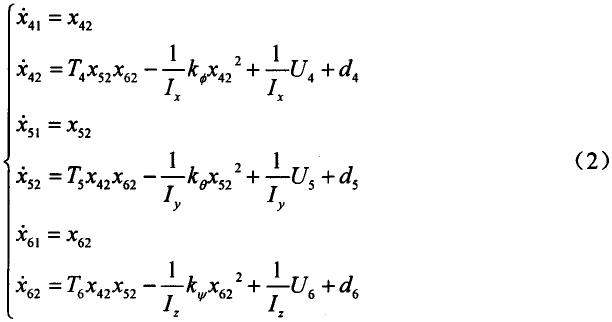
1.本专利申请通常涉及微组装控制,并且具体地涉及一种用于借助数字计算机在微组装控制中使用的基于机器学习的位置估计的系统和方法。
背景技术:
2.微米级和纳米级的颗粒操纵已经受到许多研究兴趣。可对微对象(即其尺寸以微米为单位进行测量的对象)和纳米对象(即其尺寸以纳米为单位进行测量的对象)的组装进行控制的程度可在许多技术中(包括在微制造、生物学和医学中)产生显著差异。例如,可通过能够准确控制微对象(诸如电容器和电阻器)的位置来改善可重新配置的电路的制造,以制造具有期望行为的电路。类似地,光伏太阳能电池阵列的生产可受益于能够将具有某些质量的光伏电池放到阵列上的特定位置中。此类电池可能太小而无法允许经由人类或机器人操纵进行电池的期望放置,并且需要另一种类型的运输机制。颗粒的微组装和纳米组装也可用于工程化材料(诸如组装成组织的生物细胞)的微结构。存在许多其他技术领域,其中增加对微纳对象组装的控制可提供显著的益处。
3.用于微颗粒和纳米颗粒操纵的许多技术使用电极来产生电极电势以朝向期望方向移动感兴趣的颗粒。使用传感器确定颗粒的初始位置,并且基于期望位置和初始位置来产生电极电势。然而,此类系统的吞吐量和准确性受到控制回路延迟,即在当颗粒处于特定位置中时和当基于颗粒处于该特定位置而产生电极电势时之间的延迟的显著限制。延迟的确切长度取决于用于操纵颗粒的系统的软件和硬件。延迟具有多个分量。一个分量是致动延迟,即在生成sprite(用于电极的控制信号)时和在由电极产生由sprite指定的电极电势时之间的延迟。延迟的另一个分量是感测延迟,其是在传感器观察到颗粒占用特定位置的时间和该时间之间的时间。完成传感器信号的分析以获得颗粒位置。此类延迟包括将捕获的图像流传输到存储器以进行存储和发送图像数据以进行图像分析以确定位置,以及运行图像分析算法的时间。这些延迟可以高达80ms-100ms,以及高达300ms或更高,这取决于各种延迟和处理器负载,其在60hz或更慢的帧速率下可以占高达五帧。
4.预测延迟,并且因此预测需要移动的微米级或纳米级颗粒的实际位置将允许提高微组装或纳米组装的准确性和效率。此类建模通常利用了基于物理的模型,利用操纵设置、环境(诸如组装是在空气中、液体中、在地球上、在太空中或在另一个环境中)和所移动的颗粒的已知物理特性的模型。然而,用于闭环系统的基于物理的模型不容易考虑在微颗粒或纳米颗粒操纵(诸如颗粒旋转、目标分配和发生在颗粒的小或大子集上的转移)期间发生的控制延迟的动态变化。此类基于物理的模型也不容易考虑操纵条件的不同设置之间的动态变化,诸如使用不同类型的颗粒或不同的照明条件。此类基于物理的模型在以下情况下也不稳健:对特定操纵设置(诸如颗粒静摩擦或颗粒摇摆运动)内的特定变量建模时,或者在对具有未知值的参数(诸如颗粒在控制循环期间平移的像素的平均数量)建模时。
5.因此,需要一种准确地考虑控制回路延迟以预测由于产生的电极电势而移动的颗
粒的实际位置的方式。
技术实现要素:
6.可以通过使用包括至少一个基于物理的模型和机器学习模型两者的混合模型来考虑控制回路延迟以预测被移动的微对象的位置。使用梯度增强组合模型,其中模型是在基于在先前阶段基于与训练数据的比较计算的残差拟合的阶段中的至少一个阶段期间创建的。基于所创建的模型选择针对每个阶段的损失函数。用从训练数据外推和内插的数据来评估混合模型,以防止过度拟合并且确保混合模型具有足够的预测能力。通过包括基于物理的模型和机器学习模型两者,混合模型可以考虑在微对象的移动中涉及的确定性分量和随机分量两者,从而增加微组装的准确性和吞吐量。
7.在一个实施方案中,提供了用于借助数字计算机启用机器学习的微组装控制的系统和方法。获得用于定位多个微对象中的一个或多个微对象的闭环系统的一个或多个参数,该系统包括多个可编程电极,这些电极被配置为在致动电极之后在微对象接近电极时诱导微对象的移动,致动中的每个致动包括由电极中的一个或多个电极产生一个或多个电势。获得训练数据,该训练数据包括与由于致动中的较早的致动引起的多个微对象中的一个或多个微对象的先前移动相关联的状态。定义用于预测在致动中的一个致动之后所述微对象中的至少一个微对象的位置的一个或多个基于物理的模型。经由梯度增强使用训练数据来构建用于预测在致动中的一个致动之后微对象中的至少一个微对象的位置的混合模型,该混合模型包括多个模型,所述多个模型包括基于物理的模型中的一个或多个基于物理的模型和一个或多个机器学习模型。基于至少一个传感器测量结果预测在致动中的一个致动之后的微对象中的一个或多个微对象的位置。接收微对象中的一个或多个微对象的另一位置。使用所预测的位置和另一位置执行致动中的另一个致动。
8.根据以下详细描述,本发明的另外的其他实施方案对于本领域技术人员来说将变得显而易见,其中通过说明为执行本发明而考虑的最佳模式来描述本发明的实施方案。如将实现的,本发明能够进行其他和不同的实施方案,并且其若干细节能够在各种明显的方面进行修改,所有这些都不脱离本发明的精神和范围。因此,附图和详细描述在本质上应被视为说明性的而非限制性的。
附图说明
9.图1是示出用于借助数字计算机在微组装控制中使用的基于机器学习的位置估计的系统的框图。
10.图2是示出用于借助数字计算机在微组装控制中使用的基于机器学习的位置估计的方法的流程图。
11.图3是示出根据一个实施方案的用于生成在图2的方法中使用的训练数据的例程的流程图。
12.图4是示出根据一个实施方案的用于构建在图2的方法中使用的混合模型的例程的流程图。
13.图5a和图5b是示出由记录的训练数据中的微对象获取的位置(参考图5a示出)和从记录的训练数据外推的微对象的位置(参考图5b示出)的示例的图示。
14.图6是示出估计器1.0与包括arima模型作为机器学习模型的混合模型的使用与包括rnn模型作为机器学习模型的混合模型的使用相比的测试结果的图。
15.图7是示出使用估计器1.0与外推测试数据集中的arima模型和rnn模型的结果的图。
16.图8是示出使用没有监督的经过训练的系统id模型的整个外推数据集(~50分钟)的模拟的图。
17.图9是示出使用没有监督的经过训练的系统id模型的外推数据集的模拟的图。
18.图10a和图10b是示出测试估计器2.0(混合模型)与使用简约深度(cpp)在微组装器软件中实施的线性模型、密集模型和arima模型的图。
19.图11是示出根据一个实施方案的梯度增强的图。
20.图12是在相关于复杂壳体定义时在记录的数据、外推数据和内插数据之间的关系的图示。
具体实施方式
21.下文描述的系统和方法允许在生成控制信号时考虑控制回路延迟,从而允许使用微组装或纳米组装来提高定位的准确性。如下所述,该系统和方法利用混合模型来预测在致动之后微对象的位置,其中混合模型包括一个或多个基于物理的模型和一个或多个机器学习模型。其中基于物理的模型具有以下优点:不需要构建任何数据,从而允许外推超出用于拟合参数的数据并且提供其预测的高解释性,这些模型仅捕获用于执行微组装的系统的行为中的一小部分。
22.系统10的完整行为包括未建模的自由度,并且机器学习模型的使用允许捕获这些未建模的自由度。由y给出的总系统行为是物理模型f(x;θ),其中x是先前的历史和测量结果,θ是参数,噪声n(ф),其中ф是随机噪声模型的噪声参数。作为输入和可训练权重w的函数的神经网络函数nn(x;w)根据以下捕获未建模的自由度:
[0023][0024]
混合模型的使用允许将基于物理的模型的优点(解释能力、稳定性和外推能力)与机器学习模型的灵活性以及它们捕获未建模的自由度的能力组合,从而导致更准确地预测微对象的位置并且因此提高了微组装的吞吐量。在机器学习模型考虑系统的随机分量时,基于物理的模型考虑系统的确定性分量。
[0025]
虽然在下面的描述中,被移动的对象被描述为微对象,但是也可以应用相同的技术来控制纳米对象的位置。此外,虽然下文描述的混合模型被描述为应用于特定致动硬件,但在另一实施方案中,混合模型可以用于预测使用不同硬件设置进行运动的微(或纳米)对象的位置。在又一实施方案中,混合模型可以用于控制其他种类的系统。例如,可以将混合模型应用于控制具有反冲的马达驱动的机械联动装置。马达的物理性和机械联动装置的旋转可以很容易地使用包含马达和连杆的物理参数(诸如绕组的惯性矩和串联电阻)的物理模型进行建模。联动装置的反冲复杂得多,是非线性的并且取决于先前的历史。使马达系统经历随机的一系列运动控制,改变频率和振幅,并且将所测量的响应与来自物理模型的预期响应进行比较,可获得作为马达输入和状态的函数的物理模型的误差。该数据用于神经网络的监督训练,该神经网络被训练以预测反冲误差。迫使附近的时间误差是不相关的,从
而提供对过度拟合的进一步约束。剩余的误差适合随机模型该随机模型在这种情况下是独立的、相同分布的高斯噪声。可以根据源于物理性和神经网络模型的残差来确定噪声变化。该混合模型用于系统识别,即预测作为各种控制动作和系统的过去和当前状态的函数的系统的响应。该预测可以并入各种控制算法(诸如模型预测控制)中以在更简单的先前控制算法(诸如典型的比例积分微分(pid)控制算法)上实现改进的性能。混合模型的另外其他的使用也是可能的。
[0026]
图1是示出用于借助数字计算机在微组装控制中使用的基于机器学习的位置估计的系统10的框图。系统10允许涉及多个对象11(诸如微对象)的协调组装。对象11的尺寸在纳米级(《1μm)和微米级(1um至几百μm)之间变化,但其他尺寸也是可能的。对象11可以是球形的,但其他形状也是可能的,诸如矩形形状,但另外的其他形状也是可能的。在一个实施方案中,球形对象11的直径可为5μm至50μm,但其他直径也是可能的。在一个实施方案中,矩形对象11的尺寸可为200μm
×
300μm
×
100μm,但其他尺寸也是可能的。对象11浸没在包含在外壳(未示出)内的介电流体(未示出)中,其中膜层(未示出)低于包含在外壳内的介电流体。在一个实施方案中,介电流体是m,由得克萨斯州斯普林市的exxonmobil chemical公司制造,尽管其他介电流体17也是可能的。介电流体可包括一种或多种添加剂,诸如二-2-乙基己基磺基琥珀酸酯(aot)电荷导向剂分子,但其他添加剂也是可能的。对象11可由氧化铝(alox)制成,但其他材料是可能的。对象11中的每一者可以是半导体芯片、集成电路、颗粒、纳米装置或结构,或者电极阵列可物理操纵的任何物体。在下文的描述中,物体11被称为微对象11,尽管命名物体11的其他方式也是可能的。
[0027]
在悬挂的微对象11下方是形成阵列35的多个可编程电极12,电极12被配置为产生动态势能景观,用于利用介电泳(“dep”)力和电泳(“ep”)力两者来操纵对象。膜层压在电极12上。在一个实施方案中,电极可以是正方形形状并且由铜制成,但其他形状和材料也是可能的。在一个实施方案中,正方形电极12的尺寸可为16μm的宽度和100nm的厚度,但在另一实施方案中,其他尺寸也是可能的。阵列35可包括多行电极12,其中每行包括多个电极12。
[0028]
由电极12产生的电势由光电晶体管的阵列13控制,该阵列包括设置在玻璃上的有源矩阵光电晶体管背板。背板上的多个光电晶体管形成阵列13,其中阵列13中的光电晶体管中的每个光电晶体管控制由单个电极12产生的电势。具体地,阵列13中的光电晶体管中的每个光电晶体管附接到一个电极12。光电晶体管的阵列13可具有附加特性,诸如,2019年5月的2019ieee第69届电子部件和技术会议(ectc)的第1312-1315页的rupp等人的“小芯片微组装打印机(chiplet micro-assembly printer)”中描述的那些,其公开内容以引用方式并入。
[0029]
阵列13由视频投影仪14光学寻址,以使得能够同时动态控制静电能势和操纵多个微对象11的位置。具体地,视频投影仪14用于对每个光电晶体管控制的电极12进行寻址,从而允许易做到的缩放因子改变以及缝合成较大阵列。视频投影仪14通过投影预定义图案致动电极12:基于控制输入产生的图像37:由电极产生的电势以实现微对象11的期望运动,如下文进一步描述。由投影仪14投影的构成图像的像素化光将阵列中的每个单独光电晶体管13充电到必要的程度,使得由该光电晶体管充电的电极12产生期望的电势。在一个实施方案中,高达 /-200v的电压由这些光电晶体管控制,以显示动态变化的复杂电势景观。单个电压信号与光学寻址同步,以对每个像素上的存储电容器进行充电。通过刷新投影的图像
图案(控制输入)来产生动态电场图案。已构建了具有50μm、10μm以及甚至3μm间距的阵列13,其中间距是在光电晶体管所附接的电极中心之间的距离。介电流体17介质(isopar m)和各种添加剂用于控制电荷。
[0030]
系统10还包括跟踪被移动的微对象11的位置的高速相机15。视频投影仪14和相机15两者介接到一个或多个计算装置16,这些计算装置可通过投影仪14控制电极12以引起期望的微对象11图案的形成。其他微对象11图案也是可能的。在另一实施方案中,可使用另一种传感器(诸如利用电容感测)来测量和跟踪微对象的位置。在又一实施方案中,电极阵列35可具有集成的有源矩阵寻址电子器件,阵列的每个电极上的电势在已产生期望的微对象移动所必需的电极电势时以电子方式更新。阵列13、电极12、视频投影仪14和相机15的额外特性如plochowietz等人于2020年7月2日公开的美国专利公开申请号us20200207617中所述,该专利的公开内容以引用方式并入。而且,与阵列14、电极12、视频投影仪14和相机15相互作用的系统10的附加组件也是可能的。
[0031]
一个或多个计算设备16之间的连接可以是直接的,诸如经由到物理上接近的一个或多个计算设备16的线或无线连接,或者连接可经由互联网络到达物理上远程的一个或多个计算设备16,诸如经由互联网或蜂窝网络。一个或多个计算装置16包括执行数据处理的一个或多个电路,诸如计算机处理器,但是用于处理数据的其他种类的电路也是可能的。在一个实施方案中,计算机处理器可以是中央处理单元(cpu)、图形处理单元(gpu)或者cpu和gpu的混合,尽管其他种类的处理器或处理器的混合也是可能的。在一个实施方案中,处理器中的两者或更多者可并行执行处理,如在以下专利中另外所述:matei等人于2020年11月16日提交的标题为“system and method for multi-object micro-assembly control with the aid of a digital computer”的美国专利申请序列号17/098,816,该专利的公开内容以引用方式并入。可通过用于跟踪多个颗粒和用于电压模式产生的平行计算能力来获得另外的效率和改善的可扩展性。在又一实施方案中,除cpu和gpu之外的电路可以执行上述数据处理。
[0032]
虽然一个或多个计算设备16被示为服务器,但其他类型的计算机设备是可能的。计算设备16可包括用于执行本文公开的实施方案的一个或多个模块。模块可被实现为以常规编程语言编写为源代码的计算机程序或规程,并且被呈现以供处理器作为对象或字节代码执行。另选地,模块也可在硬件中实现,作为集成电路或烧制到只读存储器部件中,并且计算设备16中的每个计算设备可充当专用计算机。例如,当模块被实现为硬件时,该特定硬件专门用于执行上述计算和通信,并且无法使用其他计算机。另外,当模块被烧制到只读存储器部件中时,存储只读存储器的计算机变得专门用于执行上文所描述的其他计算机不能执行的操作。源代码以及对象和字节代码的各种实施方案可保持在计算机可读存储介质上,诸如软盘、硬盘驱动器、数字视频盘(dvd)、随机存取存储器(ram)、只读存储器(rom)和类似的存储介质。其他类型的模块和模块功能是可能的,以及其他物理硬件部件。例如,计算设备16可包括在可编程计算设备中发现的其他部件,诸如输入/输出端口、网络接口和非易失性存储装置,但其他部件是可能的。在计算设备16是服务器的实施方案中,服务器也可以是基于云的服务器或是专用服务器。
[0033]
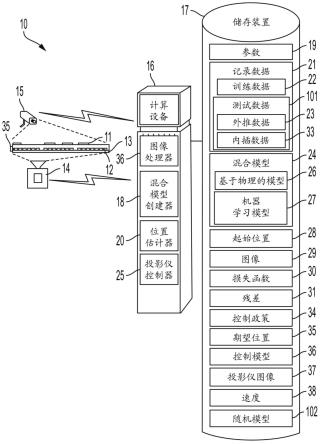
一个或多个计算装置16与存储装置17介接并且执行混合模型创建器18,其获得系统10的参数19并且将参数19存储在存储装置17中。参数19可包括微对象11的直径、电极12
的尺寸、介电流体常数(例如,ε=2)、电极12的固定位置、微对象11和电极12的材料以及微对象11和电极12之间的竖直距离(微对象11的“高度”)。其他参数19仍然是可能的。混合模型创建器18还创建用于预测特定微对象11的位置的混合模型24,其也可以存储在存储装置17中。混合模型24包括基于物理的模型26,其基于以下项来预测在电极致动之后微对象11的位置:生成的控制信号(以及因此由电极产生的电势)、微对象11在特定时间的速度以及基于由相机15捕获的微对象图像29而确定的起始位置28(在致动前的位置)。j.willard、x.jia、s.xu、m.steinbach和v.kumar的“集成基于物理的建模与机器学习:调查(integrating physics-based modeling with machine learning:a survey)”(arxiv:2003.04919[physics.stat](2020))描述了基于物理的模型的示例,其公开内容以引用方式并入,但是其他基于物理的模型26也是可能的。混合模型24还包括一个或多个机器学习模型27。机器学习模型可以包括深度模型(利用由多层制成的神经网络的机器学习模型)、线性模型、密集模型、自动回归集成移动平均(arima)模型、递归神经网络(rnn)模型,然而其他种类的机器学习模型也是可能的。在一个实施方案中,arima模型的简单rnn层可以改变为lstm(长短期存储器、rnn架构),但是其他种类的arima模型也是可能的。如上所述,基于物理的模型26考虑了系统10的确定性行为,而机器学习模型27则考虑了系统10的确定性方面。因此,系统10作为整体的行为可以由y作为物理模型的函数的f(x;θ)给出,其中x是与系统10的先前致动相关联的记录数据(称为下面的训练数据22),θ是参数,噪声n(ф),其中ф是随机噪声模型的噪声参数,系统行为进一步由神经网络函数nn(x;w)(与机器学习模型27相关联)表示,该函数是输入和可训练权重的函数。
[0034]
使用训练数据21构建混合模型24。训练数据描述与微对象11的移动相关联的状态,其包括:(1)微对象的输入状态,在控制输入致动电极之前,其最小为微对象11的位置和速度(但也可以包括其他状态,诸如取向和角度);(2)控制动作,诸如由视频投影仪14施加到光电晶体管控制电极12的照明图案(其指示由电极产生的电势)或施加到微对象11的另一个力;(3)由输入数据产生的输出状态(已在以特定时间和微对象的速度进行的致动之后实现了微对象11的位置)。训练数据22用于构成混合模型24的参数模型的序列的监督训练,如图11所示。图11所示的“传统”模型可以是基于物理的模型24,随后是例如用于残差上的模型2(如图11所示)以及拟合残差上的另外模型的神经网络模型。
[0035]
使用被用作测试数据101的内插数据33(也称为内插数据33)和外推数据23(也称为外推数据23)测试混合模型,如下文进一步所述。内插数据33最初可以是与训练数据22相同的数据集的一部分,并且包括其值在训练数据21的值的范围内的输入状态、控制动作和输出状态。外推训练数据23也可以是与训练数据21相同的数据集的一部分,并且还包括输入状态、控制动作和输出状态,但却包括位于训练数据21的输入状态、控制动作和输出状态的值的范围之外的输入状态、控制动作和输出状态中的至少一者的值。例如,微对象11的位置、速度或施加到微对象11的致动中的至少一者是针对延伸超出在训练数据21中使用的那些的值。
[0036]
图5a和图5b是实验(记录21)数据的带注释的明场图像,其中微对象11由白色圆圈突出显示,并且微对象在其之间平移的一组目标位置由洋红色正方形突出显示。图5a和图5b示出了具有两组不同目标位置的两个不同的实验。该实验数据21可以用作训练数据22。图12是在相关于复杂壳体定义时在训练数据22、外推数据23和内插数据33之间的关系的图
示。其他种类的训练数据仍是可能的。
[0037]
如下面参考图2开始进一步描述,混合模型24是使用以多个阶段实施的梯度增强来创建的,在该期间通过选择损失函数来训练一个或多个基于物理的模型,其中下一阶段是通过使用残差31和先前的输入作为新输入来选择另一个模型(机器学习模型27)以及选择用于增强(训练)下一阶段的参数的损失而实施的,其中以这种方式多次地迭代进行附加模型的创建。
[0038]
因此,在梯度增强期间,最初定义至少一个基于物理的模型26,并且随后使用损失函数30(也称为白化目标函数30)分析在输出训练数据22(在致动之后的特定时间处的微对象11的位置)和通过使用关于同时实现的微对象11的位置的基于物理的模型26做出的一个或多个预测之间的差异,如由基于输入训练数据的在相同的致动之后的输出训练数据所述。该分析的结果是一个或多个残差31(也称为伪残差31),其中每个残差31描述由基于物理的模型26基于一则输入训练数据22预测的一个位置和由进行预测所基于的一则输入训练数据22所产生的一则输出训练数据22之间的差异。随后,在下一阶段期间,使用初始基于物理的模型26导出的残差31来构建第一机器学习模型27,-第一机器学习模型27是基于该基于物理的模型26的广义残差31拟合的。随后,在下一阶段期间,以如上文所描述的相同方式基于训练数据22生成用于第一机器学习模型的残差31-通过使用损失函数30来处理基于输入训练数据22预测的微对象位置和在输出训练数据21中的位置之间的差异。来自第一机器学习模型30的残差31用于定义另一深度模型,其中以与上述相同的方式来计算用于第二深度模型的残差31。以多个阶段继续将一个机器学习模型27的广义残差拟合到下一个机器学习模型27以作为级联,直到已经生成期望数量的模型26、27(在一个实施方案中,期望数量的模型是基于关于包括一定数量的模型26、27的混合模型的准确性的过去数据;在另一实施方案中,基于对预定数量的模型是否产生期望的准确性的经验测试来设置期望数量的模型26、27)。虽然在以上描述中,仅单个基于物理的模型26被用作混合模型24的一部分,但是在另一实施方案中,多个基于物理的模型26可以被用作混合模型的一部分。混合模型24中的一个或多个基于物理的模型26充当弱学习者,即其预测仅略微优于随机猜测的模型,而经训练的机器学习模型27充当强学习者,其具有比弱学习者更高的预测准确性。所有模型26、27的预测被聚合成混合模型24的单次预测,诸如通过分配来自不同模型权重的预测并且对预测求平均,然而其他用于聚合预测的方式也是可能的。例如,根据下面的等式(2),如果残差被表示为因素而不是差异,则可以将各种模型阶段26、27的预测聚合成混合模型24的组合预测作为总和或作为结果细化。也可以向各个阶段分配各种权重。数学上,由混合建模器18执行的梯度增强可以按如下定义:
[0039]
m个学习者的序列用于细化预测的输出。弱(或基本)模型包括物理/确定性模型26,随后是机器学习模型以捕获可预测但复杂的部分。
[0040][0041]
其中,m是迭代次数,(f0)是初始猜测且(fi)是增强或另外的近似值族
[0042]
[0043]
其中
[0044][0045]
其中ψ
i(.,.)
用于阶段i的损失函数。总之,顺序方法涉及使用特定损失函数将模型拟合到先前阶段的残差的多个阶段。在物理模型的当前情况下,包含组装或物理系统的域知识是第一阶段。
[0046]
图11是示出根据一个实施方案的梯度增强的图。
[0047]
返回到图1,虽然训练数据22用于在创建混合模型24之后计算残差31,但是混合建模器18使用外推测试数据23和内插测试数据33来测试由混合模型24做出的预测。最初,针对内插测试数据33测试混合模型24。如果由混合模型24基于输入内插数据33做出的位置预测在来自输出内插数据33的某个误差阈值内(指示模型24已被充分训练),则混合模型24保持不变。如果由混合模型24做出的位置预测在误差阈值之外,则修改混合模型24。此类测试防止混合模型24的过度拟合。在用内插数据33进行测试之后,以与上述内插数据33相同的方式用外推测试数据23测试混合模型:通过将由混合模型24基于输入外推数据23做出的位置预测与输出外推数据23进行比较。如果由混合模型24基于输入外推数据23做出的位置预测在来自输出内插数据23的某个误差阈值内,则混合模型24保持不变。如果由混合模型24做出的位置预测在误差阈值之外,则修改混合模型24。使用外推数据23集的此类测试有助于确保它们的混合模型24具有足够的预测和外推能力,而不是仅被绑定至单个训练数据22集。
[0048]
如上所述,表示为如下的ψ(.,.)损失函数30用于梯度增强的阶段中的每一个期间的残差31计算期间,并且损失函数30必须由混合模型创建器18选择以用于阶段中的每一个。基于与混合模型24尝试预测(并且因此,与构建混合模型24的每个阶段相关联)的数据相关联的随机模型102(描述模型化系统的不易预测并且可以随运行变化的那些方面的模型)来选择函数30的损失。例如,当混合模型24将用于预测连续数据(诸如在微对象11的位置的情况下)时,随机模型102是高斯模型。如果预测数据是计数,则随机模型102是泊松模型。如果预测模型是类别,则随机模型102是多项式模型。其他种类的随机模型102也是可能的。
[0049]
不同的损失函数30可以用于梯度增强的不同阶段中。当基于物理的模型26为均方误差(mse)时,可以在计算残差期间使用的一个损失函数30:
[0050][0051]
是足够的,其中是残差的自相关函数的第i个滞后
[0052]ri
=y
i-f(xi)
ꢀꢀꢀ
(6)
[0053]
然而,mse通常不确保如上所述计算的残差与随机模型102兼容,其中随机模型102通常假设独立的、相同分布的(iid)随机变量。因此,混合模型创建器18使用自相关函数(诸如具有方差的零均值高斯)将梯度增强的每个阶段期间计算的残差31与随机模型102进行比较σ2。为了选择损失函数30,混合模型创建器18可以使用ljung-box(ljb)损失函数:
[0054][0055]
其中,ρ是在滞后k处的自相关函数并且n是样品尺寸。
[0056]
使用ljb函数确保了使用损失函数30产生的不相关残差31和残差与随机模型102的兼容性。在等式(7)中,l是大于可能相关的超参数。对于梯度增强的每个阶段,选择使用损失函数来朝向期望的目标驱动输出残差31(优化损失函数)。计划后续致动允许补偿控制回路延迟,并且因此改善系统10的性能。在一个实施方案中,其中帧速率为每60hz(尽管帧速率的其他值也是可能的),从当颗粒11处于物理位置时到当评估颗粒处于该位置时(由于图像转移和图像处理分析的计算成本)有约2-3帧的控制回路,并且有用于致动的约1帧的延迟(从当确定颗粒处于一个位置处至当产生电极电势以移动颗粒11时的延迟)。控制策略34允许补偿该3-4帧的延迟并且估计针对前3-4帧的颗粒位置。
[0057]
当将微对象11移动到期望的位置35最常常进行多次致动时,在每次致动之后具有微对象11的准确起始位置28对于在后续致动期间产生适当的电势以按最快的方式朝向期望位置35移动微对象11来说是至关重要的。图2是示出根据一个实施方案的用于借助数字计算机在微组装控制中使用的基于机器学习的位置估计的方法40的流程图。方法40可以使用图1的系统10来实施。最初,获得系统10的参数19,并且使用参数19生成控制模型39(步骤41)。获得训练数据22,如下面参考图3进一步描述的(步骤42)。构建用于预测一个或多个微对象11的位置的混合模型24(步骤43),如下面参考图4进一步描述的。使用如上面参考图1所描述的内插数据33来测试混合模型24的准确性(步骤44),并且如果测试结果令人满意并且通过了测试(步骤45),则方法移动至步骤46。如果测试结果不令人满意,则例程返回到步骤43。使用如上面参考图1所描述的外推数据进一步测试混合模型24的准确性(步骤46),并且如果测试结果令人满意并且通过了测试(步骤47),则方法移动至步骤48。如果测试结果不令人满意,则例程返回到步骤43。
[0058]
诸如从用户接收微对象11中的一个或多个微对象的期望位置(步骤48)。通过以下方式获得微对象11的起始位置:如果微对象11静止,则仅使用由相机15捕获的图像29,或者如果已经进行先前的致动并且微对象11现在处于运动中(并且因此控制回路延迟现在是确定其位置的因素),则使用混合模型24(其考虑了从图像29导出的数据)(步骤49)。使用起始位置28、控制模型39和期望位置35生成用于朝向期望位置35移动微对象11的控制策略34(步骤50),并且使用控制策略35经由视频投影仪14致动电极12(步骤51)。如果已经在致动之后实现期望位置35(诸如使用混合模型24确定)(步骤52),则方法40结束。如果尚未实现期望位置,则方法40返回至步骤50。
[0059]
记录数据21对于混合模型24的训练和测试都是必需的。图3是示出根据一个实施方案的用于生成在图2的方法40中使用的训练数据22和测试数据101的例程60的流程图。获得一组记录数据21(步骤61),并且将其划分为训练数据22和测试数据101,其中测试数据包括内插数据33(数据落入作为训练数据22的数据集的界限内)和外推数据23(数据落在作为训练数据22的数据集的界面外)(步骤62),则结束该例程。在一个实施方案中,用作训练数据的数据是数据集的80%,并且用作测试数据101的数据是数据集的20%,然而其他百分比也是可能的。
[0060]
使用梯度增强构建的混合模型24组合来自至少一个基于物理的模型26和一个或多个机器学习模型27的预测,以便由于考虑了系统10的随机和确定性动力学两者,在特定的时间(使用预测位置进行电极致动的时间)实现对微对象11的位置的更准确的预测。图4是示出根据一个实施方案的用于构建在图2的方法40中使用的混合模型24的例程70的流程
图。最初,设置要包括在混合模型24中的多个模型26、27,诸如基于用户输入,诸如基于具有一定数量的模型26、27的混合模型24的过去性能,或基于在方法60期间创建的混合模型24的继续测试(步骤71)。诸如使用参数19定义基于物理的模型26(步骤72)。基于一则或多则输入记录数据21,使用基于物理的模型26做出关于一个或多个微对象11在特定时间的位置的一个或多个预测(步骤73)。如上面参考图1所述,选择损失模型30以及与如上面参考图1所述预测的数据相关联的随机模型102(步骤74)。基于使用基于物理的模型做出的预测和与用于做出预测(由于与输入数据相关联的致动而实现的所记录的微对象位置)的输入数据相关联的输出数据之间的差异使用所选择的损失函数30来计算一个或多个残差31(步骤75)。为所有剩余的模型发起迭代处理循环(步骤76-81)。基于前一模型的残差构建(拟合)模型(步骤77)。基于一则或多则输入记录数据21,使用步骤77中构建的模型做出关于一个或多个微对象11在特定的时间的位置的预测(步骤78)。选择随机模型102用于如上面参考图1所述预测的数据,并且基于随机模型102选择损失函数30以用于在步骤77中构建的模型,如上面参考图1所述的(步骤79)。基于使用在步骤77中构建的模型做出的预测和用于做出预测的输入数据相关联的输出数据之间的差异使用选择的损失函数30来计算一个或多个残差31(由于与输入数据相关联的致动,在用于预测的同时所实现的记录的微对象位置)(步骤80)。步骤76-81的处理循环移动到下一模型(步骤81),直到在步骤71中设置的混合模型24中要包括的模型26、27的数量(包括在步骤62中定义的基于物理的模型26)已经实现,从而结束例程70。在以上描述中,在一个实施方案中,在循环76-81期间创建的所有模型可以是机器学习模型27。在另一实施方案中,在循环76-81期间创建的模型中的至少一些可以是基于物理的模型26。在又一实施方案中,可以在步骤72期间创建机器学习模型27而不是基于物理的模型26,并且可以在循环75-81期间创建至少一个基于物理的模型。
[0061]
以实验方式测试了使用上述的混合模型24的优点,并且出于说明和非限制的目的,下面给出了实验数据。模型24是使用简约深度cpp库在系统10中实施的(然而其他实施方案也是可能的),并且将模型24的性能与下面称为估计器1.0的性能进行比较(除了没有采用混合模型24之外,其是使用类似于系统10的系统实施的),该估计器1.0通过使用其在时间1处在反馈控制内的测量位置
–
#n*1/60s控制循环延迟以及用于控制循环延迟的估计常数#n来估计在时间1处的颗粒位置。还将混合模型24的性能与类似于系统10的系统的性能进行比较,不同的是仅使用机器学习模型26而不是混合模型24来确定颗粒位置。图6是示出与以下相比的估计器1.0的测试结果的图:使用包括rnn模型作为机器学习模型27的混合模型24(“用rnn增强的估计器1.0”);仅使用arima模型来预测颗粒位置;使用用rnn模型增强的arima模型(两个机器学习模型26)来预测颗粒位置;以及将rnn模型用作机器学习模型27。包括arima模型的混合模型24和包括rnn模型的混合模型显示了关于微对象11(称为“颗粒”)的位置(x、y,由框围绕)比估计器1.0高出两倍多的更好的预测。使用参考图5a示出的记录数据21获得这些结果(其中位置也称为“路径点”)。
[0062]
即使当外推数据23用于测试时,混合模型24也比估计器1.0执行得更好。图7是示出使用估计器1.0与外推测试数据集中的arima模型和rnn模型的结果的图。包括arima模型的混合模型24和包括用rnn模型增强的arima模型的混合模型24示出以x和y表示的(由框围绕)颗粒(微对象11)位置的约1.5倍更好的预测,其中rnn模型在外推测试数据集(由框围绕)上执行得最差。
[0063]
图8是示出使用没有监督的经过训练的系统id模型的整个外推数据集(~50分钟)的模拟的图。对于10um球形颗粒(微对象11)的最终位置,包括rnn增强的arima模型的混合模型24执行得最好,其具有~10相机像素的累积rmse误差以及5um的不准确性。估计器1.0导致约200-300相机像素的累积rmse误差(~100-150um的最终颗粒位置的不准确性)。
[0064]
图9是示出使用没有监督的训练系统id模型的外推数据集的模拟的图。对于10um球形颗粒(微对象11)的最终位置,包括rnn增强的arima模型的混合模型24执行得最好,其中真实的(灰色)和预测的(黑色)颗粒位置稍微偏离,且具有~10相机像素的累积rmse误差以及5um的不准确性。使用估计器1.0导致约200-300相机像素的累积rmse误差(~100-150um的最终颗粒位置的不准确性)。rnn模型不准确地预测了颗粒位置。
[0065][0066]
表1.
[0067]
混合模型24也比使用基于纯机器的学习模型执行得更好。表1示出了混合模型24(在表1中称为估计器2.0)与线性、密集和使用简约深度(cpp)实施的arima模型相比的比较准确性。在微组装器软件的模拟器模式中,在2h随机生成的路径点集(微对象位置)上训练模型并且在新的路径点集中测试1分钟。与改进的估计器模型,即估计器2.0(较暗的彩色框)相比,arima模型再次示出在预测颗粒位置中的2倍改进。实施运行得比60hz(控制循环时钟)更快,以用于预测数百个颗粒(微对象11)的位置,但在这个特定实验中未被放大至1000个颗粒(较浅的彩色框)。
[0068]
图10a和图10b是示出测试估计器2.0(混合模型24)与使用简约深度(cpp)在微组装器软件中实施的线性模型、密集模型和arima模型的图。图10a示出了与改进的估计器2.0模型相比,rnn(lstm)增强的arima模型的平均预测误差率降低了》1的相机像素。图10b示出了使用深度和rnn模型的实施方式运行得比用于预测《300个颗粒(微对象11)的60hz(内部控制循环时钟)更快,然而在这个特定的实验中未被放大至1000个颗粒。
[0069]
虽然已经参考本发明的实施方案特别示出和描述了本发明,但本领域技术人员将理解,在不脱离本发明的精神和范围的情况下,可在其中进行形式和细节上的前述和其他改变。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。