1.本发明基于联邦原型学习的异构软件缺陷预测方法,具体的说是一种跨项目的异构软件缺陷预测方法,属于软件测试技术领域。
背景技术:
2.软件缺陷预测(software defect prediction,sdp)是软件行业中的一个重要测试环节,软件缺陷通常是由于人为或客观原因造成的软件漏洞。软件缺陷不仅会导致用户体验的下降,还可能给使用该软件的项目带来不必要的损失,其重要性引起了研究者的极大兴趣,sdp的目标是找出软件中容易出现缺陷的模块。
3.传统的sdp模型建立于单个项目的有限数据,虽然取得了一定的成果,但由于训练数据往往不足,无法训练出令人满意的模型,因此新的方法不断被研究人员提出;一些研究是基于跨项目的软件缺陷预测,即训练数据取自不同项目的历史软件项目数据,但软件企业之间由于行业竞争、商业隐私等原因不愿共享数据,将多个项目数据集中在单个第三方节点的训练方法难以被实现,并且不同历史软件项目数据间的数据存在异构特性,因此就形成了数据拥有者只允许这些数据保存在自己手中的数据孤岛现状。
4.为解决上述软件缺陷数据孤岛问题,联邦学习方法被提出,该方法可以有效解决数据孤岛问题,让参与方在不共享数据的前提下联合构建模型。联邦学习除了注重模型性能外,还强调模型训练过程中对数据的隐私保护,这是一种应对数据隐私保护的有效措施,能够更好地应对愈加严格的数据隐私和数据安全监管环境。同时跨项目的模型训练带来了数据异构性的难题,解决异构数据的不良影响成为联邦学习的优化热点,在异构数据集上合并类别原型可以有效集成来自不同数据分布的特征表示,原型学习适合用来解决软件缺陷预测领域的异质问题,从而提升全局模型性能。
技术实现要素:
5.本发明以联邦学习和原型学习为基础,考虑历史软件缺陷数据具有特征冗余和多类异常样本点的特性,以及不同项目间的数据异质性和商业隐私权,公开一种基于联邦原型学习的异构软件缺陷预测方法;本发明以联邦学习为框架实现多个软件项目的共同训练,同时以原型学习为解决数据异构的优化方法;在解决参与方的数据隐私安全方面,利用局部原型是由嵌入向量均值化生成且不可逆的特点,实现对软件项目本地训练数据的隐私保护,因此在联邦通信阶段不需要其他手段进行加密。
6.本发明的技术方案步骤主要包括:
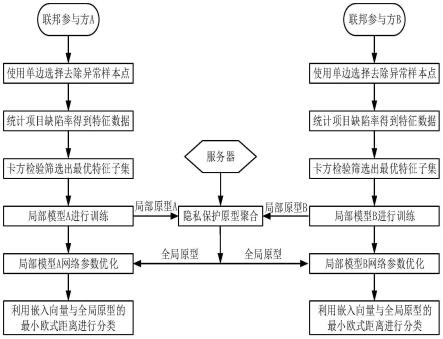
7.s1:联邦参与方对度量元数据使用oss方法去除异常样本点;
8.s2;对去除异常样本点后的度量元数据进行缺陷率统计获得特征数据;
9.s3:利用卡方检验方法对特征数据筛选获得最优特征子集;
10.s4:将最优特征子集输入本地模型,生成预测标签和同类样本嵌入向量均值表示的局部原型;
11.s5:服务器对局部原型平均聚合得到全局原型,实现联邦学习通信隐私保护,并将全局原型返回参与方;
12.s6:参与方利用全局原型正则化局部模型参数;
13.s7:利用测试样本的嵌入向量与全局原型的最短欧氏距离进行分类,获得分类结果。
14.上述步骤s1联邦参与方对度量元数据使用oss方法去除异常样本点,该方法可有效抑制异常样本对模型训练的干扰,包含以下步骤:
15.s11假设s为原始度量元数据集;
16.s12 c集合包含s集合中的所有正类样本和一个随机选择的负类样本。
17.s13使用集合c中的样本用1-nn规则对集合s中的样本进行分类,并将分类标签与真实类别的进行比较,将所有错误分类的样本从集合s转移到集合c中。
18.s14从c中删除所有参与tomek链接的所有负类样本,这就清除了被认为是异常或噪声的负类样本,所有正类样本都将保留下来,从而得到的集合称为t。
19.上述s2对软件缺陷数据集的缺陷率做出统计,统计内容包括每个项目所包含的样本总数、度量元数目、负类样本与正类样本的总数以及计算项目的缺陷率;软件企业在对软件项目进行量化管理时,需要从不同角度对软件的对象信息进行量化,包括从规模角度进行度量的loc元组、从代码复杂度提出的halstead复杂度度量元组等,而这些从不同角度出发的度量属性也被认为是软件的特征,因此一个项目的特征数据可直接从度量元数据获得。
20.上述步骤s3使用卡方检验特征选择方法对各自特征数据做出最优特征子集搜索,卡方计算公式如下:
[0021][0022]
其中c代表自由度,o代表特征观察值,e代表标签期望值,卡方值越大,表明特征与类别之间的相关度越高,因此优先选择卡方值更高的特征。
[0023]
上述步骤s4包含以下子步骤:
[0024]
s41:局部模型的cnn具体结构为:输入层
→
卷积层-1
→
relu激活函数
→
最大池化层-1
→
卷积层
→
relu激活函数
→
全连接层-1
→
dropout层
→
全连接层-2
→
softmax分类器;其中输入层的大小为5
×
5、卷积层-1的卷积核大小为2
×
2、卷积核滑动步长为1;卷积层-2的卷积核大小为2
×
2、卷积核滑动步长为1;全连接层-1的输入通道为256、输出通道为10;全连接层-2的输入通道为10、输出通道为2;
[0025]
s42:参与方用本地训练集对局部模型完成训练,模型训练结果包括预测标签与同类样本嵌入向量均值表示的局部原型,其特征在于,原型学习问题可以定义为假设有一个源集x={x1,x2,
···
,xm}和一个目标集y={y1,y2,
···yn
},分别包含m和n个元素,原型学习旨在从源集x中寻找一个原型集该子集能够最大程度地保持目标集y所蕴含的信息,同时所有元素具有最少的重叠信息,不同类型的源集和目标集将会引出实际场景中不同的任务,在此任务中原型为同类样本嵌入向量的均值,公式如下:
[0026][0027]
其中用c
i(j)
表示参与方i中的第j个类原型,原型是j类中所有样本嵌入向量fi(φi;x)的平均值。
[0028]
上述步骤s5为服务器对局部原型平均聚合得到全局原型,此方法使用局部原型作为联邦通信的信息传递,局部原型是不可逆向还原的,这样就实现了联邦学习通信隐私保护,并将全局原型返回参与方,具体实现公式如下:
[0029][0030]
其中表示来自参与方i的类j的原型,表示拥有类j的参与方集,上式对来自多个参与方的局部原型向量平均之后得到一个全局原型在服务器完成局部原型聚合之后将全局原型发送回每个联邦参与方。
[0031]
步骤s5为服务器在接收到多个联邦参与方上传的局部原型后,将所有局部原型完成平均聚合,具体实现公式如下:
[0032][0033]
其中表示来自参与方i的类j的原型,表示拥有类j的参与方集,上式对来自多个参与方的局部原型向量平均之后得到一个全局原型在服务器完成局部原型聚合之后将全局原型发送回每个联邦参与方。
[0034]
上述步骤s6参与方利用全局原型正则化局部模型参数,为了跨参与方生成一致的全局原型,参与方最小化预测标签与真实标签的欧式距离dr作为标签损失最小化局部原型与全局原型的欧式距离dr作为原型损失将标签损失与加权原型损失之和作为局部损失,即在局部损失函数中加入正则化项使c
i(j)
在最小化分类错误的同时逼近其中,损失函数定义如下:
[0035][0036]
上式中λ是原型损失权重,为被网络参数ωi和样本输入x参数化的预测标签。上述步骤s7根据测试样本的嵌入向量与全局原型的欧氏距离得到分类结果,当每个联邦参与方的局部损失函数收敛之后进入模型测试阶段,参与方i将测试样本x输入局部模型后,根据模型输出的嵌入向量f(φ;x)与全局原型的欧氏距离判定最终测试分类结果。
[0037]
有益效果:
[0038]
本发明在软件缺陷预测领域存在数据孤岛的背景下,以联邦学习和原型学习为理论基础,建立多个参与方共同训练跨项目异构软件缺陷预测模型的架构。考虑到历史软件
数据本身具有异常样本点和特征冗余的特性,采用oss方法去除多类异常样本点,降低噪声样本对模型的干扰,使用卡方检验特征选择方法对特征数据筛选出最优特征子集;考虑不同项目间存在数据异质性以及商业隐私特点,而原型学习是从少量样本中重新生成一组具有代表性的嵌入向量均值,在异构数据集上合并类别原型可以有效集成来自不同数据分布的特征表示,同时由于抽象类原型的生成过程具有不可逆的特点,实现对软件项目本地训练数据的隐私保护,因此在联邦通信阶段不需要其他手段进行加密。
附图说明
[0039]
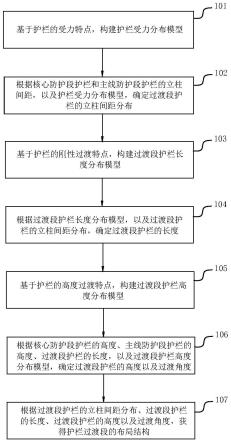
图1是本发明基于联邦原型学习的软件缺陷预测异构软件缺陷预测研究方法的流程图;
[0040]
图2是本发明本发明基于联邦原型学习的软件缺陷预测异构软件缺陷预测研究方法的框架示意图。
具体实施方式
[0041]
本具体实施方式下的一种基于联邦原型学习的软件缺陷预测异构软件缺陷预测研究方法,包括以下步骤:
[0042]
在本发明具体实施过程中提前规划训练架构和模型超参数,包括参与方本地超参数和服务器全局超参数两部分;在参与方本地超参数设置中,本地训练模型使用的优化器为sgd(stochastic gradient descent)随机梯度下降,sgd是梯度下降算法的一种,其在每次迭代时只随机的选取全部样本的一个子集进行梯度计算,这样就使得每次迭代的计算量内存需求很小,sgd通过线性迭代逐步逼近最优点,其迭代公式为:
[0043][0044]
其中x
t
是t时刻的决策变量,α是学习率,表示梯度。
[0045]
在本发明具体实施中,学习率α为0.01,损失函数的加权系数λ为1,本地训练批尺寸为32,在对数据集打包处理时shuffle为true,本地训练轮数为5;在服务器全局超参数设置中,总体训练轮数为15,参与协同的参与方个数为6。
[0046]
联邦参与方针对软件缺陷数据集具有异常值的特点,均使用oss方法剔除多类的异常样本点,使模型在生成原型向量时更具有代表性,软件缺陷预测为二分类问题,样本分为正类和负类,分别代表有缺陷和无缺陷,多类样本为负类,少类样本为正类;具体步骤如下:首先各参与方对本地软件缺陷数据集s进行样本提取得到另一个数据集c,其中集合c拥有集合s中的所有正类样本和一个集合s中的负类样本,该负类样本为随机选取的,然后利用集合c对集合s中的样本使用1-nn方法进行分类,将分类标签与真实类别的进行比较,将所有错误分类的样本从集合s转移到集合c中,从c中删除所有参与tomek链接的所有负类样本,tomek链接是成对的相近类别的一对样本点,寻找tomek链接的过程中保持正类中的样本点保持不变,使用欧氏距离找负类中与正类最接近的所有样本点,然后将其删除,这些点被认为是噪声或异常点的,欧氏距离公式如下:
[0047]
[0048]
其中d为两样本点间的距离,n为样本的特征数,pi为x1样本点的第i维特征值,qi为x2的第i维特征值,这样就清除了被认为是边缘或噪声的负类样本,所有正类样本都将保留下来,从而得到的新的集合t。
[0049]
在每个参与方对本地度量元数据做缺陷率统计得到特征数据的具体实施中,本发明采用来自两个不同数据集中的六个异构项目,这两个数据集分别为nasa软件缺陷数据集和aeeem软件缺陷数据集;nasa数据集是由美国航空航天局(nasa)公布的,这些度量数据全部来自nasa的实际软件项目,这些项目由最常用的开发语言编写,各项目由loc、halstead等几类度量元属性和是否包含缺陷的类别标签(defective)组成;aeeem数据集是由d'ambros等人分析了5个开源项目(每个项目包括61个特征值)收集形成的,具有真实可信性;当软件企业在对他们的软件项目进行量化管理时,需要从不同角度对软件的对象信息进行量化,包括从规模角度进行度量的loc元组、从代码复杂度提出的halstead度量元组等,这些度量属性被认为是软件项目的特征,因此一个项目的特征数据可直接从度量元数据得到,在对数据集做训练集、测试集划分时,训练集占本地特征数据的70%,测试集占本地特征数据的30%,均采用等比例抽样获得。
[0050]
首先对参与方各自的历史软件项目做度量元数/特征数统计,nasa的6个项目中除了mc1的度量元数为38以外,其他5个项目度量元数均为37个,这6个中包含了最多9466个样本数的项目为mc1,最少327个样本数的项目为cm1,其中缺陷率最高的为项目pc1,该项目的缺陷率约为14.02%,mc1的缺陷率最低为0.72%。在aeeem数据集中的5个项目统计中,ml为样本数最多的项目,拥有1862个样本数,eq的样本数最少,有324个样本,而在该数据集中eq的缺陷率最高、lc的缺陷率最低,缺陷率分别为39.81%、9.25%,统计结果如表1所示:
[0051]
表1历史软件项目缺陷率统计
[0052][0053][0054]
在使用卡方检验方法筛选各自特征数据的最优特征子集具体实施中,本发明使用卡方检验特征选择方法对特征数据做出最优特征子集搜索,首先对每个特征的卡方值进行计算,对于一个特征f而言,f和类别c的卡方值计算公式如下:
[0055][0056]
其中,f为特征的观测值,c为样本的标签期望,n为样本数。chi(f,c)表明了特征和类别的相关程度,然后对特征的卡方值进行排序,为了使所有参与方的cnn模型网络结构一致。选取卡方值最高的前25个特征,这样能统一构成卷积网络5
×
5的张量输入,保持之后的模型模型网络结构统一,使用各自的最优特征子集对局部模型进行训练,模型训练结果包括预测标签和同类样本嵌入向量均值表示的局部原型。
[0057]
局部模型的具体结构为:25维的特征数据转为5
×
5张量输入,经过卷积层-1,卷积层-1的输入通道为1、卷积核大小为2
×
2、滑动步长为1、四周不进行填充处理、输出通道数为32;经过卷积层-1的输出再经过relu非线性激活函数,如果输入该激活函数的数值为正,它将直接输出,否则输出为零,使用该激活函数通常能够获得更好的模型性能,经过relu激活函数的输出进入最大池化层-1,最大池化层-1的卷积核大小为2
×
2、滑动步长为2、四周填充尺寸为1;经过最大池化层-1的输出再次经过relu非线性激活函数;之后经过卷积层-2,卷积层-2的输入通道为32、卷积核尺寸为2
×
2、滑动步长为1、四周不进行填充,输出通道为64;经过卷积层-2的输出再次经过relu非线性激活函数,之后进行展平操作;随后进入全连接层-1,经过全连接层-1的输出分为两个支路,第一个支路输出样本嵌入向量fi(φi;x);最后再次进入全连接层-2,经过softmax的输出作为预测标签。
[0058]
根据本地训练集对初始模型完成指定轮数训练并输出预测标签与嵌入向量fi(φi;x),原型被定义为c
(j)
来表示中的第j个类,对于第i个参与方,原型是类j中样本的嵌入向量fi(φi;x)的平均值,公式如下:
[0059][0060]
其中d
i,j
是局部数据集di的子集,由属于第j类的训练样本组成。
[0061]
服务器将来自多个联邦参与方的局部原型完成隐私保护原型聚合,生成一个全局原型,具体实现公式如下:
[0062][0063]
其中表示来自参与方i的类j的原型,表示拥有类j的参与方集,上式对来自多个参与方的局部原型向量平均之后得到一个全局原型在服务器完成局部原型聚合之后将全局原型发送回每个联邦参与方,实现联邦学习通信隐私保护。
[0064]
在接收到服务器返回的全局原型之后,联邦参与方将预测标签与真实标签的误差作为标签损失,将局部原型与全局原型的误差作为原型损失,将标签损失与加权原型损失之和作为局部损失更新本地模型参数直至局部损失函数收敛,参与方通过均方误差损失函数最小化预测标签与真实标签的距离ds,具体实现公式:
[0065]
[0066]
其中是模型的预测标签,n是所有参与方上的样本总数,即为监督学习的优化目标,在此发明中中使用均方误差损失函数,均方误差损失函数公式为:
[0067][0068]
其中yi为第i个样本的真实标签,为模型预测输出,n为样本总数,用来计算单个参与方的模型预测标签与真实标签的损失。
[0069]
参与方通过均方误差损失函数最小化局部原型与全局原型的距离dr,在数据异构的情形中,不同参与方的代表不同的模型架构和超参数,对于参与方i,训练过程为最小化原型损失,具体实现公式如下:
[0070][0071]
将预测标签与真实标签的损失函数与加权原型损失相加作为局部优化目标,具体公式如下:
[0072][0073]
其中是监督学习的损失,可以理解为是一个正则化项,用于度量局部原型和全局原型之间的距离(使用l2距离),n是所有客户机上的实例总数,nj是所有客户机上属于类j的实例数,λ为正则化加权系数,使用全局原型正则化模型参数。
[0074]
当参与方本地的局部损失收敛后,进入局部模型测试阶段,在模型测试阶段具体实施中,参与方初始化距离张量,该张量形状的行数与每个批大小的行数相同,列数为两列,将均方差损失函数使用的l2距离作为距离度量方式,具体为度量测试样本的嵌入向量与全局原型的距离,具体公式为:
[0075][0076]
其中fi(φ;x)为模型输出样本x的嵌入向量,将距离张量中的元素进行替换,最后求该张量中的值与1相比的最小值对应的索引即为最终的预测类别。
[0077]
以下表格为本发明的实验结果,联邦参与方为pc3、pc4、mw1、eq、jdt以及lc六个项目,表2为本方法与其他四种方法的软件缺陷预测结果对比,对比实验选择了三个传统跨项目的软件缺陷预测方法,对比试验为cca 、tca 、kcca 以及ftlkd四种方法,,分别为jing等人在异构跨项目软件缺陷预测(heterogeneous cross-company defect prediction hccdp)领域引入迁移学习方法典型相关分析(canonical correlation analysis,cca ),nam等人从特征映射角度提出了tca(transfer component analysis)方法,在此基础上通过对源项目和目标项目的特征分析提出了tca ,ying等人提出的核典型相关分析(kernel canonical correlation analysis plus kcca )和wang等人提出的联邦迁移学习(federated transfer learning via knowledge distillation ftlkd),最后一列为本发明所提出的方法fpl,均使用auc和g-mean这两种评价指标。
[0078]
表2 fpl与其他软件缺陷预测方法对比
[0079][0080]
从表格2可以看出本发明提出的fpl方法在auc、g-mean指标上明显比其他方法更加优秀,从单个项目指标来看,只有eq项目相较其他方法处于劣势,但其他五个项目的指标均比其他方法更加优秀,项目jdt的auc指标为0.8192比cca 方法高出0.3428,g-mean指标比ftlkd方法高出0.1551,在6个项目的auc平均值上本方法比最低的tca 方法高出0.2345,g-mean指标上本方法比最低的tca 方法高出0.4479。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。