1.(关联申请的相互参照)
2.本技术要求2020年4月13日向日本特许厅提出申请的日本技术号第2020-71429号的利益。该日本技术如同在本说明书中明示出其申请文件(说明书、权利要求书、附图、摘要)整体那样,以所有目的通过参照而援引到本说明书中。
3.本发明属于包括再生医疗在内的细胞培养技术领域。本发明涉及用于从多能干细胞向着体细胞进行分化诱导的体液因子。详细而言,本发明涉及在从多能干细胞向着体细胞进行分化诱导时有用的肽。
背景技术:
4.为了治疗器官衰竭等而进行细胞移植时,由于供体不足,难以按需对有需求的患者提供医疗服务这一点已成为问题。因此,在生物体外由es/ips细胞等多能干细胞制备所需器官并应用于患者的再生医疗备受关注。为了制备所需器官,常规方法是在合适时机使生长因子、分化诱导因子等体液因子作用于细胞,逐渐地规定细胞分化方向。
5.但是,所使用的体液因子较为昂贵,因此制备目标细胞的总成本变高,成为再生医疗普及的壁垒。另外,还可列举所制备的细胞的功能达不到生物体内细胞的功能的问题。前者、即体液因子昂贵的原因在于,体液因子以使用动物细胞等生产的蛋白为主成分。关于后者、即功能,认为在生物体外不能充分模拟生物体内的脏器发生、即所添加的体液因子的组合不足是功能不足的理由之一。
6.为了解决前一问题,尝试了用低分子化合物代替蛋白的方法。但是,作用机制不明的情况较多,担心副作用等无法预测的风险(例如,产生感染风险(病毒、支原体、朊病毒等))。对于解决后一问题而言,提高体液因子的添加浓度、增加体液因子的种类、改进体液因子的结构是有效的。但是,导致成本进一步提高、操作进一步复杂化。
7.作为在生物体外由es/ips细胞等多能干细胞制备所需器官的具体技术,例如已知下述那样的技术。
8.专利文献1中记载的发明涉及由多能干细胞制造心肌细胞的方法,使用激活蛋白、bmp4、bfgf、vegf等体液因子能够高效地向着心肌进行分化诱导。但是,由于使用多种体液因子而成本高。
9.专利文献2~5中记载的发明涉及使用低分子化合物向着心肌进行分化诱导的方法。但是,专利文献2的发明使用了作为饲养细胞的op9,需要使用细胞分选仪的细胞分离,操作复杂。专利文献3、4和5的发明是专门针对心肌细胞的方法,尚不清楚能否用于其它分化系统。
10.专利文献6中记载的发明利用包含细胞穿膜肽和肝配蛋白的部分肽的肽对细胞进行分化诱导。但是,利用该肽的分化诱导显示出促进向肝细胞系分化的作用,因此很可能在其它分化诱导中是无法使用的。
11.专利文献7中记载的发明涉及一种分化诱导方法,其为使用包含肝素结合生长因
子的培养基将多能干细胞分化诱导为体细胞的方法,其特征在于,使细胞接触将层粘连蛋白e8片段和硫酸乙酰肝素蛋白聚糖的包含生长因子结合部位的片段连接而成的缀合物。根据该发明,能够由多能干细胞高效地向任意体细胞进行分化诱导,但是由于制造时使用动物细胞而成本高。
12.现有技术文献
13.专利文献
14.专利文献1:日本专利第6429280号公报
15.专利文献2:日本专利第5611035号公报
16.专利文献3:国际公开第2012/026491号
17.专利文献4:国际公开第2015/182765号
18.专利文献5:国际公开第2015/037706号
19.专利文献6:日本特开2011-98900号公报
20.专利文献7:国际公开第2018/088501号
技术实现要素:
21.发明要解决的问题
22.为了对细胞进行高效率的分化诱导,正在积极推进从es/ips细胞等多能干细胞进行分化诱导的方法。另一方面,这样的系统均伴有下述问题中的1种以上问题。
23.·
使用多种体液因子。
24.·
使用蛋白作为体液因子,因此成本高。
25.·
使用细胞制备蛋白,因此难以确定内容物(标准化)。
26.·
所制备的例如心肌细胞的功能不充分。
27.本发明的主要课题在于,提供能够解决从es/ips细胞等多能干细胞向着体细胞(例如心肌细胞)进行分化诱导时的上述问题的新的分化诱导剂或体液因子(肽)。另外,作为本发明的课题,可以包括例如提供用于从多能干细胞向着体细胞进行分化诱导的新方法、体细胞的新的制造方法。
28.用于解决问题的方案
29.本发明人们进行了深入研究,结果发现,在从多能干细胞向着体细胞进行分化诱导的过程中,通过与激活蛋白一起应用与fgf(fibroblast growth factors;成纤维细胞生长因子)受体结合的肽作为1天后的体液因子,从而能够向着体细胞进行分化诱导,因此能够解决上述课题,至此完成了本发明。
30.作为本发明,例如可列举以下方式。
31.[1]一种合成肽,其在分子结构上具有下述所示的氨基酸序列(序列号1)或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0032][0033]
式中,从序列(1)的n末端起第1位的x为a、r、q、v、l、k、f或h,第2位的x为e或h,第3位的x为a、q、v、y、r、l或e,第4位的x为a或s,第5位的x为e、l、h、r、g或k,第6位的x为a、k、m、r、g或y,第7位的x为e或d,第8位的x为a、q、r、y、e、k或g,第9位的x为a或i,第10位的x为e、g、
y、q、r、k或m,第11位的x为f、a、q、v、g、i、n、r、m、d、l、s、p、k或e,第12位的x为g、v、k、t、p、r、m、n、e、d、s、c、w、h或a,第13位的x为g、r、e、f、a、k、p、n、l、v、m、d、h、t或y,第14位的x为v、d、l、m、s、t、a、n、h、g、f、e、r、p、y或k,第15位的x为v、k、y、t、n、g、d、e、p、f、q、h或i,第16位的x为y、r、h、l、p、n、e、m、a、g、v、i或s,第17位的x为s、k、m、g、h、q、t、v、c、l、n、a、e、p或r,第18位的x为c、s、a、t、r、e、n、q、g、k、y、p、l、v或m,第19位的x为e、k、s、v、l、r、g、i、f、t、a、h、q、n、m或y,第20位的x为w或g,第21位的x为q、k、f或h,第22位的x为a或l,第23位的x为v、m、d、y、k、l、i、r、s、q、g、e、h、f、n或a,第24位的x为y、m、r、s、k、h、g、l、n、e、v、d或a,第25位的x为h、f、y、k、i、q、m或v,第26位的x为y、w、g、l、n、d、q、e、m、f、r、h、s、k、v或i,第27位的x为k、r或q,第28位的x为m、e、w、v、h、s、n、i、q、y、g、l、r、f或a,第29位的x为r、l、v、s、h、y、f、n、k、q、w、e、i、g或a,第30位的x为f、r、d、q、m、k、l或h,第31位的x表示q、g、y、r、n、i、s、h、e、m、l、d、c、w、v或f。
[0034]
[2]根据上述[1]所述的合成肽,其在分子结构上具有下述所示的氨基酸序列(序列号2)或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0035][0036]
式中,从序列(2)的n末端起第1位的x为f、a、q、v、g、i、n、r、m、d、l、s、p、k或e,第2位的x为g、v、k、t、p、r、m、n、e、d、s、c、w、h或a,第3位的x为g、r、e、f、a、k、p、n、l、v、m、d、h、t或y,第4位的x为v、d、l、m、s、t、a、n、h、g、f、e、r、p、y或k,第5位的x为v、k、y、t、n、g、d、e、p、f、q、h或i,第6位的x为y、r、h、l、p、n、e、m、a、g、v或i,第7位的x为s、k、m、g、h、q、t、v、c、l、n、a、e或r,第8位的x为c、s、a、t、r、e、n、q、g、k、y、p、l、v或m,第9位的x为e、k、s、v、l、r、g、i、f、t、a、h、q、n、m或y,第10位的x为w或g,第11位的x为q或k,第12位的x为a或l,第13位的x为v、m、d、y、k、l、i、r、s、q、g或e,第14位的x为y、m、r、s、k、h、g、l、n、e或v,第15位的x为y、w、g、l、n、d、q、e、m、f、r、h、s、k或v,第16位的x为k或r,第17位的x为m、e、w、v、h、s、n、i、q、y、g、l或r,第18位的x为r、l、v、s、h、y、f、n、k、q、w、e、i或g,第19位的x表示q、g、y、r、n、i、s、h、e、m、l、d、c、w或v。
[0037]
[3]根据上述[2]所述的合成肽,其中,从上述氨基酸序列(2)的n末端起第1位的x为f、a、q、v、g、i、n、r、m、d、l、s或p,第2位的x为g、v、k、t、p、r、m、n、e、d、s、c、w或h,第3位的x为g、r、e、f、a、k、p、n、l、v或m,第4位的x为v、d、l、m、s、t、a、n、h、g、f、e或r,第5位的x为v、k、y、t、n、g、d、e、p、f、q或h,第6位的x为y、r、h、l、p、n、e、m、a、g或v,第7位的x为s、k、m、g、h、q、t、v、c、l、n或a,第8位的x为c、s、a、t、r、e、n、q、g、k、y或p,第9位的x为e、k、s、v、l、r、g、i、f、t、a或h,第10位的x为w或g,第13位的x为v、m、d、y、k、l、i或r,第14位的x为y、m、r、s、k、h、g、l、n或e,第15位的x为y、w、g、l、n、d、q、e、m、f或r,第16位的x为k,第17位的x为m、e、w、v、h、s、n、i、q或y,第18位的x为r、l、v、s、h、y、f、n或k,第19位的x为q、g、y、r、n、i、s、h、e、m、l或d。
[0038]
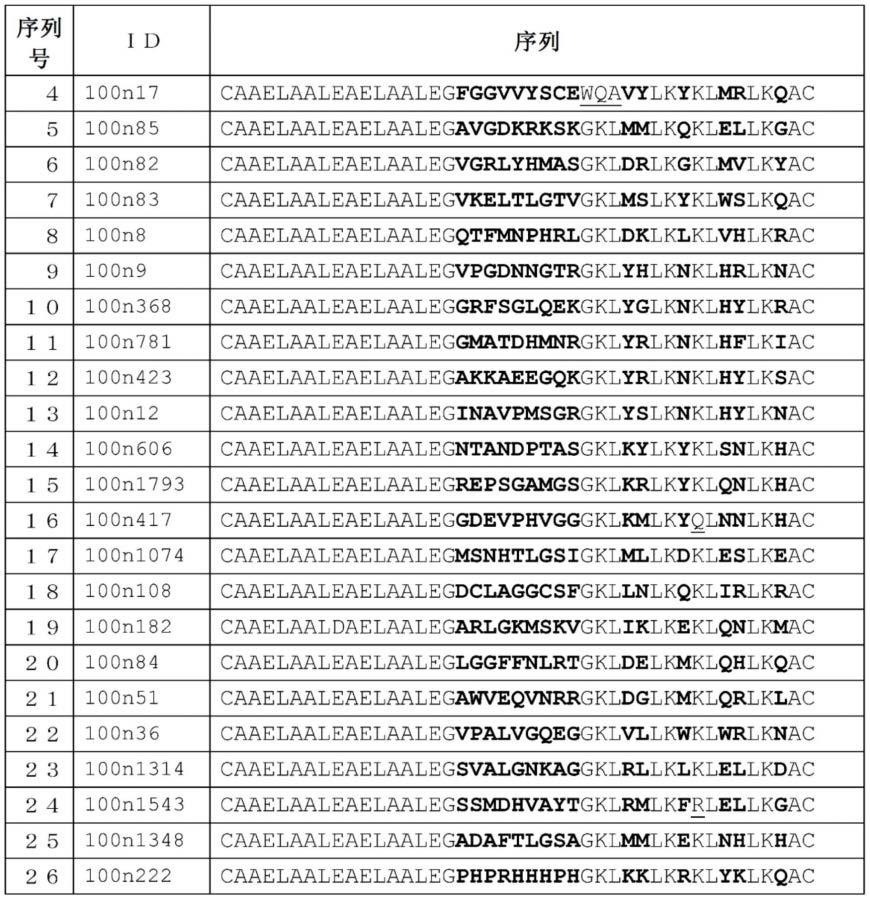
[4]根据上述[3]所述的合成肽,其中,上述氨基酸序列(1)为选自由序列号4~26组成的组中的任意氨基酸序列。
[0039]
[5]根据上述[2]所述的合成肽,其中,从上述氨基酸序列(2)的n末端起第1位的x为a、q、v、g、r、l、s、k或e,第2位的x为g、v、k、t、p、r、n、e、d、s、h或a,第3位的x为e、f、a、p、n、v、m、d、h、t或y,第4位的x为v、l、m、s、t、h、f、e、r、p、y或k,第5位的x为v、t或i,第6位的x为r、
l、m、g、v或i,第7位的x为s、m、g、t、l、n、a、e或r,第8位的x为s、t、r、q、g、l、v或m,第9位的x为k、s、v、l、r、t、a、q、n、m或y,第10位的x为g,第11位的x为k,第12位的x为l,第13位的x为v、m、l、i、s、q、g或e,第14位的x为m、s、h、g、l或v,第15位的x为y、l、q、e、m、f、r、h、s、k或v,第17位的x为e、w、v、h、n、q、g、l或r,第18位的x为r、s、h、n、q、w、e、i或g,第19位的x为q、g、r、h、e、l、d、c、w或v。
[0040]
[6]根据上述[5]所述的合成肽,其中,上述氨基酸序列(1)为选自由序列号27~46组成的组中的任意氨基酸序列。
[0041]
[7]根据上述[1]所述的合成肽,其在分子结构上具有下述所示的氨基酸序列(序列号3)或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0042][0043]
式中,从序列(3)的n末端起第1位的x为a、r、q、v、l、k、f或h,第2位的x为e或h,第3位的x为a、q、v、y、r、l或e,第4位的x为a或s,第5位的x为e、l、h、r、g或k,第6位的x为a、k、m、r、g或y,第7位的x为e或d,第8位的x为a、q、r、y、e、k或g,第9位的x为a或i,第10位的x为e、g、y、q、r、k或m,第11位的x为g或p,第12位的x为g、p、d或s,第13位的x为g或r,第14位的x为v、g或p,第15位的x为g或h,第16位的x为l、g或s,第17位的x为p或r,第18位的x为r或p,第19位的x为l或r,第20位的x为g,第21位的x为k、f或h,第22位的x为m、y、l、r、q、g、h、f、n或a,第23位的x为r、l、n、d或a,第24位的x为h、f、y、k、q、m或v,第25位的x为y、l、f、r、v或i,第26位的x为k或q,第27位的x为h、y、l、f或a,第28位的x为l、n、e、g或a,第29位的x为f、r、d、q、m、k、l或h,第30位的x表示g、n、i、h、l、w、v或f。
[0044]
[8]根据上述[7]所述的合成肽,其中,从上述氨基酸序列(1)的n末端起第17位和第18位的x为p且第19位的x为l、或者第17~19位的x均为r。
[0045]
[9]根据上述[7]或[8]所述的合成肽,其中,上述氨基酸序列(1)为序列号47或48的氨基酸序列。
[0046]
[10]根据上述[1]~[9]中任一项所述的合成肽,其由选自由序列号4~48组成的组中的任意氨基酸序列或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列构成。
[0047]
[11]根据上述[1]~[10]中任一项所述的合成肽,其中,wqpprarig(序列号49)借助接头而键合或直接键合。
[0048]
[12]根据上述[1]~[11]中任一项所述的合成肽,其中,上述合成肽经过了二聚体化。
[0049]
[13]根据上述[1]~[12]中任一项所述的合成肽,其中,上述合成肽的末端经过了分子修饰。
[0050]
[14]一种用于从多能干细胞向着体细胞进行分化诱导的组合物,其包含上述[1]~[13]中任一项所述的合成肽。
[0051]
[15]根据上述[14]所述的组合物,其中,还包含选自由激活蛋白、bfgf、bmp4、vegf、iwp-3、运铁蛋白和胞外基质组成的组中的1种以上。
[0052]
[16]根据上述[14]或[15]所述的组合物,其中,上述体细胞为外胚层系细胞、中胚
层系细胞或内胚层系细胞。
[0053]
[17]根据上述[16]所述的组合物,其中,上述外胚层系细胞为神经细胞,上述中胚层系细胞为心肌细胞,上述内胚层系细胞为肝细胞。
[0054]
[18]根据上述[14]~[17]中任一项所述的组合物,其中,上述组合物为培养基或培养基材。
[0055]
[19]一种体细胞的制造方法,其包括下述工序:使包含对fgf受体具有结合性的合成肽的体液因子作用于多能干细胞的拟胚体。
[0056]
[20]根据上述[19]所述的体细胞的制造方法,其中,上述体液因子中还包含其它分化诱导用体液因子。
[0057]
[21]根据上述[19]或[20]所述的体细胞的制造方法,其中,上述肽为1种以上的上述[1]~[13]中任一项所述的合成肽。
[0058]
[22]根据上述[20]或[21]所述的体细胞的制造方法,其中,上述其它分化诱导用体液因子为选自由激活蛋白、bfgf、bmp4、vegf、iwp-3和运铁蛋白组成的组中的1种以上。
[0059]
[23]根据上述[19]~[22]中任一项所述的体细胞的制造方法,其中,上述体细胞为外胚层系细胞、中胚层系细胞或内胚层系细胞。
[0060]
[24]根据上述[23]所述的体细胞的制造方法,其中,上述外胚层系细胞为神经细胞,上述中胚层系细胞为心肌细胞,上述内胚层系细胞为肝细胞。
[0061]
[25]一种从多能干细胞向着体细胞进行分化诱导的方法,其包括下述工序:使包含对fgf受体具有结合性的合成肽的体液因子作用于多能干细胞的拟胚体。
[0062]
[26]根据上述[25]所述的分化诱导方法,其中,上述体液因子中还包含其它分化诱导用体液因子。
[0063]
[27]根据上述[25]或[26]所述的分化诱导方法,其中,上述肽为1种以上的上述[1]~[13]中任一项所述的合成肽。
[0064]
[28]根据上述[26]或[27]所述的分化诱导方法,其中,上述其它分化诱导用体液因子为选自由激活蛋白、bfgf、bmp4、vegf、iwp-3和运铁蛋白组成的组中的1种以上。
[0065]
[29]根据上述[25]~[28]中任一项所述的分化诱导方法,其中,上述体细胞为外胚层系细胞、中胚层系细胞或内胚层系细胞。
[0066]
[30]根据上述[29]所述的分化诱导方法,其中,上述外胚层系细胞为神经细胞,上述中胚层系细胞为心肌细胞,上述内胚层系细胞为肝细胞。
[0067]
发明的效果
[0068]
本发明能够使用分子量为中等程度的合成肽从多能干细胞高效率地向着体细胞进行分化诱导,因此与现有方法相比能够节约费用等。另外,通过与bfgf等其它分化诱导用体液因子组合使用,能够更高效地促进该分化诱导。
附图说明
[0069]
图1示出心肌细胞分化诱导方案。
[0070]
图2示出噬菌体表面呈现肽文库的立体结构。
[0071]
图3示出从淘选后洗脱而得的噬菌体文库获得与fgfr1结合的噬菌体、至对来自其噬菌粒dna所含的肽文库的序列进行全面分析为止的流程图。
[0072]
图4示出利用表面等离子共振法得到的与fgfr的结合性实验的结果。左端表示对fgf受体1的结果,中间表示对fgf受体2的结果,右端表示对fgf受体3的结果。各图中,纵轴表示响应单元(ru),横轴表示时间(秒)。
[0073]
图5示出心肌基因标记的表达量。左图表示ctnt基因的表达量,右图表示辅肌动蛋白-2基因的表达量。
[0074]
图6为细胞的免疫染色照片。
[0075]
图7为细胞的免疫染色照片。
[0076]
图8示出心肌基因标记的表达量。左图表示ctnt基因的表达量,右图表示辅肌动蛋白-2基因的表达量。
[0077]
图9示出心肌基因标记的表达量。左图表示ctnt基因的表达量,右图表示辅肌动蛋白-2基因的表达量。
[0078]
图10示出心肌基因标记的表达量。左图表示ctnt基因的表达量,右图表示辅肌动蛋白-2基因的表达量。
[0079]
图11示出利用表面等离子共振法得到的、肽hbd-yx和hbd-f3-100nx与fgfr的结合性实验的结果。
[0080]
图12示出心肌分化诱导方案。
[0081]
图13示出心肌分化诱导中的基因表达分析的结果。
[0082]
图14示出肝分化诱导方案。
[0083]
图15示出肝分化中的基因表达分析的结果。
[0084]
图16示出肝分化中的cyp3a4活性测定的结果。
[0085]
图17示出神经分化诱导方案。
[0086]
图18示出神经分化中的基因表达分析的结果。
具体实施方式
[0087]
以下对本发明进行详细说明。
[0088]
需要说明的是,本说明书中特别提及的事项(例如肽的一级结构、链长)以外的、本发明的实施所必须的事项(例如,关于肽合成、细胞培养技术、以肽为成分的药剂组合物的制备等一般性事项)可作为基于细胞工程学、医学、药学、有机化学、生物化学、基因工程学、蛋白质工程学、分子生物学、卫生学等领域中的现有技术的本领域技术人员的设计事项来理解。本发明可以基于本说明书中公开的内容和该领域中的技术常识来实施。另外,在以下的说明中,有时基于iupac-iub指南中示出的氨基酸命名法则以单字母符号(其中,在序列表中为3字母符号)来表示氨基酸。本说明书中记载的氨基酸序列始终是左侧为n末端侧、右侧为c末端侧。
[0089]
本说明书中引用的全部文献的全部内容均通过参照而整合到本说明书中。
[0090]
1本发明的合成肽
[0091]
本发明的合成肽(以下称为“本发明肽”。)的特征在于,在分子结构上具有下述所示的氨基酸序列(序列号1)或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。在此,“多个”是指:处于即使发生了氨基酸残基的置换、缺失和/或添加也不损害本发明的效果的范围内的少数个,通常表示12个左右以下。所述发生
了置换、缺失和/或添加的氨基酸残基优选为10个以下。更优选为5个以下、4个以下、3个以下或2个以下。
[0092][0093]
(式中,从序列(1)的n末端起第1位的x为a、r、q、v、l、k、f或h,第2位的x为e或h,第3位的x为a、q、v、y、r、l或e,第4位的x为a或s,第5位的x为e、l、h、r、g或k,第6位的x为a、k、m、r、g或y,第7位的x为e或d,第8位的x为a、q、r、y、e、k或g,第9位的x为a或i,第10位的x为e、g、y、q、r、k或m,第11位的x为f、a、q、v、g、i、n、r、m、d、l、s、p、k或e,第12位的x为g、v、k、t、p、r、m、n、e、d、s、c、w、h或a,第13位的x为g、r、e、f、a、k、p、n、l、v、m、d、h、t或y,第14位的x为v、d、l、m、s、t、a、n、h、g、f、e、r、p、y或k,第15位的x为v、k、y、t、n、g、d、e、p、f、q、h或i,第16位的x为y、r、h、l、p、n、e、m、a、g、v、i或s,第17位的x为s、k、m、g、h、q、t、v、c、l、n、a、e、p或r,第18位的x为c、s、a、t、r、e、n、q、g、k、y、p、l、v或m,第19位的x为e、k、s、v、l、r、g、i、f、t、a、h、q、n、m或y,第20位的x为w或g,第21位的x为q、k、f或h,第22位的x为a或l,第23位的x为v、m、d、y、k、l、i、r、s、q、g、e、h、f、n或a,第24位的x为y、m、r、s、k、h、g、l、n、e、v、d或a,第25位的x为h、f、y、k、i、q、m或v,第26位的x为y、w、g、l、n、d、q、e、m、f、r、h、s、k、v或i,第27位的x为k、r或q,第28位的x为m、e、w、v、h、s、n、i、q、y、g、l、r、f或a,第29位的x为r、l、v、s、h、y、f、n、k、q、w、e、i、g或a,第30位的x为f、r、d、q、m、k、l或h,第31位的x表示q、g、y、r、n、i、s、h、e、m、l、d、c、w、v或f。)
[0094]
本发明肽可以采用下述方式(以下也称为“100nx系肽”。):在分子结构上具有在上述氨基酸序列(1)中从n末端起第1位的x为a,第2位的x为e,第3位的x为a,第4位的x为a,第5位的x为e,第6位的x为a,第7位的x为e,第8位的x为a,第9位的x为a,第10位的x为e,第16位的x为y、r、h、l、p、n、e、m、a、g、v或i,第17位的x为s、k、m、g、h、q、t、v、c、l、n、a、e或r,第21位的x为q或k,第23位的x为v、m、d、y、k、l、i、r、s、q、g或e,第24位的x为y、m、r、s、k、h、g、l、n、e或v,第25位的x为k,第26位的x为y、w、g、l、n、d、q、e、m、f、r、h、s、k或v,第27位的x为k或r,第28位的x为m、e、w、v、h、s、n、i、q、y、g、l或r,第29位的x为r、l、v、s、h、y、f、n、k、q、w、e、i或g,第30位的x为k,第31位的x为q、g、y、r、n、i、s、h、e、m、l、d、c、w或v的氨基酸序列或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0095]
即,100nx系肽在分子结构上具有下述所示的氨基酸序列(序列号2)或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0096][0097]
(式中,从序列(2)的n末端起第1位的x为f、a、q、v、g、i、n、r、m、d、l、s、p、k或e,第2位的x为g、v、k、t、p、r、m、n、e、d、s、c、w、h或a,第3位的x为g、r、e、f、a、k、p、n、l、v、m、d、h、t或y,第4位的x为v、d、l、m、s、t、a、n、h、g、f、e、r、p、y或k,第5位的x为v、k、y、t、n、g、d、e、p、f、q、h或i,第6位的x为y、r、h、l、p、n、e、m、a、g、v或i,第7位的x为s、k、m、g、h、q、t、v、c、l、n、a、e或r,第8位的x为c、s、a、t、r、e、n、q、g、k、y、p、l、v或m,第9位的x为e、k、s、v、l、r、g、i、f、t、a、h、q、n、m或y,第10位的x为w或g,第11位的x为q或k,第12位的x为a或l,第13位的x为v、m、d、y、k、l、i、r、s、q、g或e,第14位的x为y、m、r、s、k、h、g、l、n、e或v,第15位的x为y、w、g、l、n、d、q、e、m、f、r、h、s、k或v,第16位的x为k或r,第17位的x为m、e、w、v、h、s、n、i、q、y、g、l或r,第18位
的x为r、l、v、s、h、y、f、n、k、q、w、e、i或g,第19位的x表示q、g、y、r、n、i、s、h、e、m、l、d、c、w或v。)
[0098]
100nx系肽可以采用下述方式(以下也称为“100nx”或“100nx-monomer”。):在分子结构上具有在上述氨基酸序列(1)中进一步地从n末端起第11位的x为f、a、q、v、g、i、n、r、m、d、l、s或p,第12位的x为g、v、k、t、p、r、m、n、e、d、s、c、w或h,第13位的x为g、r、e、f、a、k、p、n、l、v或m,第14位的x为v、d、l、m、s、t、a、n、h、g、f、e或r,第15位的x为v、k、y、t、n、g、d、e、p、f、q或h,第16位的x为y、r、h、l、p、n、e、m、a、g或v,第17位的x为s、k、m、g、h、q、t、v、c、l、n或a,第18位的x为c、s、a、t、r、e、n、q、g、k、y或p,第19位的x为e、k、s、v、l、r、g、i、f、t、a或h,第20位的x为w或g,第23位的x为v、m、d、y、k、l、i或r,第24位的x为y、m、r、s、k、h、g、l、n或e,第26位的x为y、w、g、l、n、d、q、e、m、f或r,第27位的x为k,第28位的x为m、e、w、v、h、s、n、i、q或y,第29位的x为r、l、v、s、h、y、f、n或k,第31位的x为q、g、y、r、n、i、s、h、e、m、l或d的氨基酸选序列或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0099]
即,100nx在分子结构上具有在上述氨基酸序列(2)中进一步地从n末端起第1位的x为f、a、q、v、g、i、n、r、m、d、l、s或p,第2位的x为g、v、k、t、p、r、m、n、e、d、s、c、w或h,第3位的x为g、r、e、f、a、k、p、n、l、v或m,第4位的x为v、d、l、m、s、t、a、n、h、g、f、e或r,第5位的x为v、k、y、t、n、g、d、e、p、g、f、q或h,第6位的x为y、r、h、l、p、n、e、m、a、g或v,第7位的x为s、k、m、g、h、q、t、v、c、l、n或a,第8位的x为c、s、a、t、r、e、n、q、g、k、y或p,第9位的x为e、k、s、v、l、r、g、i、f、t、a或h,第10位的x为w或g,第13位的x为v、m、d、y、k、l、i或r,第14位的x为y、m、r、s、k、h、g、l、n或e,第15位的x为y、w、g、l、n、d、q、e、m、f或r,第16位的x为k,第17位的x为m、e、w、v、h、s、n、i、q或y,第18位的x为r、l、v、s、h、y、f、n或k,第19位的x为q、g、y、r、n、i、s、h、e、m、l或d的氨基酸序列或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0100]
另外,100nx系肽可以采用下述方式(以下也称为“f3-100nx”或“f3-100nx-monomer”。):在分子结构上具有在上述氨基酸序列(1)中进一步地从n末端起第11位的x为a、q、v、g、r、l、s、k或e,第12位的x为g、v、k、t、p、r、n、e、d、s、h或a,第13位的x为e、f、a、p、n、v、m、d、h、t或y,第14位的x为v、l、m、s、t、h、f、e、r、p、y或k,第15位的x为v、t或i,第16位的x为r、l、m、g、v或i,第17位的x为s、m、g、t、l、n、a、e或r,第18位的x为s、t、r、q、g、l、v或m,第19位的x为k、s、v、l、r、t、a、q、n、m或y,第20位的x为g,第21位的x为k,第22位的x为l,第23位的x为v、m、l、i、s、q、g或e,第24位的x为m、s、h、g、l或v,第26位的x为y、l、q、e、m、f、r、h、s、k或v,第28位的x为e、w、v、h、n、q、g、l或r,第29位的x为r、s、h、n、q、w、e、i或g,第31位的x为q、g、r、h、e、l、d、c、w或v的氨基酸序列或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0101]
即,f3-100nx在分子结构上具有在上述氨基酸序列(2)中进一步地从n末端起第1位的x为a、q、v、g、r、l、s、k或e,第2位的x为g、v、k、t、p、r、n、e、d、s、h或a,第3位的x为e、f、a、p、n、v、m、d、h、t或y,第4位的x为v、l、m、s、t、h、f、e、r、p、y或k,第5位的x为v、t或i,第6位的x为r、l、m、g、v或i,第7位的x为s、m、g、t、l、n、a、e或r,第8位的x为s、t、r、q、g、l、v或m,第9位的x为k、s、v、l、r、t、a、q、n、m或y,第10位的x为g,第11位的x为k,第12位的x为l,第13位的x为v、m、l、i、s、q、g或e,第14位的x为m、s、h、g、l或v,第15位的x为y、l、q、e、m、f、r、h、s、k或v,
第17位的x为e、w、v、h、n、q、g、l或r,第18位的x为r、s、h、n、q、w、e、i或g,第19位的x为q、g、r、h、e、l、d、c、w或v的氨基酸序列或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0102]
另一方面,本发明肽也可以采用下述方式(以下也称为“yx系肽”。):在分子结构上具有从上述氨基酸序列(1)的n末端起第11位的x为g或p,第12位的x为g、p、d或s,第13位的x为g或r,第14位的x为v、g或p,第15位的x为g或h,第16位的x为l、g或s,第17位的x为p或r,第18位的x为r或p,第19位的x为l或r,第20位的x为g,第21位的x为k、f或h,第22位的x为l,第23位的x为m、y、l、r、q、g、h、f、n或a,第24位的x为r、l、n、d或a,第26位的x为y、l、f、r、v或i,第27位的x为k或q,第28位的x为h、y、l、f或a,第29位的x为l、n、e、g或a,第31位的x为g、n、i、h、l、w、v或f的氨基酸序列或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0103]
即,yx系肽在分子结构上具有下述所示的氨基酸序列(序列号3)或该氨基酸序列中的1个或多个氨基酸残基发生了置换、缺失和/或添加而形成的氨基酸序列。
[0104][0105]
(式中,从序列(3)的n末端起第1位的x为a、r、q、v、l、k、f或h,第2位的x为e或h,第3位的x为a、q、v、y、r、l或e,第4位的x为a或s,第5位的x为e、l、h、r、g或k,第6位的x为a、k、m、r、g或y,第7位的x为e或d,第8位的x为a、q、r、y、e、k或g,第9位的x为a或i,第10位的x为e、g、y、q、r、k或m,第11位的x为g或p,第12位的x为g、p、d或s,第13位的x为g或r,第14位的x为v、g或p,第15位的x为g或h,第16位的x为l、g或s,第17位的x为p或r,第18位的x为r或p,第19位的x为l或r,第20位的x为g,第21位的x为k、f或h,第22位的x为m、y、l、r、q、g、h、f、n或a,第23位的x为r、l、n、d或a,第24位的x为h、f、y、k、q、m或v,第25位的x为y、l、f、r、v或i,第26位的x为k或q,第27位的x为h、y、l、f或a,第28位的x为l、n、e、g或a,第29位的x为f、r、d、q、m、k、l或h,第30位的x表示g、n、i、h、l、w、v或f。)
[0106]
yx系肽进一步可以采用下述方式:从上述氨基酸序列(1)或(3)的n末端起第17和18位的x为p且第19位的x为l、或者第17~19位的x均为r的方式(以下也称为“yx”或“yx-monomer”。)。
[0107]
这里,“合成肽”是指:该肽链不是仅自身即可独立地稳定地存在于自然界的物质,是人为地通过化学合成或生物合成(即,基于基因工程学的生产)制造的在规定体系(例如构成细胞分化诱导剂的组合物)中可稳定地存在的肽片段。
[0108]“肽”是表示具有多个肽键的氨基酸聚合物的术语,虽然不受肽链中所含的氨基酸残基的数量限定,但是典型情况下是指氨基酸残基总数为约100以下、优选为50以下(例如30~50或40~50左右)的分子量较小者。
[0109]“氨基酸残基”为如下术语:除了特别提及的情况以外,为肽链中所含的各氨基酸(-nh-c(r)(h)-co-),包括肽链的n末端氨基酸和c末端氨基酸。
[0110]
需要说明的是,作为本发明肽,优选全部氨基酸残基为l型氨基酸,但是只要不丧失分化诱导活性则氨基酸残基的一部分或全部也可以置换为d型氨基酸。
[0111]
通过使用与成纤维细胞生长因子受体(fgfr)结合的本发明肽(100nx、f3-100nx或yx)、或使本发明肽和与硫酸乙酰肝素结合的肽融合而成的肽(以下也称为“hbd-100nx”、“hbd-f3-100nx”或“hbd-yx”。)、或使本发明肽二聚体化而成的肽(以下也称为“100nx-dimer”、“f3-100nx-dimer”或“yx-dimer”。),能够以种类少于以往方案的体液因子从ips细胞等多能干细胞向着心肌细胞等体细胞进行分化诱导。
[0112]
另外,通过使100nx、hbd-100nx或100nx-dimer与bfgf(basic fgf:碱性成纤维细胞生长因子)一起进行作用,能够促进向着心肌细胞等体细胞的分化或使心肌细胞等体细胞成熟化。
[0113]
另外,通过使用使与fgfr结合的肽(例如100nx、yx、f3-100nx)和与硫酸乙酰肝素结合的肽融合而成的肽(例如hbd-100nx、hbd-yx、hbd-f3-100nx),从而不使用bfgf也能够从ips细胞向着心肌细胞进行分化诱导。
[0114]
另外,通过使用hbd-100nx,从而不使用bfgf也能够从ips细胞向着肝细胞或神经细胞进行分化诱导。
[0115]
100nx中,优选在分子结构上具有下述的表1所示的序列号4~26中的任意序列所示的肽的化合物或序列号4~26中的任意序列所示的肽。更优选的本发明肽为在分子结构上具有序列号5、序列号8或序列号9所示的肽的物质或序列号5、序列号8或序列号9所示的肽。
[0116]
f3-100nx中,优选在分子结构上具有下述的表2所示的序列号27~46中的任意序列所示的肽的化合物或序列号27~46中的任意序列所示的肽。更优选的本发明肽为在分子结构上具有序列号27、序列号28、序列号29、序列号30、序列号31或序列号32所示的肽的物质或序列号27、序列号28、序列号29、序列号30、序列号31或序列号32所示的肽。
[0117]
yx中,优选在分子结构上具有下述的表3所示的序列号47或48中的任意序列所示的肽的化合物或序列号47或48中的任意序列所示的肽。
[0118]
根据本发明肽的方式,构成该肽的氨基酸总数为100以下(特别是50以下),因此化学合成容易,并且廉价且操作性优异。
[0119]
表1
[0120][0121]
表2
[0122][0123]
表3
[0124][0125]
只要不损害本发明的效果,则本发明肽也可以通过对序列号1~3和4~48所示的氨基酸序列中的1个或多个氨基酸残基进行置换、缺失和/或添加而形成。所述进行置换、缺失和/或添加的氨基酸残基优选为10个以下。更优选为5个以下或2个以下。另外,作为所述进行置换、缺失和/或添加的氨基酸残基,例如序列号1~3中x所示的氨基残基是适宜的。
[0126]
作为本发明肽,可列举和与硫酸乙酰肝素结合的肽融合而成的肽(hbd-100nx)。作为所述与硫酸乙酰肝素结合的肽,可列举例如wqpprarig(序列号49)。
[0127]
本发明肽和与硫酸乙酰肝素结合的肽的融合可以直接进行或借助合适的接头进行。作为所述接头,可列举例如聚酰胺接头、聚乙二醇(peg)接头、烷基接头、聚碳酸酯接头。
[0128]
本发明肽可以进行了二聚体化(100nx-dimer)。所述二聚体化可以是2个本发明肽直接进行或借助合适的接头而进行。作为所述接头,可列举例如聚酰胺接头、聚乙二醇(peg)接头、烷基接头、聚碳酸酯接头。
[0129]
通过将本发明肽制成hbd-100nx、100nx-dimer,从而能够更高效地从多能干细胞向着体细胞进行分化诱导。
[0130]
本发明肽中,其n末端或c末端可以被合适的化合物或物质进行分子修饰。所述分子修饰通常是为了荧光标记、多聚体化等目的而进行。作为该分子修饰用的化合物等,可列
举例如生物素、噬菌体、fitc等荧光化合物。
[0131]
包括hbd-100nx、100nx-dimer以及n末端或c末端的分子修饰体在内的本发明肽,可以利用常规方法通过化学合成(或生物合成)容易地人为制造。例如,可以采用现有公知的固相合成法或液相合成法中的任意种。使用boc(叔丁氧羰基)或fmoc(9-芴基甲氧基羰基)作为氨基的保护基的固相合成法是适宜的。本发明肽可以通过使用市售的肽合成机的固相合成法来合成期望的氨基酸序列、具有修饰(c末端酰胺化等)部分的肽链。
[0132]
另外,也可以基于基因工程学方法来生物合成本发明肽。具体而言,合成编码期望的本发明肽的氨基酸序列的核苷酸序列(包括atg起始密码子。)的dna。然后根据宿主细胞而构建重组载体,所述重组载体具有由该dna和用于在宿主细胞内表达该氨基酸序列的各种调节元件(包括启动子、核糖体结合位点、终止子、增强子、控制表达水平的各种顺式元件。)构成的表达用基因构建物。
[0133]
利用常规技术将该重组载体导入规定的宿主细胞,在规定的条件下培养该宿主细胞或包含该细胞的组织、个体。由此,能够在细胞内表达、生产作为目标的多肽。然后从宿主细胞(进行分泌的情况下,培养基中)分离多肽并进行纯化,由此能够得到目标本发明肽。利用常规技术将该重组载体导入规定的宿主细胞(例如酵母、昆虫细胞),在规定的条件下培养该宿主细胞或包含该细胞的组织、个体。由此,能够在细胞内表达、生产作为目标的多肽。然后从宿主细胞(进行分泌的情况下,培养基中)分离多肽并进行纯化,由此能够得到目标本发明肽。
[0134]
重组载体的构建方法和所构建的重组载体向宿主细胞的导入方法等可以直接采用该技术领域中一直以来所进行的方法。
[0135]
例如,为了在宿主细胞内高效地大量生产,可以利用融合蛋白表达系统。即,化学合成出编码目标本发明肽的氨基酸序列的基因(dna),将该合成基因导入合适的融合蛋白表达用载体的适宜位点。然后利用该载体转化宿主细胞(典型情况下为大肠杆菌)。培养所得到的转化体,制备目标融合蛋白。接着,对该蛋白进行提取和纯化。接着,将得到的纯化融合蛋白用规定的酶(蛋白酶)切断,利用亲和色谱等方法回收游离的目标肽片段(所设计的本发明肽)。通过使用这样的现有公知的融合蛋白表达系统,可以制造本发明肽。
[0136]
另外,可以构建无细胞蛋白合成系统用模板dna(即包含编码细胞分化诱导肽的氨基酸序列的核苷酸序列的合成基因片段),使用肽合成所需的各种化合物(atp、rna聚合酶、氨基酸类等),采用所谓的无细胞蛋白合成系统来体外合成目标多肽。关于无细胞蛋白合成系统,例如可以参考shimizu等的论文(shimizu et al.,nature biotechnology,19,751-755(2001))、madin等的论文(madin et al.,proc.natl.acad.sci.usa,97(2),559-564(2000))。基于这些论文中记载的技术,本技术提出申请时已有很多企业进行多肽的受托生产,另外,无细胞蛋白合成用试剂盒也有销售。
[0137]
因此,只要设计出肽链,则可以按照其氨基酸序列利用无细胞蛋白合成系统容易地合成和生产目标本发明肽。
[0138]
只要不损害其分化诱导活性,则本发明肽也可以为盐的形态。例如,可以使用可按照常规方法使通常所用的无机酸或有机酸或者无机碱或有机碱进行加成反应而得到的该肽的酸加成盐或碱加成盐。另外,只要具有该分化诱导活性,则也可以为其它盐(例如金属盐)、水合物、溶剂化物等。本发明肽包括所述盐形态的肽。
t.et al.,dev.biol.127:224-227(1988))、猪(evans m.j.et al.,theriogenology 33:125128(1990);piedrahita j.a.et al.,theriogenology 34:879-891(1990);notarianni e.et al.,j.reprod.fert.40:51-56(1990);talbot n.c.et al.,cell.dev.biol.29a:546-554(1993))、绵羊(notarianni e.et al.,j.reprod.fert.suppl.43:255-260(1991))、牛(evans m.j.et al.,theriogenology 33:125-128(1990);saito s.et al.,roux.arch.dev.biol.201:134-141(1992))、貂(sukoyan m.a.et al.,mol.reorod.dev.33:418-431(1993))等的es细胞。
[0149]
(3)其它多能干细胞
[0150]
epis细胞为从受精卵着床后的上胚层制备的多能干细胞。
[0151]
精子干细胞为来自睾丸的多能干细胞,为用于形成精子的起源细胞。该细胞与es细胞同样地能够分化诱导为各种系列的细胞,例如具有若移植到小鼠囊胚则能够产生嵌合小鼠等性质。在包含来自神经胶质细胞系的神经营养因子(glial cell line-derived neurotrophic factor(gdnf))的培养液中能够自我复制,另外通过在与es细胞同样的培养条件下反复传代则能够得到精子干细胞。
[0152]
eg细胞为由胚胎期的原始生殖细胞建立的具有与es细胞同样的多能性的细胞,可以通过在lif、bfgf、干细胞因子(stem cell factor)等物质存在下培养原始生殖细胞而建立。作为eg细胞,可列举例如人eg细胞(shamblott,et al.,proc.natl.acad.sci usa 92:7844-7848(1995))。
[0153]
ntes细胞为来自通过核移植技术制备的克隆胚的es细胞,与来自受精卵的es细胞具有基本相同的特性。
[0154]
muse细胞为利用wo2011/007900中记载的方法制造的多能干细胞。
[0155]
这些各多能干细胞可以为人来源,也可以为小鼠、大鼠、牛、猪、猴等动物来源。此外,可以为原始(naive)态,也可以为始发(primed)态。另外,可以是将小鼠成纤维细胞(例如胎鼠成纤维细胞(mef))、人新生儿或成人的成纤维细胞作为饲养细胞而培养制备者,也可以是通过无饲养细胞培养而制备者。
[0156]
2.2体细胞
[0157]
本发明组合物可以用于如上所述的从多能干细胞向着体细胞进行分化诱导中。
[0158]
作为用本发明组合物进行分化诱导的体细胞,没有特别限制,可以为外胚层系细胞、中胚层系细胞和内胚层系细胞中的任意者。具体而言,作为外胚层来源的细胞,可列举角膜细胞、神经细胞(产多巴胺神经细胞、运动神经细胞、周围神经细胞等)、色素上皮细胞、皮肤细胞、内耳细胞等。作为内胚层来源的细胞,可列举肝细胞、胰祖细胞、产胰岛素细胞、胆管细胞、肺泡上皮细胞、肠管上皮细胞等。作为中胚层来源的细胞,可列举心肌细胞、骨骼肌细胞、血管内皮细胞、血液细胞、骨细胞、软骨细胞、肾祖细胞、肾上皮细胞等。需要说明的是,体细胞不仅包括最终分化而得的成熟细胞,还包括未达到最终分化的分化过程中的细胞。其中,本发明组合物优选用于神经细胞、心肌细胞或肝细胞的分化诱导。
[0159]
这里,在体细胞为心肌细胞时,所述心肌细胞是指具有自律特性的心肌的细胞。另外,心肌细胞可以包含心肌祖细胞,可能包含具有产生形成搏动肌肉和电传导组织的心肌细胞和血管平滑肌的能力的细胞。该心肌细胞和心肌祖细胞可以相互混杂,另外也可以为经分离的心肌祖细胞。
[0160]
对于心肌细胞和心肌祖细胞而言,例如可以通过调查作为心肌标记物的心肌肌钙蛋白(ctnt或2型肌钙蛋白t)、α辅肌动蛋白2(actn2)、αmhc(αmyosin heavy chain,α肌球蛋白重链)、gata4、cxcr4、flk1、anp的表达量来了解是否诱导出该细胞。该心肌细胞可以是相较于其它细胞种类而言含有更高比例的心肌细胞的细胞群,优选为30%以上或50%以上为心肌细胞的细胞群。
[0161]
2.3本发明组合物的形态
[0162]
本发明组合物只要至少包含本发明肽即可,可以包含其它任意的合适的成分。
[0163]
具体而言,作为本发明组合物,可列举例如细胞培养用的培养基(液体培养基、固体培养基)。例如,可以向作为常规培养基的mem(最小必需培养基)、dmem(杜尔贝科改良伊戈尔培养基)、dmem/f12或对这些加以改良而得的培养基中添加本发明肽而制作本发明组合物。制作本发明组合物的培养基中可以根据期望添加血清、蛋白质(白蛋白、运铁蛋白、生长因子等)、氨基酸、糖类、维生素类、脂肪酸类、抗生素、以及对向着目标体细胞分化诱导有效的物质(例如体液因子)等。
[0164]
本发明组合物另外可以为包含本发明肽的体细胞分化诱导(促进)用试剂盒。本发明的试剂盒除了包含本发明肽以外还可以包含其它分化诱导用体液因子。本发明肽和其它分化诱导用体液因子可以保存在不同的容器中,也可以保存在同一容器中。
[0165]
本发明组合物只要能够以不丧失其分化诱导活性的状态保持本发明肽,则可以根据使用方式而包含医药上允许的各种载体。作为稀释剂、赋形剂等,优选通常用于肽药物的载体。虽然可根据本发明组合物的用途、形态而适当地有所不同,但是典型情况下可列举水、生理学缓冲液、各种有机溶剂。可以为合适浓度的醇(乙醇等)水溶液、甘油、橄榄油之类的不干性油。另外,可以为脂质体。或者,作为本发明组合物可含有的其它成分,可列举各种填充剂、增量剂、结合剂、润湿剂、表面活性剂、色素、香料、抗生素等。或者,可以含有其它公知的细胞分化诱导因子。通过将本发明肽与其它细胞分化诱导因子(视黄酸、激活蛋白、bfgf、vegf、bmp4等)组合使用,能够促进(增强)细胞分化诱导。
[0166]
关于本发明组合物的形态,没有特别限定。例如,可列举溶液状、悬浮状、半固体状、固体状、凝胶状。作为典型的形态,可列举例如液剂、悬浮剂、乳剂、气溶胶、泡沫剂、颗粒剂、粉末剂、片剂、胶囊、软膏、水凝胶剂等。另外,为了用于注射剂等,也可以制成在即将使用前溶解于生理盐水或合适的缓冲液(例如pbs)等而制备药液的冷冻干燥物、造粒物。
[0167]
需要说明的是,以本发明肽(主成分)和各种载体(副成分)为材料制备各种形态的药剂(组合物)的过程本身按照现有公知的方法进行即可。
[0168]
3本发明的体细胞的制造方法
[0169]
作为本发明,另外可列举体细胞的制造方法(以下称为“本发明制造方法”。),其包括使包含对fgf受体具有结合性的合成肽(以下称为“fgfr结合肽”。)的体液因子作用于多能干细胞的拟胚体的工序。
[0170]
作为上述fgfr结合肽,只要是本领域技术人员基于合适的实验结果而判断为对fgf受体具有结合性者就没有特别限制。优选与fgf受体中的fgfr1和/或fgfr3具有结合性的肽。关于与fgf受体的结合性,例如可以通过表面等离子共振法(surface plasmon resonance:spr)、elisa(enzyme-linked immunosorbent assay,酶联免疫测定)来确认。
[0171]
该fgfr结合肽适宜为由50个以下的氨基酸残基构成者,优选为由30~50或40~50
个氨基酸残基构成者。另外,更优选在分子结构上具有下述序列号50的氨基酸序列者。
[0172][0173]
作为具体的该fgfr结合肽,可列举例如本发明肽、p3、c19、dekafin1。
[0174]
fgfr结合肽例如可如下获得。使用合适的噬菌粒载体(例如pcomb3、pcantab5e、psex)制备噬菌体表面呈现肽文库。接着,将得到的噬菌体表面呈现文库与人fc片段混合,对fc进行负向选择。通过该操作,可以去除噬菌体文库中与fc结合的噬菌体。之后使噬菌体文库作用于fgfr1(fgf受体1)-fc,回收结合噬菌体。从回收的噬菌体中提取噬菌粒dna,对噬菌粒dna进行全面分析。由得到的克隆的氨基酸序列基于fmoc固相合成法等合成出肽。对于所合成的肽,使用上述表面等离子共振法、elisa等技术测定结合活性,基于其测定结果可以获得作为目标的fgfr结合肽。
[0175]
作为本发明制造方法中可以使用的fgfr结合肽以外的体液因子,根据作为对象的未分化细胞种类、目的(想要制造的分化细胞的种类)等而不同,可列举例如骨形成蛋白2(bmp2:bone morphogenetic protein-2)、骨形成蛋白4(bmp4:bone morphogenetic protein-4)、骨形成蛋白7(bmp7)、碱性成纤维细胞生长因子(bfgf:basic fibroblast growth factor,也称为成纤维细胞生长因子2(fgf2))、成纤维细胞生长因子4(fgf4:fibroblast growth factor 4)、成纤维细胞生长因子8(fgf8)、成纤维细胞生长因子10(fgf10)、肝细胞生长因子(hgf:hepatocyte growth factor)、血小板衍生生长因子bb(pdgf-bb:platelet-derived growth factor-bb)、wnt3a蛋白(wnt3a)、音猬因子(shh:sonic hedgehog)、血管内皮细胞生长因子(vegf:vascular endothelial growth factor)、转化生长因子β(tgf-β:transforming growth factor-β)、激活蛋白a(activin a)、抑癌蛋白m(osm:oncostatin m)、角质细胞生长因子(kgf:keratinocyte growth factor、也称为成纤维细胞生长因子7(fgf7))、胶质细胞源性神经营养因子(gdnf:glial-cell derived neurotrophic factor)、iwp-3(cas no.687561-60-0)、运铁蛋白、上皮生长因子(egf;epidermal growth factor)等。这些体液因子可以是添加于培养基的,也可以是培养中的细胞所分泌的。该体液因子可以为1种,也可以为2种以上。
[0176]
另外,在生物体内(in vivo)对未分化细胞(例如移植到规定部位的ips细胞、es细胞等干细胞)进行分化诱导时,可以将适当量的本发明组合物(本发明肽)以例如液剂形式对患部(即生物体内)供给期望量。或者,可以以片剂等固体形态、软膏等凝胶状或水凝胶状给药于患部(例如烧烫伤、创伤之类的身体表面)。由此,能够提高(促进)存在于生物体内、典型情况下为患部或其周边的欲使其分化的目标未分化细胞(干细胞等)的分化诱导效率。需要说明的是,添加量和添加次数可根据欲进行分化诱导的细胞的种类、存在部位等条件而不同,因此没有特别限定。
[0177]
通过将本发明组合物(本发明肽)给药于生物体内需要其的部位,从而能够通过其分化诱导活性实现神经再生能力、血管新生能力、皮肤再生能力、器官再生能力等的提高。另外,由于可促进向着目标细胞种类、器官(脏器)的分化,从而能够实现例如皮肤组织的改善、移植脏器的早期定植、交通事故等物理损伤导致的创伤部、烧烫伤部的早期修复。另外,例如也可以作为通过再生医疗方法治疗帕金森病、脑梗塞、阿尔茨海默病、脊髓损伤所致的身体麻痹、脑挫伤、肌萎缩性侧索硬化、亨廷顿病、脑肿瘤、视网膜变性等神经疾病的辅助性药剂组合物来使用。
[0178]
进而,可以由作为材料的干细胞(ips细胞、es细胞)的培养细胞株高效地生产目标分化细胞(进而,分化而成的组织、器官)。即,通过采用这里公开的生产方法(在体外生产分化细胞的方法、或在体外生产由该分化细胞形成的组织体的方法),能够通过将在生物体外(体外)高效地生产的目标分化细胞(或由该分化细胞形成的组织、器官)导入需要修复、再生的患部(即患者的生物体内)而高效地进行该修复、再生。
[0179]
本发明制造方法包括使包含fgfr结合肽的体液因子作用于上述多能干细胞的拟胚体的工序,可以按照与期望体细胞种类等相应的分化诱导方案利用常规方法实施。该分化诱导通常通过培养细胞来进行,作为所述培养方法,例如可以根据由多能干细胞分化诱导的期望细胞(例如心肌细胞)从粘附培养法、漂浮培养法、悬浮培养法等中适当选择。
[0180]
作为可利用本发明制造方法制造的体细胞,可列举例如上述体细胞。其中,利用本发明制造方法制造中胚层系细胞、特别是心肌细胞时,优选使用本发明肽作为fgfr结合肽。
[0181]
例如,通过本发明制造方法得到的体细胞为心肌细胞时,可以将该心肌细胞作为动物(优选为人)心脏疾病的治疗剂使用。作为心脏疾病的治疗方法,例如可以如下进行:将得到的心肌细胞悬浮于生理盐水等并直接给药于患者心脏的心肌层;或者将得到的心肌细胞片状化并贴付于患者的心脏。前者的情况下,可以给药细胞本身,优选可以与促进存活的支架材料一起给药。这里“支架材料”可例示出胶原蛋白等生物体来源的成分、代替其的聚乳酸等合成聚合物,但是不限于这些。给药心肌片时,可通过以包覆期望部分的方式进行配置来实现。在此,以包覆期望部分的方式进行配置可以使用该领域中的公知技术来进行。配置时,期望部分较大的情况下可以以卷绕组织的方式来配置。另外就给药而言,为了得到期望效果,也可以对同一部分进行多次配置。进行多次配置时,理想的是间隔足以使期望细胞在组织上存活并进行血管新生的时间来进行。
[0182]
这样治疗心脏疾病的机制可以是由心肌片存活产生的效果,或者可以是不依赖于细胞存活的间接性作用(例如分泌诱因物质而将接受者来源细胞动员到损伤部位的效果)。在心脏疾病的治疗中使用心肌片的情况下,除了包含心肌细胞以外还可以包含胶原蛋白、纤连蛋白、层粘连蛋白等细胞支架材料(scaffold)。或者,除了包含心肌细胞以外还可以包含任意细胞种类(多种也可以)。本发明中可治疗的心脏疾病可列举心力衰竭、缺血性心脏病、心肌梗塞、心肌病、心肌炎、肥厚型心肌病、扩张型肥大型心肌病、扩张型心肌病等疾病或由障碍导致的缺损等,但是不限于这些。
[0183]
本发明中,心脏疾病的治疗中使用的心肌细胞的细胞数只要是所给药的心肌细胞或心肌片在心脏疾病的治疗中可发挥效果的量就没有特别限制,可根据患部的大小、体型大小适当增减而制备。
[0184]
4本发明的、从多能干细胞向着体细胞分化诱导的方法
[0185]
作为本发明,另外可列举从多能干细胞向着体细胞分化诱导的方法(以下称为“本发明分化诱导方法”。),其包括使包含fgfr结合肽的体液因子作用于多能干细胞的拟胚体的工序。
[0186]
作为上述fgfr结合肽,可列举与上述相同的肽。另外,fgfr结合肽以外的体液因子、多能干细胞、体细胞等术语的概念与上述同义。
[0187]
本发明分化诱导方法除了使用包含fgfr结合肽的体液因子以外可利用常规方法实施。即,按照与期望体细胞的种类等相应的分化诱导方案,在适当的时期使包含fgfr结合
肽的体液因子作用于多能干细胞的拟胚体,由此能够实施本发明分化诱导方法。
[0188]
具体而言,例如在从多能干细胞向着心肌细胞进行分化诱导时,可以按照图1(方案2、5~9)所示的分化诱导方案实施本发明分化诱导方法。图1中,方案1示出作为现有技术的专利文献1的心肌细胞分化诱导方案(以往方案)。
[0189]
如图1所示,以往方案中在开始诱导1天后使激活蛋白a、bmp4和bfgf之类的体液因子作用于多能干细胞,与此相对地,本发明分化诱导方法中上述的bmp4和bfgf并非必需,仅通过本发明肽和激活蛋白a就能够向着心肌细胞分化诱导。因此,本发明分化诱导方法能够在不使用bmp4、bfgf之类的较昂贵的蛋白的情况下使用较廉价的中等分子的本发明肽高效地向着体细胞进行分化诱导。
[0190]
另外,本发明分化诱导方法可以在开始诱导起1天后与以往方案同样地加入bfgf等其它体液因子而实施。由此通常能够更高效地向着体细胞进行诱导。
[0191]
更具体而言,本发明分化诱导方法(特别是向着心肌细胞进行分化诱导的方法)例如可包括下述工序。
[0192]
(1)从多能干细胞形成类胚体的工序
[0193]
优选在将形成了集落的多能干细胞解离成单细胞后形成类胚体。使多能干细胞解离的工序是使相互粘附成团的细胞解离(分离)成单个细胞。作为使多能干细胞解离的方法,可列举例如以力学方式解离的方法、使用具有蛋白酶活性和胶原酶活性的解离溶液(例如accutase(tm)和accumax(tm)等)或仅具有胶原酶活性的解离溶液的解离方法。优选利用下述方法:使用具有蛋白酶活性和胶原酶活性的解离溶液(特别优选accumax)将多能干细胞解离。
[0194]
作为形成类胚体的方法,可例示出:使用表面未经以提高与细胞的粘附性为目的的人工处理(例如,利用基质胶(商品名)等胞外基质、胶原蛋白、明胶、层粘连蛋白、硫酸乙酰肝素蛋白聚糖或巢蛋白的包被处理)的培养皿或使用表面经过人工粘附抑制处理(例如利用聚甲基丙烯酸羟乙酯(poly-hema)的包被处理)的培养皿悬浮培养经解离的多能干细胞。
[0195]
在诱导心肌细胞的目的之下,用于形成类胚体的合适的多能干细胞数例如为1000个至16000个,优选为2000个至8000个。
[0196]
(2)在培养液中培养类胚体的工序
[0197]
本工序中使用的培养液可以通过以用于动物细胞培养的培养基为基础培养基并向其中添加本发明肽等fgfr结合肽、激活蛋白a等来制备。
[0198]
作为基础培养基,包括例如imdm培养基、medium 199培养基、伊戈尔最小必需培养基(emem)培养基、αmem培养基、杜尔贝科改良伊戈尔(dmem)培养基、ham’s f12培养基、rpmi 1640培养基、fischer’s培养基、neurobasal培养基(life technologies)、stempro34(invitrogen)和这些的混合培养基等。培养基可以包含血清或无血清。根据需要,培养基可以包含例如白蛋白、运铁蛋白、knockout血清替代物(ksr)(es细胞培养时,fbs的血清代替物)、n2补充剂(invitrogen)、b27补充剂(invitrogen)、脂肪酸、胰岛素、胶原蛋白前体、微量元素、2-巯基乙醇、1-硫醇甘油等1种以上血清代替物,还可包含脂质、氨基酸、l-谷氨酰胺、glutamax(invitrogen)、非必需氨基酸、维生素、生长因子、低分子化合物、抗生素、抗氧化剂、丙酮酸、缓冲剂、无机盐类等1种以上物质。优选的基础培养基为含有运铁蛋白、1-硫
醇甘油、l-谷氨酰胺、抗坏血酸的stempro34。
[0199]
作为本工序中的本发明肽等fgfr结合肽的浓度,根据本发明肽、fgfr结合肽的种类等而不同,例如1pm~100μm的范围内是合适的,优选50pm~100nm的范围内,更优选50pm~5nm的范围内。
[0200]
本工序中使用激活蛋白a的情况下,作为该激活蛋白a的浓度,例如1ng/ml~100ng/ml的范围内是适当的,优选1ng/ml~50ng/ml的范围内,更优选10ng/ml~20ng/ml的范围内。
[0201]
本工序中使用bfgf的情况下,作为该bfgf的浓度,例如1ng/ml~100ng/ml的范围内是适当的,更优选1ng/ml~20ng/ml的范围内。
[0202]
本工序中使用bmp4的情况下,作为该bmp4的浓度,例如1ng/ml~100ng/ml的范围内是适当的,优选1ng/ml~50ng/ml的范围内,更优选1ng/ml~20ng/ml的范围内。
[0203]
培养条件如下所述。
[0204]
培养温度适宜为约30~40℃,优选为约37℃,期望在低氧条件下进行。在此,低氧条件是指氧分压低于大气中的氧分压(20%)的条件,可列举例如1%至15%之间的氧分压。优选为5%。可在含有co2的空气氛围下进行培养,co2浓度优选为约2~5%。
[0205]
关于培养期,可列举例如1天以上且7天以下,考虑到心肌细胞的建立效率,优选为1天以上且5天以下、1.5天以上且5天以下、2天以上且4天以下。
[0206]
(3)在含有vegf和wnt抑制剂的培养液中培养、通过再聚集而形成类胚体的工序
[0207]
通过再聚集而形成类胚体时,所使用的细胞数只要为同种细胞相互粘附而能制备细胞块的细胞数就没有特别限定,适宜为1000个以上且20000个以下细胞,优选为10000个。培养时,与工序(1)同样地,优选在表面未经以提高细胞粘附性为目的的人工处理的培养容器或使用表面经过人工粘附抑制处理的培养容器进行悬浮培养。
[0208]
本工序中使用的培养液可以通过以用于动物细胞培养的培养基为基础培养基并向其中添加vegf和wnt抑制剂来制备。作为基础培养基,可列举例如imdm培养基、medium 199培养基、伊戈尔最小必需培养基(emem)培养基、αmem培养基、杜尔贝科改良伊戈尔(dmem)培养基、ham’s f12培养基、rpmi 1640培养基、fischer’s培养基、neurobasal培养基(life technologies)、stempro34(invitrogen)和这些的混合培养基等。培养基可以包含血清或无血清。根据需要,培养基可以包含例如白蛋白、运铁蛋白、knockout血清替代物(ksr)(es细胞培养时,fbs的血清代替物)、n2补充剂(invitrogen)、b27补充剂(invitrogen)、脂肪酸、胰岛素、胶原蛋白前体、微量元素、2-巯基乙醇、1-硫醇甘油等1种以上血清代替物,还可含有脂质、氨基酸、l-谷氨酰胺、glutamax(invitrogen)、非必需氨基酸、维生素、生长因子、低分子化合物、抗生素、抗氧化剂、丙酮酸、缓冲剂、无机盐类等1种以上物质。优选的基础培养基为含有运铁蛋白、1-硫醇甘油、l-谷氨酰胺、抗坏血酸的stempro34。
[0209]
这里,“wnt抑制剂”是指抑制从wnt与受体结合直至β-连蛋白累积的信号转导的物质,只要是抑制与作为受体的frizzled家族结合的物质或促进β-连蛋白分解的物质就没有特别限定,可例示例如dkk1蛋白(例如人类情况下,ncbi登录号:nm_012242)、骨硬化蛋白(例如人类情况下,ncbi的登录号:nm_025237)、iwr-1(merck millipore)、iwp-2(sigma-aldrich)、iwp-3(sigma-aldrich)、iwp-4(sigma-aldrich)、pnu-74654(sigma-aldrich)、
xav939(sigma-aldrich)和这些的衍生物等。其中,优选iwp-3或iwp-4。
[0210]
作为培养液中的iwp-3或iwp-4等wnt抑制剂的浓度,只要为能抑制wnt的浓度就没有特别限制,例如1nm~50μm的范围内是适当的,优选10nm~25μm的范围内,更优选100nm~10μm的范围内。
[0211]
作为本工序中使用的vegf的浓度,例如1ng/ml~100ng/ml的范围内是适当的,优选1ng/ml~50ng/ml的范围内,更优选1ng/ml~20ng/ml的范围内。
[0212]
本工序中可以向基本培养基中进一步添加bmp抑制剂和/或tgfβ抑制剂。
[0213]“bmp抑制剂”可例示出脊索发生素(chordin)、头蛋白、卵泡抑制素等蛋白性抑制剂、多索啡(即,6-[4-(2-哌啶-1-基-乙氧基)苯基]-3-吡啶-4-基-吡唑并[1,5-a]嘧啶)、其衍生物、和ldn-193189(即,4-(6-(4-(哌嗪-1-基)苯基)吡唑并[1,5-a]嘧啶-3-基)喹啉)。多索啡和ldn-193189有市售,分别可由sigma-aldrich公司和stemgent公司获得。可优选多索啡。
[0214]
作为培养液中的多索啡等bmp抑制剂的浓度,只要为能抑制bmp的浓度就没有特别限制,例如1nm~50nm的范围内是适当的。
[0215]“tgfβ抑制剂”是指抑制从tgfβ与受体结合直至smad的信号转导的物质,只要是抑制与作为受体的alk家族结合的物质或抑制alk家族对smad的磷酸化的物质就没有特别限定,可列举例如lefty-1(作为ncbi登录号,可例示小鼠:nm_010094、人:nm_020997)、sb431542、sb202190(以上参照r.k.lindemann et al.,mol.cancer,2003,2:20)、sb505124(glaxosmithkline)、npc30345、sd093、sd908、sd208(scios)、ly2109761、ly364947、ly580276(lilly research laboratories)、a-83-01(wo2009146408)和这些的衍生物。优选为sb431542。
[0216]
作为培养液中的sb431542等tgfβ抑制剂的浓度,只要是能抑制alk5的浓度就没有特别限制,例如1nm~50nm的范围内是适当的。
[0217]
培养条件如下所述。
[0218]
培养温度适宜为约30~40℃,优选为约37℃,期望在低氧条件下进行。在此,低氧条件是指氧分压低于大气中的氧分压(20%)的条件,在此,低氧条件是指氧分压低于大气中的氧分压(20%)的条件可列举例如1%至15%之间的氧分压。优选为5%。可在含有co2的空气氛围下进行培养,co2浓度优选为约2~5%。
[0219]
关于培养期,由于长期培养对于心肌细胞的建立没有影响,因此不必特别设置上限,优选培养4天以上。由此,通过再聚集而形成的类胚体会分化为心肌细胞。
[0220]
(4)在含有vegf和bfgf的培养液中培养的工序
[0221]
本工序中使用的培养液可通过以用于动物细胞培养的培养基为基础培养基并向其中添加vegf和bfgf来制备。作为基础培养基,可列举例如imdm培养基、medium 199培养基、伊戈尔最小必需培养基(emem)培养基、αmem培养基、杜尔贝科改良伊戈尔(dmem)培养基、ham’s f12培养基、rpmi1640培养基、fischer’s培养基、neurobasal培养基(life technologies)、stempro34(invitrogen)和这些的混合培养基等。培养基可以包含血清或无血清。根据需要,培养基可以包含例如白蛋白、运铁蛋白、knockout血清替代物(ksr)(es细胞培养时,fbs的血清代替物)、n2补充剂(invitrogen)、b27补充剂(invitrogen)、脂肪酸、胰岛素、胶原蛋白前体、微量元素、2-巯基乙醇、1-硫醇甘油等1种以上血清代替物,还可
含有脂质、氨基酸、l-谷氨酰胺、glutamax(invitrogen)、非必需氨基酸、维生素、生长因子、低分子化合物、抗生素、抗氧化剂、丙酮酸、缓冲剂、无机盐类等1种以上物质。优选的基础培养基为含有运铁蛋白、1-硫醇甘油、l-谷氨酰胺、抗坏血酸的stempro34。
[0222]
作为本工序中使用的vegf的浓度,例如1ng/ml~100ng/ml的范围内是适当的,优选1ng/ml~50ng/ml的范围内,更优选1ng/ml~10ng/ml的范围内。
[0223]
作为本工序中使用的bfgf的浓度,例如1ng/ml~100ng/ml的范围内是适当的,优选1ng/ml~50ng/ml的范围内,更优选1ng/ml~10ng/ml的范围内。
[0224]
培养条件如下所述。
[0225]
培养温度适宜为约30~40℃,优选为约37℃,期望在低氧条件下进行。在此,低氧条件是指氧分压低于大气中的氧分压(20%)的条件,在此,低氧条件是指氧分压低于大气中的氧分压(20%)的条件,可列举例如1%至15%之间的氧分压。优选为5%。可在含有co2的空气氛围下进行培养,co2浓度优选为约2~5%。
[0226]
关于培养期,由于长期培养对于心肌细胞的建立没有影响,因此不必特别设置上限,优选培养12天以上。通过将工序(3)中得到的细胞进一步按照工序(4)进行培养,优选可提高向着心肌细胞的分化效率。
[0227]
实施例
[0228]
以下示出实施例来进一步具体地说明本发明,但是本发明不受下述实施例任何限定。
[0229]
[实施例1]本发明肽的合成
[0230]
(1)噬菌体表面呈现肽文库的制备
[0231]
首先,使用噬菌粒载体pcomb3(参照barbas,c.et al.,assembly of combinatorial antibody libraries on phage surfaces:the gene iii site.,proc.national acad.sci.,88,7978-7982(1991),fujii,i.et al.,evolving catalytic antibodies in a phage-displayed combinatorial library.,nat.biotechnol.16,463-467(1998))制备7个噬菌体表面呈现肽文库(δpta-10rc、δpta-12rc-1、δpta-12rc-2、δpta-20rc、δpta-6r-loop11-c、mfliv-8r-δpta-8rc-1、mfliv-8r-δpta-8rc-2)(图2)。构成该文库的肽链分别具有下述表4所示的氨基酸序列。
[0232]
表4
[0233][0234]
这些肽链是以由公知序列(aelaaleaelaalegggggggklaalkaklaalka;序列号51)构成的肽yt-1的氨基酸序列为基础而构成的。表中的氨基酸x是被认为在构成hlh(螺旋-环-螺旋)结构的各由14个氨基酸残基构成的2条α-螺旋中与立体结构保持无关的氨基酸,
可置换成任意氨基酸。另外,构成文库的各肽链具有添加于n末端侧的α-螺旋的n末端的2个肽ca和添加于c末端侧的α-螺旋的c末端的1个氨基酸c。需要说明的是,表4中,δpta-6r-loop11-c为使yt-1的氨基酸的环部分延伸、随机化的氨基酸序列。
[0235]
(2)生物淘选
[0236]
将上述所得到的噬菌体表面呈现文库混合,进行针对fgfr1(fgf受体1)-fc嵌合物的生物淘选。首先,作为负向选择,在200μl的pbs(ph7.4)中使10
12
cfu的肽呈递噬菌体作用于固定化有higg fc的板,回收不与higg fc结合的噬菌体。将回收的噬菌体文库与100nm的fgfr3溶液混合,在4℃下反应过夜(表5:淘选阶段1)。
[0237]
表5
[0238][0239]
反应后,用蛋白酶a修饰磁珠捕捉结合性噬菌体,用pbs-t洗涤3次后,用gly-hcl(ph2.0)洗脱结合噬菌体。将其用2m tris中和,使其感染大肠杆菌。培养4小时后加入辅助性噬菌体,用一晚时间使大肠杆菌产生噬菌体。接着由该培养上清制备噬菌体溶液。将制备的噬菌体溶液与fgfr3溶液混合,在4℃下反应过夜(表5:淘选阶段2)。反应后,将结合噬菌体洗脱。将同样制备的噬菌体溶液与fgfr3溶液混合,在4℃下反应1小时(表5:淘选阶段3)。反应后,将结合噬菌体洗脱。将该操作进一步重复2次,在淘选阶段5之后,将结合噬菌体洗脱。需要说明的是,随着阶段的叠加而增加利用pbs-t洗涤的次数(表5)。另外,求出各阶段所获得噬菌体的效价(滴度)。噬菌体的效价由在37℃培养与噬菌体接触后的大肠杆菌tg1株一晚上而得的菌落数求出。将其结果示于表5的右端。
[0240]
(3)氨基酸序列的确定
[0241]
如图3<投入噬菌体(阶段5)>所示,使淘选后洗脱而得的噬菌体文库作用于固定化有人igg fc的板,回收未结合的噬菌体而实施负向选择。之后使噬菌体文库作用于制备成100nm、10nm、1nm的各浓度的fgfr1。然后回收结合噬菌体。提取所回收的噬菌体的噬菌粒dna,按照illumina公司的miseq用方案进行样品制备,实施噬菌粒dna的全面分析。在得到的序列中,选择出序列出现比例高的23种序列(表6)。
[0242]
表6
[0243][0244]
(4)肽的合成和与fgf受体的结合性的确认
[0245]
从上述所得到的克隆的氨基酸序列中选择1种,合成100nx(x为9:序列号9,下同。)的肽。基于fmoc固相合成法合成。为了测定肽的结合活性,按照spr装置biacore t200(ge healthcare公司)的操作指南使用胺偶联法将fgfr1作为配体固定化于装置的传感器芯片cm5。另外,为了确认是否与其它种类的fgfr结合,一起准备了固定化有fgfr2、fgfr3的传感器芯片。作为参照,将乙醇胺固定化,将样品作为分析物,进行测定。
[0246]
测定全部在25℃下进行,作为运行缓冲液,使用hbs-ep 。将溶解有肽的运行缓冲液注入固定化有各种fgfr的传感器芯片cm5(流速30μl/分钟、2分钟),然后通入运行缓冲液3分钟而使肽解离。在所得到的传感器图上对反应式直接进行曲线拟合,通过非线性最小二乘法计算速率常数。通过使用biacore t200 evaluation software(ge healthcare公司)的动力学分析来计算解离常数。分析中使用1:1结合模型。将其结果示于图4。
[0247]
如图4所示,确认100nx对fgfr具有高结合性。
[0248]
[实施例2]从ips细胞向着心肌细胞的分化诱导(hbd-100nx的评价)
[0249]
然后,合成使硫酸乙酰肝素结合肽wqpprarig(序列号49)融合于100nx的肽(hbd-100nx),尝试将其用于从ips细胞向着心肌细胞的分化诱导系统。ips细胞使用“ips cell-kac、hfb(n)”(kac公司、制品编号;ips-f001)(以下记作ips-hfb)。首先,在开始分化诱导时
(第0天),将开始分化诱导前7天(第-7天)接种在100φ培养皿中的ips-hfb用4ml的pbs洗涤。添加3ml的0.5xtryple select,在37℃下静置3分钟。确认细胞成为球状后去除0.5xtryple select。进一步用4ml的pbs洗涤,添加4ml分化诱导用培养基(添加了1% l-谷氨酰胺(invitrogen)、150μg/ml运铁蛋白(roche)、50μg/ml抗坏血酸(sigma)、3.9
×
10-3
%mtg(1-硫代甘油)(sigma)、10μm rock抑制剂(y-27632、wako)、5%基质胶(corning)、和2ng/ml bmp4(r&d)的stempro34(invitrogen))。之后用细胞刮刀剥离细胞,通过移液操作分离细胞。测定细胞数,以8000个/孔的方式接种于96孔圆底平板,在37℃、5%co2条件下进行培养。
[0250]
次日(第1天),以100μl/孔添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml bmp4、5ng/ml bfgf(r&d)和6ng/ml激活蛋白a(r&d)的stempro34(以往方案;图1中的方案1)。
[0251]
另一方面,对于肽样品作用组,以100μl/孔添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、0.05μm或0.5μm hbd-100nx、以及6ng/ml激活蛋白a(r&d)的stempro34(本发明分化诱导方法;图1中的方案2)。进而,作为对照组,准备以100μl/孔添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml bmp4、和6ng/ml激活蛋白a(r&d)的stempro 34的组(图1中的方案3);以100μl/孔添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、和6ng/ml激活蛋白a(r&d)的stempro34的组(图1中的方案4)。之后3天在37℃、5%co2条件下进行培养。
[0252]
接着(第4天),将得到的eb以200g离心分离3分钟,去除培养基。添加pbs,以200g离心3分钟,去除上清。添加accumax,在37℃下静置5分钟后通过移液操作而解离成单细胞,添加2ml加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml vegf和1μm iwp-3的stempro34(第4天心肌诱导用培养基),以200g离心3分钟后去除上清。将细胞悬浮于第4天心肌诱导用培养基并测定细胞数,然后以10000个/孔接种于96孔圆底平板。然后在37℃、5%co2条件下培养4天。
[0253]
接着(第8天),将细胞块一起从96孔板移动到24孔板(每孔中细胞块为8个以下),在细胞块自然沉降后去除培养基,添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml vegf和5ng/ml bfgf的stempro34(第8天心肌诱导用培养基),使细胞自然沉降,去除上清。添加第8天心肌诱导用培养基后,在37℃、5%co2条件下进行培养。此时,2天1次地交换为同种条件的培养基。
[0254]
培养后对得到的细胞进行评价,结果,方案1或3的情况下在第16天~第22天一部分细胞块微弱地搏动或未观察到搏动,与此相对地,方案2的情况下第16天~第22天细胞块整体地搏动,80%以上的细胞块实现了搏动。
[0255]
另外,为了确认是否已分化为心肌细胞,在第23天通过定量实时pcr(rt-qpcr)调查作为心肌标记的ctnt和辅肌动蛋白的表达量。具体而言,利用qiagen rneasy kit(qiagen)回收总rna,将rna利用cdna reverse transcription kit(thermo fisher scientific公司制)逆转录而制备cdna。由得到的cdna,使用特异性扩增ctnt、辅肌动蛋白的引物和与各基因特异性结合的探针实施基于taqmanpcr法的实时pcr。测定gapdh量作为内标对照。将其结果示于图5。
[0256]
如图5所示,使用本发明肽(hbd-100nx)的方案2的情况下,ctnt和actn2的表达量与现有方案1(第1天;添加激活蛋白a、bmp4、bfgf这3种)和作为对照的方案3(第1天;仅激活蛋白a)、方案4(第1天;添加激活蛋白a、bmp4这2种)相比显著增加。另外,基因表达量呈肽浓度依赖性增加。
[0257]
进而,在第23天对辅肌动蛋白进行免疫染色,观察是否确认到心肌细胞特异性的肌节结构。具体而言,将第23天的细胞块通过胶原酶处理和accumax处理单细胞化,以10000个细胞/孔接种于涂覆了纤连蛋白的24孔板。次日将细胞用4%多聚甲醛溶液固定化,用0.1% triton-x/pbs进行透性化处理。之后用含有5%驴血浆、1%bsa的pbs进行封闭处理。用0.01%triton-x/pbs洗涤后,添加小鼠抗辅肌动蛋白抗体(sigma),在室温下反应60分钟。之后用0.01%triton-x/pbs洗涤,添加alexa594修饰抗小鼠抗体(abcam),在室温下反应60分钟,用基恩士bz-x810观察细胞的荧光。将其结果示于图6和图7。
[0258]
如图6、7所示,使用了本发明肽(hbd-100nx)的方案中确认了显著的肌节结构,观察到形成了高功能的心肌细胞。
[0259]
[实施例3]从ips细胞向着心肌细胞的分化诱导(100nx-dimer的评价)
[0260]
然后,对使100nx二聚体化而成的肽(100nx-dimer)进行评价。作为对照,使用本发明肽的单体(100nx-monomer)。
[0261]
与实施例2同样地实施心肌细胞的分化诱导,将第1天使用的培养基按照下述进行变更。肽样品作用组使用加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、0.05μm 100nx-dimer或100nx-monomer、以及6ng/ml激活蛋白a(r&d)的stempro34(本发明分化诱导方法;图1中的方案5、6)。
[0262]
培养后,对得到的细胞进行了评价,结果方案5的情况下在第11天确认到细胞块的搏动,方案6的情况下在第16天及以后确认到搏动。另外,为了确认是否已分化为心肌细胞,在第23天通过定量实时pcr(rt-qpcr)调查作为心肌标志物的ctnt和辅肌动蛋白的表达量。具体而言,利用qiagen rneasy kit(qiagen)回收总rna,利用cdna reverse transcription kit(thermo fisher scientific公司制)对rna进行逆转录而制备cdna。由得到的cdna,使用特异性扩增ctnt、辅肌动蛋白的引物和与各基因特异性结合的探针实施基于taqmanpcr法的实时pcr。测定gapdh量作为内标对照。将其结果示于图8。
[0263]
如图8所示,使用本发明肽(100nx-dimer)的方案5的情况下,ctnt和actn2的表达量与现有方案1(第1天;添加了激活蛋白a、bmp4、bfgf这3种)和作为对照的方案3(第1天;仅激活蛋白a)、方案4(第1天;添加了激活蛋白a、bmp4这2种)或方案6相比显著增加。
[0264]
[实施例4]从ips细胞向着心肌细胞的分化诱导(混合肽样品和bfgf的条件的评价)
[0265]
接下来对本发明肽和bfgf同时起作用的方法进行评价。
[0266]
与实施例2同样地实施心肌分化诱导,将第1天使用的培养基按照下述进行变更。对于肽样品作用组,使用添加有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、5ng/ml bfgf、0.05-5μm hbd-100nx或5μm 100nx-dimer或5μm 100nx-monomer、以及6ng/ml激活蛋白a(r&d)的stempro34(本发明分化诱导方法;图1中的方案7、8、9)。进而,作为对照组,准备了添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、5ng/ml bfgf和6ng/ml激活蛋白a(r&d)的stempro34的组(图1中的
方案10)。
[0267]
培养后,对得到的细胞进行了评价,结果方案7、8、9、10均在第10天~第11天及以后确认到细胞块的搏动,组间未确认到搏动情况的差异。另一方面,为了确认是否已分化为心肌细胞,在第23天通过定量实时pcr(rt-qpcr)调查了作为心肌标记的ctnt和辅肌动蛋白的表达量。具体而言,利用qiagen rneasy kit(qiagen)回收总rna,利用cdna reverse transcription kit(thermo fisher scientific公司制)对rna进行逆转录而制备cdna。从得到的cdna,使用特异性扩增ctnt、辅肌动蛋白的引物和与各基因特异性结合的探针实施基于taqmanpcr法的实时pcr。作为内标对照,对45s rrna量进行测定。将其结果示于图9和图10。
[0268]
如图9、图10所示,将本发明肽(hbd-100nx)与bfgf一起使用时,ctnt和actn2的表达量呈肽浓度依赖性上升。另外,本发明肽(hbd-100nx、100nx-dimer、100nx-monomer)与现有方案1相比均使基因表达量显著上升,hbd-100nx的情况下显示出最高值。
[0269]
由此表明,将100nx与bfgf组合使用能够促进向着心肌细胞的分化诱导或促进心肌的成熟化。
[0270]
[实施例5]噬菌体表面呈现肽文库的制备
[0271]
首先,使用噬菌粒载体pcomb3(参照barbas,c.et al.,assembly of combinatorial antibody libraries on phage surfaces:the gene iii site.,proc.national acad.sci.,88,7978-7982(1991),fujii,i.et al.,evolving catalytic antibodies in a phage-displayed combinatorial library.,nat.biotechnol.16,463-467(1998))制备6个噬菌体表面呈现肽文库。构成该文库的肽链分别具有表7所示的氨基酸序列。这些肽链是以公知序列(aelaaleaelaalegggggggklaalkaklaalka;序列号51)构成的肽yt-1的氨基酸序列为基础构成的。表中的氨基酸x是被认为在构成hlh(螺旋-环-螺旋)结构的各由14个氨基酸残基构成的2条α-螺旋中与立体结构保持无关的氨基酸,可置换为任意氨基酸。另外,构成文库的各肽链具有添加于n末端侧的α-螺旋的n末端的2个肽ca和添加于c末端侧的α-螺旋的c末端的1个氨基酸c。需要说明的是,表7中,δpta-6r-loop11-c为使yt-1的氨基酸的环部分延伸、随机化的氨基酸序列。
[0272]
表7
[0273][0274]
[实施例6]酵母表面呈现肽文库的制备
[0275]
使用酵母表达用质粒pyd11-bxxn(参照ramanayake mudiyanselage t.m.r.et al.,an immune-stimulatory helix-loop-helix peptide:selective inhibition of ctla-4-b7 interaction,acs chem.biol.,15,360-368(2020))制备6个酵母表面呈现肽文
库。构成该文库的肽链分别具有表8所示的氨基酸序列。这些肽链是以由公知序列(aelaaleaelaalegggggggklaalkaklaalka;序列号51)构成的肽yt-1的氨基酸序列为基础构成的。表中的氨基酸x和z是被认为在构成hlh(螺旋-环-螺旋)结构的各由14个氨基酸残基构成的2条α-螺旋中与立体结构保持无关的氨基酸,由ndk、nnk、bns中的任意3个碱基决定的任意氨基酸。另外,构成文库的各肽链具有添加于n末端侧的α-螺旋的n末端的2个肽ca和添加于c末端侧的α-螺旋的c末端的2个氨基酸ac。需要说明的是,表7中,δpta-6r-loop11-c、δikmnt-loop11-c、δpta-6r-δikmnt-loop11c为使yt-1的氨基酸的环部分延伸、随机化的氨基酸序列。
[0276]
表8
[0277][0278]
[实施例7]用于获得fgfr3结合肽的生物淘选
[0279]
将实施例5中得到的噬菌体表面呈现文库混合,进行针对fgfr3(fgf受体3)-fc嵌合物的生物淘选。首先,作为负向选择,在200μl的pbs(ph7.4)中使10
12
cfu的肽呈递噬菌体作用于固定化有higg fc的板,回收不与higg fc结合的噬菌体。将回收的噬菌体文库与100nm的fgfr3溶液混合,在4℃下反应过夜(表9.淘选阶段1)。反应后,用蛋白酶a修饰的磁珠捕捉结合性噬菌体,用pbs-t洗涤3次后,用gly-hcl(ph 2.0)洗脱结合噬菌体。将其用2m tris中和,使其感染大肠杆菌(tg1株)。培养4小时后,加入辅助性噬菌体,用一晚时间使大肠杆菌(tg1株)产生噬菌体。接着从该培养上清中制备噬菌体溶液。将制备的噬菌体溶液与fgfr3溶液混合,在4℃下反应过夜(表9.淘选阶段2)。反应后,将结合噬菌体洗脱。将同样制备的噬菌体溶液与fgfr3溶液混合,在4℃下反应1小时(表9.淘选阶段3)。反应后,将结合噬菌体洗脱。进一步重复该操作,在淘选阶段4之后,将结合噬菌体洗脱。需要说明的是,随着阶段的叠加而增加利用pbs-t洗涤的次数(表9)。另外,求出各阶段获得的噬菌体的效价(滴度)。噬菌体的效价由在37℃培养与噬菌体接触后的大肠杆菌tg1株一晚上而得到的菌落数求出。将其结果示于表9的右端。
[0280]
表9
[0281][0282]
[实施例8]用于获得fgfr2结合肽的生物淘选
[0283]
利用磁性细胞分选(magnetic-activated cell sorting:macs),从实施例5中得到的酵母表面呈现文库中筛选与fgfr2(fgf受体2)结合的酵母克隆。首先,将酵母表面呈现肽文库和fgfr2-fc融合蛋白混合,然后加入标记有与fc部分结合的蛋白a的磁珠。之后上样到磁性架所具备的ls柱中。为了去除不与fgfr2结合的酵母细胞,使7ml的pbsm流过ls柱2次。然后将ls柱从磁性架拆下,通入sdcaa培养基而回收fgfr2结合性酵母克隆,对其进行培养。将上述操作作为1个阶段,总计实施3个阶段(表10)。接着,从用macs回收的酵母中,使用facs(fluorescence-activated cell sorting,荧光激活细胞分选)筛选结合活性高的酵母克隆。使fgfr2-fc和小鼠抗flag抗体与酵母文库结合,之后使抗小鼠igg-alexa488和抗人fc抗体-alexa647进行结合。由于hlh肽的c末端表达有flag标签,因此可以由alexa488的荧光强度检测肽的呈递量。另外,可以由alexa647的荧光强度检测与fgfr2的结合。因此,用facs细胞分选仪(bd facs ariaiii)回收alexa488和alexa647的荧光强度高的酵母克隆。
[0284]
表10
[0285]
淘选阶段靶浓度孵育时间洗涤条件1(macs)100nm4℃下60分钟7ml pbsm 2次2(macs)100nm4℃下60分钟7ml pbsm 2次3(macs)100nm室温下60分钟7ml pbsm 2次4(facs)100nm室温下60分钟-[0286]
[实施例9]氨基酸序列的确定
[0287]
使在实施例7的淘选后洗脱而得的噬菌体文库(表9、投入噬菌体(阶段4))作用于固定化有人igg fc的板,回收未结合的噬菌体而实施负向选择。之后使噬菌体文库作用于制备成100nm、10nm、1nm的各浓度的fgfr3(图3)。然后回收结合噬菌体。提取所回收的噬菌体的基因组dna,按照illumina公司的miseq用方案进行样品制备,实施噬菌体基因组dna的全面分析。在得到的序列中,选择出序列出现比例高的20种序列(表11)。将通过实施例8的筛选而获得的酵母细胞接种于sdcaa琼脂平板并进行培养。从琼脂平板上形成的单菌落中随机选择14个,对于各克隆,使用桑格法分析酵母表达质粒中整合的肽的dna序列(表12)。
[0288]
表11
[0289][0290]
表12
[0291][0292]
[实施例10]肽的合成和与fgf受体的结合的确认
[0293]
从实施例8所得到的克隆的氨基酸序列中选择1种,基于fmoc固相合成法合成肽(f3-100nx)。按照spr装置biacore t200(biacore公司)的操作指南,使用胺偶联法将
fgfr1、fgfr2、fgfr3作为配体固定化于装置的传感器芯片cm5。作为参照,将乙醇胺固定化,将肽作为分析物进行测定。测定全部在25℃下进行,使用tbs作为运行缓冲液。将溶解于运行缓冲液的肽注入固定化有各种fgfr的传感器芯片cm5(流速30μl/分钟、2分钟),然后通入运行缓冲液3分钟而使肽解离。通过使用biacore t200 evaluation software(biacore公司)的动力学分析来计算解离常数。在所得到的传感器图上对反应式直接进行曲线拟合,通过非线性最小二乘法计算速率常数。分析中使用1:1结合模型。将结果示于图11。
[0294]
[实施例11与]fgfr1和fgfr3结合的肽(100nx)
[0295]
关于100nx,制备与实施例1同样的肽并用于实验(表6)。
[0296]
[实施例12]从ips细胞向着心肌的分化诱导(hbd-100nx、hbd-yx、hbd-f3-100nx的评价)
[0297]
合成使硫酸乙酰肝素结合肽wqpprarig(序列号49)融合于100nx、yx、f3-100nx的肽(hbd-100nx、hbd-yx、hbd-f3-100nx),尝试应用于从ips细胞向着心肌细胞分化诱导的系统。ips细胞使用“ips cell-kac、hfb(n)”(kac公司、制品编号;ips-f001)(以下记作ips-hfb)。首先,在开始分化诱导时(第0天),将在分化诱导前7天(第-7天)接种于100φ培养皿的ips-hfb用4ml的pbs洗涤。添加3ml的0.5xtryple select,在37℃下静置3分钟。确认细胞成为球状后去除0.5xtryple select。进一步用4ml的pbs洗涤,添加4ml分化诱导用培养基(添加了1% l-谷氨酰胺(invitrogen)、150μg/ml运铁蛋白(roche)、50μg/ml抗坏血酸(sigma)、3.9
×
10-3
%mtg(1-硫代甘油)(sigma)、10μm rock抑制剂(y-27632、wako)、5%基质胶(corning)、和2ng/ml bmp4(r&d)的stempro 34(invitrogen))。之后用细胞刮刀剥离细胞,通过移液操作分离细胞。测定细胞数,以8000个/孔的方式接种于96孔圆底平板,在37℃、5%co2条件下进行培养。次日(第1天),以100μl/孔添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml bmp4、5ng/ml bfgf(r&d)和6ng/ml激活蛋白a(r&d)的stempro 34(以往方案;图12中的方案1)。另一方面,对于肽样品作用组,以100μl/孔添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml bmp4、0.0005、0.005、0.05、0.5μm hbd-100nx、hbd-yx、hbd-f3-100n9(序列号27)和6ng/ml激活蛋白a(r&d)的stempro 34(本发明方案;图12中的方案2、3、4)。之后在37℃、5%co2条件下培养3天。接着(第4天)将得到的eb以200g离心分离3分钟,去除培养基。添加pbs,以200g离心3分钟,去除上清。添加accumax,在37℃下静置5分钟后,通过移液操作解离成单细胞,添加2ml的加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml vegf和1μm iwp-3的stempro 34(心肌诱导培养基第4天),以200g离心3分钟后去除上清。用心肌诱导培养基第4天悬浮细胞并测定细胞数,然后以10000个/孔接种于96孔圆底平板。然后在37℃、5%co2条件下培养4天。接着(第8天)将细胞块一起从96孔板移动到24孔板(每孔中细胞块为8个以下),在细胞块自然沉降后去除培养基,添加加入有1%l-谷氨酰胺、150μg/ml运铁蛋白、50μg/ml抗坏血酸、3.9
×
10-3
%mtg、10ng/ml vegf和5ng/ml bfgf的stempro 34(心肌诱导培养基第8天),使细胞自然沉降,除去上清。添加心肌诱导培养基第8天后,在37℃、5%co2条件下进行培养。此时,2天1次地交换为同种条件的培养基。培养后,为了确认是否已分化为心肌细胞,在第23天通过定量实时pcr(rt-qpcr)调查作为心肌标记的ctnt和辅肌动蛋白的表达量(图13)。具体而言,利用qiagen rneasy kit(qiagen)回收总rna,将rna利用cdna reverse transcription kit
(thermo fisher scientific)逆转录而制备cdna。由得到的cdna,使用特异性扩增ctnt、辅肌动蛋白的引物和与各基因特异性结合的探针实施基于taqmanpcr法的实时pcr。测定gapdh量作为内标对照。其结果是,在使用本发明的肽(hbd-100nx、hbd-yx、hbd-f3-100n9(序列号27))的方案2、3、4的情况下,虽然确认到发挥效果的浓度根据添加肽的种类而不同,但是ctnt和actn2的表达量与现有方案1(第1天;添加激活蛋白a、bmp4、bfgf这3种)相比显著增加。hbd-100nx、hbd-yx则显示出基因表达量呈肽浓度依赖性增加。hbd-f3-100n9(序列号27)与其它肽添加条件显示出不同的倾向,原因不明。
[0298]
[实施例13]从ips细胞向着肝细胞的分化诱导(100nx的评价)
[0299]
尝试在从ips细胞向着肝细胞分化诱导的系统中使用100nx。ips细胞使用“ips cell-kac、hfb(n)”(kac公司、制品编号;ips-f001)(以下记作ips-hfb)。将在分化诱导前7天(第-7天)接种于100φ培养皿的ips-hfb用4ml的pbs洗涤。添加3ml的0.5xtryple select,在37℃下静置3分钟。确认细胞成为球状后去除0.5xtryple select。进一步用4ml的pbs洗涤,添加4ml的stemfit,然后用细胞刮刀剥离,通过移液操作使细胞分离成单细胞。之后以1.5
×
105个细胞/孔接种于6孔板。在开始分化诱导当天(第0天),去除培养基,以2ml/孔添加分化诱导用培养基(添加有b-27plus supplement(thermo)、100ng/ml激活蛋白a(r&d)的rpmi1640(thermo))。使用同样的培养基在第3天进行培养基交换。在第5天去除培养基,以2ml/孔添加加入有b-27plus supplement(thermo)、20ng/ml bmp4、20ng/ml bfgf的rpmi1640(以往方案;图14中的方案1)。另一方面,对于肽样品作用组,以2ml/孔添加加入有b-27plus supplement(thermo)、20ng/ml bmp4、0.1nm hbd-100nx或100nx-monomer的rpmi1640(以往方案;图14中的方案3、4)。进而,作为对照组,以2ml/孔添加加入有b-27plus supplement(thermo)、20ng/ml bmp4的rpmi1640(以往方案;图14中的方案2)。使用同样的培养基在第8天进行培养基交换。对于全部条件,均在第10天去除培养基,以2ml/孔添加加入有b-27plus supplement(thermo)、20ng/ml hgf的rpmi1640。使用同样的培养基在第12天和第14天进行培养基交换。在第15天,使用hcm bulletkit(lonza)(含有hbm、抗坏血酸、bsa-faf、氢化可的松、transferin、ga-1000、胰岛素),以2ml/孔进行培养基交换。在第17天和第18天用同样的培养基进行培养基交换。培养后,为了确认是否已分化为肝细胞,在第20天通过定量实时pcr(rt-qpcr)调查作为肝标志物的白蛋白(alb)、cyp3a4和作为胆管标志物的itgb4的表达量(图15)。具体而言,利用qiagen rneasy kit(qiagen)回收总rna,利用cdna reverse transcription kit(thermo fisher scientific)对rna进行逆转录而制备cdna。由得到的cdna,使用特异性扩增alb、cyp3a4、itgb4的引物和与各基因特异性结合的探针实施基于taqmanpcr法的实时pcr。测定gapdh量作为内标对照。其结果是,使用本发明的肽(100nx-monomer)的方案4的情况下,alb的表达量与现有方案1(第5天;添加bmp4、bfgf这2种)和作为对照的方案2(第5天;添加bmp4)相比显著增加。另外,cyp3a4和itgb4的基因表达量与作为对照的方案2(第5天;添加bmp4)相比显著增加,与现有方案1(第5天;添加bmp4、bfgf这2种)为同等程度。以上表明,100nx-monomer以与现有的bfgf同等以上程度促进肝分化。
[0300]
[实施例14]使用100nx分化诱导而得的肝细胞的功能评价
[0301]
通过与实施例13同样的方法对ips细胞进行分化诱导,在第20天用pbs洗涤细胞后,用包含3μm萤光素-ipa的hcm bulletkit(lonza)以1ml/孔进行培养基交换。在37℃下反
应1小时后,将上清100μl转移到96孔白色平板,然后以100μl/孔添加萤光素检测试剂。在室温下反应20分钟,测定发光值。另外,将细胞破碎,使用takara bca protein assay kit(宝生物)对蛋白进行定量,对发光值进行校正。其结果是,cyp3a4活性与作为对照的方案2(第5天;添加bmp4)相比显著增加,显示与现有方案1(第5天;添加bmp4、bfgf这2种)同等程度的活性。以上表明,100nx-monomer有助于肝功能,水平与bfgf为同等程度(图16)。
[0302]
[实施例15]从ips细胞向着神经细胞的分化诱导(100nx的评价)
[0303]
尝试在从ips细胞向着神经细胞分化诱导的系统中应用100nx。ips细胞使用“ips cell-kac、hfb(n)”(kac公司、制品编号;ips-f001)(以下记作ips-hfb)。首先,在开始分化诱导时(第0天),将在分化诱导前7天(第-7天)接种于100φ培养皿的ips-hfb用4ml的pbs洗涤。添加3ml的0.5xtryple select,在37℃下静置3分钟。确认细胞成为球状后,去除0.5xtryple select。进一步用4ml的pbs洗涤,添加4ml的分化诱导用培养基(添加有20% ksr(thermo)、1xneaa(thermo)、0.1mm 2-巯基乙醇(和光纯药)、1mm丙酮酸钠(thermo)、20μm y27632(和光纯药)、3μm iwr-1-endo(和光纯药)、5μm sb431542(和光纯药)的g-mem(thermo)。之后用细胞刮刀剥离细胞,通过移液操作分离细胞。测定细胞数,以9000个/孔的方式接种于96孔圆底平板,在37℃、5%co2条件下进行培养。在第3天,以100μl/孔添加包含20% ksr(thermo)、1xneaa(thermo)、0.1mm 2-巯基乙醇(和光纯药)、1mm丙酮酸钠(thermo)、20μm y27632(和光纯药)、3μm iwr-1-endo(和光纯药)、5μm sb431542(和光纯药)、0.3nm bfgf的g-mem(以往方案;图17中的方案1)。另一方面,对于肽样品作用组,以100μl/孔添加包含20% ksr(thermo)、1xneaa(thermo)、0.1mm 2-巯基乙醇(和光纯药)、1mm丙酮酸钠(thermo)、20μm y27632(和光纯药)、3μm iwr-1-endo(和光纯药)、5μm sb431542(和光纯药)、0.25nm hbd-100nx或100nx-monomer的g-mem(图14中的方案3、4)。作为对照组,准备以100μl/孔添加包含20% ksr(thermo)、1xneaa(thermo)、0.1mm2-巯基乙醇(和光纯药)、1mm丙酮酸钠(thermo)、20μm y27632(和光纯药)、3μm iwr-1-endo(和光纯药)、5μm sb431542(和光纯药)的g-mem的组((图14中的方案2)。在第6天,用除去了y27632(和光纯药)的各条件的培养基以100μl/孔进行总量交换。同样地,在第10天和第14天进行培养基交换。在第18天去除培养基,添加包含1% n-2补充剂、1%化学定义的脂质浓缩物的dmem/f12(glutamax)(thermo),将细胞以2ml/孔移动到ezsphere(agc techno glass co.,ltd.)。在第21、24、27天,用包含1%n-2补充剂的dmem/f12(glutamax)(thermo)进行培养基交换。进而,在第30天和第33天,用包含1% n-2补充剂、1%化学定义的脂质浓缩物的dmem/f12(glutamax)(thermo)进行培养基交换。培养后,为了确认是否已分化为神经细胞,在第35天通过定量实时pcr(rt-qpcr)调查作为神经标志物的syn1、map2、nr2f1的表达量(图18)。具体而言,利用qiagen rneasy kit(qiagen)回收总rna,将rna通过cdna reverse transcription kit(thermo fisher scientific)进行逆转录而制备cdna。由得到的cdna,使用特异性扩增syn1、map2、nr2f1的引物和与各基因特异性结合的探针实施基于taqmanpcr法的实时pcr。测定gapdh量作为内标对照。其结果是,使用本发明的肽(hbd-100nx)的方案3与现有方案1(第3天;添加bfgf)和作为对照的方案2(第3天;不添加bfgf)相比,nr2f1的基因表达量显著增加。另外,syn1和map2的基因表达量与作为对照的方案2(第3天;不添加bfgf)相比显著增加,与现有方案1(第3天;添加bfgf)为同等程度。另外,使用本发明的肽(100nx-monomer)的方案4中,任一基因与作为对照的方案2(第3天;不添加bfgf)
相比,基因表达量均显示出增加倾向。其中,nr2f1的基因表达量与作为对照的方案2(第3天;不添加bfgf)相比显著增加,与现有方案1(第3天;添加bfgf)为同等程度。以上表明,hbd-100nx以与现有的bfgf同等以上的程度促进神经分化,100nx-monomer以与现有的bfgf同等程度地有助于神经分化。
[0304]
产业上的可利用性
[0305]
本发明作为使细胞分化或促进细胞分化的细胞研究用材料有用。另外,在构建用于再生医疗的组织、制备药物筛选用细胞等中也有用。
[0306]
序列表自由文本
[0307]
序列号1:作为n末端起第3位的氨基酸残基的xaa表示ala、arg、gln、val、leu、lys、phe或his。
[0308]
序列号1:作为n末端起第4位的氨基酸残基的xaa表示glu或his。
[0309]
序列号1:作为n末端起第6位的氨基酸残基的xaa表示ala、gln、val、tyr、arg、leu或glu。
[0310]
序列号1:作为n末端起第7位的氨基酸残基的xaa表示ala或ser。
[0311]
序列号1:作为n末端起第9位的氨基酸残基的xaa表示glu、leu、his、arg、gly或lys。
[0312]
序列号1:作为n末端起第10位的氨基酸残基的xaa表示ala、lys、met、arg、gly或tyr。
[0313]
序列号1:作为n末端起第11位的氨基酸残基的xaa表示glu或asp。
[0314]
序列号1:作为n末端起第13位的氨基酸残基的xaa表示ala、gln、arg、tyr、glu、lys或gly。
[0315]
序列号1:作为n末端起第14位的氨基酸残基的xaa表示ala或ile。
[0316]
序列号1:作为n末端起第16位的氨基酸残基的xaa表示glu、gly、tyr、gln、arg、lys或met。
[0317]
序列号1:作为n末端起第18位的氨基酸残基的xaa表示phe、ala、gln、val、gly、ile、asn、arg、met、asp、leu、ser、pro、lys或glu。
[0318]
序列号1:作为n末端起第19位的氨基酸残基的xaa表示gly、val、lys、thr、pro、arg、met、asn、glu、asp、ser、cys、trp、his或ala。
[0319]
序列号1:作为n末端起第20位的氨基酸残基的xaa表示gly、arg、glu、phe、ala、lys、pro、asn、leu、val、met、asp、his、thr或tyr。
[0320]
序列号1:作为n末端起第21位的氨基酸残基的xaa表示val、asp、leu、met、ser、thr、ala、asn、his、gly、phe、glu、arg、pro、tyr或lys。
[0321]
序列号1:作为n末端起第22位的氨基酸残基的xaa表示val、lys、tyr、thr、asn、gly、asp、glu、pro、phe、gln、his或ile。
[0322]
序列号1:作为n末端起第23位的氨基酸残基的xaa表示tyr、arg、his、leu、pro、asn、glu、met、ala、gly、val、ile或ser。
[0323]
序列号1:作为n末端起第24位的氨基酸残基的xaa表示ser、lys、met、gly、his、gln、thr、val、cys、leu、asn、ala、glu、pro或arg。
[0324]
序列号1:作为n末端起第25位的氨基酸残基的xaa表示cys、ser、ala、thr、arg、
glu、asn、gln、gly、lys、tyr、pro、leu、val或met。
[0325]
序列号1:作为n末端起第26位的氨基酸残基的xaa表示glu、lys、ser、val、leu、arg、gly、ile、phe、thr、ala、his、gln、asn、met或tyr。
[0326]
序列号1:作为n末端起第27位的氨基酸残基的xaa表示trp或gly。
[0327]
序列号1:作为n末端起第28位的氨基酸残基的xaa表示gln、lys、phe或his。
[0328]
序列号1:作为n末端起第29位的氨基酸残基的xaa表示ala或leu。
[0329]
序列号1:作为n末端起第30位的氨基酸残基的xaa表示val、met、asp、tyr、lys、leu、ile、arg、ser、gln、gly、glu、his、phe、asn或ala。
[0330]
序列号1:作为n末端起第31位的氨基酸残基的xaa表示tyr、met、arg、ser、lys、his、gly、leu、asn、glu、val、asp或ala。
[0331]
序列号1:作为n末端起第33位的氨基酸残基的xaa表示his、phe、tyr、lys、ile、gln、met或val。
[0332]
序列号1:作为n末端起第34位的氨基酸残基的xaa表示tyr、trp、gly、leu、asn、asp、gln、glu、met、phe、arg、his、ser、lys、val或ile。
[0333]
序列号1:作为n末端起第35位的氨基酸残基的xaa表示lys、arg或gln。
[0334]
序列号1:作为n末端起第37位的氨基酸残基的xaa表示met、glu、trp、val、his、ser、asn、ile、gln、tyr、gly、leu、arg、phe或ala。
[0335]
序列号1:作为n末端起第38位的氨基酸残基的xaa表示arg、leu、val、ser、his、tyr、phe、asn、lys、gln、trp、glu、ile、gly或ala。
[0336]
序列号1:作为n末端起第40位的氨基酸残基的xaa表示phe、arg、asp、gln、met、lys、leu或his。
[0337]
序列号1:作为n末端起第41位的氨基酸残基的xaa表示gln、gly、tyr、arg、asn、ile、ser、his、glu、met、leu、asp、cys、trp、val或phe。
[0338]
序列号2:作为n末端起第18位的氨基酸残基的xaa表示phe、ala、gln、val、gly、ile、asn、arg、met、asp、leu、ser、pro、lys或glu。
[0339]
序列号2:作为n末端起第19位的氨基酸残基的xaa表示gly、val、lys、thr、pro、arg、met、asn、glu、asp、ser、cys、trp、his或ala。
[0340]
序列号2:作为n末端起第20位的氨基酸残基的xaa表示gly、arg、glu、phe、ala、lys、pro、asn、leu、val、met、asp、his、thr或tyr。
[0341]
序列号2:作为n末端起第21位的氨基酸残基的xaa表示val、asp、leu、met、ser、thr、ala、asn、his、gly、phe、glu、arg、pro、tyr或lys。
[0342]
序列号2:作为n末端起第22位的氨基酸残基的xaa表示val、lys、tyr、thr、asn、gly、asp、glu、pro、phe、gln、his或ile。
[0343]
序列号2:作为n末端起第23位的氨基酸残基的xaa表示tyr、arg、his、leu、pro、asn、glu、met、ala、gly、val或ile。
[0344]
序列号2:作为n末端起第24位的氨基酸残基的xaa表示ser、lys、met、gly、his、gln、thr、val、cys、leu、asn、ala、glu或arg。
[0345]
序列号2:作为n末端起第25位的氨基酸残基的xaa表示cys、ser、ala、thr、arg、glu、asn、gln、gly、lys、tyr、pro、leu、val或met。
[0346]
序列号2:作为n末端起第26位的氨基酸残基的xaa表示glu、lys、ser、val、leu、arg、gly、ile、phe、thr、ala、his、gln、asn、met或tyr。
[0347]
序列号2:作为n末端起第27位的氨基酸残基的xaa表示trp或gly。
[0348]
序列号2:作为n末端起第28位的氨基酸残基的xaa表示gln或lys。
[0349]
序列号2:作为n末端起第29位的氨基酸残基的xaa表示ala或leu。
[0350]
序列号2:作为n末端起第30位的氨基酸残基的xaa表示val、met、asp、tyr、lys、leu、ile、arg、ser、gln、gly或glu。
[0351]
序列号2:作为n末端起第31位的氨基酸残基的xaa表示tyr、met、arg、ser、lys、his、gly、leu、asn、glu或val。
[0352]
序列号2:作为n末端起第34位的氨基酸残基的xaa表示tyr、trp、gly、leu、asn、asp、gln、glu、met、phe、arg、his、ser、lys或val。
[0353]
序列号2:作为n末端起第35位的氨基酸残基的xaa表示lys或arg。
[0354]
序列号2:作为n末端起第37位的氨基酸残基的xaa表示met、glu、trp、val、his、ser、asn、ile、gln、tyr、gly、leu或arg。
[0355]
序列号2:作为n末端起第38位的氨基酸残基的xaa表示arg、leu、val、ser、his、tyr、phe、asn、lys、gln、trp、glu、ile或gly。
[0356]
序列号2:作为n末端起第41位的氨基酸残基的xaa表示gln、gly、tyr、arg、asn、ile、ser、his、glu、met、leu、asp、cys、trp或val。
[0357]
序列号3:作为n末端起第3位的氨基酸残基的xaa表示ala、arg、gln、val、leu、lys、phe或his。
[0358]
序列号3:作为n末端起第4位的氨基酸残基的xaa表示glu或his。
[0359]
序列号3:作为n末端起第6位的氨基酸残基的xaa表示ala、gln、val、tyr、arg、leu或glu。
[0360]
序列号3:作为n末端起第7位的氨基酸残基的xaa表示ala或ser。
[0361]
序列号3:作为n末端起第9位的氨基酸残基的xaa表示glu、leu、his、arg、gly或lys。
[0362]
序列号3:作为n末端起第10位的氨基酸残基的xaa表示ala、lys、met、arg、gly或tyr。
[0363]
序列号3:作为n末端起第11位的氨基酸残基的xaa表示glu或asp。
[0364]
序列号3:作为n末端起第13位的氨基酸残基的xaa表示ala、gln、arg、tyr、glu、lys或gly。
[0365]
序列号3:作为n末端起第14位的氨基酸残基的xaa表示ala或ile。
[0366]
序列号3:作为n末端起第16位的氨基酸残基的xaa表示glu、gly、tyr、gln、arg、lys或met。
[0367]
序列号3:作为n末端起第18位的氨基酸残基的xaa表示gly或pro。
[0368]
序列号3:作为n末端起第19位的氨基酸残基的xaa表示gly、pro、asp或ser。
[0369]
序列号3:作为n末端起第20位的氨基酸残基的xaa表示gly或arg。
[0370]
序列号3:作为n末端起第21位的氨基酸残基的xaa表示val、gly或pro。
[0371]
序列号3:作为n末端起第22位的氨基酸残基的xaa表示gly或his。
[0372]
序列号3:作为n末端起第23位的氨基酸残基的xaa表示leu、gly或ser。
[0373]
序列号3:作为n末端起第24位的氨基酸残基的xaa表示pro或arg。
[0374]
序列号3:作为n末端起第25位的氨基酸残基的xaa表示arg或pro。
[0375]
序列号3:作为n末端起第26位的氨基酸残基的xaa表示leu或arg。
[0376]
序列号3:作为n末端起第27位的氨基酸残基的xaa表示gly。
[0377]
序列号3:作为n末端起第28位的氨基酸残基的xaa表示lys、phe或his。
[0378]
序列号3:作为n末端起第30位的氨基酸残基的xaa表示met、tyr、leu、arg、gln、gly、his、phe、asn或ala。
[0379]
序列号3:作为n末端起第31位的氨基酸残基的xaa表示arg、leu、asn、asp或ala。
[0380]
序列号3:作为n末端起第33位的氨基酸残基的xaa表示his、phe、tyr、lys、gln、met或val。
[0381]
序列号3:作为n末端起第34位的氨基酸残基的xaa表示tyr、leu、phe、arg、val或ile。
[0382]
序列号3:作为n末端起第35位的氨基酸残基的xaa表示lys或gln。
[0383]
序列号3:作为n末端起第37位的氨基酸残基的xaa表示his、tyr、leu、phe或ala。
[0384]
序列号3:作为n末端起第38位的氨基酸残基的xaa表示leu、asn、glu、gly或ala。
[0385]
序列号3:作为n末端起第40位的氨基酸残基的xaa表示phe、arg、asp、gln、met、lys、leu或his。
[0386]
序列号3:作为n末端起第41位的氨基酸残基的xaa表示gly、asn、ile、his、leu、trp、val或phe。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。