1.本发明属于人工智能技术领域,特别是涉及一种语音增强方法、系统及智能设备。
背景技术:
2.随着电商模式的不断发展,直播带货已成为最流行的网络营销方式。目前,直播的场景已经不仅仅局限于直播间,更多的是在室外场景下的户外直播。室外场景下,直播设备通常是手机、ipad等便携式智能设备,在直播过程中不可避免地受到外界非稳态噪声的干扰,考虑到直播设备通常就是主播本人在使用,如何对主播的语音信息进行语音增强以降低外界非稳态噪声的干扰是亟待解决的问题。
3.随着机器学习和神经网络技术的快速发展,深度学习的有监督神经网络语音增强算法逐渐成为研究热点,深度神经网络(deep neural networks,以下简称dnn)、cnn、rnn等语音增强模型已经逐渐取代了传统的语音增强算法。深度神经网络的语音增强技术主要是通过声学特征的提取和深度神经网络训练将语音从带噪信号中分离出来,实现语音增强。但是,特征提取和神经网络训练所需的处理资源较多,处理时间较长,而且并未考虑特定使用人的语音信息,针对某一个或多个特定使用者的语音增强效果较差。
4.目前还没有针对某一个或多个特定使用者进行快速、高效语音增强的技术,为此,提出一种语音增强方法、系统及智能设备。
技术实现要素:
5.本发明为了解决上述问题,提出一种语音增强方法、系统及智能设备。本发明的一种语音增强方法,包括:
6.采用第一训练数据训练非特定人语音增强模型;
7.在非特定人语音增强模型基础上采用特定人训练数据训练特定人语音增强模型;
8.提取语音特征信息并通过深度神经网络识别人员类别;
9.将语音数据根据人员类别输入相应模型得到增强的语音信息。
10.优选地,所述采用第一训练数据训练非特定人语音增强模型,包括步骤:
11.将标准语音数据和噪声数据按预设信噪比混叠合成的语音信号作为模拟带噪语音;
12.采用标准语音数据库作为纯净语音,模拟带噪语音及其对应的纯净语音共同构成第一训练数据;
13.将模拟带噪语音作为对抗网络生成器g的输入数据,将纯净语音作为生成器g的目标输出,输入到生成对抗网络;
14.以对抗学习的方式训练得到的生成器g即为非特定人语音增强模型。
15.进一步优选地,采用第一训练数据训练非特定人语音增强模型之后,还包括步骤、在非特定人语音增强模型的基础上采用第二训练数据训练新的非特定人语音增强模型:
16.将第一训练数据中合成的模拟带噪语音经过统计学语音增强算法处理后产生第
一增强语音,第二训练数据为模拟带噪语音及其对应的第一增强语音;所述统计学语音增强算法包括imcra-omlsa算法、imcra最小控制迭代平均算法、最优修正对数幅度估计算法的任一项或组合;
17.将模拟带噪语音作为对抗网络生成器g的输入数据,将第一增强语音作为生成器g的目标输出,输入到当前非特定人语音增强模型的对抗网络;
18.以对抗学习的方式训练得到的生成器g即为新的非特定人语音增强模型。优选地,所述特定人训练数据包括第三训练数据和/或第四训练数据,所述第三训练数据包括特定人带噪语音及其相对应的特定人纯净语音,所述特定人带噪语音是特定人纯净语音和标准噪声数据库按预设信噪比合成的语音,所述特定人纯净语音是设定的安静环境噪音下采集的特定人语音;所述第四训练数据包括特定人真实带噪语音及相对应的第四增强语音,所述特定人真实带噪语音是实际场景噪声环境下采集的特定人带噪语音,所述第四增强语音是特定人真实带噪语音经过统计学语音增强算法处理后得到的语音信息。
19.优选地,所述在非特定人语音增强模型基础上采用特定人训练数据训练特定人语音增强模型,包括步骤:
20.将第三训练数据的特定人带噪语音作为对抗网络生成器g的输入数据,将特定人纯净语音作为生成器g的目标输出,
21.或将第四训练数据的特定人真实带噪语音作为对抗网络生成器g的输入数据,将第四增强语音作为生成器g的目标输出;
22.将数据输入到当前非特定人语音增强模型对应的对抗网络;
23.以对抗学习的方式训练得到的生成器g即为特定人语音增强模型。
24.优选地,所述在非特定人语音增强模型基础上采用特定人训练数据训练特定人语音增强模型,包括步骤:
25.将第三训练数据的特定人带噪语音作为对抗网络生成器g的输入数据,将特定人纯净语音作为生成器g的目标输出,输入到当前非特定人语音增强模型的对抗网络;
26.以对抗学习的方式训练得到的生成器g即为第一特定人语音增强模型;
27.将第四训练数据的特定人真实带噪语音作为对抗网络生成器g的输入数据,将第四增强语音作为生成器g的目标输出,输入到第一特定人语音增强模型的对抗网络;
28.以对抗学习的方式再次训练得到的生成器g即为特定人语音增强模型。进一步优选地,所述以对抗学习的方式训练得到的生成器g,包括步骤:
29.将训练数据输入判别器d,判别器d的目标输出为“1”,通过误差反向传播算法对判别器d进行训练使其学习训练数据的数据分布;
30.通过反向误差传播算法对生成器g进行训练,其中,对生成器g的训练中,训练数据输入生成器g,生成器g的目标输出为使判别器d的输出为“1”;
31.通过反向误差传播算法对判别器d进行训练,其中,对判别器d的训练中,生成器g产生的信号输入判别器d,判别器d的目标输出为“0”;
32.固定判别器d的参数,调整生成器g的隐藏层参数,生成器g不断产生信号并通过判别器d对该生成信号进行判别,直至判别器d输出“1”时结束训练,训练得到的生成器g的映射关系即为所需的语音增强模型;
33.在上述训练过程中,生成器g的训练输入数据表示为隐藏层表示参量为z,pz(z)
表示生成器g学习到的分布,表示真实训练数据的分布,g的训练过程为最小化损失函数:其中,v(g)表示损失函数,附加l1正则化项最小化生成器g的生成信号和训练数据对相应语音
x
之间的欧氏距离,λ为设定的权重参数。
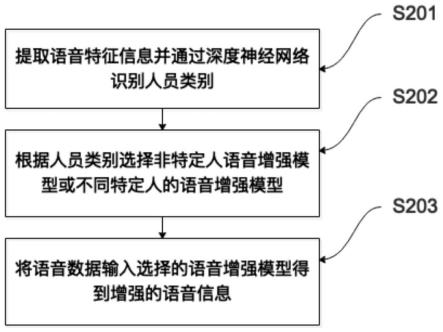
34.优选地,所述提取语音特征信息并通过深度神经网络识别人员类别,包括步骤:
35.采用第五训练数据训练深度神经网络,所述第五训练数据包括特定人语音信息及其相对应的类别信息,所述特定人语音信息是在设定的安静环境噪音下采集的一个或多个特定人的语音信息,所述类别信息是不同特定人的分类信息;
36.提取语音输入信号的特征参数,所述特征参数包括对数功率谱参数、梅尔倒谱参数、线性预测参数的任一项或多项组合;
37.将语音输入信号的特征参数输入深度神经网络得到样本特征;
38.将样本特征通过softmax分类器输出分类结果,即人员类别;所述人员类别包括不同特定人的类别、非特定人类别。
39.一种语音增强系统,包括:
40.语音输入设备;
41.处理器;
42.存储器;
43.以及
44.一个或多个程序,其中所述一个或多个程序被存储在存储器中,并且被配置成由所述处理器执行,所述程序使计算机执行上述方法。
45.一种智能设备,智能设备的存储器预先存储训练完成的非特定人语音增强模型;智能设备的麦克风采集一个或多个特定人的纯净语音或带噪语音信号;智能设备处理器运行的程序使智能设备执行如上所述的语音增强方法。
46.本发明的语音增强方法、系统及智能设备具有的优点是:
47.(1)通过训练特定人语音增强模型对智能设备的使用者(特定人)的语音数据对一个或多个特定人进行针对性的语音增强,相比传统的基于深度学习的语音增强技术,可以有效提高特定人语音的增强效果,降低外界非稳态噪声对特定人语音的干扰。
48.(2)同时采用特定人的纯净语音和带噪语音进行神经网络训练,相比传统的仅仅采用纯净语音进行训练的技术方案,提高了实际带噪场景下说话人识别的准确度。
49.(3)在非特定人语音增强模型的基础上,融合少量的特定人语音信息进行调优训练,相比现有技术中构建庞大的训练集的技术方案,可以有效降低数据训练量,快速有效地提升智能设备特定使用人的语音增强效果。
附图说明
50.图1是本发明实施例的应用场景图;
51.图2是本发明实施例的一种语音增强方法的流程图;
52.图3是一种优选实施方式中子步骤s01的流程图;
53.图4是一种优选实施方式中子步骤s02的流程图;
54.图5是一种优选实施方式中子步骤s101的流程图;
55.图6是一种优选实施方式中子步骤s1014的流程图;
56.图7是另一种优选实施方式中附加子步骤s101’的流程图;
57.图8是一种优选实施方式中子步骤s102的流程图;
58.图9是另一种优选实施方式中子步骤s102的流程图;
59.图10是另一种优选实施方式中子步骤s102的流程图;
60.图11是一种优选实施方式中子步骤s201的流程图;
61.图12是一种语音增强系统的结构示意图。
具体实施方式
62.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
63.本发明实施例中的语音增强方法、系统及智能设备主要应用于手机、汽车、智能家电、音箱等通过语音接口进行控制、唤醒或交互的应用程序,应用场景如图1所示。
64.本发明的一种语音增强方法的实施例,流程图如图2所示,包括:
65.步骤s01、采用不同训练数据训练不同的语音增强模型;
66.步骤s02、根据输入语音的特征选择相应的语音增强模型进行语音增强。
67.一种优选实施方式中,所述步骤s01、采用不同训练数据训练不同的语音增强模型,流程图如图3所示,包括:
68.步骤s101、采用第一训练数据训练非特定人语音增强模型;
69.步骤s102、在非特定人语音增强模型基础上采用特定人训练数据训练特定人语音增强模型。
70.一种优选实施方式中,所述步骤s02、根据输入语音的特征选择相应的语音增强模型进行语音增强,流程图如图4所示,包括:
71.步骤s201、提取输入语音的特征信息,通过深度神经网络识别人员类别;所述人员类别包括不同特定人的类别、非特定人类别;
72.步骤s202、根据人员类别选择非特定人语音增强模型或不同特定人的语音增强模型;
73.步骤s203、将语音数据输入选择的语音增强模型得到增强的语音信息。一种优选实施方式中,所述步骤s101、采用第一训练数据训练非特定人语音增强模型,流程图如图5所示,包括:
74.步骤s1011、将标准语音数据和噪声数据按预设信噪比混叠合成的语音信号作为模拟带噪语音;
75.步骤s1012、采用标准语音数据库作为纯净语音,模拟带噪语音及其对应的纯净语音共同构成第一训练数据;
76.步骤s1013、将模拟带噪语音作为对抗网络生成器g的输入数据,将纯净语音作为生成器g的目标输出,输入到生成对抗网络;
77.步骤s1014、以对抗学习的方式训练得到的生成器g即为非特定人语音增强模型。
78.本实施例中,生成对抗网络能够通过对抗学习以半监督的方式训练深度神经网络,以零和博弈的方式进行自我训练,从而降低对训练数据的需求。其中,生成对抗网络包括生成器g和判别器d。生成器g用于根据输入数据产生生成信号以逼近目标输出;判别器d用于判别生成器g产生的生成信号是否为纯净语音数据并以此判别为“1”或“0”,当判别为“1”时,调节判别器d的参数,当判别为“0”时,调节生成器g的参数;生成对抗网络训练时,生成器g和判别器d持续以对抗学习的方式训练直到两者进入均衡状态;训练完成后,生成器g用于执行实际语音增强。
79.上述实施方式中,非特定人语音增强模型采用至少10万条语音数据进行训练得到。标准语音数据来自于标准语音库,作为优选的,标准语音库采用timit语音数据库。标准噪声数据来自于标准噪声库,作为优选的,标准噪声库采用noizeus噪声数据库。其中,timit语音库作为非特定人纯净语音,其语音的采样频率为16khz,共有6300句语音,每段语音约3秒左右,具体由美国不同语言区、不同性别、不同年龄段的630人录制而成,并进行了标记和分割。noizeus噪声数据库由德克萨斯大学达拉斯分校的研究者采集而成,共八种噪声类型,分别为:babble(crowd of people)、car、exhibition hall、restaurant、street、airport、train station、train。
80.模拟带噪语音数据库由纯净语音和噪声按预设信噪比混叠而成。本发明实施例中将timit语音库的纯净语音和noizeus噪声库的8种噪声类型进行不同信噪比(信噪比为0、5、10db、15db)的混合,得到信噪比为0、5、10db、15db的带噪声语音,即每条语音可以混合得到8*4=32条带噪声语音。如果从timit中选取516语音,那么总共得到16512条模拟带噪语音。本发明采用多信噪比混叠的策略,构建了不同噪声场景和不同信噪比的训练数据来提高模型泛化性能,保证在复杂噪声场景和不同信噪比情况下均具有准确识别率。
81.上述实施方式中,训练了一个端对端的深度神经网络,生成器g和判别器d之间的零和博弈,首先,判别器d反向传播学习纯净语音,然后,判别器d反向传播生成器g生成的语音并对其进行判别,此过程,同时生成器训练g和判别器d;最后,冻结生成器d的参数,生成器g反向传播直至生成器d做出误判。所述步骤s1014中以对抗学习的方式训练得到的生成器g,流程图如图6所示,包括:
82.步骤s10141、训练判别器d,将纯净语音数据输入判别器d,判别器d的目标输出为“1”,通过误差反向传播算法对判别器d进行训练使其学习纯净语音的数据分布;
83.步骤s10142、通过反向误差传播算法对生成器g进行训练,其中,对生成器g的训练中,模拟带噪语音输入生成器g,生成器g的目标输出为使判别器d的输出为“1”;
84.步骤s10143、通过反向误差传播算法对判别器d进行训练,其中,对判别器d的训练中,生成器g产生的信号输入判别器d,判别器d的目标输出为“0”;
85.步骤s10144、固定判别器d的参数,调整生成器g的隐藏层参数后生成信号并输入判别器d;其中,生成器g的输入数据为模拟带噪语音,生成器g的目标输出为使判别器d的输出为“1”;生成器g不断产生信号并通过判别器d对该生成信号进行判别,直至所述判别器d输出“1”时结束训练,训练得到的生成器g的映射关系即为非特定人语音增强模型。
86.在上述训练过程中,g的训练输入是带噪语音信号和隐藏层表示参量z,pz(z)表示g所学习到的分布,表示真实训练数据的分布,实际训练的目的就是让pz(z)尽可能
接近g的输出是增强后的语音因此,理论上,g的训练过程可以阐述为最小化以下损失函数:
[0087][0088]
其中,v(g)表示损失函数,附加了l1正则化项,其实最小化生成器g的生成信号和纯净语音
x
之间的欧氏距离,λ为权重参数;训练的目的就是要得到该函数代价最小的g,让尽可能接近纯净语音
x
。
[0089]
通过上述训练过程,生成器g能够学习到从模拟带噪语音和纯净语音之间的映射关系以用于实际语音增强。生成器g训练得到的映射关系即为非特定人语音增强模型,智能设备采集的带噪语音信号输入非特定人语音增强模型进行信号处理后输出增强语音信号。
[0090]
在另一种优选实施方式中,采用步骤s101、第一训练数据训练非特定人语音增强模型之后,执行步骤s101’、在非特定人语音增强模型的基础上采用第二训练数据训练新的非特定人语音增强模型,流程图如图7所示,该步骤包括:
[0091]
步骤s101’1、将第一训练数据中合成的模拟带噪语音经过统计学语音增强算法处理后产生第一增强语音,模拟带噪语音和第一增强语音作为第二训练数据;所述统计学语音增强算法包括imcra-omlsa算法、imcra最小控制迭代平均算法、最优修正对数幅度估计算法的任一项或组合;
[0092]
步骤s101’2、将模拟带噪语音作为对抗网络生成器g的输入数据,将第一增强语音作为生成器g的目标输出,输入到当前非特定人语音增强模型的对抗网络;
[0093]
步骤s101’3、以对抗学习的方式训练得到的生成器g即为新的非特定人语音增强模型。
[0094]
本实施例中,将第一训练数据中合成的模拟带噪语音采用imcra-omlsa算法、imcra最小控制迭代平均算法、最优修正对数幅度估计算法等处理后得到第一增强语音,将模拟带噪语音和第一增强语音作为训练数据对,输入到上述实施例中训练得到的非特定人语音增强模型中,如上述步骤s10141~步骤s10144所述的方法进行对抗网络训练,即通过反向误差传播算法对生成器g进行训练,其中,对生成器g的训练中,模拟带噪语音输入生成器g,生成器g的目标输出为使判别器d的输出为“1”;通过反向误差传播算法对判别器d进行训练,其中,对判别器d的训练中,生成器g产生的信号输入判别器d,判别器d的目标输出为“0”;固定判别器d的参数,调整生成器g的隐藏层参数,生成器g不断产生信号并通过判别器d对该生成信号进行判别,直至判别器d输出“1”时结束训练,训练得到的生成器g的映射关系即为新的非特定人语音增强模型。
[0095]
本实施例中,步骤s102中所述特定人训练数据包括第三训练数据和/或第四训练数据。
[0096]
一种优选实施方式中,所述第三训练数据包括特定人带噪语音及其相对应的特定人纯净语音,特定人带噪语音是特定人纯净语音和标准噪声数据库合成的语音,所述特定人纯净语音是安静环境噪音下采集的特定人语音。本实施例中,特定人是指事先设置的一个或多个设备使用者,特定人纯净语音是事先在设定的安静环境噪音下采集的某特定人的多条语音信息,特定人带噪语音是特定人纯净语音和标准噪声数据按预设信噪比混叠而成的语音。
[0097]
一种优选实施方式中,所述第四训练数据包括特定人真实带噪语音及相对应的第四增强语音,所述特定人真实带噪语音是实际场景噪声环境下采集的特定人带噪语音,所述第四增强语音是特定人真实带噪语音经过统计学语音增强算法处理后得到的语音信息。本实施例中,特定人是指事先设置的一个或多个设备使用者,特定人真实带噪语音是事先在实际场景下采集的某特定人的多条语音信息或在实际场景下使用设备时实时采集的某特定人的语音信息,imcra-omlsa算法、imcra最小控制迭代平均算法、最优修正对数幅度估计算法的任一项或组合将特定人真实带噪语音处理为第四增强语音。
[0098]
一种优选实施方式中,所述步骤s102、在非特定人语音增强模型基础上采用特定人训练数据训练特定人语音增强模型,流程图如图8所示,包括步骤:
[0099]
s1021、将第三训练数据的特定人带噪语音作为对抗网络生成器g的输入数据,将特定人纯净语音作为生成器g的目标输出;
[0100]
s1022、将数据输入到当前非特定人语音增强模型对应的对抗网络;
[0101]
s1023、以对抗学习的方式训练得到的生成器g即为特定人语音增强模型。
[0102]
本实施例中,将特定人带噪语音和特定人纯净语音作为训练数据对,输入到上述任一实施例训练得到的非特定人语音增强模型中,如上述步骤s10141~步骤s10144所述的方法进行对抗网络训练,即通过反向误差传播算法对生成器g进行训练,其中,对生成器g的训练中,特定人带噪语音输入生成器g,生成器g的目标输出为使判别器d的输出为“1”;通过反向误差传播算法对判别器d进行训练,其中,对判别器d的训练中,生成器g产生的信号输入判别器d,判别器d的目标输出为“0”;固定判别器d的参数,调整生成器g的隐藏层参数,生成器g不断产生信号并通过判别器d对该生成信号进行判别,直至判别器d输出“1”时结束训练,训练得到的生成器g的映射关系即为特定人语音增强模型。
[0103]
由于本实施例的特定人语音增强模型是在非特定人语音增强模型的基础上进行参数调优,非特定人语音增强模型本身就是利用大规模数据充分训练得到的,在此基础上,融合少量的特定人语音信息进行调优训练,便可以提升智能设备特定使用人的语音增强效果。通常,第三训练数据一般只需几十条至上百条语音数据。
[0104]
另一种优选实施方式中,所述步骤s102、在非特定人语音增强模型基础上采用特定人训练数据训练特定人语音增强模型,流程图如图9所示,包括步骤:
[0105]
s1021’、将第四训练数据的特定人真实带噪语音作为对抗网络生成器g的输入数据,将第四增强语音作为生成器g的目标输出;
[0106]
s1022’、将数据输入到当前非特定人语音增强模型对应的对抗网络;
[0107]
s1023’、以对抗学习的方式训练得到的生成器g即为特定人语音增强模型。
[0108]
本实施例中,将特定人真实带噪语音和第四增强语音作为训练数据对,输入到上述任一实施例训练得到的非特定人语音增强模型中,采用如上述步骤s10141~步骤s10144的方法进行对抗网络训练,即通过反向误差传播算法对生成器g进行训练,其中,对生成器g的训练中,特定人真实带噪语音输入生成器g,生成器g的目标输出为使判别器d的输出为“1”;通过反向误差传播算法对判别器d进行训练,其中,对判别器d的训练中,生成器g产生的信号输入判别器d,判别器d的目标输出为“0”;固定判别器d的参数,调整生成器g的隐藏层参数,生成器g不断产生信号并通过判别器d对该生成信号进行判别,直至判别器d输出“1”时结束训练,训练得到的生成器g的映射关系即为特定人语音增强模型。本实施例的特
定人语音增强模型采用真实带噪语音和统计处理的增强语音作为训练数据对,可以在实际场景使用设备时实时采集,事先无需在安静环境下采集语音即可完成训练。
[0109]
另一种优选实施方式中,所述步骤s102、在非特定人语音增强模型基础上采用特定人训练数据训练特定人语音增强模型,流程图如图10所示,包括步骤:
[0110]
步骤s1021”、将第三训练数据的特定人带噪语音作为对抗网络生成器g的输入数据,将特定人纯净语音作为生成器g的目标输出,输入到当前非特定人语音增强模型的对抗网络;
[0111]
步骤s1022”、以对抗学习的方式训练得到的生成器g为第一特定人语音增强模型;
[0112]
步骤s1023”、将第四训练数据的特定人真实带噪语音作为对抗网络生成器g的输入数据,将第四增强语音作为生成器g的目标输出,输入到第一特定人语音增强模型的对抗网络;
[0113]
步骤s1024”、以对抗学习的方式再次训练得到的生成器g即为特定人语音增强模型。
[0114]
本实施例中,先将特定人带噪语音和特定人纯净语音作为训练数据对,输入到上述任一实施例训练得到的非特定人语音增强模型中,采用如上述步骤s10141~步骤s10144的方法进行对抗网络训练,即通过反向误差传播算法对生成器g进行训练,其中,对生成器g的训练中,特定人带噪语音输入生成器g,生成器g的目标输出为使判别器d的输出为“1”;通过反向误差传播算法对判别器d进行训练,其中,对判别器d的训练中,生成器g产生的信号输入判别器d,判别器d的目标输出为“0”;固定判别器d的参数,调整生成器g的隐藏层参数,生成器g不断产生信号并通过判别器d对该生成信号进行判别,直至判别器d输出“1”时结束训练,训练得到的生成器g的映射关系即为第一特定人语音增强模型(初步的特定人语音增强模型),在此基础上,将特定人真实带噪语音和第三增强语音作为训练数据对,输入到上述第一特定人语音增强模型中,继续采用如上述步骤s10141~步骤s10144的方法进行对抗网络训练,即通过反向误差传播算法对生成器g进行训练,其中,对生成器g的训练中,特定人真实带噪语音输入生成器g,生成器g的目标输出为使判别器d的输出为“1”;通过反向误差传播算法对判别器d进行训练,其中,对判别器d的训练中,生成器g产生的信号输入判别器d,判别器d的目标输出为“0”;固定判别器d的参数,调整生成器g的隐藏层参数,生成器g不断产生信号并通过判别器d对该生成信号进行判别,直至判别器d输出“1”时结束训练,训练得到的生成器g的映射关系即为最终的特定人语音增强模型。本实施例的特定人语音增强模型是在上述任一实施例训练得到的非特定人语音增强模型基础上,先后采用第三训练数据和第四训练数据进行对抗训练,对网络模型参数进行多重优化,得到的特定人语音增强模型可以提高智能设备特定使用人的语音增强效果。
[0115]
一种优选实施方式中,所述步骤s201、提取语音特征信息并通过深度神经网络识别人员类别,流程图如图11所示,包括步骤:
[0116]
步骤s2011、采用第五训练数据训练深度神经网络;所述第五训练数据包括特定人语音信息及其相对应的类别信息,所述特定人语音信息是在设定的安静环境噪音下采集的一个或多个特定人的语音信息,所述类别信息是不同特定人的分类信息;
[0117]
步骤s2012、提取语音输入信号的特征参数,所述特征参数包括对数功率谱参数、梅尔倒谱参数、线性预测参数的任一项或多项组合;
[0118]
步骤s2013、将语音输入信号的特征参数输入深度神经网络得到样本特征;
[0119]
步骤s2014、将样本特征通过softmax分类器输出分类结果,即人员类别。
[0120]
本实施例中,事先在设备中设定一个或多个特定人并在设定的安静环境噪音下采集相应特定人的语音信息,例如智能设备有a、b、c三个常用使用人(特定人),分别采集a、b、c三人在安静环境下的语音数据,并指定分类标签作为类别信息,获得第五训练数据。所述设定的安静环境噪音是根据不同应用场景(例如会议室、室外、医院等场景)设定的噪音分贝值范围(本实施例安静环境噪音分贝值范围为40分贝以下)。通过深度神经网络学习算法,采用第五训练数据训练得到用于识别人员类别的深度神经网络。本实施例首先提取语音输入信号的mel倒谱、语音信号功率谱和感知线性预测系数并输入到深度神经网络中,然后利用dnn进一步提取特定人语音的样本特征,最后将样本特征通过softmax分类器输出分类结果,即人员属于特定人(a或b或c)或非特定人。
[0121]
本实施例中,步骤s202、根据人员类别选择非特定人语音增强模型或不同特定人的语音增强模型,根据识别出的人员属于特定人(a或b或c)或非特定人,选择任一实施例中训练得到的相应特定人的特定人语音增强模型或非特定人语音增强模型。
[0122]
本实施例中,步骤s203、将语音数据输入选择的语音增强模型得到增强的语音信息中,将该人员的语音数据输入到选择出的语音增强模型中,语音增强模型根据生成器g的映射关系运算得到该人员语音数据对应的增强语音数据。
[0123]
一种计算机可读存储介质,其存储用于电子数据交换的计算机程序,其中,所述计算机程序被处理器执行时使计算机执行上述方法。
[0124]
一种语音增强系统,系统结构示意图如图12所示,包括:
[0125]
语音输入设备;
[0126]
处理器;
[0127]
存储器;
[0128]
以及
[0129]
一个或多个程序,其中所述一个或多个程序被存储在存储器中,并且被配置成由所述处理器执行,所述程序使计算机执行上述方法。
[0130]
在一种优选实施方式中,一种智能设备,智能设备出厂前预先训练非特定人语音增强模型(采用上述任一实施方式训练得到的非特定人语音增强模型),智能设备的存储器中存储训练完成的非特定人语音增强模型,智能设备的麦克风采集一个或多个特定人的纯净语音或带噪语音信号;智能设备处理器运行的程序使智能设备执行如上所述的语音增强方法,人员使用时根据智能设备软件界面要求设置特定人和采集相应语音。
[0131]
当然,本技术领域中的普通技术人员应当认识到,以上实施例仅是用来说明本发明的,而并非作为对本发明的限定,只要在本发明的范围内,对以上实施例的变化、变型都将落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。