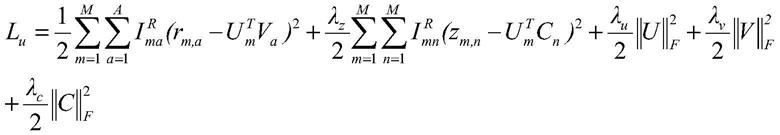
一种基于词嵌入与协同过滤技术的api推荐方法
技术领域
1.本发明涉及计算机技术领域,具体涉及一种基于词嵌入与协同过滤技术 的api推荐方法。
背景技术:
2.应用程序接口(application programming interface),简称api。智 能物联网环境下的api推荐方法是一种收集智能物联网中程序开发人员在 app开发过程中的api使用记录,通过对程序开发人员历史行为记录进行分 析来对程序开发人员进行api推荐。现有的推荐方法根据推荐所使用的数据 大致可以分为三种类型:基于内容的推荐系统、基于协同过滤的推荐系统以 及混合类型的推荐系统。基于内容的推荐系统是一种启发式方法,这种方法 认为程序开发人员倾向于使用其经常使用的api高度相似的api。一般通过 获得关于程序开发人员和api的内容文件,并计算对应相似度来进行推荐。 该方法存在推荐内容单一化,局限化的问题,其只能用于对文字呈现的信息 进行推荐,当面临多媒体信息内容时(如图片,影像,音频等),很难再去 由它的内容计算其特征权重,此外,通过目前的内容分析方法,只能判定项 目的内容相关程度,却无法得到内容到底是好还是坏。
3.协同过滤是一种非常经典的推荐模型。其侧重点在于通过用户与项目之 间的交互行为来去进行推荐。也就是说利用系统中已存在的用户行为记录去 推断用户的未来行为。纵观目前所有的协同过滤算法,大体上可以分为三类: 第一类是基于用户的协同过滤;第二类是基于项目的协同过滤;第三类是基 于模型的协同过滤。目前主流的协同过滤算法是基于模型的协同过滤,但是 基于模型的协同过滤算法存在着冷启动和数据稀疏性的问题,当推荐系统中 用户的现存数据量较少时很难取得较好的推荐效果。
4.现有的api推荐大多存在以下问题:
5.1、api根据所提供的接口所提供信息计算的相似度信息可解释性差,同 时对于开放接口较少的api推荐效果较差;
6.2、很多api的信息中不存在mashup的服务文档,同时对于单词共现的 矩阵信息进行分解所得到的特征的信息损失较大。
技术实现要素:
7.本发明的目的在于克服上述已有技术的不足,提出的模型的是一种基于 矩阵分解和词嵌入的联合矩阵分解推荐方法,以提高智能物联环境中api推 荐的准确度,加强了系统对于用户与api潜在特征的挖掘。
8.本发明解决上述技术问题的技术方案如下:
9.本发明提供一种基于词嵌入与协同过滤技术的api推荐方法,所述api 推荐方法包括:
10.s1:对api真实调用记录进行初始处理,得到api调用矩阵;
11.s2:对所述api调用矩阵中所有用户调用api的api序列进行训练,得 到api-api相
似度矩阵;
12.s3:对所述api调用矩阵中所有api跟随用户的用户序列进行训练,得 到用户-用户相似度矩阵;
13.s4:根据所述api调用矩阵、所述用户-用户相似度矩阵和所述api-api 相似度矩阵,分别得到api侧调用预测模型和用户侧调用预测模型;
14.s5:根据所述api侧调用预测模型以及所述用户侧调用预测模型,得到 最终预测模型;
15.s6:根据所述最终预测模型,输出api推荐结果。
16.可选择地,所述步骤s2包括:
17.s21:获取所述api调用矩阵中所有用户对api调用的api序列;
18.s22:将所述所有用户对api调用的api序列输入至woed2vec中进行训 练,得到api的潜在特征向量;
19.s23:根据所述api的潜在特征向量,利用余弦相似度,得到不同api 的相似度;
20.s24:利用所述不同api的相似度构建所述api-api相似度矩阵。
21.可选择地,所述步骤s23包括:
[0022][0023]
其中,s
a,b
表示apia和apib的相似度;wa,wb分别代表apia和apib的 潜在特征向量,a和b分别表示apia和apib。
[0024]
可选择地,所述步骤s3包括:
[0025]
s31:获取所述api调用矩阵整理中所有api跟随用户的用户序列;
[0026]
s32:将所述所有api跟随用户的用户序列输入至woed2vec中进行训练, 得到用户的潜在特征向量;
[0027]
s33:根据所述用户的潜在特征向量,利用余弦相似度,得到不同用户 的相似度;
[0028]
s34:利用所述不同用户的相似度构建所述用户-用户相似度矩阵。
[0029]
可选择地,所述步骤s23包括:
[0030][0031]
其中,z
m,n
表示用户m和用户n的相似度;w'm和w'n分别代表用户m和用 户n的潜在特征向量。
[0032]
可选择地,所述步骤s4包括:
[0033]
s41:对所述api调用矩阵进行矩阵分解,得到用户潜在特征和api潜 在特征;
[0034]
s42:对所述用户-用户相似度矩阵进行矩阵分解,得到第一分解结果; 和/或对所述api-api相似度矩阵进行矩阵分解,得到第二分解结果;
[0035]
s43:根据所述api调用矩阵、所述用户-用户相似度矩阵以及所述第一 分解结果,得到第一损失函数;和/或根据所述api调用矩阵、所述api-api 相似度矩阵以及所述第二分解结果,得到第二损失函数;
[0036]
s44:根据所述第一损失函数,构建所述api侧调用预测模型;和/或根 据所述第二
损失函数,构建所述用户侧调用预测模型。
[0037]
可选择地,所述步骤s42中,对所述用户-用户相似度矩阵进行矩阵分 解,得到第一分解结果为:
[0038]
z=u
t
c,
[0039]
其中,z表示用户-用户相似度矩阵,um表示第m用户的潜在特征向量, ca表示第a个用户的潜在特征向量;
[0040]
所述步骤s42中,对所述api-api相似度矩阵进行矩阵分解,得到第二 分解结果为:
[0041]
s=v
t
q,
[0042]
其中,表示api-api相似度矩阵,表示第a个api的潜在特征向量, qb表示第b个api的潜在特征向量。
[0043]
可选择地,所述步骤s43中,所述第一损失函数为:
[0044][0045]
其中,lu为第一损失函数,m表示系统中用户的总数量,n表示系统中 api的总数量,表示api调用矩阵r用户m是否对api a有调用记录,r表 示用户-api调用矩阵,r
m,a
表示调用矩阵r用户m对apia的调用情况,为0 或1;表示由调用矩阵分解以及相似矩阵分解的共同用户m的潜在特征向 量,va表示apia的潜在特征向量,λz表示控制用户相似矩阵分解在最终预 测中占比的系数,z
m,n
表示用户相似矩阵中用户m与n的相似度,cn表示由 相似矩阵分解而来的用户n的潜在特征向量,λu是用来控制用户特征向量正 则化项的系数,u表示推荐过程中所有的用户特征向量,f是正则化表达的 符号,v表示推荐过程中所有的api特征向量,λc表示用来控制用户特征向 量正则化项的系数,c表示推荐过程中由相似矩阵分解而来的用户特征向 量。
[0046]
所述步骤s43中,所述第二损失函数为:
[0047][0048]
其中,la为第二损失函数,m表示系统中用户的总数量,n表示系统中 api的总数量,表示表示api调用矩阵r用户n是否对apib有调用记录, r表示用户-api调用矩阵,r
m,a
表示调用矩阵r用户m对apia的调用情况,为 0或1;表示由调用矩阵分解以及相似矩阵分解的共同用户n的潜在特征 向量,vb表示apib的潜在特征向量,λs为控制api相似矩阵分解在最终预 测中占比的系数,s
a,b
表示api相似矩阵apia和apib的相似度,qa由api相 似度矩阵分解而来的apia的潜在特征向量,λu是用来控制用户特征向量正 则化项的系数,u表示推荐过程中所有的用户特征向量,f是正则化表达的 符号,v
b1
表示推荐过程中所有的
api特征向量,λq表示表示用来控制api特 征向量正则化项的系数,q表示推荐过程中由相似矩阵分解而来的api特征 向量。
[0049]
可选择地,所述步骤s44中,所述api侧调用预测模型为:
[0050][0051]
其中,表示api侧调用预测模型,表示api侧联合矩阵分解所 得的用户n的潜在特征向量,vb表示api侧联合矩阵分解所得的apib的潜在 特征向量,n表示用户n,b表示apib。
[0052]
所述步骤s44中,所述用户侧调用预测模型为:
[0053][0054]
其中,表示用户侧调用预测模型,表示api侧联合矩阵分解所 得的用户m的潜在特征向量,va表示联合矩阵分解所得的api a的潜在特征 向量,m表示用户m,a表示api a。
[0055]
可选择地,其特征在于,所述步骤s5中,所述最终预测模型为:
[0056][0057]
其中,表示最终预测模型,α为权重系数且α∈[0,1],表示用户侧 调用预测模型,表示api侧调用预测模型,i表示用户i,j表示apij。
[0058]
本发明具有以下有益效果:
[0059]
本发明与现有技术相比具有如下优点:
[0060]
第一,本发明设计了一种能够对于智能物联环境中不同种类信息进行挖 掘和融合的联合矩阵分解模型。建立了一个基于神经网络,相似度计算,矩 阵分解的协同api推荐框架。
[0061]
第二,本发明在构造用户特征向量与api特征向量时,使用了word2vec 模型来计算不同用户之间与不同api之间的相似度,然后通过对相似矩阵分 解来获取用户特征向量与api特征向量。通过神经网络获取到了用户和api 的隐藏高阶特征。
[0062]
第三,本发明在训练用户特征向量与api特征向量时,将用户-api调用 矩阵以及相似度矩阵通过公共的特征向量进行联合矩阵分解,训练得到具有 两个矩阵丰富信息的特征向量,从而提升了推荐的准确性。
[0063]
第四,本发明分别在用户侧以及api侧进行了联合矩阵分解,然后将这 两侧的预测结果进行线性结合,利用这种方法将用户的隐藏信息与api的隐 藏信息进行结合,大大提高了最终的推荐准确性。
附图说明
[0064]
图1为本发明实施例所提供的基于词嵌入与协同过滤技术的api推荐方 法的流程图;
[0065]
图2为图1中步骤s2的分步骤流程图;
[0066]
图3为图1中步骤s3的分步骤流程图;
[0067]
图4为图1中步骤s4的分步骤流程图。
具体实施方式
[0068]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本 发明,并非用于限定本发明的范围。
[0069]
实施例
[0070]
本发明提供一种基于词嵌入与协同过滤技术的api推荐方法,参考图1 所示,所述api推荐方法包括:
[0071]
s1:对api真实调用记录进行初始处理,得到api调用矩阵;
[0072]
在本发明所提供的具体实施方式中,首先从真实环境下收集若干用户对 api的调用记录,然后将其整理为用户-api调用矩阵,可以设置矩阵中1表 示该用户调用过相关的api,0表示对应用户未调用过相应的api。
[0073]
这样,将所有零散的用户-api调用记录整理成用户api调用矩阵,能够 便于对用户-api的调用记录进行存储,从而便于对整体的行为数据记录进行 统一的操作,以便于系统后面进行推荐。
[0074]
s2:对所述api调用矩阵中所有用户调用api的api序列进行训练,得 到api-api相似度矩阵;
[0075]
可选择地,参考图2所示,所述步骤s2包括:
[0076]
s21:获取所述api调用矩阵中所有用户对api调用的api序列;
[0077]
将用户-api调用矩阵整理为用户对api调用的api序列,每个用户的调 用api记录都可以视为一个api序列,把所有api序列整合为一个文档,得 到word2vec的输入数据。
[0078]
s22:将所述所有用户对api调用的api序列输入至woed2vec中进行训 练,得到api的潜在特征向量;
[0079]
将用户调用api的api序列输入到word2vec中进行训练,得到api的 潜在特征向量。
[0080]
这样可以通过将api序列整体化处理,通过神经网络挖掘api序列所隐 藏的不同于整体调用记录中的高阶潜在特征信息,从而得到api具有api序 列信息的潜在特征向量,将更多的api信息融入到推荐过程中去。
[0081]
s23:根据所述api的潜在特征向量,利用余弦相似度,得到不同api 的相似度;
[0082]
通过对不同api之间进行相似度计算,能够去挖掘api相似矩阵中所隐 藏的整体潜在特征信息,从而将基础用户-api调用矩阵分解所无法获得的 api信息融入到推荐过程中,进而提高推荐效果。
[0083]
可选择地,所述步骤s23包括:
[0084][0085]
其中,s
a,b
表示apia和apib的相似度;wa,wb分别代表apia和apib的 潜在特征向量,a和b分别表示apia和apib。
[0086]
s24:利用所述不同api的相似度构建所述api-api相似度矩阵。
[0087]
s3:对所述api调用矩阵中所有api跟随用户的用户序列进行训练,得 到用户-用户相似度矩阵;
[0088]
可选择地,参考图3所示,所述步骤s3包括:
[0089]
s31:获取所述api调用矩阵整理中所有api跟随用户的用户序列;
[0090]
s32:将所述所有api跟随用户的用户序列输入至woed2vec中进行训练, 得到用户的潜在特征向量;
[0091]
将原始数据整理为每个api跟随用户的用户序列。每个api的跟随用户 记录都可以视为一个用户序列,把所有的用户序列整合为一个文档,得到 word2vec的输入数据。
[0092]
这样可以通过将用户序列整体化处理,通过神经网络挖掘用户序列所隐 藏的不同于整体调用记录中的用户潜在特征信息,从而得到用户具有用户序 列信息的潜在特征向量,将更多的用户信息融入到推荐过程中去,从而提升 最终的推荐效果。
[0093]
s33:根据所述用户的潜在特征向量,利用余弦相似度,得到不同用户 的相似度;
[0094]
通过对不同用户之间进行相似度计算,能够去挖掘用户相似矩阵中所隐 藏的用户整体潜在特征信息,从而将基础用户-api调用矩阵分解所无法获得 的用户信息融入到推荐过程中,来提高推荐效果。
[0095]
可选择地,所述步骤s33包括:
[0096][0097]
其中,z
m,n
表示用户m和用户n的相似度;w'm和w'n分别代表用户m和用 户n的潜在特征向量。
[0098]
s34:利用所述不同用户的相似度构建所述用户-用户相似度矩阵。
[0099]
s4:根据所述api调用矩阵、所述用户-用户相似度矩阵和所述api-api 相似度矩阵,分别得到api侧调用预测模型和用户侧调用预测模型;
[0100]
可选择地,参考图4所示,所述步骤s4包括:
[0101]
s41:对所述api调用矩阵进行矩阵分解,得到用户潜在特征和api潜 在特征;
[0102]
对用户-api调用矩阵进行矩阵分解,将矩阵中的调用记录表征为用户潜 在特征向量与api潜在特征向量的内积:
[0103]
r=u
t
v,
[0104]
其中,r表示用户-api调用矩阵,u和v分别表示用户潜在特征与api 潜在特征,um和va分别表示表示用户m对应的潜在特征向量和api a对应的 潜在特征向量。
[0105]
s42:对所述用户-用户相似度矩阵进行矩阵分解,得到第一分解结果; 和/或对所述api-api相似度矩阵进行矩阵分解,得到第二分解结果;
[0106]
可选择地,所述步骤s42中,对所述用户-用户相似度矩阵进行矩阵分 解,得到第一分解结果为:
[0107]
z=u
t
c,
[0108]
其中,z表示用户-用户相似度矩阵,um表示第m用户的潜在特征向量, cn表示第n个用户的潜在特征向量;
[0109]
所述步骤s42中,对所述api-api相似度矩阵进行矩阵分解,得到第二 分解结果为:
[0110]
s=v
t
q,
[0111]
其中,表示api-api相似度矩阵,表示第a个api的潜在特征向量, qb表示第b个api的潜在特征向量。
[0112]
s43:根据所述api调用矩阵、所述用户-用户相似度矩阵以及所述第一 分解结果,得到第一损失函数;和/或根据所述api调用矩阵、所述api-api 相似度矩阵以及所述第二分解结果,得到第二损失函数;
[0113]
同时进行两个矩阵的分解,其中以用户特征向量/api特征向量作为共同 特征,进行联合矩阵分解,来挖取特征信息更加丰富的特征向量。
[0114]
联合矩阵分解能够同时挖掘与获取用户-api调用矩阵的信息与用户相 似度矩阵的信息,使得训练所得到的潜在特征向量具有更加丰富的用户潜在 特征信息,从而在最后推荐时利用更多的用户信息进行推荐,得到更好的推 荐效果。和/或联合矩阵分解能够同时挖掘与获取用户-api调用矩阵的信息 与api相似度矩阵的信息,使得训练所得到的潜在特征向量具有更加丰富的 api潜在特征信息,从而在最后推荐时利用更多的api信息进行推荐,得到 更好的推荐效果。
[0115]
可选择地,所述步骤s43中,所述第一损失函数为:
[0116][0117]
其中,lu为第一损失函数,m表示系统中用户的总数量,n表示系统中 api的总数量,表示api调用矩阵r用户m是否对api a有调用记录,r表 示用户-api调用矩阵,r
m,a
表示调用矩阵r用户m对apia的调用情况,为0 或1;表示由调用矩阵分解以及相似矩阵分解的共同用户m的潜在特征向 量,va表示apia的潜在特征向量,λz表示控制用户相似矩阵分解在最终预 测中占比的系数,z
m,n
表示用户相似矩阵中用户m与n的相似度,cn表示由 相似矩阵分解而来的用户n的潜在特征向量,λu是用来控制用户特征向量正 则化项的系数,u表示推荐过程中所有的用户特征向量,f是正则化表达的 符号,v表示推荐过程中所有的api特征向量,λc表示用来控制用户特征向 量正则化项的系数,c表示推荐过程中由相似矩阵分解而来的用户特征向 量。
[0118]
所述步骤s43中,所述第二损失函数为:
[0119][0120]
其中,la为第二损失函数,m表示系统中用户的总数量,n表示系统中 api的总数量,表示表示api调用矩阵r用户n是否对apib有调用记录, r表示用户-api调用矩阵,r
m,a
表示调用矩阵r用户m对apia的调用情况,为 0或1;表示由调用矩阵分解以及相似矩阵分解的共同用户n的潜在特征 向量,vb表示apib的潜在特征向量,λs为控制api相似矩阵分解在最终预 测中占比的系数,s
a,b
表示api相似矩阵apia和apib的相似度,qa由api相 似
度矩阵分解而来的apia的潜在特征向量,λu是用来控制用户特征向量正 则化项的系数,u表示推荐过程中所有的用户特征向量,f是正则化表达的 符号,v
b1
表示推荐过程中所有的api特征向量,λq表示表示用来控制api特 征向量正则化项的系数,q表示推荐过程中由相似矩阵分解而来的api特征 向量。
[0121]
s44:根据所述第一损失函数,构建所述api侧调用预测模型;和/或根 据所述第二损失函数,构建所述用户侧调用预测模型。
[0122]
可选择地,所述步骤s44中,所述api侧调用预测模型为:
[0123][0124]
其中,表示api侧调用预测模型,表示api侧联合矩阵分解所 得的用户n的潜在特征向量,vb表示api侧联合矩阵分解所得的apib的潜在 特征向量,n表示用户n,b表示apib。
[0125]
所述步骤s44中,所述用户侧调用预测模型为:
[0126][0127]
其中,表示用户侧调用预测模型,表示api侧联合矩阵分解所 得的用户m的潜在特征向量,va表示联合矩阵分解所得的apia的潜在特征 向量,m表示用户m,a表示apia。
[0128]
s5:根据所述api侧调用预测模型以及所述用户侧调用预测模型,得到 最终预测模型;
[0129]
通过将两侧的结果综合起来考虑,规避了单侧联合矩阵分解只考虑用户 序列潜在特征信息或api序列潜在特征信息的缺点,同时利用了用户侧与 api侧的丰富信息来进行推荐,使得最终的推荐结果更加准确。
[0130]
可选择地,所述步骤s5中,所述最终预测模型为:
[0131][0132]
其中,表示最终预测模型,α为权重系数且α∈[0,1],表示用户侧 调用预测模型,表示api侧调用预测模型,i表示用户i,j表示apij。
[0133]
s6:根据所述最终预测模型,输出api推荐结果。
[0134]
综上,本发明首先收集待推荐环境中的用户与api的调用数据,将这些 数据整理成用户-api调用矩阵,来标识对应用户是否调用过对应api。之后 设计了基于word2vec的用户相似度计算方法与api相似度计算方法,将其 分别整理为用户-用户相似矩阵,api-api相似矩阵,以用来挖掘用户与api 的潜在特征信息。在得到相似矩阵之后,分别将用户相似矩阵、用户-api 调用矩阵和api相似矩阵、用户-api调用矩阵进行联合矩阵分解,以预测用 户调用指定api的概率,最后结合两侧的预测结果进行最终推荐。
[0135]
本发明与现有技术相比具有如下优点:
[0136]
第一,本发明设计了一种能够对于智能物联环境中不同种类信息进行挖 掘和融合的联合矩阵分解模型。建立了一个基于神经网络,相似度计算,矩 阵分解的协同api推荐框架。
[0137]
第二,本发明在构造用户特征向量与api特征向量时,使用了word2vec 模型来计
算不同用户之间与不同api之间的相似度,然后通过对相似矩阵分 解来获取用户特征向量与api特征向量。通过神经网络获取到了用户和api 的隐藏高阶特征。
[0138]
第三,本发明在训练用户特征向量与api特征向量时,将用户-api调用 矩阵以及相似度矩阵通过公共的特征向量进行联合矩阵分解,训练得到具有 两个矩阵丰富信息的特征向量,从而提升了推荐的准确性。
[0139]
第四,本发明分别在用户侧以及api侧进行了联合矩阵分解,然后将这 两侧的预测结果进行线性结合,利用这种方法将用户的隐藏信息与api的隐 藏信息进行结合,大大提高了最终的推荐准确性。
[0140]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明 的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发 明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
