用于对相同单细胞中的蛋白质表达、单核苷酸变异和拷贝数变异进行多组学同时检测的方法、系统和设备
1.交叉引用
2.本技术要求2019年8月12日提交的美国临时申请第62/885,490号的权益和优先权,将所述申请的全部公开内容出于所有目的以引用的方式整体并入本文。
背景技术:
3.肿瘤基因组分析的最新进展已经揭示癌症疾病通过体细胞变异、克隆扩增和选择的反复过程而演化。因此,肿瘤内和肿瘤间基因组异质性已成为研究的主要领域。虽然下一代测序对癌症生物学的理解有显著贡献,但是肿瘤在单个细胞水平上的遗传异质性被整体测量提供的平均读数所掩盖。需要非常高的总体序列读取深度来鉴定较低流行率的突变。在所选细胞群体之内和之间的罕见事件和突变共现被此类平均信号遮蔽。因此,难以鉴定细胞(诸如癌细胞)中的异质细胞群体,这使得癌症治疗方案的有效性较差。
技术实现要素:
4.本文描述了用于对多个细胞进行单细胞分析以确定单个细胞的细胞基因型和表型的实施方案。在各种实施方案中,单个细胞的细胞基因型和表型为发现以前可能未知的特征在于那些基因型和表型的细胞亚群提供信息。这在其中通常存在异质细胞群体但不容易被探询或发现的癌症的情况下尤其有用。细胞亚群的鉴定为提高对疾病生物学的理解以及随后更好地设计诊断剂和治疗剂提供信息。
5.本文公开的特定实施方案涉及直接从细胞基因组dna确定细胞基因型。具体来说,基因组dna被直接加条形码,扩增和测序以确定细胞基因型(例如,snv和cnv)。与不太直接的方法相比,此类涉及从基因组dna直接确定细胞基因型的方法是优选的。例如,不太直接的方法涉及对已经从rna转录物逆转录的cdna测序,从而提供细胞基因型的间接读数。本文公开的涉及从基因组dna直接确定细胞基因型的方法包括以下优点:1)实现对跨越编码区和非编码区的细胞基因型的更广泛理解(然而不太直接的方法仅确定编码区的细胞基因型),2)避免逆转录,从而提高调用细胞突变诸如snv和cnv的准确性(例如,避免由于逆转录而产生的错误和/或加工伪迹),3)降低由于包含逆转录所需的试剂(例如,逆转录酶)而产生的单细胞工作流过程的成本。
6.本文公开了一种用于分析多个细胞的方法,所述方法包括:对于所述多个细胞中的一个或多个细胞:将所述细胞包封在包含试剂的乳液中,所述细胞包含至少一种dna分子和至少一种结合分析物的抗体缀合的寡核苷酸;裂解所述乳液中的细胞以产生包含所述至少一种dna分子和所述寡核苷酸的细胞裂解物;将包含所述至少一种dna分子和所述寡核苷酸的细胞裂解物与反应混合物一起包封在第二乳液中;使用所述反应混合物在所述第二乳液内进行核酸扩增反应以产生扩增子,所述扩增子包含:源自所述至少一种dna分子之一的第一扩增子;和源自所述寡核苷酸的第二扩增子;对所述第一扩增子和所述第二扩增子进行测序;使用至少经测序的第一扩增子确定所述细胞的一个或多个突变;使用至少所述第
二扩增子确定分析物的存在或不存在;以及在所述多个细胞中发现细胞亚群,所述细胞亚群的特征在于所述一个或多个突变以及所述分析物的存在或不存在。
7.在各种实施方案中,所述一个或多个突变包括单核苷酸变体(snv)或拷贝数变异(cnv)。在各种实施方案中,所述一个或多个突变包括单核苷酸变体(snv)和拷贝数变异(cnv)。在各种实施方案中,发现所述多个细胞中的细胞亚群包括根据所鉴定的snv或cnv对所述一个或多个细胞进行聚类。
8.在各种实施方案中,在与以下各项相关的基因中鉴定出snv或cnv:急性成淋巴细胞性白血病、急性髓性白血病、慢性淋巴细胞性白血病、慢性髓性白血病、经典霍奇金淋巴瘤、弥漫性大b细胞淋巴瘤、滤泡性淋巴瘤、套细胞淋巴瘤、多发性骨髓瘤、骨髓增生异常综合征、髓性疾病、骨髓增生性肿瘤、t细胞淋巴瘤、乳腺浸润性癌、结肠腺癌、多形性胶质母细胞瘤、肾透明细胞癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢癌、胰腺腺癌、前列腺腺癌或皮肤黑素瘤。在各种实施方案中,在以下各项中的任一者中鉴定出snv或cnv:abl1、gnb1、kmt2d、plcg2、gna13、atm、braf、jak3、ado、dnmt3a、serpina1、xpo1、pim1、ccnd1、flt3、stat3、akt1、fat1、ctcf、tp53、notch1、kras、alk、myb、dnm2、ddx3x、cd79a、ubr5、pten、apc、pax5、runx1、map2k1、cd79b、birc3、kmt2c、ar、chd4、phf6、pot1、calr、tet2、orai1、ovgp1、zmym3、myc、gata2、card11、tp53bp1、tbl1xr1、btk、whsc1、mpl、fas、cdh1、ikzf3、lrfn2、egr2、socs1、ptpn11、plcg1、cdk4、wtip、zfhx4、med12、tnfrsf14、fam46c、cdkn2a、bcor、sorcs1、rps15、tnfaip3、irf4、cbl、csf1r、rpl22、btg1、stat6、pik3ca、gnas、ctnnb1、asxl2、bcl11b、ezh2、ddr2、atrx、myd88、arid1a、fgfr3、rad21、egfr、ikzf1、smarca4、setd2、jak2、erbb2、klf9、erg、crebbp、rb1、chek2、erbb3、etv6、rpl10、bcl2、dis3、idh1、erbb4、nras、nfkbie、notch2、esr1、hcn4、sf3b1、stat5b、ccnd3、u2af1、fbxw7、cnot3、ep300、csf3r、fgfr1、usp9x、wt1、idh2、fgfr2、slc25a33、sh2b3、nf1、zfp36l2、kit、traf3、setbp1、dnah5、ncor1、abl1、asxl1、gna11、epor、gnaq、xbp1、cdkn1b、ush2a、npm1、hnf1a、frem2、lef1、hras、opn5、zrsr2、tspyl2、lmo2、jak1、b2m、tal1、mga、nfkbia、araf、zeb2、kdr、il7r、slc5a1、mycn、prdm1、map2k2、phip、met、mlh1、rel、znf217、nos1、mtor、kdm6a、sptbn5、suz12、uba2、pdgfra、pik3r1、gata3、chd2、hdac7、smc1a、raf1、mdga2、usp7、spen、ret、zfr2、smad4、itsn1、smarcb1、bcorl1、smc3、smo、rpl5、src、foxo1、stk11、ebf1、pik3cd、kmt2a、rhoa、cxcr4、ppm1d、vhl、lrp1b和stag2。
9.在各种实施方案中,确定分析物的存在或不存在包括确定分析物的表达水平,分析物被与寡核苷酸缀合的抗体结合。在各种实施方案中,分析物是以下各项中的任一者:hla-dr、cd10、cd117、cd11b、cd123、cd13、cd138、cd14、cd141、cd15、cd16、cd163、cd19、cd193(ccr3)、cd1c、cd2、cd203c、cd209、cd22、cd25、cd3、cd30、cd303、cd304、cd33、cd34、cd4、cd42b、cd45ra、cd5、cd56、cd62p(p选择蛋白(selectin))、cd64、cd68、cd69、cd38、cd7、cd71、cd83、cd90(thy1)、fcεriα、siglec-8、cd235a、cd49d、cd45、cd8、cd45ro、小鼠igg1κ、小鼠igg2aκ、小鼠igg2bκ、cd103、cd62l、cd11c、cd44、cd27、cd81、cd319(slamf7)、cd269(bcma)、cd99、cd164、kcnj3、cxcr4(cd184)、cd109、cd53、cd74、hla-dr、hla-dp、hla-dq、hla-a、hla-b、hla-c、ror1、膜联蛋白a1或cd20。
10.在各种实施方案中,在多个细胞中发现细胞亚群包括根据所确定的分析物存在或不存在对一个或多个细胞进行聚类。
11.在各种实施方案中,根据所鉴定的snv或cnv对一个或多个细胞进行聚类或根据所确定的分析物存在对一个或多个细胞进行聚类包括执行降维分析,所述降维分析选自以下中的任一者:主成分分析(pca)、线性判别分析(lda)、t分布式随机邻域嵌入(t-sne)或均匀流形近似和投影(umap)。
12.在各种实施方案中,所公开的方法还包括:在将细胞包封在乳液中之前,将细胞暴露于多种抗体缀合的寡核苷酸;并且洗涤细胞以除去过量的抗体缀合的寡核苷酸。在各种实施方案中,与多种抗体缀合的寡核苷酸包含pcr柄、标签序列和捕获序列。在各种实施方案中,所述多个细胞包含癌细胞。在各种实施方案中,癌细胞是以下各项中的任一者:急性成淋巴细胞性白血病、急性髓性白血病、慢性淋巴细胞性白血病、慢性髓性白血病、经典霍奇金淋巴瘤、弥漫性大b细胞淋巴瘤、滤泡性淋巴瘤、套细胞淋巴瘤、多发性骨髓瘤、骨髓增生异常综合征、髓性疾病、骨髓增生性肿瘤、t细胞淋巴瘤、乳腺浸润性癌、结肠腺癌、多形性胶质母细胞瘤、肾透明细胞癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢癌、胰腺腺癌、前列腺腺癌或皮肤黑素瘤。
13.在各种实施方案中,所述方法还包括将第一条形码和第二条形码与至少一种dna分子、寡核苷酸和反应混合物一起包封在第二乳液中。在各种实施方案中,第一核酸包含第一条形码。在各种实施方案中,第二核酸包含第二条形码。在各种实施方案中,第一条形码和第二条形码共享相同的条形码序列。在各种实施方案中,第一条形码和第二条形码共享不同的条形码序列。在各种实施方案中,第一条形码和第二条形码可释放地附接到第二乳液中的珠粒。
14.附图中几个视图的简述
15.参考以下描述和附图将更好地理解本发明的这些和其他特征、方面和优点,其中:
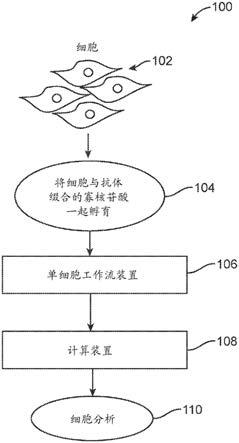
16.图(附图)1a描绘了根据一个实施方案的包括单细胞工作流装置和用于进行单细胞分析的计算装置的总体系统环境。
17.图1b示出了根据一个实施方案处理单细胞以产生用于测序的扩增核酸分子的实施方案。
18.图2示出了使用来源于单个细胞的序列读数确定细胞基因型和表型并使用细胞基因型和表型分析细胞的流过程。
19.图3a-3c示出了根据一个实施方案在第一乳液中的分析物释放的步骤。
20.图4a展示了根据一个实施方案的抗体缀合的寡核苷酸的引发和加条形码。
21.图4b展示了根据一个实施方案的基因组dna的引发和加条形码。
22.图5和图6示出了根据一个实施方案使用单细胞工作流分析的示例性基因靶标和蛋白质靶标。
23.图7描绘了用于实现参考图1-6所描绘的系统和方法的示例性计算装置。
24.图8描绘了根据不同蛋白质表达的细胞聚类。
25.图9a描绘了四种不同的细胞系和将细胞系彼此区分的snv。
26.图9b描绘了根据蛋白质表达的细胞聚类,具有细胞基因型的额外覆盖。
27.图10描绘了在4个细胞系中观察到的13个基因的基因水平拷贝数和观察到的基因水平拷贝数与cosmic数据库中已知水平的相关性。
28.图11描绘了根据cnv的细胞聚类,具有通过snv进行细胞分型的额外覆盖。
29.图12a描绘了使用从单细胞获得的snv、cnv或蛋白质数据之一对来自混合群体的不同细胞亚群进行聚类和鉴定。
30.图12b描绘了使用从单细胞获得的snv、cnv和蛋白质数据之一对来自混合群体的不同细胞亚群进行聚类和鉴定。
具体实施方式
31.定义
32.除非另有规定,否则如下文所阐述的对权利要求书和说明书中使用的术语进行定义。
33.术语“受试者”或“患者”可互换使用,并且涵盖有机体、人或非人哺乳动物或非哺乳动物雄性或雌性。
34.术语“样品”或“测试样品”可以包括通过包括静脉穿刺、排泄、射精、按摩、活检、针吸、灌洗样品、刮片、外科切口、或介入或本领域已知的其他手段等方式从受试者获取的单个细胞或多个细胞或细胞碎片或体液等分试样诸如血液样品。
35.术语“分析物”是指细胞的组分。细胞分析物可以为理解细胞的状态、行为或轨迹提供信息。因此,使用本文所述的系统和方法执行对细胞的一种或多种分析物的单细胞分析为确定细胞的状态或行为提供信息。分析物的实例包括核酸(例如,rna、dna、cdna)、蛋白质、肽、抗体、抗体片段、多糖、糖、脂质、小分子或其组合。在特定的实施方案中,单细胞分析涉及分析两种不同的分析物,诸如蛋白质和dna。在特定的实施方案中,单细胞分析涉及分析细胞的三种或更多种不同的分析物,诸如rna、dna和蛋白质。
36.短语“细胞表型”是指一种或多种蛋白质的细胞表达(例如,细胞蛋白质组学)。在各种实施方案中,使用单细胞分析确定细胞表型。在各种实施方案中,细胞表型可以指一组蛋白质(例如,涉及癌症过程的一组蛋白质)的表达。在各种实施方案中,蛋白质组(protein panel)包括涉及以下血液恶性肿瘤中任一者的蛋白质:急性成淋巴细胞性白血病、急性髓性白血病、慢性淋巴细胞性白血病、慢性髓性白血病、典型霍奇金淋巴瘤、弥漫性大b细胞淋巴瘤、滤泡性淋巴瘤、套细胞淋巴瘤、多发性骨髓瘤、骨髓增生异常综合征、髓性疾病、骨髓增生性肿瘤或t细胞淋巴瘤。在各种实施方案中,蛋白质组包括涉及以下实体瘤中任一者的蛋白质:乳腺浸润性癌、结肠腺癌、多形性胶质母细胞瘤、肾透明细胞癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢癌、胰腺腺癌、前列腺腺癌或皮肤黑素瘤。所述组中的示例性蛋白质可以包括以下各项中的任一者:hla-dr、cd10、cd117、cd11b、cd123、cd13、cd138、cd14、cd141、cd15、cd16、cd163、cd19、cd193(ccr3)、cd1c、cd2、cd203c、cd209、cd22、cd25、cd3、cd30、cd303、cd304、cd33、cd34、cd4、cd42b、cd45ra、cd5、cd56、cd62p(p选择蛋白(selectin))、cd64、cd68、cd69、cd38、cd7、cd71、cd83、cd90(thy1)、fcεriα、siglec-8、cd235a、cd49d、cd45、cd8、cd45ro、小鼠igg1κ、小鼠igg2aκ、小鼠igg2bκ、cd103、cd62l、cd11c、cd44、cd27、cd81、cd319(slamf7)、cd269(bcma)、cd99、cd164、kcnj3、cxcr4(cd184)、cd109、cd53、cd74、hla-dr、hla-dp、hla-dq、hla-a、hla-b、hla-c、ror1、膜联蛋白a1或cd20。
37.短语“细胞基因型”是指细胞的遗传组成,并且可以指细胞的一个或多个基因和/或等位基因的组合(例如,纯合的或杂合的)。短语细胞基因型还涵盖细胞的一个或多个突变,包括多态性、单核苷酸多态性(snp)、单核苷酸变体(snv)、插入、缺失、敲入、敲除、拷贝
数变异(cnv)、复制、易位和杂合性丢失(loh)。在各种实施方案中,使用单细胞分析确定细胞表型。在各种实施方案中,细胞表型可以指一组基因(例如,涉及癌症过程的一组基因)的表达。在各种实施方案中,所述组(panel)包括涉及以下血液恶性肿瘤中任一者的基因:急性成淋巴细胞性白血病、急性髓性白血病、慢性淋巴细胞性白血病、慢性髓性白血病、典型霍奇金淋巴瘤、弥漫性大b细胞淋巴瘤、滤泡性淋巴瘤、套细胞淋巴瘤、多发性骨髓瘤、骨髓增生异常综合征、髓性疾病、骨髓增生性肿瘤或t细胞淋巴瘤。在各种实施方案中,所述组包括涉及以下实体瘤中任一者的基因:乳腺浸润性癌、结肠腺癌、多形性胶质母细胞瘤、肾透明细胞癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢癌、胰腺腺癌、前列腺腺癌或皮肤黑素瘤。例如,对于急性成淋巴细胞性白血病,探询以下基因:asxl1、gata2、kit、ptpn11、tet2、dnmt3a、idh1、kras、runx1、tp53、ezh2、idh2、npm1、sf3b1、u2af1、flt3、jak2、nras、srsf2或wt1。
38.在一些实施方案中,如本文所述的离散实体是液滴。术语“乳液”、“滴”、“液滴”和“微液滴”在本文中可互换使用,是指包含由与第一流体相不可混溶的第二流体相(例如油)所界定的至少第一流体相(例如,水相(例如水))的小的通常球状的结构。在一些实施方案中,根据本公开的液滴可以包含由第二不可混溶的流体相(例如,水相流体(例如水))所界定的第一流体相(例如油)。在一些实施方案中,第二流体相将是不可混溶相载体流体。因此,根据本公开的液滴可以作为油包水乳液或水包油乳液提供。对于离散实体,液滴的尺寸和/或形状可以如本文所述。例如,根据本公开的液滴的直径通常在1μm至1000μm的范围内(包含端值)。根据本公开的液滴可以用于包封细胞、核酸(例如,dna)、酶、试剂、反应混合物和各种其他组分。术语乳液可以用于指在微流体装置中产生、在微流体装置上产生或由微流体装置产生和/或从微流体装置流出或由微流体装置施加的乳液。
39.术语“抗体”涵盖单克隆抗体(包括全长单克隆抗体)、多克隆抗体、多特异性抗体(例如,双特异性抗体)和抗原结合的抗体片段,例如抗体或其抗原结合片段。如本文所用的“抗体片段”及其所有语法变体被定义为包含完整抗体的抗原结合位点或可变区的完整抗体的一部分,其中所述部分不含完整抗体的fc区的恒定重链结构域(即ch2、ch3和ch4,取决于抗体同种型)。抗体片段的实例包括fab、fab'、fab'-sh、f(ab')2和fv片段;双抗体;作为具有由连续氨基酸残基的一个不间断序列组成的一级结构的多肽的任何抗体片段(本文称为“单链抗体片段”或“单链多肽”)。
[0040]“互补性”是指核酸形成氢键或通过传统的沃森-克里克(watson-crick)或其他非传统类型与另一核酸序列杂交的能力。如本文所用,“杂交”是指分子在低、中或高度严格条件下仅与特定核苷酸序列结合、双重化或杂交,包括当所述序列存在于复杂混合物(例如,总细胞)dna或rna中时。参见例如ausubel等人,current protocols in molecular biology,john wiley&sons,new york,n.y.,1993。如果多核苷酸的特定位置处的核苷酸能够与反平行dna或rna链中相同位置处的核苷酸形成沃森-克里克配对,则所述多核苷酸和dna或rna分子在所述位置处彼此互补。当每个分子中足够数量的相应位置被可以彼此杂交或退火以影响所需过程的核苷酸占据时,多核苷酸和dna或rna分子彼此“基本互补”。互补序列是能够在严格条件下退火以提供用作互补链的合成起点的3'-末端的序列。
[0041]
本领域已知的“同一性”是两个或更多个多肽序列或两个或更多个多核苷酸序列之间的关系,如通过比较序列所确定。在本领域中,“同一性”还指多肽或多核苷酸序列之间
的序列相关性程度,如通过这些序列的串之间的匹配所确定。“同一性”和“相似性”可容易地通过已知方法来计算,所述方法包括但不限于在computational molecular biology,lesk,a.m.编,oxford university press,new york,1988;biocomputing:informatics and genome projects,smith,d.w.编,academic press,new york,1993;computer analysis of sequence data,第i部分,griffin,a.m.和griffin,h.g.编,humana press,new jersey,1994;sequence analysis in molecular biology,von heinje,g.,academic press,1987;和sequence analysis primer,gribskov,m.和devereux,j.编,m stockton press,new york,1991;以及carillo,h.和lipman,d.,siam j.applied math.,48:1073(1988)中描述的那些。此外,可以从使用vector nti suite 8.0(informax,frederick,md.)的alignx组件的默认设置产生的氨基酸和核苷酸序列比对中获得同一性百分比值。确定同一性的优选方法被设计成在测试的序列之间提供最大匹配。确定同一性和相似性的方法编入公开可用的计算机程序中。确定两个序列之间的同一性和相似性的示例计算机程序方法包括但不限于gcg程序包(devereux,j.等人,nucleic acids research 12(1):387(1984))、blastp、blastn和fasta(atschul,s.f.等人,j.molec.biol.215:403-410(1990))。blast x程序可从ncbi和其他来源公开获得(blast manual,altschul,s.,等人,ncbinlm nih bethesda,md.20894:altschul,s.等人,j.mol.biol.215:403-410(1990)。众所周知的史密斯沃特曼算法(smith waterman algorithm)也可用于确定同一性。
[0042]
术语“扩增”、“扩增反应”及其变型通常是指核酸分子(称为模板核酸分子)的至少一部分凭借其被复制或拷贝到至少一个另外的核酸分子中的任何动作或过程。额外的核酸分子任选地包括与模板核酸分子的至少一些部分基本上相同或基本上互补的序列。模板核酸分子可以是单链或双链的,并且另外的核酸分子可以独立地是单链或双链的。在一些实施方案中,扩增包括用于产生核酸分子的至少一些部分的至少一个拷贝或产生与核酸分子的至少一些部分互补的核酸序列的至少一个拷贝的模板依赖性体外酶催化反应。扩增任选地包括核酸分子的线性或指数复制。在一些实施方案中,使用等温条件执行这种扩增;在其他实施方案中,这种扩增可包括热循环。在一些实施方案中,扩增是包括在单个扩增反应中同时扩增多个靶序列的多重扩增。至少一些靶序列可以位于包括在单个扩增反应中的相同核酸分子或不同靶核酸分子上。在一些实施方案中,“扩增”包括单独或组合扩增基于dna和rna的核酸的至少一些部分。扩增反应可以包括单链或双链核酸底物,并且可以进一步包括本领域普通技术人员已知的任何扩增过程。在一些实施方案中,扩增反应包括聚合酶链反应(pcr)。在一些实施方案中,扩增反应包括等温扩增反应,诸如lamp。在本发明中,使用术语核酸的“合成”和“扩增”。本发明中的核酸合成是指核酸从用作合成起点的寡核苷酸伸长或延伸。如果不仅这种合成而且其他核酸的形成以及这种形成的核酸的伸长或延伸反应连续发生,则这一系列反应统称为扩增。通过所采用的扩增技术产生的多核酸通常称为“扩增子”或“扩增产物”。
[0043]
可以利用任何核酸扩增方法,诸如基于pcr的测定,例如定量pcr(qpcr),或者可以使用恒温扩增来检测存在于离散实体或者其一种或多种组分(例如包封在其中的细胞)中的某些感兴趣的核酸(例如基因)的存在。此类测定可应用于微流体装置或其一部分或任何其他合适位置内的离散实体。此类扩增或基于pcr的测定的条件可以包括随时间推移检测核酸扩增,并且可以以一种或多种方式变化。
[0044]
多种核酸聚合酶可用于本文提供的某些实施方案中使用的扩增反应中,包括可催化核苷酸(包括其类似物)聚合成核酸链的任何酶。这种核苷酸聚合可以模板依赖性方式发生。这些聚合酶可包括但不限于天然存在的聚合酶及其任何亚基和截短物、突变体聚合酶、变体聚合酶、重组、融合或以其他方式工程化的聚合酶、化学修饰的聚合酶、合成分子或组装体,以及其保留催化这种聚合的能力的任何类似物、衍生物或片段。任选地,聚合酶可以是包含一个或多个突变的突变体聚合酶,所述突变涉及用其他氨基酸替换一个或多个氨基酸、从聚合酶中插入或删除一个或多个氨基酸、或连接两个或更多个聚合酶的部分。通常,聚合酶包含一个或多个活性位点,在所述位点处可以发生核苷酸结合和/或对核苷酸聚合的催化。一些示例性的聚合酶包括但不限于dna聚合酶和rna聚合酶。如本文所用,术语“聚合酶”及其变体还包括融合蛋白,所述融合蛋白包含至少两个相互连接的部分,其中第一部分包含可催化核苷酸聚合成核酸链的肽并连接至包含第二多肽的第二部分。在一些实施方案中,第二多肽可包括报告酶或加工性增强结构域。任选地,聚合酶可以具有5'核酸外切酶活性或末端转移酶活性。在一些实施方案中,聚合酶可以任选地被重新激活,例如通过使用热量、化学物质或将新的量的聚合酶重新添加至反应混合物中。在一些实施方案中,聚合酶可以包括热启动聚合酶或基于适体的聚合酶,其任选地可以被重新激活。
[0045]
术语“靶引物”或“靶特异性引物”及其变型是指与结合位点序列互补的引物。靶引物通常是单链或双链多核苷酸,通常是寡核苷酸,其包括至少一个与靶核酸序列至少部分互补的序列。
[0046]“正向引物结合位点”和“反向引物结合位点”是指模板dna和/或扩增子上正向和反向引物所结合的区域。引物用于界定在扩增期间呈指数扩增的原始模板多核苷酸的区域。在一些实施方案中,额外引物可以与正向引物和/或反向引物的5'的区域结合。在使用此类额外引物的情况下,正向引物结合位点和/或反向引物结合位点可涵盖这些额外引物的结合区以及引物本身的结合区。例如,在一些实施方案中,所述方法可以使用一个或多个与位于正向和/或反向引物结合区的5'的区域结合的额外引物。例如,在wo0028082中公开了这种方法,其公开了“置换引物”或“外引物”的用途。
[0047]“条形码”核酸识别序列可以掺入核酸引物中或连接至引物以使得独立测序和识别能够经由条形码彼此关联,该条形码涉及源自存在于相同样品内的分子的信息和识别。有许多技术可以用于将条形码附着至离散实体内的核酸。例如,可以首先扩增靶核酸,然后将其片段化成较短的片段,也可以不这样做。可以将这些分子与含有条形码的离散实体(例如液滴)结合。然后可以使用例如重叠延伸剪接术将条形码附着至分子。在该方法中,初始靶分子可以具有添加的“衔接子”序列,这些序列是引物可以合成到其上的具有已知序列的分子。当与条形码结合时,可以使用与衔接子序列和条形码序列互补的引物,使得靶核酸和条形码两者的产物扩增子可以彼此退火,并且经由延伸反应(诸如dna聚合)延伸到彼此上,从而产生包含附着至条形码序列的靶核酸的双链产物。替代性地,扩增该靶标的引物自身可以加上条形码,使得在退火并且延伸到靶标上时,产生的扩增子具有掺入其中的条形码序列。该扩增子可以与许多扩增策略一起应用,包括使用pcr的特异性扩增或使用例如mda的非特异性扩增。可以用于将条形码附着至核酸的替代性酶促反应是连接,包括平端连接或粘端连接。在该方法中,将dna条形码与靶核酸和连接酶一起孵育,导致条形码与靶标连接。核酸的末端可以根据连接的需要通过多种技术进行修饰,包括通过使用用连接酶或片
段引入的衔接子,以使得能够加大对添加到分子末端的条形码的数量的控制。
[0048]
如本文所用,术语“相同”及其变体,当用于提及两个或更多个序列时,指两个或更多个序列(例如,核苷酸或多肽序列)相同的程度。在两个或更多个序列的情形中,序列或其子序列的同一性或同源性百分比指示所有单体单元(例如,核苷酸或氨基酸)在序列的给定位置或区域相同(即约70%同一性,优选地75%、80%、85%、90%、95%、97%、98%或99%同一性)。当在比较窗口上进行最大对应性的比较和比对时,同一性百分比可以在规定的区域内,或者如使用blast或blast 2.0序列比较算法用下文描述的默认参数或通过手动比对和目视检查所测量的指定区域内。当在氨基酸水平或核苷酸水平上有至少85%同一性时,序列被称为“基本相同”。优选地,同一性存在于长度为至少约25、50或100个残基的区域内,或跨越至少一个比较序列的全长。确定序列同一性百分比和序列相似性百分比的典型算法是blast和blast 2.0算法,其描述于altschul等人,nuc.acids res.25:3389-3402(1977)中。其他方法包括smith&waterman,adv.appl.math.2:482(1981)和needleman&wunsch,j.mol.biol.48:443(1970)等的算法。两个核酸序列基本上相同的另一个指示是两个分子或其互补物在严格杂交条件下彼此杂交。
[0049]
术语“核酸”、“多核苷酸”和“寡核苷酸”是指核苷酸的生物聚合物,并且除非上下文另有说明,否则包括修饰的和未修饰的核苷酸,以及dna和rna,以及修饰的核酸骨架。例如,在某些实施方案中,核酸是肽核酸(pna)或锁核酸(lna)。通常,本文所描述的方法使用dna作为核酸模板以执行扩增。然而,其核苷酸被来自天然dna或rna的人工衍生物或修饰的核酸替换的核酸也包括在本发明的核酸中,只要其用作用于合成互补链的模板。本发明的核酸通常含于生物样品中。生物样品包括动物、植物或微生物组织、细胞、培养物和分泌物,或其提取物。在某些方面,生物样品包括细胞内寄生基因组dna或rna,例如病毒或支原体。核酸可以源自含于所述生物样品中的核酸。例如,基因组dna或从mrna合成的cdna,或基于源自生物样品的核酸扩增的核酸优选用于所描述的方法中。除非另有说明,每当表示寡核苷酸序列时,应理解核苷酸呈从左到右的5'至3'顺序,“a”表示脱氧腺苷,“c”表示脱氧胞苷,“g”表示脱氧鸟苷,“t”表示脱氧胸苷,并且“u”表示尿苷。寡核苷酸被称为具有“5'端”和“3'端”,因为单核苷酸通常通过将一个核苷酸的5'磷酸或等效基团连接至其相邻核苷酸的3'羟基或等效基团上,任选地通过磷酸二酯或其他合适的键合而反应形成寡核苷酸。
[0050]
模板核酸是在核酸扩增技术中充当用于合成互补链的模板的核酸。具有与模板互补的核苷酸序列的互补链具有与模板对应的链的含义,但两者之间的关系仅是相对的。也就是说,根据本文所描述的方法,合成为互补链的链可以再次充当模板。也就是说,互补链可以成为模板。在某些实施方案中,模板源自生物样品,例如植物、动物、病毒、微生物、细菌、真菌等。在某些实施方案中,动物是哺乳动物,例如人类患者。模板核酸通常包含一种或多种靶核酸。示例性实施方案中的靶核酸可包含可根据本公开扩增或合成的任何单链或双链核酸序列,包括怀疑或预期存在于样品中的任何核酸序列。
[0051]
本文实施方案中使用的引物和寡核苷酸包含核苷酸。核苷酸包含任何化合物,包括但不限于任何天然存在的核苷酸或其类似物,其可以选择性地结合聚合酶或被聚合酶聚合。通常,但不是必须地,核苷酸与聚合酶的选择性结合之后是核苷酸被聚合酶聚合成核酸链;然而,有时核苷酸可能会从聚合酶解离而不会并入核酸链中,此事件在本文中称为“非生产性”事件。此类核苷酸不仅包括天然存在的核苷酸,还包括任何类似物,无论其结构如
何,其可以选择性地结合聚合酶或被聚合酶聚合。虽然天然存在的核苷酸通常包含碱基、糖和磷酸部分,但本公开的核苷酸可包括缺少任何一种、一些或所有此类部分的化合物。例如,核苷酸可以任选地包括包含三个、四个、五个、六个、七个、八个、九个、十个或更多个磷原子的磷原子链。在一些实施方案中,磷链可连接至糖环的任何碳,例如5'碳。磷链可以通过中间的o或s连接至糖。在一个实施方案中,链中的一个或多个磷原子可以是具有p和o的磷酸基团的一部分。在另一实施方案中,链中的磷原子可以与中间的o、nh、s、亚甲基、取代的亚甲基、亚乙基、取代的亚乙基、cnh2、c(o)、c(ch2)、ch2ch2或c(oh)ch2r(其中r可以是4-吡啶或1-咪唑)连接在一起。在一个实施方案中,链中的磷原子可以具有含o、bh3或s的侧基。在磷链中,具有除o之外的侧基的磷原子可以是取代的磷酸基团。在磷链中,具有除o之外的中间原子的磷原子可以是取代的磷酸基团。核苷酸类似物的一些实例描述于xu的美国专利号7,405,281中。
[0052]
在一些实施方案中,核苷酸包含标记并且在本文中称为“标记的核苷酸”;标记的核苷酸的标记在本文中称为“核苷酸标记”。在一些实施方案中,标记可以是连接到末端磷酸基团(即,离糖最远的磷酸基团)的荧光部分(例如,染料)、发光部分等的形式。可用于所公开的方法和组合物中的核苷酸的一些实例包括但不限于核糖核苷酸、脱氧核糖核苷酸、修饰的核糖核苷酸、修饰的脱氧核糖核苷酸、多磷酸核糖核苷酸、多磷酸脱氧核糖核苷酸、修饰的多磷酸核糖核苷酸、修饰的多磷酸脱氧核糖核苷酸、肽核苷酸、修饰的肽核苷酸、金属核苷、膦酸核苷和修饰的磷酸-糖骨架核苷酸、上述化合物的类似物、衍生物或变体等。在一些实施方案中,核苷酸可包含非氧部分,例如硫代或硼烷部分,以代替桥接核苷酸的α磷酸和糖、或核苷酸的α和β磷酸、或核苷酸的β和γ磷酸、或核苷酸的任何其他两种磷酸之间、或其任意组合的氧部分。
[0053]“核苷酸5'-三磷酸”是指在5'位置处具有三磷酸酯基的核苷酸,有时也表示为“ntp”、或“dntp”和“ddntp”,以特别指出核糖的结构特征。三磷酸酯基可以包括对各种氧的硫取代,例如α-硫代核苷酸5'-三磷酸。有关核酸化学的综述,参见:shabarova,z.和bogdanov,a.advanced organic chemistry of nucleic acids,vch,new york,1994。
[0054]
概述
[0055]
本文描述了用于对多个细胞进行单细胞分析以确定单个细胞的细胞基因型和表型的实施方案。通常,单细胞分析涉及进行靶向dna-seq以产生来源于基因组dna的序列读数,将序列读数用于确定细胞基因型(例如,细胞突变诸如cnv和/或snv)。单细胞分析还涉及对与抗体连接的寡核苷酸进行测序,其中抗体表现出对细胞表达的特定分析物的结合亲和力。因此,将源自抗体缀合的寡核苷酸的序列读数用于确定细胞表型(例如,细胞的一种或多种分析物的表达或存在)。群体(例如异质癌细胞群体)中细胞之间的细胞基因型和表型的组合可用于辨别细胞亚群,亚群的特征在于基因型和表型的组合。细胞亚群可以代表先前未知的亚群、或不可能使用单独的细胞基因型或表型检测的亚群。
[0056]
参考图1a,其描绘了根据一个实施方案的包括单细胞工作流装置106和用于进行单细胞分析的计算装置108的总体系统环境100。获得细胞102的群体。在各种实施方案中,可以从获得自受试者或患者的测试样品中分离细胞102。在各种实施方案中,细胞102是从健康受试者获取的健康细胞。在各种实施方案中,细胞102包括从受试者获取的患病细胞。在一个实施方案中,细胞102包括从先前诊断患有癌症的受试者获取的癌细胞。例如,癌细
胞可以是可在被诊断患有癌症的受试者的血液中获得的肿瘤细胞。作为另一个实例,癌细胞可以是通过肿瘤活检获得的细胞。因此,肿瘤细胞的单细胞分析能够表征受试者癌症的细胞。在各种实施方案中,在对受试者进行治疗后(例如,在疗法诸如癌症疗法后)从受试者获得测试样品。因此,细胞的单细胞分析能够表征代表受试者对疗法的反应的细胞。
[0057]
在步骤104,将细胞102与抗体一起孵育。在各种实施方案中,抗体表现出对靶分析物的结合亲和力。例如,抗体可以表现出对靶蛋白的靶表位的结合亲和力。
[0058]
在各种实施方案中,与抗体一起孵育的细胞的数目可以是102个细胞、103个细胞、104个细胞、105个细胞、106个细胞或107个细胞。在各种实施方案中,将介于103个和107个之间的细胞与抗体一起孵育。在各种实施方案中,将介于104个和106个之间的细胞与抗体一起孵育。在各种实施方案中,将不同浓度的抗体与细胞一起孵育。在各种实施方案中,对于蛋白质组中的抗体,将浓度为0.1nm、0.5nm、1.0nm、2.0nm、3.0nm、4.0nm、5.0nm、6.0nm、7.0nm、8.0nm、9.0nm、10.0nm、20nm、30nm、40nm、50nm、60nm、70nm、80nm、90nm或100nm的抗体与细胞一起孵育。
[0059]
在各种实施方案中,将细胞102与多种不同的抗体一起孵育。在一个实施方案中,在多种不同的抗体中,每种抗体都表现出对一个组的分析物的结合亲和力。例如,每种抗体都表现出对一个组的蛋白质的结合亲和力。本文描述了包括在蛋白质组中的蛋白质的实例。细胞与抗体的孵育导致抗体与靶表位的结合。在各种实施方案中,将浓度为0.1nm、0.5nm、1.0nm、2.0nm、3.0nm、4.0nm、5.0nm、6.0nm、7.0nm、8.0nm、9.0nm、10.0nm、20nm、30nm、40nm、50nm、60nm、70nm、80nm、90nm或100nm的在抗体组(antibody panel)中的每种抗体与细胞一起孵育。
[0060]
孵育后,洗涤细胞102(例如,用洗涤缓冲液)以除去未结合的过量抗体。
[0061]
在各种实施方案中,将抗体用一种或多种寡核苷酸(也称为抗体寡核苷酸)标记。此类寡核苷酸可以用微流体加条形码和dna测序读出,从而能够检测感兴趣的细胞分析物。当抗体结合其靶标时,抗体寡核苷酸随其一起携带,并因此允许基于寡核苷酸标签的存在推断靶分析物的存在。在一些实施方式中,分析抗体寡核苷酸提供了对细胞中存在的不同表位的估计。
[0062]
单细胞工作流装置106是指处理单个细胞以产生用于测序的核酸的装置。在各种实施方案中,单细胞工作流装置106可以将单个细胞包封到乳液中,在乳液内裂解细胞,在第二乳液中对细胞裂解物执行细胞加条形码,并且在第二乳液中执行核酸扩增反应。因此,可以收集扩增的核酸并进行测序。在各种实施方案中,单细胞工作流装置106还包括用于对核酸进行测序的测序仪。
[0063]
计算装置108被配置为从单细胞工作流装置106接收测序读数。在各个实施方案中,计算装置108通信地耦接至单细胞工作流装置106,并且因此直接从单细胞工作流装置106接收序列读数。计算装置108分析序列读数以产生细胞分析110。在一个实施方案中,计算装置108分析序列读数以确定细胞基因型和表型。计算装置108使用所确定的细胞基因型和表型来发现新的细胞亚群和/或将单个细胞分类为细胞亚群。因此,在此类实施方案中,细胞分析110可以指鉴定细胞亚群或将细胞分类为细胞亚群。
[0064]
现在参考图1b,其描绘了处理单细胞以产生用于测序的扩增核酸分子的一个实施方案。具体来说,图1b描绘了包括细胞包封160、分析物释放165、细胞加条形码和靶核酸分
子的靶扩增175的步骤的工作流过程。
[0065]
通常,细胞包封步骤160涉及用试剂120将单细胞102包封到乳液中。在各种实施方案中,通过以下方式来形成乳液:将含有细胞102和试剂120的水性流体分配到载体流体(例如,油115)中,从而产生水性油包流体乳液。乳液包括包封的细胞125和试剂120。在步骤165,包封的细胞经历分析物释放。通常,试剂导致细胞裂解,从而在乳液内产生细胞裂解物130。在特定实施方案中,试剂120包括用于裂解细胞以产生细胞裂解物130的蛋白酶,诸如蛋白酶k。细胞裂解物130包括细胞的内容物,其可以包括一种或多种不同类型的分析物(例如,rna转录物、dna、蛋白质、脂质或碳水化合物)。在各种实施方案中,细胞裂解物130的不同分析物可以与乳液内的试剂120相互作用。例如,试剂120中的引物(诸如反向引物)可以引发分析物。
[0066]
细胞加条形码步骤170涉及将细胞裂解物130与条形码145和/或反应混合物140一起包封到第二乳液中。在各种实施方案中,通过将含有细胞裂解物130的水性流体分配到不可混溶的油135中来形成第二乳液。如图1b所示,反应混合物140和条形码145可以通过单独的水性流体流引入,从而将反应混合物140和条形码与细胞裂解物130一起分配到第二乳液中。
[0067]
通常,条形码145可以标记待分析的靶分析物(例如,靶核酸),这使得能够随后鉴定源自靶核酸的序列读数的起源。在各种实施方案中,多个条形码145可以标记细胞裂解物的多种靶核酸,从而使得能够随后鉴定大量序列读数的起源。
[0068]
通常,反应混合物140使得能够执行反应,诸如核酸扩增反应。靶扩增步骤175涉及扩增靶核酸。例如,使用第二乳液中的反应混合物140对细胞裂解物的靶核酸进行扩增,从而产生从靶核酸来源的扩增子。虽然图1b将细胞加条形码170和靶标扩增175描绘为两个单独的步骤,但是在各种实施方案中,靶核酸通过核酸扩增步骤用条形码145进行标记。
[0069]
如本文所提到的,图1b中所示的工作流过程是两步骤工作流过程,其中从细胞的分析物释放165与细胞加条形码170和靶标扩增175的步骤分开发生。例如,从细胞的分析物释放165在第一乳液内发生,随后在第二乳液中发生细胞加条形码170和靶标扩增175。在各种实施方案中,可以采用替代性工作流过程(例如,除了图1b所示的两步骤工作流过程之外的工作流过程)。例如,可以将细胞102、试剂120、反应混合物140和条形码145包封在乳液中。因此,分析物释放165可以在乳液内发生,随后在同一乳液内发生细胞加条形码170和靶标扩增175。
[0070]
图2是使用来源于单个细胞的序列读数确定细胞基因型和表型并使用细胞基因型和表型分析细胞的流过程。具体来说,图2描绘了在步骤205汇集扩增的核酸,对扩增的核酸进行测序,以及使用序列读数确定细胞的细胞轨迹的步骤。通常,图2中所示的流程过程是图1b中所示的工作流过程的延续。
[0071]
例如,在图1b的步骤175的靶标扩增之后,在图2所示的步骤205将扩增的核酸250a、250b和250c汇集。例如,汇集并收集扩增的核酸的乳液,并且去除乳液中不可混溶的油。因此,可以将来自多个细胞的扩增核酸汇集在一起。图2描绘了三种扩增的核酸250a、250b和250c,但是在各种实施方案中,汇集的核酸可以包括数百种、数千种或数百万种从多个细胞的分析物来源的核酸。
[0072]
在各种实施方案中,每种扩增的核酸250至少包括靶核酸240和条形码230的序列。
在各种实施方案中,扩增的核酸250可以包括另外的序列,诸如通用引物序列(例如,寡dt序列)、随机引物序列、基因特异性引物正向序列、基因特异性引物反向序列或一个或多个恒定区(例如,pcr柄)。
[0073]
在各种实施方案中,扩增的核酸250a、250b和250c来源于相同的单细胞,并且因此条形码230a、230b和230c是相同的。因此,条形码230的测序使得能够确定扩增的核酸250源自相同的细胞。在各种实施方案中,扩增的核酸250a、250b和250c被汇集并且源自不同的细胞。因此,条形码230a、230b和230c彼此不同,并且条形码230的测序使得能够确定扩增的核酸250源自不同的细胞。
[0074]
在步骤210,对汇集的扩增核酸250进行测序以产生序列读数。对于每种扩增的核酸,序列读数包括条形码和靶核酸的序列。根据扩增核酸中包含的条形码序列对源自单个细胞的序列读数进行聚类。在各种实施方案中,比对每个单细胞的一个或多个序列读数(例如,与参考基因组比对)。将序列读数与参考基因组比对使得能够确定序列读数源自基因组中的何处。例如,当与基因组位置比对时,从dna产生的多个序列读数可以揭示存在于或涉及基因组位置的一个或多个突变。在各种实施方案中,每个单细胞的一个或多个序列读数不进行比对。例如,鉴于抗体寡核苷酸不是源自细胞基因组的基因组dna,源自抗体寡核苷酸的序列读数不需要与参考基因组进行比对。
[0075]
在步骤220,分析单细胞所比对的序列读数以确定单细胞的细胞基因型和细胞表型。例如,分析从dna转录物产生的序列读数以确定细胞的一个或多个突变,诸如一个或多个cnv和snv。将从抗体缀合的寡核苷酸产生的序列读数用于确定细胞表型,其可以包括一种或多种蛋白质的存在或不存在。在各种实施方案中,从抗体缀合的寡核苷酸产生的序列读数的数量与一种或多种蛋白质的表达水平相关。总之,细胞基因型(例如,一种或多种snv和cnv)和细胞表型(例如,蛋白质的存在/不存在)提供了单细胞的基因组学和蛋白质组学的同时视图。
[0076]
在步骤225,分析细胞的细胞基因型和细胞表型。在一个实施方案中,将细胞的细胞基因型和细胞表型用于将细胞分类为以细胞基因型和表型为特征的亚群。例如,可以基于基因型和表型的组合表征已知细胞亚群的文库。因此,细胞的基因型和表型可以用于将细胞分类为共享相同或相似基因型和表型的一个或多个细胞群体。
[0077]
在一个实施方案中,细胞的细胞基因型和细胞表型用于鉴定细胞亚群。例如,细胞可以来源于细胞群体。在此类实施方案中,将细胞的细胞基因型和细胞表型与来源于细胞群体的其他细胞的细胞基因型和细胞表型结合进行分析。在各种实施方案中,分析细胞群体的细胞基因型和细胞表型包括进行降维分析和聚类分析中的一种或两种,使得具有相似基因型或表型的细胞定位于簇内。在各种实施方案中,可以从单个簇中鉴定细胞的异质亚群。在各种实施方案中,可以甚至从簇本身内鉴定细胞的异质亚群。
[0078]
鉴定具有不同基因型和表型组合的细胞亚群可以用于发现细胞群体中的细胞亚群。作为一个实例,细胞亚群可以指癌细胞亚群。因此,检测和/或鉴定癌细胞亚群的存在可用于诊断患有癌症的受试者。作为另一个实例,细胞群体可以是先前认为是同质的癌细胞群体。因此,分析癌细胞中细胞的细胞基因型和表型有助于理解癌细胞的异质性,其可以用于指导靶向细胞各种亚群的治疗的开发或选择。
[0079]
执行单细胞分析的方法
[0080]
包封、分析物释放、加条形码和扩增
[0081]
本文所述的实施方案涉及包封一个或多个细胞(例如,在图1中的步骤160)以对所述一个或多个细胞执行单细胞分析。在各种实施方案中,通过将包含细胞和试剂的水相与不可混溶的油相组合来实现细胞与试剂的包封。在一个实施方案中,包含所述细胞和试剂的水相与流动的不可混溶的油相一起流动,使得形成多种油包水乳液,其中至少一种乳液包含单细胞和试剂。在各种实施方案中,不可混溶的油相包括氟油、非离子氟表面活性剂或两者。在各种实施方案中,乳液可以具有约0.001至1000微微升或更大的内部体积,并且直径可以在0.1至1000μm的范围内。
[0082]
在各种实施方案中,包含细胞和试剂的水相不一定与不可混溶的油相同时流动。例如,水相可以流动以接触固定储存器(stationary reservoir)的不可混溶油相,从而使得油包水乳液在固定油储存器内萌发。
[0083]
在各种实施方案中,可以在微流体装置中进行水相和不可混溶油相的组合。例如,水相可以流过微流体装置的微通道以接触不可混溶油相,该不可混溶油相同时流过单独的微通道或保持在微流体装置的固定储存器中。然后,在乳液内的包封的细胞和试剂可以流过微流体装置以进行细胞裂解。
[0084]
将试剂和细胞添加到乳液中的进一步示例性实施方案可以包括合并单独含有细胞和试剂的乳液或将试剂显微注射到乳液中。在美国申请号14/420,646中描述了对示例性实施方案的进一步描述,所述申请据此以引用的方式整体并入。
[0085]
在乳液中的包封的细胞被裂解以产生细胞裂解物。在各种实施方案中,细胞被存在于试剂中的裂解剂裂解。例如,试剂可以包括洗涤剂诸如np-40和/或蛋白酶。洗涤剂和/或蛋白酶可以裂解细胞膜。在一些实施方案中,细胞裂解也可以或者取而代之依赖于不涉及试剂中的裂解剂的技术。例如,裂解可以通过机械技术来实现,所述机械技术可以使用各种几何特征来实现细胞的穿孔、剪切、研磨等。也可以使用其他类型的机械破坏,诸如声学技术。此外,热能也可以用于裂解细胞。在本文所述的方法中可以使用任何实现细胞裂解的方便手段。
[0086]
现在参考图3a-3c,其描绘了根据第一实施方案释放和处理乳液(例如乳液300)内的分析物的步骤。图3a描绘了包括细胞102和试剂120(如图1b所示)的乳液300a。具体来说,在图3a中,乳液300a包含细胞(其还包括dna 302)、抗体寡核苷酸304(来自在图1a的步骤104中用于结合细胞蛋白质的抗体)以及从试剂添加的蛋白酶310。在乳液300a内,细胞被裂解,如细胞膜的虚线所指示。在一个实施方案中,细胞被包含在试剂(诸如np40(例如0.01%np40))中的洗涤剂裂解。
[0087]
图3b描绘了当蛋白酶302消化染色质结合的dna 302,从而释放基因组dna时的乳液300b。在各种实施方案中,将乳液300b暴露于升高的温度以使蛋白酶310能够消化染色质。在各种实施方案中,将乳液300b暴露于40℃与60℃之间的温度。在各种实施方案中,将乳液300b暴露于45℃与55℃之间的温度。在各种实施方案中,将乳液300b暴露于48℃与52℃之间的温度。在各种实施方案中,将乳液300b暴露于50℃的温度。
[0088]
图3c描绘了游离基因组dna链306和存在于乳液300c中的抗体寡核苷酸304。将蛋白酶310灭活。在各种实施方案中,蛋白酶310通过将乳液300c暴露于升高的温度而失活。在各种实施方案中,将乳液300c暴露于70℃与90℃之间的温度。在各种实施方案中,将乳液
300b暴露于75℃与85℃之间的温度。在各种实施方案中,将乳液300b暴露于78℃与82℃之间的温度。在各种实施方案中,将乳液300b暴露于80℃的温度。
[0089]
在各种实施方案中,抗体寡核苷酸304和/或游离基因组dna 306在乳液300c中经历引发。在各种实施方案中,反向引物可以与抗体寡核苷酸304和/或游离基因组dna 306的一部分杂交。例如,反向引物是与游离基因组dna 306的一部分杂交的基因特异性反向引物。基因特异性引物的实例在下文进一步详细描述。作为另一个实例,反向引物是与抗体寡核苷酸304的一部分杂交的pcr柄,其在下文中关于图4a进一步详细描述。在各种实施方案中,鉴于试剂中包括与蛋白酶310一起被引入乳液300a中的反向引物,抗体寡核苷酸304的引发可以更早地例如在乳液300a或乳液300b中发生。
[0090]
在各种实施方案中,乳液300c中的抗体寡核苷酸304和游离基因组dna 306至少部分代表细胞裂解物,诸如图1b中所示的细胞裂解物130,其随后被包封在第二乳液中用于加条形码和扩增。具体来说,图1中的细胞加条形码170的步骤包括包封细胞裂解物130与反应混合物140和条形码145。在各种实施方案中,反应混合物140包括用于在靶核酸(例如抗体寡核苷酸和游离的基因组dna)上执行核酸反应的组分。例如,反应混合物140可以包括引物、用于进行核酸扩增的酶和用于掺入扩增核酸中的dntp或ddntp。
[0091]
在各种实施方案中,通过将包含反应混合物和条形码的水相与细胞裂解物和不可混溶的油相组合,将细胞裂解物与反应混合物和条形码一起包封。在一个实施方案中,包含反应混合物和条形码的水相与流动的细胞裂解物和流动的不可混溶油相一起流动,使得形成油包水乳液,其中至少一种乳液包含细胞裂解物、反应混合物和条形码。在各种实施方案中,不可混溶的油相包括氟油、非离子氟表面活性剂或两者。在各种实施方案中,乳液可以具有约0.001至1000微微升或更大的内部体积,并且直径可以在0.1至1000μm的范围内。
[0092]
在各种实施方案中,可以在微流体装置中进行水相和不可混溶油相的组合。例如,水相可以流过微流体装置的微通道以接触不可混溶油相,该不可混溶油相同时流过单独的微通道或保持在微流体装置的固定储存器中。然后,在乳液内的包封的细胞裂解物、反应混合物和条形码可以流过微流体装置以执行靶核酸的扩增。
[0093]
将反应混合物和条形码添加到乳液中的进一步示例性实施方案可以包括将分别含有细胞裂解物和反应混合物和条形码的乳液合并,或者将反应混合物和/或条形码显微注射到乳液中。合并乳液或将物质显微注射到乳液中的示例性实施方案的进一步描述见于美国申请号14/420,646中,所述申请据此以引用的方式整体并入。
[0094]
一旦将反应混合物和条形码添加到乳液中,就可以在促进核酸扩增反应的条件下孵育乳液。在各种实施方案中,乳液可以在与用于添加反应混合物和/或条形码的相同微流体装置上孵育,或者可以在单独的装置上孵育。在某些实施方案中,在用于包封细胞和裂解细胞的相同微流体装置上在促进核酸扩增的条件下孵育乳液。乳液的孵育可以采取多种形式。在某些方面,含有反应混合物、条形码和细胞裂解物的乳液可以流过在对核酸扩增有效的条件下孵育乳液的通道。微液滴流过通道可能涉及一个通道,该通道蛇形穿过保持在对pcr有效的温度下的各种温度区。例如,此类通道可以在两个或更多个温度区上循环,其中至少一个区保持在约65℃,并且至少一个区保持在约95℃。当液滴移动通过此类区时,它们的温度根据核酸扩增的需要循环。区的数量和每个区的相应温度可以由本领域技术人员容易地确定,以实现所需的核酸扩增。
[0095]
在各种实施方案中,在核酸扩增后,收集含有扩增核酸的乳液。在各种实施方案中,将乳液收集到孔中,诸如微流体装置的孔中。在各种实施方案中,将乳液收集到储存器或管(诸如eppendorf管)中。一旦收集,汇集不同乳液中的扩增的核酸。在一个实施方案中,通过提供外部刺激汇集扩增的核酸来打破乳液。在一个实施方案中,给定在水相和不可混溶油相之间的密度差异,乳液随时间自然聚集。因此,扩增的核酸汇集在水相中。
[0096]
在各种实施方案中,汇集后,扩增的核酸可以进行进一步的测序准备。例如,可以向汇集的核酸中添加测序转接器(adapter)。示例性测序转接器是p5和p7测序转接器。测序转接器使得随后能够对核酸进行测序。
[0097]
抗体缀合的寡核苷酸和基因组dna的示例性加条形码
[0098]
图4a展示了根据一个实施方案的抗体缀合的寡核苷酸的引发和加条形码。具体来说,图4a描绘了涉及抗体寡核苷酸304引发的步骤410,并且还描绘了涉及抗体寡核苷酸304的加条形码和扩增的步骤420。在各种实施方案中,步骤410发生在第一乳液中,在此期间发生细胞裂解,并且步骤420发生在第二乳液中,在此期间发生细胞加条形码和核酸扩增。在此类实施方案中,在试剂中提供引物405,并且珠粒条形码与反应混合物一起提供。在一些实施方案中,步骤410和420两者均在第二乳液内发生。在此类实施方案中,图4a中所示的引物405和珠粒条形码与反应混合物一起提供。
[0099]
抗体寡核苷酸304与抗体缀合。在各种实施方案中,抗体寡核苷酸304包括pcr柄、标签序列(例如,抗体标签)和将寡核苷酸与抗体连接的捕获序列。在各种实施方案中,抗体寡核苷酸304与抗体的一个区缀合,使得抗体结合靶表位的能力不受影响。例如,抗体寡核苷酸304可以与抗体的fc区连接,从而使抗体的可变区不受影响并可用于表位结合。在各种实施方案中,抗体寡核苷酸304可以包括独特的分子标识符(umi)。在各种实施方案中,umi可以插入在抗体标签之前或之后。在各种实施方案中,umi可以侧接抗体标签的任一末端。在各种实施方案中,umi能够鉴定特定的抗体寡核苷酸304和抗体组合。
[0100]
在各种实施方案中,抗体寡核苷酸304包括多于一个pcr柄。例如,抗体寡核苷酸304可以包括两个pcr柄,在抗体寡核苷酸304的每个末端有一个。在各种实施方案中,抗体寡核苷酸304的pcr柄之一与抗体缀合。这里,可以提供与两个pcr柄杂交的正向引物和反向引物,从而使得能够扩增抗体寡核苷酸304。
[0101]
通常,抗体寡核苷酸304的抗体标签能够随后鉴定抗体(和相应的蛋白质)。例如,抗体标签可以用作标识符,例如用于鉴定抗体结合的蛋白质类型的条形码。在各种实施方案中,结合相同靶标的抗体各自与相同的抗体标签连接。例如,与靶蛋白的相同表位结合的抗体各自与相同的抗体标签连接,从而使得能够随后确定靶蛋白的存在。在各种实施方案中,可以将结合相同靶蛋白的不同表位的抗体与相同的抗体标签连接,从而使得能够随后确定靶蛋白的存在。
[0102]
在一些实施方案中,寡核苷酸序列由其核碱基序列编码,并且因此赋予远超过使用荧光的常规方法可能有的组合标签空间。例如,10个碱基的适度标签长度提供超过一百万个独特序列,足以标记针对人蛋白质组中的每个表位的抗体。实际上,用这种方法,多路复用的限制不是唯一标签序列的可用性,而是可以在多路复用反应中检测感兴趣的表位的特异性抗体的可用性。
[0103]
步骤410描绘了用引物405引发抗体寡核苷酸304。如图4中所示,引物405可以包括
pcr柄和共有序列。这里,引物405的pcr柄与抗体寡核苷酸304的pcr柄互补。因此,鉴于pcr柄的杂交,引物405引发抗体寡核苷酸304。在各种实施方案中,从抗体寡核苷酸304的pcr柄发生延伸(如虚线箭头所指示)。在各种实施方案中,从引物405的pcr柄发生延伸,从而产生具有抗体标签和捕获序列的核酸。
[0104]
步骤420描绘了抗体寡核苷酸304的加条形码。如图4中所示,条形码(例如,细胞条形码)与珠粒可释放地附接并进一步与共有序列连接。这里,与细胞条形码连接的共有序列与连接到pcr柄、抗体标签和捕获序列的共有序列互补。延伸抗体寡核苷酸以包括共有序列和细胞条形码。
[0105]
在各种实施方案中,抗体寡核苷酸被扩增,从而产生具有细胞条形码、共有序列、pcr柄、抗体标签和捕获序列的扩增子。在各种实施方案中,捕获序列含有生物素寡核苷酸捕获位点,其使得链霉亲和素珠粒在文库制备之前富集。在各种实施方案中,可以通过从扩增的基因组dna靶标尺寸分离来富集加条形码的抗体-寡核苷酸。
[0106]
图4b展示了根据一个实施方案的基因组dna 455的引发和加条形码。具体来说,图4b描绘了涉及基因组dna 455引发的步骤460,并且还描绘了涉及基因组dna 455的加条形码和扩增的步骤470。在各种实施方案中,步骤460发生在第一乳液中,在此期间发生细胞裂解,并且步骤470发生在第二乳液中,在此期间发生细胞加条形码和核酸扩增。在此类实施方案中,将引物465添加到试剂中,并且将步骤470中所示的条形码和正向引物与反应混合物一起添加。在一些实施方案中,步骤460和步骤470两者都发生在单个乳液(例如,第二乳液)内,在此期间发生细胞加条形码和核酸扩增。在此类实施方案中,将步骤460中所示的引物465和步骤470中所示的条形码和正向引物与反应混合物一起添加。
[0107]
在步骤460,引物465(如虚线所指示)与基因组dna 455的一部分杂交。在各种实施方案中,引物465是靶向感兴趣基因的序列的基因特异性引物。因此,引物465与对应于感兴趣基因的基因组dna 455的序列杂交。在各种实施方案中,引物465还包括pcr柄或与pcr柄连接。
[0108]
在步骤470,引物475(如虚线所指示)与基因组dna 455的一部分杂交。在各种实施方案中,引物475包括pcr柄或与pcr柄连接。在各种实施方案中,引物475是基因特异性引物,其靶向感兴趣基因的与引物465靶向的序列不同的另一个序列。另外,与珠粒可释放地附接的细胞条形码(细胞bc)连接到与正向引物的pcr柄杂交的pcr柄上。核酸扩增产生扩增子,每个扩增子包括细胞条形码、pcr柄、正向引物、感兴趣的基因序列、引物465和pcr柄。
[0109]
测序和读数比对
[0110]
对扩增的核酸(例如,扩增子)进行测序,以获得用于产生测序文库的序列读数。序列读数可以通过可商购获得的下一代测序(ngs)平台来实现,所述ngs平台包括执行通过合成测序、通过连接测序、焦磷酸测序、使用可逆终止子化学测序、使用连接磷的荧光核苷酸测序或实时测序中的任一者的平台。例如,扩增的核酸可以在illumina miseq平台上进行测序。
[0111]
在焦磷酸测序时,ngs片段文库是通过使用包被有与转接器互补的寡核苷酸的颗粒捕获一个基质分子来克隆原位扩增的。每个含有相同类型基质的颗粒被放置在“油包水”类型的微气泡中,并且使用称为乳液pcr的方法克隆扩增基质。扩增后,乳液被破坏,并且颗粒被堆放于在测序反应期间充当流动池的滴定微微板(picoplate)的单独孔中。在存在测
序酶和发光报告剂诸如萤光素酶的情况下将四种dntp试剂中的每一种有序地多次施用到流动池中。在将合适的dntp添加到测序引物的3'末端的情况下,所得的atp在孔内产生闪光,这是用ccd摄像机记录的。有可能实现大于或等于400个碱基的读数长度,并且可能获得106个序列读取,从而产生高达5亿个碱基对(兆字节)的序列。焦磷酸测序的另外细节描述于voelkerding等人,clinical chem.,55:641-658,2009;maclean et al.,nature rev.microbiol.,7:287-296;美国专利号6,210,891;美国专利号6,258,568;所述文献中的每一者据此以引用的方式整体并入。
[0112]
在solexa/illumina平台上,以短读数的形式产生测序数据。在这种方法中,ngs片段文库的片段被捕获在包被有寡核苷酸锚定分子的流动池的表面上。锚定分子被用作pcr引物,但是由于基质的长度及其与附近其他锚定寡核苷酸的接近,通过pcr延伸导致分子与邻近锚定寡核苷酸杂交形成“拱形”,并在流动池表面形成桥接结构。这些dna环被变性和切割。然后使用可逆染色终止子对直链进行测序。所述序列中包含的核苷酸通过检测包含之后的荧光来确定,其中在下一个dntp添加循环之前去除每个荧光剂和封闭剂。使用illumina平台进行测序的另外细节见于voelkerding等人,clinical chem.,55:641-658,2009;maclean等人,nature rev.microbiol.,7:287-296;美国专利号6,833,246;美国专利号7,115,400;美国专利号6,969,488;所述文献中的每一者据此以引用的方式整体并入。
[0113]
使用solid技术对核酸分子进行测序包括使用乳液pcr克隆扩增ngs片段文库。之后,将含有基质的颗粒固定在玻璃流动池的衍生化表面上,并且用与转接器寡核苷酸互补的引物退火。然而,代替使用指示的引物进行3'延伸,使用其获得5'磷酸基团用于连接含有两个探针特异性碱基和随后的6个简并碱基和四种荧光标记之一的测试探针。在solid系统中,测试探针具有在每个探针的3'末端的两个碱基和在5'末端的四种荧光染料之一的16种可能的组合。荧光染料的颜色和因此每个探针的身份对应于一定的颜色空间编码方案。在探针比对、探针连接和荧光信号检测的多个循环之后,变性后使用与原始引物相比移位一个碱基的引物进行第二个测序循环。以这种方式,可以通过计算重构矩阵的序列;对矩阵碱基检查两次,这导致准确性增加。使用solid技术进行测序的另外细节见于voelkerding等人,clinical chem.,55:641-658,2009;maclean等人,nature rev.microbiol.,7:287-296;美国专利号5,912,148;美国专利号6,130,073;所述文献中的每一者以引用的方式整体并入。
[0114]
在特定的实施方案中,使用来自helicos biosciences的heliscope。通过添加聚合酶和连续添加荧光标记的dntp试剂实现测序。接通导致出现与dntp对应的荧光信号,并且在每个dntp添加周期之前,ccd摄像机捕获到指定的信号。序列的读数长度从25-50个核苷酸变化,其中每个分析工作周期的总产量超过10亿个核苷酸对。使用heliscope进行测序的另外细节见于voelkerding等人,clinical chem.,55:641-658,2009;maclean等人,nature rev.microbiol.,7:287-296;美国专利号7,169,560;美国专利号7,282,337;美国专利号7,482,120;美国专利号7,501,245;美国专利号6,818,395;美国专利号6,911,345;美国专利号7,501,245;所述文献中的每一者以引用的方式整体并入。
[0115]
在一些实施方案中,使用roche测序系统454。测序454涉及两个步骤。在第一步骤中,dna被切割成大约300-800个碱基对的片段,并且这些片段具有钝端。然后将寡核苷酸转接器连接到片段的末端。转接器作为引物用于片段的扩增和测序。片段可以例如使用含有
5'-生物素标签的转接器附接到dna捕获珠粒上,例如链霉亲和素包被的珠粒。在油-水乳液的液滴内通过pcr扩增附接到颗粒上的片段。结果是克隆扩增的dna片段在每个珠粒上有多个拷贝。在第二阶段,颗粒被捕获到孔中(几微微升的体积)。平行地对每个dna片段进行焦磷酸测序。添加一个或多个核苷酸导致光信号的产生,其被记录在测序仪器的ccd摄像机上。信号强度与所包含的核苷酸数量成比例。焦磷酸测序使用焦磷酸(ppi),其在添加核苷酸时被释放。在存在5'磷酸硫酸腺苷的情况下,使用atp硫酸化酶将ppi转化为atp。萤光素酶使用atp将萤光素转化为氧化萤光素,并且作为这种反应的结果,产生进行检测和分析的光。进行测序454的另外细节见于margulies等人(2005)nature 437:376-380,所述文献据此以引用的方式整体并入。
[0116]
离子激流技术是一种基于检测dna聚合期间释放的氢离子的dna测序方法。微孔含有待测序的ngs片段文库的片段。微孔层下是超灵敏离子传感器isfet。所有层都包含在半导体cmos芯片内,类似于电子工业中使用的芯片。当dntp掺入到不断增长的互补链中时,释放出激发超灵敏离子传感器的氢离子。如果模板序列中存在均聚物重复,则在一个循环中将包含多个dntp分子。这导致对应量的氢原子被释放,并且与更高的电信号成比例。此技术不同于其他不使用修饰的核苷酸或光学装置的测序技术。关于离子激流技术的另外细节见于science 327(5970):1190(2010);美国专利申请公开号20090026082、20090127589、20100301398、20100197507、20100188073和20100137143,所述文献中的每一者以引用的方式整体并入。
[0117]
在各种实施方案中,可以使用本领域中已知的任何算法(例如python脚本barcodecleanup.py)按质量过滤从ngs方法获得的测序读数并按条形码序列分组。在一些实施方案中,如果超过约20%的碱基的质量分数(q得分)小于q20(其指示约99%的碱基调用精度),则可以丢弃给定的测序读数。在一些实施方案中,如果超过约5%、约10%、约15%、约20%、约25%、约30%的q得分小于q10、q20、q30、q40、q50、q60或更多(其分别指示约90%、约99%、约99.9%、约99.99%、约99.999%、约99.9999%或更多的碱基调用精度),则可以丢弃给定的测序读数。
[0118]
在一些实施方案中,可以丢弃与含有少于50个读数的条形码相关联的测序读数,以确保表示单细胞的所有条形码组含有足够数量的高质量读数。在一些实施方案中,可以丢弃与含有少于30、少于40、少于50、少于60、少于70、少于80、少于90、少于100或更多个读数的条形码相关联的所有测序读数,以确保表示单细胞的条形码组的质量。
[0119]
在各种实施方案中,具有共有条形码序列的序列读数(例如,意味着序列读数源自同一细胞)可以使用本领域已知的方法与参考基因组比对以确定比对位置信息。例如,源自基因组dna的序列读数可以与参考基因组的位置范围进行比对。在各种实施方案中,源自基因组dna的序列读数可以与对应于参考基因组基因的位置范围进行比对。比对位置信息可以指示参考基因组中与给定序列读数的开始核苷酸碱基和结束核苷酸碱基对应的区域的开始位置和结束位置。参考基因组中的区域可以与靶基因或基因区段相关联。在美国申请号16/279,315中描述了用于将序列读数与参考序列比对的进一步细节,所述申请据此以引用的方式整体并入。在各种实施方案中,可以产生具有sam(序列比对图)格式或bam(二进制比对图)格式的输出文件,并且将其输出用于后续分析,诸如用于确定细胞轨迹。
[0120]
细胞基因型和表型
[0121]
分析源自基因组dna的核酸和抗体寡核苷酸的测序读数以确定细胞表型和细胞基因型。
[0122]
在各种实施方案中,确定细胞基因型是指确定细胞基因组中的一个或多个突变。在特定实施方案中,实施tapestri insights软件以鉴定细胞基因组中的一个或多个突变。在一个实施方案中,一个或多个突变包括单核苷酸改变(例如snv)或核苷酸改变的短序列(例如,短插入缺失)。这里,对照参考基因组分析源自细胞基因组dna的比对序列读数,以确定细胞突变中存在的可能核苷酸碱基与参考基因组中存在的对应核苷酸碱基之间的差异。在各种实施方案中,鉴定snv和/或短插入缺失可以通过实施任何公开可用的snv调用程序算法来实现,所述公开可用的snv调用程序算法包括但不限于:bwa、novoalign、torrent mapping alignment program(tmap)、varscan2、qsnp、shimmer、radia、soapsnv、vardict、snvmix2、splinter、snver、outlyzer、pisces、isown、somvarius和sinvict。
[0123]
在一个实施方案中,一个或多个突变包括结构变体诸如cnv和/或涵盖长序列的突变(例如,长插入缺失)。这里,拆分读取和从头组装方法可以用于鉴定cnv和/或更长的插入缺失。在各种实施方案中,cnv调用者工作流涉及以下步骤中的一个或多个:装仓(binning)、gc含量校正、可定位校正、去除离群值仓、去除离群值单元、分区段和调用绝对数。cnv调用者工作流的进一步细节在以下文献中有描述:fan,x.等人,methods for copy number aberration detection from single-cell dna sequencing data,biorxiv 696179,将其据此以引用的方式整体并入。在各种实施方案中,鉴定cnv和/或长插入缺失可以通过实施任何公开可用的cnv调用者来实现,所述公开可用的cnv调用者包括但不限于:hmmcopy、seqseg、cnv-seq、rsw-seq、freec、cnaseg、readdepth、cnvator、seqcbs、seqcna、m-hmm、ginkgo、nbcnv、aneufinder、scnv和cnv iftv。
[0124]
在各种实施方案中,序列读数在它们用于鉴定细胞基因组的一个或多个突变之前进行预处理。例如,来自细胞的读数通过细胞的总读数计数归一化,并且基于扩增子读数分布通过分级聚类来分组。将来自细胞的扩增子计数除以来自对照组(例如,具有已知cnv的对照细胞簇)的对应扩增子的中值。因此,使用测序读数的归一化百分比来计算每个基因的cnv。
[0125]
在各种实施方案中,用于确定细胞基因型的序列读数可以来源于细胞基因组的各个区。细胞基因组的这些区包括编码区和非编码区两者(例如,内含子、调控元件、转录因子结合位点、染色体易位连接)。因此,可以在编码区和非编码区中鉴定一个或多个突变(例如,snv、cnv和插入缺失)。上文详述的直接从基因组dna确定细胞基因型的单细胞工作流分析使得能够鉴定来自编码区和非编码区两者的突变,然而较不直接的方法(例如,逆转录rna的那些方法)仅鉴定来自编码区的突变。
[0126]
为了确定细胞表型,分析源自抗体缀合的寡核苷酸的序列读数。具体来说,对所述抗体寡核苷酸的抗体标签的序列进行测序。序列读数的存在表明对应的抗体(在其上缀合了寡核苷酸)先前已经与细胞的分析物结合。换句话说,序列读数的存在表明细胞表达靶分析物。
[0127]
在各种实施方案中,确定细胞表型涉及定量靶分析物的表达水平。在各种实施方案中,定量靶分析物的表达水平涉及将源自抗体缀合的寡核苷酸的序列读数归一化。在各种实施方案中,归一化序列读数涉及执行中心对数比(clr)变换。在各种实施方案中,归一
化序列读数涉及执行背景去噪和缩放(dsb)。dsb归一化的额外描述见于mul
è
,m.等人“normalizing and denoising protein expression data from droplet-based single cell profiling.”biorxiv 2020.02.24.963603,将其据此以引用的方式整体并入。
[0128]
在各种实施方案中,细胞表型可以指1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16,17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、100、500、1000、5000或10,000种靶分析物的细胞表达。因此,单细胞工作流分析可以产生细胞的多种靶分析物的表达谱。
[0129]
在各种实施方案中,细胞的基因型和表型可以用于分类细胞。例如,可以将细胞分类为至少共享细胞的基因型、至少共享表型或至少共享基因型和表型两者的细胞群体。在各种实施方案中,对细胞群体中的每个细胞进行单细胞工作流分析。因此,可以将群体中每个细胞的细胞基因型和细胞表型用于分类每个细胞以获得关于群体中细胞分布的理解。在各种实施方案中,分类的细胞提供关于存在的亚群的洞察力。在各种实施方案中,细胞分类涉及将细胞的基因型和表型与以已知基因型和表型为特征的已知细胞群体的文库进行比较。因此,如果细胞与已知细胞群体共享基因型、共享表型或共享基因型和表型两者,则可以将细胞分类为已知细胞群体的类别。
[0130]
为了提供实例,可以从疑似患有癌症的受试者获得细胞群体,可以使用单细胞工作流分析群体中的每个细胞以确定每个细胞的基因型和表型。通过与已知参考细胞的基因型和表型比较,根据它们的基因型和表型将细胞分类。因此,使用其基因型和表型对群体中的细胞进行分类揭示了可以指导选择用于受试者的癌症治疗的细胞分布。例如,如果群体中大部分细胞被分类为已知对特定疗法有抗性的已知细胞群体,那么可以选择更可能有效的替代疗法来治疗癌症。
[0131]
在各种实施方案中,将细胞的基因型和表型用于鉴定细胞群体内的亚群。这对于发现先前未知的新亚群是有用的。例如,可以分析先前认为是同质的细胞群体以揭示具有不同基因型和表型组合的细胞的多个亚群。在各种实施方案中,细胞群体可以揭示两个、三个、四个、五个、六个、七个、八个、九个、十个、十一个、十二个、十三个、十四个、十五个、十六个、十七个、十八个、十九个或二十个不同的亚群。
[0132]
在各种实施方案中,对细胞群体中的每个细胞进行单细胞工作流分析,并且将群体中细胞的细胞基因型和细胞表型用于鉴定以基因型和表型为特征的细胞亚群。在一个实施方案中,使用细胞的基因型和表型鉴定亚群涉及进行降维分析。在一个实施方案中,使用细胞的基因型和表型鉴定亚群涉及进行无监督聚类分析。在一个实施方案中,使用细胞的基因型和表型鉴定亚群涉及进行降维分析和无监督聚类分析。
[0133]
无监督聚类分析的实例包括分级聚类、k均值聚类、使用混合模型的聚类、基于密度的噪声应用空间聚类(dbscan)、点排序鉴定聚类结构(optics)或它们的组合。降维分析的实例包括主成分分析(pca)、核心pca、基于图的核心pca、线性判别分析、广义判别分析、自编码器、非负矩阵因式分解、t分布式随机邻域嵌入(t-sne)或均匀流形近似和投影(umap)和dens-umap。
[0134]
在特定实施方案中,对群体中细胞的细胞基因型或细胞表型中的至少一种进行降维分析和无监督聚类。因此,根据细胞的细胞基因型或细胞表型中的至少一种产生细胞簇。在特定实施方案中,根据一个或多个基因的检测到的snv产生细胞簇。在特定实施方案中,
根据两个、三个、四个、五个、六个、七个、八个、九个、十个、十一个、十二个、十三个、十四个、十五个、十六个、十七个、十八个、十九个、二十个、二十五个、三十个、四十个、五十个、六十个、七十个、八十个、九十个或一百个基因的检测到的snv产生细胞簇。在特定实施方案中,根据一个或多个基因的检测到的cnv产生细胞簇。在特定实施方案中,根据两个、三个、四个、五个、六个、七个、八个、九个、十个、十一个、十二个、十三个、十四个、十五个、十六个、十七个、十八个、十九个、二十个、二十五个、三十个、四十个、五十个、六十个、七十个、八十个、九十个或一百个基因的检测到的cnv产生细胞簇。在特定实施方案中,根据一种或多种分析物的分析物表达水平产生细胞簇。在特定实施方案中,根据两种、三种、四种、五种、六种、七种、八种、九种、十种、十一种、十二种、十三种、十四种、十五种、十六种、十七种、十八种、十九种、二十种、二十五种、三十种、四十种、五十种、六十种、七十种、八十种、九十种或一百种分析物的分析物表达水平产生细胞簇。
[0135]
在各种实施方案中,使用其他细胞基因型或细胞表型标记簇中的单个细胞,以揭示簇内或簇之间的细胞的任何亚群。作为一个实例,可以将细胞表型(例如,分析物表达)用于产生细胞簇,并且将细胞基因型(例如,突变)用于标记簇中的细胞。作为另一个实例,将细胞基因型用于产生细胞簇,并且将细胞表型用于标记细胞簇中的细胞。
[0136]
为了提供具体实例,对细胞的细胞表型进行降维分析和无监督聚类。具体来说,可以对源自抗体寡核苷酸的归一化序列读数值(例如,clr值)进行降维分析。然后,在降维的空间中对clr归一化的序列读数值进行无监督聚类,以产生细胞簇。这里,具有相似分析物表达谱的细胞可以聚类在共同的簇中,然而具有不同分析物表达谱的细胞可以聚类在不同的簇中。可以将细胞的细胞基因型用于标记簇内的单个细胞。例如,可以将簇内的单个细胞标记为具有特定突变(例如,基因上的特定snv或特定基因的拷贝数增加/减少)。在一些情况下,可以将簇内的单个细胞标记为具有多于一个突变(例如,一个或多个基因上的snv或一个或多个基因的拷贝数的增加/减少)。
[0137]
作为另一个实例,对细胞的细胞基因型进行降维分析和无监督聚类。具体来说,可以根据在细胞内鉴定的一个或多个基因的突变(例如,snv和/或cnv)进行降维分析。然后,在降维的空间中进行无监督聚类以产生细胞簇。这里,具有相似基因型(例如,一个或多个基因的突变)的细胞可以聚类在共同的簇中,然而具有不同基因型的细胞可以聚类在不同的簇中。可以将细胞的细胞表型用于标记簇内的单个细胞。例如,可以将簇内的单个细胞标记为表达或不表达特定分析物。在一些情况下,可以将簇内的单个细胞标记为表达多于一种分析物或不表达多于一种分析物。
[0138]
在各种实施方案中,对细胞的细胞基因型和细胞表型两者进行降维分析和无监督聚类。这里,具有相似基因型(例如,一个或多个基因的突变)和表型的细胞可以聚类在共同的簇中,然而具有不同基因型和表型的细胞可以聚类在不同的簇中。
[0139]
在一些情况下,分析标记的细胞簇可以揭示具有特定的基因型(例如突变)和表型(例如分析物表达)组合的细胞亚群。在一个实施方案中,细胞亚群可以指具有共同表型和共同基因型的细胞簇。例如,细胞亚群可以指表达分析物并在基因的特定位置具有snv的细胞簇。作为另一个实例,细胞亚群可以指不表达分析物并且具有增加的基因拷贝数的细胞簇。细胞簇的细胞表型(例如,分析物的表达或缺乏表达)和细胞基因型(例如,一种或多种snv的存在或不存在或基因拷贝数的增加/减少)的任何组合都可以被鉴定为亚群。
[0140]
细胞和细胞群体
[0141]
本文所述的实施方案涉及细胞的单细胞分析。在各种实施方案中,细胞是健康细胞。在各种实施方案中,细胞是患病细胞。患病细胞的实例包括癌细胞,诸如血液恶性肿瘤或实体瘤的细胞。血液恶性肿瘤的实例包括但不限于:急性成淋巴细胞性白血病、急性髓性白血病、慢性淋巴细胞性白血病、慢性髓性白血病、典型霍奇金淋巴瘤、弥漫性大b细胞淋巴瘤、滤泡性淋巴瘤、套细胞淋巴瘤、多发性骨髓瘤、骨髓增生异常综合征、髓性疾病、骨髓增生性肿瘤或t细胞淋巴瘤。实体瘤的实例包括但不限于乳腺浸润性癌、结肠腺癌、多形性胶质母细胞瘤、肾透明细胞癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢癌、胰腺腺癌、前列腺腺癌或皮肤黑素瘤。
[0142]
在各种实施方案中,对细胞群体进行单细胞分析。细胞群体可以是异质细胞群体。在一个实施方案中,细胞群体可以包括癌细胞和非癌细胞。在一个实施方案中,细胞群体可以包括在它们自身之间异质的癌细胞。在各种实施方案中,细胞群体可以从受试者获得。例如,从受试者获取样品,并且分离样品中的细胞群体用于进行单细胞分析。
[0143]
靶向组(targeted panel)
[0144]
本文公开的实施方案包括用于探询一个或多个基因的靶向dna组以及用于探询一种或多种蛋白质的表达和/或表达水平的蛋白质组。在各种实施方案中,针对特定癌症(例如,血液恶性肿瘤和/或实体瘤)构建靶向dna组和蛋白质组。图5和图6示出了根据一个实施方案使用单细胞工作流分析的示例性基因靶标和蛋白质靶标。具体来说,图5a中鉴定的基因和图5b中鉴定的蛋白质可以是用于检测或分析急性髓性白血病的单细胞工作流的靶基因和蛋白质。
[0145]
在各种实施方案中,靶向基因组包括1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个、26个、27个、28个、29个、30个、40个、50个、60个、70个、80个、90个、100个、125个、150个、175个、200个、250个、300个、350个、400个、450个、500个或1000个基因。在各种实施方案中,靶向蛋白质组包括至少1个、至少2个、至少5个、至少10个、至少20个、至少30个、至少40个、至少50个、至少60个、至少70个、至少80个、至少90个、至少100个、至少200个、至少300个、至少400个、至少500个或至少1000个基因。
[0146]
在各种实施方案中,靶向基因组对于检测癌症具有特异性,并且包括以下中的一个或多个基因:abl1、ado、akt1、alk、apc、ar、atm、braf、cdh1、cdk4、cdkn2a、csf1r、ctnnb1、ddr2、egfr、erbb2、erbb3、erbb4、esr1、ezh2、fbxw7、fgfr1、fgfr2、fgfr3、flt3、gna11、gnaq、gnas、hnf1a、hras、idh1、idh2、jak1、jak2、jak3、kdr、kit、kras、map2k1、map2k2、met、mlh1、mpl、mtor、notch1、nras、pdgfra、pik3ca、pten、ptpn11、raf1、rb1、ret、smad4、smarcb1、smo、src、stk11、tp53和vhl。
[0147]
在各种实施方案中,靶向基因组对于检测或分析急性成淋巴细胞性白血病具有特异性,并且包括以下中的一个或多个基因:gnb1、dnmt3a、fat1、myb、pax5、chd4、orai1、tp53bp1、ikzf3、wtip、bcor、rpl22、asxl2、atrx、ikzf1、klf9、etv6、flt3、hcn4、stat5b、cnot3、usp9x、slc25a33、zfp36l2、dnah5、egfr、abl1、cdkn1b、frem2、idh2、tspyl2、asxl1、ddx3x、tal1、zeb2、il7r、braf、notch1、kras、rb1、crebbp、med12、znf217、kdm6a、jak1、idh1、pik3r1、ezh2、gata3、hdac7、mdga2、usp7、zfr2、itsn1、bcorl1、rpl5、setd2、ebf1、
kmt2c、pten、kmt2d、serpina1、ctcf、dnm2、runx1、phf6、ovgp1、tbl1xr1、lrfn2、zfhx4、sorcs1、btg1、bcl11b、tp53、smarca4、erg、rpl10、nras、pik3ca、ccnd3、myc、wt1、sh2b3、akt1、ncor1、epor、xbp1、ush2a、lef1、opn5、jak2、lmo2、ptpn11、mga、nf1、jak3、slc5a1、mycn、fbxw7、phip、cdkn2a、cbl、nos1、sptbn5、suz12、uba2和ep300。
[0148]
在各种实施方案中,靶向基因组对于检测或分析慢性淋巴细胞性白血病具有特异性,并且包括以下中的一个或多个基因:atm、chd2、fbxw7、notch1、spen、bcor、crebbp、kras、nras、tp53、birc3、cxcr4、lrp1b、plcg2、xpo1、braf、ddx3x、map2k1、pot1、zmym3、btk、egr2、med12、rps15、card11、ezh2、myd88、setd2、cd79b、fat1、nfkbie和sf3b1。
[0149]
在各种实施方案中,靶向基因组对于检测或分析慢性髓性白血病具有特异性,并且包括以下中的一个或多个基因:dnmt3a、cdkn2a、tp53、u2af1、kit、abl1、setbp1、tet2、etv6、asxl1、ezh2、flt3和runx1。
[0150]
在各种实施方案中,靶向基因组对于检测或分析典型的霍奇金淋巴瘤具有特异性,并且包括以下中的一个或多个基因:b2m、nfkbia、socs1、tnfaip3、myb、prdm1、stat3、tp53、myc、rel和stat6。
[0151]
在各种实施方案中,靶向基因组对于检测或分析弥漫性大b细胞淋巴瘤具有特异性,并且包括以下中的一个或多个基因:atm、crebbp、myd88、stat6、b2m、ep300、notch1、tet2、bcl2、ezh2、notch2、tnfaip3、braf、foxo1、pik3cd、tnfrsf14、card11、gna13、pim1、tp53、cd79a、cd79b、kmt2d、myc、pten和socs1。
[0152]
在各种实施方案中,靶向基因组对于检测或分析滤泡性淋巴瘤具有特异性,并且包括以下中的一个或多个基因:tnfrsf14、tnfaip3、stat6、cd79b、arid1a、card11、crebbp、bcl2、notch2、ezh2、socs1、ep300、tet2、kmt2d和tp53。
[0153]
在各种实施方案中,靶向基因组对于检测或分析套细胞淋巴瘤具有特异性,并且包括以下中的一个或多个基因:atm、ccnd1、notch1、ubr5、birc3、kmt2d、tp53和whsc1。
[0154]
在各种实施方案中,靶向基因组对于检测或分析多发性骨髓瘤具有特异性,并且包括以下中的一个或多个基因:braf、fam46c、irf4、pik3ca、ccnd1、fgfr3、jak2、rb1、dis3、flt3、kras、tp53、dnmt3a、idh1、nras和traf3。
[0155]
在各种实施方案中,靶向基因组对于检测或分析骨髓增生异常综合征具有特异性,并且包括以下中的一个或多个基因:asxl1、flt3、nf1、tp53、bcor、gata2、nras、u2af1、cbl、idh1、ptpn11、zrsr2、dnmt3a、idh2、runx1、etv6、jak2、sf3b1、ezh2、kras和tet2。
[0156]
在各种实施方案中,靶向基因组对于检测或分析骨髓疾病具有特异性,并且包括以下中的一个或多个基因:asxl1、erg、kdm6a、nras、smc1a、atm、etv6、kit、phf6、smc3、bcor、ezh2、kmt2a、ppm1d、stag2、braf、flt3、kras、pten、stat3、calr、gata2、mpl、ptpn11、tet2、cbl、gnas、myc、rad21、tp53、chek2、idh1、myd88、runx1、u2af1、csf3r、idh2、nf1、setbp1、wt1、dnmt3a、jak2、npm1、sf3b1和zrsr2。
[0157]
在各种实施方案中,靶向基因组对于检测或分析骨髓增生性肿瘤具有特异性,并且包括以下中的一个或多个基因:csf3r、idh1、jak2、araf、chek2、mpl、kit、cbl、setbp1、sf3b1、nras、tet2、idh2、asxl1、calr、dnmt3a、ezh2、tp53、runx1、nf1、erbb4、ptpn11、kras和u2af1。
[0158]
在各种实施方案中,靶向基因组对于检测或分析t细胞淋巴瘤具有特异性,并且包
括以下中的一个或多个基因:alk、cdkn2a、idh2、rhoa、arid1a、ddx3x、jak3、stat3、atm、dnmt3a、kmt2c、tet2、card11、fas plcg1和tp53。
[0159]
在各种实施方案中,靶向蛋白质组包括1种、2种、3种、4种、5种、6种、7种、8种、9种、10种、11种、12种、13种、14种、15种、16种、17种、18种、19种、20种、21种、22种、23种、24种、25种、26种、27种、28种、29种、30种、40种、50种、60种、70种、80种、90种、100种、125种、150种、175种、200种、250种、300种、350种、400种、450种、500种或1000种蛋白质。在各种实施方案中,靶向蛋白质组包括至少1种、至少2种、至少5种、至少10种、至少20种、至少30种、至少40种、至少50种、至少60种、至少70种、至少80种、至少90种、至少100种、至少200种、至少300种、至少400种、至少500种或至少1000种蛋白质。在各种实施方案中,靶向蛋白质组包括以下中的一种或多种蛋白质:hla-dr、cd10、cd117、cd11b、cd123、cd13、cd138、cd14、cd141、cd15、cd16、cd163、cd19、cd193(ccr3)、cd1c、cd2、cd203c、cd209、cd22、cd25、cd3、cd30、cd303、cd304、cd33、cd34、cd4、cd42b、cd45ra、cd5、cd56、cd62p(p选择蛋白(selectin))、cd64、cd68、cd69、cd38、cd7、cd71、cd83、cd90(thy1)、fcεriα、siglec-8、cd235a、cd49d、cd45、cd8、cd45ro、小鼠igg1κ、小鼠igg2aκ、小鼠igg2bκ、cd103、cd62l、cd11c、cd44、cd27、cd81、cd319(slamf7)、cd269(bcma)、cd99、cd164、kcnj3、cxcr4(cd184)、cd109、cd53、cd74、hla-dr、hla-dp、hla-dq、hla-a、hla-b、hla-c、ror1、膜联蛋白a1或cd20。
[0160]
条形码和加条形码的珠粒
[0161]
本发明的实施方案涉及提供用于在图1所示的步骤170期间标记单细胞分析物的一个或多个条形码序列。所述一个或多个条形码序列被包封在含有从单细胞来源的细胞裂解物的乳液中。因此,所述一个或多个条形码标记细胞的分析物,从而使得能够随后确定从源自相同单细胞的分析物来源的序列读数。
[0162]
在各种实施方案中,将多个条形码添加到具有细胞裂解物的乳液中。在各种实施方案中,添加到乳液中的多个条形码包括至少102个、至少103个、至少104个、至少105个、至少105个、至少106个、至少107个或至少108个条形码。在各种实施方案中,添加到乳液中的多个条形码具有相同的条形码序列。例如,将相同条形码标记的多个拷贝添加到乳液中以标记源自细胞裂解物的多种分析物,从而使得能够鉴定分析物所来源的细胞。在各种实施方案中,添加到乳液中的多个条形码包含“唯一识别序列”(umi)。umi是具有可用于识别和/或区分与umi缀合的一个或多个第一分子和与具有不同序列的不同umi缀合的一个或多个第二分子的序列的核酸。umi通常很短,例如长度约为5至20个碱基,并且可以与一种或多种感兴趣的靶分子或其扩增产物缀合。umi可以是单链或双链的。在一些实施方案中,条形码序列和umi两者被掺入条形码中。通常,umi用于区分群体或群组内相似类型的分子,然而条形码序列用于区分源自不同细胞的群体或分子群组。在使用umi和条形码序列两者的一些实施方案中,umi的序列长度比条形码序列更短。在美国专利申请号15/940,850中进一步描述了条形码的使用,所述申请据此以引用的方式整体并入。
[0163]
在一些实施方案中,条形码是单链条形码。可以使用多种技术产生单链条形码。例如,它们可以通过获得多个dna条形码分子来产生,其中不同分子的序列至少部分不同。然后这些分子可以使用例如不对称pcr来扩增以便产生单链拷贝。替代性地,条形码分子可以被环化,并且然后进行滚动循环扩增。这将产生其中加条形码的原始dna被串联多次成为单一的长分子的产物分子。
[0164]
在一些实施方案中,可以通过对线性dna进行环化来获得包含侧翼为任意数量的恒定序列的条形码序列的环状条形码dna。与任何恒定序列退火的引物可以通过使用链置换聚合酶(诸如phi29聚合酶)来启动滚动循环扩增,从而产生条形码dna的长的线性串联体。
[0165]
在各种实施方案中,条形码可以连接到引物序列,该引物序列使得条形码能够标记靶核酸。在一个实施方案中,条形码连接到正向引物序列上。在各种实施方案中,正向引物序列是与核酸的正向靶标杂交的基因特异性引物。在各种实施方案中,正向引物序列是与附接到基因特异性引物上的互补序列杂交的恒定区域,诸如pcr柄。可以在反应混合物(例如,图1中的反应混合物140)中提供附接到基因特异性引物上的互补序列。在条形码上包括恒定的正向引物序列可能是优选的,因为条形码可以具有相同的正向引物,并且不需要单独设计成连接到基因特异性正向引物上。
[0166]
在各种实施方案中,条形码可以可释放地附接到支撑结构(诸如珠粒)上。因此,具有多个拷贝条形码的单个珠粒可以被分配到具有细胞裂解物的乳液中,从而使得能够用珠粒的条形码标记细胞裂解物的分析物。示例性珠粒包括固体珠粒(例如,二氧化硅珠粒)、聚合物珠粒或水凝胶珠粒(例如,聚丙烯酰胺、琼脂糖或海藻酸盐珠粒)。珠粒可以使用多种技术合成。例如,使用混合-分裂技术,可以合成具有相同随机条形码序列的许多拷贝的珠粒。这可以通过例如产生多个包括dna能够在其上合成的位点的珠粒来实现。可以将珠粒分为四个集合,并且每个集合都与将向其添加一个基底(诸如a、t、g或c)的缓冲液混合。通过将群体分成四个子群体,每个子群体可以具有添加到其表面上的碱基中的一种碱基。该反应能够以使得仅添加单一碱基而不添加另外的碱基的方式完成。可以将来自所有四个亚群的珠粒合并并混合在一起,然后第二次分成四个群体。在该分开步骤中,可以将来自前四个群体的珠粒随机地混合在一起。然后可以将它们添加到四种不同的溶液中,在每个珠粒的表面上添加另一种随机的碱基。可以重复该过程,以便在珠粒的表面上产生长度约等于群体被分裂和混合的次数的序列。例如,如果这样做10次,将得到这样的珠粒群体:其中每个珠粒都具有在其表面上合成的相同随机10碱基序列的许多拷贝。每个珠粒上的序列将由在每个混合-分裂循环中该珠粒粒所终止处的反应器特定序列决定。示例性珠粒及其合成的另外细节描述于国际申请号pct/us2016/016444中,所述申请据此以引用的方式整体并入。
[0167]
试剂
[0168]
本文所述的实施方案包括在乳液内用试剂包封细胞。通常,试剂在细胞裂解的条件下与包封的细胞相互作用,从而释放细胞的靶标分析物。试剂可以进一步与靶标分析物相互作用,为随后的加条形码和/或扩增做准备。
[0169]
在各种实施方案中,试剂包括一种或多种导致细胞裂解的裂解剂。裂解剂的实例包括洗涤剂,诸如triton x-100、nonidet p-40(np40)以及细胞毒素。在一些实施方案中,试剂包括np40洗涤剂,其足以破坏细胞膜并导致细胞裂解,但不破坏染色质包装的dna。在各种实施方案中,试剂包括0.01%、0.05%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.1%、1.2%、1.3%、1.4%、1.5%、1.6%、1.7%、1.8%、1.9%、2.0%、3.0%、3.1%、3.2%、3.3%、3.4%、3.5%、3.6%、3.7%、3.8%、3.9%、4.0%、4.1%、4.2%、4.3%、4.4%、4.5%、4.6%、4.7%、4.8%、4.9%或5.0%np40(v/v)。在各种实施方案中,试剂包括至少至少0.01%、至少0.05%、0.1%、至少0.5%、至少1%、至
少2%、至少3%、至少4%或至少5%np40(v/v)。
[0170]
在各种实施方案中,试剂还包括有助于细胞裂解和/或基因组dna访问的蛋白酶。蛋白酶的实例包括蛋白酶k、胃蛋白酶、蛋白酶-枯草杆菌蛋白酶carlsberg、热溶蛋白芽孢杆菌x型蛋白酶、曲霉xiii型蛋白酶saitoi。在各种实施方案中,试剂包括0.01mg/ml、0.05mg/ml、0.1mg/ml、0.2mg/ml、0.3mg/ml、0.4mg/ml、0.5mg/ml、0.6mg/ml、0.7mg/ml、0.8mg/ml、0.9mg/ml、1.0mg/ml、1.5mg/ml、2.0mg/ml、2.5mg/ml、3.0mg/ml、3.5mg/ml、4.0mg/ml、4.5mg/ml、5.0mg/ml、6.0mg/ml、7.0mg/ml、8.0mg/ml、9.0mg/ml或10.0mg/ml的蛋白酶。在各种实施方案中,试剂包括0.1mg/ml与5mg/ml之间的蛋白酶。在各种实施方案中,试剂包括0.5mg/ml与2.5mg/ml之间的蛋白酶。在各种实施方案中,试剂包括0.75mg/ml与1.5mg/ml之间的蛋白酶。在各种实施方案中,试剂包括0.9mg/ml与1.1mg/ml之间的蛋白酶。
[0171]
在各种实施方案中,试剂还可以包括dntp、稳定剂诸如二硫苏糖醇(dtt)和缓冲溶液。在各种实施方案中,试剂可以包括引物,诸如与靶分析物(例如,基因组dna或抗体寡核苷酸)杂交的反向引物。在各种实施方案中,此类引物可以是基因特异性引物。示例性引物在下文进一步详细描述。
[0172]
反应混合物
[0173]
如本文所述,向具有细胞裂解物的乳液中提供反应混合物(例如,参见图1中的细胞加条形码步骤170)。通常,反应混合物包含足以在细胞裂解物的分析物上进行反应(诸如核酸扩增)的反应物。
[0174]
在各种实施方案中,反应混合物包含当置于催化合成与核酸链互补的引物延伸产物的条件下时,能够沿互补链作为合成起始点的引物。在各种实施方案中,反应混合物包含四种不同的三磷酸脱氧核糖核苷(腺苷、鸟嘌呤、胞嘧啶和胸腺嘧啶)。在各种实施方案中,反应混合物包含用于核酸扩增的酶。用于核酸扩增的酶的实例包括dna聚合酶、用于热循环扩增的热稳定聚合酶、或用于等温扩增的多置换扩增的聚合酶。也可以应用其他不太常见形式的扩增,诸如使用依赖于dna的rna聚合酶进行扩增,以从原始dna靶标产生多个拷贝的rna,所述多个拷贝的rna其本身可以转换回dna,从而导致实质上靶标的扩增。活的有机体也可以用于扩增靶标,例如通过将靶标转化到有机体中,所述有机体然后允许或诱导在有或没有有机体复制的情况下拷贝靶标。
[0175]
在各种实施方案中,反应混合物的内容物是在合适的缓冲液中(“缓冲液”包括作为辅助因子的取代基、或影响ph、离子强度等的取代基)并在合适的温度下。
[0176]
可以通过调节反应物在反应混合物中的浓度来控制核酸扩增的程度。在一些情形中,这对于使用扩增产物的反应的微调是有用的。
[0177]
引物
[0178]
本文所述的本发明的实施方案使用引物来进行单细胞分析。例如,在图1所示的工作流过程期间应用了引物。引物可以用于与感兴趣的核酸的特异性序列引发(例如,杂交),使得可对感兴趣的核酸加条形码和/或进行扩增。具体来说,引物与靶序列杂交并且充当酶(例如聚合酶)的底物,所述酶催化核酸从引物杂交的模板链合成。如下文所述,可以在图1所示的工作流过程中在不同的步骤中提供引物。再次参考图1,在各种实施方案中,引物可以包括在与细胞102一起包封的试剂120中。在各种实施方案中,引物可以包括在与细胞裂解物130一起包封的反应混合物140中。在各种实施方案中,引物可以包括在与细胞裂解物
130一起包封的条形码145中或与其连接。在美国申请号16/749,731中描述了用于单细胞分析工作流过程中的引物的进一步描述和实例,所述申请据此以引用的方式整体并入。
[0179]
在各种实施方案中,在试剂、反应混合物或条形码中任一者中的不同引物的数量可以在下列范围内:约1个至约500个或更多个引物,例如约2个至100个引物、约2个至10个引物、约10个至20个引物、约20个至30个引物、约30个至40个引物、约40个至50个引物、约50个至60个引物、约60个至70个引物、约70个至80个引物、约80个至90个引物、约90个至100个引物、约100个至150个引物、约150个至200个引物、约200个至250个引物、约250个至300个引物、约300个至350个引物、约350个至400个引物、约400个至450个引物、约450个至500个引物、或约500个引物或更多个引物。
[0180]
对于靶向dna测序,试剂(例如,图1中的试剂120)中的引物可以包括与感兴趣的核酸(例如,dna或rna)上的反向靶序列互补的反向引物。在各种实施方案中,试剂中的引物可以是靶向感兴趣基因的反向靶序列的基因特异性引物。在各种实施方案中,在反应混合物(例如,图1中的反应混合物140)中的引物可以包括与感兴趣的核酸(例如,dna)上的正向靶序列互补的正向引物。在各种实施方案中,反应混合物中的引物可以是靶向感兴趣基因的正向靶标的基因特异性引物。在各种实施方案中,试剂的引物和反应混合物的引物形成针对核酸上的感兴趣区域的引物组(例如,正向引物和反向引物)。示例性基因特异性引物可以是靶向上述“靶向组”部分中鉴定的任何基因的引物。
[0181]
添加的用于感兴趣基因的不同正向引物或反向引物的数量可以是约1个至500个,例如约1个至10个引物、约10个至20个引物、约20个至30个引物、约30个至40个引物、约40个至50个引物、约50个至60个引物、约60个至70个引物、约70个至80个引物、约80个至90个引物、约90个至100个引物、约100个至150个引物、约150个至200个引物、约200个至250个引物、约250个至300个引物、约300个至350个引物、约350个至400个引物、约400个至450个引物、约450个至500个引物,或者约500个引物或更多个引物。
[0182]
在各种实施方案中,代替引物被包括在反应混合物(例如,图1中的反应混合物140)中,此类引物可以被包括在条形码(例如,图1中的条形码145)中或连接到其上。在特定的实施方案中,引物连接到条形码的末端,并且因此可用于与细胞裂解物中的核酸的靶序列杂交。
[0183]
在各种实施方案中,反应混合物的引物、试剂的引物或条形码的引物可以在一个步骤中或在多于一个步骤中添加到乳液中。例如,可以在两个或更多个步骤、三个或更多个步骤、四个或更多个步骤或五个或更多个步骤中添加引物。无论引物是在一个步骤中还是一个以上步骤中添加,其都可以在添加裂解剂之后、在添加裂解剂之前或与添加裂解剂同时添加。当在添加裂解剂之前或之后添加时,反应混合物的引物可以在与添加裂解剂分开的步骤中添加(例如,如图1所示的两步骤工作流过程中所示例的)。
[0184]
用于扩增靶核酸的引物组通常包括与靶核酸或其互补物互补的正向引物和反向引物。在一些实施方案中,可以在单个扩增反应中使用多个靶标特异性引物对执行扩增,其中每个引物对包括正向靶标特异性引物和反向靶标特异性引物,其中每个引物包括至少一个与样品中的相应靶序列基本上互补或基本相同的序列,并且每个引物对具有不同的相应靶序列。因此,本文中的某些方法用于检测或识别来自单细胞样品的多个靶序列。
[0185]
示例性系统和/或计算机实施方案
[0186]
此外,本文还描述了用于执行上述单细胞分析的系统和计算机实施方案。示例性系统可以包括单细胞工作流装置和计算装置,诸如图1a中所示的单细胞工作流装置106和计算装置108。在各种实施方案中,单细胞工作流装置106被配置成执行细胞包封160、分析物释放165、细胞加条形码170、靶标扩增175、核酸汇集205和测序210的步骤。在各种实施方案中,计算装置108被配置成执行读数比对215,确定细胞基因型和表型220和使用细胞基因型和表型分析细胞的计算机模拟步骤。
[0187]
在各种实施方案中,单细胞工作流装置106包括至少一个微流体装置,该微流体装置被配置成与试剂一起包封细胞、与反应混合物一起包封细胞裂解物和执行核酸扩增反应。例如,微流体装置可以包括流体地连接的一个或多个流体通道。因此,通过第一通道的水性流体和通过第二通道的载体流体的组合导致乳液液滴的产生。在各种实施方案中,微流体装置的流体通道可以具有毫米或更小量级(例如,小于或等于约1毫米)的至少一个横截面尺寸。在国际专利申请号pct/us2016/016444和美国专利申请号14/420,646中描述了微通道设计和尺寸的另外细节,所述申请中的每一者据此以引用的方式整体并入。微流体装置的一个实例是tapestri
tm
平台。
[0188]
在各种实施方案中,单细胞工作流装置106还可以包括以下中的一者或多者:(a)用于控制主题装置和/或其中的液滴的一个或多个部分的温度并且可操作地连接到微流体装置上的温度控制模块;(b)可操作地连接到微流体装置上的检测模块,即检测器,例如光学成像器;(c)可操作地连接到微流体装置上的孵育器,例如细胞孵育器;和(d)可操作地连接到微流体装置上的测序仪。所述一个或多个温度和/或压力控制模块提供对装置的一个或多个流动通道中的载体流体的温度和/或压力的控制。作为实例,温度控制模块可以是调节用于执行核酸扩增的温度的一个或多个热循环仪。所述一个或多个检测模块(即检测器,例如光学成像器)被配置成用于检测一种或多种液滴的存在、或其一个或多个特征(包括其组成)。在一些实施方案中,检测器模块被配置成识别一个或多个流动通道中的一种或多种液滴的一种或多种组分。所述测序仪被配置成执行测序(诸如下一代测序)的硬件装置。测序仪的实例包括illumina测序仪(例如,miniseq
tm
、miseq
tm
、nextseq
tm
550系列或nextseq
tm
2000)、roche测序系统454和thermo fisher scientific测序仪(例如,ion genestudio s5系统、ion torrent genexus系统)。
[0189]
图7描绘了用于实现参考图1-6所描绘的系统和方法的示例性计算装置。例如,示例性计算装置108被配置成执行读数比对215和确定细胞轨迹220的计算机模拟步骤。计算装置的实例可以包括个人计算机、台式计算机、膝上型计算机、服务器计算机、集群内的计算节点、信息处理器、手持装置、多处理器系统、基于微处理器或可编程的消费者电子装置、网络pc、小型计算机、主机计算机、移动电话、pda、平板电脑、传呼机、路由器、交换机等。
[0190]
图7展示了用于实现图1-5中所描述的系统和方法的示例性计算装置108。在一些实施方案中,计算装置108包括耦接至芯片组704的至少一个处理器702。芯片组704包括存储器控制器集线器720和输入/输出(i/o)控制器集线器722。存储器706和图形适配器712耦接至存储器控制器集线器720,且显示器718耦接至图形适配器712。存储装置708、输入接口714和网络适配器716耦接至i/o控制器集线器722。计算装置108的其他实施方案具有不同的架构。
[0191]
存储装置708是非暂时性计算机可读存储介质,例如硬盘驱动器、光盘只读存储器
(cd-rom)、dvd或固态存储器装置。存储器706保持由处理器702使用的指令和数据。输入接口714是触摸屏接口、鼠标、跟踪球或其他类型的输入接口、键盘或其一些组合,并且用于将数据输入到计算装置108中。在一些实施方案中,计算装置108可以被配置成经由来自用户的手势从输入接口714接收输入(例如命令)。图形适配器712在显示器718上显示图像和其它信息。例如,显示器718可以显示预测的细胞轨迹的指示。网络适配器716将计算装置108耦接至一个或多个计算机网络。
[0192]
计算装置108被调适来执行用于提供本文描述的功能的计算机程序模块。如本文中所使用,术语“模块”是指用于提供指定功能的计算机程序逻辑。因此,模块可以实施于硬件、固件和/或软件中。在一个实施方案中,程序模块存储于存储装置708上,载入至存储器706中且由处理器702执行。
[0193]
计算装置108的类型可以不同于本文所述的实施方案。例如,计算装置108可以缺少上述组件中的一些,诸如图形适配器712、输入接口714和显示器718。在一些实施方案中,计算装置108可以包括处理器702,用于执行储存在存储器706上的指令。
[0194]
在各种实施方案中,本文所述的方法(诸如比对序列读数的方法)、确定细胞基因型和表型的方法和/或使用细胞基因型和表型分析细胞的方法可以在硬件或软件或两者的组合中实施。在一个实施方案中,提供了一种非短暂的机器可读存储介质(诸如上文所述的介质),所述介质包括用机器可读数据编码的数据存储材料,所述数据存储材料当使用编程有使用所述数据的指令的机器时能够显示本发明的细胞轨迹的任何数据集和执行及结果。此类数据可以用于各种目的,诸如患者监测、治疗考虑等。上文所述的方法的实施方案可以在可编程计算机上执行的计算机程序中实现,所述可编程计算机包括处理器、数据存储系统(包括易失性和非易失性存储器和/或存储元件)、图形适配器、输入接口、网络适配器、至少一个输入装置和至少一个输出装置。显示器耦接至图形适配器。程序代码被应用于输入数据以执行上文所述的功能并产生输出信息。以已知的方式将输出信息应用于一个或多个输出装置。计算机可以是例如传统设计的个人计算机、微型计算机或工作站。
[0195]
每个程序可以用高级程序或面向对象的编程语言来实施以与计算机系统通信。然而,如果期望的话,程序可以汇编或机器语言来实施。在任何情况下,语言都可以是编译的或解释的语言。每个这样的计算机程序优选地储存在可由通用或专用目的可编程计算机读取的存储介质或装置(例如,rom或磁盘)上,用于当计算机读取存储介质或装置以执行本文所述的程序时配置和操作计算机。所述系统还可以被认为作为配置有计算机程序的计算机可读存储介质实现,其中如此配置的存储介质使计算机以特定和预定义的方式操作以执行本文所述的功能。
[0196]
可以在各种介质中提供签名模式及其数据库,以便于它们的使用。“介质”是指含有本发明的签名模式信息的制品。本发明的数据库可以记录在计算机可读介质(例如,计算机可以直接读取和访问的任何介质)上。此类介质包括但不限于:磁性存储介质,诸如软盘、硬盘存储介质和磁带;光存储介质,诸如cd-rom;电存储介质,诸如ram和rom;以及这些类别的混合体,诸如磁/光存储介质。本领域技术人员可以容易地理解如何使用任何当前已知的计算机可读介质来创建包含记录当前数据库信息的制品。“记录的”是指使用如本领域中已知的任何此类方法在计算机可读介质上储存信息的过程。根据用于访问存储信息的手段,可以选择任何方便的数据存储结构。可以使用多种数据处理器程序和格式进行存储,例如
文字处理文本文件、数据库格式等。
[0197]
示例性试剂盒实施方案
[0198]
本文还提供了用于进行单细胞工作流以确定细胞群体的细胞基因型和表型的试剂盒。试剂盒可以包括以下中的一者或多者:用于形成乳液的流体(例如,载体相、水相)、加条形码的珠粒、用于处理单细胞的微流体装置、用于裂解细胞和释放细胞分析物的试剂、用抗体标记细胞的试剂和缓冲液、用于执行核酸扩增反应的反应混合物、以及用于根据本文所述的方法使用任何试剂盒组分的说明。
[0199]
实施例
[0200]
实施例1:在单细胞中同时检测细胞表面蛋白和突变
[0201]
将jurkat、k562、mutz-8和raji细胞的混合群体用含有9种感兴趣的单克隆抗体加上作为阴性对照的小鼠igg1k抗体的寡核苷酸缀合的抗体库进行处理。然后洗涤细胞并将其加载到tapestri平台上,用单细胞dna aml v2 panel(128个扩增子覆盖20个基因)进行分析。用tapestri pipeline软件处理dna基因型的测序数据,并且用tapestri insights软件进一步分析以确定snv。
[0202]
使用中心对数比(clr)转换归一化抗体标签计数。使用来自所有蛋白质靶标的clr值产生t-sne图。具体来说,图8描绘了根据不同蛋白质的表达的t-sne图的细胞聚类。从图8可以看出,鉴定了具有不同蛋白质表达的四个不同的细胞簇。每个小图反映了每种相应蛋白质的clr值。
[0203]
分析来自细胞的snv数据以证实四个簇是四种不同的细胞系。图9a描绘了四种不同的细胞系和将细胞系彼此区分的已知snv。因此,从单细胞捕获的snv数据揭示了该单细胞是k562细胞、raji细胞、mutz8细胞还是jurkat细胞。
[0204]
接下来将来自每个细胞的snv数据与图8中所示的成簇的蛋白质表达数据组合。具体来说,图9b描绘了根据蛋白质表达的细胞聚类,具有细胞基因型的额外覆盖。具体来说,snv数据揭示了簇910对应于raji细胞,簇920对应于jurkat细胞,簇930对应于k562细胞,并且簇940对应于mutz8细胞。
[0205]
总之,单细胞蛋白质标记表达数据独立地将细胞聚类成与细胞基因型数据相匹配的组。这证明单细胞工作流过程能够根据其表型(例如,蛋白质标志物表达)和基因型(例如,snv)成功地将单个细胞分类为细胞群。
[0206]
实施例2:来自靶向dna测序的cnv分析
[0207]
分析从细胞获得的cnv数据以证明cnv数据可以成功地用于在四种不同群体的细胞之间作出区分。根据靶向dna测序数据,首先通过细胞的总读数计数归一化每个细胞的读数,并且通过基于扩增子读数分布的分级聚类进行分组。然后鉴定具有已知cnv的对照细胞簇,并且将来自所有细胞的扩增子计数除以来自对照组的相应扩增子的中值。在该实验中,使用来自aml组中扩增子的测序读数的归一化百分比来计算测试的每个基因的cnv。将jurkat细胞用作对照细胞系,测试的所有基因具有已知的二倍体状态。
[0208]
图10描绘了在4个细胞系中观察到的13个基因的基因水平拷贝数和观察到的基因水平拷贝数与cosmic数据库中已知水平的相关性。通常,图10证明单细胞工作流过程能够鉴定与公开可用的已知cnv(例如,来自cosmic数据库)相关的四种不同细胞系中的13个基因的cnv的量。
[0209]
具体来说,图10展示了观察到的拷贝数及其与cosmic数据库中拷贝数的比较。如小图的顶行所示,在jurkat、k562、mutz8和raji细胞中观察到的每个基因的拷贝数与cosmic数据库中的拷贝数一致。如之前所述,在k562细胞中观察到ezh2基因的拷贝数增加,这与cosmic数据库中ezh2基因的拷贝数增加一致。在cosmic数据库中观察到mutz8细胞中的flt3、kit和tet2基因以及raji细胞中的kras基因的相同增加。
[0210]
小图的底行证明了观察到的拷贝数(y轴)与cosmic拷贝数(x轴)的线性曲线拟合。出于比较的目的,在每个小图中示出了单位线性拟合(斜率=1)。
[0211]
总之,这表明单细胞工作流过程成功地鉴定了单个细胞的基因拷贝数。
[0212]
实施例3:通过cnv结果聚类细胞类型
[0213]
根据基因cnv使用t-sne聚类对细胞进行聚类。图11描绘了根据cnv的细胞聚类,具有通过snv进行细胞分型的额外覆盖。根据上文关于图9a所述的已知snv进行根据snv的细胞分型。具体来说,在图11中,将cnv数据在t-sne图上分组,并且基于先前为每个细胞系建立的snv基因型显示不同的细胞。
[0214]
图11示出了根据基因拷贝数的t-sne聚类分辨了三个单独的簇1110、1120和1130。当覆盖snv基因分型时,簇1110对应于k562细胞,簇1130对应于mutz8细胞,簇1120对应于jurkat和raji细胞。因此,这证明snv和cnv数据的组合能够对属于不同细胞类型的细胞进行分类。
[0215]
实施例4:用于揭示细胞亚群的表型和基因型分析
[0216]
针对snv/插入缺失和cnv两者,使用tapestri单细胞dna aml panel分析raji、k562、tom1和kg1细胞系。在tapestri平台上处理细胞以使用与分析物加条形码寡聚物标签缀合的一组6种抗体同时获得蛋白质表达。靶标由cd19、cd33、cd45、cd90、hla-dr和小鼠igg1κ组成。对于下游分析,仅包括选择的少数snv/插入缺失、cnv和蛋白质。
[0217]
接下来,用跨109个扩增子的、含有31个与aml、mpn和mds相关的基因的定制dna组对6名aml患者样品进行分析。此外,使用靶向以下6种蛋白质的定制蛋白质抗体组:cd3、cd11b、cd34、cd38、cd45ra和cd90。用定制的tapestri pipeline软件分析数据。使用tapestri insights软件鉴定snv和插入缺失,使用r的mision bio“tapestri-cnv”软件包分析cnv,并且使用r的mission bio“tapestri-protein”软件包整合并分析dna 蛋白质数据。
[0218]
将raji、k562、tom1和kg1细胞以等比例混合在一起,并且使用tapestri平台分析snv、插入缺失、cnv和蛋白质。
[0219]
图12a描绘了使用snv、cnv和蛋白质表达之一的四种细胞系的无监督聚类。使用snv数据(基于4种变体)对每种单独分析物的无监督聚类(例如,umap)和可视化分辨了3种细胞系。这里,不能区分k562和tom1细胞,而raji和kg1单独聚类。cnv的无监督聚类类似地产生3个簇,其中k562和kg1细胞单独聚类,但raji和tom1细胞聚类在一起。蛋白质表达的无监督聚类区分了tom1细胞群体,但具有k562、kg1和raji细胞群体的重叠簇。
[0220]
图12b描绘了使用snv、cnv和蛋白质表达中的至少两种对四种细胞系的无监督聚类。通常,当snv或cnv分别与蛋白质数据组合时,细胞系的分辨率增加,而组合的snv、cnv和蛋白质数据一起导致4种细胞系群体的最清楚的分辨率。这里,使用snv、cnv和蛋白质中的至少两种进行无监督聚类能够进一步分辨单独的细胞群体。具体来说,对snv和蛋白质的无
监督聚类能够分辨raji细胞和kg1细胞的不同群体,其中k562和tom1细胞群体的重叠最小。类似地,对cnv和蛋白质的无监督聚类能够清楚地分辨kg1细胞,其中在raji、tom1和k562细胞之间的重叠最小。最后,cnv、snv和蛋白质的无监督聚类完全分辨了四种不同的细胞系。此结果说明了用多组学方法使用来自相同细胞的更多数据获得细胞类型之间的最大分辨率的能力。这进一步证明了可以使用本文所述的单细胞工作流来区分或鉴定在异质群体中混合的细胞亚群。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
