用于低延时编码的灵活霍夫曼树近似
背景技术:
1.霍夫曼树自它们引入以后已经成为用于优化编码的事实标准。它们的应用跨度范围从实时多媒体到数据中心存储的宽广范围。霍夫曼结构是很好理解的,并且许多研究文章探索霍夫曼树性质和以软件和硬件两者的实现。尤其,霍夫曼编码从正式算法角度来看在整数长度代码的约束内最优。
2.尽管霍夫曼编码在整数长度代码的约束内最优,但是霍夫曼编码在实现算法所需要的计算资源方面可能是低效的。另外,霍夫曼编码带来针对硬件实现的有趣的挑战。
技术实现要素:
3.本发明内容被提供从而以简化的形式介绍下面在具体实施方式中进一步所描述的一系列构思。本发明内容既不旨在识别所求保护的主题的关键特征或者必要特征,其也不旨在用于限制所要求保护的主题的范围。
4.描述了用于使用新算法来编码符号的技术,该新算法提供灵活霍夫曼树近似并且可以被用于低延时编码。例如,新算法可以使用以下阶段中的一个或多个阶段来执行编码:基于香农的分箱(shannon-based binning)、编码空间优化、树完成和代码分配。
5.如本文所描述的,各种其他特征和优点可以根据需要被并入这些技术中。
附图说明
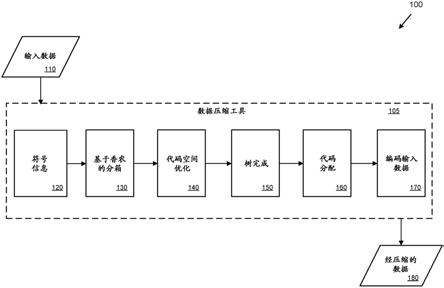
6.图1是描绘用于使用灵活霍夫曼树近似来编码数据的示例过程的框图。
7.图2a-2d描绘了用于执行用于使用灵活霍夫曼树近似来编码符号的新算法的示例过程的框图。
8.图3是用于编码符号的示例方法的流程图。
9.图4是用于编码符号的示例方法的流程图。
10.图5是一些所描述的实施例可以被实现于其中的示例计算系统的图。
11.图6是可以结合本文所描述的技术使用的示例云支持环境。
具体实施方式
12.概述
13.如本文所描述的,各种技术和技术方案可以被应用以近似霍夫曼编码算法(还被称为霍夫曼算法、霍夫曼译码或者霍夫曼编码)而不使用霍夫曼编码算法。例如,这些技术可以被应用以编码(例如,压缩)数据,其得到接近(例如,在百分之一以内)霍夫曼编码但是比霍夫曼编码更高效(例如,在计算资源、延时、硬件实现等方面)的压缩。
14.技术涉及一种用于近似霍夫曼算法的新算法。新算法还被称为量化区间霍夫曼近似(quiha)。
15.取决于实现,新算法可以具有以下性质中的一个或多个:
16.*其产生良好压缩比,通常在真霍夫曼编码的0.05%内,其可证明地是最优的。
17.*其适合于以现场可编程门阵列(fpgas)或者专用集成电路(asics)的高速实现。
18.*针对两轮压缩算法,其是霍夫曼算法的简易替换,并且不要求对解压缩器或者压缩格式规范的修改。
19.新算法可以被应用到从输入数据生成的代码符号。例如,输入数据可以是要被压缩的文件、要经由网络被发送的数据等。输入数据可以是任何类型的数据(例如,文本数据、二进制数据、视频数据、音频数据等)。新算法是无损压缩算法,其中符号以无损方式来编码(例如,压缩)。新算法产生编码有前缀代码的符号,代码是1位或者更多位长,类似于霍夫曼编码。前缀代码是用于利用可变位长代码来编码符号的项。
20.例如,新算法可以被应用为编码或者压缩过程的部分。例如,输入数据可以被接收(例如,数据文件、流媒体等)。输入数据可以被处理以生成符号(例如,作为deflate压缩算法的初始阶段、作为视频或者图像编码器的部分等等)。符号(例如,包括符号计数和频率信息)可以由新算法(例如,包括执行基于香农的分箱、代码空间优化、树完成和/或执行与新算法相关联的其他技术)处理,并且代码(例如,前缀代码)可以基于所处理的符号来分配。输入数据可以然后使用从新算法生成的代码(例如,前缀代码)以编码或者压缩格式来输出。
21.新过程基于两个基本实现。首先,具有相似频率的符号应当很可能被分配以相同或者相似的代码长度。因此,符号可以基于符号频率(下面进一步描述基于香农的分箱过程)被整理到分箱中。其次,符号长度分配实际上不依赖于符号id它们本身。因此,每个分箱中的符号的计数可以被使用,而非符号的列表或者集合,并且整个分箱可以被一次处理。一次处理符号的整个分箱比像霍夫曼编码做的那样在逐符号的基础上处理符号在计算资源方面更高效。
22.新算法引入代码空间的概念。代码空间涵盖在某种最大代码长度约束内的所有可能的符号编码。例如,xpress8(xpress8是由提供的压缩技术)具有15位的最大代码长度,因此代码空间约束2
15
=32k=32,768个可能的位长15的代码。1b(一位)符号使用一半代码(16k代码),2b(两位)符号使用四分之一代码(8k代码),以此类推。下面的表1图示了针对直到15的每个位长的使用的代码空间。
23.[0024][0025]
表1
[0026]
在一些实现中,新算法以四个阶段来实现。在第一阶段(基于香农的分箱)中,基于原始香农算法将符号分配以初始代码长度。该算法可能未充分利用代码空间并且相较于霍夫曼算法是欠佳的。随着符号被处理,它们基于它们的香农代码被放入代码长度分箱(clb)中。结果通过基于符号频率将clb分解成量化区间(qi)来进一步改进。
[0027]
由于第一阶段未使代码空间充分利用,所以随后的代码空间优化阶段通过将一些符号从它们的初始clb抬升到clb之上、基本上将它们的代码长度减少1位来改进代码长度分配。这是qi进来的地方。更优化的是缩短更频繁地出现的符号。通过优先地抬升最频繁的qi中的符号,算法实现接近最优的压缩比。
[0028]
代码空间优化的结果是相当好的。然而,代码空间优化阶段仍然是可能未使代码空间充分利用的近似启发式。诸如xpress8的一些解压缩器要求代码空间被完全分派,其等同于说,符号代码树是其中所有父节点具有两个子节点的满二叉树。第三阶段,树完成,固定得到的树并且可以得到压缩比的轻微改进。这些改进如此轻微使得该阶段可以被认为是可选的,除非由解压缩算法要求。
[0029]
最终阶段是代码分配。符号被遍历并且实际前缀代码被分配。在给出针对每个符号的先前计算的代码长度的情况下,该阶段遵循标准过程。
[0030]
下面是新算法的一些潜在特征的概述。取决于实现,下面特征中的一个或多个特征可以被实现。
[0031]
*使用霍夫曼算法的近似,从而得到压缩比的轻微减小但是快得多的硬件实现。
[0032]
*基于符号频率将符号整理到分箱中。将相同分箱中的符号分配以相同/相似代码长度。
[0033]
*使用简单香农代码用于初始代码长度估计。
[0034]
*基于符号频率分箱来进一步优化代码长度。
[0035]
*在必要时进一步优化代码长度以完成霍夫曼树。
[0036]
基于香农的分箱
[0037]
在本文所描述的技术中,基于香农的分箱被执行为新算法的部分。在一些实现中,在新算法的第一阶段中执行基于香农的分箱。
[0038]
新算法在符号上操作。符号被接收为到新算法的输入。符号可以表示文字(例如,字符字节)和/或其他字母(例如,长度、距离对)。在一些实现中,符号使用deflate压缩算法的初始阶段来生成。deflate压缩算法的初始阶段被称为lemple-zif 77(还被称为lz77)。例如,新算法可以从deflate压缩算法的初始阶段接收符号并且代替执行霍夫曼编码,新算法使用本文所描述的新算法技术来编码符号。在其他实现中,符号使用另一过程(例如,从另一压缩算法的初始阶段)来生成。
[0039]
基于香农的分箱被执行以确定针对符号的初始代码长度并且基于所分配的初始代码长度将符号放入对应的代码长度分箱(clb)中。为了确定初始代码长度,方程1被用于计算香农代码长度。然后,信息内容i()使用根据方程2的上限运算来上舍入。
[0040][0041]
clb(sym)=ceil(i(sym))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(方程2)
[0042]
在方程1中,symcnt[]是每个符号的出现次数,并且symtot是输入中的总符号(例如,由deflate压缩算法的初始阶段从要被压缩的输入文件产生的符号的总数量)。注意未出现的符号(symcnt[sym]==0)不需要代码分配并且可以被跳过。
[0043]
在一些硬件实现中,symcnt和symtot在lz77阶段期间被即时计算。随着每个符号被产生,symtot和symc[sym]被增加。符号的直方图因此在构建符号表的开始立即可用。
[0044]
例如,xpress8压缩格式使用512个符号(即,512个9位符号)。因此,使用xpress8,symcnt[]包含512个符号中的每个符号在要被压缩的输入数据中的出现次数。其他压缩格式可以使用不同数量的符号。
[0045]
代码长度分箱的数量对应于正在使用的压缩格式的最大代码长度。例如,xpress8压缩格式具有15位的最大代码长度。因此,当使用xpress8时,存在15个clb,一个用于1位代码,一个用于2位代码,一个用于3位代码,以此类推。在一些实现中,可以使用低于最大代码长度的代码长度。例如,如果压缩格式不具有严格限制或者者提供更高效的实现,那么可以使用更低的代码长度。
[0046]
针对给定符号的分配的clb表示以位为单位的初始符号长度。在一些实现中,新算法保持跟踪剩余代码空间(例如,在将符号分配给clb后)。代码空间由正在使用的最大代码长度定义。例如,对于xpress8,最大代码长度是15位,并且代码空间是32,768(其是最大可用代码空间,并且在所有代码是15位长时表示最大代码数量)。剩余代码空间可以使用方程3来跟踪。
[0047]
rem_code_space-=2
maximum_code_length-clb(sym)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(方程3)
[0048]
剩余代码空间(rem_code_space或者rcs)被初始化为最大代码空间,其在该示例中是32,768。香农代码当然是正当可实现代码,其保证rem_code_space将不会变成负的。然后,当符号被分配至clb时,剩余代码空间被更新。例如,如果符号被分配至6位clb,那么剩
余代码空间被更新:rem_code_space=32,768
–
512=32,256。如果符号然后被分配至4位clb,那么剩余代码空间被更新:rem_code_space=32,256-2,048=30,208。
[0049]
在一些实现中,每个clb被划分成许多量化区间(qi)。每个qi表示针对每个clb的信息内容的连续部分。更具体地,信息内容的分数部分被划分为qi。在一些实现中,分数部分被均等地划分为许多qi。在一些实现中,分数部分可以使用方程4被均等地划分为四个qi。
[0050]
qi(sym)3-floor((clb(sym)-i(sym))*4)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(方程4)qi 0包含给定clb的最频繁的符号,并且qi 3包含给定clb的最不频繁的符号。在其他实现中,可以使用不同数量的qi,或者可以使用(例如,除了均等地划分分数部分以外)划分分数部分的不同过程。
[0051]
在基于香农的分箱期间,计数可以针对被分派给每个clb和/或每个qi的符号的数量被维持。在一些实现中,针对基于香农的分箱的仅有计数是被分派给针对clb中的每个的qi中的每个的符号的数量。例如,如果存在15个clb,每个具有四个qi,那么60个计数可以被维持(例如,15x4的计数阵列)。
[0052]
代码空间优化
[0053]
在本文所描述的技术中,代码空间优化被执行为新算法的部分。在一些实现中,代码空间优化在新算法的第二阶段中被执行。代码空间优化被执行以将符号缩短到更短的代码长度分箱(例如,从给定的b位clb到b-1位clb)。例如,符号可以通过将符号从6位clb移动到5位clb(其是下一个更短的代码长度分箱)来缩短(还被称为“抬升”)。例如,代码空间优化可以被执行,因为基于香农的分箱可以产生未充分利用的代码空间。
[0054]
在一些实现中,代码空间优化在确定(例如,如在基于香农的分箱期间维持的)剩余代码空间大于零后被执行。如果剩余代码空间等于零,那么代码空间优化可以被跳过(例如,代码空间已经被完全利用并且没有符号需要被移动)。
[0055]
在一些实现中,剩余代码空间在代码空间优化期间被更新。例如,当符号被移动到下一个更小的clb时,剩余代码空间根据方程5被更新。代码空间优化可以前进直到剩余代码空间接近或等于零。
[0056]
rem_code_space-=2
max-b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(方程5)
[0057]
在方程5中,max是最大代码长度(例如,针对xpress8,15位)并且“b”是我们正在从其移动的clb的位数。例如,如果我们正在将符号从6位clb移动到5位clb,那么剩余代码空间将被减去512。
[0058]
在一些实现中,代码空间优化通过首先抬升在最频繁的qi中的符号来执行。例如,qi 0可以在以clb 2开始的所有clb中首先被遍历(2位clb;clb 1不可以被缩短)。针对每个qi,尽可能多的符号可以被缩短使得代码空间不是被超额配的(例如,如由剩余代码空间维持的)。以下算法可以用于缩短qi和clb中的符号。
[0059][0060]
注意reduction_per_sym总是二的幂,并且可以仅由指数而不是如所示出的整数表示。除法变成右移位,并且乘法变成左移位。作为性能优化,循环可以当rem_code_space为零时被终止。额外地,一旦rem_code_space《2
(15-clb)
,就没有必要重新考虑低编号的clb。
[0061]
抬升符号(shortensymbols(
…
)调用)仅仅涉及记录记住多少符号已经被缩短。如果所有先前的较小编号的qi已经被完全缩短,那么较大编号的qi可以仅具有缩短的符号。这是因为将防止先前qi被完全缩短的唯一事情是不足的剩余代码空间,其类似地限制稍后的qi。
[0062]
结果,每qi的缩短符号的数量不需要被跟踪。相反,这可以利用每clb的两个字段来完成。第一字段maxshortenedqi[clb]指示具有缩短的符号的最大的(最不频繁的)qi。第二字段symshortened[clb]指示该qi中多少符号被缩短。所有小于maxshortenedqi的qi被完全缩短。所有大于maxshortenedqi的qi不具有缩短的符号。
[0063][0064]
树完成
[0065]
在本文所描述的技术中,树完成可以被执行为新算法的部分。在一些实现中,树完成是可选阶段。例如,基于香农的分箱和代码空间优化阶段可以仍然使代码空间未完全利用(当被表示为二叉树结构时)。换言之,剩余代码空间可以仍然是非零的。代码树解释在于二叉树可能不是满二叉的而是包含具有仅一个子节点的父节点。注意,所有霍夫曼树是满二叉树。一些解压缩器可以预期该性质对于到来的节点成立。重要的是,牢记满二叉树不一定是霍夫曼(最优)树。然而,所有霍夫曼树是满二叉树。
[0066]
树完成阶段促进树中较低的节点到更高层级(更低长度),因此填充树中的更高的空的子节点。该算法处理任意形状的树,但是一些约束可以被观察到并且被利用于高效硬件实现。例如,可以施加空可以在树的除了第一层级(长度1)的任何层级上的约束。
[0067]
在一些实现中,树完成仅考虑符号的代码长度而不考虑对应的qi。而且,树完成可以将符号缩短多于一个位以更快地将剩余代码空间(rcs)减少为零。树完成在代码长度直方图(clh)(其是跨qi的qipop的每长度累积视图)上操作。概念上,树完成使用rcs的二进制表示作为二进制代码树中的节点空缺和盈余的指标。树完成的输出包括跟踪from-to节点促进计数的代码长度分数板(clsb)。clsb被使用在最终代码分配阶段中以缩短符号的代码长度。
[0068]
在一些实现中,下面概述的操作针对树完成被执行:
[0069]
在clh上迭代直到rcs!=0
[0070]
1.获得提供floor(log2(rcs))的结果的rcs的msb;这是较长长度符号将是升级的长度to;如果rcs是2的幂并且对应于to(目的)代码长度分箱的clh条目大于0,那么将该长度减1;该长度对应于具有节点短缺的树层级。
[0071]
2.将rcs减少由单个符号在to长度处获得的代码空间。
[0072]
3.增加to长度的clh条目。
[0073]
4.获得符号将被移除的盈余长度from;这由具有from长度》to长度的约束的更新的clh的lsb确定;该长度对应于盈余节点的树层级。
[0074]
5.减少from长度的clh条目。
[0075]
6.更新clsb以说明升级。
[0076]
在一些实现中,树完成阶段填充任何缺少的节点使得代码空间被表示为满二叉树。
[0077]
代码分配
[0078]
在本文所描述的技术中,代码分配被执行为新算法的部分。在一些实现中,代码分配在新算法的最后阶段(例如,第三阶段或第四阶段,取决于树完成是否被执行)中被执行。在代码分配期间,针对每个符号的最后代码长度可以通过重新计算clb和qi并且跟着每qi调整信息来计算。代码分配可以通过在给出针对每个符号的位长的情况下使用霍夫曼算法(例如,范式霍夫曼编码算法或者另一霍夫曼变型)来执行。
[0079]
在一些实现中,每个长度的符号的数量通过先前阶段被即时维持。因此,该信息在代码分配的开始被获知,而没有对符号的明确再访。给出该信息,代码空间按代码长度划分,从而初始化针对15个可能代码长度中的每个的代码指针(即,第一代码)(或者使用不同数量的可能代码长度,其取决于正在使用的压缩格式)。针对每个符号,它的代码长度如本文所描述的(例如,如在232处所描述的)被重新计算,并且它被分配以针对其长度的当前代
码指针。其代码指针然后被更新到下一代码。
[0080]
示例框图
[0081]
图1是描绘用于使用实现灵活霍夫曼树近似的新算法来编码数据的示例过程的框图100。由该示例过程执行的操作一般被描述为数据压缩工具105。然而,这些操作可以由软件和/或硬件资源的各种组合执行。
[0082]
在框图1中,接收输入数据110。输入数据110可以是任何类型的数据(例如,文本数据、二进制数据、视频数据、音频数据等)。在120处,从接收到的输入数据110生成符号信息。符号信息可以包括符号计数和频率信息。在一些实现中,符号信息通过使用lemple-zif 77(还被称为lz77)算法(例如,作为deflate压缩算法的初始阶段)来生成。
[0083]
在130处,执行基于香农的分箱。基于香农的分箱被执行以确定针对符号的初始代码长度并且基于所分配的初始代码长度将符号放入对应代码长度分箱中。在一些实现中,每个clb被划分为许多qi。每个qi基于香农代码长度来表示clb的连续部分。
[0084]
在140处,执行代码空间优化。代码空间优化被执行以将符号缩短到更短的代码长度分箱。
[0085]
在150处,执行树完成。在一些实现中,树完成是可选阶段。树完成促进树中较低的节点到更高层级(更低长度),因此填充树中的更高的“空洞”。
[0086]
在160处,执行代码分配。在代码分配期间,针对每个符号的最终代码长度可以被计算(例如,通过重新计算clb和qi,并且跟着每qi调整信息)。使用符号信息,前缀代码可以被生成以用于编码输入数据110。在一些实现中,前缀代码根据霍夫曼编码算法的代码分配部分(例如,根据范式霍夫曼编码算法的代码分配部分)来生成。
[0087]
在170处,使用在160处所分配的代码来编码输入数据110。经编码的数据被输出为经压缩的数据180。
[0088]
在一些实现中,框图100中所描绘的操作中的一个或多个以硬件来实现。例如,硬件部件(例如,asic或者fpga)可以将操作中的一些或者全部实现为数据压缩过程的部分。
[0089]
在一些实现中,框图100被实现为云计算服务的部分。例如,云计算服务可以提供数据存储服务。框图100中所描绘的操作中的一个或多个可以用于在数据由数据存储服务存储时压缩数据。
[0090]
在一些实现中,框图100被实现为网络数据压缩工具的部分。例如,源设备(例如,台式或者膝上型计算机、服务器、智能电话、或者另一类型的计算设备)或者网络设备(例如,路由器、网关、防火墙、交换机或者另一类型的网络设备)可以经由计算机网络接收用于传输的输入数据并且使用框图100中所描述的操作中的一些或者全部来压缩输入数据。经压缩的数据可以由随后的网络设备或者目的设备(例如,台式或者膝上型计算机、服务器、智能电话、或者另一类型的计算设备)解压缩,或者它可以以其压缩格式来存储(例如,在目的设备处)。
[0091]
示例高级操作框图
[0092]
图2a-2d描绘了灵活霍夫曼近似算法的示例高级操作框图。框图描绘了可以或者可以不在特定实现中被使用的许多实现细节。为了方便图示,该框图描绘了针对15位的最大代码长度(和15个clb)(具有高达512个符号)的新算法的示例实现,并且使用四个量化区间(4个qi)。其他实现可以具有不同最大代码长度、不同数量的符号、和/或不同数量的量化
区间。以下符号被遵循在图2a-2d中描绘的示例实现中:
[0093]
sh:符号直方图(还被称为symcnt[])
[0094]
sh[i]:符号i的符号直方图计数
[0095]
tc:总符号计数(还被称为symtot)
[0096]
qi:量化区间
[0097]
cl:代码长度(还被称为clb)
[0098]
sbt:分数板表(还被称为qipop)
[0099]
obt:优化边界表
[0100]
clh:代码长度直方图
[0101]
clsb:代码长度分数板
[0102]
rcs:剩余代码空间(还被称为rem_code_space)
[0103]
fbt:满二叉树
[0104]
一般,新算法的阶段按从左向右的顺序以框图被描绘。图2a描绘了描述基于香农的分箱阶段202的实现的框图的第一部分200。在基于香农的分箱阶段202中,该算法在所有直方图条目上迭代,从而生成对应于每个符号条目的香农编码长度并且每代码长度和每量化区间对它们记分。剩余代码空间还在直方图条目上迭代同时被跟踪(例如,根据方程3)以便获得用于随后优化步骤的剩余代码空间。
[0105]
基于香农的分箱阶段202一般执行对应于以上关于方程1和2所讨论的那些的操作来确定初始代码长度。基于香农的分箱阶段202还基于香农代码的分数部分来将代码长度分箱划分为量化区间(例如,根据方程4)。记分(计数)每代码长度分箱和每量化区间被维持,如在204处所描绘的。例如,包含在cl和qi上的符号分布的表可以被创建。
[0106]
基于香农的分箱阶段202将香农代码长度的分数部分划分为qi。在一些实现中,分数部分如表2中所描绘的被划分。注意,0的分数部分被映射到最后(最低优先级)qi,因为符号在它的理想代码长度是整数时不需要优化。
[0107][0108][0109]
表2
[0110]
代码长度表206(clt)(其在该示例中是512乘4位)包含被用作基线代码长度的理想代码长度的整数部分。它是第一优化优先级。在一些实现中,维持clt是可选的,如由虚线所指示的(例如,代码长度可以在代码分配阶段处被重新计算)。
[0111]
每符号量化区间查找表(lut)208(其在该示例中是512乘2位)包含指示符号的代码的第二优化优先级的量化区间。为了节省存储资源,每符号量化区间lut可以代替地在稍后阶段处被重新计算。在一些实现中,维持每符号量化区间lut是可选的,如由虚线所指示的(例如,量化区间可以在代码分配阶段处被重新计算)。
[0112]
图2b描绘了框图的描述代码空间优化阶段212(其还在该图中被称为代码长度优化)的实现的第二部分210。
[0113]
如在214处所描绘的,代码长度和量化区间分数板表(sbt)被维持。sbt可以包含15x4个条目。sbt提供每代码长度优化优先级。
[0114]
在一些实现中,代码空间优化阶段212利用两个嵌套循环来处理sbt,第一个在qi上然后在代码长度上,两者都按升序(优先级)顺序。在每个步骤处,优化器计算可以使它们的符号减1使得剩余代码空间不会变成负的符号的数量,优化目标是精确地到达0,其取决于符号分布不总是可能的。以这种方式,优化器有效地压缩代码树。
[0115]
如在216处所描绘的,生成优化边界表(obt)(例如,具有15个条目)。每cl优化边界表包括qi和指示多少符号可以在具有所有相同cl符号的相应qi处被优化的符号计数,其中较高优先级qi被隐含地优化。
[0116]
图2c描绘了框图的描述树完成阶段222的实现的第三部分220。树完成阶段222生成满二叉树,其暗示为零的剩余代码空间。树完成阶段222包括代码长度调整子阶段224,其按照符号升序在clt上迭代,基于来自obt的cl/qi分派来减少符号长度。代码长度调整子阶段224还构建跟踪强制执行严格二叉树性质所需要的符号代码长度分布的cl直方图(clh)(其在该示例中具有15个条目)。在一些实现中,代码长度调整子阶段224是可选的。
[0117]
树完成阶段222包括生成满二叉树(fbt)子阶段226,其在长度直方图上迭代至多两次,使用剩余代码空间二进制表示来在每个迭代步骤处引导长度减少(符号升级),从而使剩余代码空间为0。在一些实现中,满二叉树(fbt)子阶段226执行以下阶段:
[0118]
当剩余代码空间(rcs)》0时
[0119]-获得提供floor(log2(rcs))的结果的rcs的msb;这是较高长度符号将被升级的长度to;如果rcs是2的幂并且对应于to(目的)代码长度分箱的clh条目大于0,那么减1
[0120]-更新rcs、clh、clsb以说明升级;clsb跟踪每代码长度的符号计数短缺/盈余
[0121]-获得符号将被移除的盈余长度from;这由具有from长度》to长度的约束的更新的clh的lsb确定
[0122]
树完成阶段222包括生成邻接矩阵(am)子阶段228,其在clsb上迭代两次,从而将它转化成硬件优化的快速查找表,其用作from-to符号长度升级的邻接矩阵。至多2个符号可以从一个长度升级到另一个。
[0123]
图2d描绘了框图的描述代码分配阶段232的实现的第四部分230。代码分配阶段232遵循范式霍夫曼代码书生成算法,除了它即时执行符号长度减少。
[0124]
代码分配阶段232包括建立每长度第一代码子阶段234,其按照长度升序在clh上迭代,从而基于长度的直方图计数来生成针对每个长度的第一代码。第一代码(其在该示例中包含15个条目)被提供到设置每符号的代码子阶段236。设置每符号的代码子阶段236按照升序在所有符号上迭代,从而根据需要调整每个am的每个符号的长度并且根据每个符号的最终cl来分配代码。在一些实现中,设置每符号的代码子阶段236使用早前生成的代码长度表206。在其他实现中,设置每符号的代码子阶段236重新计算初始代码长度和量化区间,如基于香农的分箱阶段202中所作的那样(但是不执行分箱),并且重新计算代码长度,如设置每符号的代码子阶段236的操作中所描绘的。
[0125]
代码分配阶段232代码根据正在使用的编码算法被分配给符号。在该实现中,代码
分配阶段232将范式霍夫曼代码生成为输出。
[0126]
用于使用灵活霍夫曼树近似来编码符号的方法
[0127]
在本文的任何示例中,可以提供用于使用实现灵活霍夫曼树近似的新算法来编码符号的方法。
[0128]
图3是用于使用新算法来编码符号的示例方法300的流程图。例如,示例方法300可以由计算设备(例如,经由运行在计算设备上的软件)和/或由计算设备的硬件部件(例如,由用于fpga的asic)执行。
[0129]
在310处,执行基于香农的分箱以确定针对符号的初始代码长度并且基于所分配的初始代码长度将符号放入对应的代码长度分箱(clb)中。基于香农的分箱可以被执行为编码过程的第一阶段的部分。在一些实现中,clb被划分为量化区间。在一些实现中,符号从另一压缩或者编码工具接收,诸如从使用deflate压缩算法的工具接收。例如,要被压缩的数据可以被接收(例如,作为文件、作为流数据、或者以另一格式)。数据可以被处理以生成符号信息,其可以被提供为到示例方法300的输入。
[0130]
在320处,执行代码空间优化以将符号中的至少一些缩短到更短代码长度分箱。例如,抬升符号可以基于剩余代码空间的量来执行。代码空间优化可以被执行为编码过程的第二阶段的部分。在一些实现中,当剩余代码空间大于阈值时(例如,当代码空间大于零时)代码空间优化被执行。例如,如果剩余代码空间小于或等于阈值,那么代码空间优化可以被跳过。
[0131]
在330处,通过处理符号的二叉树表示以将二叉树转变成满二叉树来执行树完成。在一些实现中,不执行树完成(例如,树完成可以是可选阶段)。
[0132]
在340处,至少部分地基于代码长度分箱,前缀代码被分配给符号。在一些实现中,前缀代码根据霍夫曼编码算法的代码分配部分(例如,根据范式霍夫曼编码算法的代码分配部分)来分配。
[0133]
图4是用于使用新算法来编码符号的示例方法400的流程图。例如,示例方法400可以由计算设备(例如,经由运行在计算设备上的软件)和/或由计算设备的硬件部件(例如,由用于fpga的asic)执行。
[0134]
在410处,接收符号信息。符号信息从输入数据(例如,输入文件、流数据等等)被生成。符号信息包括从输入数据生成的符号以及频率信息。在一些实现中,符号信息从压缩算法(例如,使用lz77算法)被生成。
[0135]
在420处,执行基于香农的分箱以确定针对符号的初始代码长度并且基于所分配的初始代码长度将符号放入对应的代码长度分箱(clb)中。基于香农的分箱可以被执行为编码过程的第一阶段的部分。在一些实现中,clb被划分为量化区间。
[0136]
在430处,执行代码空间优化以将符号中的至少一些缩短到更短代码长度分箱。例如,抬升符号可以基于剩余代码空间的量来执行。代码空间优化可以被执行为编码过程的第二阶段的部分。在一些实现中,当剩余代码空间大于阈值时(例如,当代码空间大于零时)代码空间优化被执行。例如,如果剩余代码空间小于或等于阈值,那么代码空间优化可以被跳过。
[0137]
在440处,通过处理符号的二叉树表示以将二叉树转变成满二叉树来执行树完成。在一些实现中,不执行树完成(例如,树完成可以是可选阶段)。
[0138]
在450处,至少部分地基于代码长度分箱,前缀代码被分配给符号。在一些实现中,前缀代码根据霍夫曼编码算法的代码分配部分(例如,根据范式霍夫曼编码算法的代码分配部分)来分配。
[0139]
在460处,使用所分配的代码(例如,使用所分配的霍夫曼代码)来编码输入数据。经编码的输入数据(其现在以压缩格式)可以被输出(例如,作为压缩文件被保存在存储设备上、作为压缩数据流被发送到网络设备等等)。
[0140]
整数实现
[0141]
新算法可以使用整数实现来高效地实现(例如,以硬件,诸如asics和fpgas)。
[0142]
寄存器传输级(rtl)实现应当避免成本高并且不精确的浮点计算,尤其是log2和除法。另外,clb必须决不小于精确值,或者代码空间可能溢出,从而导致功能不正确性。为了解决这些潜在问题,高效并且精确的整数计算已经使用下面的变换来开发。
[0143]
clb(sym)=clb
[0144]
ceil(i(sym))=clb
[0145]
clb-1<i(sym)<=clb
[0146]
clb-1<-log2(symcnt[sym]/symtot)<=clb
[0147]
clb-1<log2(symtot/symcnt[sym])<=clb
[0148]2clb-1
<symtot/symcnt[sym]<=2clb
[0149]2clb-1
*symcnt[sym]<symtot<-2
clb
*symcnt[sym]
[0150]2clb
*symcnt[sym]<symtot*2<=2*2
clb
*symcnt[sym]
[0151]2clb
*symcnt[sym]<symtot*2
[0152][0153]
symtot<=2
clb
*symcnt[sym]<symtot/2
[0154]
clb可以通过首先将symcnt[sym]的高阶位与symtot的高阶位对齐并且然后与symtot进行比较来计算。将移位的位数称为clb
′
。
[0155]
clb=clb
′
if symtot<=2
clb
′
*symcnt[sym]
[0156]
clb=clb
′
1otherwise
[0157]
qi是优化,并且精确计算将不影响正确性。qi使用symtot与2*symtot之间的切割点来计算。切割点在前面被预先计算一次。在该实现中,简单线性切割点被使用,但是从信息论的角度,基于log的模式毫无争议是更精确的。利用四个qi,表3中所描绘的以下qi切割点将被使用在本实现中。
[0158]
[0159]
表3
–
量化区间边界
[0160]
以这种方式,qi还可以使用整数运算来计算。当计算分界点时求整不是关键的。
[0161]
硬件实现
[0162]
新算法可以以硬件(诸如asics和fpgas)来高效地实现。例如,该技术可以实现多个符号的并行计算。每周期处理的符号的数量将取决于诸如芯片面积约束、目标频率和正在使用的技术的因素。常见的实现可以每周期处理高达4个符号。在基于香农的分箱期间,symcnt可以例如以阵列和sram来实现。由于对符号计数的访问是顺序的,所以多个符号连续计数可以容易地被一次读取。clb和qi的计算针对每个符号是完全独立的,因此多个符号可以被并行地处理。
[0163]
对qipop的更新涉及简单逻辑和增加。对相同条目的多次增加可以被一起合并到单个加法中,由此允许多个符号被并行地记分。
[0164]
代码空间优化循环(例如,在图2b中的212处所描绘的)在对rcs的更新上被序列化。因此,每个迭代一次被处理一个。因此,循环212的每个迭代被序列化。然而,该循环可以被减少至简单整数运算,通常被实现在单个周期中。另外,代码空间优化将通常运行仅几个迭代。
[0165]
代码分配涉及通过符号的第二轮。多个符号可以通过以下操作来计算它们的最终代码长度:1)读取符号计数并且并行地计算基于香农的clb和qi,2)并行地应用来自代码空间优化的obt clb更新,以及3)并行地应用am更新树完成,以及4)并行地基于fct来分配代码。正如基于香农的分箱一样,符号计数、clb和qi可以通常使用相同硬件流水线全部被并行地读取和计算。对obt的更新可以通过在多个符号具有相同clb和qi时合并针对多个符号的更新来优化,从而允许多个符号在单个周期被处理。类似地,对am的更新可以当多个符号具有相同clb(在obt调整之后)时被合并。这在每个周期产生针对多个符号的最终代码长度。
[0166]
最终,代码通过基于最终代码长度咨询fct来分配。当多个符号在相同周期中具有相同最终代码长度时,它们对fct的更新可以被合并,从而将多个增加转换成单个小相加。这在每个周期得到针对多个符号的最终分配的代码。
[0167]
计算系统
[0168]
图5描绘了所描述的技术可以被实现于其中的适当的计算系统500的一般化示例。计算系统500不旨在暗示对使用范围或者功能的任何限制,因为这些技术可以被实现于各种各样的通用或者专用计算系统中。
[0169]
参考图5,计算系统500包括一个或多个处理单元510、515和存储器520、525。在图5中,该基本配置530被包括于虚线内。处理单元510、515运行计算机可执行指令。处理单元可以是通用中央处理单元(cpu)、专用集成电路(asic)中的处理器或者任何其他类型的处理器。处理单元还可以包括多个处理器。在多处理系统中,多个处理单元运行计算机可执行指令以提高处理能力。例如,图5示出了中央处理单元510以及图形处理单元或者协同处理单元515。有形存储器520、525可以是可由(多个)处理单元访问的易失性存储器(例如,寄存器、高速缓存、ram)、非易失性存储器(例如,rom、eeprom、闪存等)或者这两者的特定组合。存储器520、525存储以适合于由(多个)处理单元运行的计算机可执行指令的形式实现本文所描述的一个或多个技术的软件580。
[0170]
计算系统可以具有额外特征。例如,计算系统500包括存储设备540、一个或多个输入设备550、一个或多个输出设备560以及一个或多个通信连接570。诸如总线、控制器或者网络的互连机制(未示出)将计算系统500的部件互连。通常,操作系统软件(未示出)提供用于运行于计算系统500中的其他软件的操作环境并协调计算系统500的组件的活动。
[0171]
有形存储设备540可以是可移除的或者不可移除的,并且包括磁盘、磁带或盒、cd-rom、dvd或者可以用于存储信息并且可以在计算系统500内访问的任何其他介质。存储设备540存储用于实现本文描述的一个或多个技术的软件580的指令。
[0172]
(多个)输入设备550可以是诸如键盘、鼠标、笔、或者跟踪球的触摸输入设备、语音输入设备、扫描设备或者将输入提供到计算系统500的另一设备。对于视频编码,(多个)输入设备550可以是相机、视频卡、tv调谐卡、或者接受以模拟或者数字形式的视频输入的类似的设备、或者将视频样本读取到计算系统500中的cd-rom或者cd-rw。(多个)输入设备560可以是显示器、打印机、扬声器、cd刻录机、或者提供来自计算系统500的输出的另一设备。
[0173]
(多个)通信连接570实现通过通信介质到另一计算实体的通信。通信介质在调制数据信号中传达诸如计算机可执行指令、音频或者视频输入或者输出、或者其他数据的信息。调制数据信号是以将信息编码在信号中的方式使其特征中的一个或多个被设置或者改变的信号。通过举例而非限制,通信介质可以使用电气、光学、rf或者其他载体。
[0174]
这些技术可以在计算机可执行指令(诸如程序模块中包括的那些)的一般上下文中所描述,在计算系统中的目标真实或者虚拟处理器上运行。一般地,程序模块包括执行特定任务或者实现特定抽象数据类型的例程、程序、库、对象、类、组件、数据结构等。在各种实施例中,程序模块的功能可以根据需要被组合或者拆分在程序模块之间。用于程序模块的计算机可执行指令可以被运行在本地或分者布式计算系统内。
[0175]
术语“系统”和“设备”在本文可互换地被使用。除非上下文另行清楚地指示,任一术语都不暗示对一种类型的计算系统或者计算设备的任何限制。一般地,计算系统或者计算设备可以是本地的或者分布式的,并且可以包括专用硬件和/或通用硬件与实现本文所描述的功能的软件的任何组合。
[0176]
为了展示,详细描述使用如“确定”和“使用”的术语来描述计算系统中的计算机操作。这些术语是用于由计算机执行的操作的高级抽象,并且不应当与由人类执行的动作混淆。对应于这些术语的实际计算机操作取决于实现而变化。
[0177]
云支持环境
[0178]
图6是所描述的实施例、技术和工艺可以被实现于其中的适当的云支持环境600的一般化示例。在示例环境600中,各种类型的服务(例如,计算服务)由云610提供。例如,云610可以包括一些计算设备,其可以是中心定位的或者是分布式的,其将基于云的服务提供到经由诸如互联网的网络而连接的各种类型的用户和设备。实现环境600可以以不同的方式被使用以完成计算任务。例如,一些任务(例如,处理用户输入和呈现用户界面)可以在本地计算设备(例如,连接设备630、640、650)上被执行,而其他任务(要在随后处理中使用的数据的存储)可以在云610中被执行。
[0179]
在示例环境600中,云610提供用于具有各种屏幕能力的连接设备630、640、650的服务。连接设备630表示具有计算机屏幕635(例如,中等尺寸屏幕)的设备。例如,连接设备630可以是个人计算机,诸如台式计算机、膝上型计算机、笔记本、上网本等。连接设备640表
示具有计算机屏幕645(例如,小尺寸屏幕)的设备。例如,连接设备640可以是移动电话、智能电话、个人数字助理、平板计算机等。连接设备650表示具有大屏幕655的设备。例如,连接设备650可以是电视屏幕(例如,智能电视)或者连接到电视(例如,机顶盒或者游戏控制台)等的另一设备。连接设备630、640、650中的一个或多个可以包括触摸屏能力。触摸屏可以以不同的方式接受输入。例如,电容式触摸屏在对象(例如,指尖或者触笔)扭曲或者中断跨表面运行的电流时检测触摸输入。作为另一示例,触摸屏可以使用光学传感器来在来自光学传感器的光束被中断时检测触摸输入。与屏幕的表面的物理接触对于要由一些触摸屏检测的输入来说不是必要的。没有屏幕能力的设备还可以被使用在示例环境600中。例如,云610可以提供用于没有显示器的一个或多个计算机(例如,服务器计算机)的服务。
[0180]
服务可以由云610通过服务提供者620或者通过在线服务的其他提供者(未描绘)提供。例如,云服务可以依特定连接设备(例如,连接设备630、640、650)的屏幕大小、显示能力和/或触摸屏能力被定制。
[0181]
在示例环境600中,云610至少部分地使用服务提供者620将本文所描述的技术和技术方案提供到各种连接设备630、640、650。例如,服务提供者620可以提供用于各种基于云的服务的集中式技术方案。服务提供者620可以管理用于用户和/或设备(例如,用于连接设备630、640、650和/或它们相应的用户)的服务订阅。
[0182]
示例实现
[0183]
尽管所公开的方法中的一些的操作为了方便展示以特定先后顺序被描述,但是应当理解这种描述方式包含重新安排,除非特定顺序由下面所阐述的特定语言要求。例如,顺序地描述的操作可以在一些情况下被重新安排或者被并发地执行。此外,为简单起见,附图可以不示出所公开的方法可以结合其他方法被使用的各种方式。
[0184]
所公开的方法中的任何方法可以被实现为存储于一个或多个计算机可读存储介质上并且在计算设备(即,任何可用计算设备,包括智能电话或者包括计算硬件的其他移动设备)上运行的计算机可执行指令或者计算机程序产品。计算机可读存储介质是可以在计算环境内访问的有形介质(一个或多个光学介质盘,诸如dvd或者cd,易失性介质(诸如dram或者sram)或者非易失性介质(诸如闪存或者硬盘驱动器))。通过举例并且参考图5,计算机可读存储介质包括存储器520和525以及存储设备540。术语计算机可读存储介质不包括信号和载波。另外,术语计算机可读存储介质不包括通信连接,诸如570。
[0185]
用于实现所公开的技术的计算机可执行指令中的任何以及在所公开的实施例的实现期间创建和使用的任何数据可以被存储在一个或多个计算机可读存储介质上。计算机可执行指令可以是经由网络浏览器或者其他软件应用(诸如远程计算应用)访问或者下载的专用软件应用或者软件应用的部分。这样的软件可以例如运行在单个本地计算机(例如,任何适当的商用计算机)上或者使用一个或多个网络计算机的网络环境(例如,经由互联网、广域网、局域网、客户机服务器网络(诸如云计算网络)或者其他这样的网络)中。
[0186]
为清楚性,仅仅描述了基于软件的实现的某些选定方面。省略了本领域中众所周知的其他细节。例如,应当理解,所公开的技术不限于任何特定计算机语言或者程序。例如,所公开的技术可以由以c 、java、perl或者任何其他适当的编程语言编写的软件来实现。类似地,所公开的技术不限于任何特定计算机或者类型的硬件。适当的计算机和硬件的某些细节是众所周知的并且不需要在本公开中详细阐述。
[0187]
另外,基于软件的实施例(包括,例如,用于使计算机执行所公开的方法中的任何方法的计算机可执行指令)中的任何实施例可以通过适当的通信手段被上传、下载或者远程访问。这样的适当的通信手段包括例如互联网、万维网、内联网、软件应用、线缆(包括光纤线缆)、磁性通信、电磁通信(包括rf、微波和红外通信)、电子通信或者其他这样的通信手段。
[0188]
所公开的方法、装置和系统决不应当被解释为限制性的。备选地,本公开指向各种所公开的实施例的所有新颖并且非显而易见的特征和方面,单独地和以与彼此的各种组合和子组合。所公开的方法、装置和系统不限于任何特定方面或者特征或者其组合,所公开的实施例也不要求任何一个或多个特定优点存在或者问题被解决。
[0189]
来自任何示例的技术可以与其他示例中的任何一个或多个中所描述的技术相组合。鉴于所公开的技术的原理可以被应用的许多可能实施例,应当意识到,图示的实施例是所公开的技术的示例并且不应当被理解为对所公开的技术的范围的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。