基于上下文视觉的sar目标检测方法、装置和存储介质
技术领域
1.本发明属于目标检测领域,具体涉及一种基于上下文视觉的sar目标检测方法、装置和存储介质。
背景技术:
2.成孔径雷达(sar)是一种主动式微波传感器,具有不受光照和气候条件等限制实现全天时、全天候对地观测的特点,相比于光学遥感图像,sar具有巨大的应用价值。近些年,sar目标检测识别在军事侦察、态势感知、农业/林业管理、城市规划等军事/民用领域得到广泛应用。尤其是未来的战场空间将由传统的陆、海、空向太空延伸,作为一种具有独特优势的侦察手段,合成孔径雷达卫星为夺取未来战场的制信息权,甚至对战争的胜负具有举足轻重的影响。其中,sar图像目标检测识别是实现上述军事/民用应用的关键技术,其核心思想是通过检测算法将感兴趣的区域和目标能够高效筛选出来,并能够精准地识别其类别属性。
3.不同于光学图像,sar图像成像机理存在极大差别,sar目标具有强散射、边缘轮廓信息不清晰、多尺度、强稀疏、弱小、旁瓣干扰、背景复杂等特点,这为sar目标检测识别任务带来了巨大的挑战。近些年,诸多研究团队也在针对上述难点展开广泛研究。但详细研究发现,目前的sar目标检测任务仍存在以下问题,值得进一步讨论:
4.(1)在传统的sar目标检测方法中,经典的方法是恒定虚警概率下的检测器cfar,是雷达目标检测的一种常见的手段。恒虚警率检测是雷达目标自动检测的一个重要组成部分,可以作为从sar图像中提取目标的第一步,是进一步识别目标的基础。然而,传统方法过分依赖于专家经验设计手工特征,具有极大的特征局限性,且难以适应复杂场景下的sar目标检测,无法进行大规模实际应用。
5.(2)近些年,随着计算机视觉的发展,卷积神经网络被应用在sar图像的检测上,出现了大量的深度神经网络,例如alexnet,vggnet,resnet,googlenet等,这也使faster r-cnn,ssd,yolo等在sar图像识别中得到广泛应用。主要依赖cnn的优势:善于提取图像的局部特征信息,具有更精细的局部关注能力。然而,cnn中因为提取特征采用了较大的下采样系数,这样会导致网络漏检小目标。
6.(3)此外,大量研究表明:cnn中的实际感受野远小于理论感受野,这不利于充分利用上下文信息进行特征的捕获,缺乏提取全局表征的能力。虽然本发明可以通过不断的堆叠更深的卷积层来增强cnn的全局捕获能力,但这会造成两方面的影响:层数过深,模型需要学习的参数过多,难以有效收敛,精度未必能够大幅度提升;其次,会造成模型过于庞大,计算量急剧增加,时效性难以保证。
7.为此,针对上述sar图像目标检测所遇到的关键问题,本发明提出了一种全新的基于上下文视觉的sar目标检测方法。
技术实现要素:
8.为了克服上述现有技术存在的不足,本发明提供了一种基于上下文视觉的sar目标检测方法、装置和存储介质。
9.为了实现上述目的,本发明提供如下技术方案:
10.一种基于上下文视觉的sar目标检测方法,包括以下步骤:
11.获取sar图像;
12.将sar图像输入目标检测模型中,目标检测模型对sar图像中的目标物进行定位和识别,获得检测结果;
13.所述目标检测模型的构建步骤包括:
14.以双阶段目标检测器cascade-mask-rcnn作为基础架构,构建模型框架crtranssar;
15.在模型框架crtranssar中增加基于上下文联合表征学习transformer的特征提取网络crbackbone;
16.特征提取网络crbackbone以swin transformer为基础,在swin transformer中引入注意力模块block;
17.在swin transformer的patchembed中引入多维度混合卷积;
18.在述模型框架crtranssar中引入多分辨率跨尺度注意力增强caeneck,构成目标检测模型。
19.优选地,所述目标检测模型对图像进行定位和识别,具体包括:
20.利用特征提取网络crbackbone对输入的sar图像进行特征提取,对得到的特征图进行多尺度融合,得到多尺度特征图;底层特征图负责预测第一目标,高层特征图负责预测第二目标,所述第一目标小于第二目标;
21.rpn模块接收多尺度特征图并生成锚框,对特征图上的每一个点都生成对应9个anchors,对应到原图上覆盖全部出现的物体;
22.利用1x1卷积对每一个锚框进行预测得分和预测偏移量,之后将所有的锚框和标签匹配,通过计算iou的值来判断锚框是属于背景还是前景,在此建立标准来区分样本的正样本与负样本,得到一组建议框proposal;iou的全称为交并比(intersection over union),iou计算的是“预测的边框”和真实的边框的交集和并集的比值。
23.将多尺度特征图和建议框proposal送入roi pooling统一处理;
24.将处理结果送入rcnn全连接网络进行分类和回归,对目标物进行定位和识别,最终获得检测结果。
25.优选地,所述多维度混合卷积在处理图像时,当每个特征图送入patchembed的维度是2
×3×h×
w,最后送入下一个模块的维度为2
×
96
×
h/4
×
w/4,相当于通过卷积层实现了四倍降采样,并且通道数变成了96,本发明在3x3卷积之前堆叠了一层多维度混合卷积模块,卷积核大小为4,保持送入卷积的通道数不变。
26.优选地,所述自注意力模块对图像的处理步骤为:
27.特征提取网络crbackbone进行到patchembed后,通过判断特征图的宽和高确定是否进行pad扩充操作;
28.对特征图进行两次卷积,改变特征通道、特征维度、注意力模块的大小及卷积核大
小。
29.优选地,所述多分辨率跨尺度注意力增强caeneck对图像的处理步骤为:
30.多分辨率跨尺度注意力增caeneck接收特征图;
31.自上而下对特征图进行上采样和注意力增强操作,并将不同大小的特征图与进行连接;
32.自下而上对特征图进行多尺度特征融合。
33.基于同一个发明构思,本发明还提供一种基于transformer的sar目标检测装置,包括数据采集模块和数据处理模块;
34.所述数据采集模块用于采集sar图像;
35.所述数据处理模块,包括:
36.特征提取与融合模块,用于对采集的sar图像进行特征提取,对得到的特征图进行多尺度融合,得到尺度特征图;
37.锚框生产模块,用于接收多尺度特征图并生成锚框,对特征图上的每一个点都生成对应9个anchors,对应到原图上覆盖全部出现的物体;
38.偏移量预测模块,用于对每一个锚框进行预测得分和预测偏移量,之后将所有的锚框和标签匹配,通过计算iou的值来判断锚框是属于背景还是前景,在此建立标准来区分样本的正样本与负样本,得到一组建议框proposal;
39.图像定位与识别模块,用于对建议框proposal进行分类和回归,对图像进行定位和识别,最终获得检测结果。
40.本发明的另一目的在于提供一种目标检测设备,包括存储器、处理器以及存储在所述存储器中并可以在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
41.本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一项所述方法的步骤。
42.本发明提供的基于上下文视觉的sar目标检测方法具有以下有益效果:
43.首先,为解决现有基于cnn架构的sar目标检测方法只能对局部信息建模,缺少全局长距离建模和感知的能力,性能有限的难点,本发明创新地引入最新的swin transformer架构,并在此基础上,引入cnn的局部特征提取模块,重新设计一种目标检测框架,以融合提取全局和局部特征信息。本发明以cascade mask-rcnn框架作为基本目标检测框架,将原始的backbone替换为swintransformer,以提升全局特征能力。
44.其次,针对sar目标的强散射、稀疏、多尺度特性、密集小目标检测精度不高的问题,本发明融合swin transformer与cnn的各自优势,设计了一种基于上下文联合表征学习的backbone,简称为crbackbone,使得模型能够充分利用上下文信息,进行联合表征学习,提取更为丰富的上下文特征显著信息,提升对多尺度sar目标的特征描述。首先,在patchembed部分引入多维度混合卷积,以扩大感受野、深度、分辨率,提升特征感知域;进一步地,引入自注意力模块,以加强对特征图上不同window之间的上下文信息交互。
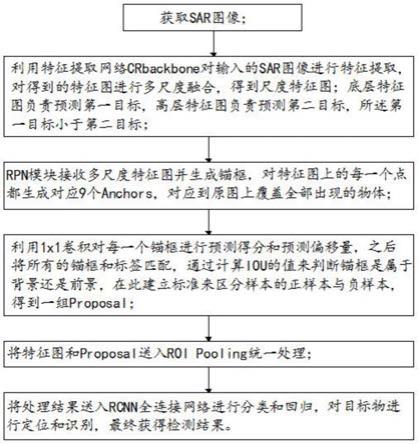
45.进一步地,为更好地适应多尺度的sar图像目标和克服复杂背景所带来的干扰,本发明构建了一种新的跨分辨率注意力增强neck,caeneck。本发明设计了一种双向的注意力增强的多尺度金字塔结构,通过从上到下和从下到上的注意力增强双向多尺度连接操作,
以指导动态注意力矩阵的学习,增强不同分辨率下的特征交互,促使模型能够更为精准的提取多尺度的目标特征信息,回归检测框和分类,抑制干扰背景信息,从而增强了视觉表示能力。在增加注意力增强模块的情况下,整个neck几乎不增加参数量和计算量也能使检测性能得到极强的增益。
附图说明
46.为了更清楚地说明本发明实施例及其设计方案,下面将对本实施例所需的附图作简单地介绍。下面描述中的附图仅仅是本发明的部分实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
47.图1为本发明实施例1的基于上下文视觉的sar目标检测方法的流程图;
48.图2为模型框架crtranssar网络整体框架图;
49.图3为swintransformer整体结构图;
50.图4为swintransformer滑动窗口;
51.图5为自注意力模块框架;
52.图6为特征提取网crbackbone整体框架;
53.图7为多分辨率跨尺度注意力增强caeneck整体框架。
具体实施方式
54.为了使本领域技术人员更好的理解本发明的技术方案并能予以实施,下面结合附图和具体实施例对本发明进行详细说明。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
55.实施例1
56.本发明提供了一种基于上下文视觉的sar目标检测方法,具体如图1所示,包括以下步骤:
57.步骤1、获取sar图像
58.步骤2、将sar图像输入目标检测模型中,目标检测模型对sar图像中的目标物进行定位和识别,获得检测结果,具体检测过程为:
59.步骤2.1、利用特征提取网络crbackbone对输入图像进行特征提取,对得到的特征图进行多尺度融合,得到多尺度特征图;底层特征图负责预测小目标,高层特征图负责预测大目标;
60.步骤2.2、rpn模块接收到多尺度特征图开始生成锚框,对特征图上的每一个点都生成对应9个anchors,对应到原图上可以覆盖全部可能出现的物体;
61.步骤2.3、利用1x1卷积对每一个锚框进行预测得分和预测偏移量,之后将所有的锚框和标签匹配,通过计算iou的值来判断锚框是属于背景还是前景,在此建立标准来区分样本正样本与负样本,得到一组建议框proposal;iou的全称为交并比(intersection over union),iou计算的是“预测的边框”和真实的边框的交集和并集的比值。
62.步骤2.3、经过以上步骤得到一组合适的建议框proposal,接收到特征图和上述的建议框proposal送入roi pooling统一处理,最后送入rcnn全连接网络进行分类和回归,对图像进行定位和识别,最终获得检测结果。
transformer、多维度混合卷积、自注意力。
80.首先,本发明引入目前在nlp及光学分类任务中表现最好的swin transformer作为基础backbone;其次,本发明融入cnn的多尺度局部信息获取思想,对swin transformer的架构进行了重新设计,受最新的efficientnet和cotnet的架构启发,本发明在patchembed部分引入多维度混合卷积,以扩大感受野、深度、分辨率,提升特征感知域;进一步地,引入自注意力模块,以加强对特征图上不同window之间的上下文信息交互。
81.swin transformer模块:针对sar图像,大场景下的小目标船只,容易在下采样的过程中丢失信息,所以本发明引入swin transformer,框架如图3所示。图3(a)为swin transformer结构图,图3(b)为swin transformerblocks。transformer拥有:通用的建模能力,与卷积形成互补,强大的建模能力以及视觉与语言更好得连接,大吞吐量,大规模并行处理的能力。当一张图片输入进本发明的的网络,本发明希望送入transformer处理,所以本发明要利用一切能处理的手段将图片切分成一个个类似于nlp中的token,以及图像中的高分辨率特性与nlp中的语言差异,所以引出一个分层的transformer,其表示是通过移动窗口来计算的。通过将自注意力计算限制为不重叠的局部窗口,同时允许跨窗口连接,移位的窗口方案带来了更高的效率。这种分层体系结构具有在各种尺度上建模的灵活性,并且相对于图像大小具有线性计算复杂性。这便是对vision transformer的一个改进,vision transforme一直都是对一开始所切分的patch做attention,后面的过程也没有对patch做任何操作,所以没有对感受野产生影响。swin-transformer是一个窗口在放大的过程,然后self-attention的计算是以窗口为单位去计算的,这样相当于引入了局部聚合的信息,和cnn的卷积过程很相似,就像是cnn的步长和卷积核大小一样,这样就做到了窗口的不重合,区别在于cnn在每个窗口做的是卷积的计算,每个窗口最后得到一个值,这个值代表着这个窗口的特征。而swin transformer在每个窗口做的是self-attention的计算,得到的是一个更新过的窗口,然后通过patch merging的操作,把窗口做了个合并,再继续对这个合并后的窗口做self-attention的计算。swin transformer通过不断地下采样的过程中将周边4个窗口的patch拼在一起,patch的数目在变少,最后整张图只有一个窗口,7个patch。所以本发明可以认为降采样是指让patch的数量减少,但是patch的大小在变大,这样增大了感受野,如图4所示。
82.swintransformer是在每一个窗口进行selfattention,与transformer进行的全局注意力计算相比,本发明假设已知msa的复杂度是图像大小的平方,根据msa的复杂度,本发明可以得出复杂度是(3
×
3)2=81。swintransformer是在每个local windows(红色部分)计算self-attention,根据msa的复杂度本发明可以得出每个红色窗口的复杂度是1
×
1的平方,也就是1的四次方。然后9个窗口,这些窗口的复杂度加和,最后的复杂度为9,大大降低了复杂度,msa与w-msa复杂度计算式如公式一、二。
83.虽然在window内部计算self-attention可能大大降低模型的复杂度,但是不同window无法进行信息交互,从而表现力欠缺。为了更好的增强模型的表现能力,引入shifted windows attention。shifted windows是在连续的swin transformerblocks之间交替移动的。
84.ω(msa)=4hwc2 2(hw)2c
85.ω(w-msa)=4hwc2 2m2hwc
86.式中h,w是每个窗口的长和宽,c窗口的通道数。
87.自注意力模块:cnn在计算机视觉任务中由于其空间局部性等特征,但只能对局部信息建模,缺乏长距离建模和感知的能力,而swin transformer引入shiftedwindowpartition来对这一缺陷进行改进,加强了不同窗口的信息交流问题,不在仅限于局部信息的交流,进而,本发明在多头注意力的基础上,受到cotnet联系上下文注意力机制的影响,提出了在swintransformer中融入注意力模块block,将transformer中独立的q、k矩阵进行了相互联系。特征提取网络进行到patchembed后,输入网络的特征图为640*640*3,之后对特征图的宽和高进行判断是否能对4进行整除,否则进行pad扩充操作,其次进行两次卷积,特征通道由之前的3通道变成了96通道,特征维度也变为了之前的1/4,最后通过注意力模块的大小为160*160*96,卷积核大小为3x3,通过联系上下文注意力模块的特征维度和特征通道不变,加强了对特征图上不同window之间的信息交流,注意力模块如图5所示。在传统的self-attention机制中,cot block结构将上下文的信息和self-attention融合到了一起。首先是定义三个变量q=x,k=x,v=xwv,v进行了1x1的卷积处理,之后k是进行了kxk的分组卷积操作记作k1,q矩阵和k1进行concat操作,再对concat之后的结果做两次1x1的卷积。计算如公式三所示。
88.a=[k1,q]w
θwδ
[0089]
式中,w
θwδ
是卷积操作,进行了两次,q、k是三个矩阵。
[0090]
这里的a不仅仅只是建模了q和k之间的关系。从而通过上下文建模引导,加强了局部之间的交流,增强了自注意力机制。之后a与v进行矩阵乘法得到k2。
[0091]
多维度混合卷积模块:为了针对sar目标特性,增大感受野,下面将详细描述所提出的方法。本发明所提出的特征提取网络是以swin transformer为基础架构进行backbone的改进。将cnn卷积以注意力机制融入patchembed模块并进行重构,整个特征提取网络结构图如图6所示。受到efficient网络的影响,在patchembed模块引入多维度混合卷积模块,之所以本发明引入此网络,根据cnn的机理特性,卷积层堆叠的越多特征图的感受野越大。本发明之前常用扩大感受野,扩增网络的深度,增大分辨率来提升网络的性能,现在本发明可以综合以上三点方法,综合混合参数扩展方式。虽然之前不乏这个方向的研究,例如mobilenet,shufflenet,m-nasnet等,通过降低参数量和计算量来压缩模型,从而应用在移动设备和边缘设备上,但在参数量和计算量显著降低的同时,模型精度获得了巨大提升。patchembed模块主要是增加由patch partition处理输入图片hxwx3划分为不重合的patch集合的每个patch的通道维度,减小特征图的大小,送入后面swin transfofmer block在进行处理。当每个特征图送入patchembed的维度2
×3×h×
w,最后送入下一个模块的维度为2
×
96
×
h/4
×
w/4,当通过卷积层实现了四倍降采样,并且通道数变成了96,本发明在3x3卷积之前堆叠了一层多维度混合卷积模块,卷积核大小为4,保持送入卷积的通道数不变,这样也加大的了感受野和网络深度,提高了模型的效率。
[0092]
第二、跨分辨率注意力增强neck:caeneck
[0093]
为了针对大场景下小目标、sar图像成像的强散射特性以及目标和背景区分度不高的特点,本发明受到sge注意力以及pan的结构的启示,本发明设计了一个新的跨分辨率注意力增强neck,caeneck,具体步骤是将特征图按通道分为g个group,再对每个group进行注意力计算,在对每个group进行全局平均池化得到g,之后g与原分组特征图进行矩阵乘
法,然后进行norm。并用sigmoid进行操作,得出的结果与原分组特征图进行矩阵乘法,具体步骤如图7所示。进行增加了连接上下文信息的注意力机制,在从上到下的连接处融入注意力,这是为了更好的融合浅层和深层特征图信息以及为了更好的提取小目标的特征以及目标的定位。本发明在特征图由上至下的传递过程中经过上采样,特征图的尺寸在增大,最深层经过注意力模块的加强作用后与中间层的特征图做concat操作,之后再经过注意力模块与最浅层特征图进行concat连接。具体步骤实现如下:neck接收到三个尺度的特征图:30*40*384,60*80*192,120*160*96,30*40*384为最深层特征,对其进行上采样和注意力增强操作,与60*80*192进行连接。最后再进行上采样和注意力增强与最浅层特征图连接,这一系列操作是自上而下进行的。之后进行自下而上的多尺度特征融合。如图1的neck部分。sar目标就是在大场景下的极小的目标,尤其是ssdd数据集的海上船舶目标,在大海中船舶本身具有的像素信息很少,在下采样的过程中就会容易丢失小物体的信息,用高层的特征图进行预测虽然语义信息丰富但是不利于对于目标的定位,底层的特征图语义信息很少但是有利于目标的位置判断。fpn结构是从上到下进行高层与底层的融合,通过上采样操作来实现,在上采样的过程中加入注意力模块,可以将上下文信息挖掘和自注意力机制集成到一个统一体内,从而不断地增强了提取目标位置的信息的能力,加上由下到上的模块之后有了一个从底层到高层的金字塔结构,实现了下采样之后的底层与高层的融合,增强了提取语义特征的信息,小特征图负责大型船舶的检测,大特征图负责小型船舶的检测,所以注意力增强非常适用于sar图像中多尺度船只检测。
[0094]
第三、损失函数
[0095]
损失函数用来估算模型输出与真实值y之间的差距,给模型的优化指引方向。本发明在head部分运用了不同的损失函数,在rpn-head中类别的损失利用交叉熵损失以及回归的损失利用smooth
l1
函数具体公式如下:
[0096]
在rpn-head(head中区域提取网络)中类别的损失利用交叉熵损失以及回归的损失利用smooth
l1
函数具体公式如下:
[0097][0098]
这里的代表了筛选出的anchors分类损失,n
class
为n个类别,pi为每个anchors的类别真值,p
i*
为每一anchor的预测类别,来平衡两部分损失的作用。代表了回归的损失,回归损失使用的函数公式如下:
[0099][0100]
ti代表类别真值,t
i*
代表预测类别;
[0101][0102]
本实施例通过从上到下和从下到上的注意力增强双向多尺度连接操作,以指导动
态注意力矩阵的学习,增强不同分辨率下的特征交互,促使模型能够更为精准的提取多尺度的目标特征信息,回归检测框和分类,抑制干扰背景信息,从而增强了视觉表示能力。在增加注意力增强模块的情况下,整个neck几乎不增加参数量和计算量也能使检测性能得到极强的增益。
[0103]
以上所述实施例仅为本发明较佳的具体实施方式,本发明的保护范围不限于此,任何熟悉本领域的技术人员在本发明披露的技术范围内,可显而易见地得到的技术方案的简单变化或等效替换,均属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
