一种基于lstm和变分自编码的移动机器人自主探索方法
技术领域
1.本发明属于智能控制领域,具体涉及含lstm和变分自编码的td3强化学习的移动机器人自主探索方法。
背景技术:
2.移动机器人自主探索是机器人任务中的一项基本任务,具有广泛的应用场景。现阶段,大多数学者都是对传统路径规划算法进行研究,例如:神经网络法、人工势场法、遗传算法、模糊逻辑算法等,但以上路径规划算法都依赖于对环境的认知,当机器人在实际应用中有要适应未知环境的需求时,使用以上的方法就有很大局限性。基于强化学习的移动机器人自主探索是该领域的一个研究热点,强化学习方法通过奖励函数来指导智能体自主学习高效有用的路径规划策略,能够实现在复杂环境下的自主探索。本发明在移动机器人自主探索强化学习网络中引入lstm和变分自编码使网络能够分析和存储过去时刻的障碍物和移动机器人自身的状态信息以预测未来时刻的相关信息,大大提升了复杂环境中移动机器人自主探索的成功率,具有重要的理论价值和实际意义。
技术实现要素:
3.本发明针对现有技术的不足,提出了一种基于lstm和变分自编码的移动机器人自主探索方法。
4.一种基于lstm和变分自编码的移动机器人自主探索方法,具体包括以下步骤:
5.步骤(1):状态空间和动作空间设定
6.移动机器人的状态空间包括自身运动的线速度v和角速度w,以移动机器人初始位置为中心,移动机器人到达目标点时的位置g=[g
x
,gy],还包括移动机器人以自身位置为中心,距离目标点的距离l
goal
和方向θ,其中的l
goal
和θ是由δt内移动机器人自身的里程计位置变化计算而来的;
[0007]
移动机器人通过搭载2d激光雷达观测环境,观测的状态空间包括障碍物的距离l
obstacle
;
[0008]
动作空间由线速度和角速度构成的连续动作组成;
[0009]
步骤(2):强化学习网络构建
[0010]
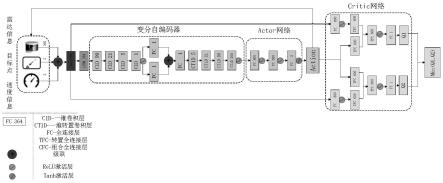
基于长短期记忆网络和变分自编码器的td3强化学习网络,该网络用于评估状态-动作对的q值,网络分为如下三部分:
[0011]
(a)利用长短时记忆网络提取出状态特征
[0012]
首先将移动机器人的状态空间输入到长短时记忆网络中,然后将长短时记忆网络的输出hn与n时刻的输入合并后,最后输入到具有relu型非线性函数的一个多层感知机对状态空间进行特征提取;hn为根据n时刻的输入和n-1时刻的中间状态值h
n-1
产生的n时刻的状态值;
[0013]
(b)利用变分自编码器优化状态特征
[0014]
将步骤(a)特征提取的结果输入到变分自编码器中,得到输出的特征embed_state;
[0015]
(c)将特征输入td3网络得到最佳动作
[0016]
td3网络分为actor和critic两种网络;actor网络由两个全连接层组成;特征经过两个全连接层后分别通过一个relu激活层,最后一层通过两个动作参数a连接到输出层,这两个动作参数分别代表移动机器人的线速度a1和角速度a2;之后对输出层应用tanh激活函数,将a1和a2的值限制在(-1,1)的范围内;
[0017]
状态-动作对q(s,a)由两个critic网络组成;两个critic网络结构相同,参数值存在差异;critic网络使用一对状态s和动作a作为输入;状态s经过一个全连接层l4和relu激活层,得到输出ls;输出ls和动作a分别通过两个独立的转换全连接层,其大小分别为τ1和τ2;这些层是按如下方式组合的:
[0018][0019]
其中lc是组合全连接层,和分别为τ1和τ2的权重;是层τ2的偏差;然后把一个relu激活层应用于组合全连接层lc后;之后,它通过一个代表q值的参数连接到输出;选择两个critic网络的最小q值作为最终输出;
[0020]
步骤(3):设计奖励函数,训练强化学习网络;
[0021]
①
奖励函数设计
[0022]
该策略根据以下函数进行奖励:
[0023][0024]
其中,在时间步t,状态动作对(s
t
,a
t
)的奖励r取决于三个条件;如果在当前时间步d
t
到目标的距离小于阈值ηd,则应用正目标奖励rg;如果检测到碰撞,则应用负碰撞奖励rc;如果这两个条件都不满足,则根据当前的线速度v,角速度w和相邻时间间隔内距离目标点的距离差d
t-1-d
t
立即给予奖励,β为设定的系数;
[0025]
②
为了引导导航策略朝向给定目标,采用延迟属性奖励法进行以下计算:
[0026][0027]
其中n是设定的奖励步数;这意味着,积极的目标奖励不仅归因于目标的状态动作对(s
t
,a
t
),而且在它之前的最后n个步骤中也会逐渐减少;
[0028]
③
虚拟环境仿真训练和测试;
[0029]
步骤(4):将仿真训练的结果迁移至真实移动机器人平台。
[0030]
作为优选,所述的变分自编码器压缩的具体步骤如下:首先将步骤(a)特征提取的结果经过四个一维卷积层和一个relu激活层后得到编码的特征encoder_state;接着将encoder_state经过一个全连接层l1得到特征的均值mean,再将encoder_state经过另一个全连接层l2得到特征的方差log,然后将均值mean,方差log和标准高斯分布epsilon结合生成服从相应高斯分布的随机数z;最后通过一个全连接层l3,四个一维转置卷积层和relu激活层得到最终的输出embed_state;
动作对的q值,网络分为如下三部分:
[0047]
(a)利用长短时记忆网络(lstm)提取出状态特征
[0048]
如图1所示,首先将移动机器人的状态空间输入到长短时记忆网络中,然后将长短时记忆网络的输出hn(根据n时刻的输入和上一时刻的中间状态值h
n-1
产生的n时刻的状态值)与n时刻的输入合并后,最后输入到具有relu型非线性函数的一个多层感知机对状态空间进行特征提取。
[0049]
(b)利用变分自编码器优化状态特征
[0050]
将步骤(a)特征提取的结果输入到变分自编码器中,得到输出的特征embed_state。变分自编码器压缩的具体步骤如下:首先将步骤(a)特征提取的结果经过四个一维卷积层和一个relu激活层后得到编码的特征encoder_state。接着将encoder_state经过一个全连接层l1得到特征的均值mean,再将encoder_state经过另一个全连接层l2得到特征的方差log,然后将均值mean,方差log和标准高斯分布epsilon结合生成服从相应高斯分布的随机数z。最后通过一个全连接层l3,四个一维转置卷积层和relu激活层得到最终的输出embed_state。
[0051]
z=mean exp(log/2)*epsilon
ꢀꢀꢀꢀꢀꢀꢀ
(5)
[0052]
(c)将特征输入td3网络得到最佳动作
[0053]
td3网络分为actor和critic两种网络。actor网络由两个全连接层组成。特征经过两个全连接层后分别通过一个relu激活层,最后一层通过两个动作参数a连接到输出层,这两个参数分别代表移动机器人的线速度a1和角速度a2。之后对输出层应用tanh激活函数,将a1和a2的值限制在(-1,1)的范围内。
[0054]
状态-动作对q(s,a)由两个critic网络组成。两个critic网络结构相同,但由于参数值存在差异,它们的更新会延迟。critic网络使用一对状态s和动作a作为输入。状态s经过一个全连接层l4和relu激活层,得到输出ls。输出ls和动作分别通过两个独立的转换全连接层,其大小分别为τ1和τ2。这些层是按如下方式组合的:
[0055][0056]
其中lc是组合全连接层(cfc),和分别为τ1和τ2的权重。是层τ2的偏差。然后把一个relu激活层应用于组合全连接层lc后。之后,它通过一个代表q值的参数连接到输出。选择两个critic网络的最小q值作为最终输出。
[0057]
步骤(3):设计奖励函数,训练强化学习网络。
[0058]
①
奖励函数设计
[0059]
该策略根据以下函数进行奖励:
[0060][0061]
其中,在时间步t,状态动作对(s
t
,a
t
)的奖励r取决于三个条件。如果在当前时间步d
t
到目标的距离小于阈值ηd,则应用正目标奖励rg。ηd的设定值为0.3m,rg的设定值为80。如果检测到碰撞,则应用负碰撞奖励rc。rc的设定值为-100。如果这两个条件都不满足,则根据当前的线速度v,角速度w和相邻时间间隔内距离目标点的距离差d
t-1-d
t
立即给予奖励。β的
设定值为30。
[0062]
②
为了引导导航策略朝向给定目标,采用延迟属性奖励法进行以下计算:
[0063][0064]
其中n是之前更新奖励的步数。这意味着,积极的目标奖励不仅归因于目标的状态动作对(s
t
,a
t
),而且在它之前的最后n个步骤中也会逐渐减少。
[0065]
③
虚拟环境仿真训练和测试。
[0066]
仿真环境为ros的kinetic版本中的gazebo(ros中含有的物理仿真环境)和rviz(ros中的图形化工具)平台。仿真中使用velodyne激光雷达传感器来感知周围环境。具体仿真训练步骤如下:首先,在每个回合开始随机初始化起始点,目标点和障碍物的位置,然后根据步骤(2)的网络策略给予移动机器人线速度v,角速度w,同时根据
①
中的奖励函数给予奖励,直至移动机器人发生碰撞或者超过t个step都没有发生碰撞就结束当前回合并随机重置机器人的初始化起始点,目标点和障碍物的位置。t的设定值为500。最后,经过一定数量的回合后,移动机器人可以在不碰撞的情况下到达目标点。
[0067]
步骤(4):将仿真训练的结果迁移至真实移动机器人平台。
[0068]
将步骤(3)仿真训练结果迁移至实际实际移动机器人平台上,在含有静态障碍物、动态障碍物以及随机走动的行人的复杂环境中进行探索测试实验。首先启动雷达节点,并打开ros中的可视化图形工具rviz,运行导航节点,根据提前设定好的目标点,即可使移动机器人使用强化学习方法边使用gmapping算法建图边规划路线动态避障,安全避开随机走动的人群及其他障碍物,顺利到达目标点位置并完成从起始点到目标点之间的建图。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
