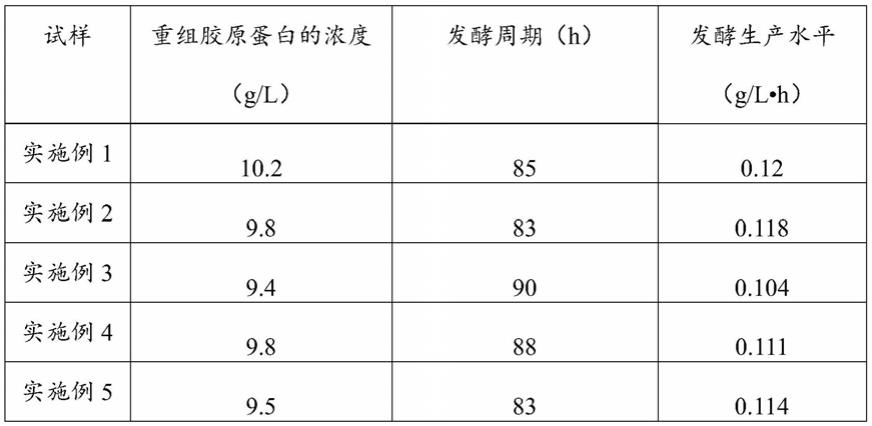
稳定化的糖苷水解酶变体
1.序列表的引用
2.本技术含有计算机可读形式的序列表。该计算机可读形式通过引用并入本文。
技术领域
3.本发明涉及糖苷水解酶的变体。这些变体可具有改善的稳定性,特别是改善的在洗涤剂和/或蛋白酶存在下的稳定性。此外,本发明涉及包含稳定化的糖苷水解酶变体的液体洗涤剂组合物。
背景技术:
4.糖苷水解酶(例如纤维素酶)通常含有由接头区域连接的催化结构域和一个或多个碳水化合物结合模块(cbm)。接头通常是提供结构化结构域之间的连接性的柔性连接物,但是它们的功能作用在很大程度上是未知的。
5.由于纤维素酶在洗衣过程中所观察到的益处,例如,颜色澄清、预防再沉积、抗起球/去除绒球和改善的白度,纤维素酶已在洗涤剂中使用多年,并且纤维素酶的特征在于能够将纤维素分子中的1,4
‑
β
‑
糖苷键切割成更小的分子。
6.在一些应用中,使用了复合纤维素酶组合物,其中该组合物包含多于一种纤维素降解酶(选自使用的内切葡聚糖酶、纤维二糖水解酶、和β
‑
葡糖苷酶),而其他应用使用主要包含一种或多种内切葡聚糖酶的酶组合物。
7.wo 1996/029397披露了用于洗涤剂用途的家族45内切葡聚糖酶。大多数商业洗涤剂组合物包含改善许多常见污渍的去除的蛋白酶。然而,蛋白酶也降解洗涤溶液中可获得的其他蛋白质,包括其他酶例如纤维素酶和其他的糖苷水解酶。因此,令人希望的是提供在蛋白酶存在下具有增加的稳定性的糖苷水解酶,例如纤维素酶及其变体。
技术实现要素:
8.本发明提供了具有糖苷水解酶或(ec 3.2.1.
‑
)活性的亲本多肽的变体,其中该变体包含催化结构域、工程化的接头区域(例如,富含脯氨酸的接头区域)、和碳水化合物结合模块(cbm)。优选地,该变体与亲本糖苷水解酶相比在包含蛋白酶的水性组合物中具有改善的接头稳定性和/或改善的cbm稳定性,并且其中该变体具有糖苷水解酶活性。
9.本发明进一步涉及多核苷酸和包含该多核甘酸的表达构建体;包含这些多核苷酸或表达构建体的宿主细胞,以及此类宿主细胞用于产生本发明的变体的用途。
10.还披露了包含变体的组合物、特别是洗涤剂组合物(例如液体洗涤剂组合物),以及此类组合物用于洗涤纺织品的用途。
11.定义
12.洗涤剂组分:本文将术语“洗涤剂组分”定义为意指可以用于洗涤剂组合物中的化学品的类型。洗涤剂组分的实例是表面活性剂、水溶助剂、助洗剂、共助洗剂、螯合剂(chelator)或螯合试剂(chelating agent)、漂白系统或漂白组分、聚合物、织物调色剂、织
物调理剂、增泡剂(foam booster)、抑泡剂、分散剂、染料转移抑制剂、荧光增白剂、香料、光学增亮剂、杀细菌剂、杀真菌剂、污垢悬浮剂、污垢释放聚合物、抗再沉积剂、酶抑制剂或稳定剂、酶活化剂、抗氧化剂和增溶剂。洗涤剂组合物可以包含一种或多种任何类型的洗涤剂组分。
13.洗涤剂组合物:术语“洗涤剂组合物”是指用于从有待清洁的物品(例如纺织品、餐具和硬表面)去除不希望的化合物的组合物。该洗涤剂组合物可以用于例如清洁纺织品、餐具以及硬表面,用于家用清洁剂和工业清洁二者和/或用于织物护理。这些术语涵盖经选择用于所希望的特定类型的清洁组合物和产品的形式(例如,液体、凝胶、粉末、颗粒、糊剂、或喷雾组合物)的任何材料/化合物,并且包括但不限于洗涤剂组合物(例如,液体和/或固体衣物洗涤剂和精细织物洗涤剂;硬表面清洁配制品,例如用于玻璃、木材、塑料、陶瓷以及金属台面和窗户的硬表面清洁配制品;地毯清洁剂;炉灶清洁剂;织物清新剂;织物软化剂;以及纺织品和衣物预去污剂(pre
‑
spotter),连同餐具洗涤剂)。除了含有本发明的酶,该洗涤剂配制品还含有一种或多种另外的酶(例如淀粉酶、蛋白酶、过氧化物酶、纤维素酶、β
‑
葡聚糖酶、木葡聚糖酶、半纤维素酶、黄原胶酶、黄原胶裂解酶、脂肪酶、酰基转移酶、磷脂酶、酯酶、漆酶、过氧化氢酶、芳基酯酶、淀粉酶、α
‑
淀粉酶、葡糖淀粉酶、角质酶、果胶酶、果胶裂解酶、角蛋白酶、还原酶、氧化酶、酚氧化酶、脂氧合酶、木质酶、角叉菜胶酶、普鲁兰酶、鞣酸酶、阿拉伯糖苷酶、透明质酸酶、软骨素酶、木葡聚糖酶、木聚糖酶、果胶乙酰酯酶、多半乳糖醛酸酶、鼠李半乳糖醛酸酶、其他的内切
‑
β
‑
甘露聚糖酶、外切
‑
β
‑
甘露聚糖酶(gh5和/或gh26)、地衣多糖酶(licheninase)、磷酸二酯酶、果胶甲基酯酶、纤维二糖水解酶、转谷氨酰胺酶、核酸酶及其组合物,或其任何混合物),和/或组分例如,表面活性剂、助洗剂、螯合剂(chelator)或螯合试剂(chelating agent)、漂白系统或漂白组分、聚合物、织物调理剂、增泡剂、抑泡剂、染料、香料、晦暗抑制剂、光学增亮剂、杀细菌剂、杀真菌剂、污垢悬浮剂、防蚀剂、酶抑制剂或稳定剂、酶活化剂、一种或多种转移酶、水解酶、氧化还原酶、上蓝剂和荧光染料、抗氧化剂以及增溶剂。
14.餐具洗涤:术语“餐具洗涤”是指洗涤餐具的所有形式,例如手动餐具洗涤(hdw)或自动餐具洗涤(adw)。洗涤餐具包括但不限于清洁所有形式的餐用器皿,例如盘子、杯子、玻璃杯、碗、所有形式的刀叉餐具(如匙、刀、叉)、以及上菜用具连同陶瓷、塑料、金属、瓷器、玻璃及丙烯酸酯。
15.餐具洗涤组合物:术语“餐具洗涤组合物”是指旨在用于清洁盘子、餐桌用具、罐、锅、刀叉餐具的组合物和用于清洁厨房中硬表面区域的所有形式的组合物。本发明不限于任何特定类型的餐具洗涤组合物或任何特定的洗涤剂。
16.洗涤液:术语“洗涤液”是指含有呈稀释形式的洗涤剂组合物的水溶液,例如但不限于含有呈稀释形式的衣物洗涤剂组合物的洗涤剂溶液,例如,在洗衣过程中的洗涤液。
17.纺织品:术语“纺织品”意指任何纺织品材料,该任何纺织品材料包括纱线、纱线中间体、纤维、非机织材料、天然材料、合成材料、以及任何其他纺织品材料,由这些材料制成的织物和由织物制成的产品(例如,服装和其他制品)。该纺织品或织物可以处于针织品、机织物(woven)、牛仔布(denim)、非机织物、毡、纱线、以及毛巾布的形式。该纺织品可以是基于纤维素的,如天然纤维素制品,包括棉、亚麻/亚麻布、黄麻、苎麻、剑麻或椰壳纤维,或者人造纤维素(例如,来源于木浆),包括粘胶纤维/人造丝、乙酸纤维素纤维(三胞)、莱赛尔纤
维(lyocell)或其共混物。纺织品或织物也可以不基于纤维素,如天然聚酰胺,包括羊毛、驼毛、羊绒、马海毛、兔毛和蚕丝,或合成聚合物如尼龙、芳族聚酰胺、聚酯、丙烯酸酯、聚丙烯和氨纶/弹性纤维(spandex/elastane)、或其共混物以及基于纤维素的纤维和不基于纤维素的纤维的共混物。共混物的实例是棉和/或人造丝/粘胶纤维与一种或多种伴随材料的共混物,该伴随材料如羊毛、合成纤维(例如聚酰胺纤维、丙烯酸纤维、聚酯纤维、聚氯乙烯纤维、聚氨酯纤维、聚脲纤维、芳族聚酰胺纤维)和/或含纤维素的纤维(例如人造丝/粘胶纤维、苎麻、亚麻/亚麻布、黄麻、乙酸纤维素纤维、莱赛尔纤维)。织物可以是常规的可洗涤衣物,例如有污渍的家用衣物。当使用术语织物或服装时,旨在还包括广义术语纺织品。
18.硬表面清洁:本文将术语“硬表面清洁”定义为清洁硬表面,其中硬表面可以包括地板、桌子、墙壁、屋顶等,连同硬物体的表面,如汽车(汽车洗涤)和餐具(餐具洗涤)。餐具洗涤包括但不限于,清洁盘子、杯子、玻璃杯、碗、刀叉餐具(如匙、刀、叉)、上菜用具、陶瓷、塑料、金属、瓷器、玻璃及丙烯酸酯。
19.白度:本文将术语“白度”定义为在不同领域并且针对不同顾客具有不同含义的广义术语。白度的损失可以例如归因于灰化、黄化、或光学增亮剂/调色剂的去除。灰化和黄化可归因于污垢再沉积、身体污垢、来自例如铁和铜离子或染料转移的着色。白度可包括来自以下列表的一个或若干个问题:着色剂或染料作用;不完全污渍去除(例如身体污垢、皮脂等);再沉积(物体的灰化、黄化或其他变色)(去除的污垢与纺织品的其他部分(弄脏的或未弄脏的)再关联);在应用过程中纺织品的化学变化;以及颜色的澄清或增辉。
20.颜色澄清:在洗涤和穿着过程中,松动或破损纤维可以在织物的表面上积聚。一种后果是由于表面污染,织物的颜色看起来不太亮或不太强烈。从纺织品上去除松动或破损纤维将部分地恢复该纺织品的原始颜色和外观。如本文所用的术语“颜色澄清”意指纺织品的原始颜色的部分恢复。
21.抗起球:术语“抗起球”表示从纺织品表面去除绒球和/或预防在纺织品表面上形成绒球。
22.织物护理:术语织物护理(也称为纺织品护理)是指保留或部分恢复或完全恢复纺织品的特性的处理,例如,通过颜色澄清、抗起球或预防在纺织品表面上形成绒球。
23.纤维素分解酶或纤维素酶:术语“纤维素分解酶”或“纤维素酶”意指水解纤维素材料的一种或多种(例如,若干种)酶。此类酶包括一种或多种内切葡聚糖酶(例如,ec 3.2.1.4)、一种或多种纤维二糖水解酶、一种或多种β
‑
葡糖苷酶、或其组合。用于测量纤维素分解酶活性的两种基本方法包括:(1)测量总纤维素分解酶活性,以及(2)测量个体纤维素分解酶活性(内切葡聚糖酶、纤维二糖水解酶和β
‑
葡糖苷酶),如在zhang等人,2006,biotechnology advances[生物技术进展]24:452
‑
481中所述的。可使用不溶性底物,包括沃特曼(whatman)
№
1滤纸、微晶纤维素、细菌纤维素、藻类纤维素、棉花、预处理的木质纤维素等,测量总纤维素分解酶活性。最常见的总纤维素分解活性测定是将沃特曼
№
1滤纸用作底物的滤纸测定。该测定是由国际纯粹与应用化学联合会(iupac)建立的(ghose,1987,pure appl.chem.[纯粹与应用化学]59:257
‑
68)。
[0024]
纤维素材料:术语“纤维素材料”意指含有纤维素的任何材料。生物质的初生细胞壁中的主要多糖是纤维素,第二丰富的是半纤维素,而第三丰富的是果胶。细胞停止生长后产生的次生细胞壁也含有多糖,并且它通过与半纤维素共价交联的聚合木质素得到强化。
纤维素是脱水纤维二糖的均聚物,并且因此是线性β
‑
(1
‑
4)
‑
d
‑
葡聚糖,而半纤维素包括多种具有一系列取代基处于复杂支链结构的化合物,例如木聚糖、木葡聚糖、阿拉伯糖基木聚糖、以及甘露聚糖。尽管纤维素通常为多形态的,但发现其在植物组织中主要作为平行葡聚糖链的不溶性晶体基质存在。半纤维素通常氢键结合至纤维素以及其他半纤维素,这有助于稳定化细胞壁基质。
[0025]
内切葡聚糖酶:术语“内切葡聚糖酶”意指催化纤维素、纤维素衍生物(如羧甲基纤维素和羟乙基纤维素)、地衣多糖中的1,4
‑
β
‑
d
‑
糖苷键,混合的β
‑
1,3
‑
β
‑
1,4葡聚糖如谷类β
‑
d
‑
葡聚糖或木葡聚糖以及含有纤维素组分的其他植物材料中的β
‑
1,4键的内切水解的酶。出于本发明的目的,根据ghose,1987,pure and appl.chem.[纯粹与应用化学]59:257
‑
268的程序,使用羧甲基纤维素(cmc)水解确定内切葡聚糖酶活性。一个单位的内切葡聚糖酶活性定义为在50℃、ph 4.8每分钟产生1.0微摩尔还原糖。
[0026]
一类特别优选的内切葡聚糖酶是“家族gh45”的那些,根据henrissat等人,biochem.j.[生物化学杂志]280:309
‑
316(1991)以及见于cazy.org的碳水化合物活性酶数据库(carbohydrate active enzymes database)中的术语,将其分类为糖苷水解酶家族45。gh45酶是ec 3.2.1.4的内切葡聚糖酶。
[0027]
糖苷水解酶:术语“糖苷水解酶”(gh)意指催化两个或更多个碳水化合物之间、或碳水化合物与非碳水化合物部分之间的糖苷键的水解的酶。更多细节,参见例如,henrissat b.,“a classification of glycosyl hydrolases based on amino
‑
acid sequence similarities.[基于氨基酸序列相似性的糖基水解酶的分类]”biochem.j.[生物化学杂志]280:309
‑
316(1991)以及见于cazy.org的碳水化合物活性酶数据库(carbohydrate active enzymes database)。
[0028]
根据本发明有用的具有报告的纤维素酶活性的示例性糖苷水解酶家族包括家族gh5、gh6、gh7、gh8、gh9、gh12、gh44、gh45、gh48、gh51、gh124的那些,其中家族gh45是特别优选的。
[0029]
碳水化合物结合模块:术语“碳水化合物结合模块”意指碳水化合物活性酶内的提供碳水化合物结合亲和力的区域(boraston等人,2004,biochem.j.[生物化学杂志]383:769
‑
781)。大多数已知的碳水化合物结合模块(cbm)是具有离散折叠的连续氨基酸序列。碳水化合物结合模块(cbm)典型地发现于酶的n
‑
末端处或c
‑
末端的端点处。已知一些cbm具有针对纤维素的特异性。
[0030]
根据本发明有用的示例性cbm家族是cbm家族1、4、17、28、30、44、72和79的那些。再一次,参考cazy.org/carbohydrate
‑
binding
‑
modules,cbm家族1包括几乎仅在真菌中发现的大约40个残基的模块。在许多情况下已经证明了纤维素结合功能,并且该纤维素结合功能似乎由间隔约10.4埃且形成扁平表面的三个芳香族残基介导。cbm家族4包括在细菌酶中发现的大约150个残基的模块。已经用木聚糖、β
‑
1,3
‑
葡聚糖、β
‑
1,3
‑
1,4
‑
葡聚糖、β
‑
1,6
‑
葡聚糖和无定形纤维素(但不用结晶纤维素)证明了这些模块的结合。cbm家族17包括大约200个残基的模块。已经证明了与无定形纤维素、纤维寡糖和衍生纤维素的结合。关于cbm家族28,来自芽孢杆菌属物种(bacillus sp.)1139的内切
‑
1,4
‑
葡聚糖酶的模块与非结晶纤维素、纤维寡糖和β
‑
(1,3)(1,4)
‑
葡聚糖结合。对于cbm家族30,已经证明了产琥珀酸丝状杆菌(fibrobacter succinogenes)celf的n
‑
末端模块与纤维素的结合。已经证明了热纤维梭菌
(clostridium thermocellum)酶的c
‑
末端cbm44模块可同样好地结合纤维素和木葡聚糖。cbm家族72包括在来自多个家族的c
‑
末端糖苷水解酶中发现的130
‑
180个残基的模块,有时作为串联重复。发现cbm72(其发现于来自未培养微生物的内切葡聚糖酶上)与广谱的多糖结合,这些多糖包括可溶性和不可溶性纤维素、β
‑
1,3/1,4
‑
混合连接的葡聚糖、木聚糖和β
‑
甘露聚糖。cbm家族79包括迄今为止仅在瘤胃球菌蛋白中发现的大约130个残基的模块。显示了黄色瘤胃球菌(r.flavefaciens)gh9酶与多种β
‑
葡聚糖的结合。最优选的是cbm家族1(也称为“cbm1”)。
[0031]
催化结构域:术语“催化结构域”意指含有该酶的催化机构的酶的区域。
[0032]
工程化的:术语“工程化的”意指合成的构建体。
[0033]
富含脯氨酸的接头:术语“富含脯氨酸的接头”意指包含一个或多个pro
‑
pro、pro
‑
xaa(或xaa
‑
pro)、xaa
‑
pro
‑
xaa或xaa
‑
xaa
‑
pro(或pro
‑
xaa
‑
xaa)单元的序列,其中pro是氨基酸脯氨酸的三字母表示而xaa是任何氨基酸的三字母表示。优选地,该富含脯氨酸的接头包含以组合和/或连续的形式重复的以上说明的单元,例如,pp、ppp、pppp(seq id no:27),px、pxp、ps、psp、pxpx(seq id no:98),xp、xpx、sp、sps、xpxp(seq idno:99),xpxxpx(seq id no:100),xxpxxp(seq id no:101)等等。
[0034]
在一方面,该富含脯氨酸的接头包含以下任选重复基序中的一个或多个:[p/s/t/r/k/d/e]p和p[s/t/r/k/d/e/n/q]p[s/t/r/k/d/e](seq id no:102)。在一方面,该富含脯氨酸的接头包含以下任选重复基序:[s/t/r/k/d/e]p[s/t/r/k/d/e/n/q]、[p/s/t/r/k/d/e][p/s/t/r/k/d/e]p和/或p[p/s/t/r/k/d/e][p/s/t/r/k/d/e]。在一方面,该富含脯氨酸的接头包含如所示的括号中的相同或不同氨基酸的任选重复基序:[p/s/t]p和p[s/e]pt(seqid no:109)。
[0035]
在一方面,该富含脯氨酸的接头包含(a)(sp)a,a=2
‑
10;(b)(ps)a,a=2
‑
10;(c)pb,b=4
‑
20,优选地4
‑
15;(d)(pept(seq id no:125))c,c=2
‑
5;(e)(pspt(seq id no:104))d,d=2
‑
5;(f)(p[s/t/r/k/d/e/n/q]p[s/t/r/k/d/e](seq id no:102))e,e=2
‑
5;(g)([s/t/r/k/d/e]p)f,f=2
‑
10,优选地2
‑
5;(h)([s/t/r/k/d/e/n/q]p[s/t/r/k/d/e])g,g=2
‑
6;(i)([s/t/r/k/d/e/n/q][s/t/r/k/d/e/n/q]p)h,h=2
‑
5;(j)(tp)i,i=2
‑
10;(k)([s/t/p][s/t/p][s/t/p])j,j=2
‑
11;(l)和/或其组合,其中考虑了各个单体单元的组合。
[0036]
在一方面,该富含脯氨酸的接头包含下文表a中的接头,例如ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)。
[0037]
优选地,该富含脯氨酸的接头包含至少25%脯氨酸,像至少28%脯氨酸、至少30%脯氨酸、至少35%脯氨酸、至少40%脯氨酸、至少50%脯氨酸,例如至少60%、至少66%、至少70%、至少75%、至少80%、至少85%、至少90%脯氨酸。优选地,该富含脯氨酸的接头包括至少4个氨基酸且不超过30个氨基酸,例如4
‑
28个氨基酸,优选地4
‑
20个氨基酸、或甚至4
‑
10个氨基酸,例如4个氨基酸、5个氨基酸、6个氨基酸、7个氨基酸、8个氨基酸、9个氨基酸或10个氨基酸。
[0038]
此外,如本文所定义的接头区域可包括在与催化结构域和/或碳水化合物结合模块的连接处的另外的1
‑
2个氨基酸的界面。
[0039]
等位基因变体:术语“等位基因变体”意指占据同一染色体基因座的基因的两种或
更多种替代形式中的任一种。等位基因变异通过突变而自然产生,并且可以导致群体内部的多态性。基因突变可以是沉默的(所编码的多肽无变化)或可以编码具有改变的氨基酸序列的多肽。多肽的等位基因变体是由基因的等位基因变体编码的多肽。
[0040]
cdna:术语“cdna”意指可以通过从获得自真核或原核细胞的成熟的、剪接的mrna分子进行反转录而制备的dna分子。cdna缺乏可以存在于对应基因组dna中的内含子序列。初始的初级rna转录物是mrna的前体,其要通过一系列的步骤(包括剪接)进行加工,然后呈现为成熟的剪接的mrna。
[0041]
编码序列:术语“编码序列”意指多核苷酸,该多核苷酸直接规定了变体的氨基酸序列。编码序列的边界通常由可读框确定,该可读框以起始密码子(例如atg、gtg、或ttg)开始并且以终止密码子(例如taa、tag、或tga)结束。编码序列可为基因组dna、cdna、合成dna、或其组合。
[0042]
控制序列:术语“控制序列”意指对于表达编码本发明的变体的多核苷酸所必需的核酸序列。每个控制序列对于编码该变体的多核苷酸来说可以是天然的(即,来自相同基因)或外源的(即,来自不同基因),或相对于彼此是天然的或外源的。此类控制序列包括但不限于前导序列、多腺苷酸化序列、前肽序列、启动子、信号肽序列、以及转录终止子。最少,控制序列包括启动子、以及转录和翻译终止信号。出于引入促进控制序列与编码变体的多核苷酸的编码区域连接的特异性限制位点的目的,控制序列可以提供有接头。
[0043]
表达:术语“表达”包括涉及变体产生的任何步骤,包括但不限于转录、转录后修饰、翻译、翻译后修饰、以及分泌。
[0044]
表达载体:术语“表达载体”意指直链或环状dna分子,该分子包含编码变体的多核苷酸并且可操作地连接到提供用于其表达的控制序列。
[0045]
片段:术语“片段”意指在成熟多肽的氨基和/或羧基末端缺失一个或多个(例如,若干个)氨基酸的多肽;其中该片段具有纤维素分解活性。在一方面,片段含有至少260个氨基酸残基(例如,seq id no:1、seq id no:2、seq id no:3、或seq id no:4的氨基酸1至260)、至少240个氨基酸残基(例如,seq id no:1、seq id no:2、seq id no:3、或seq id no:4的氨基酸1至240)、或至少对应催化结构域的残基,例如210、211、212、或216个氨基酸残基(例如,seq id no:1的氨基酸1至212或seq id no:1的氨基酸1至216、seq id no:2的氨基酸1至211或seq id no:2的氨基酸1至212、seq id no:3的氨基酸1至211或seq id no:3的氨基酸1至210氨基酸、seq id no:4的氨基酸1至211)。
[0046]
宿主细胞:术语“宿主细胞”意指易于用包含本发明的多核苷酸的核酸构建体或表达载体进行转化、转染、转导等的任何细胞类型。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不相同的任何亲本细胞子代。
[0047]
杂合多肽:术语“杂合多肽”意指包含来自不同来源(起源)的两个或更多个多肽的结构域的多肽,例如,来自一个多肽的结合模块和来自另一个多肽的催化结构域。结构域可以在n
‑
末端或c
‑
末端融合。本文中特别感兴趣的是包含以下的多肽:来自一个多肽(其可以是天然存在的或进一步经修饰的)的结合模块、工程化的接头区域(例如富含脯氨酸的接头区域(其是合成的构建体))、和来自另一个多肽(其可以是天然存在的或进一步经修饰的)的催化结构域。
[0048]
杂交:术语“杂交”意指使用标准dna印迹程序将核酸的基本上互补的链配对。杂交
可以在中、中
‑
高、高或非常高严格条件下进行。中严格条件意指在42℃,于5x sspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和35%甲酰胺中预杂交和杂交12至24小时,随后在55℃使用0.2x ssc、0.2%sds洗涤三次,每次15分钟。中
‑
高严格条件意指在42℃,于5x sspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和35%甲酰胺中预杂交和杂交12至24小时,随后在60℃使用0.2x ssc、0.2%sds洗涤三次,每次15分钟。高严格条件意指在42℃,于5x sspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和50%甲酰胺中预杂交和杂交12至24小时,随后在65℃使用0.2x ssc、0.2%sds洗涤三次,每次15分钟。非常高严格条件意指在42℃,于5x sspe、0.3%sds、200微克/ml剪切并变性的鲑鱼精子dna和50%甲酰胺中预杂交和杂交12至24小时,随后在70℃使用0.2x ssc、0.2%sds洗涤三次,每次15分钟。
[0049]
改善的特性:术语“改善的特性”意指与相比于参考酶/亲本酶有改善的变体相关的特征。本发明的一些方面涉及当变体在相关测定中测试目的特性时具有高于1的改善因子的变体,其中该参考酶/亲本酶的特性被给予1的值。
[0050]
改善的稳定性:术语“改善的稳定性”意指相对于参考酶/亲本酶的稳定性,在蛋白酶的存在下酶具有更好的稳定性,并且包括例如,蛋白质水解稳定性、洗涤剂中储存稳定性、在洗涤剂组合物生产期间改善的稳定性以及洗涤中稳定性。稳定性的改善通过以下来量化:根据本文的实例2(接头稳定性测定
‑
在蛋白酶的存在下)和/或实例7(使用蛋白酶进行的洗涤中接头稳定性测定)中所述的测定确定稳定性。
[0051]
改善的洗涤性能:本文将术语“改善的洗涤性能”定义为当对新样品和/或将样品在相同条件下储存之后进行评价时,相对于参考酶/亲本酶的洗涤性能,在洗涤剂组合物中酶例如,通过增加的颜色澄清和/或抗起球作用,表现出增加的洗涤性能。术语“改善的洗涤性能”包括在衣物洗涤并且还在例如硬表面清洁如自动化餐具洗涤(adw)中的洗涤性能。
[0052]
分离的:术语“分离的”意指处于自然界中不存在的形式或环境中的物质。分离的物质的非限制性实例包括(1)任何非天然存在的物质,(2)包括但不限于任何酶、变体、核酸、蛋白质、肽或辅因子的任何物质,该物质至少部分地从与其性质相关的一种或多种或所有天然存在的成分中去除;(3)相对于自然界中发现的物质通过人工修饰的任何物质;或(4)通过增加该物质相对于与其本质相关的其他组分的量而修饰的任何物质(例如,编码该物质的基因的多拷贝;使用比编码该物质的基因本质相关的启动子强的启动子)。分离的物质可以存在于发酵培养液样品中。
[0053]
成熟多肽:术语“成熟多肽”意指在n
‑
末端加工(例如,信号肽的去除)后处于其成熟形式的多肽。
[0054]
成熟多肽编码序列:术语“成熟多肽编码序列”意指编码具有纤维素酶(例如内切葡聚糖酶)活性的成熟多肽的多核苷酸。
[0055]
突变体:术语“突变体”意指编码变体的多核苷酸。
[0056]
核酸构建体:术语“核酸构建体”意指单链或双链的核酸分子,该核酸分子是从天然存在的基因中分离的,或以原本不存在于自然界中的方式被修饰成包含核酸的区段,或者是合成的,该核酸分子包含一个或多个控制序列。
[0057]
可操作地连接:术语“可操作地连接”意指如下构型,在该构型中,控制序列被放置在相对于多核苷酸的编码序列适当的位置处,使得该控制序列指导该编码序列的表达。
[0058]
亲本或亲本纤维素酶:术语“亲本”或“亲本纤维素酶”意指对其作出改变以产生本发明的这些酶变体的具有糖苷水解酶活性(特别是纤维素分解活性或甚至内切葡聚糖酶活性)的任何多肽。
[0059]
纯化的:术语“纯化的”意指基本上不含其他组分的核酸或多肽,如通过本领域熟知的分析技术(例如,在电泳凝胶、色谱洗脱液和/或经过密度梯度离心的培养基中,纯化的多肽或核酸可形成离散的条带)所确定。纯化的核酸或多肽是至少约50%纯的,通常是至少约60%、约65%、约70%、约75%、约80%、约85%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%、约99.5%、约99.6%、约99.7%、约99.8%或更加纯的(例如,以摩尔计的重量百分比)。在相关意义上,当在应用纯化或富集技术之后存在分子的浓度的大幅度增加时,组合物富集了分子。术语“富集”是指化合物、多肽、细胞、核酸、氨基酸或其他指定材料或组分以高于起始组合物的相对或绝对浓度存在于组合物中。
[0060]
重组:当用于提及细胞、核酸、蛋白质或载体时,术语“重组”意指已经从其天然状态经修饰。因此,例如,重组细胞表达在天然(非重组)形式的细胞内未发现的基因,或与在自然界中发现的相比,以不同水平表达或在不同条件下表达天然基因。重组核酸与天然序列的差异在于一个或多个核苷酸和/或与异源序列(例如,表达载体中的异源启动子)可操作地连接。重组蛋白与天然序列的差异可以在于一个或多个氨基酸和/或与异源序列融合。包含编码多肽的核酸的载体是重组载体。术语“重组”与“遗传修饰的”和“转基因的”同义。
[0061]
序列同一性:两个氨基酸序列之间或两个核苷酸序列之间的关联度通过参数“序列同一性”来描述。
[0062]
出于本发明的目的,使用如在emboss软件包(emboss:欧洲分子生物学开放软件包(the european molecular biology open software suite),rice等人,2000,trends genet.[遗传学趋势]16:276
‑
277)(优选5.0.0版本或更新版本)的尼德尔程序中所实施的尼德曼
‑
翁施算法(needleman
‑
wunsch algorithm)(needleman和wunsch,1970,j.mol.biol.[分子生物学杂志]48:443
‑
453)来确定两个氨基酸序列之间的序列同一性。所使用的参数是空位开放罚分10、空位延伸罚分0.5、和eblosum62(blosum62的emboss版)取代矩阵。将标记为“最长同一性”的尼德尔的输出(使用非简化选项获得)用作同一性百分比并且计算如下:
[0063]
(相同的残基x 100)/(比对长度
‑
比对中的空位总数)
[0064]
出于本发明的目的,使用如在emboss包(emboss:the european molecular biology open software suite[emboss:欧洲分子生物学开放软件套件],rice等人,2000,同上)(优选地5.0.0版本或更新版本)的尼德尔程序中所实施的尼德曼
‑
翁施算法(needleman和wunsch,1970,同上)来确定两个脱氧核糖核苷酸序列之间的序列同一性。所使用的参数是空位开放罚分10、空位延伸罚分0.5、和ednafull(ncbi nuc4.4的emboss版)取代矩阵。将标记为“最长同一性”的尼德尔的输出(使用非简化选项获得)用作同一性百分比并且计算如下:
[0065]
(相同的脱氧核糖核苷酸x 100)/(比对长度
‑
比对中的空位总数)
[0066]
变体:术语“变体”意指在一个或多个(例如,若干个)位置处包含取代的具有纤维素分解活性的多肽。取代意指用不同的氨基酸替代占据某一位置的氨基酸。本发明的这些变体具有亲本(例如seq id no:1、seq id no:2、seq id no:3或seq id no:4的成熟多肽)
的纤维素分解活性的至少20%,像至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%或至少100%。如本文所用的“变体”还可包括杂合多肽。
[0067]
野生型:提及氨基酸序列或核酸序列时术语“野生型”意指该氨基酸序列或核酸序列是天然或天然存在的序列。如本文所用,术语“天然存在的”是指在自然界中发现的任何物质(例如蛋白质、氨基酸或核酸序列)。相反,术语“非天然存在的”是指在自然界中未发现的任何物质(例如,在实验室中产生的重组核酸和蛋白质序列、或野生型序列的修饰)。
[0068]
变体命名惯例
[0069]
出于本发明的目的,将seq id no:1中披露的成熟多肽用以确定另一种纤维素酶中的对应氨基酸残基。将另一种纤维素酶的氨基酸序列与seq id no:1中披露的成熟多肽进行比对,并且基于该比对,使用如在emboss包(emboss:欧洲分子生物学开放软件套件(the european molecular biology open software suite),rice等人,2000,trends genet.[遗传学趋势]16:276
‑
277)(优选5.0.0版或更新版本)的尼德尔程序中所实施的尼德尔曼
‑
翁施算法(needleman和wunsch,1970,j.mol.biol.[分子生物学杂志]48:443
‑
453)来确定与seq id no:1中所披露的成熟多肽中的任何氨基酸残基对应氨基酸位置编号。所使用的参数是空位开放罚分10、空位延伸罚分0.5、和eblosum62(blosum62的emboss版)取代矩阵。
[0070]
另一种纤维素酶中的相对应的氨基酸残基的鉴别可以通过多个多肽序列使用若干种计算机程序使用其对应的缺省参数的一个比对来确定,这些计算机程序包括(但不限于)muscle(通过对数
‑
期望的多序列比较;3.5版或更新版;edgar,2004,nucleic acids research[核酸研究]32:1792
‑
1797)、mafft(6.857版本或更新版本;katoh和kuma,2002,nucleic acids research[核酸研究]30:3059
‑
3066;katoh等人,2005,nucleic acids research[核酸研究]33:511
‑
518;katoh和toh,2007,bioinformatics[生物信息学]23:372
‑
374;katoh等人,2009,methods in molecular biology[分子生物学方法]537:39
‑
64;katoh和toh,2010,bioinformatics[生物信息学]26:1899
‑
1900),以及采用clustalw(1.83或更新版本;thompson等人,1994,nucleic acids research[核酸研究]22:4673
‑
4680)的emboss emma。
[0071]
当其他酶与seq id no:1的成熟多肽相背离,这样使得传统的基于序列的比较方法不能检测其相互关系时(lindahl和elofsson,2000,j.mol.biol.[分子生物学杂志]295:613
‑
615),可使用其他成对序列比较算法。在基于序列的搜索中较高的敏感度可使用搜索程序来获得,这些搜索程序利用多肽家族的概率表现(谱)来搜索数据库。例如,psi
‑
blast程序通过迭代数据库搜索过程来产生多个谱,并且能够检测远距离同源物(atschul等人,1997,nucleic acids res.[核酸研究]25:3389
‑
3402)。如果多肽的家族或超家族具有在蛋白结构数据库中的一个或多个代表,可以实现甚至更高的敏感度。程序诸如genthreader(jones,1999,j.mol.biol.[分子生物学杂志]287:797
‑
815;mcguffin和jones,2003,bioinformatics[生物信息学]19:874
‑
881)利用来自多种来源(psi
‑
blast、二级结构预测、结构比对谱、以及溶剂化势)的信息作为预测查询序列的结构折叠的神经网络的输入。类似地,gough等人,2000,j.mol.biol.[分子生物学杂志]313:903
‑
919的方法可用于将未知结构的序列与存在于scop数据库中的超家族模型进行比对。这些比对进而可以用于产生多肽的同源性模型,并且使用出于该目的而开发的多种工具可以评估此类模型的准确度。
[0072]
对于已知结构的蛋白质,有若干种工具和资源可用于检索并产生结构比对。例如,蛋白质的scop超家族已经在结构上进行比对,并且那些比对是可访问且可下载的。可以使用多种算法如距离比对矩阵(holm和sander,1998,proteins[蛋白质]33:88
‑
96)或组合延伸(shindyalov和bourne,1998,protein engineering[蛋白质工程]11:739
‑
747)比对两种或更多种蛋白质结构,并且这些算法的实施可以另外用于查询具有目的结构的结构数据库,以便发现可能的结构同源物(例如,holm和park,2000,bioinformatics[生物信息学]16:566
‑
567)。
[0073]
例如,该亲本多肽可包含seq id no:2、seq id no:3、seq id no:4或其成熟多肽中的任一者。
[0074]
在描述本发明的变体时,为了便于参考,以下描述的命名法经过了调整。采用了已接受的iupac单字母或三字母的氨基酸缩写。
[0075]
取代。对于氨基酸取代,使用以下命名法:原始氨基酸、位置、取代的氨基酸。相应地,将在位置226处的苏氨酸被丙氨酸取代表示为“thr226ala”或“t226a”。多个突变通过加号(“ ”)分开,例如“gly205arg ser411phe”或“g205r s411f”代表在位置205和位置411处的甘氨酸(g)和丝氨酸(s)分别被精氨酸(r)和苯丙氨酸(f)取代。
[0076]
缺失。对于氨基酸缺失,使用以下命名法:原始氨基酸、位置、*。相应地,将在位置195处的甘氨酸的缺失表示为“gly195*”或“g195*”。多个缺失通过加号(“ ”)分开,例如“gly195* ser411*”或“g195* s411*”。
[0077]
插入。对于氨基酸插入,使用以下命名法:原始氨基酸、位置、原始氨基酸、插入的氨基酸。相应地,将在位置195处的甘氨酸之后插入赖氨酸表示为“gly195glylys”或“g195gk”。多个氨基酸的插入被表示为[原始氨基酸、位置、原始氨基酸、插入的氨基酸#1、插入的氨基酸#2;等]。例如,将在位置195处的甘氨酸之后插入赖氨酸和丙氨酸表示为“gly195glylysala”或“g195gka”。
[0078]
在此类情况下,通过将小写字母添加至在所插入的一个或多个氨基酸残基之前的氨基酸残基的位置编号而对所插入的一个或多个氨基酸残基进行编号。在以上实例中,该序列因此会是:
[0079]
亲本:变体:195195 195a 195bgg
‑
k
‑
a
[0080]
多个改变。包含多个改变的变体由加号(“ ”)分开,例如,“arg170tyr gly195glu”或“r170y g195e”代表在位置170处和位置195处的精氨酸和甘氨酸分别被酪氨酸和谷氨酸取代。
[0081]
不同改变。在可于一个位置处引入不同改变的情况下,不同的改变由逗号分开,例如,“arg170tyr,glu”代表用酪氨酸或谷氨酸取代在位置170处的精氨酸。因此,“tyr167gly,ala arg170gly,ala”表示以下变体:
[0082]“tyr167gly arg170gly”、“tyr167gly arg170ala”、“tyr167ala arg170gly”、和“tyr167ala arg170ala”。
[0083]
命名法
[0084]
出于本发明的目的,使用括号来表示在序列中的特定位置处的替代氨基酸(使用
其单字母代码)。例如,命名法[s/e]意指在此位置处的氨基酸可以是丝氨酸(ser,s)或谷氨酸(glu,e)。同样,命名法[p/s/t]意指在此位置处的氨基酸可以是脯氨酸(pro,p)、丝氨酸(ser,s)或苏氨酸(thr,t),对于如本文所述的其他组合,依次类推。使用此命名法在括号中表示的氨基酸可以通过竖线分开或者在一些情况下,不用线分开,例如[p/s/t]还可以命名为[pst]。
[0085]
在某种情况下,序列基序包括多于一组括号,每组括号独立地代表序列中的位置。因此,p[s/t/r/k/d/e/n/q]p[s/t/r/k/d/e](seq id no:102)意指:p(保守氨基酸)在第一位置处;s、t、r、k、d、e、n、或q中的任一个在第二位置处;p(保守氨基酸)在第三位置处;而s、t、r、k、d、或e中的任一个在第四位置处。此命名代表的基序因此可以是psps(seq id no:103)、pspt(seq id no:104)、pspr(seq id no:105)、pspk(seq id no:106)、pspd(seq id no:107)、pspe(seq id no:108)等等中的任一个。
[0086]
除非进一步另外限制,否则在本文中使用氨基酸x(或xaa)来代表20种天然氨基酸中的任一者。
具体实施方式
[0087]
许多蛋白质由通过接头连接的结构化结构域构成。例如,纤维素酶和其他的糖苷水解酶(gh)经常作为具有一个或多个催化结构域的模块化酶被发现,该催化结构域经由称为接头的肽与一个或多个cbm连接,该接头有时是部分糖基化的。催化结构域负责纤维素的水解降解,而当存在时,cbm通过提高底物表面附近酶的有效浓度来起作用。相反,接头通常是提供结构化结构域之间的连接性的柔性连接物,但是它们的功能作用在很大程度上是未知的。
[0088]
本发明涉及具有三结构域结构的糖苷水解酶的变体,其中催化结构域经由接头连接到一个或多个碳水化合物结合模块。本发明涉及具有肽段的变体,该肽段使天然接头更稳定,即,更不易被蛋白质水解切割。
[0089]
特别是纤维素酶,在液体洗涤剂中经常在暴露区域被蛋白酶切割(切口)或被部分或完全降解。最常见的是,蛋白酶在纤维素酶的未结构化的接头区域中切割并且由此通过降低纤维素酶与不溶性纤维素底物结合的能力,降低了纤维素酶去除绒毛和绒球的能力和使纺织品的颜色维持或恢复的能力。结合亲和力的损失严重影响了纤维素酶的性能,因此,对蛋白酶稳定的接头在液体衣物洗涤剂/餐具洗涤剂领域以及在软化剂中是十分有价值的。
[0090]
变体
[0091]
本发明提供了具有糖苷水解酶(ec 3.2.1.
‑
)活性的亲本多肽的变体,其中该变体包含催化结构域、工程化的接头区域(其可以是例如富含脯氨酸的接头区域,例如非天然存在的富含脯氨酸的接头区域)和碳水化合物结合模块(cbm),其中该变体与亲本糖苷水解酶相比在含有蛋白酶的水性洗涤剂组合物中具有改善的接头稳定性和/或改善的cbm稳定性,并且其中该变体具有糖苷水解酶活性。
[0092]
在实施例中,该亲本多肽是纤维素酶,并且甚至更优选地,是内切葡聚糖酶,并且甚至更优选地,是gh45内切葡聚糖酶。
[0093]
考虑了具有n
‑
末端和/或c
‑
末端cbm的多肽。
[0094]
接头
[0095]
根据本发明的变体包含将催化核心与cbm(接头区域)连接起来的富含脯氨酸的氨基酸序列,例如富含脯氨酸的接头区域。
[0096]
如本文所述的这些富含脯氨酸的接头包含一个或多个pro
‑
pro、pro
‑
xaa(或xaa
‑
pro)、xaa
‑
pro
‑
xaa或xaa
‑
xaa
‑
pro(或pro
‑
xaa
‑
xaa)单元,例如,pppp(seq id no:27)、pxpx(seq id no:98)、xpxp(seq id no:99)、xpxxpx(seq id no:100)、xxpxxp(seq id no:101)等等,任选地进一步组合和/或重复。
[0097]
例如,该接头区域可包含至少25%脯氨酸,例如至少28%脯氨酸、至少30%脯氨酸、至少40%脯氨酸、至少50%脯氨酸,例如至少60%、至少66%、至少70%、至少75%、至少80%、至少85%、至少90%脯氨酸。在其他实施例中,该接头包含至少50%脯氨酸,例如至少60%、至少66%、至少70%、至少75%、至少80%、至少85%、至少90%并且具有整体负电荷。例如,该接头区域包含酸性的氨基酸。
[0098]
优选的接头区域具有至少4个氨基酸且不超过30个氨基酸的长度,例如4
‑
28个氨基酸,优选地4
‑
20个氨基酸,或甚至4
‑
10个氨基酸,例如4个氨基酸、5个氨基酸、6个氨基酸、7个氨基酸、8个氨基酸、9个氨基酸或10个氨基酸的长度。
[0099]
示例性接头区域包含以下任选重复基序中的一个或多个:
[0100]
[p/s/t/r/k/d/e]p和
[0101]
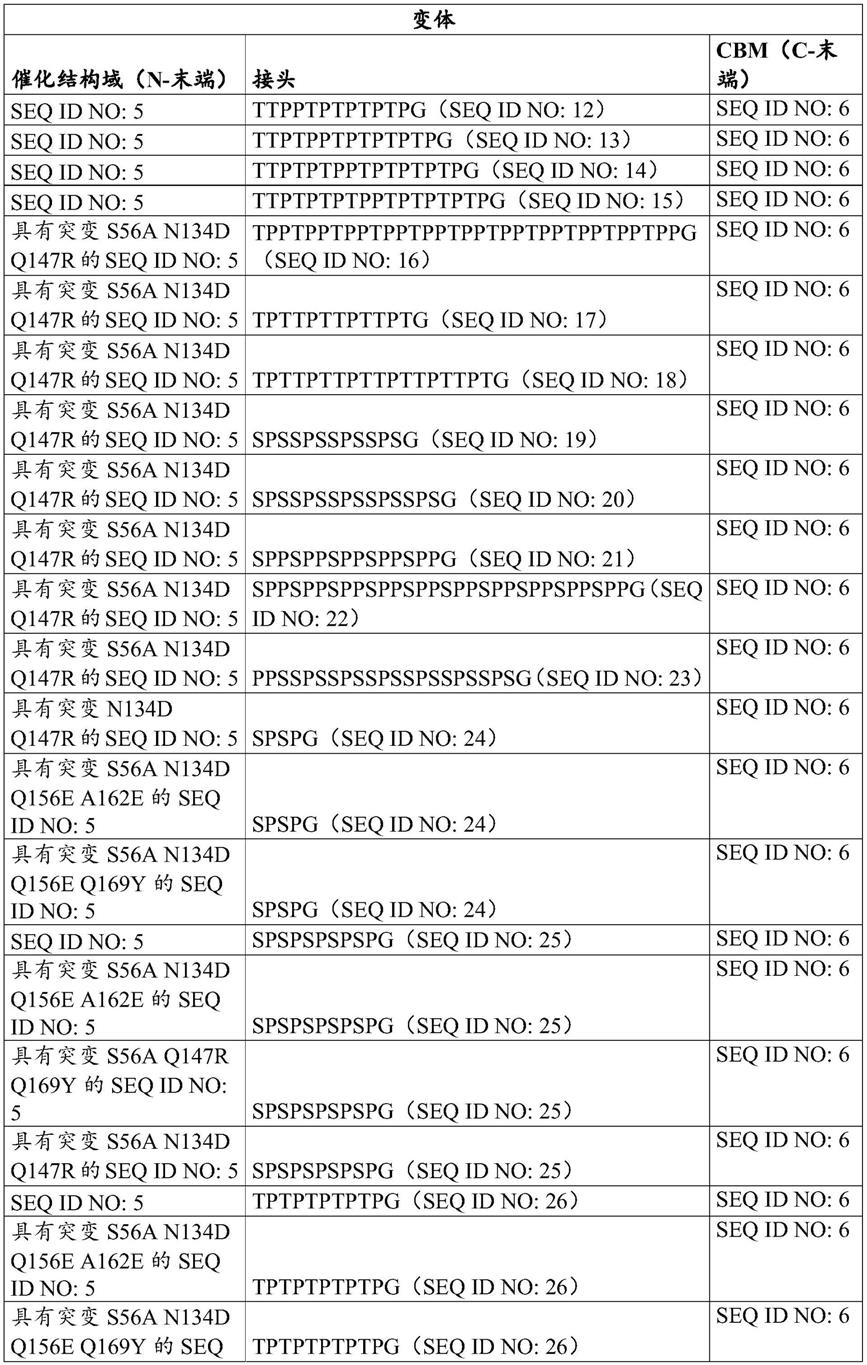
p[s/t/r/k/d/e/n/q]p[s/t/r/k/d/e](seq id no:102)
[0102]
其他优选的接头区域包括以下任选重复基序:
[0103]
[s/t/r/k/d/e]p[s/t/r/k/d/e/n/q]
[0104]
[p/s/t/r/k/d/e][p/s/t/r/k/d/e]p和/或
[0105]
p[p/s/t/r/k/d/e][p/s/t/r/k/d/e]。
[0106]
特别优选的接头包括如所示的括号中的相同或不同氨基酸的任选重复基序:
[0107]
[p/s/t]p和
[0108]
p[s/e]pt(seq id no:109)。
[0109]
或者更特别地,由[p/s/t]p代表的任选重复基序包括pppppp(seq id no:29)以及ppsptp(seq id no:110)、pptptp(seq id no:111)、ppspsp(seq id no:112)、sppptp(seq id no:113)、sptppp(seq id no:114)、sppppp(seq id no:115)、sptptp(seq id no:116)、tpppsp(seq id no:117)、tpsppp(seq id no:118)、tppppp(seq id no:119)、tpspsp(seq id no:120),并且p[s/e]pt(seq id no:109)代表的任选重复基序则包括psptpept(seq id no:121)、psptpeptpsptpept(seq id no:122)、peptpspt(seq id no:123)、peptpsptpspt(seq id no:124)等等。
[0110]
示例性接头进一步包含
[0111]
(a)(sp)
a
,a=2
‑
10;
[0112]
(b)(ps)
a
,a=2
‑
10;
[0113]
(c)p
b
,b=4
‑
20,优选地4
‑
15;
[0114]
(d)(pept(seq id no:125))
c
,c=2
‑
5;
[0115]
(e)(pspt(seq id no:104))
d
,d=2
‑
5;
[0116]
(f)(p[s/t/r/k/d/e/n/q]p[s/t/r/k/d/e](seq id no:102))
e
,e=2
‑
5;
[0117]
(g)([s/t/r/k/d/e]p)
f
,f=2
‑
10,优选地2
‑
5;
[0118]
(h)([s/t/r/k/d/e/n/q]p[s/t/r/k/d/e])
g
,g=2
‑
6;
[0119]
(i)([s/t/r/k/d/e/n/q][s/t/r/k/d/e/n/q]p)
h
,h=2
‑
5;
[0120]
(j)(tp)
i
,i=2
‑
10;
[0121]
(k)([s/t/p][s/t/p][s/t/p])
j
,j=2
‑
11;
[0122]
(l)和/或其组合,其中考虑了各个单体单元的组合。
[0123]
当包括这些基序的组合时,最小重复单元是单体单元。例如,接头包括sppept(seq id no:126)、sppspt(seq id no:127)、pspept(seq id no:128)、pspspt(seq id no:129)。
[0124]
另外的示例性接头包括:
[0125]
spsp(seq id no:130)、spspsp(seq id no:131)、spspspsp(seq id no:132)、spspspspsp(seq id no:58)、spspspspspsp(seq id no:133)、spspspspspspsp(seq id no:134)、spspspspspspspsp(seq id no:135)、pppp(seq id no:27)、ppppp(seq id no:28)、pppppp(seq id no:29)、ppppppp(seq id no:31)、pppppppp(seq id no:136)、ppppppppp(seqs id no:137)、pppppppppp(seq id no:138)、ppppppppppp(seq id no:139)、pppppppppppp(seq id no:140)、ppppppppppppp(seq id no:141)、pppppppppppppp(seq id no:142)、ppppppppppppppp(seq id no:143)、peptpept(seq id no:144)、peptpeptpept(seq id no:145)、peptpeptpeptpept(seq id no:146)、peptpeptpeptpeptpept(seq id no:79)、psptpspt(seq id no:147)、psptpsptpspt(seq id no:148)、psptpsptpsptpspt(seq id no:149)、psptpsptpsptpsptpspt(seq id no:150)、spssps(seq id no:151)、spsspssps(seq id no:152)、spsspsspssps(seq id no:153)、spsspsspsspssps(seq id no:154)、tpttpt(seq id no:155)、tpttpttpt(seq id no:156)、tpttpttpttpt(seq id no:157)、tpttpttpttpttpt(seq id no:158)、peptprptpeptprpt(seq id no:159)、peptpkptpeptpkpt(seq id no:160)、peptpqptpeptpqpt(seq id no:161)、prptpeptprpt(seq id no:162)、pkptpeptpkpt(seq id no:163)、peptpqpt(seq id no:164)、peptpqptpept(seq id no:165)、peptprptpeptprptg(seq id no:85)、peptpkptpeptpkptg(seq id no:87)、peptpqptpeptpqptg(seq id no:88)、prptpeptprptg(seq id no:89)、pkptpeptpkptg(seq id no:90)、peptpqptg(seq id no:91)、peptpqptpeptg(seq id no:92)、pppggpggpgtptstapgsgptspgggsg(seq id no:82)、ttpptptptptp(seq id no:166);ttptpptptptptp(seq id no:167)、ttptptpptptptptp(seq id no:168)、tpptpptpptpptpptpptpptpptpptpptpp(seq id no:169)。
[0126]
另外的示例性接头包含上述接头以及c
‑
末端甘氨酸,例如,spspg(seq id no:24)、spspspg、spspspspg、spspspspspg(seq id no:25)、spspspspspspg、spspspspspspspg、spspspspspspspspg、ppppg、pppppg、ppppppg、pppppppg(seq id no:30)、ppppppppg(seq id no:32)、pppppppppg(seq id no:33)、ppppppppppg(seq id no:34)、pppppppppppg(seq id no:35)、ppppppppppppg(seq id no:170)、pppppppppppppg(seq id no:36)、ppppppppppppppg(seq id no:171)、pppppppppppppppg(seq id no:172)、peptpeptg(seq id no:37)、peptpeptpeptg(seq id no:38)、peptpeptpeptpeptg(seq id no:39)、peptpeptpeptpeptpeptg(seq id no:40)、psptpsptg、psptpsptpsptg、
psptpsptpsptpsptg(seq id no:41)、psptpsptpsptpsptpsptg(seq id no:42)、spsspsg(seq id no:94)、spsspsspsg(seq id no:95)、spsspsspsspsg(seq id no:19)、spsspsspsspsspsg(seq id no:20)、tpttptg(seq id no:96)、tpttpttptg(seq id no:97)、tpttpttpttptg(seq id no:17)、tpttpttpttpttptg、peptprptpeptprptg(seq id no:85)、peptpkptpeptpkptg(seq id no:87)、peptpqptpeptpqptg(seq id no:88)、prptpeptprptg(seq id no:89)、pkptpeptpkptg(seq id no:90)、peptpqptg(seq id no:91)、peptpqptpeptg(seq id no:92)、pppggpggpgtptstapgsgptspgggsg(seq id no:82)、ttpptptptptpg(seq id no:12);ttptpptptptptpg(seq id no:13)、ttptptpptptptptpg(seq id no:14)、ttptptptpptptptptpg(seq id no:15)、tpptpptpptpptpptpptpptpptpptpptppg(seq id no:16)。
[0127]
特别优选的接头是主要包含或只包含脯氨酸的那些接头,例如,pppp(seq id no:27)、ppppp(seq id no:28)、pppppp(seq id no:29)、ppppppp(seq id no:31)、pppppppp(seq id no:136)、ppppppppp(seq id no:137)、pppppppppp(seq id no:138)、ppppppppppp(seq id no:139)、pppppppppppp(seq id no:140)、ppppppppppppp(seq id no:141)、pppppppppppppp(seq id no:142)、ppppppppppppppp(seq id no:143)、ppppg、pppppg、ppppppg、pppppppg(seq id no:30)、ppppppppg(seq id no:32)、pppppppppg(seq id no:33)、ppppppppppg(seq id no:34)、pppppppppppg(seq id no:35)、ppppppppppppg(seq id no:170)、pppppppppppppg(seq id no:36)、ppppppppppppppg(seq id no:171)、pppppppppppppppg(seq id no:172)。
[0128]
对于上文考虑的实施例,本领域技术人员将认识到,目标是将目的亲本的接头用本文的富含脯氨酸的接头替代以提供另外的稳定性。
[0129]
在替代性实施例中,该接头可以被认为是亲本分子的接头的变体,该变体具有稳定的点突变,包括突变为脯氨酸。
[0130]
相应地,在一些实施例中,该接头可包含与seq id no:1的位置213
‑
241所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0131]
在实施例中,该接头包含与seq id no:2的位置211
‑
246所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0132]
在实施例中,该接头包含与seq id no:3的位置211
‑
258所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0133]
在实施例中,该接头包含与seq id no:4的位置211
‑
240所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0134]
在特别优选的实施例中,该接头选自表a中以下接头中的任一个:
[0135]
表a.优选的接头
[0136]
ttpptptptptpg(seq id no:12)
[0137]
ttptpptptptptpg(seq id no:13)
[0138]
ttptptpptptptptpg(seq id no:14)
[0139]
ttptptptpptptptptpg(seq id no:15)
[0140]
tpptpptpptpptpptpptpptpptpptpptppg(seq id no:16)
[0141]
tpttpttpttptg(seq id no:17)
[0142]
tpttpttpttpttpttptg(seq id no:18)
[0143]
spsspsspsspsg(seq id no:19)
[0144]
spsspsspsspsspsg(seq id no:20)
[0145]
sppsppsppsppsppg(seq id no:21)
[0146]
sppsppsppsppsppsppsppsppsppsppg(seq id no:22)
[0147]
ppsspsspsspsspsspsspsg(seq id no:23)
[0148]
spspg(seq id no:24)
[0149]
spspspspspg(seq id no:25)
[0150]
tptptptptpg(seq id no:26)
[0151]
pppp(seq id no:27)
[0152]
ppppp(seq id no:28)
[0153]
pppppp(seq id no:29)
[0154]
pppppppg(seq id no:30)
[0155]
ppppppp(seq id no:31)
[0156]
ppppppppg(seq id no:32)
[0157]
pppppppppg(seq id no:33)
[0158]
ppppppppppg(seq id no:34)
[0159]
pppppppppppg(seq id no:35)
[0160]
pppppppppppppg(seq id no:36)
[0161]
peptpeptg(seq id no:37)
[0162]
peptpeptpeptg(seq id no:38)
[0163]
peptpeptpeptpeptg(seq id no:39)
[0164]
peptpeptpeptpeptpeptg(seq id no:40)
[0165]
psptpsptpsptpsptg(seq id no:41)
[0166]
psptpsptpsptpsptpsptg(seq id no:42)
[0167]
pqptpqptg(seq id no:43)
[0168]
pdptpdptg(seq id no:44)
[0169]
prptpeptg(seq id no:45)
[0170]
pqptpeptg(seq id no:46)
[0171]
pspnspnspng(seq id no:47)
[0172]
peptprptg(seq id no:48)
[0173]
pqptpeptpqptpeptpqptpeptpqptg(seq id no:49)
[0174]
pdptpdptpdptg(seq id no:50)
[0175]
pqptpqptpqptpqptg(seq id no:51)
[0176]
pqptpeptpqptpeptg(seq id no:52)
[0177]
spspspspppg(seq id no:53)
[0178]
spspspspdpg(seq id no:54)
[0179]
spspspspkpg(seq id no:55)
[0180]
spspspspapg(seq id no:56)
[0181]
spspspspspsg(seq id no:57)
[0182]
spspspspsp(seq id no:58)
[0183]
spspspspsps(seq id no:59)
[0184]
spspspspspp(seq id no:60)
[0185]
spspspspspe(seq id no:61)
[0186]
spspspspspn(seq id no:62)
[0187]
spspspspspgg(seq id no:63)
[0188]
spspspspspk(seq id no:64)
[0189]
peptpeptp(seq id no:65)
[0190]
peptpeptr(seq id no:66)
[0191]
peptpeptpeptp(seq id no:67)
[0192]
peptpeptpeptpeptpsptg(seq id no:68)
[0193]
peptpeptpeptpeptptptg(seq id no:69)
[0194]
peptpeptpeptpeptpgptg(seq id no:70)
[0195]
peptpeptpeptpeptpdptg(seq id no:71)
[0196]
peptpeptpeptpeptpetg(seq id no:72)
[0197]
peptpeptpeptpeptpeptd(seq id no:73)
[0198]
peptpepte(seq id no:74)
[0199]
peptpeptpeptpeptpep(seq id no:75)
[0200]
peptpeptpeptpeptpspt(seq id no:76)
[0201]
peptpeptpeptpeptprptt(seq id no:77)
[0202]
peptpeptpeptpeptpeptt(seq id no:78)
[0203]
peptpeptpeptpeptpept(seq id no:79)
[0204]
peptpeptpeptpeptpepts(seq id no:80)
[0205]
peptpeptpeptpeptpeptr(seq id no:81)
[0206]
pppggpggpgtptstapgsgptspgggsg(seq id no:82)
[0207]
pppggpggtgtptstapgsgptspgggsg(seq id no:83)
[0208]
ppsggpggpgtptstapgsgptspgggsg(seq id no:84)
[0209]
peptprptpeptprptg(seq id no:85)
[0210]
pkptpeptpkptpeptg(seq id no:86)
[0211]
peptpkptpeptpkptg(seq id no:87)
[0212]
peptpqptpeptpqptg(seq id no:88)
[0213]
prptpeptprptg(seq id no:89)
[0214]
pkptpeptpkptg(seq id no:90)
[0215]
peptpqptg(seq id no:91)
[0216]
peptpqptpeptg(seq id no:92)
[0217]
tpptppg(seq id no:93)
[0218]
spsspsg(seq id no:94)
[0219]
spsspsspsg(seq id no:95)
[0220]
tpttptg(seq id no:96)
[0221]
tpttpttptg(seq id no:97)
[0222]
在特定的实施例中,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)。
[0223]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:6。
[0224]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:7。
[0225]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:8。
[0226]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:9。
[0227]
在实施例中,该变体包含具有与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序
列同一性、至少99%序列同一性的氨基酸序列的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:173。
[0228]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:174。
[0229]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:175。
[0230]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:176。
[0231]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:177。
[0232]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:178。
[0233]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:179。
[0234]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:180。
[0235]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:181。
[0236]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:182。
[0237]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:183。
[0238]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:184。
[0239]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:185。
[0240]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同
一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:186。
[0241]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:187。
[0242]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:188。
[0243]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:189。
[0244]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:190。
[0245]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:191。
[0246]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:192。
[0247]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:193。
[0248]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:194。
[0249]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:195。
[0250]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:196。
[0251]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:197。
[0252]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:198。
[0253]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同
一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:199。
[0254]
在实施例中,该变体包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的催化结构域,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:200。
[0255]
在一些方面,本发明的变体具有相对于参考酶/亲本酶的改善的特性。
[0256]
在一方面,该改善的特性是增加的稳定性,例如,改善的蛋白质水解稳定性、改善的洗涤剂稳定性、改善的洗涤中稳定性或改善的热稳定性。在另一方面,该改善的特性是在洗涤剂组合物生产期间增加的稳定性或在洗涤剂组合物中储存后相对于在相似条件下储存的亲本分子的性能增加的性能。本发明的一些方面涉及当纤维素酶变体在相关测定中测试目的特性时具有高于1的改善因子的纤维素酶变体,其中该参考酶/亲本酶的特性被给予1的值。在一些方面,该特性是稳定性,例如改善的蛋白质水解稳定性。本发明的一些方面涉及当纤维素酶变体在实例2中所述的测定中测试目的特性时具有高于1的改善因子的纤维素酶变体,其中该参考酶/亲本酶的特性被给予1的值。在一些方面,该特性是稳定性,例如蛋白质水解稳定性。
[0257]
在一些方面,改进的特性是增加的稳定性,例如改进的洗涤剂稳定性,改进的洗涤稳定性和改进的热稳定性。本发明的一些方面涉及当纤维素酶变体在相关测定中测试目的特性时(例如当纤维素酶变体在实例7中所述的测定中测试目的特性时),具有高于1的改善因子的纤维素酶变体,其中该参考酶/亲本酶的特性被给予1的值。
[0258]
在一些方面,改善的特性是改善的热稳定性。
[0259]
在一些方面,改善的特性是在洗涤剂中改善的稳定性。
[0260]
在一些方面,改善的特性是改善的蛋白质水解稳定性。
[0261]
在一些方面,改善的特性是改善的热稳定性、改善的洗涤剂稳定性、改善的蛋白质水解稳定性中的一个或多个或甚至全部。
[0262]
在测量条件下,当残余活性比定义为
[0263]
残余活性比(rar)=(变体的ra)/(参考的ra)
[0264]
与参考纤维素酶相比高于1.0时,根据本发明的变体得到改善。
[0265]
在特别优选的方面,根据本发明的变体产生了改善的稳定性(例如,热稳定性、洗涤剂稳定性、蛋白质水解稳定性、或这些中的多于一个或甚至全部),其中rar>1.0。在一些方面,根据本发明的变体与亲本或参考酶相比以及特别是与seq id no:1、seq id no:2、seq id no:3或seq id no:4的纤维素酶相比,具有的残余活性比(rar)至少为:1.1;1.2;1.3;1.4;1.5;1.6;1.7;1.8;1.9;2.0;2.1;2.2;2.3;2.4;2.5;2.6;2.7、2.8;2.9;3.0、3.1;3.2;3.3;3.4;3.5、3.6、3.7、3.8、3.9;4.0、4.1;4.2;4.3;4.4;4.5、4.6、4.7、4.8、4.9、5.0、5.1;5.2;5.3;5.4;5.5、5.6、5.7、5.8、5.9;3.0、6.1;6.2;6.3;6.4;6.5、6.6、6.7、6.8、6.9;7.0、7.1;7.2;7.3;7.4;7.5、7.6、7.7、7.8、7.9;8.0、8.1;8.2;8.3;8.4;8.5、8.6、8.7、8.8、
8.9;9.0、9.1;9.2;9.3;9.4;9.5、9.6、9.7、9.8、9.9;10.0、10.1;10.2;10.3;10.4;10.5、10.6、10.7、10.8、10.9;12、15、16、20、25或30。
[0266]
一个优选的实施例涉及具有改善的稳定性的纤维素酶变体,其中与seq id no:1相比,rar>1.0。一个优选的实施例涉及具有改善的稳定性的纤维素酶变体,其中当如实例2中所述测量时,与seq id no:1相比,残余活性比(rar)是至少1.5。
[0267]
催化结构域
[0268]
特别优选的酶是具有纤维素酶例如内切葡聚糖酶活性的那些酶。特别地,相关催化结构域是来自糖苷水解酶家族45(gh45)的酶,使用了见于cazy.org的cazy数据库所述的henrissat等人的命名法。
[0269]
该催化结构域可包含野生型或其变体。
[0270]
在实施例中,该催化结构域包含与seq id no:1的位置1
‑
212所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0271]
在实施例中,该催化结构域包含与seq id no:2的位置1
‑
211所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0272]
在实施例中,该催化结构域包含与seq id no:3的位置1
‑
210所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0273]
在实施例中,该催化结构域包含与seq id no:4的位置1
‑
210所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0274]
在一方面,该催化结构域进一步包含本发明的变体中的一些取代,是2
‑
20,例如,2
‑
10和2
‑
5,例如2、3、4、5、6、7、8、9或10个取代。
[0275]
在另一方面,变体包含在选自与以下位置对应的位置处的两个取代或由其组成:seq id no:1中的25、32、41、44、56、77、104、132、146、147、156、162、169、183、186、194或201。在另一方面,在这个位置处的氨基酸被ala、arg、asn、asp、cys、gln、glu、gly、his、ile、leu、lys、met、phe、pro、ser、thr、trp、tyr、或val取代。
[0276]
在一方面,变体包含以下中的一个或多个取代或由其组成:x25g;x32s;x41t;x44d;x56a;x77n;x85i;x103a;x104k;x114w或x114f;x134d;x137k或x137r;x146d或x146s;x147r;x152k;x156e;x159d或x159e;x162e;x169y;x179t;x183v;x186r;x194l或x194s;和/或x201k。
[0277]
在一些实施例中,这些变体包含取代x32s和对应于以下的一个或多个取代:具有seq id no:1或seq id no:5的序列的多肽的取代a25g;s41t;s56a;s77n;t104k;n134d;a146d或a146s;q147r;q156e;a162e;q169y;f183v;q186r;i194l;k201r和g219w,其中该变
体具有纤维素分解活性。
[0278]
在一些实施例中,这些变体包含取代x56a和对应于以下的一个或多个取代:具有seq id no:1或seq id no:5的序列的多肽的取代a25g;a32s;s41t;s77n;t104k;n134d;a146d或a146s;q147r;q156e;a162e;q169y;f183v;q186r;i194l;k201r和g219w,其中该变体具有纤维素分解活性。
[0279]
在一些实施例中,这些变体包含取代x134d和对应于以下的一个或多个取代:具有seq id no:1或seq id no:5的序列的多肽的取代a25g;a32s;s41t;s56a;s77n;s85i;t104k;g114f;g114w;s137e;s137r;s137d;s137k;a146d或a146s;q147r;s152k;q156e;s159e;s159d;a162e;q169y;d179t;f183v;q186r;i194l;i194s;k201r和g219w,其中该变体具有纤维素分解活性。
[0280]
在一些实施例中,这些变体包含取代a146d,并且进一步包含如下取代,该取代选自与seq id no:1中以下取代对应的取代:具有seq id no:1或seq id no:5的序列的多肽的a25g;a32s;s41t;s56a;s77n;k103a;t104k;g114f;g114w;n134d;s137r;s152k;q156e;s159d;s159e;a162e;q169y;d179t;f183v;q186r;i194l;k201r和g219w,其中该变体具有纤维素分解活性。
[0281]
在一些实施例中,这些变体包含取代x147r和对应于以下的一个或多个取代:具有seq id no:1或seq id no:5的序列的多肽的取代a25g;a32s;s41t;s56a;s77n;t104k;n134d;a146d或a146s;q156e;a162e;q169y;f183v;q186r;i194l;k201r和g219w的,其中该变体具有纤维素分解活性。
[0282]
在一些实施例中,这些变体包含取代s159d,并且进一步包含如下取代,该取代选自与seq id no:1中以下取代对应的取代:具有seq id no:1或seq id no:5的序列的多肽的a25g;a32s;s41t;s56a;s77n;k103a;t104k;g114f;g114w;n134d;s137r;a146d;s152k;q156e;a162e;q169y;d179t;f183v;q186r;i194l;k201r和g219w,其中该变体具有纤维素分解活性。
[0283]
在一些实施例中,这些变体包含取代x169y和对应于以下的一个或多个取代:具有seq id no:1或seq id no:5的序列的多肽的取代a25g;a32s;s41t;s56a;s77n;t104k;n134d;a146d或a146s;q147r;q156e;a162e;f183v;q186r;i194l;k201r和g219w的,其中该变体具有纤维素分解活性。
[0284]
在实施例中,该变体包含以下组合中的一个或多个:25g 56a、25g 114w、25g 134d、25g 146d、25g 147r、25g 156e、25g 162e、25g 169y、25g 183v、56a 114w、56a 134d、56a 146d、56a 147r、56a 156e、56a 162e、56a 169y、56a 183v、114w 134d、114w 146d、114w 147r、114w 156e、114w 162e、114w 169y、114w 183v、134d 146d、134d 147r、134d 156e、134d 162e、134d 169y、134d 183v、146d 147r、146d 156e、146d 162e、146d 169y、146d 183v、147r 156e、147r 162e、147r 169y、147r 183v、156e 162e、156e 169y、156e 183v、162e 169y、162e 183v、169y 183v,其中使用seq id no:1或seq id no:5进行编号。
[0285]
在实施例中,该变体包含以下组合中的一个或多个:25g 56a 114w、25g 56a 134d、25g 56a 146d、25g 56a 147r、25g 56a 156e、25g 56a 162e、25g 56a 169y、25g 56a 183v、25g 114w 134d、25g 114w 146d、25g 114w 147r、25g 114w 156e、25g 114w 162e、25g 114w 169y、25g 114w 183v、25g 134d 146d、25g 134d 147r、25g 134d 156e、25g
134d 162e、25g 134d 169y、25g 134d 183v、25g 146d 147r、25g 146d 156e、25g 146d 162e、25g 146d 169y、25g 146d 183v、25g 147r 156e、25g 147r 162e、25g 147r 169y、25g 147r 183v、25g 156e 162e、25g 156e 169y、25g 156e 183v、25g 162e 169y、25g 162e 183v、25g 169y 183v、56a 114w 134d、56a 114w 146d、56a 114w 147r、56a 114w 156e、56a 114w 162e、56a 114w 169y、56a 114w 183v、56a 134d 146d、56a 134d 147r、56a 134d 156e、56a 134d 162e、56a 134d 169y、56a 134d 183v、56a 146d 147r、56a 146d 156e、56a 146d 162e、56a 146d 169y、56a 146d 183v、56a 147r 156e、56a 147r 162e、56a 147r 169y、56a 147r 183v、56a 156e 162e、56a 156e 169y、56a 156e 183v、56a 162e 169y、56a 162e 183v、56a 169y 183v、114w 134d 146d、114w 134d 147r、114w 134d 156e、114w 134d 162e、114w 134d 169y、114w 134d 183v、114w 146d 147r、114w 146d 156e、114w 146d 162e、114w 146d 169y、114w 146d 183v、114w 147r 156e、114w 147r 162e、114w 147r 169y、114w 147r 183v、114w 156e 162e、114w 156e 169y、114w 156e 183v、114w 162e 169y、114w 162e 183v、114w 169y 183v、134d 146d 147r、134d 146d 156e、134d 146d 162e、134d 146d 169y、134d 146d 183v、134d 147r 156e、134d 147r 162e、134d 147r 169y、134d 147r 183v、134d 156e 162e、134d 156e 169y、134d 156e 183v、134d 162e 169y、134d 162e 183v、134d 169y 183v、146d 147r 156e、146d 147r 162e、146d 147r 169y、146d 147r 183v、146d 156e 162e、146d 156e 169y、146d 156e 183v、146d 162e 169y、146d 162e 183v、146d 169y 183v、147r 156e 162e、147r 156e 169y、147r 156e 183v、147r 162e 169y、147r 162e 183v、147r 169y 183v、156e 162e 169y、156e 162e 183v、156e 169y 183v、162e 169y 183v,其中使用seq id no:1或seq id no:5进行编号。
[0286]
在实施例中,该变体包含以下组合中的一个或多个:25g 56a 114w 134d、25g 56a 114w 146d、25g 56a 114w 147r、25g 56a 114w 156e、25g 56a 114w 162e、25g 56a 114w 169y、25g 56a 114w 183v、25g 56a 134d 146d、25g 56a 134d 147r、25g 56a 134d 156e、25g 56a 134d 162e、25g 56a 134d 169y、25g 56a 134d 183v、25g 56a 146d 147r、25g 56a 146d 156e、25g 56a 146d 162e、25g 56a 146d 169y、25g 56a 146d 183v、25g 56a 147r 156e、25g 56a 147r 162e、25g 56a 147r 169y、25g 56a 147r 183v、25g 56a 156e 162e、25g 56a 156e 169y、25g 56a 156e 183v、25g 56a 162e 169y、25g 56a 162e 183v、25g 56a 169y 183v、25g 114w 134d 146d、25g 114w 134d 147r、25g 114w 134d 156e、25g 114w 134d 162e、25g 114w 134d 169y、25g 114w 134d 183v、25g 114w 146d 147r、25g 114w 146d 156e、25g 114w 146d 162e、25g 114w 146d 169y、25g 114w 146d 183v、25g 114w 147r 156e、25g 114w 147r 162e、25g 114w 147r 169y、25g 114w 147r 183v、25g 114w 156e 162e、25g 114w 156e 169y、25g 114w 156e 183v、25g 114w 162e 169y、25g 114w 162e 183v、25g 114w 169y 183v、25g 134d 146d 147r、25g 134d 146d 156e、25g 134d 146d 162e、25g 134d 146d 169y、25g 134d 146d 183v、25g 134d 147r 156e、25g 134d 147r 162e、25g 134d 147r 169y、25g 134d 147r 183v、25g 134d 156e 162e、25g 134d 156e 169y、25g 134d 156e 183v、25g 134d 162e 169y、25g 134d 162e 183v、25g 134d 169y 183v、25g 146d 147r 156e、25g 146d 147r 162e、25g 146d 147r 169y、25g 146d 147r 183v、25g 146d 156e 162e、25g 146d 156e 169y、25g 146d 156e
183v、25g 146d 162e 169y、25g 146d 162e 183v、25g 146d 169y 183v、25g 147r 156e 162e、25g 147r 156e 169y、25g 147r 156e 183v、25g 147r 162e 169y、25g 147r 162e 183v、25g 147r 169y 183v、25g 156e 162e 169y、25g 156e 162e 183v、25g 156e 169y 183v、25g 162e 169y 183v、56a 114w 134d 146d、56a 114w 134d 147r、56a 114w 134d 156e、56a 114w 134d 162e、56a 114w 134d 169y、56a 114w 134d 183v、56a 114w 146d 147r、56a 114w 146d 156e、56a 114w 146d 162e、56a 114w 146d 169y、56a 114w 146d 183v、56a 114w 147r 156e、56a 114w 147r 162e、56a 114w 147r 169y、56a 114w 147r 183v、56a 114w 156e 162e、56a 114w 156e 169y、56a 114w 156e 183v、56a 114w 162e 169y、56a 114w 162e 183v、56a 114w 169y 183v、56a 134d 146d 147r、56a 134d 146d 156e、56a 134d 146d 162e、56a 134d 146d 169y、56a 134d 146d 183v、56a 134d 147r 156e、56a 134d 147r 162e、56a 134d 147r 169y、56a 134d 147r 183v、56a 134d 156e 162e、56a 134d 156e 169y、56a 134d 156e 183v、56a 134d 162e 169y、56a 134d 162e 183v、56a 134d 169y 183v、56a 146d 147r 156e、56a 146d 147r 162e、56a 146d 147r 169y、56a 146d 147r 183v、56a 146d 156e 162e、56a 146d 156e 169y、56a 146d 156e 183v、56a 146d 162e 169y、56a 146d 162e 183v、56a 146d 169y 183v、56a 147r 156e 162e、56a 147r 156e 169y、56a 147r 156e 183v、56a 147r 162e 169y、56a 147r 162e 183v、56a 147r 169y 183v、56a 156e 162e 169y、56a 156e 162e 183v、56a 156e 169y 183v、56a 162e 169y 183v、114w 134d 146d 147r、114w 134d 146d 156e、114w 134d 146d 162e、114w 134d 146d 169y、114w 134d 146d 183v、114w 134d 147r 156e、114w 134d 147r 162e、114w 134d 147r 169y、114w 134d 147r 183v、114w 134d 156e 162e、114w 134d 156e 169y、114w 134d 156e 183v、114w 134d 162e 169y、114w 134d 162e 183v、114w 134d 169y 183v、114w 146d 147r 156e、114w 146d 147r 162e、114w 146d 147r 169y、114w 146d 147r 183v、114w 146d 156e 162e、114w 146d 156e 169y、114w 146d 156e 183v、114w 146d 162e 169y、114w 146d 162e 183v、114w 146d 169y 183v、114w 147r 156e 162e、114w 147r 156e 169y、114w 147r 156e 183v、114w 147r 162e 169y、114w 147r 162e 183v、114w 147r 169y 183v、114w 156e 162e 169y、114w 156e 162e 183v、114w 156e 169y 183v、114w 162e 169y 183v、134d 146d 147r 156e、134d 146d 147r 162e、134d 146d 147r 169y、134d 146d 147r 183v、134d 146d 156e 162e、134d 146d 156e 169y、134d 146d 156e 183v、134d 146d 162e 169y、134d 146d 162e 183v、134d 146d 169y 183v、134d 147r 156e 162e、134d 147r 156e 169y、134d 147r 156e 183v、134d 147r 162e 169y、134d 147r 162e 183v、134d 147r 169y 183v、134d 156e 162e 169y、134d 156e 162e 183v、134d 156e 169y 183v、134d 162e 169y 183v、146d 147r 156e 162e、146d 147r 156e 169y、146d 147r 156e 183v、146d 147r 162e 169y、146d 147r 162e 183v、146d 147r 169y 183v、146d 156e 162e 169y、146d 156e 162e 183v、146d 156e 169y 183v、146d 162e 169y 183v、147r 156e 162e 169y、147r 156e 162e 183v、147r 156e 169y 183v、147r 162e 169y 183v、156e 162e 169y 183v,其中使用seq id no:1或seq id no:5进行编号。
[0287]
催化结构域中特别优选的变体包括包含选自由以下组成的组的取代的变体:
[0288]
x147r x156e;
[0289]
x147r x169y;
[0290]
x56a x147r;
[0291]
x147r x162e;
[0292]
x147r x156e x162e;
[0293]
x25g x56a x147r;
[0294]
x134d x156e x162e;
[0295]
x56a x134d x156e x162e;
[0296]
x25g x56a x156e x162e;
[0297]
x25g x134d x156e x162e;
[0298]
x25g x56a x134d x169y;
[0299]
x56a x134d x162e;
[0300]
x56a x147r x169y;
[0301]
x134d x147r;
[0302]
x156e x169y;
[0303]
x56a x134d x147r;
[0304]
x56a x134d x156e x169y;
[0305]
x56a x146d x147r x169y;
[0306]
x56a x134d x147r x169y;
[0307]
x56a x147r x162e x169y;
[0308]
x2* x56a x147r x169y;
[0309]
x41t x56a x147r x169y;
[0310]
x56a x77n x147r x169y;
[0311]
x56a x104k x147r x169y;
[0312]
x56a x147r x165q x169y;
[0313]
x56a x147r x169y x194l;
[0314]
x56a x147r x169y x201r;
[0315]
x56a x147r x169y x219w;
[0316]
x44d x56a x147r x169y;
[0317]
x50e x56a x147r x169y;
[0318]
x32s x56a x147r x169y;
[0319]
x44d x56a x147r x169y;
[0320]
x56a x147r x169y x186r;
[0321]
x56a x147r x169y x183v;
[0322]
x56a x146s x147r x162e x169y;
[0323]
x56a x134d x147r;
[0324]
x56a x134d x147r x162e;
[0325]
x32s x56a x134d x147r x169y x183v;
[0326]
x56a x134d x147r x162e x169y x183v;
[0327]
x32s x56a x77n x134d x147r x162e x169y;
[0328]
x32s x56a x134d x146d x147r x169y x183v;
[0329]
x32s x56a x134d x147r x169y;
[0330]
x56a x134d x147r x162e x169y;
[0331]
x32s x56a x134d x146s x147r x169y;
[0332]
x32s x56a x134d x146d x147r x169y;
[0333]
x32s x56a x134d x147r x169y x183v;
[0334]
x32s x56a x134d x147r x169y x201r;
[0335]
x56a x134d x146d x147r x169y x183v;
[0336]
x56a x134d x146d x147r x162e x169y;
[0337]
x56a x134d x146d x147r x169y x201r;
[0338]
x56a x134d x147r x162e x169y x183v;
[0339]
x56a x134d x147r x169y x183v x201r;
[0340]
x32s x56a x77n x134d x147r x169y x183v;
[0341]
x32s x56a x77n x134d x147r x162e x169y;
[0342]
x32s x56a x134d x146s x147r x169y x183v;
[0343]
x32s x56a x134d x146d x147r x169y x183v;或
[0344]
x32s x56a x134d x146d x147r x162e x169y,
[0345]
其中使用seq id no:1或seq id no:5进行编号。
[0346]
在特别优选的实施例中,该催化结构域包含seq id no:5的变体,这些变体包含以下中的一个或多个或由其组成:a25g;a32s;s41t;n44d;s56a;s77n;s85i;k103a;t104k;g114w或g114f;n134d;s137k或s137r;a146d或a146s;q147r;s152k;q156e;s159d或s159e;a162e;q169y;d179t;f183v;q186r;i194l;k201r;及其组合。
[0347]
在实施例中,该亲本纤维素酶是具有seq id no:1或seq id no:5的纤维素酶并且该变体包含以下组合中的一个或多个:a25g s56a、a25g g114w、a25g n134d、a25g a146d、a25g q147r、a25g q156e、a25g a162e、a25g q169y、a25g f183v、s56a g114w、s56a n134d、s56a a146d、s56a q147r、s56a q156e、s56a a162e、s56a q169y、s56a f183v、g114w n134d、g114w a146d、g114w q147r、g114w q156e、g114w a162e、g114w q169y、g114w f183v、n134d a146d、n134d q147r、n134d q156e、n134d a162e、n134d q169y、n134d f183v、a146d q147r、a146d q156e、a146d a162e、a146d q169y、a146d f183v、q147r q156e、q147r a162e、q147r q169y、q147r f183v、q156e a162e、q156e q169y、q156e f183v、a162e q169y、a162e f183v、q169y f183v。
[0348]
在实施例中,该亲本纤维素酶是具有seq id no:1或seq id no:5的纤维素酶并且该变体包含以下组合中的一个或多个:a25g s56a g114w、a25g s56a n134d、a25g s56a a146d、a25g s56a q147r、a25g s56a q156e、a25g s56a a162e、a25g s56a q169y、a25g s56a f183v、a25g g114w n134d、a25g g114w a146d、a25g g114w q147r、a25g g114w q156e、a25g g114w a162e、a25g g114w q169y、a25g g114w f183v、a25g n134d a146d、a25g n134d q147r、a25g n134d q156e、a25g n134d a162e、a25g n134d q169y、a25g n134d f183v、a25g a146d q147r、a25g a146d q156e、a25g a146d a162e、a25g a146d q169y、a25g a146d f183v、a25g q147r q156e、a25g q147r a162e、a25g q147r q169y、
a25g q147r f183v、a25g q156e a162e、a25g q156e q169y、a25g q156e f183v、a25g a162e q169y、a25g a162e f183v、a25g q169y f183v、s56a g114w n134d、s56a g114w a146d、s56a g114w q147r、s56a g114w q156e、s56a g114w a162e、s56a g114w q169y、s56a g114w f183v、s56a n134d a146d、s56a n134d q147r、s56a n134d q156e、s56a n134d a162e、s56a n134d q169y、s56a n134d f183v、s56a a146d q147r、s56a a146d q156e、s56a a146d a162e、s56a a146d q169y、s56a a146d f183v、s56a q147r q156e、s56a q147r a162e、s56a q147r q169y、s56a q147r f183v、s56a q156e a162e、s56a q156e q169y、s56a q156e f183v、s56a a162e q169y、s56a a162e f183v、s56a q169y f183v、g114w n134d a146d、g114w n134d q147r、g114w n134d q156e、g114w n134d a162e、g114w n134d q169y、g114w n134d f183v、g114w a146d q147r、g114w a146d q156e、g114w a146d a162e、g114w a146d q169y、g114w a146d f183v、g114w q147r q156e、g114w q147r a162e、g114w q147r q169y、g114w q147r f183v、g114w q156e a162e、g114w q156e q169y、g114w q156e f183v、g114w a162e q169y、g114w a162e f183v、g114w q169y f183v、n134d a146d q147r、n134d a146d q156e、n134d a146d a162e、n134d a146d q169y、n134d a146d f183v、n134d q147r q156e、n134d q147r a162e、n134d q147r q169y、n134d q147r f183v、n134d q156e a162e、n134d q156e q169y、n134d q156e f183v、n134d a162e q169y、n134d a162e f183v、n134d q169y f183v、a146d q147r q156e、a146d q147r a162e、a146d q147r q169y、a146d q147r f183v、a146d q156e a162e、a146d q156e q169y、a146d q156e f183v、a146d a162e q169y、a146d a162e f183v、a146d q169y f183v、q147r q156e a162e、q147r q156e q169y、q147r q156e f183v、q147r a162e q169y、q147r a162e f183v、q147r q169y f183v、q156e a162e q169y、q156e a162e f183v、q156e q169y f183v、a162e q169y f183v。
[0349]
在实施例中,该亲本纤维素酶是具有seq id no:1或seq id no:5的纤维素酶并且该变体包含以下组合中的一个或多个:a25g s56a g114w n134d、a25g s56a g114w a146d、a25g s56a g114w q147r、a25g s56a g114w q156e、a25g s56a g114w a162e、a25g s56a g114w q169y、a25g s56a g114w f183v、a25g s56a n134d a146d、a25g s56a n134d q147r、a25g s56a n134d q156e、a25g s56a n134d a162e、a25g s56a n134d q169y、a25g s56a n134d f183v、a25g s56a a146d q147r、a25g s56a a146d q156e、a25g s56a a146d a162e、a25g s56a a146d q169y、a25g s56a a146d f183v、a25g s56a q147r q156e、a25g s56a q147r a162e、a25g s56a q147r q169y、a25g s56a q147r f183v、a25g s56a q156e a162e、a25g s56a q156e q169y、a25g s56a q156e f183v、a25g s56a a162e q169y、a25g s56a a162e f183v、a25g s56a q169y f183v、a25g g114w n134d a146d、a25g g114w n134d q147r、a25g g114w n134d q156e、a25g g114w n134d a162e、a25g g114w n134d q169y、a25g g114w n134d f183v、a25g g114w a146d q147r、a25g g114w a146d q156e、a25g g114w a146d a162e、a25g g114w a146d q169y、a25g g114w a146d f183v、a25g g114w q147r q156e、a25g g114w q147r a162e、a25g g114w q147r q169y、a25g g114w q147r f183v、a25g g114w q156e a162e、a25g g114w q156e q169y、a25g g114w q156e f183v、a25g g114w a162e q169y、a25g g114w a162e f183v、a25g g114w q169y f183v、
a25g n134d a146d q147r、a25g n134d a146d q156e、a25g n134d a146d a162e、a25g n134d a146d q169y、a25g n134d a146d f183v、a25g n134d q147r q156e、a25g n134d q147r a162e、a25g n134d q147r q169y、a25g n134d q147r f183v、a25g n134d q156e a162e、a25g n134d q156e q169y、a25g n134d q156e f183v、a25g n134d a162e q169y、a25g n134d a162e f183v、a25g n134d q169y f183v、a25g a146d q147r q156e、a25g a146d q147r a162e、a25g a146d q147r q169y、a25g a146d q147r f183v、a25g a146d q156e a162e、a25g a146d q156e q169y、a25g a146d q156e f183v、a25g a146d a162e q169y、a25g a146d a162e f183v、a25g a146d q169y f183v、a25g q147r q156e a162e、a25g q147r q156e q169y、a25g q147r q156e f183v、a25g q147r a162e q169y、a25g q147r a162e f183v、a25g q147r q169y f183v、a25g q156e a162e q169y、a25g q156e a162e f183v、a25g q156e q169y f183v、a25g a162e q169y f183v、s56a g114w n134d a146d、s56a g114w n134d q147r、s56a g114w n134d q156e、s56a g114w n134d a162e、s56a g114w n134d q169y、s56a g114w n134d f183v、s56a g114w a146d q147r、s56a g114w a146d q156e、s56a g114w a146d a162e、s56a g114w a146d q169y、s56a g114w a146d f183v、s56a g114w q147r q156e、s56a g114w q147r a162e、s56a g114w q147r q169y、s56a g114w q147r f183v、s56a g114w q156e a162e、s56a g114w q156e q169y、s56a g114w q156e f183v、s56a g114w a162e q169y、s56a g114w a162e f183v、s56a g114w q169y f183v、s56a n134d a146d q147r、s56a n134d a146d q156e、s56a n134d a146d a162e、s56a n134d a146d q169y、s56a n134d a146d f183v、s56a n134d q147r q156e、s56a n134d q147r a162e、s56a n134d q147r q169y、s56a n134d q147r f183v、s56a n134d q156e a162e、s56a n134d q156e q169y、s56a n134d q156e f183v、s56a n134d a162e q169y、s56a n134d a162e f183v、s56a n134d q169y f183v、s56a a146d q147r q156e、s56a a146d q147r a162e、s56a a146d q147r q169y、s56a a146d q147r f183v、s56a a146d q156e a162e、s56a a146d q156e q169y、s56a a146d q156e f183v、s56a a146d a162e q169y、s56a a146d a162e f183v、s56a a146d q169y f183v、s56a q147r q156e a162e、s56a q147r q156e q169y、s56a q147r q156e f183v、s56a q147r a162e q169y、s56a q147r a162e f183v、s56a q147r q169y f183v、s56a q156e a162e q169y、s56a q156e a162e f183v、s56a q156e q169y f183v、s56a a162e q169y f183v、g114w n134d a146d q147r、g114w n134d a146d q156e、g114w n134d a146d a162e、g114w n134d a146d q169y、g114w n134d a146d f183v、g114w n134d q147r q156e、g114w n134d q147r a162e、g114w n134d q147r q169y、g114w n134d q147r f183v、g114w n134d q156e a162e、g114w n134d q156e q169y、g114w n134d q156e f183v、g114w n134d a162e q169y、g114w n134d a162e f183v、g114w n134d q169y f183v、g114w a146d q147r q156e、g114w a146d q147r a162e、g114w a146d q147r q169y、g114w a146d q147r f183v、g114w a146d q156e a162e、g114w a146d q156e q169y、g114w a146d q156e f183v、g114w a146d a162e q169y、g114w a146d a162e f183v、g114w a146d q169y f183v、g114w q147r q156e a162e、g114w q147r q156e q169y、g114w q147r q156e f183v、g114w q147r a162e q169y、g114w q147r a162e f183v、g114w q147r q169y f183v、g114w q156e a162e q169y、g114w q156e a162e f183v、g114w q156e q169y
f183v、g114w a162e q169y f183v、n134d a146d q147r q156e、n134d a146d q147r a162e、n134d a146d q147r q169y、n134d a146d q147r f183v、n134d a146d q156e a162e、n134d a146d q156e q169y、n134d a146d q156e f183v、n134d a146d a162e q169y、n134d a146d a162e f183v、n134d a146d q169y f183v、n134d q147r q156e a162e、n134d q147r q156e q169y、n134d q147r q156e f183v、n134d q147r a162e q169y、n134d q147r a162e f183v、n134d q147r q169y f183v、n134d q156e a162e q169y、n134d q156e a162e f183v、n134d q156e q169y f183v、n134d a162e q169y f183v、a146d q147r q156e a162e、a146d q147r q156e q169y、a146d q147r q156e f183v、a146d q147r a162e q169y、a146d q147r a162e f183v、a146d q147r q169y f183v、a146d q156e a162e q169y、a146d q156e a162e f183v、a146d q156e q169y f183v、a146d a162e q169y f183v、q147r q156e a162e q169y、q147r q156e a162e f183v、q147r q156e q169y f183v、q147r a162e q169y f183v、q156e a162e q169y f183v。
[0350]
进一步优选的变体包含催化结构域例如,seq id no:5中的取代,这些取代选自由以下组成的组:
[0351]
q147r q156e;
[0352]
q147r q169y;
[0353]
s56a q147r;
[0354]
q147r a162e;
[0355]
q147r q156e a162e;
[0356]
a25g s56a q147r;
[0357]
n134d q156e a162e;
[0358]
s56a n134d q156e a162e;
[0359]
a25g s56a q156e a162e;
[0360]
a25g n134d q156e a162e;
[0361]
a25g s56a n134d q169y;
[0362]
s56a n134d a162e;
[0363]
s56a q147r q169y;
[0364]
n134d q147r;
[0365]
q156e q169y;
[0366]
s56a n134d q147r;
[0367]
s56a n134d q156e q169y;
[0368]
s56a a146d q147r q169y;
[0369]
s56a n134d q147r q169y;
[0370]
s56a q147r a162e q169y;
[0371]
s2* s56a q147r q169y;
[0372]
s41t s56a q147r q169y;
[0373]
s56a s77n q147r q169y;
[0374]
s56a t104k q147r q169y;
[0375]
s56a q147r k165q q169y;
[0376]
s56a q147r q169y i194l;
[0377]
s56a q147r q169y k201r;
[0378]
s56a q147r q169y g219w;
[0379]
n44d s56a q147r q169y;
[0380]
n50e s56a q147r q169y;
[0381]
a32s s56a q147r q169y;
[0382]
n44d s56a q147r q169y;
[0383]
s56a q147r q169y q186r;
[0384]
s56a q147r q169y f183v;
[0385]
s56a a146s q147r a162e q169y;
[0386]
s56a n134d q147r;
[0387]
s56a n134d q147r a162e;
[0388]
a32s s56a n134d q147r q169y f183v;
[0389]
s56a n134d q147r a162e q169y f183v;
[0390]
a32s s56a s77n n134d q147r a162e q169y;
[0391]
a32s s56a n134d a146d q147r q169y f183v;
[0392]
a32s s56a n134d q147r q169y;
[0393]
s56a n134d q147r a162e q169y;
[0394]
a32s s56a n134d a146s q147r q169y;
[0395]
a32s s56a n134d a146d q147r q169y;
[0396]
a32s s56a n134d q147r q169y f183v;
[0397]
a32s s56a n134d q147r q169y k201r;
[0398]
s56a n134d a146d q147r q169y f183v;
[0399]
s56a n134d a146d q147r a162e q169y;
[0400]
s56a n134d a146d q147r q169y k201r;
[0401]
s56a n134d q147r a162e q169y f183v;
[0402]
s56a n134d q147r q169y f183v k201r;
[0403]
a32s s56a s77n n134d q147r q169y f183v;
[0404]
a32s s56a s77n n134d q147r a162e q169y;
[0405]
a32s s56a n134d a146s q147r q169y f183v;
[0406]
a32s s56a n134d a146d q147r q169y f183v;或
[0407]
a32s s56a n134d a146d q147r a162e q169y。
[0408]
进一步优选的变体包含催化结构域例如,seq id no:5中的取代,这些取代选自由以下组成的组:
[0409]
[0410]
[0411][0412]
变体在一个或多个(例如,若干个)其他位置处可进一步包含一个或多个另外的改变。
[0413]
氨基酸改变可以具有微小性质,即,不会显著地影响蛋白质的折叠和/或活性的保守氨基酸取代或插入;典型地为1
‑
30个氨基酸的小缺失;小的氨基末端或羧基末端延伸,如氨基末端的甲硫氨酸残基;多达20
‑
25个残基的小接头肽;或小的延伸,其通过改变净电荷或另一功能(如聚组氨酸段、抗原表位或结合结构域)来促进纯化。
[0414]
保守取代的实例是在如下这些组之内:碱性氨基酸(精氨酸、赖氨酸、和组氨酸)、酸性氨基酸(谷氨酸和天冬氨酸)、极性氨基酸(谷氨酰胺和天冬酰胺)、疏水性氨基酸(亮氨酸、异亮氨酸、和缬氨酸)、芳香族氨基酸(苯丙氨酸、色氨酸、和酪氨酸)、以及小氨基酸(甘氨酸、丙氨酸、丝氨酸、苏氨酸、和甲硫氨酸)。通常不会改变比活性的氨基酸取代是本领域已知的并且例如由h.neurath和r.l.hill,1979,于the proteins[蛋白质],academic press[学术出版社],纽约中描述。常见取代为ala/ser、val/ile、asp/glu、thr/ser、ala/gly、ala/thr、ser/asn、ala/val、ser/gly、tyr/phe、ala/pro、lys/arg、asp/asn、leu/ile、leu/val、ala/glu和asp/gly。
[0415]
可替代地,这些氨基酸改变具有改变多肽的物理化学特性这样一种性质。例如,氨基酸改变可以提高多肽的热稳定性、改变底物特异性、改变最适ph,等等。
[0416]
可以根据本领域中已知的程序,诸如定点诱变或丙氨酸扫描诱变(cunningham和wells,1989,science[科学]244:1081
‑
1085)来鉴定多肽中的必需氨基酸。在后一种技术中,在分子中的每个残基处引入单一丙氨酸突变,并且测试所得突变分子的纤维素分解活性以鉴定对分子的活性关键的氨基酸残基。还参见,hilton等人,1996,j.biol.chem.[生物化学杂志]271:4699
‑
4708。酶或其他生物学相互作用的活性位点还可通过对结构的物理分析来确定,如由下述技术确定:核磁共振、晶体学(crystallography)、电子衍射、或光亲和标记,连同对推定的接触位点氨基酸进行突变。参见例如,de vos等人,1992,science[科学]255:306
‑
312;smith等人,1992,j.mol.biol.[分子生物学杂志]224:899
‑
904;wlodaver等人,1992,febs lett.[欧洲生化学会联合会快报]309:59
‑
64。还可以从与相关多肽的比对来推断必需氨基酸的身份。
[0417]
例如,具有seq id no:1的氨基酸序列的纤维素酶的催化残基被鉴定为asp 12和asp 122。
[0418]
碳水化合物结合模块(cbm)
[0419]
碳水化合物结合模块(cbm)可包含野生型或其变体,并且还考虑了,本文中的这些变体可包含第一微生物(其是野生型或其变体)的野生型催化结构域,以及通过接头区域连接的来自第二微生物的碳水化合物结合模块(其是野生型或其变体)。
[0420]
例如,该变体可包括seq id no:1的催化结构域或其变体,以及由接头区域连接的来自seq id no:2的碳水化合物结合模块。
[0421]
优选地,该cbm是cbm1。
[0422]
在实施例中,该碳水化合物结合模块/结构域包含与如seq id no:6所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0423]
在实施例中,该碳水化合物结合模块包含与如seq id no:7所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0424]
在实施例中,该碳水化合物结合模块包含与如seq id no:8所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列
同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0425]
在实施例中,该碳水化合物结合模块包含与如seq id no:9所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0426]
在实施例中,该碳水化合物结合模块包含与如seq id no:173所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0427]
在实施例中,该碳水化合物结合模块包含与如seq id no:174所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0428]
在实施例中,该碳水化合物结合模块包含与如seq id no:175所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0429]
在实施例中,该碳水化合物结合模块包含与如seq id no:176所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0430]
在实施例中,该碳水化合物结合模块包含与如seq id no:177所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0431]
在实施例中,该碳水化合物结合模块包含与如seq id no:178所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0432]
在实施例中,该碳水化合物结合模块包含与如seq id no:179所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0433]
在实施例中,该碳水化合物结合模块包含与如seq id no:180所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0434]
在实施例中,该碳水化合物结合模块包含与如seq id no:181所示的氨基酸序列
具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0435]
在实施例中,该碳水化合物结合模块包含与如seq id no:182所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0436]
在实施例中,该碳水化合物结合模块包含与如seq id no:183所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0437]
在实施例中,该碳水化合物结合模块包含与如seq id no:184所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0438]
在实施例中,该碳水化合物结合模块包含与如seq id no:185所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0439]
在实施例中,该碳水化合物结合模块包含与如seq id no:186所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0440]
在实施例中,该碳水化合物结合模块包含与如seq id no:187所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0441]
在实施例中,该碳水化合物结合模块包含与如seq id no:188所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0442]
在实施例中,该碳水化合物结合模块包含与如seq id no:189所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0443]
在实施例中,该碳水化合物结合模块包含与如seq id no:190所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0444]
在实施例中,该碳水化合物结合模块包含与如seq id no:191所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0445]
在实施例中,该碳水化合物结合模块包含与如seq id no:192所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0446]
在实施例中,该碳水化合物结合模块包含与如seq id no:193所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0447]
在实施例中,该碳水化合物结合模块包含与如seq id no:194所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0448]
在实施例中,该碳水化合物结合模块包含与如seq id no:195所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0449]
在实施例中,该碳水化合物结合模块包含与如seq id no:196所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0450]
在实施例中,该碳水化合物结合模块包含与如seq id no:197所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0451]
在实施例中,该碳水化合物结合模块包含与如seq id no:198所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0452]
在实施例中,该碳水化合物结合模块包含与如seq id no:199所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0453]
在实施例中,该碳水化合物结合模块包含与如seq id no:200所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序
列同一性、至少98%序列同一性、至少99%或100%序列同一性的氨基酸序列。
[0454]
在实施例中,该变体包含seq id no:5或其变体、和seq id no:6。在进一步的实施例中,该变体以从n
‑
末端至c
‑
末端的顺序包含seq id no:5或其变体、接头、和seq id no:6。
[0455]
在实施例中,该变体包含seq id no:5或其变体、和seq id no:7。在进一步的实施例中,该变体以从n
‑
末端至c
‑
末端的顺序包含seq id no:5或其变体、接头、和seq id no:7。
[0456]
在实施例中,该变体包含seq id no:5或其变体、和seq id no:8。在进一步的实施例中,该变体以从n
‑
末端至c
‑
末端的顺序包含seq id no:5或其变体、接头、和seq id no:8。
[0457]
在实施例中,该变体包含seq id no:5或其变体、和seq id no:9。在进一步的实施例中,该变体以从n
‑
末端至c
‑
末端的顺序包含seq id no:5或其变体、接头、和seq id no:9。
[0458]
在实施例中,该变体包含seq id no:5或其变体、和seq id no:173。在进一步的实施例中,该变体以从n
‑
末端至c
‑
末端的顺序包含seq id no:5或其变体、接头、和seq id no:173。
[0459]
在实施例中,该变体包含seq id no:5或其变体、和seq id no:174。在进一步的实施例中,该变体以从n
‑
末端至c
‑
末端的顺序包含seq id no:5或其变体、接头、和seq id no:174。
[0460]
表b1
‑
b2、c1
‑
c2和表d提供了根据本发明的示例性优选的变体,为便于比较性参考,将其以表格的形式提供。如在本文的表中所用,这些变体以从n
‑
末端至c
‑
末端的顺序以其整体进行代表,在各自列中命名的序列之间没有另外的接头或进一步的修饰。因此,在表中代表为如下
[0461]
的变体1可以同等地代表为:
[0462][0463]
表b1.
[0464]
[0465]
[0466]
[0467][0468]
表b2.
[0469]
[0470]
[0471]
[0472]
[0473]
[0474][0475]
表c1.
[0476]
[0477]
[0478]
[0479]
[0480][0481]
表c2.
[0482]
[0483]
[0484]
[0485][0486]
表d.
[0487]
[0488]
[0489][0490]
在蛋白酶存在下的稳定性
[0491]
在实施例中,与亲本酶相比,变体具有改善的在蛋白酶存在下的稳定性。优选地,与亲本纤维素酶相比,变体具有改善的在蛋白酶和表面活性剂(如洗涤剂组合物)存在下的稳定性。
[0492]
在蛋白酶存在下的稳定性对在蛋白酶存在的条件下使用例如纤维素酶而言是有益的,因为它延长了纤维素酶发挥功能和活性并且发挥其想要的功能的时间。
[0493]
本发明的变体的优选用途是在洗涤剂中,其中典型地包括蛋白酶以改善洗涤。本发明的变体的改善的稳定性意指,变体与亲本纤维素酶相比可以在洗衣过程期间发挥更长时间的纤维素分解活性,并且因此与亲本纤维素酶相比提供了改善的洗涤性能益处。
[0494]
对于液体洗涤剂组合物,本发明的这些变体进一步具有改善的在蛋白酶存在下的稳定性的益处,这意指包含蛋白酶且进一步包含本发明的变体的液体洗涤剂组合物与包含亲本纤维素酶的相同液体洗涤剂组合物相比,具有更长的保质期。
[0495]
在蛋白酶存在下的稳定性可以通过以下确定:在蛋白酶存在下的限定条件下孵育给定的纤维素酶,测量孵育后的纤维素分解活性,并将其与未与蛋白酶孵育的纤维素酶样品进行比较。
[0496]
另一种用于确定在蛋白酶存在下的稳定性的方法是:准备包含待测给定纤维素酶(其在包含蛋白酶的限定溶液中)的两个相同的试管,在高温(例如在30℃
‑
90℃的范围(应激))孵育一个试管,而在低温(例如在0℃
‑
5℃的范围(非应激))孵育另一个试管。将这些试管孵育持续预定时间,例如在1和24小时之间,典型地16小时。在孵育后,分析两个样品的纤维素分解活性,并如下确定残余活性:
[0497]
残余活性(%)=(活性,应激/活性,非应激)*100。
[0498]
例如,可以确定含有0.166v/v
‑
%蛋白酶的50%液体洗涤剂a中的残余活性,其中
在确定活性之前,将这些样品在高温(应激)和5℃(非应激)孵育16小时。应该选择温度以使亲本分子的残余活性在10%
‑
50%的范围中。
[0499]
实例1中更详细地说明了本核心稳定性方法。
[0500]
本发明的变体比亲本纤维素酶具有更高的残余活性。在一个实施例中,与亲本纤维素酶相比,本发明的变体具有至少10%更高的残余活性,例如与亲本相比至少20%更高的残余活性、例如至少30%更高的残余活性、例如至少40%更高的残余活性、例如至少50%更高的残余活性、例如至少60%更高的残余活性、例如至少70%更高的残余活性、例如至少80%更高的残余活性、例如至少90%更高的残余活性、或至少100%更高的残余活性。
[0501]
然而,在用于测试热稳定性的传统酶稳定性测定中,应激和非应激样品的活性测量典型地集中于例如通过使用小的合成底物,例如4
‑
甲基伞形酮
‑
β
‑
纤维五糖苷或可溶性羧甲基纤维素(cmc),测量影响酶分子催化位点的变化。
[0502]
然而,重要的是,在这些测定中并不一定能检测到由于应激引起的目的酶的其他特性的变化,这些特性对于酶在应用中发挥作用很重要但不直接影响酶的活性位点。一个这样的实例是糖基水解酶,其具有通过接头连接的分开的催化结构域和cbm,就如例如在衣物洗涤剂和纺织品护理产品中用于去除绒毛和绒球的纤维素酶中一样。如果应激只影响分子的接头和/或cbm部分而不影响催化结构域部分,那么这些变化将不会被如上所述和/或在实例1中所述的传统测定所检测到。当使用简单的底物例如cmc或4
‑
甲基伞形酮
‑
β
‑
纤维五糖苷时,活性将会看起来在应激期间被维持但是性能受到显著影响,因为酶分子的cbm部分在将酶引向待处理的纺织品的适当位置中起到重要的作用。
[0503]
另外,可通过将催化结构域的性能与具有完整的接头和cbm的催化结构域的性能相比较,来测试cbm对于性能的重要性。
[0504]
为检测在应激条件下储存后接头和/或cbm的变化,当测试应激是否影响酶的性能时,必须获具体的测量。这可以通过将应激前后的酶的性能进行比较来完成。可替代地,可以通过如下对其进行测试:确保酶与其天然不溶性底物(例如棉短绒)的结合被包括为用于测试稳定性的测定的一部分,和/或首先探查酶与微晶纤维素或棉短绒的结合并然后测量相比于总活性失去与纤维素结合能力的酶的活性。
[0505]
因此,接头和/或cbm稳定性通过如下进行测量:孵育在含有蛋白酶的洗涤剂中的纤维素酶,随后确定孵育的纤维素酶结合纤维素纤维的能力。如果接头或纤维素结合结构域受到蛋白酶的影响,那么纤维素酶与纤维素纤维的结合亲和力将会降低。
[0506]
实例2中所述的条件说明了这种接头和cbm特异性测定。
[0507]
亲本纤维素酶
[0508]
亲本纤维素酶可以是具有纤维素分解活性并且与具有seq id no:1、seq id no:2、seq id no:3、或seq id no:4的序列的多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性的多肽。在一方面,亲本的氨基酸序列与seq id no:1、seq id no:2、seq id no:3或seq id no:4的成熟多肽差异多达10个氨基酸,例如,1、2、3、4、5、6、7、8、9或10个。
[0509]
在另一方面,亲本包含seq id no:1、seq id no:2、seq id no:3、或seq id no:4的氨基酸序列或由其组成。
[0510]
亲本纤维素酶可以是具有纤维素分解活性并且与具有seq id no:1、seq id no:2、seq id no:3、或seq id no:4的序列的成熟多肽的催化结构域具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性的多肽。在一方面,亲本的氨基酸序列与seq id no:1、seq id no:2、seq id no:3或seq id no:4的成熟多肽的催化结构域差异多达10个氨基酸,例如,1、2、3、4、5、6、7、8、9或10个。
[0511]
在另一方面,该亲本包含seq id no:1的催化结构域,例如,seq id no:1的氨基酸1至212或氨基酸1至216。在另一方面,该亲本包含seq id no:5。
[0512]
在另一方面,该亲本包含seq id no:2的催化结构域,例如,seq id no:2的氨基酸1至211或氨基酸1至213。
[0513]
在另一方面,该亲本包含seq id no:3的催化结构域,例如,seq id no:3的氨基酸1至210。
[0514]
在另一方面,该亲本包含seq id no:4的催化结构域,例如,seq id no:4的氨基酸1至211。
[0515]
在另一实施例中,亲本是seq id no:1、seq id no:2、seq id no:3、或seq id no:4的成熟多肽或催化结构域的等位基因变体。
[0516]
多肽可以是杂合多肽,其中一种多肽的区域在另一种多肽的区域的n
‑
末端或c
‑
末端处融合。
[0517]
亲本可以是融合多肽或可切割的融合多肽,其中另一种多肽在本发明的多肽的n
‑
末端或c
‑
末端处融合。通过将编码另一种多肽的多核苷酸与本发明的多核苷酸融合来产生融合多肽。用于产生融合多肽的技术是本领域已知的,且包括连接编码多肽的编码序列使得它们符合读框,而且融合多肽的表达处于一个或多个相同的启动子和终止子的控制之下。还可以使用内含肽技术构建融合多肽,其中在翻译后产生融合多肽(cooper等人,1993,embo j.[欧洲分子生物学学会杂志]12:2575
‑
2583;dawson等人,1994,science[科学]266:776
‑
779)。
[0518]
融合多肽可进一步包含两个多肽之间的切割位点。在融合蛋白分泌之时,位点被切割,从而释放出这两种多肽。切割位点的实例包括但不限于在以下文献中披露的位点:martin等人,2003,j.ind.microbiol.biotechnol.[工业微生物生物技术杂志]3:568
‑
576;svetina等人,2000,j.biotechnol.[生物技术杂志]76:245
‑
251;rasmussen
‑
wilson等人,1997,appl.environ.microbiol.[应用与环境微生物学]63:3488
‑
3493;ward等人,1995,biotechnology[生物技术]13:498
‑
503;和contreras等人,1991,biotechnology[生物技术]9:378
‑
381;eaton等人,1986,biochemistry[生物化学]25:505
‑
512;collins
‑
racie等人,1995,biotechnology[生物技术]13:982
‑
987;carter等人,1989,proteins:structure,function,and genetics[蛋白质:结构、功能以及遗传学]6:240
‑
248;以及stevens,2003,drug discovery world[药物发现世界]4:35
‑
48。
[0519]
亲本可以从任何属的微生物中获得。出于本发明的目的,如本文中与给定的来源结合使用,术语“从
……
获得”应当意指由多核苷酸编码的亲本是由该来源或由其中已经插入来自该来源的多核苷酸的菌株产生的。在一方面,亲本是胞外分泌的。亲本可以是细菌纤维素酶。例如,亲本可以是革兰氏阳性细菌多肽,例如芽孢杆菌属(bacillus)、梭菌属
(clostridium)、肠球菌属(enterococcus)、土芽孢杆菌属(geobacillus)、乳杆菌属(lactobacillus)、乳球菌属(lactococcus)、海洋芽孢杆菌属(oceanobacillus)、葡萄球菌属(staphylococcus)、链球菌属(streptococcus)或链霉菌属(streptomyces)纤维素酶;或革兰氏阴性细菌多肽,例如弯曲杆菌属(campylobacter)、大肠杆菌(e.coli)、黄杆菌属(flavobacterium)、梭杆菌属(fusobacterium)、螺杆菌属(helicobacter)、泥杆菌属(ilyobacter)、奈瑟氏菌属(neisseria)、假单胞菌属(pseudomonas)、沙门氏菌属(salmonella)或脲原体属(ureaplasma)纤维素酶。
[0520]
在一方面,亲本是嗜碱芽孢杆菌(bacillus alkalophilus)、解淀粉芽孢杆菌(bacillus amyloliquefaciens)、短芽孢杆菌(bacillus brevis)、环状芽孢杆菌(bacillus circulans)、克劳氏芽孢杆菌(bacillus clausii)、凝结芽孢杆菌(bacillus coagulans)、坚硬芽孢杆菌(bacillus firmus)、灿烂芽孢杆菌(bacillus lautus)、迟缓芽孢杆菌(bacillus lentus)、地衣芽孢杆菌(bacillus licheniformis)、巨大芽孢杆菌(bacillus megaterium)、短小芽孢杆菌(bacillus pumilus)、嗜热脂肪芽孢杆菌(bacillus stearothermophilus)、枯草芽孢杆菌(bacillus subtilis)、或苏云金芽孢杆菌(bacillus thuringiensis)纤维素酶。
[0521]
在另一方面,亲本是类马链球菌(streptococcus equisimilis)、化脓链球菌(streptococcus pyogenes)、乳房链球菌(streptococcus uberis)、或马链球菌兽疫亚种(streptococcus equi subsp.zooepidemicus)纤维素酶。
[0522]
在另一方面,亲本是不产色链霉菌(streptomyces achromogenes)、除虫链霉菌(streptomyces avermitilis)、天蓝链霉菌(streptomyces coelicolor)、灰色链霉菌(streptomyces griseus)、或浅青紫链霉菌(streptomyces lividans)纤维素酶。
[0523]
亲本可以是真菌纤维素酶。例如,亲本可以是酵母纤维素酶,如假丝酵母属(candida)、克鲁维酵母属(kluyveromyces)、毕赤酵母属(pichia)、酵母属(saccharomyces)、裂殖酵母(schizosaccharomyces)或耶氏酵母属(yarrowia)纤维素酶;或丝状真菌纤维素酶,例如枝顶孢属(acremonium)、伞菌属(agaricus)、链格孢属(alternaria)、曲霉属、短梗霉属(aureobasidium)、葡萄座腔菌属(botryospaeria)、拟蜡菌属(ceriporiopsis)、毛喙壳属(chaetomidium)、金孢子菌属(chrysosporium)、麦角菌属(claviceps)、旋孢腔菌属(cochliobolus)、鬼伞属(coprinopsis)、乳白蚁属(coptotermes)、棒囊壳属(corynascus)、隐丛赤壳菌属(cryphonectria)、隐球菌属(cryptococcus)、色二孢属(diplodia)、黑耳属(exidia)、线黑粉酵母属(filibasidium)、镰孢属(fusarium)、赤霉属(gibberella)、全鞭毛虫属(holomastigotoides)、腐质霉属(humicola)、耙齿菌属(irpex)、香菇属(lentinula)、小腔球菌属(leptospaeria)、梨孢菌属(magnaporthe)、黑果菌属(melanocarpus)、亚灰树花菌属、毛霉属(mucor)、毁丝霉属(myceliophthora)、新美鞭菌属(neocallimastix)、链孢菌属(neurospora)、拟青霉属(paecilomyces)、青霉菌属、平革菌属(phanerochaete)、瘤胃壶菌属(piromyces)、poitrasia、假黑盘菌属(pseudoplectania)、假披发虫属(pseudotrichonympha)、根毛霉属(rhizomucor)、裂褶菌属(schizophyllum)、柱顶孢属(scytalidium)、篮状菌属(talaromyces)、嗜热子囊菌属(thermoascus)、梭孢壳霉属(thielavia)、弯颈霉属(tolypocladium)、木霉属(trichoderma)、长毛盘菌属(trichophaea)、轮枝孢属
(verticillium)、小包脚菇属(volvariella)、或炭角菌属(xylaria)纤维素酶。
[0524]
在另一方面,亲本是卡尔酵母(saccharomyces carlsbergensis)、酿酒酵母(saccharomyces cerevisiae)、糖化酵母(saccharomyces diastaticus)、道格拉氏酵母(saccharomyces douglasii)、克鲁弗酵母(saccharomyces kluyveri)、诺地酵母(saccharomyces norbensis)、或卵形酵母(saccharomyces oviformis)纤维素酶。
[0525]
在另一方面,亲本是解纤维枝顶孢霉(acremonium cellulolyticus)、棘孢曲霉(aspergillus aculeatus)、泡盛曲霉(aspergillus awamori)、臭曲霉(aspergillus foetidus)、烟曲霉(aspergillus fumigatus)、日本曲霉(aspergillus japonicus)、构巢曲霉(aspergillus nidulans)、黑曲霉(aspergillus niger)、米曲霉(aspergillus oryzae)、狭边金孢子菌(chrysosporium inops)、嗜角质金孢子菌(chrysosporium keratinophilum)、拉克淖金孢子菌(chrysosporium lucknowense)、粪状金孢子菌(chrysosporium merdarium)、毡金孢子菌(chrysosporium pannicola)、昆士兰金孢子菌(chrysosporium queenslandicum)、热带金孢子菌(chrysosporium tropicum)、带纹金孢子菌(chrysosporium zonatum)、杆孢状镰孢(fusarium bactridioides)、禾谷镰孢(fusarium cerealis)、库威镰孢(fusarium crookwellense)、黄色镰孢(fusarium culmorum)、禾谷镰孢(fusarium graminearum)、禾赤镰孢(fusarium graminum)、异孢镰孢(fusarium heterosporum)、合欢木镰孢(fusarium negundi)、尖孢镰孢(fusarium oxysporum)、多枝镰孢(fusarium reticulatum)、粉红镰孢(fusarium roseum)、接骨木镰孢(fusarium sambucinum)、肤色镰孢(fusarium sarcochroum)、拟枝孢镰孢(fusarium sporotrichioides)、硫色镰孢(fusarium sulphureum)、圆镰孢(fusarium torulosum)、拟丝孢镰孢(fusarium trichothecioides)、镶片镰孢(fusarium venenatum)、灰腐质霉(humicola grisea)、特异腐质霉(humicola insolens)、柔毛腐质霉(humicola lanuginosa)、白囊耙齿菌(irpex lacteus)、米黑毛霉(mucor miehei)、嗜热毁丝霉(myceliophthora thermophila)、粗糙脉孢菌(neurospora crassa)、绳状青霉菌(penicillium funiculosum)、产紫青霉(penicillium purpurogenum)、黄孢原毛平革菌(phanerochaete chrysosporium)、无色梭孢壳(thielavia achromatica)、成层梭孢壳(thielavia albomyces)、白毛梭孢壳(thielavia albopilosa)、澳洲梭孢壳(thielavia australeinsis)、粪梭孢壳(thielavia fimeti)、小孢梭孢壳(thielavia microspora)、卵孢梭孢壳(thielavia ovispora)、秘鲁梭孢壳(thielavia peruviana)、毛梭孢壳(thielavia setosa)、瘤孢梭孢壳(thielavia spededonium)、耐热梭孢壳(thielavia subthermophila)、土生梭孢壳(thielavia terrestris)、哈茨木霉(trichoderma harzianum)、康宁木霉(trichoderma koningii)、长枝木霉(trichoderma longibrachiatum)、里氏木霉(trichoderma reesei)、或绿色木霉(trichoderma viride)纤维素酶。
[0526]
在另一方面,亲本是土生梭孢壳纤维素酶,例如seq id no:1的纤维素酶或其成熟多肽。
[0527]
应理解的是,对于前述物种,本发明涵盖完全和不完全阶段(perfect and imperfect states),和其他分类学等同物(equivalent),例如无性型,而与它们已知的物种名无关。本领域的技术人员会容易地识别适当等同物的身份。
[0528]
这些物种的菌株可容易地在许多培养物保藏中心为公众所获得,例如美国典型培养物保藏中心(american type culture collection,atcc)、德国微生物菌种保藏中心(deutsche sammlung von mikroorganismen und zellkulturen gmbh,dsmz)、荷兰菌种保藏中心(centraalbureau voor schimmelcultures,cbs)、和美国农业研究服务专利培养物保藏中心北方地区研究中心(agricultural research service patent culture collection,northern regional research center,nrrl)。
[0529]
可以使用以上探针,从其他来源(包括从自然界(例如,土壤、堆肥、水等)分离的微生物或从天然材料(例如,土壤、堆肥、水等)直接获得的dna样品)中鉴定亲本并获得亲本。用于从天然生境中直接分离微生物和dna的技术是本领域熟知的。然后可以通过类似地筛选另一种微生物的基因组dna或cdna文库或混合dna样品来获得编码亲本的多核苷酸。一旦已经用一种或多种探针检测到编码亲本的多核苷酸,则可以通过利用对本领域的普通技术人员来说已知的技术来分离或克隆该多核苷酸(参见例如,sambrook等人,1989,同上)。
[0530]
变体的制备
[0531]
本发明还涉及用于获得具有糖苷水解酶活性的变体的方法,这些方法包括:(a)向亲本糖苷水解酶中引入亲本多肽的成熟多肽的一个或多个取代;以及(b)回收该变体。
[0532]
可以使用本领域已知的任何诱变方法,如定点诱变、合成基因构建、半合成基因构建、随机诱变、改组等制备变体。
[0533]
定点诱变是在编码亲本的多核苷酸中的一个或多个限定位点处引入一个或多个(例如,若干个)突变的技术。
[0534]
通过涉及使用含有所希望的突变的寡核苷酸引物的pcr可以体外实现定点诱变。也可以通过盒式诱变进行体外定点诱变,该盒式诱变涉及由限制酶在包含编码亲本的多核苷酸的质粒中的位点处切割并且随后将含有突变的寡核苷酸连接在多核苷酸中。通常,消化质粒和寡核苷酸的限制酶是相同的,从而允许质粒和插入物的粘性末端彼此连接。参见例如,scherer和davis,1979,proc.natl.acad.sci.usa[美国国家科学院院刊]76:4949
‑
4955;和barton等人,1990,nucleic acids res.[核酸研究]18:7349
‑
4966。
[0535]
还可以通过本领域中已知的方法在体内实现定点诱变。参见例如,美国专利申请公布号2004/0171154;storici等人,2001,nature biotechnol.[自然生物技术]19:773
‑
776;kren等人,1998,nat.med.[自然医学]4:285
‑
290;以及calissano和macino,1996,fungal genet.newslett.[真菌遗传学时事通讯]43:15
‑
16。
[0536]
可以在本发明中使用任何定点诱变程序。存在可用于制备变体的许多可商购的试剂盒。
[0537]
合成基因构建需要设计的多核苷酸分子的体外合成以编码感兴趣的多肽。基因合成可以利用多种技术来进行,例如由tian等人(2004,nature[自然]432:1050
‑
1054)所述的基于多路微芯片的技术、以及其中在光可编程的微流芯片上合成并组装寡核苷酸的类似技术。
[0538]
使用已知的诱变、重组和/或改组方法,随后进行相关的筛选程序可以做出单个或多个氨基酸取代、缺失和/或插入并对其进行测试,该相关的筛选程序例如由reidhaar
‑
olson和sauer,1988,science[科学]241:53
‑
57;bowie和sauer,1989,proc.natl.acad.sci.usa[美国国家科学院院刊]86:2152
‑
2156;wo 95/17413;或wo 95/
22625中披露的那些。其他可以使用的方法包括易错pcr、噬菌体展示(例如lowman等人,1991,biochemistry[生物化学]30:10832
‑
10837;美国专利号5,223,409;wo 92/06204)以及区域定向诱变(derbyshire等人,1986,gene[基因]46:145;ner等人,1988,dna 7:127)。
[0539]
诱变/改组方法可以与高通量、自动化的筛选方法组合以检测由宿主细胞表达的克隆的、诱变的多肽的活性(ness等人,1999,nature biotechnology[自然生物技术]17:893
‑
896)。可从宿主细胞回收编码活性多肽的诱变的dna分子,并使用本领域的标准方法快速测序。这些方法允许快速确定多肽中各个氨基酸残基的重要性。
[0540]
通过组合合成基因构建、和/或定点诱变、和/或随机诱变、和/或改组的多方面来实现半合成基因构建。半合成构建典型地是利用合成的多核苷酸片段的过程与pcr技术组合。因此,基因的限定区域可以从头合成,而其他区域可以使用位点特异性诱变引物来扩增,而还有其他区域可以进行易错pcr或非易错pcr扩增。然后可以对多核苷酸子序列进行改组。
[0541]
多核苷酸
[0542]
本发明还涉及编码本发明的变体的多核苷酸。
[0543]
核酸构建体
[0544]
本发明还涉及包含编码本发明的变体的、可操作地连接至一个或多个控制序列上的多核苷酸的核酸构建体,该一个或多个控制序列在与控制序列相容的条件下指导编码序列在适合的宿主细胞中表达。
[0545]
可以按多种方式来操纵多核苷酸以提供变体的表达。取决于表达载体,在多核苷酸插入载体之前对其进行操纵可能是理想的或必需的。用于利用重组dna方法修饰多核苷酸的技术是本领域熟知的。
[0546]
控制序列可以是启动子,即多核苷酸,其由宿主细胞识别用于表达该多核苷酸。启动子含有介导变体的表达的转录控制序列。启动子可以是在宿主细胞中显示转录活性的任何多核苷酸,包括突变型、截短型和杂合型启动子,并且可以获得自编码与宿主细胞同源或异源的细胞外或细胞内多肽的基因。
[0547]
用于在细菌宿主细胞中指导本发明核酸构建体的转录的适合启动子的实例是从以下基因中获得的启动子:解淀粉芽孢杆菌α
‑
淀粉酶基因(amyq)、地衣芽孢杆菌α
‑
淀粉酶基因(amyl)、地衣芽孢杆菌青霉素酶基因(penp)、嗜热脂肪芽孢杆菌产麦芽糖淀粉酶基因(amym)、枯草芽孢杆菌果聚糖蔗糖酶基因(sacb)、枯草芽孢杆菌xyla和xylb基因、苏云金芽孢杆菌cryiiia基因(agaisse和lereclus,1994,molecular microbiology[分子微生物学]13:97
‑
107)、大肠杆菌lac操纵子、大肠杆菌trc启动子(egon等人,1988,gene[基因]69:301
‑
315)、天蓝链霉菌琼脂水解酶基因(daga)和原核β
‑
内酰胺酶基因(villa
‑
kamaroff等人,1978,proc.natl.acad.sci.usa[美国国家科学院院刊]75:3727
‑
3731)以及tac启动子(deboer等人,1983,proc.natl.acad.sci.usa[美国国家科学院院刊]80:21
‑
25)。其他启动子描述于gilbert等人,1980,scientific american[科学美国人]242:74
‑
94的“useful proteins from recombinant bacteria[来自重组细菌的有用蛋白质]”;和sambrook等人,1989,同上。串联启动子的实例披露于wo 99/43835中。
[0548]
用于指导本发明的核酸构建体在丝状真菌宿主细胞中的转录的适合启动子的实例是从以下酶的基因获得的启动子:构巢曲霉乙酰胺酶、黑曲霉中性α
‑
淀粉酶、黑曲霉酸稳
定性α
‑
淀粉酶、黑曲霉或泡盛曲霉葡糖淀粉酶(glaa)、米曲霉taka淀粉酶、米曲霉碱性蛋白酶、米曲霉丙糖磷酸异构酶、尖孢镰孢胰蛋白酶样蛋白酶(wo 96/00787)、镶片镰孢淀粉葡糖苷酶(wo 00/56900)、镶片镰孢daria(wo 00/56900)、镶片镰孢quinn(wo 00/56900)、米黑根毛霉脂肪酶、米黑根毛霉天冬氨酸蛋白酶、里氏木霉β
‑
葡糖苷酶、里氏木霉纤维二糖水解酶i、里氏木霉纤维二糖水解酶ii、里氏木霉内切葡聚糖酶i、里氏木霉内切葡聚糖酶ii、里氏木霉内切葡聚糖酶iii、里氏木霉内切葡聚糖酶iv、里氏木霉内切葡聚糖酶v、里氏木霉木聚糖酶i、里氏木霉木聚糖酶ii、里氏木霉β
‑
木糖苷酶,以及na2
‑
tpi启动子(一种修饰的启动子,其来自曲霉属中性α
‑
淀粉酶基因,其中未翻译的前导序列由曲霉属丙糖磷酸异构酶基因的未翻译的前导序列替代;非限制性实例包括来自黑曲霉中性α
‑
淀粉酶基因的经修饰的启动子,其中已经用来自构巢曲霉或米曲霉丙糖磷酸异构酶基因的未翻译的前导序列替代未翻译的前导序列);及其突变型、截短型及杂合型启动子。
[0549]
在酵母宿主中,有用的启动子从以下的基因中获得:酿酒酵母烯醇酶(eno
‑
1)、酿酒酵母半乳糖激酶(gal1)、酿酒酵母醇脱氢酶/甘油醛
‑3‑
磷酸脱氢酶(adh1、adh2/gap)、酿酒酵母磷酸丙糖异构酶(tpi)、酿酒酵母金属硫蛋白(cup1)、以及酿酒酵母3
‑
磷酸甘油酸激酶。酵母宿主细胞的其他有用的启动子由romanos等人,1992,yeast[酵母]8:423
‑
488描述。
[0550]
控制序列也可为由宿主细胞识别以终止转录的转录终止子。终止子序列可操作地连接至编码该变体的多核苷酸的3
’‑
末端。可以使用在宿主细胞中有功能的任何终止子。
[0551]
细菌宿主细胞的优选终止子从以下的基因获得:克劳氏芽孢杆菌碱性蛋白酶(aprh)、地衣芽孢杆菌α
‑
淀粉酶(amyl)、和大肠杆菌核糖体rna(rrnb)。
[0552]
丝状真菌宿主细胞的优选终止子获得自以下的基因:构巢曲霉邻氨基苯甲酸合酶、黑曲霉葡糖淀粉酶、黑曲霉α
‑
葡糖苷酶、米曲霉taka淀粉酶、以及尖孢镰孢胰蛋白酶样蛋白酶。
[0553]
酵母宿主细胞的优选终止子从以下的基因中获得:酿酒酵母烯醇酶、酿酒酵母细胞色素c(cyc1)以及酿酒酵母甘油醛
‑3‑
磷酸脱氢酶。酵母宿主细胞的其他有用的终止子由romanos等人(1992,同上)描述。
[0554]
控制序列还可以是启动子下游和基因的编码序列上游的mrna稳定子区域,其增加该基因的表达。
[0555]
适合的mrna稳定子区域的实例是从以下获得的:苏云金芽孢杆菌cryiiia基因(wo 94/25612)和枯草芽孢杆菌sp82基因(hue等人,1995,journal of bacteriology[细菌学杂志]177:3465
‑
3471)。
[0556]
控制序列也可以是前导序列,即对宿主细胞翻译很重要的mrna的非翻译区域。前导序列可操作地连接至编码该变体的多核苷酸的5
’‑
末端。可以使用在宿主细胞中有功能的任何前导序列。
[0557]
用于丝状真菌宿主细胞的优选前导序列从米曲霉taka淀粉酶和构巢曲霉丙糖磷酸异构酶的基因获得。
[0558]
酵母宿主细胞的合适的前导序列从以下的基因中获得:酿酒酵母烯醇酶(eno
‑
1)、酿酒酵母3
‑
磷酸甘油酸激酶、酿酒酵母α
‑
因子和酿酒酵母醇脱氢酶/甘油醛
‑3‑
磷酸脱氢酶(adh2/gap)。
[0559]
控制序列还可以是多腺苷酸化序列,即被可操作地连接至变体编码序列的3
’‑
末
端并且当转录时由宿主细胞识别为将聚腺苷酸残基添加到转录的mrna上的信号的序列。可以使用在宿主细胞中有功能的任何多腺苷酸化序列。
[0560]
用于丝状真菌宿主细胞的优选多腺苷酸化序列从以下酶的基因获得:构巢曲霉邻氨基苯甲酸合酶、黑曲霉葡糖淀粉酶、黑曲霉α
‑
葡糖苷酶、米曲霉taka淀粉酶以及尖孢镰孢胰蛋白酶样蛋白酶。
[0561]
酵母宿主细胞的有用的多腺苷酸化序列由guo和sherman,1995,mol.cellular biol.[分子细胞生物学]15:5983
‑
5990描述。
[0562]
控制序列还可以是信号肽编码区域,该编码区域编码与变体的n
‑
末端连接的信号肽,并且指导该变体进入细胞的分泌途径。多核苷酸的编码序列的5
’‑
端可以固有地包含信号肽编码序列,该信号肽编码序列在翻译阅读框中与编码该变体的编码序列的区段天然地连接在一起。可替代地,编码序列的5
’‑
端可以含有对编码序列而言外源的信号肽编码序列。在编码序列不天然地含有信号肽编码序列的情况下,可能需要外源信号肽编码序列。可替代地,外源信号肽编码序列可以简单地替代天然信号肽编码序列,以便增强变体的分泌。然而,可以使用指导表达的变体进入宿主细胞的分泌途径的任何信号肽编码序列。
[0563]
用于细菌宿主细胞的有效信号肽编码序列是从芽孢杆菌ncib 11837产麦芽糖淀粉酶、地衣芽孢杆菌枯草杆菌蛋白酶、地衣芽孢杆菌β
‑
内酰胺酶、嗜热脂肪芽孢杆菌α
‑
淀粉酶、嗜热脂肪芽孢杆菌中性蛋白酶(nprt、nprs、nprm)、和枯草芽孢杆菌prsa的基因获得的信号肽编码序列。其他信号肽由simonen和palva,1993,microbiological reviews[微生物评论]57:109
‑
137描述。
[0564]
用于丝状真菌宿主细胞的有效的信号肽编码序列是从以下酶的基因获得的信号肽编码序列:黑曲霉中性淀粉酶、黑曲霉葡糖淀粉酶、米曲霉taka淀粉酶、特异腐质霉纤维素酶、特异腐质霉内切葡聚糖酶v、疏棉状腐质霉脂肪酶和米黑根毛霉天冬氨酸蛋白酶。
[0565]
用于酵母宿主细胞的有用的信号肽从酿酒酵母α
‑
因子和酿酒酵母转化酶的基因中获得。其他的有用的信号肽编码序列由romanos等人(1992,同上)描述。
[0566]
控制序列还可以是编码位于变体的n
‑
末端处的前肽的前肽编码序列。所得的多肽被称为前体酶(proenzyme)或多肽原(或在一些情况下被称为酶原(zymogen))。多肽原通常是无活性的并且可通过催化切割或自身催化切割来自多肽原的前肽而转化为活性多肽。前肽编码序列可以从以下的基因获得:枯草芽孢杆菌碱性蛋白酶(apre)、枯草芽孢杆菌中性蛋白酶(nprt)、嗜热毁丝霉(myceliophthora thermophila)漆酶(wo 95/33836)、米黑根毛霉(rhizomucor miehei)天冬氨酸蛋白酶、和酿酒酵母α
‑
因子。
[0567]
在信号肽序列和前肽序列二者都存在的情况下,该前肽序列定位成紧邻该变体的n
‑
末端并且该信号肽序列定位成紧邻该前肽序列的n
‑
末端。
[0568]
还令人希望的可以是添加相对于宿主细胞的生长来调节变体的表达的调节序列。调节系统的实例是响应于化学或物理刺激而引起基因的表达开启或关闭的那些,包括调节化合物的存在。原核系统中的调节系统包括lac、tac和trp操纵子系统。在酵母中,可以使用adh2系统或gal1系统。在丝状真菌中,可以使用黑曲霉葡糖淀粉酶启动子、米曲霉taka α
‑
淀粉酶启动子、以及米曲霉葡糖淀粉酶启动子。调节序列的其他实例是允许基因扩增的那些序列。在真核系统中,这些调节序列包括在甲氨蝶呤存在下扩增的二氢叶酸还原酶基因以及用重金属扩增的金属硫蛋白基因。在这些情况下,编码变体的多核苷酸将与调节序列
可操作地连接。
[0569]
表达载体
[0570]
本发明还涉及包含编码本发明的变体的多核苷酸、启动子、以及转录和翻译终止信号的重组表达载体。各种核苷酸和控制序列可以连接在一起以产生重组表达载体,该重组表达载体可以包括一个或多个合宜的限制位点以允许在此类位点处插入或取代编码变体的多核苷酸。可替代地,可以通过将多核苷酸或包含该多核苷酸的核酸构建体插入用于表达的适当载体中而表达该多核苷酸。在产生表达载体时,编码序列如此位于载体中,使得编码序列与用于表达的适当控制序列可操作地连接。
[0571]
重组表达载体可以是可以方便地经受重组dna程序并且可以引起多核苷酸表达的任何载体(例如,质粒或病毒)。载体的选择将典型地取决于载体与待引入载体的宿主细胞的相容性。载体可以是直链或闭合环状质粒。
[0572]
载体可以是自主复制载体,即作为染色体外实体存在的载体,其复制独立于染色体复制,例如质粒、染色体外元件、微染色体或人工染色体。载体可以含有用于确保自我复制的任何手段。可替代地,载体可以是这样的载体,当它引入宿主细胞中时整合入基因组中并与其中已整合了它的一个或多个染色体一起复制。此外,可以使用单独的载体或质粒或两个或更多个载体或质粒,其共同含有待引入宿主细胞基因组的总dna,或可以使用转座子。
[0573]
载体优选地含有允许方便地选择转化细胞、转染细胞、转导细胞等细胞的一个或多个选择性标记。选择性标记是一种基因,其产物提供了杀生物剂抗性或病毒抗性、对重金属抗性、对营养缺陷型的原养型等。
[0574]
细菌选择性标记的实例是地衣芽孢杆菌或枯草芽孢杆菌dal基因、或赋予抗生素抗性(如氨苄青霉素、氯霉素、卡那霉素、新霉素、大观霉素、或四环素抗性)的标记。酵母宿主细胞的合适的标记包括但不限于:ade2、his3、leu2、lys2、met3、trp1和ura3。用于在丝状真菌宿主细胞中使用的选择性标记包括但不限于amds(乙酰胺酶)、argb(鸟氨酸氨甲酰基转移酶)、bar(草胺膦乙酰转移酶)、hph(潮霉素磷酸转移酶)、niad(硝酸还原酶)、pyrg(乳清苷
‑5’‑
磷酸脱羧酶)、sc(硫酸腺苷基转移酶)、以及trpc(邻氨基苯甲酸合酶),连同其等同物。优选的用于曲霉细胞中的是构巢曲霉或米曲霉amds和pyrg基因以及吸水链霉菌(streptomyces hygroscopicus)bar基因。
[0575]
载体优选地含有允许载体整合到宿主细胞的基因组中或载体在细胞中独立于基因组自主复制的一个或多个元件。
[0576]
为了整合至宿主细胞基因组中,载体可以依赖于编码变体的多核苷酸序列或用于借助同源或非同源重组整合至基因组中的任何其他载体元件。可替代地,载体可以含有用于指导通过同源重组而整合入宿主细胞基因组中的一个或多个染色体中的一个或多个精确位置处的另外的多核苷酸。为了增加在精确位置处整合的可能性,整合元件应当含有足够数目的核酸,例如100至10000个碱基对、400至10000个碱基对、和800至10000个碱基对,这些核酸与相对应的靶序列具有高度序列同一性以增强同源重组的概率。整合元件可以是与宿主细胞基因组内的靶序列同源的任何序列。此外,整合元件可以是非编码或编码的多核苷酸。另一方面,载体可以通过非同源重组整合入宿主细胞的基因组中。
[0577]
为了自主复制,载体可以进一步包含复制起点,该复制起点使得载体在讨论中的
宿主细胞中自主复制成为可能。复制起点可以是在细胞中发挥作用的介导自主复制的任何质粒复制子。术语“复制起点”或“质粒复制子”意指使质粒或载体能够在体内复制的多核苷酸。
[0578]
细菌复制起点的实例是允许在大肠杆菌中复制的质粒pbr322、puc19、pacyc177、和pacyc184的复制起点,以及允许在芽孢杆菌属中复制的质粒pub110、pe194、pta1060、和pamβ1的复制起点。
[0579]
用于酵母宿主细胞中的复制起点的实例是2微米复制起点、ars1、ars4、ars1与cen3的组合、及ars4与cen6的组合。
[0580]
在丝状真菌细胞中有用的复制起点的实例是ama1和ans1(gems等人,1991,gene[基因]98:61
‑
67;cullen等人,1987,nucleic acids res.[核酸研究]15:9163
‑
9175;wo 00/24883)。可根据wo 00/24883中披露的方法完成ama1基因的分离和包含该基因的质粒或载体的构建。
[0581]
可以将多于一个拷贝的本发明的多核苷酸插入宿主细胞中以增加变体的产生。通过将序列的至少一个另外的拷贝整合到宿主细胞基因组中或者通过包括与该多核苷酸一起的可扩增的选择性标记基因可以获得多核苷酸的增加的拷贝数目,其中通过在适当的选择性试剂的存在下培养细胞可以选择包含选择性标记基因的经扩增的拷贝以及由此该多核苷酸的另外的拷贝的细胞。
[0582]
用于连接以上所述的元件以构建本发明的重组表达载体的程序是本领域的普通技术人员熟知的(参见例如,sambrook等人,1989,同上)。
[0583]
宿主细胞
[0584]
本发明还涉及重组宿主细胞,这些重组宿主细胞包含编码本发明的变体的、可操作地连接至一个或多个控制序列的多核苷酸,该一个或多个控制序列指导本发明的变体的产生。将包含多核苷酸的构建体或载体引入宿主细胞中,这样使得该构建体或载体作为染色体整合体或作为自主复制的染色体外载体维持,如较早前所述。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不相同的任何亲本细胞子代。宿主细胞的选择在很大程度上将取决于编码变体的基因及其来源。
[0585]
宿主细胞可以是在变体的重组产生中有用的任何细胞,例如原核细胞或真核细胞。
[0586]
原核宿主细胞可以是任何革兰氏阳性或革兰氏阴性细菌。革兰氏阳性细菌包括但不限于:芽孢杆菌属、梭菌属、肠球菌属、土芽孢杆菌属、乳杆菌属、乳球菌属、大洋芽孢杆菌属、葡萄球菌属、链球菌属以及链霉菌属。革兰氏阴性细菌包括但不限于:弯曲杆菌属(campylobacter)、大肠杆菌、黄杆菌属(flavobacterium)、梭杆菌属(fusobacterium)、螺杆菌属(helicobacter)、泥杆菌属(ilyobacter)、奈瑟氏菌属(neisseria)、假单胞菌属(pseudomonas)、沙门氏菌属(salmonella)、以及脲原体属(ureaplasma)。
[0587]
细菌宿主细胞可以是任何芽孢杆菌属细胞,包括但不限于嗜碱芽孢杆菌、解淀粉芽孢杆菌、短芽孢杆菌、环状芽孢杆菌、克劳氏芽孢杆菌、凝结芽孢杆菌、坚硬芽孢杆菌、灿烂芽孢杆菌、迟缓芽孢杆菌、地衣芽孢杆菌、巨大芽孢杆菌、短小芽孢杆菌、嗜热脂肪芽孢杆菌、枯草芽孢杆菌以及苏云金芽孢杆菌细胞。
[0588]
细菌宿主细胞还可以是任何链球菌属细胞,包括但不限于似马链球菌
(streptococcus equisimilis)、酿脓链球菌(streptococcus pyogenes)、乳房链球菌(streptococcus uberis)和马链球菌兽疫亚种(streptococcus equi subsp.zooepidemicus)细胞。
[0589]
细菌宿主细胞还可以是任何链霉菌属细胞,包括但不限于:不产色链霉菌、除虫链霉菌、天蓝链霉菌、灰色链霉菌、以及浅青紫链霉菌细胞。
[0590]
将dna引入芽孢杆菌属细胞中可以通过以下方式来实现:原生质体转化(参见例如,chang和cohen,1979,mol.gen.genet.[分子与普通遗传学]168:111
‑
115)、感受态细胞转化(参见例如,young和spizizen,1961,j.bacteriol.[细菌学杂志]81:823
‑
829;或dubnau和davidoff
‑
abelson,1971,j.mol.biol.[分子生物学杂志]56:209
‑
221)、电穿孔(参见例如,shigekawa和dower,1988,biotechniques[生物技术]6:742
‑
751)、或轭合(参见例如,koehler和thorne,1987,j.bacteriol.[细菌学杂志]169:5271
‑
5278)。将dna引入大肠杆菌细胞中可以通过以下方式来实现:原生质体转化(参见例如,hanahan,1983,j.mol.biol.[分子生物学杂志]166:557
‑
580)或电穿孔(参见例如,dower等人,1988,nucleic acids res.[核酸研究]16:6127
‑
6145)。将dna引入链霉菌属细胞中可以通过以下来实现:原生质体转化、电穿孔(参见例如,gong等人,2004,folia microbiol.(praha)[叶线形微生物学(布拉格)]49:399
‑
405)、轭合(参见例如,mazodier等人,1989,j.bacteriol.[细菌学杂志]171:3583
‑
3585)、或转导(参见例如,burke等人,2001,proc.natl.acad.sci.usa[美国国家科学院院刊]98:6289
‑
6294)。将dna引入假单孢菌属细胞中可以通过以下方式来实现:电穿孔(参见例如,choi等人,2006,j.microbiol.methods[微生物学方法杂志]64:391
‑
397)或轭合(参见例如,pinedo和smets,2005,appl.environ.microbiol.[应用与环境微生物学]71:51
‑
57)。将dna引入链球菌属细胞中可以通过以下方式来实现:天然感受态(natural competence)(参见例如,perry和kuramitsu,1981,infect.immun.[感染与免疫]32:1295
‑
1297)、原生质体转化(参见例如,catt和jollick,1991,microbios[微生物学]68:189
‑
207)、电穿孔(参见例如,buckley等人,1999,appl.environ.microbiol.[应用与环境微生物学]65:3800
‑
3804)、或轭合(参见例如,clewell,1981,microbiol.rev.[微生物学评论]45:409
‑
436)。然而,可以使用本领域已知的将dna引入宿主细胞中的任何方法。
[0591]
宿主细胞还可以是真核生物,如哺乳动物、昆虫、植物或真菌细胞。
[0592]
宿主细胞可以是真菌细胞。如本文所用的“真菌”包括子囊菌门(ascomycota)、担子菌门(basidiomycota)、壶菌门(chytridiomycota)和接合菌门(zygomycota)以及卵菌门(oomycota)和所有有丝分裂孢子真菌(如由hawksworth等人在以下文献中所定义:ainsworth and bisby’s dictionary of the fungi[安斯沃思和拜斯比真菌字典],第8版,1995,cab international[国际应用生物科学中心],university press[大学出版社],cambridge,uk[英国剑桥])。
[0593]
真菌宿主细胞可以为酵母细胞。如本文所用的“酵母”包括产子囊酵母(ascosporogenous yeast)(内孢霉目(endomycetales))、产担子酵母(basidiosporogenous yeast)和属于半知菌类(fungi imperfecti)(芽孢纲(blastomycetes))的酵母。由于酵母的分类可在将来变化,出于本发明的目的,酵母应当如biology and activities of yeast[酵母的生物学与活性](skinner,passmore和
davenport编辑,soc.app.bacteriol.symposium series no.9[应用细菌学学会专题论文集系列9],1980)中所描述的那样定义。
[0594]
酵母宿主细胞可以是假丝酵母属(candida)细胞、汉逊酵母属(hansenula)细胞、克鲁维酵母属(kluyveromyces)细胞、毕赤酵母属(pichia)细胞、酵母菌属(saccharomyces)细胞、裂殖酵母(schizosaccharomyces)或耶罗维亚酵母属(yarrowia)细胞、例如乳酸克鲁弗酵母(kluyveromyces lactis)细胞、卡尔酵母(saccharomyces carlsbergensis)细胞、酿酒酵母(saccharomyces cerevisiae)细胞、糖化酵母(saccharomyces diastaticus)细胞、道格拉氏酵母(saccharomyces douglasii)细胞、克鲁弗酵母(saccharomyces kluyveri)细胞、诺地酵母(saccharomyces norbensis)细胞、卵形酵母(saccharomyces oviformis)细胞或解脂耶罗维亚酵母(yarrowia lipolytica)细胞。
[0595]
真菌宿主细胞可为丝状真菌细胞。“丝状真菌”包括真菌门(eumycota)和卵菌门(oomycota)的亚门的所有丝状形式(如由hawksworth等人,1995(同上)所定义的)。丝状真菌通常的特征在于由几丁质、纤维素、葡聚糖、壳聚糖、甘露聚糖和其他复杂多糖构成的菌丝体壁。营养生长是通过菌丝延伸来进行的,而碳分解代谢是专性需氧的。相反,酵母(如酿酒酵母)的营养生长是通过单细胞菌体的出芽(budding)来进行的,而碳分解代谢可以是发酵性的。
[0596]
丝状真菌宿主细胞可以是枝顶孢属(acremonium)、曲霉属(aspergillus)、短梗霉属(aureobasidium)、烟管霉属(bjerkandera)、拟腊菌属(ceriporiopsis)、金孢子菌属(chrysosporium)、鬼伞属(coprinus)、革盖菌属(coriolus)、隐球菌属(cryptococcus)、线黑粉菌科(filibasidium)、镰孢属(fusarium)、腐质霉属(humicola)、梨孢菌属(magnaporthe)、毛霉属(mucor)、毁丝霉属(myceliophthora)、新美鞭菌属(neocallimastix)、脉胞菌属(neurospora)、拟青霉属(paecilomyces)、青霉属(penicillium)、平革菌属(phanerochaete)、射脉菌属(phlebia)、瘤胃壶菌属(piromyces)、侧耳属(pleurotus)、裂褶菌属(schizophyllum)、篮状菌属(talaromyces)、嗜热子囊菌属(thermoascus)、梭孢壳属(thielavia)、弯颈霉属(tolypocladium)、栓菌属(trametes)、或木霉属(trichoderma)细胞。
[0597]
例如,丝状真菌宿主细胞可以是泡盛曲霉、臭曲霉、烟曲霉、日本曲霉、构巢曲霉、黑曲霉、米曲霉、黑刺烟管菌(bjerkandera adusta)、干拟蜡菌(ceriporiopsis aneirina)、卡内基拟蜡菌(ceriporiopsis caregiea)、浅黄拟蜡孔菌(ceriporiopsis gilvescens)、潘诺希塔拟蜡菌(ceriporiopsis pannocinta)、环带拟蜡菌(ceriporiopsis rivulosa)、微红拟蜡菌(ceriporiopsis subrufa)、虫拟蜡菌(ceriporiopsis subvermispora)、狭边金孢子菌(chrysosporium inops)、嗜角质金孢子菌、卢克诺文思金孢子菌(chrysosporium lucknowense)、粪状金孢子菌(chrysosporium merdarium)、租金孢子菌(chrysosporium pannicola)、女王杜香金孢子菌(chrysosporium queenslandicum)、热带金孢子菌、褐薄金孢子菌(chrysosporium zonatum)、灰盖鬼伞(coprinus cinereus)、毛革盖菌(coriolus hirsutus)、杆孢状镰孢、谷类镰孢、库威镰孢、大刀镰孢、禾谷镰孢、禾赤镰孢、异孢镰孢、合欢木镰孢、尖孢镰孢、多枝镰孢、粉红镰孢、接骨木镰孢、肤色镰孢、拟分枝孢镰孢、硫色镰孢、圆镰孢、拟丝孢镰孢、镶片镰孢、特异腐质
霉、柔毛腐质霉、米黑毛霉、嗜热毁丝霉、粗糙脉孢菌、产紫青霉、黄孢原毛平革菌、射脉菌(phlebia radiata)、刺芹侧耳(pleurotus eryngii)、土生梭孢壳、长域毛栓菌(trametes villosa)、变色栓菌(trametes versicolor)、哈茨木霉、康宁木霉、长枝木霉、里氏木霉、或绿色木霉细胞。
[0598]
可以将真菌细胞通过涉及原生质体形成、原生质体转化、以及细胞壁再生的方法以本身已知的方式转化。用于转化曲霉属和木霉属宿主细胞的适合程序描述于以下文献中:ep 238023,yelton等人,1984,proc.natl.acad.sci.usa[美国国家科学院院刊]81:1470
‑
1474以及christensen等人,1988,bio/technology[生物/技术]6:1419
‑
1422。用于转化镰孢属物种的适合方法由malardier等人,1989,gene[基因]78:147
‑
156和wo 96/00787描述。可以使用由以下文献描述的程序转化酵母:becker和guarente,在abelson,j.n.和simon,m.i.编辑,guide to yeast genetics and molecular biology[酵母遗传学与分子生物学指南],methods in enzymology[酶学方法],第194卷,第182
‑
187页,academic press,inc.[学术出版社有限公司],纽约);ito等人,1983,j.bacteriol.[细菌学杂志]153:163;以及hinnen等人,1978,proc.natl.acad.sci.usa[美国国家科学院院刊]75:1920。
[0599]
产生方法
[0600]
本发明还涉及产生变体的方法,这些方法包括:(a)在适合用于该变体的表达的条件下培养本发明的宿主细胞;以及(b)回收该变体。
[0601]
使用本领域已知的方法在适合于产生变体的营养培养基中培养宿主细胞。例如,可以通过摇瓶培养,或者在适合的培养基中并在允许变体表达和/或分离的条件下在实验室或工业发酵罐中进行小规模或大规模发酵(包括连续发酵、分批发酵、分批给料发酵或固态发酵)来培养细胞。使用本领域中已知的程序,培养发生在包含碳和氮来源及无机盐的适合的营养培养基中。适合的培养基可从商业供应商获得或可以根据公开的组成(例如,在美国典型培养物保藏中心(american type culture collection)的目录中)制备。如果变体被分泌到营养培养基中,则变体可以直接从培养基回收。如果变体没有分泌,则它可以从细胞裂解液中回收。
[0602]
可以使用本领域已知的对变体特异的方法检测该变体。这些检测方法包括但不限于:特异性抗体的使用、酶产物的形成或酶底物的消失。例如,可以使用酶测定来确定变体的活性。
[0603]
可以使用本领域已知的方法回收变体。例如,可以通过多种常规程序从营养培养基中回收变体,这些常规程序包括但不限于收集、离心、过滤、提取、喷雾干燥、蒸发或沉淀。
[0604]
可以通过本领域中已知的多种程序来纯化变体以获得基本上纯的变体,这些程序包括但不限于色谱法(例如,离子交换色谱、亲和色谱、疏水作用色谱、色谱聚焦、以及尺寸排阻色谱)、电泳程序(例如,制备型等电点聚焦)、差别溶解度(例如,硫酸铵沉淀)、sds
‑
page或萃取(参见例如,protein purification[蛋白质纯化],janson和ryden编辑,vch publishers[纽约vch出版社],1989)。
[0605]
在可替代的方面,没有回收变体,而是将表达变体的本发明的宿主细胞用作变体的来源。
[0606]
洗涤剂组合物
[0607]
在一个实施例中,本发明涉及洗涤剂组合物,该洗涤剂组合物包含结合一种或多种另外的清洁组合物组分的本发明的酶。另外的组分的选择处于技术人员的能力范围内并且包括常规的成分,包括下文所阐述的示例性非限制性组分。
[0608]
对于纺织品护理,组分的选择可以包括以下考虑:待清洁的纺织品的类型、污垢的类型和/或程度、进行清洁时的温度以及洗涤剂产品的配制。尽管根据特定的功能性对以下提及的组分由通用标题进行分类,但是这并不被解释为限制,因为如将被普通技术人员所理解,组分可以包含另外的功能性。
[0609]
在一个实施例中,本发明涉及液体衣物洗涤剂组合物,该液体衣物洗涤剂组合物包含与一种或多种另外的衣物洗涤剂组合物组分(特别地,蛋白酶)组合的本发明的酶。在另一实施例中,本发明包含在衣物洗涤中使用的辅助产品,例如预去污剂或去污增强剂。本发明还涉及adw(自动餐具洗涤)组合物,该组合物包含与一种或多种另外的adw组合物组分组合的本发明的酶。另外的组分的选择处于技术人员的能力范围内并且包括常规的成分,包括下文所阐述的示例性非限制性组分。
[0610]
本发明的酶
[0611]
在本发明的一个实施例中,可以将本发明的多肽以对应以下的量添加至洗涤剂组合物中:每升的洗涤液0.001
‑
200mg的蛋白,例如0.005
‑
100mg的蛋白,优选0.01
‑
50mg的蛋白,更优选0.05
‑
20mg的蛋白,甚至更优选0.1
‑
10mg的蛋白。
[0612]
可以使用常规稳定剂稳定化本发明的洗涤剂组合物的一种或多种酶,这些常规稳定剂例如是多元醇,例如丙二醇或甘油、糖或糖醇、乳酸、硼酸或硼酸衍生物,例如芳香族硼酸酯,或苯基硼酸衍生物,例如4
‑
甲酰苯基硼酸,并且可以如在例如wo 92/19709和wo 92/19708中所描述配制该组合物。
[0613]
本发明的多肽还可以结合到wo 97/07202中所披露的洗涤剂配制品中,将其通过引用而特此并入。
[0614]
表面活性剂
[0615]
洗涤剂组合物可以包含一种或多种表面活性剂,它们可以是阴离子型和/或阳离子型和/或非离子型和/或半极性型和/或兼性离子型、或其混合物。在特定的实施例中,洗涤剂组合物包括一种或多种非离子表面活性剂和一种或多种阴离子表面活性剂的混合物。该一种或多种表面活性剂典型地以按重量计从约5%至60%(例如约5%至约50%、或约10%至约50%、或约20%至约50%)的水平存在。基于所希望的清洁应用来选择该一种或多种表面活性剂,并且该一种或多种表面活性剂可以包括本领域中已知的任何一种或多种常规表面活性剂。
[0616]
当被包括在其中时,洗涤剂将通常含有按重量计从约5%至约60%(如从约5%至约40%,包括从约10%至约25%)的一种或多种阴离子表面活性剂。阴离子型表面活性剂的非限制性实例包括硫酸盐和磺酸盐,具体地,直链烷基苯磺酸盐(las)、las的异构体、支链烷基苯磺酸盐(babs)、苯基链烷磺酸盐、α
‑
烯烃磺酸盐(aos)、烯烃磺酸盐、链烯烃磺酸盐、链烷
‑
2,3
‑
二基双(硫酸盐)、羟基链烷磺酸盐以及二磺酸盐、烷基硫酸盐(as)(如十二烷基硫酸钠(sds))、脂肪醇硫酸盐(fas)、伯醇硫酸盐(pas)、醇醚硫酸盐(aes或aeos或fes,也被称为醇乙氧基硫酸盐或脂肪醇醚硫酸盐)、仲链烷磺酸盐(sas)、石蜡磺酸盐(ps)、酯磺酸盐、磺化的脂肪酸甘油酯、α
‑
磺基脂肪酸甲酯(α
‑
sfme或ses)(包括甲酯磺酸盐(mes))、烷基
琥珀酸或烯基琥珀酸、十二烯基/十四烯基琥珀酸(dtsa)、氨基酸的脂肪酸衍生物、磺基琥珀酸的二酯和单酯或脂肪酸盐(皂)或脂肪酸、及其组合。
[0617]
当被包括在其中时,洗涤剂将通常含有按重量计从约0.1%至约10%(例如从约0.1%至约5%)的阳离子型表面活性剂。阳离子表面活性剂的非限制性实例包括烷基二甲基乙醇季胺(admeaq)、十六烷基三甲基溴化铵(ctab)、二甲基二硬脂酰氯化铵(dsdmac)、以及烷基苄基二甲基铵、烷基季铵化合物、烷氧基化季铵(aqa)化合物、酯季铵及其组合。
[0618]
当被包括在其中时,洗涤剂将通常含有按重量计从约0.2%至约60%(例如从约1%至约40%,特别是从约5%至约20%、从约3%至约15%)的非离子型表面活性剂。非离子型表面活性剂的非限制性实例包括醇乙氧基化物(ae或aeo)、醇丙氧基化物、丙氧基化的脂肪醇(pfa)、烷氧基化的脂肪酸烷基酯(例如乙氧基化的和/或丙氧基化的脂肪酸烷基酯)、烷基酚乙氧基化物(ape)、壬基酚乙氧基化物(npe)、烷基多糖苷(apg)、烷氧基化的胺、脂肪酸单乙醇酰胺(fam)、脂肪酸二乙醇酰胺(fada)、乙氧基化的脂肪酸单乙醇酰胺(efam)、丙氧基化的脂肪酸单乙醇酰胺(pfam)、多羟基烷基脂肪酸酰胺、或葡萄糖胺的n
‑
酰基n
‑
烷基衍生物(葡糖酰胺(ga)、或脂肪酸葡糖酰胺(faga))、甲酯乙氧基化物(mee)、连同在span和tween商品名下可获得的产品、及其组合。
[0619]
当被包括在其中时,该洗涤剂将通常含有按重量计从约0,1%至约10%的半极性表面活性剂。半极性表面活性剂的非限制性实例包括氧化胺(ao),如烷基二甲胺氧化物、n
‑
(椰油基烷基)
‑
n,n
‑
二甲胺氧化物和n
‑
(牛油
‑
烷基)
‑
n,n
‑
双(2
‑
羟乙基)胺氧化物以及其组合。
[0620]
当包括在其中时,该洗涤剂通常将含有按重量计从约0,1%至约10%的兼性离子表面活性剂。兼性离子表面活性剂的非限制性实例包括甜菜碱,如烷基二甲基甜菜碱、磺基甜菜碱、及其组合。
[0621]
溶剂系统:为了溶解表面活性剂和其他洗涤剂成分,需要一个溶剂系统。溶剂典型地是水、醇、多元醇、糖和/或其混合物。优选的溶剂是水、甘油、山梨醇、丙二醇(mpg、1,2
‑
丙二醇或1,3
‑
丙二醇)、二丙二醇(dpg)、聚乙二醇家族(peg300
‑
600)、己二醇、肌醇、甘露醇、乙醇、异丙醇、正丁氧基丙氧丙醇、乙醇胺(单乙醇胺、二乙醇胺和三乙醇胺)、蔗糖、右旋糖、葡萄糖、核糖、木糖以及相关的单和二吡喃糖苷和呋喃糖苷。
[0622]
溶剂系统典型地按重量计以总计5%
‑
90%、5%
‑
60%、5%
‑
40%、10%
‑
30%存在。
[0623]
包在pva膜中的单位剂量的含水量典型地在1%
‑
15%、2%
‑
12%、3%
‑
10%、5%
‑
10%的范围内。
[0624]
包在pva膜中的单位剂量的多元醇含量典型地在5%
‑
50%、10%
‑
40%、或20%
‑
30%的范围内。
[0625]
在实施例中,表面活性剂是非天然存在的表面活性剂。
[0626]
水溶助剂
[0627]
水溶助剂是如下化合物,该化合物在水溶液中溶解疏水化合物(或相反地,在非极性环境中溶解极性物质)。典型地,水溶助剂同时具有亲水的和疏水的特征(如从表面活性剂已知的所谓两亲特性),然而水溶助剂的分子结构一般并不有利于自发自聚集,参见例如hodgdon和kaler(2007),current opinion in colloid&interface science[胶体及界面科学新见]12:121
‑
128的综述。水溶助剂并不表现在形成胶束、薄层或其他明确界定的中间
相(meso
‑
phase)的表面活性剂和脂质中所见的临界浓度(高于此浓度则发生自聚集)。相反,许多水溶助剂示出了连续类型的聚集过程,在该过程中聚集物的大小随着浓度增加而增长。然而,许多水溶助剂改变了含有极性和非极性特征的物质的系统(包括水、油、表面活性剂、和聚合物的混合物)的相行为、稳定性、和胶体特性。水溶助剂常规地在从药学、个人护理、食品到技术应用的各个产业中应用。水溶助剂在洗涤剂组合物中的使用允许例如更浓的表面活性剂配制品(如在通过去除水而压缩液体洗涤剂的过程中)而不引起不希望的现象,如相分离或高粘度。
[0628]
洗涤剂可以含有按重量计0
‑
10%,例如按重量计0
‑
5%,例如约0.5%至约5%、或约3%至约5%的水溶助剂。可以利用本领域中已知的用于在洗涤剂中使用的任何水溶助剂。水溶助剂的非限制性实例包括苯磺酸钠、对甲苯磺酸钠(sts)、二甲苯磺酸钠(sxs)、枯烯磺酸钠(scs)、伞花烃磺酸钠、氧化胺、醇和聚乙二醇醚、羟基萘甲酸钠、羟基萘磺酸钠、乙基己基磺酸钠、及其组合。
[0629]
助洗剂和共助洗剂
[0630]
洗涤剂组合物可以含有约0
‑
65%、0
‑
20%、或0.5%
‑
5%的洗涤剂助洗剂或共助洗剂、或其混合物。在餐具洗涤剂中,助洗剂的水平典型地是10%
‑
65%、特别是20%
‑
40%。助洗剂和/或共助洗剂可以特别是与ca和mg形成水溶性复合物的螯合试剂。可以利用本领域中已知的用于在衣物洗涤剂中使用的任何助洗剂和/或共助洗剂。非限制性实例是柠檬酸盐、碳酸钠、碳酸氢钠、和柠檬酸钠。磷酸盐的实例包括1
‑
羟基亚乙基
‑
1,1
‑
二磷酸(hedp,依替磷酸)、二亚乙基三胺五(亚甲基磷酸)(dtpmp)、乙二胺四(亚甲基磷酸)(edtmpa)、氨基三(亚甲基磷酸)(atmp)、次氮基三亚甲基磷酸(ntmp)、2
‑
氨乙基磷酸(aepn)、二甲基甲基磷酸酯(dmpp)、四亚甲基二胺四(亚甲基磷酸)(tdtmp)、六亚甲基二胺四(亚甲基磷酸)(hdtmp)、磷酸丁烷
‑
三羧酸(pbtc)、n
‑
(磷酰甲基)亚氨基二乙酸(pmida)、2
‑
羧乙基磷酸(cepa)、2
‑
羟基磷酰羧酸(hpaa)、和氨基
‑
三
‑
(亚甲基
‑
磷酸)(amp)。l
‑
谷氨酸n,n
‑
二乙酸四钠盐(glda).、甲基甘氨酸二乙酸(mgda)。助洗剂的非限制性实例包括聚丙烯酸酯的均聚物或其共聚物,例如聚(丙烯酸)(paa)或共聚(丙烯酸/马来酸)(paa/pma)。进一步的非限制性实例包括柠檬酸盐、螯合剂(诸如氨基羧酸盐、氨基聚羧酸盐、和膦酸盐)、以及烷基琥珀酸、或烯基琥珀酸。另外的具体实例包括2,2’,2
”‑
次氨基三乙酸(nta)、乙二胺四乙酸(edta)、二亚乙基三胺五乙酸(dtpa)、亚氨基二丁二酸(ids)、乙二胺
‑
n,n
’‑
二丁二酸(edds)、甲基甘氨酸二乙酸(mgda)、谷氨酸
‑
n,n
‑
二乙酸(glda)、1
‑
羟基乙烷
‑
1,1
‑
二膦酸(hedp)、乙二胺四(亚甲基膦酸)(edtmpa)、二亚乙基三胺五(亚甲基膦酸)(dtmpa或dtpmpa)、n
‑
(2
‑
羟乙基)亚氨基二乙酸(edg)、天冬氨酸
‑
n
‑
单乙酸(asma)、天冬氨酸
‑
n,n
‑
二乙酸(asda)、天冬氨酸
‑
n
‑
单丙酸(asmp)、亚氨基二丁二酸(iminodisuccinic acid)(ida)、n
‑
(2
‑
磺甲基)
‑
天冬氨酸(smas)、n
‑
(2
‑
磺乙基)
‑
天冬氨酸(seas)、n
‑
(2
‑
磺甲基)
‑
谷氨酸(smgl)、n
‑
(2
‑
磺乙基)
‑
谷氨酸(segl)、n
‑
甲基亚氨基二乙酸(mida)、α
‑
丙氨酸
‑
n,n
‑
二乙酸(α
‑
alda)、丝氨酸
‑
n,n
‑
二乙酸(seda)、异丝氨酸
‑
n,n
‑
二乙酸(isda)、苯丙氨酸
‑
n,n
‑
二乙酸(phda)、邻氨基苯甲酸
‑
n,n
‑
二乙酸(anda)、磺胺酸
‑
n,n
‑
二乙酸(slda)、牛磺酸
‑
n,n
‑
二乙酸(tuda)以及磺甲基
‑
n,n
‑
二乙酸(smda)、n
‑
(2
‑
羟乙基)
‑
亚乙基二胺
‑
n,n’,n
”‑
三乙酸盐(hedta)、二乙醇甘氨酸(deg)、二亚乙基三胺五(亚甲基膦酸)(dtpmp)、氨基三(亚甲基膦酸)(atmp)及其组合和盐。另外的示例性助洗剂和/或共助洗剂描述于例如wo 09/102854、us 5977053中
[0631]
在实施例中,助洗剂或共助洗剂是非天然存在的助洗剂或共助洗剂。
[0632]
漂白系统
[0633]
洗涤剂可以含有按重量计0
‑
30%,如约1%至约20%的漂白系统。可以利用本领域中已知的用于在衣物洗涤剂中使用的任何漂白系统。合适的漂白系统组分包括漂白催化剂、光漂白剂、漂白活化剂、过氧化氢源如过碳酸钠、过硼酸钠和过氧化氢―脲(1:1)、预成型过酸及其混合物。合适的预成型过酸包括但不限于过氧羧酸及盐、二过氧二羧酸、过亚氨酸(perimidic acid)及盐、过氧单硫酸及盐(例如过硫酸氢钾(oxone(r))及其混合物。漂白系统的非限制性实例包括与过酸形成漂白活化剂组合的基于过氧化物的漂白系统,其可以包含例如无机盐,包括碱金属盐诸如过硼酸盐的钠盐(通常为单水合物或四水合物)、过碳酸盐、过硫酸盐、过磷酸盐、过硅酸盐。术语漂白活化剂本文意指与过氧化氢反应以经由过水解反应形成过酸的化合物。由此形成的过酸构成活化的漂白剂。本文待使用的适合的漂白活化剂包括属于酯、酰胺、酰亚胺或酸酐类别的那些。适合的实例是四乙酰乙二胺(taed)、4
‑
[(3,5,5
‑
三甲基己酰基)氧基]苯
‑1‑
磺酸钠(isonobs)、4
‑
(十二酰基氧基)苯
‑1‑
磺酸盐(lobs)、4
‑
(癸酰基氧基)苯
‑1‑
磺酸盐、4
‑
(癸酰基氧基)苯甲酸盐(dobs或doba)、4
‑
(壬酰氧基)苯
‑1‑
磺酸盐(nobs)和/或披露于wo98/17767中的那些。感兴趣的漂白活化剂的具体家族披露于ep 624154中并且该家族中特别优选的是乙酰柠檬酸三乙酯(atc)。atc或短链甘油三酸酯(像三醋汀)具有以下优点,它是环境友好的。此外,乙酰柠檬酸三乙酯和三醋汀在储存时在产品中具有良好的水解稳定性,并且是有效的漂白活化剂。最后,atc是多功能的,因为在过水解反应中释放的柠檬酸盐可以作为助洗剂起作用。可替代地,漂白系统可以包含例如酰胺、酰亚胺、或砜类型的过氧酸。漂白系统还可以包含诸如6
‑
(苯二甲酰亚氨基)过己酸(pap)的过酸。漂白系统还可以包括漂白催化剂。在一些实施例中,漂白组分可以是选自下组的有机催化剂,该组由以下组成:具有下式的有机催化剂:
[0634][0635]
(iii)及其混合物,
[0636]
其中每个r1独立地是含有从9至24个碳的支链烷基基团或含有从11至24个碳的直链烷基基团,优选地每个r1独立地是含有从9至18个碳的支链烷基基团或含有从11至18个碳的直链烷基基团,更优选地每个r1独立地选自下组,该组由以下组成:2
‑
丙基庚基、2
‑
丁基辛基、2
‑
戊基壬基、2
‑
己基癸基、十二烷基、十四烷基、十六烷基、十八烷基、异壬基、异癸基、异十三烷基以及异十五烷基。其他示例性漂白系统描述于例如wo 2007/087258、wo 2007/087244、wo 2007/087259、ep 1867708(维生素k)以及wo 2007/087242中。合适的光漂白剂可以例如是磺化的酞菁锌或酞菁铝。
[0637]
优选地,除了漂白催化剂,特别是有机漂白催化剂以外,漂白组分还包含过酸源。过酸源可以选自(a)预形成的过酸;(b)过碳酸盐、过硼酸盐或过硫酸盐(过氧化氢源),优选与漂白活化剂组合;和(c)过水解酶以及酯,用于在纺织品或硬表面处理步骤中在水的存在
下原位形成过酸。
[0638]
在实施例中,漂白系统是非天然存在的漂白系统。
[0639]
聚合物
[0640]
洗涤剂可以含有按重量计0
‑
10%(诸如0.5%
‑
5%、2%
‑
5%、0.5%
‑
2%、或0.2%
‑
1%)的聚合物。可以利用本领域中已知的用于在洗涤剂中使用的任何聚合物。该聚合物可以作为如上文提到的共助洗剂起作用,或可以提供抗再沉积、纤维保护、污垢释放、染料转移抑制、油脂清洁、和/或消泡特性。一些聚合物可以具有多于一种的上文提到的特性和/或多于一种的下文提到的基序。示例性聚合物包括(羧甲基)纤维素(cmc)、聚(乙烯醇)(pva)、聚(乙烯吡咯烷酮)(pvp)、聚(乙二醇)或聚(环氧乙烷)(peg)、乙氧基化的聚(亚乙基亚胺)、羧甲基菊粉(cmi)、和聚羧酸酯(如paa、paa/pma、聚
‑
天冬氨酸、和甲基丙烯酸月桂酯/丙烯酸共聚物)、疏水修饰的cmc(hm
‑
cmc)和硅酮、对苯二甲酸和低聚乙二醇的共聚物、聚(对苯二甲酸乙二酯)和聚(氧乙烯对苯二甲酸酯)的共聚物(pet
‑
poet)、pvp、聚(乙烯基咪唑)(pvi)、聚(乙烯吡啶
‑
n
‑
氧化物)(pvpo或pvpno)以及聚乙烯吡咯烷酮
‑
乙烯基咪唑(pvpvi)。进一步的示例性聚合物包括磺化的聚羧酸酯、聚环氧乙烷和聚环氧丙烷(peo
‑
ppo)、以及乙氧基硫酸二季铵盐。其他示例性聚合物披露于例如wo 2006/130575中。还考虑了上文提到的聚合物的盐。
[0641]
在实施例中,聚合物是非天然存在的聚合物。
[0642]
织物调色剂
[0643]
本发明的洗涤剂组合物还可以包括织物调色剂,如染料或颜料,当配制在洗涤剂组合物中时,当所述织物与洗涤液接触时织物调色剂可以沉积在织物上,该洗涤液包含所述洗涤剂组合物,并且因此通过可见光的吸收/反射改变所述织物的色彩。荧光增白剂发射至少一些可见光。相反,当织物调色剂吸收至少部分可见光谱时,它们改变表面的色彩。适合的织物调色剂包括染料和染料
‑
粘土轭合物,并且还可以包括颜料。适合的染料包括小分子染料和聚合物染料。合适的小分子染料包括选自下组的小分子染料,该组由落入颜色索引(colour index,c.i.)分类的以下染料组成:直接蓝、直接红、直接紫、酸性蓝、酸性红、酸性紫、碱性蓝、碱性紫和碱性红、或其混合物,例如于wo 2005/03274、wo 2005/03275、wo 2005/03276和ep 1876226中所描述的(将其通过引用并入本文)。洗涤剂组合物优选地包含从约0.00003wt%至约0.2wt%、从约0.00008wt%至约0.05wt%、或甚至从约0.0001wt%至约0.04wt%的织物调色剂。该组合物可以包含从0.0001wt%至0.2wt%的织物调色剂,当该组合物处于单位剂量袋的形式时,这可以是尤其优选的。合适的调色剂还披露于例如wo 2007/087257和wo 2007/087243中。
[0644]
另外的酶
[0645]
洗涤剂添加剂连同洗涤剂组合物可包含一种或多种[另外的]酶,例如水解酶(ec 3.
‑
.
‑
.
‑
),例如作用在酯键上的水解酶(ec 3.1.
‑
.
‑
),糖苷酶(ec 3.2.
‑
.
‑
),和作用在肽键上的水解酶(ec 3.4.
‑
.
‑
),氧化还原酶(ec 1.
‑
.
‑
.
‑
),例如漆酶(ec 1.10.
‑
.
‑
)或过氧化物酶(ec 1.11.
‑
.
‑
),或裂解酶(ec 4.
‑
.
‑
.
‑
),例如碳
‑
氧裂解酶(ec 4.2.
‑
.
‑
)。在特定实施例中,该洗涤剂组合物可包含一种或多种[另外的]酶,例如蛋白酶、脂肪酶、角质酶、淀粉酶、糖酶、纤维素酶、果胶酶、甘露聚糖酶、阿拉伯糖酶、半乳聚糖酶、木聚糖酶、氧化酶(例如漆酶)、和/或过氧化物酶。
[0646]
通常,选择的一种或多种酶的特性应当与所选择的洗涤剂相容(即,最适ph,与其他酶成分或非酶成分的相容性等),并且该一种或多种酶应当以有效量存在。
[0647]
纤维素酶
[0648]
合适的纤维素酶包括细菌或真菌来源的那些。包括化学修饰的突变体或蛋白质工程化的突变体。合适的纤维素酶包括来自芽孢杆菌属、假单胞菌属、腐质霉属、镰孢属、梭孢壳属、枝顶孢属的纤维素酶,例如披露于us 4,435,307、us 5,648,263、us 5,691,178、us 5,776,757以及wo 89/09259中的由特异腐质霉、嗜热毁丝霉和尖孢镰孢产生的真菌纤维素酶。
[0649]
尤其合适的纤维素酶是碱性纤维素酶或中性纤维素酶,这些纤维素酶提供或维持白度并预防再沉积或具有颜色护理益处。此类纤维素酶的实例是描述于ep 0 495 257、ep 0 531 372、wo 96/11262、wo 96/29397、wo 98/08940中的纤维素酶。其他实例诸如描述于wo 94/07998、ep 0 531 315、us 5,457,046、us 5,686,593、us 5,763,254、wo 95/24471、wo 98/12307以及wo 99/001544中的那些纤维素酶变体。
[0650]
其他纤维素酶是具有以下序列的内切
‑
β
‑
1,4
‑
葡聚糖酶,该序列与wo 2002/099091的seq id no:2的位置1至位置773的氨基酸序列具有至少97%的同一性,或具有以下序列的家族44木葡聚糖酶,该序列与wo 2001/062903的seq id no:2的位置40
‑
559具有至少60%的同一性。
[0651]
可商购的纤维素酶包括celluzyme
tm
和carezyme
tm
(诺维信公司)、carezyme premium
tm
(诺维信公司)、celluclean
tm
(诺维信公司)、celluclean classic
tm
(诺维信公司)、cellusoft
tm
(诺维信公司)、whitezyme
tm
(诺维信公司)、clazinase
tm
和puradax ha
tm
(杰能科国际有限公司(genencor international inc.))以及kac
‑
500(b)
tm
(花王株式会社(kao corporation))。
[0652]
甘露聚糖酶
[0653]
适合的甘露聚糖酶包括细菌或真菌来源的那些。包括化学或遗传修饰的突变体。甘露聚糖酶可以是家族5或26的碱性甘露聚糖酶。它可以是来自芽孢杆菌属或腐质霉属的野生型,特别是来自粘琼脂芽孢杆菌(b.agaradhaerens)、地衣芽孢杆菌(b.licheniformis)、嗜碱芽孢杆菌(b.halodurans)、克劳氏芽孢杆菌(b.clausii)、或特异腐质霉。适合的甘露聚糖酶描述于wo 1999/064619中。可商购的甘露聚糖酶是mannaway(诺维信公司)。
[0654]
蛋白酶
[0655]
合适的蛋白酶包括细菌、真菌、植物、病毒或动物来源的那些,例如植物或微生物来源。优选微生物来源。包括化学修饰的突变体或蛋白质工程化的突变体。它可以是碱性蛋白酶,如丝氨酸蛋白酶或金属蛋白酶。丝氨酸蛋白酶可以例如是s1家族(诸如胰蛋白酶)或s8家族(诸如枯草杆菌蛋白酶)的丝氨酸蛋白酶。金属蛋白酶可以例如是来自例如m4家族的嗜热菌蛋白酶或其他金属蛋白酶,如来自m5、m7或m8家族的那些。
[0656]
术语“枯草杆菌酶”是指根据siezen等人,protein eng.[蛋白质工程]4(1991)719
‑
737和siezen等人protein science[蛋白质科学]6(1997)501
‑
523的丝氨酸蛋白酶亚组。丝氨酸蛋白酶是特征为在活性位点具有与底物形成共价加合物的丝氨酸的蛋白酶的亚组。枯草杆菌酶可以被划分为6个亚类,即,枯草杆菌蛋白酶家族、嗜热蛋白酶家族、蛋白酶k
家族、羊毛硫氨酸抗生素肽酶家族、kexin家族和pyrolysin家族。
[0657]
枯草杆菌酶的实例是来源于芽孢杆菌属的那些,例如,us 7262042和wo 09/021867中所述的迟缓芽孢杆菌、嗜碱芽孢杆菌、枯草芽孢杆菌、解淀粉芽孢杆菌、短小芽孢杆菌和吉氏芽孢杆菌;和描述于wo 89/06279中的枯草杆菌蛋白酶lentus、枯草杆菌蛋白酶novo、枯草杆菌蛋白酶carlsberg、地衣芽孢杆菌、枯草杆菌蛋白酶bpn’、枯草杆菌蛋白酶309、枯草杆菌蛋白酶147和枯草杆菌蛋白酶168以及描述于(wo 93/18140)中的蛋白酶pd138。其他有用的蛋白酶可以是描述于wo 92/175177、wo 01/016285、wo 02/026024和wo 02/016547中的那些。胰蛋白酶样蛋白酶的实例是胰蛋白酶(例如猪或牛来源的)和镰孢菌蛋白酶(描述于wo 89/06270、wo 94/25583和wo 05/040372中),以及衍生自纤维单胞菌(cellumonas)的胰凝乳蛋白酶(描述于wo 05/052161和wo 05/052146中)。
[0658]
另外优选的蛋白酶是来自迟缓芽孢杆菌dsm 5483的碱性蛋白酶(如描述于例如wo 95/23221中)及其变体(描述于wo 92/21760、wo 95/23221、ep 1921147以及ep 1921148中)。
[0659]
金属蛋白酶的实例是如wo 07/044993(杰能科国际公司(genencor int.))中所描述的中性金属蛋白酶,例如来源于解淀粉芽孢杆菌的那些。
[0660]
有用的蛋白酶的实例是描述于以下中的变体:wo 92/19729、wo 96/034946、wo 98/20115、wo 98/20116、wo 99/011768、wo 01/44452、wo 03/006602、wo 04/03186、wo 04/041979、wo 07/006305、wo 11/036263、wo 11/036264,尤其是在以下位置中的一个或多个处具有取代的变体:3、4、9、15、27、36、57、68、76、87、95、96、97、98、99、100、101、102、103、104、106、118、120、123、128、129、130、160、167、170、194、195、199、205、206、217、218、222、224、232、235、236、245、248、252和274,使用bpn’进行编号。更优选地,枯草杆菌酶变体可以包含以下突变:s3t、v4i、s9r、a15t、k27r、*36d、v68a、n76d、n87s,r、*97e、a98s、s99g,d,a、s99ad、s101g,m,r s103a、v104i,y,n、s106a、g118v,r、h120d,n、n123s、s128l、p129q、s130a、g160d、y167a、r170s、a194p、g195e、v199m、v205i、l217d、n218d、m222s、a232v、k235l、q236h、q245r、n252k、t274a(使用bpn’进行编号)。
[0661]
适合的可商购蛋白酶包括以下列商品名出售的那些:适合的可商购蛋白酶包括以下列商品名出售的那些:duralase
tm
、durazym
tm
、ultra、ultra、ultra、ultra、ultra、ultra、progress 和progress(诺维信公司),以下列商品名出售的那些:purafectpreferenz
tm
、purafect purafect purafect
ꢀꢀ
effectenz
tm
、和(丹尼斯克/杜邦公司(danisco/dupont))、axapem
tm
(吉斯特布罗卡德斯公司(gist
‑
brocases n.v.))、blap(序列示于us 5352604的图29中)及其变体(汉高股份(henkel ag))以及来自花王株式会社(kao)的kap(嗜碱芽孢杆菌枯草杆菌蛋白酶)。
[0662]
脂肪酶和角质酶:
[0663]
适合的脂肪酶和角质酶包括细菌或真菌来源的那些。包括化学修饰的突变体酶或蛋白质工程化的突变体酶。实例包括来自嗜热真菌属的脂肪酶,例如,如描述于ep 258068和ep 305216中的来自疏绵状嗜热丝孢菌(早先命名为疏棉状腐质霉);来自腐质霉属的角质酶,例如特异腐质霉(wo 96/13580);来自假单胞菌属的菌株的脂肪酶(这些中的一些现在改名为伯克霍尔德菌属),例如产碱假单胞菌或类产碱假单胞菌(ep 218272)、洋葱假单胞菌(ep 331376)、假单胞菌属菌株sd705(wo 95/06720和wo 96/27002)、威斯康星假单胞菌(p.wisconsinensis)(wo 96/12012);gdsl
‑
型链霉菌属脂肪酶(wo 10/065455);来自稻瘟病菌的角质酶(wo 10/107560);来自门多萨假单胞菌的角质酶(us 5,389,536);来自褐色嗜热裂孢菌(thermobifida fusca)的脂肪酶(wo 11/084412);嗜热脂肪土芽孢杆菌脂肪酶(wo 11/084417);来自枯草芽孢杆菌的脂肪酶(wo 11/084599);以及来自灰色链霉菌(wo 11/150157)和始旋链霉菌(s.pristinaespiralis)的脂肪酶(wo 12/137147)。
[0664]
其他实例是脂肪酶变体,诸如ep 407225、wo 92/05249、wo 94/01541、wo 94/25578、wo 95/14783、wo 95/30744、wo 95/35381、wo 95/22615、wo 96/00292、wo 97/04079、wo 97/07202、wo 00/34450、wo 00/60063、wo 01/92502、wo 07/87508以及wo 09/109500中所述的那些。
[0665]
优选的商业化脂肪酶产品包括lipolase
tm
、lipex
tm
;lipolex
tm
和lipoclean
tm
(诺维信公司(novozymes a/s))、lumafast(来自杰能科公司(genencor))、以及lipomax(来自吉斯特布罗卡德斯公司(gist
‑
brocades))。
[0666]
仍其他实例是有时称为酰基转移酶或过水解酶的脂肪酶,例如与南极假丝酵母(candida antarctica)脂肪酶a具有同源性的酰基转移酶(wo 10/111143)、来自耻垢分枝杆菌(mycobacterium smegmatis)的酰基转移酶(wo 05/56782)、来自ce 7家族的过水解酶(wo 09/67279)以及耻垢分枝杆菌过水解酶的变体(特别是来自亨斯迈纺织品染化有限公司(huntsman textile effects pte ltd)的商业产品gentle power bleach中所用的s54v变体)(wo 10/100028)。
[0667]
淀粉酶:
[0668]
可以与本发明的变体一起使用的适合的淀粉酶可以是α
‑
淀粉酶或葡糖淀粉酶并且可以具有细菌或真菌起源。包括化学修饰的突变体或蛋白质工程化的突变体。淀粉酶包括例如从芽孢杆菌属、例如地衣芽孢杆菌的特定菌株(更详细地描述于gb 1,296,839中)获得的α
‑
淀粉酶。
[0669]
适合的淀粉酶包括具有wo 95/10603中的seq id no:2的淀粉酶或与seq id no:3具有90%序列同一性的其变体。优选的变体描述于wo 94/02597、wo 94/18314、wo 97/43424中以及wo 99/019467的seq id no4中,如在以下位置的一个或多个处具有取代的变体:15、23、105、106、124、128、133、154、156、178、179、181、188、190、197、201、202、207、208、209、211、243、264、304、305、391、408和444。
[0670]
不同的适合的淀粉酶包括具有wo 02/010355中的seq id no:6的淀粉酶或与seq id no:6具有90%序列同一性的其变体。seq id no:6的优选的变体是在位置181和182中具有缺失并且在位置193中具有取代的那些。
[0671]
其他合适的淀粉酶是包含示于wo 2006/066594的seq id no:6中的来源于解淀粉芽孢杆菌的α
‑
淀粉酶的残基1
‑
33和示于wo 2006/066594的seq id no:4中的地衣芽孢杆菌
α
‑
淀粉酶的残基36
‑
483的杂合α
‑
淀粉酶或其具有90%序列同一性的变体。此杂合α
‑
淀粉酶的优选的变体是在以下位置的一个或多个位置中具有取代、缺失、或插入的那些:g48、t49、g107、h156、a181、n190、m197、i201、a209、和q264。包含示于wo 2006/066594的seq id no:6中的源自解淀粉芽孢杆菌的α
‑
淀粉酶的残基1
‑
33和seq id no:4的残基36
‑
483的杂合α
‑
淀粉酶的最优选的变体是具有以下取代的那些:
[0672]
m197t;
[0673]
h156y a181t n190f a209v q264s;或
[0674]
g48a t49i g107a h156y a181t n190f i201f a209v q264s。
[0675]
另外的合适的淀粉酶是具有wo 99/019467中的seq id no:6的淀粉酶或其与seq id no:6具有90%序列同一性的变体。seq id no:6的优选的变体是在以下位置中的一个或多个位置中具有取代、缺失、或插入的那些:r181、g182、h183、g184、n195、i206、e212、e216和k269。特别优选的淀粉酶是在位置r181和g182、或位置h183和g184中具有缺失的那些。
[0676]
可以使用的另外的淀粉酶是具有wo 96/023873的seq id no:1、seq id no:3、seq id no:2或seq id no:7的那些或其与seq id no:1、seq id no:2、seq id no:3或seq id no:7具有90%序列同一性的变体。seq id no:1、seq id no:2、seq id no:3、或seq id no:7的优选的变体是在以下位置中的一个或多个位置处具有取代、缺失、或插入的那些:140、181、182、183、184、195、206、212、243、260、269、304、和476(使用wo 96/023873的seq id 2进行编号)。更优选的变体是在选自181、182、183、和184的两个位置(诸如181和182、182和183、或位置183和184)中具有缺失的那些。seq id no:1、seq id no:2、或seq id no:7的最优选的淀粉酶变体是在位置183和184中具有缺失并且在位置140、195、206、243、260、304、和476中的一个或多个位置中具有取代的那些。
[0677]
可以使用的其他淀粉酶是具有wo 08/153815的seq id no:2、wo 01/66712中的seq id no:10的淀粉酶,或与wo 08/153815的seq id no:2具有90%序列同一性的其变体,或与wo 01/66712中的seq id no:10具有90%序列同一性的其变体。wo 01/66712中的seq id no:10的优选的变体是在以下位置的一个或多个位置中具有取代、缺失、或插入的那些:176、177、178、179、190、201、207、211、和264。
[0678]
进一步适合的淀粉酶是具有wo 09/061380的seq id no:2的淀粉酶或与seq id no:2具有90%序列同一性的其变体。seq id no:2的优选的变体是在以下位置中的一个或多个位置中具有c
‑
末端截短、和/或取代、缺失、或插入的那些:q87、q98、s125、n128、t131、t165、k178、r180、s181、t182、g183、m201、f202、n225、s243、n272、n282、y305、r309、d319、q320、q359、k444、和g475。seq id no:2的更优选的变体是在以下位置中的一个或多个位置中具有取代的那些:q87e,r、q98r、s125a、n128c、t131i、t165i、k178l、t182g、m201l、f202y、n225e,r、n272e,r、s243q,a,e,d、y305r、r309a、q320r、q359e、k444e、以及g475k,和/或在位置r180和/或s181或t182和/或g183中具有缺失的那些。seq id no:2的最优选的淀粉酶变体是具有以下取代的那些:
[0679]
n128c k178l t182g y305r g475k;
[0680]
n128c k178l t182g f202y y305r d319t g475k;
[0681]
s125a n128c k178l t182g y305r g475k;或
[0682]
s125a n128c t131i t165i k178l t182g y305r g475k,其中这些变体是c
‑
末端
截短的,并且任选地进一步包含在位置243处的取代和/或在位置180和/或位置181处的缺失。
[0683]
其他合适的淀粉酶是具有wo 01/66712中的seq id no:12的α
‑
淀粉酶或与seq id no:12具有至少90%序列同一性的变体。优选的淀粉酶变体是在wo 01/66712中的seq id no:12的以下位置的一个或多个中具有取代、缺失或插入的那些:r28、r118、n174;r181、g182、d183、g184、g186、w189、n195、m202、y298、n299、k302、s303、n306、r310、n314;r320、h324、e345、y396、r400、w439、r444、n445、k446、q449、r458、n471、n484。特别优选的淀粉酶包括具有d183和g184的缺失并且具有取代r118k、n195f、r320k和r458k的变体,以及另外在一个或多个选自下组的位置处具有取代的变体:m9、g149、g182、g186、m202、t257、y295、n299、m323、e345、和a339,最优选的是另外地在所有这些位置中具有取代的变体。
[0684]
其他实例是淀粉酶变体,如在wo 2011/098531、wo 2013/001078和wo 2013/001087中描述的那些。
[0685]
可商购的淀粉酶是duramyl
tm
、termamyl
tm
、fungamyl
tm
、stainzyme
tm
、stainzyme plus
tm
、natalase
tm
和ban
tm
(来自诺维信公司(novozymes a/s))、以及rapidase
tm
、purastar
tm
/effectenz
tm
、powerase
tm
、preferenz s1000
tm preferenz s110
tm
和preferenz s100
tm
(来自杰能科国际有限公司/杜邦公司(genencor international inc./dupont))。
[0686]
过氧化物酶/氧化酶:
[0687]
过氧化物酶是由国际生物化学与分子生物学联合会(iubmb)命名委员会(nomenclature committee of the international union of biochemistry and molecular biology)所述的酶分类ec 1.11.1.7所包含的过氧化物酶,或源自其中的展示出过氧化物酶活性的任何片段。
[0688]
合适的过氧化物酶包括植物、细菌或真菌来源的那些。包括化学修饰的突变体或蛋白质工程化的突变体。有用的过氧化物酶的实例包括来自拟鬼伞属,例如来自灰盖拟鬼伞(c.cinerea)的过氧化物酶(ep 179,486),及其变体,如在wo 93/24618、wo 95/10602以及wo 98/15257中所描述的那些。
[0689]
过氧化物酶还可以包括卤代过氧化物酶,如氯过氧化物酶、溴过氧化物酶以及表现出氯过氧化物酶或溴过氧化物酶活性的化合物。根据其对卤素离子的特异性将卤代过氧化物酶进行分类。氯过氧化物酶(e.c.1.11.1.10)催化从氯离子形成次氯酸盐。
[0690]
在实施例中,卤代过氧化物酶是氯过氧化物酶。优选地,卤代过氧化物酶是钒卤代过氧化物酶,即含钒酸盐的卤代过氧化物酶。在本发明的优选的方法中,将含钒酸盐的卤代过氧化物酶与氯离子来源组合。
[0691]
已从许多不同真菌,特别是从暗色丝孢菌(dematiaceous hyphomycete)真菌组中分离出了卤代过氧化物酶,如卡尔黑霉属(caldariomyces)(例如,煤卡尔黑霉(c.fumago))、链格孢属、弯孢属(例如,疣枝弯孢(c.verruculosa)和不等弯孢(c.inaequalis))、内脐蠕孢属、细基格孢属以及葡萄孢属。
[0692]
还已从细菌如假单胞菌属(例如吡咯假单胞菌(p.pyrrocinia))和链霉菌属(例如,金色链霉菌(s.aureofaciens))中分离出了卤代过氧化物酶。
[0693]
在优选的实施例中,卤代过氧化物酶可来源于弯孢属,特别是疣枝弯孢或不等弯孢,如描述于wo 95/27046中的不等弯孢cbs 102.42;或如描述于wo 97/04102中的疣枝弯
孢cbs 147.63或疣枝弯孢cbs 444.70;或来源于如描述于wo 01/79459中的drechslera hartlebii、如描述于wo 01/79458中的盐沼小树状霉(dendryphiella salina)、如描述于wo 01/79461中的phaeotrichoconis crotalarie、或如描述于wo 01/79460中的geniculosporium属物种。
[0694]
氧化酶特别地可包括由酶分类ec 1.10.3.2所包含的任何漆酶或源自其的展现出漆酶活性的任何片段、或展现出类似活性的化合物,如儿茶酚氧化酶(ec 1.10.3.1)、邻氨基苯酚氧化酶(ec 1.10.3.4)或胆红素氧化酶(ec 1.3.3.5)。
[0695]
优选的漆酶是微生物来源的酶。这些酶可以来源于植物、细菌或真菌(包括丝状真菌和酵母)。
[0696]
来自真菌的合适的实例包括可来源于以下的菌株的漆酶:曲霉属(aspergillus)、脉孢菌属(neurospora)(例如,粗糙脉孢菌(n.crassa))、柄孢壳菌属(podospora)、葡萄孢属、金钱菌属(collybia)、层孔菌属(fomes)、香菇属(lentinus)、侧耳属(pleurotus)、栓菌属(trametes)(例如,长绒毛栓菌(t.villosa)和变色栓菌(t.versicolor))、丝核菌属(rhizoctonia)(例如,立枯丝核菌(r.solani)),拟鬼伞属(例如,灰盖拟鬼伞、毛头拟鬼伞(c.comatus)、弗瑞氏拟鬼伞(c.friesii)及褶纹鬼伞(c.plicatilis))、小脆柄菇属(psathyrella)(例如,白黄小脆柄菇(p.condelleana))、斑褶菇属(panaeolus)(例如,蝶形斑褶菇(p.papilionaceus))、毁丝霉属(例如,嗜热毁丝霉)、柱顶孢霉属(schytalidium)(例如,嗜热柱顶孢霉(s.thermophilum))、多孔菌属(polyporus)(例如,匹斯特斯多孔菌(p.pinsitus))、射脉菌属(phlebia)(例如,射脉侧菌(p.radiata))(wo92/01046)或革盖菌属(coriolus)(例如,毛革盖菌(c.hirsutus))(jp2238885)。
[0697]
来自细菌的合适的实例包括可来源于芽孢杆菌属的菌株的漆酶。
[0698]
优选的是来源于拟鬼伞属或毁丝霉属的漆酶;特别是来源于灰盖拟鬼伞的漆酶,如披露于wo 97/08325中;或来源于嗜热毁丝霉,如披露于wo95/33836中。
[0699]
核酸酶
[0700]
合适的核酸酶包括脱氧核糖核酸酶(dna酶)和核糖核酸酶(rna酶),它们是分别催化dna或rna主链中磷酸二酯键的水解切割从而降解dna和rna的任何酶。根据活性的位点有两种主要的分类。外切核酸酶从末端消化核酸。内切核酸酶作用于靶分子中间的区域。核酸酶优选为dna酶,其优选可得自微生物,优选真菌或细菌。特别地,可获自芽孢杆菌属的物种的dna酶是优选的;特别地,可获自食物芽孢杆菌(bacillus cibi)、枯草芽孢杆菌或地衣芽孢杆菌的dna酶是优选的。这些dna酶的实例在wo 2011/098579、wo 2014/087011和wo 2017/060475中描述。还特别优选的是可获自曲霉属(aspergillus)物种的dna酶;特别是可获自米曲霉(aspergillus oryzae)的dna酶,如wo 2015/155350中所述的dna酶。
[0701]
地衣多糖酶
[0702]
合适的地衣多糖酶(地衣聚糖酶)包括催化β
‑
1,4
‑
糖苷键的水解以产生β
‑
葡聚糖的酶。地衣多糖酶(或地衣多糖酶)(例如ec 3.2.1.73)水解含有(1,3)
‑
和(1,4)
‑
键的β
‑
d
‑
葡聚糖中的(1,4)
‑
β
‑
d
‑
糖苷键并且可以作用于地衣淀粉和谷类β
‑
d
‑
葡聚糖,但不作用于仅含有1,3
‑
键或1,4
‑
键的β
‑
d
‑
葡聚糖。此类地衣多糖酶的实例描述于专利申请wo 2017/097866和wo 2017/129754中。
[0703]
可以通过添加含有一种或多种酶的单独添加剂、或通过添加含有所有这些酶的组
合添加剂而将一种或多种洗涤剂酶包含于洗涤剂组合物中。本发明的洗涤剂添加剂,即单独的或组合的添加剂,可以配制成例如颗粒、液体、浆液等。优选的洗涤剂添加剂配制品是颗粒,特别是无粉尘颗粒;液体,特别是稳定化液体;或浆液。
[0704]
无粉尘颗粒例如可以如在us 4,106,991和4,661,452中所披露地产生并且可以任选地通过本领域已知的方法包衣。蜡状包衣材料的实例是平均分子量为1000至20000的聚(环氧乙烷)产品(聚乙二醇,peg);具有16至50个环氧乙烷单元的乙氧基化壬基酚;乙氧基化脂肪醇,其中该醇含有12至20个碳原子,并且其中存在15至80个环氧乙烷单元;脂肪醇;脂肪酸;以及脂肪酸的甘油单酯、和甘油二酯、和甘油三酯。适合用于通过流化床技术应用的成膜包衣材料的实例在gb 1483591中给出。液体酶制剂可以例如通过根据已确立的方法添加多元醇(如丙二醇)、糖或糖醇、乳酸或硼酸而稳定化。受保护的酶可以根据ep 238,216中披露的方法来制备。
[0705]
辅料
[0706]
还可以利用本领域中已知的用于在衣物洗涤剂中使用的任何洗涤剂组分。其他任选的洗涤剂组分包括防腐蚀剂、防缩剂、抗污垢再沉积剂、抗皱剂、杀细菌剂、粘合剂、腐蚀抑制剂、崩解剂/崩解试剂、染料、酶稳定剂(包括硼酸、硼酸盐、cmc、和/或多元醇,诸如丙二醇)、织物调理剂(包括粘土)、填充剂/加工助剂、荧光增白剂/光学增亮剂、增泡剂、泡沫(泡)调节剂、香料、污垢悬浮剂、软化剂、抑泡剂、晦暗抑制剂、以及芯吸剂,单独或组合使用。可以利用本领域中已知的用于在衣物洗涤剂中使用的任何成分。此类成分的选择完全在技术人员的技术范围内。
[0707]
分散剂
‑
本发明的洗涤剂组合物还可以包含分散剂。特别地,粉末洗涤剂可以包含分散剂。适合的水溶性有机材料包括均聚的或共聚的酸或其盐,其中聚羧酸包含被不多于两个碳原子彼此分开的至少两个羧基。合适的分散剂例如描述于powdered detergents[粉状洗涤剂],surfactant science series[表面活性剂科学系列],第71卷,马塞尔德克尔公司(marcel dekker,inc)中。
[0708]
染料转移抑制剂
‑
本发明的洗涤剂组合物还可以包括一种或多种染料转移抑制剂。合适的聚合物染料转移抑制剂包括但不局限于聚乙烯吡咯烷酮聚合物、多胺n
‑
氧化物聚合物、n
‑
乙烯吡咯烷酮和n
‑
乙烯基咪唑的共聚物、聚乙烯噁唑烷酮和聚乙烯咪唑或其混合物。当在主题组合物中存在时,染料转移抑制剂可以按该组合物的重量计以从约0.0001%至约10%、从约0.01%至约5%或甚至从约0.1%至约3%的水平存在。
[0709]
荧光增白剂
‑
本发明的洗涤剂组合物还将优选地包含另外的组分,这些组分可以给正清洁的物品着色,例如荧光增白剂或光学增亮剂。当存在时,增亮剂的水平优选为约0.01%至约0.5%。在本发明的组合物中可以使用适合用于在衣物洗涤剂组合物中使用的任何荧光增白剂。最常用的荧光增白剂是属于以下类别的那些:二氨基芪
‑
磺酸衍生物、二芳基吡唑啉衍生物和二苯基
‑
联苯乙烯基衍生物。荧光增白剂的二氨基芪
‑
磺酸衍生物型的实例包括以下的钠盐:4,4'
‑
双
‑
(2
‑
二乙醇氨基
‑4‑
苯胺
‑
s
‑
三嗪
‑6‑
基氨基)芪
‑
2,2'
‑
二磺酸盐、4,4'
‑
双
‑
(2,4
‑
二苯胺基
‑
s
‑
三嗪
‑6‑
基氨基)芪
‑
2.2'
‑
二磺酸盐、4,4'
‑
双
‑
(2
‑
苯胺基
‑4‑
(n
‑
甲基
‑
n
‑2‑
羟基
‑
乙基氨基)
‑
s
‑
三嗪
‑6‑
基氨基)芪
‑
2,2'
‑
二磺酸盐、4,4'
‑
双
‑
(4
‑
苯基
‑
1,2,3
‑
三唑
‑2‑
基)芪
‑
2,2'
‑
二磺酸盐以及5
‑
(2h
‑
萘并[1,2
‑
d][1,2,3]三唑
‑2‑
基)
‑2‑
[(e)
‑2‑
苯基乙烯基]苯磺酸钠。优选的荧光增白剂是可从汽巴
–
嘉基股份有限公司
(ciba
‑
geigy ag)(巴塞尔,瑞士)获得的天来宝(tinopal)dms和天来宝cbs。天来宝dms是4,4'
‑
双
‑
(2
‑
吗啉代
‑4‑
苯胺基
‑
s
‑
三嗪
‑6‑
基氨基)芪
‑
2,2'
‑
二磺酸盐的二钠盐。天来宝cbs是2,2'
‑
双
‑
(苯基
‑
苯乙烯基)
‑
二磺酸盐的二钠盐。还优选的是荧光增白剂是可商购的parawhite kx,由印度孟买的派拉蒙矿物与化学品公司(paramount minerals and chemicals)供应。适合用于本发明中使用的其他荧光剂包括1
‑3‑
二芳基吡唑啉和7
‑
氨烷基香豆素。
[0710]
合适的荧光增亮剂水平包括从约0.01wt%、从0.05wt%、从约0.1wt%或甚至从约0.2wt%的较低水平至0.5wt%或甚至0.75wt%的较高水平。
[0711]
污垢释放聚合物
‑
本发明的洗涤剂组合物还可以包括一种或多种污垢释放聚合物,这些污垢释放聚合物帮助从织物,例如棉或聚酯基织物上除去污垢,特别是从聚酯基织物上除去疏水污垢。污垢释放聚合物可以例如是基于非离子型或阴离子型对苯二甲酸的聚合物、聚乙烯基己内酰胺和相关共聚物、乙烯基接枝共聚物、聚酯聚酰胺,参见例如powdered detergents[粉末洗涤剂],surfactant science series[表面活性剂科学系列],第71卷,第7章,马塞尔
·
德克尔公司(marcel dekker,inc)。另一种类型的污垢释放聚合物是包含核芯结构和附接至该核芯结构的多个烷氧基化基团的两亲性烷氧基化油污清洁聚合物。核心结构可以包含聚烷基亚胺结构或聚烷醇胺结构,如在wo 2009/087523中详细描述的(通过引用并入本文)。此外,随机接枝共聚物是合适的污垢释放聚合物。适合的接枝共聚物更详细地描述于wo 2007/138054、wo 2006/108856以及wo 2006/113314中(通过引用并入本文)。其他污垢释放聚合物是取代的多糖结构,尤其是取代的纤维素结构,如修饰的纤维素衍生物,如ep 1867808或wo 2003/040279中所描述的那些(将二者都通过引用并入本文)。适合的纤维素聚合物包括纤维素、纤维素醚、纤维素酯、纤维素酰胺、及其混合物。适合的纤维素聚合物包括阴离子修饰的纤维素、非离子修饰的纤维素、阳离子修饰的纤维素、兼性离子修饰的纤维素、及其混合物。适合的纤维素聚合物包括甲基纤维素、羧甲基纤维素、乙基纤维素、羟乙基纤维素、羟丙基甲基纤维素、酯羧甲基纤维素、及其混合物。
[0712]
抗再沉积剂
‑
本发明的洗涤剂组合物还可以包括一种或多种抗再沉积剂,例如羧甲基纤维素(cmc)、聚乙烯醇(pva)、聚乙烯吡咯烷酮(pvp)、聚环氧乙烷和/或聚乙二醇(peg)、丙烯酸的均聚物、丙烯酸与马来酸的共聚物以及乙氧基化聚乙亚胺。以上在污垢释放聚合物下所描述的基于纤维素的聚合物还可以作为抗再沉积剂起作用。
[0713]
流变改性剂
‑
是结构剂或增稠剂,不同于降粘剂。流变改性剂选自下组,该组由以下组成:非聚合物结晶、羟基功能材料、聚合物流变改性剂,它们为液体洗涤剂组合物的水性液相基质赋予剪切稀化特征。可以通过本领域已知的方法修饰和调整洗涤剂的流变学和粘度,例如,如在ep 2169040中所示。
[0714]
其他适合的辅料包括但不限于防缩剂、防皱剂、杀细菌剂、粘合剂、载剂、染料、酶稳定剂、织物软化剂、填充剂、泡沫调节剂、水溶助剂、香料、色素、抑泡剂、和溶剂。
[0715]
蛋白酶抑制剂
[0716]
蛋白酶抑制剂可以是使蛋白酶稳定或抑制蛋白酶以使得洗衣皂条中的蛋白酶或其他一种或多种酶不降解的任何化合物。蛋白酶抑制剂的实例是抑肽酶、贝他定(bestatin)、钙蛋白酶抑制剂i和ii、胰凝乳蛋白酶抑制剂、亮肽素、抑肽素、苯甲基磺酰氟(pmsf)、硼酸、硼酸盐、硼砂、硼酸、苯基硼酸(如4
‑
甲酰基苯基硼酸(4
‑
fpba))、肽醛或其次
硫酸盐加合物或半缩醛加合物以及肽三氟甲基酮。可以存在一种或多种蛋白酶抑制剂,如5、4、3、2或1种抑制剂,其中至少一种是肽醛、其亚硫酸氢盐加合物或半缩醛加合物。
[0717]
肽醛抑制剂
[0718]
肽醛可以具有式p
‑
(a)
y
‑
l
‑
(b)
x
‑
b0‑
h,或其亚硫酸氢盐加合物或半缩醛加合物,其中:
[0719]
i.h是氢;
[0720]
ii.b0是具有式
‑
nh
‑
ch(r)
‑
c(=o)
‑
的l
‑
或d
‑
构型的单一氨基酸残基;
[0721]
iii.(b)
x
的x是1、2或3,并且b独立地是经由b氨基酸的c
‑
末端连接到b0上的单一氨基酸
[0722]
iv.l不存在或l独立地是式
‑
c(=o)
‑
、
‑
c(=o)
‑
c(=o)
‑
、
‑
c(=s)
‑
、
‑
c(=s)
‑
c(=s)
‑
或
‑
c(=s)
‑
c(=o)
‑
的连接基团;
[0723]
v.(a)
y
的y是0、1或2,并且a独立地是经由a氨基酸的n
‑
末端连接到l上的单一氨基酸残基,其前提是如果l不存在,那么a不存在;
[0724]
vi.p选自下组,该组由以下组成:氢和一种n
‑
末端保护基团,其条件是如果l不存在,那么p是一种n
‑
末端保护基团;
[0725]
vii.r独立地选自下组,该组由以下组成:任选地被一个或多个相同或不同的取代基r’取代的c1‑6烷基、c6‑
10
芳基或c7‑
10
芳烷基;
[0726]
viii.r’独立地选自下组,该组由以下组成:卤素、
‑
oh、
‑
or”、
‑
sh、
‑
sr”、
‑
nh2、
‑
nhr”、
‑
nr”2
、
‑
co2h、
‑
conh2、
‑
conhr”、
‑
conr”2
、
‑
nhc(=n)nh2;以及
[0727]
ix.r”是c1‑6烷基基团。
[0728]
x可以是1、2或3并且因此b对应地可以是1、2或3个氨基酸残基。因此,b可以代表b1、b2‑
b1、或b3‑
b2‑
b1,其中b3、b2、和b1各自代表一个氨基酸残基。y可以是0、1或2并且因此a可以不存在,或是对应地具有式a1或a2‑
a1的1个或2个氨基酸残基,其中a2和a1各自表示一个氨基酸残基。
[0729]
b0可以是具有l或d构型的单一氨基酸残基,它经由氨基酸的c
‑
末端被连接到h上,其中r是c1‑6烷基、c6‑
10
芳基或c7‑
10
芳烷基侧链,如甲基、乙基、丙基、异丙基、丁基、异丁基、苯基或苄基,并且其中r可以任选地被一个或多个相同或不同的取代基r’取代。特别实例是d
‑
或l
‑
形式的精氨酸(arg)、3,4
‑
二羟基苯丙氨酸、异亮氨酸(ile)、亮氨酸(leu)、甲硫氨酸(met)、正亮氨酸(nle)、正缬氨酸(nva)、苯丙氨酸(phe)、间酪氨酸、对酪氨酸(tyr)以及缬氨酸(val)。特别实施例是当b0是亮氨酸、甲硫氨酸、苯丙氨酸、对酪氨酸以及缬氨酸时。
[0730]
经由b1氨基酸的c
‑
末端连接到b0上的b1可以是脂肪族、疏水性和/或中性氨基酸。b1的实例是丙氨酸(ala)、半胱氨酸(cys)、甘氨酸(giy)、异亮氨酸(ile)、亮氨酸(leu)、正亮氨酸(nle)、正缬氨酸(nva)、脯氨酸(pro)、丝氨酸(ser)、苏氨酸(thr)以及缬氨酸(vai)。b1的特别实例是丙氨酸、甘氨酸、异亮氨酸、亮氨酸以及缬氨酸。特别实施例是当b1是丙氨酸、甘氨酸或缬氨酸时。
[0731]
如果存在,经由b2氨基酸的c
‑
末端连接到b1上的b2可以是脂肪族、疏水性、中性和/或极性氨基酸。b2的实例是丙氨酸(ala)、精氨酸(arg)、卷须霉啶(capreomycidine,cpd)、半胱氨酸(cys)、甘氨酸(giy)、异亮氨酸(ile)、亮氨酸(leu)、正亮氨酸(nle)、正缬氨酸(nva)、苯丙氨酸(phe)、脯氨酸(pro)、丝氨酸(ser)、苏氨酸(thr)以及缬氨酸(vai)。b2的特
别实例是丙氨酸、精氨酸、卷须霉啶、甘氨酸、异亮氨酸、亮氨酸、苯丙氨酸以及缬氨酸。特别实施例是当b2是精氨酸、甘氨酸、亮氨酸、苯丙氨酸或缬氨酸时。
[0732]
经由b3氨基酸的c
‑
末端连接到b2上的b3(如果存在)可以是大型、脂肪族、芳香族、疏水性和/或中性氨基酸。b3的实例是异亮氨酸(ile)、亮氨酸(leu)、正亮氨酸(nle)、正缬氨酸(nva)、苯丙氨酸(phe)、苯基甘氨酸、酪氨酸(tyr)、色氨酸(trp)以及缬氨酸(vai)。b3的特别实例是亮氨酸、苯丙氨酸、酪氨酸以及色氨酸。
[0733]
连接基团l可以不存在或选自下组,该组由以下组成:
‑
c(=o)
‑
、
‑
c(=o)
‑
c(=o)
‑
、
‑
c(=s)
‑
、
‑
c(=s)
‑
c(=s)
‑
或
‑
c(=s)
‑
c(=o)
‑
。特别的实施例包括当l不存在或l是羰基基团
‑
c(=o)
‑
时。
[0734]
经由氨基酸的n
‑
末端连接到l上的a1(如果存在)可以是脂肪族、芳香族、疏水性、中性和/或极性氨基酸。a1的实例是丙氨酸(ala)、精氨酸(arg)、卷须霉啶(cpd)、甘氨酸(giy)、异亮氨酸(ile)、亮氨酸(leu)、正亮氨酸(nle)、正缬氨酸(nva)、苯丙氨酸(phe)、苏氨酸(thr)、酪氨酸(tyr)、色氨酸(trp)以及缬氨酸(vai)。a1的特别实例是丙氨酸、精氨酸、甘氨酸、亮氨酸、苯丙氨酸、酪氨酸、色氨酸以及缬氨酸。特别实施例是当b2是亮氨酸、苯丙氨酸、酪氨酸或色氨酸时。
[0735]
经由氨基酸的n
‑
末端连接到a1上的a2残基(如果存在)可以是大型、脂肪族、芳香族、疏水性和/或中性氨基酸。a2的实例是精氨酸(arg)、异亮氨酸(ile)、亮氨酸(leu)、正亮氨酸(nle)、正缬氨酸(nva)、苯丙氨酸(phe)、苯基甘氨酸、酪氨酸(tyr)、色氨酸(trp)以及缬氨酸(vai)。a2的特别实例是苯丙氨酸和酪氨酸。
[0736]
n
‑
末端保护基团p(如果存在)可以选自甲酰基、乙酰基(ac)、苯甲酰基(bz)、三氟乙酰基、甲氧基琥珀酰基、芳香族和脂肪族氨基甲酸乙酯保护基团,如芴基甲氧基羰基(fmoc)、甲氧基羰基、(氟甲氧基)羰基、苄氧基羰基(cbz)、叔丁氧基羰基(boc)以及金刚烷基氧基羰基;对甲氧基苄基羰基(moz)、苄基(bn)、对甲氧基苄基(pmb)、对甲氧基苯基(pmp)、甲氧基乙酰基、甲基氨基羰基、甲基磺酰基、乙基磺酰基、苄基磺酰基、甲基磷酰胺基(meop(oh)(=o))以及苄基磷酰胺基(phch2op(oh)(=o))。
[0737]
肽醛的通式还可以写成:p
‑
a2‑
a1‑
l
‑
b3‑
b
2 b1‑
b0‑
h,其中p、a2、a1、l、b3、b2、b1、和b0如上文所定义。
[0738]
在具有保护基团的三肽醛(即x=2,l不存在并且a不存在)的情况下,p优选地是乙酰基、甲氧基羰基、苄氧基羰基、甲基氨基羰基、甲基磺酰基、苄基磺酰基以及苄基磷酰胺基。在具有保护基团的四肽醛(即x=3,l不存在并且a不存在)的情况下,p优选地是乙酰基、甲氧基羰基、甲基磺酰基、乙基磺酰基以及甲基磷酰胺基。
[0739]
合适的肽醛描述于wo 94/04651、wo 95/25791、wo 98/13458、wo 98/13459、wo 98/13460、wo 98/13461、wo 98/13462、wo 07/141736、wo 07/145963、wo 09/118375、wo 10/055052以及wo 11/036153中。
[0740]
更具体地说,肽醛可以是
[0741]
cbz
‑
arg
‑
ala
‑
tyr
‑
h(l
‑
丙氨酰胺,n2
‑
[(苯基甲氧基)羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0742]
ac
‑
gly
‑
ala
‑
tyr
‑
h(l
‑
丙氨酰胺,n
‑
乙酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0743]
cbz
‑
gly
‑
ala
‑
tyr
‑
h(l
‑
丙氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0744]
cbz
‑
gly
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0745]
cbz
‑
val
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
[(苯基甲氧基)羰基]
‑
l
‑
缬氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0746]
cbz
‑
gly
‑
ala
‑
phe
‑
h(l
‑
丙氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
苯乙基]
‑
),
[0747]
cbz
‑
gly
‑
ala
‑
val
‑
h(l
‑
丙氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
甲基丙基]
‑
),
[0748]
cbz
‑
gly
‑
gly
‑
tyr
‑
h(甘氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0749]
cbz
‑
gly
‑
gly
‑
phe
‑
h(甘氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
苯乙基]
‑
),
[0750]
cbz
‑
arg
‑
val
‑
tyr
‑
h(l
‑
缬氨酰胺,n2
‑
[(苯基甲氧基)羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0751]
cbz
‑
leu
‑
val
‑
tyr
‑
h(l
‑
缬氨酰胺,n
‑
[(苯基甲氧基)羰基]
‑
l
‑
亮氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
)
[0752]
ac
‑
leu
‑
gly
‑
ala
‑
tyr
‑
h(l
‑
丙氨酰胺,n
‑
乙酰基
‑
l
‑
亮氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0753]
ac
‑
phe
‑
gly
‑
ala
‑
tyr
‑
h(l
‑
丙氨酰胺,n
‑
乙酰基
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0754]
ac
‑
tyr
‑
gly
‑
ala
‑
tyr
‑
h(l
‑
丙氨酰胺,n
‑
乙酰基
‑
l
‑
酪氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0755]
ac
‑
phe
‑
gly
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
乙酰基
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0756]
ac
‑
phe
‑
gly
‑
ala
‑
phe
‑
h(l
‑
丙氨酰胺,n
‑
乙酰基
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
苯乙基]
‑
),
[0757]
ac
‑
phe
‑
gly
‑
val
‑
tyr
‑
h(l
‑
缬氨酰胺,n
‑
乙酰基
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0758]
ac
‑
phe
‑
gly
‑
ala
‑
met
‑
h(l
‑
丙氨酰胺,n
‑
乙酰基
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
(甲硫基)丙基]
‑
),
[0759]
ac
‑
trp
‑
leu
‑
val
‑
tyr
‑
h(l
‑
缬氨酰胺,n
‑
乙酰基
‑
l
‑
色氨酰基
‑
l
‑
亮氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
),
[0760]
meo
‑
co
‑
val
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
(甲氧羰基)
‑
l
‑
缬氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0761]
menhco
‑
val
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
(氨基甲基羰基)
‑
l
‑
缬氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0762]
meo
‑
co
‑
phe
‑
gly
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
(甲氧羰基)
‑
l
‑
苯丙氨酰基甘氨酰
基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0763]
meo
‑
co
‑
phe
‑
gly
‑
ala
‑
phe
‑
h(l
‑
丙氨酰胺,n
‑
(甲氧羰基)
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
苯乙基]
‑
),
[0764]
meso2
‑
phe
‑
gly
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
(甲磺酰基)
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0765]
meso2
‑
val
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
(甲磺酰基)
‑
l
‑
缬氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0766]
phch2o
‑
p(oh)(o)
‑
val
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
[羟基(苯基甲氧基)氧膦基]
‑
l
‑
缬氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0767]
etso2
‑
phe
‑
gly
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
(乙磺酰基)
‑
l
‑
苯丙氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0768]
phch2so2
‑
val
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
[(苯甲基)磺酰基]
‑
l
‑
缬氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0769]
phch2o
‑
p(oh)(o)
‑
leu
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
[羟基(苯基甲氧基)氧膦基]
‑
l
‑
亮氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),
[0770]
phch2o
‑
p(oh)(o)
‑
phe
‑
ala
‑
leu
‑
h(l
‑
丙氨酰胺,n
‑
[羟基(苯基甲氧基)氧膦基]
‑
l
‑
苯并酰胺基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
),或
[0771]
meo
‑
p(oh)(o)
‑
leu
‑
gly
‑
ala
‑
leu
‑
h;(l
‑
丙氨酰胺,n
‑
(羟基甲氧基氧膦基)
‑
l
‑
亮氨酰基甘氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑3‑
甲基丁基]
‑
)。
[0772]
优选实例是cbz
‑
gly
‑
ala
‑
tyr
‑
h。
[0773]
此类肽醛的另外的实例包括
[0774]
α
‑
mapi(3,5,8,11
‑
四氮杂十三酸,6
‑
[3
‑
[(氨基亚氨基甲基)氨基]丙基]
‑
12
‑
甲酰基
‑9‑
(1
‑
甲基乙基)
‑
4,7,10
‑
三氧代
‑
13
‑
苯基
‑2‑
(苯甲基)
‑
,(2s,6s,9s,12s)
‑
[0775]
l
‑
缬氨酰胺,n2
‑
[[(1
‑
羧基
‑2‑
苯基乙基)氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
,[1(s),2(s)]
‑
;l
‑
缬氨酰胺,n2
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
苯基乙基]
‑
(9ci);sp
‑
胰凝乳蛋白酶抑制剂b),
[0776]
β
‑
mapi(l
‑
缬氨酰胺,n2
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1r)
‑1‑
甲酰基
‑2‑
苯乙基]
‑
l
‑
缬氨酰胺,n2
‑
[[(1
‑
羧基
‑2‑
苯乙基)氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
,[1(s),2(r)]
‑
),
[0777]
phe
‑
c(=o)
‑
arg
‑
val
‑
tyr
‑
h(l
‑
缬氨酰胺,n2
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
(9ci)),
[0778]
phe
‑
c(=o)
‑
gly
‑
gly
‑
tyr
‑
h(3,5,8,11
‑
四氮杂十三酸,12
‑
甲酰基
‑
13
‑
(4
‑
羟基苯基)
‑
4,7,10
‑
三氧代
‑2‑
(苯甲基),(2s,12s)
‑
),
[0779]
phe
‑
c(=o)
‑
gly
‑
ala
‑
phe
‑
h(3,5,8,11
‑
四氮杂十三酸,12
‑
甲酰基
‑9‑
甲基
‑
4,7,10
‑
三氧代
‑
13
‑
苯基
‑2‑
(苯甲基)
‑
,(2s,9s,12s)
‑
),
[0780]
phe
‑
c(=o)
‑
gly
‑
ala
‑
tyr
‑
h(3,5,8,11
‑
四氮杂十三酸,12
‑
甲酰基
‑
13
‑
(4
‑
羟基苯基)
‑9‑
甲基
‑
4,7,10
‑
三氧代
‑2‑
(苯甲基)
‑
,(2s,9s,12s)
‑
),
[0781]
phe
‑
c(=o)
‑
gly
‑
ala
‑
leu
‑
h(3,5,8,11
‑
四氮杂十五酸,12
‑
甲酰基
‑
9,14
‑
二甲基
‑
4,7,10
‑
三氧代
‑2‑
(苯甲基)
‑
,(2s,9s,12s)
‑
),
[0782]
phe
‑
c(=o)
‑
gly
‑
ala
‑
nva
‑
h(3,5,8,11
‑
四氮杂十五酸,12
‑
甲酰基
‑9‑
甲基
‑
4,7,10
‑
三氧代
‑2‑
(苯甲基)
‑
,(2s,9s,12s)
‑
),
[0783]
phe
‑
c(=o)
‑
gly
‑
ala
‑
nle
‑
h(3,5,8,11
‑
四氮杂十六酸,12
‑
甲酰基
‑9‑
甲基
‑
4,7,10
‑
三氧代
‑2‑
(苯甲基)
‑
,(2s,9s,12s)
‑
),
[0784]
tyr
‑
c(=o)
‑
arg
‑
val
‑
tyr
‑
h(l
‑
缬氨酰胺,n2
‑
[[[(1s)
‑1‑
羧基
‑2‑
(4
‑
羟基苯基)乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
(4
‑
羟基苯基)乙基]
‑
(9ci))
[0785]
tyr
‑
c(=o)
‑
gly
‑
ala
‑
tyr
‑
h(3,5,8,11
‑
四氮杂十三酸,12
‑
甲酰基
‑
13
‑
(4
‑
羟基苯基)
‑2‑
[(4
‑
羟基苯基)甲基]
‑9‑
甲基
‑
4,7,10
‑
三氧代
‑
,(2s,9s,12s)
‑
)
[0786]
phe
‑
c(=s)
‑
arg
‑
val
‑
phe
‑
h(3,5,8,11
‑
四氮杂十三酸,6
‑
[3
‑
[(氨基亚氨基甲基)氨基]丙基]
‑
12
‑
甲酰基
‑9‑
(1
‑
甲基乙基)
‑
7,10
‑
二氧代
‑
13
‑
苯基
‑2‑
(苯甲基)
‑4‑
硫代
‑
,(2s,6s,9s,12s)
‑
),
[0787]
phe
‑
c(=s)
‑
arg
‑
val
‑
tyr
‑
h(3,5,8,11
‑
四氮杂十三酸,6
‑
[3
‑
[(氨基亚氨基甲基)氨基]丙基]
‑
12
‑
甲酰基
‑
13
‑
(4
‑
羟基苯基)
‑9‑
(1
‑
甲基乙基)
‑
7,10
‑
二氧代
‑2‑
(苯甲基)
‑4‑
硫代
‑
,(2s,6s,9s,12s)
‑
),
[0788]
phe
‑
c(=s)
‑
gly
‑
ala
‑
tyr
‑
h(3,5,8,11
‑
四氮杂十三酸,12
‑
甲酰基
‑
13
‑
(4
‑
羟基苯基)
‑9‑
甲基
‑
7,10
‑
二氧代
‑2‑
(苯甲基)
‑4‑
硫代
‑
,(2s,9s,12s)
‑
),
[0789]
抗痛素(l
‑
缬氨酰胺,n2
‑
[[(1
‑
羧基
‑2‑
苯乙基)氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
[4
‑
[(氨基亚氨基甲基)氨基]
‑1‑
甲酰基丁基]
‑
),
[0790]
ge20372a(l
‑
缬氨酰胺,n2
‑
[[[(1s)
‑1‑
羧基
‑2‑
(4
‑
羟基苯基)乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1s)
‑1‑
甲酰基
‑2‑
苯乙基]
‑
[0791]
l
‑
缬氨酰胺,n2
‑
[[[1
‑
羧基
‑2‑
(4
‑
羟基苯基)乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
,[1(s),2(s)]
‑
),
[0792]
ge20372b(l
‑
缬氨酰胺,n2
‑
[[[(1s)
‑1‑
羧基
‑2‑
(4
‑
羟基苯基)乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
[(1r)
‑1‑
甲酰基
‑2‑
苯乙基]
‑
[0793]
l
‑
缬氨酰胺,n2
‑
[[[1
‑
羧基
‑2‑
(4
‑
羟基苯基)乙基]氨基]羰基]
‑
l
‑
精氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
,[1(s),2(r)]
‑
),
[0794]
胰凝乳蛋白酶抑制剂a(l
‑
亮氨酰胺,(2s)
‑2‑
[(4s)
‑2‑
氨基
‑
3,4,5,6
‑
四氢
‑4‑
嘧啶基]
‑
n
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
[0795]
l
‑
亮氨酰胺,(2s)
‑2‑
[(4s)
‑2‑
氨基
‑
1,4,5,6
‑
四氢
‑4‑
嘧啶基]
‑
n
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
(9ci);l
‑
亮氨酰胺,l
‑2‑
(2
‑
氨基
‑
1,4,5,6
‑
四氢
‑4‑
嘧啶基)
‑
n
‑
[[(1
‑
羧基
‑2‑
苯乙基)氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
,立体异构体),
[0796]
胰凝乳蛋白酶抑制剂b(l
‑
缬氨酰胺,(2s)
‑2‑
[(4s)
‑2‑
氨基
‑
3,4,5,6
‑
四氢
‑4‑
嘧啶基]
‑
n
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
[0797]
l
‑
缬氨酰胺,(2s)
‑2‑
[(4s)
‑2‑
氨基
‑
1,4,5,6
‑
四氢
‑4‑
嘧啶基]
‑
n
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
(9ci);l
‑
缬氨酰胺,l
‑2‑
(2
‑
氨基
‑
1,4,5,6
‑
四氢
‑4‑
嘧啶基)
‑
n
‑
[[(1
‑
羧基
‑2‑
苯乙基)氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
,立体异构体),以及
[0798]
胰凝乳蛋白酶抑制剂c(l
‑
异亮氨酰胺,(2s)
‑2‑
[(4s)
‑2‑
氨基
‑
3,4,5,6
‑
四氢
‑4‑
嘧啶基]
‑
n
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
[0799]
l
‑
异亮氨酰胺,(2s)
‑2‑
[(4s)
‑2‑
氨基
‑
1,4,5,6
‑
四氢
‑4‑
嘧啶基]
‑
n
‑
[[[(1s)
‑1‑
羧基
‑2‑
苯乙基]氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
(9ci);l
‑
异亮氨酰胺,l
‑2‑
(2
‑
氨基
‑
1,4,5,6
‑
四氢
‑4‑
嘧啶基)
‑
n
‑
[[(1
‑
羧基
‑2‑
苯乙基)氨基]羰基]甘氨酰基
‑
n
‑
(1
‑
甲酰基
‑2‑
苯乙基)
‑
,立体异构体)。
[0800]
肽醛加合物
[0801]
代替肽醛,蛋白酶抑制剂可以是肽醛的加合物。加合物可以是具有式p
‑
(a)
y
‑
l
‑
(b)
x
‑
n(h)
‑
chr
‑
ch(oh)
‑
so3m的亚硫酸氢盐加合物,其中p、a、y、l、b、x以及r如上文所定义,并且m是h或碱金属、优选地na或k。可替代地,加合物可以是具有式p
‑
(a)
y
‑
l
‑
(b)
x
‑
n(h)
‑
chr
‑
ch(oh)
‑
or的半缩醛,其中p、a、y、l、b、x、和r如上文所定义。优选实施例是亚硫酸氢盐加合物,其中p=cbz,b2=gly;b1=ala;b0=tyr(因此r=phch2,r’=oh),x=2,y=0,l=a=不存在并且m=na(cbz
‑
gly
‑
ala
‑
n(h)
‑
ch(ch2‑
p
‑
c6h4oh)
‑
ch(oh)
‑
so3na,l
‑
丙氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[2
‑
羟基
‑1‑
[(4
‑
羟基苯基)甲基]
‑2‑
磺乙基]
‑
,钠盐(1:1))。
[0802]
肽醛的亚硫酸氢盐加合物的通式还可以写成:p
‑
a2‑
a1‑
l
‑
b3‑
b2‑
b1‑
n(h)
‑
chr
‑
ch(oh)
‑
so3m,其中p、a2、a1、l、b3、b2、b1、r和m如上文所定义。
[0803]
可替代地,肽醛的加合物可以是cbz
‑
gly
‑
ala
‑
n(h)
‑
ch(ch2‑
p
‑
c6h4oh)
‑
ch(oh)
‑
so3na((2s)
‑
[(n
‑
{n
‑
[((苄氧基))羰基]甘氨酰基}
‑
l
‑
丙氨酰基)氨基]
‑1‑
羟基
‑3‑
(4
‑
羟基苯基)丙烷
‑1‑
磺酸钠)或cbz
‑
gly
‑
ala
‑
n(h)
‑
ch(ch2ph)
‑
ch(oh)
‑
so3na((2s)
‑
[(n
‑
{n
‑
[((苄氧基))羰基]甘氨酰基}
‑
l
‑
丙氨酰基)氨基]
‑1‑
羟基
‑3‑
(苯基)丙烷
‑1‑
磺酸钠)或“meo
‑
co_val
‑
ala
‑
n(h)
‑
ch(ch2ch(ch3)2)
‑
ch(oh)
‑
so3na((2s)
‑
[(n
‑
{n
‑
[((苄氧基))羰基]甘氨酰基}
‑
l
‑
丙氨酰基)氨基]
‑1‑
羟基
‑3‑
(2
‑
丙基)丙烷
‑1‑
磺酸钠)。
[0804]
其他优选的肽醛亚硫酸氢盐是
[0805]
cbz
‑
arg
‑
ala
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0806]
ac
‑
gly
‑
ala
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0807]
cbz
‑
gly
‑
ala
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na(l
‑
丙氨酰胺,n
‑
[(苯基甲氧基)羰基]甘氨酰基
‑
n
‑
[2
‑
羟基
‑1‑
[(4
‑
羟基苯基)甲基]
‑2‑
磺乙基]
‑
,钠盐(1:1)),
[0808]
cbz
‑
gly
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0809]
cbz
‑
val
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0810]
cbz
‑
gly
‑
ala
‑
nhch(ch2ph)c(oh)(so3m)
‑
h,其中m=na,
[0811]
cbz
‑
gly
‑
ala
‑
nhch(ch(ch3)2)c(oh)(so3m)
‑
h,其中m=na,
[0812]
cbz
‑
gly
‑
gly
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0813]
cbz
‑
gly
‑
gly
‑
nhch(ch2ph)c(oh)(so3m)
‑
h,其中m=na,
[0814]
cbz
‑
arg
‑
val
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0815]
cbz
‑
leu
‑
val
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0816]
ac
‑
leu
‑
gly
‑
ala
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0817]
ac
‑
phe
‑
gly
‑
ala
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0818]
ac
‑
tyr
‑
gly
‑
ala
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0819]
ac
‑
phe
‑
gly
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0820]
ac
‑
phe
‑
gly
‑
ala
‑
nhch(ch2ph)c(oh)(so3m)
‑
h,其中m=na,
[0821]
ac
‑
phe
‑
gly
‑
val
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0822]
ac
‑
phe
‑
gly
‑
ala
‑
nhch(ch2ch2sch3)(so3m)
‑
h,其中m=na,
[0823]
ac
‑
trp
‑
leu
‑
val
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na,
[0824]
meo
‑
co
‑
val
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0825]
menco
‑
val
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0826]
meo
‑
co
‑
phe
‑
gly
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0827]
meo
‑
co
‑
phe
‑
gly
‑
ala
‑
nhch(ch2ph)c(oh)(so3m)
‑
h,其中m=na,
[0828]
meso2‑
phe
‑
gly
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0829]
meso2‑
val
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0830]
phch2o(oh)(o)p
‑
val
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0831]
etso2‑
phe
‑
gly
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0832]
phch2so2‑
val
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0833]
phch2o(oh)(o)p
‑
leu
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0834]
phch2o(oh)(o)p
‑
phe
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,
[0835]
meo(oh)(o)p
‑
leu
‑
gly
‑
ala
‑
nhch(ch2ch(ch3)2))c(oh)(so3m)
‑
h,其中m=na,以及
[0836]
phe
‑
脲
‑
arg
‑
val
‑
nhch(ch2c6h4oh)c(oh)(so3m)
‑
h,其中m=na。
[0837]
盐
[0838]
条中所用的盐是一价阳离子与有机阴离子的盐。一价阳离子可以是例如na
、k
或nh
4
。有机阴离子可以是例如甲酸根、乙酸根、柠檬酸根或乳酸根。由此,一价阳离子与有机阴离子的盐可以是例如甲酸钠、甲酸钾、甲酸铵、乙酸钠、乙酸钾、乙酸铵、乳酸钠、乳酸钾、乳酸铵、单柠檬酸钠、二柠檬酸钠、三柠檬酸钠、柠檬酸钠钾、柠檬酸钾、柠檬酸铵等。特别实施例是甲酸钠。
[0839]
洗涤剂产品的配制
[0840]
本发明的洗涤剂组合物可以处于任何常规形式,例如条,均匀的片剂,具有两层或更多层的片剂,具有一个或多个室的袋,规则的或压缩的粉末,颗粒,糊剂,凝胶,或规则的、压缩的或浓缩的液体。
[0841]
袋可以被配置为单一室或多室。它可以具有适合用于容持所述组合物的任何形式、形状和材料,例如在与水接触之前,不允许所述组合物从袋中释放出来。该小袋由水溶性膜制成,它包含了一个内部体积。可以将所述内部体积分成袋的室。优选的膜是聚合物材料,优选地形成膜或薄片的聚合物。优选的聚合物、共聚物或其衍生物选自聚丙烯酸酯、和水溶性丙烯酸酯共聚物、甲基纤维素、羧甲基纤维素、糊精钠、乙基纤维素、羟乙基纤维素、羟丙基甲基纤维素、麦芽糊精、聚甲基丙烯酸酯,最优选地是聚乙烯醇共聚物以及羟丙基甲基纤维素(hpmc)。优选地,聚合物在膜例如pva中的水平是至少约60%。优选的平均分子量将典型地是约20,000至约150,000。膜还可以是共混组合物,这些共混组合物包含可水解降解并且可水溶的聚合物共混物,如聚乳酸和聚乙烯醇(已知在贸易参考号m8630下,如由美国印第安纳州的monosol有限责任公司(monosol llc)销售)加增塑剂,像甘油、乙二醇、丙二醇、山梨醇及其混合物。袋可以包含固体洗衣清洁组合物或部分组分和/或液体清洁组合物或由水溶性膜分开的部分组分。用于液体组分的隔室在组成上可以与含有固体的隔室不
同。参考:(us 2009/0011970 a1)。
[0842]
可以由水溶性袋中的或片剂的不同层中的室来将洗涤剂成分彼此物理分开。因此,可以避免组分间的不良的储存相互作用。在洗涤液中,每个隔室的不同溶解曲线还可以引起选择的组分的延迟溶解。
[0843]
非单位剂量的液体或凝胶洗涤剂可以是水性的,典型地含有按重量计至少20%并且最多达95%的水,如多达约70%的水、多达约65%的水、多达约55%的水、多达约45%的水、多达约35%的水。包括但不限于链烷醇、胺、二醇、醚、以及多元醇的其他类型的液体可以被包括在水性液体或凝胶中。水性液体或凝胶洗涤剂可以含有从0
‑
30%的有机溶剂。
[0844]
液体或凝胶洗涤剂可以是非水性的。
[0845]
产生组合物的方法
[0846]
本发明还涉及产生组合物的方法。
[0847]
用途
[0848]
本发明还针对用于使用其组合物的方法。
[0849]
在洗涤剂中的用途。
[0850]
可以将本发明的多肽添加至洗涤剂组合物中并且因此使该多肽成为洗涤剂组合物的组分。
[0851]
本发明的洗涤剂组合物可以被配制为例如手洗或机洗衣物洗涤剂组合物,该组合物包括适用于预处理有污渍的织物或用于复原纺织品(例如,通过去除绒毛或绒球)以恢复织物在长期使用后的部分视觉和感觉特性以比得上新的纺织品的洗衣添加剂组合物,和漂洗添加的织物软化剂组合物,或被配制为用于一般家用硬表面清洁操作的洗涤剂组合物,或被配制用于手洗或机洗餐具洗涤操作。
[0852]
在一个特定方面,本发明提供了包含如本文所述的本发明多肽的洗涤剂添加剂。
[0853]
段落
[0854]
段落1.一种具有糖苷水解酶(ec 3.2.1.
‑
)活性的亲本多肽的变体,其中该变体包含催化结构域、富含脯氨酸的接头区域和碳水化合物结合模块(cbm),并且其中该变体具有糖苷水解酶活性。
[0855]
段落2.一种具有纤维素酶活性的亲本多肽的变体,其中该变体包含催化结构域、富含脯氨酸的接头区域和碳水化合物结合模块(cbm),并且其中该变体具有纤维素酶活性。
[0856]
段落3.一种具有内切葡聚糖酶活性的亲本多肽的变体,其中该变体包含催化结构域、富含脯氨酸的接头区域和碳水化合物结合模块(cbm),并且其中该变体具有内切葡聚糖酶活性。
[0857]
段落4.根据段落1
‑
3中任一项所述的变体,其中该变体具有与亲本相比的在包含蛋白酶的水性组合物中的改善的稳定性。
[0858]
段落5.一种具有糖苷水解酶(ec 3.2.1.
‑
)活性的亲本多肽的变体,其中该变体包含催化结构域、工程化的接头区域和碳水化合物结合模块(cbm),并且其中该变体具有糖苷水解酶活性,其中该变体具有与亲本相比的在包含蛋白酶的水性组合物中的改善的稳定性。
[0859]
段落6.一种具有纤维素酶活性的亲本多肽的变体,其中该变体包含催化结构域、工程化的接头区域和碳水化合物结合模块(cbm),并且其中该变体具有纤维素酶活性,其中
该变体具有与亲本相比的在包含蛋白酶的水性组合物中的改善的稳定性。
[0860]
段落7.一种具有内切葡聚糖酶活性的亲本多肽的变体,其中该变体包含催化结构域、工程化的接头区域和碳水化合物结合模块(cbm),并且其中该变体具有内切葡聚糖酶活性,其中该变体具有与亲本相比的在包含蛋白酶的水性组合物中的改善的稳定性。
[0861]
段落8.一种变体,该变体是具有糖苷水解酶活性,例如内切葡聚糖酶活性,优选地gh45内切葡聚糖酶活性的杂合多肽,该变体包含(a)来自具有糖苷水解酶活性,例如内切葡聚糖酶活性,优选地gh45内切葡聚糖酶活性的多肽的催化结构域,(b)选自由以下组成的组的接头:ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)和spspspspspg(seq id no:25),和(c)碳水化合物结合模块(cbm),优选地cbm1。
[0862]
段落9.根据段落8所述的杂合多肽,该杂合多肽具有与亲本相比的在包含蛋白酶的水性组合物中的改善的稳定性。
[0863]
段落10.根据前述段落中任一项所述的变体,其中改善的稳定性根据实例2和/或实例7中所述的测定来确定。
[0864]
段落11.根据前述权利要求中任一项所述的变体,该变体是家族gh45内切葡聚糖酶。
[0865]
段落12.根据前述段落中任一项所述的变体,其中该cbm是cbm1。
[0866]
段落13.根据前述段落中任一项所述的变体,其中该变体包含n
‑
末端催化结构域和c
‑
末端cbm。
[0867]
段落14.根据前述段落中任一项所述的变体,其中该变体包含c
‑
末端催化结构域和n
‑
末端cbm。
[0868]
段落15.根据前述段落中任一项所述的变体,其中该变体展示了例如,在蛋白酶的存在下储存后,相对于该亲本的改善的织物或纺织品护理和/或改善的洗涤性能。
[0869]
段落16.根据前述段落中任一项所述的变体,其中该接头包含至少25%脯氨酸,例如,至少28%脯氨酸、至少30%脯氨酸、至少35%脯氨酸、至少40%脯氨酸、至少50%脯氨酸,例如,至少60%、至少66%、至少70%、至少75%、至少80%、至少85%、至少90%脯氨酸。
[0870]
段落17.根据前述段落中任一项所述的变体,其中该接头具有至少四个氨基酸的长度,并且包含以下任选重复基序中的一个或多个:
[0871]
a.[p/s/t/r/k/d/e]p,优选地[p/s/t]p;最优选地(sp)
a
,a=2
‑
10或p
b
,b=4
‑
20,优选地4
‑
15
[0872]
b.p[s/t/r/k/d/e/n/q]p[s/t/r/k/d/e](seq id no:102),优选地p[s/e]pt(seq id no:109)。
[0873]
段落18.根据前述段落中任一项所述的变体,其中该接头具有至少四个氨基酸的长度,并且包含以下任选重复基序:[s/t/r/k/d/e]p[s/t/r/k/d/e/n/q][p/s/t/r/k/d/e][p/s/t/r/k/d/e]p和/或p[p/s/t/r/k/d/e][p/s/t/r/k/d/e]。
[0874]
段落19.根据前述段落中任一项所述的变体,其中该接头包含:
[0875]
a.(sp)
a
,a=2
‑
10;
[0876]
b.(ps)
a
,a=2
‑
10;
[0877]
c.p
b
,b=4
‑
20,优选地4
‑
15;
[0878]
d.(pept(seq id no:125))
c
,c=2
‑
5;
[0879]
e.(pspt(seq id no:104))
d
,d=2
‑
5;
[0880]
f.(p[s/t/r/k/d/e/n/q]p[s/t/r/k/d/e](seq id no:102))
e
,e=2
‑
5;
[0881]
g.([s/t/r/k/d/e]p)
f
,f=2
‑
10,优选地2
‑
5;
[0882]
h.([s/t/r/k/d/e/n/q]p[s/t/r/k/d/e])
g
,g=2
‑
6;
[0883]
i.([s/t/r/k/d/e/n/q][s/t/r/k/d/e/n/q]p)
h
,h=2
‑
5;
[0884]
j.(tp)
i
,i=2
‑
10;
[0885]
k.([s/t/p][s/t/p][s/t/p])
j
,j=2
‑
11;
[0886]
和/或其组合,其中考虑了各个单体单元的组合。
[0887]
段落20.根据前述权利要求中任一项所述的变体,其中该接头包含:
[0888]
a.(sp)
a
,a=2
‑
10;
[0889]
b.(ps)
a
,a=2
‑
10;
[0890]
c.p
b
,b=4
‑
20,优选地4
‑
15;或
[0891]
d.(pept(seq id no:125))
c
,c=2
‑
5。
[0892]
段落21.根据前述段落中任一项所述的变体,其中该接头具有至少4个氨基酸且不超过30个氨基酸的长度,例如4
‑
28个氨基酸,优选地4
‑
20个氨基酸,或甚至4
‑
10个氨基酸,例如4个氨基酸、5个氨基酸、6个氨基酸、7个氨基酸、8个氨基酸、9个氨基酸或10个氨基酸的长度。
[0893]
段落22.根据前述段落中任一项所述的变体,其中该接头包含spsp(seq id no:130)、spspsp(seq id no:131)、spspspsp(seq id no:132)、spspspspsp(seq id no:58)、spspspspspsp(seq id no:133)、spspspspspspsp(seq id no:134)、spspspspspspspsp(seq id no:135)、pppp(seq id no:27)、ppppp(seq id no:28)、pppppp(seq id no:29)、ppppppp(seq id no:31)、pppppppp(seq id no:136)、ppppppppp(seq id no:137)、pppppppppp(seq id no:138)、ppppppppppp(seq id no:139)、pppppppppppp(seq id no:140)、ppppppppppppp(seq id no:141)、pppppppppppppp(seq id no:142)、ppppppppppppppp(seq id no:143)、peptpept(seq id no:144)、peptpeptpept(seq id no:145)、peptpeptpeptpept(seq id no:146)、peptpeptpeptpeptpept(seq id no:79)、psptpspt(seq id no:147)、psptpsptpspt(seq id no:148)、psptpsptpsptpspt(seq id no:149)、psptpsptpsptpsptpspt(seq id no:150)、spssps(seq id no:151)、spsspssps(seq id no:152)、spsspsspssps(seq id no:153)、spsspsspsspssps(seq id no:154)、tpttpt(seq id no:155)、tpttptg(seq id no:96)、tpttpttpt(seq id no:156)、tpttpttpttpt(seq id no:157)、tpttpttpttpttpt(seq id no:158)、peptprptpeptprpt(seq id no:159)、peptpkptpeptpkpt(seq id no:160)、peptpqptpeptpqpt(seq id no:161)、prptpeptprpt(seq id no:162)、pkptpeptpkpt(seq id no:163)、peptpqpt(seq id no:164)、peptpqptpept(seq id no:165)、peptprptpeptprptg(seq id no:85)、peptpkptpeptpkptg(seq id no:87)、peptpqptpeptpqptg(seq id no:88)、prptpeptprptg(seq id no:89)、pkptpeptpkptg(seq id no:90)、peptpqptg(seq id no:91)、peptpqptpeptg(seq id no:92)、pppggpggpgtptstapgsgptspgggsg(seq id no:82)中的一个或多个。
[0894]
段落23.根据前述段落中任一项所述的变体,其中该接头进一步包含在c
‑
末端位
置的甘氨酸。
[0895]
段落24.根据前述段落中任一项所述的变体,其中该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)。
[0896]
段落25.根据前述段落中任一项所述的变体,其中该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是cbm1。
[0897]
段落26.根据前述段落中任一项所述的变体,其中该催化结构域包含与如seq id no:1的位置1
‑
212、seq id no:2的位置1
‑
211、seq id no:3的位置1
‑
210、seq id no:4的位置1
‑
211所示的氨基酸序列具有至少70%序列同一性,例如至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。段落27.根据前述段落中任一项所述的变体,其中该cbm包含与如seq id no:6、seq id no:7、seq id no:8、seq id no:9、seq id no:173、seq id no:174、seq id no:175、seq id no:176、seq id no:177、seq id no:178、seq id no:179、seq id no:180、seq id no:181、seq id no:182、seq id no:183、seq id no:184、seq id no:185、seq id no:186、seq id no:187、seq id no:188、seq id no:189、seq id no:190、seq id no:191、seq id no:192、seq id no:193、seq id no:194、seq id no:195、seq id no:196、seq id no:197、seq id no:198、seq id no:199、seq id no:200所示的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列。
[0898]
段落28.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是cbm1。
[0899]
段落29.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:6。
[0900]
段落30.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或
spspspspspg(seq id no:25)并且该cbm是seq id no:7。
[0901]
段落31.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:8。
[0902]
段落32.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:9。
[0903]
段落33.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:173。
[0904]
段落34.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:174。
[0905]
段落35.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:175。
[0906]
段落36.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:176。
[0907]
段落37.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同
一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:177。
[0908]
段落38.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:178。
[0909]
段落39.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:179。
[0910]
段落40.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:180。
[0911]
段落41.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:181。
[0912]
段落42.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:182。
[0913]
段落43.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或
spspspspspg(seq id no:25)并且该cbm是seq id no:183。
[0914]
段落44.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:184。
[0915]
段落45.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:185。
[0916]
段落46.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:186。
[0917]
段落47.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:187。
[0918]
段落48.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:188。
[0919]
段落49.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:189。
[0920]
段落50.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同
一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:190。
[0921]
段落51.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:191。
[0922]
段落52.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:192。
[0923]
段落53.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:193。
[0924]
段落54.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:194。
[0925]
段落55.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:195。
[0926]
段落56.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或
spspspspspg(seq id no:25)并且该cbm是seq id no:196。
[0927]
段落57.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:197。
[0928]
段落58.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:198。
[0929]
段落59.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:199。
[0930]
段落60.根据前述段落中任一项所述的变体,其中该催化结构域包含与seq id no:5的氨基酸序列具有至少70%序列同一性,例如,至少75%序列同一性、至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少96%序列同一性、至少97%序列同一性、至少98%序列同一性、至少99%序列同一性的氨基酸序列,该接头是ppppppp(seq id no:31)、pppppppg(seq id no:30)、spspspspsp(seq id no:58)或spspspspspg(seq id no:25)并且该cbm是seq id no:200。
[0931]
段落61.根据前述段落中任一项所述的变体,该变体进一步包含选自由以下组成的组的取代:
[0932]
q147r q156e;
[0933]
q147r q169y;
[0934]
s56a q147r;
[0935]
q147r a162e;
[0936]
q147r q156e a162e;
[0937]
a25g s56a q147r;
[0938]
n134d q156e a162e;
[0939]
s56a n134d q156e a162e;
[0940]
a25g s56a q156e a162e;
[0941]
a25g n134d q156e a162e;
[0942]
a25g s56a n134d q169y;
[0943]
s56a n134d a162e;
[0944]
s56a q147r q169y;
[0945]
n134d q147r;
[0946]
q156e q169y;
[0947]
s56a n134d q147r;
[0948]
s56a n134d q156e q169y;
[0949]
s56a a146d q147r q169y;
[0950]
s56a n134d q147r q169y;
[0951]
s56a q147r a162e q169y;
[0952]
s2* s56a q147r q169y;
[0953]
s41t s56a q147r q169y;
[0954]
s56a s77n q147r q169y;
[0955]
s56a t104k q147r q169y;
[0956]
s56a q147r k165q q169y;
[0957]
s56a q147r q169y i194l;
[0958]
s56a q147r q169y k201r;
[0959]
s56a q147r q169y g219w;
[0960]
n44d s56a q147r q169y;
[0961]
n50e s56a q147r q169y;
[0962]
a32s s56a q147r q169y;
[0963]
n44d s56a q147r q169y;
[0964]
s56a q147r q169y q186r;
[0965]
s56a q147r q169y f183v;
[0966]
s56a a146s q147r a162e q169y;
[0967]
s56a n134d q147r;
[0968]
s56a n134d q147r a162e;
[0969]
a32s s56a n134d q147r q169y f183v;
[0970]
s56a n134d q147r a162e q169y f183v;
[0971]
a32s s56a s77n n134d q147r a162e q169y;
[0972]
a32s s56a n134d a146d q147r q169y f183v;
[0973]
a32s s56a n134d q147r q169y;
[0974]
s56a n134d q147r a162e q169y;
[0975]
a32s s56a n134d a146s q147r q169y;
[0976]
a32s s56a n134d a146d q147r q169y;
[0977]
a32s s56a n134d q147r q169y f183v;
[0978]
a32s s56a n134d q147r q169y k201r;
[0979]
s56a n134d a146d q147r q169y f183v;
[0980]
s56a n134d a146d q147r a162e q169y;
[0981]
s56a n134d a146d q147r q169y k201r;
[0982]
s56a n134d q147r a162e q169y f183v;
[0983]
s56a n134d q147r q169y f183v k201r;
[0984]
a32s s56a s77n n134d q147r q169y f183v;
[0985]
a32s s56a s77n n134d q147r a162e q169y;
[0986]
a32s s56a n134d a146s q147r q169y f183v;
[0987]
a32s s56a n134d a146d q147r q169y f183v;或
[0988]
a32s s56a n134d a146d q147r a162e q169y。
[0989]
段落62.根据前述段落中任一项所述的变体,其中该接头如表a中所示。
[0990]
段落63.根据前述段落中任一项所述的变体,其中该变体如表b1、表b2、表c1、表c2、表d中所示。
[0991]
段落64.一种分离的多核苷酸,该分离的多核苷酸编码根据段落1
‑
63中任一项所述的变体。
[0992]
段落65.一种核酸构建体,该核酸构建体包含根据段落64所述的多核苷酸。
[0993]
段落66.一种表达载体,该表达载体包含根据段落64所述的多核苷酸。
[0994]
段落67.一种宿主细胞,该宿主细胞包含根据段落64所述的多核苷酸。
[0995]
段落68.一种产生具有糖苷水解酶(ec 3.2.1.
‑
)、纤维素酶或内切葡聚糖酶活性的变体的方法,该方法包括
[0996]
a.在适合于表达该变体的条件下培养根据段落67所述的宿主细胞;以及
[0997]
b.回收该变体。
[0998]
段落69.一种用于获得具有糖苷水解酶(ec 3.2.1.
‑
)、纤维素酶或内切葡聚糖酶活性的变体的方法,该方法包括向亲本糖苷水解酶中引入富含脯氨酸的接头区域;和回收该变体。
[0999]
段落70.一种全培养液配制品或细胞培养组合物,该全培养液配制品或细胞培养组合物包含根据段落1
‑
63中任一项所述的变体。
[1000]
段落71.一种组合物,该组合物包含根据段落1
‑
63中任一项所述的变体。
[1001]
段落72.根据段落71所述的组合物,该组合物进一步包含蛋白酶。
[1002]
段落73.根据段落71
‑
72中任一项所述的组合物,该组合物进一步包含选自由以下组成的组的一种或多种另外的酶:(另外的)蛋白酶、脂肪酶、角质酶、淀粉酶、(另外的)糖酶、(另外的)纤维素酶、果胶酶、甘露聚糖酶、阿拉伯糖酶、半乳聚糖酶、木聚糖酶、核酸酶、地衣多糖酶、氧化酶例如漆酶、和/或过氧化物酶,及其组合。
[1003]
段落74.根据段落71
‑
73中任一项所述的组合物,该组合物进一步包含淀粉酶。
[1004]
段落75.根据段落71
‑
74中任一项所述的组合物,该组合物进一步包含另一种糖酶。
[1005]
段落76.根据段落71
‑
75中任一项所述的组合物,该组合物进一步包含地衣多糖酶。
[1006]
段落77.根据段落71
‑
76中任一项所述的组合物,该组合物是洗涤剂组合物。
[1007]
段落78.根据段落71
‑
77中任一项所述的组合物,该组合物进一步包含选自表面活性剂、助洗剂和共助洗剂以及聚合物的一种或多种化合物。
[1008]
段落79.根据段落71
‑
78中任一项所述的组合物,该组合物是液体洗涤剂组合物。
[1009]
段落80.根据段落1
‑
63中任一项所述的变体用于清洁织物、纺织品或硬表面的用
途。
[1010]
段落81.根据段落1
‑
63中任一项所述的变体或根据段落71
‑
78中任一项所述的组合物用于织物或纺织品护理的用途,例如用于预处理有污渍的织物或用于复原纺织品(例如,通过去除绒毛或绒球),以恢复织物在长期使用后的视觉和感觉特性,以比得上新的纺织品。
[1011]
段落82.根据段落80
‑
81所述的用途,该用途包括根据段落1
‑
63中任一项所述的变体或根据段落71
‑
79中任一项所述的组合物用于衣物洗涤的用途。
[1012]
段落83.根据段落82所述的用途,该用途包括根据段落1
‑
63中任一项所述的变体或根据段落71
‑
79中任一项所述的组合物作为漂洗时添加的织物软化剂组合物的用途。
[1013]
段落84.一种用于减少或预防污垢再沉积的方法,该方法包括接触根据前述段落中任一项所述的多肽或组合物或洗涤剂组合物。
[1014]
段落85.一种用于织物或纺织品护理的方法,该方法使用了根据前述段落中任一项所述的多肽或组合物或洗涤剂组合物。
[1015]
段落86.一种用于洗涤物体例如织物或纺织品的方法,该方法包括
[1016]
(a)提供洗涤液,通过将根据段落1
‑
63中任一项所述的变体或根据段落71
‑
79中任一项所述的组合物在水中溶解/混合来提供洗涤液;
[1017]
(b)在该洗涤液中洗涤该物体;
[1018]
(c)排掉该洗涤液并且任选地重复该洗涤循环;以及
[1019]
(d)将该物体漂洗并任选地干燥。
[1020]
段落87.一种用于洗涤物体例如织物或纺织品的方法,该方法包括
[1021]
(a)提供水并漂洗该物体;
[1022]
(b)任选地,排掉该水并提供新水;
[1023]
(c)配量添加根据段落1
‑
63中任一项所述的变体或根据段落71
‑
79中任一项所述的组合物以形成洗涤液;
[1024]
(d)搅动该洗涤液,从而洗涤该物体,任选地加热该洗涤液;以及
[1025]
(e)排掉该洗涤液。
[1026]
实例
[1027]
材料与方法
[1028]
pcr、克隆、连接核苷酸等的通用方法是本领域普通技术人员熟知的并且可以例如发现于“molecular cloning:a laboratory manual[分子克隆:实验室手册]”,sambrook等人(1989),cold spring harbor lab.[冷泉港实验室],冷泉港,纽约州(cold spring harbor,ny);ausubel,f.m.等人(编辑);“current protocols in molecular biology[分子生物学实验指南]”,john wiley and sons[约翰威立父子公司],(1995);harwood,c.r.和cutting,s.m.(编辑);“dna cloning:apractical approach[dna克隆:实用方法],第i和ii卷”,d.n.glover编辑(1985);“oligonucleotide synthesis[寡核苷酸合成]”,m.j.gait编辑(1984);“nucleic acid hybridization[核酸杂交]”,b.d.hames和s.j.higgins编辑(1985);“apractical guide to molecular cloning[分子克隆实用指南]”,b.perbal,(1984)。
[1029]
纤维素分解活性的测定
[1030]
遵循制造商的说明书,使用由麦格酶公司(megazyme)提供的纤维素酶测定试剂盒(cellg5方法)(爱尔兰威克洛市(wicklow,ireland);产品代码:k
‑
cellg5
‑
4v)确定纤维素分解活性。
[1031]
用于测量内切
‑
纤维素酶(内切
‑
1,4
‑
β
‑
葡聚糖酶)的cellg5测定试剂含有两个组分;
[1032]
1)4,6
‑
o
‑
(3
‑
酮基亚丁基)
‑4‑
硝基苯基
‑
β
‑
d
‑
纤维五糖苷(bpnpg5)和2)热稳定的β
‑
葡糖苷酶。酮阻断基团通过bpnpg5上的β
‑
葡糖苷酶预防任何水解作用。与内切
‑
纤维素酶孵育产生非阻断比色寡糖,该寡糖被辅助β
‑
葡糖苷酶快速水解。因此,4
‑
硝基苯酚的形成速率直接与内切纤维素酶水解bpnpg5有关。
[1033]
标准洗涤剂a的组合物(液体)
[1034]
洗涤剂a的组合物(液体):成分:12%las、11%aeo biosoft n25
‑
7(ni)、7%aeos(sles)、6%mpg(丙二醇)、3%乙醇、3%tea、2.75%可可皂、2.75%大豆皂、2%甘油、2%氢氧化钠、2%柠檬酸钠、1%甲酸钠、0.2%dtmpa和0.2%pca(所有的百分数都是w/w)。
[1035]
蛋白酶
[1036]
用于实例的蛋白酶是seq id no:10的蛋白酶。其他蛋白酶包括seq id no:11或具有突变s9e n42r n74d v199i q200l y203w s253d n255w l256e的seq id no:11的那些蛋白酶。
[1037]
洗涤测定
[1038]
launder
‑
o
‑
meter(lom)模式洗涤系统
[1039]
launder
‑
o
‑
meter(lom)是中等规模标准洗涤系统,它可以应用于同时测试多达20种不同洗涤条件。lom基本上是大型温控水浴,具有20个封闭金属烧杯在其中旋转。每个烧杯构成一个小的洗衣机并且在一次实验过程中,每个烧杯将含有待测试的特定洗涤剂/酶系统的溶液连同在其上进行测试的弄脏的和未弄脏的织物。机械应力由在水浴中旋转的烧杯并且由包括在烧杯中的金属球实现。
[1040]
lom标准洗涤系统主要用于欧洲洗涤条件下进行洗涤剂和酶的中等规模测试。在lom实验中,因素如压载物与污垢的比率和织物与洗涤液的比率可以变化。因此,lom提供了在小规模实验(如amsa和微型洗涤)与在前装式洗衣机中的更费时的全规模实验之间的联系。
[1041]
迷你launder
‑
o
‑
meter(迷你lom)标准洗涤系统
[1042]
迷你lom是launder
‑
o
‑
meter(lom)的修饰的迷你洗涤系统,其是中等规模标准洗涤系统,它可以应用于同时测试多达20种不同洗涤条件。lom基本上是大型温控水浴,具有20个封闭金属烧杯在其中旋转。每个烧杯构成一个小的洗衣机并且在一次实验过程中,每个烧杯将含有待测试的特定洗涤剂/酶系统的溶液连同在其上进行测试的弄脏的和未弄脏的织物。机械应力由在水浴中旋转的烧杯并且由包括在烧杯中的金属球实现。
[1043]
lom标准洗涤系统主要用于欧洲洗涤条件下进行洗涤剂和酶的中等规模测试。在lom实验中,因素如压载物与污垢的比率和织物与洗涤液的比率可以变化。因此,lom提供了在小规模实验(如amsa和微型洗涤)与在前装式洗衣机中的更费时的全规模实验之间的联系。
[1044]
在迷你lom中,洗涤是在置于斯图尔特(stuart)旋转器中的50ml试管中进行的。
[1045]
terg
‑
o
‑
tometer(tom)洗涤测定
[1046]
terg
‑
o
‑
tometer(tom)是一种中等规模标准洗涤系统,它可以应用于同时测试12种不同的洗涤条件。tom基本上是大型温控水浴,其中浸入了多达12个开口金属烧杯。每个烧杯构成一个小的顶装式洗衣机并且在实验期间,每个烧杯将含有特定洗涤剂/酶系统的溶液并且在弄脏的和未弄脏的织物上测试其性能。通过旋转搅拌臂获得机械应力,该旋转搅拌臂搅拌在每个烧杯内的液体。因为tom烧杯没有盖子,所以能够在tom实验期间收回样品并且在洗涤期间在线分析信息。
[1047]
tom标准洗涤系统主要用于在us或la/ap洗涤条件下进行洗涤剂和酶的中等规模测试。在tom实验中,因素(如压载物与污垢的比率和织物与洗涤液的比率)可以变化。因此,tom提供了在小规模实验与在顶装式洗衣机中的更费时的全规模实验之间的联系。
[1048]
实例1:确定纤维素酶变体的稳定性(核心稳定性方法)
[1049]
在含有蛋白酶的90%液体洗涤剂a中测量纤维素酶变体的稳定性。在孵育含有蛋白酶的酶
‑
洗涤剂混合物之后,通过cellg5试剂盒测量变体的活性以评估洗涤剂中稳定性。
[1050]
90%洗涤剂a中的温度/蛋白酶应激条件:
[1051]
在96孔微板(聚苯乙烯)中,将在缓冲液(100mm hepes;0.01%吐温
‑
20;ph 7.5)中稀释的20μl的1000ppm纯化的内切
‑
纤维素酶与180μl含有0.3mg/ml活性酶蛋白酶蛋白质的洗涤剂a混合。
[1052]
将15μl的酶/洗涤剂混合物转移至两个新的384孔微板并且密封。将两个相同的板中的一个在5℃储存(参考),而另一个在高温(应激)孵育16或17小时。参见使用的应激
‑
温度结果表。孵育后,将60μl的测定缓冲液(100mm hepes;0.01%吐温
‑
20;ph 7.5)添加到两个板的样品中并且剧烈混合用于随后的活性测量。
[1053]
纤维素分解活性的测定样品(cellg5试剂盒):
[1054]
通过在uv
‑
透明384孔微板中,将20μl稀释的酶
‑
洗涤剂混合物与10μl测定缓冲液(100mm hepes;0.01%吐温
‑
20;ph 7.5)以及10μl新鲜制备的底物溶液混合来测量酶活性。通过混合10μl的瓶#2与300μl瓶#1制备cellg5测定试剂盒的底物溶液。
[1055]
使用酶标仪(帝肯(tecan);infinite m1000,专业版)动态地测量(每2分钟,持续44分钟)uv
‑
吸光度(405nm)。将表现出恒定吸光度增加的曲线部分用于计算样品的酶活性(mod/min)。之后,将残余活性计算为在高温孵育16或17小时的样品的酶活性相对于在5℃储存的对应样品的酶活性。
[1056]
残余活性(%)=(在高温下孵育的样品的活性/在5℃下孵育的样品的活性)*100
[1057]
实例2:接头稳定性测定
[1058]
原理
[1059]
接头稳定性通过如下进行测量:(a)在含有蛋白酶的洗涤剂中孵育纤维素酶,然后(b)确定孵育的纤维素酶结合纤维素纤维的能力。如果接头或纤维素结合结构域受到蛋白酶的影响,那么纤维素酶与纤维素纤维的结合亲和力将会降低。
[1060]
通过将孵育的纤维素酶的稀释液添加到纤维素纤维的悬浮液中来确定结合。在5℃孵育后,通过离心去除与纤维素结合的纤维素酶,并通过以下确定未结合纤维素的纤维素酶的量:测量(c)上清液中的纤维素酶的活性。未结合纤维素的纤维素酶的活性相对于在相似条件下孵育但是不存在纤维素酶的平行样品的活性是接头稳定性的量度。
[1061]
该活性是基于可溶性羧甲基纤维素(cmc)的水解以及随后(d)对形成的还原性末端的数目的检测。完整纤维素酶和不具有纤维素结合结构域的纤维素酶二者的底物都是cmc。
[1062]
a.在含有蛋白酶的洗涤剂中进行孵育
[1063]
化学品
[1064]
洗涤剂:标准洗涤剂a
[1065]
蛋白酶:seq id no:10
[1066]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1067]
试剂
[1068]
稀释缓冲液:50mm hepes,ph 8
[1069]
蛋白酶原液,例如,seq id no:10的蛋白酶
[1070]
具有0.3mg/ml蛋白酶的洗涤剂:300ppm,在标准洗涤剂a中
[1071]
如上的标准洗涤剂a
[1072]
程序
[1073]
1)具有0.3mg/ml蛋白酶的洗涤剂通过如下制备:将蛋白酶原液添加至100ml的洗涤剂中至在洗涤剂中的最终蛋白酶浓度为300ppm活性蛋白酶蛋白质,并在室温下通过磁力搅拌进行混合持续1小时。
[1074]
2)将纤维素酶在稀释缓冲液中稀释至300ppm。
[1075]
3)将来自(1)的270μl具有蛋白酶的洗涤剂移液至96孔聚丙烯微板(thermo scientific
tm
249944)的孔位置a1至d12中。
[1076]
4)将来自(2)的30μl稀释的纤维素酶添加至每个孔(位置a1至d12)中。对每种纤维素酶一式三份进行测试,并且将位置d4至d6用作空白对照,在其中添加30μl milli q水而不是纤维素酶。
[1077]
5)将一些小磁铁添加至每个孔(位置a1至d12)中并将该板用热封(thermo scientific
tm
粘性pcr板封ab0558)密封,随后通过磁力搅拌持续30分钟进行混合。
[1078]
6)混合后,将板以实例中所示的时间和温度进行孵育。
[1079]
b.结合至纤维素纤维
[1080]
化学品
[1081]
纤维素纤维:ph
‑
101,(西格玛公司11365)
[1082]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1083]
试剂:
[1084]
结合缓冲液:50mm hepes,ph 8
[1085]
avicel悬浮液:在结合缓冲液中的1.25g/100ml avicel,使用前混合1小时
[1086]
程序:
[1087]
1)将180μl avicel悬浮液添加至新的96孔微板(thermo scientific
tm
目录号269620)中的位置a1
‑
>d12并将180μl结合缓冲液添加至位置e1
‑
>h12中
[1088]
2)然后将来自步骤a的孵育的板中的每个孔的20μl样品等分试样分别添加至位置a1
‑
>d12和位置e1
‑
>h12的孔中。
[1089]
3)以足以使纤维素纤维保持处于悬浮的速度,将板在5℃振荡持续1小时以允许纤
维素酶结合纤维素
[1090]
4)结合后,将板以1500rpm离心10秒并将上清液在结合缓冲液中稀释2.5倍(40μl样品 60μl缓冲液)。将来自avicel孔的上清液和来自对应的无avicel的孔的上清液二者都稀释。
[1091]
c.cmc活性测定
[1092]
化学品:
[1093]
cmc:羧甲基纤维素钠(西格玛公司c5678)
[1094]
k
‑
na
‑
酒石酸:默克公司(merck)8087
[1095]
β
‑
葡糖苷酶 麦格酶公司(megazyme)(海栖热孢菌(thermotoga maritima);登录号q08638,麦格酶公司目录号e
‑
bgostm),稀释至0.1mg/ml(比活性为70u/mg以及在产品中活性为约460u/ml
‑
>6,57mg/ml)
[1096]
pahbah 4
‑
羟基苯酰肼(西格玛公司h9882)
[1097]
naoh 氢氧化钠(j.t.baker 0402.1000)
[1098]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1099]
试剂:
[1100]
测定缓冲液:50mm hepes,ph 8
[1101]
cmc底物:1.25g cmc/100ml测定缓冲液,使用前混合1小时
[1102]
pahbah缓冲液:50g/l k
‑
na
‑
酒石酸 20g/l naoh
[1103]
pahbah试剂:在pahbah缓冲液中的15mg/ml pahbah
[1104]
β
‑
葡糖苷酶溶液:在测定缓冲液中的0.1mg/mlβ
‑
葡糖苷酶
[1105]
程序:
[1106]
1)将160μl cmc底物移液至新的96孔微板(thermo scientific
tm
目录号269620)中
[1107]
2)将来自步骤b的20μl稀释的上清液与20μlβ
‑
葡糖苷酶溶液一起添加
[1108]
3)将板使用热封(thermo scientific
tm
粘性pcr板封ab0558)密封并在40℃孵育持续45分钟
[1109]
4)反应后,将来自每个孔的100μl转移至thermofast 96pcr板(thermo scientific
tm
目录号ab
‑
0600),随后添加75μl pahbah试剂
[1110]
5)然后将来自(4)的板用密封箔片(格瑞纳生物科技公司(greiner bio
‑
one)板封,目录号676001)密封并在biorad t100
tm
热循环仪pcr机中在95℃孵育10分钟,随后在10℃冷却5分钟
[1111]
6)冷却后,将100μl等分试样转移至新的96孔微板(thermo scientific
tm
目录号269620)并在405nm处读取吸光度(a
405nm
)。吸光度是上清液中纤维素酶的活性的表示。
[1112]
d.数据处理
[1113]
1)根据步骤c的吸光度读数,计算了来自无avicel的孔的3个空白对照的平均值a
405nm
(空白_参考)(位置h4
‑
>h6),并且计算了来自具有avicel的孔的3个空白对照的平均值a
405nm
(空白_avicel)(位置d4
‑
>d6)。
[1114]
2)然后将来自含有纤维素酶的孔的吸光度读数针对其各自的空白对照(即,来自(1)的那些)进行校正。
[1115]
3)将接头稳定性计算为
[1116]1‑
[活性
405nm
( avicel)/活性
405nm
(
‑
avicel)],
[1117]
其中活性
405nm
( avicel)和活性
405nm
(
‑
avicel)分别是在具有与avicel和不与avicel孵育的上清液的孔中的活性(即,针对空白对照进行校正的吸光度)。
[1118]
4)实例中报告的接头稳定性是分析的一式三份的平均值。
[1119]
此测定清楚地区分了在核心的存在和不存在下的结合,如下文实例3进一步所证明。
[1120]
实例3:纤维素结合测定
‑
无蛋白酶
[1121]
原理
[1122]
通过在稀释的洗涤剂溶液中与avicel在5℃孵育持续60分钟,允许纤维素酶(a)结合纤维素。孵育后,在上清液(b)中并相对于不存在纤维素酶的孵育的平行纤维素酶样品比较,确定未结合纤维素的纤维素酶的活性。与avicel孵育期间的温度保持较低以确保在结合步骤期间纤维素酶的催化活性对结合测定没有显著影响。
[1123]
a.结合至纤维素
[1124]
化学品
[1125]
洗涤剂:标准洗涤剂a
[1126]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1127]
纤维素纤维:ph
‑
101,(西格玛公司11365)
[1128]
试剂
[1129]
结合缓冲液:50mm hepes,ph 8
[1130]
avicel悬浮液:在结合缓冲液中的1.25g/100ml avicel,使用前混合1小时
[1131]
如上的标准洗涤剂a
[1132]
程序
[1133]
1)将纤维素酶在结合缓冲液中稀释至300ppm。
[1134]
2)将270μl洗涤剂移液至96孔聚丙烯微板(thermo scientific
tm
249944)的孔位置a1至d12中。
[1135]
3)将来自(1)的30μl稀释的纤维素酶添加至每个孔(位置a1至d12)中。对每种纤维素酶一式三份进行测试,并且将位置d4至d6用作空白对照,在其中添加30μl milli q水而不是纤维素酶。
[1136]
4)将一些小磁铁添加至每个孔(位置a1至d12)中并将该板用热封(赛默科技公司(thermo scientific)粘性pcr板封ab0558)密封,随后通过磁力搅拌持续30分钟进行混合。
[1137]
5)将160μl结合缓冲液移液至新的96孔微板(thermo scientific
tm nunc
tm
96孔聚丙烯deepwell
tm
储存板(位置a1至d12))中并将160μl avicel悬浮液移液至位置e1至h12。
[1138]
6)将20μl milli q水添加至全部孔(a1至h12)中
[1139]
7)将来自(4)的20μl纤维素酶
‑
洗涤剂样品的等分试样添加至孔中,这些孔具有avicel(a1至d12)和不具有(e1至h12)。
[1140]
8)然后将板在5℃冷室中在海道尔夫公司(heidolph)titramax 101振荡器上孵育持续60分钟以允许纤维素酶与纤维素的结合。调整振荡速度以确保纤维素在孵育期间保持悬浮。
[1141]
9)结合后,将板以1500rpm离心10秒并将上清液在结合缓冲液中稀释2.5倍(40μl
样品 60μl缓冲液)。将来自avicel孔的上清液和来自对应的无avicel的孔的上清液二者都稀释。
[1142]
b.cmc活性测定
[1143]
化学品:
[1144]
cmc:羧甲基纤维素钠(西格玛公司c5678)
[1145]
k
‑
na
‑
酒石酸:默克公司(merck)8087
[1146]
β
‑
葡糖苷酶 麦格酶公司(megazyme)(海栖热孢菌(thermotoga maritima);登录号q08638,麦格酶公司目录号e
‑
bgostm),稀释至0.1mg/ml(比活性为70u/mg以及在产品中活性为约460u/ml
‑
>6,57mg/ml)
[1147]
pahbah 4
‑
羟基苯酰肼(西格玛公司h9882)
[1148]
naoh 氢氧化钠(j.t.baker 0402.1000)
[1149]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1150]
试剂:
[1151]
测定缓冲液:50mm hepes,ph 8
[1152]
cmc底物:1.25g cmc/100ml测定缓冲液,使用前混合1小时
[1153]
pahbah缓冲液:50g/l k
‑
na
‑
酒石酸 20g/l naoh
[1154]
pahbah试剂:在pahbah缓冲液中的15mg/ml pahbah
[1155]
β
‑
葡糖苷酶溶液:在测定缓冲液中的0.1mg/mlβ
‑
葡糖苷酶
[1156]
程序:
[1157]
1)将160μl cmc底物移液至新的96孔微板(赛默科技公司目录号269620)中
[1158]
2)将来自步骤a的20μl稀释的上清液与20μlβ
‑
葡糖苷酶溶液一起添加
[1159]
3)将板使用热封(赛默科技公司粘性pcr板封ab0558)密封并在40℃孵育持续45分钟
[1160]
4)反应后,将来自每个孔的100μl转移至thermofast 96pcr板(赛默科技公司目录号ab
‑
0600),随后添加75μl pahbah试剂
[1161]
5)然后将来自(4)的板用密封箔片(格瑞纳生物科技公司(greiner bio
‑
one)板封,目录号676001)密封并在biorad t100
tm
热循环仪pcr机中在95℃孵育10分钟,随后在10℃冷却5分钟
[1162]
6)冷却后,将100μl等分试样转移至新的96孔微板(赛默科技公司目录号269620)并在405nm处读取吸光度(a
405nm
)。吸光度是上清液中纤维素酶的活性的表示。
[1163]
c.数据处理
[1164]
1)根据步骤b的吸光度读数,计算了来自无avicel的孔的3个空白对照的平均值a
405nm
(空白_参考)(位置h4
‑
>h6),并且计算了来自具有avicel的孔的3个空白对照的平均值a
405nm
(空白_avicel)(位置d4
‑
>d6)。
[1165]
2)然后将来自含有纤维素酶的孔的吸光度读数针对其各自的空白对照(即,来自(1)的那些)进行校正。
[1166]
3)将结合计算为
[1167]1‑
[活性
405nm
( avicel)/活性
405nm
(
‑
avicel)],
[1168]
其中活性
405nm
( avicel)和活性
405nm
(
‑
avicel)分别是在具有与avicel和不与
avicel孵育的上清液的孔中的活性(即,针对空白对照进行校正的吸光度)。
[1169]
实例中报告的接头稳定性是分析的一式三份的平均值。
[1170]
为证明这一点,如此实例所述,测试具有和不具有cbm的纤维素酶样品对纤维素的结合。将该比率计算为完整纤维素酶(即具有催化结构域、接头和cbm的纤维素酶)的结合相比于仅仅具有催化结构域的纤维素酶的结合。
[1171][1172]
*序列长度反映催化结构域,如通过生物信息学处理所注释
[1173]
该数据清楚地证明不存在cbm时,与纤维素的结合显著降低。
[1174]
实例4:变体的构建
[1175]
纤维素酶变体是构建自土生梭孢壳纤维素酶(seq id no:1)。使用pcr连同正确地设计的寡核苷酸(其在所得序列中引入所希望的突变),通过传统的dna片段克隆制得这些变体(sambrook等人,molecular cloning:a laboratory manual[分子克隆:实验室手册],第2版,cold spring harbor[冷泉港],1989)。可替代地,使用从供应商处(例如集成dna技术公司(idtdna))购买的合成基因片段,用新的所希望的dna序列替代天然dna序列。
[1176]
对应于所希望的一个或多个突变位点或待替代的dna段侧翼的dna序列设计寡核苷酸,其由限定插入/缺失/取代/合成的dna序列的dna碱基对分开,并购自寡核苷酸的供应商,例如idtdna。为了测试本发明的变体,将包含本发明的变体的突变dna通过同源重组而整合到感受态米曲霉菌株中,使用标准方案(基于酵母提取物的培养基,4
‑
5天,30℃)发酵,并如下进行纯化。
[1177]
将培养液通过nalgene 0.2μm过滤单元过滤以去除曲霉属宿主细胞。使用20%ch3cooh,将滤液的ph调整至ph 4.0并将调整ph的滤液应用到在20mm ch3cooh/naoh、1mm cacl2、ph 4.0中平衡的capto mmc柱(来自通用电气医疗集团(ge healthcare))上。将柱用平衡缓冲液充分地洗涤之后,将纤维素酶用50mm tris碱、1mm cacl2(未缓冲)洗脱。分析来自柱的级份的纤维素酶活性。合并纤维素酶峰并应用到在50mm tris/hcl、ph 9.0中平衡的q
‑
sepharose ff柱(来自通用电气医疗集团)上。将柱用平衡缓冲液充分地洗涤之后,将纤维素酶用在平衡缓冲液与50mm tris/hcl、5mm cacl2、500mm nacl、ph 9.0之间的线性nacl梯度经三个柱体积洗脱。分析来自柱的级份的纤维素酶活性并且将纤维素酶峰合并为纯化的产物。将纯化的变体通过sds
‑
page进行分析。由于纤维素酶变体是糖基化的,它们在考马斯染色的sds
‑
page凝胶上给出分散的条带。使用纯化的产物进行进一步表征。
[1178]
实例5:变体稳定性
[1179]
如在实例4中所述制备变体。使用实例2(接头稳定性测定
‑
在蛋白酶的存在下)中所述的测定,确定稳定性,其中应激条件是与蛋白酶(seq id no:10)在20℃孵育持续21小时,然后分析残余活性。结果示于表1中。
[1180]
表1,20℃孵育21小时后接头稳定性
[1181]
[1182]
[1183]
[1184][1185]
实例6:变体稳定性
[1186]
如在实例4中所述制备变体。使用实例2中所述的测定,确定稳定性,其中应激条件是与蛋白酶(seq id no:10)在37℃孵育持续21小时,然后分析残余活性。结果示于表2中。
[1187]
表2,37℃孵育21小时后接头稳定性
[1188]
[1189]
[1190]
[1191]
[1192][1193]
实例7:使用蛋白酶进行的洗涤中接头稳定性测定
[1194]
原理
[1195]
接头稳定性通过如下进行测量:(a)在含有蛋白酶的洗涤剂洗涤溶液中孵育纤维素酶,然后(b)确定孵育的纤维素酶结合纤维素纤维的能力。如果接头或纤维素结合结构域受到蛋白酶的影响,那么纤维素酶与纤维素纤维的结合亲和力将会降低。
[1196]
通过将孵育的纤维素酶的稀释液添加到纤维素纤维的悬浮液中来确定结合。在5℃孵育后,通过离心去除与纤维素结合的纤维素酶,并通过以下确定未结合纤维素的纤维素酶的量:测量(c)上清液中的纤维素酶的活性。未结合纤维素的纤维素酶的活性相对于在相似条件下孵育但是不存在纤维素酶的平行样品的活性是接头稳定性的量度。
[1197]
该活性是基于可溶性羧甲基纤维素(cmc)的水解以及随后(d)对形成的还原性末端的数目的检测。完整纤维素酶和不具有纤维素结合结构域的纤维素酶二者的底物都是cmc。
[1198]
e.在含有蛋白酶的洗涤剂中进行孵育
[1199]
化学品
[1200]
洗涤剂:标准洗涤剂a
[1201]
蛋白酶:具有seq id no:10的蛋白酶
[1202]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1203]
试剂
[1204]
稀释缓冲液:50mm hepes,ph 8
[1205]
具有蛋白酶的洗涤剂:0.3μg/ml活性蛋白酶蛋白质,在标准洗涤剂a中
[1206]
洗涤剂洗涤溶液:3.3g/l具有蛋白酶的洗涤剂,在具有15
°
dh水硬度的水中。
[1207]
程序
[1208]
7)制备洗涤剂洗涤溶液
[1209]
8)将纤维素酶在稀释缓冲液中稀释至300ppm。
[1210]
9)将来自(1)的270μl洗涤剂洗涤溶液移液至96孔聚丙烯微板(thermo scientific
tm
249944)的孔位置a1至d12中。
[1211]
10)将来自(2)的30μl稀释的纤维素酶添加至每个孔(位置a1至d12)中。对每种纤维素酶一式三份进行测试,并且将位置d4至d6用作空白对照,在其中添加30μl milli q水而不是纤维素酶。
[1212]
11)将一些小磁铁添加至每个孔(位置a1至d12)中并将该板用热封(thermo scientific
tm
粘性pcr板封ab0558)密封,随后通过磁力搅拌持续30分钟进行混合。
[1213]
12)混合后,将板以实例中所示的时间和温度(例如,在40℃,2小时)进行孵育。
[1214]
f.结合至纤维素纤维
[1215]
化学品
[1216]
纤维素纤维:ph
‑
101,(西格玛公司11365)
[1217]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1218]
试剂:
[1219]
结合缓冲液:50mm hepes,ph 8
[1220]
avicel悬浮液:在结合缓冲液中的1.25g/100ml avicel,使用前混合1小时
[1221]
程序:
[1222]
5)将180μl avicel悬浮液添加至新的96孔微板(thermo scientific
tm
目录号269620)中的位置a1
‑
>d12并将180μl结合缓冲液添加至位置e1
‑
>h12中
[1223]
6)然后将来自步骤a的孵育的板中的每个孔的20μl样品等分试样分别添加至位置a1
‑
>d12和位置e1
‑
>h12的孔中。
[1224]
7)以足以使纤维素纤维保持处于悬浮的速度,将板在5℃振荡持续1小时以允许纤维素酶结合纤维素
[1225]
8)结合后,将板以1500rpm离心10秒并将上清液在结合缓冲液中稀释2.5倍(40μl样品 60μl缓冲液)。将来自avicel孔的上清液和来自对应的无avicel的孔的上清液二者都稀释。
[1226]
g.cmc活性测定
[1227]
化学品:
[1228]
cmc:羧甲基纤维素钠(西格玛公司c5678)
[1229]
k
‑
na
‑
酒石酸:默克公司(merck)8087
[1230]
β
‑
葡糖苷酶麦格酶公司(megazyme)(海栖热孢菌(thermotoga maritima);登录号q08638,麦格酶公司目录号e
‑
bgostm),稀释至0.1mg/ml(比活性为70u/mg以及在产品中活性为约460u/ml
‑
>6,57mg/ml)
[1231]
pahbah4
‑
羟基苯酰肼(西格玛公司h9882)
[1232]
naoh氢氧化钠(j.t.baker 0402.1000)
[1233]
hepes:4
‑
(2
‑
羟乙基)
‑1‑
哌嗪乙磺酸,西格玛公司(sigma)h3375
[1234]
试剂:
[1235]
测定缓冲液:50mm hepes,ph 8
[1236]
cmc底物:1.25g cmc/100ml测定缓冲液,使用前混合1小时
[1237]
pahbah缓冲液:50g/l k
‑
na
‑
酒石酸 20g/l naoh
[1238]
pahbah试剂:在pahbah缓冲液中的15mg/ml pahbah
[1239]
β
‑
葡糖苷酶溶液:在测定缓冲液中的0.1mg/mlβ
‑
葡糖苷酶
[1240]
程序:
[1241]
7)将160μl cmc底物移液至新的96孔微板(thermo scientific
tm
目录号269620)中
[1242]
8)将来自步骤b的20μl稀释的上清液与20μlβ
‑
葡糖苷酶溶液一起添加
[1243]
9)将板使用热封(thermo scientific
tm
粘性pcr板封ab0558)密封并在40℃孵育持续45分钟
[1244]
10)反应后,将来自每个孔的100μl转移至thermofast 96pcr板(thermo scientific
tm
目录号ab
‑
0600),随后添加75μl pahbah试剂
[1245]
11)然后将来自(4)的板用密封箔片(格瑞纳生物科技公司(greiner bio
‑
one)板封,目录号676001)密封并在biorad t100
tm
热循环仪pcr机中在95℃孵育10分钟,随后在10℃冷却5分钟
[1246]
12)冷却后,将100μl等分试样转移至新的96孔微板(thermo scientific
tm
目录号269620)并在405nm处读取吸光度(a
405nm
)。吸光度是上清液中纤维素酶的活性的表示。
[1247]
h.数据处理
[1248]
5)根据步骤c的吸光度读数,计算了来自无avicel的孔的3个空白对照的平均值a
405nm
(空白_参考)(位置h4
‑
>h6),并且计算了来自具有avicel的孔的3个空白对照的平均值a
405nm
(空白_avicel)(位置d4
‑
>d6)。
[1249]
6)然后将来自含有纤维素酶的孔的吸光度读数针对其各自的空白对照(即,来自(1)的那些)进行校正。
[1250]
7)将接头稳定性计算为
[1251]1‑
[活性
405nm
( avicel)/活性
405nm
(
‑
avicel)],
[1252]
其中活性
405nm
( avicel)和活性
405nm
(
‑
avicel)分别是在具有与avicel和不与avicel孵育的上清液的孔中的活性(即,针对空白对照进行校正的吸光度)。
[1253]
8)实例中报告的接头稳定性是分析的一式三份的平均值。
[1254]
实例8:变体稳定性
[1255]
如在实例4中所述制备变体。使用实例2中所述的测定,确定稳定性,其中应激条件是与蛋白酶(seq id no:10)在20℃孵育持续20小时,然后分析残余活性。
[1256]
表3中示出了接头稳定性(相对于对照的接头稳定性)。
[1257]
表3,
[1258]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。