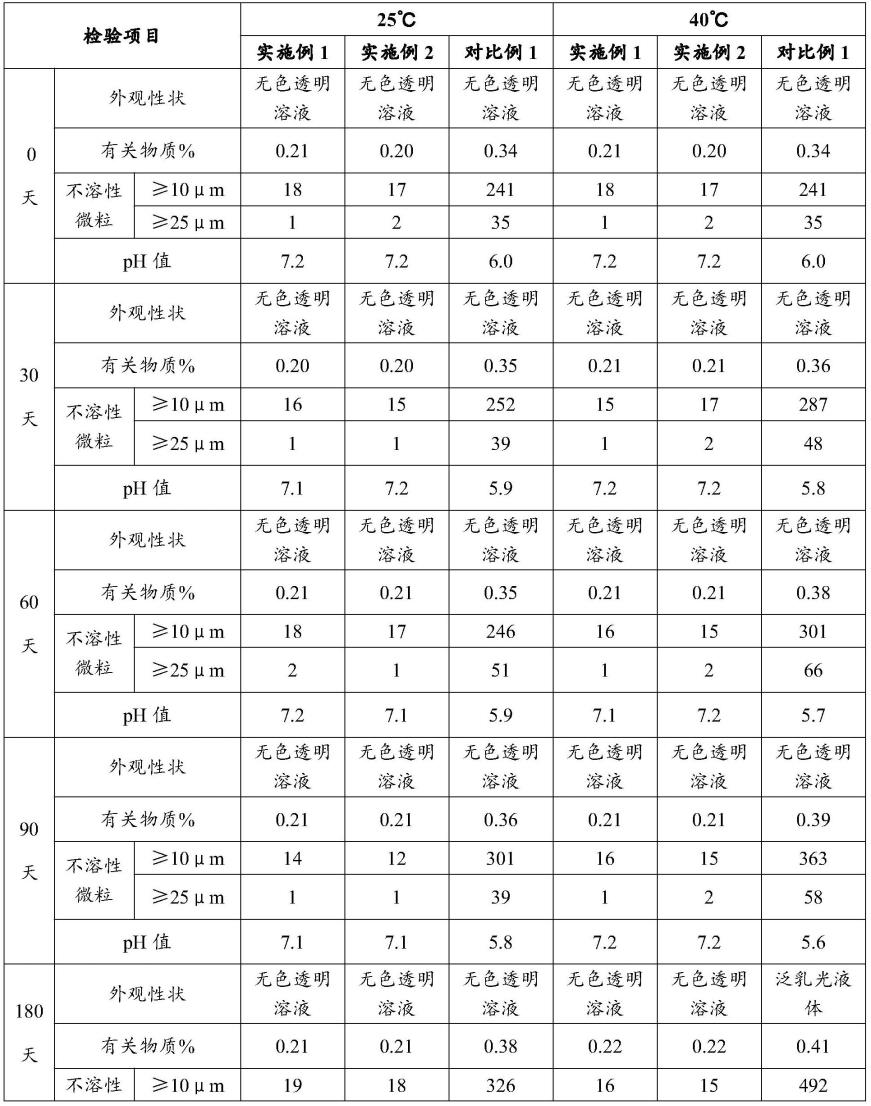
基于smote技术和随机森林算法的代谢综合征风险预测方法
技术领域
1.本发明涉及代谢综合征预测技术领域,具体的说,是一种基于smote技术和随机森林算法的代谢综合征风险预测方法。
背景技术:
2.代谢综合征是由中心性肥胖、高血脂、高血压和高血糖为主要表现的2型糖尿病和心脑血管疾病的前期状态,对全世界人民的生命健康产生了巨大威胁。近些年来,随着人口老龄化的加剧、生活方式的转变以及社会经济的飞速发展,代谢综合征患病率呈逐渐上升趋势,进而导致其近端结局2型糖尿病和心脑血管疾病的患病率、致残率和死亡率等疾病负担显著增加。不同区域由于环境气候、饮食习惯与生活行为方式独特,代谢综合征的危险因素可能不同,目前尚缺乏对于区域人群代谢综合征风险进行预测的系统性研究,亟需建立代谢综合征风险预测模型弥补该项空白。
3.在流行病学领域,研究人员多使用cox比例风险模型预测疾病风险,如著名的framingham风险评估模型、pce心血管风险评估模型(非裔美国人及非西班牙裔白人的ascvd 10年风险评估模型)、score模型(欧洲人群的首次致死性cvd10年风险评估模型)、qrisk模型(英国cvd10年风险)及china-par模型(中国ascvd10年风险预测模型)等,模型假设危险因素间无交互作用(或人为指定交互项)且危险因素与结局为线性关系。然而,既往研究表明,疾病危险因素之间可能存在交互作用或危险因素与疾病结局的关系为非线性(危险因素的non-linear interaction特征),但是,传统的疾病风险预测模型如cox比例风险模型忽略了某些危险因素的non-linear interaction特征,因此基于cox比例风险模型预测疾病风险结果与真实情况还存在差距。
4.近年来,随着电子病历的普及、生物大数据时代的到来、计算科学的发展以及计算机性能的飞速提高,研究人员开始将在拟合高维变量间复杂的non-linear interaction上表现优于传统线性模型的机器学习算法如随机森林、支持向量机、人工神经网络等算法应用到医学研究领域尤其是疾病的预测当中。其中由于随机森林训练速度快、实现较为容易及可以同时判断特征重要程度等优点,运用频率较高。然而,由于随机森林算法具有以追求最小化所有类别判断错误率(而非最小化分类别错误率)为目的、假设各种类别分布均衡以及假设不同类别被错误分类的代价相同这3个特征,对于非平衡问题显著的数据(结局的阳性数和阴性数失衡),随机森林的预测准确性反而不及其他预测器。通常在真实世界当中,自然人群疾病结局分布情况多是不平衡的(阳性数远远低于阴性数),其预测准确性受到影响。
技术实现要素:
5.本发明的目的在于提供一种基于smote技术和随机森林算法的代谢综合征风险预测方法,用于解决现有技术中风险模型预测疾病风险结果与真实情况存在差距的问题。
6.本发明通过下述技术方案解决上述问题:
7.一种基于smote技术和随机森林算法的代谢综合征风险预测方法,包括:
8.步骤s1:对目标人群构建数据样本,数据样本包括按区域划分的多个数据集,每个数据集由危险因素、危险因素对应的危险因素变量以及危险因素变量的取值构成;
9.步骤s2:分别利用smote技术对每个数据集创建smote数据集,具体包括:
10.步骤s21:在数据集中,对每个代谢综合征阳性样本i,计算其余剩余代谢综合征阳性样本j的马氏距离d(xi,xj):
[0011][0012]
其中,xi和xj是危险因素向量,包含所有危险因素变量的取值;s-1
为协方差阵的逆矩阵;i=1,2,
…
,m;j=1,2,
…
,m,i≠j;m为阳性样本数量;
[0013]
步骤s22:找出m个与样本i马氏距离最小的阳性样本,记为i_near,对应的危险因素向量记为x
i_near
;计算样本i_near与样本i危险因素间的差异diff=x
i_near-xi;
[0014]
步骤s23:在0和1之间选择一个随机数ζ,最终生成的样本为x
i_new
=xi ζdiff;
[0015]
步骤s24:对于每个阳性样本i,重复执行步骤21到步骤23k次,共新增k*m个阳性样本,则此时共有m*(1 k)个阳性样本;
[0016]
步骤s25:在阴性样本中进行采样,采样数量为m*(1 k),则共同构成代谢综合征阳性样本与阴性样本比例为1:1的smote数据集;
[0017]
步骤s3:根据构建的多个smote数据集利用随机森林构建代谢综合征风险预测模型,具体包括:
[0018]
步骤s31:将smote数据集的数据分为训练集和测试集;
[0019]
步骤s32:利用训练集创建随机森林预测模型,预设随机森林预测模型中树的数量,选择使得袋外数据oob预测误差趋于稳定的树的数量;
[0020]
步骤s33:对于每个分裂节点选择变量数,预设1,2,3,4,5,6,选择使auc最大的值,auc为将阳性样本排在阴性样本前的概率;
[0021]
步骤s34:利用测试集上测试随机森林预测模型的准确性,计算随机森林预测模型在测试集上的auc,当测试集auc与训练集auc接近时,模型测试通过;
[0022]
步骤s35:对每个smote数据集执行步骤s31-步骤s34,得到多个区域的代谢综合征风险预测模型;
[0023]
步骤s4:利用代谢综合征风险预测模型对待测试样本进行代谢综合征风险预测。
[0024]
所述危险因素包括人口学因素、社会经济因素、精神因素、生活行为方式和饮食习惯;所述人口学因素的危险因素变量包括年龄、月经状况、高血压糖尿病家族史;所述社会经济因素的危险因素变量包括区域、居住地、婚姻状况、受教育程度、职业类型和家庭年收入;所述精神因素的危险因素变量包括睡眠状况、焦虑状况和抑郁状况;所述生活行为方式的危险因素变量包括吸烟状况和体力活动;所述饮食习惯的危险因素变量包括膳食模式得分分位数、喝饮料频率、膳食补充剂、吃辣食频率、吃麻食频率和总能量摄入。
[0025]
本发明与现有技术相比,具有以下优点及有益效果:
[0026]
(1)本发明通过重建smote数据集,得到结局均衡数据集,再结合随机森林算法构建模型,降低数据不均衡问题对疾病结局预测带来的影响,相比于使用具有简单线性假设的传统cox比例风险模型或单纯使用随机森林算法,预测效能显著提高。
[0027]
(2)本发明针对区域特点确定危险因素,并据此建立风险分析模型,预测结果为区域的代谢综合征的防治策略提供了参考依据。
附图说明
[0028]
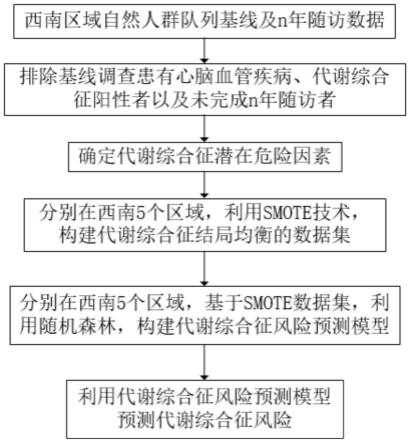
图1为本发明第一种具体实施方式的流程图;
[0029]
图2为随机森林oob数据预测误差和分类树数量关系图。
具体实施方式
[0030]
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
[0031]
实施例1:
[0032]
结合图1所示,一种基于smote技术和随机森林算法的代谢综合征代谢综合征风险预测方法,包括:
[0033]
第一步,确定研究对象和确定代谢综合征潜在危险因素:
[0034]
以中国西南区域自然人群为例,选择年龄阶段在30-79岁成年人作为目标人群,根据地域特征、居住人群的生活习惯以及对代谢综合征的影响因素,将(1)人口学因素:年龄、月经状况(含性别因素)和高血压或糖尿病家族史;(2)社会经济因素:区域、居住地、婚姻状况、受教育程度、职业类型和家庭年收入;(3)精神因素:睡眠状况、焦虑状况和抑郁状况;(4)生活行为方式:吸烟状况和体力活动;(5)饮食习惯:膳食模式、喝饮料频率、膳食补充剂食用状况、吃辣食频率、吃麻食频率以及总能量摄入;将这5类危险因素纳入模型,危险因素的赋值与定义如表1所示:
[0035]
[0036][0037]
表1代谢综合征潜在危险因素表
[0038]
表中,*met hours表示每项活动的代谢当量与活动时长的乘积。
[0039]
其中,膳食模式是基于食物频率调查表,运用因子分析中的主成分法,提取出3个特征根大于1且区分度较为明显的模式。
[0040]
通过基线调查文件、体格检查及实验室生化检测等方式,获取目标人群的数据样本,在基线调查完成后,每隔2年进行随访调查。同时该队列与全民医疗保险数据库、医院病案系统、当地疾控中心慢性病监测系统等关联,可追踪到调查对象的死亡及慢性病的发病等终点事件,最终纳入完成了队列n年随访的调查对象的数据,得到最终所得数据结构表2所示
[0041]
[0042][0043]
表2数据结构表
[0044]
第二步,利用smote技术构建新数据集。
[0045]
将第一步所得数据集,按照区域(四川、重庆、贵州、云南、藏族)分位5个数据集(记为原数据集1,原数据集2,
…
,原数据集5,由于阿坝藏族和拉萨藏族的生活环境、饮食习惯以及生活行为方式等较为接近,故归到一起),利用smote技术,重新构建代谢综合征结局均衡的5个smote数据集(记为smote数据集1,smote数据集2,
…
,smote数据集5。
[0046]
例如,smote数据集1的构建步骤如下:
[0047]
1),在原数据集1中,对于每个代谢综合征阳性样本i,计算其与剩余代谢综合征阳性样本j(j≠i)的马氏距离,即其中xi和xj是向量,包含20个元素,为第二步中的20个危险因素值,上标t表示转置,s-1
表示协方差阵的逆矩阵,然后寻找5个与样本i马氏距离最小的阳性样本;
[0048]
2),在5个样本中随机选择1个样本,记为样本i_near,其危险因素向量记为x
i_near
,计算该样本与样本i危险因素间的差异diff=x
i_near-xi;
[0049]
3),在0和1之间选择一个随机数,记为ζ,最终生成的样本为x
i_new
=xi ζdiff;
[0050]
步骤2)和3)的两次随机,使新得到的样本在与原阳性样本的各项特征较为相似的同时避免了人为选择偏倚。
[0051]
4),假设原数据集1有m个代谢综合征阳性者,n个阴性者。对于每个阳性者,重复步骤一到步骤三k次,则共新增k*m个阳性者,则此时共有m*(1 k)个阳性者。然后在阴性样本中进行采样,采样数量为m*(1 k),则共同构成代谢综合征阳性与阴性数比例为1:1的smote
数据集1。
[0052]
这一步基于原始非平衡数据集,利用smote技术构建新数据集,即增加代谢综合征阳性结局数,使数据达到均衡状态。
[0053]
第三步,基于第二步所得5个smote数据集,利用随机森林构建西南5个区域代谢综合征风险预测模型。
[0054]
随机森林(random forest,rf)将很多弱学习器组合在一起形成一个强学习器,是一种集成算法,通常用来解决分类问题,现在也用于回归问题。所谓随机,是指每次通过有放回或无放回方式,从训练集随机抽取n个新的数据集,形成n棵分类树或回归树,同时生成n个未被抽到的袋外数据(out-of-bag,oob)。在每棵树的每个节点处,随机抽取m个变量(m小于变量总数m),基于节点不纯度最小原则,选择一个变量进行分支生长,满足停止规则后树便不再生长。每棵树独立进行分类或回归,最终按照所有树投票结果选得票最高的结果或回归结果的均值。由于构建随机森林时每次均是随机选择训练集和节点,最小化了树与树之间的相关性,因此可以防止过拟合问题。随机森林的棵树和每个分裂节点选择变量数是随机森林两个重要参数。
[0055]
本研究基于smote数据1和随机森林算算法构建代谢综合征风险预测模型的具体步骤如下:
[0056]
步骤a,随机选择smote数据集1中的70%的数据作为训练集,剩余30%数据作为测试集。
[0057]
步骤b,在训练集上建模。对于随机森林树的棵树,首先预设500棵,选择使得oob数据预测误差趋于稳定的棵数。例如,假设在400棵树时,oob数据的预测误差开始趋于稳定,则最终选择400棵树。
[0058]
步骤c,对于每个分裂节点选择变量数,预设1,2,3,4,5,6,选择使auc最大的值。如图2所示,auc即roc曲线下面积,本质上是一个概率,即随机选择一个阳性样本和阴性样本,按照当前分类算法能够将阳性样本排在阴性样本前的概率即为auc,该值越大,则说明该算法越有可能将阳性样本排在阴性样本前,即能够越好地完成分类任务。
[0059]
步骤d,在测试集上测试步骤c所得模型的预测准确性,计算模型在测试集上的auc,若测试集auc与训练集auc较为接近,说明该模型的泛化能力较好。
[0060]
步骤e,分别在西南5个区域,重复步骤一到步骤四,建立西南5个区域的代谢综合征风险预测模型。
[0061]
这一步是建模,即基于第二步构建的smote数据集,利用随机森林,分别在西南5个区域建立区域特异的代谢综合征风险预测模型。
[0062]
第四步,利用代谢综合征风险预测模型对待测试样本进行代谢综合征风险预测。
[0063]
本发明将smote技术和随机森林算法结合,得到代谢综合征风险预测模型,再利用代谢综合征风险预测模型对待测试样本进行预测,得到代谢综合征风险预测结果,降低数据不均衡问题对疾病结局预测带来的影响,相比于使用具有简单线性假设的传统cox比例风险模型或单纯使用随机森林算法,预测效能显著提高。
[0064]
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本技术公开的原则
范围和精神之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。