1.本文件涉及计算机技术领域,尤其涉及一种基于机器学习的低密度脂蛋白建模方法、装置及存储介质。
背景技术:
2.心血管疾病是全世界发病和死亡的主要原因。低密度脂蛋白胆固醇被推荐作为降脂治疗的主要靶点,也是心血管风险评估的关键生物标志物。低密度脂蛋白胆固醇水平降低约60%可将主要心脑血管不良事件的风险降低15%。低密度脂蛋白胆固醇也可用于监测饮食控制和药物治疗的效果。因此,准确的低密度脂蛋白胆固醇测量对于临床诊疗非常关键。
3.低密度脂蛋白胆固醇定量的标准方法是β定量。然而,这种方法检测费用高,操作负责,不适合常规实验室开展。目前很多实验室采用直接检测法检测血液中低密度脂蛋白胆固醇的含量。直接检测法通过阻断非低密度脂蛋白胆固醇来测量低密度脂蛋白胆固醇含量。但是,不同厂家的阻断方法并不一致。此外,直接检测法需要一定的检测费用,许多实验室不使用直接检测法测量低密度脂蛋白胆固醇的含量。使用总胆固醇,高密度脂蛋白胆固醇和甘油三酯可以估算低密度脂蛋白胆固醇含量。国际上已有多种计算公式包括friedewald、martin/hopkins和sampson公式被用于临床估算低密度脂蛋白胆固醇含量。由于目前国际上广泛使用的低密度脂蛋白胆固醇计算公式主要是基于欧美人群的数据建立的。低密度脂蛋白胆固醇的含量易受生活习惯、人种差异、地域分布的影响。因此,国外的低密度脂蛋白胆固醇计算公式并不能很好的适用于中国人群。在中国,对于最佳的低密度脂蛋白胆固醇计算尚无共识。因此,亟需一种基于机器学习(ml)的低密度脂蛋白胆固醇估计方法。
技术实现要素:
4.本发明的目的在于提供一种基于机器学习的低密度脂蛋白建模方法、装置及存储介质,旨在解决现有技术中的上述问题。
5.本发明提供一种基于机器学习的低密度脂蛋白建模方法包括:
6.将获取的生物指标作为样本随机分为大小相等的数据集,将所述数据集分为训练集和测试集,其中,所述训练集和测试集用于进行交叉验证;
7.确定输入变量参数,其中,所述输入变量参数具体包括:年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值和总胆固醇/高密度脂蛋白胆固醇的比值;
8.利用训练集,采用机器学习的方法,基于多种特征选择算法,将所述输入变量参数的组合作为输入对低密度脂蛋白计算模型进行训练,得到训练好的低密度脂蛋白计算模型;
9.利用测试集对所述训练好的低密度脂蛋白计算模型进行验证,在验证通过后,得到最终的低密度脂蛋白计算模型。
10.本发明提供一种基于机器学习的低密度脂蛋白建模装置,包括:
11.处理模块,用于将获取的生物指标作为样本随机分为大小相等的数据集,将所述数据集分为训练集和测试集,其中,所述训练集和测试集用于进行交叉验证;
12.确定模块,用于确定输入变量参数,其中,所述输入变量参数具体包括:年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值和总胆固醇/高密度脂蛋白胆固醇的比值;
13.训练模块,用于利用训练集,采用机器学习的方法,基于多种特征选择算法,将所述输入变量参数的组合作为输入对低密度脂蛋白计算模型进行训练,得到训练好的低密度脂蛋白计算模型;
14.验证模块,用于利用测试集对所述训练好的低密度脂蛋白计算模型进行验证,在验证通过后,得到最终的低密度脂蛋白计算模型。
15.本发明实施例还提供一种基于机器学习的低密度脂蛋白建模装置,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述基于机器学习的低密度脂蛋白建模方法的步骤。
16.本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有信息传递的实现程序,所述程序被处理器执行时实现上述基于机器学习的低密度脂蛋白建模方法的步骤。
17.采用本发明实施例,能够建立准确计算中国人群的低密度脂蛋白胆固醇含量的低密度脂蛋白计算模型。
附图说明
18.为了更清楚地说明本说明书一个或多个实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
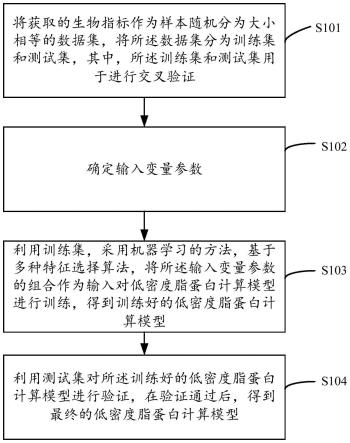
19.图1是本发明实施例的基于机器学习的低密度脂蛋白建模方法的流程图;
20.图2是本发明装置实施例一的基于机器学习的低密度脂蛋白建模装置的示意图;
21.图3是本发明装置实施例二的基于机器学习的低密度脂蛋白建模装置的示意图;
22.图4是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在测试集中的比较的示意图;
23.图5是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在测试集中的比较的示意图;
24.图6是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在不同甘油三酯水平中的比较的示意图;
25.图7是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在不同甘油三酯水平中的比较的示意图;
26.图8是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在不同低密度脂蛋白胆固醇水平中的比较的示意图;
27.图9是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在不同低密度脂蛋白胆固醇水平中的比较的示意图;
28.图10是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在不同年龄段中的比较的示意图;
29.图11是本发明实施例的机器学习模型与friedewald,martin,和martin/hopkins低密度脂蛋白公式在不同年龄段中的比较的示意图;
具体实施方式
30.为了使本技术领域的人员更好地理解本说明书一个或多个实施例中的技术方案,下面将结合本说明书一个或多个实施例中的附图,对本说明书一个或多个实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书的一部分实施例,而不是全部的实施例。基于本说明书一个或多个实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都应当属于本文件的保护范围。
31.方法实施例
32.根据本发明实施例,提供了一种基于机器学习的低密度脂蛋白建模方法,图1是本发明实施例的基于机器学习的低密度脂蛋白建模方法的流程图,如图1所示,根据本发明实施例的基于机器学习的低密度脂蛋白建模方法具体包括:
33.步骤101,将获取的生物指标作为样本随机分为大小相等的数据集,将所述数据集分为训练集和测试集,其中,所述训练集和测试集用于进行交叉验证;具体地,将获取的生物指标作为样本随机分为5个大小相等的数据集,4个作为训练集和1个作为测试集,其中,所述训练集和测试集用于进行5倍交叉验证。所述5倍交叉验证即每次使用其中的1个数据集作为测试集,剩下4个数据集作为训练集,进行模型训练和测试,如此重复5次训练测试,每次轮流使用其中的一个数据集作为测试集;
34.步骤102,确定输入变量参数,其中,所述输入变量参数具体包括:年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值和总胆固醇/高密度脂蛋白胆固醇的比值;
35.步骤103,利用训练集,采用机器学习的方法,基于多种特征选择算法,将所述输入变量参数的组合作为输入对低密度脂蛋白计算模型进行训练,得到训练好的低密度脂蛋白计算模型;
36.步骤104,利用测试集对所述训练好的低密度脂蛋白计算模型进行验证,在验证通过后,得到最终的低密度脂蛋白计算模型。
37.在执行了步骤104之后,可以使用最终的低密度脂蛋白计算模型进行低密度脂蛋白的计算。
38.在本发明的一个实施例中,所述最终的低密度脂蛋白计算模型的特征选择算法为:
39.将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋
白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为第一输入变量参数时,采用bagging m5rules算法。
40.在本发明的一个实施例中,所述最终的低密度脂蛋白计算模型的特征选择算法为:
41.将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为所述第一输入变量参数时,采用bagging randomforest算法。
42.以下对本发明实施例的上述技术方案进行详细说明。
43.收集10多万个人的血脂、年龄、性别等指标。这将样本随机分为5个大小相等数据集,其中4个作为训练集和1个作为测试集,采用5倍交叉验证方法,重复计算5次。利用训练集,使用年龄,性别和总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值、总胆固醇/高密度脂蛋白胆固醇比值作为输入变量参数开发基于机器学习的模型。使用多种特征选择算法选择最佳输入变量组合。并将训练好的机器学习模型应用于测试集。此外,还从其它医院收集数据对该模型进行外部验证。结果发现使用bagging m5rules算法结合10个输入变量(年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值、总胆固醇/高密度脂蛋白胆固醇比值);bagging randomforest算法结合10个输入变量(年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值、总胆固醇/高密度脂蛋白胆固醇比值),在测试集计算的低密度脂蛋白胆固醇结果与直接检测法测定的低密度脂蛋白胆固醇最接近。我们将这些训练好的模型与三种计算公式friedewald、martin/hopkins和sampson进行比较,发现机器学习模型与直接检测法一致性最好,包括高浓度的甘油三酯人群和低浓度的低密度脂蛋白胆固醇人群。本发明实施例使用其它医院收集的数据对该模型进行外部验证,发现在中国人群中所建立的机器学习模型性能最好。如图4-图11所示,需要说明的是,age表示年龄;tg levels表示甘油三酯含量;ldl-c levels表示低密度脂蛋白胆固醇含量;r表示相关系数;mad表示平均绝对偏差;rmse表示均方根误差;bagging-m5rules-10表示bagging m5rules算法使用10个输入变量;bagging-randomforest-10表示bagging randomforest算法使用10个输入变量。
44.装置实施例一
45.根据本发明实施例,提供了一种基于机器学习的低密度脂蛋白建模装置,图2是本发明实施例的基于机器学习的低密度脂蛋白建模装置的示意图,如图2所示,根据本发明实施例的基于机器学习的低密度脂蛋白建模装置具体包括:
46.处理模块20,用于将获取的生物指标作为样本随机分为大小相等的数据集,将所述数据集分为训练集和测试集,其中,所述训练集和测试集用于进行交叉验证;具体地,处理模块20将获取的生物指标作为样本随机分为5个大小相等的数据集,4个作为训练集和1
个作为测试集,其中,所述训练集和测试集用于进行5倍交叉验证。所述5倍交叉验证即每次使用其中的1个数据集作为测试集,剩下4个数据集作为训练集,进行模型训练和测试,如此重复5次训练测试,每次轮流使用其中的一个数据集作为测试集;
47.确定模块22,用于确定输入变量参数,其中,所述输入变量参数具体包括:年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值和总胆固醇/高密度脂蛋白胆固醇的比值;
48.训练模块24,用于利用训练集,采用机器学习的方法,基于多种特征选择算法,将所述输入变量参数的组合作为输入对低密度脂蛋白计算模型进行训练,得到训练好的低密度脂蛋白计算模型;
49.验证模块26,用于利用测试集对所述训练好的低密度脂蛋白计算模型进行验证,在验证通过后,得到最终的低密度脂蛋白计算模型。
50.在本发明实施例中,还可以包括:计算模块,用于使用最终的低密度脂蛋白计算模型进行低密度脂蛋白的计算。
51.在本发明的一个实施例中,所述最终的低密度脂蛋白计算模型的特征选择算法为:
52.将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为第一输入变量参数时,采用bagging m5rules算法。
53.在本发明的一个实施例中,所述最终的低密度脂蛋白计算模型的特征选择算法为:
54.将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为所述第一输入变量参数时,采用bagging randomforest算法。
55.本发明实施例是与上述方法实施例对应的装置实施例,各个模块的具体操作可以参照方法实施例的描述进行理解,在此不再赘述。
56.装置实施例二
57.本发明实施例提供一种基于机器学习的低密度脂蛋白建模装置,如图3所示,包括:存储器30、处理器32及存储在所述存储器30上并可在所述处理32上运行的计算机程序,所述计算机程序被所述处理器32执行时实现如方法实施例中所述的步骤。
58.装置实施例三
59.本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储有信息传输的实现程序,所述程序被处理器32执行时实现如方法实施例中所述的步骤。
60.本实施例所述计算机可读存储介质包括但不限于为:rom、ram、磁盘或光盘等。
61.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进
行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。