技术特征:
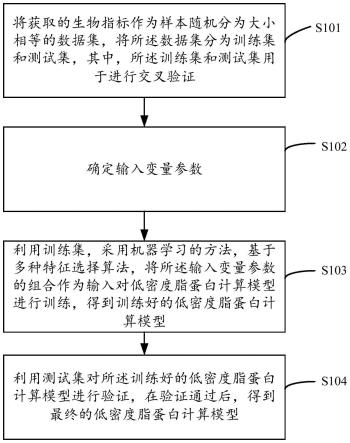
1.一种基于机器学习的低密度脂蛋白建模方法,其特征在于,包括:将获取的生物指标作为样本随机分为大小相等的数据集,将所述数据集分为训练集和测试集,其中,所述训练集和测试集进行交叉验证;确定输入变量参数,其中,所述输入变量参数具体包括:年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇、高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值以及总胆固醇/高密度脂蛋白胆固醇的比值;利用训练集,采用机器学习的方法,基于多种特征选择算法,将所述输入变量参数的组合作为输入对低密度脂蛋白计算模型进行训练,得到训练好的低密度脂蛋白计算模型;利用测试集对所述训练好的低密度脂蛋白计算模型进行验证,在验证通过后,得到最终的低密度脂蛋白计算模型。2.根据权利要求1所述的方法,其特征在于,将获取的生物指标作为样本随机分为大小相等的数据集,将所述数据集分为训练集和测试集具体包括:将获取的生物指标作为样本随机分为5个大小相等的数据集,4个作为训练集和1个作为测试集,其中,所述训练集和测试集用于进行5倍交叉验证,所述5倍交叉验证即每次使用其中的1个数据集作为测试集,剩下4个数据集作为训练集,进行模型训练和测试,如此重复5次训练测试,每次轮流使用其中的一个数据集作为测试集;所述方法进一步包括:使用最终的低密度脂蛋白计算模型进行低密度脂蛋白的计算。3.根据权利要求1所述的方法,其特征在于,所述最终的低密度脂蛋白计算模型的特征选择算法为:将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为第一输入变量参数时,采用bagging m5rules算法。4.根据权利要求1所述的方法,其特征在于,所述最终的低密度脂蛋白计算模型的特征选择算法为:将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为所述第一输入变量参数时,采用bagging randomforest算法。5.一种基于机器学习的低密度脂蛋白建模装置,其特征在于,包括:处理模块,用于将获取的生物指标作为样本随机分为大小相等的数据集,将所述数据集分为训练集和测试集,其中,所述训练集和测试集用于进行交叉验证;确定模块,用于确定输入变量参数,其中,所述输入变量参数具体包括:年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇/甘油三酯比值、以及总胆固醇/高密度脂蛋白胆固醇的比值;
训练模块,用于利用训练集,采用机器学习的方法,基于多种特征选择算法,将所述输入变量参数的组合作为输入对低密度脂蛋白计算模型进行训练,得到训练好的低密度脂蛋白计算模型;验证模块,用于利用测试集对所述训练好的低密度脂蛋白计算模型进行验证,在验证通过后,得到最终的低密度脂蛋白计算模型。6.根据权利要求5所述的装置,其特征在于,所述处理模块具体用于:将获取的生物指标作为样本随机分为5个大小相等的数据集,4个作为训练集和1个作为测试集,其中,所述训练集和测试集用于进行5倍交叉验证,所述5倍交叉验证即每次使用其中的1个数据集作为测试集,剩下4个数据集作为训练集,进行模型训练和测试,如此重复5次训练测试,每次轮流使用其中的一个数据集作为测试集;所述装置进一步包括:计算模块,用于使用最终的低密度脂蛋白计算模型进行低密度脂蛋白的计算。7.根据权利要求5所述的装置,其特征在于,所述最终的低密度脂蛋白计算模型的特征选择算法为:将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为第一输入变量参数时,采用bagging m5rules算法。8.根据权利要求5所述的装置,其特征在于,所述最终的低密度脂蛋白计算模型的特征选择算法为:将年龄、性别、总胆固醇、高密度脂蛋白胆固醇、甘油三酯、总胆固醇和高密度脂蛋白胆固醇的差值、总胆固醇和甘油三酯的差值、甘油三酯和高密度脂蛋白胆固醇差值、高密度脂蛋白胆固醇与甘油三酯的比值以及总胆固醇与高密度脂蛋白胆固醇的比值作为所述第一输入变量参数时,采用bagging randomforest算法。9.一种基于机器学习的低密度脂蛋白建模装置,其特征在于,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现如权利要求1至4中任一项所述的基于机器学习的低密度脂蛋白建模方法的步骤。10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有信息传递的实现程序,所述程序被处理器执行时实现如权利要求1至4中任一项所述的基于机器学习的低密度脂蛋白建模方法的步骤。
技术总结
本说明书实施例提供了一种基于机器学习的低密度脂蛋白建模方法、装置及存储介质,该方法包括:将获取的生物指标作为样本随机分为大小相等的训练集和测试集;确定输入变量参数;利用训练集,采用机器学习的方法,基于多种特征选择算法,将所述输入变量参数的组合作为输入对低密度脂蛋白计算模型进行训练,得到训练好的低密度脂蛋白计算模型;利用测试集对所述训练好的低密度脂蛋白计算模型进行验证,在验证通过后,得到最终的低密度脂蛋白计算模型。型。型。
技术研发人员:樊高威 王清涛
受保护的技术使用者:首都医科大学附属北京朝阳医院
技术研发日:2022.07.12
技术公布日:2022/11/22
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。