一种dna编码化合物库及化合物筛选方法
技术领域
1.本发明涉及一种dna编码化合物及其化合物库的合成和筛选方法。
背景技术:
2.在药物研发,尤其是新药研发中,针对生物靶标的高通量筛选是快速获得先导化合物的主要手段之一。然而,基于单个分子的传统高通量筛选所需时间长、设备投入巨大、库化合物数量有限(数百万),且化合物库的建成需要数十年的积累,限制了先导化合物的发现效率与可能性。近年来出现的dna编码化合物库技术(wo2005058479、wo2018166532、cn103882532),结合了组合化学和分子生物学技术,在分子水平上将每个化合物加上一个dna标签,并能在极短的时间内合成高达亿级的化合物库,成为下一代化合物库筛选技术的趋势,并开始在制药行业广泛应用,产生了诸多积极的效果(accounts of chemical research,2014,47,1247-1255)。
3.传统的dna编码化合物库进行药物筛选,首先将化合物库与靶点进行孵育,然后通过洗脱将结合到靶点上的化合物与其他化合物进行分离,再在蛋白质变性条件下将结合在靶点上的化合物进行游离,qpcr扩增,dna测序,进而数据分析获得与靶蛋白结合的化合物的化学结构(图1)。然而dna编码化合物筛选是亲和筛选,依赖于药物分子与靶点间的相互作用力的大小,其能够很好地找到与靶点有亲和力的分子,但存在一些应用上的局限,主要表现在筛选过程中需要进行洗脱,低亲和力(微摩尔-毫摩尔)的分子在洗脱过程中容易与靶点进行分离,从而导致信号上不能富集而被忽视。这样限制了dna编码化合物库的筛选效果,特别是小分子片段在混合筛选过程中的筛选结果。
4.为了解决上述技术问题,本发明提供了一种dna编码的化合物、化合物库及筛选方法。使用本发明的dna编码化合物库与靶点孵育,再通过共价交联能够增强化合物与靶点的结合,与传统的dna编码化合物库亲和筛选相比,能够提高化合物特别是低亲和力化合物在筛选信号上的区分度。
技术实现要素:
5.本发明提供了一种dna编码化合物,它具有式i所示的通式:
[0006][0007]
其中,
[0008]
x为原子或分子骨架;
[0009]
a1为包含有连接链和寡核苷酸的部分;
[0010]
a2为包含有连接链和寡核苷酸的部分;其中a1、a2中的寡核苷酸部分互补或部分互补以形成双链;
[0011]
l为包含一个或多个可操作进行共价交联基团的连接部分;
[0012]
m为包含一个或多个结构单元的功能部分。
[0013]
进一步地,x为碳原子、氮原子、环状或非环状骨架结构。
[0014]
更进一步地,所述式ⅰ通式具有式ii所示的结构:
[0015][0016]
其中,z1为在其3'末端与l1连接的寡核苷酸,z2为在其5'末端与l2连接的寡核苷酸;或者z1为在其5'末端与l1连接的寡核苷酸,z2为在其3'末端与l2连接的寡核苷酸;
[0017]
l1为包含有能与z1的3'末端或5'末端形成键的官能团的连接链;
[0018]
l2为包含有能与z2的5'末端或3'末端形成键的官能团的连接链。
[0019]
进一步具体地,z1与z2互补或部分互补以形成双链,z1、z2的长度分别为10个碱基以上,且具有10个以上的碱基对互补区。
[0020]
更进一步具体地,z1、z2均包含pcr引物序列。
[0021]
进一步具体地,l1、l2分别独立地选自双官能团的亚烷基链或双官能团的低聚二醇链,所述的官能团选自磷酸基、氨基、羟基、羧基。
[0022]
更进一步具体地,l1、l2分别独立地选自其中n为1~10的整数。优选地,n为2~6。更优选地,n为3。
[0023]
进一步具体地,l包含光敏性基团、电敏性基团或其它可与蛋白质共价交联的基团。
[0024]
更进一步具体地,l包含吖啶基团、芳基叠氮基团、二苯酮基团、磺酰氟基团、α,β-不饱和酸基团、α,β-不饱和酮基团、α,β-不饱和酯基团、α,β-不饱和磺酰基基团、α-酰基卤基团、环氧基团、醛基、氰基、硼酸基。
[0025]
进一步具体地,l具有如下结构:
[0026]-s
1-s
2-s
3-[0027]
其中,
[0028]
s1、s3选自带一个或多个官能团的环状或非环状的碳原子或者杂原子组成的连接链,所述的官能团选自磷酸基、氨基、羟基、羧基,醛基,叠氮基、炔基、卤代物;
[0029]
s2为含有一个或多个可操作进行共价交联基团的连接链。
[0030]
在本发明的一些实施方案中,s1与x相连,s3与m相连;在本发明的另一些实施方案中,s3与x相连,s1与m相连。
[0031]
更进一步具体地,s1、s3分别独立选自
的一种或几种组合或无,其中,m为1~20的整数。其中,所述s1或s3选自无时,是指与其相连的两部分通过共价键直接连接。优选地,m为1、2、3、4、5、6、7、8、9、10。
[0032]
更进一步具体地,s2中的可操作进行共价交联基团直接连接在连接链上,具有如下结构:下结构:其中r1为碳原子或氮原子,r2为氢、含碳原子或杂原子的烷烃或芳烃。
[0033]
在本发明的一些具体实施方案中,s2具有如下结构其中y选自
[0034][0034]
其中r1为碳原子或氮原子,r2为氢、含碳原子或杂原子的烷烃或芳烃。
[0035]
在本发明的一些优选实施方案中,s2选自
[0036]
更进一步具体地,所述可操作进行共价交联的基团与功能部分m的距离不超过30个原子。优选地,所述可操作进行共价交联的基团与功能部分m的距离不超过20个原子。更优选地,所述可操作进行共价交联的基团与功能部分m的距离不超过15个原子。
[0037]
更进一步具体地,所述可操作进行共价交联的基团与功能部分m的距离大于3个原子。优选地,所述可操作进行共价交联的基团与功能部分m的距离大于4个原子。更优选地,所述可操作进行共价交联的基团与功能部分m的距离大于5个原子。
[0038]
进一步具体地,所述的x选自进一步具体地,所述的x选自其中,q为1~10的整数。其中,所述结构式中的氧原子分别与l1或l2相连。
[0039]
在本发明的一些具体实施方案中,式i所示的dna编码化合物为:
[0040][0041]
其中,
[0042]
z1为在其3'末端相连的寡核苷酸,z2为在其5'末端连接的寡核苷酸;
[0043]
y选自
[0044][0045]
其中r1为碳原子或氮原子,r2为氢、含碳原子或杂原子的烷烃或芳烃;
[0046]
s3选自选自的一种或几种组合或无,其中,m为1~20的整数。其中,所述s1或s3选自无时,是指与其相连的两部分通过共价键直接连接。优选地,m为1、2、3、4、5、6、7、8、9、10;
[0047]
m为包含一个或多个结构单元的功能部分。
[0048]
本发明还提供了一种dna编码化合物库,它是由上述任一项所述的dna编码化合物组成。
[0049]
进一步地,所述dna编码化合物库包含至少10种不同的dna编码化合物。更进一步地,所述dna编码化合物库包含至少102种不同的dna编码化合物。在本发明的一些实施方案中,所述不同的dna编码化合物是指仅寡核苷酸部分和功能部分不同的dna编码化合物。
[0050]
本发明还提供了一种合成dna编码化合物库的起始片段化合物,其特征在于:它具有式iii所示的结构:
[0051][0052]
其中,
[0053]
x为原子或分子骨架;
[0054]
z1为在其3'末端与l1连接的寡核苷酸,z2为在其5'末端与l2连接的寡核苷酸;或者z1为在其5'末端与l1连接的寡核苷酸,z2为在其3'末端与l2连接的寡核苷酸;
[0055]
l1为包含有能与z1的3'末端或5'末端形成键的官能团的连接链;
[0056]
l2为包含有能与z2的5'末端或3'末端形成键的官能团的连接链;
[0057]
l为包含一个或多个可操作进行共价交联基团的连接部分;
[0058]
r为连接功能部分的反应基团。
[0059]
进一步地,x为碳原子、氮原子、环状或非环状骨架结构;
[0060]
进一步地,z1与z2互补或部分互补以形成双链,z1、z2的长度分别为5~15个碱基;
[0061]
进一步地,l1、l2分别独立地选自双官能团的亚烷基链或双官能团的低聚二醇链,所述的官能团选自磷酸基、氨基、羟基、羧基;
[0062]
进一步地,l包含光敏性基团、电敏性基团或其它可与蛋白质共价交联的基团;r选自磷酸基、氨基、羟基、羧基、醛基。
[0063]
更进一步地,x为更进一步地,x为其中,q为1~10的整数;其中,所述结构式中的氧原子分别与l1或l2相连。
[0064]
更进一步地,l1、l2分别独立地选自中n为1~10的整数;优选地,n为2~6。更优选地,n为3。
[0065]
更进一步地,l具有-s
1-s
2-s
3-的结构,s1、s3选自带一个或多个官能团的环状或非环状的碳原子或者杂原子组成的连接链,所述的官能团选自磷酸基、氨基、羟基、羧基,醛基,叠氮基、炔基、卤代物;s2为含有一个或多个可操作进行共价交联基团的连接链。
[0066]
更进一步具体地,s1、s3分别独立选自分别独立选自
的一种或几种组合或无,其中m为1~20的整数;其中,所述s1或s3选自无时,是指与其相连的两部分通过共价键直接连接。优选地,m为1、2、3、4、5、6、7、8、9、10。
[0067]
更进一步具体地,s2中的可操作进行共价交联基团直接连接在连接链上,具有如下结构:
[0068][0068]
其中r1为碳原子或氮原子,r2为氢、含碳原子或杂原子的烷烃或芳烃。
[0069]
在本发明的一些具体实施方案中,s2具有如下结构其中y选自自其中r1为碳原子或氮原子,r2为氢、含碳原子或杂原子的烷烃或芳烃。
[0070]
在本发明的一些优选实施方案中,s2选自
[0071]
更进一步具体地,所述可操作进行共价交联的基团与r距离不超过30个原子。优选地,所述可操作进行共价交联的基团与r的距离不超过20个原子。更优选地,所述可操作进行共价交联的基团与r的距离不超过15个原子。
[0072]
更进一步具体地,所述可操作进行共价交联的基团与r的距离大于3个原子。优选地,所述可操作进行共价交联的基团与r的距离大于4个原子。更优选地,所述可操作进行共价交联的基团与r的距离大于5个原子。
[0073]
在本发明的一些具体实施方案中,式iii所示的dna编码化合物库的起始片段化合物为:
[0074][0075]
其中,
[0076]
z1为在其3'末端相连的寡核苷酸,z2为在其5'末端连接的寡核苷酸;
[0077]
y选自y选自其中r1为碳原子或氮原子,r2为氢、含碳原子或杂原子的烷烃或芳烃;
[0078]
s3选自选自的一种或几种组合或无,其中,m为1~20的整数。其中,所述s1或s3选自无时,是指与其相连的两部分通过共价键直接连接。优选地,m为1、2、3、4、5、6、7、8、9、10;
[0079]
r为连接功能部分的反应基团;优选地,r选自磷酸基、氨基、羟基、羧基、醛基。
[0080]
进一步具体地,所述起始片段化合物具有以下结构:
[0081][0082][0083]
其中,
[0084]
z1为在其3'末端相连的寡核苷酸,z2为在其5'末端连接的寡核苷酸;
[0085]
y选自y选自其中r1为碳原子或氮原子,r2为氢、含碳原子或杂原子的烷烃或芳烃。
[0086]
本发明还提供了上述任一项所述的dna编码化合物库的筛选方法,包括以下步骤:
[0087]
a、将化合物库与蛋白质靶点进行孵育,然后操作进行共价交联;
[0088]
b、将蛋白-dna编码化合物共价交联复合物与未交联的dna编码化合物分离;
[0089]
c、将回收的蛋白-dna编码化合物共价交联复合物进行pcr扩增和dna测序,读取dna序列信息,获得化合物结构信息。
[0090]
进一步地,所述步骤a中共价交联通过光照、加热、通电或者直接孵育进行。
[0091]
进一步地,所述步骤b中的分离方法为:将蛋白固定化,用洗脱剂将未固定物质洗掉即可。
[0092]
更进一步地,所述将蛋白固定化是使用磁珠将蛋白固定。
[0093]
使用本发明的dna编码化合物库进行筛选,通过共价交联能够增强化合物与靶点的结合,能够提高化合物(特别是低亲和力化合物和片段化合物)筛选信号的区分度。
[0094]
本发明中所述的“功能部分”是指dna编码化合物库中的小分子部分,通过组合化学或非组合化学手段构建多样性的分子结构,用于和生物靶标进行筛选。本发明中所述的碳原子可以按照本领域技术人员的理解自由选取,例如,在二价取代时为“ch
2”,在三价取代时为“ch”。
[0095]
本发明所述的“分子骨架”、“骨架结构”可以按照本领域技术人员的理解自由选取对应的取代数,例如,二价取代时有两个取代位点,三价取代时有三个取代位点。
[0096]
本发明所述的“寡核苷酸”包括但不限于dna、rna、pna等及其之间的相互组合,仅在于本领域技术人员可以通过本领域的普通技术知识和惯用手段可以读取序列信息即可。
[0097]
本发明的dna编码化合物库适用于多种生物靶标的筛选,本领域技术人员可以根据应用情况选择本发明中各类不同的dna编码化合物库。
[0098]
本发明的dna编码化合物/库中的可操作进行共价交联基团直接连接在连接链上,极大程度降低了共价交联基团非特异性的共价结合。
[0099]
根据本发明的内容,按照本领域的普通技术知识和惯用手段,本领域技术人员可以选取dna编码化合物和编码化合物库的起始片段化合物中中适合配对进行连接的官能团。
[0100]
显然,根据本发明的上述内容,按照本领域的普通技术知识和惯用手段,在不脱离本发明上述基本技术思想前提下,还可以做出其它多种形式的修改、替换或变更。
[0101]
以下通过实施例形式的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。凡基于本发明上述内容所实现的技术均属于本发明的范围。
附图说明
[0102]
图1:传统dna编码化合物库筛选流程;
[0103]
图2:实施例1中合成得到的4种dna编码化合物示例;
[0104]
图3:实施例1中测定kd值的4种化合物示例,其与caix靶点的kd值依次增大,即亲和力依次减小;其中r1部分为荧光基团,用于kd值测定;
[0105]
图4:dna编码化合物筛选流程,;
[0106]
图5:实施例1中dna编码化合物筛选回收率结果;
[0107]
图6:实施例2中dna编码化合物库筛选信号结果;
[0108]
图7:实施例3构建的dna编码化合物库结构示意图;
[0109]
图8:实施例3中dna编码化合物库筛选信号结果。
具体实施方式
[0110]
下面结合具体的实施例对本发明的技术方案进行完整的,清楚的描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。本发明所用原料与设备均为已知产品,通过购买市售产品所得。
[0111]
本发明中dna-nh2或是单链或双链dna与接头基团形成的带有-nh2接头的dna结构,例如wo2005058479中“compound1”的dna-nh2结构。也例如下述的dna结构:
[0112][0113]
其中,a为腺嘌呤,t为胸腺嘧啶,c为胞嘧啶,g为鸟嘌呤。
[0114]
其他缩写:fmoc表示芴甲氧羰基;dmt-mm表示2-氯-4,6-二甲氧基-1,3,5-三嗪;dipea表示n,n-二异丙基乙胺;dma表示n,n-二甲基乙酰胺;hatu表示2-(7-氧化苯并三氮唑)-n,n,n',n'-四甲基脲六氟磷酸酯。
[0115]
实施例1、dna编码化合物的合成及筛选
[0116]
步骤1、dna编码化合物的合成
[0117][0118]
(1)将dna-nh2溶于250mm,ph=9.4硼酸缓冲溶液配置成1mm的溶液,混合预先分别放置于-20℃冰箱中降温5分钟的化合物1(50当量,200mm的dma溶液),hatu(50当量,400mm的dma溶液)和dipea(100当量,400mm的dma溶液),然后放置于4℃冰箱中保存5分钟。将上述混合物加入到配置好的dna-nh2的溶液中,再将反应液用涡旋振荡充分混匀,将反应液置于室温条件下12小时。
[0119]
反应完毕后进行:乙醇沉淀,向溶液中加入总体积10%的5m的氯化钠溶液,然后继续加入总体积的3倍的无水乙醇,振荡均匀后,将反应置于干冰中冷冻2小时,之后在12000rpm的转速下离心半个小时,倒掉上清液,余下沉淀用去离子水溶解,得到化合物2粗品,粗品不纯化直接用于下一步反应。
[0120]
(2)将上述得到的化合物2粗品用纯水溶解配置成1mm的溶液,往该溶液中加入总体积10%的哌啶,涡旋振荡充分混匀后将反应液置于室温反应1-3小时。
[0121]
反应完毕后进行:乙醇沉淀,向溶液中加入总体积10%的5m的氯化钠溶液,然后继续加入总体积的3倍的无水乙醇,振荡均匀后,将反应置于干冰中冷冻2小时,之后在12000rpm的转速下离心半个小时,倒掉上清液,余下沉淀用去离子水溶解,得到化合物3粗品,粗品不纯化直接用于下一步反应。
[0122]
(3)将上述得到的化合物3溶于250mm,ph=9.4硼酸缓冲溶液配置成1mm的溶液,依次加入羧酸化合物4(100当量,100mm的dma溶液)和dmt-mm溶液(100当量,100mm的去离子水溶液),用涡旋振荡充分混匀后将反应液置于室温条件下12-16小时。
[0123]
反应完毕后进行:乙醇沉淀,向溶液中加入总体积10%的5m的氯化钠溶液,然后继续加入总体积的3倍的无水乙醇,振荡均匀后,将反应置于干冰中冷冻2小时,之后在12000rpm的转速下离心半个小时,倒掉上清液,余下沉淀用去离子水溶解,得到化合物5粗品,粗品用制备色谱纯化得到干净的化合物5。
[0124]
(4)将上述得到的100nmol的化合物5溶解于纯水中配置成1mm的溶液(100ul),加入引物1(166.6nmol,1.67当量,2mm的水溶液,83.3ul)、10
×
ligation缓冲液(66.6ul),t4 dna ligase(9.6ul,13.97ug/ul)和去离子水(407ul),用涡旋振荡后放置于20℃下反应16小时。
[0125]
反应完毕后进行:乙醇沉淀,向溶液中加入总体积10%的5m的氯化钠溶液,然后继续加入总体积的3倍的无水乙醇,振荡均匀后,将反应置于干冰中冷冻2小时,之后在12000rpm的转速下离心半个小时,倒掉上清液,余下沉淀用去离子水溶解,得到粗品。
[0126]
将上述粗品用纯水溶解配置成1mm的溶液(100ul),加入连接好的dna片段1-dna片段2-dna片段3-引物2-library id(100nmol,1当量,2mm的水溶液,50ul),10
×
ligation缓冲液(80ul),t4 dna ligase(4.31ul,13.97ug/ul)和去离子水(165ul),反应混合物用涡旋振荡后放置于20℃下反应16小时。
[0127]
反应完毕后进行:乙醇沉淀,向溶液中加入总体积10%的5m的氯化钠溶液,然后继续加入总体积的3倍的无水乙醇,振荡均匀后,将反应置于干冰中冷冻2小时,之后在12000rpm的转速下离心半个小时,倒掉上清液,余下沉淀用去离子水溶解,得到化合物6。
[0128]
按照上述合成方法合成得到4种化合物6(化合物6-1、化合物6-2、化合物6-3、化合物6-4),具体结构如图2。
[0129]
步骤2、dna编码化合物筛选
[0130]
在1.5ml离心管中将终浓度为0.2nm的dna编码化合物和100pmol的靶点蛋白配置于总体积为100μl筛选缓冲液中(筛选缓冲液成分为12.5mm tris,150mm nacl,0.3mg/ml ssdna,0.05%tween20,ph 7.5),同时平行设置空白对照组(不加入靶点蛋白),靶点蛋白组和空白对照组同时各做2组。将加入反应物的离心管置于旋转混合器上,20rpm,25℃孵育60min。将孵育后的样品(靶点组和空白对照组各一组)置于365nm的uv条件下置于冰上光照10min,进行光交联反应;同时将另一组样品(靶点组和空白对照组各一组)不进行365nm的uv光照,并同时置于冰上10min。
[0131]
然后将经过3次、每次250μl筛选缓冲液平衡后的25μl ni-charged磁珠投入到经过uv光照或不光照的样品中,将离心管置于旋转混合器上,20rpm,25℃孵育30min,通过靶点蛋白标签与特异性磁珠的亲和作用,用磁力架将靶点蛋白及靶点蛋白结合了dna编码化合物的复合体从溶液中分离出来,并收集保留上清。
[0132]
用500μl筛选缓冲液重悬分离后的磁珠,于旋转混合器上,20rpm,25℃洗涤1min,洗掉非特异性结合的dna编码化合物,用磁力架分离磁珠和上清液,重复5次。
[0133]
用100μl洗脱缓冲液(12.5mm tris,150mm nacl,ph 7.5)重悬洗涤后的磁珠,在金属浴中加热到95℃洗脱10min,用磁力架将磁珠和洗脱下来的dna编码化合物分离,beads上即为通过光交联得到的dna编码化合物样品,elution上清液为通过亲和作用得到的dna编码化合物样品。
[0134]
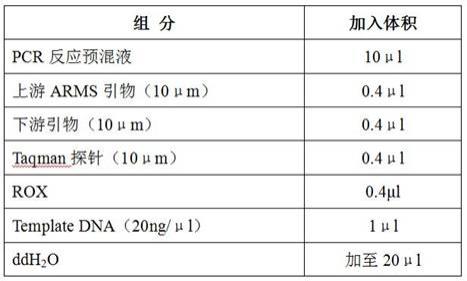
用稀释缓冲液(10mm tris,ph 8.0,0.05%tween20)对elution上清液和beads进行20倍稀释,同时将dna编码化合物稀释100倍,将上述样品、引物、去离子水及qpcr mix(abi,a25778)配置成20ul的反应溶液,于以下条件进行qpcr检测:95℃预变性10min,35个循环的(95℃变性10s,55℃退火10s,72℃延伸10s),设置信号收集于延伸步骤。qpcr反应完毕后进行分析,根据阿伏伽德罗常数进行样品分子拷贝数的计算及样品间分子拷贝数差异分析。
[0135]
上述筛选试验结果如图5所示。试验结果表明,传统dna编码化合物库筛选条件下(非光照条件),dna回收率比值区间为0.51-1.67,筛选信号上没有明显的区分度。使用本发明的dna编码化合物和筛选方法,dna回收率比值区间为2.27-151.92,筛选信号区分度明显
提升,且回收率比值与化合物活性(图3)呈正相关性。
[0136]
实施例2、dna编码化合物库的合成及磷酸酶靶点筛选
[0137]
用实施例1制备的起始dna(化合物3)原料,参照wo2005058479中描述的dna编码化合物库构建方法,构建包含有962个化合物的如下结构的dna编码化合物库:
[0138][0139]
对上述的化合物库进行以下步骤进行筛选
[0140]
(1)在1.5ml离心管中将终浓度为5.65nm的dna编码化合物库和250pmol的靶点蛋白配置于总体积为100μl筛选缓冲液中(筛选缓冲液成分为50mm hepes,150mm nacl,0.01%tween-20,0.3mg/ml ssdna,10mm imidazole,ph 7.4),同时平行设置空白对照组(不加入靶点蛋白),靶点蛋白组和空白对照组同时各做2组。将加入反应物的离心管置于旋转混合器上,20rpm,25℃孵育60min。将孵育后的样品(靶点组和空白对照组各一组)置于365nm的uv条件下置于冰上光照10min,进行光交联反应;同时将另一组样品(靶点组和空白对照组各一组)不进行365nm的uv光照,并同时置于冰上10min。
[0141]
(2)然后将经过3次、每次200μl筛选缓冲液平衡后的20μl ni-charged磁珠投入到经过uv光照或不光照的样品中,将离心管置于旋转混合器上,20rpm,25℃孵育30min,通过靶点蛋白标签与特异性磁珠的亲和作用,用磁力架将靶点蛋白及靶点蛋白结合了dna编码化合物库的复合体从溶液中分离出来,并收集保留上清。
[0142]
(3)用500μl筛选缓冲液重悬分离后的磁珠,于旋转混合器上,20rpm,25℃洗涤1min,洗掉非特异性结合的dna编码化合物库,用磁力架分离磁珠和上清液,重复5次。
[0143]
(4)用55μl洗脱缓冲液(50mm hepes,300mm nacl,ph 7.4)重悬洗涤后的磁珠,在金属浴中加热到95℃洗脱10min,用磁力架将磁珠和洗脱下来的dna编码化合物库分离,beads上即为通过光交联得到的dna编码化合物样品,elution上清为通过亲和作用得到的dna编码化合物样品。
[0144]
(5)用稀释缓冲液(10mm tris,ph 8.0,0.05%tween20)对elution上清液和beads进行20倍稀释,同时将dna编码化合物稀释100倍,将上述样品、引物、去离子水及qpcr mix(abi,a25778)配置成20ul的反应溶液,于以下条件进行qpcr检测:95℃预变性10min,35个循环的(95℃变性10s,55℃退火10s,72℃延伸10s),设置信号收集于延伸步骤。qpcr反应完毕后进行分析,根据阿伏伽德罗常数进行样品分子拷贝数的计算。
[0145]
使用上述化合物库和筛选方法所得试验结果见图6。图中纵坐标s3/s4 elution为传统dna编码化合物库筛选信号结果,纵坐标数值为dna回收率比值,结果表明所有化合物的dna回收率比值为0-2之间,无明显信号区分度。图中横坐标s1/s3 beads为本发明dna编码化合物库筛选信号结果,纵坐标数值为dna回收率比值,结果表明化合物的dna回收率比值为0-60之间,具有明显的信号区分度。
[0146]
实施例3、dna编码化合物库的合成及激酶靶点筛选
[0147]
参照实施例1和wo2005058479中描述的dna编码化合物库构建方法,构建图7所示的包含有7417个化合物的dna编码化合物库:其中l为不同长度的连接链。
[0148]
参照实施例2筛选方法使用上述化合物库对激酶靶点pak4进行筛选。筛选分组情况如表1所示。其中“ ”表示具有该条件,
“‑”
表示无该条件。
[0149]
表1、筛选分组情况
[0150] pak4蛋白uv光照竞争分子对照蛋白未加入靶点筛选对照组-
‑‑
pak4-进行光照组
‑‑
pak4-未进行光照组
‑‑‑
pak4-进行光照组且加入竞争分子 -其它靶点-进行光照组- -
[0151]
筛选信号结果如图8。图示中横纵坐标分别为不同筛选组的筛选信号富集情况(分子富集情况),数值表示富集程度。图一至四表明本发明的化合物库和筛选方法能够得到较好的信号富集情况。此外,图一表明了分子不会富集在蛋白以外的材料上(如磁珠等),图二表明光照共价交联下分子富集程度远高于非光照条件下的富集程度,图三表明分子能够被竞争分子降低信号强度,说明其作用在正确的靶点口袋,图四表明分子不会出现严重的非特异性结合情况。
[0152]
试验结果表明,使用本发明的dna编码化合物/库和筛选方法,能够增强化合物与靶点的结合,提高化合物特别是低亲和力化合物在筛选信号上的区分度,并产生积极的效果。
[0153]
综上,本发明提供了一种dna编码化合物、化合物库的合成和筛选方法。使用本发明的dna编码化合物库与靶点孵育,再通过共价交联能够增强化合物与靶点的结合,与传统的dna编码化合物库亲和筛选相比,能够提高化合物特别是低亲和力化合物在筛选信号上的区分度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。