1.本发明涉及一种车辆防侧翻驾驶策略,尤其涉及一种考虑路面附着条件的大型营运车辆防侧翻决策方法,属于汽车安全技术领域。
背景技术:
2.近年来,随着汽车保有量的爆发性增长,加之我国道路条件和交通状况复杂,致使交通事故频发,导致交通中断、财产损失和人员伤亡。国家统计局发布的相关数据显示,我国每年因道路交通事故造成的直接财产损失超过13亿元,间接损失约1万亿元。营运车辆作为道路运输的主要承担者,因其发生交通事故所造成的财产损失占比约40%。在各类交通安全事故中,侧翻事故的危害程度和发生频率仅次于碰撞事故,位居第2位。不同于一般的乘用车辆,大型营运车辆具有载质量大、轮距小、质心位置高等特点,导致其侧倾稳定性较差,发生侧翻事故的频率更高,且极易诱发大型、特大型安全事故。目前,我国营运车辆侧翻事故的防控形势依旧严峻。
3.作为提升交通安全的有效手段,智能车路系统(intelligent vehicle
‑
infrastructure system,ivis)得到了越来越多的关注。ivis中的车路通信、车车通信等车用无线通信功能(vehicle to everything,v2x),能够实时地将前方路况、交通环境等信息发送给行驶车辆,为包括防侧翻在内的各类驾驶决策提供更为全面、准确的信息支撑。在防侧翻层面,可以有效减少或避免紧急制动、急转向、路面湿滑等情况下的侧翻事故。此外,随着《营运车辆车路/车车通信终端性能要求和检测方法》(jt 2018
‑
37)、《营运车辆车路交互信息集》(jt/t 1324
‑
2020)等交通运输行业标准的制订和实施,v2x功能在营运车辆大规模落地应用得到了有力保障。因此,研究智能车路系统下的大型营运车辆防侧翻驾驶决策方法,对于提升我国道路运输车辆的安全水平,提高道路运输重特大事故防控能力具有重要意义。
4.已有专利、文献对营运车辆的防侧翻驾驶决策方法进行了研究,主要包括基于人工设计规则的决策方法和基于智能体自学习的决策方法两类。然而,已有方法主要针对干燥的沥青路面、混凝土路面等常规场景进行防侧翻驾驶决策建模,未考虑路面附着条件对行车安全的影响。具体而言,不同于常规的干燥路面,潮湿、雨水、冰雪等路面的附着系数较低,导致营运车辆的横摆稳定性和制动稳定性下降,易引发轮胎打滑、车辆侧滑等情况,更容易发生侧翻事故。因此,不同路面附着系数下的驾驶策略存在明显的差异,若忽略这一差异而对不同路面条件采用相同的决策策略将会危及行车安全。已有的决策方法往往在某种特定的路面条件下较准确,但在其他路面条件下准确性不足。
5.总体而言,现有的营运车辆防侧翻驾驶决策方法,难以适应不同的路面条件,尚缺乏准确、有效、适应不同路面条件的大型营运车辆防侧翻驾驶决策方法。
技术实现要素:
6.发明目的:针对营运车辆防侧翻决策方法缺乏路面条件适应性和准确性的问题,
本发明公开了一种考虑路面附着条件的防侧翻驾驶决策方法。该方法能够为驾驶员提供节气门开度、制动踏板开度、方向盘转角控制量等精确量化的驾驶建议,且能够适应不同的路面附着条件,提高了大型营运车辆防侧翻决策方法的准确性和适应性。
7.技术方案:本发明针对智能车路系统下的大型营运车辆,如大型载货汽车、危险品运输罐车,提出了一种考虑路面附着条件的防侧翻驾驶决策方法,该方法包括:
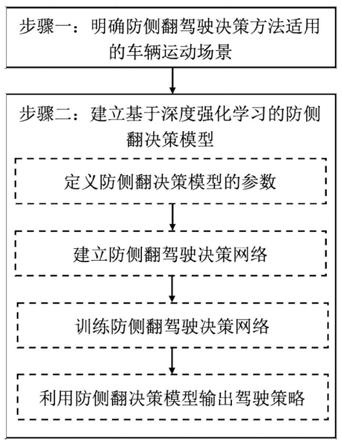
8.步骤一:明确防侧翻驾驶决策方法适用的车辆运动场景
9.其适用的运动场景为:
10.具备车路通信功能的大型营运车辆在高等级公路上行驶,路面存在潮湿和/或积水和/或积雪情况,车辆的前方存在其他交通参与者;交叉口的龙门架、道路两侧设有路侧单元,路侧单元以10赫兹的频率向车辆发送道路状况信息,包括:路面附着系数信息、道路曲率信息、纵向坡度信息、横向坡度信息、车道限制信息和速度限制信息;当车辆进行制动、车道变换或经过弯道时,应为驾驶员提供包括制动减速、转向的驾驶策略,以避免侧翻事故的发生;
11.步骤二:建立基于深度强化学习的防侧翻决策模型
12.综合考虑路面条件、行驶工况对车辆侧翻的影响,采用td3算法建立防侧翻驾驶决策模型,具体包括以下4个子步骤:
13.子步骤1:定义防侧翻决策模型的参数
14.首先,将最优驾驶决策问题规范化为一个马尔科夫决策过程(s
t
,a
t
,p
t
,r
t
),并对模型的基础参数进行定义:t时刻的状态空间s
t
、t 1时刻的状态空间s
t 1
、t时刻的防侧翻动作决策a
t
、t时刻的状态转移概率p
t
以及t时刻的奖励函数r
t
,其次,对马尔科夫决策过程的基础参数进行定义,具体地
15.(1)定义状态空间为:
16.s
t
=[p
lon
,p
lat
,v
lon
,v
lat
,a
lon
,a
lat
,θ
str
,β,μ,ρ,α
lon
,α
lat
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0017]
式中,s
t
为t时刻的状态空间,p
lon
,p
lat
分别表示车辆的纵向位置和横向位置,单位均为米,v
lon
,v
lat
分别表示车辆的纵向速度和侧向速度,单位均为米每秒,通过安装在车辆质心处的厘米级高精度差分gps测量获得;a
lon
,a
lat
分别表示车辆的纵向加速度和侧向加速度,单位均为米每二次方秒,β为车辆的侧倾角,单位为度,通过安装在车辆底盘中心的mems陀螺仪测量获得;θ
str
为车辆的方向盘转角,单位为度,通过can总线获得;μ为路面附着系数,ρ为道路曲率,单位为米的负一次方,α
lon
,α
lat
分别表示纵向坡度、横向坡度,单位为度,通过与路侧单位信息交互获得;
[0018]
(2)定义动作空间为:
[0019]
a
t
=[θ
str
,δ]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0020]
式中,θ
str
为归一化后的方向盘转角控制量,范围为[
‑
1,1],当θ
str
>0时,表示车辆向左转向,当θ
str
<0时,表示车辆向右转向,δ表示节气门/制动踏板开度控制量,单位为百分数,范围为[
‑
1,1],当δ>0时,表示车辆通过控制节气门开度进行加速,当δ<0时,表示车辆通过控制制动踏板开度进行减速;
[0021]
(3)定义奖励函数为:
[0022]
r
t
=r1 r2 r3 r4 r5ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0023]
式中,r
t
为t时刻的奖励函数,r1为防侧翻奖励函数,r2为安全距离奖励函数,r3为
急动度奖励函数,r4为速度奖励函数,r5为惩罚函数;
[0024]
设计与侧向加速度、侧倾角相关的防侧翻奖励函数r1:
[0025]
r1=
‑
ω1·
(β
thr
‑
β)
‑
ω2·
(a
lat_thr
‑
a
lat
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0026]
式中,β
thr
为车辆的侧倾角阈值,a
lat_thr
为车辆的侧向加速度阈值,ω1,ω2为表示防侧翻奖励函数的权重系数;
[0027]
设计自适应路面条件的安全距离奖励函数r2:
[0028][0029]
式中,d
f
表示营运车辆与前方车辆的相对距离,ω3为安全距离奖励函数的权重系数;前方车辆是指位于营运车辆行驶道路前方,且位于同一车道线内、行驶方向相同、距离最近的车辆;
[0030]
设计急动度奖励函数r3:
[0031][0032]
式中,为车辆的纵向急动度,可通过纵向位置对时间求三阶导数获得,ω4为急动度奖励函数的权重系数;
[0033]
设计速度奖励函数r4:
[0034][0035]
式中,v
thr
为道路限速值,单位为千米每小时,可通过与路侧单位信息交互获得,ω5为速度奖励函数的权重系数;
[0036]
最后,为了避免决策策略出现错误动作,设计惩罚函数r5:
[0037][0038]
子步骤2:建立防侧翻驾驶决策网络
[0039]
利用演员
‑
评论家架构搭建防侧翻驾驶决策网络,包括演员网络和评论家网络两部分;其中,演员网络将状态空间信息作为输入,输出驾驶决策,即动作空间;评论家网络将状态空间信息和驾驶决策作为输入,输出当前“状态
‑
动作”的价值;
[0040]
首先,利用全连接神经网络建立演员网络;将状态空间s
t
依次与全连接层f1、全连接层f2、全连接层f3相连,得到输出动作空间a
t
;
[0041]
其次,利用多个隐藏层结构的神经网络建立评论家网络;首先,将状态空间s
t
输入到隐藏层f4中;同时,将动作决策a
t
输入到隐藏层f5中;其次,隐藏层f4和f5通过张量相加的方式进行合并;最后,依次通过全连接层f6和f7后,输出用于策略梯度计算的q值;
[0042]
其中,设置全连接层f1,f2,f3,f4,f5,f6,f7的神经元数量分别为12、50、50、12、2、50、50;各全连接层的激活函数为sigmoid函数,其表达式为
[0043]
子步骤3:训练防侧翻驾驶决策网络
[0044]
训练防侧翻驾驶决策网络,并对网络参数进行迭代更新,在训练过程中,若车辆发
生侧翻或碰撞事故,则终止当前回合并开始新的回合进行训练;当迭代达到最大步数或损失值小于给定阈值时,训练结束;
[0045]
子步骤4:利用防侧翻驾驶决策模型输出驾驶决策
[0046]
将状态空间中的各参数输入到训练后的防侧翻驾驶决策模型中,实时输出节气门/制动踏板开度、方向盘转角控制量,为驾驶员提供精确量化的防侧翻驾驶建议
[0047]
有益效果:相比于一般的防侧翻驾驶决策方法,本发明提出的方法具有更为准确、有效、自适应的特点,具体体现在:
[0048]
(1)本发明提出的方法综合考虑行驶工况、路面条件对车辆侧翻的影响,以数值的形式将方向盘转角、节气门/制动踏板开度等驾驶策略精确量化,实现了准确、有效的大型营运车辆防侧翻驾驶决策,为营运车辆的安全运行提供了有力支撑;
[0049]
(2)本发明提出的决策方法,以进行舒缓的减速制动为主,可以避免因紧急制动、转向过度导致的车辆失稳侧翻,进一步提高了大型营运车辆防侧翻驾驶决策的有效性;
[0050]
(3)本发明提出的方法,能够适应干燥、湿滑、结冰等不同的路面条件,输出的驾驶策略能够根据路面条件变化进行自适应调整,克服了现有的营运车辆防侧翻决策方法缺乏环境适应性和准确性的不足;
[0051]
(4)本发明提出的方法无需进行复杂的动力学建模,计算方法简单清晰。
附图说明
[0052]
图1是本发明的技术路线示意图。
具体实施方式
[0053]
下面结合附图对本发明的技术方案作进一步的说明。
[0054]
大型营运车辆具有载质量大、轮距小、质心位置高等特点,导致其侧倾稳定性较差,发生侧翻事故的频率更高,且极易诱发大型、特大型安全事故。作为提升交通安全的有效手段,智能车路系统(intelligent vehicle
‑
infrastructure system,ivis)得到了越来越多的关注。ivis中的车路通信、车车通信等车用无线通信功能(vehicle to everything,v2x),能够实时地将前方路况、交通环境等信息发送给行驶车辆,为包括防侧翻在内的各类驾驶决策提供更为全面、准确的信息支撑。在防侧翻层面,可以有效减少或避免紧急制动、急转向、路面湿滑等情况下的侧翻事故。
[0055]
已有专利、文献对营运车辆的防侧翻驾驶决策方法进行了研究,主要包括基于人工设计规则的决策方法和基于智能体自学习的决策方法两类。然而,已有方法主要针对干燥的沥青路面、混凝土路面等常规场景进行防侧翻驾驶决策建模,未考虑路面附着条件对行车安全的影响。具体而言,不同于常规的干燥路面,潮湿、雨水、冰雪等路面的附着系数较低,导致营运车辆的横摆稳定性和制动稳定性下降,易引发轮胎打滑、车辆侧滑等情况,更容易发生侧翻事故。因此,不同路面附着系数下的驾驶策略存在明显的差异,若忽略这一差异而对不同路面条件采用相同的决策策略将会危及行车安全。已有的决策方法往往在某种特定的路面条件下较准确,但在其他路面条件下准确性不足。
[0056]
总体而言,现有的营运车辆防侧翻驾驶决策方法,难以适应不同的路面条件,尚缺乏准确、有效、适应不同路面条件的大型营运车辆防侧翻驾驶决策方法。
[0057]
为了建立准确、有效、自适应不同路面条件的防侧翻驾驶策略,本发明针对大型营运车辆,如大型载货汽车、危险品运输罐车,提出了一种考虑路面附着条件的防侧翻驾驶决策方法。首先,明确防侧翻驾驶决策方法适用的车辆运动场景。其次,将防侧翻驾驶决策问题描述为马尔科夫决策过程,利用双延迟深度确定性策略梯度算法建立大型营运车辆的防侧翻决策模型,得到不同路面条件和行驶工况下的防侧翻决策策略。本发明的技术路线如图1所示,具体步骤如下:
[0058]
步骤一:明确防侧翻驾驶决策方法适用的车辆运动场景
[0059]
紧急制动、急转向、在附着系数较低的路面上同时进行制动和转向是大型营运车辆发生侧翻事故的主要原因。现有的防侧翻驾驶决策方法往往将道路附着系数视为常值,未对湿滑、结冰等特殊路面做针对性考虑,导致部分工况下的防侧翻驾驶决策的准确性和有效性存在不足。本发明提出了一种考虑路面附着条件的防侧翻决策方法,其适用的运动场景为:
[0060]
具备车路通信功能的大型营运车辆在高等级公路上行驶,路面可能存在潮湿、积水、积雪等情况,车辆的前方可能存在其他交通参与者。交叉口的龙门架、道路两侧设有路侧单元,路侧单元以10赫兹的频率向车辆发送道路状况信息,包括:路面附着系数信息、道路曲率信息、纵向坡度信息、横向坡度信息、车道限制信息和速度限制信息。当车辆进行制动、车道变换或经过弯道时,应准确、有效地为驾驶员提供制动减速、转向等驾驶策略,以避免侧翻事故的发生。
[0061]
步骤二:建立基于深度强化学习的防侧翻决策模型
[0062]
为了实现准确、有效、自适应路面条件的防侧翻驾驶决策,本发明综合考虑路面条件、行驶工况对车辆侧翻的影响,建立大型营运车辆的防侧翻驾驶决策模型。
[0063]
常见的驾驶决策方法包括基于人工设计规则和基于智能体自学习的决策算法两类。(1)基于人工设计规则的决策算法,是利用人为设定的规则描述驾驶状态与道路环境的关系,进而实现驾驶动作的生成。然而,在车辆运动过程中,路面条件、行驶工况均存在不确定性,制定的规则难以遍历所有交通场景,难以保证决策的适应性和准确性。(2)基于智能体自学习的决策算法,是利用算法模仿人类对知识或技能的学习过程,通过交互式的自学习机制实现自身学习性能的不断改进。其中,基于深度强化学习的方法将深度学习的感知能力和强化学习的决策能力相结合,能够在不同的道路环境和行驶工况中,探索出最佳的驾驶策略。因此,本发明采用深度强化学习算法建立防侧翻驾驶决策模型。
[0064]
基于深度强化学习的决策方法主要包括:基于值函数、基于策略搜索和基于演员
‑
评论家架构的决策方法三类。基于演员
‑
评论家架构的决策方法结合了值函数估计和策略搜索的优势,具有较快的更新速度,其中的双延迟深度确定性策略梯度算法(twin delayed deep deterministic policy gradient,td3)解决了策略学习受到q函数误差影响而中断的问题,在输出连续动作方面取得了较好的效果。因此,本发明采用td3算法建立防侧翻驾驶决策模型,通过与交通环境的不断交互式,探索不同路面条件和行驶工况下的最优驾驶决策。具体包括以下4个子步骤:
[0065]
子步骤1:定义防侧翻决策模型的参数
[0066]
首先,将最优驾驶决策问题规范化为一个马尔科夫决策过程(s
t
,a
t
,p
t
,r
t
),并对模型的基础参数进行定义:t时刻的状态空间s
t
、t 1时刻的状态空间s
t 1
、t时刻的防侧翻动
作决策a
t
、t时刻的状态转移概率p
t
以及t时刻的奖励函数r
t
,其次,对马尔科夫决策过程的基础参数进行定义,具体地
[0067]
(1)定义状态空间
[0068]
大型营运车辆的行驶安全不仅与车辆运动状态有关,还与道路状况信息有关,因此,本发明将状态空间定义为:
[0069]
s
t
=[p
lon
,p
lat
,v
lon
,v
lat
,a
lon
,a
lat
,θ
str
,β,μ,ρ,α
lon
,α
lat
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0070]
式中,s
t
为t时刻的状态空间,p
lon
,p
lat
分别表示车辆的纵向位置和横向位置,单位均为米,v
lon
,v
lat
分别表示车辆的纵向速度和侧向速度,单位均为米每秒,可通过安装在接近车辆质心处的厘米级高精度差分gps(global positioning system)测量获得。a
lon
,a
lat
分别表示车辆的纵向加速度和侧向加速度,单位均为米每二次方秒,β为车辆的侧倾角,单位为度,可通过安装在车辆底盘中心的mems陀螺仪测量获得。θ
str
为车辆的方向盘转角,单位为度,可通过can总线获得。μ为路面附着系数,ρ为道路曲率,单位为米的负一次方,α
lon
,α
lat
分别表示纵向坡度、横向坡度,单位为度,可通过与路侧单位信息交互获得。
[0071]
(2)定义动作空间
[0072]
考虑到车辆的运动控制包括横向和纵向两个部分,本发明以方向盘转角、节气门/制动踏板开度作为控制量,将动作空间(即防侧翻驾驶策略)定义为:
[0073]
a
t
=[θ
str
,δ]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0074]
式中,θ
str
为归一化后的方向盘转角控制量,范围为[
‑
1,1],当θ
str
>0时,表示车辆向左转向,当θ
str
<0时,表示车辆向右转向,δ表示节气门/制动踏板开度控制量,单位为百分数,范围为[
‑
1,1],当δ>0时,表示车辆通过控制节气门开度进行加速,当δ<0时,表示车辆通过控制制动踏板开度进行减速。
[0075]
(3)定义奖励函数
[0076]
通过建立形式化的奖励函数,精确量化防侧翻驾驶策略的优劣程度,将奖励函数定义为:
[0077]
r
t
=r1 r2 r3 r4 r5ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0078]
式中,r
t
为t时刻的奖励函数,r1为防侧翻奖励函数,r2为安全距离奖励函数,r3为急动度奖励函数,r4为速度奖励函数,r5为惩罚函数。
[0079]
首先,为了避免营运车辆发生侧翻,在行驶过程中,应避免出现较大的侧向加速度、侧倾角,设计防侧翻奖励函数r1:
[0080]
r1=
‑
ω1·
(β
thr
‑
β)
‑
ω2·
(a
lat_thr
‑
a
lat
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0081]
式中,β
thr
为车辆的侧倾角阈值,a
lat_thr
为车辆的侧向加速度阈值,ω1,ω2为表示防侧翻奖励函数的权重系数。
[0082]
其次,营运车辆在防止自身发生侧翻的同时,还应与前方车辆保持一定的安全距离,以避免碰撞事故的发生。同时,考虑到在低附着系数的路面上行车时,车辆制动距离较长,营运车辆应与前方车辆保持更大行车间距。因此,设计自适应路面条件的安全距离奖励函数r2:
[0083][0084]
式中,d
f
表示营运车辆与前方车辆的相对距离,ω3为安全距离奖励函数的权重系
数。在本发明中,前方车辆是指位于大型营运车辆行驶道路前方,且位于同一车道线内、行驶方向相同、距离最近的车辆。
[0085]
再次,为了进一步降低侧翻风险,当大型营运车辆即将驶入急弯或前方路面存在积水、积雪等情况时,应提前进行较为舒缓的减速制动,即连续平稳踩踏制动踏板,避免因紧急制动或转向过度导致的车辆失稳侧翻。因此,设计急动度奖励函数r3:
[0086][0087]
式中,为车辆的纵向急动度,可通过纵向位置对时间求三阶导数获得,ω4为急动度奖励函数的权重系数。
[0088]
此外,不同等级、不同路面条件下的道路限速情况有所不同,如交通运输部在《道路运输驾驶员应急驾驶操作指南(试行)》(交办运函〔2021〕679号)中规定了:危险品运输车辆在高速公路上行驶速度不得超过80千米每小时;机动车在冰雪道路行驶时,最高行驶速度不得超过30千米每小时等。在大型营运车辆在不超速、不侧翻的情况下,为了提高车辆行车效率,设计速度奖励函数r4:
[0089][0090]
式中,v
thr
为道路限速值,单位为千米每小时,可通过与路侧单位信息交互获得,ω5为速度奖励函数的权重系数。
[0091]
最后,为了避免决策策略出现错误动作,设计惩罚函数r5:
[0092][0093]
子步骤2:建立防侧翻驾驶决策网络
[0094]
利用演员
‑
评论家架构搭建防侧翻驾驶决策网络,包括演员网络和评论家网络两部分。其中,演员网络将状态空间信息作为输入,输出驾驶决策(即动作空间)。评论家网络将状态空间信息和驾驶决策作为输入,输出当前“状态
‑
动作”的价值。
[0095]
首先,利用全连接神经网络建立演员网络。将状态空间s
t
依次与全连接层f1、全连接层f2、全连接层f3相连,得到输出动作空间a
t
。
[0096]
其次,利用多个隐藏层结构的神经网络建立评论家网络。首先,将状态空间s
t
输入到隐藏层f4中;同时,将动作决策a
t
输入到隐藏层f5中。其次,隐藏层f4和f5通过张量相加的方式进行合并。最后,依次通过全连接层f6和f7后,输出用于策略梯度计算的q值。
[0097]
其中,设置全连接层f1,f2,f3,f4,f5,f6,f7的神经元数量分别为12、50、50、12、2、50、50。各全连接层的激活函数为sigmoid函数,其表达式为
[0098]
子步骤3:训练防侧翻驾驶决策网络
[0099]
训练防侧翻驾驶决策网络,并对网络参数进行迭代更新,具体训练过程可见参考文献(fujimoto s,hoof h v,meger d.addressing function approximation error in actor
‑
critic methods[j].2018.)。在训练过程中,若车辆发生侧翻或碰撞事故,则终止当前回合并开始新的回合进行训练。当迭代达到最大步数或损失值小于给定阈值时,训练结
束。
[0100]
子步骤4:利用防侧翻驾驶决策模型输出驾驶决策
[0101]
将状态空间中的各参数输入到训练后的防侧翻驾驶决策模型中,可以实时输出合理的节气门/制动踏板开度、方向盘转角控制量,为驾驶员提供精确量化的防侧翻驾驶建议,从而实现了准确、有效、自适应路面条件的大型营运车辆防侧翻驾驶决策。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。