1.本技术涉及计算机技术领域,尤其涉及一种策略模型的训练方法、装置、电子设备和存储介质。
背景技术:
2.目前,在工业系统存在大量的生产控制环节,相关技术中,通常基于采用在线强化学习框架所学习得到的控制策略模型,对工业系统的各个生产控制环节运行控制。然而,在训练控制策略模型,在线强化学习框架需要与一个高保真度仿真器或者真实系统环境进行大量的交互、试错,收集系统状态、动作数据进行模型寻优训练。然而,由于工业系统通常较为复杂,获取与真实工业系统所对应的高保真度仿真器成本极高没有贴近真实场景的虚拟环境进行交互,从而导致训练出的控制策略模型,针对工业系统的控制效果不佳。因此,如何准确训练控制策略模型是亟需解决的问题。
技术实现要素:
3.本技术涉及计算机技术领域,尤其涉及一种策略模型的训练方法、装置、电子设备和存储介质。
4.本技术一方面实施例提出了一种策略模型的训练方法,所述方法包括:获取工业控制场景信息的历史运行数据集;获取基于所述历史运行数据集进行预训练所得到的系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型;根据所述预训练策略模型和所述系统动态特性模型,获取基于所述历史运行数据集所得到的仿真运行数据集;将所述历史运行数据集和所述仿真运行数据集混合,以得到混合训练集;根据所述混合训练集,对所述预训练策略模型、所述预训练收益模型和所述预训练损失模型进行联合训练,直至在训练后的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,结束训练;将结束训练时所得到的策略模型作为所述工业控制场景信息的目标策略模型。
5.本技术的一个实施例中,所述根据所述预训练策略模型和所述系统动态特性模型,获取基于所述历史运行数据集所得到的仿真运行数据集,包括:针对所述历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据输入到所述预训练策略模型中,以得到所述状态量数据对应的预测控制量数据;将所述状态量数据和所述预测控制量数据输入到所述系统动态特性模型中,以预测出在所述状态量数据下执行所述预测控制量数据之后所得到下一个状态量数据;根据所述下一个状态量数据,确定在所述状态量数据下执行所述预测控制量数据之后所得到的预测收益数据和预测损失数据;根据所述状态量数据、所述预测控制量数据、所述下一个状态量数据、所述预测收益数据和预测损失数据,形成所述当前条历史运行数据所对应的一条仿真运行数据;根据各条历史运行数据所对应的一条仿真运行数据,形成所述仿真运行数据集。
6.本技术的一个实施例中,所述获取基于所述历史运行数据集进行预训练所得到的
系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型,包括:针对所述历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据和控制量数据作为初始系统动态特性模型的输入,并将所述当前条历史运行数据中的下一个状态量数据作为所述初始系统动态特性模型的输出,对所述初始系统动态特性模型进行预训练,以得到所述系统动态特性模型;将所述当前条历史运行数据中的状态量数据和控制量数据作为初始收益模型的输入,并基于当前条历史运行数据中的长期收益作为所述初始收益模型的输出,对所述初始收益模型进行预训练,以得到所述预训练收益模型;将所述当前条历史运行数据中的状态量数据和控制量数据作为初始损失模型的输入,并基于当前条历史运行数据中的长期损失作为所述初始损失模型的输出,对所述初始损失模型进行预训练,以得到所述预训练损失模型;将所述当前条历史运行数据中的状态量数据作为初始策略模型的输入,并将所述当前历史运行数据中的控制量作为所述初始策略模型的输出,对所述初始策略模型进行预训练,以得到所述预训练策略模型。
7.本技术的一个实施例中,在所述将所述历史运行数据集和所述仿真运行数据集混合,以得到混合训练集之前,所述方法还包括:根据历史运行数据集,确定所述仿真运行数据集的置信度;确定所述置信度超过预设置信度阈值;确定所述仿真运行数据集中存在对数概率密度下界值小于或者等于预设阈值的至少一条目标仿真运行数据。
8.本技术的一个实施例中,所述确定所述仿真运行数据集中存在对数概率密度下界值小于或者等于预设阈值的至少一条目标仿真运行数据,包括:针对所述仿真运行数据集中的每条仿真运行数据,根据当前条仿真运行数据中的状态量数据和控制量数据,确定当前条仿真运行数据的对数概率密度下界值;在所述当前条仿真运行数据的对数概率密度下界值大于预设阈值的情况下,将所述当前条仿真运行数据作为所述目标仿真运行数据。
9.本技术的一个实施例中,所述预训练收益模型包括模型参数不同的第一预训练收益模型和第二预训练收益模型,所述根据所述混合训练集,对所述预训练策略模型、所述预训练收益模型和所述预训练损失模型进行联合训练,直至在训练后的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,结束训练,包括:针对混合训练集中的每条运行数据,将当前条运行数据中的状态量数据输入到所述预训练策略模型,以得到所述预训练策略模型输出的预测控制量数据;将所述预测控制量数据和当前条运行数据中的状态量数据分别输入到所述第一预训练收益模型和第二预训练收益模型,以得到所述第一预训练收益模型输出的第一收益数据和所述第二预训练收益模型输出的第二收益数据;将所述预测控制量数据和当前条运行数据中的状态量数据输入到所述预训练损失模型中,以得到所述预训练损失模型输出的损失数据;选择所述第一收益数据和所述第二收益数据中的较小值作为第三收益数据;根据各条运行数据的第三收益数据,确定在所述预测控制量数据下的收益平均值,并根据各条运行数据的损失数据,确定在所述预测控制量数据下的损失平均值;在所述损失平均值小于或者等于所述预设损失阈值的情况下,如果存在收益平均值大于所述预测控制量数据的其他控制量数据,则分别调整所述预训练策略模型、所述预训练损失模型和所述预训练收益模型的模型参数,并基于调整后的策略模型、损失模型和收益模型继续进行联合训练;在所述损失平均值小于或者等于所述预设损失阈值的情况下,如果不存在收益平均值大于所述预测控制量数据的其他控制量数据,则结束训练。
10.本技术提出一种策略模型的训练方法,通过获取工业控制场景信息的历史运行数据集进行预训练,得到系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型,然后将预训练策略模型和系统动态特性模型得到的仿真运行数据集与历史运行数据集混合,以得到混合数据集,并基于预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,以得到能够使得训练后损失模型输出的损失数据小于预设损失阈值,并且收益模型输出的收益数据达到最大值情况下的目标策略模型,由此,通过对仿真运行数据集与历史运行数据集混合,将得到混合数据集进行混合训练,实现离线强化学习,使得工业控制场景中优化控制策略效果更佳。
11.本技术另一方面实施例提出了一种策略模型的训练装置,所述装置包括:第一获取模块,用于获取工业控制场景信息的历史运行数据集;第二获取模块,用于获取基于所述历史运行数据集进行预训练所得到的系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型;第三获取模块,用于根据所述预训练策略模型和所述系统动态特性模型,获取基于所述历史运行数据集所得到的仿真运行数据集;混合模块,用于将所述历史运行数据集和所述仿真运行数据集混合,以得到混合训练集;训练模块,用于根据所述混合训练集,对所述预训练策略模型、所述预训练收益模型和所述预训练损失模型进行联合训练,直至在训练后的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,结束训练;输出模块,用于将结束训练时所得到的策略模型作为所述工业控制场景信息的目标策略模型。
12.本技术的一个实施例中,所述第三获取模块,包括:输入单元,用于针对所述历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据输入到所述预训练策略模型中,以得到所述状态量数据对应的预测控制量数据;预测单元,用于将所述状态量数据和所述预测控制量数据输入到所述系统动态特性模型中,以预测出在所述状态量数据下执行所述预测控制量数据之后所得到下一个状态量数据;确定单元,用于根据所述下一个状态量数据,确定在所述状态量数据下执行所述预测控制量数据之后所得到的预测收益数据和预测损失数据;第一生成单元,用于根据所述状态量数据、所述预测控制量数据、所述下一个状态量数据、所述预测收益数据和预测损失数据,形成所述当前条历史运行数据所对应的一条仿真运行数据;第一生成单元,用于根据各条历史运行数据所对应的一条仿真运行数据,形成所述仿真运行数据集。
13.本技术的一个实施例中,所述第二获取单元,具体用于:针对所述历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据和控制量数据作为初始系统动态特性模型的输入,并将所述当前条历史运行数据中的下一个状态量数据作为所述初始系统动态特性模型的输出,对所述初始系统动态特性模型进行预训练,以得到所述系统动态特性模型;将所述当前条历史运行数据中的状态量数据和控制量数据作为初始收益模型的输入,并基于当前条历史运行数据中的长期收益作为所述初始收益模型的输出,对所述初始收益模型进行预训练,以得到所述预训练收益模型;将所述当前条历史运行数据中的状态量数据和控制量数据作为初始损失模型的输入,并基于当前条历史运行数据中的长期损失作为所述初始损失模型的输出,对所述初始损失模型进行预训练,以得到所述预训练损失模型;将所述当前条历史运行数据中的状态量数据作为初始策略模型的输入,并
将所述当前历史运行数据中的控制量作为所述初始策略模型的输出,对所述初始策略模型进行预训练,以得到所述预训练策略模型。
14.本技术的一个实施例中,所述装置还包括:第一确定模块,用于根据历史运行数据集,确定所述仿真运行数据集的置信度;第二确定模块,用于确定所述置信度超过预设置信度阈值;第三确定模块,用于确定所述仿真运行数据集中存在对数概率密度下界值小于或者等于预设阈值的至少一条目标仿真运行数据。
15.本技术的一个实施例中,所述第三确定模块,具体用于:针对所述仿真运行数据集中的每条仿真运行数据,根据当前条仿真运行数据中的状态量数据和控制量数据,确定当前条仿真运行数据的对数概率密度下界值;在所述当前条仿真运行数据的对数概率密度下界值大于预设阈值的情况下,将所述当前条仿真运行数据作为所述目标仿真运行数据。
16.本技术的一个实施例中,所述预训练收益模型包括模型参数不同的第一预训练收益模型和第二预训练收益模型,所述训练模块,具体用于:针对混合训练集中的每条运行数据,将当前条运行数据中的状态量数据输入到所述预训练策略模型,以得到所述预训练策略模型输出的预测控制量数据;将所述预测控制量数据和当前条运行数据中的状态量数据分别输入到所述第一预训练收益模型和第二预训练收益模型,以得到所述第一预训练收益模型输出的第一收益数据和所述第二预训练收益模型输出的第二收益数据;将所述预测控制量数据和当前条运行数据中的状态量数据输入到所述预训练损失模型中,以得到所述预训练损失模型输出的损失数据;选择所述第一收益数据和所述第二收益数据中的较小值作为第三收益数据;根据各条运行数据的第三收益数据,确定在所述预测控制量数据下的收益平均值,并根据各条运行数据的损失数据,确定在所述预测控制量数据下的损失平均值;在所述损失平均值小于或者等于所述预设损失阈值的情况下,如果存在收益平均值大于所述预测控制量数据的其他控制量数据,则分别调整所述预训练策略模型、所述预训练损失模型和所述预训练收益模型的模型参数,并基于调整后的策略模型、损失模型和收益模型继续进行联合训练;在所述损失平均值小于或者等于所述预设损失阈值的情况下,如果不存在收益平均值大于所述预测控制量数据的其他控制量数据,则结束训练。
17.本技术提出一种策略模型的训练装置,通过获取工业控制场景信息的历史运行数据集进行预训练,得到系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型,然后将预训练策略模型和系统动态特性模型得到的仿真运行数据集与历史运行数据集混合,以得到混合数据集,并基于预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,以得到能够使得训练后损失模型输出的损失数据小于预设损失阈值,并且收益模型输出的收益数据达到最大值情况下的目标策略模型,由此,通过对仿真运行数据集与历史运行数据集混合,将得到混合数据集进行混合训练,实现离线强化学习,使得工业控制场景中优化控制策略效果更佳。
18.本技术另一方面实施例提出了一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现策略模型的训练方法。
19.本技术另一方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现策略模型的训练方法。
20.上述可选方式所具有的其他效果将在下文中结合具体实施例加以说明。
附图说明
21.图1是本技术实施例所提供的一种策略模型的训练方法的流程示意图。
22.图2是本技术实施例所提供的另一种策略模型的训练方法的流程示意图。
23.图3是本技术实施例所提供的一种离线强化学习框架流程示意图。
24.图4是本技术实施例所提供的一种离线强化学习流程示意图。
25.图5是本技术实施例所提供的另一种策略模型的训练方法的流程示意图。
26.图6是本技术实施例所提供的一种限制性探索流程示意图。
27.图7是本技术实施例的一个策略模型的训练装置的结构示意图。
28.图8是本技术实施例的另一个策略模型的训练装置的结构示意图。
29.图9是根据本技术一个实施例的电子设备的框图。
具体实施方式
30.下面详细描述本技术的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本技术,而不能理解为对本技术的限制。
31.下面参考附图描述本技术实施例的策略模型训练方法、装置和电子设备。
32.图1是本技术实施例所提供的一种策略模型训练方法的流程示意图。其中,需要说明的是,本实施例提供的策略模型训练方法的执行主体为策略模型训练装置,该策略模型训练装置可以由软件和/或硬件的方式实现,该实施例中的策略模型训练装置可以配置电子设备中,本实施例中的电子设备可以包括服务器,该实施例对电子设备不作具体限定。
33.图1是本技术实施例所提供的一种策略模型训练方法的流程示意图。
34.如图1所示,该策略模型训练方法可以包括:
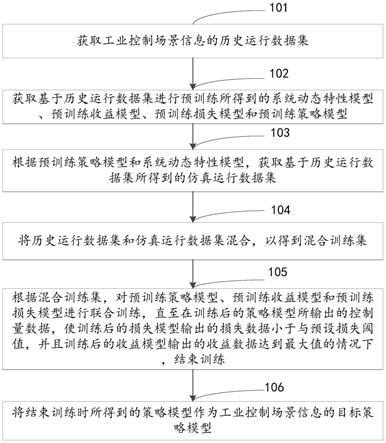
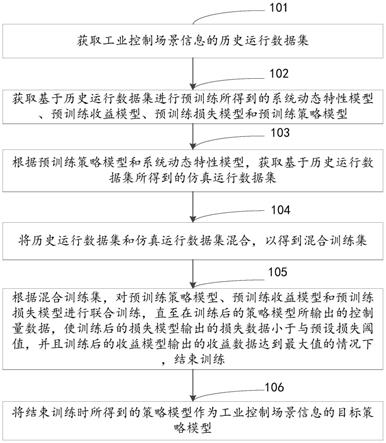
35.步骤101,获取工业控制场景信息的历史运行数据集。
36.在本技术的一些实施例中,工业控制场景信息的历史运行数据集可以是工业场景信息所对应的智能机器记录的数据,该实施例对此不做具体限定。
37.其中,本实施例中的工业控制场景信息可以包括能源、工业、冶金、制造等工业控制场景信息,该实施例对工业场景信息所对应的工业类型不作具体限定。
38.步骤102,获取基于历史运行数据集进行预训练所得到的系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型。
39.在一些实施例中,基于历史运行数据集进行预训练得到系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型的一种可能实现方式为:针对历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据和控制量数据作为初始系统动态特性模型的输入,并将当前条历史运行数据中的下一个状态量数据作为初始系统动态特性模型的输出,对初始系统动态特性模型进行预训练,以得到系统动态特性模型。将当前条历史运行数据中的状态量数据和控制量数据作为初始收益模型的输入,并基于当前条历史运行数据中的长期收益作为初始收益模型的输出,对初始收益模型进行预训练,以得到预训练收益模型。将当前条历史运行数据中的状态量数据和控制量数据作为初始损失模型的输入,并基于当前条历史运行数据中的长期损失作为初始损失模型的输出,对初始损失模型进行预训练,以得到预训练损失模型。将当前条历史运行数据中的状态量
数据作为初始策略模型的输入,并将当前历史运行数据中的控制量作为初始策略模型的输出,对初始策略模型进行预训练,以得到预训练策略模型。
40.在一些实施例中,在每条历史运行数据中的收益不是长期收益的情况下,在基于历史运行数据对收益模型以及损失模型进行预训练时,可根据当前条历史运行数据中的收益,利用时序差分的方法,将单步的r映射到一个长期的收益,以及将单步的c映射到一个长期的损失,并将当前历史运行数据中的状态量数据以及控制量数据输入到收益模型中,以得到对应的预测长期收益,根据将预测长期收益,与映射得到的长期收益,对收益模型进行预训练。对于损失模型,将当前历史运行数据中的状态量数据以及控制量数据输入到损失模型中,以得到对应的预测长期损失,根据将预测长期损失,与映射得到的长期损失,对损失模型进行预训练。
41.步骤103,根据预训练策略模型和系统动态特性模型,获取基于历史运行数据集所得到的仿真运行数据集。
42.在一些实施例中,根据预训练策略模型和系统动态特性模型,获取基于历史运行数据集所得到的仿真运行数据集的一种可能实现方式可以为:针对所述历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据输入到预训练策略模型,以得到一个新的预测控制量数据,将状态量数据和预测控制量数据输入到系统动态特性模型中,以得到预测出在状态量数据下执行预测控制量数据之后的下一个状态量数据,根据下一个状态量数据可以计算出预测收益数据和预测损失数据,形成当前条历史运行数据所对应的一条仿真运行数据,并根据各条历史运行数据所对应的一条仿真运行数据,形成仿真运行数据集。
43.在本技术的另一个示例性的实施方式中,上述根据所述预训练策略模型和所述系统动态特性模型,获取基于所述历史运行数据集所得到的仿真运行数据集的一种可能实现方式为:基于预存的历史运行数据集、预训练策略模型和系统动态特性模型三者之间的对应关系,获取出与该历史运行数据集、预训练策略模型和所述系统动态特性模型所对应的仿真运行数据集。
44.步骤104,将历史运行数据集和仿真运行数据集混合,以得到混合训练集。
45.步骤105,根据混合训练集,对预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,直至在训练后的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,结束训练。
46.也就是说,在本实施例中可将混合训练集中的状态量数据输入到预训练策略模型中,得到的策略模型所输出的控制量数据,并将状态量以及控制量数据输入到损失模型中,以得到损失模型的损失数据,并将状态量以及控制量数据输入到收益模型中,以得到收益模型的收益数据,如果确定损失模型输出的损失数据小于与预设损失阈值,并且该收益数据达到最大值,则确定满足了模型训练结束条件,结束预训练。
47.其中,可以理解的是,通常对于不同的工业控制场景信息,其对应的安全约束条件是不同的,进而其所对应的工业控制场景信息所对应的预设损失阈值是不同的,在一些实施例中,为了可以准确训练得到策略模型,上述预设损失阈值可以是通过下述方式得到的:获取工业控制场景信息的安全约束条件,并获取与该安全约束条件对应的损失阈值,并将
所获取到的损失阈值作为上述预设损失阈值。
48.步骤106,将结束训练时所得到的策略模型作为工业控制场景信息的目标策略模型。
49.可以理解的是,当得到的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,把此时的略模型作为工业控制场景信息的目标策略模型。
50.本技术提出一种策略模型的训练方法,通过获取工业控制场景信息的历史运行数据集进行预训练,得到系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型,然后将预训练策略模型和系统动态特性模型得到的仿真运行数据集与历史运行数据集混合,以得到混合数据集,并基于预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,以得到能够使得训练后损失模型输出的损失数据小于预设损失阈值,并且收益模型输出的收益数据达到最大值情况下的目标策略模型,由此,通过对仿真运行数据集与历史运行数据集混合,将得到混合数据集进行混合训练,实现离线强化学习,使得工业控制场景中优化控制策略效果更佳。
51.基于上述实施例的基础上,为了缓解了离线强化中常见的高估的问题,在一些实施例中,上述预训练收益模型包括模型参数不同的第一预训练收益模型和第二预训练收益模型,上述根据混合训练集,对预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,直至在训练后的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,结束训练的一种可能实现方式为括:针对混合训练集中的每条运行数据,将当前条运行数据中的状态量数据输入到预训练策略模型,以得到预训练策略模型输出的预测控制量数据,将预测控制量数据和当前条运行数据中的状态量数据分别输入到第一预训练收益模型和第二预训练收益模型,以得到第一预训练收益模型输出的第一收益数据和第二预训练收益模型输出的第二收益数据。将预测控制量数据和当前条运行数据中的状态量数据输入到预训练损失模型中,以得到预训练损失模型输出的损失数据。选择第一收益数据和第二收益数据中的较小值作为第三收益数据。根据各条运行数据的第三收益数据,确定在预测控制量数据下的收益平均值,并根据各条运行数据的损失数据,确定在预测控制量数据下的损失平均值。在损失平均值小于或者等于预设损失阈值的情况下,如果存在收益平均值大于预测控制量数据的其他控制量数据,则分别调整预训练策略模型、预训练损失模型和预训练收益模型的模型参数,并基于调整后的策略模型、损失模型和收益模型继续进行联合训练。在损失平均值小于或者等于预设损失阈值的情况下,如果不存在收益平均值大于预测控制量数据的其他控制量数据,则结束训练。
52.图2是本技术实施例所提供的另一种策略模型的训练方法的流程示意图。
53.如图2所示,该方法可以包括:
54.步骤201,获取工业控制场景信息的历史运行数据集。
55.步骤202,获取基于历史运行数据集进行预训练所得到的系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型。
56.其中,需要说明的是,关于步骤201和步骤202的具体实现方式,可参见上述实施例中的相关描述,此处不再赘述。
57.步骤203,针对历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据输入到预训练策略模型中,以得到状态量数据对应的预测控制量数据。
58.步骤204,将状态量数据和预测控制量数据输入到系统动态特性模型中,以预测出在状态量数据下执行预测控制量数据之后所得到下一个状态量数据。
59.步骤205,根据下一个状态量数据,确定在状态量数据下执行预测控制量数据之后所得到的预测收益数据和预测损失数据。
60.步骤206,根据状态量数据、预测控制量数据、下一个状态量数据、预测收益数据和预测损失数据,形成当前条历史运行数据所对应的一条仿真运行数据。
61.步骤207,根据各条历史运行数据所对应的一条仿真运行数据,形成仿真运行数据集。
62.步骤208,将历史运行数据集和仿真运行数据集混合,以得到混合训练集。
63.步骤209,根据混合训练集,对预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,直至在训练后的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,结束训练。
64.步骤210,将结束训练时所得到的策略模型作为工业控制场景信息的目标策略模型。
65.本技术提出一种策略模型的训练方法,通过获取工业控制场景信息的历史运行数据集进行预训练,得到系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型,将历史运行数据集中的每一条历史运行数据中的状态量数据输入到预训练策略模型中,以得到预测控制量数据,再把状态量数据和预测控制量数据输入到系统动态特性模型中,得到状态量数据下执行预测控制量数据之后的下一个状态量数据,继而确定预测收益数据和预测损失数据,从而形成当前条历史运行数据所对应的一条仿真运行数据,所有条的仿真运行数据,形成仿真运行数据集,然后将预训练策略模型和系统动态特性模型得到的仿真运行数据集与历史运行数据集混合,以得到混合数据集,并基于预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,以得到能够使得训练后损失模型输出的损失数据小于预设损失阈值,并且收益模型输出的收益数据达到最大值情况下的目标策略模型,由此,通过对仿真运行数据集与历史运行数据集混合,将得到混合数据集进行混合训练,实现离线强化学习,使得工业控制场景中优化控制策略效果更佳。
66.为了使得本领域的技术人员可以清楚了解本技术的技术方案,下面结合图3对该实施例进行进一步描述。图3是本技术实施例所提供的一种离线强化框架流程示意图。
67.在本技术的一些实施例中,提供的离线强化学习框架包括四个模块:系统动态特性模型、安全约束、限制性探索以及混合训练,通过这四个模块实现强化离线学习。
68.其中,强化学习(reinforcement learning,rl)是机器学习中的一个领域,强调如何基于环境状态,而选择最优的动作策略,以取得最大化的预期收益。在本技术中,离线强化学习是强化学习方法的一个分支,其可基于真实的历史数据集来训练获取策略模型。
69.本一些实施例中,真实数据为工业控制场景中采集的历史数据集,包括工业控制场景下的测点信息:温度、压力、流量、风速、原料投放量等等,以及周期性检测信息数据:煤质信息、原油成分检测等等。完成历史数据的收集后,把历史数据集和仿真运行数据集进行
混合,得到混合数据集(s,a,s’,r,c)。其中,s表示工业控制场景中观测的状态量,a表示工业控制场景中的控制量,例如,阀门开度、原料投放量等;s’为在状态量s的情况下执行a之后所得到下一个状态量;r表示在状态量s的情况下执行a之后所得到的的收益情况;c表示在状态量s的情况下执行a之后所得到的损失情况。
70.其中,需要说明的是,对于仿真运行数据,每条仿真运行数据中的r以及c是通过s’计算出的。
71.在一些实施例中,离线强化框架中包含系统动态特性模型,策略模型,收益模型,损失模型,具体如下:
72.系统动态特性模型可以类似为一个仿真器,仿真器的作用是模拟环境,比如有一条数据s,a,s’,r,c,将s输入到策略模型中,可以得到与该状态量数据对应的控制量数据a*,将a*输入到系统动态特性模型中,以得到在当前状态量数据的情况下,执行该控制量数据a*之后所得到的下一个虚拟的状态量数据s’,通过虚拟的状态量数据s’去计算虚拟的r以及c,就会产生一条虚拟的仿真运行数据。这条仿真运行数据包括真实的s,包括虚拟的a*、s’,虚拟r以及c。
73.策略模型输出的是多个动作量在每个时刻的取值是多少,输出的是与实际控制非常一致的比较的好的控制量。例如,在火电控制场景中,排烟升高了,策略模型可输出当前一次风的值为多少,此时,工业系统可基于策略模型输出的值,来调整一次风的取值。
74.收益模型输出的是一个长期的收益,训练样本中的r是一个单步的收益,利用时序差分的方法,将单步的r映射到一个长期的q,利用模型计算出的q以及映射出的q进行一个拟合,让他们之间的距离越小越好,越小的话说明模型的评估越准确,其中收益模型的输入特征是s以及a。
75.损失模型时基于当前条历史运行数据中的长期损失,其输入特征为s以及a。
76.为了使得本领域的技术人员可以清楚了解本技术的技术方案,图4是本技术实施例所提供的一种离线强化学习流程示意图。
77.在一些实施例中,用所有的真实数据,s,a,s’对系统动态特性模型、收益模型、损失模型和策略模型进行预训练。
78.在另一些实施例中,为了缓解了离线rl中常见的高估问题,本实施例中的上述收益模型为两个,在对收益模型进行预训练之前,可基于随机的模型参数对上述两个收益模型进行初始化,并基于工业控制场景信息所对应的历史运行数据,对上述初始化后的收益模型进行预训练。其中,更新网络中模型更新顺序为:收益模型、损失模型、策略模型。
79.本技术引入了额外的损失模型满足工业过程优化中安全优化的限制问题,根据工业生产过程过中的安全限制条件,配置对应地损失模型来修正策略模型的训练方向。
80.本技术将真实数据和仿真运行数据结合起来,通过混合训练方式,训练策略模型,在保证数据有效性的基础上,对整体数据做进一步扩充,提高对历史数据的利用率。
81.为了使得本领域的技术人员可以清楚了解本技术的技术方案,下面结合图5对该实施例的技术方案进行进一步描述。
82.步骤501,系统动态特性模型。
83.本技术的系统动态特性模型,从历史运行数据中学习数据驱动的非完美动态模型,来生成未来的状态。
84.在一些实施例中,可根据工业控制场景的具体应用选择不同的深度神经网络,可选网络结构有深度循环神经网络(rnn)、深度神经网络(dnn)等。如在火力发电中可以将rnn作为燃烧过程的系统动态特性模型。
85.为了进一步加强该模型,本技术采用了噪声数据增强的方法。在训练过程中,对状态输入添加逐渐消失的高斯噪声,这可以被视为数据增强的一种手段。这种处理有助于提高模型的鲁棒性和防止过拟合。
86.步骤502,安全策略优化。
87.本技术在满足安全约束要求的同时,对当前策略模型优化,使长期收益最大化。因此,设置两个q函数,qr和qc,分别表示当前策略下的长期收益和长期损失,策略优化目标函数具体描述如下:
[0088][0089]
s.t.e
a~π
[q
c
(s,a)]≤l
[0090]
其中,l是一个常数,需在实践中具体环境中确定。是指计算出两个收益模型各自对应的收益,取两个收益较小的那个。期望类似于均值的,策略输出的动作,使得qr越大。
[0091]
在一些实施例中,两个收益模型的初始参数是随机的,例如:在模型反传参数的过程中,会随机参数30%(或者40%)的参数不变,这30%的选取也是随机选取的,因此,在更新的过程中,两个模型也会有所不同。
[0092]
本技术采用了double q技术,通过使用两个qr函数来惩罚qr中的不确定性,缓解了离线rl中常见的高估问题。这个技巧并不适用于损失模型,因为它可能会潜在地低估长期损失。为解决这一问题,采用拉格朗日松弛法,引入以下拉格朗日函数:
[0093][0094]
其中λ为拉格朗日乘数。原始约束问题,拉格朗日函数可以转换为以下不受约束的形式:
[0095][0096]
λ
←
[λ η(e
a~π
[q
c
(s,a)]
‑
l)]
[0097]
其中η为步长,[λ η(e
a~π
[q
c(s,a)
]
‑
l)]
=max{0,λ η(e
a~π
[q
c(s,a)
]
‑
l)}为在对偶空间(λ≥0)上的投影。在初始阶段,修正了二元变量λ,并在策略模型π上进行策略梯度更新。在对策略模型的梯度更新的同时,根据相应梯度更新λ。
[0098]
步骤503,限制性探索。
[0099]
为了保证仿真运行数据集的准确性和有效性,本技术设计了一种新的限制性探索策略,从模型和数据的角度充分利用模拟器的泛化性。整体流程图如图6所示。
[0100]
综上所述,模型准确度可以衡量模型对数据集的泛化能力。从模型的角度来看,使用这个度量来检测模型是否准确。从仿真运行数据中,可以表明系统动态特性模型生成数据是否准确。因此有样本置信度定义如下:
[0101][0102]
其中,∈i~n(0,σi),i∈{1,
…
,k}为高斯噪声。同时,定义批量置信数据集如下:
[0103]
τ
m
:={τ
s
|u
s,t
<l
u
}
[0104]
其中,∈i为第i个噪声,随机产生一个符合正态分布的噪声。
[0105]
其中,lu是置信度阈值。在实践中,选择它为离线数据集b中所有状态
‑
动作对的置信度百分位阈值βu。t为训练步骤。
[0106]
在b的低密度区域缺乏数据,可能无法提供足够的信息来完整准确地描述系统动态。为了解决这个问题,本技术提出了基于数据密度的过滤来鼓励在高密度区域的探索。关键是要仔细区分正样本(高密度区域)和负样本(低密度或ood)。在实际应用中,使用状态
‑
行为变分自编码器(vae)来拟合真实数据集的数据分布。vae的最大化下界(elbo)目标:
[0107][0108]
其中,p(s,a)指的是对数概率密度下界。
[0109]
其中,第一项表示重构损失,第二项为编码器输出与先验n(0,1)之间的kl散度。设τm为训练步骤t通过基于模型准确度过滤后的的仿真样本,通过上式将τm分成正样本τ 和负样本τ
‑
,阈值为lp。
[0110]
其中,kl描述分布差异性的值,相对熵。
[0111]
τ
:={τ
m
|p
m
>l
p
},τ
‑
:={τ
m
|p
m
<l
p
}
[0112]
与lu一样,选择离线数据集b中所有状态
‑
动作对的βp百分位值作为lp。
[0113]
步骤504,混合训练。
[0114]
本技术通过设置仿真模拟数据和真实数据相结合的混合训练策略,在混合训练中,保留正样本作为其原始形式,鼓励充分利用系统动态特性模型的可推广性,同时设置对负样本的惩罚,引导策略学习的方向远离高风险区域。
[0115]
负样本收益惩罚定义如下:
[0116][0117]
其中[η(l
p
‑
p
m
(s
t
,a
t
))]
=max{η(l
p
‑
p
m
(s
t
,a
t
)),0},η为控制奖励惩罚规模的超参数。本技术构造了数据缓冲池,将真实、正、负模拟数据结合起来进行训练。为了控制缓冲池中真实样本与仿真样本的比例,用一个参数α来进行控制真实样本与仿真样本的比例,λ的大小决定了更倾向于收益还是稳定性。
[0118]
仿真样本:真实样本=1:λ
[0119]
为了保证预测精度,用真实数据对系统动态特性模型进行预热和更新,然后再使用它来生成新的仿真运行数据。
[0120]
本技术提出一种策略模型的训练方法,通过历史运行数据集建立系统动态特性模型,并对得到的仿真运行数据集进行安全策略优化和限制性探索,最后对仿真运行数据集与历史运行数据集进行混合训练,由此,通过对仿真运行数据集与历史运行数据集混合,将
得到混合数据集进行混合训练,实现离线强化学习,使得工业控制场景中优化控制策略效果更佳。
[0121]
图7是本技术一个实施例的策略模型的训练装置的结构示意图。
[0122]
如图7所示,该策略模型的训练装置700包括:
[0123]
第一获取模块701,用于获取工业控制场景信息的历史运行数据集。
[0124]
第二获取模块702,用于获取基于历史运行数据集进行预训练所得到的系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型。
[0125]
第三获取模块703,用于根据预训练策略模型和系统动态特性模型,获取基于历史运行数据集所得到的仿真运行数据集。
[0126]
混合模块704,用于将历史运行数据集和仿真运行数据集混合,以得到混合训练集。
[0127]
训练模块705,用于根据混合训练集,对预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,直至在训练后的策略模型所输出的控制量数据,使训练后的损失模型输出的损失数据小于与预设损失阈值,并且训练后的收益模型输出的收益数据达到最大值的情况下,结束训练。
[0128]
输出模块706,用于将结束训练时所得到的策略模型作为工业控制场景信息的目标策略模型。
[0129]
本技术提出一种策略模型的训练装置,通过获取工业控制场景信息的历史运行数据集进行预训练,得到系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型,然后将预训练策略模型和系统动态特性模型得到的仿真运行数据集与历史运行数据集混合,以得到混合数据集,并基于预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,以得到能够使得训练后损失模型输出的损失数据小于预设损失阈值,并且收益模型输出的收益数据达到最大值情况下的目标策略模型,由此,通过对仿真运行数据集与历史运行数据集混合,将得到混合数据集进行混合训练,实现离线强化学习,使得工业控制场景中优化控制策略效果更佳。
[0130]
在本技术的一个实施例中,如图8,第三获取模块703,包括:
[0131]
输入单元7031,用于针对历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据输入到预训练策略模型中,以得到状态量数据对应的预测控制量数据。
[0132]
预测单元7032,用于将状态量数据和预测控制量数据输入到系统动态特性模型中,以预测出在状态量数据下执行预测控制量数据之后所得到下一个状态量数据。
[0133]
确定单元7033,用于根据下一个状态量数据,确定在状态量数据下执行预测控制量数据之后所得到的预测收益数据和预测损失数据。
[0134]
第一生成单元7034,用于根据状态量数据、预测控制量数据、下一个状态量数据、预测收益数据和预测损失数据,形成当前条历史运行数据所对应的一条仿真运行数据。
[0135]
第二生成单元7035,用于根据各条历史运行数据所对应的一条仿真运行数据,形成仿真运行数据集。
[0136]
在本技术的一个实施例中,第二获取模块702,具体用于:针对历史运行数据集中的每一条历史运行数据,将当前条历史运行数据中的状态量数据和控制量数据作为初始系
统动态特性模型的输入,并将当前条历史运行数据中的下一个状态量数据作为初始系统动态特性模型的输出,对初始系统动态特性模型进行预训练,以得到系统动态特性模型。
[0137]
将当前条历史运行数据中的状态量数据和控制量数据作为初始收益模型的输入,并基于当前条历史运行数据中的长期收益作为初始收益模型的输出,对初始收益模型进行预训练,以得到预训练收益模型。
[0138]
将当前条历史运行数据中的状态量数据和控制量数据作为初始损失模型的输入,并基于当前条历史运行数据中的长期损失作为初始损失模型的输出,对初始损失模型进行预训练,以得到预训练损失模型。
[0139]
将当前条历史运行数据中的状态量数据作为初始策略模型的输入,并将当前历史运行数据中的控制量作为初始策略模型的输出,对初始策略模型进行预训练,以得到预训练策略模型。
[0140]
在本技术的一个实施例中,如图8,该装置还包括:
[0141]
第一确定模块707,用于根据历史运行数据集,确定仿真运行数据集的置信度。
[0142]
第二确定模块708,用于确定置信度超过预设置信度阈值。
[0143]
第三确定模块709,用于确定仿真运行数据集中存在对数概率密度下界值小于或者等于预设阈值的至少一条目标仿真运行数据。
[0144]
在本技术的一个实施例中,第三确定模块709,具体用于:针对仿真运行数据集中的每条仿真运行数据,根据当前条仿真运行数据中的状态量数据和控制量数据,确定当前条仿真运行数据的对数概率密度下界值。
[0145]
在当前条仿真运行数据的对数概率密度下界值大于预设阈值的情况下,将当前条仿真运行数据作为目标仿真运行数据。
[0146]
在本技术的一个实施例中,预训练收益模型包括模型参数不同的第一预训练收益模型和第二预训练收益模型,所述训练模块705,具体用于:针对混合训练集中的每条运行数据,将当前条运行数据中的状态量数据输入到预训练策略模型,以得到预训练策略模型输出的预测控制量数据。
[0147]
将预测控制量数据和当前条运行数据中的状态量数据分别输入到第一预训练收益模型和第二预训练收益模型,以得到第一预训练收益模型输出的第一收益数据和第二预训练收益模型输出的第二收益数据。
[0148]
将预测控制量数据和当前条运行数据中的状态量数据输入到预训练损失模型中,以得到预训练损失模型输出的损失数据。
[0149]
选择第一收益数据和第二收益数据中的较小值作为第三收益数据。
[0150]
根据各条运行数据的第三收益数据,确定在预测控制量数据下的收益平均值,并根据各条运行数据的损失数据,确定在预测控制量数据下的损失平均值。
[0151]
在损失平均值小于或者等于预设损失阈值的情况下,如果存在收益平均值大于预测控制量数据的其他控制量数据,则分别调整预训练策略模型、预训练损失模型和预训练收益模型的模型参数,并基于调整后的策略模型、损失模型和收益模型继续进行联合训练。
[0152]
在损失平均值小于或者等于预设损失阈值的情况下,如果不存在收益平均值大于预测控制量数据的其他控制量数据,则结束训练。
[0153]
本技术提出一种策略模型的训练装置,通过获取工业控制场景信息的历史运行数
据集进行预训练,得到系统动态特性模型、预训练收益模型、预训练损失模型和预训练策略模型,然后将预训练策略模型和系统动态特性模型得到的仿真运行数据集与历史运行数据集混合,以得到混合数据集,并基于预训练策略模型、预训练收益模型和预训练损失模型进行联合训练,以得到能够使得训练后损失模型输出的损失数据小于预设损失阈值,并且收益模型输出的收益数据达到最大值情况下的目标策略模型,由此,通过对仿真运行数据集与历史运行数据集混合,将得到混合数据集进行混合训练,实现离线强化学习,使得工业控制场景中优化控制策略效果更佳。
[0154]
根据本技术的实施例,本技术还提供了一种电子设备和一种可读存储介质。
[0155]
如图9所示,是根据本技术一个实施例的电子设备的框图。
[0156]
如图9所示,该电子设备该电子设备包括:
[0157]
存储器901、处理器902及存储在存储器901上并可在处理器902上运行的计算机指令。
[0158]
处理器902执行指令时实现上述实施例中提供的策略模型的训练方法。
[0159]
进一步地,电子设备还包括:
[0160]
通信接口903,用于存储器901和处理器902之间的通信。
[0161]
存储器901,用于存放可在处理器902上运行的计算机指令。
[0162]
存储器901可能包含高速ram存储器,也可能还包括非易失性存储器(non
‑
volatile memory),例如至少一个磁盘存储器。
[0163]
处理器902,用于执行程序时实现上述实施例的策略模型的训练方法。
[0164]
如果存储器901、处理器902和通信接口903独立实现,则通信接口903、存储器901和处理器902可以通过总线相互连接并完成相互间的通信。总线可以是工业标准体系结构(industry standard architecture,简称为isa)总线、外部设备互连(peripheral component,简称为pci)总线或扩展工业标准体系结构(extended industry standard architecture,简称为eisa)总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,图9中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
[0165]
可选的,在具体实现上,如果存储器901、处理器902及通信接口903,集成在一块芯片上实现,则存储器901、处理器902及通信接口903可以通过内部接口完成相互间的通信。
[0166]
处理器902可能是一个中央处理器(central processing unit,简称为cpu),或者是特定集成电路(application specific integrated circuit,简称为asic),或者是被配置成实施本技术实施例的一个或多个集成电路。
[0167]
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本技术的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
[0168]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本技术的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技
术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0169]
尽管上面已经示出和描述了本技术的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本技术的限制,本领域的普通技术人员在本技术的范围内可以对上述实施例进行变化、修改、替换和变型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。