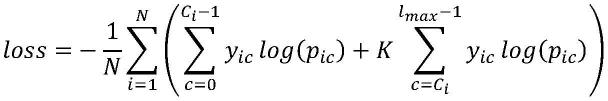
1.本发明涉及一种中文语音识别模型,特别是一种基于拼音的双阶段解耦合中文语音识别模型。
背景技术:
2.语音识别技术是一种将人的语音转换为文本序列的技术。作为一种便捷的人机交互方式,语音识别技术已在各种交互式智能设备中得到了相当广泛的应用,包括智能音箱、车载系统和问答机器人等。
3.传统的语音识别架构中都包含声学模型和语言模型,声学模型负责把语音输入转换成声学表示的输出,语言模型负责从候选的字符序列中找出概率最大的字符串序列。端到端模型同时训练声学模型和语言模型,虽然简化了训练过程,但由于解码器替代了传统架构中的语言模型,训练时又只能用成对的音频文本数据,因此大大增加了对语音标注数据的需求。另外,端到端模型由于整合了声学模型和语言模型,模型体积较大,对计算和内存提出了高要求。
技术实现要素:
4.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于拼音的双阶段解耦合中文语音识别模型。
5.为了解决上述技术问题,本发明公开了一种基于拼音的双阶段解耦合中文语音识别模型,包括如下步骤:
6.步骤1,从中文语音数据集获取音频数据并进行预处理,得到语音数据训练集、验证集和测试集;构建基于拼音的双阶段解耦合中文语音识别模型,包括声学模型和语言模型;
7.步骤2,对所得语音数据训练集的mel谱特征做动态数据增强,包括时间掩蔽和频率掩蔽;
8.步骤3,将动态数据增强后的mel谱特征送入声学模型,进行声学模型训练,得到联结时序分类(connectionist temporal classification,ctc)损失,优化声学模型参数;重复步骤2和步骤3所述的动态数据增强和声学模型训练过程,直到声学模型收敛;
9.步骤4,进行声学模型性能评估;
10.步骤5,从中文文本数据集获取文本数据并进行预处理;
11.步骤6,根据步骤5中预处理后的文本数据建立拼音词典、汉字词典和同音字词典,得到包括中文文本的文本数据训练集;
12.步骤7,将所得文本数据训练集中中文文本对应的拼音序列以及同音字序列送入语言模型,进行语言模型训练,得到交叉熵损失,优化语言模型参数;重复步骤7所述的语言模型训练过程,直到语言模型收敛;
13.步骤8,进行语言模型性能评估和基于拼音的双阶段解耦合中文语音识别模型的
联合评估。
14.本发明步骤1中所述数据预处理包括:
15.将所有音频数据以统一的采样率进行重采样;对音频数据进行预加重、分帧和加窗得到有重叠的分帧信号;对分帧信号进行短时傅里叶变换得到短时幅度谱;通过mel滤波器组得到mel谱特征数据;将所得mel谱特征数据划分为不相交的训练集、验证集和测试集。
16.本发明步骤2中对所得语音数据训练集的mel谱特征做动态数据增强过程中,对时间掩蔽和频率掩蔽的掩蔽比例为随机数。
17.本发明步骤3中,所述声学模型由混合下采样模块、多路径交叉卷积模块和多层前馈神经网络组成;
18.其中,混合下采样模块使用多路径融合使用最大池化和均匀池化,减少下采样过程中有用信息的丢失;多路径交叉卷积模块包含两个相同的分组,其中每个分组由多路不同分辨率的二维卷积级联而得,提取不同感受野下的低层特征,多路径交叉卷积模块内部还使用了密集连接的残差结构;多层前馈神经网络将输入的高级特征映射到拼音的维度空间,并使用softmax函数获得概率分布。
19.本发明步骤4中所述声学模型性能评估,包括:测试集字符识别错误率和推理延迟;其中,字符识别错误率cer通过动态字符串对齐计算得到,方法如下:
[0020][0021]
其中,s表示对齐过程中产生的替换次数,d表示删除次数,i表示插入次数,n表示目标句子中的字符数。
[0022]
本发明步骤5中所述中文文本数据集为现存的数据集或收集整理得到的中文文本;所述预处理包括:
[0023]
复句分割为多个单句、数字转汉字、繁体转简体、去除句末标点符号以及去除包含非汉字字符的句子,得到仅包含简体汉字的句子;将所得句子划分为不相交的训练集、验证集,同时去除与最终测试所用数据集中重叠的句子。
[0024]
本发明步骤6中所述词典以python字典格式存储;其中,拼音词典以拼音为键,以递增索引为值;汉字词典以汉字为键,以递增索引为值;同音字词典以拼音为键,以子词典为值,该子字典的键为同拼音的汉字,值为递增索引。
[0025]
本发明步骤7中所述语言模型为基于同音字建模的transformer模型,将拼音到汉字的转录过程作为一对一的翻译过程,并将翻译结果限制在输入拼音对应的同音字空间中。
[0026]
本发明步骤8中,语言模型性能评估包括测试集识别准确率和推理延迟;基于拼音的双阶段解耦合中文语音识别模型的联合评估包括整体模型参数量大小、测试集识别准确率和推理延迟。
[0027]
本发明步骤1中所述验证集和测试集中的说话人均不在训练集中出现。
[0028]
本发明利用混合下采样、多路径交叉卷积和残差结构构建了高效的全卷积声学模型,进行从音频的mel谱特征到拼音的识别,使用基于同音字建模的transformer语言模型进行从拼音到汉字的转录。与现有端到端中文语音识别模型相比,本发明的特点是,声学模型与语言模型的解耦合,大大减少了对语音标注数据的需求,同时可以充分利用大量存在
的中文文本进行自监督训练来得到高效的语言模型;以拼音为建模单元,通过混合下采样、多路径卷积和密集连接的残差结构建立了高效的全卷积声学模型,在保证识别准确率的同时降低了模型的复杂度和训练难度,节约了训练时间和计算资源;对拼音和同音字之间的关系进行建模,而不是对拼音和所有汉字之间的关系进行建模,建立了高效的transformer语言模型,在减少一半以上模型参数的同时,达到了远超其它模型的转录准确率。
[0029]
有益效果:
[0030]
提出了一种混合利用最大池化和均匀池化的新型下采样方法,在语音识别任务上的效果远超最大池化或均匀池化。全卷积神经网络构建的声学模型,通过混合下采样和多路径卷积增强了不同维度下的浅层特征的提取与融合,通过残差结构减轻了梯度消失现象,加强了特征在低层与高层之间的传递,在保证识别准确率的同时大幅降低了模型的复杂度和训练难度,节约了训练时间和计算资源。以同音字词典空间为transformer模型输出目标空间,建立了高效的语言模型,在减少一半以上模型参数的同时,达到了远超其它模型的转录精确度。
附图说明
[0031]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0032]
图1是本发明总体架构示意图。
[0033]
图2是本发明声学模型部分的架构示意图。
[0034]
图3是本发明语言模型部分的架构示意图。
[0035]
图4是实施例1训练时的数据流示意图。
[0036]
图5时实施例2训练时的数据流示意图。
[0037]
图6是实施例1和实施例2联合推理时的数据流示意图。
具体实施方式
[0038]
如图1所示,一种基于拼音的双阶段解耦合中文语音识别模型,包括如下步骤:
[0039]
步骤1,从中文语音数据集获取音频数据并进行预处理,得到语音数据训练集、验证集和测试集;构建基于拼音的双阶段解耦合中文语音识别模型,包括声学模型和语言模型;
[0040]
所述数据预处理包括:将所有音频数据以统一的采样率进行重采样;对音频数据进行预加重、分帧和加窗得到有重叠的分帧信号;对分帧信号进行短时傅里叶变换得到短时幅度谱;通过mel滤波器组得到mel谱特征数据;将所得mel谱特征数据划分为不相交的训练集、验证集和测试集。所述验证集和测试集中的说话人均不在训练集中出现。
[0041]
步骤2,对所得语音数据训练集的mel谱特征做动态数据增强,包括时间掩蔽和频率掩蔽;对所得语音数据训练集的mel谱特征做动态数据增强过程中,对时间掩蔽和频率掩蔽的掩蔽比例为随机数。
[0042]
步骤3,将动态数据增强后的mel谱特征送入声学模型,进行声学模型训练,得到联结时序分类(connectionist temporal classification,ctc)损失,优化声学模型参数;重复步骤2和步骤3所述的动态数据增强和声学模型训练过程,直到声学模型收敛;
[0043]
所述声学模型由混合下采样模块、多路径交叉卷积模块和多层前馈神经网络组成;
[0044]
其中,混合下采样模块使用多路径融合使用最大池化和均匀池化,减少下采样过程中有用信息的丢失;多路径交叉卷积模块包含两个相同的分组,其中每个分组由多路不同分辨率的二维卷积级联而得,提取不同感受野下的低层特征,多路径交叉卷积模块内部还使用了密集连接的残差结构,用以缓解梯度消失问题,加强特征在低层与高层之间的传递;多层前馈神经网络将输入的高级特征映射到拼音的维度空间,并使用softmax函数获得概率分布。
[0045]
步骤4,进行声学模型性能评估;
[0046]
所述声学模型性能评估,包括:测试集字符识别错误率和推理延迟;其中,字符识别错误率cer通过动态字符串对齐计算得到,方法如下:
[0047][0048]
其中,s表示对齐过程中产生的替换次数,d表示删除次数,i表示插入次数,n表示目标句子中的字符数。
[0049]
步骤5,从中文文本数据集获取文本数据并进行预处理;
[0050]
所述中文文本数据集为现存的数据集或收集整理得到的中文文本;所述预处理包括:
[0051]
复句分割为多个单句、数字转汉字、繁体转简体、去除句末标点符号以及去除包含非汉字字符的句子,得到仅包含简体汉字的句子;将所得句子划分为不相交的训练集、验证集,同时去除与最终测试所用数据集中重叠的句子。
[0052]
步骤6,根据步骤5中预处理后的文本数据建立拼音词典、汉字词典和同音字词典,得到包括中文文本的文本数据训练集;
[0053]
所述词典以python字典格式存储;其中,拼音词典以拼音为键,以递增索引为值;汉字词典以汉字为键,以递增索引为值;同音字词典以拼音为键,以子词典为值,该子字典的键为同拼音的汉字,值为递增索引。
[0054]
步骤7,将所得文本数据训练集中中文文本对应的拼音序列以及同音字序列送入语言模型,进行语言模型训练,得到交叉熵损失,优化语言模型参数;重复步骤7所述的语言模型训练过程,直到语言模型收敛;
[0055]
所述语言模型为基于同音字建模的transformer模型(参考文献:vaswani2017attention,attention is all you need,vaswani,ashish and shazeer,noam and parmar,niki and uszkoreit,jakob and jones,llion and gomez,aidan n and kaiser,lukasz and polosukhin,illia,advances in neural information processing systems,30,2017),将拼音到汉字的转录过程作为一对一的翻译过程,并将翻译结果限制在输入拼音对应的同音字空间中,减少了模型的参数量,大大降低了模型的转录错误率,同时简化了模型的识别过程。
[0056]
步骤8,进行语言模型性能评估和基于拼音的双阶段解耦合中文语音识别模型的联合评估。
[0057]
语言模型性能评估包括测试集识别准确率和推理延迟;基于拼音的双阶段解耦合
中文语音识别模型的联合评估包括整体模型参数量大小、测试集识别准确率和推理延迟。
[0058]
实施例1
[0059]
本发明公开了一种基于混合下采样和多路径交叉卷积结构的全卷积声学模型,如图2所示,本实施例包括一个由混合下采样模块和多路径交叉卷积模块组成的编码器和一个多层前馈神经网络组成的解码器,进行从语音信号的mel谱到拼音的转换。
[0060]
本实施例提供了一种基于混合下采样和多路径交叉卷积结构的全卷积声学模型,训练流程如图4所示,详细过程如下:
[0061]
1、从中文语音数据集获取音频数据
[0062]
本实施例使用的数据集为希尔贝壳科技有限公司开源的中文普通话语音数据集“aishell-asr0009-os1”(aishell-1)。
[0063]
2、数据预处理
[0064]
将所有音频以统一的采样率16khz进行重采样;使用一阶高通滤波器对音频进行预加重;以10ms的帧移进行分帧,得到帧长25ms的分帧信号;使用汉明窗函数对分帧信号进行加窗处理;对每帧信号进行短时傅里叶变换得到短时幅度谱;通过mel滤波器组得到80维的mel谱特征。
[0065]
3、划分数据集
[0066]
aishell-1数据集已经提前将数据划分为不相交的训练集、验证集和测试集三个部分,且验证集和测试集中的说话人均不在训练集中出现。因此在aishell-1数据集上训练时这一步可以省略。
[0067]
4、数据增强
[0068]
对mel谱特征进行随机的时域掩蔽和频域掩蔽,最大掩蔽比例为0.2,训练过程中,每次从数据集中获取数据时生成一个0~0.2的随机数,并使用该随机数作为掩蔽比例进行数据增强。
[0069]
5、计算得到ctc损失,优化声学模型参数
[0070]
将所得增强mel特征送入所述声学模型,计算得到ctc损失,进而使用adamw优化器优化声学模型的参数。
[0071]
所述声学模型如图2所示,其中包含:混合下采样模块、多路径交叉卷积模型以及多层前馈神经网络。混合下采样模块首先在并行的两条卷积路径上分别使用最大池化和均匀池化,提取时域和频域上的不同特征模式,避免了经验主义地选择池化方案:
[0072]fmax
(x)=relu(avg_pool(conv(x))),
[0073]favg
(x)=relu(avg_pool(conv(x))),
[0074]
其中,conv为2维卷积操作,relu为线性整流激活函数:
[0075]
relu(x)=max(x,0),
[0076]
然后将最大池化和平均池化的输出特征图拼接在一起,并通过1x1卷积融合进行特征提取与降维:
[0077]
y=relu(conv1×1(concat(f
max
,f
avg
))),
[0078]
1x1卷积引入了可学习的参数,能够自适应地激活和增强最大池化与平均池化输出结果中重要的特征。混合下采样在保留最大池化和平均池化各自优点的同时,使它们互相弥补了对方的缺陷。从图2中可以看到,声学模型总共使用了三次混合下采样模块,其中,
每个混合下采样模块对时域下采样2倍,对频域下采样2倍。
[0079]
多路径交叉卷积模块(参考:《towards end-to-end speech recognition with deep multipath convolutional neural networks》,towards end-to-end speech recognition with deep multipath convolutional neural networks,zhang,wei and zhai,minghao and huang,zilong and liu,chen and li,wei and cao,yi,international conference on intelligent robotics and applications,332
‑‑
341,2019,springer)包含两个相同的分组以及分组之间密集连接的残差结构。在每个分组之中,首先对输入的特征图执行不同分辨率的三路卷积:
[0080]fi,j
=relu(conv(xi)),i=1,2;j=1,2,3
[0081]
其中,i表示分组编号,xi表示第i个分组的输入,j表示路径编号,f
i,j
表示第i个分组中第j条路径的输出。
[0082]
然后使用1x1卷积对多条并行路径输出的特征进行融合,同时对特征图的通道数进行压缩:
[0083]
yi=conv1×1(concat(f
i,1
,f
i,2
,f
i,3
)),i=1,2
[0084]
其中,yi表示第i个分组的输出。多路径交叉卷积模块在两个分组之上引入了密集连接的残差结构(参考:huang2017densely,densely connected convolutional networks,huang,gao and liu,zhuang and van der maaten,laurens and weinberger,kilian q,proceedings of the ieee conference on computer vision and pattern recognition,4700
‑‑
4708,2017):
[0085]
x2=x1 y1,
[0086]
y=x1 y1 y2,
[0087]
其中,x1与y1是第一个分组的输入与输出,x2与y2是第二个分组的输入与输出,x1与y是多路径交叉卷积模块的输出。多路径交叉卷积模块不断地执行路径的分离与聚合,充分发挥出多路径强大的特征提取能力,有效地提取和融合不同感受野下的浅层特征,另外,密集连接的残差结构的引入,保证特征在低层和高层之间的传递,缓解了梯度消失的问题。
[0088]
多层前馈神经网络使用两个全连接层,将特征维度映射到拼音空间的大小,最后使用softmax激活函数获得拼音的概率分布。其中,全连接层的输出神经元数量为512-1191,构成一个最简单的瓶颈网络。
[0089]
6、模型性能评估
[0090]
使用测试集数据进行声学模型ctc损失的客观评估,以评价模型的识别准确率、泛化能力和推理速度。
[0091]
实施例2
[0092]
本发明公开了一种基于同音字建模的transformer语言模型,如图3所示,本实施例包括一个由自注意力模块和前馈神经网络堆叠而成的编码器和一个由掩码注意力模块、编码器-解码器注意力模块以及前馈神经网络堆叠而成的解码器,进行从拼音到汉字的转换。
[0093]
本实施例提供了一种基于同音字建模的transformer语言模型,训练流程如图5所示,详细过程如下:
[0094]
1、从中文文本数据集获取文本数据
[0095]
本实施例使用的数据集为多语言语料库“oscar”中的部分中文文本数据,但也可以使用任何其它中文文本数据集,或者自己整理创建的中文文本数据集。
[0096]
2、数据预处理
[0097]
将复句分割为多个单句;将所有的阿拉伯数字转换为汉字;将所有的繁体字转换为简体字;去除所有句末标点符号;去除所有包含非汉字字符的句子,得到了仅包含简体汉字的规范化纯文本数据;将所得数据划分为不相交的训练集和验证集,并删除在aishell-1测试集标签文本中出现的句子。
[0098]
3、建立词典
[0099]
遍历训练集、验证集和测试集,建立拼音词典、汉字词典以及同音字词典。所有词典均以python字典格式存储,其中,拼音词典以拼音为键,以递增索引为值;汉字词典以汉字为键,以递增索引为值;同音字词典以拼音为键,以子词典为值,该子字典的键为同拼音的汉字,值为递增索引。
[0100]
4、计算得到交叉熵损失,优化语言模型参数
[0101]
每组文本数据输入模型前需要进行预处理:对每组文本数据,首先将其转化为拼音序列,并根据拼音词典获得编码器输入序列;然后根据同音字词典从拼音序列和文本序列得到同音字序列,并在同音字序列首部添加起始符“《sos》”得到解码器输入序列,在同音字序列尾部添加终止符“《eos》”得到解码器目标序列。
[0102]
模型训练:将编码器输入序列输入语言模型的编码器,得到编码器输出序列;将编码器输出序列、解码器输入序列输入语言模型的解码器,得到解码器输出序列;根据解码器输出序列以及解码器目标序列计算带惩罚交叉熵损失,并使用adam优化器优化语言模型参数。其中,带惩罚交叉熵损失的计算公式如下:
[0103][0104]
其中,n表示输入序列长度,ci表示输入序列中第i个拼音对应的同音字序列的长度,y
ic
表示表示位置i处的样本真实类别为c的概率,p
ic
表示位置i处的样本分类到类别c的概率,l
max
表示解码器输出维度,即同音字词典中最大序列长度,k表示惩罚系数,对解码器输出的概率分布在同音字序列以外部分进行惩罚,取值为10。
[0105]
5、模型性能评估
[0106]
使用测试集数据进行transformer语言模型交叉熵损失的客观评估,以评价模型的识别准确率、泛化能力和推理速度。
[0107]
本发明提供了一种基于拼音的双阶段解耦合中文语音识别模型的思路及方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。