预测brca突变患者对侧乳腺癌发病风险的模型及应用
技术领域
1.本技术涉及医疗技术领域,尤其涉及预测brca突变患者对侧乳腺癌发病风险的模型及应用。
背景技术:
2.5%-10%的乳腺癌病例具有家族聚集现象,且被证实其肿瘤发生与特定的易感基因相关。其中,brca1和brca2基因是最重要的两个乳腺癌易感基因。携带brca1和brca2突变的欧美健康女性患者终身累积乳腺癌发病风险可达70%,且家系中有2名及以上乳腺癌患者的健康携带者其乳腺癌发病风险是无家族史携带者的2倍左右。来自中国的研究数据发现,携带brca1/2突变的中国健康女性到70岁累积乳腺癌发病风险为37.9%和36.5%,是一般中国健康女性乳腺癌发病风险(3.6%)的10倍左右。更重要的是,已经确诊为单侧乳腺癌的brca1/2突变携带者,对侧乳腺癌的发病风险也显著升高。国外研究显示, brca1/2突变携带者的对侧乳腺癌发病风险为2%-4%/年,显著高于一般散发乳腺癌人群(0.4%/年)。
3.因此,现在亟需可以个体化预测brca1/2突变携带者的对侧乳腺癌发病风险的方法,以协助临床决策。
技术实现要素:
4.为解决现有技术中的问题,本技术实施例提供了预测brca突变患者对侧乳腺癌发病风险的模型及应用,解决现有技术中评估brca突变乳腺癌患者对侧乳腺癌风险模型不够准确的问题。
5.本技术实施例提供了一种预测brca突变患者对侧乳腺癌发病风险的模型,包括,所述模型为:lp=β1×
x1 β2×
x2 β3×
x3 β4×
x4;其中,lp为风险分值;x1为突变位点靠近brca1/2基因的3' cdna编码区的风险因素,x2为一级亲属乳腺癌和卵巢癌家族史的风险因素,x3为乳腺癌首诊年龄的风险因素,x4为激素受体状态的风险因素,β1、β2、β3、β4为各项风险因素的偏回归系数。
6.作为本技术实施例的一个方面,所述风险因素x1的偏回归系数β1取值范围为0.72-0.75,所述风险因素x2的偏回归系数β2取值范围为0.73-0.76,所述风险因素x3的偏回归系数β3取值范围为0.79-0.82,所述风险因素x4的偏回归系数β4取值范围为0.62-0.64。
7.作为本技术实施例的一个方面,所述突变位点靠近brca1/2基因的3' cdna编码区具体包括:突变位点位于brca1 c.4072 to 3'或brca2 c.6402 to 3'区域。
8.作为本技术实施例的一个方面,所述突变位点为brca突变乳腺癌患者的brca1/2突变位点,若患者的突变位点位于brca1 c.4072-3'或brca2 c.6402-3'则x3为1,患者的突变位点位于brca1 5'-c.4071或brca2 5'-c.6401则x3为0;所述一级亲属乳腺癌和卵巢癌家族史为brca突变乳腺癌患者的一级亲属乳腺癌和卵巢癌家族史,当一级亲属乳腺癌和卵巢癌家族史≥1例时,x2为1,无一级亲属乳腺癌和卵巢癌家族史时,x2为0;所述乳腺癌首诊
年龄为brca突变乳腺癌患者的乳腺癌首诊年龄,当乳腺癌首诊年龄≤45岁时,x1为1,当乳腺癌首诊年龄>45岁时,x1为0;所述激素受体状态为brca突变乳腺癌患者的激素受体状态,当激素受体阳性时,x4为1,当激素受体阴性时,x4为0。
9.作为本技术实施例的一个方面,通过列线图来展示上述模型的预测结果,其中列线图第一行为分值标尺;第二行为brca1/2突变位点,突变位点为brca1 c.4072-3'或brca2 c.6402-3'则选择“within 3'_cluster_region”,患者的突变位点为brca1 5'-c.4071或brca2 5'-c.6401则选“outside 3'_cluster_region”, 所述brca1/2突变位点分别对应第一行的一个相应分值;第三行为患者一级亲属乳腺癌和卵巢癌家族史,分别为一级亲属乳腺癌和卵巢癌家族史≥1例一级患病亲属,以及无一级患病亲属,并分别对应第一行一个相应分值;第四行为患者乳腺癌首诊年龄,分别为乳腺癌首诊年龄≤45,以及乳腺癌首诊年龄》45,并分别对应第一行一个相应分值;第五行为患者激素受体状态,分别为激素受体状态呈阳性,以及激素受体状态呈阴性,并分别对应第一行的相应分值;第六行为患者总分值,将第二至第五行的4个指标在第一行对应的分值进行相加,得出总分值,在第六行选择总分分值,对应投射至第七、八行上,分别得出患者5年及10年的对侧乳腺癌发病风险预测值。
10.本技术实施例还提供了一种构建所述模型的方法,包括,选取诊断为单侧乳腺癌、检测有brca1/2致病胚系突变的乳腺癌患者的样本数据;通过cox比例风险模型筛选所述样本数据中的突变位点靠近brca1/2基因的3' cdna编码区、一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄、激素受体状态进行多因素分析;得到所述模型为:lp=β1×
x1 β2×
x2 β3×
x3 β4×
x4;其中,lp为风险分值;x1为突变位点靠近brca1/2基因的3' cdna编码区的风险因素,x2为一级亲属乳腺癌和卵巢癌家族史的风险因素,x3为乳腺癌首诊年龄的风险因素,x4为激素受体状态的风险因素,β1、β2、β3、β4为各项风险因素的偏回归系数。
11.本技术实施例还提供了一种利用上述模型的预测方法,包括,获取待测用户的数据;将所述待测用户的数据输入到所述模型中,计算该待测用户针对不同累积时间的brca突变患者对侧乳腺癌发病风险评估值。
12.本技术实施例还提供了一种构建如上述模型的装置,包括,训练样本数据获取单元,用于选取诊断为单侧乳腺癌、检测有brca1/2致病胚系突变的乳腺癌患者的样本数据;数据分析单元,用于通过cox比例风险模型筛选所述样本数据中的突变位点靠近brca1/2基因的3' cdna编码区、乳腺癌首诊年龄、一级亲属乳腺癌和卵巢癌家族史、激素受体状态进行多因素分析;模型输出单元,用于得到所述模型:lp=β1×
x1 β2×
x2 β3×
x3 β4×
x4;其中,lp为风险分值;x1为突变位点靠近brca1/2基因的3' cdna编码区的风险因素,x2为一级亲属乳腺癌和卵巢癌家族史的风险因素,x3为乳腺癌首诊年龄的风险因素,x4为激素受体状态的风险因素,β1、β2、β3、β4为各项风险因素的偏回归系数。
13.本技术实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法。
14.本技术实施例还提供了一种计算机可读存储介质,其上存储有计算机指令,该计算机指令被处理器执行时实现上述的方法。
15.利用本技术实施例,可以更加准确的对brca突变乳腺癌患者对侧乳腺癌风险进行预测;并且通过真实病例的验证,本技术实施例的brca突变乳腺癌患者对侧乳腺癌风险模型对对侧乳腺癌发病风险的准确度都较高;与现有其他模型相比较,预测结果也更加准确。
附图说明
16.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
17.图1所示为本技术实施例一种预测brca突变患者对侧乳腺癌发病风险的模型的建立方法流程图;图2所示为本技术实施例一种应用预测brca突变患者对侧乳腺癌发病风险的模型的预测方法的流程图;图3所示为本技术实施例一种预测brca突变患者对侧乳腺癌发病风险的模型的建立装置的结构示意图;图4所示为本技术实施例建立的预测brca突变乳腺癌人群对侧乳腺癌发病风险的列线图;图5所示为本技术实施例预测的5年无对侧乳腺癌生存几率与患者真实的5年无对侧乳腺癌生存几率的校正曲线图;图6所示为本技术实施例预测的10年无对侧乳腺癌生存几率与患者真实的10年无对侧乳腺癌生存校正曲线图;图7所示为本技术针对实施例1中brca突变乳腺癌患者对侧乳腺癌风险预测模型用于预测患者对侧乳腺癌累积发病风险的受试者操作特征曲线图;图8所示为本技术实施例一种计算设备的结构示意图。
18.【附图标记说明】301、训练样本数据获取单元;302、数据分析单元;303、模型输出单元;304、预测单元;802、计算设备;804、处理设备;806、存储资源;808、驱动机构;810、输入/输出模块;812、输入设备;814、输出设备;816、呈现设备;
818、图形用户接口;820、网络接口;822、通信链路;824、通信总线。
具体实施方式
19.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
20.突变携带者个体风险的高低因家族史、肿瘤临床病理参数等因素不同而不同。其中,乳腺癌首诊年龄和乳腺癌家族史是影响对侧乳腺癌发病风险的重要危险因素。据国外研究报道,brca1/2突变患者的对侧乳腺癌发病风险随着初诊年龄的增加而降低。例如美国的一项回顾性研究中,首诊年龄≤50岁和》50岁的brca1/2突变患者的10年累积风险分别为23.9%和14.7%;在另一项来自荷兰的研究中,乳腺癌首诊年龄≤40的brca1/2突变患者的10年对侧乳腺癌累积发病风险为23.9%,而41-50岁患者的风险为12.6%。目前多数研究证实,有乳腺癌家族史的突变患者相比无家族史的突变患者,对侧乳腺癌风险可以增加2-3倍。
21.经过本技术发明人的研究发现,对于我国女性,有乳腺癌家族史的brca1/2突变乳腺患者的10年对侧乳腺癌发病风险可达27%。此外,不同的brca1/2突变位点其乳腺癌发病风险也不同,突变位于brca1基因和brca2基因3'端的患者的乳腺癌发病风险高于基因中间区域。本技术的技术方案通过针对中国女性人群的分析,还采用了其他一些目前存在争议的高危因素作为brca突变乳腺癌患者对侧乳腺癌风险的高危因素。
22.对于乳腺癌高风险人群,临床上已有预防性乳腺全切手术、双侧卵巢预防性切除手术、药物预防、严密监测等多种干预手段。以预防性乳腺全切手术为例,一方面,该手术能有效降低90%以上的乳腺癌发病风险,且长期随访数据显示可以提高总体生存。另一方面,预防性乳腺全切手术仍然是一种有创手术操作,可能存在伤口感染、整形美容效果不佳等术后并发症。美国国家综合癌症网络(national comprehensive cancer network guidelines,nccn)降低乳腺癌风险指南(2020.v1)建议终生发病风险≥20%,且预期寿命≥10年的高风险患者进行专业咨询,决定是否接受预防性治疗方案。而如何准确预测brca突变乳腺癌患者对侧乳腺癌风险是采取后续诊断和治疗的前提条件,本技术的实施例提供了对患者对侧乳腺癌风险预测更加准确的模型,能够对例如5年、10年的brca突变乳腺癌患者对侧乳腺癌风险预测的auc(area under curve)可以分别达到0.765和0.669,优于国外针对乳腺癌一般人群的对侧乳腺癌发病风险预测模型(0.59-0.63)。
23.如图1所示为本技术实施例一种预测brca突变患者对侧乳腺癌发病风险的模型的建立方法流程图,在图1中描述了建立brca突变乳腺癌患者对侧乳腺癌风险预测模型的方法,在本技术的方法中将乳腺癌首诊年龄≤45岁,一级亲属乳腺癌和卵巢癌家族史,突变位点靠近brca1/2基因的3' cdna编码区,以及激素受体(雌激素或孕激素受体)状态作为brca1/2突变患者对侧乳腺癌风险的风险因素,训练得到预测brca突变患者对侧乳腺癌发病风险的模型,该方法具体包括:
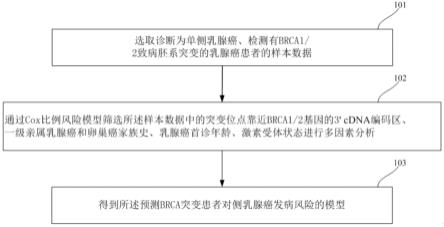
步骤101,选取诊断为单侧乳腺癌、检测有brca1/2致病胚系突变的乳腺癌患者的样本数据;步骤102,通过cox比例风险模型筛选所述样本数据中的突变位点靠近brca1/2基因的3' cdna编码区、一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄、激素受体状态进行多因素分析;步骤103,得到所述预测brca突变患者对侧乳腺癌发病风险的模型。
24.其中,预测brca突变患者对侧乳腺癌发病风险的模型为:lp=β1×
x1 β2×
x2 β3×
x3 β4×
x4;其中,lp为风险分值;x1为突变位点靠近brca1/2基因的3' cdna编码区的风险因素,x2为一级亲属乳腺癌和卵巢癌家族史的风险因素,x3为乳腺癌首诊年龄的风险因素,x4为激素受体状态的风险因素,β1、β2、β3、β4为各项风险因素的偏回归系数。
25.其中,cox比例风险模型是一种半参数回归模型,它可同时研究多个风险因素和事件结局发生情况、发生时间的关系。
26.作为本技术实施例的一个方面,在获取乳腺癌患者的样本数据之中还包括:通过dna测序技术和多重连接探针扩增技术(multiplex ligation-dependent probe amplification ,mlpa)筛选出所述brca1/2致病胚系突变乳腺癌患者。
27.在本实施例中,还可以采用其他技术对乳腺癌患者进行筛选,以上筛选方法只是举例说明,并不限制其他手段筛选得到所述brca1/2致病突变乳腺癌患者。
28.作为本技术实施例的一个方面,所述突变位点靠近brca1/2基因的3' cdna编码区具体包括:突变位点位于brca1 c.4072 to 3'或brca2 c.6402 to 3'区域。
29.在本实施例中,对于brca1/2突变位点的因子选择,目前没有研究报道过不同brca1/2突变位点对对侧乳腺癌发病风险的影响,本技术发明人发现当突变位于brca1 c.4072 to 3'或brca2 c.6402 to 3'区域时,经过多风险因素校正后,仍显著增加对侧乳腺癌发病风险,故纳入本技术的brca突变乳腺癌患者对侧乳腺癌风险预测模型。
30.作为本技术实施例的一个方面, 在lp=β1×
x1 β2×
x2 β3×
x3 β4×
x4中,x1为突变位点靠近brca1/2基因的3' cdna编码区的风险因素,x2为一级亲属乳腺癌和卵巢癌家族史的风险因素,x3为乳腺癌首诊年龄的风险因素,x4为激素受体状态的风险因素,β1、β2、β3、β4为各项风险因素的偏回归系数。
31.作为本技术实施例的一个方面,所述风险因素x1的偏回归系数β1取值范围为0.72-0.75,所述风险因素x2的偏回归系数β2取值范围为0.73-0.76,所述风险因素x3的偏回归系数β3取值范围为0.79-0.82,所述风险因素x4的偏回归系数β4取值范围为0.62-0.64。
32.所述突变位点为brca突变乳腺癌患者的brca1/2突变位点,若患者的突变位点位于brca1 c.4072-3'或brca2 c.6402-3'则x1为1,患者的突变位点位于brca1 5'-c.4071或brca2 5'-c.6401则x1为0;所述一级亲属乳腺癌和卵巢癌家族史为brca突变乳腺癌患者的一级亲属乳腺癌和卵巢癌家族史,当一级亲属乳腺癌和卵巢癌家族史≥1例时,x2为1,无一级亲属乳腺癌和卵巢癌家族史时,x2为0;所述乳腺癌首诊年龄为brca突变乳腺癌患者的乳腺癌首诊年龄,当乳腺癌首诊年龄≤45岁时,x3为1,当乳腺癌首诊年龄>45岁时,x3为0;所述激素受体状态为brca突变乳腺癌患者的激素受体状态,当激素受体阳性时,x4为1,当激
素受体阴性时,x4为0。
33.本技术实施例中基于brca突变乳腺癌患者的brca突变数据及临床特征数据基础,通过cox比例风险模型建立预测brca突变患者对侧乳腺癌发病风险的模型(后文称为预测模型)。所述预测模型具有个体化、简便等优点,能够对brca突变乳腺癌患者的对侧乳腺癌发病风险进行有效评估,对个体化风险监测、优化临床治疗决策及加强临床风险干预具有重要的指导意义。
34.如图2所示为本技术实施例一种应用预测brca突变患者对侧乳腺癌发病风险的模型的预测方法的流程图,在图2中描述了应用如上述图1所示预测brca突变患者对侧乳腺癌发病风险的模型的brca突变乳腺癌患者对侧乳腺癌风险预测方法,在本实施例中可以将待测用户的数据输入到所述brca突变乳腺癌患者对侧乳腺癌风险预测模型中得到分值,根据分值得到所述待测用户的风险评估值,该方法具体包括:步骤201,获取待测用户的数据;步骤202,将所述待测用户的数据输入到所述模型中,计算该待测用户针对不同累积时间的brca突变患者对侧乳腺癌发病风险评估值。
35.作为本技术实施例的一个方面,所述待测用户的数据包括:brca1/2基因突变位点、一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄(是否≤45岁)以及激素受体状态。
36.作为本技术实施例的一个方面,计算该待测用户针对不同累积时间的brca突变患者对侧乳腺癌发病风险评估值具体包括:采用列线图(nomogram)的评分方法针对突变位点靠近brca1/2基因的3' cdna编码区、一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄≤45岁以及激素受体状态中每一项的风险因素进行评分,将4种风险因素的评分相加后得到针对不同累积时间的brca突变患者对侧乳腺癌发病风险评估值。
37.作为本技术实施例的一个方面,所述累积时间包括以月为单位的累积时间,或者以年为单位的累积时间。
38.在本步骤中,累积时间可以例如为12个月、14个月、3年、5年或者10年。
39.上述本技术所采用的列线图对不同累积时间的brca突变患者对侧乳腺癌发病风险评估值进行计算只是本技术的一个实施例,还可以采用例如在网页上输入待测用户的数据,直接计算出不同累积时间的brca突变患者对侧乳腺癌发病风险评估值,即累积时间-风险可能性百分数的对应关系;或者针对大量待测人群进行不同累积时间的brca突变患者对侧乳腺癌发病风险评估时,可以采用其他形式的计算机软件程序来根据每个待测用户的4种风险因素输入到所述预测brca突变患者对侧乳腺癌发病风险的模型进行计算,并将风险预测(风险评估)结果集中输出,例如,将累积时间统一为同一个时间尺度,列出每个待测用户的风险评估结果(即百分数),或者利用其他统计软件根据风险评估结果列出其他形式的统计结果图示。
40.所述列线图可以参考本技术附图4,其中第一行为分值标尺;第二行为brca1/2突变位点,突变位点为brca1 c.4072-3'或brca2 c.6402-3'则选择“within 3'_cluster_region”,患者的突变位点为brca1 5'-c.4071或brca2 5'-c.6401则选“outside 3'_cluster_region”, 所述brca1/2突变位点分别对应第一行的一个相应分值;第三行为患者
一级亲属乳腺癌和卵巢癌家族史,分别为一级亲属乳腺癌和卵巢癌家族史≥1例一级患病亲属,以及无一级患病亲属,并分别对应第一行一个相应分值;第四行为患者乳腺癌首诊年龄,分别为乳腺癌首诊年龄≤45,以及乳腺癌首诊年龄》45,并分别对应第一行一个相应分值;第五行为患者激素受体状态,分别为激素受体状态呈阳性,以及激素受体状态呈阴性,并分别对应第一行的相应分值;第六行为患者总分值,将第二至第五行的4个指标在第一行对应的分值进行相加,得出患者总分值,在第六行选择患者总分值,对应投射至第七、八行上,分别得出患者5年及10年的对侧乳腺癌发病风险预测值。
41.如图3所示为本技术实施例一种预测brca突变患者对侧乳腺癌发病风险的模型的建立装置的结构示意图,在图3中描述了通过计算机通用处理芯片或者特定处理芯片构成的模型建立装置,该装置中的各个功能模块、单元可以通过软件程序实现,也可以通过在通用或者特定处理芯片中烧制特定的逻辑电路来实现,具体包括:训练样本数据获取单元301、数据分析单元302;训练样本数据获取单元301,用于选取诊断为单侧乳腺癌、检测有brca1/2致病胚系突变的乳腺癌患者的样本数据;数据分析单元302,用于通过cox比例风险模型筛选所述样本数据中的突变位点靠近brca1/2基因的3' cdna编码区、乳腺癌首诊年龄、一级亲属乳腺癌和卵巢癌家族史、激素受体状态进行多因素分析;模型输出单元303,用于得到所述模型为:lp=β1×
x1 β2×
x2 β3×
x3 β4×
x4;其中,lp为风险分值;x1为突变位点靠近brca1/2基因的3' cdna编码区的风险因素,x2为一级亲属乳腺癌和卵巢癌家族史的风险因素,x3为乳腺癌首诊年龄的风险因素,x4为激素受体状态的风险因素,β1、β2、β3、β4为各项风险因素的偏回归系数。
42.作为本技术实施例的一个方面,所述训练样本数据获取单元301进一步用于筛选出brca1/2致病突变乳腺癌患者的临床病理参数和brca1/2突变信息作为训练样本数据。
43.其中,所述brca1/2致病突变乳腺癌患者的临床病理参数包括乳腺癌首诊年龄≤45岁、一级亲属乳腺癌和卵巢癌家族史以及激素受体状态,所述brca1/2突变信息包括突变位点靠近brca1/2基因的3' cdna编码区。
44.在其他的实施例中,还包括例如连接医院信息管理系统(his)数据库的通信单元,用于获取待测使用者的一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄等信息,还包括例如相应的检测仪器,用于获取激素受体状态和突变位点靠近brca1/2基因的3' cdna编码区的信息。
45.更加具体的,所述突变位点靠近brca1/2基因的3' cdna编码区具体包括:突变位点位于brca1 c.4072 to 3'或brca2 c.6402 to 3'区域。
46.在上述预测brca突变患者对侧乳腺癌发病风险的模型的建立装置的基础之上还包括,预测单元304,用于将所述待测用户的数据输入到所述模型中,计算该待测用户针对不同累积时间的预测brca突变患者对侧乳腺癌发病风险模型的评估值。
47.通过上述本技术的实施例,通过针对中国brca突变乳腺癌患者的样本数据,形成了以突变位点靠近brca1/2基因的3' cdna编码区、一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄以及激素受体状态作为风险因素的对侧乳腺癌风险预测模型,可以更加准确的对中国brca突变乳腺癌患者进行对侧乳腺癌风险预测,其中选择的4种风险因素中,考虑到
中国的“小家庭”的特点将一级亲属乳腺癌和卵巢癌家族史作为风险因素,并且创新的考虑到突变位点靠近brca1/2基因的3' cdna编码区的特点,预测模型更加贴近中国brca突变乳腺癌患者的特殊情况,使得预测结果更加准确;通过列线图等表现手段,可以让使用者更加方便的向待预测用户进行解释和比较,适于对一对一、小样本人群进行风险评估,列线图使用图表的形式简单且易于操作,在临床医师和病人一对一进行遗传咨询和制定临床决策时,具有简洁经济的优点;也可以使用r语言等特定计算机软件处理,通过输入4个高危因素的信息,计算过程无需人工操作,从而实现计算和结果呈现;还可以根据预测结果对应不同发病风险的个体化治疗指导模型,以方便使用者对病患进行后续的诊断和治疗。
48.实施例1根据患者的临床病理参数和brca1/2突变信息从医疗数据库中筛选出491名2003年至2015年诊断为单侧乳腺癌且检测有brca1/2突变的患者,这些患者的数据被纳入训练样本数据。中位随访时间为7.5年。该部分人群入排标准为:排除iv期乳腺癌,排除临床病理信息记录不完整者,排除接受对侧预防性乳房全切手术者,排除随访时间少于6个月者。
49.将风险因素分为遗传因素和临床因素两大类,其中,遗传因素主要包括brca1/2突变类型、brca1/2突变位点和肿瘤家族史;临床因素主要包括乳腺癌首诊年龄、绝经状态、肿瘤大小、组织学类型、组织学分级、激素受体、her2状态、淋巴结状态、化疗、放疗和双侧卵巢-附件切除手术。
50.通过cox比例风险模型进行多风险因素回归计算后,最终选择brca1/2突变位点(即突变位点靠近brca1/2基因的3' cdna编码区,后续称为brca1/2突变位点),一级亲属乳腺癌和卵巢癌家族史,乳腺癌首诊年龄和激素受体4种风险因素来进行多因素分析。
51.使用cox比例风险模型的多因素分析显示,brca1/2突变位点 (hr=2.09; 95% ci, 1.27-3.42; p=0.004),一级亲属乳腺癌和卵巢癌家族史(hr=2.12; 95% ci, 1.30-3.46; p=0.003),乳腺癌首诊年龄(hr=2.25; 95% ci, 1.34-3.79; p=0.002)和激素受体(hr=1.85; 95% ci, 1.13-3.01; p=0.014)是影响对侧乳腺癌风险的显著因素。
52.其中,当突变位于brca1 c.4072 to 3'或brca2 c.6402 to 3'区域时,经过多因素校正后,仍显著增加对侧乳腺癌发病风险,故纳入brca突变乳腺癌患者对侧乳腺癌风险预测模型建立,且该项因子从未被纳入既往报道的乳腺癌发病风险预测模型中;针对于中国brca突变乳腺癌患者病例的特点,选择了乳腺癌首诊年龄≤45岁,而非≤50岁能更准确的预测中国brca突变人群的对侧乳腺癌发病风险。
53.对于肿瘤家族史的哑变量选择,国外有研究报道一级亲属乳腺癌家族史(≥1名一级亲属有乳腺癌病史)是独立的危险因素。在本技术发明人的研究过程中发现,一级亲属乳腺癌家族史、一级亲属乳腺癌和卵巢癌家族史(≥1名一级亲属有乳腺癌和/或卵巢癌病史)均显著影响对侧乳腺癌发病风险,但是结合我国小家系结构(即兄弟姐妹较少)的特点,在本技术的实施例中选择一级亲属乳腺癌和卵巢癌家族史,而非一级亲属乳腺癌家族史,在保证模型预测能力的同时,更有利于临床实际应用。一级亲属指有1/2相同遗传背景的父母亲、子女、亲兄弟姐妹。
54.使用r语言中的rms包根据上述步骤中491个brca突变乳腺癌患者的突变位点、一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄、激素受体和风险分数绘制对侧乳腺癌发病风险预测列线图(多因素cox回归分析构建列线图),并以此计算出待预测乳腺癌患者的t
年对侧乳腺癌发病风险。
55.如图4所示为本技术实施例建立的预测brca突变乳腺癌人群对侧乳腺癌发病风险的列线图,命名为brca-crisk列线图。该列线图可用于预测brca突变乳腺癌人群5年及10年的对侧乳腺癌发病风险。列线图第一行为分值标尺;第二行为brca1/2突变位点,突变位于brca1 c.4072-3'或brca2 c.6402-3'区域,则选择“within 3'_cluster_region”,患者的突变位于brca1 5'-c.4071或brca2 5'-c.6401区域,则选“outside 3'_cluster_region”,分别对应第一行的一个相应得分;第三行为患者一级亲属乳腺癌和卵巢癌家族史,“≥1一级患病亲属”及“无一级患病亲属”分别对应第一行一个相应得分;第四行为患者乳腺癌首诊年龄,“≤45”及“》45”分别对应第一行一个相应得分;第五行为患者肿瘤激素受体,
“ꢀ
阳性”和“阴性”分别对应第一行的相应分值;第六行为患者总分值,将第二至第五行的4个指标在第一行对应的得分进行相加,得出总分,在第六行选择总分分值,对应投射至第七、八行上,分别得出患者5年及10年的对侧乳腺癌发病风险。
56.举例说明,若张三携带有brca1 c.5470_5477del的致病性胚系突变,则在brca1/2突变位点得分为100分;其母亲有乳腺癌病史,则在一级亲属乳腺癌和卵巢癌家族史得分为94;张三35岁患左乳腺癌,则在乳腺癌首诊年龄得分为100分;张三免疫组化显示激素受体阳性 ,则在激素受体状态得分为84分;该患者总得分为378分,相对应5年对侧乳腺癌发病风险为29.5%,10年对侧乳腺癌发病风险为61.0%。
57.实施例2如图5所示为本技术实施例预测的5年无对侧乳腺癌生存几率与患者真实的5年无对侧乳腺癌生存几率的校正曲线图,横坐标为预测的5年无对侧乳腺癌生存几率,纵坐标为真实的5年无对侧乳腺癌生存几率,曲线越接近45度提示brca突变乳腺癌患者对侧乳腺癌风险预测模型的预测准确度越高。图6为本技术实施例预测的10年无对侧乳腺癌生存几率与患者真实的10年无对侧乳腺癌生存校正曲线图,横坐标为预测的10年无对侧乳腺癌生存几率,纵坐标为真实的10年无对侧乳腺癌生存几率,可见本技术实施例的brca突变乳腺癌患者对侧乳腺癌风险预测模型brca突变乳腺癌病人5年及10年对侧乳腺癌发病风险的准确度都很高。其中,图5、图6上部的竖线段代表抽样样本的分布。
58.实施例3如图7所示为本技术例针对实施例1中brca突变乳腺癌患者对侧乳腺癌风险预测模型用于预测患者对侧乳腺癌累积发病风险的受试者操作特征曲线图(receiver operating characteristic curve,roc),在图7中带
▪
的曲线为本技术实施例中brca突变乳腺癌患者对侧乳腺癌风险预测模型的5年对侧乳腺癌发病风险的roc曲线,没有
▪
的曲线为本技术实施例中brca突变乳腺癌患者对侧乳腺癌风险预测模型的10年对侧乳腺癌发病风险的roc曲线,通过图7可以看出本技术实施例中的brca突变乳腺癌患者对侧乳腺癌风险预测模型auc(受试者工作曲线下面积)在预测5年对侧乳腺癌发病风险为0.765,10年对侧乳腺癌发病风险为0.669,均比目前报道的两个针对一般乳腺癌患者的cbcrisk模型(0.59-0.65)和predictcbc模型(0.63)高,证明我们的预测模型可以准确预测brca突变乳腺癌患者的对侧乳腺癌发病风险。
59.如图8所示为本技术实施例一种计算设备的结构示意图,上述实施例中的方法均可以运行于本实施例中的计算设备上,计算设备802可以包括一个或多个处理设备804,诸
如一个或多个中央处理单元(cpu),每个处理单元可以实现一个或多个硬件线程。计算设备802还可以包括任何存储资源806,其用于存储诸如代码、设置、数据等之类的任何种类的信息。非限制性的,比如,存储资源806可以包括以下任一项或多种组合:任何类型的ram,任何类型的rom,闪存设备,硬盘,光盘等。更一般地,任何存储资源都可以使用任何技术来存储信息。进一步地,任何存储资源可以提供信息的易失性或非易失性保留。进一步地,任何存储资源可以表示计算设备802的固定或可移除部件。在一种情况下,当处理设备804执行被存储在任何存储资源或存储资源的组合中的相关联的指令时,计算设备802可以执行相关联指令的任一操作。计算设备802还包括用于与任何存储资源交互的一个或多个驱动机构808,诸如硬盘驱动机构、光盘驱动机构等。
60.计算设备802还可以包括输入/输出模块810(i/o),其用于接收各种输入(经由输入设备812)和用于提供各种输出(经由输出设备814))。一个具体输出机构可以包括呈现设备816和相关联的图形用户接口(gui)818。计算设备802还可以包括一个或多个网络接口820,其用于经由一个或多个通信链路822与其他设备交换数据。一个或多个通信总线824将上文所描述的部件耦合在一起。
61.通信链路822可以以任何方式实现,例如,通过局域网、广域网(例如,因特网)、点对点连接等、或其任何组合。通信链路822可以包括由任何协议或协议组合支配的硬连线链路、无线链路、路由器、网关功能、名称服务器等的任何组合。
62.本技术实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如下步骤:选取诊断为单侧乳腺癌、检测有brca1/2致病胚系突变的乳腺癌患者的样本数据;通过cox比例风险模型筛选所述样本数据中的突变位点靠近brca1/2基因的3' cdna编码区、一级亲属乳腺癌和卵巢癌家族史、乳腺癌首诊年龄、激素受体状态进行多因素分析;得到所述模型:;其中,lp为风险分值;x1为突变位点靠近brca1/2基因的3' cdna编码区的风险因素,x2为一级亲属乳腺癌和卵巢癌家族史的风险因素,x3为乳腺癌首诊年龄的风险因素,x4为激素受体状态的风险因素,β1、β2、β3、β4为各项风险因素的偏回归系数。
63.本技术实施例提供的计算机设备还可以实现本技术前述实施例的方法。
64.本技术实施例还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述方法的步骤。
65.本技术实施例还提供一种计算机可读指令,其中当处理器执行所述指令时,其中的程序使得处理器执行如本技术前述实施例的方法。
66.应理解,在本技术的各种实施例中,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本技术实施例的实施过程构成任何限定。
67.还应理解,在本技术实施例中,术语“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系。例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本技术中字符“/”,一般表示前后关联对象是一种“或”的关系。
68.本领域普通技术人员可以意识到,结合本技术中所公开的实施例描述的各示例的
单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
69.所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
70.在本技术所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口、装置或单元的间接耦合或通信连接,也可以是电的,机械的或其它的形式连接。
71.所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本技术实施例方案的目的。
72.另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以是两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
73.所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
74.本技术中应用了具体实施例对本技术的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本技术的方法及其核心思想;同时,对于本领域的一般技术人员,依据本技术的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本技术的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。