1.本发明涉及生物技术领域,特别是涉及一种基于宏基因组学的病原微生物检测方法及装置。
背景技术:
2.微生物广泛存在于自然界,多数为单细胞生物。微生物通常包括病毒、细菌、真菌、原生动物和某些藻类等。在医疗的应用角度,快速检测出临床样本中的病原微生物对感染性疾病的诊断、治疗和预后有重要的临床意义。
3.微生物组学研究在过去的几十年里发展迅速,尤其是宏基因组测序技术(metagenomic next
‑
generation sequencing)在病原微生物检测中的应用发挥了巨大的作用。下一代测序可以实现疾病的诊断、审问及传染病的追踪。当前纳米孔测序的有很多的缺点:测序错误较多、通量较低、每个碱基的平均测序代价较高,因此限制了纳米孔测序的应用。相对于纳米孔测序,mngs测序对于病原体检测的具有非常明显的优势。
4.然而,目前利用宏基因组测序检测病原微生物中的方法中存在检测时间长、准确性低、光度窄,未知的感染病原体不能被检测出来的问题。
技术实现要素:
5.针对于上述问题,本发明提供一种基于宏基因组学的病原微生物检测方法及装置,提升了病原微生物检测适用性范围和病原检测准确性。
6.为了实现上述目的,本发明提供了如下技术方案:一种基于宏基因组学的病原微生物检测方法,包括:获取待检测样本的宏基因组测序数据;对所述宏基因组测序数据进行预处理,得到目标数据,所述目标数据为满足目标质量条件的宏基因组测序数据;对所述目标数据进行筛选,得到目标序列;对所述目标序列进行聚类分析,获得所述待测样本的候选物种类别;将所述目标数据与非冗余参考基因集进行比对,并计算每个基因在单个样本中的丰度,得到所述待测样本的目标物种分类信息;将所述目标数据与病原微生物可检测数据库中的信息进行比对,获得所述待测样本的耐药基因和毒性元件信息;将所述目标物种分类信息、所述耐药基因和所述毒性元件信息,确定为所述待检测样本的检测结果。
7.可选地,所述对所述宏基因组测序数据进行预处理,得到目标数据,包括:对所述宏基因组测序数据进行过滤,得到高质量的序列;去除所述高质量的序列中宿主测序序列,并将冗余序列去除,去除后的序列;将所述去除后的序列与参考序列进行比对处理,得到目标数据。
8.可选地,还包括:若所述去除后的序列的长度小于预设长度阈值,将去除后的序列进行拼接,得到拼接后的序列。
9.可选地,所述对所述目标数据进行筛选,得到目标序列,包括确定开放阅读框的长度,并利用所述长度的开放阅读框识别所述目标数据,得到初始序列;将所述初始序列中的序列中间存在终止密码子,且若两个有重叠的初始序列翻译的起始坐标的差值不是三的倍数的初始序列进行过滤,得到过滤后的序列;根据翻译的氨基酸,将过滤后的序列中含有终止密码子的序列去除,得到目标序列。
10.可选地,所述对所述目标序列进行聚类分析,获得所述待测样本的候选物种类别,包括:获取每一所述目标序列的读码的绝对位置信息;基于所述绝对位置信息对所述目标序列进行拼接,并将拼接后的目标序列组合成基因向量矩阵;根据所述基因向量矩阵生成基因特征自学习求解器,并获得学习率的最优解;根据所述学习率最优解进行基因预测,得到所述待测样本的候选物种类别。
11.一种基于宏基因组学的病原微生物检测装置,包括:获取单元,用于获取待检测样本的宏基因组测序数据;预处理单元,用于对所述宏基因组测序数据进行预处理,得到目标数据,所述目标数据为满足目标质量条件的宏基因组测序数据;筛选单元,用于对所述目标数据进行筛选,得到目标序列;分析单元,用于对所述目标序列进行聚类分析,获得所述待测样本的候选物种类别;计算单元,用于将所述目标数据与非冗余参考基因集进行比对,并计算每个基因在单个样本中的丰度,得到所述待测样本的目标物种分类信息;比对单元,用于将所述目标数据与病原微生物可检测数据库中的信息进行比对,获得所述待测样本的耐药基因和毒性元件信息;确定单元,用于将所述目标物种分类信息、所述耐药基因和所述毒性元件信息,确定为所述待检测样本的检测结果。
12.可选地,所述预处理单元包括:第一过滤子单元,用于对所述宏基因组测序数据进行过滤,得到高质量的序列;第一去除子单元,用于去除所述高质量的序列中宿主测序序列,并将冗余序列去除,去除后的序列;比对子单元,用于将所述去除后的序列与参考序列进行比对处理,得到目标数据。
13.可选地,还包括:拼接子单元,用于若所述去除后的序列的长度小于预设长度阈值,将去除后的序列进行拼接,得到拼接后的序列。
14.可选地,所述筛选单元包括
识别子单元,用于确定开放阅读框的长度,并利用所述长度的开放阅读框识别所述目标数据,得到初始序列;第二过滤子单元,用于将所述初始序列中的序列中间存在终止密码子,且若两个有重叠的初始序列翻译的起始坐标的差值不是三的倍数的初始序列进行过滤,得到过滤后的序列;第二去除子单元,用于根据翻译的氨基酸,将过滤后的序列中含有终止密码子的序列去除,得到目标序列。
15.可选地,所述分析单元包括:获取子单元,用于获取每一所述目标序列的读码的绝对位置信息;序列拼接子单元,用于基于所述绝对位置信息对所述目标序列进行拼接,并将拼接后的目标序列组合成基因向量矩阵;生成子单元,用于根据所述基因向量矩阵生成基因特征自学习求解器,并获得学习率的最优解;预测子单元,用于根据所述学习率最优解进行基因预测,得到所述待测样本的候选物种类别。
16.相较于现有技术,本发明提供了一种基于宏基因组学的病原微生物检测方法及装置,包括:获取待检测样本的宏基因组测序数据;对宏基因组测序数据进行预处理,得到目标数据,目标数据为满足目标质量条件的宏基因组测序数据;对目标数据进行筛选,得到目标序列;对目标序列进行聚类分析,获得待测样本的候选物种类别;将目标数据与非冗余参考基因集进行比对,并计算每个基因在单个样本中的丰度,得到待测样本的目标物种分类信息;将目标数据与病原微生物可检测数据库中的信息进行比对,获得待测样本的耐药基因和毒性元件信息;将目标物种分类信息、耐药基因和毒性元件信息,确定为待检测样本的检测结果。本发明提升了病原微生物检测适用性范围和病原检测准确性。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
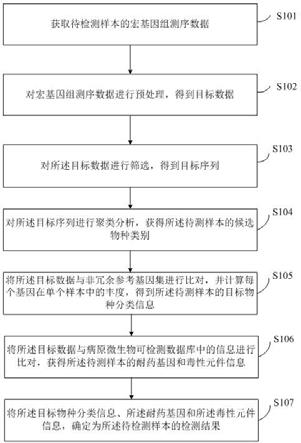
18.图1为本发明实施例提供的一种基于宏基因组学的病原微生物检测方法的流程示意图;图2为本发明实施例提供的一种病原微生物自学习检测系统的流程图;图3为本发明实施例提供的一种基于宏基因组学的病原微生物检测装置的结构示意图。
具体实施方式
19.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实
施例,都属于本发明保护的范围。
20.本发明的说明书和权利要求书及上述附图中的术语“第一”和“第二”等是用于区别不同的对象,而不是用于描述特定的顺序。此外术语“包括”和“具有”以及他们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有设定于已列出的步骤或单元,而是可包括没有列出的步骤或单元。
21.在本发明实施例中提供了一种宏基因组学的病原微生物检测方法,属于病原微生物筛查与检测领域,主要基于获取原始测序数据、质量控制、去除宿主、基因注释、分冗余序列集注释和输出检测结果。实现了适用范围广、筛选物种全面、检测准确,并且可以精确筛查样本中微生物的组成和致病基因。
22.为了便于对本发明进行说明,现将相关术语进行解释。
23.原始测序数据(raw reads):指的是从测序仪中直接取下来的数据,也即高通量测序的原始下机数据。
24.测序序列(read,一般也可称为读段或读长):通过测序技术,得到的由碱基组成的一段序列信息。
25.开放阅读框(orfs):指的是在给定的阅读框架中,不包含终止密码子的一串序列,这段序列是生物个体的基因组中可能作为蛋白质编码序列的部分。
26.参见图1,为本发明实施例提供的一种基于宏基因组学的病原微生物检测方法的流程示意图,该方法可以包括以下步骤:s101、获取待检测样本的宏基因组测序数据。
27.待检测样本为待检测的未知病原微生物的样本,其对应的宏基因组测序数据是原始测序数据(raw reads)即未经过高质量筛选等处理的测序数据。
28.s102、对宏基因组测序数据进行预处理,得到目标数据。
29.为了保证后续数据处理的精确性和处理效率,在本技术实施例中先对原始测序数据进行预处理,得到满足目标质量条件的宏基因组测序数据,其中,目标质量条件为基于实际应用场景确定的条件,可以包括滤除哪些序列、高质量序列的条件等。
30.在本发明实施例的一种实施方式中,所述对所述宏基因组测序数据进行预处理,得到目标数据,包括:对所述宏基因组测序数据进行过滤,得到高质量的序列;去除所述高质量的序列中宿主测序序列,并将冗余序列去除,去除后的序列;将所述去除后的序列与参考序列进行比对处理,得到目标数据。
31.具体的,将待检测样本的宏基因组测序数据(即原始测序数据)进行过滤,筛选出该高质量的序列,将得到的高质量的序列比对到参考基因组上去除宿主的基因组的序列。其中,筛选高质量序列的过程为高质量目标序列与参考基因组比对,包括参考基因组知识库构建和高质量reads比对两个部分。参考基因组建库:对于冗余的病原微生物参考基因组,可以将冗余的序列进行去除。高质量reads比对与分析:将处理后得到的clean reads与宏基因组参考序列进行比对,得到比对后的序列。
32.需要说明的是,在预处理过程中还包括:若所述去除后的序列的长度小于预设长度阈值,将去除后的序列进行拼接,得到拼接后的序列。即为了便于处理,可以将短的序列拼接成较长的长序列(即scaffold),从而实现适用于短reads的处理。
33.s103、对所述目标数据进行筛选,得到目标序列。
34.在获得了目标数据后,也就是clean reads。为了便于后续获取到物种注视和功能注视信息,需要获取多个弱学习器的开放阅读框(orfs),识别上述目标数据集合中的orfs,即获得生物个体的基因组中可能作为蛋白质编码序列的部分。需要说明的是,在本发明实施例中开放阅读框的提取长度是可以依据实际需求进行确定,即可以提取满足实际需求任意长度的序列。在提取后需要过滤掉对应的假基因,并且根据翻译的氨基酸,将含有终止密码子的序列去掉,最终获得目标序列。
35.s104、对所述目标序列进行聚类分析,获得所述待测样本的候选物种类别。
36.在获得目标序列后,基于目标序列的绝对位置信息,将基因进行扩展,即将满足调教的目标序列进行拼接,然后将拼接后的序列转换为对应的基因向量矩阵,进行自学习求解,以获得预测到的新基因,即可能的基因物种类型。
37.s105、将所述目标数据与非冗余参考基因集进行比对,并计算每个基因在个样本中的丰度,得到所述待测样本的目标物种分类信息;s106、将所述目标数据与病原微生物可检测数据库中的信息进行比对,获得所述待测样本的耐药基因和毒性元件信息;s107、将所述目标物种分类信息、所述耐药基因和所述毒性元件信息,确定为所述待检测样本的检测结果。
38.在确定了候选物种类别后,需要进一步确定物种分类,即基于丰度计算可以确定待检测样本的物种分类信息,在本发明实施例中病原微生物检测得到的物种分类可以包括:细菌、病毒、真菌、寄生虫、分岐杆菌、支原体、衣原体、立克次氏体、古细胞和新冠病毒covid
‑
19。将将所述目标数据与病原微生物可检测数据库中的信息进行比对,获得所述待测样本的耐药基因和毒性元件信息,然后将目标物种分类信息、所述耐药基因和所述毒性元件信息作为待检测样本的最终检测结果进行输出,例如,可以根据这些信息生成检测报告。
39.需要说明的是,在本发明实施例中获得目标物种分类信息、耐药基因和毒性元件信息的过程是自学习的过程,可以主要采用无监督学习方式或者其他自学习方式,使得数据处理系统能够对物种分类信息、耐药基因、抗性基因、毒力因子进行学习,获得对应的原始病原微生物知识库,在获得样本数据后与对应的知识库中的数据进行比对,获得最终的检测结果。具体的实施过程将在本发明后续实施例中进行详细说明。
40.本发明提供了一种基于宏基因组学的病原微生物检测方法,包括:获取待检测样本的宏基因组测序数据;对宏基因组测序数据进行预处理,得到目标数据,目标数据为满足目标质量条件的宏基因组测序数据;对目标数据进行筛选,得到目标序列;对目标序列进行聚类分析,获得待测样本的候选物种类别;将目标数据与非冗余参考基因集进行比对,并计算每个基因在单个样本中的丰度,得到待测样本的目标物种分类信息;将目标数据与病原微生物可检测数据库中的信息进行比对,获得待测样本的耐药基因和毒性元件信息;将目标物种分类信息、耐药基因和毒性元件信息,确定为待检测样本的检测结果。本发明提升了病原微生物检测适用性范围和病原检测准确性。
41.在本发明实施例的一种实施方式中,所述对所述目标数据进行筛选,得到目标序列,包括确定开放阅读框的长度,并利用所述长度的开放阅读框识别所述目标数据,得到
初始序列;将所述初始序列中的序列中间存在终止密码子,且若两个有重叠的初始序列翻译的起始坐标的差值不是三的倍数的初始序列进行过滤,得到过滤后的序列;根据翻译的氨基酸,将过滤后的序列中含有终止密码子的序列去除,得到目标序列。
42.其中,开放阅读框的长度是根据实际的检测需求以及检测样本的属性确定的提取目标部分的长度。具体的,获取多个弱学习器的开放阅读框(orfs)集,识别目标数据中的orfs。然后,得到的orfs有终止密码子在序列中间时,与真正的基因是不符合的orfs,直接过滤掉。同时,两个有重叠的两条orfs,翻译的起始坐标的差值必须是3的倍数,不满足要求的orfs判别为假基因,将假基因过滤掉。根据翻译的氨基酸,将含有终止密码子的序列截去,真实的蛋白参考序列中终止密码子不翻译氨基酸,并且没有表示出来,后期验证的时候截去orfs集中的终止密码子。
43.在本发明的另一实施例中,所述对所述目标序列进行聚类分析,获得所述待测样本的候选物种类别,包括:获取每一所述目标序列的读码的绝对位置信息;基于所述绝对位置信息对所述目标序列进行拼接,并将拼接后的目标序列组合成基因向量矩阵;根据所述基因向量矩阵生成基因特征自学习求解器,并获得学习率的最优解;根据所述学习率最优解进行基因预测,得到所述待测样本的候选物种类别。
44.在该实施方式中,需要统一orfs集的输出坐标,将基因进行扩展。其中,输出坐标指的是在基于orf的起始位置和终止位置,确定的坐标参数。将orf对应的dna scaffold比对,找出读码的绝对位置。定义orf1的位置为(x1,y1),orf2的位置为(x2,y2),分三种情况处理:(1)y2<=y1,并且(x2
‑
x1)%3==0,保留orf1;(2)x2<=y1,并且y1<=x2,同时满足(x2
‑
x1)%3==0,将orf1与orf2进行拼接,组成新的orf3(x1,y2);(3)y1<=x2,保留orf1和orf2,这里x表示每个orf的起始位置,y表示每个orf的终止位置。
45.将上述orfs集在学习方法中的分布情况转化每一个orf的支持行向量gi,所有的基因行向量{g1,g2,
…
,gi},组合成基因向量矩阵g,其中i取1~n之间的自然数。将orfs是否为判别真正的基因作为聚类标签,是为1,否为0,生成标签向量h,生成gx=h的基因特征自学习求解器,其中限制条件为学习率x的总和为1。根据基因特征自学习求解器,生成学习率的最优解x*=max{n/n},其中n表示所有正确的orf的个数,n表示所有基因的总和。将最优学习率x*作为基因预测模型的输入,预测新的基因,即获得待测样本的候选物种类别。
46.在本发明实施例中采用基因的相对丰度对物种进行衡量。将目标数据比对到非冗余参考基因集上,计算每个基因在各样本中的丰度。参考基因的相对丰度计算方法,对于任意的样本s,本发明中计算物种相对丰度的方法如下:计算每一个物种的拷贝数,计算方法为:ci=si/li;计算物种i的相对丰度,计算方法为:ai=ci/(∑cj)=(si/li)/[∑(sj/lj)]。其中:ai表示物种i相对于样本s的相对丰度;li表示物种i的序列长度;si表示物种i在样本s中可以被检测到的reads总数;ci样本s中物种i的副本总数;∑表示求和符号。
[0047]
在本发明实施例中,耐药基因和毒性元件筛选:比对病原微生物可检测的数据库。需要说明,在本发明实施例的病原微生物检测自学习检测过程中能够大规模检测致病源,
知识库涵盖了人类常见的病毒、细菌等十多个大范围物种的检测,还包括新冠病毒covid
‑
19的核酸数据。能够准确检测出患者感染的病原微生物,帮助临床医生快速识别致病菌,促进mngs病原微生物的精准检测。
[0048]
下面以具体的应用场景对本发明实施例进行说明。
[0049]
采用mngs测序获取的75bp的双端reads数据,mngs的标准测序样本(样本编号:s1),采样类型:拭子,接下来将s1用于本发明病原微生物检测系统的测试。病原微生物自学习检测系统的流程图如图2所示。
[0050]
本发明采用无监督学习genemarks
‑
2、隐马尔可夫学习fraggenescan、得分策略metageneannotator 、动态规划prodigal、神经网络学习orphelia、内插马尔可夫glimmer3的方法。其中,检测系统可以实现的功能包括但不局限于:数据质控及统计、去除宿主及统计、知识库比对、物种分类、统计各比对结果、物种及基因丰度统计、数据库注释等。
[0051]
在本发明实施例中可以下载来自ncbi和gisaid等核酸序列数据库、耐药基因、抗性基因、毒力因子等,建立原始病原微生物知识库,通过gclust算法建立非冗余序列集。当需要进行组装式,组装与基因组预测:数 据 过 滤 采 用 双 端 模 式 trimmomatic( version 0.36,参数设置: slidingwindow 4:15 leading 3 trailing 3 minlen 90 maxinfo 80:0.5)。metaspades软件的参数设置:
ꢀ‑
meta
ꢀ–
only
ꢀ‑
assembler,其余参数使用默认值。实验输出结果 k
‑
mer 为 k21、 k33、 k55,标准输出的综合结果为 k55,将此 scaffolds 组装结果作为预测软件的输入。
[0052]
reads过滤前后的统计结果如表1所示,通过原始reads与过滤后reads在每个位置上的碱基质量结果可以看出,过滤之前的总reads数为22,665,207条,过滤后clean reads的数目为22,609,981,q30的占比为96.015。病原微生物的物种层级数据分布的定性结果如表2所示,上述结果表示,检测出丰度最高的为表皮葡萄球菌,其他物种的检测丰度如表。表3表示s1样本检测出的病原微生物的具体物种检测丰度列表。基因与通路分析如表4
‑
表6。耐药基因和抗性基因的结果如表7
‑
表8所示。通过card数据库的注释,可以找到抗生素抗性基因、以及作用机制等信息,抗性基因,比对上的reads总数为262条,表8所示。毒力元件筛选结果如表9所示。
[0053]
表1 样本s1的reads过滤前后的统计结果表2 样本s1的病原微生物检测定性结果
表3 样本s1的检测出的病原微生物的具体物种检测丰度列表表4 样本s1的基因家族的丰度列表基因家族是一组进化上相关的蛋白质编码序列,通常具有相似的功能。在群体水平上对基因家族丰度进行分层,以显示已知物种和未知物种的贡献度。基因家族丰度以rpk(reads per kilobase,每千碱读长数)单位报告,以使基因长度标准化;rpk单位代表基因或转录本在群体中的拷贝数。rpk值可以进一步和标准化,以调整不同样本的测序深度差异。nmapped表示核酸和蛋白搜索后,仍无法比对的reads数量。uniref90_unknown 代表可比对到chocophlan数据库,但没有注释。注:本表只列出前5个基因家族。
[0054]
表5 样本s1的通路丰度结果
通路丰度代表群体中通路的丰度,即有群体水平,又有物种水平丰度。通路按丰度大小排序,物种组分也按丰度大小排序,全为0的通路不输出。注:本表只列出前5条通路。
[0055]
表6 样本s1的通路覆盖度结果
通路覆盖度提供了一种有(1)和无(0)的群体通路计算法,而不是相对丰度。只输出非零丰度的通路,群体水平比物种水平更可信,通路覆盖度与通路丰度顺序相同。
[0056]
表7 样本s1的耐药基因结果表8 样本s1的抗性基因结果
注:本表只列出前5个抗性基因。
[0057]
表9 样本s1的毒力元件筛选结果
注:本表只列出前5个毒力基因的注释结果。
[0058]
本发明提供的病原微生物自学习检测系统提供了基于mngs数据的病原微生物快速检测的方法,并且能够实现未知微生物的基因组组装以及抗性基因注释等。在检测范围方面,本发明能够准确快速地检测包括细菌、病毒、真菌、寄生虫、分歧杆菌、支原体、衣原体、立克次氏体、古生菌、原生动物以及covid
‑
19在内的多种病原微生物,极大地提高了临床诊断的效率。在准确性方面,本发明所提供的自学习分析能够通过生成基因特征自学习求解器筛选出学习率的最优解并以此作为基因预测模型的输入,从而有效提高了基因预测的准确性。在未知微生物方面,本发明能够实现对未知微生物基因组的组装和耐药基因、抗性基因以及毒力因子等的注释,为探索此类微生物的相关致病性提供可靠的依据。
[0059]
在本发明实施例中还提供了一种基于宏基因组学的病原微生物检测装置,参见图3,包括:获取单元10,用于获取待检测样本的宏基因组测序数据;预处理单元20,用于对所述宏基因组测序数据进行预处理,得到目标数据,所述目标数据为满足目标质量条件的宏基因组测序数据;筛选单元30,用于对所述目标数据进行筛选,得到目标序列;分析单元40,用于对所述目标序列进行聚类分析,获得所述待测样本的候选物种类别;计算单元50,用于将所述目标数据与非冗余参考基因集进行比对,并计算每个基因在单个样本中的丰度,得到所述待测样本的目标物种分类信息;比对单元60,用于将所述目标数据与病原微生物可检测数据库中的信息进行比对,获得所述待测样本的耐药基因和毒性元件信息;确定单元70,用于将所述目标物种分类信息、所述耐药基因和所述毒性元件信息,确定为所述待检测样本的检测结果。
[0060]
进一步地,所述预处理单元包括:第一过滤子单元,用于对所述宏基因组测序数据进行过滤,得到高质量的序列;第一去除子单元,用于去除所述高质量的序列中宿主测序序列,并将冗余序列去除,去除后的序列;比对子单元,用于将所述去除后的序列与参考序列进行比对处理,得到目标数据。
[0061]
可选地,还包括:拼接子单元,用于若所述去除后的序列的长度小于预设长度阈值,将去除后的序列进行拼接,得到拼接后的序列。
[0062]
可选地,所述筛选单元包括识别子单元,用于确定开放阅读框的长度,并利用所述长度的开放阅读框识别所述目标数据,得到初始序列;第二过滤子单元,用于将所述初始序列中的序列中间存在终止密码子,且若两个有重叠的初始序列翻译的起始坐标的差值不是三的倍数的初始序列进行过滤,得到过滤后的序列;第二去除子单元,用于根据翻译的氨基酸,将过滤后的序列中含有终止密码子的序列去除,得到目标序列。
[0063]
进一步,所述分析单元包括:获取子单元,用于获取每一所述目标序列的读码的绝对位置信息;序列拼接子单元,用于基于所述绝对位置信息对所述目标序列进行拼接,并将拼接后的目标序列组合成基因向量矩阵;生成子单元,用于根据所述基因向量矩阵生成基因特征自学习求解器,并获得学习率的最优解;预测子单元,用于根据所述学习率最优解进行基因预测,得到所述待测样本的候选物种类别。
[0064]
本发明实施例提供了一种基于宏基因组学的病原微生物检测装置,包括:获取待检测样本的宏基因组测序数据;对宏基因组测序数据进行预处理,得到目标数据,目标数据为满足目标质量条件的宏基因组测序数据;对目标数据进行筛选,得到目标序列;对目标序列进行聚类分析,获得待测样本的候选物种类别;将目标数据与非冗余参考基因集进行比对,并计算每个基因在单个样本中的丰度,得到待测样本的目标物种分类信息;将目标数据与病原微生物可检测数据库中的信息进行比对,获得待测样本的耐药基因和毒性元件信息;将目标物种分类信息、耐药基因和毒性元件信息,确定为待检测样本的检测结果。本发明提升了病原微生物检测适用性范围和病原检测准确性。
[0065]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0066]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。