1.本发明整体上涉及基因治疗领域,并且更具体地涉及遗传性基因疾病的治疗和预防。特别地,本公开提供了通过插入人工外显子(artex)对细胞进行基因修饰以便在特定细胞类型中递送治疗性蛋白质的方法,并且更特别地提供了用于将转基因表达到患者大脑的工程化的细胞。
背景技术:
2.由于在通常编码酶的基因中的缺陷,先天性代谢错误是一大类单基因病症。这种遗传缺陷导致各种组织中未降解底物的积累,导致可变的临床表现,其通常会影响中枢神经系统。这些疾病的护理标准(如果可用)通常涉及静脉内递送治疗性蛋白质。这可以改善病症,因为治疗性蛋白质被受影响的细胞所吸收,从而纠正了缺陷。这种在一个细胞中制造的基因产品(或以治疗方式递送)被受影响的细胞吸收以纠正缺陷的策略被称为交叉纠正。然而,治疗性地将蛋白质递送到血浆中并不能解决在这些患者中看到的神经系统缺陷,因为该蛋白质不能穿过血脑屏障(或没有足够数量的蛋白质穿过血脑屏障)。因此,用于这些疾病的将治疗性蛋白质递送至血浆的任何治疗性策略,诸如静脉转移治疗性蛋白质或用基因疗法将肝脏或任何其它器官转换为治疗性蛋白质生产设施,将无法消散该疾病的神经症状。
3.因此,特别需要用于向大脑递送以治疗遗传性疾病的方法和治疗性组合物。
4.仅为提供信息目的而提供该背景信息。不一定承认且不应该解决任何前述信息构成针对本发明的现有技术。
技术实现要素:
5.应当理解的是,上述对实施方式的一般描述以及下列详细描述均是示例性的,因此不限制实施方式的范围。
6.在一个方面,本发明提供了基因修饰的造血干细胞(hsc),其包括在合适的基因座处共表达的治疗性基因产物,该合适的基因座在多种造血谱系中很活跃,诸如巨噬细胞,并且更特别地是填充大脑的组织驻留小胶质细胞。本文所描述的方法可以通过治疗性基因产物在髓系统和来源于它的组织中的外源性表达来治疗患者。本发明特别有利的是,通过从造血谱系衍生出来的填充大脑的小胶质细胞,将健康等位基因交叉表达到大脑中,以获得有害等位基因的交叉纠正。
7.在另一方面,本发明依赖于使用可编程核酸酶(诸如转录激活器样效应物核酸酶(talen)、锌指核酸酶(zfn)、簇状规则间隔的短回文重复序列(crispr)-cas、大范围核酸酶和megatal(融合至大范围核酸酶的转录激活器样(tal))加上用于该基因座的修复模板的递送对造血干细胞(hsc)或ips细胞的离体修饰,修复模板提供有促进基因座的同源定向修复(hdr)的重组腺相关病毒(raav)。使用该策略,可以将修复模板dna中编码的任何基因修饰并入在靶基因座处,包括并入治疗性基因产物,诸如互补dna(cdna)。在一些实施方式中,
治疗性基因产物将受到靶基因座的调控控制并且促进造血细胞且特别是小胶质细胞中的表达。随后通过过继细胞转移或自体hsc移植将经修饰的细胞返回到患者。该方法将全身性递送治疗性基因产物以治疗身体,并且局部递送在大脑中以治疗疾病的全部症状。
8.在另一方面,本发明提供了一种将转基因表达到患者大脑中的方法,包括:
9.i)获得基因修饰的造血干细胞(hsc),其中hsc分离自患者或者获自来源于患者并且分化成hsc的诱导多能干(ips)细胞,其中基因修饰的hsc被工程化为包括整合在小胶质细胞中表达的基因座处的转基因;和
10.ii)将基因修饰的hsc移植到患者中,以使其分化为将转基因表达到患者大脑中的小胶质细胞。
11.在另一方面,本发明提供了一种将转基因表达到患者大脑中的方法,包括:
12.i)获得基因修饰的造血干细胞(hsc),其中hsc分离自相容供体或者获自来源于相容供体并且分化成hsc的诱导多能干(ips)细胞,其中基因修饰的hsc被工程化为包括整合在小胶质细胞中表达的基因座处的转基因;
13.ii)将基因修饰的hsc移植到患者中,以使其分化为将转基因表达到患者大脑中的小胶质细胞。
14.在另一方面,本发明提供了一种分离的hsc或ips细胞,其具有整合在选自tmem119、cd11b、b2m、cx3cr1或s100a9的基因座处的转基因,所述转基因受所述基因的内源性启动子的转录控制。在一些实施方式中,hsc或ips细胞用于用作药物。在一些实施方式中,hsc或ips细胞用于在治疗在与转基因同源的内源基因的表达方面有缺陷的患者中使用(交叉纠正)。在一些实施方式中,hsc或ips细胞用于在溶酶体贮积病的治疗中使用。
15.在一些实施方式中,在小胶质细胞中表达的基因座选自由以下组成的组:tmem119、s100a9、cd11b、b2m、cx3cr1、mertk、cd164、tlr4、tlr7、cd14、fcgr1a、fcgr3a、tbxas1、dok3、abca1、tmem195、mr1、csf3r、fgd4、tspan14、tgfbri、ccr5、gpr34、serpine2、slco2b1、p2ry12、olfml3、p2ry13、hexb、rhob、jun、rab3il1、ccl2、fcrls、scoc、siglech、slc2a5、lrrc3、plxdc2、usp2、ctsf、cttnbp2nl、atp8a2、lgmn、mafb、egr1、bhlhe41、hpgds、ctsd、hspa1a、lag3、csf1r、adamts1、f11r、golm1、nuak1、crybb1、ltc4s、sgce、pla2g15、ccl3l1、abhd12、ang、ophn1、sparc、pros1、p2ry6、lair1、il1a、epb41l2、adora3、rilpl1、pmepa1、ccl13、pde3b、scamp5、ppp1r9a、tjp1、ak1、b4galt4、gtf2h2、trem2、ckb、acp2、pon3、agmo、tnfrsf17、fscn1、st3gal6、adap2、ccl4、entpd1、tmem86a、kctd12、dst、ctsl2、abcc3、pdgfb、pald1、tubgcp5、rapgef5、stab1、lacc1、tmc7、nrip1、kcnd1、tmem206、hps4、dagla、extl3、mlph、arhgap22、cxxc5、p4ha1、cysltr1、fgd2、kcnk13、gbgt1、c18orf1、cadm1、bco2、adrb1、c3ar1、large、leprel1、liph、upk1b、p2rx7、slc46a1、ebf3、ppp1r15a、il10ra、rasgrp3、fos、tppp、slc24a3、havcr2、nav2、apbb2、clstn1、blnk、gnaq、ptprm、frmd4a、cd86、tnfrsf11a、spint1、ppm1l、tgfbr2、cmklr1、tlr6、gas6、hist1h2ab、atf3、acvr1、abi3、lrp12、ttc28、plxna4、adamts16、rgs1、icam1、snx24、ly96、dnajb4和ppfia4。在一些实施方式中,转基因的多个拷贝被整合在由2a自切割肽序列间隔开的同一基因座上。
16.作为独立的实施方式,本专利申请提供了一种将外源性编码序列整合到内源性内含子基因组区域的方法,优选地,其允许将所述外源性编码序列整合在所述基因组区域的
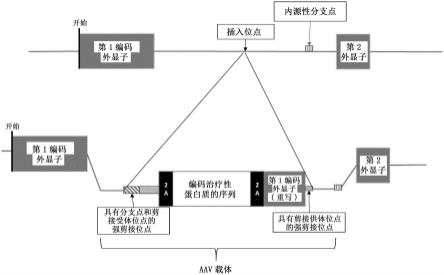
第一内源性外显子和第二内源性外显子之间。在一些实施方式中,图2所示的该方法具有保留hsc的干性及其分化为各种骨髓细胞的能力的优点。在一些实施方式中,使用稀有切割核酸内切酶和/或病毒载体将转基因插入到hsc或ips细胞中。在一些实施方式中,病毒载体是aav载体。该方法(也称为“artex”)允许插入人工外显子编码转基因(其置于内源性基因座的转录控制下),优选地插入到内含子序列中而不必使存在于所述基因座的内源性外显子的表达失活。
17.该方法更特别地包括以下步骤中的一个或多个:
[0018]-提供包括内源性内含子基因组区域的细胞,
[0019]-向所述细胞中引入包括外源性编码序列的多核苷酸模板,其中所述多核苷酸模板包括:
[0020]
a)第一同源多核苷酸序列,其与插入位点上游的内含子序列同源,
[0021]
b)第一强剪接位点序列,其包括分支点和剪接受体;
[0022]
c)编码2a自切割肽的第一序列;
[0023]
d)编码目的蛋白质的外源序列;
[0024]
e)编码2a自切割肽的第二序列;
[0025]
f)第一外显子的编码序列的拷贝;
[0026]
g)包括剪接供体的第二强剪接位点序列;和
[0027]
h)第二同源多核苷酸序列,其与插入位点下游的内含子序列同源;以及任选地
[0028]-诱导所述外源性多核苷酸整合到所述内含子序列中,优选地通过同源重组,以使所述外源性编码序列与第一外显子和优选第二外显子或其拷贝一起在所述内源性基因座上转录。
[0029]
该方法特别有用于大量基因疾病(尤其是遗传性疾病)中缺陷性蛋白质表达的交叉纠正。
[0030]
在一些实施方式中,转基因为用于治疗粘多糖病i型(scheie、hurler-scheie或hurler综合征)的idua。
[0031]
在一些实施方式中,转基因为用于治疗粘多糖病ii型(hunter)的ids。
[0032]
在一些实施方式中,转基因为用于治疗粘多糖病vi型(maroteaux-lamy)的arsb。
[0033]
在一些实施方式中,转基因为用于治疗粘多糖病vii型(sly)的gusb。
[0034]
在一些实施方式中,转基因为用于治疗x连锁肾上腺脑白质营养不良(x-linked adrenoleukodystrophy)的abcd1。
[0035]
在一些实施方式中,转基因为用于治疗球形细胞脑白质营养不良(krabbe)的galc。
[0036]
在一些实施方式中,转基因为用于治疗异染性脑白质营养不良的arsa。
[0037]
在一些实施方式中,转基因为用于治疗戈谢病的gba。
[0038]
在一些实施方式中,转基因为用于治疗岩藻糖苷贮积症的fuca1。
[0039]
在一些实施方式中,转基因为用于治疗α-甘露糖苷过多症的man2b1。
[0040]
在一些实施方式中,转基因为用于治疗天冬氨酰葡萄糖胺尿症的aga。
[0041]
在一些实施方式中,转基因为用于治疗farber的asah1。
[0042]
在一些实施方式中,转基因为用于治疗泰-萨克斯病(tay-sachs)的hexa。
[0043]
在一些实施方式中,转基因为用于治疗庞贝氏症(pompe)的gaa。
[0044]
在一些实施方式中,转基因为用于治疗尼曼匹克症(niemann pick)的smpd1。
[0045]
在一些实施方式中,转基因为用于治疗沃尔曼综合征的lipa。
[0046]
在一些实施方式中,转基因为用于cdkl5-缺陷相关疾病的cdkl5。
[0047]
从以下的详细描述,本发明的其它目的(特别是载体、细胞及所得的细胞群)以及其它特征和优点将变得显而易见。然而,应当理解的是,详细描述和具体实施例(虽然指示了本发明的具体实施方式)仅以说明的方式给出,因为对于本领域技术人员而言,从该详细描述,在本发明精神和范围内的各种变化和修改均将变得显而易见。
附图说明
[0048]
本领域技术人员将理解,以下描述的附图仅用于说明目的。附图不旨在以任何方式限制本教导的范围。
[0049]
图1.将治疗性基因表达靶向包括小胶质细胞的髓系统的体外基因治疗平台的示意图。
[0050]
图2.根据本发明,为获得向包括小胶质细胞在内的组织驻留骨髓细胞的治疗性基因表达的一种基因编辑策略的示意图。所提出的策略靶向选定的内源性基因座的内含子序列(intronic sequence),其中优选的基因座是tmem119、mertk、cd164、tlr7、cd14、fcgr3a(cd16)、tbxas1、dok3、abca1、tmem195、tlr4、mr1、fcgr1a(cd64)、csf3r、fgd4、tspan14、cxcr3、cd11b、s100a9和b2m。本技术中详细说明的该策略使得外源性治疗基因能够插入到内源性内含子序列中,以在基因座处存在的内源性启动子的转录控制下,在骨髓细胞中转录和表达治疗性蛋白质。
[0051]
图3.小胶质细胞中靶向基因座(tmem119)的表达模式。将人类原代hsc移植到nbsgw小鼠中,以分化为人类小胶质细胞。将cd11b标志物用作确立的小胶质细胞特异性分化标志物。a:工程化细胞的3个重复(在ccr5基因座上,使用aav作为多核苷酸模板和tale-核酸酶作为稀有切割核酸内切酶位点定向插入)。b:非工程化原代hsc。这些实验表明,根据本发明,人类hsc可有助于小胶质细胞在大脑中的周转以用作向大脑递送治疗性分子的载体。
[0052]
图4.在工程化hsc细胞上进行的pcr实验。在ccr5基因座上插入bfp报告基因。a:pcr阳性结果,显示转基因整合在预期基因座上。b:bfp流式细胞术测量结果显示基因组修饰率不影响表达,并且与骨髓特异性分化相关(cd14标志物)。
[0053]
图5.在来自小鼠大脑匀浆的小胶质细胞中的表达模式。将cd11b标志物用作确立的小胶质细胞特异性分化标志物。a:cd11b/ccr5。b:将cd11b/f4-80用作对照。c:cd11b/cx3cr1。d:cd11b/tmem119。结果显示,cx3cr1和tmem119更加均匀地表达(tmem119)或至少与f4-80的表达水平相当(cx3cr1),因此表现为比ccr5更适合作为基因座,以在小胶质细胞中表达转基因,用于根据本发明的方法将治疗性多肽递送至大脑。
[0054]
图6.通过靶向内含子序列获得治疗性基因在骨髓细胞中特异性表达的基因编辑策略的示意图。该策略具有的主要优点是其可以避免附带效应(collateral effect)(nhej事件)。
[0055]
图7.实施例中描绘的实验设计的示意图。
[0056]
图8.a.在cd11b或s100a9基因座上靶向整合gfp后,cd14hi hsc中gfp 细胞的百分比。b.在cd11b基因座上靶向整合gfp后,cd11b和gfp的cd14hi hsc的流式细胞术结果。c.在s100a9基因座上靶向整合gfp后,s110a9和gfp的cd14hi hsc的流式细胞术结果。
[0057]
图9.在cd11b或s100a9基因座上靶向整合idua基因后,idua的量化结果。
[0058]
图10.与未处理的(ut)细胞相比,在s100a9基因座上靶向整合gfp后,通过在血液(a)或在骨髓(b)中检测的人类细胞%年龄表征的嵌合性百分比。流式细胞术的示例通过对小鼠和人类cd45阳性细胞的量化显示了脾脏中的嵌合性。
[0059]
图11.血液(a)或骨髓(b)中的hcd45 或hcd45和hcd33 细胞中s100a9基因座上gfp的靶向整合百分比。
[0060]
图12.a.大脑中嵌合性的百分比(人类细胞的百分比)。b.在大脑中检测的人类细胞内小胶质细胞(p2ry12/tmem119 细胞)的百分比。
[0061]
图13.a.与未处理的hsc(对照)相比,在cd11b或s100a9基因座中通过hsc编辑的慢病毒载体或通过靶向人工外显子插入增加的idua的表达。b.在移植经编辑的hsc后,在血液、脾脏、骨髓中检测到的人类细胞的嵌合性百分比。c.在大脑中人类细胞和人类小胶质细胞(tmem119 和p2ry12 )的检测。
[0062]
图14.用于在hsc或ips中通过artex插入来治疗疾病的本发明方法的示意图,考虑了将转基因表达到不同的造血谱系中以在病理细胞类型中获得缺陷蛋白质的交叉纠正。hsc经离体工程化并且被注入到患者中。artex是指通过基因靶向插入将包括编码交叉纠正的蛋白质的序列的人工外显子引入到内源性基因座的内含子中,而不改变其它外显子在所述基因座的表达。该基因座因其在各自选定的细胞系或细胞类型(祖细胞、血液细胞、t细胞、b细胞、血小板、中性粒细胞、单核细胞
……
)中的表达而被选中。
具体实施方式
[0063]
本文公开了用于将转基因表达到患者大脑中的方法。该方法包括获得基因修饰的造血干细胞(hsc)或ips细胞(能够分化成hsc),其中细胞包括编码治疗性蛋白质的转基因,该转基因至少在小胶质细胞中表达的基因座处整合在细胞中。该方法进一步包括将基因修饰的hsc移植到患者内,从而细胞分化成小胶质细胞并在患者大脑中表达治疗性蛋白质。造血干细胞或ips细胞可以来自患者(自体方法)或来自供体(同种异体方法)。本发明可以被认为是将治疗性蛋白质递送到患者内以纠正基因疾病或病症(例如代谢疾病或溶酶体贮积病(lsd))的方法,其中患者表达蛋白质的缺陷拷贝。通过将编码功能性蛋白质的转基因靶向插入至少在小胶质细胞中表达的基因座中来修饰细胞,从而治疗疾病。本发明的方法还允许将通过源自基因工程化hsc的小胶质细胞表达的治疗性蛋白质或酶递送至大脑解决遗传或非遗传起源的中枢神经系统疾病。
[0064]
治疗性蛋白质可以从小胶质细胞中分泌出,从而能够影响大脑中不具有对应于转基因的功能性蛋白质的其它细胞或被其它细胞吸收。本发明还提供了用于生产工程化hsc细胞的方法,该工程化hsc细胞产生高水平的治疗剂,其中将这些工程化细胞群引入患者内将提供治疗疾病或病症所需的蛋白质。
[0065]
因此,本发明的方法和组合物可用于从转基因表达来自在小胶质细胞中表达的基因座的治疗上有益的蛋白质,以替代遗传性代谢疾病中缺陷的蛋白质,或将治疗性蛋白质
或酶递送至大脑。例如,通过小胶质细胞可以向大脑中表达多巴脱羧酶[ec 4.1.1.28],以将l-多巴转化为多巴胺,这缓解帕金森病的症状。
[0066]
此外,本发明提供了通过将序列插入到小胶质细胞中表达的基因座中来治疗这些疾病的方法和组合物。
[0067]
在一些实施方式中,将转基因引入从患者或相容供体分离的hsc细胞中。在一些实施方式中,将转基因引入源自ips细胞的hsc中,或者在ips细胞分化成hsc之前将其引入ips细胞。当hsc分化为小胶质细胞时,它们将表达治疗有效量的替代蛋白,以递送到大脑中的细胞。
[0068]
现在将详细参考本发明的当前优选实施方式,其连同附图和以下实施例一起用于说明本发明的原理。这些实施方式足够详细地描述以使本领域技术人员能够实践本发明,并且应当理解的是,可以使用其它实施方式,并且在不背离本发明的精神和范围的情况下可以进行结构、生物和化学变化。除非另有定义,否则本文中使用的所有技术和科学术语具有与本领域普通技术人员通常理解的相同含义。
[0069]
除非另有说明,否则本发明的实践采用分子生物学(包括重组技术)、微生物学、细胞生物学、生物化学和免疫学的常规技术,这些技术在本领域的技术范围内。文献中充分说明了这些技术。参见例如sambrook et al.molecular cloning:a laboratory manual,2
nd edition(1989);current protocols in molecular biology(f.m.ausubel et al.eds.(1987));the series methods in enzymology(academic press,inc.);pcr:a practical approach(m.macpherson et al.irl press at oxford university press(1991));pcr 2:a practical approach(m.j.macpherson,b.d.hames and g.r.taylor eds.(1995));antibodies,a laboratory manual(harlow and lane eds.(1988));using antibodies,a laboratory manual(harlow and lane eds.(1999));和animal cell culture(r.i.freshney ed.(1987))。
[0070]
除非本文特别定义,否则所使用的所有技术和科学术语具有与基因治疗、生物化学、遗传学、免疫学、癌症和分子生物学领域中技术人员通常理解的相同含义。分子生物学中常用术语的定义可参见例如benjamin lewin,genes vii,published by oxford university press,2000(isbn 019879276x);kendrew et al.(eds.);the encyclopedia of molecular biology,published by blackwell publishers,1994(isbn 0632021829);和robert a.meyers(ed.),molecular biology and biotechnology:a comprehensive desk reference,published by wiley,john&sons,inc.,1995(isbn 0471186341)。
[0071]
为了解释本说明书的目的,将适用以下定义,并且在适当时,以单数形式使用的术语也将包括复数,反之亦然。如果下文提出的任何定义与该词在任何其它文献(包括通过引用并入本文的任何文献)中的使用相冲突,则出于解释本说明书及其相关权利要求的目的,下文提出的定义应始终优先,除非明确指示相反含义(例如在最初使用该术语的文献中)。除非另有说明,否则使用的“或”是指“和/或”。如在说明书和权利要求书中使用的单数形式“一个(a)”、“一种(an)”和“该(the)”包括复数引用,除非上下文另有明确规定。例如,术语“一个细胞”包括多个细胞,包括它们的混合物。使用的“包括(comprise)”、“包含(comprises)”、“含有(comprising)”、“包括(include)”、“包含(includes)”和“含有(including)”是可互换的,并且不旨在限制。此外,在一个或多个实施方式的描述使用术语“包括”的情况下,本领域技术人员将理解,在一些特定情况下,一个或多个实施方式可以替代地使用“基本上由
……
组成”和/或“由
……
组成”来描述。
[0072]
如本文所用,术语“约”是指与其一起使用的数字的数值的加或减10%。
[0073]
如本文所用,术语“造血干细胞”(或“hsc”)是指具有自我更新并分化为包括多样谱系的成熟血细胞的能力的未成熟血细胞,多样谱系包括但不限于粒细胞(例如早幼粒细胞、中性粒细胞、嗜酸性粒细胞、嗜碱性粒细胞)、红细胞(例如网织红细胞、红细胞)、凝血细胞(例如原巨核细胞、产生血小板的巨核细胞、血小板)、单核细胞(例如单核细胞、巨噬细胞)、树突细胞、小胶质细胞、破骨细胞和淋巴细胞(例如nk细胞、b细胞和t细胞)。本领域已知此类细胞可能包括或可能不包括cd34 细胞。cd34 细胞是表达cd34细胞表面标志物的未成熟细胞。在人类中,cd34 细胞被认为包括具有上述干细胞特性的细胞亚群,而在小鼠中,hsc是cd34-。此外,hsc还指长期重新填充hsc(lt-hsc)和短期重新填充hsc(st-hsc)。lt-hsc和st-hsc根据功能潜力和细胞表面标志物表达进行区分。例如,在一些实施方式中,人类hsc是cd34 、cd38-、cd45ra-、cd90 、cd49f 和lin-(对包括cd2、cd3、cd4、cd7、cd8、cd10、cd11b、cd19、cd20、cd56、cd235a在内的成熟谱系标志物呈阴性)。在小鼠中,骨髓lt-hsc是cd34-、sca-1 、c-kit 、cd135-、slamfl/cd150 、cd48-和lin-(对包括ter119、cd11b、gr1、cd3、cd4、cd8、b220、il7ra在内的成熟谱系标志物呈阴性),而st-hsc是cd34 、sca-1 、c-kit 、cd135-、slamfl/cd150 和lin-(对包括ter119、cd11b、gr1、cd3、cd4、cd8、b220、il7ra在内的成熟谱系标志物呈阴性)。此外,在稳态条件下,st-hsc比lt-hsc更不静止(即更活跃)且更增殖。然而,lt-hsc具有更大的自我更新潜力(即它们可以在整个成年期存活,并且可以通过连续的接受者连续移植),而st-hsc的自我更新能力有限(即它们只能存活一段有限的时间,并且不具备连续移植潜力)。任何这些hsc都可以用于任何本文的方法中。在一些实施方式中,st-hsc是有用的,因为它们是高度增殖的,因此可以更快地产生分化的后代。
[0074]
如本文所用,“接受者”是接受移植物如含有造血干细胞群或分化细胞群的移植物的患者。施用于接受者的移植细胞可以是例如自体、同基因或同种异体细胞。
[0075]
如本文所用,“供体”是人类或动物,从其分离一种或多种细胞,然后将细胞或其子代施用于接受者。在将细胞或其子代施用于接受者之前,一种或多种细胞可以是要根据本发明的方法进行扩增、强化(enrich)或维持的造血干细胞群。
[0076]
如本文所用,术语“药物组合物”是指活性剂与药学上可接受的载体(例如制药工业中常用的载体)的组合。本文使用的短语“药学上可接受的”是指在合理的医学判断范围内,适合与人类和动物的组织接触使用而没有过度的毒性、刺激性、过敏反应或其它问题或并发症,与合理的效益/风险比相称的那些化合物、材料、组合物和/或剂型。
[0077]
如本文所用,术语“施用”是指通过导致在所需部位至少部分递送药剂的方法或途径将本文公开的化合物、细胞或细胞群置于受试者体内。包括本文公开的化合物或细胞的药物组合物可以通过在受试者中产生有效治疗的任何合适途径施用。
[0078]
如本文所用,“核酸”或“多核苷酸”是指核苷酸和/或多核苷酸,例如脱氧核糖核酸(dna)或核糖核酸(rna)、寡核苷酸、由聚合酶链式反应(pcr)产生的片段、以及由连接、断裂、核酸内切酶作用和核酸外切酶作用中任何一种产生的片段。核酸分子可由天然存在的核苷酸(例如dna和rna)或天然存在的核苷酸的类似物(例如天然存在的核苷酸的对映体形式)或两者的组合组成。修饰的核苷酸可以在糖部分和/或嘧啶或嘌呤碱基部分中具有改
变。糖修饰包括例如用卤素、烷基、胺和叠氮基替换一个或多个羟基,或者糖可以被官能化为醚或酯。此外,整个糖部分可以用空间上和电子上相似的结构代替,例如氮杂糖和碳环糖类似物。碱基部分中修饰的实例包括烷基化的嘌呤和嘧啶、酰化的嘌呤或嘧啶、或其它众所周知的杂环取代物。核酸单体可以通过磷酸二酯键或这种键的类似物连接。核酸可以是单链的或双链的。
[0079]
术语“多肽”、“肽”和“蛋白质”可互换使用,指氨基酸残基的聚合物。该术语也适用于其中一种或多种氨基酸是相应天然氨基酸的化学类似物或修饰衍生物的氨基酸聚合物。
[0080]“序列特异性试剂”是指具有特异性识别来自基因组基因座的选定多核苷酸序列的能力的任何活性分子,考虑到修改基因组基因座的表达,优选长度至少9bp,更优选至少10bp,甚至更优选至少12pb。在一个实施方式中,诱导稳定突变的序列特异性试剂是具有切口酶或核酸内切酶活性的试剂。
[0081]
术语“核酸内切酶”是指能够催化dna或rna分子(优选dna分子)内核酸之间的键的水解(切割)的任何野生型或变体酶。核酸内切酶不切割dna或rna分子而不管其序列如何,而是在特定的多核苷酸序列(进一步称为“靶序列”或“靶位点”)处识别和切割dna或rna分子。
[0082]“有效量”或“治疗有效量”是指本文的组合物的量,该量当施用于受试者(例如人)时足以帮助治疗疾病。构成“治疗有效量”的组合物的量将根据细胞制剂、病症及其严重程度、施用方式和待治疗受试者的年龄而变化,但可以由本领域普通技术人员在考虑到自己的知识和本公开内容后常规地确定。当提及单独施用的单个活性成分或组合物时,治疗有效剂量是指该单独的成分或组合物。当提及组合时,治疗有效剂量是指导致治疗效果的活性成分、组合物或两者的组合量,无论是连续施用、并行施用还是同时施用。
[0083]
当通常具有长度大于10个碱基对(bp)的多核苷酸识别位点时,核酸内切酶可归类为稀有切割核酸内切酶。在一些实施方式中,稀有切割核酸内切酶具有14-55bp的识别位点。稀有切割核酸内切酶通过在特定位点诱导dna双链断裂(dsb)而显著增加同源性重组,从而允许基因修复或基因插入治疗(pingoud,a.and g.h.silva(2007).nat.biotechnol.25(7):743-4)。
[0084]“锌指dna结合蛋白”(或结合结构域)是一种蛋白质、或较大蛋白质内的结构域,其通过一个或多个锌指以序列特异性方式结合dna,锌指是结合结构域内的氨基酸序列的区域,其结构通过锌离子的配位而稳定。术语锌指dna结合蛋白通常缩写为锌指蛋白或zfp。
[0085]“tale dna结合结构域”或“tale”是包括一个或多个tale重复结构域/单元的多肽。重复结构域参与tale与其同源靶dna序列的结合。单个“重复单元”(也称为“重复”)的长度通常为33-35个氨基酸,并且与天然存在的tale蛋白内的其它tale重复序列表现出至少一定序列同源性。
[0086]
锌指和tale结合域可以被“工程化”以结合预定的核苷酸序列,例如通过工程化(改变一个或多个氨基酸)天然存在的锌指或tale蛋白的识别螺旋区。因此,工程化的dna结合蛋白(锌指或tale)是非天然存在的蛋白质。用于工程化dna结合蛋白的方法的非限制性例子是设计和选择。设计的dna结合蛋白是自然界中不存在的蛋白质,其设计/组成主要来自合理的标准。用于设计的合理标准包括应用替换规则和计算机化算法来处理存储现有zfp和/或tale设计和结合数据的信息的数据库中的信息。参见例如美国专利号6,140,081;
6,453,242;和6,534,261;还参见wo 98/53058;wo 98/53059;wo 98/53060;wo 02/016536和wo 03/016496以及美国公开号20110301073。
[0087]
在一些实施方式中,核酸内切酶是工程化的并且在自然界中不存在。在一些实施方式中,核酸内切酶是使用诸如噬菌体展示、相互作用陷阱或杂交选择等方法产生的。参见例如美国专利号5,789,538;5,925,523;6,007,988;6,013,453;6,200,759;以及wo 95/19431;wo 96/06166;wo 98/53057;wo 98/54311;wo 00/27878;wo 01/60970;wo 01/88197;wo 02/099084和美国专利申请公开号2011/0301073。
[0088]“重组”是指在两个多核苷酸之间交换遗传信息的过程。为了本公开的目的,“同源重组(hr)”是指此类交换的特殊形式,例如在通过同源定向修复机制修复细胞中的双链断裂期间发生。该过程需要核苷酸序列同源性,并且通常使用“供体”分子(也称为“多核苷酸模板”)通过同源重组或nhej修复整合到内源基因座(“靶”序列)中。这导致遗传信息从供体转移到靶。不希望受任何特定理论的束缚,这种转移可涉及对在断裂靶和供体之间形成的异源双链dna的错配纠正,和/或其中供体用于重新合成将成为靶的一部分的遗传信息的“合成依赖性链退火”,和/或相关过程。这种专门的hr通常导致靶分子序列的改变,使得供体多核苷酸的部分或全部序列并入靶多核苷酸中。
[0089]“突变”意指多核苷酸(cdna、基因)或多肽序列中多达一、二、三、四、五、六、七、八、九、十、十一、十二、十三、十四、十五、二十、二十五、三十、四十、五十或更多个核苷酸/氨基酸的取代、缺失、插入。在一些实施方式中,突变可以影响基因的编码序列或其调控序列。它还可能影响基因组序列的结构或所编码的mrna的结构/稳定性。
[0090]“载体”是指一种核酸分子,其能够运输与其连接的另一种核酸。本发明中的“载体”包括但不限于病毒载体、质粒、寡核苷酸、rna载体或线性或环状dna或rna分子,其可以由染色体、非染色体、半合成或合成核酸组成。优选的载体是能够自主复制(附加型载体)和/或表达它们所连接的核酸(表达载体)的那些载体。大量合适的载体是本领域技术人员已知的并且是可商购的。病毒载体包括:逆转录病毒,腺病毒,细小病毒(例如腺相关病毒(aav),冠状病毒,负链rna病毒例如正粘病毒(例如流感病毒),弹状病毒(例如狂犬病和水疱性口炎病毒),副粘病毒(例如麻疹和仙台),正链rna病毒例如小核糖核酸病毒和甲病毒,以及双链dna病毒,包括腺病毒、疱疹病毒(例如单纯疱疹病毒1型和2型、爱泼斯坦-巴尔病毒、巨细胞病毒)和痘病毒(例如牛痘、鸡痘和金丝雀痘)。例如,其它病毒包括例如诺沃克病毒、披膜病毒、黄病毒、呼肠孤病毒、乳多空病毒、嗜肝dna病毒和肝炎病毒。逆转录病毒的例子包括:禽白血病-肉瘤,哺乳动物c型病毒、b型病毒、d型病毒,htlv-blv组,慢病毒,泡沫病毒(coffin,j.m.,retroviridae:the viruses and their replication,in fundamental virology,third edition,b.n.fields,et al.,eds.,lippincott-raven publishers,philadelphia,1996)。
[0091]
如本文所用,术语“基因座”是dna序列(例如基因的)在基因组中的特定物理位置。术语“基因座”可以指稀有切割核酸内切酶靶序列在染色体上或感染剂基因组序列上的特定物理位置。这样的基因座可以包括被根据本发明的序列特异性核酸内切酶识别和/或切割的靶序列。应当理解的是,本发明的目的基因座不仅可以限定存在于细胞遗传物质主体(即染色体中)的核酸序列,而且可以限定可以独立于遗传物质的所述主体而存在的遗传物质的一部分,例如质粒、附加体、病毒、转座子或在细胞器中,例如作为非限制性实例的线粒
体。
[0092]
术语“切割”是指多核苷酸共价骨架的断裂。切割可以通过多种方法引发,包括但不限于磷酸二酯键的酶水解或化学水解。单链切割和双链切割都是可能的,并且双链切割可以作为两个不同单链切割事件的结果而发生。双链dna、rna或dna rna杂合切割可导致产生平末端或交错末端。
[0093]“同一性”是指两个核酸分子或多肽之间的序列同一性。同一性可以通过比对为了对比目的而对齐的每个序列中的位置来确定。当比较的序列中的一个位置被相同碱基占据时,则分子在该位置是同一的。核酸或氨基酸序列之间的相似性或同一性程度是取决于多个核酸序列共有的位置处相同或匹配核苷酸数目。可以使用各种比对算法和/或程序来计算两个序列之间的同一性,包括fasta或blast,它们可作为gcg序列分析包的一部分而获得(university of wisconsin,madison,wis.),并可以以例如默认设置使用。例如,考虑了与本文描述的特定多肽具有至少70%、85%、90%、95%、98%或99%同一性并且优选地表现出基本相同功能的多肽,以及编码此类多肽的多核苷酸。
[0094]
如本文用,术语“治疗(treat)”、“治疗(treatment)”、“治疗(treating)”等是指获得期望药理学和/或生理学效果。就完全或部分预防疾病或其症状而言,效果可以是预防性的,和/或就部分或完全治愈疾病和/或归因于该疾病的副作用而言,效果可以是治疗性的。如本文所用,“治疗”涵盖哺乳动物(特别是人类)疾病的任何治疗,并且包括:(a)防止疾病在可能易患该疾病但尚未诊断患有该疾病的受试者中发生;(b)抑制疾病,即阻止其发展;和(c)缓解疾病,例如导致疾病消退,例如完全或部分消除疾病症状。
[0095]
在细胞的背景下的“扩增”是指从可能相同或可能不同的细胞的初始细胞群开始,一种或多种特征性细胞类型的数量增加。用于扩增的初始细胞可能与扩增产生的细胞不同。
[0096]“细胞群”是指真核哺乳动物细胞,优选人类细胞,其分离自生物来源,例如血液制品或组织,并来源于多于一种细胞。
[0097]
当在细胞群的背景下使用时,“富集的”是指基于存在的一种或多种标志物(例如cd34 )而选择的细胞群。
[0098]
术语“cd34 细胞”是指在其表面表达cd34标记的细胞。可以使用例如流式细胞术和荧光标记的抗-cd34抗体检测和计数cd34 细胞。
[0099]“富含cd34 细胞”是指已基于cd34标志物的存在选择细胞群。因此,选择方法后细胞群中cd34 细胞的百分比高于基于cd34标志物的选择步骤之前的初始细胞群中cd34 细胞的百分比。例如,cd34 细胞可占富含cd34 细胞的细胞群中细胞的至少50%、60%、70%、80%或至少90%。
[0100]
如本文所用,术语“受试者”或“患者”包括动物界的所有成员,包括非人类灵长类动物和人类。
[0101]
在本文中说明数值限制或范围的情况下,包括端点。此外,数值限制或范围内的所有值和子范围都被特别地包括在内,如同明确写出一样。
[0102]
治疗方法
[0103]
在一个实施方式中,本发明提供了一种将转基因表达到患者大脑中的方法,包括:
[0104]
i)获得基因修饰的造血干细胞(hsc),其中hsc分离自患者或者获自来源于患者并
且分化成hsc的诱导多能干(ips)细胞,其中基因修饰的hsc被工程化为包括整合在小胶质细胞中表达的基因座上的转基因;和
[0105]
ii)将基因修饰的hsc移植到患者中,使其分化为将转基因表达到患者大脑中的小胶质细胞。
[0106]
在另一个实施方式中,本发明提供了一种将转基因表达到患者大脑中的方法,包括:
[0107]
i)获得基因修饰的造血干细胞(hsc),其中hsc分离自相容供体或者获自来源于相容供体并且分化成hsc的诱导多能干(ips)细胞,其中基因修饰的hsc被工程化为包括整合在小胶质细胞中表达的基因座上的转基因;和
[0108]
ii)将基因修饰的hsc移植到患者中,使其分化为将转基因表达到患者大脑中的小胶质细胞。
[0109]
在另一个实施方式中,本发明提供了一种治疗患者中疾病或病症的方法,包括向患者施用有效量的基因修饰的hsc,其中基因修饰的hsc被工程化为包括整合在小胶质细胞中表达的基因座上的转基因,其中基因修饰的hsc在患者中分化为小胶质细胞并且将转基因表达到患者大脑中。在一些实施方式中,hsc分离自相容供体或者获自来源于相容供体并且分化成hsc的诱导多能干(ips)细胞。在一些实施方式中,hsc分离自患者或者获自来源于患者并且分化成hsc的诱导多能干(ips)细胞。
[0110]
在一些实施方式中,患者患有单基因疾病或病症。在一些实施方式中,患者在与转基因同源的内源性基因的表达方面具有缺陷。在一些实施方式中,患者患有溶酶体贮积病。在一些实施方式中,疾病或病症选自粘多糖病i型(scheie、hurler-scheie或hurler综合征)、粘多糖病ii型(亨特综合征)、粘多糖病vi型(maroteaux-lamy综合征)、粘多糖病vii型(sly疾病)、x连锁肾上腺脑白质营养不良、球形细胞脑白质营养不良(克拉伯病)、异染性脑白质营养不良、戈谢病、岩藻糖苷贮积症、α-甘露糖苷过多症、天冬氨酰葡萄糖胺尿症、farber病、泰-萨克斯病、庞贝氏病、尼曼匹克病和沃尔曼病。在一些实施方式中,患者患有中枢神经系统(cns)疾病。在一些实施方式中,cns疾病选自阿尔茨海默病、帕金森病、亨廷顿氏病、多发性硬化症疾病。在一些实施方式中,患者患有cdkl5-缺陷相关疾病。在一些实施方式中,cdkl5-缺陷疾病选自婴儿早期癫痫性脑病(eiee)、非典型rett综合征、cdkl5相关癫痫性脑病和韦斯特综合征。
[0111]
该方法可以是自体治疗的一部分或同种异体治疗的一部分。自体是指用于治疗患者的细胞来源于所述患者。同种异体是指用于治疗患者的细胞或细胞群不是源自所述患者而是源自供体。
[0112]
在一些实施方式中,将细胞施用于正接受免疫抑制治疗的患者。在一个实施方式中,使施用的细胞对至少一种免疫抑制剂具有抗性。在一些实施方式中,免疫抑制治疗有助于基因修饰的hsc在患者内的选择和扩增。
[0113]
细胞的施用可以任何方便的方式进行,包括通过雾化吸入、注射、摄取、输液、植入或移植。本文描述的组合物可以皮下、皮内、瘤内、结节内、髓内、肌内、通过静脉内或淋巴内注射、或腹膜内施用于患者。在一个实施方式中,细胞组合物通过静脉内注射施用,其中能够迁移至骨髓。
[0114]
尽管个体需求不同,但对于特定疾病或病症,确定给定细胞类型的有效量的最佳
范围在本领域的技术范围内。有效量是指提供治疗或预防益处的量。施用的剂量将取决于接受者的年龄、健康和体重、并存治疗的种类(如果有的话)、治疗频率和所需效果的性质。在一些实施方式中,细胞或细胞群的施用包括施用约10
4-109个细胞/kg体重。在一些实施方式中,施用约105至106个细胞/kg体重。那些范围内的细胞数的所有整数值都被考虑在内。
[0115]
细胞可以以一剂或多剂施用。在另一个实施方式中,有效量的细胞作为单剂量施用。在另一个实施方式中,有效量的细胞在一段时间内作为多于一个剂量施用。施用时间在主治医师的判断范围内,并且取决于患者的临床状况。
[0116]
在一些实施方式中,施用基因修饰的hsc细胞可以包括用清髓性和/或免疫抑制性方案治疗患者以消耗宿主骨髓干细胞并防止排斥。在一些实施方式中,对患者施用化学疗法和/或放射疗法。在一些实施方式中,对患者施用减少剂量的化疗方案。在一些实施方式中,以标准剂量的25%使用白消安的减少剂量化疗方案可足以实现修饰细胞的显著植入,同时降低与调理相关的毒性(aiuti a.et al.(2013),science 23;341(6148))。更强的化疗方案可以基于施用白消安和氟达拉滨两者作为内源性hsc的消耗剂。在一些实施方式中,白消安和氟达拉滨的剂量约为标准同种异体移植中所用剂量的50%和30%。在另一个实施方式中,在b细胞消融疗法后施用细胞,例如与cd20反应的试剂,例如利妥昔单抗(rituxan)。在一些实施方式中,向患者施用化疗剂例如氟达拉滨、外照射放射疗法(xrt)、环磷酰胺或抗体例如okt3或campath。
[0117]
在某些实施方案中,将基因修饰的细胞作为包括免疫抑制剂的联合疗法施用于受试者。示例性的免疫抑制剂包括西罗莫司、他克莫司、环孢霉素、麦考酚酯、抗胸腺细胞球蛋白、皮质类固醇、神经钙调蛋白抑制剂、抗代谢物诸如甲氨蝶呤、移植后环磷酰胺或其任何组合。在一些实施方式中,使用仅西罗莫司或他克莫司预治疗受试者作为针对gvhd的预防。在一些实施方式中,在免疫抑制剂之前将细胞施用于受试者。在一些实施方式中,在免疫抑制剂之后将细胞施用于受试者。在一些实施方式中,将细胞与免疫抑制剂同时施用于受试者。在一些实施方式中,细胞在没有免疫抑制剂的情况下施用于受试者。在一些实施方式中,接受基因修饰细胞的患者接受少于6个月、5个月、4个月、3个月、2个月、1个月、3周、2周或1周的免疫抑制剂。
[0118]
转基因和疾病
[0119]
如本文所用的转基因编码疾病相关基因的治疗性蛋白质。疾病相关基因是在疾病中以某种方式存在缺陷的基因。在一些实施方式中,待治疗的疾病和转基因如下表1所示。
[0120]
表1.单基因疾病和用于其治疗的转基因。
id no:2。
[0125]
在一些实施方式中,ids的核苷酸序列包括seq id no:3并且氨基酸序列包括seq id no:4。
[0126]
在一些实施方式中,arsb的核苷酸序列包括seq id no:5并且氨基酸序列包括seq id no:6。
[0127]
在一些实施方式中,gusb的核苷酸序列包括seq id no:7并且氨基酸序列包括seq id no:8。
[0128]
在一些实施方式中,abcd1的核苷酸序列包括seq id no:9并且氨基酸序列包括seq id no:10。
[0129]
在一些实施方式中,galc的核苷酸序列包括seq id no:11并且氨基酸序列包括seq id no:12。
[0130]
在一些实施方式中,arsa的核苷酸序列包括seq id no:13并且氨基酸序列包括seq id no:14。
[0131]
在一些实施方式中,psap的核苷酸序列包括seq id no:15并且氨基酸序列包括seq id no:16。
[0132]
在一些实施方式中,gba的核苷酸序列包括seq id no:17并且氨基酸序列包括seq id no:18。
[0133]
在一些实施方式中,fuca1的核苷酸序列包括seq id no:19并且氨基酸序列包括seq id no:20。
[0134]
在一些实施方式中,man2b1的核苷酸序列包括seq id no:21并且氨基酸序列包括seq id no:22。
[0135]
在一些实施方式中,aga的核苷酸序列包括seq id no:23并且氨基酸序列包括seq id no:24。
[0136]
在一些实施方式中,asah1的核苷酸序列包括seq id no:25并且氨基酸序列包括seq id no:26。
[0137]
在一些实施方式中,hexa的核苷酸序列包括seq id no:27并且氨基酸序列包括seq id no:28。
[0138]
在一些实施方式中,gaa的核苷酸序列包括seq id no:29并且氨基酸序列包括seq id no:30。
[0139]
在一些实施方式中,smpd1的核苷酸序列包括seq id no:31并且氨基酸序列包括seq id no:32。
[0140]
在一些实施方式中,lipa的核苷酸序列包括seq id no:33并且氨基酸序列包括seq id no:34。
[0141]
在一些实施方式中,cdkl5的核苷酸序列包括seq id no:35并且氨基酸序列包括seq id no:36。
[0142]
在一些实施方式中,转基因包括选自seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33和35中任一者的核苷酸序列的一个或多个拷贝。
[0143]
在一些实施方式中,转基因包括编码选自seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34和36中任一者的氨基酸序列的核苷酸序列的一个或多个拷贝。
[0144]
在一些实施方式中,转基因包括编码治疗性蛋白质的核苷酸序列,治疗性蛋白质是seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34和36中任一者的变体。
[0145]
编码治疗性蛋白质的特定核苷酸序列可以在其全长上与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33或35中的编码序列相同。替代地,由于编码seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34和36的多肽的遗传密码的简并性或密码子使用的变化,编码治疗性蛋白质的特定核苷酸序列可以是seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33或35的替代形式。在一些实施方式中,转基因包括与编码治疗性蛋白质的多核苷酸序列高度同一性(具有至少90%同一性)的核苷酸序列,或与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33或35中阐述的编码核苷酸序列具有至少90%同一性的核苷酸序列。在一些实施方式中,转基因包括与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33或35中阐述的核苷酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的核苷酸序列。
[0146]
当包括编码本发明的治疗性蛋白质的多核苷酸的转基因用于治疗性蛋白质的重组生产时,多核苷酸本身可以包括全长多肽或其片段的编码序列;全长多肽或片段的编码序列与其它编码序列(例如编码前导或分泌序列、前蛋白质序列或原蛋白质序列或前原蛋白质序列或其它融合肽部分的那些序列)处于相同的阅读框。多核苷酸还可以含有非编码的5'和3'序列,例如转录的非翻译的序列、剪接和多腺苷酸化信号、核糖体结合位点和稳定mrna的序列。
[0147]
在一些实施方式中,治疗性蛋白质可以进一步包括允许其由本发明的基因编辑细胞分泌的分泌信号肽。下表2列出了此类信号肽的一些实例。
[0148]
表2:有用的信号肽的实例
[0149][0150]
在一些实施方式中,治疗性蛋白质可以进一步包括允许细胞摄取的肽,例如细胞穿透肽(cpp)和载脂蛋白。下表3中列出了细胞穿透肽和载脂蛋白的实例。
[0151]
表3:有用的cpp和载脂蛋白的实例
[0152][0153][0154]
在一些实施方式中,转基因包括多核苷酸,该多核苷酸与编码具有seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34和36中氨基酸序列的治疗性蛋白质的核苷酸序列具有至少90%同一性且更优选地具有至少91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的核苷酸序列。
[0155]
可以使用利用已知的计算机程序的常规手段,例如bestfit程序(wisconsin序列分析包,版本10,unix,genetics computer group.university research park,575science drive,madison,wis.53711)来确定特定的核酸序列是否与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33或35中所示核苷酸序列任一者具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的同一性。
[0156]
在一些实施方式中,转基因包括编码治疗性蛋白质的多核苷酸,该治疗性蛋白质具有seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32或34的治疗性蛋白质的氨基酸序列,其中多个、1、1-2、1-3、1-5、5-10或10-20个氨基酸残基以任何组合被取代、缺失或添加。
[0157]
在一些实施方式中,转基因包括在它们的全长上与编码具有seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36中列出的氨基酸序列的治疗性蛋白质的
多核苷酸具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的多核苷酸。
[0158]
在一些实施方式中,由转基因表达的治疗性蛋白质与蛋白质的野生型氨基酸序列(例如seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36中任一项)是相同的。
[0159]
在一些实施方式中,由转基因表达的治疗性蛋白质为seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36中任一者的功能性片段或变体。
[0160]
在一些实施方式中,治疗性蛋白质包括seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36的多肽,以及具有活性并且与seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36的多肽包括至少90%同一性的多肽和片段,或相关部分并且更优选与seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36的多肽包含至少96%、97%或98%的同一性,并且还更优选与seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36的多肽具有至少91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性。
[0161]
治疗性蛋白质可以是较大蛋白质(诸如融合蛋白)的一部分。通常有利的是包括含有分泌或前导序列、原序列或可能有助于稳定性的其它序列的另外的氨基酸序列。
[0162]
在一些实施方式中,转基因编码seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32或34中任一者的生物活性片段。片段是具有与上述治疗性蛋白质之一的氨基酸序列的一部分但不是全部完全相同的氨基酸序列的多肽。与全长治疗性蛋白质一样,片段可以是“独立的”或包括在更大多肽中,在该更大多肽中,它们形成一部分或区域,最优选形成为单个连续区域。在一些实施方式中,片段可以构成seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36中的约10个连续氨基酸。
[0163]
在一些实施方式中,片段包括例如具有治疗性蛋白质的氨基酸序列的截短多肽,除了缺失包括氨基末端的一系列连续残基,或缺失包括羧基末端的一系列连续残基,或缺失两个系列连续残基,一个包括氨基末端且一个包括羧基末端。还优选以结构或功能属性为特征的片段,例如包括α-螺旋和α-螺旋形成区、β-折叠和β-折叠形成区、转角和转角形成区、线圈和线圈形成区、亲水区、疏水区、α两亲区、β两亲区、柔性区、表面形成区、底物结合区和高抗原指数区的片段。功能性片段是介导野生型蛋白质的蛋白质活性的那些片段,包括具有相似活性或改进活性的那些片段。
[0164]
在一些实施方式中,片段可以缺少seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36中任一者的n-末端和/或c-末端的1-20个氨基酸(即1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个氨基酸)。
[0165]
在一些实施方式中,转基因编码具有与seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36具有至少90%同一性的氨基酸序列的多肽、或其功能片段,该功能片段与seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34或36的对应片段具有至少90%同一性,它们全部均保留了治疗性蛋白质的生物活性。该组中包括的是确定序列和片段的变体。在一些实施方式中,变体是通过保守氨基酸取代而与参考序列不同的那些变体,即用相同特性的另一个残基取代的那些变体。典型的取代在ala、val、leu和ile中;在ser和thr中;在酸性残基asp和glu中;在asn和gln中;以及在碱性残基lys和arg
中,或芳香族残基phe和tyr中。在一些实施方式中,转基因编码多肽变体,其中1-20氨基酸以任何组合被取代、缺失或添加。
[0166]
cdkl5-缺陷相关疾病:
[0167]
婴儿早期癫痫性脑病(eiee)
[0168]
婴儿早期癫痫性脑病(eiee)是一种以癫痫发作为特征的神经系统疾病。这种疾病影响新生儿,通常在生命的头三个月内(最常见的是头10天内)以癫痫发作的形式出现。婴儿主要有强直性癫痫发作(这导致身体肌肉僵硬,通常是背部、腿部和手臂的肌肉),但也可能出现部分性癫痫发作,并且很少出现肌阵挛性癫痫发作(这导致上半身、手臂或腿猛拉或抽搐)。发作可能每天发生超过一百次。大多数患有这种病症的婴儿表现出部分或全部大脑半球发育不全或结构异常。有些病例是由代谢紊乱或多个不同基因的突变引起的。许多病例的原因无法确定。有多种类型的早期婴儿癫痫性脑病。eeg揭示了高压尖峰波放电的特征性模式,随后几乎没有活动。这种模式被称为“突发抑制”。与这种疾病相关的癫痫发作难以治疗,并且该综合征严重地进展。一些患有这种病症的儿童继续发展为其他癫痫性病症,例如韦斯特综合征和lennox-gestaut综合征。
[0169]
eiee可能是不同病因的结果。许多病例与脑结构异常有关。一些病例是由于代谢紊乱(细胞色素c氧化酶缺乏症、肉碱棕榈酰转移酶ii缺乏症)或脑畸形(如孔洞脑或半侧巨脑畸形)引起的,这些疾病可能起源于遗传,也可能非遗传。eiee的遗传变异与某些基因的突变有关,诸如arx(xp22.13)、cdkl5(xp22)、sl25a22(11p15.5)和stxbp1(9q34.1)等。遗传异常被认为会导致eiee,因为它们与神经元功能障碍或大脑发育不全有关。
[0170]
非典型rett综合征
[0171]
非典型rett综合征是一种神经发育障碍,当儿童有rett综合征的一些症状但不符合所有诊断标准时被诊断出来。与经典形式的rett综合征一样,非典型rett综合征主要影响女孩。非典型rett综合征患儿的症状可能比rett综合征更轻或更严重。已经定义了多种非典型rett综合征的亚型。早发性癫痫发作类型的特点是出生后头几个月癫痫发作,随后出现rett特征(包括发育问题、语言技能丧失和反复拧手或洗手动作)。它通常由x连锁cdkl5基因(xp22)的突变引起。
[0172]
cdkl5相关癫痫性脑病
[0173]
cdkl5相关癫痫性脑病的特点是由早期癫痫(第1阶段)、然后是婴儿痉挛(第2阶段)和最后的多灶性和难治性肌阵挛性癫痫(第3阶段)组成的3阶段演变。参见例如bahi-buisson et al.epilepsia.49:1027
–
1037(2008)。细胞周期蛋白依赖性激酶样5(cdkl5)的遗传异常导致早发性癫痫性脑病。
[0174]
韦斯特综合征
[0175]
韦斯特综合征是一种癫痫症,其特征是痉挛、称为高节律失常的异常脑电波模式,并且有时还有智力障碍。发生的痉挛可能包括剧烈的屈身或全身弯曲成两半的“额手礼”运动,或者它们也可能只是肩膀的轻微抽搐或眼睛的变化。这些痉挛通常在出生后的最初几个月开始,并且有时可以通过药物治疗。韦斯特综合征有许多不同的致因,并且如果可以确定特定原因,则可以诊断为有症状的韦斯特综合征。如果无法确定致因,则诊断为隐源性韦斯特综合征。约70-75%的受影响者可以确定韦斯特综合征的特定原因。x连锁韦斯特综合征(x连锁婴儿痉挛综合征或issx)可由x染色体上的cdkl5基因或arx基因突变引起。
[0176]
粘多糖病
[0177]
粘多糖病(mps)是与酶缺陷相关的退行性基因疾病。特别地,mps是由溶酶体酶缺乏或溶酶体酶不活跃引起的,溶酶体酶催化称为糖胺聚糖(gag)的复杂糖分子的逐渐代谢。这些酶缺乏导致gag在细胞、组织且特别是受影响受试者的细胞溶酶体中积累,导致永久性和进行性细胞损伤,这会影响外观、身体能力、器官功能和在大多数情况下受影响受试者的心理发展。
[0178]
已鉴定出11种不同的酶缺陷,对应于mps的7种不同临床类别。每种mps的特点是一种或多种降解粘多糖的酶(即硫酸乙酰肝素、硫酸皮肤素、硫酸软骨素和硫酸角质素)的缺乏或无活性。
[0179]
mps i根据症状的严重程度分为三个亚型。所有这三种类型都是由于酶α-l-艾杜糖醛酸酶(idija)的不存在或水平不足导致的。父母一方为mps i的儿童携带缺陷基因。
[0180]
mps i h(也称为hurler综合征或α-l-艾杜糖醛酸酶缺乏症)是mps i亚型中最严重的一种。在第一年结束时发育迟缓很明显,并且患者通常在2至4岁之间停止发育。随后是进行性智力衰退和身体技能丧失。由于听力损失和舌头扩大,语言可能会受到限制。适时地,角膜的透明层变得混浊,并且视网膜可能开始退化。腕管综合征(或身体其它部位的类似神经压迫)和关节活动受限很常见。受影响的儿童在出生时可能很大并且看起来很正常,但可能有腹股沟疝(在腹股沟)或脐疝(脐带穿过腹部)。身高的增长可能比正常情况更快,但在第一年结束之前开始放缓,通常在3岁左右结束。许多儿童的身体躯干很短并最大身高不到4英尺。不同的面部特征(包括脸部扁平、鼻梁凹陷和额头凸出)在第二年变得更加明显。到2岁时,肋骨已经变宽且呈桨状。肝脏、脾脏和心脏经常肿大。儿童可能会经历嘈杂的呼吸和反复出现的上呼吸道和耳部感染。一些儿童可能难以进食,而且许多会出现周期性的肠道问题。患有hurler综合征的儿童通常在10岁之前死于阻塞性气道疾病、呼吸道感染和心脏并发症。
[0181]
mps i s,scheie综合征,是mps 1最温和的形式。症状通常在5岁后开始出现,最常在10岁后作出诊断。患有scheie综合征的儿童智力正常或可能有轻度学习障碍;有些可能有精神问题。青光眼、视网膜变性和角膜混浊可能会严重损害视力。其它问题包括腕管综合征或其它神经压迫、关节僵硬、爪形手和畸形脚、短颈和主动脉瓣疾病。一些受影响的个体还患有阻塞性气道疾病和睡眠呼吸暂停。患有scheie综合征的人可以活到成年。
[0182]
mps i h-s,hurler-scheie综合征,严重性比单独的hurler综合征要轻。症状通常在3至8岁之间开始。儿童可能有中度智力障碍和学习困难。骨骼和全身异常包括身材矮小、颚部明显变小、进行性关节僵硬、脊髓受压、角膜混浊、听觉损失、心脏病、面部特征粗糙和脐疝。青春期可能会出现呼吸问题、睡眠呼吸暂停和心脏病。一些mps i h-s患者在睡眠期间需要持续气道正压通气以缓解呼吸。预期寿命一般在十几岁(late teens)或二十出头(early twenties)。
[0183]
mps ii,也称为亨特综合征,是由缺乏艾杜糖醛酸硫酸酯酶引起的。亨特综合征有两种临床亚型,并且(因为它显示x连锁隐性遗传)是唯一一种只有母亲才能将缺陷基因传给儿子的粘多糖病。亨特综合征的发病率估计为每100,000至150,000名男性新生儿中的有1名。
[0184]
ids基因的突变导致mps ii。ids基因提供产生i2s酶的指令,该酶参与称为糖胺聚
糖(gag)的大糖分子的分解。具体地,i2s从称为硫酸化α-l-艾杜糖醛酸的分子中去除称为硫酸根(sulfate)的化学基团,该分子存在于称为硫酸乙酰肝素和硫酸皮肤素的两种gag中。i2s位于溶酶体中,在消化和回收不同类型分子的细胞隔室内。
[0185]
粘多糖病vi型(mps vi)或maroteaux-lamy疾病是粘多糖病组的溶酶体贮积病,其特点是严重的躯体受累和缺乏心理-智力退化。这种罕见粘多糖病的患病率在1/250,000至1/600,000个出生人数之间。在严重的形式下,第一个临床表现发生在6到24个月之间,并逐渐加重:面部畸形(巨舌,嘴经常半张,厚的特征),关节受限,非常严重的多发性成骨异常(扁平椎、驼背、脊柱侧凸、鸡胸、膝外翻、长骨变形),小尺寸(小于1.10m),肝肿大,心脏瓣膜损伤,心肌病,耳聋,角膜混浊。智力发育通常正常或几乎正常,但听觉和眼科损伤会导致学习困难。疾病的症状和严重程度因患者相差悬殊,并且存在中间形式,甚至还存在非常温和的形式(与心血管受累相关的脊椎骨骺线-骨骺线发育不良)。与其它粘多糖病一样,maroteaux-lamy病与粘多糖代谢酶的缺陷有关,在这种情况下恰当地为n-乙酰半乳糖胺-4-硫酸酯酶(也称为芳基硫酸酯酶b)(arsb)。这种酶代谢硫酸皮肤素的硫酸基团(neufeld et al.:"the mucopolysaccharidoses"the metabolic basis of inherited diseases,eds.scriver et al,new york,mcgraw-hill,1989,p.1565-1587)。这种酶缺陷阻断了硫酸皮肤素的逐渐降解,从而导致硫酸皮肤素在储存组织的溶酶体中积累。
[0186]
粘多糖病vii型(mps vii)或sly疾病是粘多糖病组中一种非常罕见的溶酶体贮积病。症状极其异质:产前形式(非免疫性胎儿胎盘全身水肿),严重的新生儿形式(具有畸形、疝气、肝脾肿大、畸形足、骨发育不全、显著的肌张力减退以及演变为生长迟缓和生存时严重智力缺陷的神经系统问题)以及在青春期或甚至成年时发现的非常温和的形式(胸椎后凸)。该疾病是由于β-d-葡萄糖醛酸酶(gusb)的缺陷导致各种糖胺聚糖(硫酸皮肤素、硫酸乙酰肝素和硫酸软骨素)在溶酶体中积累引起的。目前针对这种疾病还没有有效治疗方法。
[0187]
x连锁肾上腺脑白质营养不良
[0188]
肾上腺脑白质营养不良(ald)是一种x连锁疾病,影响1/20,000的男性,无论是儿童期的脑ald还是成人的肾上腺脑神经病(adrenomyleneuropathy)(amn)。儿童期ald是更严重的形式,在5-12岁之间出现神经系统症状。中枢神经系统脱髓鞘进展迅速,并在几年内发生死亡。amn是一种较温和的疾病形式,发病年龄为15-30岁并且病程进展较快。肾上腺功能不全(爱迪生氏病)可能仍然是ald的唯一临床表现。ald的主要生化异常是由于过氧化物酶体中的-氧化受损导致超长链脂肪酸(vlcfa)的积累。
[0189]
已发现abcd1基因中超过650个突变会导致x连锁肾上腺脑白质营养不良。这种病症的特点是不同程度的认知和运动问题以及激素失衡。导致x连锁肾上腺脑白质营养不良的突变在大约75%患有这种病症的人中阻止产生任何aldp。患有x连锁肾上腺脑白质营养不良的其他人可以产生aldp,但该蛋白质无法发挥其正常功能。在很少或没有功能性aldp的情况下,vlcfa不会被分解,并且它们会在体内积聚。这些脂肪的积累可能对肾上腺(每个肾脏顶部的小腺体)和体内包围许多神经的脂肪绝缘层(髓磷脂)有毒。研究表明,vlcfa的积累会引发大脑中的炎症反应,这可能导致髓磷脂的分解。这些组织的破坏导致x连锁肾上腺脑白质营养不良的体征和症状。
[0190]
球形细胞脑白质营养不良
[0191]
婴儿球形细胞白质营养不良(gld,半乳糖神经酰胺脂沉积症或克拉伯病)是一种
罕见的中枢和外周神经系统常染色体隐性遗传退行性疾病。在美国的发病率估计为1:100.000。它的特征是存在球状细胞(具有多个核的细胞)、神经保护性髓鞘层的退化和大脑中细胞的损失。gld导致严重的精神减退和运动迟缓。它是由缺乏半乳糖脑苷脂-β-半乳糖苷酶(galc)引起的,galc是髓磷脂代谢中必不可少的酶。这种疾病通常会影响6个月大之前的婴儿,但它也可能出现在青年或成人中。症状包括易怒、不明原因的发烧、四肢僵硬(高血压)、癫痫发作、与食物摄入有关的问题、呕吐以及智力和运动能力的发育迟缓。其它症状包括肌肉无力、痉挛、耳聋和失明。
[0192]
半乳糖基神经酰胺酶基因(galc)长约60kb,并且由17个外显子组成。已在鼠和人类galc基因中鉴定出许多突变和多态性,导致严重程度不同的gld。
[0193]
异染性脑白质营养不良
[0194]
异染性脑白质营养不良是一种遗传性病症,其特点是细胞中称为硫苷脂的脂肪积累。这种积累尤其影响神经系统中产生髓磷脂的细胞,髓磷脂是绝缘和保护神经的物质。被髓磷脂覆盖的神经细胞构成了一种称为白质的组织。产生髓磷脂的细胞中的硫苷脂积累会导致整个神经系统的白质(脑白质营养不良)进行性破坏,包括大脑和脊髓(中枢神经系统)中的神经以及将大脑和脊髓连接到肌肉和感觉细胞的神经,感染细胞检测诸如触觉、疼痛、热和声音(周围神经系统)等感觉。
[0195]
在患有异染性脑白质营养不良的人中,白质损伤会导致智力功能和运动技能(例如行走能力)进行性恶化。受影响的个体还会发展四肢感觉丧失(周围神经病变)、失禁、癫痫发作、瘫痪、无法说话、失明和听力损失。最终,他们丧失对周围环境的意识,变得反应迟钝。虽然神经系统问题是异染性脑白质营养不良的主要特征,但已经报道了硫苷脂积累对其它器官和组织的影响,最常见涉及胆囊。
[0196]
最常见的异染性脑白质营养不良形式,其影响患有这种病症的所有个体的约50%至60%,被称为婴幼儿后期形式。这种形式的病症通常出现在生命的第二年。受影响的儿童失去他们已经发展的任何语言,变得虚弱,并出现行走问题(步态障碍)。随着疾病的恶化,肌张力通常首先降低,然后增加至僵硬点。患有婴幼儿后期形式异染性脑白质营养不良的个体通常无法活过童年。
[0197]
在20%至30%的异染性脑白质营养不良个体中,在4岁至青春期之间发病。在这种青少年形式中,病症的最初迹象可能是行为问题和学业难度增加。该病症的进展比婴幼儿后期形式慢,并且受影响的个体在确诊后可能存活约20年。
[0198]
大多数患有异染性脑白质营养不良的个体的arsa基因中具有突变,该基因提供了制备酶芳基硫酸酯酶a的指令。这种酶位于称为溶酶体的细胞结构中,溶酶体是细胞的回收中心。在溶酶体内,芳基硫酸酯酶a有助于分解硫苷脂。少数患有异染性脑白质营养不良的个体的psap基因中具有突变。该基因提供了制备蛋白质的指令,该蛋白质被分解(切割)成更小的蛋白质,帮助酶分解各种脂肪。这些较小蛋白质中的一种称为皂化蛋白b;这种蛋白质与芳基硫酸酯酶a一起分解硫苷脂。
[0199]
arsa或psap基因中的突变导致分解硫苷脂的能力下降,从而导致这些物质在细胞中积累。过量的硫苷脂对神经系统有毒。积累逐渐破坏产生髓磷脂的细胞,导致在异染性脑白质营养不良中发生的神经系统功能受损。
[0200]
在某些情况下,芳基硫酸酯酶a活性非常低的个体不会表现出异染性脑白质营养
不良的症状。这种病症也称为伪芳基硫酸酯酶缺乏症。
[0201]
成人形式的异染性脑白质营养不良影响约15%至20%患有这种病症的个体。在这种形式中,最初的症状出现在青少年时期或更晚。通常,行为问题,例如酗酒、药物滥用、或在学校或工作中遇到困难是最先出现的症状。受影响的个体可能会经历精神症状,例如妄想或幻觉。患有成人形式异染性脑白质营养不良的人在确诊后可存活20至30年。在此期间,可能会有一些相对稳定的时期和其它更快速衰退的时期。
[0202]
异染性脑白质营养不良的名称来源于在显微镜下观察时出现的具有硫脂苷积累的细胞的方式。硫苷脂形成被描述为异染性的颗粒,这意味着在染色检查时,它们呈现出与周围的细胞物质不同的颜色。
[0203]
戈谢病
[0204]
戈谢病是一种遗传性疾病,其影响许多的身体器官和组织。这种病症的体征和症状在受影响的个体中差异很大。研究人员根据其特征性特征描述了多种类型的戈谢病。
[0205]
1型戈谢病是这种病症最常见的形式。1型也称为非神经元病性戈谢病,因为大脑和脊髓(中枢神经系统)通常不受影响。这种病症的特征从轻微到严重不等,并且从童年到成年的任何时候都可能出现。主要体征和症状包括肝脏和脾脏肿大(肝脾肿大)、红细胞数量减少(贫血)、血小板减少引起的易瘀伤(血小板减少症)、肺部疾病和骨骼异常(如骨痛、骨折和关节炎)。
[0206]
2型和3型戈谢病被称为该病症的神经元病形式,因为它们的特点是影响中枢神经系统的问题。除了上述体征和症状外,这些病症还可能导致异常眼球运动、癫痫发作和脑损伤。2型戈谢病通常会从婴儿期开始导致危及生命的医疗问题。3型戈谢病也会影响神经系统,但它的恶化往往比2型慢。
[0207]
最严重的戈谢病类型称为围产期致死形式。从出生前或婴儿期开始,这种病症会导致严重或危及生命的并发症。围产期致死形式的特征可能包括由出生前积液引起的广泛肿胀(胎儿水肿);干燥、鳞状皮肤(鱼鳞癣)或其它皮肤异常;肝脾肿大;独特的面部特征;和严重的神经问题。顾名思义,大多数患有围产期致命形式戈谢病的婴儿在出生后只能存活几天。
[0208]
另一种形式的戈谢病被称为心血管类型,因为它主要影响心脏,导致心脏瓣膜硬化(钙化)。患有心血管形式戈谢病也可能有眼睛异常、骨骼疾病和脾脏轻度肿大(脾肿大)。
[0209]
gba基因中的突变导致戈谢病。gba基因提供了制备称为β-葡萄糖脑苷脂酶的酶的指令。这种酶将一种叫做葡萄糖脑苷脂的脂肪物质分解成糖(葡萄糖)和更简单的脂肪分子(神经酰胺)。gba基因中的突变大大降低或消除了β-葡萄糖脑苷脂酶的活性。如果没有足够的这种酶,葡萄糖脑苷脂和相关物质会在细胞内积累到毒性水平。这些物质的异常积累和储存会损害组织和器官,导致戈谢病的特征性特征。
[0210]
岩藻糖苷贮积症
[0211]
岩藻糖苷贮积症是一种影响身体许多区域的病症,尤其是大脑。受影响的个体的智力残疾会随着年龄的增长而恶化,并且许多人在以后的生活中会患上痴呆症。患有这种病症的人通常会延迟运动技能的发育,例如行走;他们确实获得的技能会随着时间的推移而退化。岩藻糖苷贮积症的其它体征和症状包括生长受损;骨发育异常(多发性成骨异常);癫痫发作;肌肉异常僵硬(痉挛);扩大的血管簇在皮肤上形成小而深的红色斑点(血管角质
瘤);通常被描述为“粗糙”的独特面部特征;反复呼吸道感染;和异常大的腹部器官(内脏肥大)。
[0212]
在严重的情况下,症状通常出现在婴儿期,并且受影响的个体通常会活到童年晚期。在较轻的情况下,症状从1岁或2岁开始,并且受影响的个体往往会存活到成年中期。
[0213]
过去,研究人员根据症状和发病年龄描述了两种这种病症的类型,但目前的观点是,这两种类型实际上是体征和症状的严重程度各不相同的单一病症。
[0214]
fuca1基因中的突变导致岩藻糖苷贮积症。fuca1基因提供了制备称为α-l-岩藻糖苷酶的指令。这种酶在与某些蛋白质(糖蛋白)和脂肪(糖脂)相连的糖分子复合物(寡糖)的分解中起作用。α-l-岩藻糖苷酶负责在分解过程结束时切断(裂开)称为岩藻糖的糖分子。
[0215]
fuca1基因突变严重降低或消除了α-l-岩藻糖苷酶的活性。缺乏酶活性导致糖脂和糖蛋白的不完全分解。这些部分分解的化合物逐渐积聚在全身的各种细胞和组织中,并导致细胞发生故障。脑细胞对糖脂和糖蛋白的积累特别敏感,这会导致细胞死亡。脑细胞的丢失被认为会导致岩藻糖苷贮积症的神经系统症状。糖脂和糖蛋白的积累也发生在其它器官中,如肝脏、脾脏、皮肤、心脏、胰腺和肾脏,导致岩藻糖苷贮积症的其它症状。
[0216]
α-甘露糖苷过多症
[0217]
α-甘露糖苷过多症是一种常染色体隐性遗传的溶酶体贮积症,其临床特征已得到很好的表征(m.a.chester et al.,1982,in genetic errors of glycoprotein metabolism pp 90-119,springer verlag,berlin)。糖蛋白通常在溶酶体中逐步降解,并且步骤之一(即在n-连接糖蛋白有序降解期间切割自非还原端的α-连接甘露糖残基)由酶溶酶体α-甘露糖苷酶(ec 3.2.1.24)催化。然而,在α-甘露糖苷过多症中,缺乏酶α-甘露糖苷酶会导致富含甘露糖的寡糖积累。结果,溶酶体尺寸增大并膨胀,从而损害细胞功能。
[0218]
α-甘露糖苷过多症的症状包括精神运动迟缓、共济失调、听力受损、外周血中的空泡化淋巴细胞和骨骼变化。
[0219]
man2b1基因中的突变导致α-甘露糖苷过多症。该基因提供了制备酶α-甘露糖苷酶的指令。这种酶在溶酶体中起作用,溶酶体是消化和回收细胞中物质的隔室。在溶酶体内,这种酶有助于分解附着在某些蛋白质(糖蛋白)上的糖分子复合物(寡糖)。特别是,α-甘露糖苷酶有助于分解含有称为甘露糖的糖分子的寡糖。
[0220]
man2b1基因中的突变会干扰α-甘露糖苷酶在分解含甘露糖的寡糖中发挥作用的能力。这些寡糖在溶酶体中积聚并导致细胞发生故障并最终死亡。组织和器官因寡糖的异常积累和由此产生的细胞死亡而受损,导致α-甘露糖苷过多症的特征性特征。
[0221]
天冬氨酰葡萄糖胺尿症
[0222]
天冬氨酰葡萄糖胺尿症是一种导致精神功能进行性下降的疾病。患有天冬氨酰葡萄糖胺尿症的婴儿在出生时看起来很健康,并且在整个童年早期发育通常是正常的。这种病症的第一个体征在2或3岁左右很明显,通常是言语延迟。轻度智力障碍然后变得明显,并且学习速度变慢。智力障碍在青春期逐渐恶化。大多数患有这种病症的人失去了他们所学的大部分语言,并且受影响的成年人的词汇量通常只有几个单词。患有天冬氨酰葡萄糖胺尿症的成年人可能会出现癫痫发作或运动问题。
[0223]
患有这种病症的人的骨骼也可能逐渐变弱并容易骨折(骨质疏松症),关节运动范围异常大(运动过大)和皮肤松弛。受影响的个体往往具有特征性的面部外观,包括眼睛间
距宽(两眼距离过远)、小耳朵和厚嘴唇。鼻子短而宽,并且脸通常是方形的。患有这种病症的儿童可能比他们的年龄高,但在青春期缺乏生长突增,通常会导致成年人身材矮小。受影响的儿童也往往有频繁的上呼吸道感染。患有天冬氨酰葡萄糖胺尿症的人通常会活到成年中期。
[0224]
aga基因中的突变导致天冬氨酰葡萄糖胺尿症。aga基因提供了产生称为天冬氨酰氨基葡萄糖苷酶的指令。这种酶在溶酶体中具有活性,溶酶体是细胞内充当回收中心的结构。在溶酶体内,酶有助于分解附着在某些蛋白质(糖蛋白)上的糖分子的复合物(寡糖)。
[0225]
aga基因突变导致溶酶体中天冬氨酰氨基葡萄糖苷酶的缺失或缺乏,从而阻止糖蛋白的正常分解。结果,糖蛋白可在溶酶体内积聚。过量的糖蛋白会破坏细胞的正常功能,并可能导致细胞破坏。糖蛋白的堆积似乎特别影响大脑中的神经细胞;这些细胞的损失会导致天冬氨酰葡萄糖胺尿症的许多体征和症状。
[0226]
farber病
[0227]
farber病是一种遗传性病症,涉及体内脂肪的分解和使用(脂质代谢)。患有这种病症的人在整个身体的细胞和组织中,特别是在关节周围存在异常的脂质(脂肪)积累。farber病的特点是三个典型症状:声音嘶哑或哭声微弱,皮下和其它组织中的小脂肪块(脂肪肉芽肿),以及关节肿胀和疼痛。其它症状可包括呼吸困难、肝脏和脾脏肿大(肝脾肿大)和发育迟缓。研究人员根据其特征性特征描述了七种类型的farber病。这种病症是由asah1基因中的突变引起的,并以常染色体隐性方式遗传。
[0228]
泰-萨克斯病
[0229]
泰-萨克斯病是一种罕见的遗传性病症,会逐渐破坏大脑和脊髓中的神经细胞(神经元)。
[0230]
泰-萨克斯病最常见的形式在婴儿期变得明显。患有这种病症的婴儿通常在3到6个月年龄之前表现正常,此时他们的发育减慢并且用于运动的肌肉变弱。受影响的婴儿会失去运动技能,例如翻身、坐姿和爬行。他们还会对大声的噪音产生夸张的惊吓反应。随着疾病的进展,患有泰-萨克斯病的儿童会出现癫痫发作、视力和听力丧失、智力障碍和瘫痪。这种病症的特点是一种称为樱桃红斑的眼睛异常,可以通过眼科检查来识别。患有这种严重婴儿型泰-萨克斯病的儿童通常只能活到幼儿期。
[0231]
其它形式的泰-萨克斯病病非常罕见。体征和症状可能出现在儿童期、青春期或成年期,并且通常比婴儿形式看到的症状和症状要轻。特征性特征包括肌肉无力、肌肉协调性丧失(共济失调)和其它运动问题、言语问题和精神疾病。这些体征和症状在患有迟发性形式的泰-萨克斯病的人群中差异很大。
[0232]
hexa基因中的突变导致泰-萨克斯病。hexa基因提供了制备称为β-己糖胺酶a的酶的一部分的指令,该酶在大脑和脊髓中起关键作用。这种酶位于溶酶体中,溶酶体是细胞中分解有毒物质并充当回收中心的结构。在溶酶体内,β-己糖胺酶a有助于分解一种叫做gm2神经节苷脂的脂肪物质。
[0233]
hexa基因中的突变破坏了β-己糖胺酶a的活性,从而阻止酶分解gm2神经节苷脂。结果,这种物质积累到毒性水平,特别是在大脑和脊髓的神经元中。由gm2神经节苷脂的堆积引起的进行性损伤会导致这些神经元的破坏,从而导致泰-萨克斯病病的体征和症状。
[0234]
因为泰-萨克斯病损害溶酶体酶的功能并涉及gm2神经节苷脂的堆积,这种病症有
时被称为溶酶体贮积症或gm2-神经节苷脂贮积病。
[0235]
庞贝氏病
[0236]
庞贝氏病(也称为糖原贮积病ii型;酸性α-葡糖苷酶缺乏症;酸性麦芽糖酶缺乏症;gaa缺乏症;gsd ii;糖原病ii型;糖原病,全身性,心脏型;弥漫性糖原性心肥大;酸性麦芽糖酶缺乏症;amd;或α-1,4-葡萄糖苷酶缺乏症)是一种常染色体隐性代谢遗传病症,其特点是溶酶体酶酸性α-葡萄糖苷酶(gaa)(也称为酸性麦芽糖酶)的基因中的突变。gaa基因中的突变消除或降低了gaa酶水解糖原、麦芽糖和异麦芽糖中的α-1,4和α-1,6键的能力。结果,糖原在全身细胞的溶酶体和细胞质中积累,导致细胞和组织破坏。特别受影响的组织包括骨骼肌和心肌。积累的糖原导致进行性肌肉无力,导致心脏肥大、行走困难和呼吸功能不全。
[0237]
已经确定了三种类型的庞贝氏病,包括典型的婴儿期发病的疾病、非经典型婴儿期发病的疾病和迟发型疾病。典型的婴儿期发病形式的特点是肌肉无力、肌张力差、肝肿大和心脏缺陷。该疾病的发病率约为140,000人中1人。患有这种形式疾病的患者通常在出生后的第一年死于心力衰竭。该疾病的非经典婴儿期发病形式的特点是运动技能延迟、进行性肌肉无力和在某些情况下心脏肥大。由于呼吸衰竭,患有这种形式疾病的患者通常只能活到幼儿期。迟发形式的疾病可能出现在童年晚期、青春期或成年期,并且特点是腿部和躯干进行性肌肉无力。
[0238]
尼曼匹克病
[0239]
尼曼匹克病是一种影响许多身体系统的病症。它的症状范围很广,严重程度各不相同。尼曼匹克病分为四种主要类型:a型、b型、c1型和c2型。这些类型基于遗传原因和病症的体征和症状进行分类。
[0240]
患有a型尼曼匹克病的婴儿通常会在3个月大时出现肝脏和脾脏肿大(肝脾肿大),并且无法以预期的速度增加体重和生长(无法茁壮成长)。受影响的儿童发育正常,直到1岁左右,他们的心智能力和运动能力逐渐丧失(精神运动退化)。患有a型尼曼匹克病的儿童也会出现广泛的肺损伤(间质性肺病),可导致反复肺部感染并最终导致呼吸衰竭。所有受影响的儿童都有一种称为樱桃红斑的眼睛异常,可以通过眼科检查来识别。患有a型尼曼匹克病的儿童通常无法存活过幼儿期。
[0241]
b型尼曼匹克病通常出现在儿童中期。这种类型的体征和症状与a型相似,但没有那么严重。患有b型尼曼匹克病的患者通常有肝脾肿大、反复肺部感染和血液中的血小板数低(血小板减少症)。它们还具有身材矮小和骨矿化缓慢(骨龄延迟)。大约三分之一受影响个体患有樱桃红斑眼异常或神经功能缺损。患有b型尼曼匹克病的人通常能活到成年。
[0242]
a型和b型尼曼匹克病是由smpd1基因中的突变引起的。该基因提供了产生一种称为酸性鞘磷脂酶的指令。这种酶存在于溶酶体中,溶酶体是细胞内分解并回收不同类型分子的隔室。酸性鞘磷脂酶负责将称为鞘磷脂的脂肪(脂质)转化为称为神经酰胺的另一种脂质。smpd1中的突变导致酸性鞘磷脂酶缺乏,这导致鞘磷脂的分解减少,从而导致这种脂肪在细胞中积累。这种脂肪堆积会导致细胞故障并最终死亡。随着时间的推移,细胞损失会损害a型和b型尼曼匹克病患者的组织和器官(包括脑、肺、脾和肝)功能。
[0243]
沃尔曼病
[0244]
溶酶体酸性脂肪酶缺乏症是一种遗传性病症,其特点是体内脂肪和胆固醇的分解
和使用问题(脂质代谢)。在受影响的个体中,有害数量的脂肪(脂质)积累在全身的细胞和组织中,这通常会导致肝脏疾病。有两种形式的病症。最严重和最罕见的形式始于婴儿期。不太严重的形式可以从童年开始到成年后期。
[0245]
在严重的早发性形式的溶酶体酸性脂肪酶缺乏症中,在生命的最初几周内,脂质会在全身积累,尤其是在肝脏中。这种脂质积累会导致多种健康问题,包括肝脏和脾脏肿大(肝脾肿大)、体重增加不足、皮肤和眼白呈黄色(黄疸)、呕吐、腹泻、脂性粪(脂肪痢)、以及从食物中吸收营养不良(吸收不良)。此外,受影响的婴儿通常在每个肾脏顶部的产生激素的小腺体(肾上腺)中有钙沉积,血液中的铁含量低(贫血)和发育迟缓。疤痕组织在肝脏中迅速堆积,导致肝脏疾病(肝硬化)。患有这种形式溶酶体酸性脂肪酶缺乏症的婴儿会出现多器官功能衰竭和严重的营养不良,且通常活不过1年。
[0246]
在迟发性形式的溶酶体酸性脂肪酶缺乏症中,体征和症状各不相同,并且通常在儿童中期开始,尽管它们可以在到成年后期的任何时间出现。几乎所有受影响的个体都会出现肝脏肿大(肝肿大);也可能发生脾肿大(脾肿大)。大约三分之二的人患有肝纤维化,最终导致肝硬化。大约三分之一迟发性形式的个体有吸收不良、腹泻、呕吐和脂肪痢。患有这种形式溶酶体酸性脂肪酶缺乏症的个体可能会具有增加的肝酶和高胆固醇水平,这可以通过血液检查来检测。
[0247]
患有这种迟发性形式溶酶体酸性脂肪酶缺乏症的一些人会在动脉壁上积累脂肪沉积物(动脉粥样硬化)。尽管这些沉积物在普通人群中很常见,但它们通常在溶酶体酸性脂肪酶缺乏症患者的较早年龄开始。沉积物使动脉变窄,增加了心脏病发作或中风的机会。患有迟发性溶酶体酸性脂肪酶缺乏症的个体的预期寿命取决于相关健康问题的严重程度。
[0248]
这两种形式的溶酶体酸性脂肪酶缺乏症曾被认为是不同的病症。早发性形式称为沃尔曼病,而迟发性形式称为胆固醇酯贮积病。尽管这两种病症具有相同的遗传原因并且现在被认为是单一病症的形式,但这些名称有时仍用于区分溶酶体酸性脂肪酶缺乏症的形式。
[0249]
lipa基因中的突变导致溶酶体酸性脂肪酶缺乏症。lipa基因提供了产生称为溶酶体酸性脂肪酶的酶的指令。这种酶存在于称为溶酶体的细胞隔室中,溶酶体可以消化并回收细胞不再需要的物质。溶酶体酸性脂肪酶分解脂类,如胆固醇酯和甘油三酯。通过这些过程产生的脂质、胆固醇和脂肪酸被身体使用或运输到肝脏以去除。
[0250]
lipa基因中的突变导致功能性溶酶体酸性脂肪酶的短缺(缺乏)。病症的严重程度取决于有多少工作酶可用。患有早发性形式溶酶体酸性脂肪酶缺乏症的个体没有正常的酶活性。患有迟发性形式的那些个体被认为保留了一些酶活性,并且其数量通常决定体征和症状的严重程度。
[0251]
溶酶体酸性脂肪酶活性降低会导致胆固醇酯、甘油三酯和其它脂质在溶酶体内积聚,从而导致多个组织中的脂肪堆积。身体无法从这些脂质的分解中产生胆固醇,导致替代胆固醇产生方法的增加和血液中胆固醇水平高于正常水平。过量的脂质被运送到肝脏以去除。因为它们中的许多没有被适当地分解,因此它们无法从体内去除;相反,它们会在肝脏中积累,导致肝脏疾病。组织中脂质的进行性积累导致器官功能障碍以及溶酶体酸性脂肪酶缺乏的体征和症状。
[0252]
造血干细胞
[0253]
如本文所用,造血干细胞(hsc)是指动物(优选哺乳动物,更优选人类)细胞,其具有分化成多种血细胞类型的能力,包括红细胞、白细胞,包括淋巴样细胞和骨髓细胞。hsc可以包括具有体内长期移植潜力的造血细胞。可以使用动物模型或体外模型确定长期移植潜力(例如长期造血干细胞)。用于候选人类造血干细胞群的长期移植潜力的动物模型包括scid-hu骨模型(kyoizumi et al.(1992)blood 79:1704;murray et al.(1995)blood 85(2)368-378)和子宫内绵羊模型(zanjani et al.(1992)j.clin.invest.89:1179)。有关人类造血用动物模型的综述,请参见srour et al.(1992)j.hematother.1:143-153和其中引用的参考文献。干细胞的体外模型是长期培养起始细胞(ltcic)测定,基于5-8周后基质共培养中产生的克隆源性细胞数量的有限稀释分析(sutherland et al.(1990)proc.nat'l acad.sci.87:3584-3588)。ltcic测定已被证明与另一种常用的干细胞测定(即鹅卵石区域形成细胞(cafc)测定)相关,并且与体内长期移植潜力相关(breems et al.(1994)leukemia 8:1095)。
[0254]
造血干细胞(hsc)存在于骨髓中,并且具有产生所有不同成熟血细胞类型和组织的独特能力。hsc是自我更新的细胞:当它们增殖时,至少它们的一些子细胞仍然是hsc,因此干细胞库不会耗尽。其它细胞分化成产生淋巴细胞的普通淋巴祖细胞和产生单核细胞的普通骨髓祖细胞。
[0255]
在一些实施方式中,从骨髓中分离出用于本文基因修饰的造血干细胞。在一些实施方式中,可以使用针头或注射器从骨盆的髂嵴处取出hsc。
[0256]
在一些实施方式中,造血干细胞可以来源于人类脐带血或动员的外周血。从人类外周血获得的造血干细胞可以通过多种策略之一进行动员。可用于诱导造血干细胞从骨髓动员到外周血中的示例性药剂包括趋化因子(c-x-c基序)受体4(cxcr4)拮抗剂,诸如amd3100(也称为普乐沙福和mozobil(genzyme,boston,mass.))和粒细胞集落刺激因子(gcsf),在临床实验中,它们的组合已被证明可以快速动员cd34 细胞。此外,趋化因子(c-x-c基序)配体2(cxcl2,也称为gro)代表另一种能够诱导造血干细胞从骨髓动员到外周血的药剂。与本发明的组合物和方法一起使用的能够诱导造血干细胞动员的药剂可以彼此组合使用。例如,cxcr4拮抗剂(例如amd3100)、cxcl2和/或gcsf可以以单一混合物顺序或同时施用于受试者,以诱导造血干细胞从骨髓动员到外周血中。这些药剂作为造血干细胞动员的诱导剂的用途描述于例如pelus,current opinion in hematology 15:285(2008)中,其公开内容通过引用并入本文。
[0257]
在一些实施方式中,从循环的外周血中采集hsc,同时向献血者注射从骨髓中动员hsc的药剂。在一些实施方式中,将hsc从骨髓动员到外周血的药剂是细胞因子,例如粒细胞集落刺激因子(g-csf)。在一些实施方式中,从外周血中分离的hsc群体富含cd34 细胞,并且包括至少50%、至少70%或至少90%的cd34 细胞。
[0258]
在一些实施方式中,对于动员外周血(mpb)白细胞除去法,cd34 细胞通常可以使用免疫磁珠诸如clinimacs进行处理和富集,可以在细胞培养级干细胞因子(scf)存在下、在无血清培养基中将纯化的cd34 细胞以1x106个细胞/ml接种在培养袋上,优选300ng/ml(amgen inc.,thousand oaks,ca,usa),优选具有fms-样酪氨酸激酶3配体(flt3l)300ng/ml和促血小板生成素(tpo),优选约100ng/ml以及进一步的白细胞介素il-3,优选多于60ng/ml(均来自cell genix technologies),在优选12至24小时之后,转移至包括序列特
异性试剂(例如,mrna)的电穿孔缓冲液。电穿孔后,将细胞转移回培养基中,然后重新悬浮在盐水中并转移到注射器中进行输注。
[0259]
用于在细胞混合物中富集或消耗特定细胞群的方法是本领域众所周知的。例如,可以通过密度分离法、玫瑰花结四元聚体抗体复合物介导的富集/去除、磁激活细胞分选(macs)、基于多参数荧光的分子表型如荧光激活细胞分选(facs)或其任何组合来富集或耗尽细胞群。总的来说,这些富集或消耗细胞群的方法在本文中通常可以称为“分选”细胞群或“在一定条件下”接触细胞以形成或产生富集的( )或耗尽的(-)细胞群。
[0260]
在收集动员的细胞后,取出的造血干细胞可以如本文进行基因修饰,然后输注到有需要的患者体内,该患者可以是供体或另一受试者,例如与供体至少部分hla-匹配的受试者,用于治疗本文描述的疾病。
[0261]
在一些实施方式中,这些细胞形成细胞群,其优选源自单个供体或患者。这些细胞群可以在封闭的培养接受者下扩增,以符合最高的生产实践要求,并且可以在输注到患者体内之前冷冻,从而提供“现成的”或“即用型”的治疗组合物。
[0262]
在一些实施方式中,hsc是cd34 。在一些实施方式中,hsc可以被进一步描述为cd133 、cd90 、cd38-、cd45ra-、lin-或其任何组合。
[0263]
在一些实施方式中,能够分化成小胶质细胞的hsc来源于多能干细胞,如诱导多能干细胞(ips)。参见例如abud et al.,neuron 94,278
–
293(2017)。在一些实施方式中,如本文所描述的对ips细胞进行基因修饰并且然后分化成hsc细胞。在一些实施方式中,ips细胞分化成hsc,然后如本文所描述的对hsc进行基因修饰。在进一步的实施方式中,可以对细胞进行基因编辑,然后重编程成ips细胞和hsc,如例如国际申请号pct/ep2018/083180中所描述的。在一些实施方式中,可以从待治疗的患者中分离或从相容的供体中分离造血干细胞。
[0264]
在一些实施方式中,造血干细胞获自诱导多能干(ips)细胞,该ips细胞来源于待治疗的患者的细胞或相容的供体。
[0265]
在一些实施方式中,hsc可以在基因修饰这些细胞和/或将其输注到患者体内之前进行离体扩增。参见例如美国专利号9,580,426;9,956,249;9,527,828;9,428,748;9,394,520;9,328,085;9,226,942;9,115,341;8,927,281。
[0266]
在一些实施方式中,细胞分离自供体,该供体是hla匹配的同胞供体、hla匹配的无关供体、部分匹配的无关供体、单倍体相合相关供体、自体供体、hla不匹配供体、供体库或其任何组合。在一些实施方式中,治疗性细胞群是同种异体的。在一些实施方式中,治疗性细胞群是自体的。在一些实施方式中,治疗性细胞群是单倍体相合的。
[0267]
基因修饰的细胞
[0268]
在一些实施方式中,本发明提供了根据本文描述的方法的实施方式的任一个可获得的基因修饰的hsc或ips细胞。
[0269]
在一些实施方式中,本发明提供了基因修饰的hsc或ips细胞,其包括整合在至少在小胶质细胞中具有转录活性的基因座处的转基因,其中转基因在基因座的内源启动子的转录控制下。在一些实施方式中,转基因包括选自由idua、ids、arsb、gusb、abcd1、galc、arsa、psap、gba、fuca1、man2b1、aga、asah1、hexa、gaa、smpd1、lipa和cdkl5组成的组中的基因的编码序列。
[0270]
在一些实施方式中,转基因的多个拷贝整合在hsc或ips细胞中。在一些实施方式
中,多个拷贝整合在不同的基因座处。在一些实施方式中,多个拷贝整合在同一基因座处。在一些实施方式中,整合在同一基因座处的多个拷贝由2a自切割肽序列分隔开。
[0271]
在一些实施方式中,引入的转基因受小胶质细胞中内源性启动子的控制。在一些实施方式中,在小胶质细胞中具有活性的基因座选自由以下组成的组:tmem119、s100a9、cd11b、b2m、cx3cr1、mertk、cd164、tlr4、tlr7、cd14、fcgr1a、fcgr3a、tbxas1、dok3、abca1、tmem195、mr1、csf3r、fgd4、tspan14、tgfbri、ccr5、gpr34、serpine2、slco2b1、p2ry12、olfml3、p2ry13、hexb、rhob、jun、rab3il1、ccl2、fcrls、scoc、siglech、slc2a5、lrrc3、plxdc2、usp2、ctsf、cttnbp2nl、atp8a2、lgmn、mafb、egr1、bhlhe41、hpgds、ctsd、hspa1a、lag3、csf1r、adamts1、f11r、golm1、nuak1、crybb1、ltc4s、sgce、pla2g15、ccl3l1、abhd12、ang、ophn1、sparc、pros1、p2ry6、lair1、il1a、epb41l2、adora3、rilpl1、pmepa1、ccl13、pde3b、scamp5、ppp1r9a、tjp1、ak1、b4galt4、gtf2h2、trem2、ckb、acp2、pon3、agmo、tnfrsf17、fscn1、st3gal6、adap2、ccl4、entpd1、tmem86a、kctd12、dst、ctsl2、abcc3、pdgfb、pald1、tubgcp5、rapgef5、stab1、lacc1、tmc7、nrip1、kcnd1、tmem206、hps4、dagla、extl3、mlph、arhgap22、cxxc5、p4ha1、cysltr1、fgd2、kcnk13、gbgt1、c18orf1、cadm1、bco2、adrb1、c3ar1、large、leprel1、liph、upk1b、p2rx7、slc46a1、ebf3、ppp1r15a、il10ra、rasgrp3、fos、tppp、slc24a3、havcr2、nav2、apbb2、clstn1、blnk、gnaq、ptprm、frmd4a、cd86、tnfrsf11a、spint1、ppm1l、tgfbr2、cmklr1、tlr6、gas6、hist1h2ab、atf3、acvr1、abi3、lrp12、ttc28、plxna4、adamts16、rgs1、icam1、snx24、ly96、dnajb4和ppfia4。
[0272]
在一些实施方式中,基因修饰的hsc或ips细胞包括整合在在小胶质细胞中具有转录活性的基因座处的转基因,基因座选自tmem119、cd11b、b2m、cx3cr1或s100a9,其中转基因受基因座的内源性启动子的转录控制。
[0273]
在一些实施方式中,基因修饰的造血干细胞通过直接基因修饰造血干细胞来获得。在一些实施方式中,基因修饰的造血干细胞通过基因修饰诱导的多能干(ips)细胞并且将ips细胞分化以成为造血干细胞来获得。
[0274]
在一些实施方式中,造血干细胞(hsc)或ips细胞被基因修饰,使得细胞在它们分化成小胶质细胞后能够表达转基因。在一些实施方式中,细胞中经基因修饰的基因座在小胶质细胞中具有转录活性。
[0275]
在一些实施方式中,使富集的hsc群经受一种方法以基因修饰细胞。在一些实施方式中,富集的群包括至少50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更多的cd34 hsc。
[0276]
在一些实施方式中,使用序列特异性试剂对hsc或ips细胞进行基因修饰。在一些实施方式中,序列特异性试剂识别在小胶质细胞中表达的基因座中存在的一个或多个序列。在一些实施方式中,序列特异性试剂切割细胞中的核酸。
[0277]
在一些实施方式中,本发明提供了一种制备基因修饰的hsc或ips细胞的方法,包括将转基因整合在hsc或ips细胞中。在一些实施方式中,该方法包括使细胞与序列特异性试剂接触,序列特异性试剂切割在小胶质细胞中表达的基因座处的核酸序列。在一些实施方式中,该方法进一步包括使细胞与包括转基因的供体核酸接触。
[0278]
在一些实施方式中,用于基因编辑本发明细胞的序列特异性试剂是稀有切割核酸内切酶,例如tale-核酸酶(以cellectis商标市售)。优选的试剂切割本说明书表
4中报道的一种或几种靶序列。
[0279]
在一些实施方式中,序列特异性试剂靶向cx3cr1的内含子,优选位于第一编码外显子和第二编码外显子之间的cx3cr1的第一个内含子(seq id no:76)。本发明还提供了特异性tale核酸酶,其优先靶向与seq id no:77至87类似的cx3cr1的内源性多核苷酸序列。在一些实施方式中,序列特异性试剂是crispr-cas或crispr-cpf,其使用grna靶向与seq id no:97至106类似的内源性序列。
[0280]
在一些实施方式中,序列特异性试剂靶向cd11b的内含子,优选cd11b的第一个内含子。本发明还提供了特异性tale核酸酶,其优先靶向与seq id no:108至137类似的cd11b的内源性多核苷酸序列。在一些实施方式中,序列特异性试剂是crispr-cas或crispr-cpf,其使用grna靶向与seq id no:138至147类似的内源性序列。
[0281]
在一些实施方式中,序列特异性试剂靶向s100a9的内含子,优选s100a9的第一个内含子。本发明还提供了特异性tale核酸酶,其优先靶向与seq id no:149至178类似的s100a9的内源性多核苷酸序列。在一些实施方式中,序列特异性试剂是crispr-cas或crispr-cpf,其使用grna靶向与seq id no:179至188类似的内源性序列。
[0282]
在一些实施方式中,多核苷酸模板包括如本文所描述的转基因的编码序列。在一些实施方式中,多核苷酸模板包括选自由以下组成的组的基因的编码区:idua、ids、arsb、gusb、abcd1、galc、arsa、psap、gba、fuca1、man2b1、aga、asah1、hexa、gaa、smpd1、lipa和cdkl5。
[0283]
在一些实施方式中,供体核酸包括选自由以下组成的组的核苷酸序列:seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35和如本文所描述的其变体。
[0284]
在一些实施方式中,供体核酸编码治疗性蛋白质,该治疗性蛋白质包括从seq id no:2、4、6、8、10、12、14、16、18、20、22、24、26、28、30、32、34、36和如本文所描述的的其变体中选择的氨基酸序列。
[0285]
在一些实施方式中,序列特异性试剂可以是包括dna结合结构域和展示催化活性的另一结构域的嵌合多肽。这种催化活性可以是切口酶或双切口酶,以通过产生粘性末端优先进行基因插入,从而通过同源重组促进基因整合。
[0286]
在一些实施方式中,核酸酶试剂诱导nhej或同源重组机制,其具有将稳定且可遗传的突变引入在小胶质细胞中表达的基因组基因座中的优势。
[0287]“核酸酶试剂”是指通过本身或作为诸如指导rna cas9等复合物的亚基有助于靶细胞中核酸酶催化反应(优选核酸内切酶反应)的核酸分子,优选导致切割核酸序列靶标。
[0288]
本发明的核酸酶试剂通常是“序列特异性核酸酶试剂”,意指它们可以在细胞中在预定位点诱导dna切割,延伸称为“靶向基因”。被序列特异性试剂识别的核酸序列称为“靶序列”。所述靶序列通常被选择为在细胞基因组中是稀有的或独特的,并且在人类基因组中更广泛选择,这可以使用软件和来自人类基因组数据库的数据来确定,例如http://www.ensembl.org/index.html。
[0289]
在一些实施方式中,根据本发明使用的序列特异性核酸酶试剂(其特异性切割基因座内的序列)也可用于诱导外源性模板在基因座处的整合。“外源性序列”是指最初在选定基因座处不存在的任何核苷酸或核酸序列。外源性序列优选包括编码如本文所描述的用于治疗本文疾病的治疗性多肽的序列。根据本发明的方法通过插入多核苷酸进行基因修饰
以表达由其编码的多肽的内源性序列,广义地称为外源性编码序列。在一些实施方式中,靶向的基因插入包括编码如本文所描述的治疗性多肽的外源性序列。
[0290]
美国专利号5,789,538;5,925,523;6,007,988;6,013,453;6,410,248;6,140,466;6,200,759;和6,242,568;以及wo 98/37186;wo 98/53057;wo 00/27878;wo 01/88197和gb 2,338,237中公开了适用于dna结合结构域的示例性选择方法,包括噬菌体展示和双杂交系统。
[0291]
靶位点的选择;用于设计和构建融合蛋白(和编码其的多核苷酸)的核酸酶和方法是本领域技术人员已知的,并且在美国专利申请公开号20050064474和20060188987中进行详细描述,通过引用将其全部内容并入本文。
[0292]
dna结构域可以工程化为与靶基因座中选择的任何序列结合。在一些实施方式中,用序列特异性试剂对细胞进行基因修饰,该序列特异性试剂已被工程化以结合在小胶质细胞中具有转录活性的基因座。与天然存在的dna结合域相比,工程化的dna结合域可以具有新的结合特异性。工程化方法包括但不限于合理设计和各种类型的选择。合理设计包括例如使用包括三联体(或四联体)核苷酸序列和单个(例如锌指)氨基酸序列的数据库,其中每个三联体或四联体核苷酸序列与dna结合结构域的一个或多个氨基酸序列相关联,氨基酸序列结合特定的三联体或四联体序列。参见,例如,美国专利号6,453,242和6,534,261,通过引用将其全部内容并入本文。也可以进行tal效应物结构域的合理设计。参见例如美国专利申请公开号2011/0301073。
[0293]
此外,如这些和其它参考文献中所公开的,可以使用任何合适的接头序列将dna结合结构域(例如多指锌指蛋白)连接在一起,包括例如5个或更多个氨基酸的接头。对于长度为6个或更多氨基酸的示例性接头序列,参见例如题美国专利号6,479,626;6,903,185;和7,153,949。本文所描述的蛋白质可以在蛋白质的各个dna结合结构域之间包括适合接头的任何组合。还参见美国专利申请公开号2011/0301073。
[0294]
包括转基因的外源性/供体序列在其整个长度上与在小胶质细胞中表达的基因座内的序列不相同。供体序列可以含有由有两个同源区侧翼的非同源序列,以允许在目的位置进行有效的hdr。替代地,供体可能与dna中的靶位置没有同源区域,并且可以在靶位点切割后通过nhej依赖性末端连接进行整合。此外,供体序列可以包括载体分子,该载体分子含有与细胞染色质中目的区域不同源的序列。供体分子可以含有多个与细胞染色质同源的不连续区域。例如,为了靶向插入通常不存在于目的区域中的序列,所述序列可以存在于供体核酸分子中并且由与目的区域中的序列同源的区域侧翼。
[0295]
在一些实施方式中,序列特异性试剂是编码“工程化的”或“可编程的”稀有切割核酸内切酶的核酸,稀有切割核酸内切酶诸如例如wo 2004067736中描述的归巢核酸内切酶、例如urnov f.,et al.(nature 435:646-651(2005))描述的锌指核酸酶(zfn)、例如mussolino et al.(nucl.acids res.39(21):9283-9293(2011))描述的tale-核酸酶、或例如boissel et al.(nucleic acids research 42(4):2591
ꢀ‑
2601(2013))描述的megatal核酸酶。
[0296]
在一些实施方式中,核酸内切酶试剂瞬时表达到细胞中,这意味着该试剂不应该整合到基因组中或长时间持续存在,例如rna(更特别是mrna)、蛋白质或者混合蛋白质和核酸的复合物(例如:核糖核蛋白)的情况。
tevii和i-teviii。它们的识别序列是已知的。还参见美国专利号5,420,032;美国专利号6,833,252;belfort et al.(1997)nucleic acids res.25:3379-3388;dujon et al.(1989)gene 82:115-118;perler et al.(1994)nucleic acids res.22,1125-1127;jasin(1996)trends genet.12:224-228;gimble et al.(1996)j.mol.biol.263:163-180;argast et al.(1998)j.mol.biol.280:345-353以及新英格兰生物实验室目录。
[0302]
在一些实施方式中,核酸酶包括工程化的(非天然存在的)归巢核酸内切酶(大范围核酸酶)。在一些实施方式中,归巢核酸内切酶和大范围核酸酶的dna结合特异性可以被工程化以结合非天然靶位点。参见例如chevalier et al.(2002)molec.cell 10:895-905;epinat et al.(2003)nucleic acids res.31:2952-2962;ashworth et al.(2006)nature 441:656-659;paques et al.(2007)current gene therapy 7:49-66;美国专利公开号20070117128。归巢核酸内切酶和大范围核酸酶的dna结合结构域可以在整个核酸酶的背景下发生改变(即使得核酸酶包括同源切割结构域)或可以融合到异源性切割结构域。
[0303]
在一些实施方式中,dna结合结构域包括天然存在的或工程化的(非天然存在的)tal效应物dna结合结构域。参见例如美国专利申请公开号2011/0301073,其通过引用整体并入本文。已知黄单胞菌属(genus xanthomonas)的植物病原菌在重要的农作物中引起许多疾病。黄单胞菌的致病性取决于保守的iii型分泌(t3s)系统,该系统将超过25种不同的效应蛋白注入植物细胞。在这些注入的蛋白质中有转录激活器样效应物(tale),它模拟植物转录激活器并操纵植物转录组(kay et al.(2007)science 318:648-651)。这些蛋白质含有dna结合结构域和转录激活结构域。表征最完善的tale之一是来自野油菜黄单胞菌辣椒斑点病致变种(xanthomonas campestgris pv.vesicatoria)的avrbs3(见bonas et al.(1989)mol gen genet 218:127-136和wo 2010/079430)。tale含有串联重复的集中结构域,每个重复含有约34个氨基酸,这是这些蛋白质dna结合特异性的关键。此外,它们含有核定位序列和酸性转录激活结构域(对于综述,参见schornack s,et al.(2006)j plant physiol 163(3):256-272)。此外,在植物病原菌青枯雷尔氏菌中发现了两个基因,称为brg11和hpx17,它们与青枯雷尔氏菌生物变型1菌株gmi1000和生物变型4菌株rs1000中的黄单胞菌属的avrbs3家族同源(参见heuer et al.(2007)appl and envir micro 73(13):4379-4384)。这些基因在核苷酸序列上彼此有98.9%的同一性,但不同之处在于在hpx17的重复结构域中缺失了1,575bp。然而,两个基因产物与黄单胞菌的avrbs3家族蛋白的序列同一性均低于40%。
[0304]
在一些实施方式中,与靶基因座中的靶位点结合的dna结合结构域是来自tal效应物的工程化结构域,类似于源自植物病原体黄单胞菌(参见boch et al.(2009)science 326:1509-1512和moscou and bogdanove(2009)science 326:1501)和雷尔氏菌(参见heuer et al.(2007)applied and environmental microbiology 73(13):4379-4384);美国专利号8,420,782和8,440,431以及美国专利申请公开号2011/0301073)的那些效应物。
[0305]
在一些实施方式中,dna结合结构域包括锌指蛋白。在一些实施方式中,锌指蛋白是非天然存在的,因为它被工程化以结合选择的靶位点。参见例如beerli et al.(2002)nature biotechnol.20:135-141;pabo et al.(2001)ann.rev.biochem.70:313-340;isalan et al.(2001)nature biotechnol.19:656-660;segal et al.(2001)curr.opin.biotechnol.12:632-637;choo et al.(2000)curr.opin.struct.biol.10:
411-416;美国专利号6,453,242;6,534,261;6,599,692;6,503,717;6,689,558;7,030,215;6,794,136;7,067,317;7,262,054;7,070,934;7,361,635;7,253,273;和美国专利申请公开号2005/0064474;2007/0218528;2005/0267061,全部通过引用将其全部内容并入本文。
[0306]
与天然存在的锌指蛋白相比,工程化的锌指结合或tale结构域可以具有新的结合特异性。工程化方法包括但不限于合理设计和各种类型的选择。合理设计包括例如使用包括三联体(或四联体)核苷酸序列和单独的锌指氨基酸序列的数据库,其中每个三联体或四联体核苷酸序列与结合特定三联体或四联体序列的锌指的一个或多个氨基酸序列相关联。参见例如美国专利号6,453,242和6,534,261,通过引用将其全部内容并入本文。
[0307]
在一些实施方式中,dna结构域(例如,多指锌指蛋白或tale结构域)可以使用任何合适的接头序列连接在一起,包括例如长度为5个或更多个氨基酸的接头。对于长度为6个或更多个氨基酸的示例性接头序列,还参见美国专利号6,479,626;6,903,185;和7,153,949。本文描述的dna结合蛋白可以在蛋白质的各个锌指之间包括适合接头的任何组合。此外,在共同拥有的wo 02/077227中已经描述了对锌指结合结构域的结合特异性的增强。
[0308]
用于设计和构建融合蛋白(和编码它们的多核苷酸)的dna结合结构域和方法是本领域技术人员已知的,并且在美国专利号6,140,0815;789,538;6,453,242;6,534,261;5,925,523;6,007,988;6,013,453;6,200,759;wo 95/19431;wo 96/06166;wo 98/53057;wo 98/54311;wo 00/27878;wo 01/60970wo 01/88197;wo 02/099084;wo 98/53058;wo 98/53059;wo 98/53060;wo 02/016536和wo 03/016496以及美国专利申请公开号2011/0301073中进行了详细地描述。
[0309]
可以将任何合适的切割结构域可操作地连接至dna结合结构域以形成核酸酶。例如,已将zfp dna-结合结构域与核酸酶结构域融合以创建zfn-一种功能实体,其能够通过其工程化(zfp)dna结合结构域识别其预期的核酸靶,并导致dna在zfp结合位点附近经由核酸酶活性被切割。参见例如kim et al.(1996)proc nat'l acad sci usa 93(3):1156-1160。最近,zfn已被用于多种生物体中的基因组修饰。参见例如美国专利申请公开号:2003/0232410;2005/0208489;2005/0026157;2005/0064474;2006/0188987;2006/0063231;以及国际公开wo 07/014275。同样地,已经将tale dna-结合结构域融合至核酸酶结构域以创建talen。参见例如美国专利申请公开号2011/0301073。
[0310]
如上所看到的,切割结构域可以与dna结合结构域异源,例如锌指dna结合结构域和来自核酸酶的切割结构域或talen dna-结合结构域和切割结构域,或大范围核酸酶dna结合结构域和来自不同核酸酶的切割结构域。异源性切割结构域可以从任何核酸内切酶或核酸外切酶获得。可以衍生切割结构域的示例性核酸内切酶包括但不限于限制性核酸内切酶和归巢核酸内切酶。参见例如2002-2003catalogue,new england biolabs,beverly,mass.;和belfort et al.(1997)nucleic acids res.25:3379-3388。切割dna的其它酶是已知的(例如s1核酸酶;绿豆核酸酶;胰腺dnase i;微球菌核酸酶;酵母ho核酸内切酶;还参见linn et al.(eds.)nucleases,cold spring harbor laboratory press,1993)。可以将这些酶(或其功能片段)中的一种或多种用作切割结构域和切割半结构域的来源。
[0311]
类似地,切割半结构域可以衍生自任何核酸酶或其部分,如上所给出的,其需要二聚化以实现切割活性。通常,如果融合蛋白包括切割半结构域,则切割需要两种融合蛋白。
替代地,可以使用包括两个切割半结构域的单一蛋白质。两个切割半结构域可以来自相同的核酸内切酶(或其功能片段),或每个切割半结构域可以衍生自不同的核酸内切酶(或其功能片段)。此外,优选使两个融合蛋白的靶位点相对于彼此布置,使得两个融合蛋白与其各自靶位点的结合将切割半结构域置于彼此的空间方向上,从而允许切割半结构域形成功能性切割结构域,例如,通过二聚化。因此,在某些实施方案中,靶位点的近边缘被5-8个核苷酸或15-18个核苷酸分隔开。然而,任何整数个核苷酸或核苷酸对都可以插入两个靶位点之间(例如,2到50个核苷酸对或更多)。通常,切割位点位于靶位点之间。
[0312]
在一些实施方式中,二聚化切割半结构域包括一个非活性切割结构域和一个活性切割结构域,使得靶向的dna在一条链上被切口而不是被完全切割(“切口酶”,参见美国专利申请公开号2010/0047805)。在其它实施方式中,使用两对此种切口酶来切割靶,其在两条dna链上都有切口。
[0313]
限制性核酸内切酶(限制性内切酶)存在于许多物种中,并且能够与dna序列特异性结合(在识别位点),并在结合位点处或附近切割dna。某些限制性酶(例如iis型)在从识别位点移除的位点切割dna,并具有可分离的结合和切割结构域。例如,iis型酶fok i催化dna的双链切割,在一条链上距其识别位点9个核苷酸并且在另一条链上距其识别位点13个核苷酸。参见例如美国专利号5,356,802;5,436,150和5,487,994;以及li et al.(1992)proc.natl.acad.sci.usa 89:4275-4279;li et al.(1993)proc.natl.acad.sci.usa 90:2764-2768;kim et al.(1994)proc.natl.acad.sci.usa 91:883-887;kim et al.(1994)j.biol.chem.269:31,978-31,982。在一个实施方式中,融合蛋白包括来自至少一种iis型限制性酶的切割结构域(或切割半结构域)和一个或多个锌指结合结构域,其可以工程化或可以不经工程化。
[0314]
切割结构域与结合域可分离的示例性iis型限制酶是fok i。该特定酶作为二聚体具有活性。bitinaite et al.(1998)proc.natl.acad.sci.usa 95:10,570-10,575。因此,出于本公开的目的,在所公开的融合蛋白中使用的fok i酶的部分被认为是切割半结构域。因此,对于使用锌指-fok i融合物的细胞序列的靶向双链切割和/或靶向置换,可以使用各自包括fok i切割半结构域的两种融合蛋白来重构催化活性切割结构域。替代地,也可以使用包括dna结合结构域和两个fok i切割半结构域的单个多肽分子。
[0315]
切割结构域或切割半结构域可以是保留切割活性或保留多聚化(例如二聚化)以形成功能性切割结构域的能力的蛋白质的任何部分。
[0316]
整体并入本文的国际公开wo 07/014275中描述了示例性的iis型限制性酶。其它限制性酶也含有可分开的结合结构域和切割结构域,并且本公开预期了这些。参见例如roberts et al.(2003)nucleic acids res.31:418-420。
[0317]
在某些实施方式中,切割结构域包括一种或多种工程化的切割半结构域(也称为二聚化结构域突变体),其最小化或防止同二聚化,如例如美国专利申请公开号2005/0064474;2006/0188987和2008/0131962中所描述的,它们的全部公开内容均通过引用整体并入本文。fok i的位置446、447、479、483、484、486、487、490、491、496、498、499、500、531、534、537和538的氨基酸残基都是影响fok i切割半结构域二聚化的靶。
[0318]
形成专性异二聚体的示例性工程化的fok i切割半结构域包括一对,其中第一个切割半结构域在fok i的位置490和538的氨基酸残基处包括突变,并且第二个切割半结构
域在氨基酸残基486和499处包括突变。
[0319]
因此,在一个实施方式中,490处的突变将glu(e)替换为lys(k);538处的突变将iso(i)替换为lys(k);486处的突变将gln(q)替换为glu(e);并且位置499处的突变将iso(i)替换为lys(k)。具体地,在一个切割半结构域中通过突变位置490(e
→
k)和538(i
→
k)以产生命名为“e490k:1538k”的工程化的切割半结构域并且在另一切割半结构域中通过突变位置486(q
→
e)和499(i
→
l)以产生命名为“q486e:i499l”的工程化的切割半结构域,来制备本文描述的工程化的切割半结构域。本文描述的工程化的切割半结构域是专性异二聚体突变体,其中异常切割被最小化或消除。参见例如美国专利公开号2008/0131962,其公开的全部内容通过引用整体并入用于所有目的。
[0320]
在一些实施方式中,工程化的切割半结构域在位置486、499和496(相对于野生型fok i编号)包括突变,例如这样的突变:将位置486处的野生型gln(q)残基替换为glu(e)残基,将位置499处的野生型iso(i)残基替换为leu(l)残基和将位置496处的野生型asn(n)残基替换为asp(d)或glu(e)残基(也分别称为“eld”和“ele”结构域)。在其它实施方式中,工程化的切割半结构域在位置490、538和537(相对于野生型foki编号)处包括突变,例如这样的突变:将位置490处的野生型glu(e)残基替换为lys(k)残基,将位置538处的野生型iso(i)残基替换为lys(k)残基和将位置537处的野生型his(h)残基替换为lys(k)残基或arg(r)残基(也分别称为"kkk"和"kkr"结构域)。在其它实施方式中,工程化的切割半结构域在位置490和537(相对于野生型foki编号)处包括突变,例如这样的突变:将位置490处的野生型glu(e)残基替换为lys(k)残基和将位置537处的野生型his(h)残基替换为lys(k)残基或arg(r)残基(也分别称为"kik"和"kir"结构域)。(参见美国专利申请公开号2011/0201055,通过引用并入本文)。可以使用任何适合的方法制备本文描述的工程化的切割半结构域,例如通过如美国专利申请公开号2005/0064474;2008/0131962;和2011/0201055中描述的野生型切割半结构域(fok i)的位点定向诱变。
[0321]
在一些实施方式中,可以使用所谓的“分裂酶”技术在体内在核酸靶位点组装核酸酶(参见例如美国专利申请公开号2009/0068164)。此类分裂酶的组分可以在单独的表达构建体上表达,或者可以连接在一个开放阅读框中,其中各个组分例如通过自切割2a肽或ires序列分隔开。组分可以是单独的锌指结合结构域或大范围核酸酶核酸结合结构域的结构域。
[0322]
可以在使用前筛选核酸酶的活性,例如在wo 2009/042163和2009/0068164中描述的基于酵母的染色体系统中。可以使用本领域已知的方法容易地设计核酸酶表达构建体。参见例如美国专利申请公开号:2003/0232410;2005/0208489;2005/0026157;2005/0064474;2006/0188987;2006/0063231;和国际公开wo 07/014275。核酸酶的表达可以在组成型启动子或诱导型启动子的控制下,例如半乳糖激酶启动子,其在棉子糖和/或半乳糖存在下被激活(去抑制)并且在葡萄糖存在下被抑制。
[0323]
在一些实施方式中,核酸内切酶试剂是要与rna引导的核酸内切酶结合使用的rna指导,例如cas9或cpf1,诸如尤其根据doudna,j.et al.,(science 346(6213):1077)(2014))和zetsche,b.et al.(cell 163(3):759-771(2015))的教导,其教导通过引用并入本文。
[0324]
在一些实施方式中,使用crispr(簇状规则间隔的短回文重复序列)/cas(crispr
相关的)核酸酶系统来对细胞进行基因修饰。crispr/cas是一种基于细菌系统的工程化核酸酶系统,可用于基因组工程。它基于许多细菌和古细菌的适应性免疫反应的一部分。当病毒或质粒入侵细菌时,入侵者的dna区段会通过
‘
免疫’反应转化为crispr rna(crrna)。然后,该crrna通过部分互补的区域与另一种称为tracrrna的rna相关联,以将cas9核酸酶引导至与靶dna中称为“原型间隔区”的crrna同源的区域。cas9切割dna以在dsb处在由crrna转录本中包括的20个核苷酸引导序列指定的位点处产生平末端。cas9需要crrna和tracrrna进行位点特异性dna识别和切割。该系统现已经工程化,使得crrna和tracrrna可以组合成一个分子(“单向导rna”),并且单向导rna的crrna等效部分可以工程化为引导cas9核酸酶以靶向任何所需的序列(参见jinek et al.(2012)science 337,p.816-821,jinek et al.,(2013),elife 2:e00471,和david segal,(2013)elife 2:e00563)。
[0325]
编码系统的rna组分的crispr(簇状规则间隔的短回文重复序列)基因座以及编码蛋白质的cas(crispr-相关的)基因座(jansen et al.,2002.mol.microbiol.43:1565-1575;makarova et al.,2002.nucleic acids res.30:482-496;makarova et al.,2006.biol.direct 1:7;haft et al.,2005.plos comput.biol.1:e60)构成了crispr/cas核酸酶系统的基因序列。微生物宿主中的crispr基因座含有crispr相关(cas)基因以及能够编程crispr介导的核酸切割特异性的非编码rna元件的组合。
[0326]
ii型crispr是表征最完善的系统之一,并且在四个连续步骤中进行靶向dna双链断裂。首先,从crispr基因座转录两个非编码rna,前-crrna阵列和tracrrna。其次,tracrrna与前-crrna的重复区域杂交,并介导前-crrna加工成含有单个间隔区序列的成熟crrna。第三,成熟的crrna:tracrrna复合物通过crrna上的间隔区和与原型间隔区相邻基序(pam)相邻的靶dna上的原型间隔区之间的沃森-克里克碱基配对将cas9引导至靶dna,这是对靶标识别的附加需求。最后,cas9介导靶dna的切割,以在原型间隔区内产生双链断裂。crispr/cas系统的活性包括三个步骤:(i)在称为“适应”的过程中,将外来dna序列插入crispr阵列以防止未来的攻击,(ii)表达相关蛋白质以及表达和处理阵列,然后是(iii)rna介导的对外来核酸的干扰。因此,在细菌细胞中,多种所谓的
‘
cas’蛋白涉及crispr/cas系统的自然功能,并在诸如插入外来dna等功能中发挥作用。
[0327]
在某些实施方式中,cas蛋白可以是天然存在的cas蛋白的“功能衍生物”。天然序列多肽的“功能衍生物”是具有与天然序列多肽共同的定性生物学特性的化合物。“功能衍生物”包括但不限于天然序列的片段和天然序列多肽的衍生物及其片段,条件是它们具有与相应天然序列多肽共同的生物学活性。本文所考虑的生物活性是功能衍生物将dna底物水解成片段的能力。术语“衍生物”包括多肽的氨基酸序列变体、共价修饰及其融合物。cas多肽或其片段的合适衍生物包括但不限于cas蛋白或其片段的突变体、融合体、共价修饰。cas蛋白(包括cas蛋白或其片段)以及cas蛋白或其片段的衍生物可以从细胞中获得或化学合成或通过这两种程序的组合获得。细胞可以是天然产生cas蛋白的细胞,或天然产生cas蛋白并且经基因工程化以更高表达水平产生内源性cas蛋白或从外源引入的核酸产生cas蛋白的细胞,该核酸编码与内源性cas相同或不同的cas。在某些情况下,细胞不会自然产生cas蛋白,而是经过基因工程化以产生cas蛋白。还包括在本发明含义中的rna引导的核酸内切酶中的是核酸内切酶cpf1,如zetsche,b.et al.(cell 163(3):759-771(2015))所教导的。
256:808-813(1992);nabel&feigner,tibtech 11:211-217(1993);mitani&caskey,tibtech 11:162-166(1993);dillon,tibtech 11:167-175(1993);miller,nature 357:455-460(1992);van brunt,biotechnology 6(10):1149-1154(1988);vigne,restorative neurology and neuroscience 8:35-36(1995);kremer&perricaudet,british medical bulletin 51(1):31-44(1995);haddada et al.,in current topics in microbiology and immunology,doerfler and bohm(eds.)(1995);和yu et al.,gene therapy 1:13-26(1994)。
[0337]
在一些实施方式中,核酸的非病毒递送方法包括电穿孔、脂质转染、显微注射、基因枪、病毒体、脂质体、免疫脂质体、聚阳离子或脂质:核酸缀合物、裸dna、裸rna、加帽rna、人工病毒体和试剂增强的dna吸收。使用例如sonitron 2000系统(rich-mar)的声穿孔也可用于核酸的递送。
[0338]
在一些实施方式中,电穿孔步骤可用于转染细胞。在一些实施方式中,这些步骤通常在包括平行板电极的封闭室中进行,在所述平行板电极之间产生大于100伏特/cm且小于5,000伏特/cm的脉冲电场,在整个治疗体积中基本均匀,例如在wo 2004/083379中描述的,其通过引用并入,尤其是从第23页第25行至第29页第11行。一种此类电穿孔室优选地具有由电极间隙的平方(cm2)除以室体积(cm3)的商定义的几何因子(cm-1
),其中几何因子小于或等于0.1cm-1
,其中细胞和序列特异性试剂的悬浮液在培养基中,该培养基经过调整,使培养基的电导率在0.01至1.0毫西门子范围内。通常,细胞悬浮液经历一个或多个脉冲电场。采用该方法,悬浮液的处理体积可扩展,并且腔室中细胞的处理时间基本均匀。
[0339]
在一些实施方式中,不同的转基因或转基因的多个拷贝可以包括在一个载体中。载体可以包括编码核糖体跳跃序列(例如编码2a肽的序列)的核酸序列。在小核糖核酸病毒的口蹄疫病毒亚群中鉴别的2a肽会导致核糖体从一个密码子“跳跃”到下一个密码子,而不会在由密码子编码的两个氨基酸之间形成肽键(参见donnelly et al.,j.of general virology 82:1013-1025(2001);donnelly et al.,j.of gen.virology 78:13-21(1997);doronina et al.,mol.and.cell.biology 28(13):4227-4239(2008);atkins et al.,rna 13:803-810(2007))。
[0340]“密码子”是指mrna(或dna分子的有义链)上的三个核苷酸,它们被核糖体翻译成一个氨基酸残基。因此,当多肽被框内的2a寡肽序列分开时,可以从mrna内的单个连续开放阅读框合成两条多肽。这种核糖体跳跃机制在本领域是众所周知的并且已知被多种载体用于表达由单个信使rna编码的多种蛋白质。
[0341]
在一个实施方式中,编码根据本发明的序列特异性试剂的多核苷酸可以是直接引入细胞中的mrna,例如通过电穿孔。在一些实施方式中,可以使用细胞脉冲技术对细胞进行电穿孔,该技术允通许过使用脉冲电场瞬时透化活细胞以将材料递送到细胞中。该技术基于使用pulseagile(btx havard apparatus,84october hill road,holliston,mass.01746,usa)电穿孔波形允许精确控制脉冲持续时间、强度以及脉冲之间的间隔(参见美国专利号6,010,613和公布的国际申请wo 2004/083379)。所有这些参数都可以修改,以达到高转染效率和最低死亡率的最佳条件。第一个高电场脉冲允许孔形成,而随后的较低电场脉冲允许将多核苷酸移动到细胞中。
[0342]
其它示例性的核酸递送系统包括amaxa biosystems(cologne,germany),
maxcyte,,inc.(rockville,md.)、btx molecular delivery systems(holliston,mass.)和copernicus therapeutics inc.(参见例如美国专利号6,008,336)描述的那些。例如美国专利号5,049,386;4,946,787;和4,897,355中描述了脂质转染并且脂质感染试剂在市场上有售(例如transfectam和lipofectin)。适用于多核苷酸的有效受体-识别脂质转染的阳离子和中性脂质包括felgner、wo 91/17424、wo 91/16024的那些。
[0343]
脂质:核酸复合物(包括靶向的脂质体,例如免疫脂质复合物)的制备为本领域技术人员所众所周知(参见例如crystal,science 270:404-410(1995);blaese et al.,cancer gene ther.2:291-297(1995);behr et al.,bioconjugate chem.5:382-389(1994);remy et al.,bioconjugate chem.5:647-654(1994);gao et al.,gene therapy 2:710-722(1995);ahmad et al.,cancer res.52:4817-4820(1992);美国专利号4,186,183、4,217,344、4,235,871、4,261,975、4,485,054、4,501,728、4,774,085、4,837,028和4,946,787)。
[0344]
在一些实施方式中,供体序列和/或序列特异性试剂由病毒载体编码。在一些实施方式中,可以使用基于腺病毒的系统。基于腺病毒的载体能够在许多细胞类型中实现非常高的转导效率,并且不需要细胞分裂。使用此类载体,已经获得了高滴度和高水平的表达。这种载体可以在相对简单的系统中大量生产。腺相关病毒(“aav”)载体也用于用靶核酸转导细胞,例如在核酸和肽的体外生产中,以及用于体内和离体基因疗法程序(参见例如west et al,virology 160:38-47(1987);美国专利号4,797,368;wo 93/24641;kotin,human gene therapy 5:793-801(1994);muzyczka,j.clin.invest.94:1351(1994))。重组aav载体的构建在许多出版物中都有描述,包括美国专利号5,173,414;tratschin et al.,mol.cell.biol.5:3251-3260(1985);tratschin,et al.,mol.cell.biol.4:2072-2081(1984);hermonat&muzyczka,pnas 81:6466-6470(1984);和samulski et al.,j.virol.63:03822-3828(1989)。
[0345]
重组腺相关病毒载体(raav)是一种基于缺陷和非致病性细小病毒腺相关2型病毒的有前景的替代基因传递系统。所有载体均源自仅保留转基因表达盒侧翼的aav 145bp反向末端重复的质粒。由于整合到转导细胞的基因组中,有效的基因转移和稳定的转基因递送是该载体系统的关键特征。(wagner et al.,lancet 351:9117 1702-3(1998),kearns et al.,gene ther.9:748-55(1996))。根据本发明还可以使用其它aav血清型(包括非限制性示例的aav1、aav3、aav4、aav5、aav6、aav8、aav 8.2、aav9和aav rh10)以及假型aav(诸如aav2/8、aav2/5和aav2/6)。
[0346]
在一些实施方式中,细胞被施用有效量的一种或多种半胱天冬酶抑制剂与aav载体的组合。
[0347]
可以使用相同或不同的系统递送核酸酶编码序列和供体构建体。例如,供体多核苷酸可以由病毒载体携带,而一种或多种核酸酶可以作为mrna组合物递送。
[0348]
在一些实施方式中,可以使用纳米颗粒将一种或多种试剂递送至细胞。在一些实施方式中,纳米颗粒涂有对hsc表面蛋白如cd105(uniprot#p17813)具有特异性亲和力的配体如抗体。在一些实施方式中,纳米粒子是可生物降解的聚合物纳米颗粒,其中多核苷酸形式的序列特异性试剂与聚β氨基酯的聚合物复合并涂有聚谷氨酸(pga)。
[0349]
外显子整合到内源性内含子基因组基因座的策略
[0350]
作为特定的实施方式,本专利申请提供了一种将外源性编码序列整合到内源性内含子基因组区域的方法,其允许将所述外源性编码序列优选地整合在所述基因组区域的第一内源性编码外显子和第二内源性编码外显子之间。
[0351]
方法特别有用,例如,当进入基因组区域的外显子通常从位于第一外显子上游的共同内源性启动子主动转录时,例如图2所示。
[0352]
所述方法具有防止破坏编码内源性外显子区域的转录物同时允许它们与外源性编码序列一起转录的优点。
[0353]
一般而言,所述方法包括下列步骤中的一个或多个:
[0354]-提供包括内源性内含子基因组区域的细胞,
[0355]-向所述细胞中引入包括外源性编码序列的多核苷酸模板,
[0356]
所述多核苷酸模板在5’至3’方向上包括或由以下组成:
[0357]
·
第一同源多核苷酸序列,其与插入位点上游的内含子序列同源,
[0358]
同时所述第一多核苷酸序列优选不包括分支点;
[0359]
·
第一强剪接位点序列,优选地包括分支点和剪接受体;
[0360]
·
编码2a自切割肽的第一序列;
[0361]
·
编码目的蛋白质的外源序列;
[0362]
·
编码2a自切割肽的第二序列;
[0363]
·
第一外显子的编码序列的拷贝,任选地重写;
[0364]
·
第二强剪接位点序列,优选地包括剪接供体;和
[0365]
·
第二同源多核苷酸序列,其与插入位点下游的内含子序列同源;
[0366]-诱导所述外源性多核苷酸整合到所述内含子序列中,优选通过同源重组,以使所述外源性编码序列在所述内源性基因座处连同第一外显子和优选地第二(内源性)外显子或其拷贝一起被转录。
[0367]
一般而言,第一外显子的拷贝下游的第二同源多核苷酸包括分支点,优选最初存在于内源性序列中的分支点,以允许正确的rna剪接和第二外显子的表达。
[0368]
作为优选的实施方式,所述第一外显子的序列的拷贝可以在多核苷酸水平上重写用于密码子优化和/或减少与内源性基因座序列的核苷酸序列同源性。
[0369]
可以通过使用本领域公知的方法来执行上述每个步骤。根据优选的实施方式,也根据hsc或由其分化的细胞递送治疗性蛋白质,细胞可源自患者本人、供体或ips细胞,例如根据wo2018/189360中描述的方法,其通过引用并入。
[0370]
本方法的步骤通常离体进行,这意味着细胞在人体外培养和制造。一般而言,细胞不是生发细胞或源自人类胚胎的细胞,并且该方法不旨在改变人类的生殖线或遗传特性。
[0371]
通过在插入位点切割稀有切割核酸内切酶,可以促进通过同源重组将多核苷酸模板整合到所述内含子序列中。因此,用于外显子整合的所述方法由此可以包括以下步骤:向细胞中引入或表达稀有切割核酸内切酶,特别是tale-核酸酶、锌指核酸酶、大范围核酸酶、例如本技术中已经描述的crispr,以在插入位点切割所述内含子序列。
[0372]
因此,插入位点通常由所述稀有切割核酸内切酶的靶序列确定。因此,插入位点包括在稀有切割核酸内切酶靶序列中,该靶序列本身包括在所选基因座的内含子序列中,并且更具体地包括在本发明所考虑的用于工程化本文公开的hsc的基因座中。
[0373]
优选的基因座是为了治疗性蛋白质的表达和递送所选择的那些基因座,其包括至少两个内源性外显子序列,特别地是选自以下的内含子序列之一:cxcr3(seq id no:76)、cd11b(seq id no:107)、s100a9(seq id no:148)、tmem119(seq id no:189)、mertk(seq id no:190)、cd164(seq id no:191)、tlr7(seq id no:192)、cd14(seq id no:193)、fcgr3a(cd16)(seq id no:194)、tbxas1(seq id no:195)、dok3(seq id no:196)、abca1(seq id no:197)、tmem195(seq id no:198)、tlr4(seq id no:199)、mr1(seq id no:200)、fcgr1a(cd64)(seq id no:201)、csf3r(seq id no:202)、fgd4(seq id no:203)和tspan14(seq id no:204)以及b2m(seq id no:205)。
[0374]
用于整合外源性编码序列的多核苷酸模板通常包括与上述内含子序列同源的第一多核苷酸序列和第二多核苷酸序列,或与所述多核苷酸序列具有或至少80%,优选至少75%、至少80%、至少90或甚至优选至少95%的同一性。第一和第二同源序列通常优选在超过50个碱基对(bp)上,更优选在超过100bp、200bp、500bp并且甚至更优选在50至500bp上分别与插入位点上游和下游的内源性序列同源。
[0375]
根据所提出的方法,要插入到内源性内含子基因组序列中的多核苷酸模板包括外源性编码序列上游和下游的强剪接位点序列。剪接位点是特定的基序,剪接体通过这些基序识别外显子并去除介于中间的内含子。外源性剪接位点序列可以通过克隆或替代地通过将突变引入同源性序列来引入。文献中提供了鉴别或设计强剪接位点的标准以及此类序列的示例,例如shepard,p.j et al.[efficient internal exon recognition depends on near equal contributions from the 3'and 5'splice sites(2011)nucleic acids research,39(20),8928-37]。
[0376]
通常选择第一同源序列(即上游同源序列或左同源臂)以排除分支点,该分支点通常位于第二外显子序列上游10至100bp之间,优选20至50bp之间。对分支点序列的人类共识通常是yunay,其中a是分支点并且小写的嘧啶(
‘
y’)不如大写的u和a保守。分支点通常位于内含子3’端上游的21-34个核苷酸处,而所谓的多嘧啶道跨越分支点下游的4-24个核苷酸[gao,k.,et al.(2008).human branch point consensus sequence is yunay.nucleic acids research,36(7),2257-67]。
[0377]
2a自切割肽或2a肽是一类18
–
22个氨基酸长的肽,其可在细胞内诱导重组蛋白的切割。2a肽来源于病毒基因组的2a区。2a肽家族的四个成员经常用于生命科学研究:p2a、e2a、f2a和t2a。更常用的f2a来源于口蹄疫病毒18;e2a来源于马鼻炎a病毒;p2a来源于猪捷申病毒-1 2a;t2a来源于thosea asigna病毒2a[liu et al.(2017)."systematic comparison of 2a peptides for cloning multi-genes in a polycistronic vector".scientific reports.7(1)]。
[0378]
用于将外源性编码序列整合到内源性内含子基因组区的本方法本身可以被视为一项发明,因为其广泛适用于不限于hsc的任何类型的细胞,并且与可以插入内源性基因座的外源性编码序列的类型无关。
[0379]
然而,已发现所述方法特别适用于hsc以产生如本文所描述的治疗性细胞。使用上述方法整合基因的纠正的拷贝或附加拷贝具有显著优势,以便它们随后在分化的hsc中表达以获得遗传缺陷的交叉纠正。实际上,这尽可能地保留了插入所靶向的内源性基因座的表达,因此不太容易干扰细胞分化和所得细胞的细胞功能。这对于旨在分化为巨噬细胞以
实现大脑中小胶质细胞功能的工程化hsc尤为重要。
[0380]
因此,本发明涵盖通过上述方法可获得并在图2中说明用于将外源性编码序列整合到内源性内含子基因组区的细胞,尤其是专门用于基因疗法的细胞,尤其是用于缺陷等位基因的交叉纠正的细胞。这种基因插入可以在hsc中进行,以获得更多分化阶段的表达,例如用于将治疗性蛋白质递送到大脑用于治疗疾病的那些细胞,特别是巨噬细胞和小胶质细胞,如图14中更具体描述的。
[0381]
如前所提及的,本发明涉及一种将外源性编码序列整合到内源性内含子基因组区域或基因座中的通用方法,其不会使存在于该基因座的内源性外显子的表达失活,尤其是不会使插入位点下游的序列失活。因此,这种方法可以防止在转基因基因组整合中通常观察到的所谓“极性效应”。
[0382]
所述方法包括下列步骤:
[0383]-提供包括内源性内含子基因组区域的细胞,
[0384]-向所述细胞中引入包括外源性编码序列的多核苷酸模板,其中所述多核苷酸模板包括:
[0385]
a)第一同源多核苷酸序列,其与插入位点上游的内含子序列同源,
[0386]
b)第一强剪接位点序列,其包括分支点和剪接受体;
[0387]
c)编码2a自切割肽的第一序列;
[0388]
d)编码目的蛋白质的外源序列;
[0389]
e)编码2a自切割肽的第二序列;
[0390]
f)第一外显子的编码序列的拷贝;
[0391]
g)包括剪接供体的第二强剪接位点序列;和
[0392]
h)第二同源多核苷酸序列,其与插入位点下游的内含子序列同源;以及任选地
[0393]-诱导所述外源性多核苷酸整合到所述内含子序列中,优选通过同源重组,以使所述外源性编码序列在所述内源基因座处连同第一外显子或其拷贝被转录。
[0394]
通过本发明的方法,上述整合形成人工外显子(artex),其可以被引入造血干细胞(hsc)中以获得例如外源性编码序列到至少一种造血细胞谱系中的表达。
[0395]
在一些优选的实施方式中,所述外源性编码序列编码用于治疗遗传疾病的目的蛋白质,其在祖细胞、红细胞、粒细胞、巨核细胞、单核细胞、b细胞和/或t细胞中的表达,如图14所示。
[0396]
根据一些实施方式,该方法用于在祖细胞中表达选自fanca、fancc或fancg中的蛋白质。
[0397]
根据一些实施方式,该方法用于在红细胞中表达选自hbb、pklr或rps19中的蛋白质。
[0398]
根据一些实施方式,该方法用于在粒细胞中表达选自hax1、cyba、cybb、ncf1、ncf2或ncf4中的蛋白质。
[0399]
根据一些实施方式,该方法用于在巨核细胞中表达选自因子8、因子9、因子11或was中的蛋白质。
[0400]
根据一些实施方式,该方法用于在单核细胞中表达选自idua、ids、arsb、gusb、abcd1、galc、arsa、psap、gba、fuca1、man2b1、aga、asah1、hexa、gaa、smpd1、lipa和cdkl5中
的蛋白质。
[0401]
根据一些实施方式,该方法用于在b细胞中表达选自ada、il2rg、was或btk中的蛋白质。
[0402]
根据一些实施方式,该方法用于在t细胞中表达选自ada、il2rg、was、btk或ccr5中的蛋白质。
[0403]
因此,所述外源性编码序列的表达产生允许交叉纠正内源性缺陷蛋白的目的蛋白。该方法可以离体进行以产生工程化治疗性细胞,用于治疗在图14中列出的至少一种疾病,尤其是迄今为止鉴定的多种形式的溶酶体贮积病(lsd)。
[0404]
本发明还涉及可用于进行上述方法的插入载体,例如aav载体,优选aav6,其特征在于其包括用于插入内源性基因座处的外源性多核苷酸序列,该外源性多核苷酸序列包括以下序列:
[0405]
a)第一同源多核苷酸序列,其与插入位点上游的内含子序列同源,
[0406]
b)第一强剪接位点序列,其包括分支点和剪接受体;
[0407]
c)编码2a自切割肽的第一序列;
[0408]
d)编码目的蛋白质的外源序列;
[0409]
e)编码2a自切割肽的第二序列;
[0410]
f)第一外显子的编码序列的拷贝;
[0411]
g)包括剪接供体的第二强剪接位点序列;和
[0412]
h)第二同源多核苷酸序列,其与插入位点下游的内含子序列同源。
[0413]
在优选的实施方式中,所述第一同源序列和第二同源序列与选自以下的内源性基因座同源:tmem119、s100a9、cd11b、b2m、cx3cr1、mertk、cd164、tlr4、tlr7、cd14、fcgr1a、fcgr3a、tbxas1、dok3、abca1、tmem195、mr1、csf3r、fgd4、tspan14、tgfbri、ccr5、gpr34、serpine2、slco2b1、p2ry12、olfml3、p2ry13、hexb、rhob、jun、rab3il1、ccl2、fcrls、scoc、siglech、slc2a5、lrrc3、plxdc2、usp2、ctsf、cttnbp2nl、atp8a2、lgmn、mafb、egr1、bhlhe41、hpgds、ctsd、hspa1a、lag3、csf1r、adamts1、f11r、golm1、nuak1、crybb1、ltc4s、sgce、pla2g15、ccl3l1、abhd12、ang、ophn1、sparc、pros1、p2ry6、lair1、il1a、epb41l2、adora3、rilpl1、pmepa1、ccl13、pde3b、scamp5、ppp1r9a、tjp1、ak1、b4galt4、gtf2h2、trem2、ckb、acp2、pon3、agmo、tnfrsf17、fscn1、st3gal6、adap2、ccl4、entpd1、tmem86a、kctd12、dst、ctsl2、abcc3、pdgfb、pald1、tubgcp5、rapgef5、stab1、lacc1、tmc7、nrip1、kcnd1、tmem206、hps4、dagla、extl3、mlph、arhgap22、cxxc5、p4ha1、cysltr1、fgd2、kcnk13、gbgt1、c18orf1、cadm1、bco2、adrb1、c3ar1、large、leprel1、liph、upk1b、p2rx7、slc46a1、ebf3、ppp1r15a、il10ra、rasgrp3、fos、tppp、slc24a3、havcr2、nav2、apbb2、clstn1、blnk、gnaq、ptprm、frmd4a、cd86、tnfrsf11a、spint1、ppm1l、tgfbr2、cmklr1、tlr6、gas6、hist1h2ab、atf3、acvr1、abi3、lrp12、ttc28、plxna4、adamts16、rgs1、icam1、snx24、ly96、dnajb4和ppfia4。
[0414]
本发明还包括一种通过任何前述方法可获得的工程化细胞,且更具体地是特征在于外源性多核苷酸序列已被插入内源性基因座处内含子中的工程化细胞,其中所述多核苷酸序列优选地包括:
[0415]-第一强剪接位点序列,包括分支点和受体位点;
[0416]-编码2a自切割肽的第一序列;
[0417]-编码目的蛋白质(诸如治疗性蛋白质)的外源序列;
[0418]-编码2a自切割肽的第二序列;
[0419]-与所述基因座内源的前一外显子的编码序列的拷贝;
[0420]-包括剪接供体位点的第二强剪接位点序列;
[0421]
2.还根据一些优选的实施方式,所述工程化细胞中的所述外源性多核苷酸序列可以插入在选自以下的内源性基因座处:tmem119、s100a9、cd11b、b2m、cx3cr1、mertk、cd164、tlr4、tlr7、cd14、fcgr1a、fcgr3a、tbxas1、dok3、abca1、tmem195、mr1、csf3r、fgd4、tspan14、tgfbri、ccr5、gpr34、serpine2、slco2b1、p2ry12、olfml3、p2ry13、hexb、rhob、jun、rab3il1、ccl2、fcrls、scoc、siglech、slc2a5、lrrc3、plxdc2、usp2、ctsf、cttnbp2nl、atp8a2、lgmn、mafb、egr1、bhlhe41、hpgds、ctsd、hspa1a、lag3、csf1r、adamts1、f11r、golm1、nuak1、crybb1、ltc4s、sgce、pla2g15、ccl3l1、abhd12、ang、ophn1、sparc、pros1、p2ry6、lair1、il1a、epb41l2、adora3、rilpl1、pmepa1、ccl13、pde3b、scamp5、ppp1r9a、tjp1、ak1、b4galt4、gtf2h2、trem2、ckb、acp2、pon3、agmo、tnfrsf17、fscn1、st3gal6、adap2、ccl4、entpd1、tmem86a、kctd12、dst、ctsl2、abcc3、pdgfb、pald1、tubgcp5、rapgef5、stab1、lacc1、tmc7、nrip1、kcnd1、tmem206、hps4、dagla、extl3、mlph、arhgap22、cxxc5、p4ha1、cysltr1、fgd2、kcnk13、gbgt1、c18orf1、cadm1、bco2、adrb1、c3ar1、large、leprel1、liph、upk1b、p2rx7、slc46a1、ebf3、ppp1r15a、il10ra、rasgrp3、fos、tppp、slc24a3、havcr2、nav2、apbb2、clstn1、blnk、gnaq、ptprm、frmd4a、cd86、tnfrsf11a、spint1、ppm1l、tgfbr2、cmklr1、tlr6、gas6、hist1h2ab、atf3、acvr1、abi3、lrp12、ttc28、plxna4、adamts16、rgs1、icam1、snx24、ly96、dnajb4和ppfia4。优选的内源性基因基因座是s100a9或cd11b。
[0422]
根据本发明的一些优选实施方式,将所述外源性多核苷酸序列插入到第一和第二内源性编码外显子之间的内含子中,如图2所示。第一和第二编码2自切割肽通常不同以避免不期望的稀有重组事件,其可以选自seq id no:216和seq id no:217。
[0423]
根据一些优选的实施方式,上述第一剪接位点包括实施例中所示的seq id no:206或seq id no:207。
[0424]
编码序列,特别是由于图2所示的本整合方法可被同源重组替换的第一内源性外显子的编码序列,可以进行密码子优化(即重写)以增加多核苷酸序列多样性并防止不希望的内源性基因座处的重组事件。因此,本发明更特别地提供了工程化的细胞,其中编码从idua、ids、arsb、gusb、abcd1、galc、arsa、psap、gba、fuca1、man2b1、aga、asah1、hexa、gaa、smpd1、lipa和cdkl5(seq id no:1至seq id no:35
–
见表1)中选择的治疗性蛋白质的一个外源性序列被整合在从tmem119、mertk、cd164、tlr7、cd14、fcgr3a(cd16)、tbxas1、dok3、abca1、tmem195、tlr4、mr1、fcgr1a(cd64)、csf3r、fgd4、tspan14、cxcr3、cd11b、s100a9和b2m中选择的一个基因座处,更特别地整合在它们的内含子多核苷酸序列中或与所述多核苷酸序列具有至少80%(优选至少75%、至少80%、至少90或至少95%)同一性的任何内含子序列中(考虑到这些序列在整个动物界且特别是人类物种中的可变性)。
[0425]
因此,本发明更具体地涉及以下类型的工程化细胞之一,其中:
[0426]-idua被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0427]-ids被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0428]-arsb被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0429]-gusb被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0430]-abcd1被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0431]-galc被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0432]-arsa被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0433]-psap被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0434]-gba被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0435]-fuca1被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0436]-man2b1被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0437]-aga被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0438]-asah1被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0439]-hexa被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0440]-gaa被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0441]-smpd1被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0442]-lipa被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0443]-cdkl5被引入在cxcr3基因座处,优选地引入seq id no:76中;
[0444]-idua被引入在cd11b基因座处,优选地引入seq id no:107中;
[0445]-ids被引入在cd11b基因座处,优选地引入seq id no:107中;
[0446]-arsb被引入在cd11b基因座处,优选地引入seq id no:107中;
[0447]-gusb被引入在cd11b基因座处,优选地引入seq id no:107中;
[0448]-abcd1被引入在cd11b基因座处,优选地引入seq id no:107中;
[0449]-galc被引入在cd11b基因座处,优选地引入seq id no:107中;
[0450]-arsa被引入在cd11b基因座处,优选地引入seq id no:107中;
[0451]-psap被引入在cd11b基因座处,优选地引入seq id no:107中;
[0452]-gba被引入在cd11b基因座处,优选地引入seq id no:107中;
[0453]-fuca1被引入在cd11b基因座处,优选地引入seq id no:107中;
[0454]-man2b1被引入在cd11b基因座处,优选地引入seq id no:107中;
[0455]-aga被引入在cd11b基因座处,优选地引入seq id no:107中;
[0456]-asah1被引入在cd11b基因座处,优选地引入seq id no:107中;
[0457]-hexa被引入在cd11b基因座处,优选地引入seq id no:107中;
[0458]-gaa被引入在cd11b基因座处,优选地引入seq id no:107中;
[0459]-smpd1被引入在cd11b基因座处,优选地引入seq id no:107中;
[0460]-lipa被引入在cd11b基因座处,优选地引入seq id no:107中;
[0461]-cdkl5被引入在cd11b基因座处,优选地引入seq id no:107中;
[0462]-idua被引入在s100a9基因座处,优选地引入seq id no:148中;
[0463]-ids被引入在s100a9基因座处,优选地引入seq id no:148中;
[0464]-arsb被引入在s100a9基因座处,优选地引入seq id no:148中;
[0465]-gusb被引入在s100a9基因座处,优选地引入seq id no:148中;
[0466]-abcd1被引入在s100a9基因座处,优选地引入seq id no:148中;
[0467]-galc被引入在s100a9基因座处,优选地引入seq id no:148中;
[0468]-arsa被引入在s100a9基因座处,优选地引入seq id no:148中;
[0469]-psap被引入在s100a9基因座处,优选地引入seq id no:148中;
[0470]-gba被引入在s100a9基因座处,优选地引入seq id no:148中;
[0471]-fuca1被引入在s100a9基因座处,优选地引入seq id no:148中;
[0472]-man2b1被引入在s100a9基因座处,优选地引入seq id no:148中;
[0473]-aga被引入在s100a9基因座处,优选地引入seq id no:148中;
[0474]-asah1被引入在s100a9基因座处,优选地引入seq id no:148中;
[0475]-hexa被引入在s100a9基因座处,优选地引入seq id no:148中;
[0476]-gaa被引入在s100a9基因座处,优选地引入seq id no:148中;
[0477]-smpd1被引入在s100a9基因座处,优选地引入seq id no:148中;
[0478]-lipa被引入在s100a9基因座处,优选地引入seq id no:148中;
[0479]-cdkl5被引入在s100a9基因座处,优选地引入seq id no:148中;
[0480]-idua被引入在tmem119基因座处,优选地引入seq id no:189中;
[0481]-ids被引入在tmem119基因座处,优选地引入seq id no:189中;
[0482]-arsb被引入在tmem119基因座处,优选地引入seq id no:189中;
[0483]-gusb被引入在tmem119基因座处,优选地引入seq id no:189中;
[0484]-abcd1被引入在tmem119基因座处,优选地引入seq id no:189中;
[0485]-galc被引入在tmem119基因座处,优选地引入seq id no:189中;
[0486]-arsa被引入在tmem119基因座处,优选地引入seq id no:189中;
[0487]-psap被引入在tmem119基因座处,优选地引入seq id no:189中;
[0488]-gba被引入在tmem119基因座处,优选地引入seq id no:189中;
[0489]-fuca1被引入在tmem119基因座处,优选地引入seq id no:189中;
[0490]-man2b1被引入在tmem119基因座处,优选地引入seq id no:189中;
[0491]-aga被引入在tmem119基因座处,优选地引入seq id no:189中;
[0492]-asah1被引入在tmem119基因座处,优选地引入seq id no:189中;
[0493]-hexa被引入在tmem119基因座处,优选地引入seq id no:189中;
[0494]-gaa被引入在tmem119基因座处,优选地引入seq id no:189中;
[0495]-smpd1被引入在tmem119基因座处,优选地引入seq id no:189中;
[0496]-lipa被引入在tmem119基因座处,优选地引入seq id no:189中;
[0497]-cdkl5被引入在tmem119基因座处,优选地引入seq id no:189中;
[0498]-idua被引入在mertk基因座处,优选地引入seq id no:190中;
[0499]-ids被引入在mertk基因座处,优选地引入seq id no:190中;
[0500]-arsb被引入在mertk基因座处,优选地引入seq id no:190中;
[0501]-gusb被引入在mertk基因座处,优选地引入seq id no:190中;
[0502]-abcd1被引入在mertk基因座处,优选地引入seq id no:190中;
[0503]-galc被引入在mertk基因座处,优选地引入seq id no:190中;
[0504]-arsa被引入在mertk基因座处,优选地引入seq id no:190中;
[0505]-psap被引入在mertk基因座处,优选地引入seq id no:190中;
[0506]-gba被引入在mertk基因座处,优选地引入seq id no:190中;
[0507]-fuca1被引入在mertk基因座处,优选地引入seq id no:190中;
[0508]-man2b1被引入在mertk基因座处,优选地引入seq id no:190中;
[0509]-aga被引入在mertk基因座处,优选地引入seq id no:190中;
[0510]-asah1被引入在mertk基因座处,优选地引入seq id no:190中;
[0511]-hexa被引入在mertk基因座处,优选地引入seq id no:190中;
[0512]-gaa被引入在mertk基因座处,优选地引入seq id no:190中;
[0513]-smpd1被引入在mertk基因座处,优选地引入seq id no:190中;
[0514]-lipa被引入在mertk基因座处,优选地引入seq id no:190中;
[0515]-cdkl5被引入在mertk基因座处,优选地引入seq id no:190中;
[0517]-idua被引入在cd164基因座处,优选地引入seq id no:191中;
[0518]-ids被引入在cd164基因座处,优选地引入seq id no:191中;
[0519]-arsb被引入在cd164基因座处,优选地引入seq id no:191中;
[0520]-gusb被引入在cd164基因座处,优选地引入seq id no:191中;
[0521]-abcd1被引入在cd164基因座处,优选地引入seq id no:191中;
[0522]-galc被引入在cd164基因座处,优选地引入seq id no:191中;
[0523]-arsa被引入在cd164基因座处,优选地引入seq id no:191中;
[0524]-psap被引入在cd164基因座处,优选地引入seq id no:191中;
[0525]-gba被引入在cd164基因座处,优选地引入seq id no:191中;
[0526]-fuca1被引入在cd164基因座处,优选地引入seq id no:191中;
[0527]-man2b1被引入在cd164基因座处,优选地引入seq id no:191中;
[0528]-aga被引入在cd164基因座处,优选地引入seq id no:191中;
[0529]-asah1被引入在cd164基因座处,优选地引入seq id no:191中;
[0530]-hexa被引入在cd164基因座处,优选地引入seq id no:191中;
[0531]-gaa被引入在cd164基因座处,优选地引入seq id no:191中;
[0532]-smpd1被引入在cd164基因座处,优选地引入seq id no:191中;
[0533]-lipa被引入在cd164基因座处,优选地引入seq id no:191中;
[0534]-cdkl5被引入在cd164基因座处,优选地引入seq id no:191中;
[0535]-idua被引入在tlr7基因座处,优选地引入seq id no:192中;
[0536]-ids被引入在tlr7基因座处,优选地引入seq id no:192中;
[0537]-arsb被引入在tlr7基因座处,优选地引入seq id no:192中;
[0538]-gusb被引入在tlr7基因座处,优选地引入seq id no:192中;
[0539]-abcd1被引入在tlr7基因座处,优选地引入seq id no:192中;
[0540]-galc被引入在tlr7基因座处,优选地引入seq id no:192中;
[0541]-arsa被引入在tlr7基因座处,优选地引入seq id no:192中;
[0542]-psap被引入在基因座tlr7处,优选地引入seq id no:192中;
[0543]-gba被引入在tlr7基因座处,优选地引入seq id no:192中;
[0544]-fuca1被引入在tlr7基因座处,优选地引入seq id no:192中;
[0545]-man2b1被引入在tlr7基因座处,优选地引入seq id no:192中;
[0546]-aga被引入在tlr7基因座处,优选地引入seq id no:192中;
[0547]-asah1被引入在tlr7基因座处,优选地引入seq id no:192中;
[0548]-hexa被引入在tlr7基因座处,优选地引入seq id no:192中;
[0549]-gaa被引入在tlr7基因座处,优选地引入seq id no:192中;
[0550]-smpd1被引入在tlr7基因座处,优选地引入seq id no:192中;
[0551]-lipa被引入在tlr7基因座处,优选地引入seq id no:192中;
[0552]-cdkl5被引入在tlr7基因座处,优选地引入seq id no:192中;
[0553]-idua被引入在cd14基因座处,优选地引入seq id no:193中;
[0554]-ids被引入在cd14基因座处,优选地引入seq id no:193中;
[0555]-arsb被引入在cd14基因座处,优选地引入seq id no:193中;
[0556]-gusb被引入在cd14基因座处,优选地引入seq id no:193中;
[0557]-abcd1被引入在cd14基因座处,优选地引入seq id no:193中;
[0558]-galc被引入在cd14基因座处,优选地引入seq id no:193中;
[0559]-arsa被引入在cd14基因座处,优选地引入seq id no:193中;
[0560]-psap被引入在基因座cd14处,优选地引入seq id no:193中;
[0561]-gba被引入在cd14基因座处,优选地引入seq id no:193中;
[0562]-fuca1被引入在cd14基因座处,优选地引入seq id no:193中;
[0563]-man2b1被引入在cd14基因座处,优选地引入seq id no:193中;
[0564]-aga被引入在cd14基因座处,优选地引入seq id no:193中;
[0565]-asah1被引入在cd14基因座处,优选地引入seq id no:193中;
[0566]-hexa被引入在cd14基因座处,优选地引入seq id no:193中;
[0567]-gaa被引入在cd14基因座处,优选地引入seq id no:193中;
[0568]-smpd1被引入在cd14基因座处,优选地引入seq id no:193中;
[0569]-lipa被引入在cd14基因座处,优选地引入seq id no:193中;
[0570]-cdkl5被引入在cd14基因座处,优选地引入seq id no:193中;
[0571]-idua被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0572]-ids被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0573]-arsb被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0574]-gusb被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0575]-abcd1被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0576]-galc被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0577]-arsa被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0578]-psap被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0579]-gba被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0580]-fuca1被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0581]-man2b1被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0582]-aga被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0583]-asah1被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0584]-hexa被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0585]-gaa被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0586]-smpd1被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0587]-lipa被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0588]-cdkl5被引入在fcgr3a基因座处,优选地引入seq id no:194中;
[0589]-idua被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0590]-ids被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0591]-arsb被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0592]-gusb被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0593]-abcd1被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0594]-galc被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0595]-arsa被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0596]-psap被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0597]-gba被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0598]-fuca1被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0599]-man2b1被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0600]-aga被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0601]-asah1被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0602]-hexa被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0603]-gaa被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0604]-smpd1被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0605]-lipa被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0606]-cdkl5被引入在tbxas1基因座处,优选地引入seq id no:195中;
[0607]-idua被引入在dok3基因座处,优选地引入seq id no:196中;
[0608]-ids被引入在dok3基因座处,优选地引入seq id no:196中;
[0609]-arsb被引入在dok3基因座处,优选地引入seq id no:196中;
[0610]-gusb被引入在dok3基因座处,优选地引入seq id no:196中;
[0611]-abcd1被引入在dok3基因座处,优选地引入seq id no:196中;
[0612]-galc被引入在dok3基因座处,优选地引入seq id no:196中;
[0613]-arsa被引入在dok3基因座处,优选地引入seq id no:196中;
[0614]-psap被引入在dok3基因座处,优选地引入seq id no:196中;
[0615]-gba被引入在dok3基因座处,优选地引入seq id no:196中;
[0616]-fuca1被引入在dok3基因座处,优选地引入seq id no:196中;
[0617]-man2b1被引入在dok3基因座处,优选地引入seq id no:196中;
[0618]-aga被引入在dok3基因座处,优选地引入seq id no:196中;
[0619]-asah1被引入在dok3基因座处,优选地引入seq id no:196中;
[0620]-hexa被引入在dok3基因座处,优选地引入seq id no:196中;
[0621]-gaa被引入在dok3基因座处,优选地引入seq id no:196中;
[0622]-smpd1被引入在dok3基因座处,优选地引入seq id no:196中;
[0623]-lipa被引入在dok3基因座处,优选地引入seq id no:196中;
[0624]-cdkl5被引入在dok3基因座处,优选地引入seq id no:196中;
[0625]-idua被引入在abca1基因座处,优选地引入seq id no:197中;
[0626]-ids被引入在abca1基因座处,优选地引入seq id no:197中;
[0627]-arsb被引入在abca1基因座处,优选地引入seq id no:197中;
[0628]-gusb被引入在abca1基因座处,优选地引入seq id no:197中;
[0629]-abcd1被引入在abca1基因座处,优选地引入seq id no:197中;
[0630]-galc被引入在abca1基因座处,优选地引入seq id no:197中;
[0631]-arsa被引入在abca1基因座处,优选地引入seq id no:197中;
[0632]-psap被引入在abca1基因座处,优选地引入seq id no:197中;
[0633]-gba被引入在abca1基因座处,优选地引入seq id no:197中;
[0634]-fuca1被引入在abca1基因座处,优选地引入seq id no:197中;
[0635]-man2b1被引入在abca1基因座处,优选地引入seq id no:197中;
[0636]-aga被引入在abca1基因座处,优选地引入seq id no:197中;
[0637]-asah1被引入在abca1基因座处,优选地引入seq id no:197中;
[0638]-hexa被引入在abca1基因座处,优选地引入seq id no:197中;
[0639]-gaa被引入在abca1基因座处,优选地引入seq id no:197中;
[0640]-smpd1被引入在abca1基因座处,优选地引入seq id no:197中;
[0641]-lipa被引入在abca1基因座处,优选地引入seq id no:197中;
[0642]-cdkl5被引入在abca1基因座处,优选地引入seq id no:197中;
[0643]-idua被引入在tmem195基因座处,优选地引入seq id no:198中;
[0644]-ids被引入在tmem195基因座处,优选地引入seq id no:198中;
[0645]-arsb被引入在tmem195基因座处,优选地引入seq id no:198中;
[0646]-gusb被引入在tmem195基因座处,优选地引入seq id no:198中;
[0647]-abcd1被引入在tmem195基因座处,优选地引入seq id no:198中;
[0648]-galc被引入在tmem195基因座处,优选地引入seq id no:198中;
[0649]-arsa被引入在tmem195基因座处,优选地引入seq id no:198中;
[0650]-psap被引入在tmem195基因座处,优选地引入seq id no:198中;
[0651]-gba被引入在tmem195基因座处,优选地引入seq id no:198中;
[0652]-fuca1被引入在tmem195基因座处,优选地引入seq id no:198中;
[0653]-man2b1被引入在tmem195基因座处,优选地引入seq id no:198中;
[0654]-aga被引入在tmem195基因座处,优选地引入seq id no:198中;
[0655]-asah1被引入在tmem195基因座处,优选地引入seq id no:198中;
[0656]-hexa被引入在tmem195基因座处,优选地引入seq id no:198中;
[0657]-gaa被引入在tmem195基因座处,优选地引入seq id no:198中;
[0658]-smpd1被引入在tmem195基因座处,优选地引入seq id no:198中;
[0659]-lipa被引入在tmem195基因座处,优选地引入seq id no:198中;
[0660]-cdkl5被引入在tmem195基因座处,优选地引入seq id no:198中;
[0661]-idua被引入在tlr4基因座处,优选地引入seq id no:199中;
[0662]-ids被引入在tlr4基因座处,优选地引入seq id no:199中;
[0663]-arsb被引入在tlr4基因座处,优选地引入seq id no:199中;
[0664]-gusb被引入在tlr4基因座处,优选地引入seq id no:199中;
[0665]-abcd1被引入在tlr4基因座处,优选地引入seq id no:199中;
[0666]-galc被引入在tlr4基因座处,优选地引入seq id no:199中;
[0667]-arsa被引入在tlr4基因座处,优选地引入seq id no:199中;
[0668]-psap被引入在tlr4基因座处,优选地引入seq id no:199中;
[0669]-gba被引入在tlr4基因座处,优选地引入seq id no:199中;
[0670]-fuca1被引入在tlr4基因座处,优选地引入seq id no:199中;
[0671]-man2b1被引入在tlr4基因座处,优选地引入seq id no:199中;
[0672]-aga被引入在tlr4基因座处,优选地引入seq id no:199中;
[0673]-asah1被引入在tlr4基因座处,优选地引入seq id no:199中;
[0674]-hexa被引入在tlr4基因座处,优选地引入seq id no:199中;
[0675]-gaa被引入在tlr4基因座处,优选地引入seq id no:199中;
[0676]-smpd1被引入在tlr4基因座处,优选地引入seq id no:199中;
[0677]-lipa被引入在tlr4基因座处,优选地引入seq id no:199中;
[0678]-cdkl5被引入在tlr4基因座处,优选地引入seq id no:199中;
[0679]-idua被引入在mr1基因座处,优选地引入seq id no:200中;
[0680]-ids被引入在mr1基因座处,优选地引入seq id no:200中;
[0681]-arsb被引入在mr1基因座处,优选地引入seq id no:200中;
[0682]-gusb被引入在mr1基因座处,优选地引入seq id no:200中;
[0683]-abcd1被引入在mr1基因座处,优选地引入seq id no:200中;
[0684]-galc被引入在mr1基因座处,优选地引入seq id no:200中;
[0685]-arsa被引入在mr1基因座处,优选地引入seq id no:200中;
[0686]-psap被引入在mr1基因座处,优选地引入seq id no:200中;
[0687]-gba被引入在mr1基因座处,优选地引入seq id no:200中;
[0688]-fuca1被引入在mr1基因座处,优选地引入seq id no:200中;
[0689]-man2b1被引入在mr1基因座处,优选地引入seq id no:200中;
[0690]-aga被引入在mr1基因座处,优选地引入seq id no:200中;
[0691]-asah1被引入在mr1基因座处,优选地引入seq id no:200中;
[0692]-hexa被引入在mr1基因座处,优选地引入seq id no:200中;
[0693]-gaa被引入在mr1基因座处,优选地引入seq id no:200中;
[0694]-smpd1被引入在mr1基因座处,优选地引入seq id no:200中;
[0695]-lipa被引入在mr1基因座处,优选地引入seq id no:200中;
[0696]-cdkl5被引入在mr1基因座处,优选地引入seq id no:200中;
[0697]-idua被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0698]-ids被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0699]-arsb被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0700]-gusb被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0701]-abcd1被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0702]-galc被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0703]-arsa被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0704]-psap被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0705]-gba被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0706]-fuca1被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0707]-man2b1被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0708]-aga被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0709]-asah1被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0710]-hexa被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0711]-gaa被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0712]-smpd1被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0713]-lipa被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0714]-cdkl5被引入在fcgr1a基因座处,优选地引入seq id no:201中;
[0715]-idua被引入在csf3r基因座处,优选地引入seq id no:202中;
[0716]-ids被引入在csf3r基因座处,优选地引入seq id no:202中;
[0717]-arsb被引入在csf3r基因座处,优选地引入seq id no:202中;
[0718]-gusb被引入在csf3r基因座处,优选地引入seq id no:202中;
[0719]-abcd1被引入在csf3r基因座处,优选地引入seq id no:202中;
[0720]-galc被引入在csf3r基因座处,优选地引入seq id no:202中;
[0721]-arsa被引入在csf3r基因座处,优选地引入seq id no:202中;
[0722]-psap被引入在csf3r基因座处,优选地引入seq id no:202中;
[0723]-gba被引入在csf3r基因座处,优选地引入seq id no:202中;
[0724]-fuca1被引入在csf3r基因座处,优选地引入seq id no:202中;
[0725]-man2b1被引入在csf3r基因座处,优选地引入seq id no:202中;
[0726]-aga被引入在csf3r基因座处,优选地引入seq id no:202中;
[0727]-asah1被引入在csf3r基因座处,优选地引入seq id no:202中;
[0728]-hexa被引入在csf3r基因座处,优选地引入seq id no:202中;
[0729]-gaa被引入在csf3r基因座处,优选地引入seq id no:202中;
[0730]-smpd1被引入在csf3r基因座处,优选地引入seq id no:202中;
[0731]-lipa被引入在csf3r基因座处,优选地引入seq id no:202中;
[0732]-cdkl5被引入在csf3r基因座处,优选地引入seq id no:202中;
[0733]-idua被引入在fgd4基因座处,优选地引入seq id no:203中;
[0734]-ids被引入在fgd4基因座处,优选地引入seq id no:203中;
[0735]-arsb被引入在fgd4基因座处,优选地引入seq id no:203中;
[0736]-gusb被引入在fgd4基因座处,优选地引入seq id no:203中;
[0737]-abcd1被引入在fgd4基因座处,优选地引入seq id no:203中;
[0738]-galc被引入在fgd4基因座处,优选地引入seq id no:203中;
[0739]-arsa被引入在fgd4基因座处,优选地引入seq id no:203中;
[0740]-psap被引入在fgd4基因座处,优选地引入seq id no:203中;
[0741]-gba被引入在fgd4基因座处,优选地引入seq id no:203中;
[0742]-fuca1被引入在fgd4基因座处,优选地引入seq id no:203中;
[0743]-man2b1被引入在fgd4基因座处,优选地引入seq id no:203中;
[0744]-aga被引入在fgd4基因座处,优选地引入seq id no:203中;
[0745]-asah1被引入在fgd4基因座处,优选地引入seq id no:203中;
[0746]-hexa被引入在fgd4基因座处,优选地引入seq id no:203中;
[0747]-gaa被引入在fgd4基因座处,优选地引入seq id no:203中;
[0748]-smpd1被引入在fgd4基因座处,优选地引入seq id no:203中;
[0749]-lipa被引入在fgd4基因座处,优选地引入seq id no:203中;
[0750]-cdkl5被引入在fgd4基因座处,优选地引入seq id no:203中;
[0751]-idua被引入在tspan14基因座处,优选地引入seq id no:204中;
[0752]-ids被引入在tspan14基因座处,优选地引入seq id no:204中;
[0753]-arsb被引入在tspan14基因座处,优选地引入seq id no:204中;
[0754]-gusb被引入在tspan14基因座处,优选地引入seq id no:204中;
[0755]-abcd1被引入在tspan14基因座处,优选地引入seq id no:204中;
[0756]-galc被引入在tspan14基因座处,优选地引入seq id no:204中;
[0757]-arsa被引入在tspan14基因座处,优选地引入seq id no:204中;
[0758]-psap被引入在tspan14基因座处,优选地引入seq id no:204中;
[0759]-gba被引入在tspan14基因座处,优选地引入seq id no:204中;
[0760]-fuca1被引入在tspan14基因座处,优选地引入seq id no:204中;
[0761]-man2b1被引入在tspan14基因座处,优选地引入seq id no:204中;
[0762]-aga被引入在tspan14基因座处,优选地引入seq id no:204中;
[0763]-asah1被引入在tspan14基因座处,优选地引入seq id no:204中;
[0764]-hexa被引入在tspan14基因座处,优选地引入seq id no:204中;
[0765]-gaa被引入在tspan14基因座处,优选地引入seq id no:204中;
[0766]-smpd1被引入在tspan14基因座处,优选地引入seq id no:204中;
[0767]-lipa被引入在tspan14基因座处,优选地引入seq id no:204中;
[0768]-cdkl5被引入在tspan14基因座处,优选地引入seq id no:204中;
[0769]-idua被引入在b2m基因座处,优选地引入seq id no:205中;
[0770]-ids被引入在b2m基因座处,优选地引入seq id no:205中;
[0771]-arsb被引入在b2m基因座处,优选地引入seq id no:205中;
[0772]-gusb被引入在b2m基因座处,优选地引入seq id no:205中;
[0773]-abcd1被引入在b2m基因座处,优选地引入seq id no:205中;
[0774]-galc被引入在b2m基因座处,优选地引入seq id no:205中;
[0775]-arsa被引入在b2m基因座处,优选地引入seq id no:205中;
[0776]-psap被引入在b2m基因座处,优选地引入seq id no:205中;
[0777]-gba被引入在b2m基因座处,优选地引入seq id no:205中;
[0778]-fuca1被引入在b2m基因座处,优选地引入seq id no:205中;
[0779]-man2b1被引入在b2m基因座处,优选地引入seq id no:205中;
[0780]-aga被引入在b2m基因座处,优选地引入seq id no:205中;
[0781]-asah1被引入在b2m基因座处,优选地引入seq id no:205中;
[0782]-hexa被引入在b2m基因座处,优选地引入seq id no:205中;
[0783]-gaa被引入在b2m基因座处,优选地引入seq id no:205中;
[0784]-smpd1被引入在b2m基因座处,优选地引入seq id no:205中;
[0785]-lipa被引入在b2m基因座处,优选地引入seq id no:205中;和
[0786]-cdkl5被引入在b2m基因座处,优选地引入seq id no:205中。
[0787]
此类工程化细胞(优选人类细胞)更特别地特征在于它们在一个内源性基因座处包括多核苷酸序列,该多核苷酸序列包括以下各项:
[0788]-第一强剪接位点序列,其优选地包括分支点和受体位点;
[0789]-编码2a自切割肽的第一序列;
[0790]-编码目的蛋白质(诸如治疗性蛋白质)的外源序列;
[0791]-编码2a自切割肽的第二序列;
[0792]-与所述基因座内源的前一外显子的编码序列的拷贝,优选重写;
[0793]-任选地,第二强剪接位点序列,优选地包括剪接供体位点。
[0794]
本发明还涉及dna模板或任何多核苷酸,其可用作有用于进行上述细胞工程化的插入载体,尤其是aav载体,更优选aav6载体,如ling,c.et al.[high-efficiency transduction of primary human hematopoietic stem/progenitor cells by aav6 vectors:strategies for overcoming donor-variation and implications in genome editing(2016)scientific reports 6:35495]中描述的。此类多核苷酸的特征在于它们包括以下序列中的一种或多种:
[0795]-第一强剪接位点,其包括分支点和受体位点;
[0796]-编码2a自切割肽的第一序列;
[0797]-编码目的蛋白质的外源序列;
[0798]-编码2a自切割肽的第二序列;
[0799]-与所述基因座内源的前一外显子的编码序列的拷贝,优选重写;
[0800]-任选地,第二强剪接位点,其包括剪接供体位点。
[0801]
根据优选的实施方式,所述多核苷酸还包括上游和下游序列,它们与如前所述的内源性基因座同源。一般而言,这些上游和下游序列中的至少一者或两者与内含子序列同源,尤其是在本文中称为seq id no:76、seq id no:107、seq id no:148和seq id no:189至seq id no:205的那些内含子序列,并且更优选地与此类内含子序列排他地同源(即在基因座处存在跨越外显子序列)。
[0802]
组合物
[0803]
本发明还涉及一种组合物,其包括有效量的如本文所述的基因工程化的hsc或ips细胞。在一些实施方式中,本发明提供了一种药物组合物,其包括有效量的如本文所述的基因工程化的hsc或ips细胞。
[0804]
在一些实施方式中,组合物可以用作药物。在一些实施方式中,组合物可以用于治疗如本文所述的单基因病。
[0805]
在一些实施方式中,组合物包括细胞群,其中该群中细胞的至少40%已经根据本文描述的任一何种方法进行了修饰。在一些实施方式中,群中细胞的至少50%、60%、70%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%已经根据本文描述的方法的任何一种进行了修饰。在一些实施方式中,组合物包括纯细胞群,其中100%的细胞已经如本文描述的进行了基因修饰。
[0806]
基因修饰的细胞可以单独给药,或者作为与稀释剂和/或与其它组分组合的药物组合物给药。在一些实施方式中,药物组合物可包括如本文描述的基因修饰的hsc或ips细胞,以及与一种或多种药学或生理学可接受的载体、稀释剂或赋形剂的组合。此类组合物可包括缓冲剂,例如中性缓冲盐水、磷酸盐缓冲盐水等;碳水化合物,例如葡萄糖、甘露糖、蔗糖或葡萄聚糖、甘露醇;蛋白质;多肽或氨基酸,例如甘氨酸;抗氧化剂;螯合剂,例如edta或谷胱甘肽;佐剂(例如氢氧化铝);和防腐剂。在一些实施方式中,组合物被配制用于静脉内给药。
[0807]
基因修饰的hsc或ips细胞可以用作治疗疾病的药物。在一些实施方式中,基因修饰的hsc或ips细胞用于在治疗在与转基因同源的内源性基因表达方面具有缺陷的患者(交叉纠正)中使用。在一些实施方式中,基因修饰的hsc或ips细胞用于在治疗溶酶体贮积病中使用。在一些实施方式中,基因修饰的hsc或ips细胞用于在治疗从粘多糖病i型(scheie、hurler-scheie或hurler综合征)、粘多糖病ii型(亨特综合征)、粘多糖病vi型(maroteaux-lamy综合征)、粘多糖病vii型(sly疾病)、x连锁肾上腺脑白质营养不良、球形细胞脑白质营养不良(克拉伯病)、异染性脑白质营养不良、戈谢病、岩藻糖苷贮积症、α-甘露糖苷过多症、天冬氨酸葡萄糖胺尿症、farber病、泰-萨克斯病、庞贝氏病、尼曼匹克病和沃尔曼病中选择的疾病中使用。
[0808]
在一些实施方式中,如本文描述的hsc和ips细胞可以被冷冻保存。在一些实施方式中,细胞可以在它们从受试者分离之后并且在任何基因修饰之前被冷冻保存。在一些实施方式中,基因修饰的细胞在基因修饰之后且在输注到受试者中之前被冷冻保存。在一些实施方式中,基因修饰的细胞在它们已经离体扩增后被冷冻保存。
[0809]
在一个实施方式中,本发明提供了一种冷冻保存的药物组合物,其包括:(a)基因修饰的hsc或ips细胞的存活(viable)组合物;(b)足以冷冻保存hsc或ips细胞的量的冷冻保存剂;和(c)药学上可接受的载体。
[0810]
如本文所用,“冷冻保存”是指通过冷却至零以下低温来保存细胞,例如(通常)77k或-196℃(液氮的沸点)。冷冻保存也指在没有任何冷冻保存剂的情况下将细胞储存在0
°‑
10℃的温度下。在这些低温下,任何生物活动,包括会导致细胞死亡的生化反应,都会被有效地停止。冷冻保护剂通常在零以下温度下使用,以保护细胞免受由于低温冷冻或升温至室温造成的损害。
[0811]
在一些实施方式中,与冷冻相关的有害影响可以通过以下方式来避免:(a)使用冷冻保护剂,(b)控制冷冻速率,和(c)在足够低的温度下储存以最小化降解反应。
[0812]
可以使用的冷冻保护剂包括但不限于二甲亚砜(dmso)、甘油、聚乙烯吡咯烷、聚乙二醇、白蛋白、葡萄聚糖、蔗糖、乙二醇、异赤藓糖醇、d-山梨糖醇、d-甘露糖醇、d-山梨糖醇、异肌醇、d-乳糖、氯化胆碱、氨基酸、甲醇、乙酰胺、甘油单乙酸酯和无机盐。在优选的实施方式中,以低浓度使用dmso,一种对细胞无毒的液体。作为一种小分子,dmso自由渗透细胞并
通过与水结合来保护细胞内的细胞器,从而改变其可冷冻性并防止结冰造成的损害。加入血浆(例如至浓度20-25%)可以增强dmso的保护作用。添加dmso后,细胞应保持在0-4℃直到冻住,因为约1%的dmso浓度在高于4℃的温度下有毒。
[0813]
不同的冷冻保护剂(rapatz,g.,et al.,1968,cryobiology 5(1):18-25)和不同的细胞类型具有不同的最佳冷却速率(关于冷却速度对骨髓干细胞存活及其移植潜力的影响,参见例如rowe,a.w.和rinfret,a.p.,1962,blood 20:636;rowe,a.w.,1966,cryobiology 3(1):12-18;lewis,j.p.,et al.,1967,transfusion 7(1):17-32;和mazur,p.,1970,science 168:939-949)。水变成冰的熔相(fusion phase)热量应该是最小的。可以通过使用例如可编程冷冻装置或甲醇浴程序来进行冷却程序。
[0814]
彻底冷冻后,细胞可以迅速转移到长期低温储存容器中。在一个实施方式中,扩增的hsc或ips细胞可以低温储存在液氮(-196℃)或其蒸气(-165℃)中。通过可用的高效液氮冰箱极大地促进了这种储存,这种冰箱类似于具有极低真空和内部超级绝缘的大型热水瓶容器,从而将热泄漏和氮损失保持在绝对最小值。
[0815]
在特定的实施方式中,使用current protocols in stem cell biology,2007,(mick bhatia,et.al.,ed.,john wiley and sons,inc.)中描述并在此通过引用并入的冷冻保存程序。主要是当10-cm组织培养板上的hsc达到约50%的汇合度时,吸出板内的培养基并用磷酸盐缓冲盐水冲洗hsc。然后通过3ml的0.025%胰蛋白酶/0.04% edta处理使粘附的hsc脱附。通过7ml培养基中和胰蛋白酶/edta,并通过以200xg离心2分钟收集脱附的hsc。吸出上清液并将hsc团粒重悬于1.5ml培养基中。将一等分1ml100% dmso添加到hsc悬浮液中并轻轻混合。然后将该hsc在dmso中的悬浮液的1ml等分试样分配到cryules中,为冷冻保存做准备。无菌储存cryules的盖子最好在里面有螺纹,这允许轻松处理而不会造成污染。合适的托架系统是市售的,并且可用于对单个样本进行编目、存储和检索。
[0816]
例如,可以在通过引用并入本文的以下参考文献中找到对hsc(特别是来自骨髓或外周血的hsc)的操作、冷冻保存和长期储存的注意事项和程序:gorin,n.c.,1986,clinics in haematology 15(1):19-48;bone-marrow conservation,culture and transplantation,proceedings of a panel,moscow,jul.22-26,1968,international atomic energy agency,vienna,pp.107-186。
[0817]
可供使用和设想使用活细胞冷冻保存的其它方法或其修改(例如,cold metal-minor techniques;livesey,s.a.和linner,j.g.,1987,nature 327:255;linner,j.g.,et al.,1986,j.histochem.cytochem.34(9):1123-1135;美国专利号4,199,022、3,753,357和4,559,298),并且这些全部均在此通过引用以其整体并入。
[0818]
在一些实施方式中,将冷冻的hsc或ips细胞快速解冻(例如,在保持在37
°‑
41℃的水浴中)并在解冻后立即在冰上冰镇。特别地,可以将装有冷冻hsc或ips细胞的低温小瓶浸入温水浴中直至其颈部;温和的旋转将确保细胞悬浮液在其解冻时混合,并增加从温水到内部冰块的热传递。冰完全融化后,可以立即将小瓶放入冰中。
[0819]
在一个实施方式中,current protocols in stem cell biology 2007(mick bhatia,et al.,ed.,john wiley and sons,inc.)中描述了冷冻保存后的解冻程序并且在此通过引用并入。从低温冷冻箱中取出低温小瓶后,立即将小瓶在双手之间滚动10至30秒,直到小瓶外部无霜。然后将小瓶直立在37℃水浴中直至内容物明显解冻。将小瓶浸入95%
乙醇中或喷洒70%乙醇以杀死水浴中的微生物并在无菌罩中风干。然后使用无菌技术将小瓶的内容物转移到含有9ml培养基的10-cm无菌培养物中。然后,可以在37℃和5%加湿co2的培养箱中培养hsc并进一步扩增。
[0820]
可能需要处理hsc或ips细胞以防止在解冻时细胞凝结。为了防止凝结,可以使用各种程序,包括但不限于在冷冻之前和/或之后添加dnase(spitzer,g.,et al.,1980,cancer 45:3075-3085)、低分子量葡聚糖和柠檬酸盐、羟乙基淀粉(stiff,p.j.,et al.,1983,cryobiology 20:17-24)。
[0821]
如果冷冻保护剂对人体有毒,则应在解冻的hsc或ips细胞的治疗性用途之前去除。在使用dmso作为冷冻保存剂的实施方式中,优选省略该步骤以避免细胞损失,因为dmso没有严重的毒性。然而,在需要去除冷冻保护剂的情况下,优选在解冻时完成去除。
[0822]
去除冷冻保护剂的一种方式是通过稀释至微不足道的浓度。这可以通过添加培养基来完成,随后如果需要,进行一个或多个离心循环以团粒化细胞、去除上清液和重悬细胞。例如,可以将解冻细胞中的细胞内dmso降低到不会对回收细胞产生不利影响的水平(小于1%)。这优选缓慢地进行,以尽量最小化在去除dmso期间发生的潜在破坏性渗透梯度。
[0823]
在去除冷冻保护剂后,可以进行细胞计数(例如通过使用血细胞计数器)和活力测试(例如通过台盼蓝排除;kuchler,r.j.1977,biochemical methods in cell culture and virology,dowden,hutchinson&ross,stroudsburg,pa.,pp.18-19;1964,methods in medical research,eisen,h.n.,et al.,eds.,vol.10,year book medical publishers,inc.,chicago,pp.39-47)以确认细胞存活。
[0824]
在一个实施方式中,通过如本文描述的活力(例如台盼蓝排除)和微生物无菌性的标准测定法来测试解冻细胞,并测试以确认和/或确定它们相对于接受者的特性。
[0825]
尽管结合各种实施方式描述了本教导,但本教导并不旨在限于此类实施方式。相反,如本领域技术人员将理解的,本教导包括各种替代、修改和等效物。
[0826]
在整个本公开中,通过识别引文来引用各种出版物、专利和公布的专利说明书。这些出版物、专利和公布的专利说明书的公开内容在此通过引用并入本公开中以更全面地描述本发明所属的现有技术。
[0827]
表4:定义用于对本发明的细胞进行基因编辑的优选靶序列
[0828]
[0829]
[0830]
[0831]
[0832][0833]
根据本公开,本发明更特别地包括下列项目:
[0834]
1.一种将转基因表达到患者大脑中的方法,包括:
[0835]
i)获得基因修饰的造血干细胞(hsc),其中hsc分离自患者或者获自来源于患者并且分化成hsc的诱导多能干(ips)细胞,其中基因修饰的hsc被工程化为包括整合在小胶质细胞中表达的基因座上的转基因;和
[0836]
ii)将基因修饰的hsc移植到患者中,使其分化为将转基因表达到患者大脑中的小胶质细胞。
[0837]
2.一种将转基因表达到患者大脑中的方法,包括:
[0838]
i)获得基因修饰的造血干细胞(hsc),其中hsc分离自相容供体或者获自来源于相容供体并且分化成hsc的诱导多能干(ips)细胞,其中基因修饰的hsc被工程化为包括整合在小胶质细胞中表达的基因座上的转基因;和
[0839]
ii)将基因修饰的hsc移植到患者中,使其分化为将转基因表达到患者大脑中的小胶质细胞。
[0840]
3.根据项目1或2的方法,其中所述基因座选自由以下组成的组:tmem119、s100a9、cd11b、b2m、cx3cr1、mertk、cd164、tlr4、tlr7、cd14、fcgr1a、fcgr3a、tbxas1、dok3、abca1、tmem195、mr1、csf3r、fgd4、tspan14、tgfbri、ccr5、gpr34、serpine2、slco2b1、p2ry12、olfml3、p2ry13、hexb、rhob、jun、rab3il1、ccl2、fcrls、scoc、siglech、slc2a5、lrrc3、plxdc2、usp2、ctsf、cttnbp2nl、atp8a2、lgmn、mafb、egr1、bhlhe41、hpgds、ctsd、hspa1a、lag3、csf1r、adamts1、f11r、golm1、nuak1、crybb1、ltc4s、sgce、pla2g15、ccl3l1、abhd12、ang、ophn1、sparc、pros1、p2ry6、lair1、il1a、epb41l2、adora3、rilpl1、pmepa1、ccl13、pde3b、scamp5、ppp1r9a、tjp1、ak1、b4galt4、gtf2h2、trem2、ckb、acp2、pon3、agmo、tnfrsf17、fscn1、st3gal6、adap2、ccl4、entpd1、tmem86a、kctd12、dst、ctsl2、abcc3、pdgfb、pald1、tubgcp5、rapgef5、stab1、lacc1、tmc7、nrip1、kcnd1、tmem206、hps4、dagla、extl3、mlph、arhgap22、cxxc5、p4ha1、cysltr1、fgd2、kcnk13、gbgt1、c18orf1、cadm1、bco2、adrb1、c3ar1、large、leprel1、liph、upk1b、p2rx7、slc46a1、ebf3、ppp1r15a、il10ra、rasgrp3、fos、tppp、slc24a3、havcr2、nav2、apbb2、clstn1、blnk、gnaq、ptprm、frmd4a、cd86、tnfrsf11a、spint1、ppm1l、tgfbr2、cmklr1、tlr6、gas6、hist1h2ab、atf3、acvr1、abi3、lrp12、ttc28、plxna4、adamts16、rgs1、icam1、snx24、ly96、dnajb4和ppfia4。
[0841]
4.根据项目1-3中任一项的方法,其中所述基因座为cx3cr1。
[0842]
5.根据项目1-3中任一项的方法,其中所述基因座为cd11b。
[0843]
6.根据项目1-3中任一项的方法,其中所述基因座为tmem119。
[0844]
7.根据项目1-3中任一项的方法,其中所述基因座为s100a9。
[0845]
8.根据项目1-7中任一项的方法,其中细胞已经使用序列特异性试剂和包括转基因的供体序列进行了基因修饰。
[0846]
9.根据项目8的方法,其中将包括转基因的供体序列在病毒载体中提供给细胞。
[0847]
10.根据项目9的方法,其中病毒载体为aav载体。
[0848]
11.根据项目8-10中任一项的方法,其中序列特异性试剂包括工程化的稀有切割核酸内切酶。
[0849]
12.根据项目11的方法,其中工程化的稀有切割核酸内切酶选自由以下组成的组:转录激活器样效应物核酸酶(talen)、锌指核酸酶(zfn)、簇状规则间隔的短回文重复序列(crispr)-cas、大范围核酸酶和megatal。
[0850]
13.根据项目12的方法,其中序列特异性试剂作为核酸提供给细胞。
[0851]
14.根据项目13的方法,其中核酸为mrna。
[0852]
15.根据任一项目1至14的方法,其中所述转基因包括用于治疗粘多糖病i型(scheie、hurler-scheie或hurler综合征)的idua。
[0853]
16.根据任一项目1至14的方法,其中所述转基因包括用于治疗粘多糖病ii型(hunter)的ids。
[0854]
17.根据任一项目1至14的方法,其中所述转基因包括用于治疗粘多糖病vi型(maroteaux-lamy)的arsb。
[0855]
18.根据任一项目1至14的方法,其中所述转基因包括用于治疗粘多糖病vii型(sly)的gusb。
[0856]
19.根据任一项目1至14的方法,其中所述转基因包括用于治疗x连锁肾上腺脑白质营养不良的abcd1。
[0857]
20.根据任一项目1至14的方法,其中所述转基因包括用于治疗球形细胞脑白质营养不良(krabbe)的galc。
[0858]
21.根据任一项目1至14的方法,其中所述转基因包括用于治疗异染性脑白质营养不良的arsa。
[0859]
22.根据任一项目1至14的方法,其中所述转基因包括用于治疗戈谢病的gba。
[0860]
23.根据任一项目1至14的方法,其中所述转基因包括用于治疗岩藻糖苷贮积症的fuca1。
[0861]
24.根据任一项目1至14的方法,其中所述转基因包括用于治疗α-甘露糖苷过多症的man2b1。
[0862]
25.根据任一项目1至14的方法,其中所述转基因包括用于治疗天冬氨酸葡萄糖胺尿症的aga。
[0863]
26.根据任一项目1至14的方法,其中所述转基因包括用于治疗farber的asah1。
[0864]
27.根据任一项目1至14的方法,其中所述转基因包括用于治疗泰-萨克斯病的hexa。
[0865]
28.根据任一项目1至14的方法,其中所述转基因包括用于治疗庞贝氏症的gaa。
[0866]
29.根据任一项目1至14的方法,其中所述转基因包括用于治疗尼曼匹克症的
smpd1。
[0867]
30.根据任一项目1至14的方法,其中所述转基因包括用于治疗沃尔曼综合征的lipa。
[0868]
31.根据任一项目1至14的方法,其中所述转基因包括用于治疗cdkl5-缺陷相关疾病的cdkl5。
[0869]
32.一种基因修饰的hsc或ips细胞,其具有整合在选自tmem119、cd11b或cx3cr1的基因座处的转基因,所述转基因在所述基因的内源性启动子的转录控制下。
[0870]
33.根据项目32的hsc或ips细胞,用作药物使用。
[0871]
34.根据项目32的hsc或ips细胞,用于在治疗在与所述转基因同源的内源性基因表达方面具有缺陷的患者(交叉纠正)中使用。
[0872]
35.根据项目33的hsc或ips细胞,用于在治疗溶酶体贮积病中使用。
[0873]
36.根据项目32的hsc或ips细胞,其中所述转基因包括idua以用于在治疗粘多糖病i型(scheie、hurler-scheie或hurler综合征)中使用。
[0874]
37.根据项目32的hsc或ips细胞,其中所述转基因包括ids,以用于在治疗粘多糖病ii型(hunter)中使用。
[0875]
38.根据项目32的hsc或ips细胞,其中所述转基因包括arsb,以用于在治疗粘多糖病vi型(maroteaux-lamy)中使用。
[0876]
39.根据项目32的hsc或ips细胞,其中所述转基因包括gusb,以用于在治疗粘多糖病vii型(sly)中使用。
[0877]
40.根据项目32的hsc或ips细胞,其中所述转基因包括用于治疗x连锁肾上腺脑白质营养不良的abcd1。
[0878]
41.根据项目32的hsc或ips细胞,其中所述转基因包括galc以用于在治疗球形细胞脑白质营养不良(krabbe)中使用。
[0879]
42.根据项目32的hsc或ips细胞,其中所述转基因包括arsa,以用于在治疗异染性脑白质营养不良中使用。
[0880]
43.根据项目32的hsc或ips细胞,其中所述转基因包括gba,以用于在治疗戈谢病中使用。
[0881]
44.根据项目32的hsc或ips细胞,其中所述转基因包括fuca1,以用于在治疗岩藻糖苷贮积症中使用。
[0882]
45.根据项目32的hsc或ips细胞,其中所述转基因包括man2b1,以用于在治疗α-甘露糖苷过多症中使用。
[0883]
46.根据项目32的hsc或ips细胞,其中所述转基因包括aga,以用于在治疗天冬氨酸葡萄糖胺尿症中使用。
[0884]
47.根据项目32的hsc或ips细胞,其中所述转基因包括asah1,以用于在治疗farber中使用。
[0885]
48.根据项目32的hsc或ips细胞,其中所述转基因包括用于治疗泰-萨克斯病的hexa。
[0886]
49.根据项目32的hsc或ips细胞,其中所述转基因包括gaa,以用于在治疗庞贝氏症中使用。
[0887]
50.根据项目32的hsc或ips细胞,其中所述转基因包括smpd1,以用于在治疗尼曼匹克症中使用。
[0888]
51.根据项目32的hsc或ips细胞,其中所述转基因包括lipa,以用于在治疗沃尔曼综合征中使用。
[0889]
52.根据项目32的hsc或ips细胞,其中所述转基因包括cdkl5,以用于在治疗cdkl5-缺陷相关疾病中使用。
[0890]
53.根据项目32-50中任一项的hsc或ips细胞,其中所述转基因的多个拷贝被整合在由2a自切割肽序列分隔开的同一基因座处。
[0891]
54.一种药物组合物,包括根据项目32-51中任一项的hsc或ips细胞。
[0892]
55.一种用于在插入位点将外源性编码序列整合到内源性内含子基因组区域中的方法,包括下列步骤:
[0893]-提供包括内源性内含子基因组区域的细胞,
[0894]-向所述细胞中引入包括外源性编码序列的多核苷酸模板,其中所述多核苷酸模板包括:
[0895]
a)第一同源多核苷酸序列,其与插入位点上游的内含子序列同源,
[0896]
b)第一强剪接位点序列,其包括分支点和剪接受体;
[0897]
c)编码2a自切割肽的第一序列;
[0898]
d)编码目的蛋白质的外源序列;
[0899]
e)编码2a自切割肽的第二序列;
[0900]
f)第一外显子的编码序列的拷贝;
[0901]
g)包括剪接供体的第二强剪接位点序列;和
[0902]
h)第二同源多核苷酸序列,其与插入位点下游的内含子序列同源;
[0903]-诱导所述外源性多核苷酸整合到所述内含子序列中,优选地通过同源重组,以使所述外源性编码序列与第一外显子和优选第二外显子或其拷贝一起在所述内源性基因座上转录。
[0904]
56.一种插入载体,诸如aav载体,其特征在于它包括用于插入在内源性基因座处的外源性多核苷酸序列,该外源性多核苷酸序列包括以下序列:
[0905]
a)第一同源多核苷酸序列,其与插入位点上游的内含子序列同源,
[0906]
b)第一强剪接位点序列,其包括分支点和剪接受体;
[0907]
c)编码2a自切割肽的第一序列;
[0908]
d)编码目的蛋白质的外源序列;
[0909]
e)编码2a自切割肽的第二序列;
[0910]
f)第一外显子的编码序列的拷贝;
[0911]
g)包括剪接供体的第二强剪接位点序列;和
[0912]
h)第二同源多核苷酸序列,其与插入位点下游的内含子序列同源。
[0913]
57.根据项目56的插入载体,其中所述第一和第二同源序列与选自以下的内源性基因座同源:tmem119、s100a9、cd11b、b2m、cx3cr1、mertk、cd164、tlr4、tlr7、cd14、fcgr1a、fcgr3a、tbxas1、dok3、abca1、tmem195、mr1、csf3r、fgd4、tspan14、tgfbri、ccr5、gpr34、serpine2、slco2b1、p2ry12、olfml3、p2ry13、hexb、rhob、jun、rab3il1、ccl2、fcrls、scoc、
siglech、slc2a5、lrrc3、plxdc2、usp2、ctsf、cttnbp2nl、atp8a2、lgmn、mafb、egr1、bhlhe41、hpgds、ctsd、hspa1a、lag3、csf1r、adamts1、f11r、golm1、nuak1、crybb1、ltc4s、sgce、pla2g15、ccl3l1、abhd12、ang、ophn1、sparc、pros1、p2ry6、lair1、il1a、epb41l2、adora3、rilpl1、pmepa1、ccl13、pde3b、scamp5、ppp1r9a、tjp1、ak1、b4galt4、gtf2h2、trem2、ckb、acp2、pon3、agmo、tnfrsf17、fscn1、st3gal6、adap2、ccl4、entpd1、tmem86a、kctd12、dst、ctsl2、abcc3、pdgfb、pald1、tubgcp5、rapgef5、stab1、lacc1、tmc7、nrip1、kcnd1、tmem206、hps4、dagla、extl3、mlph、arhgap22、cxxc5、p4ha1、cysltr1、fgd2、kcnk13、gbgt1、c18orf1、cadm1、bco2、adrb1、c3ar1、large、leprel1、liph、upk1b、p2rx7、slc46a1、ebf3、ppp1r15a、il10ra、rasgrp3、fos、tppp、slc24a3、havcr2、nav2、apbb2、clstn1、blnk、gnaq、ptprm、frmd4a、cd86、tnfrsf11a、spint1、ppm1l、tgfbr2、cmklr1、tlr6、gas6、hist1h2ab、atf3、acvr1、abi3、lrp12、ttc28、plxna4、adamts16、rgs1、icam1、snx24、ly96、dnajb4和ppfia4。
[0914]
58.根据项目56或57的插入,其中由所述外源性编码序列编码的所述治疗性蛋白质与idua、ids、arsb、gusb、abcd1、galc、arsa、psap、gba、fuca1、man2b1、aga、asah1、hexa、gaa、smpd1、lipa和cdkl5(seq id no:1至seq id no:35
–
见表1)具有至少80%多肽序列同一性。
[0915]
59.一种工程化细胞,其特征在于外源性多核苷酸序列已经插入在内源性基因座处,该外源性多核苷酸序列包括以下各项:
[0916]-第一强剪接位点序列,其包括分支点和受体位点;
[0917]-编码2a自切割肽的第一序列;
[0918]-编码目的蛋白质(诸如治疗性蛋白质)的外源序列,;
[0919]-编码2a自切割肽的第二序列;
[0920]-与所述基因座内源的前一外显子的编码序列的拷贝;
[0921]-包括剪接供体位点的第二强剪接位点序列。
[0922]
60.根据项目59的工程化细胞,其中所述外源性多核苷酸序列被插入在选自以下的内源性基因座处:tmem119、s100a9、cd11b、b2m、cx3cr1、mertk、cd164、tlr4、tlr7、cd14、fcgr1a、fcgr3a、tbxas1、dok3、abca1、tmem195、mr1、csf3r、fgd4、tspan14、tgfbri、ccr5、gpr34、serpine2、slco2b1、p2ry12、olfml3、p2ry13、hexb、rhob、jun、rab3il1、ccl2、fcrls、scoc、siglech、slc2a5、lrrc3、plxdc2、usp2、ctsf、cttnbp2nl、atp8a2、lgmn、mafb、egr1、bhlhe41、hpgds、ctsd、hspa1a、lag3、csf1r、adamts1、f11r、golm1、nuak1、crybb1、ltc4s、sgce、pla2g15、ccl3l1、abhd12、ang、ophn1、sparc、pros1、p2ry6、lair1、il1a、epb41l2、adora3、rilpl1、pmepa1、ccl13、pde3b、scamp5、ppp1r9a、tjp1、ak1、b4galt4、gtf2h2、trem2、ckb、acp2、pon3、agmo、tnfrsf17、fscn1、st3gal6、adap2、ccl4、entpd1、tmem86a、kctd12、dst、ctsl2、abcc3、pdgfb、pald1、tubgcp5、rapgef5、stab1、lacc1、tmc7、nrip1、kcnd1、tmem206、hps4、dagla、extl3、mlph、arhgap22、cxxc5、p4ha1、cysltr1、fgd2、kcnk13、gbgt1、c18orf1、cadm1、bco2、adrb1、c3ar1、large、leprel1、liph、upk1b、p2rx7、slc46a1、ebf3、ppp1r15a、il10ra、rasgrp3、fos、tppp、slc24a3、havcr2、nav2、apbb2、clstn1、blnk、gnaq、ptprm、frmd4a、cd86、tnfrsf11a、spint1、ppm1l、tgfbr2、cmklr1、tlr6、gas6、hist1h2ab、atf3、acvr1、abi3、lrp12、ttc28、plxna4、adamts16、rgs1、icam1、snx24、ly96、
dnajb4和ppfia4。
[0923]
61.根据项目59或60的工程化细胞,其中由所述外源性编码序列编码的治疗性蛋白质与idua、ids、arsb、gusb、abcd1、galc、arsa、psap、gba、fuca1、man2b1、aga、asah1、hexa、gaa、smpd1、lipa和cdkl5(seq id no:1至seq id no:35
–
见表1)具有至少80%多肽序列同一性。
[0924]
已经对本发明进行了一般性描述,通过参考某些具体实施例可以获得进一步的理解,本文中提供这些实施例仅用于说明目的,并不旨在限制所要求保护的发明的范围。
[0925]
实施例
[0926]
实施例1:材料和方法
[0927]
细胞培养:
[0928]
hsc培养:将由gcs-f动员的leukopak(miltenyi)制备的hsc解冻并以0.4x106个细胞/ml接种到由stem span ii培养基(cat.#09655,stemcell technologies)组成的hsc培养基中,该培养基具有1x最终浓度的cd34 扩增混合物(cocktail)(#02691,stemcell technologies)和pen-strep(#15140-122,gibco life technologies)。将细胞在37℃和5% co2下温育48小时以在解冻后恢复,然后进行talen转染和aav转导。
[0929]
修复模板构建体:
[0930]
对于s100a9,使用从vigene获得的aav6颗粒将合成外显子序列插入s100a9基因座的第一个内含子中。该供体含有用于该内含子区域的左同源臂(seq id no:209),随后是3’白蛋白剪接信号序列(seq id no:206),随后是编码gsg接头的序列(seq id no:215),随后是编码p2a肽的序列(seq id no:224),随后是编码egfp的序列(seq id no:218)或编码idua的序列(seq id no:2),没有终止密码子,随后是t2a自切割肽(seq id no:225),随后是s100a9的第一个外显子(seq id no:210),随后是5’白蛋白剪接信号序列(seq id no:208),随后是用于该内含子区域的右同源臂(seq id no:211)。
[0931]
对于cd11b,使用从vigene获得的aav6颗粒将合成外显子序列插入cd11b基因座的第一个内含子中。该供体含有用于该内含子区的左同源臂(seq id no:212),随后是3’白蛋白剪接信号序列(seq id no:206),随后是编码gsg接头的序列(seq id no:215),随后是p2a自切割肽(seq id no:224),随后是编码egfp的序列(seq id no:218)或编码idua的序列(seq id no:2),没有终止密码子,随后是t2a自切割肽(seq id no:225),随后是cd11b重写的第一个外显子(seq id no:213),随后是5’白蛋白剪接信号序列(seq id no:208),随后是用于该内含子区域的右同源臂(seq id no:214)。
[0932]
tale-核酸酶试剂:
[0933]
根据先前描述的协议(poirot et al.2015),生产了编码靶向cd11b(seq id no:talen_cd11b左和seq id no:talen_cd11b右)以及s100a9(seq id no:talens100a9左和seq id no:talen s100a9右)的tale-核酸酶的mrna。对于cd11b,所靶向的序列是tacaacatattctatcagcctcttggtctgcaaaacctaaaatttacta(seq idno:125),而对于s100a9基因座,所靶向的序列为ttaggggccctgacagctctccataggtggaggcctcaggcaggcagga(seq id no:175)。(talen是指定由cellectis(8rue de la croix jarry,paris,france)设计的tale-核酸酶异二聚体的商标,包括如wo2011072246中描述的fok-1核酸酶催化头。
[0934]
基因编辑协议:转染
percoll梯度中,用70% percoll梯度做底层,并在600g下旋转25分钟以去除髓磷脂。回收percoll梯度界面中的细胞、洗涤和染色以用于流式细胞术或保留用于基因组dna提取。
[0948]
流式细胞术
[0949]
将细胞在400xg下旋转5分钟。去除上清液并在facs缓冲液(1mm edta 0.5%bsa在pbs中)中洗涤细胞一次。洗涤后,将细胞重悬于50μl在facs缓冲液中以5μg/ml稀释的fc封阻液(bd bioscience,cat号564220)中。在4℃下温育5分钟后,向细胞中加入50μl在facs缓冲液中稀释的表面抗体母液混合液,并在4℃下再温育30分钟。然后将细胞在facs缓冲液中洗涤两次,然后在4℃下在100μμl固定剂/perm溶液(bd bioscience,cat号554722)中固定20分钟。将细胞在透化缓冲液中洗涤一次,然后在4℃下在细胞内抗体混合物(在透化缓冲液中稀释)中温育30分钟。将细胞在透化缓冲液中再次洗涤一次并重悬于100-200μl facs缓冲液中,然后在bd canto上进行分析。
[0950]
对于体外髓样分化,使用下列抗体:cd11b apc(miltenyi 130-110-554)、cd14 vioblue(miltenyi 130-113-152)和s100a9 pe(invitrogen ma5-28130)。对于骨髓细胞的染色,使用下列抗体:hcd45 pe-cy7(bd 103114)、mcd45 v450(bd 560501)、cd33 pe(miltenyi 130-113-349)、cd3 percp-cy5.5(bd 560835)、cd34 apc-v770(miltenyi 130-113-180)、cd19 fitc(bd 555412)。对于分离的脑细胞染色,使用以下抗体:hcd45 fitc(miltenyi 130-113-117)、mcd45 apc-cy7(bd 557659)、p2ry12 bv421(biolegend 392106)、纯化的tmem119(biolegend 853302)、抗-migg2b af647(biolegend 406716)、cd11b pe(biolegend 101208)。对于每种抗体,包括荧光减一(fluorescence minus one,荧光扣除)(fmo)对照和单染色补偿珠。
[0951]
实施例2:用于表达gfp的人工外显子(artex)可以被插入在外显子#1和#2之间并且充分处理以用于表达
–
体外结果
[0952]
在髓样基因s100a9或cd11b的2个第一个外显子之间插入人工外显子,应该实现从髓样谱系中表达治疗性蛋白质,而不损害s100a9或cd11b的内源性表达。为了概念验证,我们生成了靶向每个基因的内含子区域的talen,以及携带允许表达监测的gfp盒的aav供体。作为我们方法的谱系特异性表达的对照,我们还生成了将含有gfp盒的启动子插入aavs1基因座的试剂,作为将在所有血液谱系中表达的更传统的安全港方法。
[0953]
用靶向aavs1、s100a9和cd11b基因座的talen mrna转染预刺激的hsc,并用增加剂量的相应aav-gfp修复模板进行转导。然后,在骨髓样细胞中分化经编辑的hsc。十四天后,通过流式细胞仪筛选分化细胞以表征不同细胞子集中的gfp表达。
[0954]
分化后十四天,40-60%的细胞为cd14 。在cd14高细胞中,由gfp表达定义的基因编辑率为26%至60%,很大程度上取决于所使用的aav剂量,对于cd11b和s100a9基因座,实现的最大值分别为56%和60%(图8a)。我们还评估了cd 14高细胞中内源性s100a9和cd11b的表达。所有cd14高细胞对cd11b和s100a9都是阳性的,无论它们是否被编辑(gfp )或未编辑(gfp-)(图8b和8c)。
[0955]
在任一基因座中都存在大量gfp细胞,这表明gfp盒已充分插入第一2个外显子之间,并且我们添加的剪接信号已被剪接细胞机器充分处理。这种artex策略允许表达双功能mrna分子,该分子能够为插入的基因(即gfp)蛋白和内源性cd11b或s100a9蛋白进行翻译。
[0956]
实施例3:用于表达idua的人工外显子可以插入外显子#1和#2之间并充分处理以
用于表达和分泌-体外结果
[0957]
用靶向s100a9和cd11b基因座的talen mrna转染预刺激的hsc,并用增加剂量的相应aav-idua修复模板进行转导。将编辑的hsc放入髓样分化培养基中。十四天后,将髓样分化细胞接种用于idua生产,而没有任何富集(髓样的%在40-60%之间)。3天后收集细胞上清液并通过elisa定量idua。我们观察到在cd11b和s100a9基因座编辑的细胞分泌的idua分别是未编辑对照的10x倍和15x倍多(图9)。
[0958]
这些结果证实,artex策略允许特异性表达和治疗性蛋白质分泌。
[0959]
实施例4:经编辑的hsc成功移植到动物模型的血液和骨髓中:体内结果
[0960]
作为我们治疗方法的基础,hsc更相关的特征之一是它们能够在一次干预后提供终生供应的编辑细胞的能力。为此,hsc需要植入到骨髓中,增殖并产生血细胞,这些血细胞随后将填充体内的多个组织。
[0961]
为了提供对这种hsc能力的一些了解,使用了免疫缺陷动物模型。具有靶向s100a9基因座的上述gfp盒的经编辑的hsc在编辑后24小时注射到条件nsg雌性动物中。该动物模型已显示出维持人类hsc在动物骨髓中的移植。
[0962]
注射经编辑的hsc后16周,在所有动物中检测到血液和骨髓中的移植,在研究组中的水平相似,血液中平均为3.3%且骨髓中平均为40.8%(图10a和b)。此外,在动物的脾脏中可以检测到24%至30%的人体细胞(图10c)。更重要的是,在所有这些隔室中可以检测经编辑的细胞。
[0963]
分析了这些动物血液中经编辑的细胞的存在。在大量人类cd45细胞上,我们发现在注射了在s100a9基因座处编辑的hsc的动物血液中平均有1.4%的gfp 细胞。然而,当分析到髓样隔室(在该模型中定义为cd33 细胞)时,编辑率增加到3.3%,是大批群体的两倍高(图11a)。
[0964]
还分析了骨髓中经编码的细胞的百分比,并且1.3%的人类细胞是gfp 。此外,骨髓中2.8%的hcd45 和cd33 人类细胞是gfp (图10b)。
[0965]
实施例5:经编辑的hsc成功地移植到动物模型的大脑中:体内结果
[0966]
这种治疗方法的另一个潜在优势是hsc衍生的小胶质细胞能够在脑室中分泌缺乏的lsd酶的能力,从而能够治疗与这些lsd疾病相关的破坏性神经症状。为了研究这一潜在特征,分析了上述动物大脑中人类细胞的存在。
[0967]
在分离小鼠大脑和细胞处理后,在小鼠大脑中可以检测到大量人类细胞。大脑中平均2.7%的细胞来源于人类(图12a)。更重要的是,使用p2ry12和tmem119小胶质细胞标志物,这些人类细胞中有18.5%含有衍生的小胶质细胞(图12b)。由于在这些动物外周血中存在的任何人类细胞中均未发现这2种标志物,这排除了在提取过程中外周血细胞对脑分离物的任何潜在污染。
[0968]
在该脑室中,gfp阳性细胞分别占所有人类细胞和人类小胶质细胞的至少1.2%和1.6%。
[0969]
实施例6:artex编辑的hsc具有高分泌谱
[0970]
比较了artex编辑的hsc与经典慢病毒编辑的hsc关于它们分泌治疗性蛋白质的能力。
[0971]
未经处理的hsc、用允许表达idua的慢病毒载体转导的hsc以及如前述实施例所描
述的在s100a9或cd11b基因座处靶向整合idua的hsc。将经编辑的hsc放入髓样分化培养基中。十四天后,将髓样分化细胞接种用于idua生产。3天后收集细胞上清液并通过elisa定量idua。我们观察到,在cd11b和s100a9基因座处编辑的细胞分泌的idua分别是未编辑的对照的10x和15x倍多(图13a)。
[0972]
结果表明,artex编辑的hsc能够通过10倍因子刺激idua分泌,而用慢病毒载体转导的hsc通过5倍因子刺激idua分泌。
[0973]
此外,在小鼠中测试了hsc的移植效率,并且如先前观察到的,经编辑的hsc可以有效地移植入骨髓(50%)、脾脏(41%)和血液(45%),并且最重要的是移植入大脑中,高达3.3%,具有大量的小胶质细胞(图13b和c)。
[0974]
总之,这些结果表明,甚至在大脑中,artex策略具有分泌高水平治疗性蛋白质的潜力。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。