a/mhc复合体提呈水平至少为健康组织提呈水平的1.2倍;优选为至少为健康组织或细胞提呈水平的2倍,更优选为5倍至10倍。
[0491]
在一实施方案中,mage-a/mhc复合体提呈细胞的mage-a/mhc复合体拷贝数大于50、大于80、大于100、大于120、大于150、大于300、大于400、大于600、大于800、大于1000、大于1500、大于2000,优选为mage-a/mhc拷贝数为50至2000,例如,80至2000,例如,100至2000,例如,120至2000。
[0492]
本文中的“拷贝数”系指细胞(如mage-a/mhc提呈细胞,例如:癌细胞或健康细胞)的细胞表面上提呈的本发明背景下定义的mage-a/mhc复合体数。蛋白质的拷贝数可透过多种本领域已知的方法来测定,包括用萤光标记的抗原结合蛋白对患病细胞进行facs分析。
[0493]
本文中的“健康细胞”系指无癌细胞的细胞,优选为本文中的健康细胞系指在mage-a/mhc提呈细胞周围的组织细胞、在mage-a/mhc复合体提呈癌细胞周围的组织细胞。但是,在某些情况下,健康细胞也可能在其表面表达和提呈mage-a/mhc复合体。通常情况下,如本领域技术人员了解的,在本发明背景下的健康细胞中mage-a/mhc复合体提呈数量(拷贝数)比在癌细胞中少。
[0494]
健康细胞优选为选自由星形细胞、gaba神经元、心肌细胞、心脏微血管内皮细胞、软骨细胞、冠状动脉内皮细胞、皮肤微血管内皮细胞、间充质干细胞、鼻上皮细胞、外周血单核细胞、肺动脉平滑肌细胞(优选为gaba神经元、心肌细胞、心脏微血管内皮细胞、软骨细胞、冠状动脉内皮细胞、鼻上皮细胞、外周血单核细胞、肺动脉平滑肌细胞)组成的组。
[0495]
在一实施方案中,抗原结合蛋白对mage-a/mhc复合体提呈细胞的ec
50
比对健康细胞的ec
50
值高≥1000、≥15000、≥9000倍,优选为健康细胞选自由星形胶质细胞、gaba神经元、心肌细胞、心脏微血管内皮细胞、软骨细胞、冠状动脉内皮细胞、皮肤微血管内皮细胞、间充质干细胞、鼻上皮细胞、外周血单核细胞、肺成纤维细胞、气管平滑肌细胞、表皮角质形成细胞、肾皮质上皮细胞和肺动脉平滑肌细胞,优选为星形胶质细胞、gaba神经元、心肌细胞、心脏微血管内皮细胞、软骨细胞、冠状动脉内皮细胞、皮肤微血管内皮细胞、间充质干细胞、鼻上皮细胞、外周血单核细胞和肺动脉平滑肌细胞,更优选为gaba神经元、心肌细胞、心脏微血管内皮细胞、软骨细胞、冠状动脉内皮细胞、鼻上皮细胞、外周血单核细胞、肺动脉平滑肌细胞组成的组。
[0496]
在一优选实施方案中,抗原结合蛋白对mage-a/mhc复合体提呈细胞的ec
50
比针对健康细胞的ec
50
值高≥9000或≥10000倍,其中优选情况为,所述健康细胞选自由ipsc衍生星形胶质细胞、gaba神经元、心肌细胞、成骨细胞、肺成纤维细胞、气管平滑肌细胞、表皮角质形成细胞和肾皮质上皮细胞组成的组。
[0497]
因此,在一实施方案中,健康细胞的mage-a/mhc复合体拷贝数小于50、小于20、小于10,优选为mage-a/mhc复合体拷贝数小于10,优选为mage-a/mhc复合体拷贝数介于0至10之间。
[0498]
在一实施方案中,本发明的抗原结合蛋白对mage-a/mhc复合体提呈细胞的ec
50
比针对类似肽/mhc提呈细胞的ec
50
高≥100、≥500、≥1000、≥2000、≥3000、≥4000、≥5000、≥6000倍,例如,针对mage-a/mhc复合体提呈细胞的ec
50
比针对类似肽/mhc提呈细胞的ec
50
值高500至12000倍,优选为高1000至12000倍。
[0499]“类似肽”的定义见上文。
[0500]
因此,类似肽/mhc提呈细胞是在其细胞表面上提呈类似肽/mhc复合体的细胞。
[0501]
在一实施方案中,类似肽/mhc提呈细胞的类似肽/mhc拷贝数大于10、大于20、大于40、大于50、大于80、大于100、大于120、大于150、大于300、大于400、大于500、大于800,优选为类似肽/mhc拷贝数为50至1000,例如,50至8000,例如,50至500,例如,100至500。
[0502]
本发明提出了抗原结合蛋白,其能够在体内诱导肿瘤消退,更特别地在受测条件下完全消退。抗原结合蛋白的制备和评价采用不同剂量,针对植入移植有人pbmc的雌性nog小鼠中的可测量hs695t肿瘤异种移植物(参见实施例7)。tcer
tm
靶向mag-003(seq id no:127和130,第3组;seq id no:135和136,第4组)从第18天至研究结束(第25天)在所有小鼠中诱导了hs695t肿瘤完全缓解,相比之下,随机分配当天的基础水平为86mm3(第3组)和80mm3(第4组)。
[0503]
因此,在一实施方案中,本发明的抗原结合蛋白抑制或减少了肿瘤生长,更特别地,本发明的抗原结合蛋白减少肿瘤的平均肿瘤体积大于80%、大于85%、大于90%、大于92%、大于94%、大于96%、大于98%、大于99%,例如,95%至100%、96%至100%、98%至100%,例如,98%、99%或100%,优选为100%,其中所述肿瘤为下文“治疗方法和用途”章节中定义的癌症。在一实施例中,抗原结合蛋白诱导了癌症肿瘤的完全缓解,其中癌症如下文所定义,例如,人肿瘤细胞系hs695t。
[0504]
在一实施方案中,本发明抗原结合蛋白的半衰期(t
1/2
)为6至7天,例如6或7天。
[0505]
从实施例,特别是实施例1和图1中可进一步看出,天然tcr(例如天然tcr r7p1d5)既不能在酵母中也不能在cho细胞中以可溶性形式表达。与此相反,本发明的抗原结合蛋白(特别是tcer
tm
分子,优选为本文所述的优选tcer
tm
分子)不仅可溶,而且还可在cho细胞中以》10mg/l(细胞培养物)、》20mg/l甚或40mg/l的量进行暂态表达。因此,在一实施方案中,本发明的抗原结合蛋白可在宿主细胞中以高产量表达,其中优选宿主细胞为cho细胞,并且其中优选产量大于10、大于15、18、20、22、24、26、28、30、35、40、45mg/l(细胞培养物),例如,5至50、5至45、5至40、5至35、10至35、10至30、10至25、10至20mg/l(细胞培养物)。在一实施例中,抗原结合蛋白在暂态转染的cho-s细胞中表达,其中,细胞在总体积为320ml的ge healthcaretm培养基中培养,培养条件为t=0、密度4x106/ml、37℃。一天后,添加进料溶液(cellboost 7a和b),温度降低至32℃。在培养总共12天和进料3次后收获了细胞并因此收获了抗原结合蛋白。
[0506]
从实施例中可进一步看出,发明人例如在实施例4和5中证明,与参考蛋白(例如与包含天然tcr r7p1d5的cdr、优选为包含所述天然tcr r7p1d5框架区的抗原结合蛋白)相比,本发明的抗原结合蛋白改善了稳定性。
[0507]
因此,在一实施方案中,与参考蛋白相比,本发明的抗原结合蛋白改善了稳定性。在本发明的背景下,稳定性改善系指,例如,当暴露于热应力时物理稳定性增加。因此,本发明的新开发抗原结合蛋白可比参考抗原结合蛋白更好地耐受应力条件,特别是热应力。
[0508]
本发明背景下的术语“稳定性”系指物理稳定性,并且可以使用本领域中描述的各种分析技术进行定性和/或定量评估,综述参见,例如,peptide and protein drug delivery,247-301,vincent lee ed.,marcel dekker,inc.,new york,n.y.,pubs.(1991)and jones,a.adv.drug delivery rev.10:29-90(1993)。在本发明的背景下,这些方法特别涉及评估聚集物形成(例如:使用尺寸排阻色谱法、透过测量浊度和/或透过目视检查)。为了测量稳定性,可在稳定性研究中测试包含本发明抗原结合蛋白的样本,其中样本在选定时间段内被暴露于应力条件,然后使用适当的分析技术对化学和物理稳定性进行定量和任选进行定性分析。
[0509]
在一实施方案中,例如,当暴露于应力条件下一定时间,例如:暴露于40℃的温度下14天后,本发明的抗原结合蛋白具有物理稳定性。
[0510]
在本发明的背景下,“物理稳定性”基本上系指抗原结合蛋白无聚集、沉淀和/或变性迹象。
[0511]
评估物理稳定性的方法的实例如:尺寸排阻色谱法(sec)、动态光散射法(dls)、光遮蔽法(lo)以及颜色和净度(例如,透过目视检查法确定)。
[0512]“无聚集迹象”意指,例如,包含抗原结合蛋白的样本在缓冲液(如pbs)中暴露于应力条件(例如40℃的温度)14天后,单体含量大于80%、大于86%、大于88%、大于90%、大于92%、大于94%、大于96%、大于97%、大于98%、大于99%,例如,当透过sec(例如sec-hplc)在缓冲液(例如pbs)中测量时,单体含量为94%至99%、95%至99%、96%至99%、97%至99%。
[0513]
因此,在一实施方案中,与参考蛋白相比,本发明的抗原结合蛋白例如在暴露于应力条件下时聚集性降低。
[0514]
使用尺寸排阻色谱法(sec)时,根据所用的色谱柱、操作压力和缓冲液流速,在受测条件下,1%、2%、3%、4%,优选为1%或2%(例如2%)的单体含量差异在本发明背景下被视为具有显著差异。
[0515]
这意味着,当参考抗原结合蛋白的单体含量为96%而本发明抗原结合蛋白的单体含量为97%时,本发明抗原结合蛋白的单体含量具有显著差异,因此,在相同条件下测量时,与参考抗原结合蛋白相比显著增加。
[0516]
在一实施方案中,本发明的抗原结合蛋白在暴露于应力条件后聚集性降低,更特别地,当在暴露于所述应力条件之前和之后测量应力诱导的聚集体时,本发明的抗原结合蛋白的聚集小于10%、小于4%、小于3%、小于2%。
[0517]
核酸、载体和重组宿主细胞
[0518]
本发明的另一个目的涉及一种分离的核酸序列,其包含编码上文定义的本发明抗原结合蛋白的序列或由其组成。
[0519]
通常情况下,所述核酸为dna或rna分子,其可以包含于任何合适的载体(例如:质粒、粘粒、附加体、人工染色体、噬菌体或病毒载体)中。
[0520]
术语“载体”、“克隆载体”和“表达载体”意指可将dna或rna序列(例如,外源基因)
引入宿主细胞以转化宿主并促进所引入序列表达(例如,转录和翻译)的载体。
[0521]
因此,本发明的另一个目的涉及包含本发明核酸的一种载体。
[0522]
此类载体可包含调节元件,诸如启动子、增强子、终止子等,以在受试者给药后引起或对准所述多肽的表达。用于动物细胞表达载体的启动子和增强子实例包括sv40的早期启动子和增强子(mizukami t.et al.1987)、moloney小鼠白血病病毒的ltr启动子和增强子(kuwana y et al.1987)、免疫球蛋白h链的启动子(mason jo et al.1985)和增强子(gillies sd et al.1983)等。
[0523]
只要可以插入和表达编码人抗体c区的基因,即可使用任何动物细胞的表达载体。合适的载体实例包括(miyaji h et al.1990)、page103(mizukami t et al.1987)、phsg274(brady g et al.1984)、pkcr(o'hare k et al.1981)、psg1|βd2-4-(miyaji h et al.1990)等。质粒的其他实例包括:包含复制起点的复制质粒或整合质粒,例如puc、pcdna、pbr等。
[0524]
病毒载体的其他实例包括腺病毒、逆转录病毒、疱疹病毒和aav载体。此类重组病毒可透过本领域已知的技术生产,例如:透过转染包装细胞或透过以辅助质粒或病毒暂态转染。病毒包装细胞的典型实例包括pa317细胞、psicrip细胞、gpenv 细胞、293细胞等。产生此类复制缺陷的重组病毒的详细方案可参见,例如:wo95/14785、wo96/22378、us5,882,877、us6,013,516、us4,861,719、us5,278,056和wo94/19478。
[0525]
术语“病毒载体”系指核酸载体构建体,其包括至少一种病毒来源的元件,有被包装入病毒载体颗粒的能力,并编码至少一种外源核酸。载体和/或颗粒可用于在体外或体内将任何核酸转移至细胞之目的。多种形式的病毒载体为本领域已知。
[0526]
术语“病毒体”、指单个感染性病毒颗粒。“病毒载体”、“病毒载体颗粒”和“病毒颗粒”也指具有其dna或rna核心和蛋白质外壳的完整病毒颗粒,因为该病毒存在于细胞外部。例如,病毒载体可选自腺病毒、痘病毒、α病毒、晕病毒、黄病毒、弹状病毒、逆转录病毒、慢病毒、疱疹病毒、副粘病毒或微小核糖核酸病毒。
[0527]
病毒可指天然存在的病毒以及人造病毒。根据本发明一些实施方案的病毒可能是包膜病毒或无包膜病毒。细小病毒(例如aav)是无包膜病毒的实例。在一优选实施方案中,病毒可能是包膜病毒。在优选实施方案中,病毒可能是逆转录病毒,特别是慢病毒。可以促进真核细胞病毒感染的病毒包膜蛋白可能包括hiv-1衍生慢病毒载体(lv),这些载体用水疱性口炎病毒(vsv-g)的包膜糖蛋白(gp)、修饰的猫内源性逆转录病毒(rd114tr)和修饰的长臂猿白血病病毒(galvtr)处理成为假型。这些包膜蛋白可以有效地促进其他病毒的进入,例如细小病毒,包括腺相关病毒(aav),从而证明它们的广泛效率。例如,可使用其他病毒包膜蛋白,包括莫洛尼鼠白血病病毒(mlv)4070env(如merten et al.,j.virol.79:834-840,2005一文中所述;其内容透过引用并入本文)、rd114 env、嵌合包膜蛋白rd114pro或rdpro(透过用hiv-1基质/衣壳(ma/ca)切割序列取代rd114的r肽切割序列构建的rd114-hiv嵌合体,如bell et al.experimental biology and medicine 2010;235:1269
–
1276一文中所述;其内容透过引用并入本文)、杆状病毒gp64 env(如wang et al.j.virol.81:10869-10878,2007一文中所述;其内容透过引用并入本文)或galv env(如merten et al.,j.virol.79:834-840,2005一文中所述;其内容透过引用并入本文)或其衍生物。
[0528]
本发明的另一目的涉及用根据本发明的核酸和/或载体转化、转导或转染的宿主
细胞。
[0529]
术语“转化”原先系指基因转移入宿主细胞中的自然过程,所述过程涉及细胞透过细胞膜吸收基因物质(例如:核酸,如dna或rna),从而使宿主细胞表达引入的基因或序列以产生所需的物质,所述物质通常为引入基因或序列编码的蛋白质或酶。有两种类型的转化,称为自然转化以及人工或诱导转化。人工或诱导转化方法在实验室条件下进行,通常称为转染。
[0530]
透过转化过程接受和表达外源核酸(例如,dna或rna)的宿主细胞已被“转化”。
[0531]
术语“转染”系指基因转移的一种方式,涉及在宿主细胞的细胞膜上创建孔,使宿主细胞能够接收外来基因物质。通常情况下,转染系指真核细胞(例如,昆虫或哺乳动物细胞)的转化。化学介导的转染涉及使用例如磷酸钙或阳离子聚合物或脂质体。非化学介导的转染方法通常为电穿孔、声穿孔、穿刺转染、光学转染或水动力递送。基于颗粒的转染使用基因枪技术,其中纳米颗粒用于将核酸转移至宿主细胞,或透过另一种称为磁转染的方法。核转染和使用热休克是成功转染的另外的演变方法。透过转染方法接收外来核酸的宿主细胞已被“转染”。
[0532]
术语“转导”通常理解为涉及将外来核酸(例如,dna或rna)透过病毒或病毒载体转移至细胞中。透过病毒或病毒载体接受和表达外来核酸(例如,dna或rna)的宿主细胞已被“转导”。
[0533]
在一些实施方案中,可使用us20190216852描述的方法转导细胞,该专利内容透过引用整体并入本文。
[0534]
本发明的核酸可用于在合适的表达系统中产生本发明的重组抗原结合蛋白。
[0535]
本发明的核酸可用于在合适的表达系统中产生本发明的重组抗原结合蛋白。
[0536]
术语“表达系统”意指合适条件下的宿主细胞和相容性载体,例如,用于表达由载体携带并引入宿主细胞的外来dna编码的蛋白质。
[0537]
常见的表达系统包括:大肠杆菌宿主细胞和质粒载体、昆虫宿主细胞和杆状病毒载体以及哺乳动物宿主细胞和载体。宿主细胞的其他实例包括但不限于:原核细胞(例如,细菌)和真核细胞(例如,酵母细胞、哺乳动物细胞、昆虫细胞、植物细胞等)。特定的实例包括:大肠杆菌、克鲁维酵母或酿酒酵母、哺乳动物细胞系(例如,vero细胞、cho细胞、3t3细胞、cos细胞等)以及原代或确定的哺乳动物细胞培养物(例如,由淋巴母细胞、成纤维细胞、胚胎细胞、上皮细胞、神经细胞、脂肪细胞等形成的培养物)。实例还包括:小鼠sp2/0-ag14细胞(atcc crl1581)、小鼠p3x63-ag8.653细胞(atcc crl1580)、cho细胞(其中二氢叶酸还原酶基因(下称“dhfr基因”)有缺陷,urlaub g et al;1980)、大鼠yb2/3hl.p2.g11.16ag.20细胞(atcc crl1662,下称“yb2/0细胞”)等。在一些实施方案中,可优选yb2/0细胞,这是因为当嵌合或人源化抗体在该细胞中表达时,其adcc活性增强。
[0538]
本发明还涉及包含根据本发明的抗原识别构建体的宿主细胞。具体地,本发明的宿主细胞包含如上所述的核酸或载体。宿主细胞可以是真核细胞,例如植物、动物、真菌或藻类,也可以是原核细胞,例如细菌或原生动物。宿主细胞可以是培养细胞或原代细胞,即直接从生物体(例如人)分离。宿主细胞可以是贴壁细胞或悬浮细胞(即,在悬浮液中生长的细胞)。为了产生抗原结合蛋白(例如,重组tcr、多肽或蛋白)之目的,宿主细胞优选为哺乳动物细胞。最优选地,宿主细胞为人细胞。虽然宿主细胞可以是任何细胞类型,可以来自任
何类型的组织,可以是任何发育阶段的细胞,但是宿主细胞优选为外周血白细胞(pbl)或外周血单核细胞(pbmc)。更优选地,宿主细胞为t细胞。t细胞可以是任何t细胞,诸如培养的t细胞,例如,原代t细胞或来自培养t细胞系的t细胞,例如jurkat、supt1等,或获得自哺乳动物的t细胞,优选为来自人类患者的t细胞或t细胞前体。如果获得自哺乳动物,t细胞可从许多来源获得,包括但不限于血液、骨髓、淋巴结、胸腺或其他组织或液体。t细胞还可以是富集或纯化的。优选地,t细胞为人t细胞。更优选地,t细胞是分离自人的t细胞。t细胞可以是任何类型的t细胞并且可以是任何发育阶段的,包括但不限于cd4阳性和/或cd8阳性、cd4阳性辅助t细胞,例如,th1和th2细胞、cd8-阳性t细胞(例如,细胞毒性t细胞)、肿瘤浸润细胞(til)、记忆t细胞、幼稚t细胞等。优选地,t细胞为cd8阳性t细胞或cd4阳性t细胞。宿主细胞优选为对表达magea4和/或magea8的肿瘤细胞具有特异性的肿瘤反应性t细胞。
[0539]
根据以上内容,在一实施方案中,本发明涉及一种包含上文定义的本发明抗原结合蛋白或本发明核酸或载体的宿主细胞,其中所述宿主细胞优选为a)淋巴细胞,诸如t淋巴细胞或t淋巴细胞祖细胞,例如:cd4或cd8阳性t细胞,或b)用于重组表达的细胞,诸如中国仓鼠卵巢(cho)细胞。
[0540]
特别是,为了表达本发明的一些抗原结合蛋白,表达载体的类型可以是:其中编码第一多肽(例如,抗体重链或α链)的基因和编码第二多肽(例如,抗体轻链或β链)的基因存在于分开的载体上;也可以是这样的类型:其中两种基因都存在于同一载体上(串联型)。从构建抗原结合蛋白表达载体的容易程度、引入动物细胞的容易程度以及动物细胞中抗体h和l链表达水平之间的平衡方面考虑,优选串联型人源化抗体表达载体(shitara k et al.j immunol methods.1994jan.3;167(1-2):271-8)。串联型人源化抗体表达载体的实例包括:pkantex93(wo 97/10354)、pee18等。
[0541]
在一实施方案中,此类重组宿主细胞可用于产生至少一种本发明的抗原结合蛋白。
[0542]
产生本发明抗原结合蛋白的方法
[0543]
本发明还涉及产生上文定义的抗原结合蛋白的方法,其包含
[0544]
a.提出合适的宿主细胞,
[0545]
b.提出一种基因构建体,其包含编码本发明抗原结合蛋白的编码序列,
[0546]
c.将所述基因构建体引入所述合适的宿主细胞,和
[0547]
d.由所述合适的宿主细胞表达所述基因构建体,且任选地
[0548]
e.选择表达和/或分泌所述抗体的细胞。
[0549]
本发明的抗原结合蛋白的定义见相应章节。
[0550]
本文的“基因构建体”表示可在宿主中表达编码区的核酸,因此系指核酸(如上文所述的载体)或rna。
[0551]
在一实施方案中,所述方法可能进一步包括在所述合适宿主细胞上进行细胞表面提呈所述抗原识别构建体的步骤。
[0552]
在其他的优选实施方案中,b)中的基因构建体包含编码本发明抗原结合蛋白的核酸。此类核酸的定义见上文“核酸、载体和重组宿主细胞”章节。
[0553]
在一相关实施方案中,所述基因构建体是包含与所述编码序列可操作地连接的启动子序列的表达构建体。
[0554]
在一相关实施方案中,使用转化、转导或转染方法将基因构建体引入合适的宿主。转化、转导或转染的定义见上文相关章节。
[0555]
理想情况是,用于将基因构建体引入所述合适宿主细胞的转染系统为上文核酸、载体和重组宿主细胞章节中所述的逆转录病毒或慢病毒载体系统。此类系统是本领域技术人员所熟知的。
[0556]
在一实施方案中,所述方法进一步包括从宿主细胞中分离和纯化抗原结合蛋白,以及任选地在t细胞中重建抗原结合蛋白。
[0557]
本发明的抗原结合蛋白可透过本领域已知的任何技术产生,例如但不限于,任何化学、生物学、基因学或酶学技术,可以单独或组合使用。
[0558]
在一些特定的实施方案中,本发明的抗原结合蛋白具有抗体或免疫球蛋白样框架。
[0559]
产生多肽(如,抗体或其片段和tcr或其片段)的标准技术为本领域已知,并且本领域技术人员可将这些技术转移使用于本发明的抗原结合蛋白。例如,可使用熟知的固相方法进行合成,特别是使用市售的肽合成设备(例如,加利福尼亚州福斯特城applied biosystems制造的肽合成设备)并按照制造商的说明进行合成。或者,本发明的抗原结合蛋白(例如,抗体或其片段和tcr或其片段)可透过本领域熟知的重组dna技术进行合成。例如,在将编码所需(多)肽的dna序列掺入表达载体中并将此类载体引入表达所需多肽的合适真核或原核宿主之后,可获得片段作为dna表达产物,之后可使用熟知的技术进行将其分离。
[0560]
在一实施例中,即在tcer
tm
双特异性分子的情况下,可透过例如基因合成获得编码vh和v
l
以及可变α(vα)和可变β(vβ)各种组合的dna序列,以及编码连接子的序列。可将得到的dna序列分别框内克隆至编码衍生自人igg4[登录号:k01316]和igg1[登录号:p01857]的铰链区、c
h2
和c
h3
结构域的表达载体中,并进一步进行改造。可进行改造以将杵臼突变并入到c
h3
结构域中,其具有和不具有额外的链间二硫键稳定性;去除c
h2
中的n-糖基化位点(例如:n297q突变);或引入fc沉寂突变;根据reiter et al.(stabilization of the fv fragments in recombinant immunotoxins by disulfide bonds engineered into conserved framework regions.biochemistry,1994,33,5451
–
5459)所述的方法,分别将额外的二硫键稳定化引入v
l
和vh中;纳入提高稳定性或可制造性的突变。
[0561]
本发明的抗原结合蛋白可透过免疫球蛋白纯化方法(例如,蛋白a-琼脂糖凝胶、蛋白l-琼脂糖凝胶、蛋白g-琼脂糖凝胶、羟磷灰石色谱、凝胶电泳、透析或亲和色谱)从培养基中适当地分离。
[0562]
在一实施方案中,本文中回收表达抗原结合蛋白或多肽系指实施蛋白a色谱、蛋白l色谱、κ选择色谱和/或尺寸排阻色谱,优选为蛋白l色谱和/或尺寸排阻色谱,更优选为蛋白l色谱和尺寸排阻色谱法。
[0563]
产生本发明抗原结合蛋白的方法涉及重组dna,基因转染技术为本领域熟知的(参见morrison sl.et al.(1984)和专利文献us5,202,238以及us5,204,244)。
[0564]
此外,基于常规重组dna和基因转染技术产生人源化抗体的方法为本领域熟知的(参见,例如,riechmann l.et al.1988;neuberger ms.et al.1985),并可容易地应用于生产本发明的抗原结合蛋白。
[0565]
在一实施例中,用于表达本发明重组抗原结合蛋白的载体设计为单顺反子,例如,
由hcmv衍生的启动子元件puc19-衍生物控制。例如,根据标准培养方法在大肠杆菌中扩增质粒dna,随后使用市售套件(macherey&nagel)纯化。例如,根据制造商的说明书(expicho
tm
system;thermo fisher scientific)或利用电穿孔系统(maxcyte stx),将纯化的质粒dna用于cho-s细胞的暂态转染。例如,将转染的cho细胞在32℃至37℃下培养6-14天,并接受一至两次expicho
tm
feed或cellboost 7a和7b(ge healthcare
tm
)溶液进料。例如,利用sartoclearlab filter aid(sartorius)透过过滤(0.22μm)澄清条件细胞上清液。例如,使用配备的pure 25l fplc系统(ge lifesciences)纯化双特异性抗原结合蛋白,以线上进行亲和力和尺寸排阻色谱。例如,按照标准亲和色谱方案,在蛋白a或l色谱柱(ge lifesciences)上进行亲和层析。例如,在从亲和柱洗脱(ph 2.8)后直接进行尺寸排阻色谱,以使用superdex 200pg 16/600柱(ge lifesciences)按照标准方案获得高纯度单体蛋白。例如,使用根据预测的蛋白质序列计算的消光系数,在nanodrop系统(thermo scientific)上测定蛋白质浓度。如有需要,使用vivaspin装置(sartorius)调整浓度。最后,将纯化的分子在2-8℃温度下以约1mg/ml的浓度保存在例如磷酸盐缓冲盐水中。
[0566]
纯化的双特异性抗原结合蛋白的品质,透过例如hplc-sec在mabpac sec-1色谱柱(5μm,4x300 mm)上测定,所述色谱柱在vanquish uhplc系统内例如包含300mm nacl的50mm磷酸钠ph 6.8中运行。
[0567]
在一特定实施方案中,步骤a)中提出了如上所定义的t细胞,并且抗原结合蛋白为tcr或其片段。因此,抗原结合蛋白在t细胞的细胞表面上表达。因此,所述方法可产生在其表面表达抗原结合蛋白(例如tcr)的t细胞,所述抗原结合蛋白对本发明背景下定义的癌细胞具有特异性。
[0568]
药物组合物
[0569]
本发明还涉及一种药物组合物,其包含本发明的抗原结合蛋白、本发明的核酸、本发明的载体或本发明的宿主细胞以及药用载体。
[0570]
本发明还涉及根据本发明所述的用作药剂的抗原结合蛋白。本发明还涉及用作药剂的本发明药物组合物。
[0571]
本发明还涉及根据本发明所述的抗原结合蛋白或/和本发明药物组合物在制备药剂中的用途。
[0572]
本文使用的术语“药物组合物”或“治疗组合物”系指正确给予受试者时能够诱导所期望治疗效果的化合物或组合物。
[0573]
在一些实施方案中,受试者也可称为患者。
[0574]
此类治疗或药物组合物可包含有效治疗量的本发明抗原结合蛋白或进一步包含治疗剂的抗原结合蛋白,与被选择为适合于给药方式的药学上或生理上可接受的制剂混合。
[0575]
本发明的抗原结合蛋白通常作为无菌药物组合物的一部分提供,其通常包括药用载体。
[0576]“药学的”或“药用”系指当正确给予哺乳动物,特别是人时,不会产生不良、过敏性或其他不良反应的分子实体和组合物。药用载体或赋形剂系指任何类型的无毒固体、半固体或液体填充剂、稀释剂、包囊材料或制剂助剂。
[0577]“药用载体”也可称为“药用稀释剂”或“药用溶媒”,可包括溶剂、填充剂、稳定剂、分散介质、包衣、抗菌剂、抗真菌剂、等渗剂和吸收延迟剂等,它们在生理学上是相容的。因此,在一实施方案中,载体为水性载体。
[0578]
另一方面,当与本文所述的抗原结合蛋白组合时,水性载体能够改善性质,例如改善溶解度、疗效和/或改进免疫治疗。
[0579]
药物组合物的剂型、给药途径、剂量和给药方案自然取决于需治疗的病症、疾病的严重程度、患者的年龄、体重和性别、期望的治疗持续时间等。此药物组合物可为任何合适的剂型(取决于患者用药的所需方法)。它可以以单位剂型提供,通常以密封容器中提供,并且可以作为套件的一部分提供。此类套件通常(但不一定)包括使用说明书。它可包括多个所述单位剂型。
[0580]
经验考虑因素(如,生物半衰期)通常将有助于确定剂量。给药频率可在治疗过程中确定和调整,并且基于癌细胞减少数量、维持减少癌细胞、减少癌细胞增生或杀灭癌细胞。或者,抗原结合蛋白的持续缓释制剂可能合适。用于实现缓释的各种制剂和装置为本领域已知。
[0581]
在一实施方案中,抗原结合蛋白的剂量可在已接受一次或多次给药的个体中凭经验确定。个体的抗原结合蛋白剂量逐渐增加。为了评估抗原结合蛋白的疗效,可追踪癌细胞状态的标志物。这些包括透过facs、其他成像技术直接测量癌细胞的增生和细胞死亡;透过此类测量方法评估健康改善状况,或透过公认的检测测量生活品质提高情况或生存时间延长情况。对于本领域技术人员显而易见的是,剂量将根据个体、疾病阶段以及所使用的既往和伴随治疗而变化。
[0582]
特别是,药物组合物包含溶媒,其对于可注射的制剂是药学上可接受的。特别是,这些可为等渗无菌盐水溶液(磷酸一钠或磷酸二钠、氯化钠、氯化钾、氯化钙或氯化镁等,或此类盐的混合物)或干燥的,尤其是冻干组合物,其根据情况添加无菌水或生理盐水后,可配制可注射溶液。
[0583]
为了制备药物组合物,可将有效量的本发明抗原结合蛋白溶解或分散于药用载体或水性介质中。
[0584]
适用于注射用途的药物剂型包括无菌水溶液或分散液;制剂包括麻油、花生油或丙二醇水溶液;以及用于临时制备无菌注射液或分散液的无菌粉剂。所有情况下,剂型必须为无菌的且必须具备易于注射程度的流动性。它在生产和储存条件下必须稳定,并且保存时必须防止受到微生物(如,细菌和真菌)污染。
[0585]
作为游离碱或药用盐的活性化合物溶液可在与表面活性剂(如,羟丙基纤维素)适当混合的水中制备。分散液也可在甘油、液体聚乙二醇及其混合物和油中制备。在常规储存和使用条件下,这些制剂含有防腐剂以防止微生物生长。
[0586]
本发明的抗原结合蛋白可使用药用盐配制为中性或盐形式的组合物。
[0587]
无菌注射溶液的制备方法为:将所需量的活性化合物掺入根据需要含有上述各种其他成分的适当溶剂中,然后进行过滤灭菌。通常情况下,分散液的制备方法为:将各种灭菌的活性成分掺入无菌溶媒,所述无菌溶媒包含基本分散介质和上述所需的其他成分。对于用于制备无菌注射溶液的无菌粉末,优选的制备方法为真空干燥和冷冻干燥技术,其可从先前的无菌过滤溶液中产生活性成分加上任何其他所需成分的粉末。
[0588]
也考虑了制备更多或高度浓缩的溶液用于直接注射,其中设想使用dmso作为溶剂以使之以极快的速度渗透,从而将高浓度的活性剂递送至小肿瘤区域。
[0589]
配制后,以与剂量制剂相容的方式和以治疗有效量来给予溶液。所述制剂易于以多种剂型给予,例如上述可注射溶液类型,但是也可采用药物释放胶囊等。
[0590]
治疗方法和用途
[0591]
发明人在体外实验章节的实施例6中展示了本发明的几种抗原结合蛋白,特别是本发明的tcer
tm
分子,例如可溶性tcer
tm
分子#114-iso0-ucht1(17)、#114-iso1-ucht1(17)、#114-iso2-ucht1(17)、#114-iso0-bma031(36)、#114-iso1-bma031(36)和#114-iso2-bma031(36),以及这些分子对于mage-003阳性癌细胞系(例如,hs695t、a375和u2os)的细胞毒性活性。本发明人还证明了所述细胞毒性活性具有高度特异性,并且限于mag-003阳性细胞,这是因为在表达hla-a*02但不提呈肽mag-003的细胞系中,双特异性抗原结合蛋白仅诱导少量裂解。
[0592]
此外,发明人证明了本发明的抗原结合蛋白,例如,tcer
tm
靶向mag-003(seq id no:127和130,第3组;seq id no:135和136,第4组)的体内疗效,导致在nog小鼠中hs695t肿瘤完全缓解,详细描述见实施例7,如图11所示。
[0593]
如发明人所证明的,本发明的抗原结合蛋白可用于在受试者(优选为患者)中产生免疫反应,其中该免疫反应可毁灭肿瘤细胞。源自该治疗性疫苗的免疫反应预期能够高度特异性地对抗肿瘤细胞,因为肽kvlehvvrv(seq id no:1)不以可相比的拷贝数目在正常组织上提呈或过度提呈,防止患者发生对抗正常细胞的不良自体免疫反应的风险。此外,如本说明书的引言部分所示,本发明的抗原结合蛋白与kvlehvvrv特异性结合,特别是与本文所定义的所述肽mag-003的表位结合,因此,不会透过交叉反应识别存在于正常组织中的其他相关肽抗原(类似肽),也不会与它们发生交叉反应。因此,本发明的抗原结合蛋白可用于免疫疗法。
[0594]
因此,本发明的抗原结合蛋白,特别是双特异性抗原结合蛋白(例如,tcer
tm
分子)可用于治疗癌症。
[0595]
本发明的抗原结合蛋白可用于人和/或非人类哺乳动物(特别是人)之治疗目的。
[0596]
在一实施方案中,本发明的抗原结合蛋白可与肿瘤细胞结合,并降低肿瘤细胞的生长和/或杀灭肿瘤细胞,所述肿瘤细胞在其细胞表面提呈肽kvlehvvrv(seq id no:1)/mhc复合体。可理解,抗原结合蛋白的给药浓度为在生理(例如,体内)条件下可促进结合。
[0597]
因此,在一实施方案中,本发明的抗原结合蛋白可用于针对不同组织(例如,结肠、肺、乳腺、前列腺、卵巢、胰腺、肾脏等)肿瘤细胞的免疫疗法。在另一实施方案中,本发明的抗原结合蛋白可与肿瘤细胞结合并减少肿瘤细胞的生长和/或杀灭肿瘤细胞。
[0598]
因此,本发明涉及一种治疗或预防增生性疾病或病症的方法,所述方法包括向有需要的受试者给予有效治疗量的根据本发明所述的抗原结合蛋白、核酸或载体、宿主细胞或药物组合物,定义参见上文“抗原结合蛋白”、“核酸”或“药物组合物”章节。
[0599]
在一特定实施方案中,本发明涉及一种治疗增生性疾病受试者的方法,所述方法包括向所述受试者给予细胞表面上表达本发明抗原结合蛋白的t细胞。
[0600]
在另一实施方案中,本发明涉及在增生性疾病受试者中引发免疫反应的方法,所述方法包括向所述受试者给予一种组合物,其包含细胞表面上表达本发明抗原识别构建体
的t细胞。
[0601]
在一实施方案中,所述方法中提及的免疫反应为细胞毒性t细胞反应。
[0602]
本发明还涉及用于诊断、预防和/或治疗增生性疾病的本发明的抗原结合蛋白、本发明的核酸或本发明的载体、本发明的宿主细胞或本发明的药物组合物。
[0603]
本发明还涉及本发明的抗原结合蛋白、本发明的核酸或本发明的载体、本发明的宿主细胞或本发明的药物组合物在制造用于诊断、预防和/或治疗增生性疾病的一种药剂中的用途。
[0604]
在一实施方案中,本发明涉及根据本发明所述的抗原结合蛋白、核酸或载体、宿主细胞或药物组合物在治疗或预防受试者增生性疾病或病症中的用途。
[0605]
在优选实施方案中,t细胞为受试者自体细胞或为受试者同种异体细胞,优选为自体细胞。优选情况是,t细胞获自肿瘤浸润淋巴细胞或外周血单核细胞。优选情况是,t细胞以组合物形式给予。在一优选的相关实施方案中,所述组合物还包含佐剂,其中所述佐剂的定义见上文药物组合物章节。
[0606]
术语“受试者”或“个体”可互换使用,例如,可以为人或非人哺乳动物,优选为人。
[0607]
在本发明的背景下,术语“治疗”系指治疗性用途(即,用于患有特定疾病的受试者),意指逆转、减轻、抑制此类疾病或病症的一种或多种症状进展。因此,治疗不仅指使疾病完全治愈的治疗,而且还指减缓疾病进展和/或延长受试者存生存期的治疗。
[0608]“预防”意指预防性用途(即,用于易患特定疾病的受试者)。
[0609]
在一实施方案中,“疾病”或“病症”是从本发明抗原结合蛋白治疗中受益的任何状况。在一实施方案中,这包括慢性和急性病症或疾病,包括让受试者易患所述病症的那些病理状况。
[0610]
术语“需要治疗”系指已经患有病症受试者以及需要预防该病症的受试者。因此,在一实施方案中,受试者为患者。
[0611]“增生性疾病”(例如,癌症)涉及细胞的失调控和/或不适当增生。
[0612]
在一实施方案中,增生性病症或疾病为,例如,以所述肿瘤疾病的癌症或肿瘤细胞有magea4和/或magea8表达为特征的肿瘤疾病。
[0613]
因此,特别优选的癌症为magea4和/或magea8阳性癌症。
[0614]
在本发明的背景下,如果根据nci指南,》98%所有癌症中提呈相关肽(例如mag-003肽),则该癌症视为“magea4和/或magea8“阳性
””
。在本文指出的所有其他适应症中,可进行活检,因为这是这些癌症治疗中的标准手段,并且可根据和相关方法鉴定肽(根据wo 03/100432;wo 2005/076009;wo 2011/128448;wo 2016/107740、us7,811,828、us 9,791,444和us 2016/0187351,各文献内容透过引用整体并入本文)。在一实施方案中,例如透过使用本发明的抗原结合蛋白可较容易地测定(即,诊断)癌症。使用抗原结合蛋白鉴定抗原表达癌症的方法为本领域技术人员已知。应当理解,本文中术语“癌症”(cancer)和“上皮癌”(carcinoma)不能互换使用,因为上皮癌(carcinoma)是出现在皮肤中或在内衬或覆盖身体器官的组织中的特定类型癌症。但是,实施例11中使用的组织样本来自肿瘤患者,并且将样本分配至患者的疾病。
[0615]
在一实施方案中,magea4和/或magea8“阳性”(即提呈靶肽)的癌症选自由肺癌(例如,非小细胞肺癌、小细胞肺癌)、肝癌、头颈癌、皮肤癌、肾细胞癌、脑癌、胃癌、结直肠癌、肝
细胞癌、胰腺癌、前列腺癌、白血病、乳腺癌、默克尔细胞癌、黑色素瘤、卵巢癌、膀胱癌、子宫癌、胆囊和胆管癌、骨肉瘤和食道癌组成的组。
[0616]
在一实施方案中,magea4和/或magea8“阳性”(即提呈靶肽)的癌症选自由肺癌(例如,非小细胞肺癌、小细胞肺癌)、肝癌、头颈癌、皮肤癌、胃癌、结直肠癌、肝细胞癌、胰腺癌、乳腺癌、黑色素瘤、卵巢癌、膀胱癌、子宫癌、胆囊和胆管癌和食道癌组成的组。
[0617]
在另一实施方案中,肺癌为非小细胞肺癌(nsclc),优选为非小细胞肺癌腺癌或鳞状细胞非小细胞肺癌(snsclc)或小细胞肺癌(sclc)。在另一实施方案中,癌症为皮肤癌,优选为黑色素瘤。在另一实施方案中,癌症为头颈癌,优选为头颈鳞状细胞癌(hnscc)。在另一实施方案中,癌症为肝癌,优选为肝细胞癌(hcc)。在另一实施方案中,癌症为食道癌,优选为胃食管交界癌。
[0618]
cancer,principles and practice of oncology,4th edition,devita et al,eds.j.b.lippincott co.,philadelphia,pa.(1993)是为癌症治疗提供指导的文章。适当的治疗方法根据相关领域公认的癌症具体类型和其他因素(例如,患者一般状况)选择。本发明的抗原结合蛋白可单独使用,也可加入其他抗癌药物(常用于治疗癌症患者)的治疗方案中。
[0619]
因此,在一些实施方案中,本发明的抗原结合蛋白可在广泛用于癌症治疗的多种药物和治疗方法(例如,化学治疗剂、非化学治疗剂、抗肿瘤剂和/或放射疗法,优选为化学治疗剂)的同时、之前或之后给予。
[0620]
本文中的“诊断”系指医学诊断,并指确定哪种疾病或状况可解释患者的症状和体征。
[0621]“有效治疗量”的抗原结合蛋白或其药物组合物意指足够量的抗原结合蛋白以适用于任何医学治疗的合理受益/风险比来治疗所述增生性疾病。但是,应了解,本发明的抗原结合蛋白、核酸或载体、宿主细胞或药物组合物的每日或每月总使用量将由主治医师在合理医疗判断范围内来决定。对于任何特定患者而言,具体有效治疗剂量水平将取决于多种因素,包括:所治疗的病症或疾病以及病症的严重程度;所使用的特异性抗原结合蛋白的活性;所使用的特定组合物,患者的年龄、体重、一般健康状况、性别和饮食;所使用特定多肽的给药时间、给药途径和排泄速率;治疗持续时间;与所使用的特定多肽联合或同时使用的药物;以及医学领域熟知的因素。例如,为本领域技术人员熟知的是,以低于达到期望治疗作用所需的剂量水平开始使用化合物的剂量,并逐渐增加剂量直至达到期望的效果。
[0622]
在一实施方案中,本发明抗原结合蛋白的治疗疗效在体内测定,例如,在癌症小鼠模型中测定,并透过测量例如治疗组和对照组之间的肿瘤体积变化来测定。
[0623]
本发明的药物组合物、载体、核酸和细胞可以以基本上纯的形式提供,例如,其中,存在按重量计至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%的相同类型抗原结合蛋白。
[0624]
本发明的抗原结合蛋白、本发明的核酸或本发明的载体、本发明的宿主细胞或本发明的药物组合物可透过任何可行的方法给予。
[0625]
如本文所公开的,在一些实施方案中,宿主细胞,优选为淋巴细胞(例如t淋巴细胞或t淋巴细胞祖细胞,例如cd4或cd8阳性t细胞),最优选为t细胞,用于本文所述的医疗用途或治疗方法。
[0626]
因此,本发明的宿主细胞,优选为t细胞,可用作治疗组合物的活性成分。因此,本发明也提出了一种杀伤患者靶细胞的方法,所述方法包括给予患者以上定义的有效量的宿主细胞,优选t细胞。在此方法的背景下,宿主细胞在给予受试者后,优选引发免疫反应。
[0627]
为了本发明方法之目的,其中将宿主细胞或细胞群给予受试者,宿主细胞可以是受试者的同种异体(来自另一名受试者)或自体细胞。优选情况是,细胞为受试者的自体细胞。
[0628]
如果宿主细胞为同种异体细胞,也就是来自另一名受试者,则所述另一名受试者是健康的。
[0629]
在一些实施方案中,可根据us20190175650、美国申请号16/271,393和美国申请号16/361,043中所述的方法制造t细胞,这些文献的内容透过引用整体并入本文。
[0630]“健康的”意指受试者一般健康状况良好,优选为免疫系统合格,更优选为无任何可很容易测试或检测的疾病。
[0631]
在特定的实施例中,宿主细胞为t细胞。因此,在本发明的背景下,当上文所定义的t细胞用作药剂时,则t细胞通常透过血液成分单采法从受试者中采集。然后,对t细胞进行基因工程改造,以在其细胞表面表达本发明的抗原结合蛋白,之后,对基因工程改造的t细胞进行扩增,然后重新注入受试者中。在此实施例中,抗原结合蛋白优选为tcr。
[0632]
在另一方法中,宿主细胞可以为干细胞(例如,间充质干细胞)并改造成表达本发明的抗原结合蛋白。在此实施例中,抗原结合蛋白为如本文定义的可溶性蛋白(例如,抗体、sctcr或可溶性抗原结合蛋白),更优选为双特异性可溶性抗原结合蛋白,例如本文所述的tcer
tm
。
[0633]
因此,宿主细胞用根据本发明所述的核酸和/或载体转化、转导或转染,定义见上文“核酸、载体和重组宿主细胞”章节。
[0634]
当宿主细胞被转化、转导或转染以表达本发明的抗原结合蛋白时,优选为所述细胞包含能够表达抗原结合蛋白的表达载体。当宿主细胞表达了本发明的抗原结合蛋白后,所述宿主细胞可称为激活的宿主细胞。
[0635]
t细胞过继转移方案为本领域所熟知的方案。综述可发现于:gattioni等人和morgan等人的文章(gattinoni,l.et al.,nat.rev.immunol.6(2006):383-393;morgan,r.a.et al.,science 314(2006):126-129)。
[0636]
可使用一些方法来体外生成t细胞。例如,自体肿瘤浸润性淋巴细胞可用于生成ctl。plebanski等人(plebanski,m.et al.,eur.j immunol 25(1995):1783-1787)使用自体外周血淋巴细胞(plb)制得t细胞。此外,b细胞可用于制备自体t细胞。
[0637]
也可用同种异体细胞制得t细胞,在us6805861中详细描述了一种方法,以引用方式并入本文。
[0638]
一方面,tcr引发的免疫反应或t细胞反应可指透过在体外或体内与mag-003/mhc复合体结合而诱导效应子功能的增生和激活。对于mhc i类限制性细胞毒性t细胞,例如,效应子功能可能为溶解肽脉冲的、肽前体脉冲的或天然肽提呈的靶细胞、分泌细胞因子,优选为肽诱导的干扰素-γ、tnf-α或il-2、分泌效应分子,例如,肽诱导的颗粒酶或穿孔素,或脱颗粒。
[0639]
如上文所述,表达与mag-003/mhc复合体特异性结合的本发明抗原结合蛋白的宿
主细胞(例如,t细胞)可用于治疗。因此,本发明的另一方面提出了用本发明前述方法制得的激活宿主细胞。
[0640]
透过上述方法产生的激活宿主细胞可选择性地识别靶细胞。
[0641]
本文中的“靶细胞”系指上文“抗原结合蛋白”章节中定义的mage-a/mhc提呈细胞。
[0642]
在一实施方案中,靶细胞优选为癌细胞,其中所述癌症如上文所定义。
[0643]
根据本发明,cd8-阳性t细胞的体内靶细胞可为肿瘤细胞(有时表达mhc-ii类抗原)和/或肿瘤(肿瘤细胞)周围的基质细胞(有时也表达mhc-ii类抗原(dengjel,j.et al.,clin cancer res 12(2006):4163-4170)。
[0644]
套件
[0645]
最后,本发明还提出了套件,其包含至少一种本发明的抗原结合蛋白。
[0646]
在一实施方案中,套件包含
[0647]
a)上文“抗原结合蛋白”章节中所定义的至少一种本发明的抗原结合蛋白,
[0648]
b)任选为包装材料,以及
[0649]
c)任选为所述包装材料内所含的标签或药物仿单,提示所述抗原结合蛋白可有效治疗癌症或可用于治疗癌症。
[0650]
在一相关实施方案中,本发明的至少一种抗原结合蛋白包含于单室和/或多室预填充式注射器(例如,液体注射器和冻干注射器)中。
[0651]
在一实施方案中,本发明包括用于产生单剂量给药单位的套件。
[0652]
因此,在一实施方案中,如本发明套件的a)中提及的本发明至少一种抗原结合蛋白为第一容器中包含的本发明的干燥抗原结合蛋白。套件进一步包含具有水性制剂的第二容器。
[0653]
因此,在一实施方案中,套件包含
[0654]
a)第一容器,其包含至少一种上文“抗原结合蛋白”章节中所定义的本发明的干燥抗原结合蛋白,
[0655]
b)第二容器,其包含水性制剂;
[0656]
c)任选为包装材料,以及
[0657]
d)任选为所述包装材料内所含的标签或药物仿单,提示所述抗原结合蛋白可有效治疗癌症或可用于治疗癌症。
[0658]
水性制剂通常指包含上文“药物组合物”章节中所定义的药用载体的水溶液。在一相关实施方案中,“第一容器”和“第二容器”系指多室预填充式注射器(例如,冻干注射器)的腔室。
[0659]
本发明背景下的癌症定义见上文。
[0660]
在整个本技术中,术语“和/或”为语法上连词,应解释为包含与其连接的一个或多个情况可能发生。例如,措辞“可使用标准重组和/或合成方法制备此类天然序列蛋白”表示可使用标准重组和合成方法来制备天然序列蛋白,或者可使用标准重组方法来制备天然序列蛋白或可使用合成方法制备天然序列蛋白。
[0661]
此外,在整个本技术中,术语“包含”应解释为包含所有特别提及的特征以及可选的、附加的、未指定的特征。如本文中所用的,术语“包含”的使用还公开了实施方案,其中不存在特别提及特征之外的特征(即,“由
……
组成”)。
[0662]
此外,不定冠词“一”或“一个”不排除有多个。在相互不同的从属权利要求中叙述某些措施这一事实并不表示不能使用这些措施的组合。
[0663]
现在将参考以下附图和实施例对本发明进行更详细的描述。本文引用的所有文献和专利档透过引用整体并入本文。虽然本发明已经在前面的描述中进行了详细的说明和描述,实施例被认为是说明性的或示例性的而非限制性的。
[0664]
序列说明
[0665]
[0666]
[0667]
[0668]
[0669]
[0670]
[0671]
[0672]
[0673]
[0674]
[0675]
[0676][0677]
附图
[0678]
图1-18描绘了本文的实施方案。
[0679]
图1显示了透过酵母表面展示技术将tcr转化为稳定sctcr的结果。展示于转化酿酒酵母eby100表面上的sctcr分子用fitc标记的抗vβ8抗体和pe标记的hla-a*02/mag-003四聚体染色。将未修饰的sctcr r7p1d5(左图,seq id no:19)与带有两个稳定单点突变的sctcr变体(右图,seq id no:22)进行比较,其源自随机突变sctcr文库的选择。从中可以看出,带有两个稳定单点突变的sctcr变体显示hla-a*02/mag-003四聚体染色增加。
[0680]
图2a显示了cdr3α的sctcr亲和力成熟的酵母表面展示技术结果。包含未修饰和成熟的cdr3α的稳定sctcr用浓度为15nm的hla-a*02/mag-003单体进行染色。用10种hla-a*02四聚体的混合物复染,各四聚体均以10nm的浓度施用,其含有与mag-003(seq id no:1)具有高度序列相似性的肽(seq id no:23至32)。含有未修饰的α链cdr3序列caeyssaskiif(seq id no:7)的稳定sctcr(seq id no:22)与分别包含亲和力成熟的α链cdr3序列caefssaskiif(seq id no:38)、caemtseskiif(seq id no:35)、caeftseskiif(seq id no:36)、caefnseskiif(seq id no:37)和caeatseskiif(seq id no:39)的sctcr变体进行比较。由此可看出,含有突变的cdrα2(seq id no:56、57、59)、β1(seq id no:62)或β2(seq id no:63、64、65、66、70)的酵母克隆还揭示了结合大大改善,同时主要保留了对hla-a*02/mag-003的特异性。
[0681]
图2b分别显示了cdr2α、cdr3α、cdr1β和cdr2β的sctcr亲和力成熟的酵母表面展示结果。用hla-a*02/mag-003单体(目标phla单体)对包含未修饰和成熟cdr的稳定sctcr进行染色,并用10种hla-a*02四聚体的混合物复染,各四聚体均以10nm的浓度施用,其含有与mag-003(seq id no:1)具有高度序列相似性的肽(seq id no:23至32)。(a)含有未修饰(seq id no:6)和成熟的α链cdr2序列iyssqdq(seq id 56)、iyssqdv(seq id 57)和iyssqds(seq id 59)的sctcr变体进行比较,分别用40nm hla-a*02/mag-003单体染色。(b)
含有未修饰(seq id no:7)和成熟的α链cdr3序列caefssaskiif(seq id no:38)、caemtseskiif(seq id no:35)、caeftseskiif(seq id no:36)、caefnseskiif(seq id no:37)和caeatseskiif(seq id no:39)的sctcr变体进行比较,分别用15nm hla-a*02/mag-003单体染色。(c)含有未修饰(seq id no:12)和成熟的β链cdr1序列pghdy(seq id no:62)的sctcr变体进行比较,分别用40nm hla-a*02/mag-003单体染色。(d)含有未修饰(seq id no:13)和成熟的β链cdr2序列fcyghp(seq id no:63)、fcygvp(seq id no:64)、fcygtp(seq id no:65)、fcygap(seq id no:66)、fcygmp(seq id no:70)的sctcr变体进行比较,分别用5nm hla-a*02/mag-003单体染色。与亲本tcr r7p1d5相比,所有r7p1d5 cdra3突变体的hla-a*02/mag-003四聚体染色均显著增加,这表明与这些突变的变体的肽-hla结合改善。
[0682]
图3显示了用pe标记的hla-a*02/mag-003四聚体和fitc标记的抗vβ8抗体染色表达成熟r7p1d5 tcr变体的人cd8 t细胞。出于对照目的,表达没有tcr(空白对照)或对nyeso1-001特异的1g4 tcr,并且使用pe标记的hla-a*02/nyeso1-001四聚体进行染色。
[0683]
图4显示了应对mag-003的表达成熟r7p1d5 tcr变体的人cd8 t细胞的ifn-γ释放。出于对照目的,表达没有tcr(空白对照)或对nyeso1-001特异的1g4 tcr。在电穿孔的cd8 t细胞与载有连续稀释的mag-003的t2细胞共培养后,透过elisa法测定ifn-γ释放。减去基线的ifn-γ水平(由空白对照电穿孔的cd8 t细胞与分别载入的t2细胞共培养后释放)。与亲本tcr r7p1d5相比,成熟的r7p1d5 cdra3突变体1-5显示了应对mag-003,ifn-γ释放增加。
[0684]
图5显示了应对mag-003和不同相似肽的表达成熟r7p1d5 tcr变体的人cd8 t细胞的ifn-γ释放。出于对照目的,表达没有tcr(空白对照)或对nyeso1-001特异的1g4 tcr。在电穿孔的cd8 t细胞与载有10μm肽的t2细胞共培养后,透过elisa法测定ifn-γ释放。减去基线的ifn-γ水平(由空白对照电穿孔cd8 t细胞与分别载入的t2细胞共培养后释放)。与亲本tcr r7p1d5相比,成熟的r7p1d5 cdra3突变体1-5显示了应对mag-003,ifn-γ释放增加,并且对于受测的类似肽没有ifn-γ释放。
[0685]
图6显示了应对mag-003和相应丙氨酸取代肽的表达成熟r7p1d5 tcr变体的人cd8 t细胞的ifn-γ释放。出于对照目的,表达没有tcr(空白对照)或对nyeso1-001特异的1g4tcr。在电穿孔的cd8 t细胞与载有10μm肽的t2细胞共培养后,透过elisa法测定ifn-γ释放。减去基线的ifn-γ水平(由空白对照电穿孔cd8 t细胞与分别载入的t2细胞共培养后释放)。
[0686]
图7a显示了可溶性sctcr-fab抗原结合蛋白的产量和热应力稳定性资料,所述可溶性sctcr-fab抗原结合蛋白包含具有不同亲和力成熟的cdr和/或框架突变的tcr可变结构域。
[0687]
图7b显示了透过生物膜层干涉法测得的可溶性sctcr-fab抗原结合蛋白s、#1、#2和i与和hla-a*02复合的mag-003的结合曲线。增加溶液中hla-a*02/mag-003单体浓度可用于每次相互作用的测量,单位为nm。
[0688]
图7c显示了可溶性sctcr-fab抗原结合蛋白i(灰色曲线))和#19(黑色曲线)与和hla-a*02复合的mag-003以及正常组织衍生脱靶肽(分别为syne3-001、tpx2-001、psme2-001)的结合曲线。使用生物膜层干涉法用于测量,并在溶液中应用浓度为1μm的sctcr-fab。
[0689]
图8a显示了可溶性tcer
tm
抗原结合蛋白的产量和热应力稳定性资料,所述可溶性
tcer
tm
抗原结合蛋白包含tcr可变结构域,其具有选定亲和力成熟的cdr并组合了人源化t细胞募集抗体bma031(36)的不同vh/vl序列以及人源化t细胞募集抗体ucht1的不同变体17、17opt、21、23。
[0690]
图8b显示了tcer
tm
抗原结合蛋白(包含tcr可变结构域变体114-iso0、114-iso1和114-iso2与ucht1(17)和bma031(36)组合)与和hla-a*02复合的mag-003的结合曲线。使用生物膜层干涉术进行测量,并增加溶液中tcer
tm
分子的浓度,以nm表示。
[0691]
图8c显示了114-iso1-bma(36)和114-iso2-ucht1(17)tcer
tm
分子分别与和二硫键稳定的hla-a*02复合的mag-003以及正常组织衍生脱靶肽nomap-1-0320、nomap-1-1223、odc-001的结合曲线。使用生物层干涉法进行测量,并应用浓度为1μm的tcer
tm
溶液。
[0692]
图9显示了具有可检测的mag-003表达(hs695t和a375)和没有可检测的mag-003表达(bv173)的hla-a*02阳性肿瘤细胞系的tcer
tm
介导杀伤的体外疗效资料。检测了包含ucht1(17)抗体可变结构域与tcr变体#114-iso0(seq id no:127和130)、#114-iso1(seq id no:131和130)和#114-iso2(seq id no:133和130)的可变结构域的tcer
tm
分子(上图)。此外,检测了包含bma031(36)抗体可变结构域与tcr变体#114-iso0(seq id no:135和136)和#114-iso2(seq id no:139和136)的可变结构域的tcer
tm
分子(下图)。将肿瘤细胞与来自健康hla-a*02 供体的人pbmc(hbc-720)以1:10的比例共孵育,并透过ldh-释放测定法分析在tcer
tm
分子浓度递增情况下的细胞毒性活性。48小时后,利用cytotox 96非放射性细胞毒性测定套件(promega)测量靶细胞系的裂解情况。包含ucht1(17)和bma031(36)抗体的tcer
tm
分子显示出了有效的细胞裂解作用。
[0693]
图10显示了具有可检测的mag-003表达(hs695t、a375和u2os)的hla-a*02阳性肿瘤细胞系的tcer
tm
介导的体外杀伤情况。检测了包含ucht1(17)抗体可变结构域与tcr变体#114-iso1(seq id no:131和130)和#114-iso2(seq id no:133和130)的可变结构域的tcer
tm
分子以及包含bma031(36)抗体可变结构域与tcr变体#114-iso1(seq id no:137和136)的可变结构域的tcer
tm
分子。将肿瘤细胞与来自健康hla-a*02 供体的人pbmc(hbc-982)以1:10的比例共孵育,并透过ldh-释放测定法分析在tcer
tm
分子浓度递增情况下的细胞毒性活性。48小时后,利用cytotox 96非放射性细胞毒性测定套件(promega)测量肿瘤细胞系的裂解情况。包含ucht1(17)和bma031(36)抗体的tcer
tm
分子显示出了有效的肿瘤细胞裂解作用。
[0694]
图11显示了在人pbmc移植的免疫缺陷型nog小鼠中对抗hs695t细胞肿瘤异种移植物(为hla-a*02阳性肿瘤细胞系,含有可检测到提呈量的mag-003(seq id no:1)和prame-004(seq id no:168))的tcer
tm
介导的体内疗效。包含ucht1(17)抗体可变结构域与tcr变体#114-iso0(seq id no:127和130,第3组)的可变结构域的tcer
tm
与包含bma031(36)抗体可变结构域与tcr变体#114-iso0(seq id no:135和136,第4组)的可变结构域的tcer
tm
进行了比较。使用prame-004靶向tcer(seq id no:169和170,第2组)作为对照。第1组代表溶媒治疗的对照组,其中第11天时由于出现肿瘤溃疡而处死了一只动物。线连接的每个符号代表个体动物,箭头表示治疗天数。包含进行t细胞募集的ucht1(17)抗体和bma031(36)抗体的tcer
tm
分子显示出了完全缓解。
[0695]
图12显示了根据用11种来自不同器官的人hla-a*02阳性正常组织原代细胞进行ldh杀伤实验评估结果的tcer
tm
分子114-iso1-bma(36)(seq id no:137和136)的体外安全
性资料。将不同的细胞与来自健康hla-a*02 供体的pbmc效应细胞以1:10的比例和递增的tcer
tm
浓度进行了共培养。细胞在原代组织细胞特异性培养基和t细胞培养基的50%混合物中进行了共孵育。为了确定安全窗,tcer
tm
分子在相同的环境下与mag-003阳性肿瘤细胞系hs695t进行了共孵育。安全窗的定义基于最低观测效应水平(loel),该水平根据表现出超过临界值反应的首个tcer
tm
浓度确定。临界值定义为([所有三份样本的标准差x 3] 不含tcer的正常对照组织样本),在各细胞毒性图中以虚线表示。对于每种正常组织细胞类型,基于loel的安全窗大于1,000倍或10,000倍,表明114-iso1-bma(36)tcer
tm
分子的安全性特征良好。
[0696]
图13显示了在人pbmc移植的免疫缺陷型nog小鼠中对抗hs695t细胞肿瘤异种移植体(为hla-a*02阳性肿瘤细胞系,含有可检测到提呈量的mag-003(seq id no:1))的tcer
tm
介导的体内疗效。包含ucht1(v17opt)抗体可变结构域和tcr变体114-iso1可变结构域(seq id no:131和167,第3组)的tcer
tm
分子与包含bma031(36)抗体可变结构域和tcr变体114-iso1可变结构域(seq id no:137和136,第2组)的tcer
tm
进行了比较。第1组表示经溶媒治疗的对照组。这些图显示了获得自每组六只(第2组和第3组)至十只(溶媒组)小鼠的平均肿瘤体积。在每周一次静脉内给予0.01mg/kg体重药物后,用于t细胞募集的包含ucht1(17opt)抗体和bma031(36)抗体的tcer
tm
分子显示出了完全缓解。
[0697]
图14显示了114-iso1-ucht1(17)tcer
tm
分子在nog小鼠中的药代动力学特征。小鼠接受2mg/kg体重剂量的单次静脉内注射。不同时间点采集样本的tcer
tm
血浆浓度透过elisa法测定检测特定蛋白结构域(fc-v
l
测定法)或双特异性结合活性(cd3
–
pmhc测定法)的存在。
[0698]
图15显示了tcer
tm
分子的设计。双特异性t细胞衔接受体(tcer
tm
)为融合蛋白,其包含亲和力成熟的tcr的可变结构域(vα,vβ)和人源化t细胞募集抗体的可变结构域(vh,v
l
)。分子使用效应子功能沉默的fc部分,可延长半衰期,同时提高稳定性/可制造性。
[0699]
图16根据用12种来自不同器官的人hla-a*02阳性正常组织原代细胞进行ldh杀伤实验评估结果,其显示了tcer
tm
分子114-iso1-bma(36)(seq id no:137和136)的体外安全性资料。将不同的细胞与来自健康hla-a*02 供体的pbmc效应细胞以1:10的比例和递增的tcer
tm
浓度进行了共培养。细胞在原代组织细胞特异性培养基和t细胞培养基的50%混合物中进行了共孵育。为了确定安全窗,tcer
tm
分子在相同的环境下用mag-003阳性肿瘤细胞系hs695t进行了共孵育。安全窗的定义基于最低观测效应水平(loel),该水平根据表现出超过临界值反应的首个tcer
tm
浓度确定。临界值定义为([所有三份样本的标准差x 3] 不含tcer的正常对照组织样本),在各细胞毒性图中以虚线表示。对于每种正常组织细胞类型,基于loel的安全窗大于1,000倍或10,000倍,表明114-iso1-bma(36)tcer
tm
分子的安全性特征良好。
[0700]
图17显示了表达r7p1d5 tcr变体的成熟人cd8 t细胞应对提呈不同拷贝数hla-a*02/mag-003的肿瘤细胞系的细胞毒性和ifn-γ释放。出于对照目的,表达无tcr(空白对照)或对nyeso1-001特异的1g4 tcr。在电穿孔的cd8 t细胞与肿瘤细胞系共培养后,测定上清液中的ldh和ifn-γ水平。
[0701]
图18:进行肽提呈分析的正常组织和肿瘤样本已根据其起源器官进行了分组。上面部分:绘制了检测到该肽的单一hla-a*02阳性正常(左图)以及肿瘤样本(右图)根据技术
重复测量值和等分试样测量值得出的中位值ms信号强度为点。箱须图表示多个样本的归一化信号强度,并在对数空间中定义。箱显示中位值、第25和第75百分位数。须延伸到最低资料点仍在下四分位数的1.5四分位数范围(iqr)内,最高资料点仍在上四分位数的1.5iqr内。下面部分:每个器官的相对肽检测频率显示为脊柱图。图表下面的数字表示本分析中每个器官的可评估总样本数中检测到肽的样本数(正常样本n=581,肿瘤样本n=771)。如果在一个样本上检测到肽,但因技术原因无法量化,则该样本纳入检测频率图中,但图表上面部分不显示任何点。
[0702]
使用的缩写词:脂肪:脂肪组织;adrenal gl:肾上腺;膀胱:膀胱;bloodvess:血管;esoph:食管;gall bl:胆囊;intest.la:大肠;intest.sm:小肠;nerve cent:中枢神经;nerve perith:周围神经;parathyr:甲状旁腺;perit:腹膜;pituit:垂体;skel.mus:骨骼肌;aml:急性髓性白血病;brca:乳腺癌;ccc:胆管细胞癌;cll:慢性淋巴细胞白血病;crc:结直肠癌节;gbc:胆囊癌;gbm:胶质母细胞瘤;gc:胃癌;gejc:胃食管交界癌;hcc:肝细胞癌;hnscc:头颈部鳞状细胞癌;mel:黑色素瘤;nhl:非霍奇金淋巴瘤;nsclcadeno:非小细胞肺癌腺癌;nsclcother:无法明确分配至nsclcadeno或nsclcsquam的nsclc样本;nsclcsquam:鳞状细胞非小细胞肺癌;oc:卵巢癌;oscar:食管癌;paca:胰腺癌;prca:前列腺癌;rcc:肾细胞癌;sclc:小细胞肺癌;ubc:膀胱癌;uec:子宫和子宫内膜癌。
实施例
[0703]
与靶向作用于病毒抗原的tcr相比,抗癌抗原的t细胞受体(tcr)通常亲和力较低,这可能是肿瘤免疫逃逸的一种可能解释(aleksic et al.2012,eur j immunol.2012dec;42(12):3174-9)。因此,希望产生更高亲和力的tcr变体用作过继细胞疗法中的癌症抗原靶向构建体,或者作为可溶性治疗药物的识别模组,即,双特异性分子(hickman et al.2016,j biomol screen.2016sep;21(8):769-85)。因此,本发明涉及t细胞受体r7p1d5的修饰和优化,其基于对肿瘤相关肽mag-003(seq id no:1)的高亲和力和选择性根据人天然tcr库鉴定。tcr r7p1d5包含具有seq id no:4氨基酸序列的α可变结构域以及具有seq id no:11氨基酸序列的β可变结构域,这在wo 2017/158103中公开。
[0704]
实施例1:稳定sctcr的产生
[0705]
对于本发明,tcr r7p1d5(seq id no:2和9,全长)被转化为单链tcr构建体(sctcr r7p1d5,seq id no:19),转化方法为使用可变α(seq id no:4)和β(seq id no:11)结构域和适当的甘氨酸-丝氨酸连接子序列。为了透过酵母表面展示tcr成熟,合成相应序列的dna并将其与基于pct302的含有前导序列和aga2p酵母交配蛋白(seq id no:19)的酵母展示载体转化至酿酒酵母eby100(mata aga1::::ura3trp1pep4::his3 prbd1.6r can1 gal)(gal)()中(boder and wittrup,methods enzymol.2000;328:430-44)。在酵母中同源重组后得到的融合蛋白(seq id no:16)在aga2p蛋白的n-端含有前导肽(负责展示目的蛋白)(boder and wittrup,nat biotechnol.1997jun;15(6):553-7)、短肽标签,包括用于表达对照的连接子序列(seq id no:18和20)和目的蛋白质,即sctcr r7p1d5(seq id no:19)或其变体。透过跨越sctcr r7p1d5的完整基因序列的随机突变pcr方法产生sctcr变体的文库。如wo 2018/091396中所述进行酵母细胞转化,每个文库产生多达109个酵母克隆。
mag-003和潜在脱靶肽(图5)。基于与mag-003存在高度序列相似性(相似性blast搜索),从正常组织提呈hla-a*02结合肽数据库(xpresident数据库)中选择潜在的脱靶肽。与亲本tcr r7p1d5相比,成熟r7p1d5 cdra3突变体1-5显示反应性增加(图4),如诱导半数最大ifn-γ释放所需的3至9倍更低浓度(ec50值,表3)所示。如所预期的,对于不表达额外tcr(空白对照)的t细胞或表达对nyeso1-001特异的1g4对照tcr的t细胞仅观察到背景ifn-γ释放。为了分析成熟r7p1d5 tcr变体对mag-003的识别选择性,分析了应对负载不同相似肽(seq id no:23至34)的t2细胞的ifn-γ释放。透过减去空白对照电穿孔的cd8 t细胞与分别载入t2细胞共培养后释放的ifn-γ水平,对背景ifn-γ释放资料进行了校正。除了r7p1d5 cdra3突变体5显示对数种类似肽的信号略微增加和r7p1d5 cdra3突变体2对mia3-001的低信号之外,所有其他成熟的r7p1d5 tcr变体都具有高度选择性,对受测类似肽无交叉反应性(图5)。与亲本tcr相比,所有tcr突变体变体均诱导明显更高的mag-003特异性ifn-γ释放,因此r7p1d5 cdra3突变体4、1和3(和可能包括2)是基于细胞tcr的肿瘤靶向作用最有前景的候选者。对r7p1d5 cdra3突变体1-5的结合表位进一步描述表征,方法是突变分析。r7p1d5 cdra3突变体1-4显示了广泛的结合表位,并严格识别第1、5、7和8位置,因为这些位置的丙氨酸取代消除了所述反应。对于某些r7p1d5变体(例如突变体1)在第3位置的丙氨酸取代也观察到了轻微影响。与其对类似肽所示的较低特异性一致,与突变体1-4相比,r7p1d5 cdra3突变体5tcr以降低严格性识别了的第7和8位置(图6)。在提呈不同拷贝数hla-a*02/mag-003的肿瘤细胞系上进一步评估了cdra3突变tcr变体的功能活性。rna电穿孔的cd8 t细胞与肿瘤细胞系以效应子与靶标比率为3:1共培养(nci-h1755、mcf-7:25,000个细胞/孔;hs695t、a375、u2o:12,500个细胞/孔)。如上所述验证了导入tcr变体在cd8 t细胞中的表达。将效应细胞和靶细胞共同培养24h后,定量检测释放至上清液中的ldh和ifn-γ水平。用cytotox96非放射性细胞毒性测定套件(promega)测定ldh水平,细胞毒性计算为减去效应子和靶细胞的自发ldh释放量后总裂解对照物的百分比。与亲本tcr相比,所有cdra3突变tcr变体均对所有分析的肿瘤细胞系诱导更强的杀伤力,而对靶标阴性的mcf-7细胞则无杀伤力。对于提呈较低靶拷贝数的肿瘤细胞系(a375、u2os),野生型tcr仅发现了很小的细胞毒性,然而尤其是成熟的变体1-4能够诱导重大杀伤,这表明这些变体将可以治疗靶拷贝数较低的患者人群。与野生型相比,表达成熟tcr变体的t细胞也观察到ifn-γ释放增强,这与细胞毒性资料一致。
[0712]
表3:亲本r7p1d5和cdra3突变体1-5的半数最大ifn-γ释放浓度[nm]。亲本tcr r7p1d5基于seq id no:2和11,而突变体变体tcr 1-5分别基于seq id no:40至44以及seq id no:11。
[0713]
[0714][0715]
实施例4:sctcr变体的生产、纯化和特征分析
[0716]
由vα和vβ结构域组成的tcr以单链(sctcr)形式与衍生自人源化cd3特异性t细胞募集抗体ucht1的fab片段一起设计、生产和测试。因此,产生了含有人源化ucht1抗体的轻链(对于变体s为seq id no:123,对于除s以外的其他变体为seq id no:80)或与人源化ucht1抗体的vh-ch1的c-端偶联的各sctcr序列,它们由hcmv衍生的启动子元件控制。
[0717]
表4:与fab片段一起表达的用于产生sctcr变体的序列组合。为了进行转染,含有轻链序列的质粒与含有各fab重链序列的质粒混合。
[0718]
变体轻链(seq id no:)重链(seq id no:)s123124i80126#18058#28076#1980125#208060#218061#298067#308068#318069#328075
[0719]
根据标准培养方法在大肠杆菌中扩增质粒dna,随后使用市售套件(macherey&nagel)纯化。根据制造商的说明书(expicho
tm
system;thermo fisher scientific),将纯化的质粒dna用于cho-s细胞的暂态转染。将转染的cho细胞在32℃至37℃下培养10-12天,并接受一次expicho
tm
feed进料。
[0720]
利用sartoclearlab filter aid(sartorius)透过过滤(0.22μm)澄清条件细胞上清液。使用配备的pure 25l fplc系统(ge lifesciences)纯化双特异性抗原结合蛋白,以线上进行亲和力和尺寸排阻色谱。按照标准亲和层析方案,在蛋白l柱(ge lifesciences)上进行亲和层析。在从亲和柱酸洗脱(ph 2.8)后直接进行尺寸排阻色谱,以使用superdex 200pg16/600柱(ge lifesciences)按照标准方案获得高纯度单体蛋白。使用根据预测的蛋白质序列计算的消光系数,在nanodrop系统(thermo scientific)上测定蛋白质浓度。如有需要,使用vivaspin装置(sartorius)调整浓度。最后,将纯化的分子在2-8℃温度下以约1mg/ml的浓度保存在磷酸盐缓冲盐水(dpbs,ph 7.2)中。透过计算产量来评估每个分子的产率[纯化的毫克蛋白/升细胞上清液]。
[0721]
纯化的sctcr-fab抗原结合蛋白的品质,透过hplc-sec在mabpac sec-1色谱柱(5μm,7.8x300 mm)上测定,所述色谱柱在vanquish uhplc系统内包含300mm nacl的50mm磷酸钠ph 6.8中运行。检测器波长设定为214nm。使用相同的方法分析各分子的热应力样本(在40℃下以1mg/ml储存于dpbs中7或14天后)。诱导的聚集体按[聚集体百分比(应力后)]-[聚
集体百分比(开始时)]计算。单体回收率按[单体峰面积(应力后)]/[单体峰面积(开始时)]
×
100%计算。如图7a所示,不同的sctcr变体之间观察到产量(左图)和热应力稳定性存在明显差异。含有野生型cdr序列并与两个框架突变(as19a,af57y)组合的稳定sctcr变体s(seq id no:124)只能以低水平表达。亲和力成熟的cdra2、cdra3和cdrb1序列(变体#1)和亲和力成熟的cdra2、cdra3和cdrb1序列掺在一起且亲和力成熟的cdrb2序列与相邻框架突变bi66c(变体i)结合后,可提高表达水平并提高热应力稳定性。使用两个cdr成熟的sctcr变体i和#1测试了框架区的进一步修饰情况,以提高表达产量和热应力稳定性。3个构架突变(al50p、bm46p和bm47g)掺入变体#1产生更高产量的变体#30,可透过将构架突变as19a替换为as19v(变体#32)来进一步提高产量。变体#29(代表具有as19反向突变的变体#32)突出显示了as19a或as19v突变的影响,这使产率大大降低并且聚集水平升高。值得注意的是,as19反向突变对产量的负面影响可透过引入框架突变aa48k(变体#31)逆转。在cdr成熟的sctcr变体i的背景下,β链cdr3中另一个框架突变bi54f(变体#19)和bn109d突变(变体#20)以单独或组合(变体#21)的形式进行了测试。cdrb3中的突变bn109d将nt-基序(可能易于对asn残基进行脱醯胺化)转化为dt基序,这可能有利于设计移除cdr序列内序列责任的方法。将bi54f框架突变引入变体i(变体#19)提高了产量并提高了sctcr的热应力稳定性。将cdrb3突变bn109d额外引入变体#19产生了sctcr变体#21,热应力稳定性进一步大大改善,尽管与变体i相比,单独的bn109d突变(变体#20)仅显示产率稍有提高且稳定性类似。
[0722]
sctcr-fab抗原结合蛋白对与hla-a*02复合的seq id no:1mage-a抗原肽的结合亲和力透过生物膜层干涉法进行了分析。使用制造商推荐的设置在octet red384系统上进行测量。简言之,在30℃和1000rpm转速下以pbs、0.05%吐温-20、0.1%bsa用作缓冲液来测量结合动力学。在分析连续稀释的肽-hla-a*02复合体之前,将双特异性分子载入到生物感测器(fab2g)上。包含稳定的sctcr变体s(seq id no:123和124)的双特异性抗原结合蛋白,在浓度高达500nm时仅显示非常弱的结合信号(图7b,表5)。引入亲和力成熟的cdra2、cdra3和cdrb1序列(变体#1和变体#2)可大大改善与靶肽-mhc的结合。变体#1(seq id no:80、58)和变体#2(seq id no:80、76)的kd值测定为2-3nm。成熟的cdrb2序列与框架突变bi66c一起额外纳入sctcr变体#2使变体i(seq id no:80、126)的结合亲和力进一步提高,测得kd为150pm。
[0723]
表5:变体s(seq id no:123、124)、#1、#2和i(seq id no:80分别与58、76或126组合)的框架突变、cdr组合和kd值。透过生物膜层干涉法测量kd值。
[0724][0725]
*浓度高达500nm时无相关结合信号
[0726]
sctcr-fab抗原结合蛋白的特异性透过分析与hla-a*02复合的潜在脱靶肽的结合而进一步对其特征进行表述。基于透过相似性blast搜索确定的序列相似性,从正常组织提呈的hla-a*02结合肽数据库(xpresident数据库)中选择潜在脱靶肽。结合情况基本上如上所述透过生物膜层干涉法分析。所有相互作用的结合信号在双特异性sctcr-fab浓度1μm下使用his1k生物感测器载入肽-hla-a*02复合体来测定。分析了潜在脱靶肽缔合阶段结束时的结合反应。与sctcr变体i(seq id no:80、126)相比,包含额外框架突变bi54f的变体#19(seq id no:80、125)除了如上所示产量和稳定性提高以外,结合特异性也改善(图7c,表6)。尽管两种变体的mag-003(seq id no:1)结合曲线相似(图7c),但变体#19缺乏结合信号(表6),显示与脱靶肽syne3-001(seq id no:27)、tpx2-001(seq id no:26)和psme2-001(seq id no:30)的结合消失。
[0727]
表6:具有sctcr变体i(seq id no:80、126)和变体#19(seq id no:80、125)的sctcr-fab抗原结合蛋白的特异性。透过生物膜层干涉法测量了1μm双特异性抗体的结合动力学。缔合阶段结束时的反应(以nm或mag-003信号的百分比表示)如下。
[0728][0729]
实施例5:双特异性tcer
tm
分子的生产、纯化和特征分析
[0730]
图15显示了根据本公开一实施方案所述的双特异性tcer
tm
分子。双特异性t细胞衔接受体(tcer
tm
)为融合蛋白,其包含亲和力成熟的tcr的可变结构域(vα,vβ)和人源化t细胞
募集抗体的可变结构域(vh,v
l
)。分子使用效应子功能沉默的fc部分,可延长半衰期,同时提高稳定性/可制造性。
[0731]
双特异性tcer
tm
分子的设计基于具有优选cdr和框架突变的选定tcrα和β链可变结构域。将sctcr变体#21的各tcr可变结构域与有益的框架突变as19v和aa48k组合,从而获得tcr变体#114-iso0(seq id no:138和seq id no:150)。为了进一步优化tcr#114-iso0的可变结构域序列,分别位于cdra1(ad27e)和cdra2(as65q)内的两个潜在异构化位点(ds-诱发因素)进行取代,从而获得tcr变体#114-iso1(seq id:151和seq id no:150)和114-iso2(seq id:152和seq id no:150),其分别在cdr内具有一个或没有翻译后修饰共有序列。上述tcr变体#114-iso0、#114-iso1和#114-iso2的可变结构域与v
l-和v
h-结构域组合,v
l-和v
h-结构域分别源自衍生自两个新人源化t细胞募集抗体bma031(36)(seq id no:159和160)、ucht1(17)(seq id no:153和154)的变体以及不同的ucht1(17)变体ucht1(17opt)(seq id no:153和162)、ucht1(21)(seq id no:153和164)和ucht1(23)(seq id no:153和156)。
[0732]
我们使用tcr/抗体双抗体-fc形式设计了tcer
tm
分子(表7中所示的示例性全长序列)和带有单顺反子的各载体(由hcmv衍生的启动子元件puc19衍生物控制)。根据标准培养方法在大肠杆菌中扩增质粒dna,随后使用市售套件(macherey&nagel)纯化。纯化的质粒dna用于透过电穿孔系统(maxcyte stx)暂态转染cho-s细胞。将转染的cho细胞在32℃至37℃下培养10-12天,并接受一至三次cellboost 7a和7b(ge healthcare
tm
)溶液进料。
[0733]
表7:用于产生tcer
tm
分子各变体的tcr可变结构域序列和t细胞募集抗体可变结构域序列的组合。为了进行转染,含有a链的质粒与含有b链的质粒混合。
[0734]
tcer
tm
分子a链seq id no:b链seq id no:114-iso0-ucht1(17)127130114-iso1-ucht1(17)131130114-iso2-ucht1(17)133130114-iso0-bma(36)135136114-iso1-bma(36)137136114-iso2-bma(36)139136
[0735]
利用sartoclearlab filter aid(sartorius)透过过滤(0.22μm)澄清条件细胞上清液。使用配备的pure 25l fplc系统(ge lifesciences)纯化双特异性抗原结合蛋白,以线上进行亲和力和尺寸排阻色谱。按照标准亲和层析方案,在mabselect sure或蛋白l柱(ge lifesciences)上进行亲和层析。在从亲和柱洗脱(ph 2.8)后直接进行尺寸排阻色谱,以使用superdex 200pg 26/600柱(ge lifesciences)按照标准方案获得高纯度单体蛋白。使用根据预测的蛋白质序列计算的消光系数,在nanodrop系统(thermo scientific)上测定蛋白质浓度。如有需要,使用vivaspin装置(sartorius)调整浓度。最后,将纯化的分子在2-8℃温度下以约1mg/ml的浓度保存在磷酸盐缓冲盐水中。
[0736]
纯化的双特异性抗原结合蛋白的品质,透过hplc-sec在mabpac sec-1色谱柱(5μm,4x300 mm)上测定,所述色谱柱在vanquish uhplc系统内包含300mm nacl的50mm磷酸钠ph 6.8中运行。检测器波长设定为214nm。诱导的聚集体按[聚集体百分比(应力后)]-[聚集
体百分比(开始时)]计算。单体回收率按[单体峰面积(应力后)]/[单体峰面积(开始时)]
×
100%计算。
[0737]
图8a显示了不同tcer
tm
分子的产率和应力稳定性资料。除了变体114-iso1-ucht1(17opt)外,所有其他变体的产量均超过10mg/l(图8,左图)。40℃下进行的分子热应力测试提示,经受14天热应力后,所有产生的tcer
tm
分子具有非常好至可接受的稳定性,聚集体形成均少于10%(图8a,右图)。
[0738]
对于双特异性tcer
tm
抗原结合蛋白(包含tcr变体114-iso0、114-iso1和114-iso2分别与ucht1(17)和bma031(36)组合,如表7所示),使用生物膜层干涉法对其与和hla-a*02复合的mage-a抗原肽(seq id no:1)的结合亲和力(图8a,表8)特征进行了分析。使用制造商推荐的设置在octet red384系统上进行测量。简言之,在30℃和1000rpm转速下以pbs、0.05%吐温-20、0.1%bsa用作缓冲液来测量结合动力学。在分析连续稀释的双特异性tcer
tm
分子之前,将肽-hla-a*02复合体载入到生物感测器(his1k)上。tcer
tm
变体114-iso0、114-iso1和114-iso2与和hla-a*02复合的mag-003强烈结合,可相比的kd值分别为1.8nm、2.0nm和2.3nm,表明hla-a*02/mag-003的结合不受移除tcr可变α结构域cdra1(ad27e)和cdra2(as65q)中两个异构化位点影响。
[0739]
表8:tcer
tm
变体114-iso0、114-iso1和114-iso2与ucht1(17)和bma031(36)组合(如表7所示)的亲和力分析。kd值透过生物膜层干涉法测量。
[0740][0741]
tcr变体114-iso0、114-iso1和114-iso2的特异性,透过使用生物层干涉分析法分析与正常组织来源脱靶肽的结合,对其进行了表征。如上所述进行了测量。对于114-iso0-ucht1(17)对与hla-a*02复合的mag-003(seq id no:1)和脱靶肽cnot1-003(seq id no:32)、col6a3-010(seq id no:179)、fam115a-001(seq id no:180)、heatr5a-001(seq id no:31)、herc4-001(seq id no:29)、ints4-002(seq id no:171)、phtf2-001(seq id no:181)、ppp1ca-006(seq id no:173)、rpl-007(seq id no:174)、rpp1-001(seq id no:182)、samh-001(seq id no:172)、setd1a-001(seq id no:175)的结合亲和力,进行了测定,并计算了亲和力窗。亲和力窗的范围为200倍以上至完全无脱靶结合(表9)。114-iso1-bma(36)和114-iso2-ucht1(17)的特异性透过测量以1μm tcer
tm
的浓度和与hla-a*02复合的mag-003(seq id no:1)和脱靶肽odc-001(seq id no:178)、nomap-1-0320(seq id no:176)和nomap-1-1223(seq id no:177)的结合信号来分析(图8c,表10)。检测到mag-003信号1%或更低的结合反应,表明tcr变体对mag-003具有高度特异性。
[0742]
表9:tcer
tm
分子114-iso0-ucht1(17)的特异性。透过生物层干涉法分析114-iso0-ucht1(17)的系列稀释液(500nm、250nm、125nm、62.5nm)来测量kd值。亲和力窗计算为kd(相似肽)/kd(mag-003)。
[0743][0744][0745]
表10:tcer
tm
分子114-iso1-bma(36)和114-iso2-ucht1(17)的特异性。透过生物膜层干涉法测量了1μm tcer
tm
的结合动力学。缔合阶段结束时的反应(以nm或mag-003信号的百分比表示)如下。
[0746][0747]
实施例6:tcer
tm
介导的mag-003阳性和肿瘤细胞系杀伤
[0748]
成熟的tcr变体以tcr/抗cd3双抗体-fc形式表示为可溶性tcer
tm
分子#114-iso0-ucht1(17)、#114-iso1-ucht1(17)、#114-iso2-ucht1(17)、#114-iso0-bma031(36)、#114-iso1-bma031(36)和#114-iso2-bma031(36)(另请参见表7)。双特异性tcer
tm
分子对抗mag-003阳性和mag-003阴性肿瘤细胞系的细胞毒活性分别透过ldh-释放测定法分析。因此,在tcer
tm
分子浓度递增情况下,将细胞表面上提呈不同量hla-a*02/mag-003分子的肿瘤细胞系与来自健康hla-a*02 供体的pbmc共同孵育。48小时后,利用cytotox 96非放射性细胞毒性测定套件(promega)测量靶细胞系的裂解情况。如图9和图10所示,根据基于质谱法的hla-a*02/mag-003复合体定量测定结果,tcer
tm
分子显示可有效裂解mag-003阳性肿瘤细胞系hs695t、a375和u2os(分别展示1100、230和120拷贝/肿瘤细胞)。为了进行杀伤力测定,使用来自两个健康供体的pbmc(图9中的hbc-720和图10中的hbc-982)。在同一实验中,对于表达hla-a*02但不提呈可检测水平mag-003肽的bv-173细胞系,双特异性tcer
tm
分子未诱导出细胞裂解或仅诱导了少量细胞裂解,表明tcr结构域具有特异性。
[0749]
实施例7:在负有异种移植瘤的nog小鼠中的体内疗效
[0750]
在免疫力高度缺陷的nog小鼠品系中进行了药效学研究,目的是检测tcer
tm
分子透过与t细胞抗原特异性结合以及与人癌症细胞上的人肿瘤特异性hla-肽复合体特异性结合来募集人免疫t细胞活性的能力。负有皮下注射人肿瘤细胞系hs695t的nog小鼠品系透过静脉注射人外周血单核(pbmc)细胞异种移植物。当根据卡尺法测量值计算单个hs695t肿瘤体积达到50mm3时,在24小时内移植人pbmc(1x107个细胞/小鼠)。人血细胞移植后一小时内开始治疗。每组8至10只雌性小鼠(根据肿瘤大小随机分组)接受尾静脉静脉推注(5ml/kg体重,每周两次,共6剂)。tcer
tm
分子的注射剂量为0.5(第2组)和0.05(第3和第4组)mg/kg体重x注射,溶媒对照组(第1组)使用pbs。如图11所示,单个小鼠用tcer
tm
分子治疗诱导出明显的抗肿瘤反应。用靶向作用于prame-004(seq id no:168)的tcer
tm
(seq id no:169和170)(第2组)治疗可强烈抑制肿瘤生长(肿瘤平均体积增加下降),在第25天时,该治疗组的肿瘤平均体积从基础水平(开始随机分组时)的90mm3增加至209mm3,而相比之下,第25天时,观察到溶媒对照组1从基础水平的74mm3增加至1081mm3。用靶向作用于mag-003的tcer
tm
治疗(seq id no:127和130,第3组;seq id no:135和136,第4组)在第18天至第25天研究结束时在所有小鼠中均诱导出hs695t肿瘤完全缓解,相较于随机分组日时的基础水平为86mm3(第3组)和80mm3(第4组)。
[0751]
实施例8:原代健康细胞的体外安全性
[0752]
tcer
tm
分子114-iso1-bma(36)的安全性特征在使用来自不同器官的人正常组织原代细胞进行的ldh杀伤实验中进行了评估。图12显示了11种不同原代正常组织细胞(hla-a*02 )与来自健康hla-a*02 供体的pbmc效应细胞在tcer
tm
浓度递增的情况下以1:10的比例共培养的结果。细胞在健康组织原代细胞特异性培养基和t细胞培养基1:1比例混合物中进行了共孵育。为了确定安全窗,在正常组织原代细胞的相应培养基组合物中,tcer
tm
分子在相同的环境下与mag-003阳性肿瘤细胞系hs695t进行了共孵育。共培养48小时后,收集上清液,并使用ldh-glo
tm
套件(promega)透过测量ldh释放来分析肿瘤细胞的裂解情况。
[0753]
在图12中,各细胞毒性图显示了在pbmc和递增浓度的tcer分子共孵育后,在相同培养基组合物下,正常组织原代细胞类型(空心圆圈)相对于对照肿瘤细胞系hs695t(实心圆圈)的ldh释放。在所有情况下,对正常组织原代细胞的反应都过低,无法计算ec50。相反,我们基于最低观测效应水平(loel)定义了安全窗,所述loel确定为超过临界值反应的首个tcer
tm
浓度。临界值定义为([所有三份样本的标准差x 3] 不含tcer
tm
的正常对照组织样本),在各细胞毒性图中以虚线表示。对于每种正常组织细胞类型,基于loel的安全窗被确定大于1,000倍。
[0754]
在第二项ldh杀伤力实验中,使用12种不同原代健康组织细胞(hla-a*02 ),其中一些细胞与第一次实验重叠,评估了tcer
tm
分子114-iso1-bma(36)的安全性特征。实验条件如上所述。
[0755]
在图16中,各细胞毒性图显示了在pbmc和递增浓度的tcer
tm
分子共孵育后,在相同培养基组合物下,正常组织原代细胞类型(空心圆圈)相对于对照肿瘤细胞系hs695t(实心圆圈)的ldh释放。在所有情况下,对正常组织原代细胞的反应都过低,无法计算ec
50
。相反,我们基于最低观测效应水平(loel)定义了安全窗,所述loel确定为超过临界值反应的首个tcer
tm
浓度。临界值定义为([所有三份样本的标准差x 3] 不含tcer
tm
的正常对照组织样
本),在各细胞毒性图中以虚线表示。对于每种正常组织细胞类型,基于loel的安全窗被确定大于1,000倍。
[0756]
实施例9:在负有异种移植瘤的nog小鼠中每周一次治疗的体内疗效
[0757]
在超免疫缺陷nog小鼠品系中进行了药效学研究,目的是检测tcer
tm
分子透过与t细胞抗原特异性结合以及与人癌症细胞上的人肿瘤特异性hla-肽复合体特异性结合来募集人免疫t细胞活性的能力。容留皮下注射人肿瘤细胞系hs695t的nog小鼠品系透过静脉注射人外周血单核(pbmc)细胞异种移植物。当根据卡尺法测量值计算单个hs695t肿瘤体积达到50mm3时,在24小时内移植人pbmc(1x107个细胞/小鼠)。人血细胞移植后一小时内开始治疗。每组6至10只雌性小鼠(根据肿瘤大小随机分组)接受尾静脉静脉推注(5ml/kg体重,每周一次,共3剂)。tcer
tm
分子的注射剂量为0.01mg/kg体重x注射(第2组和第3组),溶媒对照组(第1组)使用pbs。如图13所示,用tcer
tm
分子治疗诱导出明显的抗肿瘤反应。使用mag-003tcer
tm
分子114-iso1-bma(36)(seq id no:137和136,第2组)和114-iso1-ucht1(v17opt)(seq id no:131和167,第3组)治疗第21天时,在所有小鼠中诱导了hs695t肿瘤缓解。第21天时肿瘤平均体积增加从基础水平(开始随机分组时)的84mm3下降至8mm3(第2组)和83mm3下降至14mm3(第3组),而相比之下,第21天时,溶媒对照组(第1组)观察到从基础水平的85mm3增加至1024mm3,这提示治疗强烈抑制了肿瘤生长。第2组和第3组发现各有2只小鼠获得完全缓解。
[0758]
实施例10:nog小鼠中的体内药代动力学
[0759]
在接受2mg/kg体重单次静脉内注射的超免疫缺陷nog小鼠中,分析了tcer
tm
114-iso1-ucht1(17)(seq id no:130和131)的药代动力学特性。在不同时间点(0h、0.1h、2h、8h、24h、48h、120h、240h和360h)从眼球后丛中收集血浆样本。透过elisa、使用两种不同的测定法设置(fc
–vl
测定法和cd3
–
pmhc测定法)来测定114-iso1-ucht1(17)的血浆水平。使用fc-v
l
测定法设置、透过检测各蛋白质亚单位来定量tcer
tm
血浆水平。简言之,用2μg/ml浓度的山羊抗人igg fc(在pbs中)在4℃下包被过夜。使用含有2%bsa的pbs封闭其余的结合位点。在用蛋白质l-hrp和
tm
b受质溶液检测之前,使在封闭缓冲液中稀释的样本在室温下孵育1个小时。使用cd3
–
pmhc测定法,透过tcer
tm
114-iso1-ucht1(17)的双特异性结合活性,仅测量能够同时与两个靶分子结合的分子来测定其血浆水平。透过将人cd3δ和cd3ε的细胞外结构域与fc结构域的n端融合生成cd3δε-fc,如tcer
tm-构建体(包含杵臼结构突变和其他c端his-标签)内使用的一样。cd3δε-fc分子在expicho细胞中表达,先使用蛋白a亲和力色谱法、接着使用如上所述的尺寸排阻色谱法进行纯化。用1μg/ml浓度的cd3δε-fc(在pbs中)在4℃下包被过夜。如上所述进行封闭和样本孵育,然后使用hla-a*02/mag-003和抗b2m-hrp进行两步法检测。透过从相应的标准曲线插补获得样本的血浆浓度。两种测定法设置均可测定出相似的tcer
tm
血浆浓度,表明血浆中的分子保留了蛋白质完整性以及结合活性(图14)。24h、48h、120h、240h和360h时间点的线性回归显示血浆终末半衰期为150h。结果表明114-iso1-ucht1(17)的半衰期(t1/2)约为6-7天。
[0760]
实施例11:透过质谱法检测原代组织上的mag-003肽
[0761]
对来自急速冷冻的组织样本的hla分子进行纯化,并分离hla相关肽。将分离的肽分开,并透过线上纳米-电喷雾-电离(nanoesi)液相色谱-质谱(lc-ms)实验鉴定序列。多个组织样本上鉴定的mag-003用无标记lc-ms资料的离子计数方法进行量化。所述方法假定肽
的lc-ms信号区域与样本中其丰度相关。各种lc-ms实验中肽的所有量化信号在集中趋势基础上进行归一化,根据每个样本进行平均,并合并入图(被称为提呈图)。提呈图整合了不同分析方法,如:蛋白资料库检索、谱分群、电荷状态解卷积(除电)和保留时间校准。对所有自动得出的定量和定性资料进行了手动检查(参见图18)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。