1.本发明涉及数据对比技术领域,具体为一种数据一致性比对系统。
背景技术:
2.目前企业内部使用多个厂商的数据库,有商用的,开源的等。因业务发展需要,需同步各个数据库之间的数据,随着数据量的增长,使得数据比对、校验的工作变得越来越困难,同时复制两端数据不一致而又很难及时发现,这些不一致既影响业务系统运行,又影响数据备份、恢复等连锁问题。
技术实现要素:
3.鉴于现有一种数据一致性比对系统中存在的问题,提出了本发明。
4.因此,本发明的目的是提供一种数据一致性比对系统,解决了目前企业内部使用多个厂商的数据库,有商用的,开源的等。因业务发展需要,需同步各个数据库之间的数据。随着数据量的增长,使得数据比对、校验的工作变得越来越困难。同时复制两端数据不一致而又很难及时发现,这些不一致既影响业务系统运行,又影响数据备份、恢复等连锁问题的问题。
5.为解决上述技术问题,根据本发明的一个方面,本发明提供了如下技术方案:
6.一种数据一致性比对系统,先配置要进行数据库比对的数据源,用于比对不同类型的数据库;再比对源端与目的端的数据的2张表,进行总行数计算;
7.再比对源端与目的端数据的2张表,进行哈希计算,哈希计算是使用java内置函数hashcode(),将表中每行的数据取出,并将所用列的字符拼接,通过hashcode()为每行数据生成唯一的哈希值,生成的哈希值临时存放在指定的服务器上;
8.再对于存在差异的数据,在比对报告展现数据的差异,唯一的哈希值的结果集存放在特定的服务器上,2张表的哈希结果集用nest loop的方式逐行进行对比,如果目的端的哈希值在源表中不存在,则对此行数据标记为不一致;
9.最后对于差异数据生成用于同步用途的更新sql,并在页面快速完成差异化数据的同步,如数据一致,将源端的行数据取出,在程序将行中的所有数据取出,拼接为一条insert插入语句,先将目的端数据有差异的行删除,然后在目的端运行这条insert插入语句。
10.作为本发明所述的一种数据一致性比对系统的一种优选方案,其中:nest loop在进行比对前,需要先建立测试表,再进行测试。
11.作为本发明所述的一种数据一致性比对系统的一种优选方案,其中:在进行比对源端与目的端的数据的2张表,进行总行数计算前,先进行数据行数对比:用于对比数据的两个表的行数据是否一致。
12.作为本发明所述的一种数据一致性比对系统的一种优选方案,其中:所述比对源端与目的端数据的2张表并进行哈希计算前,需要先进行哈希值对比:对将要进行对比数据
的表数据进行排序,然后每一行数据生成哈希值,2个表的哈希值进行逐一对比。
13.作为本发明所述的一种数据一致性比对系统的一种优选方案,其中:还包括:数据检验结果功能:数据库校验后,将2个表之间不一致的数据进行展现,生成比对报告,可按要求对不同步的行进行同步。
14.作为本发明所述的一种数据一致性比对系统的一种优选方案,其中:还包括:数据比对功能设置:通过对数据库用户,表,字段进行比对设置。
15.作为本发明所述的一种数据一致性比对系统的一种优选方案,其中:生成的哈希值临时存放在指定的服务器上的作用是用于后期做数据差异性对比。
16.作为本发明所述的一种数据一致性比对系统的一种优选方案,其中:在目的端运行这条insert插入语句,达到数据手工同步的目的。
17.与现有技术相比:
18.1、数据比对期间,不需要停止应用对数据变更,不影响业务的运行;自定义数据比对的粒度,按用户,按多表,按列进行数据比对;
19.2、数据比对结果可视化,生成的对比报告可知道表中哪些数据不一致;对存在差异的数据库,可通过页面手工对不一致的行数据库进行同步;
20.3、解决了目前企业内部使用多个厂商的数据库,有商用的,开源的等。因业务发展需要,需同步各个数据库之间的数据,随着数据量的增长,使得数据比对、校验的工作变得越来越困难;同时复制两端数据不一致而又很难及时发现,这些不一致既影响业务系统运行,又影响数据备份、恢复等连锁问题;
21.4、配置要进行数据库比对的数据源,用于比对不同类型的数据库,比对源端与目的端的数据的2张表,进行总行数计算,要比对源端与目的端数据的2张表,进行哈希计算,哈希计算是使用java内置函数hashcode(),将表中每行的数据取出,并将所用列的字符拼接,通过hashcode()为每行数据生成唯一的哈希值,生成的哈希值临时存放在指定的服务器上,用于后期做数据差异性对比,对于存在差异的数据,在比对报告展现数据的差异。唯一的哈希值的结果集存放在特定的服务器上,2张表的哈希结果集用nest loop的方式逐行进行对比,如果目的端的哈希值在源表中不存在,则对此行数据标记为不一致,对于差异数据生成用于同步用途的更新sql,并在页面快速完成差异化数据的同步,如数据一致,将源端的行数据取出,在程序将行中的所有数据取出,拼接为一条insert插入语句,先将目的端数据有差异的行删除,然后在目的端运行这条insert插入语句,达到数据手工同步的目的。
附图说明
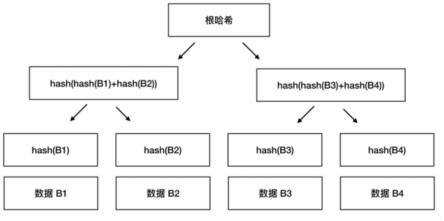
22.图1为本发明提供的hash函数的原理图。
具体实施方式
23.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明的实施方式做进一步的详细描述。
24.本发明提供一种数据一致性比对系统,请参阅图1,先配置要进行数据库比对的数据源,用于比对不同类型的数据库;再比对源端与目的端的数据的2张表,进行总行数计算;
25.再比对源端与目的端数据的2张表,进行哈希计算,哈希计算是使用java内置函数
hashcode(),将表中每行的数据取出,并将所用列的字符拼接,通过hashcode()为每行数据生成唯一的哈希值,生成的哈希值临时存放在指定的服务器上;
26.再对于存在差异的数据,在比对报告展现数据的差异,唯一的哈希值的结果集存放在特定的服务器上,2张表的哈希结果集用nest loop的方式逐行进行对比,如果目的端的哈希值在源表中不存在,则对此行数据标记为不一致;
27.最后对于差异数据生成用于同步用途的更新sql,并在页面快速完成差异化数据的同步,如数据一致,将源端的行数据取出,在程序将行中的所有数据取出,拼接为一条insert插入语句,先将目的端数据有差异的行删除,然后在目的端运行这条insert插入语句。
28.nest loop在进行比对前,需要先建立测试表,再进行测试;
29.建立测试表
30.31.[0032][0033]
2.进行测试
[0034]
[0035]
[0036][0037]
在进行比对源端与目的端的数据的2张表,进行总行数计算前,先进行数据行数对比:用于对比数据的两个表的行数据是否一致。
[0038]
所述比对源端与目的端数据的2张表并进行哈希计算前,需要先进行哈希值对比:对将要进行对比数据的表数据进行排序,然后每一行数据生成哈希值,2个表的哈希值进行
逐一对比。
[0039]
还包括:数据检验结果功能:数据库校验后,将2个表之间不一致的数据进行展现,生成比对报告,可按要求对不同步的行进行同步。
[0040]
还包括:数据比对功能设置:通过对数据库用户,表,字段进行比对设置。
[0041]
生成的哈希值临时存放在指定的服务器上的作用是用于后期做数据差异性对比。
[0042]
在目的端运行这条insert插入语句,达到数据手工同步的目的。
[0043]
在具体使用时,配置要进行数据库比对的数据源,用于比对不同类型的数据库,比对源端与目的端的数据的2张表,进行总行数计算,比对源端与目的端数据的2张表,进行哈希计算,哈希计算是使用java内置函数hashcode(),将表中每行的数据取出,并将所用列的字符拼接,通过hashcode()为每行数据生成唯一的哈希值,生成的哈希值临时存放在指定的服务器上,用于后期做数据差异性对比;对于存在差异的数据,在比对报告展现数据的差异,唯一的哈希值的结果集存放在特定的服务器上,2张表的哈希结果集用nest loop的方式逐行进行对比,如果目的端的哈希值在源表中不存在,则对此行数据标记为不一致;对于差异数据生成用于同步用途的更新sql,并在页面快速完成差异化数据的同步,如数据一致,将源端的行数据取出,在程序将行中的所有数据取出,拼接为一条insert插入语句,先将目的端数据有差异的行删除,然后在目的端运行这条insert插入语句,达到数据手工同步的目的。
[0044]
虽然在上文中已经参考实施方式对本发明进行了描述,然而在不脱离本发明的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,本发明所披露的实施方式中的各项特征均可通过任意方式相互结合起来使用,在本说明书中未对这些组合的情况进行穷举性的描述仅仅是出于省略篇幅和节约资源的考虑。因此,本发明并不局限于文中公开的特定实施方式,而是包括落入权利要求的范围内的所有技术方案。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。