1.本发明涉及自然语言处理、金融两个交叉领域,具体是一种基于实体词属性特征和回译的中文金融文本数据增强方法。
背景技术:
2.文本数据增强是自然语言处理(natural language processing,nlp)中一项基础且重要的技术,是应用nlp技术处理下游任务过程中重要的一环。然而,由于文本离散化,字与字、字与词、词与词之间存在较强前后关系的特点,通常更改其中的某个字或某个词,尤其是核心词时,会导致句子的语义与原意产生巨大差异,使得文本数据增强存在一定的难度。因此,当前中文文本增强技术、尤其是金融领域的文本增强技术生成的文本质量尚存在巨大的提升空间。现阶段中文文本增强方法及其优缺点主要存在以下几点:
3.(1)token的增删查改:常见的有同义词替换,同音词替换,字符的随机插入、删除、替换等。这类方法的优势是方法简单、直观,缺点是生成的文本与原文本之间的语法结构极为相似,多样性不足,生成的新文本在语义上较为依赖中文分词模型的性能及加载的近义词等相关词表质量。
4.(2)词嵌入扰动:按一定比例随机对中文文本词向量的某些维度进行噪声化处理丢弃文本的词向量,对文本的词向量随机添加一定的噪声。该方法的优点是通用性较强,简单易用;缺点是针对不同任务、不同质量的文本数据,扰动参数的调整极为耗时且依赖专家经验,在大规模语料的无监督或自监督训练场景尤为明显。
5.(3)使用深度学习生成相似文本:具有代表性的方法包括,回译,simbert等深度学习开源模型。这类方法的优点是生成文本的语法结构多样;缺点是文本生成质量高度依赖模型的性能,在金融领域,通常无法准确生成金融属性的专有名词。
6.在当前的“ai 金融”背景下,金融行业每天都在产生大量的、实时的无标签金融文本数据。面对标签数据不足,人工标注任务量大,常规数据增强方法生成的文本质量差等问题,一种泛化性强,鲁棒性高的金融文本数据增强方法来处理这类金融文本数据时非常迫切的。
技术实现要素:
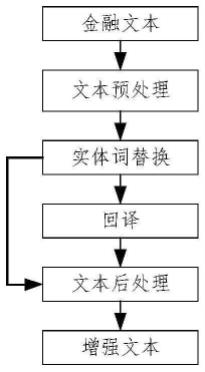
7.针对以上挑战,本发明提出一种基于实体词属性特征和回译的中文金融文本数据增强方法,该方法包括:金融文本的清洗和预处理;紧接着,通过命名实体识别和词汇匹配的方法对金融文本中翻译难度较大的实体词使用指代字符进行实体词指代替换以生成金融文本的中间文本和指代字符-实体映射关系字典;之后,使用回译的方法增强金融文本的中间文本,并使用指代字符-实体映射关系字典还原文本中的指代字符,进而生成与原文本语义相似的新文本。此外,本方法在中文金融文本的数据增强任务中,首次关注并分析了实体词属性特征对文本数据增强结果的影响,并将不同种类的实体词属性特征分层次处理,提高了数据增强后得到文本的质量。
8.本发明公开的方法是通过以下技术方案来实现的:一种基于实体词属性特征和回译的中文金融文本数据增强方法,包括以下步骤:
9.(1)将金融文本依次进行英文字母大小写统一、中英文标点符号统一、繁体中文转简体中文、删除乱码及无法打印字符的操作;
10.(2)识别并抽取步骤(1)处理好的金融文本中的实体词,将抽取的实体词使用指代字符进行指代替换以生成金融文本的中间结果和指代字符和实体词之间的映射关系字典;其中实体词的属性特征包括:公司名实体词、金融名词实体词、货币描述实体词、人名实体词及时间实体词,公司名包含股票名、公司名全称、公司名简称、公司名别称以及公司曾用名;指代字符-实体词映射关系形式如下::{c1:com1,c2:com2,c3:com3…
},{f1:fin1,f2:fin2,f3:fin3…
},{m1:mon1,m2:mon2,m3:mon3…
},{p1:per1,p2:per2,p3:per3…
},{t1:time1,t2:time2,t3:time3…
},其中,代表公司名实体词、代表金融名词实体词、m代表货币描述实体词、p代表人名实体词、代表时间描述实体词;
11.(3)使用通用的机器学习翻译算法将金融文本的中间结果翻译成其他语种的文本;然后,通过机器学习翻译算法将其他语种的文本结果再次翻译为中文文本,完成回译;
12.(4)使用步骤(2)生成的映射关系字典复原步骤(3)回译后金融文本中的指代字符。
13.进一步地,所述步骤(2)中,金融文本中的实体词为公司名实体词,所述将抽取的实体词使用指代字符进行指代替换以生成金融文本的中间结果和指代字符和实体词之间的映射关系字典包括以下子步骤:
14.(2.1)收集带有公司名实体识别的有标签数据集,并将文本中公司名实体词的位置标志为1,其他位置标志为0;以bert和mlp模型为基础构建命名实体识别模型;将经过步骤(1)处理的有标签数据输入命名实体识别模型进行训练;然后,将需要增强的金融文本输入训练后的命名实体识别模型,得到实体命名识别模型识别出的公司名实体词列表入训练后的命名实体识别模型,得到实体命名识别模型识别出的公司名实体词列表
15.(2.2)引入公司名实体词词库,建立公司名实体词字典树,根据该公司名实体词字典树使用前向最大匹配算法抽取待增强的金融文本中包含的公司名实体词典树使用前向最大匹配算法抽取待增强的金融文本中包含的公司名实体词将公司名实体词词库中的所有公司名实体词以空格为隔断拼接生成公司名长字符串com
str
;所述公司名实体词词库包含股票名、公司名全称、公司名简称、公司名别称以及公司曾用名;
16.(2.3)建立公司名实体词黑名单com
black
和歧义公司名实体词列表com
diff
;公司名实体词黑名单com
black
包括指代性公司名实体词;歧义公司名实体词列表com
diff
包括既是公司名简称实体词、又可以表示人名实体词或其他实体词的实体词;
17.(2.4)将命名实体识别模型得到的每个公司名实体词与公司名实体词黑名单com
black
和公司名实体词长字符串com
str
进行逻辑判断,若判定结果为1,则保留该公司名实体词若判定为0,则丢弃该公司名实体词逻辑判断公式为:
[0018][0019]
(2.5)将前向最大匹配算法匹配出的每个公司名实体词与歧义公司名实
体词列表com
diff
和命名实体识别模型识别出的公司名实体词com
ner
进行逻辑判断,若判断结果为1,则保留该公司名实体词若判断结果为0,则丢弃该公司名实体词判定公式为:
[0020][0021]
(2.6)将过滤后的com
matc
h与com
ner
进行去重合并,生成公司名实体词列表com,使用指代字符c=[c1,c2,c3…
]替换待增强金融文本中的公司名实体词com生成金融文本的中间结果,并建立指代字符与公司名实体词之间的映射字典{c1:com1,c2:com2,c3:com3…
}。
[0022]
进一步地,所述步骤(2)中,金融文本中的实体词为金融名词实体词,所述将抽取的实体词使用指代字符进行指代替换以生成金融文本的中间结果和指代字符和实体词之间的映射关系字典包括以下子步骤:
[0023]
(a)引入金融名词实体词词库,删除与公司名实体词词库重叠的词,建立金融名词实体词字典树,根据该金融名词实体词字典树使用前向最大匹配算法抽取待增强的金融文本中出现的金融名词实体词fin={fin1,fin2,fin3…
};
[0024]
(b)使用开源的自然语言词性标注工具加载步骤(a)中引入的金融名词实体词词库,对待增强的金融文本进行分词和词性标注;
[0025]
(c)将前向最大匹配算法匹配出的每个公司名实体词fini,与自然语言词性标注工具识别出的词性进行逻辑判断,若判定结果为1,则保留该金融名词实体词,若判定结果为0,则丢弃该金融名词实体词,判定公式为:
[0026][0027]
在词性标注集中,j,n,nz分别表示缩写词、一般名词和其他名词;
[0028]
(d)使用指代字符f=[f1,f2,f3…
]替换金融文本中的金融名词实体词fin生成金融文本的中间文本,并建立指代字符与金融名词实体词之间的映射关系字典{f1:fin1,f2:fin2,f3:fin3…
}。
[0029]
进一步地,所述步骤(2)中,金融文本中的实体词为货币描述实体词、人名实体词或时间描述实体词,所述将抽取的实体词使用指代字符进行指代替换以生成金融文本的中间结果和指代字符和实体词之间的映射关系字典包括以下子步骤:货币描述实体词、人名实体词及时间描述实体词的识别、抽取及字符指代替换包括以下子步骤:
[0030]
(a)使用paddlenlp开源函数识别并抽取金融文本中的货币描述实体词、人名实体词和时间实体词;
[0031]
(b)使用指代字符t=[t1,t2,t3…
]、m=[m1,m2,m3…
]、p=[p1,p2,p3…
]替换文本中的时间实体词、货币描述实体词以及人名实体词生成金融文本的中间结果,并建立指代字符与时间实体词、货币描述实体词以及人名实体词之间的映射关系字典:{m1:mon1,m2:mon2,m3:mon3…
},{p1:per1,p2:per2,p3:per3…
},{t1:time1,t2:time2,t3:time3…
}。
[0032]
本发明的有益效果是,本发明在中文金融文本的数据增强任务中,首次关注并分析了实体词属性特征对文本数据增强结果的影响,并将不同种类的实体词属性特征分层次处理,提高了数据增强后得到文本的质量。
附图说明
[0033]
图1一种基于实体词属性特征和回译的中文金融文本数据增强方法流程示意图;
[0034]
图2实体词替换模块流程示意图;
[0035]
图3公司名实体词替换流程示意图;
[0036]
图4金融名词实体词替换流程示意图;
[0037]
图5货币描述实体词、人名实体词和时间实体词指代替换流程示意图。
具体实施方式
[0038]
下面根据附图进一步地对本发明进行说明:
[0039]
参考图1,本发明提供了一种基于实体词属性特征和回译的中文金融文本数据增强方法,首先对输入的金融文本进行文本预处理工作,紧接着,进行实体词替换,具体是通过命名实体识别和词汇匹配的方法对金融文本中翻译难度较大的实体词使用指代字符进行实体词指代替换以生成金融文本的中间文本和指代字符-实体映射关系字典;之后,使用回译的方法增强金融文本的中间文本,并使用指代字符-实体映射关系字典还原文本中的指代字符完成文本后处理工作,进而生成与原文本语义相似的新文本。
[0040]
所述文本预处理具体用于清洗输入的金融文本,包括英文字母大小写统一、中英文标点符号统一、繁体中文转简体中文、删除乱码及无法打印字符的操作。
[0041]
所述实体词替换具体是识别并抽取预处理好的金融文本中的较难翻译的实体词,将抽取的实体词使用指代字符进行指代替换以生成金融文本的中间结果和指代字符和实体词之间的映射关系字典。其中实体词的属性特征包括:公司名(包含股票名、公司名全称、公司名简称、公司名别称以及公司曾用名)、金融名词、货币描述实体词、人名及时间等实体词;指代字符-实体词映射关系形式如下::{c1:com1,c2:com2,c3:com3…
},{f1:fin1,f2:fin2,f3:fin3…
},{m1:mon1,m2:mon2,m3:mon3…
},{p1:per1,p2:per2,p3:per3…
},{t1:time1,t2:time2,t3:time3…
},其中c代表公司名实体词、f代表金融名词实体词、m代表货币描述实体词、p代表人名实体词、代表时间描述实体词。
[0042]
所述实体词替换具体是使用通用的机器学习翻译算法将实体词替换模块中输出的金融文本中间结果翻译成其他语种的文本。然后,通过机器学习翻译算法将其他语种的文本结果再次翻译为中文文本,完成回译。
[0043]
所述文本后处理具体是使用实体词替换生成的指代字符-实体映射关系字典复原回译生成的金融文本中的指代字符。
[0044]
参考图2,实体词替换流程示意图,主要包括公司名实体词替换方法、金融名词实体词替换方法、时间实体词替换方法、货币描述实体词替换方法以及人名实体词替换方法分别对输入的金融文本中的公司名实体、金融名词实体、货币描述实体词、人名实体词及时间实体词使用字符进行指代替换生成金融文本的中间结果和指代字符与实体词之间的映射关系字典。
[0045]
参考图3,公司名实体词替换流程示意图,通过命名实体识别与前向最大匹配的方法识别文本中的公司名实体词,并使用指代字母c进行替换,具体实施方式为:
[0046]
收集带有公司名实体识别的有标签数据集,并将文本中公司名实体词的位置标志为1,其他位置标志为0;以bert和mlp模型为基础构建命名实体识别模型;将经过文本预处
理的有标签数据输入命名实体识别模型进行训练。然后,将需要增强的金融文本输入训练后的命名实体识别模型,得到模型识别出的公司名实体词列表后的命名实体识别模型,得到模型识别出的公司名实体词列表
[0047]
引入公司名实体词词库(包含股票名、公司名全称、公司名简称、公司名别称以及公司曾用名),建立公司名实体词字典树,根据该公司名实体词字典树使用前向最大匹配算法抽取待增强的金融文本中出现的公司名实体词将公司名实体词词库中的所有公司名实体词以空格为隔断拼接生成公司名长字符串com
str
;所述公司名实体词词库包含股票名、公司名全称、公司名简称、公司名别称以及公司曾用名;
[0048]
建立公司名实体词黑名单com
black
,具体指“公司”,“集团”这种指代性公司名实体词;建立歧义公司名实体词列表com
diff
,具体指“红太阳”、“林肯”这种既是公司名简称实体词、又可以表示人名实体词或其他实体词。
[0049]
将命名实体识别模型得到的每个公司名实体词与公司名实体词黑名单com
black
和公司名实体词长字符串com
str
进行逻辑判断,若判定结果为1,则保留该公司名实体词若判定为0,则丢弃该公司名实体词逻辑判断公式为:
[0050][0051]
将前向最大匹配算法匹配出的每个公司名实体词与歧义公司名实体词列表com
diff
和命名实体识别模型识别出的公司名实体词com
ner
进行逻辑判断,若判断结果为1,则保留该公司名实体词若判断结果为0,则丢弃该公司名实体词判定公式为:
[0052][0053]
将过滤后的com
match
与com
ner
进行去重合并,生成公司名实体词列表com,使用指代字符c=[c1,c2,c3…
]替换待增强金融文本中的公司名实体词com生成金融文本的中间结果,并建立指代字符与公司名实体词之间的映射字典{c1:com1,c2:com2,c3:com3…
}。
[0054]
参考图4,金融名词实体词替换流程示意图,通过开源的自然语言词性标注工具与前向最大匹配的方法识别文本中的金融名词实体词,并使用指代字母f进行替换,具体实施方式为:
[0055]
引入金融名词实体词词库,删除与公司名实体词词库重叠的词,建立金融名词实体词字典树,根据该金融名词实体词字典树使用前向最大匹配算法抽取待增强的金融文本中出现的金融名词实体词fin={fin1,fin2,fin3…
};
[0056]
使用开源的自然语言词性标注工具加载引入的金融名词实体词词库,对待增强的金融文本进行分词和词性标注;
[0057]
将前向最大匹配算法匹配出的每个公司名实体词i,与自然语言词性标注工具识别出的词性进行逻辑判断,若判定结果为1,则保留该金融名词实体词,若判定结果为0,则丢弃该金融名词实体词,判定公式为:
[0058][0059]
在词性标注集中,j,n,nz分别表示缩写词、一般名词和其他名词。
[0060]
使用指代字符f=[f1,f2,f3…
]替换金融文本中的金融名词实体词fin生成金融文本的中间文本,并建立指代字符与金融名词实体词之间的映射关系字典{f1:fin1,f2:fin2,f3:fin3…
}。
[0061]
参考图5,货币描述实体词、人名实体词和时间实体词替换流程示意图,通过paddlenlp开源函数识别出金融文本中的货币描述实体词、人名实体词和时间实体词,并使用指代字母t、m、p分别进行替换,具体实施方式为:
[0062]
使用paddlenlp开源函数抽取金融文本中的货币描述实体词、人名实体词和时间实体词。
[0063]
使用指代字符t=[t1,t2,t3…
]、m=[m1,m2,m3…
]、p=[p1,p2,p3…
]替换文本中的时间实体词、货币描述实体词以及人名实体词生成金融文本的中间结果,并建立指代字符与时间实体词、货币描述实体词以及人名实体词之间的映射关系字典:{m1:mon1,m2:mon2,m3:mon3…
},{p1:per1,p2:per2,p3:per3…
},{t1:time1,t2:time2,t3:time3…
}。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。