维生素k代谢相关基因的分型试剂盒、引物和分型方法
技术领域
1.本发明涉及基因检测技术领域,具体讲,涉及一种维生素k代谢相关基因的分型试剂盒、引物和分型方法。
背景技术:
2.维生素k是血块形成的必需脂溶性维生素。天然有两种天然形式:由绿色植物合成的叶绿醌(vk1)和由细菌合成的甲基萘醌(vk2)。vk3、vk4是人式合成产物,属于水溶性,本身不具备活性,在体内肝中可被烷化为mk4(vk2)而有生物活性。维生素k对于将非活性前体转化为功能性凝血因子是至关重要的,因此它对血块形成是必不可少的。一旦维生素k被利用,它会变得无活性,必须重新激活,才能发挥其生物作用。这种维生素k回收过程被称为维生素k循环。维生素k对骨骼健康也很重要。骨钙素是一种参与骨矿化的蛋白质,需要维生素k来进行生物学作用。足够的维生素k有助于防止骨质流失。vk1、vk2为脂溶性,主要在回肠吸收,其吸收有赖于胆汁酸盐和体内脂肪吸收的正常状态,然后并入乳糜微粒并摄入肝脏。vk3、vk4,不依赖胆汁分泌,均能有良好吸收而直接进入血循环,随β脂蛋白转运,在肝脏内被代谢利用。维生素k主要通过胆汁和尿液排出。
3.已知与维生素k代谢相关的基因有apoe基因、cyp4f2基因、ggcx基因、npc1l1基因、nqo1基因、vkorc1基因。
4.维生素k代谢相关基因单核苷酸多态性(single nucleotide polymorphism,snp)的检测不仅可以了解食物中的维生素k对人体吸收与代谢的影响,还可以了解各类食物中维生素k对不同人体基因敏感的差异。
5.目前常用的检测snp位点的方法有pcr-直接测序法、pcr-限制性片段长度多态性分析法(pcr-rflp)、pcr-基因芯片法、荧光定量pcr法、高通量测序法等,这些技术在基因分型和基因突变检测中有着广泛的应用。
6.pcr-直接测序法是公认的检测基因分型的金标准,但检测周期长、检测通量低、灵敏度低、成本较高、对试剂和仪器有特殊要求,不易普及。pcr-限制性片段长度多态性分析法检测灵敏度同样不高、通量低、操作步骤繁琐、只适用于部分snp位点分型,检测的结果仍需进行一代测序法的再次验证,尤其当样本量多时极易造成pcr产物的交叉污染,且容易出现酶切不充分或酶切过度,从而造成假阴性或假阳性结果。pcr-基因芯片法通量高,但检测结果的准确性和重复性均较差,灵敏度低,成本高,需要特殊的仪器设备,并且操作复杂。荧光定量pcr的检测方法虽然具有灵敏度高,分型准确,操作简便快捷,结果重复性好,所用仪器容易普及推广等优点,是检测snp位点的一种非常好的手段,但该方法通量有限,无法方便快捷地满足临床对于多基因的数十个至数百个位点检测的需求,并且探针成本较高,所以主要适于对少量位点、大样本进行分型。高通量测序虽然通量极高,但其成本、耗时、人员需求等不适用于基因snp位点的检测。
7.因此,急需找到一种简便易行、准确性高、自动化程度高的与维生素k代谢相关基因的分型试剂盒和分型方法。
技术实现要素:
8.为了解决上述技术问题,本发明提供了一种维生素k代谢相关基因的分型试剂盒、引物和分型方法。
9.本发明提出一种维生素k代谢相关基因的分型试剂盒,至少包括核酸扩增试剂和单碱基延伸反应试剂;核酸扩增试剂中含有如seq id no:1~ seq id no:22所示的pcr扩增引物;单碱基延伸反应试剂中含有如seq id no:23~ seq id no:43所示的单碱基延伸引物。
10.本发明提出一种维生素k代谢相关基因分型的引物,选自如seq id no:1~ seq id no:22所示核苷酸序列的至少一组;引物还包括如seq id no:44、seq id no:45所示的参考参考引物对。
11.本发明提出一种维生素k代谢相关基因的分型方法,至少包括以下步骤:s1、利用如seq id no:1~ seq id no:22所示的pcr扩增引物进行pcr扩增反应,获得特异性扩增产物;s2、利用碱性磷酸酶消化,去除所述特异性扩增产物中的dntp,获得消化后产物;s3、利用seq id no:23 ~ seq id no:43所示的单碱基延伸引物对所述消化后产物进行单碱基延伸反应,获得延伸反应产物;s4、对所述延伸反应产物进行脱盐处理,获得脱盐产物;s5、通过高效液相色谱-质谱联用对所述脱盐产物进行检测,分析后获得维生素k代谢相关基因的分型结果。
12.本发明提供的技术方案与现有技术相比具有如下优点:本发明的试剂盒和检测方法能够提高维生素k代谢相关基因的分型检测效率、降低样本用量。并且简便易行、准确性高、自动化程度高。
具体实施方式
13.为了能够更清楚地理解本发明的上述目的、特征和优点,下面将对本发明的方案进行进一步描述。需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
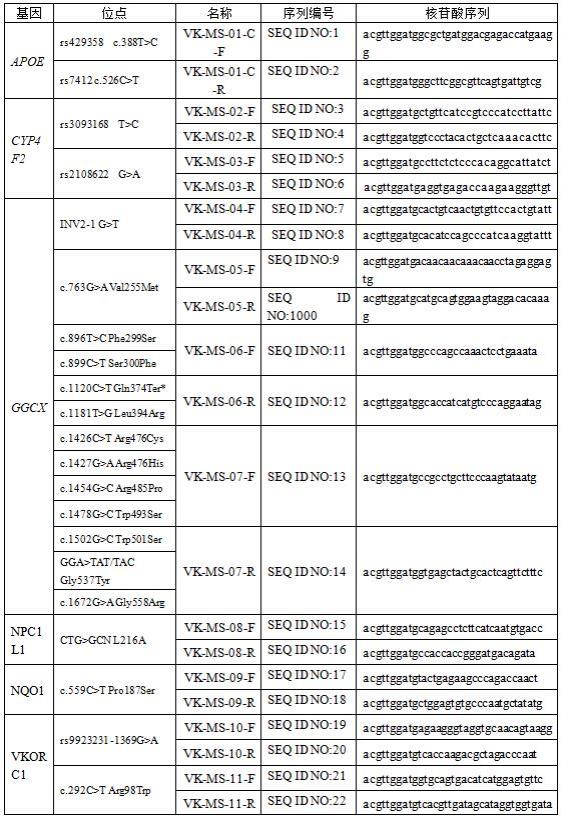
14.在下面的描述中阐述了很多具体细节以便于充分理解本发明,但本发明还可以采用其他不同于在此描述的方式来实施;显然,说明书中的实施例只是本发明的一部分实施例,而不是全部的实施例。
15.本发明实施例的第一方面提出一种维生素k代谢相关基因的分型试剂盒,至少包括核酸扩增试剂和单碱基延伸反应试剂,其中:本发明实施例经对维生素k代谢相关的基因的突变位点进行了筛选,提出用于扩增apoe基因、cyp4f2基因、ggcx基因、npc1l1基因、nqo1基因、vkorc1基因中如表1所示的突变位点的引物对,这些突变位点与维生素k在人体内吸收代谢过程的联系更为密切。本发明实施例的核酸扩增试剂中含有如seq id no:1 ~ seq id no:22所示的pcr扩增引物;单碱基延伸反应试剂中含有如seq id no:23 ~ seq id no:43所示的单碱基延伸引物。
16.本发明实施例的试剂盒可以显著提高分型检测效率、降低样本用量,并且准确性高。
17.除pcr扩增引物外,核酸扩增试剂中还含有10
×
pcr buffer、mgcl2、dntp mix、dna聚合酶等。
18.具体的,pcr扩增引物的核苷酸序列信息如表1所示:表1
本发明实施例分型试剂盒中,碱基延伸反应试剂中含有如seq id no:23~ seq id no:43所示的单碱基延伸引物。除单碱基延伸引物外,碱基延伸反应试剂内还含有10
×
pcr buffer、mgcl2、dntp mix、dna聚合酶等。
19.具体的,单碱基延伸引物的序列信息如表2所示:表2
除核酸扩增试剂和单碱基延伸反应试剂外,在本发明实施例的分型试剂盒中还包括碱性磷酸酶反应液和/或脱盐试剂;其中,碱性磷酸酶反应液用于消化去除pcr体系中的dntp,脱盐试剂用于去除pcr反应体系中的k
、na
、mg
2
等离子,防止其干扰质谱检测结果。
20.具体的,碱性磷酸酶反应液中的碱性磷酸酶选自虾碱性磷酸酶、小牛肠碱性磷酸酶、大肠杆菌碱性磷酸酶、大鼠碱性磷酸酶中的至少一种。具体的,碱性磷酸酶的浓度为1.7 u/
µ
l,分析过程中可采用碱性磷酸酶与缓冲液配制成碱性磷酸酶的浓度为0.255 u/ul的碱性磷酸酶反应液。
21.具体的,脱盐试剂选自脱盐树脂,购于广州达瑞的脱盐树脂或agena bioscience的clean resin脱盐树脂。
22.作为本发明实施例分型试剂盒的一种改进,核酸扩增试剂分为a1管和b1管进行分装,每管分装部分pcr扩增引物,在进行pcr扩增反应时,分为两管进行扩增可以避免干扰,提高部分引物的扩增效率。具体的分装方式为:a1管中含有如seq id no:3 ~ seq id no:18所示的pcr扩增引物,b1管中含有如seq id no:1、seq id no:2、seq id no:19 ~ seq id no:22所示的pcr扩增引物。采用该分装方式可以显著提高引物seq id no:1、seq id no:2、seq id no:19 、seq id no:22的扩增效率。
23.优选的,核酸扩增试剂还包括c1管、d1管,c1管、d1管中分别含有如seq id no:44、seq id no:45所示的参考引物,用于进行参考基因(纯合突变阳性对照品、阴性对照品及杂合突变阳性对照品)的扩增,参考引物的核苷酸序列具体如表3所示。
24.表3更优选的,在a1管中,如seq id no:3 ~ seq id no:18所示引物的浓度均为0.3 ~ 0.8
µ
mol/l、优选为0.5
ꢀµ
mol/l;在b1管中,如seq id no:1、seq id no:2、seq id no:19 ~ seq id no:22所示引物的浓度0.3~0.8
µ
mol/l、优选为0.5
ꢀµ
mol/l;在c1管和d1管中,seq id no:44、seq id no:45所示引物的浓度均为0.3 ~ 0.8
µ
mol/l、优选为0.5
ꢀµ
mol/l。
25.具体如表4所示。
26.表4为了配合pcr扩增引物的四个管,单碱基延伸反应试剂要根据pcr扩增产物将单碱基延伸引物也为四管,分为a2管、b2、c2和d2管:a2和c2管中均含有如seq id no:25 ~ seq id no:41所示的单碱基延伸引物,b2和d2管中均含有如seq id no:23、seq id no:24、seq id no:42、seq id no:43所示的单碱基延伸引物。
27.在a2管和c2管中,如seq id no:25、seq id no:28、seq id no:31、seq id no:41所示引物的浓度均为8 ~ 20
µ
mol/l、优选为10
ꢀµ
mol/l;如seq id no:26、seq id no:29、
seq id no:32、seq id no:35~37、seq id no:39所示引物的浓度均为10 ~ 15
µ
mol/l、优选为12.5
ꢀµ
mol/l;如seq id no:27、seq id no:30、seq id no:33、seq id no:34、seq id no:38、seq id no:40所示引物的浓度均为15 ~ 20
ꢀµ
mol/l、优选18.5
ꢀµ
mol/l;在b2管和d2管中,如seq id no:23、seq id no:43所示引物的浓度均为8 ~ 12
ꢀµ
mol/l、优选10
ꢀµ
mol/l,如seq id no:24、seq id no:42所示引物的浓度均为10 ~ 15
ꢀµ
mol/l、优选12.5
ꢀµ
mol/l。
28.具体如表5所示。
29.表5单碱基延伸引物在反应体系中选用了不同的浓度,从而可以增大部分的位点延伸效率,提高了的质谱响应值。
30.作为本发明实施例分型试剂盒的一种改进,分型试剂盒中还包括纯合突变阳性对照品、阴性对照品和杂合突变阳性对照品,具体如表6所示:表6本发明实施例的第二方面还涉及维生素k代谢相关基因分型的引物,具体选自如seq id no:1~ seq id no:22所示核苷酸序列的至少一对引物,并优选全部pcr扩增引物。优选的,引物中还包括如seq id no:44、seq id no:45所示的参考引物对。
31.本发明实施例的第三方面还涉及维生素k代谢相关基因的分型方法,至少包括以下步骤:s1、利用如seq id no:1~ seq id no:22所示的pcr扩增引物进行pcr扩增反应,获得特异性扩增产物;s2、利用碱性磷酸酶消化,去除特异性扩增产物中的dntp,获得消化后产物;s3、利用seq id no:22 ~ seq id no:43所示的单碱基延伸引物对消化后产物进行单碱基延伸反应,获得延伸反应产物;s4、对延伸反应产物进行脱盐处理,获得脱盐产物;s5、通过高效液相色谱-质谱联用对脱盐产物进行检测,分析后获得维生素k代谢相关基因的分型结果。
32.本发明实施例的方法主要基于多重pcr和单碱基延伸pcr技术,其原理是通过能够特异性扩增包含snp位点区域的目标基因片段的引物和dna聚合酶系进行pcr扩增,pcr结束后加入碱性磷酸酶消化处理,去除反应液中的dntp。之后,在反应液中加入snp位点特异的延伸引物及ddntp等相关组分并进行单碱基延伸反应,反应过程中,snp位点特异的延伸引物能够与待测的snp位点的5’端进行特异结合并根据碱基互补配对原则延伸出与目标snp基因型互补的碱基,根据不同的基因型的dna模板可得到不用的延伸产物。不同碱基的分子量不同,根据延伸产物的分子量能够确定所分析snp位点的基因型。本发明实施例的检测方法可以显著提高分型检测效率、降低样本用量,并且准确性高。
33.在s1中,seq id no:1~ seq id no:22所示的pcr扩增引物如表1所示,具体扩增过程中还添加有表3所示的参考引物。
34.在配制pcr扩增体系时,将a1管和b1管分别配制两个扩增体系,两个扩增体系内的pcr扩增引物浓度具体如表4所示。pcr扩增体系可按照本领域常用方法进行配制。
35.pcr扩增反应的程序也按照本领域常用pcr扩增反应程序,具体可选用:90 ~ 98℃预变性、30秒~10分钟;90 ~ 95℃变性、10秒~1分钟,50 ~ 60℃退火、10秒~1分钟,68 ~ 72℃延伸、30秒~10分钟,扩增25 ~ 45个循环;68 ~ 72℃后延伸,5分钟;优选为:95℃预变性,2 ~ 4分钟;95℃变性、30秒,56℃退火、30秒,72℃延伸,1.5分钟,扩增25 ~ 45个循环,72℃后延伸,5分钟。
36.在s2中,碱性磷酸酶的浓度为1.7 u/
µ
l,在反应液中浓度为0.255 u/
µ
l;消化的条件为:30 ~ 40℃消化处理10 ~ 60分钟,70 ~ 85℃加热变性5 ~ 30分钟,2 ~ 8℃终止;优选为:37℃消化处理40分钟,85℃加热变性5分钟,4℃终止;在s3中,如seq id no:23 ~ seq id no:43所示的单碱基延伸引物如表2所示。单碱基延伸反应的反应体系,也按照根据pcr扩增产物将单碱基延伸引物分为a2管和b2管:两个单碱基延伸反应体系内的单碱基延伸引物浓度具体如表5所示。单碱基延伸反应体系可按照本领域常用方法进行配制。
37.单碱基延伸反应的程序也按照本领域常用单碱基延伸反应程序,具体可选用:90 ~ 98℃热启动,30秒~10分钟;90 ~ 98℃变性,5秒;50 ~ 58℃退火、5秒,65 ~ 85℃延伸、5秒,扩增40个循环;68 ~ 75℃终延伸,1 ~ 10分钟;优选为:94℃热启动,30秒;98℃变性,5秒;52℃退火、5秒,80℃延伸、5秒,扩增40个循环;72℃终延伸,3分钟。
38.在s4中,脱盐方式为树脂脱盐。还可包括层析、超滤等任意去除溶液中盐离子的方
式。通过去除pcr反应体系中的k
、na
、mg
2
等离子,防止其干扰质谱检测结果。
39.吸附的具体方法为:向含有9 μl上述反应体系的pcr管中加入15 ~ 25 mg的树脂,再加入40~ 90 μl蒸馏水。将上述含有单碱基延伸产物和树脂的pcr管固定到旋转混匀以上,慢速旋转30分钟。
40.在s5中,质谱仪器为液相色谱-质谱联用仪(lc-ms)检测系统。还可包括基质辅助激光解吸飞行时间质谱仪(maldi-tofms)等其它类型的能够检测核酸分子量的质谱类仪器。经过脱盐处理后的反应液上机进行液相分离、质谱检测并得到图谱。由于各延伸产物的分子量不同,因此在各自的分子量(质荷比)位置查看是否出现检测峰,然后判断该样本的snp分型。lc-ms质谱平台特异性良好,最低检测下限为5 ng基因组dna,对比试验选择的金标准技术sanger测序技术,符合性为100%。
41.高效液相色谱可选用高分离度的阴离子交换色谱柱,具体可选用dnapac分析柱(thermo公司产品),可对合成型和经过修饰的寡核苷酸进行高分辨率分析和纯化。参数为:2.1
×
100 mm,柱温为:60℃;上样量为10 μl。
42.对于dnapac分析柱来讲,通常使用的流动相为:六氟异丙醇和三乙胺的流动相。本发明实施例所采用的为含有六氟异丙醇和三乙胺的流动相,具体的,a相为含有六氟异丙醇和三乙胺的水;六氟异丙醇的体积百分比为0.4 ~ 0.6%、优选为0.49%,三乙胺的体积百分比0.1 ~ 0.12%、优选为0.11%;b相为含有六氟异丙醇和三乙胺的甲醇;六氟异丙醇的体积百分比为0.4~ 0.6%、优选为0.49%,三乙胺的体积百分比0.1 ~ 0.12%、优选为0.11%。
43.色谱梯度如表7所示:表7流速为0.2 ml/min。
44.质谱的条件如下表8所示:表8
在s5中,分析采用与质谱仪适配的软件进行分析,例如thermo biopharma finder软件,设置软件参数后,对基因分型结果进行判读,判读标准如表9所示:表9
下面通过实施例对本发明实施例进行进一步的说明:实施例所用到的仪器设备、试剂、耗材:1、仪器设备:生物安全柜:海尔,hr40
‑ⅱ
a2;pcr仪:美国赛默飞,veriti dx 96(有医疗器械许可证);低温高速离心机:美国赛默飞,biofuge primo r;移液器:德国eppendorf,2.5μl、10μl、100μl、1000μl;单孔电热恒温水浴锅:北京长安永创科学仪器厂,hh
·
s11-ni1;涡漩混合器:海门市其林贝尔仪器制造有限公司,vortex-5;迷你离心机:海门市其林贝尔仪器制造有限公司,lx-200;超微量分光光度计:德国implen,np80-touch;电泳仪:北京六一生物科技有限公司,dyy-6c;水平电泳槽:北京六一生物科技有限公司,dycp-31dn;转移脱色摇床:海门市其林贝尔仪器制造有限公司,ts-8;凝胶成像系统:通宝达成科技(北京)有限公司,gi-1;微波炉:格兰仕(广东),p70d20tj-03;迷你离心机:美国精骐有限公司,mlx-206;立式压力蒸汽灭菌器:上海申安,ldzx-50kb;旋转混匀仪:scilogex(美国),mx-rl-e;高效液相色谱系统:thermo,vaquish;质谱:thermo,qe plus。
45.2、试剂dna提取试剂盒:天根生化科技(北京)有限公司,ydp304-03;琼脂糖:biowest,100g;6
×
loading buffer:宝日医生物技术(北京)有限公司(takara),9156;100bp dna ladder:new england biolabs,n3231v;无水乙醇:天津市光复科技发展有限公司,分析纯;
tris碱:amresco,ar0497/500g;edta二钠盐:amresco,0105/1000g;乙酸:国药集团试剂有限公司,分析纯;去离子水:质谱级;引物:华大基因合成;飞行时间质谱检测系统样本预处理试剂pro:agena bioscience;faststart taq dna polymerase酶系:罗氏;甲醇(质谱纯):fisher,4l;三乙胺(tea):sigma-aldrich,纯度≥99.5%,73487,5ml;六氟异丙醇(hfip):sigma-aldrich,纯度≥99.8%,52517,50ml;pierce
™ꢀ
ltq velos esi positive ion calibration solution:thermo scientific,10ml;pierce
™ꢀ
negative ion calibration solution:thermo scientific,10ml。
46.3、实验耗材:ep管:美国axygen,0.2ml、1.5ml、2ml;移液器吸头:美国axygen,2.5μl、20μl、200μl、1000μl;thermo dnapac分析柱:thermo,2.1x 100mm;dnapac tm pr guard columns:thermo,2.1
×
10mm,088925;cartridge holder version 2:thermo,069580;内插管,聚丙烯(带弹簧):安捷伦,250
ꢀµ
l;样本瓶/盖:thermo,2ml。
47.实施例1一种试剂盒,其组成如表10所示:表10实施例2 分型方法1、提取基因组dna:详见血液细胞组织基因组dna提取标准操作规程(bjhh-sop-pcr-qt-001)。
48.2、pcr扩增2.1引物mix配制,特异性扩增引物mix配置方法如表11所示,单碱基延伸引物mix配置方法如表12所示:表11
表122.2 pcr扩增体系具体如表13~表14所示:表13:多重pcr扩增体系(agena酶系)
注:内参基因与a1均用此反应体系进行扩增。
49.表14:多重pcr扩增体系(faststart酶系)注:b1用此反应体系进行扩增。
50.由于采用agena酶系对b1组位点扩增效率较低,a1管采用agena酶系的dna聚合酶,b1管采用faststart酶系的dna聚合酶;两种酶系配合,可保证整体的扩增效率。阴阳质控配制方式与a1和b1相同,不同点仅在于模板dna不同。
51.2.3pcr反应条件,具体如表15、表16所示:表15:agena酶系pcr反应条件表16:faststart酶系pcr反应条件2.4pcr产物的检测
2.4.1配置2%琼脂糖凝胶(0.4g琼脂糖加去离子水定容至20ml,微波炉溶解,室温凝胶);2.4.2取100bp ladder的dna分子量标准2.5μl上样;2.4.3上述pcr扩增产物各5.0μl加1.0μl 6
×
载样缓冲液(loading buffer)混匀后上样;2.4.4以1
×
tae为电泳缓冲液,在2%琼脂糖凝胶上恒压120v电泳40min;(50
×
tae配制方法:tris 242g,na2edta2h2o 37.2g,乙酸57.1ml,加入约800ml去离子水,充分搅拌溶解;加去离子水将溶液定容至1l后,室温保存);2.4.5在含有gelstain的nacl溶液(0.1mnacl溶液加gelred20μl)中染色20min(1m nacl溶液配置方法:2.92gnacl纯净水定容到50ml;每次配置200ml染液,其中20ml 1m nacl溶液、20μl gelstain、180ml di水);2.4.6用凝胶扫描成像系统进行检查及图像分析;2.4.7结果分析:阳性对照凝胶上显示明亮条带,阴性对照应无条带(引物二聚体除外)。
52.3、碱性磷酸酶消化3.1消化体系如表17所示:表173.2消化程序:37℃ 40min,85℃ 5min,4℃ ∞。
53.4、单碱基延伸pcr4.1单碱基延伸pcr体系如表18所示:表18注:配制方法同上对应。
54.4.2单碱基延伸pcr程序如表19所示:表19
5、树脂脱盐向含有9μl上述反应体系的pcr管中加入15 ~ 25mg的脱盐树脂,再加入40~90μl蒸馏水。将上述含有单碱基延伸产物和树脂的pcr管固定到旋转混匀以上,慢速旋转30分钟。
55.6、lc-ms上机:取上清至新的pcr管中,准备上机。
56.6.1色谱条件(1)色谱柱及柱温:thermo dnapac 分析柱,2.1x 100mm,60℃,上样量10μl;(2)流动相及流速:流速:0.2ml/min;a相:水(200ml) hfip(4.211ml) tea(0.23ml)b相:甲醇(200ml) hfip(4.211ml) tea(0.23ml)(3)液相梯度/程序如表7所示。
57.6.2质谱条件如表8所示。
58.7、结果分析7.1 thermo biopharma finder软件分析质谱数据结果参数设置如表20所示:表20
7.2判定方法如表9。
59.实验例1本实施例用于说明上述试剂盒和检测方法的准确性。
60.采用五个正常人的dna样本进行检测(样本名分别为rjj、lxj、slp、jyx和zhf)、纯
合突变阳性对照品(mut)、阴性对照品(wt)杂合突变阳性对照品(con),采用上述试剂盒和检测方法进行检测。
61.1.采用上述试剂盒进行液质检测结果;(1)a管/c管质谱结果如表21所示:表21“/”表示没有检测到对应的ms分子量。
62.采用多重pcr测序检测的测序结果如表22所示;表22b管/d管质谱结果如表23所示:表23“/”表示没有检测到对应的ms分子量。
63.采用多重pcr测序检测的测序结果如表24所示:表24备注:标注*基因型为杂合突变型,标注#基因型为纯合突变型。
64.结果发现:两种检测方式得到的基因型判读一致,说明上述试剂盒检测方法结果准确。
65.实验例2本实验例用于说明pcr引物设计的技术效果:设计pcr引物如表25所示。
66.表25
1.采用vk-ms-01-f/r引物对,对正常人的dna样本(样本名分别为lxj、rjj、zfy、zhf)进行检测,得到试验结果如表26所示:表26其中,
““
/”表示没有检测到对应的ms分子量;数值表示检测到对应的ms分子量的相对丰度。
67.如表26所示实验结果,采用vk-ms-01-f/r引物对,无法延伸出目标产物。
68.2.采用vk-ms-01-f/r引物对,增大浓度3倍,得到试验结果如表27所示:表27
其中,“/”表示没有检测到对应的ms分子量;数值表示检测到对应的ms分子量的相对丰度。
69.如表27所示实验结果,仍无法延伸出目标产物。
70.3.更换vk-ms-01-a-f/r、vk-ms-01-b-f/r引物对,仍无法延伸出目标产物,结果与上述数据基本相同。
71.4.更换本发明实施例vk-ms-01-c-f/r引物对,得到试验结果如表28所示:表28其中,“/”表示没有检测到对应的ms分子量;数值表示检测到对应的ms分子量的相对丰度。
72.如表27所示实验结果,位点可正常延伸,得到预期结果。
73.实验例3本实施例用于说明pcr引物分组效果的对比。
74.1.将正常人的dna样本(样本名分别为lxj、rjj、zfy、zhf)进行检测,采用实施例方法检测,区别在于全部采用agena酶系、不进行分组。结果如表29所示:
表29其中,“/”表示没有检测到对应的ms分子量;数值表示检测到对应的ms分子量的相对丰度。
75.由表29的试验数据可知,apoe的延伸引物(位点对应t1~t2)没有延伸产物;c.1426c》t arg476cys(位点对应t11)延伸产物强度稍低。
76.2. 将正常人的dna样本(样本名分别为lss、lxj、lsy)进行检测,采用实施例方法检测,区别在于全部采用faststart酶系、不进行分组。
77.结果如表30所示:表30
其中,“/”表示没有检测到对应的ms分子量;数值表示检测到对应的ms分子量的相对丰度。
78.由表30的试验数据可知,t11~t17单碱基延伸产物较少,对应的ggcx基因的exon10-12;faststart taq dna polymerase对于该段扩增产物的ms-07-f/r的扩增效率低;apoe的扩增引物vk-ms-01-c-f/r在faststart taq dna polymerase条件下扩增较好,延伸产物响应较高。
79.以上所述仅是本发明的具体实施方式,使本领域技术人员能够理解或实现本发明。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所述的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
