1.本发明涉及深度学习视频理解技术领域,具体涉及少数民族舞蹈视频描述中视觉互参考语义检测方法。
背景技术:
2.近年来,我国在经济、技术等领域全面发展,少数民族地区的生活水平极大改善,少数民族文化宣传也成为重点工作之一,利用深度学习技术对少数民族舞蹈视频进行自动理解,有利于少数民族文化传播,同时伴随短视频平台的大量涌现,监控和自动审查短视频的内容也成为研究的热点问题。当前对于少数民族舞蹈视频的自动描述技术并不常见,对视频的自动审查也主要依靠人工手段,现有算法并不能实现对视频内容的充分认识和理解。
3.当前视频描述算法中越来越多地涉及到视频的语义特征,将语义特征作为编码特征,利用长短时记忆等网络对语义特征进行解析进而生成视频的文本描述结果。专利《一种提高视频文本描述准确性的编码器网络模型设计方法》(公开号: cn111985612a)公开了一种视频文本描述的编解码方法,利用视频特征获取语义特征,并且采用s-lstm网络解码得到视频的文本描述,在编码阶段通过增大单词之间的差异得到更准确的语义特征。专利《基于目标空间语义对齐的视频描述方法》(公开号:cn114154016a)公开了一种视频描述方法,其利用时序高斯空洞卷积获取视频长期时序关系,通过语义重构网络得到句子级概率分布差异,增强视频内容和生成语句的内在关联,输出更准确的文本句子。
4.语义特征在其它视频理解任务中也应用广泛,专利《一种基于视频序列深度学习的人物行为语义识别方法》(公开号:cn107038419a)公开了一种视频中人物动作识别方法,该方法对视频提取关键帧后,充分利用人体轮廓信息,以轮廓信息作为rbf神经网络的输入特征,得到代表人物行为的语义特征。专利《双通道语义定位多粒度注意互增强的视频问答方法与系统》(公开号: cn114020891a)提出一种视频问答方法,采用多模块设计将不同粒度的特征信息定义为视觉和文本两个通道,并分别设计辅助定位机制,利用增强共享表征得到与问题最相关的特征信息。
5.上述利用语义特征获取视频文本描述的方法中,语义特征是一种多分类标签形式的特征表示,语义特征不准确会直接影响视频描述效果,不利于少数民族舞蹈视频的描述;不利于安防监控和短视频内容审查的实际应用。因此如何提升语义特征的表达能力,进而生成准确的文本描述成为一个热点问题。
技术实现要素:
6.本发明的目的在于,提供一种少数民族舞蹈视频描述中视觉互参考语义检测方法,其通过3d和2d信息的互参考增强语义有效性,并采用多阶段迭代操作提升特征表达能力。
7.为实现上述目的,本技术提出一种少数民族舞蹈视频描述中视觉互参考语义检测
方法,其将输入视觉特征经过视觉互参考语义检测结构进行处理,输出表达能力较强的视频语义信息。所述视觉互参考语义检测结构以3d卷积神经网络和 2d卷积神经网络处理得到的视频3d视觉特征和2d视觉特征为输入,分别经 3d语义检测支路和2d语义检测支路提取语义特征,在语义提取过程中将3d视觉特征引入2d语义检测支路,将2d视觉特征引入3d语义检测支路,实现3d 和2d信息的交互作用,同时采用多阶段迭代操作进一步提升语义特征表达能力,将两支路最终输出的3d语义特征和2d语义特征拼接融合来表达视频语义。将该语义特征输入至长短时记忆网络进行解码,可以得到较准确的视频文本描述。
8.所述视觉互参考语义检测结构包括3d语义检测支路和2d语义检测支路,其用于提取语义特征的基本单元均为语义检测单元。
9.所述视觉互参考语义检测结构输入3d视觉特征v
3d
和2d视觉特征v
2d
,输出语义特征s,三者均为一维特征向量,具体为:
10.(1)输入的3d视觉特征v
3d
,是视频经过3d卷积神经网络处理后输出,并且即将输入到3d语义检测支路的特征向量。
11.(2)输入的2d视觉特征v
2d
,是视频经过2d卷积神经网络处理后输出,并且即将输入到2d语义检测支路的特征向量。
12.(3)在3d语义检测支路中,对3d视觉特征采用语义检测单元a1处理,获取3d语义特征s
a1
,将其与2d视觉特征v
2d
拼接融合,得到新3d语义特征 s
a1
。
13.(4)在2d语义检测支路中,对2d视觉特征采用语义检测单元b1处理,获取2d语义特征s
b1
,将其与3d视觉特征v
3d
拼接融合,得到新2d语义特征 s
b1
。
14.(5)在3d语义检测支路中,将语义检测单元a1处理和特征拼接融合进行多阶段迭代操作,迭代m次后输出3d语义特征s
am
。同理在2d语义检测支路中,将语义检测单元b1处理和特征拼接融合进行多阶段迭代操作,迭代m次后输出2d语义特征s
bm
。
15.(6)在3d语义检测支路中,对3d语义特征s
am
再次采用语义检测单元 end-a处理,得到该支路的输出—3d语义特征s
end-a
。在2d语义检测支路中,对2d语义特征s
bm
再次采用语义检测单元end-b处理,得到该支路的输出—2d 语义特征s
end-b
。
16.(7)将3d语义特征s
end-a
和2d语义特征s
end-b
拼接融合,得到视觉互参考语义检测结构的最终输出—语义特征s。
17.具体的,视觉互参考语义检测结构有两个支路,在两个支路中均多次迭代使用语义检测单元生成语义特征,最终将两种语义特征拼接融合,提升语义特征的有效性。此外,在此过程中分别将3d视觉特征与2d语义特征拼接融合,2d视觉特征与3d语义特征拼接融合,实现3d和2d两支路信息的互参考,有效提升特征的表达能力。
18.具体的,所述语义检测单元是视觉互参考语义检测结构中,3d语义检测支路和2d语义检测支路的基本语义提取单元,除多层感知机的层数及相应层神经元个数可以不同外,两支路中语义检测单元结构均相同。以语义检测单元a1为例,输入3d视觉特征v
3d
,输出3d语义特征s
a1
,具体为:
19.(1)输入的3d视觉特征v
3d
,是视频经过3d卷积神经网络处理后输出,并且即将输入到3d语义检测支路中语义检测单元a1的特征向量。
20.(2)将3d视觉特征v
3d
与相应权重进行全连接计算,得到中间特征m1。
21.(3)将中间特征m1与相应偏置相加,输出中间特征n1。
22.(4)对中间特征n1进行非线性激活操作,得到中间特征w1。
23.(5)对中间特征w1进行随即删除神经元操作,得到中间特征x1。
24.(6)上述全连接计算、偏置相加、非线性激活和随机删除神经元处理,属于语义检测单元的第1层,对以上操作进行多次迭代得到语义检测单元的第n 层特征xn。
25.(7)对特征xn,进行softmax多分类操作,得到3d语义特征s
a1
。
26.语义检测单元是3d语义检测支路和2d语义检测支路的基本单元,也是视觉互参考语义检测结构的最基本单元,该单元由多个特征提取层构成,可以生成表达多分类信息的语义特征。
27.本发明采用的以上技术方案,与现有技术相比,具有的优点是:
28.(1)适用于少数民族舞蹈视频描述
29.本发明中可以通过提升语义特征的表达能力,提升视频描述性能,可以对少数民族舞蹈视频进行自动文本描述,有利于少数民族舞蹈文化的推广传播。
30.(2)适用于利用视觉特征获取语义特征的情况
31.本发明中以视频视觉特征作为输入,分为两个支路提取语义信息,通过3d 和2d信息的互参考增强语义有效性,并采用多阶段迭代操作提升特征表达能力;适用于通过视觉特征获取语义特征的情况。
32.(3)适用于视频描述任务
33.本发明中以视频经过卷积神经网络输出的视觉特征为输入,通过本发明提出的方法生成语义特征,将语义特征和视觉特征作为长短时记忆网络的输入,输出准确的视频文本描述。
34.(4)适用于图像描述任务
35.本发明可以提升视频描述性能,相对于视频序列,静态图像所包含的目标、动作、属性等视觉因素更为简单,所以也可以更好地应用于图像描述任务。
36.(5)适用于安防监控系统
37.本发明中可以通过视觉互参考语义检测方法生成较为有效的语义特征,将该特征输入至视频描述模型,可提升视频描述性能,自动生成准确的视频文本描述,其中目标、行为、属性等文本信息可以作为安防监控系统的提示信息,提升安防监控系统工作效率。
38.(6)适用于短视频内容审查系统
39.本发明中可以通过视觉互参考语义检测方法生成较为有效的语义特征,将该特征输入至视频描述模型,可提升视频描述性能,自动生成准确的视频文本描述,其中目标、行为、属性等文本信息可以作为短视频内容审查系统的提示信息,高效降低短视频中违法、违规、不具正能量的因素,构造良好网络环境。
附图说明
40.图1是视觉互参考语义检测结构的示意图;
41.图2是语义检测单元示意图;
42.图3是3d语义检测支路示意图;
43.图4是2d语义检测支路示意图;
44.图5是实施例1中少数民族舞蹈视频描述场景情况示意图;
45.图6是实施例2中安防监控场景情况示意图;
46.图7是实施例3中短视频内容审查情况示意图。
具体实施方式
47.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术,即所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。
48.本发明方法是在视觉互参考语义检测结构中实现的,如图1所示,该结构分为3d语义检测支路和2d语义检测支路,其均包括多层感知机形式的语义检测单元。两个支路分别对两种视觉特征初步提取语义信息,进一步与另一条支路的视觉信息融合,实现3d和2d信息的互参考,并通过多阶段迭代方式提升语义特征的有效性。互参考语义检测方法具体实施步骤如下:
49.第1步:将视频分别经过3d卷积神经网络和2d卷积神经网络处理后得到 3d视觉特征v
3d
和2d视觉特征v
2d
,尺寸分别为1*a和1*b,如v
3d
的具体形式为v
3d
={v1,v2,
…
,va};
50.第2步:所述3d视觉特征v
3d
在3d语义检测支路中进行特征提取、所述 2d视觉特征v
2d
在2d语义检测支路中进行特征提取,分别得到3d语义特征s
a1
和2d语义特征s
b1
;
51.具体的,以3d视觉特征v
3d
在3d语义检测支路中进行特征提取为例进行说明:
52.首先利用语义检测单元a1提取语义特征,输出3d语义特征s
a1
,其网络示意图如图2所示,具体操作如式(1)~(6);
[0053][0054]
如式(1)所示为语义检测单元a1的第1层全连接计算,其中u
1,i
是权重 u1的每一列向量,3d视觉特征v
3d
与u
1,i
做向量乘法计算,表示特征的拼接融合,得到中间特征m1,m1的尺寸为1*q1;
[0055]
将得到的中间特征m1与偏置相加:
[0056][0057]
其中,d1是常数形式的偏置项,b
ro1
(
·
)是广播操作,通过拓展该常量数字与向量相加,得到中间特征n1,其尺寸为1*q1。
[0058]
所述中间特征n1进行非线性激活处理,当特征中的元素小于或等于1时,将其置为0,否则特征元素值不变;如式(3)所示:
[0059][0060]
其中,n
1,i
是n1的每一个特征元素,函数a
relu
(
·
)是非线性激活函数,对特征非线性激活可以提升特征有效性,得到中间特征w1,其尺寸为1*q1;
[0061]
在以上操作基础上,进行随机删除神经元操作,如式(4)所示:
[0062][0063]
其中,函数的作用是随机删除神经元操作,使其中的部分神经元暂时失去作用,在当前阶段不进行反向传播,防止过拟合。k1是保留参数,可以取 k1=0.9;得到第1层输出特征x1。
[0064]
对第1层输出特征x1提取过程进行多次循环操作,得到语义检测单元a1 的第1层、第2层、
…
、第n层输出特征:
[0065][0066]
对语义检测单元a1第n层特征进行softmax多标签分类操作:
[0067][0068]
其中,x
n,i
是特征xn的每一个特征元素,函数exp(
·
)是指数函数表达,通过对该特征进行softmax分类处理,得到多标签分类形式的语义特征向量s
a1
,其向量尺寸是1*qn;
[0069]
以上操作由3d视觉特征v
3d
经过语义检测单元a1处理得到3d语义特征 s
a1
,采用同样的处理方式,2d视觉特征v
2d
经过语义检测单元b1处理得到2d 语义特征s
b1
。
[0070]
第3步:将所述3d语义特征s
a1
和2d视觉特征v
2d
进行拼接融合获取新3d 语义特征:
[0071][0072]
其中,s
a1
为特征向量拼接得到的新3d语义特征,其尺寸为1*(qn b)。
[0073]
将所述2d语义特征s
b1
和3d视觉特征v
3d
进行拼接融合获取新2d语义特征:
[0074][0075]
其中,s
b1
为特征向量拼接得到的新2d语义特征,其尺寸为1*(qn a)。
[0076]
上述操作将3d语义特征和2d视觉特征拼接融合,2d语义特征和3d视觉特征拼接融合,实现两条支路信息,即3d和2d信息的交互作用,提升特征的表达能力。
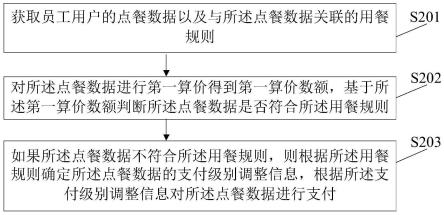
[0077]
第4步:在3d语义检测支路中,对第2步语义特征提取操作、第3步特征拼接融合操作进行多阶段迭代,迭代次数为m,则该支路逐次输出如下3d语义特征:
[0078][0079]
在2d语义检测支路中,对第2步语义特征提取操作、第3步特征拼接融合操作进行多阶段迭代,迭代次数为m,则该支路逐次输出如下2d语义特征:
[0080]
[0081]
对上述语义提取和特征拼接融合操作进行多阶段迭代,可以逐步提升语义特征的表达能力。
[0082]
第5步:在3d语义检测支路中,对3d语义特征s
am
采用语义检测单元end-a 进行最后一次语义提取,获取3d语义特征s
end-a
;在2d语义检测支路中,对2d 语义特征s
bm
采用语义检测单元end-b进行最后一次语义提取,得到2d语义特征s
end-b
;其中语义检测单元end-a和语义检测单元end-b,与上述语义检测单元a1的特征提取方式相同。
[0083]
第6步:将3d语义特征s
end-a
和2d语义特征s
end-b
进行拼接融合,输出尺寸为1*2qn的语义特征s:
[0084][0085]
对本发明中技术名词进行解释:(1)3d视觉特征:对少数民族舞蹈等视频进行3d卷积处理,并且即将输入到视觉互参考语义检测结构中的3d语义检测支路的特征向量。(2)2d视觉特征:对少数民族舞蹈等视频进行2d卷积处理,并且即将输入到视觉互参考语义检测结构中的2d语义检测支路的特征向量。(3) 语义特征:可以表示视频中所涉及词汇的多分类标签向量,本发明中语义特征也特指,视觉互参考语义检测结构的最终输出特征。(4)3d语义检测支路:视觉互参考语义检测结构中,以3d视觉特征为输入,在中间过程引入2d视觉特征,并且输出3d语义特征的通道。(5)2d语义检测支路:视觉互参考语义检测结构中,以2d视觉特征为输入,在中间过程引入3d视觉特征,并且输出2d语义特征的通道。(6)语义检测单元:单元的结构为多层感知机,用于在两个支路中提取3d语义特征或2d语义特征。(7)3d语义特征:3d语义检测支路中,每一个语义检测单元输出的特征。(8)2d语义特征:2d语义检测支路中,每一个语义检测单元输出的特征。
[0086]
本实施例中迭代次数和单元层数约束条件可以为:(1)两个支路的语义检测单元均一一对应,特征拼接融合操作同样对应,即两个支路中语义检测单元的个数相同,均为m 1个。(2)为保证在输入视觉特征不同的情况下,均能得到较好的互参考语义检测结构,本发明采用4种迭代次数,即上述m∈{1,2,3,4}。 (3)为保证在输入特征不同的情况下,均能得到性能较好的语义检测单元,本发明采用5种特征提取层数,即层数n∈{2,3,4,5,6}。语义检测单元a1、语义检测单元a2、
…
、语义检测单元am、语义检测单元end-a、语义检测单元b1、语义检测单元b2、
…
、语义检测单元bm、语义检测单元end-b均可以选择5 种特征提取层数中的1种。
[0087]
本实施例中特征尺寸约束条件可以为:(1)3d语义检测支路输入的3d视觉特征v
3d
尺寸是[1*a]的特征向量。该支路输出的3d语义特征s
end-a
尺寸是[1*qn] 的特征向量。其中a=1536,qn=300。(2)2d语义检测支路输入的2d视觉特征 v
2d
尺寸是[1*b]的特征向量。该支路输出的2d语义特征s
end-b
尺寸是[1*qn]的特征向量。其中b=2048,qn=300。(3)视觉互参考语义检测结构输出的语义特征 s是[1*2qn]维度的特征向量,是两支路输出特征的拼接融合操作所得,其中 2qn=600。(4)当n=2时(n为语义检测单元的特征处理层数),1到2层输出特征的尺寸分别为(1*512,1*300)。(5)当n=3时(n为语义检测单元的特征处理层数),1到3层输出特征的尺寸分别为(1*512,1*300,1*300)。(6) 当n=4时(n为语义检测单元的特征处理层数),1到4层输出特征的尺寸分别为(1*1024,1*512,1*300,1*300)。(7)当n=5时(n为语义检测单元的特征处理层数),1到5层输出特征的尺寸分别为(1*1024,1*512,1*
512,1*300,1*300)。(8)当n=6时(n为语义检测单元的特征处理层数),1到6层输出特征的尺寸分别为(1*1024,1*1024,1*512,1*512,1*300,1*300)。
[0088]
实施例1:
[0089]
少数民族舞蹈视频描述场景情况
[0090]
如图5所示,将本实例应用于少数民族舞蹈视频描述场景,采用本专利方法获取表达能力较强的语义特征,将其作为视频编码,在解码网络中解码得到舞蹈视频的文本描述,该文本信息可以让大众更熟悉少数民族舞蹈文化,有利于少数民族舞蹈文化的传播。
[0091]
实施例2:
[0092]
安防监控场景情况
[0093]
如图6所示,将本实例应用于安防监控的场景,采用本专利方法获取表达能力较强的语义特征,将其作为视频编码,在解码网络中解码得到安防监控视频对应的文本描述,该文本信息可以有效防止危险和违法等情况的发生,并提高排查监控视频的效率。
[0094]
实施例3:
[0095]
短视频内容审查情况
[0096]
如图7所示,将本实例应用于短视频内容审查,采用本专利方法获取表达能力较强的语义特征,将其作为视频编码,在解码网络中解码得到与短视频内容对应的文本描述,该文本信息可以有效防止短视频中违法、违规等负能量内容,有利于构造良好的网络环境。
[0097]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。