一种基于分层回报td3的hev能量管理方法及系统
技术领域
1.本发明属于混合动力车辆能量管理技术领域,更具体地,涉及一种基于分层回报td3的hev能量管理方法及系统。
背景技术:
2.在所有环境友好型车辆中,混合动力汽车(hev)与纯电动汽车相比,享有更长的行驶距离,与传统燃油汽车相比,燃料消耗更低,对环境更加友好。然而,混合动力汽车能量管理系统远比传统燃油汽车和纯电动汽车复杂。因此,混合动力车辆的能量管理策略(energy management strategy,ems)已经成为汽车领域的研究热点。
3.现有的混合动力车辆能量管理策略可以分为三个主要类别:基于规则的策略、基于优化的策略和基于学习的策略。虽然基于规则的能量管理策略容易实现,但是难以为非常复杂的工况制定合理的规则。基于优化的能量管理策略包括全局优化策略和实时优化策略。典型的全局优化策略算法计算成本高,通常在离线状态下进行,经常作为评估其他在线ems有效性的基准。实时优化策略如庞特里亚金最小原则的优化效率很好,但共同状态(co-state)难以获得,计算量相对较大。实时优化策略如等效燃油消耗最小化策略具有良好的实时特性,但用于计算等效油耗的历史道路信息往往不能够代表未来的驾驶条件,导致算法的鲁棒性差。实时优化策略如模型预测控制成功的关键是快速预测和快速优化策略,需要提前预测路况,这在很大程度上依赖性能优越的模型。基于强化学习算法q-learning的能量管理策略与传统的基于规则的策略相比,它可以极大地提高车辆的燃油经济性能,但存在“维度灾难”问题。深度确定性策略梯度(deep deterministic policy gradient,ddpg)策略虽然可以在具有连续或离散状态空间和连续动作空间的环境中训练,但存在对价值函数过度估计导致增量偏差和次最优策略的问题。双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient,td3)策略虽然能够弥补ddpg策略过度估计的问题,但现有的基于td3的能量管理方法无法根据车辆的不同行驶状态针对性地调整控制策略,能量管理策略整体性能有待进一步提高。
技术实现要素:
4.本发明通过提供一种基于分层回报td3的hev能量管理方法及系统,解决现有技术中基于td3的能量管理方案无法根据车辆的不同行驶状态针对性地调整控制策略的问题。
5.本发明提供一种基于分层回报td3的hev能量管理方法,包括以下步骤:
6.建立并联式混合动力车辆模型;
7.结合所述并联式混合动力车辆模型,选取hev能量管理策略的状态空间信号和动作空间信号;
8.结合所述并联式混合动力车辆模型,构建分层回报函数;所述分层回报函数包括第一回报函数和第二回报函数,根据激活条件激活所述第一回报函数或所述第二回报函数,且所述第一回报函数和所述第二回报函数均根据电池荷电状态的范围分别划分为两个
不同的调节层;
9.基于所述状态空间信号、所述动作空间信号和所述分层回报函数,构建基于分层回报td3的hev能量管理学习网络;
10.训练所述基于分层回报td3的hev能量管理学习网络,通过训练好的基于分层回报td3的hev能量管理学习网络执行能量管理策略。
11.优选的,所述并联式混合动力车辆模型中车辆的工作模式包括纯电动模式、空挡模式和并联模式。
12.优选的,所述状态空间信号为s=(v,soc,mf,cs),所述动作空间信号为a=(t
eng
|t
eng
∈[-250,841]);其中,v表示车辆的行驶速度,soc表示电池荷电状态,mf表示发动机燃油消耗率;cs表示车辆离合器的状态,cs为0表示离合器断开,cs为1表示离合器闭合;t
eng
表示发动机输出转矩。
[0013]
优选的,所述分层回报函数的激活方式为:对离合器状态进行判断,若离合器断开则激活所述第一回报函数,若离合器闭合则对瞬时车速进行判断;若瞬时车速为零则激活所述第一回报函数,若瞬时车速不为零则激活所述第二回报函数;
[0014]
所述第一回报函数r
soc
表示为:
[0015][0016]
所述第二回报函数r
com
表示为:
[0017][0018]
其中,第一调节层l1对应soc(t)>0.8或者soc(t)<0.3;第二调节层l2对应0.3≤soc(t)≤0.8;mf表示发动机燃油消耗率的实际值;soc
ref
表示电池荷电状态的参考值;soc(t)表示电池荷电状态的实际值;pen表示常数惩罚因子;δ1和δ2是两个权重因子,用于平衡燃油消耗率和电池荷电状态变化对车辆油耗的影响;ω1、ω2和ω3是三个常数,用于保证各调节层回报函数的数值都处在同一个数量级。
[0019]
优选的,获取车辆标准工况仿真行驶中影响能量管理的参数和观测值,基于标准工况下的参数和观测值对所述基于分层回报td3的hev能量管理学习网络进行训练。
[0020]
优选的,得到训练好的基于分层回报td3的hev能量管理学习网络后,还包括:获取车辆实际行驶中影响能量管理的参数和观测值,基于实际行驶下的参数和观测值对训练好的基于分层回报td3的hev能量管理学习网络进行验证,通过训练好并验证后的基于分层回报td3的hev能量管理学习网络执行能量管理策略。
[0021]
另一方面,本发明提供一种基于分层回报td3的hev能量管理系统,包括:处理器和存储器;所述存储器存储有控制程序,所述控制程序被所述处理器执行时用于实现上述的基于分层回报td3的hev能量管理方法。
[0022]
本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:
[0023]
在本发明中,结合并联式混合动力车辆模型选取hev能量管理策略的状态空间信
号和动作空间信号,并采用分层回报结构,分层回报结构包括两种回报函数,共计四个调节层,可以根据车辆的不同行驶状态针对性调整控制策略,减少不必要的重复探索行为,提高能量管理策略整体性能。即本发明使用分层回报双延迟深度确定性策略梯度算法,不仅解决离散动作空间深度强化学习能量管理策略维度灾难问题和深度确定性策略梯度过估计问题,而且由于具有四个调节层的分层回报结构可以根据工况和车辆运行模式的不同针对性地调整控制策略,能够提高能量管理策略的最优性。
附图说明
[0024]
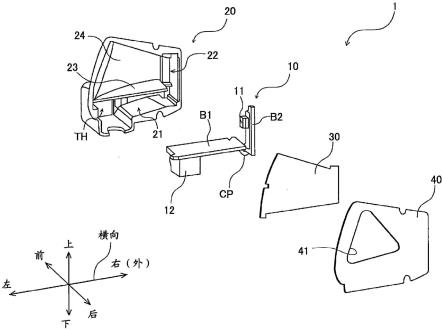
图1为本发明实施例1提供的一种基于分层回报td3的hev能量管理方法对应的混合动力车辆示意图;
[0025]
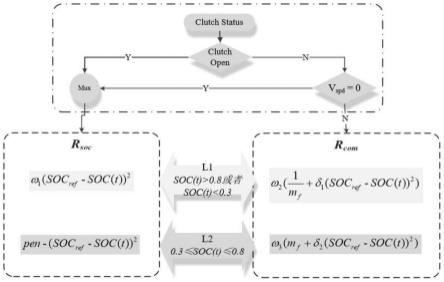
图2为本发明实施例1提供的一种基于分层回报td3的hev能量管理方法中的分层回报结构示意图;
[0026]
图3为本发明实施例1提供的一种基于分层回报td3的hev能量管理方法中的深度强化学习td3代理基本架构图;
[0027]
图4为标准工况速度变化曲线;
[0028]
图5为实际道路速度变化曲线。
具体实施方式
[0029]
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
[0030]
实施例1:
[0031]
实施例1提供了一种基于分层回报td3的hev能量管理方法,包括以下步骤:
[0032]
步骤1:建立并联式混合动力车辆模型。
[0033]
具体可通过matlab/simulink建立并联式混合动力车辆模型。
[0034]
建立的并联式混合动力车辆模型中,发动机和电机以并联的形式连接,并且发动机可以通过离合器实现与车轮的结合或者分离。车辆主要在纯电动模式、空挡模式以及并联模式下运行。以上三种车辆工作模式取决于离合器的状态和挡位,其结构图如图1所示。
[0035]
车辆动力系统必须提供车辆行驶所需要的牵引力,可以由汽车动力学方程计算得出,所述汽车动力学方程如公式(1)所示:
[0036][0037]
其中,f
t
是汽车行驶驱动力,ff是汽车行驶滚动阻力,fi是汽车行驶坡度阻力,f
ω
是汽车行驶空气阻力,fj是汽车行驶加速阻力,m是汽车质量,g是重力加速度,f为滚动阻力系数,α是汽车道路坡度,ρ是空气密度,a是汽车迎风面积,cd空气阻力系数,v是汽车行驶速
度,δ是旋转质量换算系数,a是汽车行驶加速度。
[0038]
步骤2:结合并联式混合动力车辆模型,选取hev能量管理策略的状态空间信号和动作空间信号。
[0039]
混合动力车辆能量管理策略旨在减少燃油消耗并保持电池soc在合理的区间内。根据控制目标选取hev能量管理策略的状态空间信号为s=(v,soc,mf,cs)。其中,v表示车辆行驶速度,soc表示电池荷电状态,mf是发动机燃油消耗率,cs是一个布尔值0(离合器断开)或1(离合器闭合),表示车辆离合器的状态。动作空间信号选定为发动机输出转矩t
eng
,a=(t
eng
|t
eng
∈[-250,841]),通过传感器获取相应状态信息。
[0040]
步骤3:设计分层回报结构并制定回报函数。
[0041]
分层回报结构对于td3能量管理策略非常重要。一个精心设计的回报结构不仅可以充分利用环境反馈的信息,而且还可以减少不必要的重复探索行为,使代理能够更快、更深入地与环境互动,加快学习过程,提高能量管理策略整体性能。
[0042]
本发明结合所述并联式混合动力车辆模型,构建分层回报函数;所述分层回报函数包括第一回报函数和第二回报函数,根据激活条件激活所述第一回报函数或所述第二回报函数,且所述第一回报函数和所述第二回报函数均根据电池荷电状态的范围分别划分为两个不同的调节层。
[0043]
具体的,正如在步骤1中所述,车辆主要工作在纯电动模式、空挡模式以及并联模式。当车辆运行在纯电动模式或者空挡模式时,车辆的发动机熄火(电动模式)或者虽然发动机通过离合器与车轮相连,但是可以任意改变转速(空挡模式),车辆的主要能量消耗在于电池,因此我们设计一个基于电池soc的回报函数r
soc
,这意味着保持soc值在合理的区间是最主要的目的。相应地,当车辆运行在并联模式,发动机和电机同时提供车辆行驶所需要的动力,我们设计一个综合回报函数r
com
,协调燃油消耗并保持电池soc在合理范围内两个目标,以实现最小的能量消耗。以上两个回报函数又根据soc的范围分别划分为两个不同的调节层。分层回报函数的结构如图2所示,分层回报结构根据离合器状态和瞬时车速v
spd
激活r
soc
或者r
com
。
[0044]
具体的,参见图2,所述分层回报函数的激活方式为:对离合器状态进行判断,若离合器断开则激活第一回报函数,若离合器闭合则对瞬时车速进行判断;若瞬时车速为零则激活第一回报函数,若瞬时车速不为零则激活第二回报函数。
[0045]
所述第一回报函数r
soc
表示为:
[0046][0047]
所述第二回报函数r
com
表示为:
[0048][0049]
其中,第一调节层l1对应soc(t)>0.8或者soc(t)<0.3;第二调节层l2对应0.3≤soc(t)≤0.8;mf表示发动机燃油消耗率的实际值;soc
ref
表示电池荷电状态的参考值;soc
(t)表示电池荷电状态的实际值;pen表示常数惩罚因子;δ1和δ2是两个权重因子,用于平衡燃油消耗率和电池荷电状态变化对车辆油耗的影响,这两个值越大表明能量管理策略越注重电池的保护;ω1、ω2和ω3是三个常数,用于保证各调节层回报函数的数值都处在同一个数量级。
[0050]
即本发明创新性地设计合理而且高效的分层回报结构,分层回报td3的hev能量管理策略会根据接收到的状态信号s做出能够最大化回报函数r的动作a,控制车辆节能,稳定且高效地行驶。
[0051]
步骤4:基于状态空间信号、动作空间信号和分层回报函数,构建基于分层回报td3的hev能量管理学习网络。
[0052]
利用深度神经网络的原理分别搭建critic网络和actor网络,共同构建双延迟深度确定性策略梯度策略的基本网络框架即actor-critic网络,深度强化学习td3代理基本架构图如图3所示,以构建基于分层回报td3的hev能量管理学习网络,并对所述actor-critic网络参数进行初始化和状态数据归一化处理。分层回报td3的hev能量管理策略具体实施细节如表1所示。
[0053]
表1分层回报td3算法执行步骤
[0054][0055]
步骤5:获取车辆标准工况仿真行驶中影响能量管理的参数和观测值,基于标准工况下的参数和观测值对基于分层回报td3的hev能量管理学习网络进行训练。
[0056]
即获取汽车标准工况仿真行驶中影响能量管理的参数和观测值,结合分层回报td3的hev能量管理策略目标训练学习网络,获得训练后的深度强化学习代理。
[0057]
可以使用三种典型的标准工况对学习网络进行训练,但不限于此。三种工况的速度参数如图4所示,每个工况的特点如表2所示。
[0058]
表1标准工况特点
[0059][0060]
步骤6:获取车辆实际行驶中影响能量管理的参数和观测值,基于实际行驶下的参数和观测值对训练好的基于分层回报td3的hev能量管理学习网络进行验证,通过训练好并验证后的基于分层回报td3的hev能量管理学习网络执行能量管理策略。
[0061]
例如,采集真实车辆在武汉市区行驶数据,制作实际道路工况,导入到驾驶员模型,对已经训练好的分层回报td3能量管理策略进行验证,测试该能量管理策略的优化性能,实际道路速度参数如图5所示。
[0062]
实施例2:
[0063]
实施例2提供了一种基于分层回报td3的hev能量管理系统,包括:处理器和存储器;所述存储器存储有控制程序,所述控制程序被所述处理器执行时用于实现如实施例1所述的基于分层回报td3的hev能量管理方法。
[0064]
本发明实施例提供的一种基于分层回报td3的hev能量管理方法及系统至少包括如下技术效果:
[0065]
(1)本发明精确设计分层回报结构,该结构有两种回报函数,共计四个调节层,可以根据车辆的不同行驶状态针对性调整控制策略,减少不必要的重复探索行为,既保证了回报函数针对不同行驶模式的全面调节,又避免了车载运算资源浪费,使代理能够更快、更深入地与环境互动,加快深度强化学习智能体的学习速度并且能够使提高能量管理策略整体性能。
[0066]
(2)本发明不仅采集能耗指标mf和电池soc,而且还采集车辆动力性指标车速v和离合器状态cs作为深度强化学习状态空间信号。根据车速和离合器状态进行两种回报函数的切换,可以针对车辆不同的行驶模式选择精确而且高效的回报函数。本发明不仅能够保证车辆行驶过程中燃油经济性最优,而且能够保证电池工作在合适的soc区间,防止过充电或过放电现象的发生损伤电池,延长电池使用寿命。
[0067]
(3)本发明采用分层回报双延迟深度确定性策略梯度能量管理策略,不仅能够弥补离散动作空间深度强化学习能量管理策略维度灾难的问题,而且能够解决深度确定性策略梯度过估计,训练不稳定的问题。
[0068]
最后所应说明的是,以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。