1.本发明属于冶金技术领域,具体涉及一种钒钛矿高炉炉况稳定性评价方法。
背景技术:
2.钒钛矿高炉冶炼由于入炉tio2负荷高,炉渣中tio2含量高,炉料高熔点相多,炉渣粘度高且熔化性温度高,tio2过还原受温度影响大等特点,高炉参数控制范围窄,高炉上部气流及炉缸工作状况受参数变化,易出现大的波动,为了及时判定高炉操作参数对煤气流、炉缸工作状态的影响,需要对大量样本数据进行分析及建立评价模型。目前已有人工筛选参数、设定权重和阈值的评价模型,但该模型具有较大的局限性,不仅构建模型的过程复杂,而且存在评价不及时、评价吻合度不够可靠的问题。
技术实现要素:
3.本发明要解决的技术问题是提供一种能够快速评价钒钛矿高炉炉况稳定性,且评价吻合度较人工模型更为可靠的方法。
4.本发明解决其技术问题所采用的技术方案是:钒钛矿高炉炉况稳定性评价方法,包括下列步骤:
5.步骤一,选取影响评价因子的主要参数,评价因子为钒钛矿冶炼产量、炉缸活跃性、焦比、铁水硅钛差和煤气流分布中的至少一种;
6.步骤二,判断步骤一选取的主要参数是否有因变量参考值;
7.若有因变量参考值,则先通过相关性矩阵和二元齐次方差分析,或者互信息熵值计算分析,再选择与评价因子相关性显著的操作参数作为模型输入xi;
8.若没有因变量参考值,则先进行pca分析,构建因变量,再进行相关性矩阵和二元齐次方差分析,或者互信息熵值计算分析,之后选择相关性显著的操作参数作为模型输入xi;
9.步骤三,对步骤二选择的xi进行pca分析,计算满足特征参数累计贡献率大于85%的降维变量个数及其权重,并组合成炉况判定参数yi;
10.步骤四,采用自适应模糊神经网络对炉况判定参数yi进行学习与预报,形成钒钛矿高炉炉况稳定性评价模型和模糊规则知识库;
11.步骤五,利用步骤四形成的钒钛矿高炉炉况稳定性评价模型,对钒钛矿高炉的炉况稳定性进行评价。
12.进一步的是,步骤一中,选取相关系数r≥0.7的主要参数。
13.进一步的是,步骤四中,炉况判定参数yi按四区间规则进行学习与预报,钒钛矿高炉炉况稳定性评价模型的评价体系为:指数在1个西格玛波动以内评价为优,指数在1~2个西格玛波动评价为良,指数在2~3个西格玛内波动评价为中,指数大于3个西格玛波动评价为差。
14.进一步的是,步骤一中,选取m个主要参数x1~xm,m为大于1的整数;
15.若主要参数有因变量参考值,步骤二中,按公式进行相关性分析和显著性检验,选择影响yi的显著性参数p<0.05的变量常数项xi和xixj组合作为新的输入变量x
in
;
16.步骤三中,对新的输入变量x
in
进行pca分析得到主成分个数m,并计算特征值λi(i=1,...,m),计算m个主成分pm的相对权重,计算得到综合ai表示回归方程中的xi系数,b
ij
表示回归方程中的xixj回归系数,xixj表示自变量xi和xj两两相乘,γk表示第k个特征值占特征累计值的比例,k表示m个主成分中第k个主成分,pk表示第k个主成分对应的原始数据矩阵,zy表示对m个主成分按权重加权计算得到的综合评价值;
17.若主要参数没有因变量参考值,步骤二和步骤三中,通过pca分析构建zy后,重复步骤一,并更新zy;
18.步骤四,采用自适应模糊神经网络对数据集(x
in
,zyi)进行自适应模糊神经网络学习。
19.进一步的是,评价因子为钒钛矿冶炼产量;
20.步骤四中,形成的钒钛矿高炉炉况稳定性评价模型为t-s模型,并形成有钒钛矿高炉产量的影响因子及结果因子,作为单独模型可组合的输入与输出。
21.本发明的有益效果是:该评价方法采用相关性矩阵和二元齐次方差,或者互信息熵值计算,对因变量参考值或pca分析构建的因变量进行分析,并选择相关性较为显著的影响自变量因子作为评价模型输入,再采用pca算法降维和权重计算,并将降维后的主成分作为评价输入参数,接着采用自适应模糊神经网络重新构建评价模型或组合模型,模型的整个构建过程简单、快捷,最后利用构建的模型能够对钒钛矿高炉的炉况稳定性进行快速评价,且与现有的人工模型评价方法相比,具有筛选参数、计算权重和阈值随样本增加而变更等优点,其评价吻合度更为可靠,利于指导生产。
附图说明
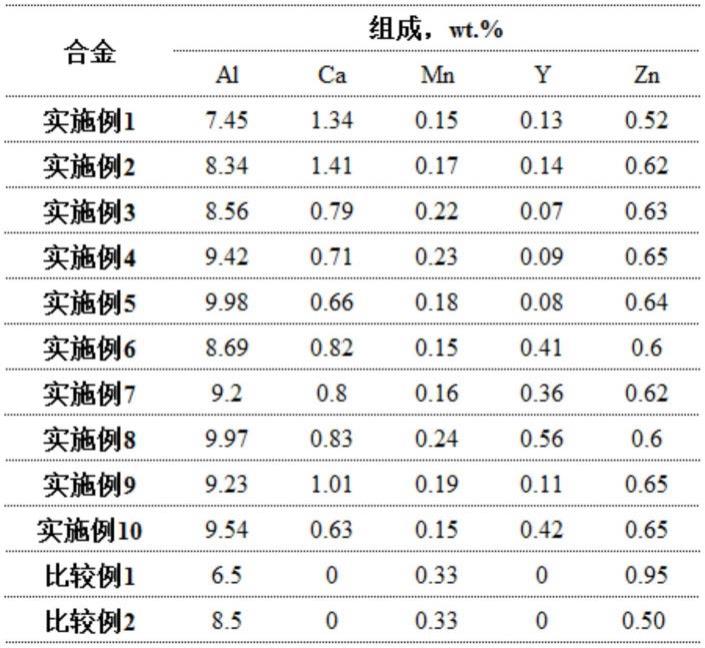
22.图1是本发明实施例1的pca分析结果图;
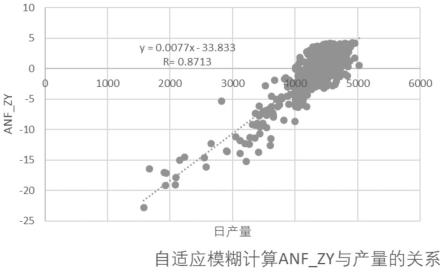
23.图2是本发明实施例1的自适应模糊计算anf_zy与钒钛矿冶炼产量的对应关系图。
具体实施方式
24.下面结合附图和实施例对本发明作进一步的说明。
25.钒钛矿高炉炉况稳定性评价方法,包括下列步骤:
26.步骤一,选取影响评价因子的主要参数,评价因子为钒钛矿冶炼产量、炉缸活跃性、焦比、铁水硅钛差和煤气流分布中的至少一种;影响钒钛矿冶炼产量的主要参数一般包括料速、批重、焦炭负荷、风量、风压、顶压、富氧率和标准风速,影响炉缸活跃性的主要参数一般包括风口回旋区占比、冶炼期、富氧率、鼓风动能、实际风速、tf和炉热指数;选取主要参数时一般选择相关系数r≥0.7的主要参数;
27.步骤二,判断步骤一选取的主要参数是否有因变量参考值;
28.若有因变量参考值,则先通过相关性矩阵和二元齐次方差分析,或者互信息熵值计算分析,再选择与评价因子相关性显著的操作参数作为模型输入xi;
29.若没有因变量参考值,则先进行pca分析,构建因变量,再进行相关性矩阵和二元齐次方差分析,或者互信息熵值计算分析,之后选择相关性显著的操作参数作为模型输入xi;
30.步骤三,对步骤二选择的xi进行pca分析,计算满足特征参数累计贡献率大于85%的降维变量个数及其权重,并组合成炉况判定参数yi;
31.步骤四,采用自适应模糊神经网络对炉况判定参数yi进行学习与预报,形成钒钛矿高炉炉况稳定性评价模型和模糊规则知识库;该步骤中一般采用西格玛作为评价规则,优选的,炉况判定参数yi按四区间规则进行学习与预报,钒钛矿高炉炉况稳定性评价模型的评价体系为:指数在1个西格玛波动以内评价为优,指数在1~2个西格玛波动评价为良,指数在2~3个西格玛内波动评价为中,指数大于3个西格玛波动评价为差;
32.步骤五,利用步骤四形成的钒钛矿高炉炉况稳定性评价模型,对钒钛矿高炉的炉况稳定性进行评价。
33.作为本发明的一种优选方案,该钒钛矿高炉炉况稳定性评价方法,步骤一中,选取m个主要参数x1~xm,m为大于1的整数;
34.若主要参数有因变量参考值,步骤二中,按公式进行相关性分析和显著性检验,选择影响yi的显著性参数p<0.05的变量常数项xi和xixj组合作为新的输入变量x
in
;
35.步骤三中,对新的输入变量x
in
进行pca分析得到主成分个数m,并计算特征值λi(i=1,...,m),计算m个主成分pm的相对权重,计算得到综合ai表示回归方程中的xi系数,b
ij
表示回归方程中的xixj回归系数,xixj表示自变量xi和xj两两相乘,即交互影响;γk表示第k个特征值占特征累计值的比例,k表示m个主成分中第k个主成分,pk表示第k个主成分对应的原始数据矩阵,zy表示对m个主成分按权重加权计算得到的综合评价值;
36.若主要参数没有因变量参考值,步骤二和步骤三中,通过pca分析构建zy后,重复步骤一,并更新zy;
37.步骤四,采用自适应模糊神经网络对数据集(x
in
,zyi)进行自适应模糊神经网络学习。
38.具体的,评价因子为钒钛矿冶炼产量;
39.步骤四中,形成的钒钛矿高炉炉况稳定性评价模型为t-s模型,并形成有钒钛矿高炉产量的影响因子及结果因子,作为单独模型可组合的输入与输出。
40.实施例1
41.某次利用本发明提供的钒钛矿高炉炉况稳定性评价方法,建立评价模型,对钒钛矿高炉炉况稳定性进行评价,过程如下:
42.本次采用的评价因子为钒钛矿冶炼产量,钒钛矿冶炼产量一般指日产量;
43.(1)根据相关性系数矩阵(或者互信息熵值计算,用来判定非线性相关),选择相关系数r》=0.7的参数作为评价产量好坏的输入,具体见下表1;
44.表1:影响钒钛矿冶炼产量的主要参数
45.yx1x2x3x4日产量料速批重焦炭负荷风量x5x6x7x
8 风压顶压富氧率标准风速 46.(2)对y作x1~x9的二次齐次方差分析,选择显著性参数p<0.05数据一次项、二次项作为模型的最终输入:
47.‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
方差分析表
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
48.;
49.‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
参数估计
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
50.[0051][0052]
得到p<0.05的变量为x1~x8,x1*x3,x1*x4,x1*x7,x2*x3,x2*x5,x2*x6,x2*x8,x3*x7,x4*x7,x5*x7,x6*x7,x7*x8,x4*x4,x5*x5共计22个输入参数。对这22个参数进行pca分析,用过程参数来评价结果参数。xi是根据样本数据的相关性计算,系统自动选择二次齐次式的组合方式。
[0053]
把上述组合参数作为输入,对其pca分析结果如图1所示;
[0054]
计算得到γk分别为80.9786、12.6587、6.3627,zy=80.978*m1 12.6587*m2 6.3627*m2主成分其中ui为样本xi的均值,σi样本xi的均值的标准偏差,αi主成分xi在m1的载荷矩阵,图1中右侧已列出,图1中左侧为原始数据。
[0055]
m1m2m3自适应模糊计算zy部分输出-1.2854-2.2665-1.9685-1.4530-1.0408-2.1416-1.6172-1.2169-0.3704-1.6104-1.1141-0.5746-1.4750-1.7842-0.9618-1.4815-1.0993-1.4964-1.4563-1.1723-0.4884-1.4143-1.6844-0.6818-0.4248-1.4789-1.5046-0.6269-0.5090-1.6179-1.5882-0.7180
[0056]
对mi(i=3)及zy构成的样本进行按4个高斯隶属函数进行自适应模糊学习,得到zy1的学习模型与产量预报;由此得到日产量的降维影响因子mi和对应的zy(anf_zy),如图2所示。将zy1作为输出,对数据集(x
in
,zyi)进行自适应模糊神经网络学习(t-s模型)后,对钒钛矿高炉炉况稳定性进行评价。
[0057]
评估高炉稳定性通过过程参数与结果参数的相关性进行预测评估,从综合评估值与最终结果(产量指标)的相关性来看,实例1的评估吻合度较直接多项式回归的相关性略高。
[0058]
实施例2
[0059]
某次利用本发明提供的钒钛矿高炉炉况稳定性评价方法,建立评价模型,对钒钛矿高炉炉况稳定性进行评价,过程如下:
[0060]
本次采用的评价因子为炉缸活跃状态;
[0061]
由于对于炉缸活跃性好坏评价没有明确的指导值,先进行pca主成分分析,形成组合zy2,再以zy2作为因变量,与自变量进行相关性分析或互信息分析(非线性),将显著性p值<0.05的相关参数一并纳入,并进行二次齐次分析,形成组合输入指标来表征,具体见下表2。并将组合后的pca结果作为新的zy2。
[0062]
表2:影响炉缸活跃性的主要参数
[0063]
yx1x2x3x4zy2风口回旋区占比冶炼期富氧率鼓风动能x5x6x7[ti][s]实际风速tf炉热指数
ꢀꢀ
[0064]
根据多元齐次方差分析,得到影响zy2及其降维参数m2i;
[0065]
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
方差分析表
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
[0066][0067]
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
参数估计
‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑
[0068]
[0069]
[0070][0071]
得到p<0.05的变量为x1~x9,x1*x8,x1*x9,x2*x3,x2*x7,x2*x8,x2*x9,x3*x4,x3*x5,x3*x7,x4*x5、x4*x7,x5*x7,x6*x8,x6*x9,x8*x9,x2*x2,x3*x3,x4*x4,x5*x5,x6*x6,x9*x9共计30个输入参数。对这30个参数进行pca分析,用过程参数来评价结果参数。xi是根据样本数据的相关性计算,系统自动选择二次齐次式的组合方式。把上述组合参数作为输入,对其pca分析结果如下,根据实施例1的分析方法,得到炉缸活跃性影响因子m2i(i=5)及并更新zy2。将zy2作为输出,对数据集(x
in
,zyi)进行自适应模糊神经网络学习(t-s模型)后,对钒钛矿高炉炉况稳定性进行评价。
[0072]
评估高炉稳定性通过过程参数与结果参数的相关性进行预测评估,从综合评估值与最终结果(产量指标)的相关性来看,实例2的评估吻合度较直接多项式回归的相关性略高。
[0073]
实施例3
[0074]
某次利用本发明提供的钒钛矿高炉炉况稳定性评价方法,建立评价模型,对钒钛矿高炉炉况稳定性进行评价,过程如下:
[0075]
本次采用的评价因子为煤气流分布;
[0076]
按实施例2相同的方法进行建模,通过pca构建综合评价参数zy3,并进行相关性分析或者互信息分析,选择显著性相关性较强参数,再次进行pca分析,并输入m3(i=5),将上述实施例1和实施例2中的m1(i=3),m2(i=5),m3(i=5)作为输入参数,将zy1、zy2和zy3作为输出,对数据集(x
in
,zyi)进行自适应模糊神经网络学习(t-s模型),按六西格玛原理,形
成钒钛矿高炉炉况稳定性综合评价指数,并确定指数在1个西格玛以内波动为优,1~2个西格玛波动为良,2~3个西格玛内波动为中,大于3个西格玛内波动为差的评价体系,用以判定炉况的稳定性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。