一种人体3d姿态估计方法、装置及系统
技术领域
1.本发明实施例涉及人工智能技术领域,具体涉及一种人体3d姿态估计方法、装置及系统。
背景技术:
2.人体3d姿态估计是从二维图像中识别出人体所做的三维动作的技术,对于人体动作判别、意图识别、行为检测、运动教学等都有重要的应用价值和实用意义。本发明提出了一种基于transformer编码器架构及考虑人体3d关键点相对距离的人体3d姿态估计方法,输入单张图片,输出该图片中人的3d关键点坐标。
技术实现要素:
3.为此,本发明实施例提供一种人体3d姿态估计方法、装置及系统,基于transformer编码器架构及考虑人体3d关键点相对距离,实现人体3d姿态估计,输入单张图片,输出该图片中人的3d关键点坐标。
4.为了实现上述目的,本发明实施例提供如下技术方案:
5.根据本发明实施例的第一方面,提出了一种人体3d姿态估计方法,所述方法包括:
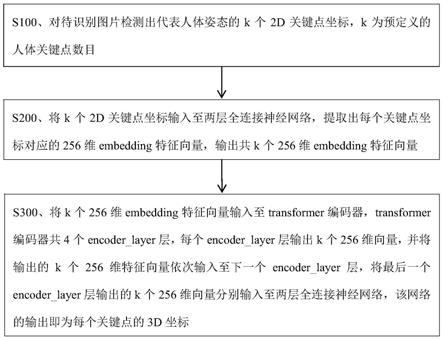
6.对待识别图片检测出代表人体姿态的k个2d关键点坐标,k为预定义的人体关键点数目;
7.将k个2d关键点坐标输入至两层全连接神经网络,提取出每个关键点坐标对应的256维embedding特征向量,输出共k个256维embedding特征向量;
8.将k个所述256维embedding特征向量输入至transformer编码器,transformer编码器共4个encoder_layer层,每个encoder_layer层输出k个256维向量,并将输出的k个256维特征向量依次输入至下一个encoder_layer层,将最后一个encoder_layer层输出的k个256维向量分别输入至两层全连接神经网络,该网络的输出即为每个关键点的3d坐标。
9.进一步地,每个encoder_layer层的计算过程包括以下步骤:
10.a、将k个256维特征向量输入至multi-head attention层,得到k个256维特征向量;
11.b、然后步骤a得到的k个256维向量与该encoder_layer层输入的k个256维特征向量相加,得到k个256维特征向量;
12.c、然后将步骤b得到的k个256维特征向量,做layernorm运算,得到归一化的k个256维向量;
13.d、然后将步骤c得到的k个256维向量,将每个向量输入至两层全连接神经网络,得到k个256维向量,其中,k个向量共享一个全连接前馈网络;
14.e、最后将步骤c和步骤d分别得到的k个向量相加,并对相加后的k个向量做layernorm运算,得到归一化的k个256维向量,将这k个256维特征向量输入至下一个encoder_layer层。
15.进一步地,将k个256维特征向量输入至multi-head attention层,得到k个256维特征向量,具体包括:
16.每个256维特征向量通过3个变换矩阵变换为3个256维特征向量qi,ki,vi,i∈(1,2,3
……
k),得到共3个张量q,k,v,其中q,k,v的形状均为(k,256);
17.将q,k,v变形为形状为(k,8,32)的张量,并进一步置换为形状为(8,k,32)的张量pq,pk,pv,其中8为multi-head attention层的头数,32为每个头的特征向量维数;
18.将pq分解为8个形状为(k,32)的矩阵pqi,i∈(1,2,3
……
8),将pk分解为8个形状为(k,32)的矩阵pki,i∈(1,2,3
……
8),8个形状为(k,32)的矩阵pqi分别与8个形状为(k,32)的矩阵pki转置相乘,得到8个形状为(k,k)的矩阵,该矩阵除以得到8个形状为(k,k)的注意力系数矩阵attn_1;
19.定义两个人体关节点之间的相对距离为,骨骼图上连接两个关节点之间的骨骼数,且该骨骼数构成这两个关节点之间的最短距离,由k个关节点构成的人体骨骼图,其相对距离矩阵记为r,形状为(k,k),其第(i,j)个元素,代表第i个关节点距离第j个关节点的相对距离;
20.每个相对距离值对应一个8维的权重向量,8是head数,不同的相对距离对应不同的权重向量,用r中的每个相对距离查询对应的权重向量,得到形状为(k,k,8)的张量,进一步置换为形状为(8,k,k)的张量,记为rw;
21.将rw分解为8个形状为(k,k)的矩阵,该矩阵除以得到注意力系数矩阵attn_2;
22.得到的8个注意力系数矩阵attn_1和得到的8个注意力系数矩阵attn_2相加,得到8个形状为(k,k)的矩阵,进一步对该矩阵的列进行softmax操作,得到最终的8个注意力系数矩阵attni,i∈(1,2,3
……
8);
23.将得到的pv分解为8个形状为(k,32)的矩阵pvi(i从1到8),将8个形状为(k,k)的矩阵attni分别与8个形状为(k,32)的矩阵转置相乘,得到8个形状为(k,32)的矩阵,将这8个形状为(k,32)的矩阵构成形状为(8,k,32)张量,进一步置换为形状为(k,8,32)的张量,再进一步变形为形状为(k,256)的张量;
24.将得到的张量分解为k个256维特征向量,输入一个变换矩阵,得到k个256维特征向量。
25.进一步地,对待识别图片检测出代表人体姿态的k个2d关键点坐标,k为预定义的人体关键点数目,具体包括:
26.通过将待识别图片输入至maskrcnn网络中获取代表人体姿态的k个2d关键点坐标。
27.进一步地,所述方法还包括:
28.若待识别图片中存在多人,则将图片裁剪为单人图像后再进行处理。
29.根据本发明实施例的第二方面,提出了一种人体3d姿态估计装置,其特征在于,所述装置包括:
30.2d人体姿态检测模块,用于将k个2d关键点坐标输入至两层全连接神经网络,提取出每个关键点坐标对应的256维embedding特征向量,输出共k个256维embedding特征向量;
31.3d人体姿态估计模块,用于将k个所述256维embedding特征向量输入至transformer编码器,transformer编码器共4个encoder_layer层,每个encoder_layer层输出k个256维向量,并将输出的k个256维特征向量依次输入至下一个encoder_layer层,将最后一个encoder_layer层输出的k个256维向量分别输入至两层全连接神经网络,该网络的输出即为每个关键点的3d坐标。
32.根据本发明实施例的第三方面,提出了一种人体3d姿态估计系统,所述系统包括:处理器和存储器;
33.所述存储器用于存储一个或多个程序指令;
34.所述处理器,用于运行一个或多个程序指令,用以执行如上任一项所述的方法。
35.根据本发明实施例的第四方面,提出了一种计算机存储介质,所述计算机存储介质中包含一个或多个程序指令,所述一个或多个程序指令用于被一种人体3d姿态估计系统执行如上任一项所述的方法。
36.本发明实施例具有如下优点:
37.本发明实施例提出的一种人体3d姿态估计方法、装置及系统,基于transformer编码器架构,并考虑人体3d关键点相对距离,实现人体3d姿态估计,输入单张图片,输出该图片中人的3d关键点坐标,3d姿态估计的准确度高。
附图说明
38.为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引伸获得其它的实施附图。
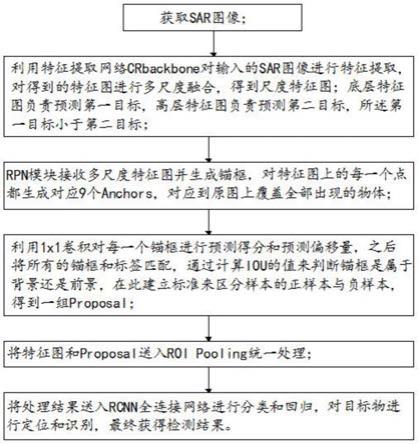
39.图1为本发明实施例1提供的一种人体3d姿态估计方法的流程示意图;
40.图2为本发明实施例1提供的一种人体3d姿态估计方法中的人体关节点骨骼图。
具体实施方式
41.以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
42.实施例1
43.如图1所示,本实施例提出了一种人体3d姿态估计方法,该方法包括:
44.s100、对待识别图片检测出代表人体姿态的k个2d关键点坐标,k为预定义的人体关键点数目。
45.本实施例中,通过将待识别图片输入至maskrcnn网络中获取代表人体姿态的k个2d关键点坐标,记为p1=(x1,y1),p2=(x2,y2),
……
pk=(xk,yk)。maskrcnn也可以替换为其他2d人体姿态检测器。
46.s200、将k个2d关键点坐标输入至两层全连接神经网络,提取出每个关键点坐标对应的256维embedding特征向量,输出共k个256维embedding特征向量。全连接神经网络n的
输入有k个节点,第i个节点(i从1到k)的输入如下:(p1,p2
……
,pk)。
47.s300、将k个256维embedding特征向量输入至transformer编码器,transformer编码器共4个encoder_layer层,每个encoder_layer层输出k个256维向量,并将输出的k个256维特征向量依次输入至下一个encoder_layer层,将最后一个encoder_layer层输出的k个256维向量分别输入至两层全连接神经网络,该网络的输出即为每个关键点的3d坐标。其中,每个向量共享一个全连接网络(即k个向量共用一个全连接神经网络的权重)。
48.进一步地,每个encoder_layer层的计算过程包括以下步骤:
49.a、将k个256维特征向量输入至multi-head attention层,得到k个256维特征向量;
50.b、然后步骤a得到的k个256维向量与该encoder_layer层输入的k个256维特征向量相加,得到k个256维特征向量;
51.c、然后将步骤b得到的k个256维特征向量,做layernorm运算,得到归一化的k个256维向量;
52.d、然后将步骤c得到的k个256维向量,将每个向量输入至两层全连接神经网络,得到k个256维向量,其中,k个向量共享一个全连接前馈网络;
53.e、最后将步骤c和步骤d分别得到的k个向量相加,并对相加后的k个向量做layernorm运算,得到归一化的k个256维向量,将这k个256维特征向量输入至下一个encoder_layer层。
54.进一步地,将k个256维特征向量输入至multi-head attention层,得到k个256维特征向量,具体包括:
55.每个256维特征向量通过3个变换矩阵变换为3个256维特征向量qi,ki,vi,i∈(1,2,3
……
k),得到共3个张量q,k,v,其中q,k,v的形状均为(k,256);
56.将q,k,v变形(reshape)为形状为(k,8,32)的张量,并进一步置换(permute)为形状为(8,k,32)的张量pq,pk,pv,其中8为multi-head attention层的头数(head),32为每个头head的特征向量维数;
57.将pq分解为8个形状为(k,32)的矩阵pqi,i∈(1,2,3
……
8),将pk分解为8个形状为(k,32)的矩阵pki,i∈(1,2,3
……
8),8个形状为(k,32)的矩阵pqi分别与8个形状为(k,32)的矩阵pki转置相乘,得到8个形状为(k,k)的矩阵,该矩阵除以得到8个形状为(k,k)的注意力系数矩阵attn_1;
58.定义两个人体关节点之间的相对距离为,骨骼图上连接两个关节点之间的骨骼数,且该骨骼数构成这两个关节点之间的最短距离,按此定义,图2所示的17个关节点(k=17)构成的骨骼图,其相对距离矩阵记为r,形状为(k,k),其第(i,j)个元素,代表第i个关节点距离第j个关节点的相对距离;
59.以下为图2所示骨骼结构的相对距离矩阵:
60.[[0,1,2,3,1,2,3,1,2,3,4,3,4,5,3,4,5],
[0061]
[1,0,1,2,2,3,4,2,3,4,5,4,5,6,4,5,6],
[0062]
[2,1,0,1,3,4,5,3,4,5,6,5,6,7,5,6,7],
[0063]
[3,2,1,0,4,5,6,4,5,6,7,6,7,8,6,7,8],
[0064]
[1,2,3,4,0,1,2,2,3,4,5,4,5,6,4,5,6],
[0065]
[2,3,4,5,1,0,1,3,4,5,6,5,6,7,5,6,7],
[0066]
[3,4,5,6,2,1,0,4,5,6,7,6,7,8,6,7,8],
[0067]
[1,2,3,4,2,3,4,0,1,2,3,2,3,4,2,3,4],
[0068]
[2,3,4,5,3,4,5,1,0,1,2,1,2,3,1,2,3],
[0069]
[3,4,5,6,4,5,6,2,1,0,1,2,3,4,2,3,4],
[0070]
[4,5,6,7,5,6,7,3,2,1,0,3,4,5,3,4,5],
[0071]
[3,4,5,6,4,5,6,2,1,2,3,0,1,2,2,3,4],
[0072]
[4,5,6,7,5,6,7,3,2,3,4,1,0,1,3,4,5],
[0073]
[5,6,7,8,6,7,8,4,3,4,5,2,1,0,4,5,6],
[0074]
[3,4,5,6,4,5,6,2,1,2,3,2,3,4,0,1,2],
[0075]
[4,5,6,7,5,6,7,3,2,3,4,3,4,5,1,0,1],
[0076]
[5,6,7,8,6,7,8,4,3,4,5,4,5,6,2,1,0]]
[0077]
每个相对距离值对应一个8维的权重向量(训练中是可学习的参数),8是head数,不同的相对距离对应不同的权重向量,用r中的每个相对距离查询对应的权重向量,得到形状为(k,k,8)的张量,进一步置换(permute)为形状为(8,k,k)的张量,记为rw;
[0078]
将rw分解为8个形状为(k,k)的矩阵,该矩阵除以得到注意力系数矩阵attn_2;
[0079]
得到的8个注意力系数矩阵attn_1和得到的8个注意力系数矩阵attn_2相加,得到8个形状为(k,k)的矩阵,进一步对该矩阵的列进行softmax操作,得到最终的8个注意力系数矩阵attni,i∈(1,2,3
……
8);
[0080]
将得到的pv分解为8个形状为(k,32)的矩阵pvi(i从1到8),将8个形状为(k,k)的矩阵attni分别与8个形状为(k,32)的矩阵转置相乘,得到8个形状为(k,32)的矩阵,将这8个形状为(k,32)的矩阵构成形状为(8,k,32)张量,进一步置换(permute)为形状为(k,8,32)的张量,再进一步变形(reshape)为形状为(k,256)的张量;
[0081]
将得到的张量分解为k个256维特征向量,输入一个变换矩阵,得到k个256维特征向量。
[0082]
进一步地,该方法还包括:若待识别图片中存在多人,则将图片裁剪为单人图像后再进行处理。
[0083]
本实施例提出的一种人体3d姿态估计方法,基于transformer编码器架构,并考虑人体3d关键点相对距离,实现人体3d姿态估计,输入单张图片,输出该图片中人的3d关键点坐标,3d姿态估计的准确度高。
[0084]
实施例2
[0085]
与上述实施例1相对应的,本实施例提出了一种人体3d姿态估计装置,其特征在于,该装置包括:
[0086]
2d人体姿态检测模块,用于将k个2d关键点坐标输入至两层全连接神经网络,提取出每个关键点坐标对应的256维embedding特征向量,输出共k个256维embedding特征向量;
[0087]
3d人体姿态估计模块,用于将k个256维embedding特征向量输入至transformer编码器,transformer编码器共4个encoder_layer层,每个encoder_layer层输出k个256维向量,并将输出的k个256维特征向量依次输入至下一个encoder_layer层,将最后一个
encoder_layer层输出的k个256维向量分别输入至两层全连接神经网络,该网络的输出即为每个关键点的3d坐标。
[0088]
本发明实施例提供的一种人体3d姿态估计装置中各部件所执行的功能均已在上述实施例1中做了详细介绍,因此这里不做过多赘述。
[0089]
实施例3
[0090]
与上述实施例相对应的,本实施例提出了一种人体3d姿态估计系统,系统包括:处理器和存储器;
[0091]
存储器用于存储一个或多个程序指令;
[0092]
处理器,用于运行一个或多个程序指令,用以执行如上实施例1的方法。
[0093]
实施例4
[0094]
与上述实施例相对应的,本实施例提出了一种计算机存储介质,该计算机存储介质中包含一个或多个程序指令,一个或多个程序指令用于被一种人体3d姿态估计系统执行如实施例1的方法。
[0095]
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。