1.本发明属于自然语言处理技术领域,涉及一种跨域文本分类方法。
背景技术:
2.现在的互联网处于大数据时代,容纳了各个领域的海量数据和信息,如何对这些信息进行有效地组织和管理,并快速、准确地在这些信息里找到用户需要的信息是当前信息技术面临的一项难题。传统的文本分类方法,通常以词作为文本的基本单元,不仅容易造成语义信息的缺失,还易导致文本特征的高维性和稀疏性。目前文本分类技术的应用多是机器学习,该方法通常提取tf
‑
idf(term frequency
‑
inverse document frequency,词频
‑
逆文件频率)或者词袋特征,然后给lr模型进行训练,这里模型有很多,如;贝叶斯、svm等。而面对特性多样的文本数据,又易导致基于传统方法的文本分类器的泛化能力下降。近些年,深度学习技术迅速发展,已经被应用于各个领域,并且成效颇为显著。深度学习利用自身独特的网络结构可以改善文本预处理的效果,可以很好的解决当前文本分类面临的问题,它给自然语言处理开辟了一条新的道路,也为广大业界学者提供了一个重要的研究方向。神经网络语言模型是用词向量来度量单词之间的语义相关性,bert(bidirectional encoder representations from transformers)模型是google在2018年10月发布的语言表示模型,本质上是一种语言编码器,它可以将输入的句子和段落转化为相应的特征向量。基于深度学习的文本分类方法用词向量对词语进行语义表示,再通过语义组合的方式获得文本的语义表示。词嵌入是将词语映射为数字的方式,但一个单纯的实数包含的信息太少,一般我们映射为一个数值向量。自然语言处理过程中,需要保留语言本身的一些抽象特征,如语义和句法等。纵观nlp的发展史,很多革命性的成果都是词嵌入的发展成果,如word2vec、elmo和bert,它们都是很好地将自然语言的特征在转换过程中进行了保留。神经网络语义组合的方法主要有卷积神经网络、循环神经网络和注意力机制等,这些方法通过不同的组合方法从词语的语义表示上升到文本的语义表示。
技术实现要素:
3.本发明的目的是提供一种跨域文本分类方法,采用该方法能够对文本中的关键词进行分类,提高查找效率。
4.本发明所采用的技术方案是,一种跨域文本分类方法,具体包括如下步骤:
5.步骤1,获取文本信息中的词向量;
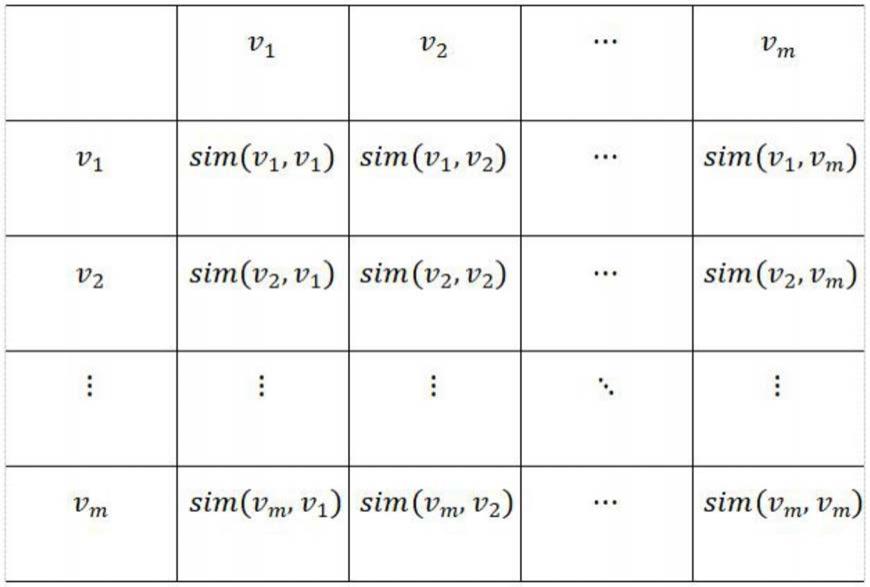
6.步骤2,从步骤1获取的词向量中任意选取其中两个词向量,计算两个词向量之间的余弦值,利用余弦值衡量两个词向量间的相似度,并创建相似度矩阵;
7.步骤3,对步骤2所得的相似度矩阵进行降维;
8.步骤4,对步骤3降维后的矩阵进行聚类操作,实现文本分类。
9.本发明的特点还在于:
10.步骤1的具体过程为:若文本信息中含有中文,则采用bert模型来获取文本的词向
量;若数据集中不含中文,则采用word2vec模型来获取文本的词向量。
11.步骤2中,计算两个词向量之间的余弦值过程为:取任意两个词向量a和b,将词向量a与词向量b之间的夹角记为θ,向量a的表示形式为[a1,a2,...,a
n
],向量b的表示形式为[b1,b2,...,b
n
],则词向量a与b的夹角θ的余弦计算如公式(1)所示:
[0012][0013]
创建相似度矩阵的具体过程为:
[0014]
对于一个网络图h,相似度矩阵s=[s
ij
]
m
×
m
;其中m表示网络图h中的节点;矩阵s中的元素是两个节点之间的相似度s
ij
=sim(ν
i
,ν
j
),ν
i
,ν
j
为任意两个节点。
[0015]
步骤3中,采用深度稀疏自动编码器对步骤2所得的相似度矩阵进行降维,将原m维矩阵降为p维矩阵,p<m。
[0016]
步骤4中,通过k
‑
means聚类方法对降维后的矩阵进行聚类测试。
[0017]
本发明的有益效果是:本发明提供的一种跨域文本分类方法,将文本使用词嵌入方式表示为数学向量的形式,计算向量之间的相似性,再利用k
‑
means聚类方法可以有效对文本进行分类,提高关键词的查找效率。
附图说明
[0018]
图1是本发明一种跨域文本分类方法的流程图。
具体实施方式
[0019]
下面结合附图和具体实施方式对本发明进行详细说明。
[0020]
本发明一种跨域文本分类方法,如图1所示,具体包括如下步骤:
[0021]
步骤1,获取文本信息中的词向量;
[0022]
步骤1的具体过程为:若文本信息中含有中文,则采用bert模型来获取文本的词向量;若数据集中不含中文,则采用word2vec模型来获取文本的词向量。
[0023]
bert模型是一种基于深度学习的语言表示模型,bert技术的出现,改变了预训练产生词向量和下游具体任务的关系。bert模型的核心模块是transformer,transformer的核心是注意力机制,注意力机制借鉴了人类视觉上的注意力,它可以让神经网络把重点关注对象放在一部分输入,也就是可以区分不同部分的输入对输出的影响。bert的网络架构采用多层transformer结构。将文本摘要关键信息输入到bert模型,得到对应的向量表示。
[0024]
word2vec是google在2013年提出的nlp模型,它的特点是将所有的词表示成低维稠密向量,从而可以在词向量空间上定性衡量词与词之间的相似性。越相似的词在向量空间上的夹角会越小。
[0025]
步骤2,从步骤1获取的词向量中任意选取其中两个词向量,计算两个词向量之间的余弦值,利用余弦值衡量两个词向量间的相似度,并创建相似度矩阵;余弦相似度:也称为余弦距离,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
[0026]
步骤2中,计算两个词向量之间的余弦值过程为:取任意两个词向量a和b,将词向
量a与词向量b之间的夹角记为θ,向量a的表示形式为[a1,a2,...,a
n
],向量b的表示形式为[b1,b2,...,b
n
],则词向量a与b的夹角θ的余弦计算如公式(1)所示:
[0027][0028]
创建相似度矩阵的具体过程为:
[0029]
对于一个网络图h(表1),相似度矩阵s=[s
ij
]
m
×
m
;其中m表示网络图h中的节点;矩阵s中的元素是两个节点之间的相似度s
ij
=sim(ν
i
,ν
j
),ν
i
,ν
j
为任意两个节点,相似度矩阵如下表1所示:
[0030]
表1
[0031][0032]
步骤3,对步骤2所得的相似度矩阵进行降维;
[0033]
采用深度稀疏自动编码器对步骤2所得的相似度矩阵进行降维,将表1中的原m维矩阵降为p维矩阵,p<m。
[0034]
深度稀疏自动编码器是基于稀疏自动编码器构成的,其最大的特点是输入层结点数和输出层结点数相同而隐藏层结点个数少于它们两个。自动编码器通常被用于降维或特征学习。自动编码器是一种数据的压缩算法,属于无监督学习,以自身x作为输出值,但输出值x’和自身x之间还是有一些差异的。自动编码器也是一种有损压缩,可以通过使得损失函数最小来实现x’近似于x的值。
[0035]
步骤4,对步骤3降维后的矩阵进行聚类操作,实现文本分类。
[0036]
步骤3得到降维后的矩阵,随后进行聚类测试,可以通过k
‑
means算法得到k个社区数,通过聚类评价指标选取最佳的聚类效果的参数,以达到良好的文本分类结果。
[0037]
实施例
[0038]
将5000条跨域论文的abstract,首先使用bert模型进行训练生成文本对应的向
量。文本之间的相似度可以使用向量在空间上的位置差异来表示,所以我们结合余弦定理完成对文本词向量的处理并计算余弦相似度,同时创建相似度矩阵。然后利用深度稀疏自编码器训练,进行矩阵的降维,然后使用k
‑
means聚类方法进行测试,分别在输入为不同的社区数对数据集进行分析。
[0039]
将数据通过k
‑
means聚类方法分别按照评价指标得到以下结论:利用calinski
‑
harabaz index评价指标对数据分析,随着社区数量的增多评价指标值越小,根据该评价指标可知图像越陡分类效果越好。利用轮廓系数评级指标可知,当社区个数越少时效果最好最具研究意义,从而达到本次实验分类的目的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。