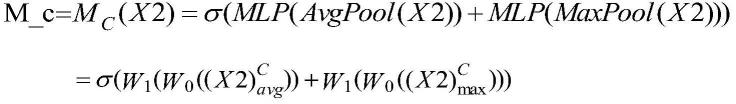
卷积块注意力模块嵌入regnety网络的词义消歧
技术领域:
1.本发明涉及一种卷积块注意力模块嵌入regnety网络的词义消歧方法,该方法在自然语言处理技术领域中有着很好的应用。
背景技术:
2.在自然语言处理领域中,词汇普遍具有一词多义现象。词义消歧的目的是确定歧义词汇在特定上下文环境中的语义。词义消歧在机器翻译、自动文摘、信息检索和文本分类中有着重要的应用,这些系统性能的好坏与词义消歧紧密相关。
3.经常使用一些常见的算法对词汇进行消歧,例如:k-means、朴素贝叶斯、基于关联规则的分类方法和人工神经网络等。但是,传统的算法存在着一些缺点和不足。所提取的消歧特征只局限于局部区域,分类器的训练效果不是很好。近年来,深度学习算法已被广泛地应用到自然语言处理领域。将cbam嵌入regnety之中,来处理特征,以获取更加精确的消歧特征,解决了手动提取消歧特征的问题。在regnety中,神经元的权值是共享的。这使得神经元可以共享资源,降低了网络模型的复杂度,防止出现过拟合现象。将cbam嵌入regnety可以很好地对歧义词汇进行消歧,实现语义的正确分类。
技术实现要素:
4.为了解决自然语言处理领域中的词汇歧义问题,本发明公开了一种基于cbam嵌入regnety网络的词义消歧方法。
5.为此,本发明提供了如下技术方案:
6.1.基于cbam嵌入regnety网络的词义消歧方法,歧义词汇m具有n个语义类别s1,s2,
…
,sn,该方法包括以下步骤:
7.步骤1:对semeval-2007:task#5的训练语料和测试语料进行分词、词性标注、拼音首字母标注、声调标注和语义类标注处理,选取歧义词m左右具有名词、动词、形容词、数词、量词和代词词性的邻接词汇单元的词形、词性、语义类、拼音首字母和声调作为消歧特征。
8.步骤2:利用word2vec工具对从semeval-2007:task#5的训练语料中抽取的消歧特征进行向量化处理,得到训练数据,利用word2vec工具对从semeval-2007:task#5的测试语料中抽取的消歧特征进行向量化处理,得到测试数据。
9.步骤3:训练包括前向传播和反向传播两个过程,利用训练数据优化cbamregnety,得到优化后的cbamregnety。
10.步骤4:测试过程为前向传播过程,即语义分类过程。在优化后的cbamregnety上,输入测试数据,计算歧义词汇m在每个语义类别下的权重,其中,权重最大的语义类别即为歧义词汇的语义类别。
11.2.根据权利要求1所述的基于cbam嵌入regnety网络的词义消歧方法,其特征在于,所述步骤1中,具体步骤为:
12.步骤1-1利用汉语分词工具对汉语句子进行词汇切分;
13.步骤1-2利用汉语词性标注工具标注句子中所有词汇的词性;
14.步骤1-3利用汉语语义标注工具标注句子中所有词汇的语义类;
15.步骤1-4利用汉字转拼音工具标注出句子中所有词汇的拼音首字母和音调;
16.步骤1-5选取歧义词左右具有名词、动词、形容词、数词、量词和代词词性的邻接词汇单元;
17.步骤1-6将选中的邻接词汇单元的词形、词性、语义类、拼音首字母、声调作为消歧特征。
18.3.根据权利要求1所述的基于cbam嵌入regnety网络的词义消歧方法,其特征在于,所述步骤2中,具体步骤为:
19.步骤2-1利用word2vec工具对从semeval-2007:task#5的训练语料中抽取的消歧特征进行向量化处理,得到训练数据;
20.步骤2-2利用word2vec工具对从semeval-2007:task#5的测试语料中抽取的消歧特征进行向量化处理,得到测试数据。
21.4.根据权利要求1所述的基于cbam嵌入regnety网络的词义消歧方法,其特征在于,所述步骤3中,具体步骤为:
22.步骤3-1把训练数据输入到初始化的cbamregnety中;
23.步骤3-2经过卷积层1,提取特征x1;
24.步骤3-3经过通道注意力卷积层,提取特征x2,所述的通道注意力卷积层包括通道注意力模块se和卷积层2;
25.步骤3-4经过卷积块注意力卷积层,提取特征x3,所述的卷积块注意力卷积层包括卷积块注意力模块cbam和卷积层3,cbam的输出计算过程如下:
[0026][0027][0028]
其中,σ是sigmoid函数,mlp是两层神经网络,avgpool(x2)表示对x2做平均池化操作,maxpool(x2)表示对x2做最大池化操作,m_c*x2为将m_c和输入特征x2做乘法操作,cbam的输出为m_s*(m_c*x2);
[0029]
步骤3-5经过自适应平均池化层,计算歧义词汇m在语义类别si下的权重w(si|m),i=1,2,...,n;
[0030]
步骤3-6利用交叉熵损失函数来计算误差loss,所述误差loss的计算过程如下所示:
[0031]
[0032]
其中,loss表示训练数据的平均误差,n是训练数据的个数,yk是第k个训练数据的标签;
[0033]
步骤3-7根据误差loss反向传播,逐层更新参数,参数更新过程如下:
[0034][0035]
其中,θ表示参数集,θ'表示更新后的参数集,a为学习率;
[0036]
步骤3-8不断迭代步骤3-1至步骤3-7,直到达到规定的循环次数为止,得到优化后的cbamregnety。
[0037]
5.根据权利要求1所述的基于cbam嵌入regnety网络的词义消歧方法,其特征在于,在所述步骤4中,具体过程为:
[0038]
步骤4-1把测试数据输入到优化后的cbamregnety之中;
[0039]
步骤4-2经过卷积层1,提取特征x1;
[0040]
步骤4-3经过通道注意力卷积层,提取特征x2,所述的通道注意力卷积层包括通道注意力模块se和卷积层2;
[0041]
步骤4-4经过卷积块注意力卷积层,提取特征x3,所述的卷积块注意力卷积层包括卷积块注意力模块cbam和卷积层3,cbam的输出计算过程如下:
[0042][0043][0044]
其中,σ是sigmoid函数,mlp是两层神经网络,avgpool(x2)表示对x2做平均池化操作,maxpool(x2)表示对x2做最大池化操作,m_c*x2为将m_c和输入特征x2做乘法操作,cbam的输出为m_s*(m_c*x2);
[0045]
步骤4-5经过自适应平均池化层,计算歧义词汇m在语义类别si下的权重w(si|m),i=1,2,...,n;
[0046]
步骤4-6选择最大权重所对应的语义类别作为歧义词汇m的语义类别:
[0047][0048]
其中,s表示歧义词汇m的语义类别。
[0049]
有益效果:
[0050]
1.本发明是一种基于cbam嵌入regnety网络的词义消歧方法。选取歧义词左右具有名词、动词、形容词、数词、量词和代词词性的邻接词汇单元的词形、词性、语义类、拼音首字母和声调作为消歧特征。利用word2vec工具分别对消歧特征进行向量化处理,所提取的消歧特征具有较高的质量。
[0051]
2.本发明所使用的消歧模型为cbam嵌入regnety网络,最大的特点是局部感知和参数共享,覆盖到了待识别的更多特征,最终判别语义类别的正确率也更高,能够很好地处理高维数据,无需手动选取数据特征。cbam让regnety学会了关注重点信息。增强有效特征,
抑制无效特征,能够提取更完整的消歧特征,减少数据和参数量,防止出现过拟化。
[0052]
3.在训练消歧模型时,采用随机梯度下降法进行参数更新。计算误差,误差通过反向传播沿原路线返回,即从输出层反向经过各中间隐藏层,逐层更新每一层参数,最终回到输入层。不断地进行前向传播和反向传播,以减小误差,更新模型参数,直到消歧模型训练好为止。随着误差反向传播不断地对参数进行更新,cbam嵌入regnety网络能够对输入数据进行准确消歧。
附图说明:
[0053]
图1为本发明实施方式中的汉语句子词义消歧的流程图;
[0054]
图2为本发明实施方式中的基于cbam嵌入regnety网络的词义消歧模型的训练过程。
[0055]
图3为本发明实施方式中的基于cbam嵌入regnety网络的词义消歧模型的测试过程。
具体实施方式:
[0056]
为了使本发明的实施例中的技术方案能够清楚和完整地描述,以包含歧义词汇“中医”的测试句子“会议强调要以医改为契机继续深化中医医疗机构改革”为例,结合实施例中的附图,对本发明进行进一步的详细说明,歧义词汇“中医”有两个语义类别,s1:practitioner_of_chinese_medicine,s2:traditional_chinese_medical_science。
[0057]
本发明实施例基于cbam嵌入regnety网络的词义消歧方法的流程图,如图1所示,包括以下步骤:
[0058]
步骤1消歧特征的提取过程如下:
[0059]
步骤1-1利用汉语分词工具对汉语句子进行词汇切分,具体结果如下:
[0060]
分词结果:会议强调要以医改为契机继续深化中医医疗机构改革
[0061]
步骤1-2利用汉语词性标注工具标注句子中所有词汇的词性,具体结果如下:
[0062]
词性标注:会议/n强调/v要/v以/p医改/j为/v契机/n继续/v深/v中医/n医疗/n机构/n改革/vn
[0063]
步骤1-3利用汉语语义标注工具标注句子中所有词汇的语义类,具体结果如下:
[0064]
语义类标注:会议/n/di23强调/v/gb21要/v/ag04以/p/di02医改/j/-1为/v/ih01契机/n/ca04继续/v/ig03深化/v/ih10中医/n/ae15医疗/n/hg20机构/n/di09改革/vn/ha04
[0065]
步骤1-4利用汉字转拼音工具标注出句子中所有词汇的拼音首字母和音调,具体结果为:
[0066]
拼音首字母和音调标注:会议/n/di23/hy/44强调/v/gb21/qd/24要/v/ag04/y/4以/p/di02/y/3医改/j/-1/yg/13为/v/ih01/w/4契机/n/ca04/qj/41继续/v/ig03/jx/44深化/v/ih10/sh/14中医/n/ae15/zy/11医疗/n/hg20/yl/12机构/n/di09/jg/14改革/vn/ha04/gg/32
[0067]
步骤1-5选取歧义词左右具有名词、动词、形容词、数词、量词和代词词性的邻接词汇单元,具体结果为:
[0068]
会议/n/di23/hy/44强调/v/gb21/qd/24要/v/ag04/y/4为/v/ih01/w/4契机/n/ca04/qj/41继续/v/ig03/jx/44深化/v/ih10/sh/14医疗/n/hg20/yl/12机构/n/di09/jg/14改革/vn/ha04/gg/32
[0069]
步骤1-6将选中的邻接词汇单元的词形、词性、语义类、拼音首字母、声调作为消歧特征,具体结果为:
[0070]
词形词性语义类拼音首字母声调会议ndi23hy44强调vgb21qd24要vag04y4为vih01w4契机nca04qj41继续vig03jx44深化vih10sh14医疗nhg20yl12机构ndi09jg14改革vnha04gg32
[0071]
步骤2获取测试数据和训练数据:
[0072]
步骤2-1利用word2vec工具对从semeval-2007:task#5的训练语料中抽取的消歧特征进行向量化处理,得到训练数据;
[0073]
步骤2-2利用word2vec工具对从semeval-2007:task#5的测试语料中抽取的消歧特征进行向量化处理,得到测试数据,结果为:
[0074]
tensor([[-2.1511e-04,9.0341e-05,2.2727e-03,...,-2.1809e-03,-1.6873e-03,-3.8032e-03],
[0075]
[3.5645e-03,-2.1729e-03,3.7584e-03,...,-3.0925e-03,1.5182e-03,9.5325e-05],
[0076]
[2.1334e-03,-3.1879e-03,1.7961e-03,...,-1.9394e-03,-8.0814e-04,2.8975e-03],
[0077]
...,
[0078]
[1.9837e-03,-4.4545e-03,3.3295e-03,...,2.1458e-04,-1.3078e-03,-5.0350e-04],
[0079]
[-4.2148e-03,-1.8479e-03,-1.7771e-03,...,1.3312e-03,4.8244e-04,-2.3722e-03],
[0080]
[-2.5976e-03,3.2163e-03,9.0198e-04,...,3.1928e-03,2.0543e-03,1.2940e-03]])
[0081]
步骤3使用训练数据来优化cbamregnety;
[0082]
步骤3-1把训练数据输入到初始化的cbamregnety中;
[0083]
步骤3-2经过卷积层1,提取特征x1;
[0084]
步骤3-3经过通道注意力卷积层,提取特征x2,所述的通道注意力卷积层包括通道注意力模块se和卷积层2;
[0085]
步骤3-4经过卷积块注意力卷积层,提取特征x3,所述的卷积块注意力卷积层包括卷积块注意力模块cbam和卷积层3,cbam的输出计算过程如下:
[0086][0087][0088]
其中,σ是sigmoid函数,mlp是两层神经网络,avgpool(x2)表示对x2做平均池化操作,maxpool(x2)表示对x2做最大池化操作,m_c*x2为将m_c和输入特征x2做乘法操作,cbam的输出为m_s*(m_c*x2);
[0089]
步骤3-5经过自适应平均池化层,计算歧义词汇“中医”在语义类别s1=practitioner_of_chinese_medicine,s2=traditional_chinese_medical_science下的权重w(si|m),i=1,2;
[0090]
步骤3-6利用交叉熵损失函数计算实际输出与期望输出之间的误差loss
中医
,计算过程如下:
[0091]
loss
中医
=0.588
[0092]
步骤3-7根据误差loss
中医
反向传播,逐层更新参数,参数更新过程如下:
[0093][0094]
其中,θ
中医
表示参数集,θ'
中医
表示更新后的参数集,a为学习率;
[0095]
步骤3-8不断迭代步骤3-1至步骤3-7,直到达到规定的次数为止,得到优化后的cbamregnety。
[0096]
步骤4对歧义词汇“中医”进行语义分类:
[0097]
步骤4-1把“中医”的测试数据输入到优化后的cbamregnety之中;
[0098]
步骤4-2经过卷积层1,提取特征x1;
[0099]
步骤4-3经过通道注意力卷积层,提取特征x2,所述的通道注意力卷积层包括通道注意力模块se和卷积层2;
[0100]
步骤4-4经过卷积块注意力卷积层,提取特征x3,所述的卷积块注意力卷积层包括卷积块注意力模块cbam和卷积层3,cbam的输出计算过程如下:
[0101][0102]
[0103]
其中,σ是sigmoid函数,mlp是两层神经网络,avgpool(x2)表示对x2做平均池化操作;maxpool(x2)表示对x2做最大池化操作;m_c*x2为将m_c和输入特征x2做乘法操作,cbam的输出为m_s*(m_c*x2);
[0104]
步骤4-5经过自适应平均池化层,计算歧义词汇“中医”在语义类别s1=practitioner_of_chinese_medicine,s2=traditional_chinese_medical_science下的权重w(si|m),i=1,2;
[0105]
输出歧义词汇“中医”在语义类别s1=practitioner_of_chinese_medicine和s2=traditional_chinese_medical_science下分配的权重:
[0106]
w(practitioner_of_chinese_medicine|中医)=0.0628
[0107]
w(traditional_chinese_medical_science|中医)=0.0825
[0108]
步骤4-6输出最大权重的语义类别,如下:
[0109][0110]
s=traditional_chinese_medical_science表示歧义词汇“中医”所对应的语义类别。
[0111]
通过优化后的cbam嵌入regnety网络的词义消歧模型,对包含歧义词汇“中医”的汉语句子“政府大力提倡继续深化中医医疗机构的发展。”进行词义消歧,歧义词汇“中医”所对应的语义类别为traditional_chinese_medical_science。
[0112]
本发明实施方式中的cbam嵌入regnety网络的词义消歧方法,能够选择精确的消歧特征,并采用cbam嵌入regnety网络来确定歧义词汇的语义类别,具有较高的正确率。
[0113]
以上所述是结合附图对本发明的实施例进行的详细介绍,本文的具体实施方式只是用于帮助理解本发明的方法。对于本技术领域的普通技术人员,依据本发明的思想,在具体实施方式及应用范围内均可有所变更和修改,故本发明书不应理解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。