1.本发明属于灵巧手强化学习控制领域,尤其涉及一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法。
背景技术:
2.由于灵巧手的高自由度,如何既要提升灵巧手强化学习控制算法的控制效果,又要提升训练样本数据的利用率成为灵巧手强化学习控制算法领域的难点。当前,强化学习控制算法按智能体(agent)是否理解环境与自身的动态模型可分为无模型强化学习算法与基于模型的强化学习算法。通过强化学习算法,智能体可针对特定的任务自主同环境进行交互试错,并在过程中获取环境反馈奖励,从而改变智能体的行为使得在下一次与环境交互过程中,环境反馈奖励最大化。
3.目前可应用于灵巧手控制主流的无模型强化学习控制算法例如有:deep deterministic policy gradient(ddpg)、soft actor critic(sac)、proximal policy optimization(ppo)等,无模型强化学习控制算法有较好的控制性能,然而对数据的样本利用率低,需要收集大量的样本数量,这需要大量的时间成本并在现实中往往难以应用。而基于模型的强化学习控制算法的优点是对样本数据的利用率。目前主流的基于模型的强化学习控制算法例如有:alphazero、imagination-augmented agents(i2a)、mbmf等。这些算法或需要领域专家根据专业知识提供系统动力学模型或需要从环境的交互过程中学习系统动力学。然而,由灵巧手-被抓持物体所构成的系统由于碰撞场景多,难以事先给定系统动力学模型,需要通过监督式学习得到近似的系统动力学模型。常用的监督式学习动力学模型方法例如有:sparse identification of nonlinear dynamics(sindy)、动力学参数识别、神经网络拟合动力学模型等。sindy及相关方法需要给定一个泛函字典集,因而存在应用难度大的缺点。动力学参数识别需要提前给定系统动力学模型框架,在富含碰撞的灵巧手-被抓持物体构成的系统中并不适用。而目前采用神经网络拟合动力学模型方法则存在着稳定性差、易产生过拟合现象等问题。
技术实现要素:
4.本发明目的在于提供一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法,以解决目前系统无法给定动力学模型、给定泛函字典集难度高、神经网络拟合动力学模型稳定性差,易产生过拟合现象的技术问题。
5.为解决上述技术问题,本发明的一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法的具体技术方案如下:
6.一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法,包括如下步骤:
7.步骤1:灵巧手使用sac算法策略π
θ
在环境内同抓持物体交互并训练,采集系统状
态转移数据并放入样本缓存区;
8.步骤2:设定模糊聚类的类别个数并对样本缓存区内状态转移数据进行模糊聚类;
9.步骤3:搭建包含状态增量方向概率子网络模型fd与状态增量增幅子网络模型fa的灵巧手动力学模型f;
10.步骤4:对模糊聚类的各类别依据隶属度生成样本采样概率,进行采样得到训练样本;
11.步骤5:灵巧手动力学模型训练,并进行环境系统状态预测。
12.进一步地,步骤1使用mujoco物理仿真引擎对灵巧手与被抓持物体进行抓持过程仿真,仿真环境不断产生呈高斯分布的外力与扭矩噪声施加在被抓持物体的质心与灵巧手关节转矩上,以模拟现实场景下随机的外力干扰;随着仿真器内部时间推移,灵巧手与被抓持物体的状态会发生变化,整个过程符合马尔可夫决策过程,用五元组《s,a,p,r,γ》表示,其中s表示灵巧手与被抓持物体构成的系统状态空间,a表示灵巧手关节动作空间,p表示状态转移概率,r表示奖励空间,γ表示奖励折扣系数。
13.进一步地,步骤1使用无模型强化学习算法sac的actor网络作为灵巧手控制策略π
θ
,将系统目标g设定为抓持物体至随机方位,若被抓持物体掉落则视为本次仿真结束并重置仿真环境,在仿真器中记录灵巧手与被抓持物体状态转移数据(s,a,s
′
,r),其中s为当前时刻系统状态,a为当前时刻系统输入动作,s
′
为系统下一时刻状态,r为根据抓持目标计算得到的奖励值,保存状态转移数据,得到数据集data:
14.data={(s1,a1,s2,r1),(s2,a2,s3,r2),...,(s
n-1
,a
n-1
,sn,r
n-1
)};
15.并使用data训练actor与critic网络。
16.进一步地,步骤2包括如下具体步骤:
17.对数据集data进行模糊聚类,随机设置模糊聚类中心集c={c1,c2,...,ck},其中聚类中心c包含元素个数与系统状态s相同;计算数据集data内每个状态s与每个聚类中心c的欧式距离d得到距离矩阵其中d
ij
=‖s
i-cj‖表示第i个状态与第j个聚类中心的欧式距离值;调整模糊聚类中心集c,使得距离矩阵d
t
各元素平方和最小;计算数据集data内状态s对聚类类别隶属度u得到隶属度矩阵其中表示第i个状态对第j个聚类类别的隶属度。
18.进一步地,步骤3包括如下具体步骤:
19.使用pytorch深度神经网络框架搭建状态增量方向概率子网络模型fd,与状态增量增幅子网络模型fa;fd与fa的输入包含灵巧手与被抓持物体系统的状态s与灵巧手关节输入动作a,并由三层线性层、两层relu层、两层正负极性通道层构成,fd在网络尾部另设置有一层sigmoid层;fd与fa的输出分别为系统状态变化量δs的方向与绝对值。
20.进一步地,步骤4包括如下具体步骤:
21.对每个聚类类别进行动力学模型训练样本采样;根据隶属度矩阵u计算数据集
data状态s在每个类别中被采样概率p得到概率矩阵其中表示第i个状态在第j个聚类类别中被采样的概率,若状态si被采得,则(si,ai,s
′i)作为一个训练样本。
22.进一步地,步骤5包括如下具体步骤:
23.对fd进行训练,设定损失函数为:
24.j
trand
(α)=e
(s,a,s
′
)~date(p)
[(fd(s,a)-g(s
′‑
s))2] 0.0005‖α‖2[0025]
其中α为fd所有参数;
[0026]
使用梯度下降法,优化器使用adam;
[0027]
对fa进行训练,设定损失函数为:
[0028]jtrana
(β)=e
(s,a,s
′
)~date(p)
[(fa(s,a)-|s
′‑
s|)2] 0.0005‖β‖2[0029]
其中β为fa所有参数;
[0030]
使用梯度下降法,优化器使用adam;
[0031]
进一步地,步骤5使用包含状态增量方向概率子网络模型fd与状态增量增幅子网络模型fa的灵巧手动力学模型f,将当前灵巧手与被抓持物体的状态s与灵巧手关节输入动作a输入fd与fa,得到状态增量方向概率值与状态增量增幅值,从而得到下一时刻状态预测值值其中dir~fd(s,a)。
[0032]
本发明的一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法具有以下优点:本发明通过设计一个包含状态增量方向概率子网络模型与状态增量增幅子网络模型的深度神经网络动力学模型,用上述两个子深度网络模型分别预测系统状态增量方向与系统状态增量增幅,提高了动力学模型的精准度。同时通过对数据样本进行模糊聚类,对训练样本进行预处理,从而减小在动力学模型训练过程中局部过拟合现象。进而减小动力学模型预测误差、提高稳定性,并在控制算法层面提升控制效果。
附图说明
[0033]
图1是本发明中灵巧手抓持过程结构框图;
[0034]
图2是本发明中模糊聚类流程图;
[0035]
图3是本发明中fd模型结构图;
[0036]
图4是本发明中fa模型结构图;
[0037]
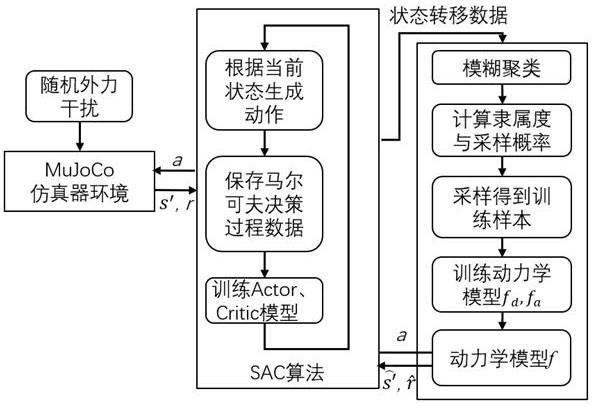
图5是本发明中灵巧手动力学模型f使用框架图。
具体实施方式
[0038]
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法做进一步详细的描述。
[0039]
一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法,在真实环境中收集灵巧手-被抓持物体所构成的系统状态转移数据,对系统状态转移数据进行模糊
聚类预处理,并采样预处理后的数据得到动力学模型训练样本,训练灵巧手动力学模型,并用于预测灵巧手-被抓持物体构成的系统下一时刻的状态。
[0040]
包括如下步骤:(1)灵巧手使用sac算法策略π
θ
在环境内同抓持物体交互并训练,采集系统状态转移数据并放入样本缓存区;(2)设定模糊聚类的类别个数并对样本缓存区内状态转移数据进行模糊聚类;(3)搭建包含状态增量方向概率子网络模型fd与状态增量增幅子网络模型fa的灵巧手动力学模型f;(4)对模糊聚类的各类别依据隶属度生成样本采样概率,进行采样得到训练样本。(5)灵巧手动力学模型训练,并进行环境系统状态预测。
[0041]
优先的使用mujoco物理仿真引擎对灵巧手与被抓持物体进行抓持过程仿真。仿真环境会不断产生呈高斯分布的外力与扭矩噪声施加在被抓持物体的质心与灵巧手关节转矩上,模拟现实场景下随机的外力干扰。随着仿真器内部时间推移,灵巧手与被抓持物体的状态会发生变化,整个过程符合马尔可夫决策过程(mdp),可用五元组《s,a,p,r,γ》表示。其中s表示灵巧手与被抓持物体构成的系统状态空间,a表示灵巧手关节动作空间,p表示状态转移概率,r表示奖励空间,γ表示奖励折扣系数。
[0042]
优先的使用无模型强化学习算法sac的actor网络作为灵巧手控制策略π
θ
,将系统目标g设定为抓持物体至随机方位,若被抓持物体掉落则视为本次仿真结束并重置仿真环境。在仿真器中记录灵巧手与被抓持物体状态转移数据(s,a,s
′
,r),其中s为当前时刻系统状态,a为当前时刻系统输入动作,s
′
为系统下一时刻状态,r为根据抓持目标计算得到的奖励值。保存状态转移数据,得到数据集data:
[0043]
data={(s1,a1,s2,r1),(s2,a2,s3,r2),...,(s
n-1
,a
n-1
,sn,r
n-1
)}。
[0044]
并使用data训练actor与critic网络。
[0045]
优先的对数据集data进行模糊聚类,随机设置模糊聚类中心集c={c1,c2,...,ck},其中聚类中心c包含元素个数与系统状态s相同。计算数据集data内每个状态s与每个聚类中心c的欧式距离d得到距离矩阵其中d
ij
=‖s
i-cj‖表示第i个状态与第j个聚类中心的欧式距离值。调整模糊聚类中心集c,使得距离矩阵d
t
各元素平方和最小。计算数据集data内状态s对聚类类别隶属度u得到隶属度矩阵和最小。计算数据集data内状态s对聚类类别隶属度u得到隶属度矩阵其中表示第i个状态对第j个聚类类别的隶属度。
[0046]
优先的对每个聚类类别进行动力学模型训练样本采样。根据隶属度矩阵u计算数据集data状态s在每个类别中被采样概率p得到概率矩阵其中表示第i个状态在第j个聚类类别中被采样的概率,若状态si被采得,则(si,ai,s
′i)作为一个训练样本。
[0047]
优先的使用pytorch深度神经网络框架搭建状态增量方向概率子网络模型fd,与状态增量增幅子网络模型fa。fd与fd的输入包含灵巧手与被抓持物体系统的状态s与灵巧手
关节输入动作a,并由三层线性层、两层relu层、两层正负极性通道层构成,fd在网络尾部另设置有一层sigmoid层。fd与fd的输出分别为系统状态变化量δs的方向与绝对值。
[0048]
对fd进行训练,设定损失函数为:
[0049]jtrand
(α)=e
(s,a,s
′
)~date(p)
[(fd(s,a)-g(s
′‑
s))2] 0.0005‖α‖2[0050]
其中α为fd所有参数。
[0051]
使用梯度下降法,优化器使用adam。
[0052]
对fa进行训练,设定损失函数为:
[0053]jtrana
(β)=e
(s,a,s
′
)~date(p)
[(fa(s,a)-|s
′‑
s|)2] 0.0005‖β‖2[0054]
其中β为fa所有参数。
[0055]
使用梯度下降法,优化器使用adam。
[0056]
优先的使用包含状态增量方向概率子网络模型fd与状态增量增幅子网络模型fa的灵巧手动力学模型f,将当前灵巧手与被抓持物体的状态s与灵巧手关节输入动作a输入fd与fa,得到状态增量方向概率值与状态增量增幅值,从而得到下一时刻状态预测值其中dir~fd(s,a)。
[0057]
下面结合具体实施例,进一步阐明本发明。
[0058]
本发明设计了一种基于深度神经网络的灵巧手抓持过程动力学模型搭建及训练方法,用于灵巧手强化学习抓持物体,抓持过程结构框图如图1。
[0059]
步骤1:根据灵巧手三维模型与被抓持物体三维模型与动力学参数在mujoco仿真器中搭建仿真环境。设置灵巧手关节驱动器与关节角度、角速度、转矩传感器,灵巧手指尖触觉传感器,被抓持物体位置、速度传感器。设置呈高斯分布的外力噪声,施加于灵巧手关节与被抓持物体质心模拟真实环境中不可预测噪声干扰。系统状态s包含灵巧手关节角度、角速度、转矩、被抓持物体位置、速度、灵巧手指尖接触力。系统输入动作a包含灵巧手关节驱动器输出值。
[0060]
步骤2:使用策略π
θ
,在mujoco仿真环境中根据当前系统状态s生成灵巧手关节驱动器动作a并进行仿真,得到下一时刻系统的状态s
′
、根据抓持目标计算得到当前奖励值r,状态转移概率p设置为1,即确定型环境,奖励折扣系数γ设为0.99。其中仿真时间步长为0.02秒。mdp数据保存在样本缓存区。根据样本缓存区内的数据训练actor与critic模型,采用sac算法。
[0061]
步骤3:对样本缓存区内的数据进行模糊聚类,首先确定模糊聚类的类别中心点个数,并随机化类别中心。再如图2计算样本与类别中心的欧式距离,并根绝总欧式距离平方值更新类别中心直至收敛。最后根据样本与类别中心的欧式距离计算对应类别隶属度,再根据隶属度求得该样本在该类别中被采样的概率。
[0062]
步骤4:使用pytorch深度神经网络框架搭建状态增量方向概率子网络模型fd,与状态增量增幅子网络模型fa。fd结构如图3,fa结构如图4。fd与fa的输入包含灵巧手与被抓持物体系统的状态s与灵巧手关节输入动作a,并由三层线性层、两层relu层、两层正负极性通道层构成,fd在网络尾部另设置有一层sigmoid层。fd与fa的输出分别为系统状态变化量δs的方向与绝对值。在步骤3中每个类别进行训练样本采样得到训练样本,并分别训练fd与fa。
[0063]
步骤5:使用包含状态增量方向概率子网络模型fd与状态增量增幅子网络模型fa的灵巧手动力学模型f。如图5所示,对样本缓存区采样得到状态s,再根据当前策略π
θ
生成动作a。将采样得到的状态s与动作a输入fd与fa,得到状态增量方向概率值与状态增量增幅值,进而得到下一时刻状态预测值其中dir~fd(s,a)。再根据所设定的抓持目标计算得到奖励值使用训练actor与critic网络。
[0064]
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本技术的权利要求范围内的实施例都属于本发明所保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。