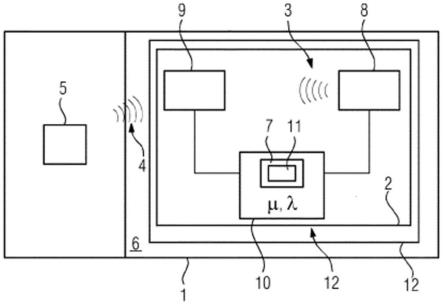
1.本发明涉及语音识别技术领域,尤其涉及一种计算机语音识别方法。
背景技术:
2.语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
3.通过对声音的录入,然后再对录入的声音进行识别,从而将声音转换为信息文字。
4.经检索,中国专利号为cn113851111a的发明专利,公开了一种语音识别方法和语音识别装置,该方法包括:对语音数据流进行加窗处理,确定位于窗口内的语音数据;对窗口内的语音数据进行对象识别处理,并根据对象识别处理结果对窗口进行长度调整,并将位于调整后的窗口内的语音数据确定为目标语音段;基于识别模型对目标语音段进行语音识别处理,得到目标识别结果。这样,在对语音数据流进行加窗处理时,根据对象识别处理的结果灵活调整窗口长度,以得到不同大小的目标语音段,能够兼顾识别速度和识别效果,从而综合改善端对端语音识别场景的语音识别性能。
5.然而上述语音识别方法在使用过程中仅能够对对窗口内的语音数据进行对象识别处理,并根据对象识别处理结果对窗口进行长度调整,从而改善端对端语音识别场景的语音识别性能,在实际使用过程中,由于缺乏对录入语音的有效识别,从而无法根据各个词组之间的意思进行准确的翻译,同时外部的噪音大大增加语音识别的难度,进而降低语音识别的准确率,因此需要一种计算机语音识别方法。
技术实现要素:
6.本发明的目的是为了解决现有技术中存在缺乏对录入语音的有效识别,从而无法根据各个词组之间的意思进行准确的翻译,同时外部的噪音大大增加语音识别的难度的缺点,而提出的一种计算机语音识别方法。
7.为了实现上述目的,本发明采用了如下技术方案:
8.一种计算机语音识别方法,包括以下步骤:
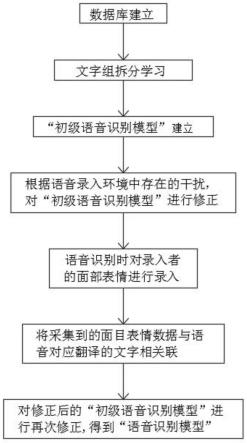
9.步骤一:音频数据库建立:通过互联网以及人工录入音频,建立音频数据库,并基于音频翻译出对应的文字;
10.步骤二:文字组学习:计算机中装载嵌入式处理芯片,通过嵌入式处理芯片对录入的音频进行拆分,拆分为“单字”、“双字”、“三字”...直到“句子的全部文字”,将拆分后的文字记作“文字组”,根据拆分出的“文字组”与数据库相匹配,判断出“文字组”的实际意义;
11.步骤三:模型建立:将大量文字组学习的结果与录入时的音频相结合,以实际文字翻译为基准进行深度学习,从而生成“初级语音识别模型”;
12.步骤四:模型修正:通过人工进行语音录入,然后通过“初级语音识别模型”进行语音识别,选择在不同的环境中进行录入,根据“初级语音识别模型”识别出的文字与实际录入文字相比对,寻求出文字存在的差异,通过获得差异对“初级语音识别模型”进行修正;
13.步骤五:图像采集:在进行语音的过程中对录入者的面部表情进行获取,同时根据获取的面部表情与对应的语音相关联;
14.步骤六:将采集到的面目表情数据与语音对应翻译的文字相关联,从而对修正后的“初级语音识别模型”进行再次修正,进而得到“语音识别模型”;
15.步骤七:实时语音识别:进行语音识别的过程中,对获取进行音频进行实时导入到“语音识别模型”,通过“语音识别模型”进行实时语音识别。
16.上述技术方案进一步包括:
17.音频数据库在建立的过程中同时对词组数据库进行建立。
[0018]“文字组”在与词组数据库进行对比的过程中,根据字数多少以及语音语调,对词组数据库内部的词组进行分列。
[0019]
在嵌入式处理芯片中安装降噪模组用于对接收语音中的噪音进行降噪,同时降噪模组与“语音识别模型”相配合形成对录入语音的充分降噪。
[0020]
在计算机内部的图像采集装置对音频录入人员的面部图像进行采集,对采集后的图像进行处理,降低图像中的噪点,增强图像中的纹理,然后对处理后的图像进行识别。
[0021]
在将面目表情数据与翻译时的文字相结合的过程中引入情感分析机制。
[0022]
通过情感分析机制对语音录入者的语气态度进行识别,增加语音识别的成功率。
[0023]
对于不同的口音建立不同的数据库以及“语音识别模型”。
[0024]
相比现有技术,本发明的有益效果为:
[0025]
本发明中,通过大量“文字组”学习的结果与录入时的音频相结合,从而生成出“初级语音识别模型”,并且通过人工进行语音录入与“初级语音识别模型”进行训练,根据外部环境造成的影响,对“初级语音识别模型”进行修正,最后再通过对录入者的面部表情的深度学习,从而对修正后的“初级语音识别模型”进行二次修正,最终得到“语音识别模型”,通过“语音识别模型”实现对语音的快速识别,且大大提升识别的准确率。
附图说明
[0026]
图1为本发明提出的一种计算机语音识别方法的流程框图。
具体实施方式
[0027]
实施例一
[0028]
第一步,通过互联网以及人工录入音频,建立音频数据库,并基于音频翻译出对应的文字,音频数据库在建立的过程中同时对词组数据库进行建立,在计算机中装载嵌入式处理芯片;
[0029]
通过嵌入式处理芯片对录入的音频进行拆分,同时拆分的个数为“单字”、“双字”、“三字”...直到“句子的全部文字”,“文字组”在与词组数据库进行对比的过程中,根据字数多少以及语音语调,对词组数据库内部的词组进行分列;
[0030]
将拆分后的文字记作“文字组”,根据拆分出的“文字组”与数据库相匹配,判断出“文字组”的实际意义;
[0031]
第二步,将大量文字组学习的结果与录入时的音频相结合,以实际文字翻译为基准进行深度学习,从而生成“初级语音识别模型”;
[0032]
第三步,通过人工进行语音录入,然后通过“初级语音识别模型”进行语音识别,选择在不同的环境中进行录入;
[0033]
根据“初级语音识别模型”识别出的文字与实际录入文字相比对,寻求出文字存在的差异,通过获得差异对“初级语音识别模型”进行修正;
[0034]
第四步,在进行语音的过程中对录入者的面部表情进行获取,同时根据获取的面部表情与对应的语音相关联;
[0035]
在计算机内部的图像采集装置对音频录入人员的面部图像进行采集,对采集后的图像进行处理,降低图像中的噪点,增强图像中的纹理,然后对处理后的图像进行识别;
[0036]
第五步,将采集到的面目表情数据与语音对应翻译的文字相关联,在将面目表情数据与翻译时的文字相结合的过程中引入情感分析机制,通过情感分析机制对语音录入者的语气态度进行识别,增加语音识别的成功率,从而对修正后的“初级语音识别模型”进行再次修正,进而得到“语音识别模型”;
[0037]
在嵌入式处理芯片中安装降噪模组用于对接收语音中的噪音进行降噪,同时降噪模组与“语音识别模型”相配合形成对录入语音的充分降噪,对于不同的口音建立不同的数据库以及“语音识别模型”;
[0038]
第六步,进行语音识别的过程中,对获取进行音频进行实时导入到“语音识别模型”,通过“语音识别模型”进行实时语音识别。
[0039]
基于实施例一的一种计算机语音识别方法进行语音识别录入,通过大量“文字组”学习的结果与录入时的音频相结合,从而生成出“初级语音识别模型”,并且通过人工进行语音录入与“初级语音识别模型”进行训练,根据外部环境造成的影响,对“初级语音识别模型”进行修正,最后再通过对录入者的面部表情的深度学习,从而对修正后的“初级语音识别模型”进行二次修正,最终得到“语音识别模型”,通过“语音识别模型”实现对语音的快速识别,且大大提升识别的准确率,测试的语句如下表所示:
[0040]
录入语句数量单句数量总字数单句识别准确率单字识别准确率52649794.3%98.3%。
[0041]
实施例二
[0042]
第一步,通过互联网以及人工录入音频,建立音频数据库,并基于音频翻译出对应的文字,音频数据库在建立的过程中同时对词组数据库进行建立,在计算机中装载嵌入式处理芯片;
[0043]
通过嵌入式处理芯片对录入的音频进行拆分,同时拆分的个数为“单字”、“双字”、“三字”...直到“句子的全部文字”,“文字组”在与词组数据库进行对比的过程中,根据字数多少以及语音语调,对词组数据库内部的词组进行分列;
[0044]
将拆分后的文字记作“文字组”,根据拆分出的“文字组”与数据库相匹配,判断出“文字组”的实际意义;
[0045]
第二步,将大量文字组学习的结果与录入时的音频相结合,以实际文字翻译为基准进行深度学习,从而生成“初级语音识别模型”;
[0046]
第三步,通过人工进行语音录入,然后通过“初级语音识别模型”进行语音识别,选择在不同的环境中进行录入;
[0047]
根据“初级语音识别模型”识别出的文字与实际录入文字相比对,寻求出文字存在的差异,通过获得差异对“初级语音识别模型”进行修正;
[0048]
在嵌入式处理芯片中安装降噪模组用于对接收语音中的噪音进行降噪,同时降噪模组与修正后的“语音识别模型”相配合形成对录入语音的充分降噪,对于不同的口音建立不同的数据库以及修正后的“语音识别模型”;
[0049]
第四步,进行语音识别的过程中,对获取进行音频进行实时导入到修正后的“语音识别模型”,通过修正后的“语音识别模型”进行实时语音识别。
[0050]
基于实施例一的一种计算机语音识别方法进行语音识别录入,通过大量“文字组”学习的结果与录入时的音频相结合,从而生成出“初级语音识别模型”,并且通过人工进行语音录入与“初级语音识别模型”进行训练,根据外部环境造成的影响,对“初级语音识别模型”进行修正,通过修正后的“语音识别模型”实现对语音的快速识别,且大大提升识别的准确率,测试的语句如下表所示:
[0051]
录入语句数量单句数量总字数单句识别准确率单字识别准确率52442688.3%94.1%。
[0052]
实施例三
[0053]
第一步,通过互联网以及人工录入音频,建立音频数据库,并基于音频翻译出对应的文字,音频数据库在建立的过程中同时对词组数据库进行建立,在计算机中装载嵌入式处理芯片;
[0054]
通过嵌入式处理芯片对录入的音频进行拆分,同时拆分的个数为“单字”、“双字”、“三字”...直到“句子的全部文字”,“文字组”在与词组数据库进行对比的过程中,根据字数多少以及语音语调,对词组数据库内部的词组进行分列;
[0055]
将拆分后的文字记作“文字组”,根据拆分出的“文字组”与数据库相匹配,判断出“文字组”的实际意义;
[0056]
第二步,将大量文字组学习的结果与录入时的音频相结合,以实际文字翻译为基准进行深度学习,从而生成“初级语音识别模型”;
[0057]
第三步,在进行语音的过程中对录入者的面部表情进行获取,同时根据获取的面部表情与对应的语音相关联;
[0058]
在计算机内部的图像采集装置对音频录入人员的面部图像进行采集,对采集后的图像进行处理,降低图像中的噪点,增强图像中的纹理,然后对处理后的图像进行识别;
[0059]
第四步,将采集到的面目表情数据与语音对应翻译的文字相关联,在将面目表情数据与翻译时的文字相结合的过程中引入情感分析机制,通过情感分析机制对语音录入者的语气态度进行识别,增加语音识别的成功率,从而对“初级语音识别模型”进行修正,进而得到“语音识别模型”;
[0060]
对于不同的口音建立不同的数据库以及“语音识别模型”;
[0061]
第五步,进行语音识别的过程中,对获取进行音频进行实时导入到“语音识别模型”,通过“语音识别模型”进行实时语音识别。
[0062]
基于实施例一的一种计算机语音识别方法进行语音识别录入,通过大量“文字组”学习的结果与录入时的音频相结合,从而生成出“初级语音识别模型”,通过对录入者的面
部表情的深度学习,从而对“初级语音识别模型”进行修正,最终得到“语音识别模型”,通过“语音识别模型”实现对语音的快速识别,且大大提升识别的准确率,测试的语句如下表所示:
[0063]
录入语句数量单句数量总字数单句识别准确率单字识别准确率52953983.7%89.5%。
[0064]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。