1.本发明属于群聊金融信息预测领域,尤其涉及一种基于双向长短期记忆神经网络和条件随机场以及梯度提升决策树算法的群聊金融信息的需求预测方法。
背景技术:
2.金融业是一个传统行业,同时在我国也是一个发展中的行业,与我们的生活息息相关。对于金融行业的发展近几年是突飞猛进,金融业的发展带动了巨大的商机,不难发现在当下的一些聊天软件之类的社交软件当中,例如微信群聊中,会有很多资金方或者需求方发出的一些金融信息,这些信息的一个特点就是文本较短,需求方以较少的字将自己的需求描述清楚;另一个特点就是这些群聊金融信息当中绝大部分都是资金方的供给信息然而需求方发出的信息很少,这部分很少数目的需求信息是一个很大的商机,挖掘出这部分需求信息能够给供给方提供客户,有重要的商业价值。当下推荐系统和预测系统应用在很多领域,如淘宝,今日头条等软件,利用推荐系统以及预测系统能够把用户可能购买的产品进行预测,从而推送给用户;能够给用户推送可能喜欢的文章、视频。这些推荐系统以及预测系统能够给商家带来很大的商业价值,如今的互联网日益成熟这些推荐系统以及预测系统将会有很大的发展前景。然而当下对于金融行业研究的各种预测算法或者方法却很少涉及到需求群聊金融信息的预测,大多数都是研究金融产品的价格趋势预测,金融市场趋势预测方法,金融时间序列预测。如果将预测算法能够应用在群聊金融信息的需求预测上,进一步挖掘出稀少的需求群聊金融信息,利用这一部分需求群聊金融信息创造较高的商业价值。
3.群聊金融信息数据预处理现在已有的方法是首先数据清洗,然后进行中文文本向量化。数据清洗先去掉文本数据中的符号,包括标点符号等得到纯中文文本,一般借助于正则表达式python编程语言的re模块中的compile函数,然后利用分词技术,把纯中文的群聊金融信息进行分词,这个分词大多数依赖python编程语言的一个分词工具“jieba”进行分词,分词之后再借助于停用词表把分词之后的数据进行停用词去除。数据清洗之后得到的是群聊金融信息的词语,然而这些词语无法直接让算法模型所识别,还需要进行中文文本的向量化。中文文本向量化是将我们已有的文本数据转化为数字向量,这个数字向量就是算法模型可以进行训练的数据,一条群聊金融信息对应着一个n维的数字向量,这个向量的维数取决于群聊金融信息的特征个数,其特征为群聊金融信息数据清洗后得到的词语,n维向量对应着n个特征,即代表某一条群聊金融信息在n个特征下的分别取值。现在已有的中文文本向量化的工具其中之一是onehot编码,onehot编码就是将我们分词后的所有的文本数据的词语去掉重复之后作为特征,对一条文本数据onehot编码时将本条文本已有的特征标为1,其余的特征标为0。然而直接使用onehot编码处理群聊金融信息形成数字向量,在群聊金融信息的需求预测当中会面临生成数字向量效率低、得到的数字向量质量差的问题,严重降低算法模型预测的准确率。当数据量很大的时候,比如2万条群聊金融信息,那么onehot编码将会产生很多特征,这就会导致向量的维数变得很大甚至是几千维的向量,然
而其中一条数据能标为1特征很少,这就会加大训练模型的难度,影响算法模型的准确率;其次是有一些对于分类贡献很小的词语也作为了训练模型的特征进行算法模型的训练,比如“这里”、“存在”等词语对模型分类训练的贡献很小,将这些词语作为特征加入到模型的训练中会增加模型训练的时间开销,同时降低算法模型对需求群聊金融信息预测的准确率。在深度学习神经网络算法模型中,词嵌入也是作为将群聊金融信息转化为模型训练数据的一种方式,但是由于需求群聊金融信息稀少,利用词嵌入的方式得到的训练数据对于预测需求群聊金融信息效果很差。
技术实现要素:
4.本发明针对现有技术在预处理群聊金融信息获取有效特征的不足以及算法模型预测需求群聊金融信息准确率低的问题,提供了一种基于双向长短期记忆神经网络和条件随机场以及梯度提升决策树算法的需求群聊金融信息的预测方法。
5.本发明采用以下的技术方案:
6.利用bilstm(bi-directional long short-term memory双向长短期记忆神经网络)和crf(conditional random field algorithm条件随机场)模型,即bilstm crf模型对群聊金融信息进行处理从而获得特征词语,并基于群聊金融信息对应的特征词语的词频进行向量化,后续利用gbdt(gradient boosting decision tree梯度提升决策树)算法模型进行训练及预测,包含以下步骤:
7.步骤一,将群聊金融信息进行分类结果标注,将需求类型的群聊金融信息标为1,将供给类型的群聊金融信息标为0;选取部分群聊金融信息用于训练双向长短期记忆神经网络和条件随机场模型,部分群聊金融信息的数量选取取决于群聊金融信息的数量,选取的数量为群聊金融信息的10%到20%之间,假如1000条群聊金融信息可以选取200条,假如10000条群聊金融信息可以选取1000条;将群聊金融信息的业务类型词语(例如:贷款、融资)、机构类型词语(例如:银行、公司)、联系类型词语(例如:联系、电话)、与业务相关表示情感的动词(例如:需要、提供)作为特征词语,在进行群聊金融信息的特征词语标注时选用“bio”(begin inside outside)标注体系进行标注,将用于训练双向长短期记忆神经网络和条件随机场模型的群聊金融信息进行特征词语标注,标注后作为训练双向长短期记忆神经网络和条件随机场模型的训练数据记为训练数据集。
8.步骤二,通过步骤一所述得到的训练双向长短期记忆神经网络和条件随机场模型的训练数据集,将训练数据集划分为第一训练集和第一测试集,在本发明中将按照8:2的比例进行划分,第一训练集用于训练双向长短期记忆神经网络和条件随机场模型,第一测试集用于测试训练得到的双向长短期记忆神经网络和条件随机场模型;然后利用第一训练集和第一测试集进行双向长短期记忆神经网络和条件随机场模型的训练及测试;利用训练完成的双向长短期记忆神经网络和条件随机场模型将群聊金融信息进行特征词语的预测处理,得到第一特征词语,每一条群聊金融信息预测处理的结果是:将原本一条复杂的群聊金融信息提取为这条群聊金融信息包含的特征词语。
9.步骤三,将步骤二所述得到的第一特征词语去掉重复的词语后,作为训练梯度提升决策树算法模型的特征词袋,假设有n个特征,然后根据每一条群聊金融信息对应的特征词语在特征词袋中的词频,将群聊金融信息进行编码,经过编码之后每一条群聊金融信息
转化为对应的n维词频数字向量,词频数字向量的维数和梯度提升决策树算法模型的特征个数相同。
10.步骤四,在进行梯度提升决策树模型训练之前需要先把步骤三所述得到的n维词频数字向量进行分类,分为两类:第二训练集和第二测试集,第二训练集用于训练梯度提升决策树算法模型,第二测试集测试训练得到的梯度提升决策树算法模型;在本发明中将第二训练集和第二测试集的占比设为8:2;利用第二训练集及对应的步骤一所述分类结果的标注对梯度提升决策树算法模型进行训练,得到训练完成的梯度提升决策树算法模型,利用训练完成的梯度提升决策树算法模型对第二测试集进行分类预测;根据预测结果与对应的步骤一所述分类结果的标注进行比较分析得到梯度提升决策树算法模型的准确率。
11.本发明的有益效果是:与现有的技术相比本发明通过双向长短期记忆神经网络和条件随机场将群聊金融信息中的词语进行筛选得到对算法模型训练价值高的特征词语,提高了群聊金融信息数据集的质量,有效缩短了预测算法模型的训练时间;结合梯度提升决策树算法模型进行需求群聊金融信息的预测,通过进行实验可以得到该方法的需求预测的准确率达到了87.3%,对比当前现有的基于cnn(convolutional neural networks卷积神经网络)的需求预测的准确率为68.4%,可知在群聊金融信息的需求预测问题上这是一个可靠的方法。
附图说明
12.附图1是对群聊金融信息进行特征词语标注的流程图。
13.附图2是bilstm crf模型的训练、测试以及利用训练完成的bilstm crf模型对群聊金融信息进行特征词语预测处理的流程图。
14.附图3是将群聊金融信息转化为词频数字向量的流程图。
15.附图4是利用群聊金融信息的词频数字向量进行gbdt算法的训练以及测试gbdt算法准确率的流程图。
16.附图5是总的流程图,群聊金融信息特征词语预测处理和训练gbdt算法模型及其预测。
具体实施方式
17.步骤一,将群聊金融信息进行分类结果标注,将需求类型的群聊金融信息标为1,将供给类型的群聊金融信息标为0;选取部分群聊金融信息用于训练双向长短期记忆神经网络和条件随机场模型,部分群聊金融信息的数量选取取决于群聊金融信息的数量,选取的数量为群聊金融信息的10%到20%之间,假如1000条群聊金融信息可以选取200条,假如10000条群聊金融信息可以选取1000条;将群聊金融信息的业务类型词语(例如:贷款、融资)、机构类型词语(例如:银行、公司)、联系类型词语(例如:联系、电话)、与业务相关表示情感的动词(例如:需要、提供)作为特征词语,在进行群聊金融信息的特征词语标注时选用“bio”(begin inside outside)标注体系进行标注,将用于训练双向长短期记忆神经网络和条件随机场模型的群聊金融信息进行特征词语标注,标注后作为训练双向长短期记忆神经网络和条件随机场模型的训练数据记为训练数据集。
18.实施例具体实施过程为:
19.选取部分群聊金融信息,根据步骤一中的特征词语,将群聊金融信息的特征词语进行标注。标注采用了“bio”体系,b-ins代表特征词语的开头,i-ins代表特征词语的中间到结尾,o代表非特征词语。
20.假设有5000条群聊金融信息可以选取500条群聊金融信息用作于训练双向长短期记忆神经网络和条件随机场。
21.一条群聊金融信息为:“正大金融有限公司:实力资金方,诚寻全国优质实体项目,欢迎全国有能力的商务对接人士洽谈合作。”22.这条群聊金融信息为供给类型故标注这条群聊金融信息的分类结果为0,对这条群聊金融信息的特征词语的标注为:
23.表一:群聊金融信息特征词语的标注
24.正大金融有限公司:实力资金oooooob-insi-insooob-insi-ins方,诚寻全国优质实体项目,oob-insi-insoooooob-insi-inso欢迎全国有能力的商务对接人b-insi-insooooooooooo士洽谈合作。
ꢀꢀꢀꢀꢀꢀꢀ
ob-insi-insb-insi-inso
ꢀꢀꢀꢀꢀꢀꢀ
25.选取合适量的用于训练bilstm crf模型的群聊金融信息,将群聊金融信息进行特征词语标注的预处理,得到训练数据集。这将是个一劳永逸的过程,随着训练数据集数量的增加,得到的bilstm crf模型进行特征词语的预测的准确率会越来越高。
26.步骤二,通过步骤一所述得到的训练双向长短期记忆神经网络和条件随机场模型的训练数据集,将训练数据集划分为第一训练集和第一测试集,在本发明中将按照8∶2的比例进行划分,第一训练集用于训练双向长短期记忆神经网络和条件随机场模型,第一测试集用于测试训练得到的双向长短期记忆神经网络和条件随机场模型;然后利用第一训练集和第一测试集进行双向长短期记忆神经网络和条件随机场模型的训练及测试;利用训练完成的双向长短期记忆神经网络和条件随机场模型将群聊金融信息进行特征词语的预测处理,得到第一特征词语,每一条群聊金融信息预测处理的结果是:将原本一条复杂的群聊金融信息提取为这条群聊金融信息包含的特征词语。
27.实施例具体实施过程为:
28.运用编程语言python3.6版本,搭建bilstm选用的是torch框架,设置bilstm的词向量的维度max_len为50,dropout为0.5,防止bilstm模型出现过拟合现象。crf模型采用tri-gram形式,在crf模型的获取选择sklearn-crfsuite这个库,利用sklearn-crfsuite.crf方法引入模型。为了保证得到的crf模型的准确率对模型的参数进行设定,运算法则algorithm选择lbfgs算法,此算法能够节省大量的空间以及计算资源;c1值设为0.1;c2的值设为0.1;最大迭代次数max_iterations设为100;所有可能的转换all_possible_transitions值设定为true。利用train方法将第一训练集训练bilstm模型,将bilstm模型的输出作为crf模型的输入,然后训练crf模型。bilstm crf模型训练完成后,利用第一测试集进行bilstm crf模型的性能评估,最后利用bilstm crf模型将群聊金融信息
进行特征词语的预测处理,得到第一特征词语。
29.假设一条需求群聊金融信息:希望能够与有资金的朋友合作共赢。
30.利用训练完成的bilstm crf模型将这条群聊金融信息进行特征词语的预测,最终的预测结果为这条群聊金融信息所包含的特征词语,输出的预测结果为:
‘
资金合作’。
31.步骤三,将步骤二所述得到的第一特征词语去掉重复的词语后,作为训练梯度提升决策树算法模型的特征词袋,假设有n个特征,然后根据每一条群聊金融信息对应的特征词语在特征词袋中的词频,将群聊金融信息进行编码,经过编码之后每一条群聊金融信息转化为对应的n维词频数字向量,词频数字向量的维数和梯度提升决策树算法模型的特征个数相同。
32.实施例具体实施过程为:
33.通过步骤二的处理得到了所有群聊金融信息的特征词语,将这些特征词语存放在一个words列表中,用python编程语言对这部分词语进行去重复操作。设置一个词袋vocab接收去重复后的词语,具体的语句如下:vocab=sorted(set(words),key=words.index),其中sorted是排序函数,设置排序的对象是存放特征词语的words列表,key为带一个参数的函数用来为每个元素提取比较值,设置key值为words.index即words列表的索引。初始化一个二维数组count,利用for循环遍历每一条经过步骤二处理的群聊金融信息,将群聊金融信息中的每一个特征词语a与词袋vocab中的词语进行比较,找到特征词语a在词袋中的位置并记录count[i][pos]=count[i][pos] 1,其中i为第i条群聊金融信息,pos为特征词语a在词袋中的位置,设置count[i][pos]=count[i][pos] 1相当于群聊金融信息对应的特征词语的词频计数。利用python编程语言的pandas库的dataframe函数生成词频数字向量countvector,countvector的具体编码实现为:countvector=dataframe(count,columns=vocab),将赋值完的count向量传入dataframe函数中,设置countvector词频数字向量的列为词袋vocab,每一条群聊金融信息对应一行。到此可以得到基于步骤二生成的群聊金融信息对应的词频数字向量,词频数字向量的维数为词袋vocab中的特征词语个数。
[0034]
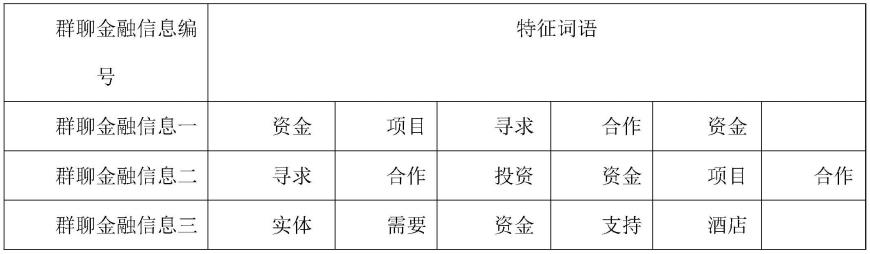
假设有三条群聊金融信息,在经过步骤二之后得到的特征词语如下表所示:
[0035]
表二:特征词语表
[0036][0037]
这三条群聊金融信息去重复后的特征词语有:资金、项目、寻求、合作、投资、实体、需要、支持、酒店共9个特征词语,将这9个特征词语加入词袋vocab作为词频数字向量的维数。将这些特征词语也将作为训练gbdt算法模型的特征。
[0038]
生成词频数字向量如下表:
[0039]
表三:群聊金融信息对应的词频数字向量
[0040][0041]
每一条群聊金融信息生成的词频数字向量中的数字代表该群聊金融信息包含这个特征词语的个数。具体而言,群聊金融信息三的词频数字向量为[1,0,0,0,0,1,1,1,1]。
[0042]
步骤四,在进行梯度提升决策树模型训练之前需要先把步骤三所述得到的n维词频数字向量进行分类,分为两类:第二训练集和第二测试集,第二训练集用于训练梯度提升决策树算法模型,第二测试集测试训练得到的梯度提升决策树算法模型;在本发明中将第二训练集和第二测试集的占比设为8:2;利用第二训练集及对应的步骤一所述分类结果的标注对梯度提升决策树算法模型进行训练,得到训练完成的梯度提升决策树算法模型,利用训练完成的梯度提升决策树算法模型对第二测试集进行分类预测;根据预测结果与对应的步骤一所述分类结果的标注进行比较分析得到梯度提升决策树算法模型的准确率。
[0043]
实施例具体实施过程为:
[0044]
获取gbdt算法模型时使用编程语言python提供的库sklearn.ensemble中的方法gradientboostingclassifier创建。gradientboostingclassifier方法中相关参数具体取值为:初始子模型init为none、学习率(缩减)learning_rate为0.1、损失函数loss为deviance、最大深度max_depth为3、节点分裂时参与判断的最大特征数max_features为none、最大叶节点数max_leaf_nodes为none、叶节点最小样本数min_simples_leaf为1、分裂所需的最小样本数min_simples_split为2、叶节点最小样本权重总值min_weight_fraction_leaf为0.0、子模型数量n_estimators为100、随机器对象random_state为none、子采样率subsample为1.0、日志冗长度verbose为0、是否热启动(如果是则下一次训练是以追加树的形式进行)warm_start为false。建立好的gbdt算法模型利用方法fit进行训练,fit方法中需要传入第二训练集以及与第二训练集对应的群聊金融信息的分类结果的标注两个对象。训练完的gbdt算法模型对其评价准确率,利用方法predict进行预测评价,predict方法中传入第二测试集对象。利用库sklearn中的方法metrics,对于gbdt算法模型准确率的评估需要用到metrics方法中的accuracy_score函数,accuracy_score函数的两个对象为第二测试集的经过predict方法输出的预测分类结果以及第二测试集对应的群聊金融信息的分类结果的标注;对于gbdt算法模型的召回率的评估用到的是metrics方法的recall_score函数,recall_score函数有三个对象,其中的两个对象和accuracy_score函数一样,第三个对象为字符串数据的平均值累型average为macro。
[0045]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替
代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。