1.本发明涉及鉴定用于细胞维持(cell maintenance)和细胞转化(cell conversion)的细胞培养因子的方法。
2.相关申请
3.本技术要求新加坡专利申请10201905939w的优先权,其内容通过引用以其全文并入本文。
背景技术:
4.自从首次分离胚胎干细胞以来,培养和控制细胞状态的能力一直在提高。然而,该领域中最具挑战性的方面之一是寻找用于体外维持细胞的理想细胞培养条件。如果不采用正确的条件,则细胞要么转化为不同的细胞状态,要么死亡。因此,迫切需要在体外尽可能接近地模拟体内微环境条件。为了增加培养基对细胞类型的特异性,需要添加细胞特异性因子,如细胞外基质(extracellularmatrix,ecm)的组分、生长因子和其他环境因素。
5.此外,细胞治疗进步的主要挑战是需要在化学上定义的细胞培养条件,正在努力开发用于维持各种细胞类型的无血清培养基。同样,对于分化,正在不断努力确定用于获得细胞治疗用细胞的无血清的在化学上定义的方案。这些方案使用外部因素,如模拟自然发育过程的信号传导分子;例如,内皮细胞、小胶质细胞和心肌细胞的分化。此外,已显示信号传导分子如vegf可重塑内皮分化中主调控基因基因座(master regulator gene loci)的表观遗传谱。这表明信号传导分子能够启动表观遗传调控以维持细胞状态或者分化。
6.已知的人细胞类型超过400种,并且随着单细胞测序技术的最新进展,在胚胎发育过程中有更多新的细胞类型正在被鉴定出来,例如感觉神经元类型和血细胞类型。因此,需要系统地鉴定用于任何人细胞类型的细胞培养条件和/或分化刺激。转录因子(tf)介导的转分化(transdifferentiation)是一个已被充分研究的领域,并且有越来越多的数据驱动的计算方法被开发出来,用于使用基因表达数据例如cellnet、d’alessioac et al.和mogrify来预测tf。然而,目前并没有系统地鉴定用于体外跨多种细胞类型的细胞维持或细胞转化的信号传导分子的计算方法。
7.需要鉴定用于维持培养中的细胞和将细胞转化为不同细胞类型的因子的新方法。
8.说明书中对任何现有技术的引用并非承认或表明该现有技术构成了任何司法管辖范围中的公知常识的一部分,或者可以合理预期该现有技术被本领域技术人员理解、视为相关和/或与其他现有技术部分组合。
技术实现要素:
9.本发明提供了一种确定感兴趣的细胞的细胞身份基因(cell identity gene)的方法,所述方法包括以下步骤:
[0010]-确定感兴趣的细胞中蛋白编码基因的h3k4me3修饰区的差异宽度(differential breadth);
[0011]-基于h3k4me3修饰区的差异宽度和至少一个网络上每个所述蛋白编码基因的蛋白产物之间的相互作用,来确定每个所述蛋白编码基因的网络得分(network score),其中所述网络含有关于所述蛋白编码基因的产物之间的相互作用的信息;
[0012]-基于差异宽度和网络得分的组合,确定每个所述蛋白编码基因的细胞身份得分(cell identity score);
[0013]-根据每个蛋白编码基因的细胞身份得分对所述每个蛋白编码基因进行优先级排序(prioritising);
[0014]
从而确定感兴趣的细胞的细胞身份基因。
[0015]
本发明提供了一种确定感兴趣的细胞的细胞身份基因的方法,所述方法包括以下步骤:
[0016]-确定感兴趣的细胞中每个蛋白编码基因的h3k4me3修饰区的差异宽度;
[0017]-基于h3k4me3修饰区的差异宽度和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,来确定感兴趣的细胞中每个蛋白编码基因的网络得分,其中所述网络含有关于蛋白编码基因的产物之间的相互作用的信息;
[0018]-基于差异宽度和网络得分的组合,确定感兴趣的细胞中每个蛋白编码基因的细胞身份得分;
[0019]-根据每个蛋白编码基因的细胞身份得分对所述每个蛋白编码基因进行优先级排序;
[0020]
从而确定感兴趣的细胞的细胞身份基因。
[0021]
本发明还提供了一种确定感兴趣的细胞的细胞身份基因的方法,所述方法包括以下步骤:
[0022]-确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(differential broadness score,dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区宽度与不同细胞类型的群体中相同蛋白编码基因的h3k4me3修饰区的中值宽度(medianbreadth)相比的差异;
[0023]-基于dbs和至少一个网络上每个蛋白编码基因的产物之间的相互作用,来确定感兴趣的细胞中每个蛋白编码基因的网络得分,其中所述网络含有关于细胞中蛋白编码基因的产物之间的相互作用的信息;
[0024]-基于dbs和网络得分的组合,确定感兴趣的细胞中每个蛋白编码基因的细胞身份得分(regdbs);
[0025]-根据每个蛋白编码基因的regdbs对所述每个蛋白编码基因进行优先级排序;
[0026]
从而鉴定出感兴趣的细胞的细胞身份基因。
[0027]
本发明还提供了一种确定在体外维持细胞类型所需的因子的方法,所述方法包括以下步骤:
[0028]-确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区的宽度与不同细胞类型的群体中相同蛋白编码基因的h3k4me3修饰区的中值宽度相比的差异;
[0029]-基于dbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,来确定感兴趣的细胞中每个蛋白编码基因的网络得分,其中所述网络含有关于细胞中每个蛋白
编码基因的产物与其他蛋白编码基因产物之间的相互作用的信息;
[0030]-基于dbs和网络得分的组合,确定感兴趣的细胞中每个蛋白编码基因的细胞身份得分(regdbs);
[0031]-根据每个蛋白编码基因的regdbs对所述每个蛋白编码基因进行优先级排序,从而鉴定出感兴趣的细胞的细胞身份基因,其中每个细胞身份基因编码与感兴趣的细胞的细胞身份相关的因子;
[0032]
从而鉴定出在体外维持感兴趣的细胞所需的因子。
[0033]
在任意实施方案中,h3k4me3修饰区的差异宽度可以通过以下确定:获得关于感兴趣的细胞中每个蛋白编码基因的h3k4me3修饰区宽度的信息,从而获得细胞中每个蛋白编码基因的基因峰宽度得分(gene peak breadth score,b),并计算细胞中每个基因的基因宽度得分与不同类型细胞的群体中相同基因的中值基因宽度得分(median gene breadth score)之间的差异,由此确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(dbs)。
[0034]
h3k4me3修饰区的宽度可以基于chip-seq信息确定,更优选地,其中所述信息是从表观基因组roadmap、blueprint或encode数据库中任一个获得的。在任意实施方案中,确定基因峰宽度得分(b)包括:首先定义其中存在显著h3k4me3修饰的基因组区域(组蛋白修饰参考峰基因座,或rpl)。优选地,rpl通过合并跨所有细胞类型获得的chip-seq峰区域来获得。优选地,合并的峰区域是重叠的峰区域。
[0035]
优选地,h3k4me3修饰区的宽度基于chip-seq信息确定,任选地,其中所述信息来源于h3k4me3图谱分析方法(h3k4me3 profiling method),例如cut&run、scchic-seq,更优选地,其中所述信息从encode数据库获得。
[0036]
在一个优选的实施方案中,确定每个蛋白编码基因的基因峰宽度得分(b)可以包括:排除其中鉴定出h3k4me3和h3k27me3修饰区的基因(即,准备态基因(poised gene))。
[0037]
在任意实施方案中,确定dbs可以包括:组合关于每个蛋白编码基因的h3k4me3修饰区的宽度的差异的信息(与对照/背景细胞相比)与该宽度差异的显著性。在某些实施方案中,确定dbs可以包括:将宽度差异和差异的显著性相乘、标准化或相加,优选地,其中,通过将峰宽度的差异与差异的显著性相加,来确定dbs。更优选地,通过将h3k4me3峰宽度差异与显著性的-log
10
值相加,来确定dbs。
[0038]
h3k4me3修饰区的宽度差异的显著性可以通过任意标准统计学方法确定。在一个实例中,使用的方法是单样本威尔科克森检验(one sample wilcoxon test)。
[0039]
在任意实施方案中,确定感兴趣的细胞中每个蛋白编码基因的网络得分包括:组合关于每个蛋白编码基因的dbs的信息、基因的出度节点(outdegree node)的数量和基因在网络中的关联水平(level ofconnection)。在优选的实施方案中,网络得分通过将关联基因的dbs相加来确定,针对基因的出度节点的数量和关联水平进行加权,以获得网络中关联蛋白编码基因的dbs的加权总和。
[0040]
通常,蛋白-蛋白相互作用网络是string数据库,尽管也可以使用如本文所提到的含有关于给定细胞类型内蛋白的相互作用的信息的任何子网络(sub-network)。
[0041]
应当理解,细胞身份得分(regdbs)是每个蛋白编码基因对细胞身份的调控影响的指标(indicator)。
[0042]
在任意实施方案中,确定regdbs可以包括:优先加权编码调控因子的蛋白编码基
因。
[0043]
在任意实施方案中,确定每个蛋白编码基因的regdbs可以包括:将dbs得分与感兴趣的细胞中跨所有基因的标准化网络得分相加。优选地,dbs和网络得分的加和过程进一步包括:以2:1、1:1、3:1、4:1、5:1和1:2的因数相对于网络得分对dbs进行加权。更优选地,通过相对于网络得分以因数2对dbs得分进行加权,来确定regdbs。
[0044]
在任意实施方案中,根据每个蛋白编码基因的regdbs对其进行优先级排序的步骤可以包括:基于regdbs值对所述基因进行排序(ordering)。
[0045]
在一个优选的实施方案中,所述方法包括:选择编码受体-配体对的细胞身份基因,从而鉴定出在体外维持感兴趣的细胞所需的信号传导分子。优选地,在体外维持感兴趣的细胞所需的因子选自由参与细胞信号传导的细胞表面受体或配体组成的组。优选地,确定在体外维持感兴趣的细胞所需的因子包括:根据编码细胞表面受体的每个蛋白编码基因的regdbs得分对所述蛋白编码基因进行排名(ranking)。所述方法可以进一步包括:基于每个配体的dbs得分对与受体相关的配体进行优先级排序,以获得受体和配体的组合排名,并且其中所述组合排名鉴定出用于补充培养基以在体外维持感兴趣的细胞的配体。
[0046]
在进一步的实施方案中,用于在体外维持感兴趣的细胞的因子可以包括转录因子或表观遗传重塑因子(epigenetic remodelling factor)。因此,所述方法可以进一步包括:选择编码转录因子的细胞身份基因,从而鉴定出在体外维持感兴趣的细胞所需的转录因子。
[0047]
因此,本发明还提供了一种确定感兴趣的细胞的细胞身份基因的方法,所述方法包括以下步骤:
[0048]-确定感兴趣的细胞(x)中每个蛋白编码基因(g)的h3k4me3基因峰宽度得分(b),其中基因峰宽度得分是每个蛋白编码基因的启动子中包含h3k4me3修饰的区域的长度的总和;
[0049]-确定感兴趣的细胞与代表背景基因峰宽度得分的细胞群体的中值基因峰宽度得分之间的基因峰宽度得分的标准化差异(δ峰宽度
xg
),以及该差异的显著性(pval);
[0050]-将δ峰宽度和p val值相加,以获得细胞中每个蛋白编码基因的差异广度得分(dbs
xg
);
[0051]-通过组合关于网络中关联基因(r)的差异广度得分(dbs
xg
)的信息,确定感兴趣的细胞中每个蛋白编码基因的网络得分(n
xg
),其中所述网络含有关于细胞中每个蛋白编码基因的产物和其他蛋白编码基因产物之间的相互作用的信息;其中将差异广度得分针对基因的出度节点的数量(o)和基因的关联水平(l)进行校正;其中优选地,计算差异广度得分(dbs
xg
)的加权总和(高至关联的第三水平);
[0052]-将感兴趣的细胞(x)中所有蛋白编码基因(g)的网络得分net
xg
标准化;
[0053]-基于差异广度得分(dbs
xg
)和网络得分(net
xg
)的组合对感兴趣的细胞中的每个蛋白编码基因进行评分,从而确定感兴趣的细胞中每个蛋白编码基因的调控差异广度得分(regdbs
xg
);其中regdbs
xg
是每个蛋白编码基因对细胞身份的调控影响的指标;
[0054]-根据每个基因的regdbs
xg
对其进行优先级排序,
[0055]
从而鉴定出感兴趣的细胞的细胞身份基因。
[0056]
优选地,如果网络中的实验得分(experimental score)大于零并且组合得分
(combined score)大于500,则选择基因节点(gene node)之间的相互作用。
[0057]
在进一步的实施方案中,确定网络得分包括:从蛋白-蛋白相互作用网络中去除没有相关峰h3k4me3宽度的蛋白编码基因。
[0058]
优选地,对感兴趣的细胞中的每个蛋白编码基因进行评分包括:将基因的差异广度得分(dbs
xg
)与标准化网络得分(net
xg
)相加,更优选地,其中相对于标准化网络得分(net
xg
)以因数2对差异广度得分(dbs
xg
)进行加权。
[0059]
本发明还提供了一种确定将源细胞(source cell)转化为表现目标细胞类型的至少一种特征的细胞所需的因子的方法,所述方法包括以下步骤:
[0060]-确定源细胞和目标细胞类型中蛋白编码基因的h3k4me3修饰区的差异宽度,以获得源细胞和目标细胞类型中蛋白编码基因的h3k4me3修饰的得分(dbs);
[0061]-计算源细胞dbs和目标细胞dbs之间的差异,以获得源细胞和目标细胞之间每个蛋白编码基因的h3k4me3修饰的差异的度量值(细胞转化dbs);
[0062]-基于细胞转化δdbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,来确定从源细胞类型到目标细胞类型的转化的网络得分,其中所述网络含有关于细胞中蛋白编码基因的产物之间的相互作用的信息;
[0063]-基于细胞转化δdbs和网络得分的组合,确定目标细胞中每个蛋白编码基因的细胞身份转化得分;
[0064]-根据每个蛋白编码基因的细胞身份转化得分对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标细胞的细胞身份相关的因子;
[0065]
从而确定将源细胞转化为表现出目标细胞类型的至少一种特征的细胞所需的因子。
[0066]
本发明还提供了一种确定将源细胞转化为表现出目标细胞类型的至少一种特征的细胞所需的因子的方法,所述方法包括以下步骤:
[0067]-确定源细胞和目标细胞类型中每个蛋白编码基因的h3k4me3修饰区的差异宽度,以获得源细胞和目标细胞类型中每个蛋白编码基因(dbs)的h3k4me3修饰的得分;
[0068]-计算源细胞的dbs和目标细胞的dbs之间的差异,以获得源细胞和目标细胞之间每个蛋白编码基因的h3k4me3修饰的差异的度量值(细胞转化δdbs);
[0069]-基于细胞转化δdbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,来确定从源细胞类型到目标细胞类型的转化的网络得分,其中所述网络含有关于细胞中每个蛋白编码基因产物和其他基因产物之间的相互作用的信息;
[0070]-基于细胞转化δdbs和网络得分的组合,确定目标细胞中每个蛋白编码基因的细胞身份转化得分;
[0071]-根据每个蛋白编码基因的细胞身份转化得分对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标细胞的细胞身份相关的因子;
[0072]
从而确定将源细胞转化为表现出目标细胞类型的至少一种特征的细胞所需的因子。
[0073]
本发明还提供了一种确定从源细胞转化为表现出目标细胞类型的至少一种特征
的细胞所需的因子的方法,所述方法包括以下步骤:
[0074]-确定源细胞和目标细胞中每个蛋白编码基因的差异广度得分(dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区的宽度与不同细胞类型的群体中相同蛋白编码基因的h3k4me3修饰区的中值宽度相比的差异;
[0075]-计算源细胞的dbs和目标细胞的dbs之间的差异,以获得每个蛋白编码基因的细胞转化δdbs;
[0076]-基于细胞转化δdbs和至少一个网络上每个基因的蛋白产物之间的相互作用,来确定从源细胞类型到目标细胞类型的细胞转化的网络得分,其中所述网络含有关于细胞中每个蛋白编码基因的产物和其他蛋白编码基因产物之间的相互作用的信息;
[0077]-基于细胞转化δdbs和网络得分的组合,确定目标细胞中每个蛋白编码基因的细胞身份转化得分(regδdbs)
[0078]-根据每个蛋白编码基因的细胞转化regδdbs对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标细胞的细胞身份相关的因子;
[0079]
从而确定从源细胞转化为表现出目标细胞类型的至少一种特征的细胞所需的因子。
[0080]
在任意实施方案中,h3k4me3修饰区的差异宽度通过以下确定:获得关于源细胞和目标细胞中每个蛋白编码基因的h3k4me3修饰区的宽度的信息,以获得每种细胞类型中每个基因的基因峰宽度得分(b),并计算细胞类型中每个蛋白编码基因的基因峰宽度得分与跨不同类型细胞的群体的相同基因的中位基因峰宽度得分之间的差异,从而确定源细胞和目标细胞两者中每个基因的差异广度得分(dbs)。
[0081]
h3k4me3修饰区的宽度可以基于chip-seq信息确定,更优选地,其中所述信息是从表观基因组roadmap、blueprint或encode数据库中任一个获得的。在任意实施方案中,确定基因峰宽度得分(b)包括:首先定义其中存在显著h3k4me3修饰的基因组区域(组蛋白修饰参考峰基因座,或rpl)。优选地,rpl通过合并跨所有细胞类型获得的chip-seq峰区域来获得。优选地,合并的峰区域是重叠的峰区域。
[0082]
优选地,基于chip-seq信息确定h3k4me3修饰区的宽度,更优选地,其中所述信息是从encode数据库获得的。
[0083]
在一个优选的实施方案中,确定每个蛋白编码基因的基因峰宽度得分(b)包括:排除其中已鉴定出h3k4me3和h3k27me3修饰区的基因(即,准备态基因)。
[0084]
在任意实施方案中,确定源细胞和目标细胞中每个蛋白编码基因的dbs可以包括:关于每个蛋白编码基因的h3k4me3宽度的差异的信息(与背景h3k4me3宽度相比)与该差异的显著性进行组合。在某些实施方案中,确定dbs可以包括将峰宽度的差异和差异的显著性相乘、标准化或相加,优选地,其中dbs通过将峰宽度的差异与差异的显著性相加来确定。更优选地,dbs通过将峰宽度的差异与显著性的-log
10
值相加来确定。
[0085]
h3k4me3修饰区的宽度的差异的显著性可以通过任何标准统计学方法确定。在一个实例中,所使用的方法是单样本威尔科克森检验。
[0086]
在一个优选的实施方案中,计算源细胞的dbs和目标细胞的dbs之间的差异以获得每个基因的细胞转化δdbs包括:从每个基因的目标细胞dbs中减去每个蛋白编码基因的源
细胞dbs,以获得每个基因的细胞转化δdbs。每个蛋白编码基因的细胞转化δdbs提供了源细胞和目标细胞之间给定蛋白编码基因的h3k4me3修饰区的宽度的差异的度量值。
[0087]
优选地,从源细胞到目标细胞的细胞转化的网络得分是网络中关联基因的细胞转化δdbs的加权组合。例如,确定细胞转化的网络得分可以包括:将关于网络中每个基因的细胞转化δdbs的信息、基因的出度节点的数量和基因在网络中的关联水平组合。在优选的实施方案中,网络得分通过将关联基因的细胞转化δdbs相加确定,并针对基因的出度节点的数量和关联水平进行加权,以获得网络中关联基因的细胞转化δdbs的加权总和。
[0088]
通常,蛋白-蛋白相互作用网络是string数据库,尽管可以使用如本文所提到的含有关于给定细胞类型内蛋白相互作用的信息的任何子网络。
[0089]
应当理解,细胞转化身份得分(细胞转化regδdbs)是每个蛋白编码基因对细胞身份的变化的调控影响的指标。
[0090]
在任意实施方案中,确定细胞转化regδdbs可以包括:优先加权编码调控因子的蛋白编码基因。
[0091]
在任意实施方案中,确定每个蛋白编码基因的细胞转化regδdbs包括:将细胞转化δdbs得分与跨所有蛋白编码基因的标准化细胞转化网络得分相加。优选地,细胞转化δdbs和细胞转化网络得分的加和过程进一步包括:以2:1、1:1、3:1、4:1、5:1和1:2的因数相对于细胞转化网络得分对细胞转化δdbs进行加权。更优选地,细胞转化regδdbs通过相对于网络得分以因数2对细胞转化δdbs得分进行加权来确定。
[0092]
在任意实施方案中,根据每个蛋白编码基因的细胞转化regδdbs对所述每个蛋白编码基因进行优先级排序的步骤包括:基于细胞转化regδdbs值对基因进行排序。
[0093]
在一个优选的实施方案中,细胞转化因子包括转录因子或表观遗传重塑因子。因此,所述方法可以进一步包括选择编码转录因子的基因,从而鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的转录因子。优选地,转化是已分化的源细胞向已分化的目标细胞的转分化。
[0094]
在一个替代的实施方案中,所述方法包括选择编码受体-配体对的蛋白编码基因,从而鉴定出从源细胞转化为目标细胞所需的信号传导分子。优选地,从源细胞转化为目标细胞所需的因子选自由参与细胞信号传导的细胞表面受体或配体组成的组。优选地,确定将源细胞转化为目标细胞所需的因子包括:根据编码细胞表面受体的每个基因的细胞转化regδdbs得分对所述基因进行排名。所述方法可以进一步包括基于每个配体的细胞转化δdbs得分对与受体相关的配体进行优先级排序,以获得受体和配体的组合排名,并且其中组合排名鉴定出用在补充培养基中将源细胞转化为目标细胞的配体。优选地,转化是从多能源细胞向已分化的目标细胞的定向分化。
[0095]
因此,本发明还提供了一种确定从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子的方法,所述方法包括以下步骤:
[0096]-确定感兴趣的源细胞(s)和目标细胞(t)中每个蛋白编码基因(g)的h3k4me3基因峰宽度得分(b),其中基因峰宽度得分是每个蛋白编码基因的启动子中包含h3k4me3修饰的区域的长度的总和;
[0097]-确定源细胞与代表背景基因峰宽度得分的细胞群体的中值基因峰宽度得分之间的基因峰宽度得分的标准化差异(δ峰宽度
sg
),以及该差异的显著性(pval
sg
);
[0098]-确定目标细胞与代表背景基因宽度得分的细胞群体的中值基因宽度得分之间的基因宽度得分的标准化差异(δ峰宽度
tg
),以及该差异的显著性(pval
tg
);
[0099]-将δ峰宽度
sg
和pval
sg
值相加,以获得源细胞中每个蛋白编码基因的差异广度得分(dbs
sg
);
[0100]-将δ峰宽度
tg
和pval
tg
值相加,以获得目标细胞中每个蛋白编码基因的差异广度得分(dbs
tg
);
[0101]-从目标细胞中每个蛋白编码基因的差异广度得分(dbs
tg
)中减去源细胞中相同基因的差异广度得分(dbs
sg
),以获得目标细胞中每个蛋白编码基因的细胞转化δdbs(δdbs
t-sg
);
[0102]-通过组合网络中关联基因(r)的细胞转化差异广度得分(δdbs
t-sg
),来确定目标细胞中每个基因的网络得分(n
t-sg
),其中所述网络含有关于细胞中每个蛋白编码基因的产物之间的相互作用的信息;其中差异广度得分针对基因的出度节点的数量(o)和基因的关联水平(l)进行校正;其中优选地,计算细胞转化差异广度得分(δdbs
t-sg
)的加权总和(高至关联的第三水平);
[0103]-将所有蛋白编码基因的细胞转化网络得分net
t-sg
标准化;
[0104]-基于细胞转化差异广度得分(δdbs
t-sg
)和细胞转化网络得分(net
t-sg
)的组合对每个蛋白编码基因进行评分,从而确定每个蛋白编码基因的细胞转化调控差异广度得分(regδdbs
t-sg
);其中regδdbs
t-sg
是每个蛋白编码基因对目标细胞与对源细胞的调控影响的差异的指标;
[0105]-根据每个蛋白编码基因的regδdbs
t-sg
对所述每个蛋白编码基因进行优先级排序,
[0106]
从而鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子。
[0107]
优选地,如果网络中的实验得分大于零并且组合得分大于500,则选择基因节点之间的相互作用。
[0108]
在进一步的实施方案中,确定网络得分包括:从蛋白-蛋白相互作用网络中去除没有相关峰h3k4me3宽度的基因。
[0109]
优选地,对感兴趣的细胞中的每个蛋白编码基因进行评分包括:将基因的差异广度得分(δdbs
t-sg
)与网络得分(net
t-sg
)相加,更优选地,其中相对于网络得分(net
t-sg
)以至少2的因数对差异广度得分(δdbs
t-sg
)进行加权。
[0110]
在上述方面的任意实施方案中,所述方法包括选择编码转录因子的蛋白编码基因的子集,从而鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的转录因子。优选地,所鉴定出的因子用于已分化的源细胞向已分化的目标细胞的转分化。
[0111]
在上述方面的进一步的实施方案中,所述方法包括选择编码受体-配体对的蛋白编码基因,从而鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的信号传导分子。优选地,所鉴定出的因子用于多能源细胞向已分化的目标细胞的定向分化。
[0112]
在进一步的实施方案中,所述方法进一步包括确定受体-配体对中编码受体的基因和编码受体配体的基因的组合排名,其中所述排名基于regdbs以及与受体和配体各自的dbs,从而鉴定出细胞维持所需的受体-配体对。
[0113]
在上述方面的进一步的实施方案中,所述方法进一步包括从每种细胞类型的排名列表中去除转录冗余的tf(transcriptionally redundant tf)的步骤。
[0114]
此外,在任意上述方法中,所述方法可以包括随后使感兴趣的细胞的群体或源细胞与一种或多种鉴定出的因子接触,以便在体外维持感兴趣的细胞或将源细胞转化为表现目标细胞的至少一种特征的细胞。或者,所述方法可以包括用编码一种或多种所述因子的核酸转染感兴趣的细胞或源细胞,以便在体外维持感兴趣的细胞或将源细胞转化为表现目标细胞的至少一种特征的细胞。
[0115]
本发明还提供了一种在体外维持细胞的群体的方法,所述方法包括:
[0116]-提供在细胞培养中的感兴趣的细胞的群体;
[0117]-确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区的宽度与不同细胞类型的群体中相同基因的h3k4me3修饰区的中值宽度相比的差异;
[0118]-基于dbs和至少一个网络上每个基因的蛋白产物之间的相互作用,确定感兴趣的细胞中每个蛋白编码基因的网络得分,其中所述网络含有关于细胞中每个蛋白编码基因的产物和其他蛋白编码基因产物之间的相互作用的信息;
[0119]-基于dbs和网络得分的组合对感兴趣的细胞中每个蛋白编码基因进行评分,从而确定感兴趣的细胞中每个蛋白编码基因的regdbs;其中regdbs是每个蛋白编码基因对于细胞身份的重要性的指标;
[0120]-根据每个蛋白编码基因的regdbs对所述每个蛋白编码基因进行优先级排序,从而鉴定出感兴趣的细胞的细胞身份基因,其中每个细胞身份基因编码与感兴趣的细胞的细胞身份相关的因子;
[0121]-使感兴趣的细胞的群体与一种或多种与感兴趣的细胞的细胞身份相关的因子接触;
[0122]-将细胞的群体在允许在细胞培养中维持感兴趣的细胞的条件下培养足够长的时间,
[0123]
从而在体外维持细胞的群体。
[0124]
在某些实施方案中,使细胞与所述因子接触可以包括:用一种或多种编码所述因子的核酸分子转染细胞和在细胞中表达所述因子。或者,接触可以包括:使细胞与增加一种或多种所述因子表达的试剂接触。
[0125]
本发明还提供了一种在体外维持星形胶质细胞群体的方法,所述方法依次包括以下步骤:
[0126]-提供在细胞培养中的星形胶质细胞群体;
[0127]-使星形胶质细胞群体与选自以下的一组因子接触:fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3或其变体,以维持星形胶质细胞的至少一种特征,
[0128]-将星形胶质细胞群体在允许在细胞培养中维持星形胶质细胞的条件下培养足够长的时间;
[0129]
从而在体外维持星形胶质细胞群体。
[0130]
优选地,所述因子包含以下、由以下组成或基本上由以下组成:fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3。
[0131]
在某些实施方案中,所述方法包括使星形胶质细胞与fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3中的一种或多种、两种或更多种、三种或更多种、四种或更多种、五种或更多种、或6种接触。
[0132]
在一个优选的实施方案中,所述方法包括使星形胶质细胞与fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3接触。
[0133]
在一个实施方案中,所述方法包括使星形胶质细胞与至少fn1、lamb1或col1a2接触(任选地使星形胶质细胞与fn1和lamb1或与fn1和col1a2或与fn1、lamb1和col1a2的所有三种接触)。任选地,col4a1、adam12和edil3的一种或多种也用于接触星形胶质细胞。
[0134]
在任意实施方案中,可以使用任何一种因子例如fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3的功能性变体。
[0135]
在本文所述的任何方法中,所述方法可以进一步包括将根据本方法制备的星形胶质细胞或细胞群体施用给个体的步骤。
[0136]
本发明还提供了一种在体外维持心肌细胞群体的方法,所述方法包括:
[0137]-提供在细胞培养中的心肌细胞群体;
[0138]-使心肌细胞群体与一种或多种选自以下的因子接触:fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3、cxcl12,用于维持心肌细胞的至少一种特征,
[0139]-将心肌细胞群体在适合于在细胞培养中维持心肌细胞的条件下培养足够长的时间;
[0140]
从而在体外维持心肌细胞群体。
[0141]
优选地,所述因子包含以下、由以下组成或基本上由以下组成:fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3、cxcl12。
[0142]
在某些实施方案中,所述方法包括使心肌细胞与fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3、cxcl12的一种或多种、两种或更多种、三种或更多种、四种或更多种、五种或更多种、6种或更多种、7种或更多种、8种或更多种或9种接触。
[0143]
在一个优选的实施方案中,所述方法包括使心肌细胞与至少fn1、col3a1(胶原iii)、tfp1、fgf7和apoe或其功能性变体接触。
[0144]
在进一步优选的实施方案中,所述方法包括使心肌细胞与fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3和cxcl12接触。
[0145]
在任意实施方案中,可以使用任意一种因子例如fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3和cxcl12的功能性变体。
[0146]
在本文所述的任何方法中,所述方法可以进一步包括将根据本方法制备的心肌细胞或细胞群体施用给个体的步骤。
[0147]
本发明还提供了一种在体外维持平滑肌细胞群体的方法,所述方法包括:
[0148]-提供在细胞培养中的平滑肌细胞群体;
[0149]-使平滑肌细胞群体与一种或多种选自以下的因子接触:lama5、col4a1、lama4、nid1、col6a3、col4a6、col4a5、fgf10、fgf7、gnas、col7a1、col1a1和thbs1,用于维持平滑肌细胞的至少一种特征,
[0150]-将平滑肌细胞群体在适合于在细胞培养中维持平滑肌细胞的条件下培养足够长的时间;
[0151]
从而在体外维持平滑肌细胞群体。
[0152]
优选地,所述因子包含以下、由以下组成或基本上由以下组成:lama5、col4a1、lama4、nid1、col6a3、col4a6、col4a5、fgf10、fgf7、gnas、col7a1、col1a1和thbs1。
[0153]
在某些实施方案中,所述方法包括使平滑肌细胞与以下的一种或多种、两种或更多种、三种或更多种、四种或更多种、五种或更多种、6种或更多种、7种或更多种、8种或更多种或9种或更多种接触:lama5、col4a1、lama4、nid1、col6a3、col4a6、col4a5、fgf10、fgf7、gnas、col7a1、col1a1和thbs1。
[0154]
在一个优选的实施方案中,所述方法包括使平滑肌细胞与胶原蛋白4、nid1、胶原蛋白6、fgf10、fgf7、胶原蛋白1和thbs1接触。
[0155]
在任意实施方案中,可以使用任意一种因子例如lama5、col4a1、lama4、nid1、col6a3、col4a6、col4a5、fgf10、fgf7、gnas、col7a1、col1a1和thbs1的功能性变体。
[0156]
在本文所述的任何方法中,所述方法可以进一步包括将根据本方法制备的平滑肌细胞或根细胞群体施用给个体的步骤。
[0157]
本发明还提供了一种在体外维持内皮细胞群体,优选主动脉内皮细胞群体的方法,所述方法包括:
[0158]-提供在细胞培养中的内皮细胞群体;
[0159]-使内皮细胞群体与一种或多种选自以下的因子接触:bmp6、adam9、lamb1、lama4、thbs1、ctgf、bmp4、pdgfb、fn1和cyr61,用于维持内皮细胞的至少一种特征,
[0160]-将内皮细胞群体在适合于在细胞培养中维持内皮细胞的条件下培养足够长的时间;
[0161]
从而在体外维持内皮细胞群体。
[0162]
优选地,所述因子包含以下、由以下组成或基本上由以下组成:bmp6、adam9、lamb1、lama4、thbs1、ctgf、bmp4、pdgfb、fn1和cyr61。
[0163]
在某些实施方案中,所述方法包括使内皮细胞与以下的一种或多种、两种或更多种、三种或更多种、四种或更多种、五种或更多种、6种或更多种、7种或更多种、8种或更多种或9种或更多种接触:bmp6、adam9、lamb1、lama4、thbs1、ctgf、bmp4、pdgfb、fn1和cyr61。
[0164]
在一个优选的实施方案中,所述方法包括使内皮细胞与bmp6、thbs1、ctgf、bmp4、pdgfb、fn1和cyr61接触。
[0165]
在任意实施方案中,可以使用任意一种因子例如mp6、adam9、lamb1、lama4、thbs1、ctgf、bmp4、pdgfb、fn1和cyr61的功能性变体。
[0166]
在本文所述的任何方法中,所述方法可以进一步包括将根据本方法制备的内皮细胞或细胞群体施用给个体的步骤。
[0167]
在用于维持感兴趣的细胞的任何上述方法中,所述方法可以包括维持正在转分化的、未分化的、已分化的和已转分化的细胞的方法。
[0168]
本发明还提供了一种将源细胞转化为表现目标细胞类型的至少一种特征的细胞的方法,所述方法包括以下步骤:
[0169]-通过本文所述的任意方法鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子;
[0170]-提供源细胞,
[0171]-使源细胞与一种或多种鉴定为用于从源细胞转化为目标细胞的因子接触,
[0172]-将源细胞在允许源细胞转化为表现目标细胞类型的至少一种特征的细胞的条件下培养足够长的时间;
[0173]
从而将源细胞转化为表现目标细胞类型的至少一种特征的细胞。
[0174]
本发明还提供了一种将源细胞转化为表现目标细胞类型的至少一种特征的细胞的方法,所述方法包括以下步骤:
[0175]-通过本文所述的任意方法鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子;
[0176]-提供源细胞,
[0177]-使源细胞接触鉴定为用于将源细胞转化为目标细胞的一种或多种因子,或增加所述一种或多种因子的量,
[0178]-将源细胞在允许源细胞转化为表现目标细胞类型的至少一种特征的细胞的条件下培养足够长的时间;
[0179]
从而将源细胞转化为表现目标细胞类型的至少一种特征的细胞。
[0180]
在优选的实施方案中,源细胞是h9胚胎干细胞并且目标细胞类型是表3中列出的任意细胞类型。
[0181]“增加
”……
的量可以包括在源细胞中表达编码所述一种或多种因子的核酸;或使源细胞与用于增加该细胞表达所述因子的试剂接触。
[0182]
本发明提供了一种用于分化源细胞的方法,所述方法包括使源细胞接触一种或多种因子或其变体,或增加源细胞中一种或多种因子或其变体的蛋白表达,其中源细胞被分化而表现目标细胞的至少一种特征,其中:
[0183]-源细胞是多能干细胞或祖细胞,目标细胞是表3中列出的任意细胞;和
[0184]-对于给定的目标细胞类型,所述因子选自表3中列出的因子。任选地,所述方法中使用了表3中列出的因子中的两种或更多种、三种或更多种、四种或更多种、五种或更多种、六种或更多种、七种或更多种、八种或更多种、或九种或更多种、或10种或更多种、或11种或更多种、或12种或更多种、或13种或更多种、或14种或更多种。
[0185]
本发明提供了一种用于分化源细胞的方法,所述方法包括增加源细胞中一种或多种因子或其变体的蛋白表达,其中源细胞被分化而表现目标细胞的至少一种特征,其中:
[0186]-源细胞是多能干细胞或祖细胞,目标细胞是星形胶质细胞;和
[0187]-所述因子选自:fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3。
[0188]
本发明提供了一种从多能干细胞或祖细胞产生表现星形胶质细胞的至少一种特征的细胞的方法,所述方法包括:
[0189]-使多能干细胞或祖细胞与源细胞中一种或多种选自fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3的因子或其变体接触;和
[0190]-将多能干细胞或祖细胞在允许分化为星形胶质细胞的条件下培养足够长的时间;从而从多能干细胞或祖细胞产生表现星形胶质细胞的至少一种特征的细胞。
[0191]
本发明还提供了一种分化多能干细胞,优选胚胎干细胞或祖细胞的方法,所述方法包括增加干细胞中fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3中的一种或多种或其变体的蛋白表达,其中干细胞被分化而显示出星形胶质细胞的至少一种特征。
[0192]
本发明提供了一种使多能干细胞、优选胚胎干细胞或祖细胞分化为显示星形胶质细胞的至少一种特征的细胞的方法,包括:i)提供多能干细胞或祖细胞,或包含多能干细胞或祖细胞的细胞群体;ii)用一种或多种包含编码一种或多种对星形胶质细胞身份重要的因子的核苷酸序列的核酸转染所述多能干细胞;和iii)培养所述细胞或细胞群体,并任选地监测细胞或细胞群体中星形胶质细胞的至少一种特征,其中优选地,使多能干细胞或祖细胞分化为星形胶质细胞的因子,或产生表现星形胶质细胞的至少一种特征的细胞的因子,包含以下、由以下组成或基本上由以下组成:fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3。
[0193]
在某些实施方案中,祖细胞优选是神经祖细胞或从神经祖细胞群体获得的细胞。
[0194]
优选地,多能干细胞是胚胎干细胞。
[0195]
本发明提供了一种从胚胎干细胞产生表现星形胶质细胞的至少一种特征的细胞的方法,所述方法包括:
[0196]-增加胚胎干细胞中fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3的任何一种或多种或其变体的量;和
[0197]-将胚胎干细胞在用于分化成星形胶质细胞的条件下培养足够长的时间;从而从胚胎干细胞产生表现星形胶质细胞的至少一种特征的细胞。
[0198]
在某些实施方案中,增加一种或多种上述因子的量包括在源细胞(即,干细胞)中表达编码一种或多种所述因子的核酸。或者,所述因子可以通过细胞培养基的方式直接提供给细胞。
[0199]
通常,适合目标细胞分化的条件包括将细胞在合适的培养基中培养足够长的时间。足够长的培养时间可以是至少1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天或30天。合适的培养基可以是如表4所示的培养基。
[0200]
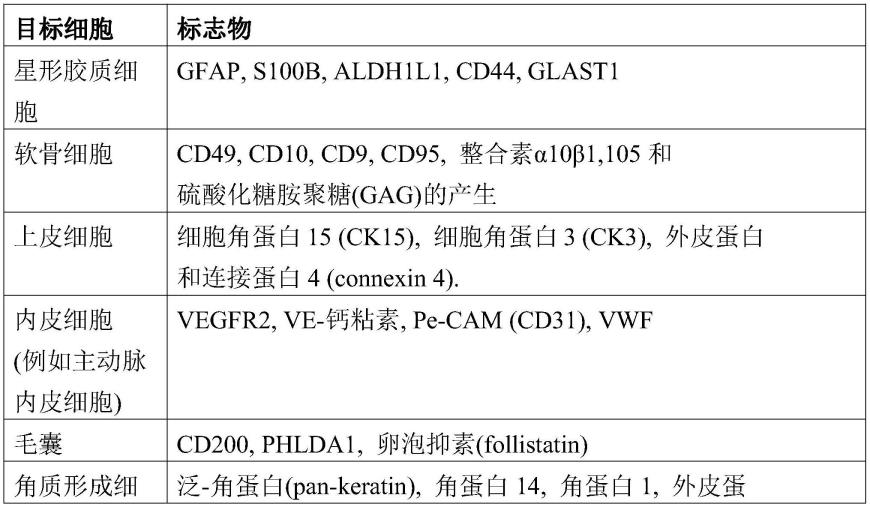
优选地,星形胶质细胞的所述至少一种特征是任意一种或多种星形胶质细胞标志物的上调和/或细胞形态的变化。相关标志物在本文中有描述并且是本领域技术人员已知的。星形胶质细胞的示例性标志物包括:gfap、s100b、aldh1l1、cd44和glast1,或表1中列出的任意标志物。
[0201]
优选地,心肌细胞的所述至少一种特征是任意一种或多种心肌细胞标志物的上调和/或细胞形态的变化。相关标志物在本文中有描述并且是本领域技术人员已知的。心肌细胞的示例性标志物包括:nkx2.5、gata4、gata6、mef2c、myh6、actn1、cdh2和gja1,或表1中列出的任意标志物。
[0202]
优选地,平滑肌细胞的所述至少一种特征是任意一种或多种平滑肌细胞标志物的上调和/或细胞形态的变化。相关标志物在本文中有描述并且是本领域技术人员已知的。平滑肌细胞的示例性标志物包括:sm22和α-sma,或表1中列出的任意标志物。
[0203]
优选地,内皮细胞的所述至少一种特征是任意一种或多种内皮细胞标志物的上调和/或细胞形态的变化。相关标志物在本文中有描述并且是本领域技术人员已知的。内皮细胞的示例性标志物包括:cd31和vwf,或表1中列出的任何标志物。
[0204]
本发明还提供了通过如本文所述的方法产生的细胞,其表现星形胶质细胞、心肌细胞、平滑肌细胞或内皮细胞的至少一种特征。
[0205]
在本文所述的任何方法中,所述方法可以进一步包括扩增表现星形胶质细胞的至少一种特征的细胞的步骤,以增加群体中表现星形胶质细胞的至少一种特征的细胞比例。扩增细胞的步骤可以是在用于产生如下所述的细胞群体的条件下培养足够长的时间。
[0206]
在本文所述的任何方法中,所述方法可以进一步包括扩增表现心肌细胞的至少一种特征的细胞的步骤,以增加群体中表现出心肌细胞的至少一种特征的细胞比例。扩增细胞的步骤可以是在用于产生如下所述的细胞群体的条件下培养足够长的时间。
[0207]
在本文所述的任何方法中,所述方法可以进一步包括向个体施用表现星形胶质细胞、心肌细胞、平滑肌细胞或内皮细胞的至少一种特征的细胞或细胞群体的步骤。
[0208]
本发明还提供了包含一组因子的组合物,用于(i)在体外维持星形胶质细胞群体,或(ii)用于从多能干细胞产生表现星形胶质细胞的至少一种特征的细胞。优选地,所述组合物包含选自以下的一组因子:fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3,或其变体。优选地,所述一组因子包含以下、由以下组成或基本上由以下组成:fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3,或其变体。在某些实施方案中,所述组合物可以包含以下一种或多种、两种或更多种、三种或更多种、四种或更多种、五种或更多种或6种:fn1、col4a1、lamb1、adam12、wnt5a、col1a2和edil3,或其变体。在一个实施方案中,所述组合物包含至少fn1、lamb1或col1a2(任选地,fn1和lamb1或fn1和col1a2或所有三种)。任选地,所述组合物进一步包含col4a1、adam12和edil3的一种或多种。
[0209]
本发明还提供了一种包含一组用于在体外维持心肌细胞群体的因子的组合物。优选地,所述组合物包含选自以下的一组因子:fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3、cxcl12或其变体。优选地,所述一组因子包含以下、由以下组成或基本上由以下组成:fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3、cxcl12或其变体。在某些实施方案中,所述组合物可以包含以下的一种或多种、两种或更多种、三种或更多种、四种或更多种、五种或更多种、6种或更多种、7种或更多种、8种或更多种或9种:fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3、cxcl12或其变体。最优选地,所述因子包含fn1、col3a1(胶原iii)、tfp1、fgf7和apoe,由其组成或基本上由其组成。
[0210]
在任何方面,组合物可以进一步包含一种或多种用于支持体外培养中的细胞生长或维持的组分。
[0211]
在任何方面,组合物可以是细胞培养基。
[0212]
在任何方面,组合物可包含所述因子(即蛋白)或编码所述因子的核酸。
[0213]
本发明还提供了生产用于以下的细胞培养基的方法:(i)在体外维持星形胶质细胞群体,(ii)用于从多能干细胞或祖细胞产生表现星形胶质细胞的至少一种特征的细胞,或(iii)在体外维持心肌细胞群体,(iv)在体外维持平滑肌细胞群体,或(v)在体外维持内皮细胞群体,
[0214]
所述方法包括将如本文所述的组合物添加到细胞培养基中。
[0215]
本发明还提供了细胞群体,其中至少5%的细胞表现心肌细胞的至少一种特征,并且这些细胞是通过如本文所述的方法产生的。优选地,群体中至少10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的细胞表现出心肌细胞的至少一种特征。
[0216]
本发明还提供了细胞群体,其中至少5%的细胞表现星形胶质细胞的至少一种特
征,并且这些细胞是通过如本文所述的方法产生的。优选地,群体中至少10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的细胞表现星形胶质细胞的至少一种特征。
[0217]
本发明还提供了细胞群体,其中至少5%的细胞表现出平滑肌细胞的至少一种特征,并且这些细胞是通过如本文所述的方法产生的。优选地,群体中至少10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的细胞表现出平滑肌细胞的至少一种特征。
[0218]
本发明还提供了细胞群体,其中至少5%的细胞表现出内皮细胞的至少一种特征,并且这些细胞是通过如本文所述的方法产生的。优选地,群体中至少10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的细胞表现出内皮细胞的至少一种特征。
[0219]
本发明还涉及用于如本文所公开在体外维持细胞的试剂盒。在一些实施方案中,试剂盒包含一种或多种核酸,其具有一种或多种编码本文所述的因子或其变体的核酸序列。或者,所述试剂盒包含一种或多种用于补充如本文所述使用的细胞培养基的蛋白因子。优选地,所述试剂盒可用于维持培养的星形胶质细胞、心肌细胞、平滑肌细胞或内皮细胞。在一些实施方案中,所述试剂盒进一步包含在体外维持细胞,优选星形胶质细胞、心肌细胞、平滑肌细胞或内皮细胞的说明书。
[0220]
本发明还涉及用于产生如本文所公开的表现目标细胞,优选星形胶质细胞或心肌细胞的至少一种特征的细胞的试剂盒。在一些实施方案中,试剂盒包含一种或多种核酸,其具有一种或多种编码本文所述的因子或其变体的核酸序列。或者,试剂盒可以包含一种或多种补充到用于本文所述的定向分化的培养基的蛋白。优选地,试剂盒可用于产生表现星形胶质细胞的至少一种特征或心肌细胞的至少一种特征的细胞。优选地,试剂盒可以与胚胎干细胞一起使用。在一些实施方案中,试剂盒进一步包含关于根据本文公开的方法将源细胞转化为表现目标细胞的至少一种特征的细胞的说明书。优选地,本发明提供了用于本文所述的本发明的方法中的试剂盒。
[0221]
优选实施方案
[0222]
以下项(statement)涉及本发明的优选实施方案:
[0223]
1.一种在体外维持细胞的方法,所述方法包括以下步骤:
[0224]-提供在细胞培养中的感兴趣的细胞;
[0225]-确定所述细胞中每个蛋白编码基因的h3k4me3修饰区的差异宽度;
[0226]-确定所述细胞中每个蛋白编码基因的差异广度得分(dbs);
[0227]-基于dbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,确定所述细胞中每个蛋白编码基因的网络得分,
[0228]-基于dbs和网络得分的组合,确定所述细胞中每个蛋白编码基因的细胞身份得分(regdbs);
[0229]-根据每个蛋白编码基因的regdbs对所述每个蛋白编码基因进行优先级排序,从
而鉴定出所述细胞的细胞身份基因,其中每个细胞身份基因编码与感兴趣的细胞的细胞身份相关的因子;
[0230]-使所述感兴趣的细胞与一种或多种与所述细胞的细胞身份相关的因子接触;
[0231]-将所述感兴趣的细胞在允许在细胞培养中维持所述细胞的条件下培养足够长的时间;
[0232]
从而在体外维持感兴趣的细胞。
[0233]
2.一种在体外维持细胞的方法,所述方法包括:
[0234]
i.提供在细胞培养中的感兴趣的细胞;
[0235]
ii.鉴定出编码促进所述细胞的维持的因子或其变体的蛋白编码基因,其中所述蛋白编码基因包含至少一个h3k4me3修饰区;
[0236]
iii.使所述感兴趣的细胞与至少两种因子或其变体接触,用于维持所述细胞的至少一种特征;
[0237]
iv.将所述感兴趣的细胞在允许在细胞培养中维持所述细胞的条件下培养足够长的时间;
[0238]
从而在体外维持感兴趣的细胞。
[0239]
3.一种在体外维持细胞的方法,所述方法包括:
[0240]
i.提供在细胞培养中的感兴趣的细胞;
[0241]
ii.鉴定出编码促进所述细胞的维持的因子或其变体的蛋白编码基因,其中所述蛋白编码基因包含至少一个h3k4me3修饰区;
[0242]
iii.使所述感兴趣的细胞与一种或多种因子或其变体接触,用于维持所述细胞的至少一种特征;
[0243]
iv.将所述感兴趣的细胞在允许在细胞培养中维持所述细胞的条件下培养足够长的时间;
[0244]
从而在体外维持感兴趣的细胞。
[0245]
4.如项1至3中任一项所述的方法,其中感兴趣的细胞是已分化的细胞、正在分化的细胞、未分化的细胞或已转分化的细胞。
[0246]
5.如项1至4中任一项所述的方法,其中感兴趣的细胞是组织。
[0247]
6.如项1至5中任一项所述的方法,其中感兴趣的细胞选自衍生自外胚层、中胚层和内胚层胚层的细胞。
[0248]
7.如项1至6中任一项所述的方法,其中感兴趣的细胞选自由以下组成的组:星形胶质细胞、神经球(neurosphere)、心肌细胞、平滑肌细胞、内皮细胞、肌细胞、成纤维细胞、黑素细胞、上皮细胞、角质形成细胞、黑素细胞和单核细胞,或表2中列出的任何细胞或组织。
[0249]
8.如项1至7中任一项所述的方法,其中与细胞身份相关的因子是表2中列出的任意一种或多种因子。
[0250]
9.如项1至8中任一项所述的方法,其中将感兴趣的细胞在允许维持所述细胞的条件下培养足够长的时间,包括将细胞培养至少3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天、30天或更多天。
[0251]
10.如项1至9中任一项所述的方法,其中h3k4me3修饰区的差异宽度由以下确定:
[0252]-获取关于感兴趣的细胞中每个蛋白编码基因的h3k4me3修饰区的宽度的信息,以获得细胞中每个蛋白编码基因的基因峰宽度得分(b);和
[0253]-计算细胞中每个基因的基因宽度得分与跨不同类型细胞的群体的相同基因的平均基因峰宽度得分之间的差异,从而确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(dbs)。
[0254]
11.如项10所述的方法,其中确定基因峰宽度得分(b)包括首先定义基因组中存在显著h3k4me3修饰的区域,并将这些区域定义为组蛋白修饰参考峰基因座(reference peak loci,rpl)。
[0255]
12.如项10所述的方法,其中rpl是通过合并跨所有细胞类型获得的chip-seq峰区域获得的,优选地,其中合并的峰区域是重叠的峰区域。
[0256]
13.如项9至12中任一项所述的方法,其中每个蛋白编码基因的基因峰宽度得分(b)包括:排除其中已鉴定出h3k4me3和h3k27me3修饰区的基因,其中将所述基因鉴定为准备态基因。
[0257]
14.如项1至13中任一项所述的方法,其中确定细胞身份得分(regdbs)包括:优先加权编码调控因子的蛋白编码基因。
[0258]
15.如项1至14中任一项所述的方法,其中用于在体外维持感兴趣的细胞的因子选自由以下组成的组:参与细胞信号传导的受体-配体对,优选受体-配体对的配体、转录因子和表观遗传重塑因子。
[0259]
16.如权利要求1至15中任一项所述的方法,其中所述方法包括选择编码参与细胞信号传导的受体-配体对的细胞身份基因,从而鉴定出在体外维持感兴趣的细胞所需的信号传导分子。
[0260]
17.如项16所述的方法,其中编码细胞表面受体的每个蛋白编码基因根据其regdbs得分进行排名,并且与受体相关的每种配体根据其dbs得分进行排名,以获得受体和配体的组合排名,并且其中所述组合排名鉴定出补充到用于在体外维持感兴趣的细胞的培养基的配体。
[0261]
18.如项16或17所述的方法,其中细胞身份基因编码参与细胞信号传导途径的受体-配体对,所述细胞信号传导途径例如通过wnt、notch、hegdehog、hippo、gpcr、整合素、tgfb家族(bmp、激活素、tgfb受体)、受体酪氨酸激酶(例如egfr、fgfr、vegf、pdgf、met、mst、scf-kit、胰岛素受体、erbb2、ntrk)、非受体酪氨酸激酶(ptk6)、mtor和视黄酸的信号传导。
[0262]
19.如项1至18中任一项所述的方法,其中所述方法进一步包括选择编码转录因子的细胞身份基因,从而鉴定出在体外维持感兴趣的细胞所需的转录因子。
[0263]
20.如项1至19中任一项所述的方法,其中确定网络得分包括:从所述蛋白-蛋白相互作用网络中去除没有相关峰h3k4me3宽度的蛋白编码基因。
[0264]
21.如项1至20中任一项所述的方法,其中通过使感兴趣的细胞与增加所述两种或更多种因子的表达的试剂接触,从而使感兴趣的细胞与所述两种或更多种因子接触。
[0265]
22.如项21所述的方法,其中试剂选自由核苷酸序列、蛋白、适体和小分子及其类似物或变体组成的组。
[0266]
23.一种通过实施如项1至22中任一项所述的方法在体外维持细胞群体的方法。
[0267]
24.一种细胞群体,其中至少5%的细胞表现感兴趣的细胞的至少一种特征,并且这些细胞是通过如项1至22中任一项所述的方法产生的。
[0268]
25.如项24所述的细胞群体,其中群体中至少10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的细胞表现感兴趣的细胞的至少一种特征。
[0269]
26.如项1至23中任一项所述的方法,其中所述方法进一步包括将感兴趣的细胞施用给个体,或将如项22或23所述的细胞群体施用给个体的步骤。
[0270]
27.一种将源细胞转化为表现目标细胞类型的至少一种特征的细胞的方法,所述方法包括以下步骤:
[0271]-提供源细胞;
[0272]-确定源细胞和目标细胞类型中每个蛋白编码基因的h3k4me3修饰区的差异宽度,以获得源细胞和目标细胞类型中每个蛋白编码基因的h3k4me3修饰的得分(dbs);
[0273]-计算源细胞的dbs和目标细胞的dbs之间的差异,以获得源细胞和目标细胞之间每个蛋白编码基因的h3k4me3修饰的差异的度量值(细胞转化δdbs);
[0274]-基于细胞转化δdbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,来确定从源细胞类型到目标细胞类型的转化的网络得分,其中所述网络含有关于细胞中每种蛋白编码基因产物与其他基因产物之间的相互作用的信息;
[0275]-基于细胞转化dbs和网络得分的组合,确定目标细胞中每个蛋白编码基因的细胞身份转化得分;
[0276]-根据每个蛋白编码基因的细胞身份转化得分对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标细胞的细胞身份相关的因子;
[0277]-将源细胞在允许源细胞转化为表现目标细胞类型的至少一种特征的细胞的条件下培养足够长的时间;
[0278]
从而将源细胞转化为表现目标细胞类型的至少一个特征的细胞,任选地,其中增加所述一种或多种因子的量包括i)使源细胞与因子或与增加细胞中所述因子表达的试剂接触;或ii)用编码因子的核酸转染源细胞并在细胞中表达核酸。
[0279]
28.如项27所述的方法,其中转化方法是分化、重编程或转分化的方法。
[0280]
29.如项27所述的方法,其中源细胞是已分化的细胞、正在分化的细胞、未分化的细胞或已转分化的细胞。
[0281]
30.如项27所述的方法,其中源细胞是胚胎干细胞并且目标细胞是表3中列出的细胞之一。
[0282]
31.如项30所述的方法,其中源细胞是胚胎干细胞,并且用于转化源细胞的因子列于表3中。
[0283]
如本文所用,除非上下文另有要求,否则术语“包含(comprise)”和该术语的变体,例如“comprising”、“comprises”和“comprised”,不旨在排除其他的添加物、组分、整数或步骤。
[0284]
本发明的其他方面和前述段落中描述的各方面的其他实施方案将从以下通过实施例的方式给出并参考附图的描述中变得显而易见。
[0285]
附图简要说明
[0286]
图1:h3k4me3组蛋白修饰对细胞身份基因进行标记。(a)描述本研究中使用的细胞类型数量的维恩图。通过h3k4me3和h3k27me3 chip-seq获得的组蛋白修饰数据和从encode库获得的rna-seq的基因表达数据。(b)定义chip-seq峰宽度和峰高度的图示。(c)对细胞类型代表性chip-seq谱的基因注释的示例。将chip-seq谱图定位到人类基因组(grch38),以比较细胞类型之间的峰,我们通过跨所有细胞类型合并chip-seq谱定义了参考峰基因座(rpl)。该表总结了分配给每个rpl的基因以及在每个基因座处计算的峰宽度(b)和高度(h)值。(d)通过根据跨40种常见细胞类型的相关h3k4me3峰宽度和基因表达而排序的基因,进行细胞身份和管家基因集的富集。x轴由h3k4me3宽度值或基因表达水平按降序排名的基因的累积数据帧(cumulative bin)组成,并且累积数据帧以1百分位数间隔(one percentile interval)增加。使用fet(fisher精确检验(fisher exact test))计算富集得分。(e)同样地,跨111种细胞类型,对于按h3k4me3宽度值排名并且相关h3k4me3宽度大于峰宽度分布的87%的基因,获得细胞身份基因集的最高富集得分。n是指细胞类型的数量。
[0287]
图2:细胞身份基因的鉴定和用于细胞维持的信号传导分子的预测。(a)使用相关的广h3k4me3峰开发用以模建细胞身份基因的数据驱动方法的示意图。对于每个基因,差异广度得分(dbs)是通过比较感兴趣的目标细胞类型和背景细胞类型之间的广h3k4me3宽度值来计算的。dbs是一个综合得分,计算为相关宽度值的差异(δ峰宽度)和此差异的显著性(p值)。蛋白编码基因通过dbs进行排名。(b)为了对具有调控影响的基因进行优先级排序,对于每个基因,调控差异广度得分(regulatory differential broadness score,regdbs)计算为蛋白-蛋白相互作用(ppi)网络中基因的dbs和关联基因的dbs的加权总和。细胞特异性regdbs用于预测(i)细胞身份基因和(ii)用于细胞维持的信号传导分子。(c)通过不同评分标准(例如通过峰宽度值(峰宽度)、dbs和regdbs对基因进行排名)对细胞身份基因集的富集是通过gsea(基因集富集分析,gene set enrichment analysis)进行计算的。对于每种评分标准,给出了跨所有细胞类型的gsea富集得分的总和(nes*-log10 p值)。(d)对用于细胞体外维持的信号传导分子如受体和配体的epimogrify预测的图示。受体由感兴趣的细胞类型产生,而配体可以由细胞类型本身产生或支持细胞类型。基于受体的regdbs和相应配体的dbs值对受体和配体对进行排名。将来自排名的受体-配体对的最靠前的预测的配体添加到培养条件中以进行体外细胞维持。
[0288]
图3:星形胶质细胞在体外的细胞维持。a)在向星形胶质细胞原代细胞培养物和衍生自神经干细胞的星形胶质细胞中补充所预测的配体后第3天进行细胞计数。对照没有任何补充物,matrigel用作金标准。b)原代星形胶质细胞和衍生自神经干细胞的星形胶质细胞的细胞增殖率,在补充所预测的因子后第3天通过细胞增殖测定(brdu)检测。c)在指定培养条件下,原代星形胶质细胞上星形胶质细胞特异性标志物(例如gfap(红色)和s100b(绿色))的免疫荧光(if)图像。(d)同样地,在特定培养条件下,衍生自神经干细胞的星形胶质细胞上星形胶质细胞特异性标志物的if图像。将细胞用dapi复染。比例尺=25μm。使用未配对的单尾t检验以比较预测条件和对照。*p《0.05,**p《0.01,***p《0.001,****p《0.0001,ns表示不显著。
[0289]
图4:星形胶质细胞在体外的细胞维持。a)在向心肌细胞中补充所预测的配体后第3天的细胞计数。阴性对照是没有额外配体的条件,阳性对照是在仅有geltrex的条件下。b)
esc和小脑的星形胶质细胞之间显著上调的基因,(iv)epimogrify grn(基因调控网络)是一个基因集,其含有具有正regdbs得分的原代星形胶质细胞身份基因和在string网络上的关联基因直至第一个被调控的邻居,和(v)人基础grn(humanbase grn)是从humanbase数据库获得的星形胶质细胞特异性网络。将细胞用dapi复染。比例尺=25μm。使用未配对的单尾t检验以比较所预测的条件和对照。*p《0.05,**p《0.01;***p《0.001,ns表示不显著。
[0294]
图9:心肌细胞在体外的定向分化。(a)从h9胚胎干细胞(h9 esc)向心肌细胞的体外分化的示意图。3天后,在不同的预测条件和仅matrigel的阳性对照下接种h9 esc。在第12天和第20天进行免疫荧光(if)和荧光激活细胞分选(facs)。(b)所有条件下的心脏标志物cd82 和cd13 细胞的facs。(c)进行if以获得具有ctnt心脏标志物的dapi 区域的百分比。(d)所有条件下的第21天ctnt(绿色)的if。将细胞用dapi复染。比例尺=25μm。使用未配对的单尾t检验以比较预测条件和对照。*p《0.05,**p《0.01,ns表示不显著。
[0295]
图10:用于实施本文所述方法的实施方案和/或特征的一种类型的计算机处理系统600的框图。
具体实施方式
[0296]
应当理解,在本说明书中公开和定义的本发明扩展到从文本或附图中提及或显而易见的两个或更多个单独特征的所有替代组合。所有这些不同的组合构成了本发明的各个替代方面。
[0297]
现在将详细参考本发明的某些实施方案。尽管将结合实施方案描述本发明,但是应当理解,不旨在将本发明限于这些实施方案。相反,本发明旨在涵盖所有可包括在由权利要求限定的本发明的范围内的替代、修改和等同物。
[0298]
本领域技术人员将知晓许多与本文描述的那些相似或等同的方法和材料,它们可用于本发明的实践中。本发明决不限于所描述的方法和材料。应当理解,在本说明书中公开和定义的本发明扩展到从文本或附图中提及或显而易见的两个或更多个单独特征的所有替代组合。所有这些不同的组合构成了本发明的各个替代方面。
[0299]
为了理解本说明书的目的,以单数形式使用的术语也将包括复数形式,反之亦然。
[0300]
本发明人旨在系统地鉴定出促进无血清的、在化学上所定义的细胞维持和分化的培养基的开发的因子。为了鉴定用于细胞维持或细胞转化的因子,有必要分别对细胞身份或细胞身份的变化进行模建(model)。
[0301]
本发明提供了一种新的计算方法(epimogrify),其采用了可获得的表观遗传数据集(例如,通过encode和roadmap联合),并使用h3k4me3和h3k27me3组蛋白修饰对细胞的表观遗传状态进行模建。epimogrify使用数据驱动的阈值、统计学并结合蛋白-蛋白相互作用网络信息,来对调控细胞身份的关键基因进行优先级排序(并从而鉴定给定细胞的细胞身份基因)。本发明的方法系统地预测用于在多种细胞类型中进行细胞维持和定向分化的信号传导分子。此外,本发明的方法还可以对其他蛋白类别进行优先级排序,所述其他蛋白类别例如用于细胞维持或细胞转化的转录因子(tf)或表观遗传重塑子(epigenetic remodeler)。
[0302]
epimogrify算法
[0303]
本发明提供了一种确定细胞类型的细胞身份基因的方法,所述方法包括:
[0304]-基于根据蛋白编码基因对细胞身份的影响对细胞类型中的蛋白编码基因进行的优先级排序,选择蛋白编码基因的子集,
[0305]
其中给定蛋白编码基因的优先级排序是基于将关于每个蛋白编码基因的h3k4me3修饰区的宽度的信息以及细胞中蛋白编码基因产物与其他蛋白编码基因产物的调控影响进行组合。
[0306]
本发明的方法(如本文中描述为“epimogrify”)对细胞的表观遗传状态进行模建,以预测对细胞身份、细胞维持和细胞转化重要的因子。所述算法的主要部分包括:
[0307]
(i)定义组蛋白修饰参考峰基因座
[0308]
(ii)鉴定细胞身份和细胞维持因子
[0309]
(iii)鉴定用于定向分化和转分化的细胞转化因子。
[0310]
所述方法旨在通过利用表观遗传组蛋白修饰如h3k4me3修饰(其是公知的转录激活标志物)对细胞状态进行模建。对于多种人类细胞类型的h3k4me3和h3k27me3(阻遏物标志)组蛋白修饰谱的chip-seq数据都是可获得的,包括从encode和roadmap联合数据库获得。
[0311]
chip-seq峰的宽度可以定义为具有组蛋白修饰沉积的基因组区域的碱基对长度(bp),chip-seq峰的高度可以定义为组蛋白修饰或信号值的平均富集。应当理解,chip-seq峰宽的范围可以从窄峰到广峰(broadpeek),并且chip-seq峰高的范围可以从矮峰到高峰。
[0312]
(i)定义组蛋白修饰参考峰基因座
[0313]
对于每种细胞类型,可以将样本合并在一起以获得细胞类型代表性chip-seq谱。细胞类型代表性chip-seq峰宽度通常是通过合并跨多个样本的峰区域和跨所有样本通过最大峰高计算的峰高来计算的。为了跨多种细胞类型比较chip-seq峰,我们定义了参考峰基因座(rpl),其是通过组合跨所有细胞类型的代表性峰而获得的一组区域。
[0314]
设n为细胞类型的数量。对于在x1、x2、..xn范围内的每种细胞类型,设b为细胞类型chip-seq峰宽,h为chip-seq峰高。参考峰基因座(rpl)的基因组位置是通过跨所有细胞类型合并峰区域获得的。对于rpl中的每个基因座r1、r2、..rn,峰宽(b)是通过跨细胞类型合并重叠峰计算的,峰高(h)是通过重叠峰的最大峰高而给出的。
[0315][0316][0317]
可以基于峰的基因组位置和基因的转录起始位点(transcription start site,tss),将蛋白编码基因分配至rpl。由于h3k4me3组蛋白修饰是公知的启动子标记,如果峰与基因的启动子区域(距tss 500bp)重叠,则通常将基因分配至峰基因座。然而,应当理解,rpl可以位于基因中相对于其tss的另一个区域中(包括将所述区域扩展至距tss 500bp以上,包括距tss 1000bp、2000bp或更远)。
[0318]
优选地,在每种细胞类型(x)中,基因(g)的峰宽度得分(b)计算为注释到(annotated to)该基因的n个峰的峰宽度之和。而基因的峰高值计算为注释到该基因的n个峰的最大高度。是给定细胞类型x在rpl(参考峰基因座)处的峰宽度谱(peakbreadthprofile)。
[0319][0320]
(ii)细胞身份基因和细胞维持因子的鉴定
[0321]
epimogrify采用h3k4me3 chip-seq峰宽度对细胞状态进行模建。
[0322]
epimogrify使用三步法(three-step approach)来鉴定对细胞类型特异的因子。首先,基于h3k4me3 chip-seq峰宽度,计算每个rpl处的差异广度得分。然后,基于蛋白-蛋白相互作用网络上的关联基因的数值,来确定每个基因的调控影响。最后,基于排序的蛋白编码基因预测细胞身份基因,并且epimogrify预测用于维持细胞状态的信号传导分子。
[0323]
如本文所用,关于蛋白编码基因的术语“每个”可以指给定细胞类型中的多个蛋白编码基因。所述多个可以包括所述细胞类型中的每个蛋白编码基因。或者,所述多个可以包括所述细胞类型中蛋白编码基因的子集。因此,“每个蛋白编码基因”可以包含“细胞类型中的每个蛋白编码基因”或“细胞类型中的每个蛋白编码基因,进一步细化为仅包含这些基因的子集”。
[0324]
此外,应当理解,当本发明的方法需要“确定感兴趣的细胞中每个蛋白编码基因的h3k4me3修饰区的差异宽度”并且所述基因不包含h3k4me3修饰区时,相关基因将被排除在进一步分析之外。因此,本发明限于评估至少存在h3k4me3修饰的基因。
[0325]
在某些实施方案中,所述多个蛋白编码基因的子集可以在所述方法的一个或多个步骤排除。例如,优选在计算dbs之前,从模型中去除在基因的tss处同时存在h3k4me3和h3k27me3 chip-seq峰的准备态基因。
[0326]
技术人员将理解,分析中包括的蛋白编码基因的数量越多,细胞身份因子的预测就越稳健。此外,技术人员将认识到需要在上述特点和需求之间平衡,从而考虑包括提供关于细胞身份的最大信息的蛋白编码基因(例如在tss处或tss附近仅包含h3k4me3修饰的那些蛋白编码基因)。
[0327]
此外,应当理解,在epimogrify方法的后续步骤中,确定了差异h3k4me3宽度的那些基因也将包括在后续的网络分析中。换句话说,在所述方法的第一步(确定差异广度得分)中考虑的基因通常也将在随后的网络得分计算中被考虑。
[0328]
第1步:计算差异广度得分
[0329]
为了获得目标细胞类型特异的chip-seq谱,可以将感兴趣的目标细胞类型与组内的一组背景细胞类型进行比较。例如,如果感兴趣的目标细胞类型是一种原代细胞类型,那么背景中的细胞类型将是其余的原代细胞类型和干细胞类型。
[0330]
如果背景集中的细胞类型与目标细胞类型不相似,则模建的统计学显著性得到提高。因此,在一个优选的实施方案中,仅当chip-seq谱与目标细胞类型的斯皮尔曼相关性(spearman correlation)小于0.9时,才选择背景细胞类型。
[0331]
在感兴趣的目标细胞类型(x)中,如果多于一个参考峰基因座(rpl)分配给基因(g),则基因峰宽度得分(b)通过所分配的rpl峰宽度(b)值之和得出。bg
xg
是基因g处背景细胞类型的一组基因峰宽度得分,且背景细胞类型是基于与目标细胞类型(x)的区别性(distinctiveness)选择的。δ峰宽度
xg
是目标细胞类型与背景细胞类型的平均基因峰宽度得分之间的基因宽度得分的标准化差异。可以理解,为了确定δ峰宽度
xg
,可以采用多种方法来对基因峰宽度得分进行平均。尽管在这个示例中使用了中值,但本领域技术人员将理
解,也可以使用平均值、众数或其他平均值的指标。
[0332]
这种差异的显著性(p.值)可以通过技术人员已知的任何合适的统计学方法来评估(例如,单样本威尔科克森检验)。细胞类型(x)和基因(g)的差异广度得分(dbs)可以测量为标准化的δ峰宽度和pval的总和,如下所示,但可以理解的是,可以使用任何数量的用于组合峰宽度差异和该差异的显著性的方法(包括乘法、减法、标准化或其组合)。
[0333][0334][0335][0336][0337][0338]
第2步:计算调控差异广度得分
[0339]
为了计算基因对细胞类型的细胞身份基因的调控影响,纳入了string v10(一种蛋白-蛋白相互作用网络)的信息。
[0340]
蛋白-蛋白相互作用网络,例如string,提供了有关预测相互作用的信息来源的信息。例如,相互作用可以基于实验数据或计算机数据,或两者。在string中,也对这些相互作用进行评分,这提供了所预测的相互作用的可靠性的度量。在本发明的某些实施方案中,如果网络中提供的实验得分大于零并且组合得分大于500,则选择基因节点之间的相互作用。这确保了利用具有实验证据的高质量网络来确定基因的调控影响。
[0341]
对于string网络(v)中的所有基因,可以基于基因子网络(vg)中关联基因(r)的dbs的组合来计算网络得分,并针对所述基因的出度节点的数量(o)和关联水平(l)进行校正。为了获得细胞特异性网络,可以去除string网络中没有相关广h3k4me3峰的基因。可以计算关联基因的dbs得分的加权总和(高至关联的第三水平)。
[0342][0343]
细胞类型x中跨所有蛋白编码基因g的标准化网络得分(net)
[0344][0345]
dbs和net得分的不同组合可用于确定细胞身份得分(regdbs)。在优选的实施方案中,如下所示使用比率为2:1的dbs与网络得分(net)。
[0346][0347]
第三步:预测细胞身份基因和细胞维持因子
[0348]
epimogrify通过基于细胞身份得分(regdbs)对基因进行排名来预测标记细胞身份的蛋白编码基因。
[0349]
应当理解,蛋白-蛋白相互作用网络提供了关于蛋白编码基因的产物(即,蛋白)的关联性而不是基因本身的关联性的信息。此外,本领域技术人员理解,可以存在蛋白编码基
因的多于一种“产物”。因此,在本发明的方法中,蛋白编码基因的产物将理解为包含来自给定蛋白编码基因的所有产物的任何单个或所有组合。
[0350]
对于细胞维持,epimogrify预测了信号传导分子,例如对细胞生长和存活至关重要的受体和配体。发明人已经认识到,约三分之二的配体是由细胞以自分泌方式产生的,其余的配体是通过支持细胞类型模拟微环境而产生的。因此,为了将此并入本模型,可以对基于细胞特异性regdbs的受体进行优先级排序,因为它们应该是细胞特异的并且对感兴趣的细胞类型具有调控影响。然后,可以对来自感兴趣的细胞类型和基于dbs的支持细胞类型的配体进行优先级排序。最后,可以通过受体和配体的组合排名,对受体-配体对进行优先级排序。这种方法能够鉴定和按优先级排序所预测的受体-配体对中用于补充到细胞培养条件的配体。
[0351]
(iii)用于定向分化和转分化的细胞转化因子的鉴定
[0352]
epimogrify采用三步法来鉴定细胞转化因子。首先,对于从源细胞类型到目标细胞类型的细胞转化,计算差异广度得分的变化。然后,确定基因对细胞状态变化的调控影响。最后,预测用于转分化的转录因子并预测用于定向分化的信号传导分子。
[0353]
简言之:细胞转化差异广度得分通过下式计算
[0354][0355][0356][0357]
其中s是源细胞类型,t是目标细胞类型。首先,计算源细胞类型和目标细胞类型的差异广度得分(dbs)。然后,为了获得细胞转化δdbs,计算源dbs得分和靶dbs得分之间的差异。
[0358]
接下来,将从源细胞类型到目标细胞类型的细胞转化的调控网络得分(n)计算为关联节点的细胞转化δdbs得分的加权总和。与细胞特异性regdbs计算相似,将细胞转化regdbs计算为细胞转化δdbs和标准化网络得分(net)的比率为2:1时的综合得分。
[0359][0360][0361][0362]
对于每个细胞转化,通过regδdbs值对蛋白编码基因进行排名。对于转分化,epimogrify预测了转录因子(tf),其是基于tfclass分类定义的蛋白编码基因的子集。对于定向分化,epimogrify预测信号传导分子,例如受体和配体对。通过细胞转化regδdbs对受体进行优先级排序,通过细胞转化δdbs对相应的配体进行优先级排序。最后,通过受体和配体的组合排名对受体-配体对进行优先级排序。预测的受体-配体对中的配体可以补充到分化方案中。
[0363]
总之,epimogrify对广h3k4me3组蛋白修饰特征进行模建,并预测细胞身份蛋白编
码基因、用于细胞维持的信号传导分子、用于定向分化的信号传导分子和用于转分化的tf。
[0364]
定义
[0365]
如本文所用,用于维持培养中的细胞的“因子”或用于从源细胞转化为目标细胞的因子可以包括蛋白、小分子或其他试剂,用于补充细胞培养基。优选地,所述因子是蛋白。所述蛋白可以是信号传导分子,包括与同源受体结合的配体,其优选在细胞表面上,并在细胞内引发信号级联反应,以维持所述细胞类型的至少一种特征。或者,所述因子可以是转录因子,其促进与细胞身份相关的基因的表达,并且从而促进细胞类型的体外维持。在因子是转录因子的情况下,所述转录因子可以直接提供给细胞,或者通过核酸表达载体等的方式在细胞中表达。
[0366]
在某些实施方案中,本方法包括使用小分子,其重复本文所鉴定的因子的作用,或其作用于细胞以增加本文所述的因子的量(例如,增加编码所述因子的基因的转录)。
[0367]
在某些实施方案中,所述因子可以外源提供,例如以重组蛋白或合成蛋白/肽的形式补充到培养基中。在进一步的实施方案中,所述因子可以以旁分泌方式提供,例如,其中所述因子从不同的细胞分泌至感兴趣的细胞。更进一步地,所述因子可以以自分泌方式提供,由此处理感兴趣的细胞以诱导所述因子的表达/产生(例如,由感兴趣的细胞或源细胞进行编码所述因子的核酸分子或载体的表达,视情况而定)。还应当理解,可以使用外源、旁分泌和自分泌方法的组合来提供所述因子。
[0368]
如本文所用,“h3k4”修饰是指影响基因表达调控的染色质的表观遗传修饰。h3k4是指在组蛋白h3蛋白上的赖氨酸4处添加的一个甲基。因此,h3k4me3是指添加的3个甲基(在同一赖氨酸残基上的三甲基化)。组蛋白h3蛋白用于在真核细胞中包装dna,对组蛋白的修饰会改变基因对转录的可及性。h3k4me3通常与附近基因的转录激活有关。h3k4三甲基化通过nurf复合物的染色质重塑来调控基因表达。在二价染色质中,h3k4me3可以与阻遏性修饰h3k27me3共定位以控制基因调控。
[0369]
本发明的方法可用于鉴定用于感兴趣的细胞或细胞集合的维持、转分化、重编程、定向分化和/或从源细胞转化为目标细胞的因子。
[0370]
应当理解,“在体外维持感兴趣的细胞”可以包括在细胞培养条件下培养细胞,使得细胞保留其主要的形态学特征和生物物理特征。这可以例如通过确认与感兴趣的细胞相关的标志物在细胞培养中的数次传代后被保留来测量。应当理解,“维持感兴趣的细胞”和“保留主要的形态学特征和生物物理特征”可以包括维持培养中至少50%、至少60%、至少70%、至少80%、至少90%或更多的细胞的存活率。优选地,将细胞维持至少2天、至少5天、至少10天、至少20天、至少30天、至少60天或更长。此外,“保留主要和生物物理特征”可以理解为意指根据本发明方法维持在培养中的细胞将保留至少90%、至少80%、至少70%、至少60%或至少50%的与感兴趣的细胞相关的标志物。优选地,细胞在培养期间将保留至少70%的标志物。此外,“保留主要和生物物理特征”也可以理解为意指根据本发明方法维持在培养中的细胞将保留至少90%、至少80%、至少70%、至少60%或至少50%的与感兴趣的细胞相关的形态学特性。优选地,细胞在培养期间将保留至少70%的与感兴趣的细胞相关的形态学特性。
[0371]
应当理解,术语“细胞转化”(例如,从源细胞到目标细胞)可以指去分化、转分化、重编程或定向分化。
[0372]
如本文所用,去分化是指将终末分化的细胞回复到其自身谱系内的低分化阶段的方法,这使能够增殖。定向分化是指从多能细胞状态(例如,干细胞)分化为特定类型的已分化的目标细胞。
[0373]
转分化通常是指细胞被修饰到可以转换谱系的节点的过程,或者其也可以直接在两种不同细胞类型之间发生。
[0374]
细胞重编程通常是指将成熟的特化细胞回复到诱导多能干细胞的过程。
[0375]
如本文所用,感兴趣的细胞是需要鉴定用于体外维持所述细胞所需的因子(包括受体/配体对、配体、转录因子或其他试剂)的任何细胞。感兴趣的细胞可以是在三个胚胎胚层(即,外胚层、中胚层和内胚层)的任一个中发现的任何细胞。如本文所用,外胚层是指外部身体组织,例如皮肤、指甲;中胚层是指组织如肌肉,但也包括血液;内胚层是指内衬层如消化道细胞。表2中提供了多种感兴趣的细胞的实例。衍生自中胚层的感兴趣的细胞的实例包括骨骼肌、骨骼、皮肤真皮、结缔组织、泌尿生殖系统、心脏、血液(淋巴细胞)和脾脏的细胞。衍生自内胚层的细胞的实例包括胃、结肠、肝脏、胰腺、膀胱的细胞;尿道内层、气管上皮部分、肺、咽、甲状腺、甲状旁腺、肠道。衍生自外胚层的细胞的实例包括中枢神经系统、视网膜和晶状体、颅和感觉(sensory)、神经节和神经、色素细胞、头部结缔组织、表皮、毛发和乳腺的细胞。
[0376]“感兴趣的细胞”可以包括适合在组织培养中维持的任何细胞。感兴趣的细胞的非限制性实例包括在表2中列出的那些细胞。更具体地,本文所用的“感兴趣的细胞”或“源细胞”可以是原代细胞(非永生化细胞),或者可以是衍生自细胞系的细胞(永生化细胞),或者可以是分离自个体的组织。感兴趣的细胞也可以是祖细胞,例如神经祖细胞(neural progenitor cell)、造血祖细胞(haematopoietic progenitor cell)、肌原祖细胞(myogenic progenitor cell)、内皮祖细胞(endothelial progenitor cell)和普通淋巴细胞(common lymphocyte)或髓系祖细胞(myeloidprogenitor cell)。感兴趣的细胞可以指细胞群体,例如混合细胞群体,例如组织或从组织获得的那些细胞。在一些实施方案中,感兴趣的细胞或源细胞是未分化的细胞。在其他实施方案中,感兴趣的细胞或源细胞是已转分化的细胞或正在转分化的细胞。已转分化的细胞是已经从转分化过程(即,将一个体细胞的表型改变为另一个体细胞)中产生的细胞。如本文所用,“体细胞”是衍生自其中一个胚层(外胚层、内胚层或中胚层)的细胞。正在转分化的细胞是正在经历转分化过程的细胞,即,体细胞的表型正在向另一个体细胞的表型变化,其中最终体细胞的标志物尚未完全建立。在其他实施方案中,感兴趣的细胞或源细胞是特化细胞类型的已分化细胞。
[0377]
如本文所用,源细胞或感兴趣的细胞可以是本文所述的任何细胞类型,包括体细胞或病变细胞(diseased cell)。体细胞可以是成体细胞(adult cell)或衍生自成体的细胞,其表现出成体或非胚胎细胞的一种或多种可检测的特征。源细胞的其他实例包括祖细胞,例如造血细胞,例如淋巴细胞、髓系细胞;颊粘膜细胞、表皮细胞、间充质细胞、角质形成细胞、肝细胞、胚胎细胞、干细胞或已经处理而具有干细胞的一种或多种特征的细胞。在病变细胞的情况下,病变细胞可以是表现出疾病或病况的一种或多种可检测的特征的细胞,例如,病变细胞可以是表现出癌症的一种或多种临床或生化标志物的癌细胞。
[0378]
源细胞或感兴趣的细胞也可以是干细胞,包括多能干细胞,优选诱导多能干细胞(inducedpluripotent stem cell,ipsc)。
[0379]
如本文所用,术语“体细胞”是指形成生物体身体的任何细胞,与生殖系细胞相对。在哺乳动物中,生殖系细胞(也称为“配子”)是精子和卵子,它们在受精过程中融合以产生一种称为合子的细胞,由此发育出整个哺乳动物胚胎。哺乳动物身体中的所有其他细胞类型均为体细胞,除了精子和卵子、制造它们的细胞(配子体)和未分化的干细胞之外,内脏器官、皮肤、骨骼、血液和结缔组织均由体细胞组成。在一些实施方案中,体细胞是“非胚胎体细胞”,其意指这样的体细胞,其不存在于或不获得于胚胎中,并且不是由此类细胞在体外的增殖产生。在一些实施方案中,体细胞是“成体体细胞”,其意指这样的细胞,其存在于或获得于除胚胎或胎儿以外的生物体,或由此类细胞在体外的增殖产生。体细胞可以经永生化以提供无限的细胞供应,例如,通过增加端粒酶逆转录酶(telomerase reverse transcriptase,tert)的水平。例如,可以通过增加来自内源基因的tert的转录,或通过任何基因递送方法或系统引入转基因,来增加tert的水平。
[0380]
除非另有说明,否则用于体细胞转化的方法可以在体内和体外进行(当体细胞存在于受试者中时,在体内进行,当使用维持在培养中的分离的体细胞时,在体外进行)。
[0381]
胚胎细胞,例如胚胎干细胞,可以是衍生自胚胎细胞系的细胞,而不直接衍生自胚胎或胎儿。或者,胚胎细胞可以衍生自胚胎或胎儿,而所述细胞是在不破坏胚胎或胎儿或对胚胎或胎儿发育没有任何负面影响的情况下获得或分离的。
[0382]
本发明还涉及使用诱导多能干细胞(inducedpluripotent stem cell,ipsc)。
[0383]
已分化的体细胞,包括来自胎儿、新生儿、幼年或成年灵长类动物(包括人、个体)的细胞,是本发明方法中合适的源细胞(或感兴趣的细胞)。合适的体细胞包括但不限于骨髓细胞、上皮细胞、内皮细胞、成纤维细胞、造血细胞、角质形成细胞、肝细胞、肠细胞、间充质细胞、髓系前体细胞和脾细胞。或者,体细胞可以是自身能够增殖和分化成其他类型细胞(包括血液干细胞、肌/骨干细胞、脑干细胞和肝干细胞)的细胞。合适的体细胞是接受性的,或者可以使用科学文献中通常已知的方法使其变得具有接受性,以摄取转录因子(包括编码转录因子的遗传物质)。增强摄取的方法可以因细胞类型和表达系统而异。用于制备具有合适转导效率的接受性体细胞的示例性条件是本领域普通技术人员公知的。起始体细胞可以具有约二十四小时的倍增时间。
[0384]
如本文所用,术语“分离的细胞”是指已从最初发现它的生物体中取出的细胞或此类细胞的后代。任选地,所述细胞已经在体外培养,例如在存在其他细胞的情况下。任选地,随后将细胞引入第二生物体或重新引入分离它的生物体(或它所起源的细胞)。
[0385]
如本文所用,针对分离的细胞群体的术语“分离的群体”是指已从混合的或异质的细胞群体中取出和分离的细胞群体。在一些实施方案中,与细胞由之分离或富集的异质群体相比,分离的群体是基本上纯的细胞群体。
[0386]
针对特定细胞群体的术语“基本上纯的”是指相对于组成总细胞群体的细胞来说至少约75%、优选至少约85%、更优选至少约90%、且最优选至少约95%纯的细胞群体。或者,针对目标细胞群体的术语“基本上纯的(substantially pure)”或“根本上纯化的(essentially purified)”是指这样的细胞群体,其含有少于约20%,更优选少于约15%、10%、8%、7%,最优选少于约5%、4%、3%、2%、1%或少于1%的不是本文中术语所定义的目标细胞或其后代的细胞。
[0387]
如本文所用,对“目标细胞(target cell)”可以是指在本文中称为目标细胞或目
标细胞类型的任意一种或多种细胞。
[0388]
目标细胞可以是代表三个胚胎胚层(即,内胚层、中胚层和外胚层)的任一个的细胞。例如,目标细胞是通常发现于以下中的细胞:骨骼肌、骨骼、皮肤真皮、结缔组织、泌尿生殖系统、心脏、血液(淋巴细胞)和脾(中胚层);胃、结肠、肝脏、胰腺、膀胱;尿道内衬、气管上皮部分、肺、咽、甲状腺、甲状旁腺、肠道(内胚层);或中枢神经系统、视网膜和晶状体、颅和感觉、神经节和神经、色素细胞、头部结缔组织、表皮、头发、乳腺(外胚层)。
[0389]
通过本发明的方法,当源细胞显示出目标细胞类型的至少一种特征时,确定源细胞转化为目标细胞或变成目标样细胞(target-like cell)。例如,当人成纤维细胞显示出目标细胞类型的至少一种特征时,鉴定其转化为角质形成细胞样细胞。通常,细胞将显示出目标细胞类型的1种、2种、3种、4种、5种、6种、7种、8种或更多种特征。例如,在目标细胞是角质形成细胞的情况下,当可检测到任意一种或多种角质形成细胞标志物上调和/或细胞形态的变化,将细胞鉴定为或确定为角质形成细胞样细胞,优选地,所述角质形成细胞标志物包括角蛋白1、角蛋白14和外皮蛋白(involucrin),细胞形态呈鹅卵石外表。在本发明的任何方面,可以通过分析细胞形态、基因表达谱、活性测定、蛋白表达谱、表面标志物谱或分化能力,来确定目标细胞特征。特征或标志物的实例包括如本文所述的那些和技术人员已知的那些。相关标志物的其他实例包括,例如角质形成细胞向造血干细胞(hsc)的转化:cd45(泛造血标志物)、cd19/20(b细胞标志物)、cd14/15(髓系)、cd34(祖细胞/sc标志物)、cd90(sc)和α-整合素(不由hsc表达的角质形成细胞标志物);人类胚胎干细胞向造血干细胞的转化:runx1(gfp)、cd45(泛造血标志物)、cd19/20(b细胞标志物)、cd14/15(髓系)、cd34(祖细胞/sc标志物)、cd90(sc)、tra-1-160(不在esc中表达的esc标志物);老化或成体hsc的复壮(rejuvenation):比较年轻的和老化的人hsc的转录特征(例如,使用rna-seq),并通过将复壮的细胞移植到动物中来对“复壮的hsc”进行功能性表征,然后在1、3和6个月后进行评估以确定髓系偏倚(myeloidbias),其中髓系偏倚的消失表明“复壮的”hsc。本文所述的许多转化的标志物的实例如下表1所示。
[0390]
表1:感兴趣的细胞或目标细胞的示例性标志物
[0391]
[0392][0393]
表2:所鉴定的各种细胞的细胞身份/维持因子
[0394]
[0395]
[0396]
[0397]
[0398]
[0399]
[0400]
[0401]
[0402]
[0403]
[0404][0405]
在具体的实施方案中,将表2中列出的因子(配体)中的一种、两种、三种、四种或五种或更多种添加至感兴趣的细胞或用于接触感兴趣的细胞,以在体外维持感兴趣的细胞。在其他的实施方案中,将表2中列出的因子(配体)中的六种、七种、八种、九种、10种、11种、12种、13种、14种、15种或更多种、20种或更多种、25种或更多种、30种或更多种或35种或更多种添加至感兴趣的细胞或用于接触感兴趣的细胞。
[0406]
本发明还提供了将源细胞转化为目标细胞的方法。本文进一步解释了鉴定用于此
类转化的因子的方法。除了本文别处概述的实施方案之外,在某些实施方案中,源细胞是胚胎干细胞,用于将胚胎干细胞转化为目标细胞的因子如在下表中提供:
[0407]
表3:用于h9胚胎干细胞分化/转化为各种目标细胞类型的因子
[0408]
[0409]
[0410]
[0411]
[0412]
[0413][0414]
在具体的实施方案中,将表3中列出的一种、两种、三种、四种或五种或更多种因子添加至源细胞或用于接触源细胞,以在体外将源细胞转化为目标细胞。在可选的实施方案中,使细胞与用于增加一种或多种上述因子的表达的试剂接触,例如本文进一步的描述。在其他的实施方案中,将表3中列出的因子(配体)中的六种、七种、八种、九种、10种、11种、12种、13种、14种、15种或更多种、20种或更多种、25种或更多种、30种或更多种或35种或更多种添加至源细胞或用于接触源细胞,以将其转化为目标细胞。
[0415]
本领域技术人员将熟悉上表2和表3中所示的每种配体/因子。下文进一步提供了
一些特别优选的实例:
[0416]
如本文所用,fn1是指纤连蛋白,一种细胞外基质的高分子量(~440kda)糖蛋白,其与称为整合素的跨膜受体蛋白结合。fn1也称为cig、ed-b、finc、fn、fnz、gfnd、gfnd2、lets、msf、纤连蛋白1、smdcf。纤连蛋白的示例性氨基酸序列在uniprot登录号p02751中提供,并且由以登录号ensg00000115414为示例的核酸序列编码。
[0417]
如本文所用,col4a1是指:胶原α-1(iv)链(也称为hanac、ich、poren1、arresten、bsvd、rator、iv型胶原α1、iv型胶原α1链、bsvd1)。col4a1的示例性氨基酸序列在uniprot登录号p02462中提供,并且由以登录号ensg00000187498为示例的核酸序列编码。
[0418]
如本文所用,col1a2是指胶原蛋白α-2(i)链(也称为oi4、i型胶原蛋白α2、i型胶原蛋白α2链、edscv、edsarth2)。col1a2的示例性氨基酸序列在uniprot登录号p08123中提供,并且由以登录号ensg00000164692为示例的核酸序列编码。
[0419]
如本文所用,edil3是指“egf样重复和盘状结构域3(egf like repeats and discoidin domains 3)”,一种在人体中由edil3基因编码的蛋白。由这个基因编码的蛋白是整合素配体。它在介导血管生成中起重要作用,并且可能在血管壁重塑和发育中起重要作用。它还影响内皮细胞的行为。edil3的示例性氨基酸序列在uniprot登录号o43854中提供,并且由以登录号ensg00000164176为示例的核酸序列编码。
[0420]
如本文所用,adam12是指含有去整合素和金属蛋白酶结构域的蛋白12(disintegrin and metalloproteinase domain-containing protein 12,以前称为meltrin),一种在人中由adam12基因编码的酶。adam12具有两个剪接变体:adam12-l(长形式,具有一个跨膜区),以及adam12-s(较短变体,是可溶的并且缺少跨膜和细胞质结构域)。adam12也称为adam12-ot1、car10、mcmp、mcmpmltna、mltn、mltna、adam金属肽酶结构域12。adam12的示例性氨基酸序列在uniprot登录号o43184中提供,并且由以登录号ensg00000148848为示例的核酸序列编码。
[0421]
如本文所用,wnt5a(也称为hwnt家族成员5a)是一种在人体中由wnt5a基因编码的蛋白。wnt5a的示例性氨基酸序列在uniprot登录号p41221中提供,并且由以登录号ensg00000114251为示例的核酸序列编码。
[0422]
如本文所用,lamb1是指编码层粘连蛋白(laminin)亚基β-1的基因。这种蛋白也称为clm、lis5和层粘连蛋白β1。层粘连蛋白是细胞外基质糖蛋白家族,是基底膜的主要非胶原成分。它们参与多种生物学过程,包括细胞粘附、分化、迁移、信号传导、神经突生长和转移。层粘连蛋白包含3条不同的链:层粘连蛋白α、β和γ(以前分别为a、b1和b2),并且它们形成由3条短臂(每条短臂由不同的链形成)和一条长臂(包含全部3条链)组成的十字形结构。lamb1的示例性氨基酸序列在uniprot登录号p07942中提供,并且由以登录号ensg00000091136为示例的核酸序列编码。
[0423]
如本文所用,col3a1是指iii型胶原蛋白,它是同三聚体,或包含三条相同肽链(单体)的蛋白,每条肽链称为iii型胶原蛋白的α1链。在形式上,这些单体被称为iii型胶原蛋白α-1链,并且在人体中由col3a1基因编码。iii型胶原蛋白是纤维状胶原蛋白的一种,其蛋白具有长的、非柔性的三螺旋结构域。col3a1也由标识符eds4a、iii型胶原蛋白α1、iii型胶原蛋白α1链、edsvasc和pmgedsv指代。col3a1的示例性氨基酸序列在uniprot登录号p02461中提供,并且由以登录号ensg00000168542为示例的核酸序列编码。
[0424]
如本文所用,tfpi是指组织因子途径抑制剂(tissue factor pathway inhibitor),一种能够可逆地抑制因子xa(xa)的单链多肽。当xa被抑制时,xa-tfpi复合物随后也能够抑制fviia-组织因子复合物。tfpi也由标识符epi、laci、tfi、tfpi1指代。tfpi的示例性氨基酸序列在uniprot登录号p10646中提供,并且由以登录号ensg00000003436为示例的核酸序列编码。
[0425]
如本文所用,fgf7(也称为hbgf-7或kgf)是指角质形成细胞生长因子,一种在人中由fgf7基因编码的蛋白。fgf家族成员具有广泛的促有丝分裂和细胞存活活性,并且参与多种生物学过程,包括胚胎发育、细胞生长、形态发生、组织修复、肿瘤生长和侵袭。这种蛋白是一种强力的上皮细胞特异性生长因子,其促有丝分裂活性主要表现在角质形成细胞中,但不表现在成纤维细胞和内皮细胞中。fgf7的示例性氨基酸序列在uniprot登录号p21781中提供,并且由以登录号ensg00000140285为示例的核酸序列编码。
[0426]
如本文所用,fgf10是指成纤维细胞生长因子10,一种在人中由fgf10基因编码的蛋白。fgf家族成员具有广泛的促有丝分裂和细胞存活活性,并参与多种生物学过程,包括胚胎发育、细胞生长、形态发生、组织修复、肿瘤生长和侵袭。成纤维细胞生长因子10是一种旁分泌信号传导分子,其最先见于肢芽和器官发生发育中。fgf10信号传导为上皮分支(epithelialbranching)所需要。因此,所有的分支形态发生的器官(branching morphogen organ),例如肺、皮肤、耳和唾液腺均需要fgf10的持续表达。这种蛋白表现出使表皮细胞角质化的促有丝分裂活性,但对成纤维细胞基本上没有活性,这与fgf7的生物学活性相似。fgf10的示例性氨基酸序列在uniprot登录号o15520中提供,并由以登录号ccds3950.1为示例的核酸序列编码。
[0427]
如本文所用,apoe是指载脂蛋白e(也称为ad2、apo-e、ldlcq5、lpg、apoe4),一种参与体内脂肪代谢的蛋白。apoe的示例性氨基酸序列在uniprot登录号p02649中提供,并且由以登录号ensg00000130203为示例的核酸序列编码。
[0428]
如本文所用,c3是指补体组分3,一种在补体系统中起核心作用并且有助于先天免疫的蛋白。所述蛋白还可以由标识符ahus5、armd9、asp、c3a、c3b、cpamd1、hel-s-62p和补体组分3指代。c3的示例性氨基酸序列在uniprot登录号p01024中提供,并且由以登录号ensg00000125730为示例的核酸序列编码。
[0429]
如本文所用,serpine1是指纤溶酶原激活物抑制剂-1(plasminogen activator inhibitor-1,pai-1),也称为内皮纤溶酶原激活物抑制剂或丝氨酸蛋白酶抑制剂e1(serpin e1),一种在人中由serpine1基因编码的蛋白。pai-1是一种丝氨酸蛋白酶抑制剂(serpin),其作为组织纤溶酶原激活物(tpa)和尿激酶(upa)(纤溶酶原以及从而纤维蛋白溶解(血凝块的生理性分解)的激活物)的主要抑制剂起作用。它是一种丝氨酸蛋白酶抑制剂(serpin)蛋白(serpine1)。serpine1的示例性氨基酸序列在uniprot登录号p05121中提供,并且由以登录号ensg00000106366为示例的核酸序列编码。
[0430]
如本文所用,col6a3是指胶原蛋白α-3(vi)链,一种在人中由col6a3基因编码的蛋白。这种基因编码α3链,vi型胶原蛋白的三个α链之一,其是一种发现于大多数结缔组织中的珠状细丝胶原蛋白(beaded filament collagen)。vi型胶原的α3链比α1和α2链大得多。这种大小差异主要归因于亚结构域数量的增加,类似于a型血管性血友病因子(vonwillebrand factor)结构域,发现于所有α链的氨基末端球状结构域中。除了全长转录
物外,还鉴定了四种编码具有不同大小的n末端球状结构域的蛋白的转录物变体。col6a3的示例性氨基酸序列在uniprot登录号p12111中提供,并且由以登录号ensg00000163359为示例的核酸序列编码。
[0431]
如本文所用,cxcl12是指基质细胞衍生因子1(stromal cell-derived factor1,sdf1),也称为c-x-c基序趋化因子12、irh、pbsf、scyb12、sdf1、tlsf、tpar1和c-x-c基序趋化因子配体12。编码cxcl12的基因通过选择性剪接产生7种同种型。cxcl12的示例性氨基酸序列在uniprot登录号p48061中提供,并且由以登录号ensg00000107562为示例的核酸序列编码。
[0432]
如本文所用,tgfb2和tgfb3分别是指转化生长因子β2和转化生长因子β3。两种蛋白均是参与细胞分化、胚胎发生和发育的细胞因子。tgfb2的一个示例性登录号是p61812。tgfb3的一个示例性登录号是p10600。
[0433]
如本文所用,gdf5是指生长/分化因子5,并且由gdf5基因编码。由这种基因编码的蛋白与骨形态发生蛋白(bmp)家族密切相关,并且是tgf-β超家族的成员。gdf5的一个示例性登录号是p43026。
[0434]
如本文所用,nid1是指nidogen-1(nid-1),以前称为巢蛋白(entactin),是一种在人中由nid1基因编码的蛋白。nidogen-1和nidogen-2与其他组分例如iv型胶原蛋白、蛋白聚糖(硫酸乙酰肝素和糖胺聚糖)、层粘连蛋白和纤连蛋白一起作为基底膜的重要组分。nid1的一个示例性登录号是p14543。
[0435]
如本文所用,thbs1是指血小板反应蛋白1(thrombospondin 1),缩写为thbs1,是一种在人中由thbs1基因编码的蛋白。血小板反应蛋白1是二硫键连接的同三聚体蛋白的亚基。这种蛋白是一种介导细胞与细胞以及细胞与基质之间相互作用的粘附性糖蛋白。这种蛋白可以与纤维蛋白原、纤连蛋白、层粘连蛋白、v型和vii型胶原蛋白以及整合素α-v/β-1结合。thbs1的一个示例性登录号是p07996。
[0436]
如本文所用,bmp4和bmp6分别是指骨形态发生蛋白4(bone morphogenetic protein 4)和骨形态发生蛋白6(bone morphogenetic protein 6)。由这些基因编码的蛋白是tgfβ超家族的成员。骨形态发生蛋白以其诱导骨和软骨生长的能力而著称。bmp4在进化上是高度保守的。bmp4发现于腹侧边缘区和眼、心脏血液和耳囊泡的早期胚胎发育中。bmp6能够诱导间充质干细胞中的所有成骨标志物。bmp6的一个示例性登录号是p12644。bmp6的一个示例性登录号是p22004。
[0437]
如本文所用,ctgf也称为ccn2或结缔组织生长因子,是细胞外基质相关肝素结合蛋白的ccn家族的基质细胞蛋白(也参见ccn细胞间信号传导蛋白)。ctgf在许多生物学过程中都具有重要作用,包括细胞粘附、迁移、增殖、血管生成、骨骼发育和组织伤口修复,并且与纤维化疾病和数种癌症形式密切相关。ctgf的一个示例性登录号是p29279。
[0438]
如本文所用,pdgfb是指血小板衍生生长因子亚基b,是一种在人中由pdgfb基因编码的蛋白。由这种基因编码的蛋白是血小板衍生生长因子家族的成员。这个家族的四个成员是间充质起源的细胞的促有丝分裂因子,并且其特征在于八个半胱氨酸的基序。这种基因产物可以以同二聚体(pdgf-bb)存在或者以与血小板衍生生长因子α(pdgfa)多肽的异二聚体(pdgf-ab)存在,其中二聚体通过二硫键连接。pdgfb的一个示例性登录号是p01127。
[0439]
应当理解,在优选的实例中,用于维持感兴趣的细胞的相关因子(配体)可以直接
提供给细胞以使细胞与相关因子“接触”。此外,如本文所用,术语“接触”、“处理”或“引入”可互换使用以意指将细胞进行任何种类的过程或条件,例如用外源dna转染或将试剂引入细胞。
[0440]
例如,培养基可以直接补充相关因子。在可选的实施方案中,可以用编码相关因子的核酸分子(或编码一种或多种相关因子的载体)转染细胞,使得所述因子随后由细胞表达。
[0441]
此外,可以以增加细胞中相关因子的量的方式处理细胞。同样,这可以通过直接补充细胞培养基,或通过重组方法来增加细胞中内源基因的表达,或通过提供编码相关因子的外源核酸来源,表达核酸并从而增加细胞中所述因子的量。
[0442]
类似地,对于转化细胞的方法(包括转分化和定向分化方法),用于转化的因子可以直接在培养物中提供,或者在源细胞中表达以促进向目标细胞的转化。
[0443]
应当理解,可以将身为蛋白的因子(包括转录因子和其他调控因子)根据本文所述的方法提供给细胞。或者,可以提供所述因子的变体以实现相同的结果。
[0444]
术语“变体”是指与全长多肽至少70%、80%、85%、90%、95%、98%或99%同一的多肽。本发明涉及使用如本文所述的因子的变体。所述变体可以是全长多肽的片段或天然存在的剪接变体。所述变体可以是与所述多肽的片段至少70%、80%、85%、90%、95%、98%或99%同一的多肽,其中所述片段是至少50%、60%、70%、80%、85%、90%、95%、98%或99%,前提是全长野生型多肽或其结构域具有感兴趣的功能活性,例如促进源细胞类型转化为目标细胞类型的能力。在一些实施方案中,所述结构域的长度为至少100个、200个、300个或400个氨基酸,从序列中的任意氨基酸位置开始并向c末端延伸。优选地避免本领域已知会消除或显著降低蛋白活性的变异。在一些实施方案中,变体缺少全长多肽的n末端和/或c末端部分,例如缺少自任一末端多达10个、20个或50个氨基酸。在一些实施方案中,多肽具有成熟(全长)多肽的序列,这表示在正常细胞内蛋白水解加工期间(例如,在共翻译或翻译后加工期间)已去除一个或多个部分如信号肽的多肽。在蛋白以除通过从天然表达它的细胞中纯化以外的方式生产的一些实施方案中,所述蛋白是嵌合多肽,这表示它含有来自两个或更多个不同物种的部分。在蛋白以除通过从天然表达它的细胞中纯化以外的方式生产的一些实施方案中,所述蛋白是衍生物,这表示所述蛋白包含与所述蛋白不相关的额外序列,只要这些序列不显著减少所述蛋白的生物学活性。使用本领域已知的测定法,本领域技术人员将知晓或能够容易地确定特定的多肽变体、片段或衍生物是否有功能。例如,转录因子的变体将源细胞转化为目标细胞类型的能力可以使用如本文实施例中所公开的测定法来评估。其他便捷的测定法包括测定激活含有转录因子结合位点的报告构建体的转录的能力,所述转录因子结合位点可操作地连接至编码可检测标志物如荧光素酶的核酸序列。在本发明的某些实施方案中,功能性变体或片段具有全长野生型多肽的至少50%、60%、70%、80%、90%、95%或更高的活性。
[0445]
关于因子的增加量,术语“增加
……
的量”是指增加感兴趣的细胞(例如,星形胶质细胞、心肌细胞、平滑肌细胞、内皮细胞或源细胞,用于转化为目标细胞)中因子的量。在一些实施方案中,当因子的量相对于对照(例如,未引入指导编码一种或多种转录因子的多核苷酸表达的表达盒的细胞)至少10%、20%、30%、40%、50%、60%、70%、80%、90%或更多时,则因子的量在感兴趣的细胞(例如,已引入所述表达盒的细胞)中“增加”。然而,涵盖了
增加转录因子的量的任何方法,包括增加转录因子(或编码它的pre-mrna或mrna)的转录、翻译、稳定性或活性的量、速率或效率的任何方法。此外,还考虑下调或干扰转录表达的负调节剂,增加现有转录的效率(例如,sineup)。
[0446]
在针对细胞或生物体中的蛋白、基因、核酸或多核苷酸使用时,术语“外源的”是指已通过人工或天然方式引入细胞或生物体的蛋白、基因、核酸或多核苷酸;在针对细胞使用时,该术语是指被分离并随后通过人工或天然方式引入其他细胞或生物体的细胞。外源核酸可以来自不同的生物体或细胞,或者它可以是在生物体或细胞内天然存在的核酸的一个或多个额外拷贝。外源细胞可以来自不同的生物体,或者它可以来自相同的生物体。作为非限制性示例,外源核酸是位于与天然细胞中染色体位置不同的染色体位置的核酸,或者是侧翼为与自然界中发现的核酸序列不同的核酸序列的核酸。外源核酸也可以是染色体外的,例如游离型载体。
[0447]
本公开的方法可以通过任何可接受的小型化方法在测定系统中被“小型化”,所述可接受的小型化方法包括但不限于多孔板,例如每个平板24个、48个、96个或384个孔,微芯片或载玻片。所述测定可以减小尺寸以在微芯片支持物上进行,有利地的是涉及较少量的试剂和其他材料。对方法进行的有助于高通量筛选的任何小型化都在本发明的范围内。
[0448]
在本发明的任何方法中,可以将目标细胞转移到获得源细胞的同一哺乳动物中。换言之,本发明方法中使用的源细胞可以是自体细胞,即,可以从要被施用目标细胞的同一个体获得。或者,可以将目标细胞同种异体地转移到另一个个体中。优选地,在治疗或预防个体中的医学病况的方法中,细胞对于个体是自体的。
[0449]
如本文所指的术语“细胞培养基”(本文也称为“培养基(culture medium或medium)”)是用于培养细胞的培养基,其含有维持细胞活力和支持增殖的营养物。细胞培养基可以含有合适组合的任意以下:盐、缓冲液、氨基酸、葡萄糖或其他糖、抗生素、血清或血清替代物,以及其他组分,例如肽生长因子等。通常用于特定细胞类型的细胞培养基是本领域技术人员已知的。用于本发明方法的示例性细胞培养基如表4所示。
[0450]
术语“表达”是指涉及产生rna和蛋白以及分泌蛋白(视情况而定)的细胞过程,包括但不限于例如转录、翻译、折叠、修饰和加工。
[0451]
如本文所用,术语“分离的”或“部分纯化的”在核酸或多肽的情况下是指这样的核酸或多肽,其分离自在所述核酸或多肽的天然来源中发现与其一起存在的至少一种其他组分(例如,核酸或多肽)和/或分离自当由细胞表达或分泌(在分泌多肽的情况下)时与所述核酸或多肽一起存在的至少一种其他组分(例如,核酸或多肽)。化学合成的核酸或多肽或使用体外转录/翻译合成的核酸或多肽被认为是“分离的”。
[0452]
术语“载体”是指载体dna分子,其中可以插入dna序列以引入宿主或源细胞中。优选的载体是那些能够自主复制和/或表达与它们连接的核酸的载体。能够指导与它们可操作的连接的基因的表达的载体在本文中称为“表达载体”。因此,“表达载体”是含有在宿主细胞中表达感兴趣的基因所需的必要调控区域的特化载体。在一些实施方案中,感兴趣的基因在载体中与另一个序列可操作地连接。载体可以是病毒载体或非病毒载体。如果使用病毒载体,则优选病毒载体是复制缺陷型的,这可以例如通过去除所有用以复制而编码的病毒核酸来实现。复制缺陷型病毒载体将仍保留其感染特性,并以与复制型腺病毒载体类似的方式进入细胞,但是一旦进入细胞,复制缺陷型病毒载体不会增殖或倍增。载体还涵盖
脂质体和纳米颗粒,以及将dna分子递送至细胞的其他方式。
[0453]
术语“可操作的连接”意指将表达编码序列所需的调控序列置于dna分子中相对于编码序列的合适位置以实现编码序列的表达。这一定义有时适用于表达载体中编码序列和转录控制元件(例如,启动子、增强子和终止元件)的排列。术语“可操作的连接”包括在要表达的多核苷酸序列前面具有合适的起始信号(例如,atg),并保持正确的阅读框,以允许所述多核苷酸序列在表达控制序列的控制下表达,并产生由所述多核苷酸序列编码的目标多肽。
[0454]
术语“病毒载体”是指使用病毒或病毒相关载体作为核酸构建体进入细胞的载体。构建体可以整合并包装到非复制缺陷型病毒基因组中,例如腺病毒、腺相关病毒(aav)或单纯疱疹病毒(hsv)或其他病毒,包括逆转录病毒和慢病毒载体,用于感染或转导至细胞中。载体可以并入或不并入细胞的基因组中。如果需要,构建体可以包括用于转染的病毒序列。或者,构建体可以并入到能够进行游离型复制(episomal replication)的载体中,例如epv和ebv载体。
[0455]
如本文所用,术语“腺病毒”是指腺病毒科的病毒。腺病毒是中等大小(90-100nm)、无包膜(裸)的二十面体病毒,其包含核衣壳和双链线性dna基因组。
[0456]
如本文所用,术语“非整合病毒载体”是指不整合到宿主基因组中的病毒载体;由病毒载体递送的基因的表达是暂时的。由于几乎没有或没有整合到宿主基因组中,因此非整合病毒载体的优势是没有由于插入基因组中随机点而导致的dna突变。例如,非整合病毒载体保留在染色体外,并且不将其基因插入宿主基因组中(可能会破坏内源基因的表达)。非整合病毒载体可包括但不限于以下:腺病毒、甲病毒、小核糖核酸病毒和牛痘病毒。这些病毒载体是本文使用的术语“非整合”病毒载体,尽管它们中的任何一种可能在一些罕见的情况下将病毒核酸整合到宿主细胞的基因组中。重要的是,本文所述方法中使用的病毒载体通常或作为其生命周期的主要部分在所采用的条件下不会将其核酸整合到宿主细胞的基因组中。
[0457]
可以使用科学文献中通常已知的方法构建和工程化本文所述的载体,以提高其在治疗中使用的安全性,纳入选择和富集标志物(如果需要),以及优化其上所含核苷酸序列的表达。载体应包括允许载体在源细胞类型中自我复制的结构组件。例如,已知的epstein barr orip/核抗原-1(ebna-i)组合(参见,例如,lindner,s.e.and b.sugden,the plasmid replicon ofepstein-barr virus:mechanistic insights into efficient,licensed,extrachromosomal replication in human cells,plasmid 58:1(2007),其通过引用并入,如同在本文中以其全文示出)足以支持载体自我复制,并且也可以使用已知在哺乳动物尤其是灵长类动物细胞中起作用的其他组合。用于构建适用于本发明的表达载体的标准技术是本领域普通技术人员公知的,并且可见于出版物例如sambrook j,et al.,"molecular cloning:a laboratory manual,"(第3版,cold spring harbor press,cold spring harbor,n.y.2001),其通过引用并入本文,如同以其全文示出。
[0458]
在本发明的方法中,将编码转化所需的相关因子的遗传物质通过一种或多种细胞转化载体递送到源细胞中。可以将每种因子作为多核苷酸转基因引入源细胞,所述多核苷酸转基因编码可操作地连接至能够驱动所述多核苷酸在源细胞中表达的异源启动子的因子。
[0459]
合适的细胞转化载体是本文所述的任何载体,包括游离型载体,例如质粒,其不编码足以产生感染性病毒或可复制型病毒的病毒基因组的全部或部分,尽管所述载体可以含有从一种或多种病毒获得的结构元件。可以将一种或多种细胞转化载体引入单个源细胞。可以在单细胞转化载体上提供一种或多种转基因。一种强的组成型转录启动子可以为多种转基因提供转录控制,这些转基因可以作为表达盒提供。载体上的独立表达盒可以在独立的强组成型启动子的转录控制下,这些启动子可以是相同启动子的数个拷贝或可以是不同的启动子。各种异源启动子是本领域已知的,并且可以根据例如转录因子的所需表达水平之类的因素来使用。如下例示,有利的是使用在源细胞中具有不同强度的不同启动子来控制不同表达盒的转录。选择转录启动子的另一个考虑因素是启动子沉默的速率。技术人员理解,在基因产物已完成或基本上完成其在细胞转化方法中的作用之后,减少一种或多种转基因或转基因表达盒的表达可能是有利的。示例性启动子是人ef1α延伸因子启动子、cmv巨细胞病毒即早期启动子和cag鸡白蛋白启动子,以及来自其他物种的相应同源启动子。在人类体细胞中,ef1α和cmv均是强启动子,但cmv启动子的沉默比ef1α启动子更有效,因此在前者控制下的转基因表达比在后者控制下的转基因表达关闭得更早。转录因子可以在源细胞中以可以变化以调控细胞转化效率的相对比率来表达。优选地,在单个转录物上编码多个转基因的情况下,在远离转录启动子的转基因上游提供内部核糖体进入位点。尽管因子的相对比率可以根据所递送的因子而变化,但知晓本公开的普通技术人员可以确定因子的最佳比率。
[0460]
本领域技术人员理解,通过单个载体而不是通过多个载体引入所有因子对于效率更有利。因此,本发明涉及使用单个载体(或减少数量的载体),其中所述单个或减少数量的载体编码转化或细胞维持所需的多个因子,视情况而定。
[0461]
在引入转化载体后,并且当源细胞正在被转化时,载体可以在目标细胞中持续存在,同时转录和翻译引入的转基因。在已被转化为目标细胞类型的细胞中,转基因表达可以被有利地下调或关闭。细胞转化载体可以保持在染色体外。在极低的效率下,载体可以整合到细胞的基因组中。以下示例旨在说明但绝不在于限制本发明。
[0462]
本发明用于核酸递送以转化细胞、组织或生物体的合适方法被认为包括实际上可以将核酸(例如,dna)引入细胞、组织或生物体中的任何方法,如本文所述或如本领域普通技术人员所知晓的(例如,stadtfeld and hochedlinger,nature methods 6(5):329-330(2009);yusa et al.,nat.methods 6:363-369(2009);woltjen,et al.,nature 458,766-770(2009年4月9日))。此类方法包括但不限于直接递送dna,例如通过离体转染(wilson et al.,science,244:1344-1346,1989,nabel and baltimore,nature 326:711-713,1987),任选地使用基于脂质的转染试剂如fugene6(roche)或lipofectamine(invitrogen)通过注射(美国专利号5,994,624、5,981,274、5,945,100、5,780,448、5,736,524、5,702,932、5,656,610、5,589,466和5,580,859,其通过引用并入本文),包括显微注射(harland and weintraub,j.cell biol.,101:1094-1099,1985;美国专利号5,789,215,其通过引用并入本文);通过电穿孔(美国专利号5,384,253,其通过引用并入本文;tur-kaspa et al.,mol.cell biol.,6:716-718,1986;potter et al.,proc.nat'lacad.sci.usa,81:7161-7165,1984);通过磷酸钙沉淀(graham and van der eb,virology,52:456-467,1973;chen and okayama,mol.cell biol.,7(8):2745-2752,1987;rippe et al.,mol.cell biol.,
10:689-695,1990);通过使用deae-葡聚糖然后使用聚乙二醇(gopal,mol.cell biol.,5:1188-1190,1985);通过直接声波加载(fechheimer et al.,proc.nat'lacad.sci.usa,84:8463-8467,1987);通过脂质体介导的转染(nicolau and sene,biochim.biophys.acta,721:185-190,1982;fraley et al.,proc.nat'lacad.sci.usa,76:3348-3352,1979;nicolau et al.,methods enzymol.,149:157-176,1987;wong et al.,gene,10:87-94,1980;kaneda et al.,science,243:375-378,1989;kato et al.,j biol.chem.,266:3361-3364,1991)和受体介导的转染(wu andwu,biochemistry,27:887-892,1988;wu andwu,j.biol.chem.,262:4429-4432,1987);以及此类方法的任何组合,其每一个通过引用并入本文。
[0463]
许多能够介导将相关分子引入细胞中的多肽都已有在先描述并且可以适用于本发明。参见,例如,langel(2002)cell penetrating peptides:processes and applications,crc press,pharmacology and toxicology series。增强跨膜转运的多肽序列的实例包括但不限于果蝇同源异型蛋白触角足转录蛋白(drosophila homeoprotein antennapedia transcriptionprotein,anthd)(joliot et al.,new biol.3:1121-34,1991;joliot et al.,proc.natl.acad.sci.usa,88:1864-8,1991;le roux et al.,proc.natl.acad.sci.usa,90:9120-4,1993)、单纯疱疹病毒结构蛋白vp22(elliott and o'hare,cell 88:223-33,1997);hiv-1转录激活子tat蛋白(green and loewenstein,cell 55:1179-1188,1988;frankel and pabo,cell 55:1289-1193,1988);卡波西fgf信号序列(kfgf);蛋白转导结构域-4(ptd4);penetratin,m918,转运素-10(transportan-10);核定位序列,pep-1肽;两亲肽(例如,mpg肽);递送增强转运蛋白,例如美国专利号6,730,293中所述(包括但不限于在30个、40个或50个氨基酸的连续设置中包含至少5-25个或更多个连续精氨酸或5-25个或更多个精氨酸的肽序列;包括但不限于具有足够的例如至少5个胍基或脒基部分的肽);和市售的penetratin
tm
1肽,以及可从法国巴黎的daitos s.a.获得的平台的diatos肽载体(“diatos peptide vector,dpv”)。另参见wo/2005/084158和wo/2007/123667以及其中描述的其他转运蛋白。这些蛋白不仅可以穿过质膜,并且其他蛋白(例如,本文所述的转录因子)的附着足以刺激这些复合物的细胞摄取。
[0464]
表4:可用于培养各种细胞类型的细胞培养基。
[0465]
[0466]
[0467][0468]
对于分化方法,上述相关细胞类型培养基可用于促进分化。对于细胞维持,可以仅使用本文鉴定的用于细胞维持的因子来培养细胞。例如:
[0469]-将正常人星形胶质细胞(nha)(lonzabioscience)解冻并在matrige中维持1代。(matrigel是由engelbreth-holm-swarm(ehs)小鼠肉瘤细胞分泌的凝胶状蛋白混合物的商品名,并由corning life sciences和bd biosciences生产和销售。trevigen,inc.以商品名cultrex bme销售他们自己的版本。matrigel类似于在许多组织中发现的复杂细胞外环境,并且被细胞生物学家用作培养细胞的底物(基底膜基质))。随后使用accutase将细胞传代并接种到各条件下:无底物、matrigel、fn1(纤连蛋白)、col4a1(胶原蛋白4)、lamb1(ln221)、adam12、col1a2(胶原蛋白i)、edil3和所有因子(上述底物和生长因子的组合,不含matrigel)。
[0470]-原代人心肌细胞培养解冻和维持培养基可以从promocell(heidelberg,德国)购买。细胞在补充有2%胎牛血清、egf(5ng/ml)、fgf2(2ng/ml)、egf(0.5ng/ml)和胰岛素(0.5μg)的肌细胞生长培养基(promocell,c-22011)中培养。随后使用0.04%胰蛋白酶/0.03%
edta(promocell)对细胞进行传代并接种到各条件下:无底物、geltrex(life technologies)、fn1(纤连蛋白)(sigmaaldrich)、col1a2(胶原蛋白i)(sigma aldrich)、tfpi(组织因子途径抑制剂)(prospec-tany technogene ltd)、apoe(载脂蛋白e)(novus biologicals)、fgf7(成纤维细胞生长因子7)(stemcell technologies)和所有配体(上述底物和配体的组合,不含geltrex)。将ren vm细胞(millipore)保存在具有b27补充剂(gibco)、1%肝素(heparin)(stem cell technologies)、1%青霉素和链霉素(gibco)、20ng/ml egf(peprotech)和20ng/ml fgf2(miltenyi biotec)的dmem/f12(gibco)中。使用accutase(stem cell technologies)对细胞进行传代并接种到包被有matrigel(corning)的烧瓶上。为了分化成星形胶质细胞,将培养物转移到星形胶质细胞培养基(dmem high glucosse、n2、10%fbs;gibco)中2周。使用表面标志物cd44(103028,biolegend)分离细胞并重新接种到各条件下:无底物、matrigel、fn1(纤连蛋白)(sigmaaldrich)、col4a1(胶原蛋白iv)(sigma aldrich)、lamb1(层粘连蛋白221)(biolamina)、adam12(sigmaaldrich)、col1a2(胶原蛋白i)(sigmaaldrich)、edil3(r&dsystems)和所有配体(上述底物和分泌配体的组合,不含matrigel)。在第2代(进入传代3天和6天)分析细胞。
[0471]-原代肺动脉平滑肌细胞(hpasmc)和人主动脉内皮细胞(haoec)培养解冻和维持培养基可分别从gibco(c0095c,life technologies,usa)和promocell(c-12271,heidelberg,德国)购买。将平滑肌细胞在补充有胎牛血清4.9%v/v、人碱性成纤维细胞生长因子(2ng/ml)、人类表皮生长因子(0.5ng/ml)、肝素(5ng/ml)、重组人胰岛素样生长因子-i(0.01μg/ml)和bsa(0.2μg/ml)的培养基231(life technologies,usa)中培养。随后使用tryple express(life technologies)对细胞进行传代并接种到各条件下:无底物、geltrex(life technologies)、nid1(nidogen-1)(merck)、col1a1(胶原蛋白i)(southern biotech)、col4a1(胶原蛋白4)(merck)、col6a1(胶原蛋白6)(rockland)、thbs1(血小板反应蛋白1)(merck)、fgf10(成纤维细胞生长因子10)(stemcell technologies)、fgf7(成纤维细胞生长因子7)(stemcell technologies)和所有配体(上述底物和配体的组合,不含geltrex)。
[0472]-在补充有含有胎牛血清(0.05ml/ml)、表皮生长因子(重组人)(5ng/ml)、碱性成纤维细胞生长因子(重组人)(10ng/ml)、胰岛素样生长因子(long r3igf)(20ng/ml)、血管内皮生长因子(重组人)(0.5ng/ml)、抗坏血酸(1μg/ml)和氢化可的松(0.2μg/ml)的补充混合物的内皮细胞生长培养基mv 2(promocell,c-22022)中培养内皮细胞。随后使用tryple express(life technologies)对细胞进行传代并接种到各条件下:无底物、geltrex(life technologies)、fn1(纤连蛋白)(merck)、thbs1(血小板反应蛋白1)(merck)、ctgf(结缔组织生长因子)(life technologies)、pdgfb(血小板衍生的生长因子亚基b)(stemcell technologies)、cyr61(富含半胱氨酸的血管生成诱导剂61)(novus)、bmp4(骨形态发生蛋白4)(life technologies)、bmp6(骨形态发生蛋白6)(merck)和所有配体(上述底物和配体的组合,不含geltrex)。
[0473]-将h9胚胎干细胞保存在包被有玻连蛋白(vitronectin)(gibco)的烧瓶中,并在essential 8培养基(gibco)中培养。
[0474]-对于星形胶质细胞分化,从h9干细胞经由神经祖细胞,将细胞以5x104个细胞/cm2的密度在神经诱导培养基中接种到包被有matrigel的烧瓶中,所述神经诱导培养基含有
dmem/f12、不含维生素a补充剂的b27(gibco)、n2补充剂(gibco)、0.1%2-巯基乙醇(gibco)、0.66%牛血清白蛋白(gibco)、1%丙酮酸钠(gibco)、1%非必需氨基酸(gibco)、1%青霉素和链霉素,100ng/ml ldn193189(tocris bioscience),持续14天。随后将细胞分选以获得ncam 细胞(使用抗psa-ncam抗体,130-115-809,miltenyi biotec),并在包被有matrigel的烧瓶中再扩增7天。扩增一周后,将细胞传代并重新接种到各条件下于星形胶质细胞培养基(gibco)中:matrigel、fn1(纤连蛋白)(sigma aldrich)、col4a1(胶原蛋白4)(sigmaaldrich)、lamb1(ln221)(biolamina)、matrigel adam12(sigma aldrich)、col1a2(胶原蛋白i)(sigma aldrich)、matrigel edil3(r&d systems)和所有因子(上述底物和生长因子的组合,不含matrigel)。然后在第14天和第21天对细胞进行分析。
[0475]-对于心脏分化,根据条件将细胞在第-3天以5x104个细胞/cm2的密度在essential 8培养基(gibco)中接种于matrigel或col1a2-包被的平板上。在第0天,将培养基更换为补充有不含胰岛素的b27补充剂(gibco)、1%青霉素和链霉素(gibco)、213g/ml抗坏血酸(sigma-aldrich)、0.66%牛血清白蛋白(gibco)的rpmi1640(gibco)5天,每天更换培养基。在第0-2天,还向培养物补充3μm chir。在第3天,撤回chir。在第4天和第5天,向培养物补充5μm iwr。第5天后,将培养基随后更换为补充有b27补充剂(gibco)、1%青霉素和链霉素(gibco)、213g/ml抗坏血酸(sigma-aldrich)、0.66%牛血清白蛋白(gibco)的rpmi1640(gibco),每2天更换一次培养基。在分化过程中,细胞在分化培养基中进行它们各自的条件:matrigel(对照)、fgf7(peprotech,10ng/ml)(miyashita et al.,2013)、tgfb3(stemcell technologies,10ng/ml)(dahlin et al.,2014)、tgfb2(stemcell technologies,10ng/ml)、gdf5(stemcell technologies,50ng/ml)、col1a2(胶原蛋白i)(sigma aldrich)和所有配体(上述底物和分泌配体与col1a2包被平板的组合)。除非另有说明,否则根据制造商的建议使用底物和配体。
[0476]
计算机实施的方法
[0477]
本文所述方法的实施方案可以在计算机处理系统中实施。因此,在进一步的方面,本发明提供了一种适合于进行本文公开的任何一种方法的实施方案的计算机处理系统。
[0478]
图10提供了用于实施本文所述的方法的实施方案和/或特征的一种类型的计算机处理系统600的框图。系统600是概括性的计算机处理系统。应当理解,图10没有示出计算机处理系统的所有功能性或物理性组件。例如,没有示出电源或电源接口。然而,系统600将携带电源或被设置为与电源连接(或两者)。还应当理解,特定类型的计算机处理系统将决定合适的硬件和体系结构,并且适于实施本发明的各方面的可选计算机处理系统可以具有与所示出的那些相比额外的、替代的或更少的组件。
[0479]
计算机处理系统600包括至少一个处理单元602。处理单元602可以是单个计算机处理设备(例如,中央处理单元、图形处理单元或其他计算设备),或者可以包括多个计算机处理设备。在一些情况下,所有处理都将通过处理单元602进行;然而,在其他情况下,处理也可以通过系统600可访问和可用(以共享或专用方式)的远程处理设备来进行。
[0480]
通过通信总线(comunications bus)604,处理单元602与一个或多个机器可读存储(存储器)设备进行数据通信,所述存储设备存储用于控制处理系统600的操作的指令和/或数据。在这种情况下,系统600包括系统存储器606(例如,bios)、易失性存储器608(例如,随机存取存储器,例如一个或多个dram模块)和非易失性存储器610(例如,一个或多个硬盘
或固态硬盘)。在一些实施方案中,本文所述的方法中使用的任意一个或多个数据源可以存储在非易失性存储器中(例如,存储chip-seq信息的数据库、蛋白-蛋白相互作用网络数据、基因序列数据库)。
[0481]
系统600还包括一个或多个接口(interface),一般由612表示,系统600通过所述接口与各种设备和/或网络连接。一般而言,其他设备可以与系统600整合,或者可以是单独的。在设备独立于系统600的情况下,设备和系统600之间可以通过有线或无线硬件和通信协议连接,并且可以是直接或间接(例如,联网)连接。
[0482]
与其他设备/网络的有线连接可以通过任何合适的标准或专有硬件和连接协议。例如,系统600可以被设置为通过以下一项或多项与其他设备/通信网络进行有线连接:usb;火线(firewire);esata;雷电接口(thunderbolt);以太网(ethernet);os/2;并行(parallel);串行(serial);hdmi;dvi;vga;scsi;音频接口(audioport)。当然,其他有线连接也是可能的。
[0483]
与其他设备/网络的无线连接可以类似地通过任何合适的标准或专有硬件和通信协议。例如,系统600可以被设置为使用以下一项或多项与其他设备/通信网络进行无线连接:红外线(infrared);蓝牙(bluetooth);wifi;近场通信(near field communications,nfc);全球移动通信系统(global system for mobile communications,gsm)、增强型数据gsm环境(enhanced data gsm environment,edge)、长期演进(long term evolution,lte)、宽带码分多址(wideband code division multiple access,w-cdma)、码分多址(code division multiple access,cdma)。当然,其他无线连接也是可能的。
[0484]
一般而言,与系统600连接的设备(无论是通过有线方式还是无线方式)包括一个或多个输入设备以允许数据输入到系统600/由系统600接收以供处理单元602处理,以及一个或多个输出设备以允许系统600输出数据。下文描述了示例性设备,但是应当理解,并非所有计算机处理系统都将包括所有提到的设备,并且可以很好地使用其他设备和那些所提及设备的替代设备。
[0485]
例如,系统600可以包括或连接到一个或多个输入设备,信息/数据通过所述输入设备输入到系统600中(由系统600接收)。这样的输入设备可以包括键盘、鼠标、轨迹板(trackpad)、麦克风、加速度计(accelerometer)、接近传感器(proximity sensor)、gps设备等。系统600还可以包括或连接到由系统600控制的一个或多个输出设备,以输出信息。这样的输出设备可以包括例如crt显示器、lcd显示器、led显示器、等离子显示器、触摸屏显示器、扬声器、振动模块、led/其他灯等的设备。系统600还可以包括或连接到可以作为输入和输出设备两者的设备,例如系统600可以从其中读取数据和/或向其中写入数据的存储器设备(硬盘驱动器、固态硬盘、磁盘驱动器、紧凑型闪存卡、sd卡等),以及既能显示(输出)数据又能接收触摸信号(输入)的触摸屏显示器。
[0486]
系统600还可以连接到一个或多个通信网络(例如,互联网、局域网、广域网、个人热点等)以将数据传送到联网设备和从联网设备接收数据,这些联网设备本身可以是其他计算机处理系统。
[0487]
系统600可以是任何合适的计算机处理系统,例如,作为非限制性示例,服务器计算机系统、台式计算机、膝上型计算机、上网本计算机、平板计算设备、移动/智能电话、个人数字助理、个人媒体播放器、机顶盒、游戏控制器。
[0488]
通常,系统600将至少包括用户输入和输出设备614(例如触摸屏显示器)和用于与网络150通信的通信接口616。
[0489]
系统600存储或可访问计算机程序/软件(例如指令和数据),其在由处理单元602执行时能设置系统600从而接收、处理和输出数据。此类程序通常包括操作系统,例如microsoftapple osx、apple ios、android、unix或linux。
[0490]
系统600还存储或可访问指令和数据(即软件应用程序),其在由处理单元602执行时能设置系统600从而根据上述各种实施方案进行各种计算机实施的过程/方法。应当理解,在一些情况下,部分或所有的给定的计算机实施的方法将由系统600本身进行,而在其他情况下,处理可以由与系统600进行数据通信的其他设备进行。
[0491]
指令和数据存储在系统600可访问的非瞬态机器可读介质上。例如,指令和数据可以存储在非瞬态存储器610上。指令可以通过传输通道中的数据信号而传输到系统600/由系统600接收,例如通过有线或无线网络连接实现。在一些实施方案中,本文所述的方法中使用的任意一个或多个数据源可以存储在远程数据存储器或服务器系统中。在此类情况下,可以通过有线或无线网络连接实现的传输信道中的数据信号,将数据提供给系统600。例如,存储chip-seq信息的数据库、蛋白-蛋白相互作用网络数据、基因序列数据库可以位于系统600的远端并通过计算机网络(例如能够进行本文所述的方法的互联网)访问。
[0492]
本发明包括以下非限制性实施例。
[0493]
实施例
[0494]
实施例1:数据预处理:组蛋白修饰chip-seq和rna-seq数据
[0495]
由原代细胞、干细胞和组织组成的所有可获得的人类细胞类型的组蛋白修饰数据来自encode存储库。2017年4月20日的代表116种细胞类型的316个样本的h3k4me3 chip-seq数据和代表91种细胞类型的208个样本的h3k27me3 chip-seq数据于2018年1月20日下载。通过使用不同的处理管线参数来获得存储在encode中的经处理的chip-seq数据或定位到不同的人类基因组版本(hg19或hg38)。因此,为了确保一致且凝聚性的chip-seq数据处理,组蛋白chip-seq和相应的控制/输入chip-seq测序文件以bam格式下载,并使用bwa将测序读数与hg38人类基因组和注释版本v25进行重新比对。对于roadmap项目实现的数据集,产生了tagalign fasta格式化文件而不是bam文件,并且将tagalign fasta文件与hg38人类基因组进行比对。使用phantompeakqualtools确定样本质量和片段大小。基于样本(用h3k4me3或h3k27me3抗体处理)中测序读段相对于输入(无抗体对照)的相对富集,来检测chip-seq峰。对于h3k4me3和h3k27me3 chip-seq数据,使用q值阈值为0.1的macs2来调用广峰(call broadpeak),用于与输入样本相比利用组蛋白抗体对样本中读段的富集。对于h3k4me3 chip-seq数据,基于弃峰率(rate ofdiscardedpeaks)和q值严谨性(q-value stringency)增加,来确定系统性峰质量过滤阈值,并且发现在q值为10-5
时,跨所有样本的弃峰率下降到10%以下。因此,使用10-5
的q值来过滤掉h3k4me3 chip-seq数据中的低质量峰。对于h3k27me3 chip-seq数据,由于当q值严谨性增加到0.01时弃掉了许多样本,因此使用默认q值阈值0.1。此外,还去除了少于10,000个峰的低质量样本,以确保使用高质量的样本对细胞类型进行模建。h3k4me3和h3k27me3 chip-seq数据分别有111和81种细胞类型(图1a)。
[0496]
实施例2:epimogrify算法
[0497]
已经开发了一种称为“epimogrify”的计算方法。所述方法对细胞的表观遗传状态进行模建,以预测对细胞身份、细胞维持和细胞转化重要的因子。
[0498]
算法的主要部分如下:
[0499]
(i)定义组蛋白修饰参考峰基因座
[0500]
(ii)鉴定出细胞身份和细胞维持因子
[0501]
(iii)鉴定出用于定向分化和转分化的细胞转化因子
[0502]
(i)定义组蛋白修饰参考峰基因座
[0503]
对于每种细胞类型,将样本合并在一起以获得细胞类型代表性chip-seq谱。细胞类型代表性chip-seq峰宽度是通过跨样本合并峰区域来计算的,峰高度是通过跨所有样本的最大峰高度来计算的。为了比较跨各种细胞类型的chip-seq峰,对所定义的参考峰基因座(reference peak loci,rpl)进行定义,这是通过组合跨所有细胞类型的代表性峰而获得的一组区域(图1c)。设n为细胞类型的数量。对于在x1、x2、
……
xn范围内的每种细胞类型,设b为细胞类型chip-seq峰宽度,h为chip-seq峰高度。参考峰基因座(rpl)的基因组位置是通过合并跨所有细胞类型的峰区域获得的。对于rpl中的每个基因座r1、r2、
……
rn,峰宽度(b)是通过合并跨细胞类型的重叠峰来算的,峰高度(h)通过重叠峰的最大峰高度给出。
[0504][0505][0506]
可以基于峰的基因组位置和基因的转录起始位置(tss),将蛋白编码基因分配给rpl。由于h3k4me3组蛋白修饰是公知的启动子标记,如果峰与基因的启动子区域(距tss 500bp)重叠,则通常将基因分配给峰基因座。然而,应当理解,rpl可以定位于基因中相对于其tss的另一个区域中(包括将所述区域扩展到距tss 500bp以上,包括距tss 1000bp、2000bp或更远)。
[0507]
优选地,在每种细胞类型(x)中,基因(g)的峰宽度值(b)计算为注释到所述基因的n个峰的峰宽度总和。然而,基因的峰高度值计算为注释到所述基因的n个峰的最大高度。是给定细胞类型x在rpl(参考峰基因座)处的峰宽度谱(peakbreadthprofile)。
[0508][0509]
(ii)细胞身份基因和细胞维持因子的鉴定
[0510]
观察到与广h3k4me3 chip-seq宽度相关的基因富含细胞身份基因,因此epimogrify采用h3k4me3 chip-seq峰宽度来对细胞状态进行模建。从这个模型中去除了在基因的tss处同时存在h3k4me3和h3k27me3 chip-seq峰的准备态基因。epimogrify使用三步法来鉴定对细胞类型特异的因子(图2)。首先,基于h3k4me3 chip-seq峰宽度,计算每个rpl处的差异广度得分。然后,基于关联基因在蛋白-蛋白相互作用网络上的值,来确定基因的调控影响。最后,基于排名的蛋白编码基因来预测细胞身份基因,并且epimogrify预测了用于维持细胞状态的信号传导分子。
[0511]
第1步:计算差异广度得分
[0512]
原代细胞和干细胞是均质的细胞群体,而组织由异质的细胞群体组成。因此,将原
代细胞和干细胞作为一组,将组织细胞类型作为另一组,进行比较。为了获得目标细胞类型特异性chip-seq谱,将目标细胞类型与组内的一组背景细胞类型进行比较。例如,如果目标细胞是原代细胞类型,则背景中的细胞类型将是剩余的原代细胞和干细胞类型。由于背景集中的细胞类型不应与目标细胞类型相似,因此仅当chip-seq谱与目标细胞类型的斯皮尔曼相关性小于0.9时才选择背景细胞类型。
[0513]
在感兴趣的目标细胞类型(x)中,如果多于一个参考峰基因座(rpl)分配给基因(g),则基因峰宽度得分(b)由分配的rpl峰宽度(b)值的总和得出。bg
xg
是基因g处背景细胞类型的一组基因峰宽度得分,并且背景细胞类型是基于与目标细胞类型(x)的区别性选择的。δ峰宽度
xg
是目标细胞类型和背景细胞类型的中位基因峰宽度得分之间的基因峰宽度得分的标准化差异。通过单样本威尔科克森检验来评估这种差异的显著性(p值)。细胞类型(x)和基因(g)的差异广度得分(dbs)计算为标准化δ峰宽度和pval的总和。
[0514][0515][0516][0517][0518][0519]
第2步:计算调控差异广度得分
[0520]
为了计算基因对细胞类型的细胞身份基因的调控影响,纳入string v10(一种蛋白-蛋白相互作用网络)的信息。如果实验得分大于零并且组合得分大于500,则选择基因节点之间的相互作用。这确保了使用具有实验证据的高质量网络来确定基因的调控影响。使用了如mogrify中使用的类似的网络得分(net)计算。对于string网络(v)中的所有基因,可以基于基因子网络(vg)中关联基因(r)的dbs的总和来计算网络得分,并针对所述基因的出度节点的数量(o)和关联水平(l)进行校正。为了获得细胞特异性网络,可以去除string网络中没有相关广h3k4me3峰的基因。可以计算关联基因的dbs得分的加权总和(高至关联的第三水平)。
[0521][0522]
细胞类型x中跨所有蛋白编码基因g的标准化网络得分(net)
[0523][0524]
为了构建一个细胞类型特异性网络,去除了峰值宽度小于宽度阈值(87%)的基因(图1e)。检测了dbs和net得分的不同组合对细胞身份基因的富集,并且确定了dbs与网络得分(net)比例为2:1时显示细胞身份基因的最高富集。
[0525][0526]
第三步:预测细胞身份基因和细胞维持因子
[0527]
epimogrify通过基于regdbs对基因进行排名来预测标记细胞身份的蛋白编码基因。对于细胞维持,epimogrify预测了对细胞生长和存活至关重要的信号传导分子,例如受体和配体。受体-配体相互作用对是从一项研究中获得的,并且这些配对是基于跨不同细胞类型的基因表达来鉴定的。注意到约三分之二的配体是由细胞以自分泌方式产生的,其余的配体是通过支持细胞类型模拟微环境而产生的。因此,为了将其并入本模型,对基于细胞特异性regdbs的受体进行优先级排序,因为它们应该是细胞特异性的并且对感兴趣的细胞类型具有调控影响。然后对来自感兴趣的细胞类型和支持细胞类型的配体基于dbs进行优先级排序。最后,通过受体和配体的组合排名对受体-配体对进行优先级排序。可以将预测的受体-配体对中的配体补充到细胞培养条件中。
[0528]
(iii)用于定向分化和转分化的细胞转化因子的鉴定
[0529]
epimogrify采用三步法来鉴定细胞转化因子。首先,对于从源细胞类型到目标细胞类型的细胞转化,计算差异广度得分的变化。然后,确定基因对细胞状态变化的调控影响。最后,预测用于转分化的转录因子并预测用于定向分化的信号传导分子。
[0530]
第1步:计算细胞转化差异广度得分
[0531]
对于细胞转化,设s为源细胞类型,t为目标细胞类型。首先,计算源细胞类型和目标细胞类型的差异广度得分(dbs)。然后,为了获得细胞转化δdbs,计算源dbs得分和靶dbs得分之间的差异。
[0532][0533][0534][0535]
第2步:计算细胞转化调控差异广度得分
[0536]
接下来,将细胞从源细胞类型转化为目标细胞类型的调控网络得分(n)计算为关联节点的细胞转化δdbs得分的加权和。与细胞特异性regdbs计算相似,将细胞转化regδdbs计算为细胞转化δdbs和标准化网络得分的比率为2:1时的综合得分。
[0537][0538][0539][0540]
第3步:预测用于定向分化和转分化的细胞转化因子
[0541]
对于每个细胞转化,通过regδdbs值对蛋白编码基因进行排名。对于转分化,epimogrify预测了转录因子(tf),其是基于tfclass分类定义的蛋白编码基因的子集。对于定向分化,epimogrify预测了信号传导分子,例如受体和配体对。通过细胞转化regδdbs对受体进行优先级排序,通过细胞转化δdbs对相应的配体进行优先级排序。最后,通过受体和配体的组合排名对受体-配体对进行优先级排序。预测的受体-配体对中的配体可以补充到分化方案中。
[0542]
总之,epimogrify对广h3k4me3组蛋白修饰特征(broad h3k4me3 histone modification feature)进行模建,并预测了细胞身份蛋白编码基因、用于细胞维持的信号传导分子、用于定向分化的信号传导分子和用于转分化的tf。
[0543]
实施例3:h3k4me3和h3k27me3组蛋白修饰的特征
[0544]
细胞状态可以通过利用表观遗传组蛋白修饰(即h3k4me3和h3k27me3修饰,其分别是公知的转录激活物和阻遏物标记)进行建模。从encode和roadmap联合数据存储库中获得了各种人细胞类型的h3k4me3和h3k27me3组蛋白修饰谱的chip-seq数据。为了确保跨不同样本和实验对chip-seq数据集具有一致的下游处理,实施了分析管线,并在需要时使用数据驱动的阈值来调用h3k4me3和h3k27me3谱中的显著峰。在过滤低质量峰后,保留了代表具有h3k4me3谱的111种不同细胞类型(51种原代细胞、53种组织、7种干细胞)和具有h3k27me3谱的81种细胞类型(28种原代细胞、45种组织、8种干细胞)的样本(图1a)。为了研究组蛋白修饰对转录状态的影响,使用了来自encode的由137种细胞类型(64种原代细胞、68种组织、5种干细胞)组成的基因表达谱。有40种共同细胞类型可获得表观遗传数据(通过h3k4me3和h3k27me3 chip-seq)和转录数据(通过rna-seq)。chip-seq峰的宽度定义为具有组蛋白修饰沉积的基因组区域的碱基对长度(bp),chip-seq峰的高度定义为组蛋白修饰或信号值的平均富集(图1b)。chip-seq峰宽范围从窄峰到广峰,chip-seq峰高范围从矮峰到高峰,并且这种分布跨所有细胞类型。此外,与h3k4me3相比,h3k27me3具有更多数量的窄和广chip-seq峰,并且已知h3k27me3存在于基因间区域和沉默基因中。
[0545]
接下来,跨所有细胞类型确定了h3k4me3和h3k27me3 chip-seq谱的基因组位置偏好(genomic locationpreference)。评估了蛋白编码基因转录起始位点(tss)周围2000bp窗口内的chip-seq峰的频率。值得注意的是,与h3k27me3标记相比,h3k4me3在距tss 500bp内的峰频率更高。
[0546]
接下来,将h3k4me3和h3k27me3 chip-seq谱注释到蛋白编码基因,并且为了这个目的,基于相关的chip-seq峰宽度或高度分配基因值。图1c显示了蛋白编码基因注释和分配的基因值的详细示意图。对于每种细胞类型,通过合并多个样本或重复样本来获得细胞类型代表性h3k4me3和h3k27me3 chip-seq峰谱(详见方法部分)。接下来,定义了参考chip-seq峰区域,称为参考峰基因座(rpl),其通过合并跨细胞类型的重叠峰获得。对于每个rpl,当基因的启动子区域与基因座重叠时,对蛋白编码基因相对所述基因座进行注释。对于h3k4me3标记,将启动子区域定义为距离基因的tss500bp,因为发现在这个区域中存在更高频率的h3k4me3 chip-seq峰。对于h3k27me3标记,将启动子区域定义为距基因tss-500bp,以考虑内含子处h3k27me3标记进行排除。图1c中的表格给出了基因注释到rpl的实例,以及基于每种细胞类型的chip-seq峰宽度和高度的相应基因值。
[0547]
实施例4:对h3k4me3谱进行模建的数据驱动方法,用以鉴定细胞身份基因
[0548]
为了确定用以模建细胞身份的最佳特征,测试了组蛋白修饰特征例如chip-seq峰宽度和高度,以及转录特征例如基因表达水平。首先,基于h3k4me3和h3k27me3 chip-seq峰宽度和高度的分布以及基因表达,将蛋白编码基因分组到5百分位数的数据帧中。接下来,预测是否有任何组蛋白修饰或基因表达特征仅在细胞身份基因中富集。细胞身份基因通对细胞类型相关go生物过程的文本挖掘来定义,富集的显著性通过fisher精确检验(fet)来计算。观察到在所有细胞类型中,具有高基因表达的数据帧显示出在细胞身份基因和管家
基因富集的显著性更高。发现高h3k4me3 chip-seq峰富集在管家基因中,而广h3k4me3 chip-seq峰显著富集在细胞身份基因中,如先前的研究所示。如预期,h3k27me3阻遏物标记跨所有细胞类型而并未富集在细胞身份基因或管家基因中。由于具有高基因表达或广h3k4me3chip-seq峰的基因显著富集在细胞身份基因中,因此进一步检查这些特征以鉴定出对细胞身份基因进行模建的最佳度量(h3k4me3、rna-seq表达或两者)。对于40种共有的细胞类型,基于其基因表达或h3k4me3 chip-seq峰宽度对基因进行降序排序,并将基因以增加1百分位数的累积窗口进行分组(图1d)。对于每个累积窗口,计算了跨共有细胞类型的细胞身份和管家基因的富集显著性。发现高基因表达与细胞身份和管家基因两者有关,而由广h3k4me3 chip-seq峰标记的基因仅在细胞身份基因中富集(图1d)。接下来,为了确定能够有效鉴定细胞身份基因的h3k4me3 chip-seq峰宽度阈值,检查了细胞身份基因的富集显著性。发现高于峰宽分布的第87百分位数的h3k4me3 chip-seq峰宽度在跨111种细胞类型具有最高的富集显著性(图1e)。对于每种细胞类型,这个阈值(第87百分位数)对应于范围从3,611至15,035个碱基对的chip-seq峰宽度。总之,这些分析表明,广h3k43 chip-seq峰宽度是与细胞身份相关的特征。
[0549]
接下来,开发了一种数据驱动的方法和“基因得分”,通过系统地分析广h3k4me3 chip-seq峰特征来对细胞状态进行模建并鉴定细胞特异性基因。为了鉴定细胞特异性基因,将感兴趣的目标细胞类型与背景细胞类型进行比较。背景细胞类型是基于通过斯皮尔曼相关性计算的与目标细胞类型的区别性来选择的。图2a显示了用于对细胞特异性基因进行优先级排序的方法的示意图。对于每种细胞类型和蛋白编码基因,计算了差异广度得分(dbs),其是通过目标细胞类型和背景之间的chip-seq峰宽度的差异以及这种差异的显著性计算得出的综合得分。根据dbs进行排名的蛋白编码基因是细胞特异性基因,并且为了对具有对细胞的调控影响的细胞特异性基因进行优先级排序,计算了调控差异广度得分(regdbs)(图2b)。regdbs是通过基因的dbs和蛋白-蛋白相互作用网络得分计算的综合得分(composite score)。使用这种方法,可以系统地对111种细胞类型的细胞特异性蛋白编码基因进行优先级排序,并根据regdbs得分对每个基因进行排名。
[0550]
问题是,这种方法与之前的研究相比是否提高了检测细胞身份基因的准确性。通过使用gsea(基因集富集分析(gene set enrichmentanalysis))测量细胞身份基因的富集,比较了模建h3k4me3 chip-seq峰宽度的不同评分度量(图2c)。结果发现,与仅通过h3k4me3 chip-seq峰宽度对蛋白编码基因进行排名相比,dbs显示出细胞身份基因富集分别高2.5倍、3.5倍和3.5倍。regdbs跨所有细胞类型而具有细胞身份基因的最高富集,并且与按峰宽度排序的基因相比,富集增加约5.3倍,与dbs相比增加1.5倍。这证实了本方法在鉴定具有与细胞身份相关的本体(ontology)的基因方面具有更高的准确性。特别地,利用调控网络信息的regdbs得分可用于对细胞特异性基因进行优先级排序。
[0551]
实施例5:epimogrify预测用于细胞维持(例如星形胶质细胞)的因子
[0552]
由于本方法可以有效地对细胞身份基因进行优先级排序,因此假设优先级排序的信号传导分子如受体和配体对于细胞存活和细胞状态的维持至关重要。用于预测细胞维持的信号传导分子的epimogrify方法如图2d所示。假设通过基于regdbs度量对受体进行优先级排序,将有可能鉴定出可以触发细胞身份基因激活的受体(因为这些受体通过其调控影响进行加权)。然而,激活这些受体所需的配体既可以由目标细胞类型以自分泌方式产生,
也可以由支持细胞类型以旁分泌方式产生。因此,相应的配体通过dbs进行优先排序,并获得对目标细胞类型重要的受体-配体对排名(图2d)。当细胞从体内系统转移到体外条件时,它们将表达所需的受体。然而,激活这些受体所需的配体可能会丢失。因此,对于体外细胞维持,假设epimogrify可以预测可以添加到细胞维持培养基中的配体。为了评估epimogrify预测的准确性,在体外在星形胶质细胞上测试了预测用于生长和维持的配体。星形胶质细胞是一种多功能细胞类型,其为神经元提供代谢和结构支持,调控神经发生和大脑连线(brain wiring),并且星形胶质细胞的任何功能障碍都可导致重大的神经系统疾病。因此,为了研究神经系统疾病,提高扩增和维持星形胶质细胞的能力是至关重要的。
[0553]
对于星形胶质细胞的细胞维持,epimogrify预测的前七种信号传导分子是细胞外基质(ecm)中的组分,如fn1、col4a1、lamb1和col1a2,以及分泌的配体,如adam12和edil3。由于lamb1是层粘连蛋白三聚体的一部分,因此使用由lama2组成的星形胶质细胞特异性层粘连蛋白211复合物,并预测了lamb1且预测了lamc1。在从两个不同来源获得的星形胶质细胞,即从神经干细胞和原代星形胶质细胞分化而来的星形胶质细胞中测试了所预测的因子。通过单独补充和一起补充所预测的信号传导分子,在培养条件下培养星形胶质细胞。将不包含额外配体的培养基用作阴性对照,并与作为阳性对照的matrigel进行比较。
[0554]
结果发现,与matrigel相比,在具有epimogrify预测的因子的培养条件下的细胞生长显著增加。(图3a和3b)接下来,对星形胶质细胞标志物例如s100b和gfap进行免疫荧光检测,并且证实了生长速率的增加不会影响细胞的细胞身份(细胞表达了从神经干细胞和原代星形胶质细胞分化而来的星形胶质中的两种标志物)(图3c和3d)。显示了使用仅少量信号传导分子(例如fn1、col1a2或lamb1)即可实现细胞维持,并且在一些情况下,生长效率相当于使用matrigel(在化学上未定义的复合物)。
[0555]
实施例6:epimogrify预测用于细胞维持(例如心肌细胞)的因子
[0556]
对于心肌细胞的维持,epimogrify预测的前七种信号传导分子是fn1、col3a1、tfpi、fgf7和apoe。通过单独补充和一起补充所预测的信号传导分子,在培养条件下培养心肌细胞。将不包含额外配体的培养基用作阴性对照,并与作为阳性对照的geltrex进行比较。
[0557]
结果发现,与geltrex相比,具有epimogrify预测的因子的培养条件下的细胞生长显著增加。(图4a和4b)接下来,对心肌细胞标志物例如gata4和nkx2.5进行免疫荧光检测,并且证实了生长速率的增加不会影响细胞身份(细胞表达所述两种标志物)(图4c)。
[0558]
实施例7:epimogrify预测用于细胞维持(例如平滑肌细胞)的因子
[0559]
接下来,对epimogrify预测的条件进行测试,以确定这些条件是否可以促进平滑肌细胞的体外维持。为了测试在平滑肌细胞中的预测,在体外培养人肺动脉平滑肌细胞(hpasmc)。
[0560]
由于hpasmc的h3k4me3 chip-seq数据不可用,因此使用可获得的最接近的细胞类型“组织:胃平滑肌”的h3k4me3谱,来预测用于平滑肌细胞维持的配体。epimogrify预测的用于平滑肌细胞维持的前13种配体是lama5、col4a1、lama4、nid1、col6a3、col4a6、col4a5、fgf10、fgf7、gnas、col7a1、col1a1和thbs1。这些预测中的一些是复杂蛋白如胶原蛋白4的亚基,胶原蛋白4包含所预测的亚基col4a1、col4a6和col4a5,胶原蛋白6由col6a3得到,并且胶原蛋白1由col1a1得到。因此,测试了胶原蛋白4、nid1、胶原蛋白6、fgf10、fgf7、胶原蛋
白1和thbs1对平滑肌细胞维持的作用。通过单独补充或全部一起补充所预测的配体,来在培养条件下培养平滑肌细胞,将没有额外配体的培养条件作为阴性对照,且将具有化学上未定义的复杂混合物(geltrex)的培养条件作为阳性对照。
[0561]
为了评估预测的有效性,细胞数量的计数和对增殖率的评估一起进行,作为每种条件下细胞生长的替代物。与阴性对照相比,观察到在具有epimogrify预测的配体(例如所有配体一起,胶原蛋白6、胶原蛋白1、nid1和fgf7)的多个培养条件下,增殖率显著增加(图5a和5b)。此外,与阴性对照相比,在含有所有epimogrify预测的维持条件下的平滑肌细胞表达了显著更高百分比的平滑肌标志物α-sma(图5c)。接下来,对平滑肌标志物sm22进行免疫荧光检测,以证明epimogrify预测的条件保留了细胞身份(图5d)。
[0562]
实施例8:epimogrify预测用于细胞维持例如内皮细胞)的因子
[0563]
为了测试在内皮细胞中的预测,我们在体外培养了原代人主动脉内皮细胞(haoec)。由于haoec的h3k4me3 chip-seq数据无法获得,因此使用可获得的最接近的细胞类型“原代细胞:脐静脉内皮细胞”的h3k4me3谱,来预测用于内皮细胞维持的配体。epimogrify预测的用于内皮细胞维持的前十种配体是bmp6、adam9、lamb1、lama4、thbs1、ctgf、bmp4、pdgfb、fn1和cyr61。其中,bmp6、thbs1、ctgf、bmp4、pdgfb、fn1和cyr61在haoec内皮细胞维持中进行了测试。
[0564]
采用与平滑肌细胞相似的实验设计,以在epimogrify预测的条件(组合和单独)中维持内皮细胞,并与阴性和阳性对照(geltrex)进行比较。与阴性对照相比,epimogrify预测的条件(所有配体一起和单独的因子,例如pdgfb、thbs1、ctgf、bmp4、pdgfb和cyr61)能够维持显著更高的细胞数量和增殖率(图6a和b)。此外,epimogrify预测的条件表达了内皮标志物cd31和vwf(图6c和d)。尽管与阴性对照相比,表达vwf标志物的细胞没有显著增加,但在epimogrify定义的条件(具有单独的配体和所有配体一起的条件)下,与化学上未定义的复合物(geltrex)相比,表达所述标志物的细胞显著增加。
[0565]
实施例9:epimogrify预测用于细胞转化(例如星形胶质细胞)的因子
[0566]
由于epimogrify预测了可以维持细胞状态的因子,因此假设通过对细胞状态变化进行模建,可以鉴定细胞转化所需的因子。图7a显示了从源细胞类型到目标细胞类型的细胞状态变化的细胞转换得分计算的详细示意图。可以基于目标细胞类型和源细胞类型之间基因dbs的差异,对细胞状态变化特异的基因进行优先级排序。接下来,基于每个基因对细胞状态变化施加的调控影响,对每个基因进行加权,以得出每个基因的regδdbs得分。对于每个细胞转化,epimogrify对由regδdbs进行排名的蛋白编码基因(包括tf和信号传导分子)进行优先级排序。存在一些经过实验验证的方法来对细胞的转录状态(或转录状态的变化)进行模建并鉴定用于细胞转化的tf,所述方法包括cellnet、d'alessioac et al(这里称为“jsd”,因为它使用jensen-shannon散度统计)和mogrify。将基于表观遗传的epimogrify的预测与基于转录的计算方法的预测进行比较。在epimogrify和jsd之间有29种共有的细胞类型,在epimogrify和mogrify之间有43种,在所有三种方法之间有25种。使用gsea发现,对于共有的细胞转化,epimogrify预测的tf显著富集在jsd(所有转化的76.4%)、mogrify(60.7%)或jsd和mogri两者(69.3%)预测的tf(图7b)。发现epimogrify预测的tf与其他方法之间有显著重叠。已发表的tf高频出现在epimogrify预测的前10种tf中,(图7c),这表明epimogrify在鉴定用于细胞转化的tf上准确性高。
[0567]
接下来,使用epimogrify对用于从胚胎干细胞定向分化为星形胶质细胞的信号传导分子进行优先级排序。在分化方案中测试了所预测的信号传导分子。
[0568]
对epimogrify预测针对星形胶质细胞分化进行了评估,并鉴定出因子,例如fn1、col4a1、lamb1、col1a2、edil3、adam12和wnt5a。将星形胶质细胞分化方案应用于h9胚胎干细胞(图8a),并且在分化的第35天,在“所有配体”条件(所有预测的因子的组合)下观察到呈星形胶质细胞标志物cd44阳性细胞的显著增加。随后在第42天,与matrigel对照相比,在用fn1、col4a1、lamb1、col1a2和“所有配体”处理的h9细胞中观察到表达cd44的细胞显著增加(图8b)。进行免疫荧光,以获得在所有条件下具有gfap和s100b星形细胞标志物的dapi 细胞的百分比(图8d)。在预测的条件下,培养物还在第42天表达星形胶质细胞标志物s100b和gfap(图8c),这表明预测的因子提高了星形胶质细胞分化的效率。
[0569]
对于指示星形胶质细胞特异性(星形胶质细胞转录特征)的一组基因,tpm中基因表达谱的平均z得分是跨三个样本计算的,这些样本在每个时间点和条件下都进行了测序。星形胶质细胞转录特征是(i)从我们的rna-seq数据获得的h9 esc和原代星形胶质细胞之间显著上调的基因,(ii)从fantom5(f5)数据库获得的h9 esc和来自大脑皮层的星形胶质细胞之间显著上调的基因,(iii)从f5数据库获得的h9 esc和来自小脑的星形胶质细胞之间显著上调的基因,(iv)epimogrify grn(基因调控网络)是一个基因集,其含有具有正regdbs得分的原代星形胶质细胞身份基因以及在string网络上的关联基因,直至第一个被调控的邻居,和(v)humanbase grn是从humanbase数据库中获得的星形胶质细胞特异性网络(图8d)。
[0570]
实施例10:epimogrify预测用于细胞转化(例如心肌细胞)的因子
[0571]
接下来对epimogrify预测的转化条件测试心肌细胞分化(fgf7(成纤维细胞生长因子7)、col1a2(胶原蛋白i)、tgfb3(转化生长因子β3)、col6a3(胶原蛋白vi)、efna1(ephrina1)、tgfb2(转化生长因子β2)和gdf5(生长分化因子5))。为此,在h9 esc分化期间将配体单独或一起补充到培养基中(图9a),使用matrigel作为对照。在分化的第12天,观察到在预测条件下表达早期心脏谱系标志物cd82和cd13的细胞显著增加(图9b)。第20天,其余条件也导致细胞表达早期心脏谱系标志物表达,但与matrigel对照相比,预测条件显示在第12天和第20天晚期心脏标志物ctnt的表达显著更高(图9cd)。此外,基于分化细胞搏动(beat)的潜力来确定分化的心肌细胞的表型,表明与matrigel相比,使用epimogrify预测的条件(所有预测因子相结合)时,平板中搏动细胞的比例更大。总之,这些数据表明心脏分化效率增加,产生更高百分比的功能性心肌细胞。
[0572]
实施例11:实验方法
[0573]
细胞计数测定
[0574]
在以下各条件下,将5x103个ren星形胶质细胞和原代星形胶质细胞接种到48孔板上:无底物、matrigel、fn1(纤连蛋白)(sigmaaldrich)、col4a1(胶原蛋白iv)(sigmaaldrich)、lamb1(laminin221)(biolamina)、adam12(sigma aldrich)、col1a2(胶原蛋白i)(sigmaaldrich)、edil3(r&d systems)和所有配体(上述底物和生长因子的组合,不含matrigel)。3天后,使用胰蛋白酶/edta溶液(te)(gibco)解离细胞并使用eve自动细胞计数器(nanoentek inc.)进行计数。
[0575]
对于原代心肌细胞,在以下各条件下将5x104个细胞/孔接种到12孔板上:无底物、
geltrex、fn1(纤连蛋白)、col1a2(胶原蛋白i)、tfpi(组织因子途径抑制剂)、apoe(载脂蛋白e)、fgf7(成纤维细胞生长因子-7)和所有配体(上述底物和配体的组合,不含geltrex。72小时后,使用0.04%胰蛋白酶/0.03%edta(promocell)解离细胞并使用luna-ii
tm
自动细胞计数器(logos biosystem,inc.)进行计数。
[0576]
对于平滑肌细胞,在以下各条件下将5x104个细胞/孔接种到12孔板上:无底物、geltrex、nid1(nidogen-1)、col1a1(胶原蛋白i)、col4a1(胶原蛋白4)、col6a1(胶原蛋白6)、thbs1(血小板反应蛋白1)、fgf10(成纤维细胞生长因子-10)、fgf7(成纤维细胞生长因子-7)和所有配体(上述底物和配体的组合,不含geltrex)。对于内皮细胞:无底物、geltrex、fn1(纤连蛋白)、thbs1(血小板反应蛋白1)、ctgf(结缔组织生长因子)、pdgfb(血小板衍生生长因子亚基b)、cyr61(富含半胱氨酸的血管生成诱导剂61)、bmp4(骨形态发生蛋白4)、bmp6(骨形态发生蛋白6)和所有配体(上述底物和配体的组合,不含geltrex)。72小时后,使用tryple express(life technologies)解离细胞并使用luna-ii
tm
自动细胞计数器(logos biosystem,inc.)进行计数。
[0577]
brdu增殖测定
[0578]
将5x103个ren星形胶质细胞和原代星形胶质细胞接种到底部透明的96孔黑色平板(corning)上。12小时后,根据制造商的建议(细胞增殖elisa,brdu(化学发光),roche)将brdu标记添加到孔中。72小时后,将细胞固定并用抗brdu抗体标记,然后进行底物反应并使用pherastar fsx酶标仪(bmg labtech)进行分析。对于原代心肌细胞,根据制造商的说明使用brdu细胞增殖测定试剂盒(biovision inc.)。简言之,将所示的细胞以5x103个细胞/孔接种到96孔组织培养处理平板(costar)中。72小时后,将brdu溶液添加到每个测定孔中,并在37℃下孵育3小时。通过酶联免疫吸附测定检测正在增殖的细胞并入的brdu。
[0579]
对于平滑肌和内皮细胞,根据制造商的说明使用brdu细胞增殖测定试剂盒(biovision inc.)。简言之,将所示细胞以5x103个细胞/孔接种到96孔组织培养处理平板(costar)中。72小时后,将brdu溶液添加到每个测定孔中,并在37℃下孵育4小时。通过酶联免疫吸附测定检测正在增殖的细胞并入的brdu。
[0580]
流式细胞仪
[0581]
对于分化实验,使用accutase(stem cell technologies)解离培养物并以400xg沉淀5分钟。然后将细胞重悬于含apc-cy7 cd44抗体(103028,biolegend)或pe-cy7 cd13(56159,bd biosciences)和pe cd82(342104,biolegend)的2%胎牛血清(fbs)(gibco)和磷酸盐缓冲液(pbs)(gibco)中,并在4℃下孵育15分钟。用pbs洗涤细胞悬浮液并以400xg沉淀5分钟用于分析。使用4',6-二脒基-2-苯基吲哚(4',6-diamidino-2-phenylindole,dapi)(life technologies)测定细胞的活力。使用bd facsdiva软件(bd bioscience)通过lsr iia分析仪(bd biosciences)分析样品。
[0582]
对于原代心肌细胞、平滑肌细胞和内皮细胞,使用0.04%胰蛋白酶/0.03%edta(promocell)解离细胞并以300xg沉淀5分钟。然后在室温下将细胞悬浮固定在4%多聚甲醛(pfa)中,在facs缓冲液(1x pbs,0.2%bsa)中洗涤两次,并用0.1%triton x-100渗透。心肌细胞的一抗是兔抗人nkx2.5(cell signaling)和兔抗人gata-4(novus biologicals)。用于平滑肌细胞和内皮细胞的一抗分别是针对α平滑肌肌动蛋白的小鼠单克隆抗体(abcam)和针对血管性血友病因子(vonwillebrandfactor)的兔多克隆抗体(abcam)。使用
的二抗包括alexa fluor 488山羊抗兔(life technologies)和alexa fluor 647山羊抗兔(life technologies)。将细胞在室温下用一抗染色30分钟。洗涤两次后,将细胞与二抗孵育,洗涤两次并重悬于facs缓冲液中,使用bd facs-fortessa仪器(bd biosciences)进行流式细胞术分析。
[0583]
免疫荧光
[0584]
将培养的细胞在含4%pfa(sigmaaldrich)的pbs中固定10分钟,然后在含有0.3%triton x-100(sigmaaldrich)的pbs中透化。然后将培养物与一抗和随后的二抗一起孵育(参见以下稀释度)。添加4',6-二脒基-2-苯基吲哚(dapi)(1:1000)(life technologies)以显示细胞核。使用倒置荧光显微镜和附带的相机(nikon eclipse ti)拍摄图像。研究中使用的一抗是:抗s100b(6673,sigmaaldrich,1:200)、抗gfap(ab7260,abcam,1:500)、ctnt(ms-295-p1,thermo fisher,1:100)。研究中使用的二抗(均为1:400)是alexa fluor488驴抗小鼠igg(a21202,life technologies)、alexa fluor 555驴抗兔igg(a31572,life technologies)、alexa fluor 488山羊抗小鼠igg(a28175,life technologies)。
[0585]
对于内皮细胞和平滑肌细胞,将培养的细胞在含4%pfa(sigmaaldrich)的pbs中固定10分钟,然后在含有0.1%triton x-100(sigmaaldrich)的pbs中透化。然后将培养物与一抗和随后的二抗一起孵育(参见以下稀释度)。添加hoechst 33342(1:1000)(life technologies)以显示细胞核。用倒置荧光显微镜拍摄图像。用于内皮细胞和平滑肌细胞的一抗分别是:抗cd31(abcam,1:200)和抗抗tagln/转凝蛋白(transgelin)(abcam,1:200)。研究中使用的二抗(均为1:400)是alexafluor488山羊抗小鼠(life technologies)和alexa fluor488驴抗山羊(life technologies)。
[0586]
rna-seq文库制备和分析
[0587]
使用trizol
tm
试剂(thermo fisher scientific)从27个样本(h9 esc、原代星形胶质细胞和星形胶质细胞分化期间第7、14和21天的细胞)中分离总rna。使用nebnext ultra ii定向rna文库制备试剂盒结合polya mrna富集和用于的multiplex oligos(96个独特的双索引引物对(unique dual index primer pair))并遵循制造商的方案,将rin为8.5-10的100-200ng总rna用于制备rna-seq文库。为了去除多余的引物和接头二聚体(adaptor dimer),使用spri珠子(beckman coulter)将pcr产物纯化两次。使用agilent bioanalyzer dna 1000芯片(duke-nus genome facility)评估文库的质量,并使用kapa文库定量试剂盒(roche)确定每个文库的摩尔浓度。将三个合并的文库(每个文库含有9个样本,在30ul中的合并浓度为8nm)送至illumina hiseq4000(novogeneait genomics singapore)上进行测序。
[0588]
对来自h9 esc、原代星形胶质细胞和星形胶质细胞分化期间不同时间点(第7、14和21天)以及在对照matrigel和epimogrify预测的所有配体的条件下的上述rna-seq数据进行基因表达分析。使用trimmomatic v0.39修整测序读段,并使用starv2.7.3将读段与grch38人类基因组进行比对。使用featurecounts v1.6.0生成样本的基因表达谱,并使用deseq2 v1.26.0计算差异基因表达谱。为了将我们rna-seq数据的基因表达谱与星形胶质细胞转录特征进行比较,使用每百万转录物(transcripts permillion,tpm)标准化法对数据进行标准化。接下来,选择了在原代星形胶质细胞中表达(tpm》1)的5,475个基因,并且对于这些基因,我们计算了跨所有样本(h9 esc、原代星形胶质细胞和不同时间点和条件下分
化的星形胶质细胞)的基因z得分。为了获得星形胶质细胞的转录特征,从fantom5基因表达谱中获得了h9 esc和小脑中的星形胶质细胞之间以及h9和大脑皮层中的星形胶质细胞之间的差异基因表达谱。epimogrify grn由星形胶质细胞身份基因(具有正的regdbs得分的基因)和在string网络上与这些细胞身份基因直接关联的基因组成。humanbase星形胶质细胞特异性grn是从数据库中获得的。
[0589]
应当理解,本说明书中公开和定义的本发明延伸到文本或附图中提及或明显得出的两个或更多个单独特征的所有替代组合。所有这些不同的组合构成了本发明的各种可选方面。
[0590]
本发明的项和实施方案
[0591]
i.一种确定感兴趣的细胞的细胞身份基因的方法,所述方法包括以下步骤:
[0592]-确定感兴趣的细胞中每个蛋白编码基因的h3k4me3修饰区的差异宽度;
[0593]-基于h3k4me3修饰区的差异宽度和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,确定感兴趣的细胞中每个蛋白编码基因的网络得分,其中所述网络含有关于蛋白编码基因的产物之间的相互作用的信息;
[0594]-基于差异宽度和网络得分的组合,确定感兴趣的细胞中每个蛋白编码基因的细胞身份得分;
[0595]-根据每个蛋白编码基因的细胞身份得分对所述每个蛋白编码基因进行优先级排序;
[0596]
从而鉴定出感兴趣的细胞的细胞身份基因。
[0597]
ii.如项i所述的方法,其中确定h3k4me3修饰区的差异宽度包括:确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区的宽度与不同细胞类型的群体中相同基因的h3k4me3修饰区的中位宽度相比的差异。
[0598]
iii.如项ii所述的方法,其中确定网络得分是基于dbs和至少一个网络上每个蛋白编码基因的产物之间的相互作用。
[0599]
iv.一种确定在体外维持细胞类型所需的因子的方法,所述方法包括以下步骤:
[0600]-确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区的宽度与不同细胞类型的群体中相同蛋白编码基因的h3k4me3修饰区的中位宽度相比的差异;
[0601]-基于dbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,确定感兴趣的细胞中每个蛋白编码基因的网络得分,其中所述网络含有关于每个蛋白编码基因的产物与细胞中其他蛋白编码基因产物之间的相互作用的信息;
[0602]-基于dbs和网络得分的组合,确定感兴趣的细胞中每个蛋白编码基因的细胞身份得分(regdbs);
[0603]-根据每个蛋白编码基因的regdbs对所述每个蛋白编码基因进行优先级排序,从而鉴定出感兴趣的细胞的细胞身份基因,其中每个细胞身份基因编码与感兴趣的细胞的细胞身份相关的因子;
[0604]
从而鉴定出在体外维持感兴趣的细胞所需的因子。
[0605]
v.如项i至iv中任一项所述的方法,其中h3k4me3修饰区的差异宽度通过以下确
定:
[0606]-获得关于感兴趣的细胞中每个蛋白编码基因的h3k4me3修饰区的宽度的信息,以获得细胞中每个蛋白编码基因的基因峰宽度得分(b);和
[0607]-计算细胞中每个基因的基因宽度得分与不同类型细胞的群体中相同基因的中值基因宽度得分之间的差异,从而确定感兴趣的细胞中每个蛋白编码基因的差异峰广度得分(dbs)。
[0608]
vi.如项i至v中任一项所述的方法,其中h3k4me3修饰区的宽度基于chip-seq信息确定,优选地其中所述信息从encode数据库获得。
[0609]
vii.如项v或vi所述的方法,其中确定基因峰宽度得分(b)包括:首先定义存在显著h3k4me3修饰的基因组的区域并将这些区域定义为组蛋白修饰参考峰基因座(rpl)。
[0610]
vii.如项vii所述的方法,其中rpl通过合并跨所有细胞类型获得的chip-seq峰区域而获得,优选其中合并的峰区域是重叠的峰区域。
[0611]
ix.如项v至viii中任一项所述的方法,其中每个蛋白编码基因的基因峰宽度得分(b)包括:排除其中鉴定出h3k4me3和h3k27me3修饰区的基因,其中将所述基因鉴定为准备态基因。
[0612]
x.如项i至ix中任一项所述的方法,其中所述h3k4me3修饰包含h3k4me3修饰。
[0613]
xi.如项ii至ix中任一项所述的方法,其中确定h3k4me3修饰区(dbs)的差异宽度包括:组合关于每个蛋白编码基因的h3k4me3修饰区的宽度的差异的信息与该宽度差异的显著性。
[0614]
xii.如项xi所述的方法,其中dbs通过将峰宽的差异与该差异的显著性相加来确定,优选地,其中dbs通过将h3k4me3峰宽差异与显著性的-log10 p值相加来确定。
[0615]
xiii.如项i至xii中任一项所述的方法,其中确定感兴趣的细胞中每个蛋白编码基因的网络得分包括:组合关于网络中每个蛋白编码基因的h3k4me3修饰区的差异宽度(dbs)的信息、基因的出度节点的数量和基因的关联水平。
[0616]
xiv.如项xiii所述的方法,其中网络得分通过将关联基因的dbs相加确定,针对基因的出度节点的数量和关联水平进行加权,以获得网络中关联蛋白编码基因的dbs的加权和。
[0617]
xv.如项i至xiv中任一项所述的方法,其中蛋白-蛋白相互作用网络是string数据库。
[0618]
xvi.如项i至xv中任一项所述的方法,其中细胞身份得分(regdbs)是每个蛋白编码基因对细胞身份的调控影响的指标。
[0619]
xvii.如项i至xvi中任一项所述的方法,其中确定细胞身份得分(regdbs)包括:对编码调控因子的蛋白编码基因进行优先加权。
[0620]
xviii.如项i至xvii中任一项所述的方法,其中确定每个蛋白编码基因的细胞身份得分(regdbs)包括:将h3k4me3修饰区的差异广度(dbs)得分与感兴趣的细胞中跨所有基因的标准化网络得分相加。
[0621]
xix.如项xviii所述的方法,其中dbs和网络得分的加和过程包括:以2:1的因数将dbs相对于网络得分进行加权。
[0622]
xx.如项i至xix中任一项所述的方法,其中根据每个蛋白编码基因的细胞身份得
分(regdbs)对所述每个蛋白编码基因进行优先级排序的步骤包括:基于regdbs值对基因进行排序。
[0623]
xxi.如项i至xx中任一项所述的方法,其中用于在体外维持感兴趣的细胞的因子选自由以下组成的组:参与细胞信号传导的受体-配体对(优选受体-配体对的配体),转录因子和表观遗传重塑因子。
[0624]
xxii.如项i至xxi中任一项所述的方法,其中所述方法包括选择编码参与细胞信号传导的受体-配体对的细胞身份基因,从而鉴定在体外维持感兴趣的细胞所需的信号传导分子。
[0625]
xxiii.如项xxii所述的方法,其中编码细胞表面受体的每个蛋白编码基因根据其regdbs得分进行排名,并且与受体相关的每个配体都根据其dbs得分进行排名,以获得受体和配体的组合排名,并且其中所述组合排名鉴定出补充到用于在体外维持感兴趣的细胞的培养基的配体。
[0626]
xxiv.如项i至xxi中任一项所述的方法,其中所述方法进一步包括选择编码转录因子的细胞身份基因,从而鉴定出在体外维持感兴趣的细胞所需的转录因子。
[0627]
xxv.一种确定感兴趣的细胞的细胞身份基因的方法,所述方法包括以下步骤:
[0628]-确定感兴趣的细胞(x)中每个蛋白编码基因(g)的h3k4me3基因峰值宽度得分(b),其中所述基因峰宽度得分是每个蛋白编码基因的启动子中包含h3k4me3修饰的区域的长度的总和;
[0629]-确定感兴趣的细胞与代表背景基因峰宽度得分的细胞群体的中值基因峰宽度得分之间的基因峰宽度得分的标准化差异(δ峰宽度
xg
),以及该差异的显著性(pval);
[0630]-通过将δ峰宽度和p val值相加,来确定细胞中每个蛋白编码基因的差异广度得分(dbs
xg
);
[0631]-通过组合关于网络中关联基因(r)的差异广度得分(dbs
xg
)的信息,来确定感兴趣的细胞中每个蛋白编码基因的网络得分(netxg),其中所述网络含有关于每个蛋白编码基因的产物与细胞中其他蛋白编码基因产物之间的相互作用的信息;其中针对基因的出度节点的数量(o)和基因的关联水平(l)校正了差异广度得分;其中优选地,计算差异广度得分(dbs
xg
)的加权和(高至关联的第三水平);
[0632]-对感兴趣的细胞(x)中跨所有蛋白编码基因(g)进行网络得分net
xg
的标准化;
[0633]-通过基于差异广度得分(dbs
xg
)和网络得分(net
xg
)的组合对感兴趣的细胞中的每个蛋白编码基因进行评分,来确定感兴趣的细胞中每个蛋白编码基因的调控差异广度得分(regdbs
xg
),其中regdbs
xg
是每个蛋白编码基因对细胞身份的调控影响的指标;
[0634]-根据每个基因的regdbs
xg
对所述每个基因进行优先级排序;
[0635]
从而鉴定出感兴趣的细胞的细胞身份基因。
[0636]
xxvi.如项i至xxv中任一项所述的方法,其中,如果蛋白-蛋白网络中的实验得分大于零并且组合得分大于500,则选择蛋白编码基因产物的节点之间的相互作用,纳入到网络得分的计算中。
[0637]
xxvii.如项i至xxvi中任一项所述的方法,其中确定网络得分包括:从蛋白-蛋白相互作用网络中去除不具有相关峰h3k4me3宽度的蛋白编码基因。
[0638]
xxviii.一种确定从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需
的因子的方法,所述方法包括以下步骤:
[0639]-确定源细胞和目标细胞类型中每个蛋白编码基因的h3k4me3修饰区的差异宽度,以获得源细胞类型和目标细胞类型中每个蛋白编码基因的h3k4me3修饰的得分(dbs);
[0640]-计算源细胞的dbs和目标细胞的dbs之间的差异,以获得源细胞和目标细胞之间每个蛋白编码基因的h3k4me3修饰的差异的度量值(细胞转化δdbs);
[0641]-基于细胞转化δdbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,确定从源细胞类型转化为目标细胞类型的网络得分,其中所述网络含有关于每个蛋白编码基因产物与细胞中其他基因产物之间的相互作用的信息;
[0642]-基于细胞转化δdbs和网络得分的组合,确定目标细胞中每个蛋白编码基因的细胞身份转化得分;
[0643]-根据每个蛋白编码基因的细胞身份转换得分对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标细胞的细胞身份相关的因子;
[0644]
从而确定从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子。
[0645]
xxix.一种确定从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子的方法,所述方法包括以下步骤:
[0646]-确定源细胞和目标细胞中每个蛋白编码基因的差异广度得分(dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区的宽度与不同细胞类型的群体中相同蛋白编码基因的h3k4me3修饰区的中值宽度相比的差异;
[0647]-计算源细胞的dbs与目标细胞的dbs之间的差异,以获得每个蛋白编码基因的细胞转化δdbs;
[0648]-基于细胞转化δdbs和至少一个网络上每个基因的蛋白产物之间的相互作用,确定从源细胞类型到目标细胞类型的细胞转化的网络得分,其中所述网络含有关于每个蛋白编码基因的产物与细胞中其他蛋白编码基因产物之间的相互作用的信息;
[0649]-基于细胞转化δdbs和网络得分的组合,确定目标细胞中每个蛋白编码基因的细胞身份转化得分(regδdbs);
[0650]-根据每个蛋白编码基因的细胞转化regδdbs对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标细胞的细胞身份相关的因子;
[0651]
从而确定从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子。
[0652]
xxx.如项xxviii至xxix中任一项所述的方法,其中h3k4me3修饰区的差异宽度由以下确定:
[0653]-获取关于源细胞和目标细胞中每个蛋白编码基因的h3k4me3修饰区的宽度的信息,以获得每个细胞类型中每个基因的基因峰宽度得分(b);和
[0654]-计算细胞类型中每个蛋白编码基因的基因峰宽度得分与不同类型细胞的群体中相同基因的中值基因峰宽度得分之间的差异,从而确定源细胞和目标细胞中每个基因的差异广度得分(dbs)。
[0655]
xxxi.如项xxvii至xxx中任一项所述的方法,其中h3k4me3修饰区的宽度是基于chip-seq信息确定,优选地其中所述信息从encode数据库获得。
配体对、转录因子或表观遗传重塑因子组成的组。
[0672]
xlviii.如项xxviii至xlvii中任一项所述的方法,其中所述方法进一步包括:选择转录因子的因子子集,从而鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的转录因子,优选地,其中转化是已分化的源细胞向已分化的目标细胞的转分化。
[0673]
xlix.如项xxviii至xlvii中任一项所述的方法,其中所述方法包括:选择是参与细胞信号传导的受体-配体对的因子子集,从而鉴定出从源细胞转化为目标细胞所需的信号传导分子,优选地其中所鉴定的因子用于多能源细胞向分已化的目标细胞的定向分化。
[0674]
l.如项xlix所述的方法,其中根据编码细胞表面受体的每个蛋白编码基因的regdbs得分对所述基因进行排名,并且根据与所述受体相关的每个配体的dbs得分对所述配体进行排名,以获得受体和配体的组合排名,并且其中所述组合排名鉴定出用于补充用于在体外维持感兴趣的细胞的培养基的配体。
[0675]
li.一种确定从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子的方法,所述方法包括以下步骤:
[0676]-确定感兴趣的源细胞(s)和目标细胞(t)中每个蛋白编码基因(g)的h3k4me3基因峰宽度得分(b),其中所述基因宽度得分是每个蛋白编码基因的启动子中包含h3k4me3修饰的区域的长度的总和;
[0677]-确定源细胞与代表背景基因峰宽度得分的细胞的群体的中值基因峰宽度得分之间的基因峰宽度得分的标准化差异(δ峰宽度
sg
),以及该差异的显著性(pval
sg
);
[0678]-确定目标细胞与代表背景基因峰宽度得分的细胞群体的中值基因峰宽度得分之间的基因峰宽度得分的标准化差异(δ峰宽度
tg
),以及该差异的显著性(pval
sg
);
[0679]-将δ峰宽度
sg
和pval
tg
值相加,以获得源细胞中每个蛋白编码基因的差异广度得分(dbs
sg
);
[0680]-将δ峰宽度
tg
和pval
tg
值相加,以获得目标细胞中每个蛋白编码基因的差异广度得分(dbs
tg
);
[0681]-从目标细胞中每个蛋白编码基因的差异广度得分(dbs
tg
)中减去源细胞中相同基因的差异广度得分(dbs
sg
),以获得目标细胞中每个蛋白编码基因的细胞转化δdbs(δdbs
t-sg
);
[0682]-通过将网络中关联基因(r)的细胞转化差异广度得分(δdbs
t-sg
)进行组合,确定目标细胞中每个基因的网络得分(net
t-sg
),其中所述网络含有关于细胞中每个蛋白编码基因的产物之间的相互作用的信息;其中,针对基因的出度节点的数量(o)和基因的关联水平(l)对差异广度得分进行校正;其中优选地,计算细胞转化差异广度得分(δdbs
t-sg
)的加权和(高至关联的第三水平);
[0683]-对跨所有蛋白编码基因的细胞转化网络得分net
t-sg
进行标准化;
[0684]-基于细胞转化差异广度得分(δdbs
t-sg
)和细胞转化网络得分(net
t-sg
)的组合,对每个蛋白编码基因进行评分,从而确定每个蛋白编码基因的细胞转化调控差异广度得分(regδdbs
t-sg
);其中regδdbs
t-sg
是每个蛋白编码基因对目标细胞与对源细胞相比的调控影响的差异的指标;
[0685]-根据每个蛋白编码基因的细胞身份得分regδdbs
t-sg
对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标
细胞的细胞身份相关的因子;
[0686]
从而鉴定出从源细胞转化为表现目标细胞类型的至少一种特征的细胞所需的因子。
[0687]
lii.如项xxviii至li中任一项所述的方法,其中如果蛋白-蛋白相互作用网络中的实验得分大于零并且组合得分大于500,则选择所述网络中蛋白编码基因产物的节点之间的相互作用。
[0688]
liii.如项xxviii至lii中任一项所述的方法,其中确定网络得分包括:从蛋白-蛋白相互作用网络中去除不具有相关峰h3k4me3宽度的基因。
[0689]
liv.如项xlviii所述的方法,进一步包括从每种细胞类型的排名列表中去除转录冗余的tf的步骤。
[0690]
lv.一种在体外维持细胞群体的方法,所述方法包括:
[0691]-提供在细胞培养中的感兴趣的细胞的群体;
[0692]-确定感兴趣的细胞中每个蛋白编码基因的差异广度得分(dbs),其中dbs是基于所有蛋白编码基因的h3k4me3修饰区的宽度与不同细胞类型的群体中相同基因的h3k4me3修饰区的中值宽度相比的差异;
[0693]-基于dbs和至少一个网络上每个基因的蛋白产物之间的相互作用,来确定感兴趣的细胞中每个蛋白编码基因的网络得分,其中所述网络含有关于每个蛋白编码基因的产物与细胞中其他蛋白编码基因产物之间的相互作用的信息;
[0694]-基于dbs和网络得分的组合对感兴趣的细胞中的每个蛋白编码基因进行评分,从而确定感兴趣的细胞中每个蛋白编码基因的regdbs;其中regdbs是每个蛋白编码基因对细胞身份的重要性的指标;
[0695]-根据每个蛋白编码基因的regdbs对所述每个蛋白编码基因进行优先级排序,从而鉴定出感兴趣的细胞的细胞身份基因,其中每个细胞身份基因编码与感兴趣的细胞的细胞身份相关的因子;
[0696]-使感兴趣的细胞的群体与一种或多种与感兴趣的细胞的细胞身份相关的因子接触;
[0697]-将细胞群体在允许在细胞培养中维持感兴趣的细胞的条件下培养足够长的时间,
[0698]
从而在体外维持细胞群体。
[0699]
lvi.一种在体外维持星形胶质细胞的群体的方法,所述方法依次包括以下步骤:
[0700]-提供在细胞培养中的星形胶质细胞的群体;
[0701]-使星形胶质细胞的群体与一种或多种用于维持星形胶质细胞的至少一种特征的因子接触,
[0702]-将星形胶质细胞群体在允许在细胞培养中维持星形胶质细胞的条件下培养足够长的时间;
[0703]-其中所述因子选自:fn1、col4a1、edil3、wnt5a、lamb1、adam12和col1a2,
[0704]
从而在体外维持星形胶质细胞的群体。
[0705]
lvii.如项lvi所述的方法,其中所述因子包含以下、由以下组成或基本上由以下组成:fn1、col4a1、edil3、wnt5a、lamb1、adam12和col1a2。
[0706]
lviii.如项lvi或lvii所述的方法,其中所述方法包括使星形胶质细胞与fn1、col4a1、edil3、wnt5a、lamb1、adam12和col1a2中的1种或多种、2种或更多种、3种或更多种、4种或更多种、5种或更多种接触。
[0707]
lix.如项lvi至lix中任一项所述的方法,其中所述方法进一步包括将星形胶质细胞施用给个体的步骤。
[0708]
lx.一种在体外维持心肌细胞的群体的方法,所述方法包括:
[0709]-提供在细胞培养中的心肌细胞的群体;
[0710]-使心肌细胞的群体与一种或多种用于维持心肌细胞的至少一种特征的因子接触,
[0711]-将心肌细胞群体在适合于在细胞培养中维持心肌细胞的条件下培养足够长的时间;
[0712]-其中所述因子选自:fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3和cxcl12;
[0713]
从而在体外维持心肌细胞的群体。
[0714]
lxi.如项lx所述的方法,其中所述因子包含以下、由以下组成或基本上由以下组成:fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3和cxcl12。
[0715]
lxii.如项lx或lxi所述的方法,其中所述方法包括使心肌细胞与fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3和cxcl12中的一种或多种接触,任选地与fn1、col3a1、tfpi、fgf7、apoe、c3、col1a2、serpine1、col6a3和cxcl12中的2种或更多种、3种或更多种、4种或更多种、5种或更多种或6种或更多种接触;优选地,其中所述因子是fn1、col3a1、tfp1、fgf7和apoe。
[0716]
lxiii.如项lx至lxii中任一项所述的方法,其中所述方法进一步包括将心肌细胞或细胞群体施用给个体的步骤。
[0717]
lxiv.一种将源细胞转化为表现目标细胞类型的至少一种特征的细胞的方法,所述方法包括以下步骤:
[0718]-提供源细胞;
[0719]-确定源细胞和目标细胞类型中每个蛋白编码基因的h3k4me3修饰区的差异宽度,以获得源细胞类型和目标细胞类型中每个蛋白编码基因的h3k4me3修饰的得分(dbs);
[0720]-计算源细胞的dbs和目标细胞的dbs之间的差异,以获得源细胞和目标细胞之间每个蛋白编码基因的h3k4me3修饰的差异的量度值(细胞转化δdbs);
[0721]-基于细胞转化δdbs和至少一个网络上每个蛋白编码基因的蛋白产物之间的相互作用,确定从源细胞类型转化为目标细胞类型的网络得分,其中所述网络含有关于每个蛋白编码基因产物与细胞中其他基因产物之间的相互作用的信息;
[0722]-基于细胞转化δdbs和网络得分的组合,确定目标细胞中每个蛋白编码基因的细胞身份转化得分;
[0723]-根据每个蛋白编码基因的细胞身份转化得分对所述每个蛋白编码基因进行优先级排序,以鉴定出目标细胞的细胞身份基因,其中每个细胞身份基因编码与目标细胞的细胞身份相关的因子;
[0724]-将源细胞在允许源细胞转化为表现目标细胞类型的至少一种特征的细胞的条件
下培养足够长的时间;
[0725]
从而将源细胞转化为表现目标细胞类型的至少一种特征的细胞,任选地,其中增加一种或多种因子的量包括:i)使源细胞与因子或增加细胞表达所述因子的试剂接触;或ii)用编码所述因子的核酸转染源细胞并在细胞中表达所述核酸。
[0726]
lxv.一种用于源细胞分化的方法,所述方法包括增加源细胞中一种或多种因子或其变体的蛋白表达,其中源细胞经分化以表现目标细胞的至少一种特征,其中:
[0727]-源细胞是多能干细胞,且目标细胞是星形胶质细胞;和
[0728]-所述因子是以下一种或多种:fn1、col4a1、col1a2、edil3、adam12、lamb1和wnt5a。
[0729]
lxvi.一种从多能干细胞或神经祖细胞产生表现星形胶质细胞的至少一种特征的细胞的方法,所述方法包括:
[0730]-使多能干细胞或神经祖细胞与源细胞中的因子fn1、col4a1、col1a2、edil3、adam12、lamb1和wnt5a中的一种或多种或其变体接触;和
[0731]-将多能干细胞或神经祖细胞在允许分化为星形胶质细胞的条件下培养足够长的时间;从而从多能干细胞或神经祖细胞产生表现出星形胶质细胞的至少一种特征的细胞。
[0732]
lxvii.一种用于将多能干细胞(优选胚胎干细胞或神经祖细胞)分化为表现星形胶质细胞的至少一种特征的细胞的方法,所述方法包括:i)提供多能干细胞或包含多能干细胞的细胞群体或神经祖细胞;ii)用一种或多种核酸转染所述多能干细胞或神经祖细胞,所述核酸包含编码一种或多种对星形胶质细胞细胞身份重要的因子的核苷酸序列;和iii)培养所述细胞或细胞群体,并且任选地监测所述细胞或细胞群体中的至少一种星形胶质细胞特征,其中:
[0733]
用于将多能干细胞分化为星形胶质细胞的因子,或用于产生表现星形胶质细胞的至少一种特征的细胞的因子包含以下、由以下组成或基本上由以下组成:fn1、col4a1、col1a2、edil3、adam12、lamb1和wnt5a。
[0734]
lxviii.一种从胚胎干细胞或神经祖细胞产生表现星形胶质细胞的至少一种特征的细胞的方法,所述方法包括:
[0735]-增加胚胎干细胞或神经祖细胞中fn1、col4a1、col1a2、edil3、adam12、lamb1和wnt5a中的任意一种或多种或其变体的量;和
[0736]-将胚胎干细胞在用于分化为星形胶质细胞的条件下培养足够长的时间;从而从胚胎干细胞或神经祖细胞产生表现星形胶质细胞的至少一种特征的细胞。
[0737]
lxix.如项lxviii所述的方法,其中增加一种或多种所述因子的量包括:在源细胞中表达编码一种或多种因子的核酸。
[0738]
lxx.如项lxiv至lxix中任一项所述的方法,其中星形胶质细胞的所述至少一种特征是任意一种或多种星形胶质细胞标志物的上调和/或细胞形态的改变,优选其中所述星形胶质细胞标志物选自:gfap、s100b、aldh1l1、cd44和glast1。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。